shapiq
shapiq 是一款专为机器学习设计的 Python 开源库,旨在量化模型预测中的特征交互效应。传统的可解释性工具(如 SHAP)通常只关注单个特征的独立贡献,却忽略了特征之间协同作用产生的“合力”。shapiq 通过引入博弈论中的沙普利交互指数(Shapley Interaction Index),能够计算任意阶数的特征交互值,从而揭示多个特征组合在一起时如何共同影响模型结果,提供比单一归因更全面、深入的视角。
这款工具特别适合机器学习研究人员、数据科学家以及需要深度分析模型行为的开发者使用。无论是探究复杂模型的决策逻辑,还是验证博弈论算法在 ML 领域的表现,shapiq 都能提供强有力的支持。其核心技术亮点在于不仅兼容现有的 SHAP 工作流,还扩展了对高阶交互效应的近似计算能力,支持从成对交互到多特征协同的全面分析。用户只需几行代码即可加载数据、训练模型并可视化交互结果,同时底层模块也为算法研究者提供了灵活的基准测试环境。如果你希望超越表面归因,真正理解特征间复杂的协同机制,shapiq 是一个值得尝试的专业工具。
使用场景
某金融风控团队正在优化房贷违约预测模型,急需深入理解特征间复杂的非线性关系以提升模型可解释性。
没有 shapiq 时
- 只能依赖传统的 SHAP 值分析单个特征的贡献,完全忽略了“收入”与“负债率”等特征组合产生的协同效应。
- 面对模型对特定高风险群体的误判,无法定位是哪几个特征相互作用导致了异常预测,排查如同大海捞针。
- 试图手动计算高阶交互项时,面临指数级增长的计算复杂度,导致分析过程耗时数天且结果往往不收敛。
- 向业务部门汇报时,仅能展示孤立的特征重要性图表,难以解释为何某些看似低风险的客户组合会被模型标记为高危。
使用 shapiq 后
- 利用
TabularExplainer直接计算高达 4 阶的 k-SII 交互值,精准量化了“年龄”与“信用历史长度”之间的协同风险贡献。 - 通过
interaction_values快速锁定导致误判的具体特征组合(如“自由职业”叠加“短期居住”),将归因分析时间从数天缩短至分钟级。 - 借助内置的近似算法,在有限的计算预算(budget)内高效获取任意阶次的交互指标,无需担心计算资源爆炸。
- 结合
shapiq.plot生成直观的交互热力图,向业务方清晰展示了多特征耦合如何共同推高违约概率,显著提升了信任度。
shapiq 通过量化特征间的“协同效应”,让黑盒模型中隐藏的复杂逻辑变得透明且可操作。
运行环境要求
未说明
未说明
快速开始
shapiq: 用于机器学习的夏普利交互 
![]()
![]()
![]()
![]()




![]()

一次交互可能胜过千次主效应。
Shapley Interaction Quantification (shapiq) 是一个 Python 包,用于 (1) 近似任意阶的夏普利交互值,(2) 对机器学习中的博弈论算法进行基准测试,(3) 解释模型预测中的特征交互。shapiq 扩展了广为人知的 shap 包,既适用于从事机器学习中博弈论研究的研究人员,也适用于需要解释模型的最终用户。SHAP-IQ 在个体夏普利值的基础上,进一步量化了实体(即博弈论术语中的“玩家”)之间的协同效应,例如解释性特征、数据点或集成模型中的弱学习器。玩家之间的协同作用能够提供对机器学习模型更为全面的理解。
🛠️ 安装
shapiq 旨在与 Python 3.12 及以上版本 一起使用。
可以通过 uv 进行安装:
uv add shapiq
或者通过 pip:
pip install shapiq
👀 即将推出的功能
请在我们的 GitHub 项目板 上查看该库的未来规划。我们在此处规划并跟踪即将推出的功能、改进和维护任务,包括新的解释器、性能优化以及更广泛的模型支持。
⭐ 快速入门
您可以使用 shapiq.explainer 解释您的模型,并用 shapiq.plot 可视化夏普利交互值。如果您对底层的博弈论算法感兴趣,请查看 shapiq.approximator 和 shapiq.games 模块。
计算任意阶的特征交互
使用夏普利交互来解释您的模型:
只需加载数据和模型,然后使用 shapiq.Explainer 计算夏普利交互。
import shapiq
# 加载数据
X, y = shapiq.load_california_housing(to_numpy=True)
# 训练模型
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor()
model.fit(X, y)
# 设置一个计算 k-SII 交互值、最高阶数为 4 的解释器
explainer = shapiq.TabularExplainer(
model=model,
data=X,
index="k-SII",
max_order=4
)
# 解释模型对第一个样本的预测
interaction_values = explainer.explain(X[0], budget=256)
# 分析交互值
print(interaction_values)
>> InteractionValues(
>> index=k-SII, max_order=4, min_order=0, estimated=False,
>> estimation_budget=256, n_players=8, baseline_value=2.07282292,
>> 前 10 个交互:
>> (0,): 1.696969079 # 特征 0 的归因
>> (0, 5): 0.4847876
>> (0, 1): 0.4494288 # 特征 0 和 1 之间的交互
>> (0, 6): 0.4477677
>> (1, 5): 0.3750034
>> (4, 5): 0.3468325
>> (0, 3, 6): -0.320 # 特征 0、3 和 6 之间的交互
>> (2, 3, 6): -0.329
>> (0, 1, 5): -0.363
>> (6,): -0.56358890
>> )
计算您熟悉的 SHAP 式夏普利值
如果您习惯使用 SHAP,也可以用 shapiq 以相同的方式计算夏普利值:
您可以加载数据和模型,然后使用 shapiq.Explainer 计算夏普利值。如果将索引设置为 'SV',您将得到与 SHAP 中相同的夏普利值。
import shapiq
data,模型 = ... # 获取您的数据和模型
explainer = shapiq.Explainer(
model=model,
data=data,
index="SV", # 夏普利值
)
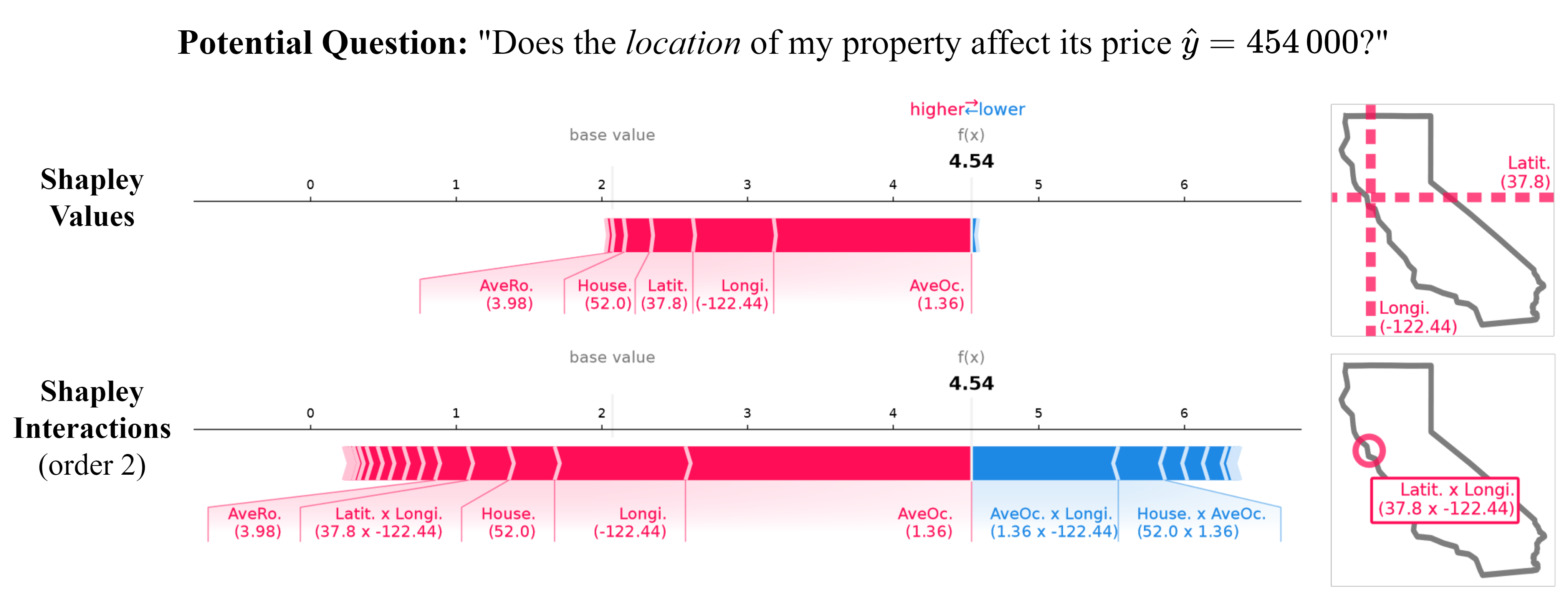
shapley_values = explainer.explain(data[0])
shapley_values.plot_force(feature_names=...)
一旦您获得了夏普利值,也可以轻松计算交互值:
explainer = shapiq.Explainer(
model=model,
data=data,
index="k-SII", # k-SII 交互值
max_order=2 # 指定您想要的任何阶数
)
interaction_values = explainer.explain(data[0])
interaction_values.plot_force(feature_names=...)
使用 ProxySPEX(代理稀疏解释器)
对于大规模应用场景,您还可以尝试 👓ProxySPEX 近似器。
# 加载具有大量特征的数据和模型
data,模型,n_features = ...
# 直接使用 ProxySPEX 近似器
approximator = shapiq.ProxySPEX(n=n_features, index="FBII", max_order=2)
fbii_scores = approximator.approximate(budget=2000, game=model.predict)
# 或者结合 ProxySPEX 与解释器使用
explainer = shapiq.Explainer(
model=model,
data=data,
index="FBII",
max_order=2,
approximator="proxyspex" # 指定 ProxySPEX 作为近似器
)
explanation = explainer.explain(data[0])
可视化特征交互
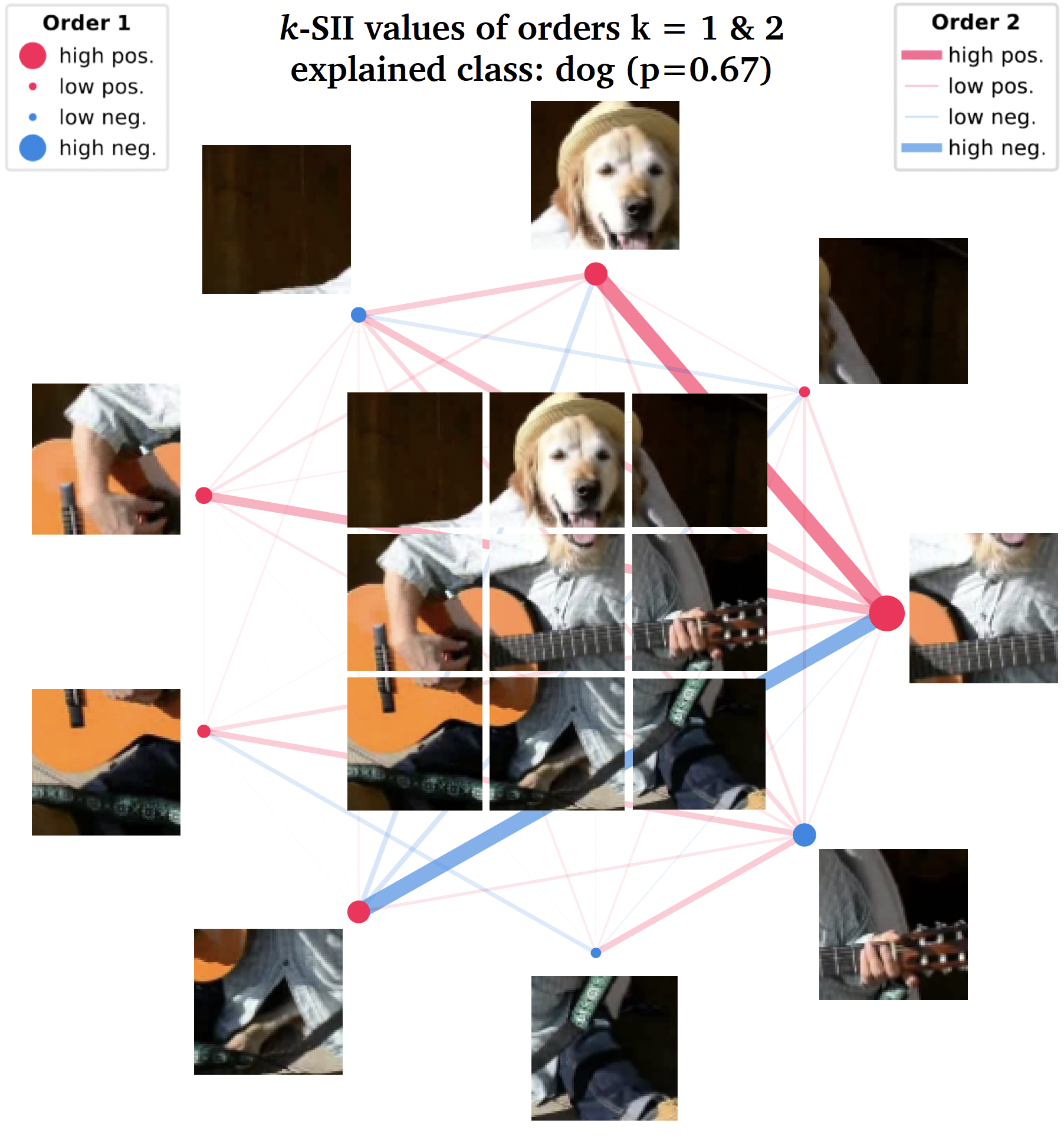
可视化二阶及以下交互得分的一种便捷方式是使用网络图。下面是一个此类图的示例。节点代表特征的归因值,边则表示特征之间的交互作用。节点和边的强度与大小分别与归因值和交互作用的绝对值成正比。
shapiq.network_plot(
first_order_values=interaction_values.get_n_order_values(1),
second_order_values=interaction_values.get_n_order_values(2)
)
# 或者使用
interaction_values.plot_network()
上述伪代码可以生成如下图表(此处也附上图片):
解释 TabPFN
借助 shapiq,您还可以通过使用 shapiq.TabPFNExplainer 中实现的“移除并重新上下文化”解释范式来解释 TabPFN。
import tabpfn, shapiq
data, labels = ... # 加载您的数据
model = tabpfn.TabPFNClassifier() # 获取 TabPFN
model.fit(data, labels) # “拟合” TabPFN(可选)
explainer = shapiq.TabPFNExplainer( # 设置解释器
model=model,
data=data,
labels=labels,
index="FSII"
)
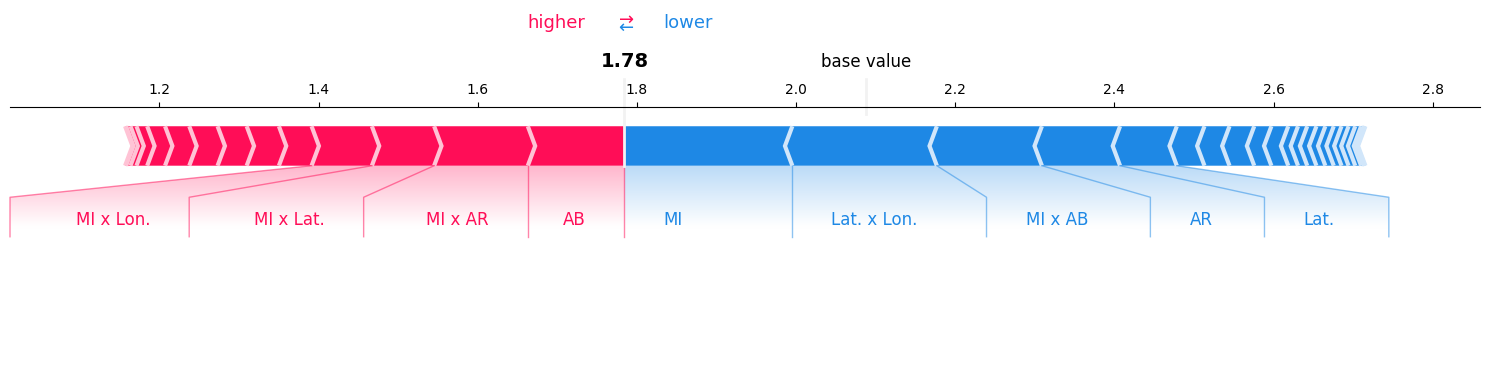
fsii_values = explainer.explain(data[0]) # 使用忠实 Shapley 值进行解释
fsii_values.plot_force() # 绘制力图
📖 包含教程的文档
shapiq 的文档可在 https://shapiq.readthedocs.io 上找到。如果您对 Shapley 值或 Shapley 交互还不熟悉,建议从 简介 和 示例与教程 开始阅读。这里有许多优质资源可以帮助您快速入门 Shapley 值和交互。
💬 引用
如果您使用了 shapiq 并对其感到满意,请考虑引用我们的 NeurIPS 论文,或者为本仓库点个赞。
@inproceedings{Muschalik.2024b,
title = {shapiq: 用于机器学习的 Shapley 交互},
author = {Maximilian Muschalik、Hubert Baniecki、Fabian Fumagalli、Patrick Kolpaczki、Barbara Hammer 和 Eyke H\"{u}llermeier},
booktitle = {第38届神经信息处理系统大会数据集与基准测试赛道},
year = {2024},
url = {https://openreview.net/forum?id=knxGmi6SJi}
}
📦 贡献
我们欢迎对 shapiq 的任何形式的贡献!如果您有兴趣参与贡献,请查看我们的 贡献指南。如有任何问题,欢迎随时与我们联系。我们通过 项目看板 和 问题 部分跟踪进展。如果您发现错误或有功能请求,请提交一个问题,或者通过打开拉取请求来帮助我们修复。
📜 许可证
本项目采用 MIT 许可证 许可。
💰 资助
这项工作以 MIT 许可证公开发布。部分作者感谢德国研究基金会 (DFG) 在编号 TRR 318/1 2021 – 438445824 的资助下提供的财政支持。
由 shapiq 团队用心打造。
版本历史
v1.4.12025/11/10v1.4.02025/10/31v1.3.22025/10/14v1.3.12025/07/11v1.3.02025/06/17v.1.2.32025/03/24v1.2.22025/03/11v1.2.12025/02/17v1.2.02025/01/15v1.1.12024/11/13v1.1.02024/11/08v1.0.12024/06/05v1.0.02024/06/04v.0.0.6-alpha2024/03/20v.0.0.5-alpha2024/03/18v.0.0.4-alpha2023/11/29v0.0.3-alpha2023/11/17v0.0.2-alpha2023/10/23相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。