Deep-Photo-Enhancer
Deep-Photo-Enhancer 是一款基于 TensorFlow 实现的开源图像增强工具,源自 CVPR 2018 的焦点论文。它利用生成对抗网络(GAN)技术,能够自动将曝光不足、色彩暗淡或对比度低的原始照片,处理成具有专业摄影师修图效果的精美图片。
该工具核心解决了传统图像增强方法依赖大量“原图 - 修图后”配对数据进行训练的难题。通过引入“无配对学习”机制,Deep-Photo-Enhancer 无需严格的图像对应关系,仅利用未配对的普通照片与高质量修图样本即可进行训练,大大降低了数据准备门槛,同时能有效保留图像细节并避免过度平滑。
这款工具非常适合计算机视觉研究人员、AI 开发者以及需要批量处理图像的设计师使用。对于研究者,它提供了监督与非监督两种训练模式的完整代码及实验数据,便于深入探索 GAN 在图像处理中的应用;对于开发者,其提供的推理模型可快速集成到工作流中,实现自动化照片美化。虽然普通用户也可通过其演示网站体验效果,但要充分利用其开源特性,建议具备一定的深度学习基础。
使用场景
一位独立摄影师正在整理一批十年前用旧相机拍摄的旅行照片,准备举办一场线上回顾展,但原始文件普遍存在曝光不足、色彩灰暗和噪点明显的问题。
没有 Deep-Photo-Enhancer 时
- 必须手动在 Lightroom 中逐张调整曝光、对比度和色彩平衡,处理几百张照片需要耗费数天时间。
- 由于缺乏成对的“原图 - 精修图”训练数据,传统监督学习模型无法直接应用,难以批量自动化修复。
- 强行使用普通滤镜会导致画面失真,暗部细节丢失严重,且无法还原真实的光照氛围。
- 聘请专业修图师成本高昂,对于个人创作者而言预算难以承受。
使用 Deep-Photo-Enhancer 后
- 利用其无配对学习(Unpaired Learning)特性,直接输入低质量原图即可批量生成具有专业级光影效果的照片,效率提升数十倍。
- 基于 GAN 的生成能力智能补充暗部细节并去除噪点,同时保持图像自然纹理,避免了过度锐化或伪影。
- 模型在 HDR 数据集上训练过,能自动识别并恢复高动态范围场景,让逆光或大光比照片重现层次感。
- 无需昂贵的标注数据或人工干预,个人开发者即可在本地部署 TensorFlow 版本,零成本实现影院级画质增强。
Deep-Photo-Enhancer 通过先进的无配对生成对抗网络技术,将原本耗时费力的专业修图工作转化为高效的自动化流程,让老旧照片瞬间焕发新生。
运行环境要求
- 未说明
需要 NVIDIA GPU(基于 TensorFlow 和 GAN 架构推断),具体型号和显存大小未说明,CUDA 版本未说明
未说明

快速开始
深度照片增强器:基于GAN的无配对学习用于从照片中进行图像增强
[演示网站] [YouTube] [论文] [补充材料] [下载演示视频]
[亮点报告视频] [亮点报告PDF] [海报]


[更新 2019年6月5日] 重命名模型脚本
我在下面的下载链接中添加了rename_model.py。
[更新 2019年3月31日] 推理模型(有监督和无监督)。
下载链接:这里。代码与我在演示网站中使用的完全相同。(抱歉,我没有时间对其进行优化……)
简化教程:在TF.py中使用getInputPhoto和processImg函数。
[更新 2018年12月18日] 数据和代码(有监督和无监督)。
太多人要求我发布代码,尽管代码并不完善且像我一样“丑陋”。因此,我将我的“丑陋”代码和数据放在了这里。我还提供了有监督的代码。代码中有很多不必要的部分。我会尽快重构代码。关于数据,我们将所用图片的名称标注在了MIT-Adobe FiveK数据集上。我直接使用Lightroom将图片解码为TIF格式,并调整图片长边至512分辨率(标签图来自修图师C)。我不确定是否有权公开我们从Flickr收集的HDR数据集,因此只提供了这些图片的ID。您可以根据ID下载这些图片。(代码是在TensorFlow 0.12版本上运行的。代码中的A-WGAN部分并未实施降低lambda值的操作,因为当时的初始lambda值已经相对较小。)
一些有用的问题:#6, #16, #18, #24, #27, #38, #39
结果
| 方法 | 描述 |
|---|---|
| 标签 | 由MIT-Adobe 5K数据集的摄影师修图而成 [1] |
| 我们(HDR) | 我们基于无配对数据训练的HDR模型 |
| 我们(SL) | 我们基于MIT-Adobe 5K数据集的配对数据训练的模型(有监督学习) |
| 我们(UL) | 我们基于MIT-Adobe 5K数据集的无配对数据训练的模型 |
| CycleGAN(HDR) | CycleGAN基于我们的HDR数据集训练的无配对模型 [2] |
| DPED_device | DPED基于特定设备的配对数据训练的模型(有监督学习) [3] |
| CLHE | 来自[4]的启发式方法 |
| NPEA | 来自[5]的启发式方法 |
| FLLF | 来自[6]的启发式方法 |
| 输入 | 标签 | 我们的(HDR) |
|---|---|---|
 |
 |
 |
| 我们的(SL) | 我们的(UL) | CycleGAN(HDR) |
 |
 |
 |
| DPED_iPhone6 | DPED_iPhone7 | DPED_Nexus5x |
 |
 |
 |
| CLHE | NPEA | FLLF |
 |
 |
 |
| 输入(MIT-Adobe) | 我们的(HDR) | DPED_iPhone7 | CLHE |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
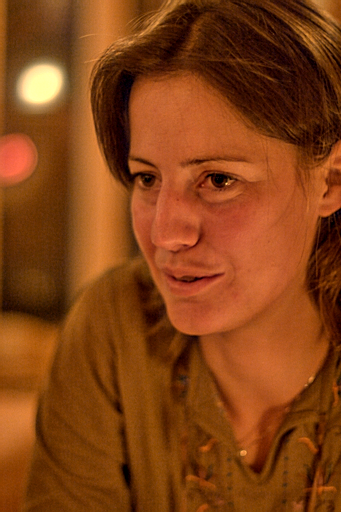 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
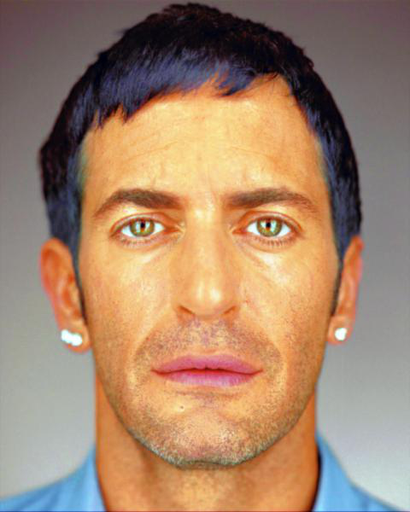
| 输入(互联网) | 我们的(HDR) | DPED_iPhone7 | CLHE |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
用户研究
| 偏好矩阵 (20名参与者和20张图像,采用成对比较法) |
||||||
| CycleGAN | DPED | NPEA | CLHE | 我们的方法 | 总计 | |
|---|---|---|---|---|---|---|
| CycleGAN | - | 32 | 27 | 23 | 11 | 93 |
| DPED | 368 | - | 141 | 119 | 29 | 657 |
| NPEA | 373 | 259 | - | 142 | 50 | 824 |
| CLHE | 377 | 281 | 258 | - | 77 | 993 |
| 我们的方法 | 389 | 371 | 350 | 323 | - | 1433 |
| 我们在HDR图像上训练的模型排名第一,CLHE位居第二。在将我们的模型与CLHE进行比较时,81%的用户(400人中有323人)更倾向于我们的结果。 | ||||||
全局U-Net、A-WGAN和iBN的其他应用
本文提出了三项改进:全局U-Net、自适应WGAN(A-WGAN)和个体批归一化(iBN)。这些改进通常能够提升效果;对于某些应用而言,改进幅度足以跨越门槛并取得成功。我们已将这些技术应用于其他一些场景。
| 输入 | 真实标签 | 全局U-Net | U-Net |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| 对于全局U-Net,我们将其应用于牛津-IIIT宠物数据集上的宠物三元图分割任务。U-Net和全局U-Net的准确率分别为0.8759和0.8905。 | |||
| λ = 0.1 | λ = 10 | λ = 1000 | |
|---|---|---|---|
| WGAN-GP |  |
 |
 |
| A-WGAN |  |
 |
 |
| 在不同的λ值下,WGAN-GP的表现可能成功也可能失败。而提出的A-WGAN对λ的依赖性较低,在三个λ值下均取得了成功。 | |||
| 男性 -> 女性 | 女性 -> 男性 | ||||
|---|---|---|---|---|---|
| 输入 | 使用iBN | 不使用iBN | 输入 | 使用iBN | 不使用iBN |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| 我们将双向GAN应用于人脸图像的性别转换任务。如图所示,双向GAN在此任务中未能成功,但在采用我们提出的iBN后成功实现了目标。 | |||||
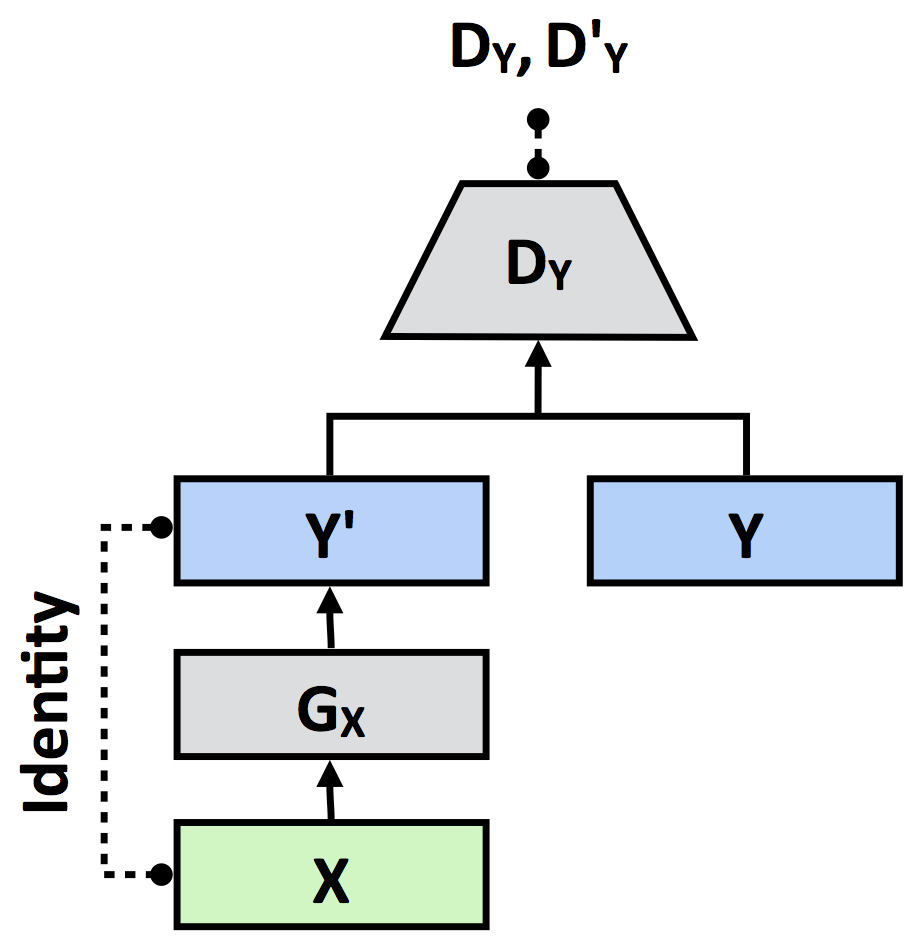
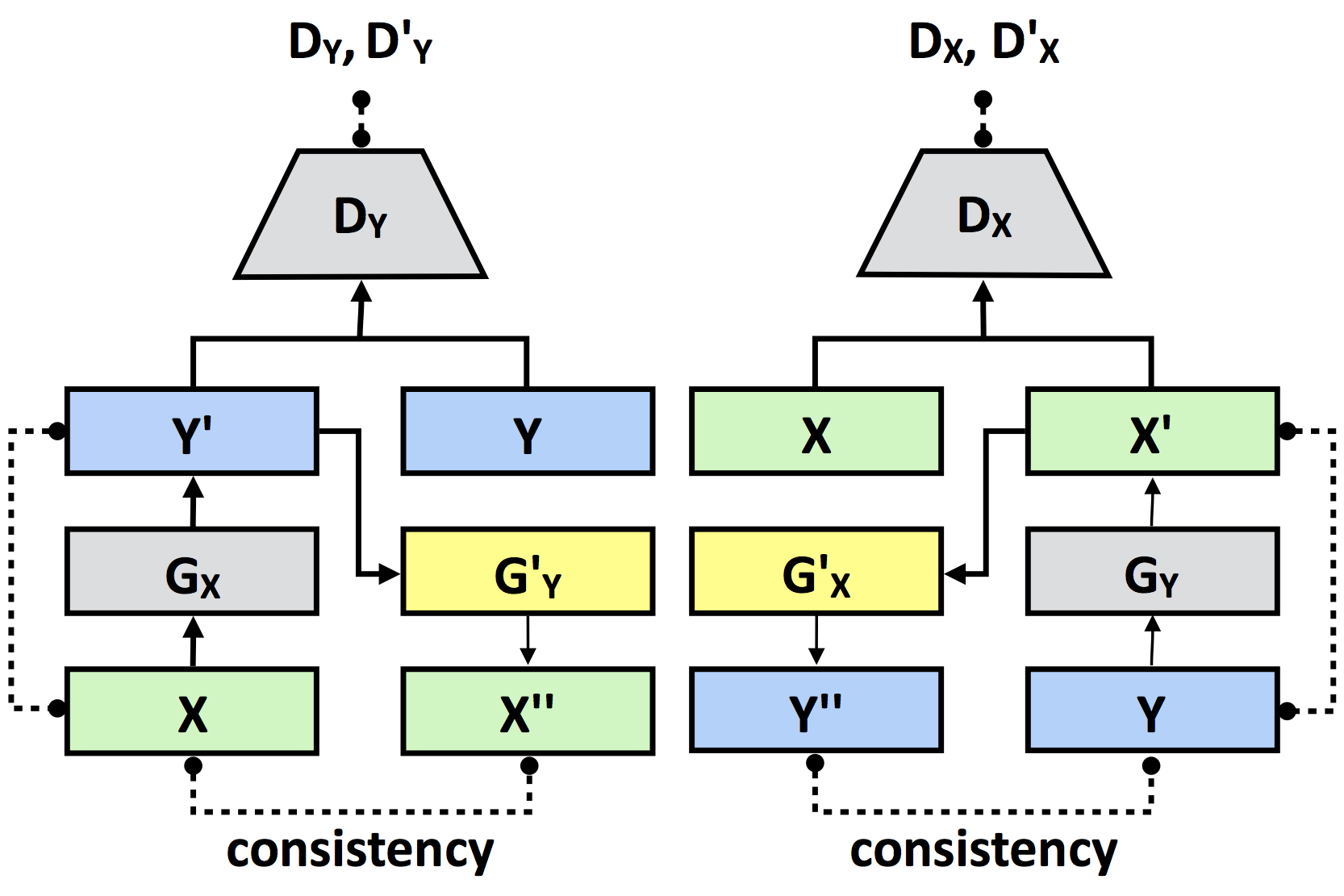
架构
| 生成器 | |
|---|---|
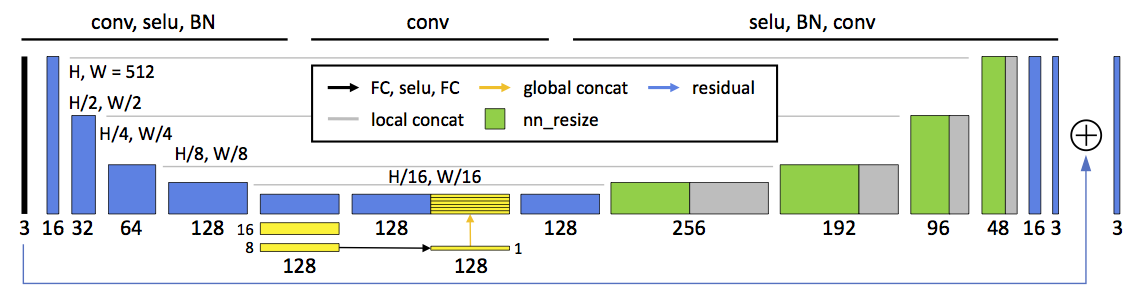 |
|
| 判别器 | |
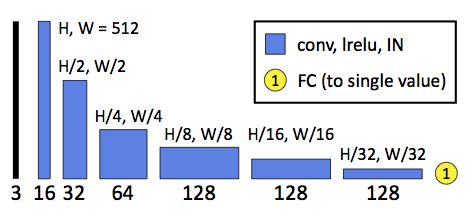 |
|
| 单向GAN | 双向GAN |
 |
 |
出版物
深度照片增强器:基于生成对抗网络的无配对摄影图像增强学习。IEEE 国际计算机视觉与模式识别会议 2018 年论文集(CVPR 2018),即将发表,2018 年 6 月,美国盐湖城。
引用格式
@INPROCEEDINGS{Chen:2018:DPE,
AUTHOR = {Yu-Sheng Chen and Yu-Ching Wang and Man-Hsin Kao and Yung-Yu Chuang},
TITLE = {Deep Photo Enhancer: Unpaired Learning for Image Enhancement from Photographs with GANs},
YEAR = {2018},
MONTH = {June},
BOOKTITLE = {Proceedings of IEEE International Conference on Computer Vision and Pattern Recognition (CVPR 2018)},
PAGES = {6306--6314},
LOCATION = {Salt Lake City},
}
参考文献
- Bychkovsky, V., Paris, S., Chan, E., Durand, F.: 利用输入/输出图像对数据库学习摄影全局色调调整。载于 2011 年 IEEE 计算机视觉与模式识别会议论文集,第 97–104 页。CVPR'11(2011)
- Zhu, J. Y., Park, T., Isola, P., Efros, A. A.: 基于循环一致对抗网络的无配对图像到图像转换。载于 2017 年 IEEE 国际计算机视觉会议论文集,第 2242–2251 页。ICCV'17(2017)
- Ignatov, A., Kobyshev, N., Vanhoey, K., Timofte, R., Van Gool, L.: 使用深度卷积网络在移动设备上实现单反相机质量的照片。载于 2017 年 IEEE 国际计算机视觉会议论文集,第 3277–3285 页。ICCV'17(2017)
- Wang, S., Cho, W., Jang, J., Abidi, M. A., Paik, J.: 基于对比度的饱和度调整用于户外图像增强。JOSA A,第 2532–2542 页。(2017)
- Wang, S., Zheng, J., Hu, H. M., Li, B.: 保留自然感的非均匀光照图像增强算法。IEEE 图像处理汇刊,第 3538–3548 页。TIP'13(2013)
- Aubry, M., Paris, S., Hasinoff, S. W., Kautz, J., Durand, F.: 快速局部拉普拉斯滤波器:理论与应用。ACM 图形学汇刊,第 167 号文章。TOG'14(2014)
联系方式
如有任何问题,欢迎随时联系我(陈宇升 nothinglo@cmlab.csie.ntu.edu.tw)。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。