meme-search
meme-search 是一款开源的表情包搜索引擎,旨在帮助用户高效管理和检索本地存储的海量表情包。面对日益增多的图片素材,传统文件夹分类往往难以快速定位特定内容,而 meme-search 利用人工智能技术,自动提取图片中的文字并分析视觉语义,建立本地索引。用户只需输入自然语言描述,即可通过语义搜索瞬间找到目标表情包,彻底解决了“存图容易找图难”的痛点。
该工具最大的亮点在于完全本地化运行。从图像文字识别、向量嵌入到搜索匹配,所有数据处理均在用户自己的设备上完成,无需上传云端,充分保障了隐私安全与数据主权。它支持多种规模的图像转文本模型,用户可根据硬件配置灵活选择,同时提供 Docker 容器化部署方案,简化了安装与维护流程。此外,它还具备批量生成、拖拽上传、深色模式及自定义筛选等实用功能。
meme-search 非常适合注重隐私的技术爱好者、开发者以及拥有大量表情包收藏的普通用户使用。对于希望搭建私有化媒体库的个人或团队,它也是一个轻量级且强大的解决方案。无论是为了日常聊天快速调图,还是进行本地图像数据的语义分析实验,meme-search 都能提供流畅、安全的体验。
使用场景
某社区运营团队需要管理数万张历史积累的梗图(Meme),以便在社交媒体热点出现时能迅速找到匹配素材进行响应。
没有 meme-search 时
- 检索效率极低:只能依靠人工记忆或按文件名查找,面对海量图片库,找一张特定主题的梗图往往需要花费半小时以上翻找文件夹。
- 内容无法识别:图片内的文字信息未被提取,无法通过搜索图中的“关键台词”或“具体情节”来定位图片,导致大量优质素材沉睡。
- 语义匹配缺失:无法理解图片的深层含义,例如搜索“尴尬的沉默”无法关联到画面中人物面面相觑但无文字说明的图片。
- 隐私与成本顾虑:若使用在线 AI 服务批量处理图片,不仅面临高昂的 API 调用费用,还存在将内部素材上传至第三方服务器的数据泄露风险。
使用 meme-search 后
- 秒级精准定位:利用本地部署的 AI 模型建立索引,运营人员输入关键词即可在毫秒级时间内从万张图片中锁定目标,响应速度提升百倍。
- 图文双重索引:meme-search 自动提取图片内文字并结合视觉内容进行向量化,无论是搜台词还是搜画面描述,都能准确召回相关结果。
- 智能语义理解:基于大模型的语义搜索能力,即使不记得具体文字,仅描述“想表达无奈但好笑”的场景,也能智能推荐最贴切的梗图。
- 安全低成本运行:所有图像转文本、向量嵌入及搜索过程均在本地 Docker 容器中完成,无需联网上传数据,既保护了素材隐私又节省了云端算力开支。
meme-search 通过将非结构化的图片库转化为可语义交互的智能资产,让创意团队从繁琐的文件管理中解放出来,真正实现“梗随心动”。
运行环境要求
- Linux
- macOS
- Windows
- 非必需
- 支持 CPU 运行(推荐使用 Moondream2-INT8 模型,显存需求约 1.5-2GB)
- 若使用较大模型(如 Moondream2 全精度),可能需要约 5GB 显存
- 未指定具体 CUDA 版本
最低约 2GB (使用量化模型且仅 CPU),推荐 8GB+ 以流畅运行较大模型及数据库服务

快速开始
一款用 Python、Ruby 和 Docker 自托管的迷因搜索引擎
利用 AI 根据内容和文本为你的迷因建立索引,让你轻松检索,尽享迷因大战的乐趣。
所有处理——从图像转文本提取、向量嵌入到搜索——均在本地完成。
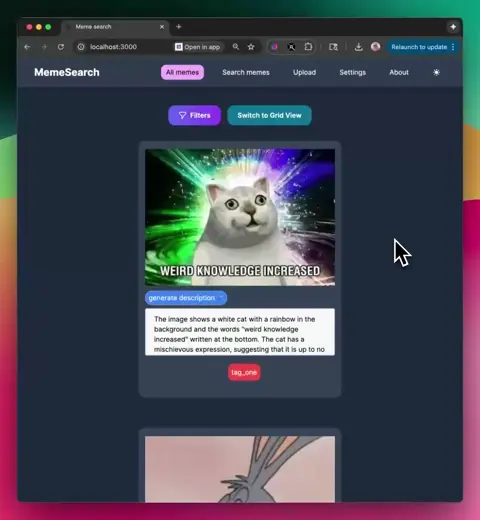
本仓库包含代码、教程笔记本以及用于索引、搜索和基于语义搜索内容与文本轻松检索迷因的应用程序。
本 README 剩余部分的目录:
迷因搜索
功能
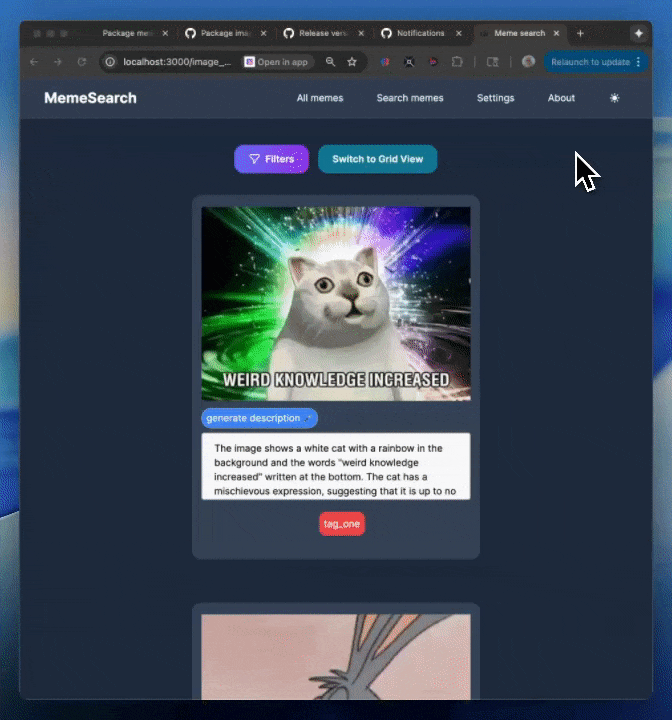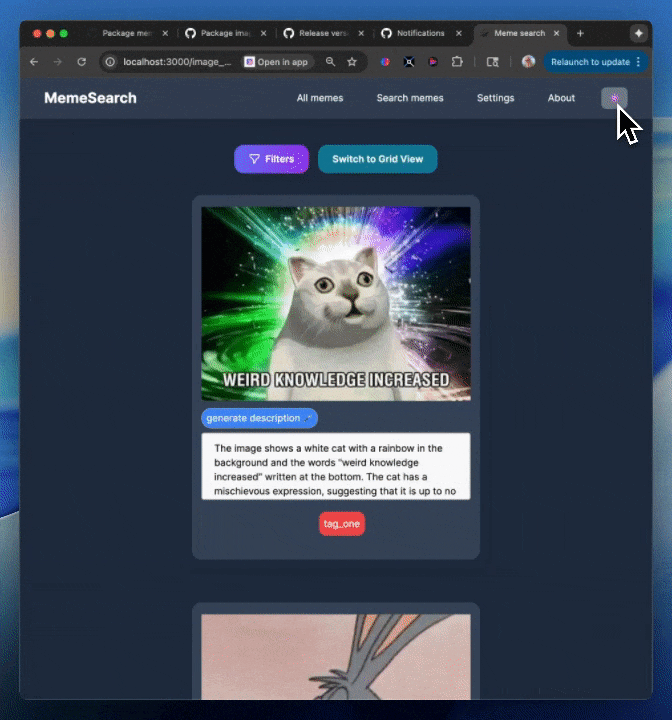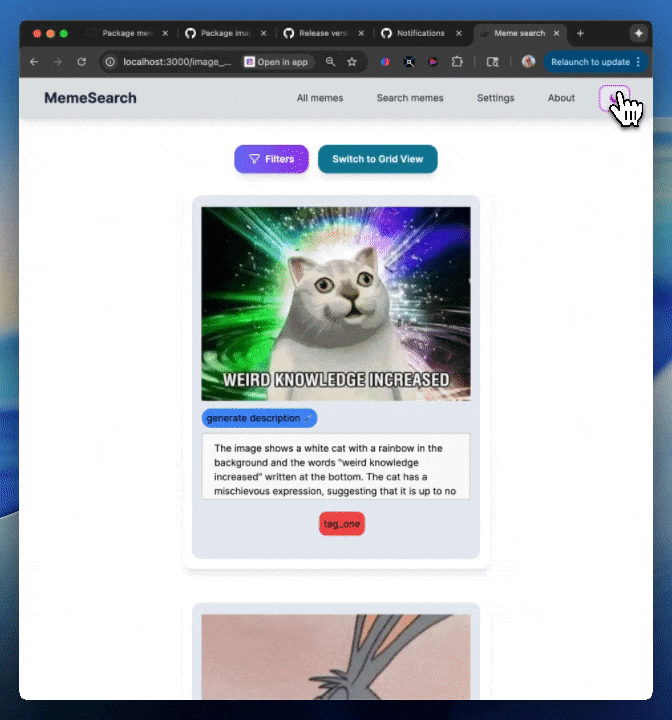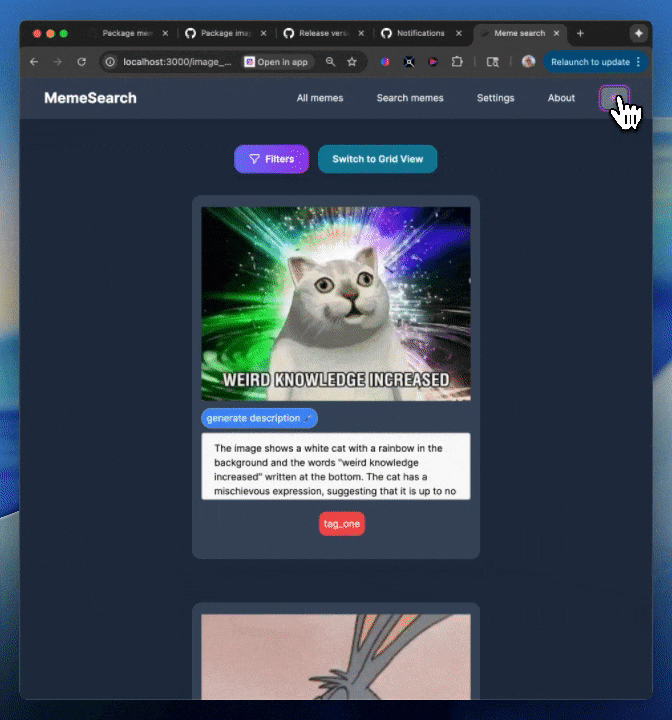
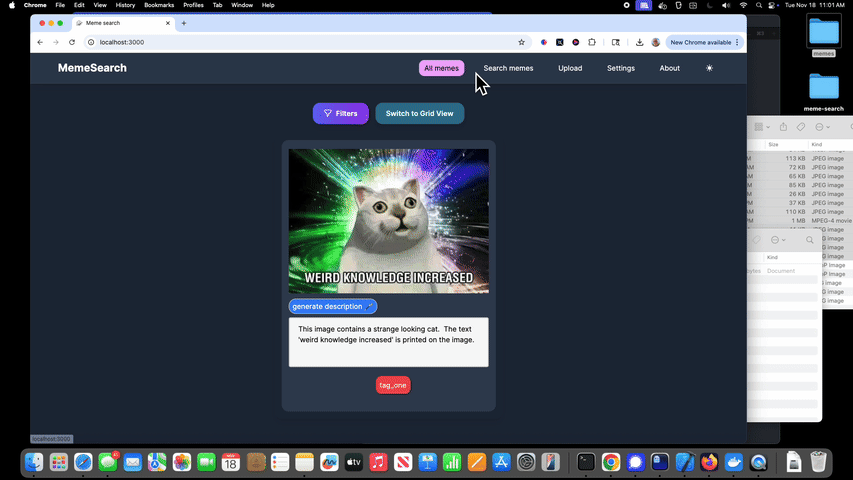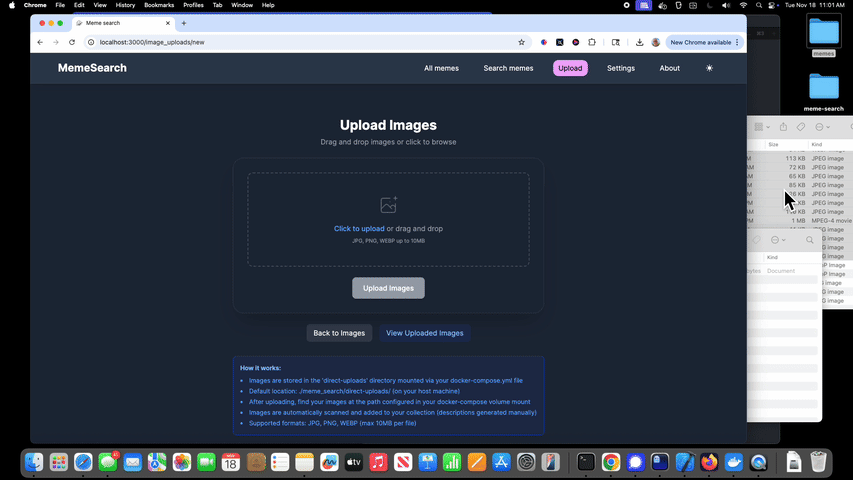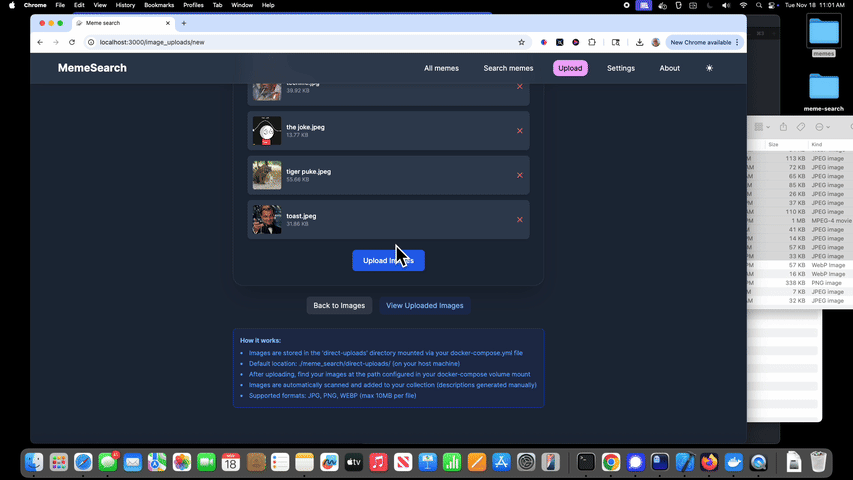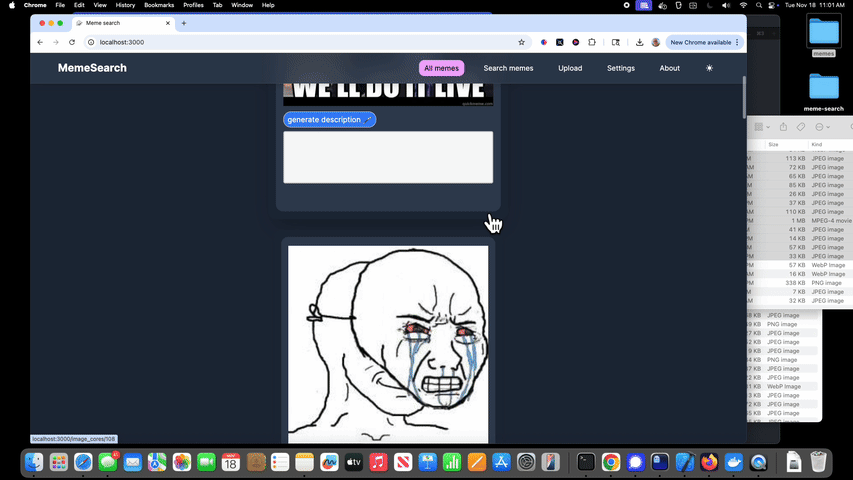
迷因搜索的功能包括:
多种图像转文本模型
根据你的需求和资源选择合适的图像转文本模型——从小型(约 2 亿参数)到大型(约 20 亿参数)。
目前迷因搜索可用的图像转文本模型如下,以默认模型开始:
- Florence-2-base —— 微软开发的一系列流行的轻量级视觉语言模型,包括 2.5 亿参数的基础版和 7 亿参数的大版。*这是迷因搜索中使用的默认模型*。
- Florence-2-large —— Florence-2 系列中的 7 亿参数视觉语言模型变体。
- SmolVLM-256 —— Hugging Face 开发的 2.56 亿参数视觉语言模型。
- SmolVLM-500 —— Hugging Face 开发的 5 亿参数视觉语言模型。
- Moondream2 —— 用于图像描述或提取图像文本的 20 亿参数视觉语言模型。
- Moondream2-INT8 —— 针对内存受限硬件的 Moondream2 INT8 量化版本。可在几乎不损失质量的情况下将内存占用从约 5GB 降至 1.5–2GB,非常适合仅配备 CPU 的设备。
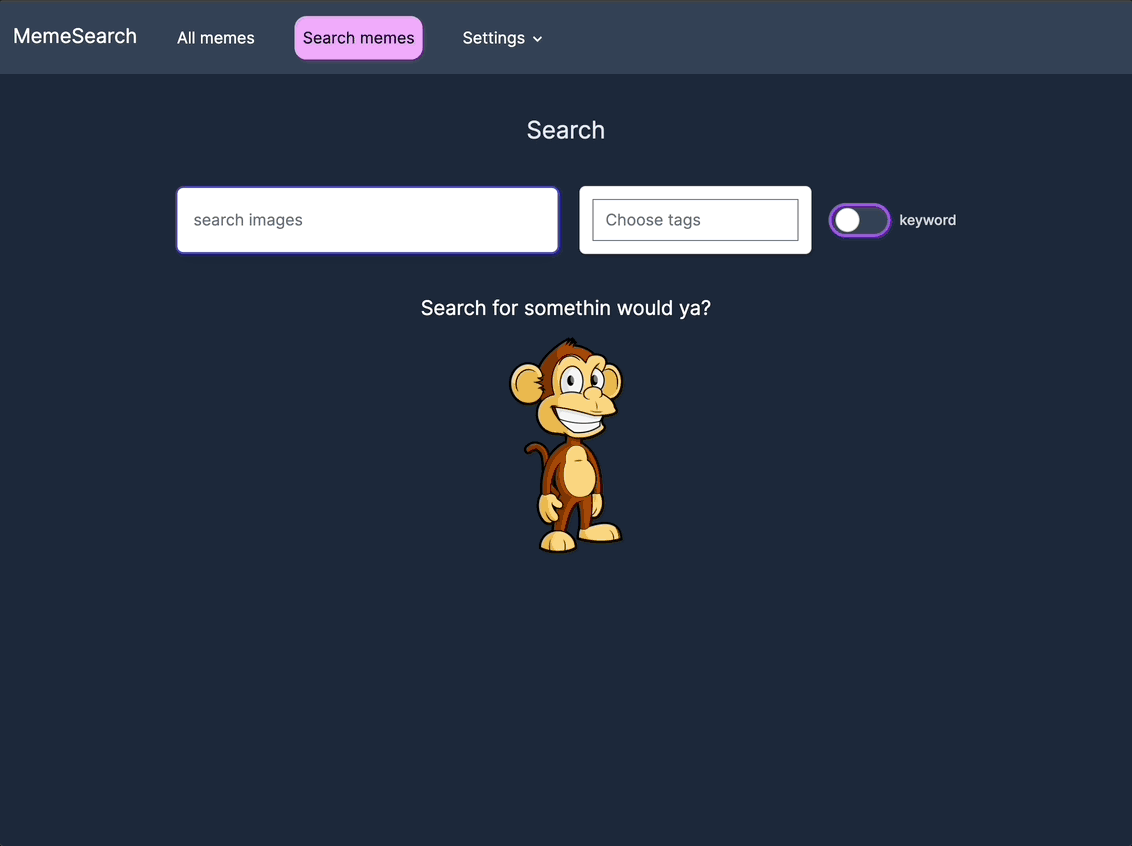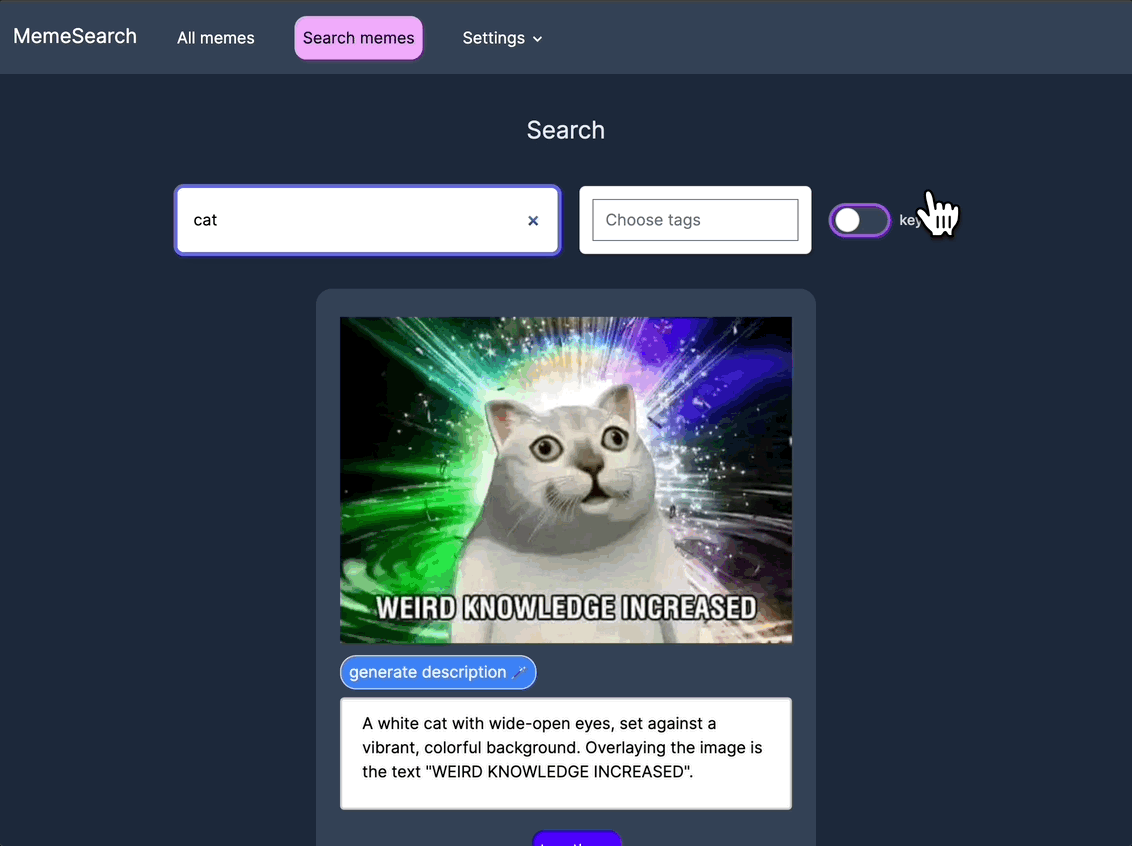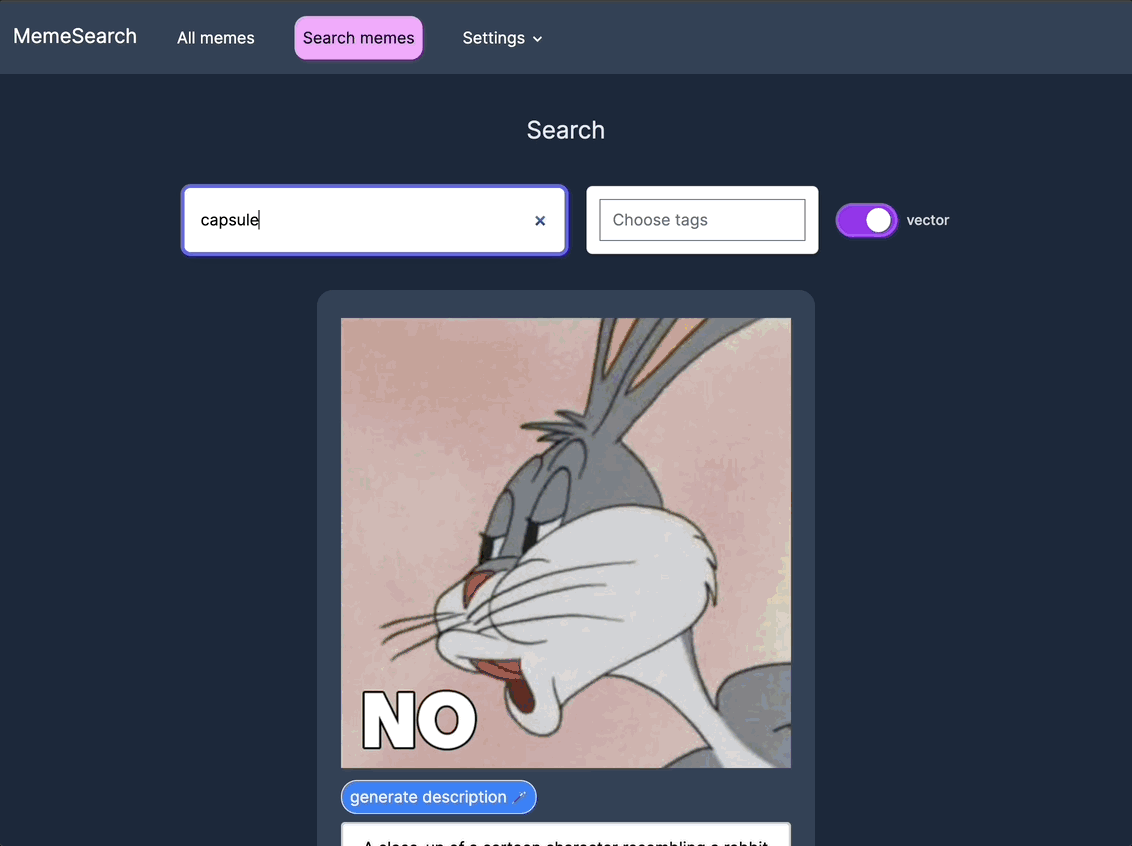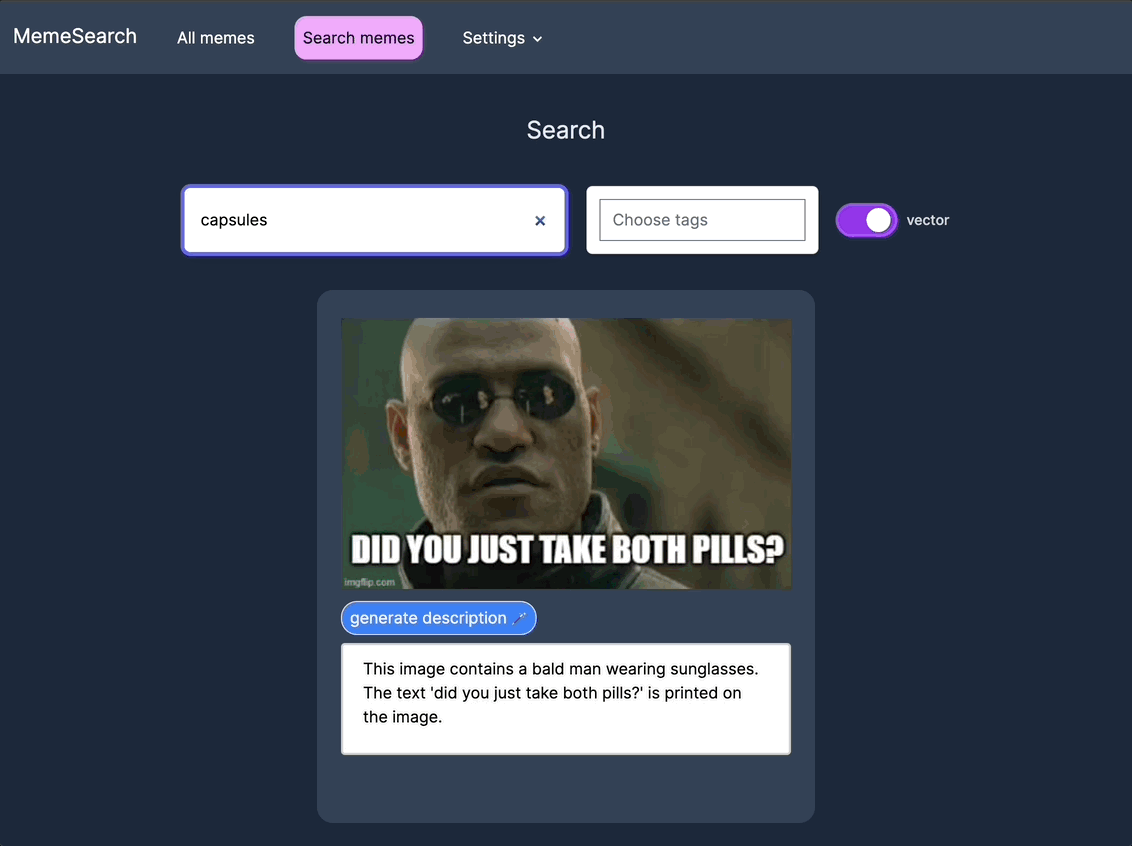
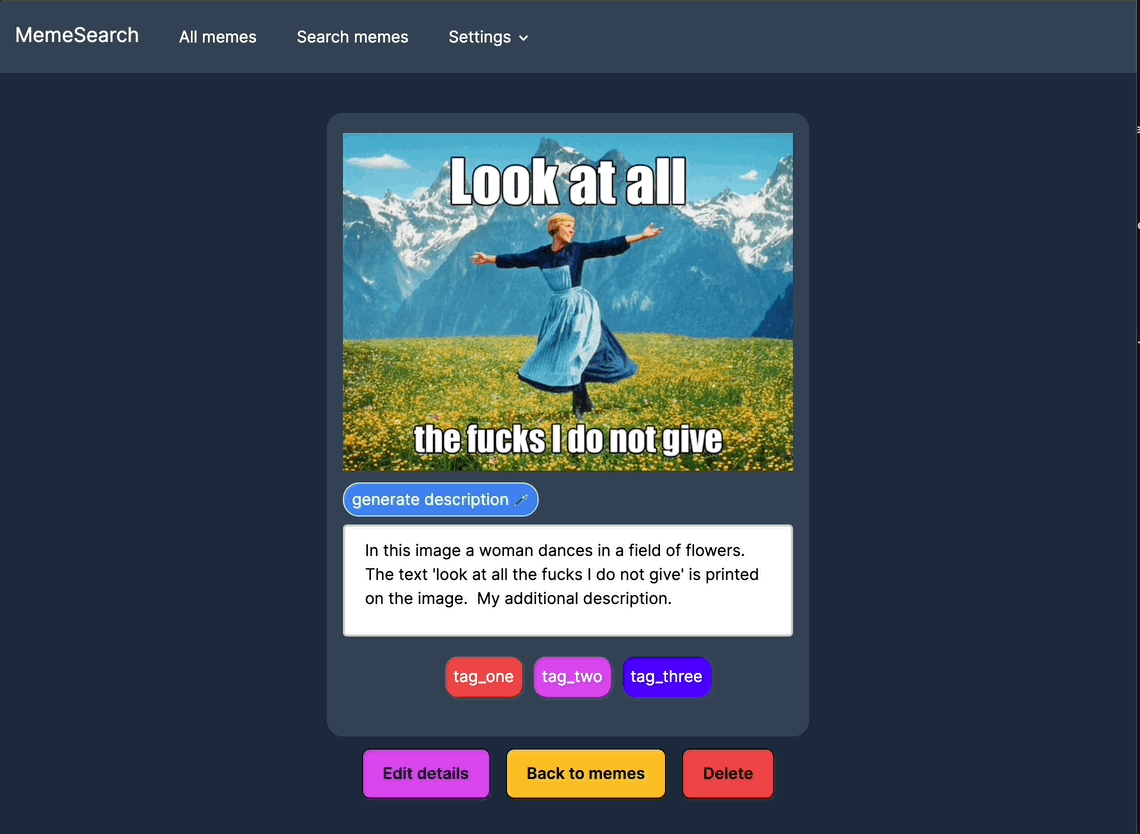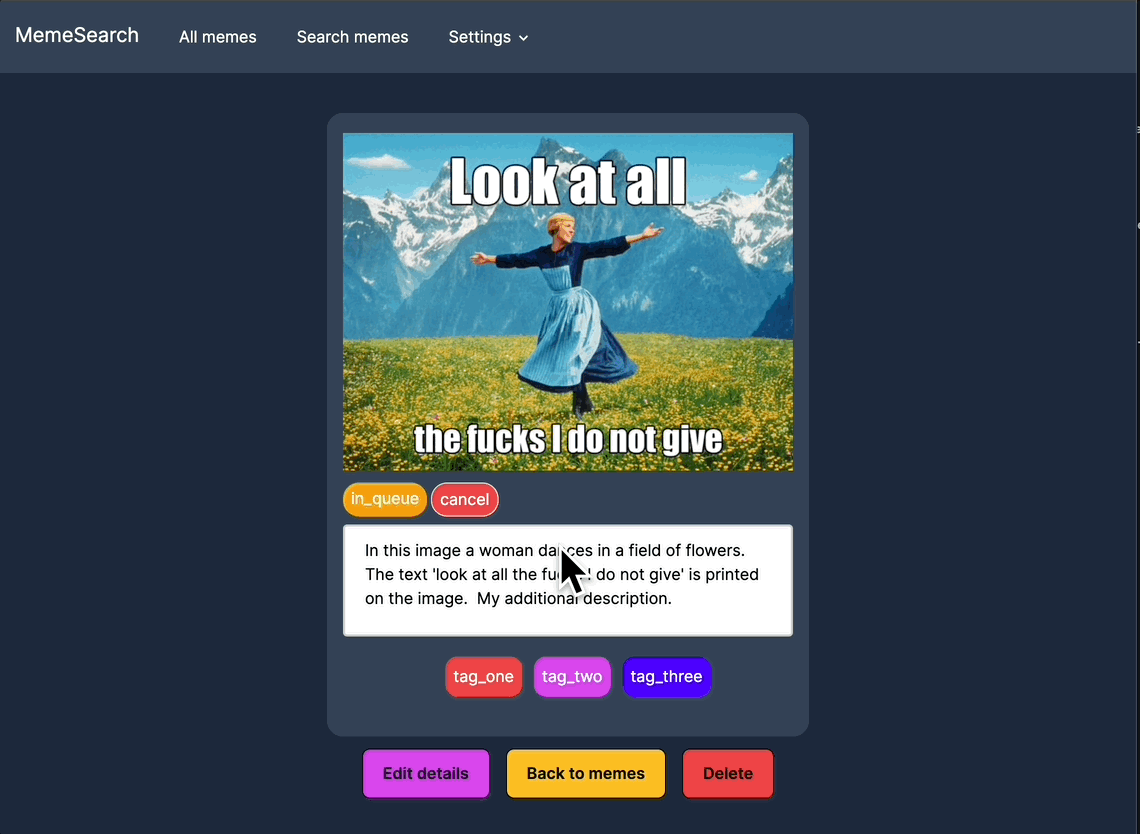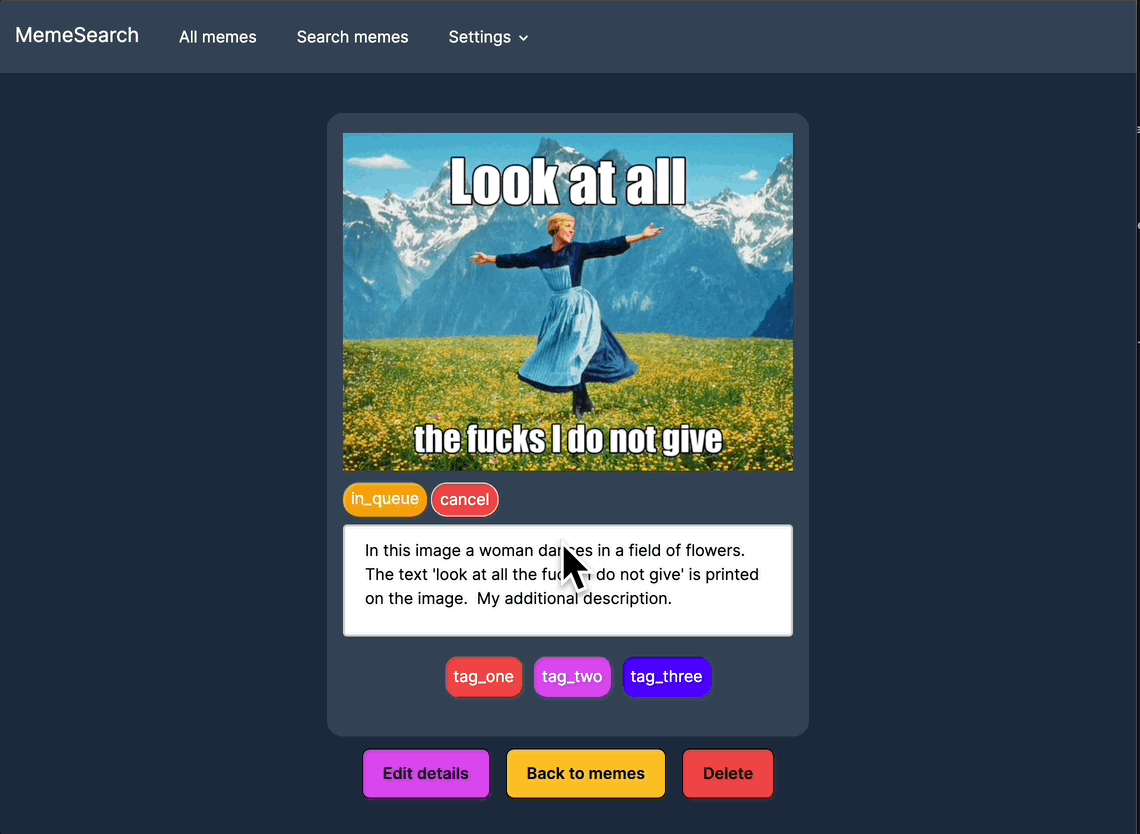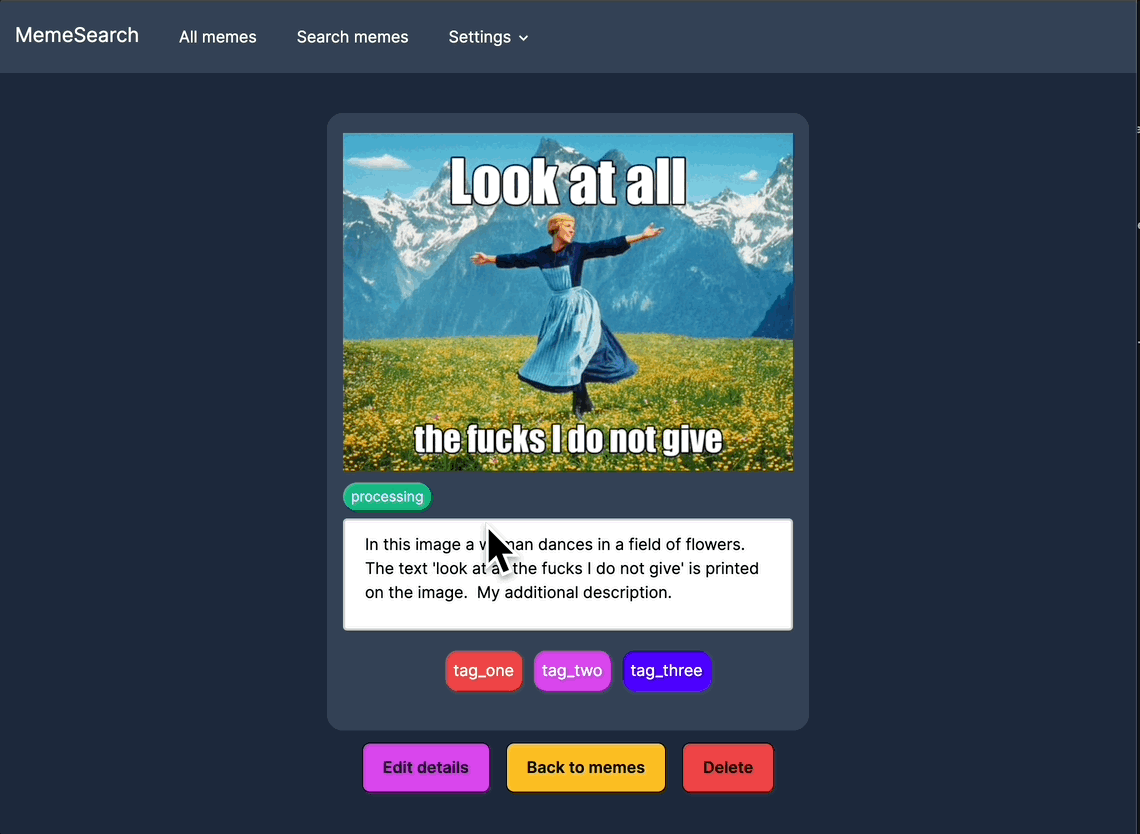
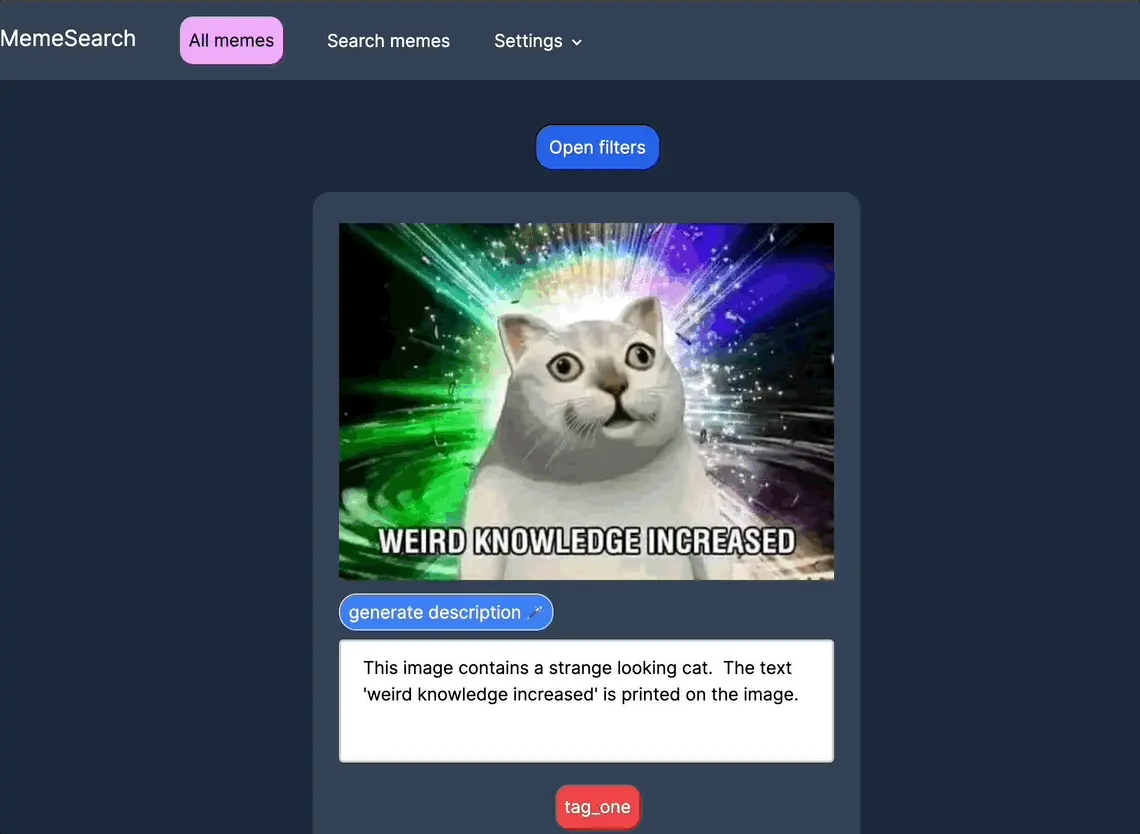
自动生成迷因描述
可以针对特定迷因而非整个目录进行自动描述生成。
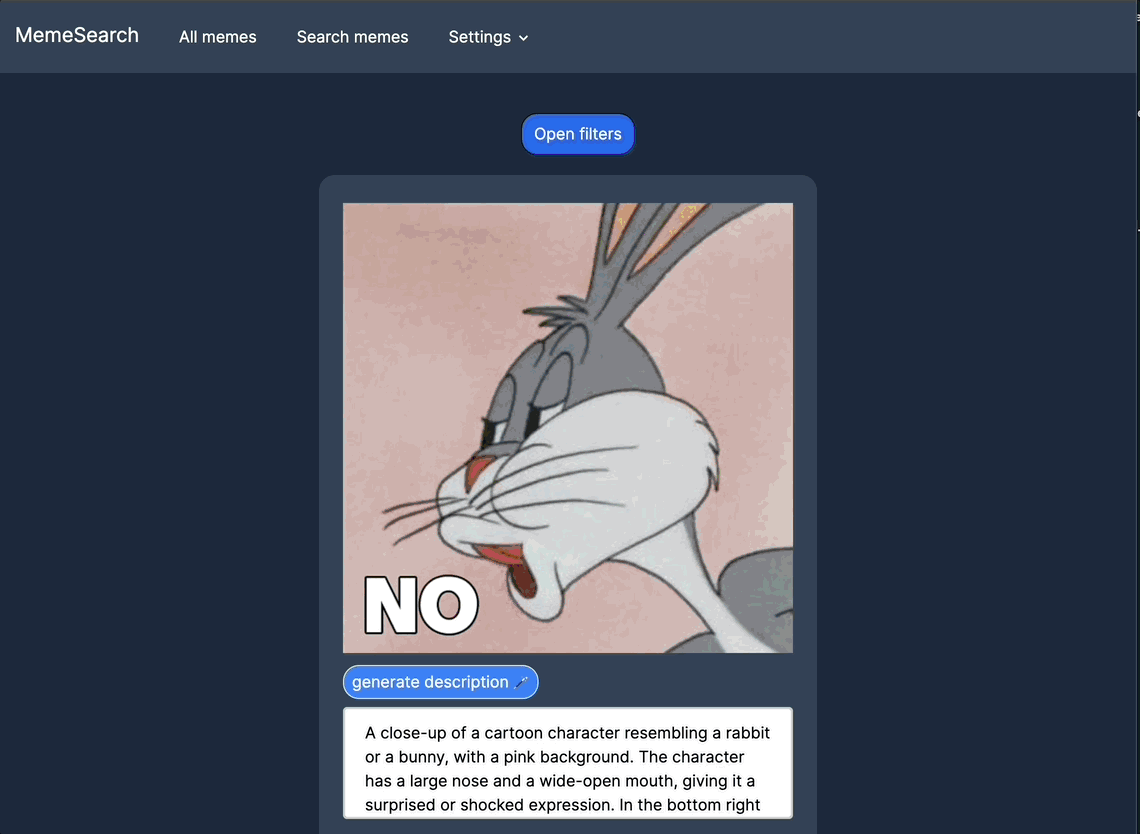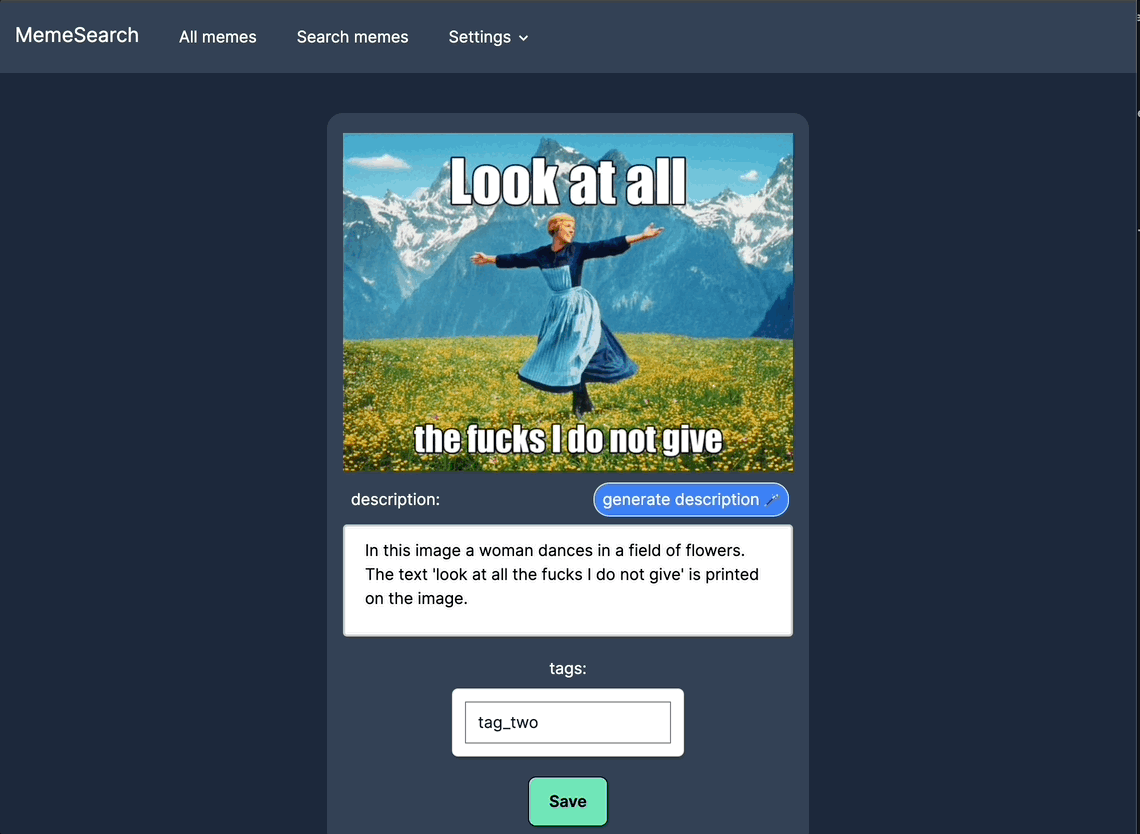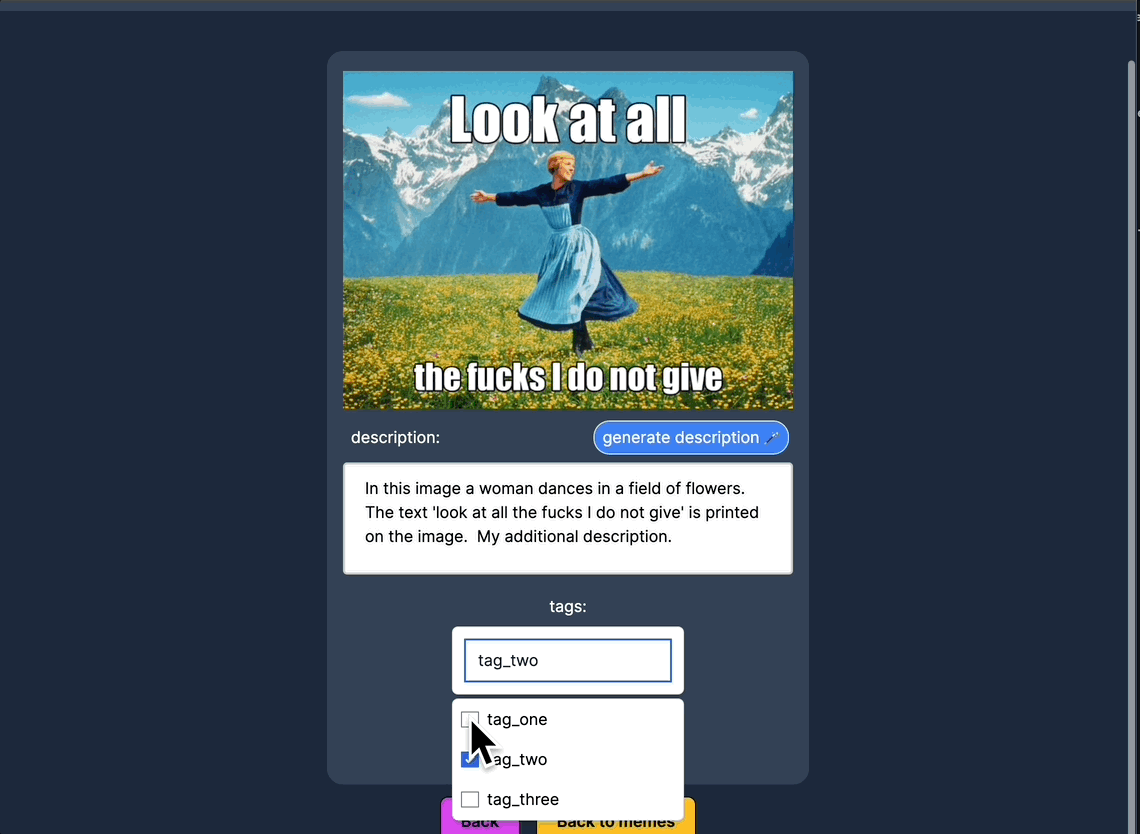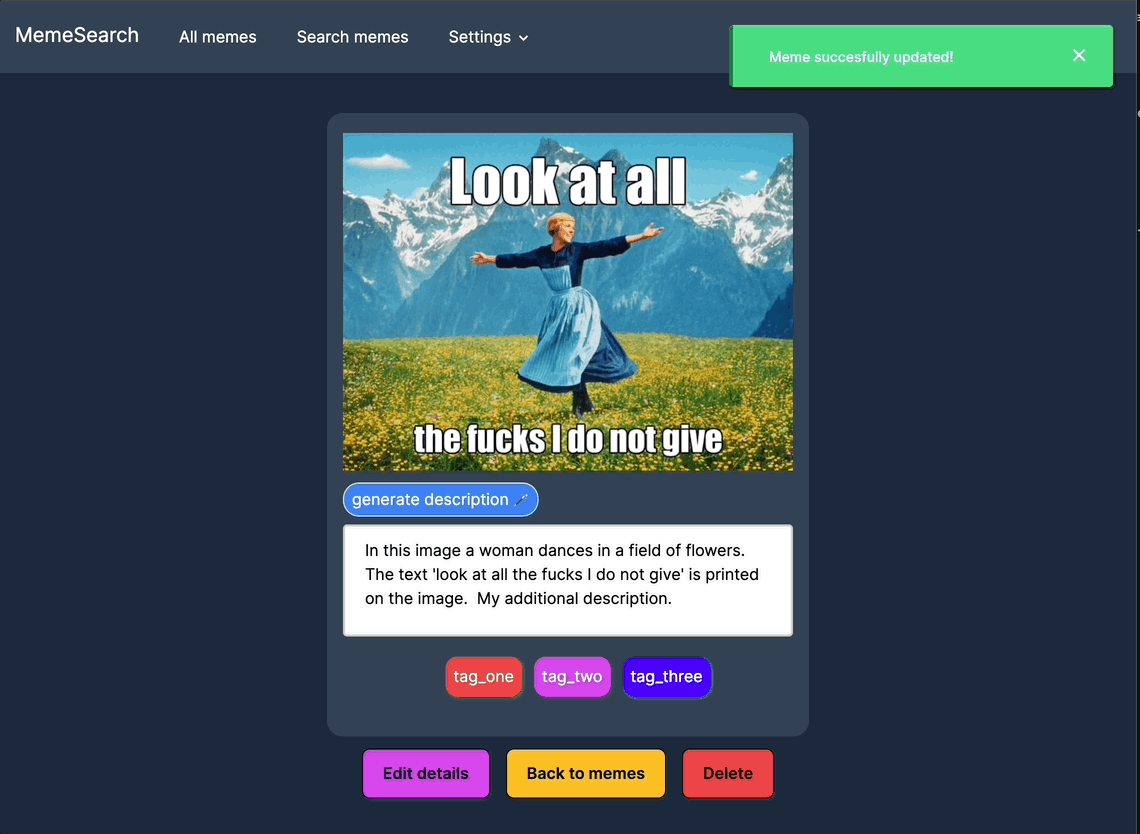
手动编辑迷因描述
为了获得更好的搜索结果,可以手动编辑或添加描述;如果你不想等待自动生成功能,也可以直接进行操作。
标签
为迷因创建、编辑并分配标签,以便更好地组织和筛选搜索结果。
快速向量搜索
基于 Postgres 和 pgvector,享受更快速的关键词和向量搜索,同时优化数据库事务流程。
目录路径
可以将迷因组织到多个子目录中,无需全部存储在一个文件夹内。
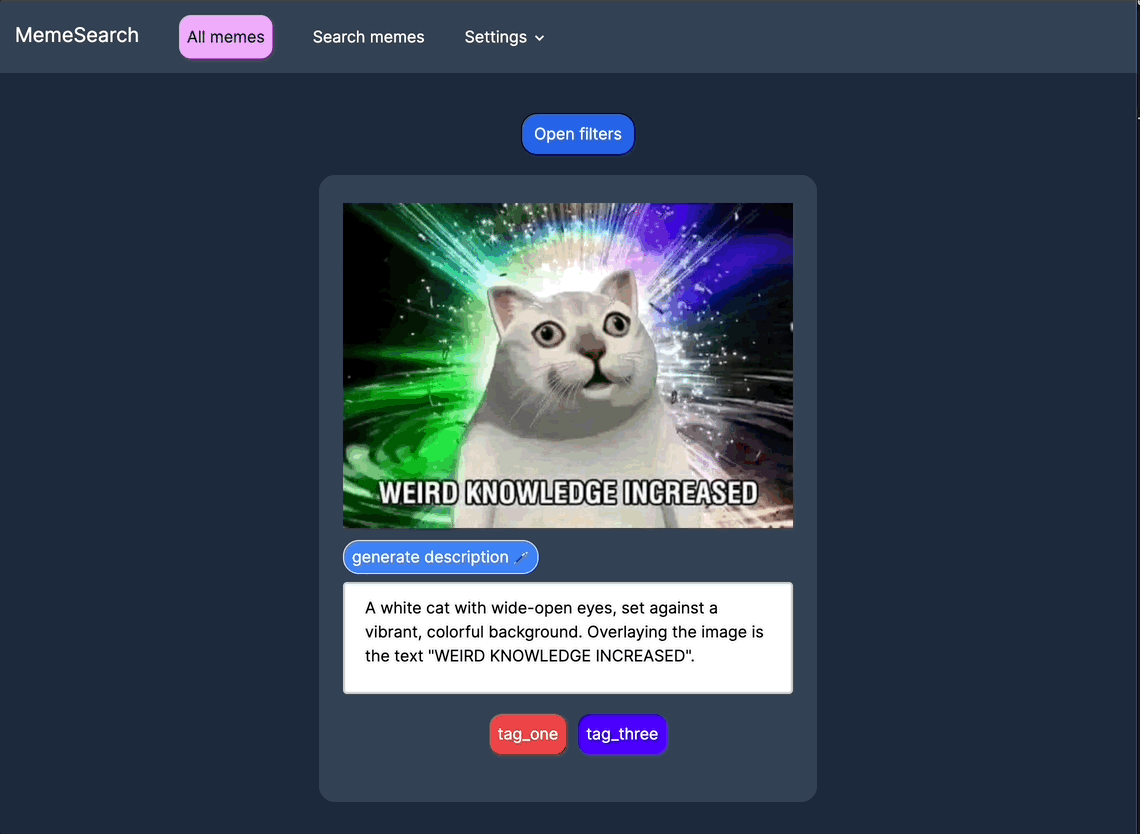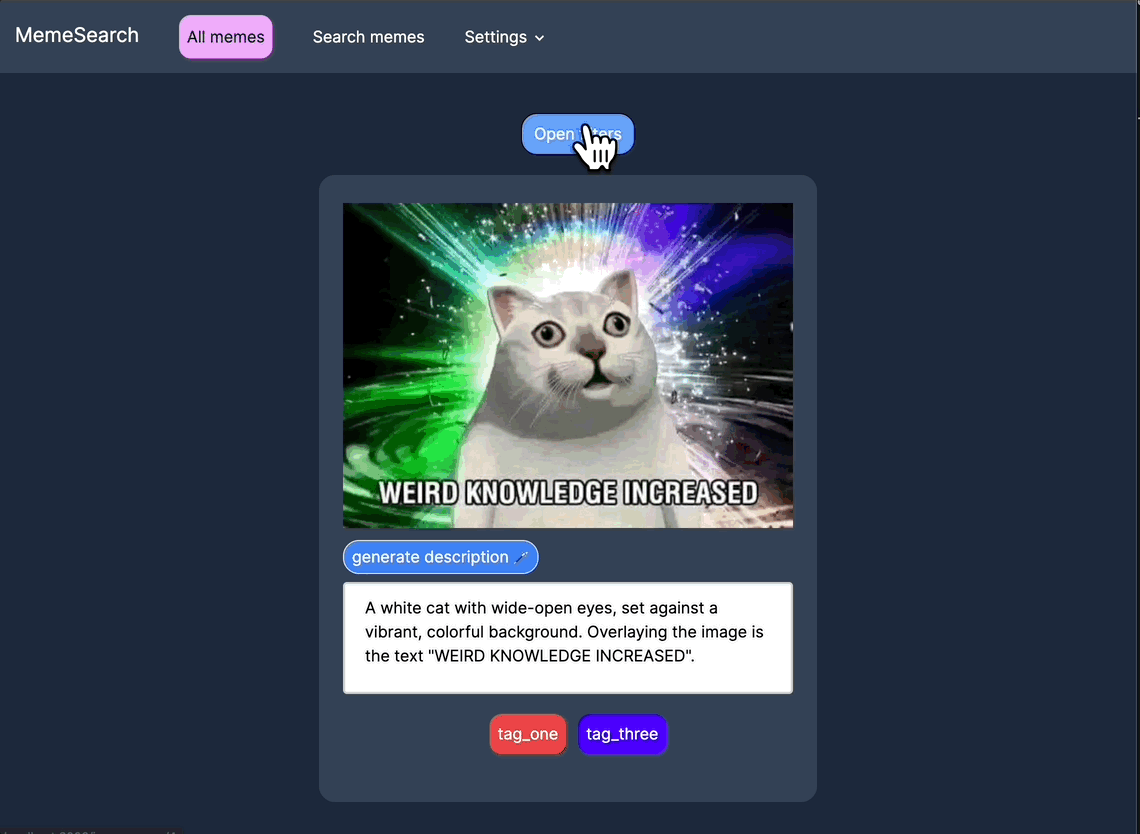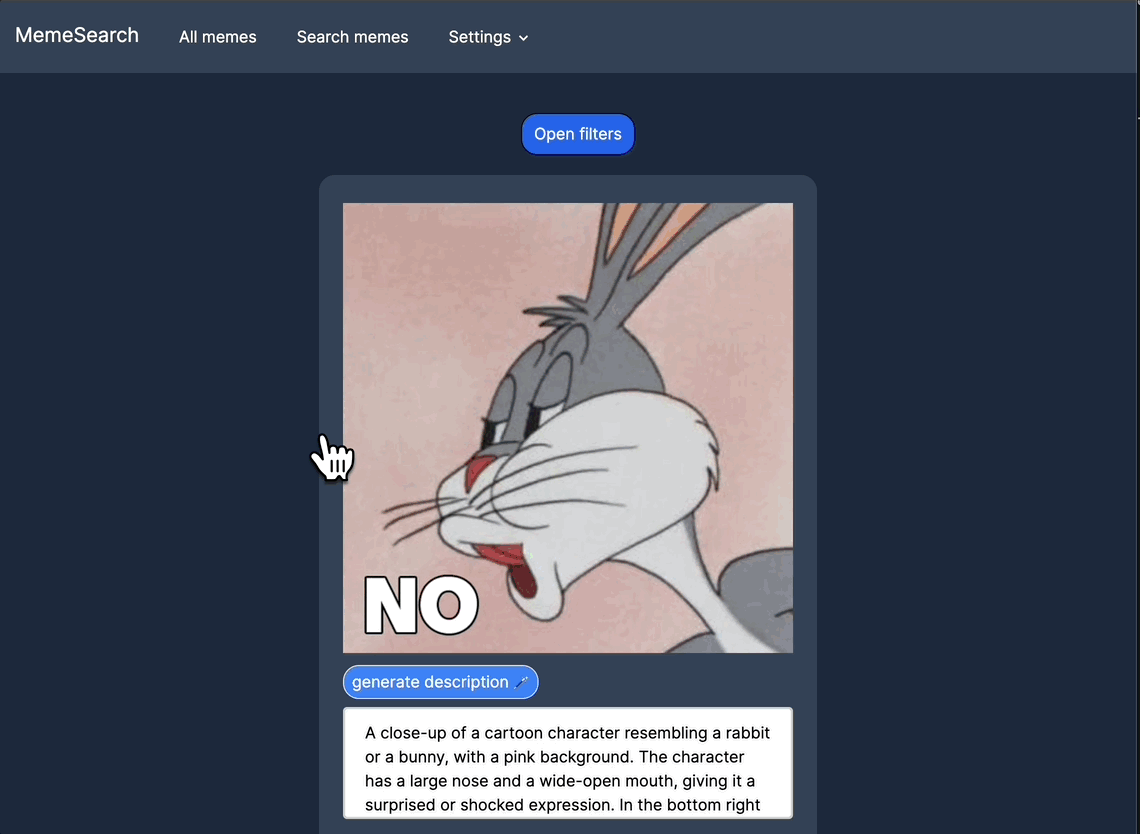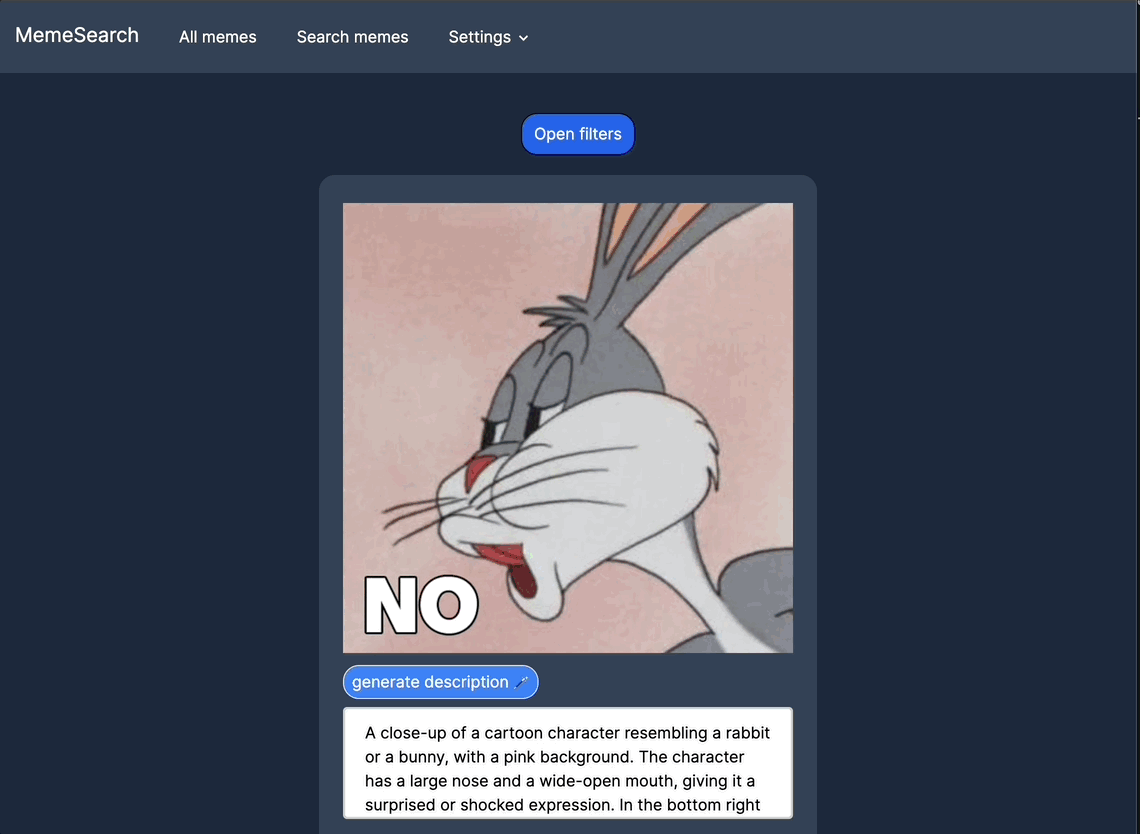
新的组织工具
按标签、目录路径和描述嵌入进行筛选,并在关键词搜索和向量搜索之间切换,以实现更精细的控制。
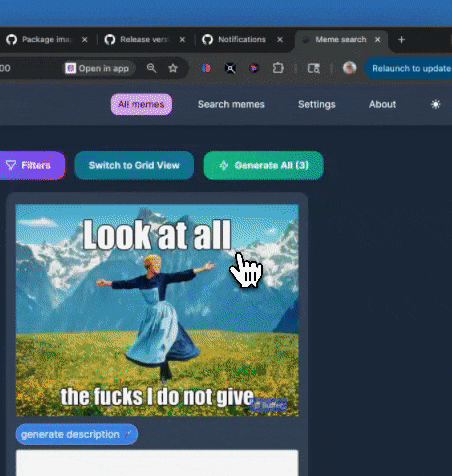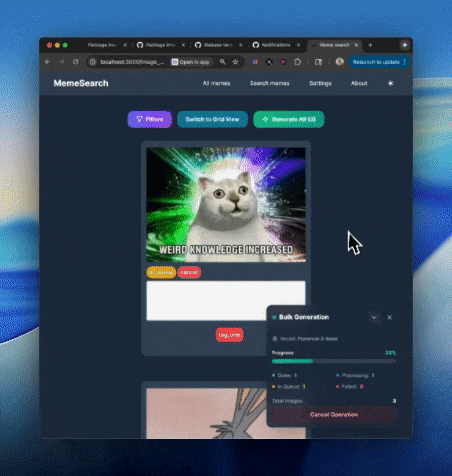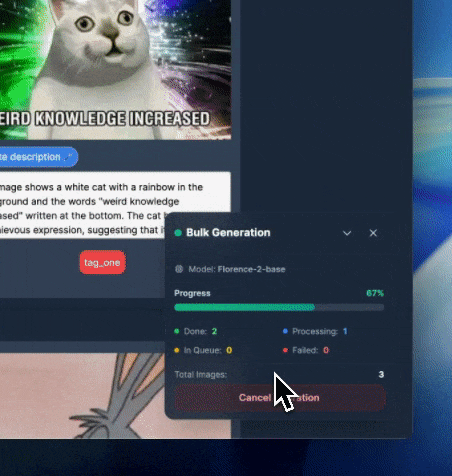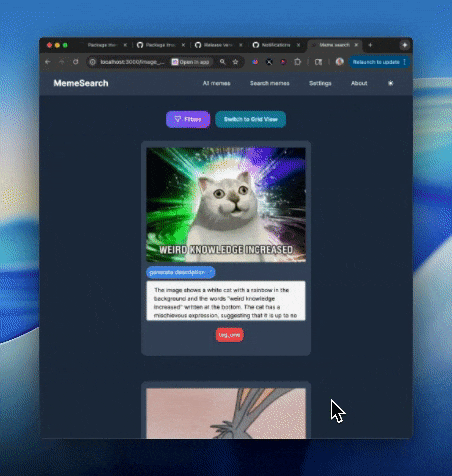
批量描述生成
可以一次性为多个迷因生成描述,从而加快索引速度。
暗色模式
在任何环境下都能舒适浏览,可切换浅色和暗色主题。
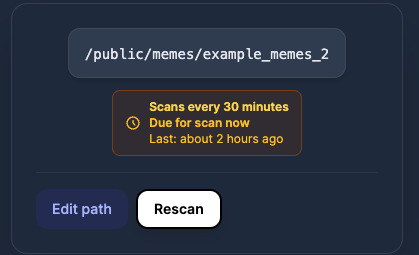
目录重新扫描
自动检测并索引你目录中新添加的迷因。
拖放上传
通过网页界面支持拖放上传迷因。文件会存储在
direct-uploads目录中(可通过 Docker 卷挂载进行配置),并自动扫描以进行索引。支持 JPG、PNG 和 WEBP 格式,可批量上传(最多 50 个文件),实时跟踪进度,并自动处理重复文件名问题。
要求
对于 Docker 部署(推荐):
- Docker 和 Docker Compose
对于本地开发:
- Ruby 3.4.2
- Rails 8.0.4
- Python 3.12
- Node.js 20 LTS
- PostgreSQL 17 并带有 pgvector 扩展
我们建议使用 mise 来管理 Ruby、Python 和 Node.js 的版本。详细设置说明请参阅 CLAUDE.md。
安装说明
要启动应用,请拉取此仓库并使用 docker-compose 启动服务器集群:
docker compose up
这将拉取并启动应用、数据库和自动描述生成器的容器。应用本身将在端口 3000 上运行,可通过以下地址访问:
http://localhost:3000
如果只想单独启动应用,请拉取仓库并进入 meme_search/meme_search/meme_search_app 目录。进入后,执行以下命令以在开发模式下启动应用:
./bin/dev
执行此操作时,请确保本地已运行一个可用的 PostgreSQL 实例,且监听端口为 5432。
注意:Linux 用户:为了实现容器间的通信,您可能需要在 meme_search 服务中添加以下 extra_hosts 配置:
extra_hosts:
- "host.docker.internal:host-gateway"
首次生成/模型下载时间
首次自动生成表情包描述所需的时间会比平时更长,因为此时需要下载并缓存图像转文本模型的权重。后续的生成速度会更快。
您可以在应用的设置选项卡中下载其他模型。
索引您的表情包
您可以通过创建自己的描述或自动生成功能来索引您的表情包,如下所示。
要开始索引您自己的表情包,首先调整 compose 文件,在 meme_search 和 image_to_text_generator 服务中添加 volume 挂载,以便将您本地的表情包子目录正确连接到应用。
例如,假设您的某个表情包目录名为 new_memes,位于您机器上的以下路径:/local/path/to/my/memes/new_memes。
要将该子目录正确挂载到 meme_search 服务,需将其配置中的 volumes 部分调整为如下内容:
volumes:
- ./meme_search/memes/:/app/public/memes # <-- 示例仓库中的表情包目录
- /local/path/to/my/memes/new_memes/:/rails/public/memes/new_memes # <-- 您的个人表情包集合,必须挂载到容器内的 /rails/public/memes 目录下
注意:您的 new_memes 目录必须挂载到容器内部的 /rails/public/memes 目录中,如上所示。
同样,要将该子目录正确挂载到 image_to_text_generator 服务,需将其配置中的 volumes 部分调整为如下内容:
volumes:
- ./meme_search/memes/:/app/public/memes # <-- 示例仓库中的表情包目录
- /local/path/to/my/memes/new_memes/:/app/public/memes/new_memes # <-- 您的个人表情包集合,必须挂载到容器内的 /app/public/memes 目录下
...
注意:您的 new_memes 目录必须挂载到容器内部的 /app/public/memes 目录中,如上所示。
如果您担心应用程序会修改您现有的表情包库,作为预防措施,您可以在卷挂载行中添加 ro 参数,使其变为只读模式,如下所示:
volumes:
- ./meme_search/memes/:/app/public/memes # <-- 示例仓库中的表情包目录
- /local/path/to/my/memes/new_memes/:/app/public/memes/new_memes:ro
...
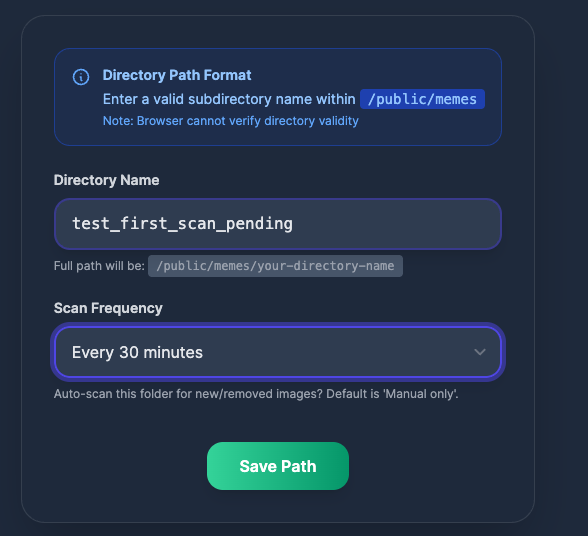
现在重启应用,并通过 UI 注册 new_memes 目录,路径为:设置 -> 路径 -> 创建新路径,如下图所示。在提供的字段中输入 new_memes 并按回车键。
一旦在应用中注册成功,您的表情包就可以进行索引、打标签等操作了!
模型下载
用于自动生成表情包描述的图像转文本模型均为开源模型,且大小不一。
自定义应用端口
您可以轻松自定义应用的端口,以便更方便地与 Unraid 或 Portainer 等工具配合使用,或者是因为您已经在默认的 meme_search 应用端口 3000 上运行了其他服务。
要自定义主应用端口,请在目录根目录下创建一个 .env 文件。在此文件中,您可以定义以下自定义环境变量,用于指定如何访问应用、图像转文本生成器和数据库。这些值如下:
APP_PORT= # 应用的端口,默认为3000
该值会通过 docker-compose-pro.yml 文件自动检测并加载到各个服务中。
使用 Docker 在本地构建应用
Docker 镜像仅支持手动构建,没有针对发布版本或标签的自动化 CI 构建流程。
要构建应用(包括 docker-compose.yml 文件中定义的所有服务),请在终端中运行本地的 compose 文件:
docker compose -f docker-compose-local-build.yml up --build
对于多平台构建(AMD64 + ARM64)以及推送到 GitHub Container Registry 的操作,可以使用本地构建脚本:
bash scripts/build_and_push.sh
这将构建应用、数据库和自动描述生成器的 Docker 镜像,并在 http://localhost:3000 启动应用。
运行测试
要在本地运行测试,请拉取仓库并进入 meme_search/meme_search/meme_search_app 目录。安装所需的 gem 包:
bundle install
然后可以运行测试:
bash run_tests.sh
执行此操作时,请确保本地已运行一个可用的 PostgreSQL 实例,且监听端口为 5432。
对 /app 子目录运行代码风格检查:
rubocop app
以确保代码整洁且格式规范。
在本地运行 CI(可选)
您可以通过 act 在本地运行完整的 GitHub Actions CI 流程:
# 安装 act(macOS)
brew install act
# 运行所有 CI 作业
act --container-architecture linux/amd64 -P ubuntu-latest=catthehacker/ubuntu:act-latest
# 运行特定作业
act -j pro_app_unit_tests --container-architecture linux/amd64 -P ubuntu-latest=catthehacker/ubuntu:act-latest
这可以帮助您在推送到 GitHub 之前验证更改是否符合 CI 规范。
Docker 端到端测试(仅限本地验证)
Docker 端到端测试会验证完整的微服务栈(Rails + Python + PostgreSQL)在隔离的 Docker 容器中是否正常工作。这些测试基于全新的 Docker 构建,用于测试服务间的通信、Webhook 以及类似生产环境的部署。
当前状态:7 项烟雾测试中有 6 项通过(覆盖率 85%)——详情请参阅 playwright-docker/README.md。
# 运行所有 Docker 端到端测试
npm run test:e2e:docker
# 使用 UI 模式运行(推荐用于调试)
npm run test:e2e:docker:ui
这些测试涵盖的内容:
- 完整的图像处理流水线(Rails → Python → Rails Webhook)
- 带有嵌入生成的向量搜索
- 关键字搜索功能
- 并发处理与任务队列
- 嵌入刷新操作
重要提示:由于 Docker 构建时间较长(约 10–15 分钟)以及资源需求,这些测试不会在 CI 环境中运行。贡献者必须在本地运行这些测试,然后再提交以下方面的 Pull Request:
- Docker 配置
- 跨服务通信
- 图像转文本生成工作流
- 嵌入生成
请参阅 playwright-docker/README.md 获取完整文档。
Discord 服务器
加入我们的 Discord 服务器 ,讨论新功能、Bug 修复以及其他开源项目(例如 ytgify——一款可以直接从 YouTube 播放器截取 GIF 的浏览器扩展!)
更改日志
Meme Search 目前正处于积极开发中!请查看此仓库中的 CHANGELOG.md 文件,了解最近的更改记录。
功能请求与贡献
我们欢迎功能请求和贡献!
请访问此仓库的讨论区,提出您对功能改进的建议,并参与讨论或投票!
有关贡献的基本规则,请参阅 CONTRIBUTING.md 文件。
以下是使用 gitdiagram 生成的仓库结构图,清晰展示了其主要组件及相互关系:
flowchart TD
%% 全局实体
User["用户"]:::user
%% Docker & Compose 编排
Docker["Docker & Compose 编排"]:::docker
%% 主要服务
Rails["Rails Meme Search 应用程序"]:::rails
Python["图像转文本生成器(Python)"]:::python
DB["PostgreSQL 数据库(带 pgvector 插件)"]:::database
%% 共享文件卷子图
subgraph "共享模因文件"
PublicMemes["公开模因"]:::volume
MemeDir["模因目录"]:::volume
end
%% 相互交互
User -->|"交互"| Rails
Rails -->|"数据库查询更新"| DB
Rails -->|"API 请求"| Python
Python -->|"API 响应"| Rails
%% 卷挂载访问
Rails ---|"卷挂载访问"| PublicMemes
Python ---|"卷挂载访问"| MemeDir
%% Docker 编排链接
Docker ---|"编排"| Rails
Docker ---|"编排"| Python
Docker ---|"编排"| DB
%% 点击事件
click Rails "https://github.com/neonwatty/meme-search/tree/main/meme_search/meme_search_app"
click Python "https://github.com/neonwatty/meme-search/tree/main/meme_search/image_to_text_generator"
click DB "https://github.com/neonwatty/meme-search/blob/main/meme_search/meme_search_app/config/database.yml"
click Docker "https://github.com/neonwatty/meme-search/blob/main/docker-compose.yml"
click PublicMemes "https://github.com/neonwatty/meme-search/tree/main/meme_search/meme_search_app/public/memes"
click MemeDir "https://github.com/neonwatty/meme-search/tree/main/meme_search/memes"
%% 样式定义
classDef user fill:#fceabb,stroke:#d79b00,stroke-width:2px;
classDef rails fill:#c8e6c9,stroke:#388e3c,stroke-width:2px;
classDef python fill:#bbdefb,stroke:#1976d2,stroke-width:2px;
classDef database fill:#ffe082,stroke:#f9a825,stroke-width:2px,stroke-dasharray: 5 5;
classDef docker fill:#d1c4e9,stroke:#673ab7,stroke-width:2px,stroke-dasharray: 3 3;
classDef volume fill:#ffcdd2,stroke:#e53935,stroke-width:2px,stroke-dasharray: 2 2;
版本历史
v2.0.22026/01/092.0.12025/11/192.0.02025/11/13v1.1.52025/02/20v1.1.42024/11/08v1.1.32024/07/241.1.22024/07/19常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。