InvoiceNet
InvoiceNet 是一款基于深度神经网络的开源工具,专为从发票文档中智能提取关键信息而设计。它有效解决了传统人工录入发票数据效率低下、易出错,以及通用自动化方案难以适应不同发票版式的痛点。
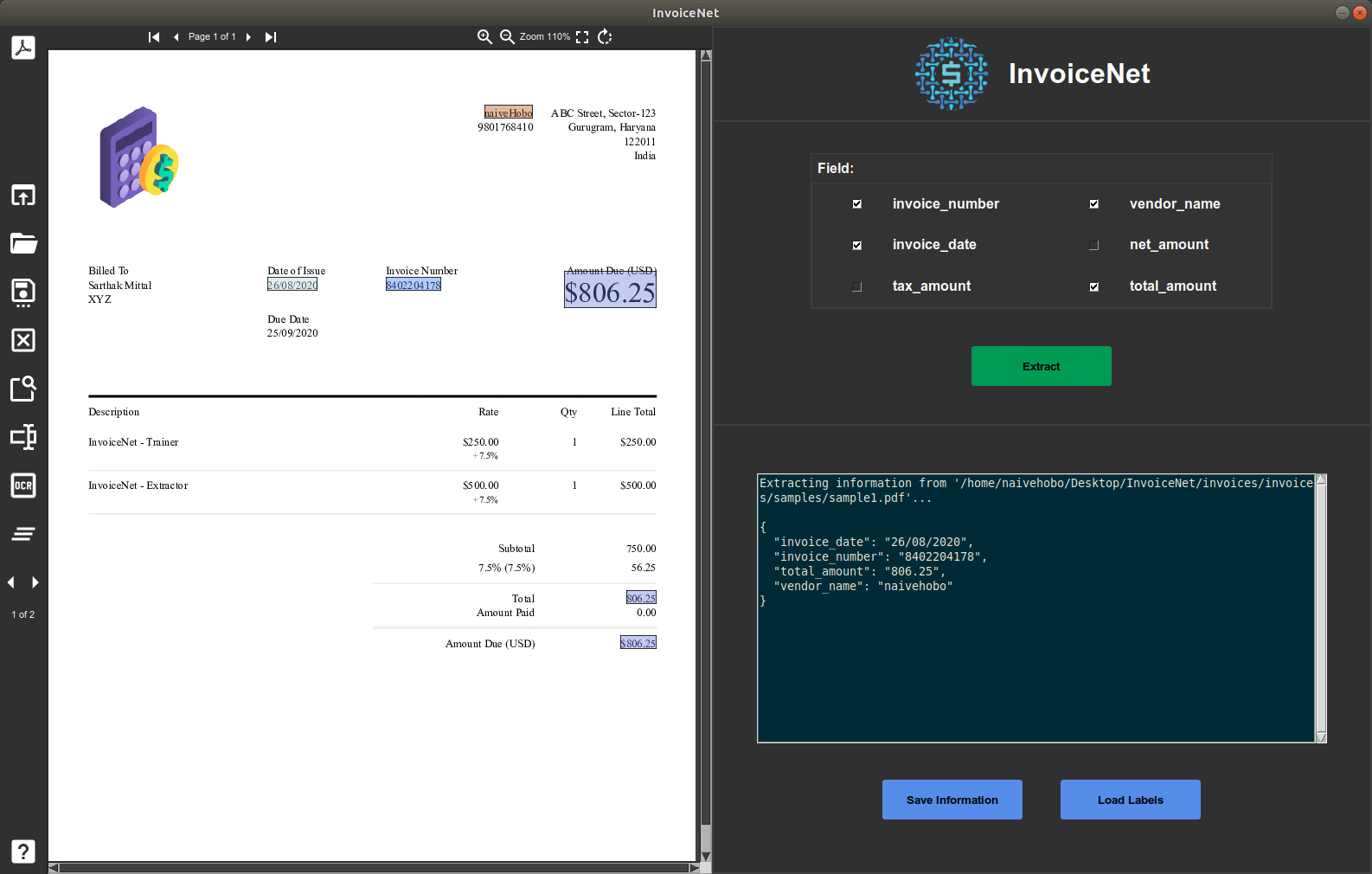
通过直观的图形用户界面(UI),用户可以直接查看 PDF 或图片格式的发票,一键提取并保存结构化数据。其核心亮点在于高度的灵活性:不仅支持自定义添加或移除提取字段,还配备了专门的训练界面,允许用户利用自有数据集定制专属模型,从而适应特定业务场景的需求。
目前,InvoiceNet 主要面向开发者和研究人员。虽然官方暂未提供通用的预训练模型,但它开放了完整的数据准备脚本和训练流程,非常适合希望构建私有化发票识别系统、或有意贡献数据以推动建立大规模公共发票数据集的技术团队。对于需要在 Ubuntu 或 Windows 环境下部署 OCR 与深度学习流程的用户而言,InvoiceNet 提供了一个透明、可扩展且易于上手的基础平台。
使用场景
某中型电商企业的财务团队每天需处理来自全球供应商的数百份 PDF 和图片格式发票,急需将非结构化文档转化为可录入 ERP 系统的结构化数据。
没有 InvoiceNet 时
- 财务人员必须手动逐张打开发票,肉眼识别并键盘录入供应商名称、日期、金额等关键字段,耗时且枯燥。
- 面对不同国家、不同版式的发票,人工判断字段位置极易出错,导致入账金额偏差或重复支付风险。
- 新增一种特殊格式的发票时,需要重新培训员工或编写复杂的正则规则脚本,响应业务变化的周期长达数周。
- 提取后的数据分散在 Excel 表格中,无法直接通过一键操作同步至公司内部数据库,二次整理成本高昂。
使用 InvoiceNet 后
- 利用其内置的 UI 界面批量上传 PDF 或 JPG 发票,深度神经网络自动在秒级内完成关键信息的智能提取与展示。
- 通过 Trainer UI 使用企业自有数据集训练定制模型,轻松适应各种非标发票版式,显著降低人为识别错误率。
- 只需修改配置文件即可灵活增加或删除提取字段(如税号、订单号),无需重写代码即可快速响应新的财务合规需求。
- 确认提取结果无误后,点击按钮即可将结构化 JSON 数据直接保存并集成到现有系统中,实现从文档到数据库的自动化闭环。
InvoiceNet 将原本需要数小时的人工核对工作压缩至分钟级,让财务团队从繁琐的数据搬运中解放出来,专注于高价值的财务分析工作。
运行环境要求
- Linux (Ubuntu 20.04)
- Windows 10
需要 NVIDIA GPU,CUDA 版本需为 11.8,配合 cuDNN 8.9.7
未说明

快速开始

基于深度神经网络的发票文档智能信息提取工具。
简而言之
- 一个易于使用的界面,用于查看PDF/JPG/PNG格式的发票并提取信息。
- 使用训练界面在您自己的数据集上训练自定义模型。
- 根据需要添加或删除发票字段。
- 一键将提取的信息保存到您的系统中。
:star: 您的点赞对我们非常重要!
InvoiceNet的标志由Sidhant Tibrewal设计。查看他的作品,欣赏更多精美设计。
免责声明:
目前尚未提供针对一些通用发票字段的预训练模型,但很快就会推出。训练GUI和数据准备脚本已经开放使用。
由于发票文件包含敏感信息,收集足够规模的数据集一直颇具挑战性。这使得像我们这样的开发者难以训练大规模的通用模型并向社区开放。
如果您拥有愿意与我们共享的发票数据集,请联系我们(sarthakmittal2608@gmail.com)。我们具备创建首个公开可用的大规模发票数据集以及结构化信息提取软件平台的工具。
安装
Ubuntu 20.04
InvoiceNet已在Ubuntu 20.04上开发并测试完成,使用的CUDA版本为11.8,cuDNN版本为8.9.7,TensorFlow版本为2.13.1。
要在Ubuntu上安装InvoiceNet,请执行以下命令:
git clone https://github.com/naiveHobo/InvoiceNet.git
cd InvoiceNet/
# 运行安装脚本
./install.sh
install.sh脚本将安装所有依赖项,创建虚拟环境,并在该虚拟环境中安装InvoiceNet。
要使用InvoiceNet,您需要激活安装包所在的虚拟环境。
# 激活虚拟环境
source env/bin/activate
Windows 10
推荐的方式是在Anaconda环境中安装InvoiceNet及其依赖项:
git clone https://github.com/naiveHobo/InvoiceNet.git
cd InvoiceNet/
# 创建并激活conda环境
conda create --name invoicenet python=3.7
conda activate invoicenet
# 安装InvoiceNet
pip install .
# 安装poppler
conda install -c conda-forge poppler
此外,在Windows 10上运行InvoiceNet之前,还需要单独安装一些依赖项:
数据准备
训练数据必须组织在一个目录中。发票文件应为PDF格式,且每张发票都应有一个同名的JSON标签文件。您的训练数据应如下所示:
train_data/
invoice1.pdf
invoice1.json
nike-invoice.pdf
nike-invoice.json
12345.pdf
12345.json
...
JSON标签文件应具有以下格式:
{
"vendor_name":"Nike",
"invoice_date":"12-01-2017",
"invoice_number":"R0007546449",
"total_amount":"137.51",
... 其他字段
}
要开始数据准备过程,可在GUI中点击“准备数据”按钮,或者如果您使用命令行界面,请按照以下说明操作。
添加自定义字段
要向InvoiceNet添加自定义字段,请打开invoicenet/init.py。
预定义了4种字段类型:
- FIELD_TYPES["general"]:一般字段,如名称、地址、发票编号等。
- FIELD_TYPES["optional"]:可选字段,可能并非所有发票都包含。
- FIELD_TYPES["amount"]:表示金额的字段。
- FIELD_TYPES["date"]:表示日期的字段。
为字段选择合适的类型,并添加下方所示的代码行。
# 在文件末尾添加以下行
# 例如,添加total_amount字段
FIELDS["total_amount"] = FIELD_TYPES["amount"]
# 例如,添加invoice_date字段
FIELDS["invoice_date"] = FIELD_TYPES["date"]
# 例如,添加tax_id字段(可能是可选的)
FIELDS["tax_id"] = FIELD_TYPES["optional"]
# 例如,添加vendor_name字段
FIELDS["vendor_name"] = FIELD_TYPES["general"]
使用GUI
InvoiceNet提供了一个图形用户界面,允许您基于自己的数据训练模型,并使用该模型从发票文档中提取信息。
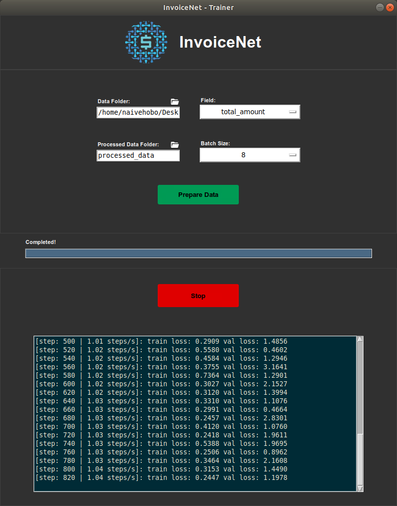
运行以下命令以启动训练GUI:
python trainer.py
运行以下命令以启动提取GUI:
python extractor.py
首先需要准备好用于训练的数据。您可以通过将数据文件夹字段设置为您训练数据所在的目录,然后点击准备数据按钮来完成。数据准备好后,即可点击开始按钮进行训练。
使用命令行
训练
首先通过运行以下命令准备训练数据:
python prepare_data.py --data_dir train_data/
然后使用以下命令训练InvoiceNet:
python train.py --field enter-field-here --batch_size 8
# 例如,针对total_amount字段
python train.py --field total_amount --batch_size 8
预测
如果您尝试使用不同的OCR引擎,请在运行predict.py之前更改此函数中的ocr_engine create_ngrams.py。
单张发票
要从单张发票文件中提取某个字段,运行以下命令:
python predict.py --field enter-field-here --invoice path-to-invoice-file
# 例如,从invoices/1.pdf中提取total_amount字段
python predict.py --field total_amount --invoice invoices/1.pdf
多张发票
要使用已训练好的InvoiceNet模型提取信息,只需将PDF格式的发票文件按以下格式放置在一个目录中:
predict_data/
invoice1.pdf
invoice2.pdf
...
然后使用以下命令运行InvoiceNet:
python predict.py --field enter-field-here --data_dir predict_data/
# 例如,针对total_amount字段
python predict.py --field total_amount --data_dir predict_data/
参考文献
本实现主要基于 R. Palm 等人的工作,若在科学出版物中使用,请引用该工作(或其之前的会议论文):
[1] Palm, Rasmus Berg, Florian Laws, and Ole Winther. “Attend, Copy, Parse:端到端的文档信息抽取”。2019 年国际文档分析与识别会议(ICDAR)。IEEE,2019 年。
@inproceedings{palm2019attend,
title={Attend, Copy, Parse End-to-end information extraction from documents},
author={Palm, Rasmus Berg and Laws, Florian and Winther, Ole},
booktitle={2019 International Conference on Document Analysis and Recognition (ICDAR)},
pages={329--336},
year={2019},
organization={IEEE}
}
注
基于论文 “Cloudscan——一种使用循环神经网络的无配置发票分析系统” 的较差(且略有缺陷)的发票处理系统实现可在此处获取:这里。
[2] Palm, Rasmus Berg, Ole Winther, and Florian Laws. “Cloudscan——一种使用循环神经网络的无配置发票分析系统”。2017 年第 14 届 IAPR 国际文档分析与识别会议(ICDAR)。第 1 卷。IEEE,2017 年。
@inproceedings{palm2017cloudscan,
title={Cloudscan-a configuration-free invoice analysis system using recurrent neural networks},
author={Palm, Rasmus Berg and Winther, Ole and Laws, Florian},
booktitle={2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR)},
volume={1},
pages={406--413},
year={2017},
organization={IEEE}
}
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备