ComfyUI-SeedVR2_VideoUpscaler
ComfyUI-SeedVR2_VideoUpscaler 是字节跳动 SeedVR2 模型在 ComfyUI 平台上的官方实现,专为高质量视频与图像超分辨率放大而设计。它能有效解决低分辨率素材模糊、细节丢失的问题,通过先进的 AI 算法重建纹理,显著提升画面清晰度,同时支持多显卡并行处理以加速渲染。
这款工具特别适合熟悉 ComfyUI 工作流的创作者、视频后期设计师以及需要批量处理高清内容的开发者使用。其独特亮点在于不仅作为节点嵌入 ComfyUI,还能作为独立命令行工具运行,灵活适配不同硬件环境。最新版本进一步优化了跨平台兼容性,包括苹果 Silicon 芯片的内存管理、10-bit 色彩深度输出以减少色彩断层,以及对 GGUF 量化模型的支持,大幅降低了显存占用并提升了推理效率。此外,它还增强了安全性,防止恶意模型文件执行代码。无论是修复老视频还是提升生成式 AI 产出画质,ComfyUI-SeedVR2_VideoUpscaler 都提供了一个稳定且高效的解决方案。
使用场景
一位独立纪录片创作者需要将十年前用老式摄像机拍摄的 480p 家庭影像修复为 4K 分辨率,以便在现代高清电视上播放并存档。
没有 ComfyUI-SeedVR2_VideoUpscaler 时
- 画质模糊且细节丢失:传统双三次插值放大导致画面边缘锯齿严重,人物面部纹理完全糊成一片,缺乏真实感。
- 色彩断层明显:在天空或渐变背景中出现明显的色带(Banding),尤其是在导出为 8 位视频时,视觉体验极不自然。
- 处理流程繁琐易崩:尝试组合多个 AI 节点进行分帧处理时,常因显存优化不足导致进程挂起或崩溃,尤其在长视频渲染中频繁中断。
- 动态闪烁问题:帧与帧之间的修复风格不一致,导致视频播放时出现令人头晕的闪烁噪点,后期逐帧手动修正耗时巨大。
使用 ComfyUI-SeedVR2_VideoUpscaler 后
- 超清细节重建:利用 SeedVR2 模型强大的生成能力,不仅将分辨率提升至 4K,还智能还原了皮肤纹理和衣物褶皱等高频细节。
- 平滑渐变色彩:内置支持 10-bit FFmpeg 后端编码,有效消除了色彩断层,使天空和阴影过渡如电影般平滑自然。
- 稳定高效的多卡渲染:依托其优化的多 GPU standalone 模式和显存切片技术,轻松处理长视频序列,不再出现进程假死或显存溢出。
- 时序一致性保障:算法专门针对视频时序优化,确保相邻帧修复结果高度连贯,彻底解决了画面闪烁问题,无需额外去闪处理。
ComfyUI-SeedVR2_VideoUpscaler 将原本需要数天人工精修的老旧视频复活工作,缩短为几小时的一键自动化流程,同时达到了广播级的画质标准。
运行环境要求
- Linux
- macOS
- Windows
- 支持 NVIDIA GPU (需 CUDA,支持 Flash Attention 2/3, SageAttention, CUDNN_ATTENTION),AMD GPU (ROCm),Intel Gaudi,以及 Apple Silicon (MPS)
- 旧款 GPU (如 GTX 970) 可自动回退至不支持 bfloat16 的模式运行
- 显存需求未明确说明,但具备流式处理和多 GPU 支持以优化长视频处理的显存占用
未说明 (支持通过 --chunk_size 标志进行分块流式处理,以突破内存限制处理任意长度视频)

快速开始
ComfyUI-SeedVR2_视频超分辨率
这是为 ComfyUI 官方发布的 SeedVR2 插件,可实现高质量的视频和图像超分辨率。
它也可以作为 多 GPU 独立 CLI 运行,详情请参阅 🖥️ 作为独立 CLI 运行 部分。

📋 快速访问
🆙 未来工作
我们正在积极开发改进和新功能。如需了解最新动态:
- 📌 跟踪开发进展:访问 Issues 查看当前开发情况、报告问题或提出新功能需求。
- 💬 加入社区:在 Discussions 中向他人学习、分享你的工作流并获得帮助。
- 🔮 下一代模型调查:我们正在征求社区意见,以确定下一个开源的超强通用修复模型。请在 Issue #164 中提出你的建议。
🚀 发布说明
2025年12月24日 - 版本 2.5.24
- 🍎 修复:MPS 内存泄漏回归问题 - 恢复了在 VAE 编码/解码操作后清除 MPS 缓存的功能,该功能在 v2.5.23 的代码清理过程中被意外移除。
2025年12月24日 - 版本 2.5.23
- 🔒 安全性:防止模型加载时执行代码 - 通过仅允许反序列化张量来增加对恶意 .pth 文件的防护。
- 🎥 修复:FFmpeg 视频写入器可靠性问题 - 通过重定向 stderr 并添加缓冲区刷新解决了 ffmpeg 进程挂起的问题,并改进了错误信息以便调试 (感谢 @thehhmdb)
- ⚡ 修复:GGUF VAE 模型支持 - 启用了卷积运算的自动权重去量化功能,使 GGUF 量化的 VAE 模型完全可用 (感谢 @naxci1)
- 🛡️ 修复:VAE 切片边缘情况 - 在使用小分割尺寸和高时间下采样时,防止了因除以零而导致的崩溃 (感谢 @naxci1)
- 🎨 修复:LAB 颜色转换精度问题 - 通过确保矩阵运算前浮点类型一致,解决了视频超分辨率过程中的 dtype 不匹配错误。
- 🔧 修复:PyTorch 2.9+ 兼容性问题 - 将 Conv3d 内存绕过方案扩展到所有 PyTorch 2.9+ 版本,修复了较新版本 PyTorch 上 VRAM 使用量增加两倍的问题。
- 📦 修复:Bitsandbytes 兼容性问题 - 添加了针对非 Gaudi 系统上 Intel Gaudi 版本检测失败的 ValueError 异常处理。
- 🍎 MPS:内存优化 - 减少了 Apple Silicon 上编码/解码操作期间的内存占用 (感谢 @s-cerevisiae)
2025年12月13日 - 版本 2.5.22
- 🎬 CLI:支持 10 位的 FFmpeg 视频后端 - 新增
--video_backend ffmpeg和--10bit标志,启用 x265 编码并支持 10 位色深,与 8 位 OpenCV 输出相比,可减少渐变中的条带伪影 (基于 @thehhmdb 的 PR - 感谢!) - 🍎 修复:MPS 双三次插值兼容性问题 - 在 PyTorch 2.8.0 之前的版本中,增加了双三次+抗锯齿插值的 CPU 备用方案,解决了 Apple Silicon 上 RGBA 透明度插值时出现的错误。
- ⚡ 修复:跨平台直方图匹配问题 - 用 argsort+index_select 替代 scatter_ 操作,提高了在 CUDA、ROCm 和 MPS 后端上的可靠性。
- 🧹 MPS:移除同步开销 - 恢复了在 v2.5.21 中引入的不必要的
torch.mps.synchronize()调用,以保持与 CUDA 流水线的一致行为。
2025年12月12日 - 版本 2.5.21
- 🛠️ 修复:MPS 上 GGUF 去量化错误 - 解决了在 2.5.20 中引入的形状不匹配错误,原因是跳过了 GGUF 量化缓冲区进行精度转换——这些缓冲区必须保持打包格式,以便在推理过程中进行即时去量化。
- 🍎 MPS:消除 CPU 同步开销 - 在 Apple Silicon 统一内存架构上,跳过不必要的 CPU 张量卸载操作,避免了导致速度下降的同步停滞。输入图像和输出视频现在在整个流程中都保留在 MPS 设备上。
- ⚡ MPS:预加载文本嵌入 - 在第一阶段编码之前加载文本嵌入,以避免第二阶段开始时的同步停滞,从而提高时间准确性和吞吐量。
- 🧹 MPS:优化模型清理 - 在统一内存上删除模型前,跳过冗余的 CPU 移动操作。
2025年12月12日 - 版本 2.5.20
- ⚡ 扩展注意力机制后端 - 完全支持 Flash Attention 2 (Ampere+)、Flash Attention 3 (Hopper+)、SageAttention 2 和 SageAttention 3 (Blackwell/RTX 50xx),并在不可用时自动回退到 PyTorch SDPA (基于 @naxci1 的 PR - 感谢!)
- 🍎 macOS/Apple Silicon 兼容性 - 在整个 VAE 和 DiT 流程中,将 MPS 自动混合精度替换为显式的数据类型转换,解决了 M 系列 Mac 上的卡顿和崩溃问题。BlockSwap 现在会自动禁用并发出警告(由于统一内存的存在,它已无意义)。
- 🛡️ Flash Attention 优雅回退 - 添加了针对损坏或部分安装的 flash_attn/xformers DLL 的兼容性适配层,防止启动时崩溃。
- 🛡️ AMD ROCm:解决 bitsandbytes 冲突问题 - 防止了当 diffusers 尝试重新导入损坏的 bitsandbytes 安装时出现的内核注册错误。
- 📦 ComfyUI Manager:macOS 分类器修复 - 移除了导致 macOS 上出现“不支持 GPU”虚假警告的 NVIDIA CUDA 分类器。
- 📚 文档更新 - 更新了 README,加入了注意力机制后端的详细信息、BlockSwap 的 macOS 注意事项以及更清晰的模型缓存描述。
2025年12月10日 - 版本 2.5.19
- 🎨 新的页眉 logo 设计 - 更新了 ASCII 艺术横幅 (感谢 @naxci1)
- 🧹 移除已废弃的 FlashAttention 包装器 - 从 FP8CompatibleDiT 中移除了遗留代码;FlashAttentionVarlen 已通过其
attention_mode属性自动处理后端切换 - 🛡️ 修复 FlashAttention 的优雅降级机制 - 添加了针对损坏的 flash_attn/xformers DLL 文件的兼容性适配层,防止 CUDA 扩展损坏时启动崩溃
- 📊 改进显存跟踪功能 - 分离已分配与预留内存的跟踪,仅在 Windows 上实现溢出检测(WDDM 分页行为)
- ♻️ 统一后端检测逻辑 - 在整个代码库中统一了
is_mps_available()、is_cuda_available()和get_gpu_backend()辅助函数 - 🔄 恢复 2.5.14 版本的显存限制强制执行 - 移除了
set_per_process_memory_fraction调用;溢出检测和警告功能仍保留。
2025年12月9日 - 版本 2.5.18
- 🚀 CLI:长视频流式处理模式 - 新增
--chunk_size标志,以受内存限制的分块方式处理视频,从而支持任意长度的视频而无 RAM 限制。配合模型缓存功能(--cache_dit/--cache_vae),可在不同分块间重复使用缓存数据 (灵感来自 disk02 的 PR 贡献) - ⚡ CLI:多 GPU 流式处理 - 现在每个 GPU 都会独立进行内部分段处理,并采用独立的模型缓存策略,从而提升内存效率,并支持在 GPU 边界处启用
--temporal_overlap混合功能 - 🔧 CLI:修复大视频内存错误 - 使用共享内存传输替代 NumPy 序列化,避免在高分辨率或长视频输出时发生崩溃 (灵感来自 FurkanGozukara 的 PR 贡献)
2025年12月5日 - 版本 2.5.17
- 🔧 修复:旧款 GPU 兼容性(如 GTX 970 等) - 运行时 bf16 CUBLAS 探测取代了计算能力启发式方法,能够正确检测不支持的 GPU,同时不影响 RTX 20XX 系列
2025年12月5日 - 版本 2.5.16
- 🔧 修复:旧款 GPU 兼容性(如 GTX 970 等) - 自动回退至不支持 bfloat16 的 GPU
- 🐛 修复:质量回归问题 - 恢复了导致伪影问题的 bfloat16 检测逻辑
- 📋 调试:环境信息显示 - 在调试模式下显示系统信息,便于问题报告
- 📚 文档:简化贡献流程 - 流程现已精简为仅向主分支提交
2025年12月3日 - 版本 2.5.15
- 🍎 修复:MPS 兼容性 - 禁用 MPS 张量的抗锯齿功能,并修复 bfloat16 arange 的问题
- ⚡ 修复:自动混合精度设备类型 - 使用正确的设备类型属性,防止自动混合精度错误
- 📊 内存:精确显存跟踪 - 使用 max_memory_reserved 提供更精准的峰值报告
- 🔧 修复:Triton 兼容性 - 为 bitsandbytes 0.45+ 和 triton 3.0+ 添加适配层,解决 PyTorch 2.7 安装错误
2025年12月1日 - 版本 2.5.14
- 🍎 修复:MPS 设备比较 - 规范设备字符串,防止不必要的张量移动
- 📊 内存:显存交换检测 - 峰值统计现在会显示 GPU 和交换内存的细分数据,当发生溢出时还会发出警告
- 🛡️ 内存:强制执行物理显存上限 - PyTorch 现在会在超出显存限制时直接抛出 OOM 错误,而不是默默切换到共享内存(可防止 Windows 系统上的极端性能下降)
2025年11月30日 - 版本 2.5.13
- 🔧 修复:PyTorch 2.7+ Triton 导入错误 - 解决了因较新版本 Triton 中 triton.ops 导入链导致的安装崩溃问题
- 💾 修复:长视频转 float32 时的 OOM 错误 - 当内存不足以进行 float32 转换时,将优雅地回退到原生数据类型
- 🍎 修复:macOS 上 CLI 水印错误 - 解决了 Apple Silicon 上 MPS 相关水印处理崩溃的问题
2025年11月28日 - 版本 2.5.12
- 🐛 修复:颜色伪影回归问题 - 恢复了视频转换流水线中的原位张量操作,该操作曾导致部分图像出现颜色伪影
2025年11月28日 - 版本 2.5.11
- ⚡ 功能:CUDNN 注意力后端 - 添加了对 PyTorch 2.3+ CUDNN_ATTENTION 后端的支持,并为旧版本提供自动回退机制(感谢 @eadwu)
- 💾 修复:长视频内存激增问题 - VAE 解码现在直接流式写入预分配的张量,从而消除长视频处理过程中的 OOM 错误
- 🎨 修复:LAB 颜色校正伪影 - 使用小波重建预处理解决了瓦片边界伪影问题
- 🎨 修复:颜色参考错位 - 修正了颜色校正帧与时间重叠之间的对齐问题
- 🍎 修复:MPS 检测可靠性 - 切换到规范的
torch.backends.mps.is_available()API,以确保一致的 Apple Silicon 检测结果 - 🖥️ 修复:Mac 子进程错误 - CLI 现在在 Mac 上直接运行,避免子进程中 MPS 分配器失败的情况
- 🖥️ 修复:多 GPU 设备分配 - 现在会在进程创建前设置 CUDA_VISIBLE_DEVICES,以确保工作进程正确继承设备
- 📊 修复:BlockSwap 日志记录 - 现在显示有效/总块数(例如 32/32),而非原始请求值
- 🔧 功能:自动 bfloat16 检测 - 自动检测 bfloat16 支持情况,以防止旧款 GPU 上出现 CUBLAS 错误
- 📊 功能:峰值内存跟踪 - 在调试摘要中增加了内存使用情况,与显存一同显示
- ⚡ 性能:原位张量操作 - 通过在整个流水线中使用原位操作,减少了内存分配开销
- 📖 文档:多 GPU 说明 - 明确了多 GPU 设置下帧级并行性的预期行为
2025年11月13日 - 版本 2.5.10
- 🎯 修复:确定性生成 - 使用相同种子生成的图像,在不同会话和批次位置上都会产生完全一致的结果
- 🔧 修复:带 BlockSwap 的模型缓存 - 解决了当 VAE 缓存状态发生变化时,已缓存的 DiT 模型无法正确重新加载的问题
- 💾 修复:Runner 缓存优化 - Runner 模板现在无论缓存顺序如何,只要 DiT 和 VAE 都被缓存,就会正确缓存
- 📁 修复:模型路径大小写不敏感 - YAML 配置中的额外模型路径现在无论大小写如何都能正常工作(seedvr2、SEEDVR2、SeedVR2 等)
- 🐛 修复:高分辨率瓦片调试崩溃 - 修复了在使用最大分辨率且启用 VAE 瓦片化时出现的 “NoneType 对象没有 log 属性” 错误
- 📊 修复:时间重叠日志记录 - 当时间重叠自动调整时,修正了帧数报告问题
- 🔍 功能:增强模型路径调试 - 添加了详细日志记录,帮助排查模型加载问题(可在调试模式下查看)
2025年11月12日 - 版本 2.5.9
- 🐛 修复:瓦片调试可视化崩溃 - 修复了在某些系统上使用 VAE 瓦片调试模式时出现的 OpenCV 错误。
- 🍎 修复:macOS MPS 加载错误 - 在某些 PyTorch/macOS 版本中,针对 MPS 分配器问题添加了自动回退到 CPU 的机制。
- 🖥️ 修复:Windows 日志缓冲 - 在 Windows 上的 ComfyUI 中,为 print 语句添加了刷新功能,以实现实时日志可见性。
- 📦 修复:ComfyUI 注册表 logo - 更新了图标 URL,使其在 ComfyUI 节点注册表中正常显示。
- ℹ️ 功能:版本显示 - 在节点名称以及 CLI/ComfyUI 头部添加了版本号,以便更好地追踪版本。
- 💝 功能:GitHub 赞助 - 添加了赞助按钮,用于支持项目开发。感谢大家的支持!
- 📜 许可证:Apache 2.0 - 将许可证从 MIT 重新改为 Apache 2.0,以与字节跳动 Seed 项目保持一致。
2025年11月10日 - 版本 2.5.8
- 🐛 修复(CLI):Windows 批处理重复文件问题 - 修复了由于 Windows 文件系统不区分大小写导致 CLI 批处理模式下每个文件被处理两次的问题。同时将目录扫描性能提升了 2-3 倍。
- 📁 修复(CLI):输出文件夹位置 - 现在输出文件会创建在更合理的路径下:批处理模式会在原文件所在目录下创建一个同级的
{folder_name}_upscaled/文件夹,并保留原始文件名;单文件模式则会在同一目录下添加_upscaled后缀。所有日志现在都会显示绝对路径,以提高清晰度。 - 🎨 修复(CLI):RGBA 透明通道支持 - 现在带有透明度的 PNG 图像会被正确检测并保留在超分辨率处理流程中,与 ComfyUI 的行为一致。
2025年11月10日 - 版本 2.5.7
- 🔧 修复:Conv3d 替代方案兼容性 - 改进了平台检测,并添加了优雅的回退机制,以防止在 PyTorch 开发版和 AMD ROCm 系统上出现错误。
2025年11月9日 - 版本 2.5.6
- 🎨 修复:恢复 7b 模型的自然外观 - 修正了 torch.compile 优化导致的过度塑料感和高光泽度问题,该问题曾出现在使用 7b 模型进行超分辨率处理的视频中。
- 💾 内存:修复长视频的内存泄漏问题 - 采用按需重建的方式,使用轻量级的批次索引代替存储完整的变换后视频;修复了 release_tensor_memory 函数,使其能够一致地处理 CPU/CUDA/MPS 内存释放问题,并重构了批次处理辅助函数。
2025年11月8日 - 版本 2.5.4
- 🎨 修复:AdaIN 颜色校正 - 将
.view()替换为.reshape(),以处理空间填充后的非连续张量,从而解决“视图大小与输入张量的大小和步幅不兼容”的错误。 - 🔴 修复:AMD ROCm 兼容性 - 在 Conv3d 替代方案中添加了 cuDNN 可用性检查,以防止在 ROCm 系统(AMD GPU 在 Windows/Linux 上)上出现“ATen 未编译 cuDNN 支持”的错误。
2025年11月8日 - 版本 2.5.3
- 🍎 修复:Apple Silicon MPS 设备处理 - 修正了 MPS 设备枚举逻辑,使用
"mps"而不是"mps:0",从而解决了 M 系列 Mac 上的无效设备错误。 - 🪟 修复:Windows 上的 torch.mps AttributeError - 添加了对
torch.mps.is_available()的防御性检查,以应对在非 Mac 平台上该方法不存在的 PyTorch 版本。
2025年11月7日 - 版本 2.5.0 🎉
⚠️ 重大变更:这是一个需要重新创建工作流的重大更新。所有节点和 CLI 参数都经过重新设计,以提升易用性和一致性。请观看 AInVFX 的最新视频,深入了解此次更新,并查看使用说明部分。
📦 官方发布:现已在主分支上线,并支持 ComfyUI Manager,方便用户安装及自动跟踪版本。更新的依赖项和本地导入避免了与其他 ComfyUI 自定义节点的冲突。
🎨 ComfyUI 改进
- 四节点模块化架构:拆分为专门的 DiT 模型、VAE 模型、torch.compile 设置以及主超分辨率节点,实现更精细的控制。
- 全局模型缓存:模型现在可在多个超分辨率实例之间共享,并自动更新配置,无需重复加载。
- ComfyUI V3 迁移:完全兼容 ComfyUI V3 的无状态节点设计。
- RGBA 支持:原生支持透明通道处理,并通过边缘引导的超分辨率技术实现干净的透明效果。
- 改进的内存管理:流式架构可防止无论视频长度如何,VRAM 都不会出现峰值。
- 灵活的分辨率支持:可将视频或图像放大到任何能被 2 整除的分辨率,采用无损填充方式(取代了限制性的裁剪操作)。
- 增强的参数设置:新增了
uniform_batch_size、temporal_overlap、prepend_frames和max_resolution等参数,以提供更好的控制。
🖥️ CLI 增强
- 批量目录处理:高效地处理包含视频/图片的整个文件夹,同时利用模型缓存提升效率。
- 单张图片支持:直接对图片进行超分辨率处理,无需转换为视频。
- 智能输出检测:根据输入类型自动检测输出格式(MP4/PNG)。
- 多 GPU 性能提升:通过时间重叠混合技术,进一步优化了负载分配。
- 统一参数:CLI 和 ComfyUI 现在使用相同的参数名称,以确保一致性。
- 更好的用户体验:自动显示帮助信息、改进验证机制、跟踪进度,并使输出更加整洁。
⚡ 性能与优化
- torch.compile 支持 - 使用完整图编译后,DiT 速度提升 20-40%,VAE 速度提升 15-25%。
- 优化的 BlockSwap - 采用自适应内存清理(阈值为 5%),分离 I/O 组件处理,降低开销。
- 增强的 VAE 瓦片处理 - 支持张量卸载至累积缓冲区,并可单独配置编码和解码过程。
- 原生数据类型流水线 - 消除了不必要的类型转换,在整个流程中保持 bfloat16 精度,以兼顾速度和质量。
- 优化的张量操作 - 用原生 PyTorch 操作替换了 einops 的重新排列,使转换速度提升了 2-5 倍。
🎯 质量提升
- LAB 颜色校正 - 引入新的感知色彩转移方法,具有更出色的色彩准确性(现为默认设置)。
- 额外的颜色方法 - 包括 HSV 饱和度匹配、小波自适应以及混合方法。
- 确定性生成 - 基于种子的可重复性,采用特定阶段的种子策略。
- 更好的时间一致性 - 使用汉宁窗混合技术,使不同批次之间的过渡更加平滑。
💾 内存管理
- 更智能的卸载 - 对 DiT、VAE 和张量分别进行独立的设备配置(CPU/GPU/无)。
- 四阶段流水线 - 每个批次的所有阶段(编码→超分辨率→解码→后处理)完成后才会进入下一阶段,从而最大限度地减少模型切换。
- 更好的清理 - 根据阶段进行资源管理,并正确释放张量内存。
- 峰值 VRAM 跟踪 - 对每个阶段的内存使用情况进行监控,并提供汇总显示。
🔧 技术改进
- GGUF量化支持:新增对低显存设备上4位/8位推理的完整GGUF支持
- GGUF处理优化:修复了显存泄漏问题,增强了与torch.compile的兼容性,并解决了非持久化缓冲区问题。
- Apple Silicon支持:全面支持Apple Silicon Mac上的MPS(Metal Performance Shaders)。
- AMD ROCm兼容性:为PyTorch ROCm 7+版本添加了条件性的FSDP导入支持。
- Conv3d内存绕过方案:修复了PyTorch 2.9及以上版本中cuDNN内存使用问题,内存占用减少至原来的三分之一。
- Flash Attention可选:当Flash Attention不可用时,可优雅地回退到SDPA。
📚 代码质量
- 模块化架构:将单体文件拆分为多个专注功能的模块(如generation_phases、model_configuration等)。
- 全面文档:所有模块均配有详尽的文档字符串及类型提示。
- 更好的错误处理:提前验证输入,提供清晰的错误信息和安装说明。
- 统一的日志记录:采用统一的缩进格式,分类更清晰,日志信息更加简洁。
2025年8月7日
- 🎯 统一调试系统:引入新的结构化日志系统,包含类别、计时器和内存跟踪功能。主节点现已支持
enable_debug选项。 - ⚡ 智能FP8优化:FP8模型现在保留原生FP8存储格式,仅在进行算术运算时转换为BFloat16——相比FP16更快且更节省显存。
- 📦 模型注册表:支持多仓库(numz/ & AInVFX/),自动发现用户自定义模型,并新增混合FP8变体以解决7B模型中的伪影问题。
- 💾 模型缓存:
cache_model功能已移至主节点,同时通过正确的RoPE和包装器清理修复了内存泄漏问题。 - 🧹 代码清理:引入新的模块化结构(constants.py、model_registry.py、debug.py),并移除了遗留代码。
- 🚀 性能提升:通过
torch.cuda.ipc_collect()实现更好的显存管理,并改进了RoPE处理方式。
2025年7月17日
- 🛠️ 新增7B锐化模型:推出两款输出更锐利的7B模型。
2025年7月11日
- 🎬 完整教程发布:来自AInVFX的Adrien制作了一篇深入的ComfyUI SeedVR2指南,内容涵盖从基础设置到高级BlockSwap技术,适用于消费级显卡运行。非常适合理解如何优化显存以及对带有Alpha通道的图像序列进行超分辨率处理!观看教程
2025年9月7日
- 🛠️ Blockswap集成:特别感谢来自AInVFX的Adrien Toupet,此功能对显存有限的用户非常有用(详见使用方法部分)。
2025年7月3日
- 🛠️ 支持独立模式运行,且可利用多GPU加速,详情请参阅🖥️ 独立运行。
2025年6月30日
- 🚀 提升处理速度并减少显存占用。
- 🛠️ 修复了3B模型中的内存泄漏问题。
- ❌ 现在可以在需要时中断进程。
- ✅ 对代码进行了重构,以便更好地与社区共享,欢迎提出Pull Request。
- 🛠️ 移除了对Flash Attention的依赖(感谢luke2642!!)。
2025年6月24日
- 🚀 处理速度最高可提升至4倍。
2025年6月22日
- 💪 FP8兼容!
- 🚀 全流程加速。
- 🚀 显存消耗更低(RTX4090建议保持高显存,batch_size=1,我正在努力解决这个问题)。
- 🛠️ 更好的基准测试即将推出。
2025年6月20日
- 🛠️ 初始推送。
🎯 功能特性
核心能力
- 高质量扩散模型超分辨率:一步式扩散模型用于视频和图像增强。
- 时间一致性:通过可配置的批处理方式,保持视频帧之间的连贯性。
- 多格式支持:支持RGB和RGBA(Alpha通道)格式的视频和图像。
- 任意视频长度:适用于任何长度的视频。
模型支持
- 多种模型变体:提供3B和7B参数量的不同精度版本。
- FP16、FP8和GGUF量化:根据显存需求,可选择全精度(FP16)、混合精度(FP8)或高度量化的GGUF模型。
- 自动模型下载:首次使用时会自动从HuggingFace下载所需模型。
内存优化
- BlockSwap技术:在GPU和CPU内存之间动态交换Transformer块,从而在有限显存条件下运行大型模型。
- VAE分块处理:通过分块编码/解码大分辨率图像来降低显存占用。
- 智能卸载:在不同处理阶段间将模型和中间张量卸载到CPU或辅助GPU上。
- GGUF量化支持:使用4位或8位量化模型以极大节省显存。
性能特性
- torch.compile集成:启用PyTorch 2.0+编译后,DiT速度可提升20-40%,VAE速度可提升15-25%。
- 多GPU命令行界面:通过自动的时间重叠混合,将工作负载分配到多个GPU上。
- 模型缓存:在单GPU目录处理或多GPU流式传输中,可将模型保留在内存中以供后续使用。
- 灵活的注意力后端:可根据硬件支持情况,选择PyTorch SDPA(稳定且始终可用)、Flash Attention 2/3或SageAttention 2/3以获得更快的计算速度。
质量控制
- 高级色彩校正:提供五种方法,包括LAB(推荐用于最高保真度)、小波变换、自适应小波变换、HSV和AdaIN。
- 噪声注入控制:可微调输入和潜在噪声比例,以减少高分辨率下的伪影。
- 可配置的分辨率限制:设置目标和最大分辨率,并自动保持宽高比。
工作流程特性
- ComfyUI集成:提供四个专用节点,实现对超分辨率流程的完全控制。
- 独立命令行界面:用于批量处理和自动化任务。
- 调试日志记录:提供全面的调试模式,包含内存跟踪、时间信息和处理细节。
- 进度报告:在处理过程中实时显示进度。
🔧 系统要求
硬件
借助当前的优化技术(分块处理、BlockSwap、GGUF量化),SeedVR2可在多种硬件上运行:
- 最低显存(8GB或以下):使用开启BlockSwap和VAE分块处理的GGUF Q4_K_M模型。
- 中等显存(12-16GB):根据需要使用带BlockSwap或VAE分块处理的FP8模型。
- 高显存(24GB以上):使用FP16模型以获得最佳质量和速度,无需额外的内存优化措施。
软件
- ComfyUI:建议使用最新版本。
- Python:3.12及以上版本(经测试并推荐使用Python 3.12和3.13)。
- PyTorch:2.0及以上版本以支持torch.compile(可选但推荐)。
- Triton:使用inductor后端进行torch.compile时必需(可选)。
- Flash Attention / SageAttention:Flash Attention 2(Ampere及以上)、Flash Attention 3(Hopper及以上)、SageAttention 2或SageAttention 3(Blackwell)可在支持的硬件上提供更快的注意力计算(可选,若不可用则回退到PyTorch SDPA)。
方法一:ComfyUI 管理器(推荐)
- 在 ComfyUI 界面中打开 ComfyUI 管理器。
- 点击“自定义节点管理器”。
- 搜索“ComfyUI-SeedVR2_VideoUpscaler”。
- 点击“安装”,然后重启 ComfyUI。
注册表链接:ComfyUI 注册表 - SeedVR2 视频超分辨率插件
方法二:手动安装
- 克隆仓库到你的 ComfyUI 自定义节点目录:
cd ComfyUI
git clone https://github.com/numz/ComfyUI-SeedVR2_VideoUpscaler.git custom_nodes/seedvr2_videoupscaler
- 使用独立 Python 安装依赖:
# 安装所需依赖(从同一 ComfyUI 目录运行)
# Windows:
.venv\Scripts\python.exe -m pip install -r custom_nodes\seedvr2_videoupscaler\requirements.txt
# Linux/macOS:
.venv/bin/python -m pip install -r custom_nodes/seedvr2_videoupscaler/requirements.txt
- 重启 ComfyUI
模型安装
模型将在首次使用时自动下载,并保存到 ComfyUI/models/SEEDVR2 目录下。
你也可以手动从以下地址下载模型:
- 主要模型可在 numz/SeedVR2_comfyUI 和 AInVFX/SeedVR2_comfyUI 获取。
- 额外的 GGUF 模型可在 cmeka/SeedVR2-GGUF 下载。
📖 使用说明
🎬 视频教程
最新版本深度解析(推荐)
由 AInVFX 的 Adrien 制作的 v2.5 完整讲解视频,涵盖了全新的 4 节点架构、GGUF 支持、内存优化以及生产工作流等内容:
本教程详细介绍了:
- 如何通过 ComfyUI 管理器安装 v2.5 并解决冲突问题
- 新的 4 节点模块化架构及其重构原因
- 使用 GGUF 量化在 8GB 显存上运行 7B 模型
- 根据硬件配置设置 BlockSwap、VAE 平铺及 torch.compile
- 带有 Alpha 通道的图像和视频超分辨率工作流
- 用于批量处理和多 GPU 渲染的命令行工具
- 针对不同显存水平的内存优化策略
- 实际生产中的技巧以及关键的 batch_size 公式(4n+1)
旧版本教程
作为参考,这里提供最初的发布版教程:

注:该教程介绍的是之前的单节点架构。虽然 v2.5 的界面已大幅变化,但关于 BlockSwap 和内存管理的核心概念仍然很有价值。
节点设置
SeedVR2 采用模块化节点架构,包含四个专用节点:
1. SeedVR2 (下载)DiT 模型
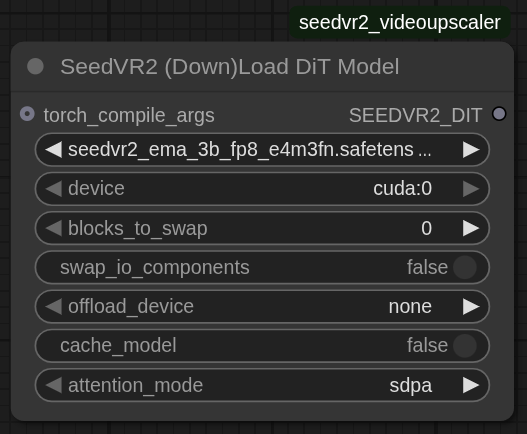
用于配置用于视频超分辨率的 DiT(扩散 Transformer)模型。
参数说明:
model:选择你的 DiT 模型
- 3B 模型:速度较快,显存需求较低
seedvr2_ema_3b_fp16.safetensors:FP16(最佳质量)seedvr2_ema_3b_fp8_e4m3fn.safetensors:FP8 8 位(良好质量)seedvr2_ema_3b-Q4_K_M.gguf:GGUF 4 位量化(可接受质量)seedvr2_ema_3b-Q8_0.gguf:GGUF 8 位量化(良好质量)
- 7B 模型:质量更高,显存需求更大
seedvr2_ema_7b_fp16.safetensors:FP16(最佳质量)seedvr2_ema_7b_fp8_e4m3fn_mixed_block35_fp16.safetensors:FP8,最后一层用 FP16 减少伪影(良好质量)seedvr2_ema_7b-Q4_K_M.gguf:GGUF 4 位量化(可接受质量)seedvr2_ema_7b_sharp_*:锐化变体,增强细节
- 3B 模型:速度较快,显存需求较低
device:执行 DiT 推理的 GPU 设备(例如
cuda:0)offload_device:在不活跃时卸载 DiT 模型的设备
none:将模型保留在推理设备上(最快,占用显存最多)cpu:卸载到系统内存(减少显存占用)cuda:X:卸载到另一块 GPU(如果有条件,效果较好)
cache_model:在工作流之间将 DiT 模型保留在 offload_device 上
- 对于批量处理非常有用,可避免重复加载
- 需要同时设置 offload_device
blocks_to_swap:启用 BlockSwap 内存优化功能
0:禁用(默认)1-32:适用于 3B 模型的变换块数量1-36:适用于 7B 模型的变换块数量- 数值越高,节省的显存越多,但处理速度会变慢
- 需要设置 offload_device,且不能与 device 相同
swap_io_components:卸载输入输出嵌入层和归一化层
- 与 blocks_to_swap 结合使用可进一步节省显存
- 需要设置 offload_device,且不能与 device 相同
attention_mode:注意力计算后端
sdpa:PyTorch scaled_dot_product_attention(默认,始终可用)flash_attn_2:Flash Attention 2(Ampere+,需安装 flash-attn 包)flash_attn_3:Flash Attention 3(Hopper+,需安装支持 FA3 的 flash-attn 包)sageattn_2:SageAttention 2(需安装 sageattention 包)sageattn_3:SageAttention 3(Blackwell/RTX 50xx,需安装 sageattn3 包)
torch_compile_args:连接到 SeedVR2 Torch Compile Settings 节点,以获得 20-40% 的速度提升。
BlockSwap 解释:
BlockSwap 可以让显存有限的 GPU 运行大型模型,它会在推理过程中动态地在 GPU 和 CPU 内存之间交换 Transformer 块。
注意:BlockSwap 在 macOS 上不可用。Apple Silicon Mac 采用统一内存架构,GPU 和 CPU 共享同一内存池,因此 BlockSwap 没有意义。如果在 macOS 上尝试启用此选项,系统会自动禁用并发出警告。
其工作原理如下:
- 作用:只将当前需要的 Transformer 块保留在 GPU 上,其余部分存储在 CPU 或其他设备上。
- 适用场景:在超分辨率阶段遇到 OOM(内存不足)错误时。
- 配置方法:
- 将
offload_device设置为cpu或另一块 GPU。 - 初始设置
blocks_to_swap=16(即一半的块数)。 - 如果仍出现 OOM 错误,则增加到 24 或 32(3B)/36(7B)。
- 启用
swap_io_components以最大限度地节省显存。 - 如果显存充足,可以降低数值或直接设为 0,以提高处理速度。
- 将
低显存(8GB)配置示例:
- model:
seedvr2_ema_3b-Q8_0.gguf - device:
cuda:0 - offload_device:
cpu - blocks_to_swap:
32 - swap_io_components:
True
2. SeedVR2 (下载)VAE 模型
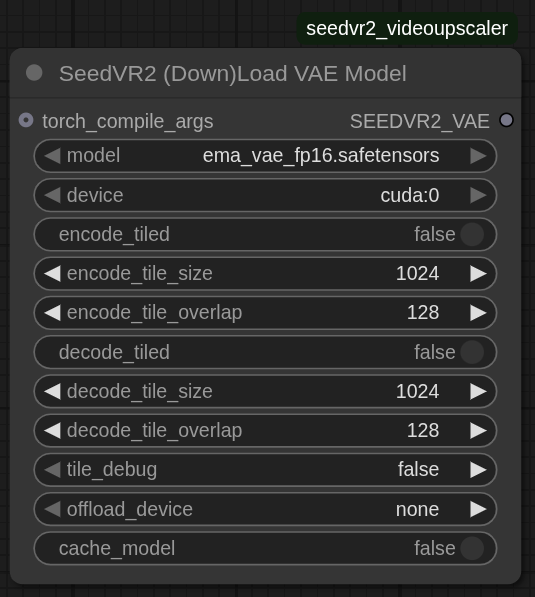
用于配置 VAE(变分自编码器)模型,以进行视频帧的编码和解码。
参数说明:
model:选择 VAE 模型
ema_vae_fp16.safetensors:默认且推荐
device:执行 VAE 推理的 GPU 设备(例如
cuda:0)offload_device: 在不主动处理时,将 VAE 模型卸载到的设备
none: 将模型保留在推理设备上(默认,速度最快)cpu: 卸载到系统内存(减少显存占用)cuda:X: 卸载到另一块 GPU(如果有其他 GPU 可用,则平衡较好)
cache_model: 在工作流运行之间,将 VAE 模型保留在 offload_device 上
- 需要先设置 offload_device
encode_tiled: 启用分块编码以减少编码阶段的显存使用
- 如果在调试日志中“编码”阶段出现 OOM 错误,请启用
encode_tile_size: 编码分块大小,单位为像素(默认:1024)
- 同时应用于高度和宽度
- 值越小,显存占用越低,但处理时间可能会增加
encode_tile_overlap: 编码分块重叠区域,单位为像素(默认:128)
- 减少分块之间的可见接缝
decode_tiled: 启用分块解码以减少解码阶段的显存使用
- 如果在调试日志中“解码”阶段出现 OOM 错误,请启用
decode_tile_size: 解码分块大小,单位为像素(默认:1024)
decode_tile_overlap: 解码分块重叠区域,单位为像素(默认:128)
torch_compile_args: 连接到 SeedVR2 Torch Compile Settings 节点,可获得 15-25% 的速度提升
VAE 分块说明:
VAE 分块技术通过将大分辨率图像分割成较小的块来处理,从而降低显存需求。使用方法如下:
- 先不启用分块运行,并监控调试日志(在主节点上启用
enable_debug)。 - 如果“编码”阶段出现 OOM:
- 启用
encode_tiled。 - 如果仍然 OOM,减小
encode_tile_size(例如尝试 768、512 等)。
- 启用
- 如果“解码”阶段出现 OOM:
- 启用
decode_tiled。 - 如果仍然 OOM,减小
decode_tile_size。
- 启用
- 调整重叠区域(默认 128),如果输出中出现明显的接缝,则增大;如果处理时间过长,则减小。
高分辨率(4K)示例配置:
- encode_tiled:
True - encode_tile_size:
1024 - encode_tile_overlap:
128 - decode_tiled:
True - decode_tile_size:
1024 - decode_tile_overlap:
128
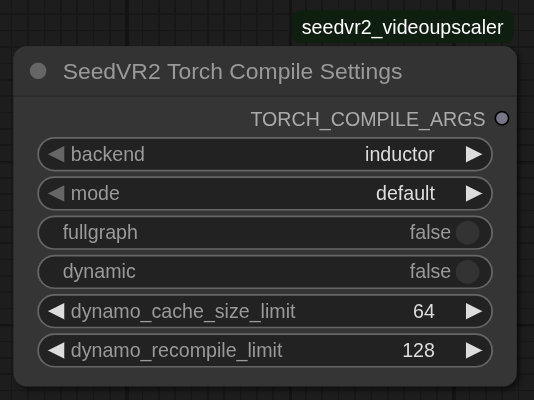
3. SeedVR2 Torch Compile 设置(可选)
配置 torch.compile 优化,可使 DiT 加速 20-40%,VAE 加速 15-25%。
要求:
- PyTorch 2.0+
- Triton(用于 inductor 后端)
参数:
backend: 编译后端
inductor: 使用 Triton 生成内核并进行融合的完整优化(推荐)cudagraphs: 使用 CUDA 图的轻量级封装,无内核优化
mode: 优化级别(编译时间 vs 运行时性能)
default: 快速编译且有良好加速效果(开发阶段推荐)reduce-overhead: 开销更低,针对小型模型优化max-autotune: 编译最慢,运行时性能最佳(生产环境推荐)max-autotune-no-cudagraphs: 类似 max-autotune,但不使用 CUDA 图
fullgraph: 将整个模型编译为单个图,不允许中断
False: 允许图中断以提高兼容性(默认,推荐)True: 强制不允许中断以实现最大优化(可能因动态形状而失败)
dynamic: 处理不同输入形状而不重新编译
False: 针对精确输入形状进行优化(默认)True: 创建可适应形状变化的动态内核(在处理不同分辨率或批量大小时启用)
dynamo_cache_size_limit: 每个函数最多缓存的编译版本数(默认:64)
- 数值越高,占用内存越多;数值越低,重新编译次数越多。
dynamo_recompile_limit: 在回退到 eager 模式之前的最大重新编译次数(默认:128)
- 安全限制,防止编译循环。
使用方法:
- 将此节点添加到您的工作流中。
- 将其输出连接到 DiT 和/或 VAE 加载节点的
torch_compile_args输入。 - 第一次运行会较慢(因为需要编译),后续运行会快得多。
适用场景:
- torch.compile 只有在处理 多批次、长视频或大量分块 时才有意义。
- 对于单张图片或短片段,编译时间会超过速度提升带来的收益。
- 最适合批量处理工作流或长视频。
推荐设置:
- 开发/测试阶段:
mode=default,backend=inductor,fullgraph=False。 - 生产阶段:
mode=max-autotune,backend=inductor,fullgraph=False。
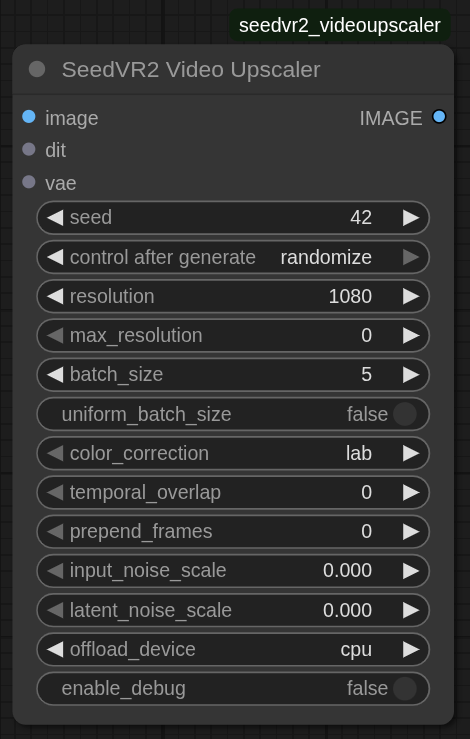
4. SeedVR2 视频超分辨率(主节点)
主要的超分辨率节点,使用 DiT 和 VAE 模型处理视频帧。
所需输入:
- image: 输入视频帧,以图像批次形式提供(RGB 或 RGBA 格式)。
- dit: 来自 SeedVR2 (Down)Load DiT Model 节点的 DiT 模型配置。
- vae: 来自 SeedVR2 (Down)Load VAE Model 节点的 VAE 模型配置。
参数:
seed: 随机种子,用于生成结果的可重复性(默认:42)。
- 相同的种子和输入会产生完全相同的输出。
resolution: 目标分辨率,以短边像素数表示(默认:1080)。
- 自动保持宽高比。
max_resolution: 任意边的最大分辨率(默认:0 = 无限制)。
- 如果超过此限制,会自动缩小分辨率以防止 OOM。
batch_size: 每批处理的帧数(默认:5)。
- 关键要求:必须符合 4n+1 公式(1, 5, 9, 13, 17, 21, 25, …)。
- 原因:模型利用这些帧进行时间一致性计算。
- 至少 5 帧才能保证时间一致性:仅当处理单张图片或不需要时间一致性时,才可使用 1 帧。
- 理想情况下匹配镜头长度:为了获得最佳效果,应将 batch_size 设置为与镜头长度一致(例如,batch_size=21 表示一个 20 帧的镜头)。
- 显存影响:batch_size 越大,质量和速度越好,但需要更多显存。
- 如果 batch_size=5 时出现 OOM:请先尝试优化手段(模型卸载、BlockSwap、GGUF 模型等),再考虑降低 batch_size 或输入分辨率,因为这些会直接影响质量。
uniform_batch_size(默认:False):
- 将最后一组补足至
batch_size大小,以实现统一处理。 - 防止当最后一组明显小于其他组时产生时间伪影。
- 例如,45 帧使用
batch_size=33时,会生成 [33, 33] 而不是 [33, 12]。 - 建议在使用较大 batch_size 且视频长度不是
batch_size的整数倍时启用。 - 会略微增加显存占用,但能确保所有批次之间的时间连贯性一致。
- 将最后一组补足至
temporal_overlap: 批次之间的重叠帧数(默认:0)。
- 用于批次间的混合,以减少时间伪影。
- 范围:0-16 帧。
prepend_frames: 预置帧数(默认:0)。
- 在视频开头预置反向帧,以减少开头的伪影。
- 处理完成后会自动移除。
- 范围:0-32 帧。
color_correction: 色彩校正方法(默认值为 "wavelet")
lab: 完整的感知色彩匹配,同时保留细节(推荐用于实现与原图最高的保真度)wavelet: 基于频率的自然色彩,能很好地保留细节wavelet_adaptive: 小波基底结合针对性的饱和度校正hsv: 基于色相条件的饱和度匹配adain: 统计风格迁移none: 不进行色彩校正
input_noise_scale: 输入噪声注入比例 0.0–1.0(默认值为 0.0)
- 向输入帧添加噪声,以减少超高分辨率下的伪影
- 如果在高输出分辨率下出现伪影,可尝试设置为 0.1–0.3
latent_noise_scale: 隐空间噪声比例 0.0–1.0(默认值为 0.0)
- 在扩散过程中添加噪声,可以柔化过度的细节
- 如果 input_noise 无效,可尝试设置为 0.05–0.15
offload_device: 用于存储处理阶段之间中间张量的设备(默认值为 "cpu")
none: 所有张量保留在推理设备上(速度最快,但显存占用最高)cpu: 将张量卸载到系统内存(推荐用于长视频,传输速度较慢)cuda:X: 将张量卸载到另一块 GPU 上(如果有可用资源,效果较好,比 CPU 快)
enable_debug: 启用详细调试日志记录(默认值为 False)
- 显示内存使用情况、计时信息和处理细节
- 强烈建议启用此选项以排查 OOM 问题
输出:
- 应用了色彩校正的超分辨率视频帧
- 格式(RGB/RGBA)与输入一致
- 取值范围 [0, 1] 归一化,以兼容 ComfyUI
典型工作流设置
基础工作流(高显存 – 24GB+):
加载视频帧
↓
SeedVR2 加载 DiT 模型
├─ model: seedvr2_ema_3b_fp16.safetensors
└─ device: cuda:0
↓
SeedVR2 加载 VAE 模型
├─ model: ema_vae_fp16.safetensors
└─ device: cuda:0
↓
SeedVR2 视频超分辨率器
├─ batch_size: 21
└─ resolution: 1080
↓
保存视频/帧
低显存工作流(8–12GB):
加载视频帧
↓
SeedVR2 加载 DiT 模型
├─ model: seedvr2_ema_3b-Q8_0.gguf
├─ device: cuda:0
├─ offload_device: cpu
├─ blocks_to_swap: 32
└─ swap_io_components: True
↓
SeedVR2 加载 VAE 模型
├─ model: ema_vae_fp16.safetensors
├─ device: cuda:0
├─ encode_tiled: True
└─ decode_tiled: True
↓
SeedVR2 视频超分辨率器
├─ batch_size: 5
└─ resolution: 720
↓
保存视频/帧
高性能工作流(24GB+,配合 torch.compile):
加载视频帧
↓
SeedVR2 Torch Compile 设置
├─ mode: max-autotune
└─ backend: inductor
↓
SeedVR2 加载 DiT 模型
├─ model: seedvr2_ema_7b_sharp_fp16.safetensors
├─ device: cuda:0
└─ torch_compile_args: connected
↓
SeedVR2 加载 VAE 模型
├─ model: ema_vae_fp16.safetensors
├─ device: cuda:0
└─ torch_compile_args: connected
↓
SeedVR2 视频超分辨率器
├─ batch_size: 81
└─ resolution: 1080
↓
保存视频/帧
🖥️ 独立运行(CLI)
独立 CLI 提供强大的批处理能力,支持多 GPU,并具备复杂的优化选项。
前置条件
根据您的安装选择合适的设置:
选项 1:已安装 ComfyUI 和 SeedVR2
如果您已经通过 ComfyUI 安装指南 将 SeedVR2 作为 ComfyUI 的一部分安装好了,可以直接使用 CLI:
# 进入您的 ComfyUI 目录
cd ComfyUI
# 使用独立 Python 运行 CLI(显示帮助信息)
# Windows:
.venv\Scripts\python.exe custom_nodes\seedvr2_videoupscaler\inference_cli.py --help
# Linux/macOS:
.venv/bin/python custom_nodes/seedvr2_videoupscaler/inference_cli.py --help
请跳至下方的 命令行使用说明。
选项 2:独立安装(无需 ComfyUI)
如果您希望在不安装 ComfyUI 的情况下使用 CLI,请按照以下步骤操作:
- 安装 uv(现代 Python 包管理工具):
# Windows
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
# macOS 和 Linux
curl -LsSf https://astral.sh/uv/install.sh | sh
- 克隆仓库:
git clone https://github.com/numz/ComfyUI-SeedVR2_VideoUpscaler.git seedvr2_videoupscaler
cd seedvr2_videoupscaler
- 创建虚拟环境并安装依赖:
# 创建 Python 3.13 的虚拟环境
uv venv --python 3.13
# 激活虚拟环境
# Windows:
.venv\Scripts\activate
# Linux/macOS:
source .venv/bin/activate
# 安装支持 CUDA 的 PyTorch
# 根据您的环境查看相应命令:https://pytorch.org/get-started/locally/
uv pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu130
# 安装 SeedVR2 的依赖
uv pip install -r requirements.txt
# 运行 CLI(显示帮助信息)
# Windows:
.venv\Scripts\python.exe inference_cli.py --help
# Linux/macOS:
.venv/bin/python inference_cli.py --help
命令行使用说明
CLI 提供了针对单 GPU、多 GPU 以及批处理工作流的全面选项。
基本使用示例:
# 基本图像超分辨率
python inference_cli.py image.jpg
# 基本视频超分辨率,带时间一致性
python inference_cli.py video.mp4 --resolution 720 --batch_size 33
# 长视频流式处理模式(内存高效),输出 10 位视频(需 FFMPEG)
# 每次处理 330 帧,避免将整个视频加载到内存中
# 使用 --temporal_overlap 确保各片段之间的平滑过渡
python inference_cli.py long_video.mp4 \
--resolution 1080 \
--batch_size 33 \
--chunk_size 330 \
--temporal_overlap 3 \
--video_backend ffmpeg \
--10bit
# 多 GPU 处理,带时间重叠
python inference_cli.py video.mp4 \
--cuda_device 0,1 \
--resolution 1080 \
--batch_size 81 \
--uniform_batch_size \
--temporal_overlap 3 \
--prepend_frames 4
# 低显存优化(8GB)
python inference_cli.py image.png \
--dit_model seedvr2_ema_3b-Q8_0.gguf \
--resolution 1080 \
--blocks_to_swap 32 \
--swap_io_components \
--dit_offload_device cpu \
--vae_offload_device cpu
# 高分辨率,VAE 分块处理
python inference_cli.py video.mp4 \
--resolution 1440 \
--batch_size 31 \
--uniform_batch_size \
--temporal_overlap 3 \
--vae_encode_tiled \
--vae_decode_tiled
# 目录批量处理,带模型缓存
python inference_cli.py media_folder/ \
--output processed/ \
--cuda_device 0 \
--cache_dit \
--cache_vae \
--dit_offload_device cpu \
--vae_offload_device cpu \
--resolution 1080 \
--max_resolution 1920
命令行参数
输入/输出:
<input>:输入文件(.mp4、.avi、.png、.jpg 等)或目录--output:输出路径(默认:在 'output/' 目录中自动生成)--output_format:输出格式:'mp4'(视频)或 'png'(图像序列)。默认:根据输入类型自动检测--video_backend:视频编码后端:'opencv'(默认)或 'ffmpeg'(需在 PATH 中包含 ffmpeg)--10bit:使用 x265 编码器和 yuv420p10le 像素格式保存 10 位视频(可减少渐变中的色带现象)。若不启用此标志,ffmpeg 将使用 x264(yuv420p)以实现最大兼容性。需配合 --video_backend ffmpeg 使用--model_dir:模型目录(默认:./models/SEEDVR2)
模型选择:
--dit_model:要使用的 DiT 模型。选项包括 3B/7B 的 fp16/fp8/GGUF 变体(默认:3B FP8)
处理参数:
--resolution:目标短边分辨率(像素),默认为 1080--max_resolution:任意边的最大分辨率。超过该值时会进行缩放。0 表示无限制(默认:0)--batch_size:每批处理的帧数(必须符合 4n+1 规则:1、5、9、13、17、21…)。理想情况下应与镜头长度匹配,以获得最佳时间一致性(默认:5)--seed:用于复现结果的随机种子(默认:42)--skip_first_frames:跳过前 N 帧(默认:0)--load_cap:从视频中最多加载的总帧数。0 表示加载全部(默认:0)--chunk_size:流式处理模式下的每块帧数。当大于 0 时,视频将以内存受限的 N 帧块进行处理,每处理完一块即写入,再加载下一块。这对于可能超出内存容量的长视频至关重要。建议与--temporal_overlap配合使用,以实现平滑的块间过渡。0 表示一次性加载所有帧(默认:0)--prepend_frames:在视频开头添加 N 帧反转帧,以减少起始处的伪影(处理后会自动移除)(默认:0)--temporal_overlap:批次或 GPU 之间用于平滑融合的重叠帧数(默认:0)
质量控制:
--color_correction:颜色校正方法:'lab'(感知型,推荐)、'wavelet'、'wavelet_adaptive'、'hsv'、'adain' 或 'none'(默认:lab)--input_noise_scale:输入噪声注入强度(0.0–1.0)。可在高分辨率下减少伪影(默认:0.0)--latent_noise_scale:潜在空间噪声强度(0.0–1.0)。必要时可柔化细节(默认:0.0)
内存管理:
--dit_offload_device:用于卸载 DiT 模型的设备:'none'(保留在 GPU 上)、'cpu' 或 'cuda:X'(默认:none)--vae_offload_device:用于卸载 VAE 模型的设备:'none'、'cpu' 或 'cuda:X'(默认:none)--blocks_to_swap:要交换的 Transformer 块数量(0=禁用,3B:0–32,7B:0–36)。需配合 dit_offload_device 使用(默认:0)。macOS 系统不支持此功能。--swap_io_components:卸载 I/O 组件以进一步节省显存。需配合 dit_offload_device 使用。macOS 系统不支持此功能。
VAE 分块处理:
--vae_encode_tiled:启用 VAE 编码分块以减少编码过程中的显存占用--vae_encode_tile_size:VAE 编码分块的尺寸(像素),默认为 1024--vae_encode_tile_overlap:VAE 编码分块之间的重叠区域(像素),默认为 128--vae_decode_tiled:启用 VAE 解码分块以减少解码过程中的显存占用--vae_decode_tile_size:VAE 解码分块的尺寸(像素),默认为 1024--vae_decode_tile_overlap:VAE 解码分块之间的重叠区域(像素),默认为 128--tile_debug:可视化分块:'false'(默认)、'encode' 或 'decode'
性能优化:
--allow_vram_overflow:允许显存溢出至系统内存。可防止 OOM 错误,但可能导致严重性能下降--attention_mode:注意力机制后端:'sdpa'(默认)、'flash_attn_2'(Ampere+)、'flash_attn_3'(Hopper+)、'sageattn_2' 或 'sageattn_3'(Blackwell)--compile_dit:为 DiT 模型启用 torch.compile(速度提升 20–40%,需 PyTorch 2.0+ 和 Triton)--compile_vae:为 VAE 模型启用 torch.compile(速度提升 15–25%,需 PyTorch 2.0+ 和 Triton)--compile_backend:编译后端:'inductor'(全面优化)或 'cudagraphs'(轻量级)(默认:inductor)--compile_mode:优化级别:'default'、'reduce-overhead'、'max-autotune'、'max-autotune-no-cudagraphs'(默认:default)--compile_fullgraph:将整个模型编译为单个图(速度更快但灵活性较低)(默认:False)--compile_dynamic:无需重新编译即可处理不同形状的输入(默认:False)--compile_dynamo_cache_size_limit:每个函数最多缓存的编译版本数(默认:64)--compile_dynamo_recompile_limit:在回退之前允许的最大重新编译次数(默认:128)
模型缓存(批处理):
--cache_dit:在多次生成之间将 DiT 模型保留在内存中。适用于单 GPU 目录处理或多 GPU 流式处理(--chunk_size)。需配合--dit_offload_device使用--cache_vae:在多次生成之间将 VAE 模型保留在内存中。适用于单 GPU 目录处理或多 GPU 流式处理(--chunk_size)。需配合--vae_offload_device使用
多 GPU:
--cuda_device:CUDA 设备 ID。可以是单个 ID(如 '0')或逗号分隔的列表(如 '0,1')以实现多 GPU 处理
调试:
--debug:启用详细调试日志记录
多GPU处理详解
CLI的多GPU模式采用帧级并行:视频被分割成多个片段,每个GPU独立地对各自负责的片段执行全部4个阶段(编码→超分→解码→后处理)。这种方式非常适合长视频,通过分配工作负载来缩短总处理时间。
工作原理:
- 视频帧均匀分配到各个GPU上(例如,100帧分配给2个GPU,则每个GPU处理50帧)。
- 每个GPU加载自己的模型副本,并独立处理其负责的片段。
- 当启用
--temporal_overlap时,片段之间会包含重叠帧,以实现无缝拼接。 - 最终将各GPU的结果拼接起来(并在重叠区域进行混合),生成完整的视频。
示例:100帧分配给2个GPU,temporal_overlap设置为4:
GPU 0:帧0-53(50帧基础部分 + 结尾4帧重叠,作为独立视频处理)
GPU 1:帧50-99(50帧,开头4帧重叠,作为独立视频处理)
结果:帧0-99,在过渡处平滑融合
重要注意事项:
- 每个GPU将其负责的片段当作一个单独的视频来处理,且各自进行批处理划分。
batch_size仅控制单个GPU内部的批处理大小,不会跨GPU生效。- 对于短视频(少于100帧),由于模型加载开销较大,通常使用单GPU更为高效。
- 多GPU模式会使显存占用翻倍(每个GPU都会加载完整模型),但大致可将处理时间减半。
何时使用多GPU:
- 长视频(100帧以上),分割处理能显著节省时间。
- 当你有多块显存充足的GPU时。
何时使用单GPU:
- 短视频:模型加载开销可能超过并行化带来的收益。
- 需要所有帧一起处理以保证最佳的时间一致性时。
最佳实践:
- 设置
--temporal_overlap为2-4帧,以确保GPU片段之间的平滑过渡。 - 重叠帧越多,过渡越平滑,但也会增加冗余计算量。
- 使用
--prepend_frames减少视频开头的伪影。 - 对于短视频,建议使用单GPU,并将
batch_size设置为与镜头长度一致,以获得最佳质量。
⚠️ 限制
模型限制
批处理大小约束:由于时间一致性架构的设计要求,模型的batch_size必须遵循4n+1公式(1, 5, 9, 13, 17, 21, 25, ...)。同一批次内的所有帧会同时处理以保持时间一致性,随后可通过temporal_overlap参数对不同批次进行混合。理想情况下,应将batch_size设置为与镜头长度匹配,以获得最佳质量。
性能考虑
VAE瓶颈:即使采用了优化后的DiT超分技术(BlockSwap、GGUF、torch.compile),VAE的编码/解码阶段仍可能成为性能瓶颈,尤其是在高分辨率下。VAE本身速度较慢,可以通过增大batch_size来缓解这一问题。
显存占用:尽管当前集成已支持低显存系统(8GB或更少,经过适当优化即可运行),但显存使用量会因以下因素而异:
- 输入/输出分辨率(越高,显存需求越大)。
- 批处理大小(越大,显存需求越高,但时间一致性和速度更好)。
- 模型选择(FP16 > FP8 > GGUF,显存占用依次递减)。
- 优化设置(BlockSwap和VAE分块技术可显著降低显存使用)。
速度:处理速度取决于:
- GPU性能(计算能力、显存带宽及架构世代)。
- 模型规模(3B比7B更快)。
- 批处理大小(较大的批处理可以提高每帧处理效率,从而提升整体速度)。
- 优化设置(torch.compile可带来显著加速)。
- 分辨率(分辨率越高,处理速度越慢)。
最佳实践
- 开启调试模式,以便了解显存的具体使用情况。
- 编码阶段出现OOM错误时:启用VAE编码分块功能,并减小分块尺寸。
- 超分阶段出现OOM错误时:启用BlockSwap功能,并增加
blocks_to_swap参数值。 - 解码阶段出现OOM错误时:启用VAE解码分块功能,并减小分块尺寸。
- 如果尝试上述方法后仍出现OOM错误:请降低
batch_size或分辨率。
- 如果尝试上述方法后仍出现OOM错误:请降低
- 追求最佳质量时:使用较高的
batch_size(与镜头长度匹配)、FP16模型以及LAB色彩校正。 - 追求速度时:使用FP8/GGUF模型,启用torch.compile,并在可用时使用Flash Attention。
- 在处理长视频之前,先用一段短片测试配置。
🤝 贡献
我们欢迎任何形式的贡献!非常重视社区的意见和改进。
详细的贡献指南请参阅CONTRIBUTING.md。
快速入门:
- 克隆仓库并创建分支。
- 创建你的功能分支(
git checkout -b feature/AmazingFeature)。 - 提交更改(
git commit -m 'Add some AmazingFeature')。 - 推送到分支(
git push origin feature/AmazingFeature)。 - 向main分支发起拉取请求。
获取帮助:
- YouTube:AInVFX频道
- GitHub Issues:用于报告问题和提出功能需求。
- GitHub Discussions:用于提问和社区支持。
- Discord:adrientoupet & NumZ#7184
🙏 致谢
本ComfyUI实现是由NumZ(GitHub链接)和AInVFX(Adrien Toupet,YouTube频道)合作完成的,基于字节跳动Seed团队的原始SeedVR2项目。
特别感谢我们的社区贡献者,包括naxci1、thehhmdb、s-cerevisiae、benjaminherb、cmeka、FurkanGozukara、JohnAlcatraz、lihaoyun6、Luchuanzhao、Luke2642、proxyid、q5sys,以及其他众多贡献者,感谢他们提供的改进、Bug修复和测试支持。
📜 许可证
本仓库中的代码根据Apache 2.0许可证发布,详细信息请参阅LICENSE文件。
版本历史
v2.5.232025/12/24v2.5.222025/12/13v2.5.212025/12/12v2.5.202025/12/12v2.5.192025/12/10v2.5.182025/12/09v2.5.172025/12/06v2.5.162025/12/05v2.5.152025/12/03v2.5.142025/12/01v2.5.132025/11/30v2.5.122025/11/28v2.5.112025/11/28v2.5.102025/11/13v2.5.92025/11/12v2.5.82025/11/11常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。