BertWithPretrained
BertWithPretrained 是一个基于 PyTorch 框架实现的 BERT 模型开源项目,旨在帮助开发者从零开始理解并应用这一强大的自然语言处理技术。它不仅提供了完整的 BERT 模型代码实现,还涵盖了文本分类、语义蕴含、多项选择、问答系统以及命名实体识别等多种主流下游任务的具体应用示例。
对于希望深入掌握 Transformer 架构原理的研究人员和深度学习开发者而言,BertWithPretrained 解决了“黑盒使用”的痛点。许多现有库仅允许调用预训练模型,而该项目通过从底层自注意力机制到上层任务逻辑的全流程代码复现,让用户能清晰洞察模型内部运作机制。此外,它还支持基于 NSP(下一句预测)和 MLM(掩码语言模型)任务从头训练 BERT,为定制化研究提供了坚实基础。
该项目特别适合具备一定 Python 和 PyTorch 基础的 AI 工程师、算法研究员及高校学生。无论是想要复现经典论文实验,还是希望针对中文或英文场景进行二次开发,都能从中获得详尽的代码参考与理论指导。其结构清晰、注释丰富,并配套了今日头条分类、SQuAD 问答等真实数据集,是学习与实践 BERT 技术的理想入门资源。
使用场景
某金融科技公司的算法团队正急需构建一个能自动识别新闻中“公司实体”并判断其“情感倾向”的风控监控系统。
没有 BertWithPretrained 时
- 重复造轮子耗时久:团队需从零手写 Transformer 的自注意力机制和嵌入层,花费数周调试底层代码而非关注业务逻辑。
- 任务适配门槛高:面对命名实体识别(NER)和文本分类两种不同任务,缺乏统一的微调框架,需分别摸索数据预处理和模型接口。
- 预训练资源难整合:难以直接加载标准的中文 BERT 预训练权重,导致模型冷启动效果差,且无法复现论文中的 NSP 和 MLM 预训练过程。
- 教学与实战脱节:新入职员工缺乏对 BERT 原理的直观代码参考,只能阅读晦涩论文,上手周期长达一个月。
使用 BertWithPretrained 后
- 开箱即用提效率:直接调用
BasicBert模块即可复用完整的 BERT 架构,将原本数周的基础搭建工作缩短至几天。 - 多任务统一框架:利用内置的
TaskForChineseNER和TaskForSingleSentenceClassification脚本,快速适配实体抽取和情感分析任务,代码结构清晰统一。 - 无缝衔接预训练模型:一键加载
bert_base_chinese权重,并支持基于 WikiText 或宋词数据进行自定义 NSP/MLM 预训练,显著提升模型在金融语料上的表现。 - 代码即教材:新员工通过阅读其详细的模块化实现(如
MyTransformer.py),迅速理解双向 Transformer 原理,培训周期缩短至一周。
BertWithPretrained 通过将复杂的 BERT 理论转化为模块化、可执行的 PyTorch 代码,让开发者能从繁琐的底层实现中解放出来,专注于下游业务价值的挖掘。
运行环境要求
- 未说明
未说明
未说明

快速开始
BertWithPretrained
本项目基于 PyTorch 框架实现了 BERT 模型及其相关的下游任务。同时,项目还包含了对 BERT 模型以及各个底层任务原理的详细讲解。
BERT: 用于语言理解的深度双向 Transformer 预训练
在开始使用本项目之前,您需要先通过以下三个示例了解 Transformer 的相关原理:翻译、分类 和 对联生成。
实现内容
- 1. 从零开始实现 BERT 模型
- 2. 基于 BERT 预训练模型的中文文本分类任务
- 3. 基于 BERT 预训练模型的英文文本蕴含(MNLI)任务
- 4. 基于 BERT 预训练模型的英文多项选择(SWAG)任务
- 5. 基于 BERT 预训练模型的英文问答(SQuAD)任务
- 6. 基于 NSL 和 MLM 任务从零开始训练 BERT 任务
- 7. 基于 BERT 预训练模型的命名实体识别任务
项目结构
bert_base_chinese包含 bert_base_chinese 预训练模型及配置文件bert_base_uncased_english包含 bert_base_uncased_english 预训练模型及配置文件data包含所有下游任务使用的数据集。SingleSentenceClassification是来自今日头条的 15 类中文分类数据集。PairSentenceClassification是 MNLI(多类型自然语言推理语料库)的数据集。MultipeChoice是 SWAG 的数据集。SQuAD是 SQuAD-V1.1 的数据集。WikiText是用于预训练的维基百科英文语料库。SongCi是用于中文模型预训练的宋词数据。ChineseNER是用于训练中文命名实体识别的数据集。
model是各个模块的实现BasicBert包含基础的 BERT 实现MyTransformer.py自注意力机制的实现。BertEmbedding.py输入嵌入的实现。BertConfig.py用于导入config.json配置文件。Bert.pyBERT 模型的实现。
DownstreamTasks包含所有下游任务的实现BertForSentenceClassification.py句子分类的实现。BertForMultipleChoice.py多项选择的实现。BertForQuestionAnswering.py问题回答(文本片段)的实现。BertForNSPAndMLM.pyNSP 和 MLM 的实现。BertForTokenClassification.py标记分类的实现。
Task是每个下游任务的训练和推理实现TaskForSingleSentenceClassification.py单句分类任务的实现,例如句子分类。TaskForPairSentence.py双句分类任务的实现,例如 MNLI。TaskForMultipleChoice.py多项选择任务的实现,例如 SWAG。TaskForSQuADQuestionAnswering.py问题回答(文本片段)任务的实现,例如 SQuAD。TaskForPretraining.pyNSP 和 MLM 任务的实现。TaskForChineseNER.py中文命名实体识别任务的实现。
test是每个下游任务的测试用例。utilsdata_helpers.py是每个下游任务的数据预处理和数据集构建模块;log_helper.py是日志打印模块。creat_pretraining_data.py用于构建 BERT 预训练任务的数据集。
Python 环境
Python 3.6 及以下包版本:
torch==1.5.0
torchtext==0.6.0
torchvision==0.6.0
transformers==4.5.1
numpy==1.19.5
pandas==1.1.5
scikit-learn==0.24.0
tqdm==4.61.0
使用方法
第一步:下载数据集
下载各个数据集以及相应的 BERT 预训练模型(如果尚未下载),并将其放置在对应的目录中。具体操作请参阅每个数据(data)目录下的 README.md 文件。
第二步:运行
进入 Tasks 目录并运行相应模型。
2.1 中文文本分类任务
模型结构与数据处理:
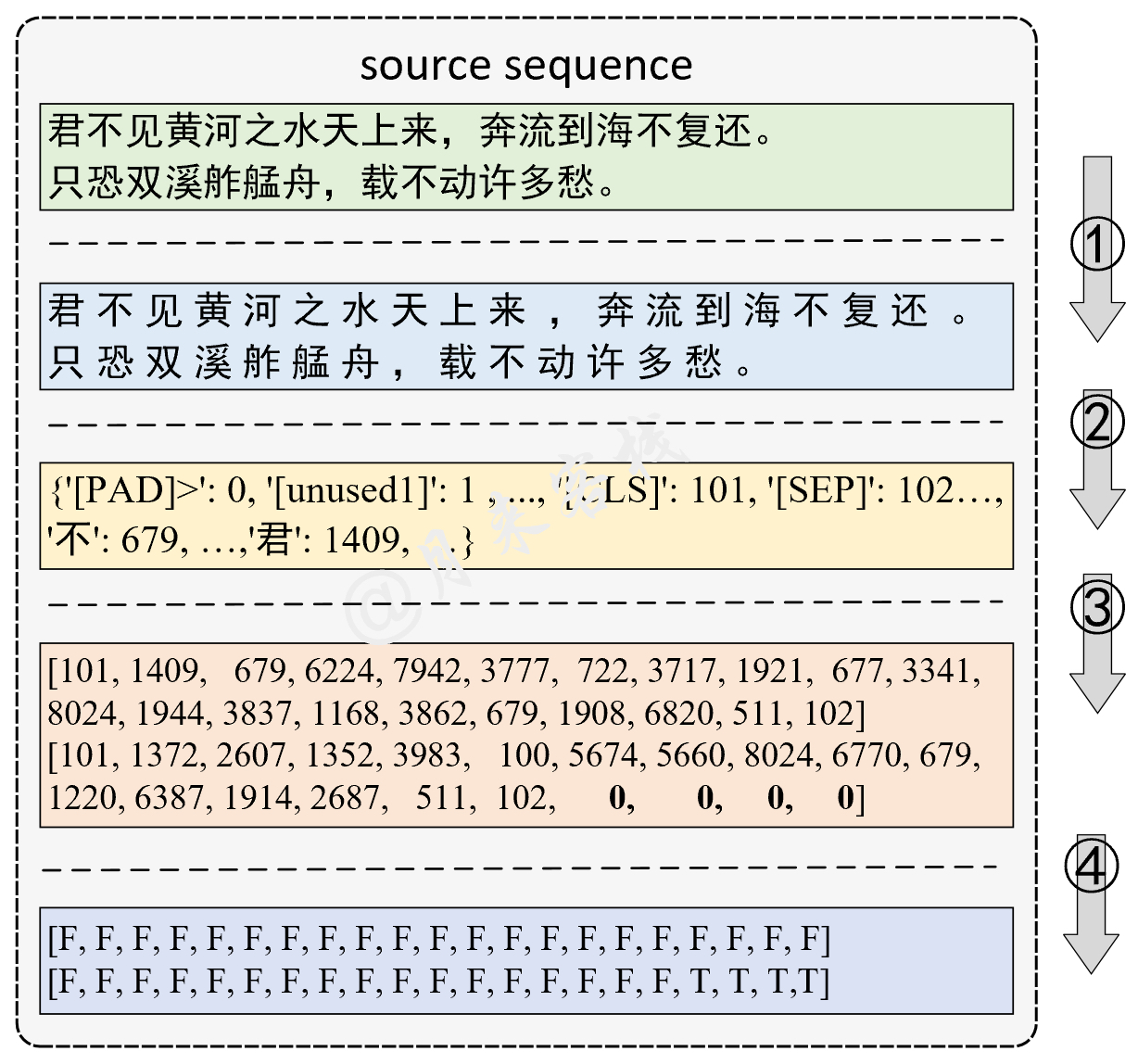
python TaskForSingleSentenceClassification.py
结果:
-- INFO: Epoch: 0, Batch[0/4186], 训练损失 :2.862, 训练准确率: 0.125
-- INFO: Epoch: 0, Batch[10/4186], 训练损失 :2.084, 训练准确率: 0.562
-- INFO: Epoch: 0, Batch[20/4186], 训练损失 :1.136, 训练准确率: 0.812
-- INFO: Epoch: 0, Batch[30/4186], 训练损失 :1.000, 训练准确率: 0.734
...
-- INFO: Epoch: 0, Batch[4180/4186], 训练损失 :0.418, 训练准确率: 0.875
-- INFO: Epoch: 0, 训练损失: 0.481, 训练时长 = 1123.244秒
...
-- INFO: Epoch: 9, Batch[4180/4186], 训练损失 :0.102, 训练准确率: 0.984
-- INFO: Epoch: 9, 训练损失: 0.100, 训练时长 = 1130.071秒
-- INFO: 验证集准确率 0.884
-- INFO: 验证集准确率 0.888
2.2 文本蕴含任务
模型结构与数据处理:

python TaskForPairSentenceClassification.py
结果:
-- INFO: Epoch: 0, Batch[0/17181], 训练损失 :1.082, 训练准确率: 0.438
-- INFO: Epoch: 0, Batch[10/17181], 训练损失 :1.104, 训练准确率: 0.438
-- INFO: Epoch: 0, Batch[20/17181], 训练损失 :1.129, 训练准确率: 0.250
-- INFO: Epoch: 0, Batch[30/17181], 训练损失 :1.063, 训练准确率: 0.375
...
-- INFO: Epoch: 0, Batch[17180/17181], 训练损失 :0.367, 训练准确率: 0.909
-- INFO: Epoch: 0, 训练损失: 0.589, 训练时长 = 2610.604秒
...
-- INFO: Epoch: 9, Batch[0/17181], 训练损失 :0.064, 训练准确率: 1.000
-- INFO: Epoch: 9, 训练损失: 0.142, 训练时长 = 2542.781秒
-- INFO: 验证集准确率 0.827
-- INFO: 验证集准确率 0.830
2.3 多选题(SWAG)任务
模型结构与数据处理:
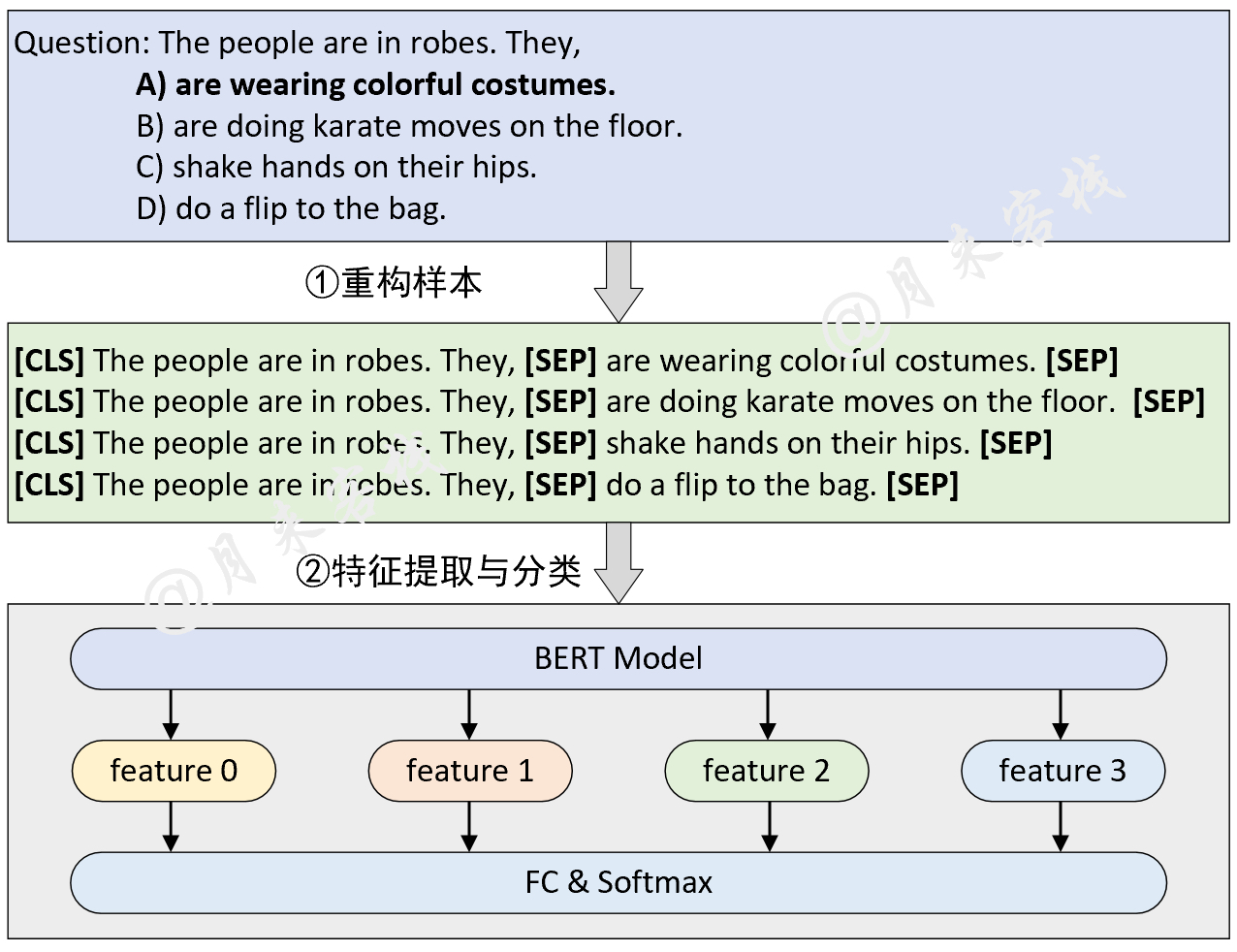
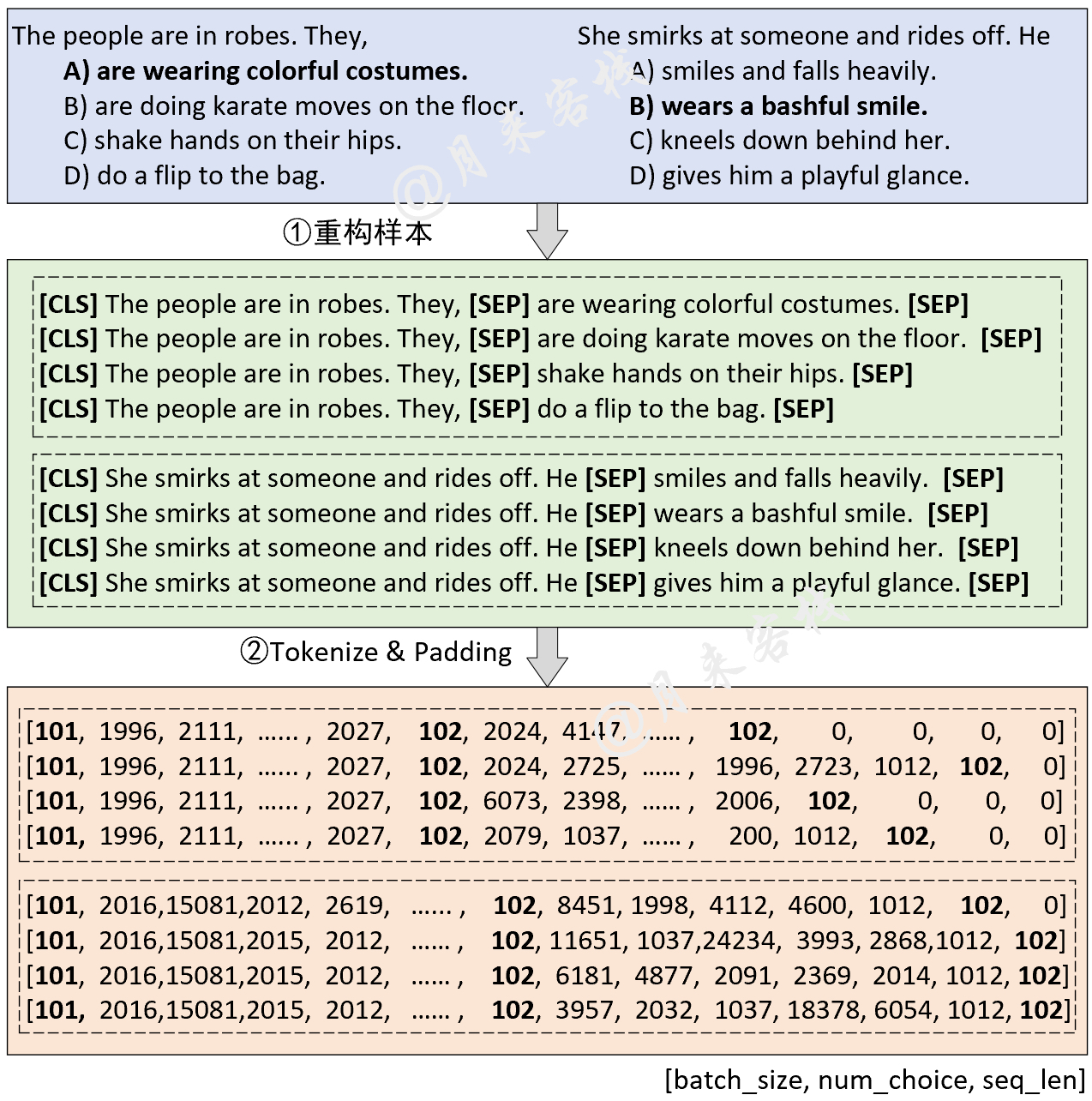
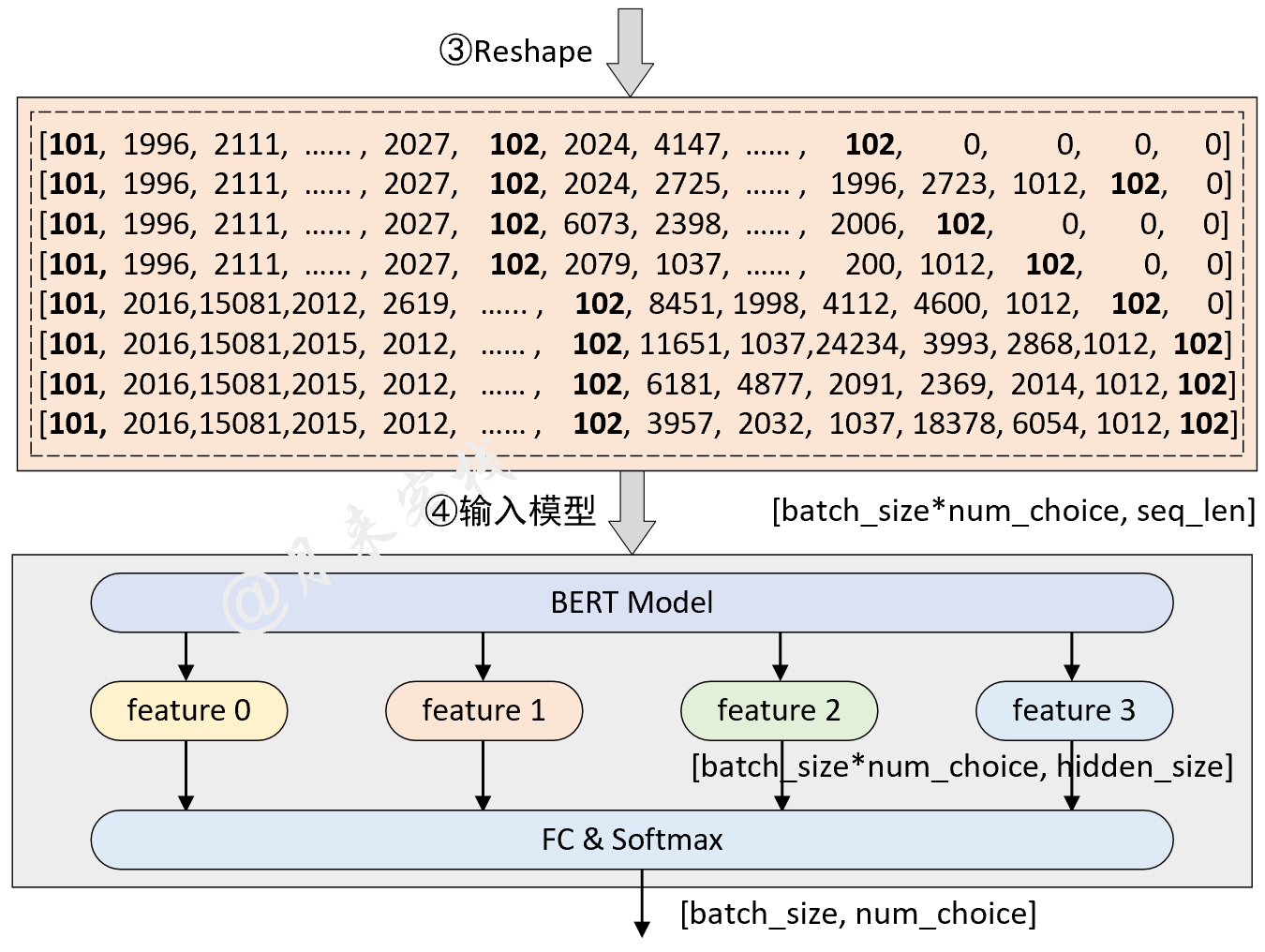
python TaskForMultipleChoice.py
结果:
[2021-11-11 21:32:50] - INFO: 第0轮, 第[0/4597]批, 训练损失:1.433, 训练准确率:0.250
[2021-11-11 21:32:58] - INFO: 第0轮, 第[10/4597]批, 训练损失:1.277, 训练准确率:0.438
[2021-11-11 21:33:01] - INFO: 第0轮, 第[20/4597]批, 训练损失:1.249, 训练准确率:0.438
......
[2021-11-11 21:58:34] - INFO: 第0轮, 第[4590/4597]批, 训练损失:0.489, 训练准确率:0.875
[2021-11-11 21:58:36] - INFO: 第0轮, 批次平均损失:0.786, 轮次耗时 = 1546.173秒
[2021-11-11 21:28:55] - INFO: 第0轮, 第[0/4597]批, 训练损失:1.433, 训练准确率:0.250
[2021-11-11 21:30:52] - INFO: 他在向墙上投掷飞镖。一位女士蹲在他身旁,手持枪左右移动。 ## 错误
[2021-11-11 21:30:52] - INFO: 他在向墙上投掷飞镖。一位女士正在向飞镖靶投掷飞镖。 ## 错误
[2021-11-11 21:30:52] - INFO: 他在向墙上投掷飞镖。一位女士突然倒下,跌落在地板上。 ## 错误
[2021-11-11 21:30:52] - INFO: 他在向墙上投掷飞镖。一位女士正站在他旁边。 ## 正确
[2021-11-11 21:30:52] - INFO: 验证集准确率 0.794
2.4 问答(SQuAD)任务
模型结构与数据处理:
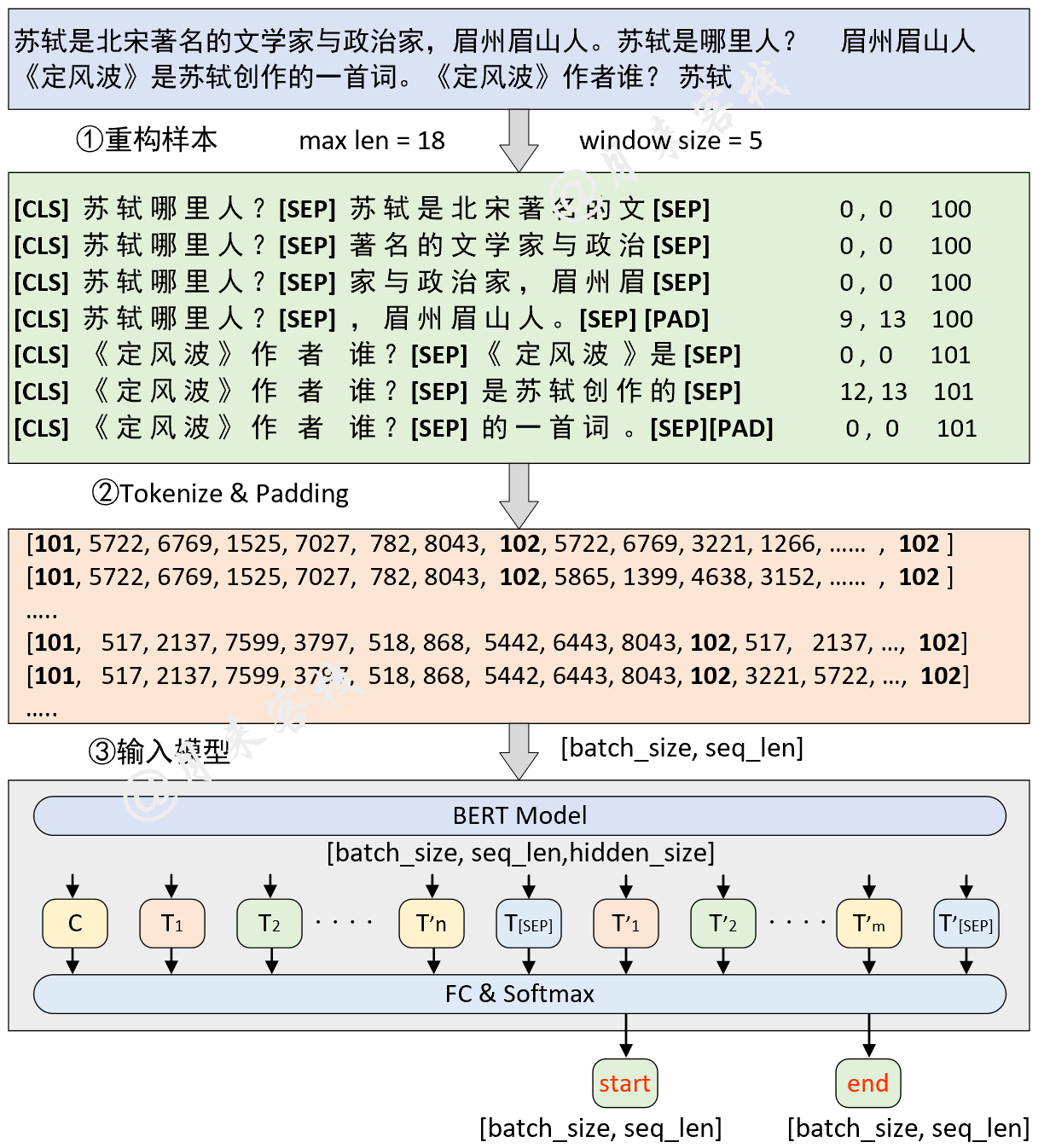
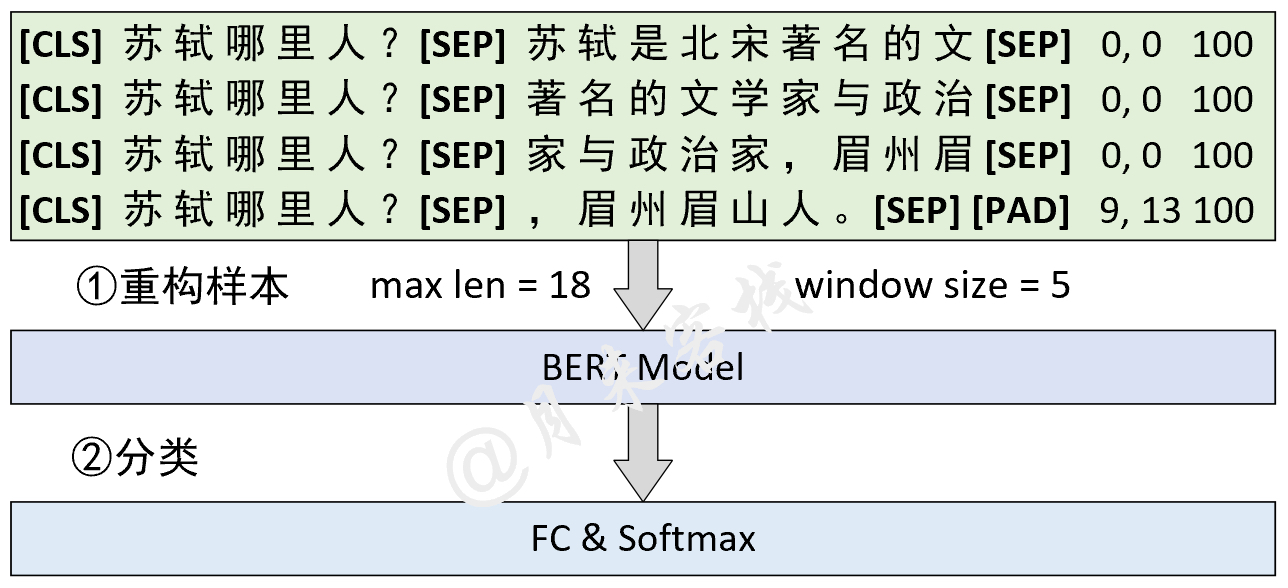
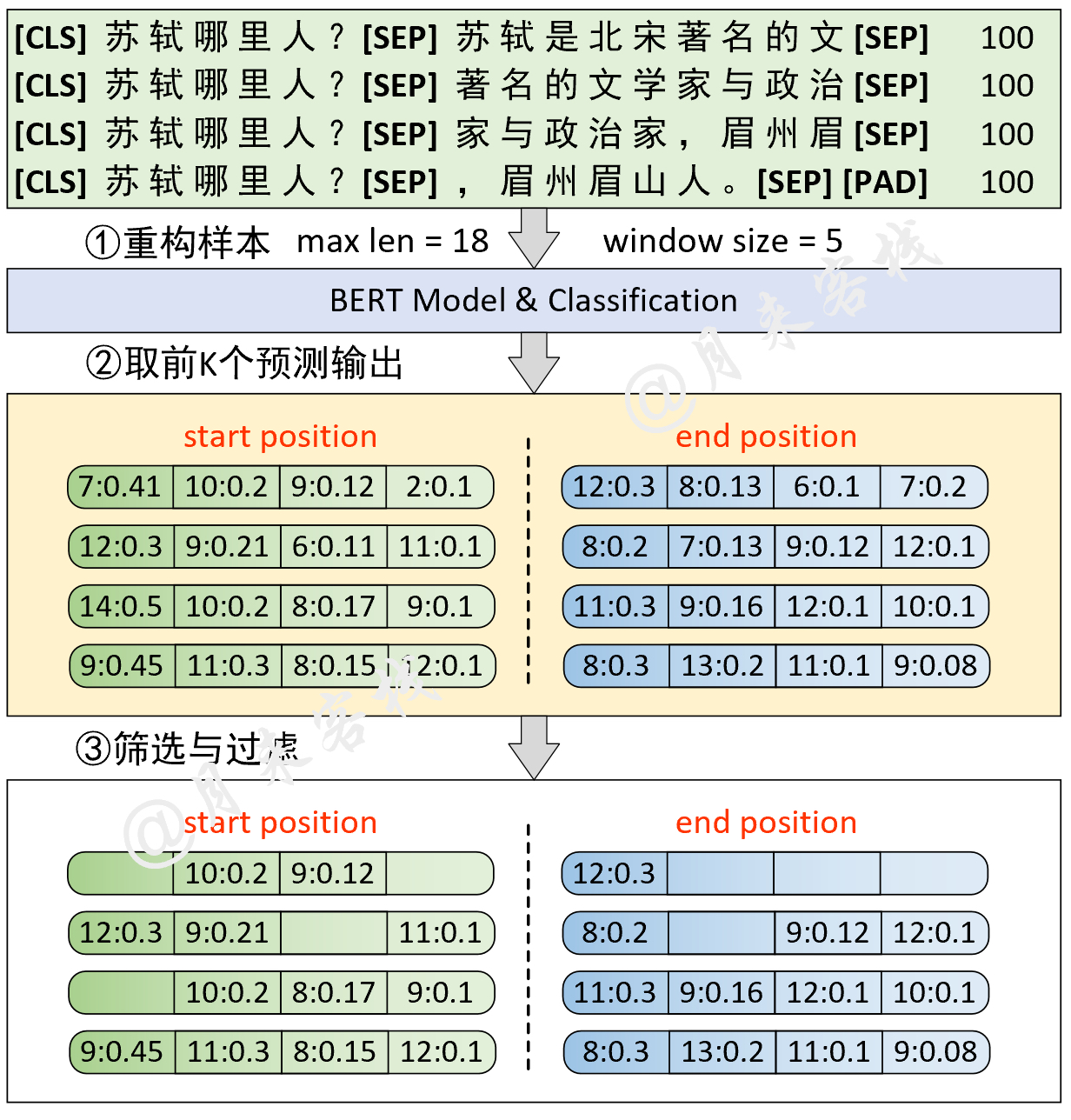
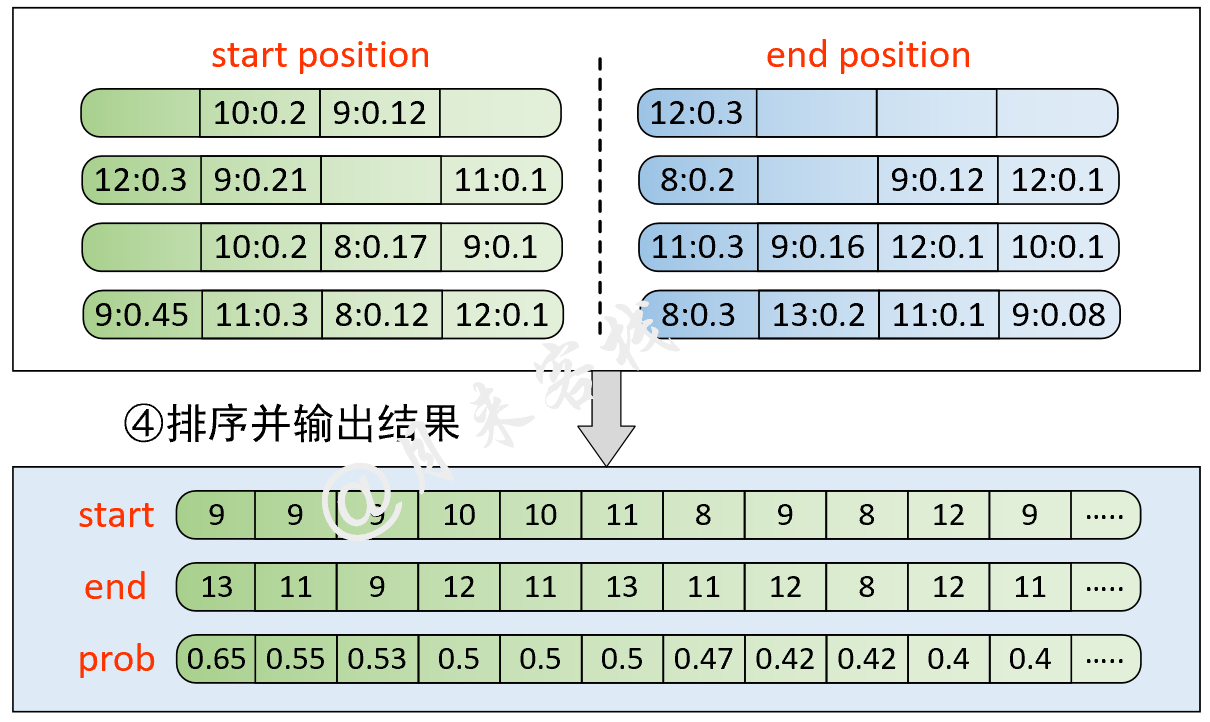
python TaskForSQuADQuestionAnswering.py
结果:
[2022-01-02 14:42:17] 缓存文件 ~/BertWithPretrained/data/SQuAD/dev-v1_128_384_64.pt 不存在,重新处理并缓存!
[2022-01-02 14:42:17] - DEBUG: <<<<<<<< 进入新的example >>>>>>>>>
[2022-01-02 14:42:17] - DEBUG: ## 正在预处理数据 utils.data_helpers is_training = False
[2022-01-02 14:42:17] - DEBUG: ## 问题 id: 56be5333acb8001400a5030d
[2022-01-02 14:42:17] - DEBUG: ## 原始问题 text: Which performers joined the headliner during the Super Bowl 50 halftime show?
[2022-01-02 14:42:17] - DEBUG: ## 原始描述 text: CBS broadcast Super Bowl 50 in the U.S., and charged an average of $5 million for a ....
[2022-01-02 14:42:17]- DEBUG: ## 上下文长度为:87, 剩余长度 rest_len 为 : 367
[2022-01-02 14:42:17] - DEBUG: ## input_tokens: ['[CLS]', 'which', 'performers', 'joined', 'the', 'headline', '##r', 'during', 'the', ...]
[2022-01-02 14:42:17] - DEBUG: ## input_ids:[101, 2029, 9567, 2587, 1996, 17653, 2099, 2076, 1996, 3565, 4605, 2753, 22589, 2265, 1029, 102, 6568, ....]
[2022-01-02 14:42:17] - DEBUG: ## segment ids:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...]
[2022-01-02 14:42:17] - DEBUG: ## orig_map:{16: 0, 17: 1, 18: 2, 19: 3, 20: 4, 21: 5, 22: 6, 23: 7, 24: 7, 25: 7, 26: 7, 27: 7, 28: 8, 29: 9, 30: 10,....}
[2022-01-02 14:42:17] - DEBUG: ======================
....
[2022-01-02 15:13:50] - INFO: 第0轮, 第[810/7387]批, 训练损失:0.998, 训练准确率:0.708
[2022-01-02 15:13:55] - INFO: 第0轮, 第[820/7387]批, 训练损失:1.130, 训练准确率:0.708
[2022-01-02 15:13:59] - INFO: 第0轮, 第[830/7387]批, 训练损失:1.960, 训练准确率:0.375
[2022-01-02 15:14:04] - INFO: 第0轮, 第[840/7387]批, 训练损失:1.933, 训练准确率:0.542
......
[2022-01-02 15:15:27] - INFO: ### 问题:[CLS] 瑞士的第一所大学是什么时候成立的?
[2022-01-02 15:15:27] - INFO: ## 预测答案:1460年
[2022-01-02 15:15:27] - INFO: ## 正确答案:1460年
[2022-01-02 15:15:27] - INFO: ## 正确答案索引:(tensor(46, tensor(47))
[2022-01-02 15:15:27] - INFO: ### 问题:普利茅斯有多少个区选举两名议员?
[2022-01-02 15:15:27] - INFO: ## 预测答案:17个区中,有3个区选举三名……
[2022-01-02 15:15:27] - INFO: ## 正确答案:3名
[2022-01-02 15:15:27] - INFO: ## 正确答案索引:(tensor(25, tensor(25))
运行结束后,data/SQuAD目录中会生成一个名为best_result.json的预测文件,此时只需要切换到该目录下,并运行以下代码即可得到在dev-v1.1.json的测试结果:
python evaluate-v1.1.py dev-v1.1.json best_result.json
"exact_match" : 80.879848628193, "f1": 88.338575234135
2.5 NSL和MLM任务
模型结构与数据处理:
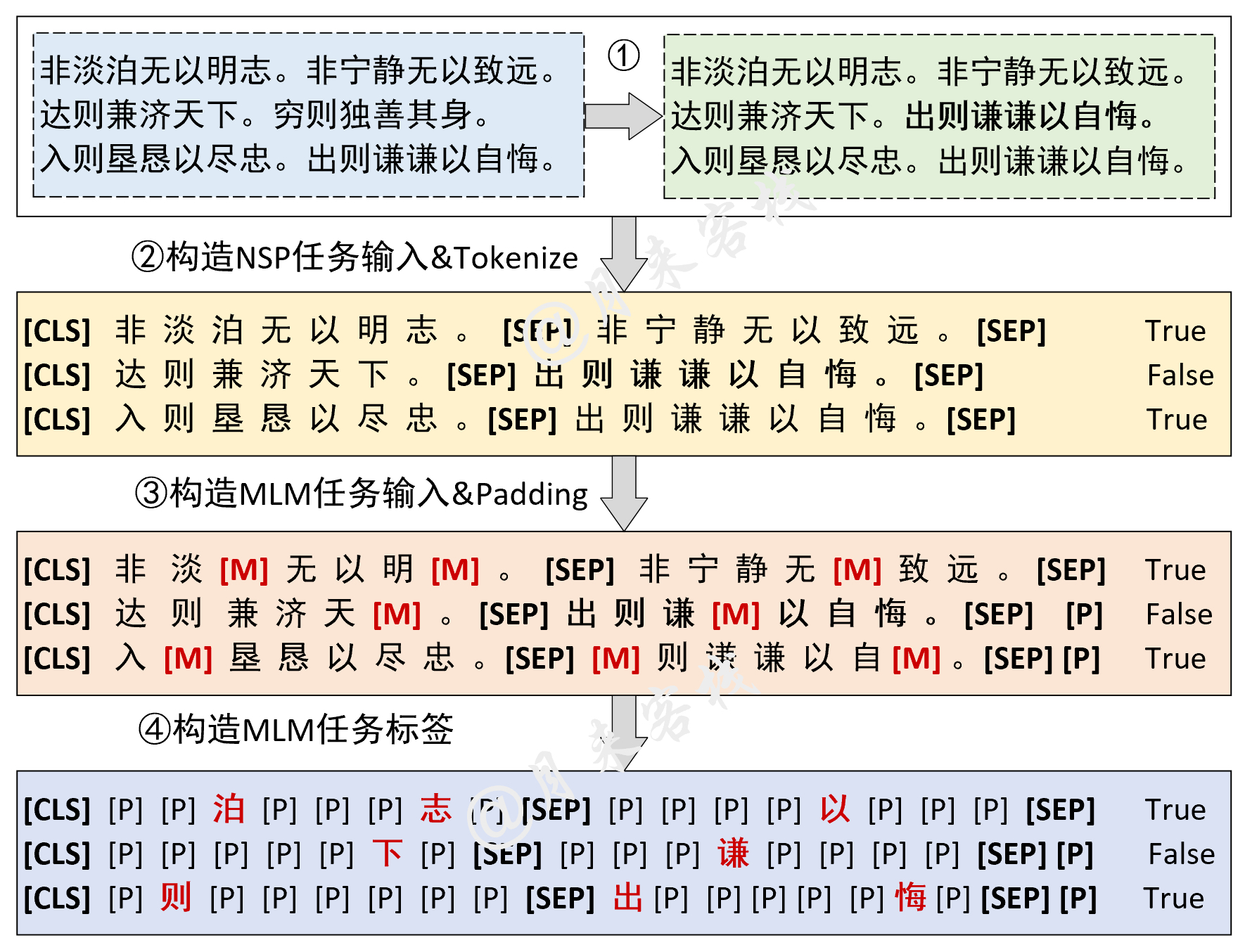
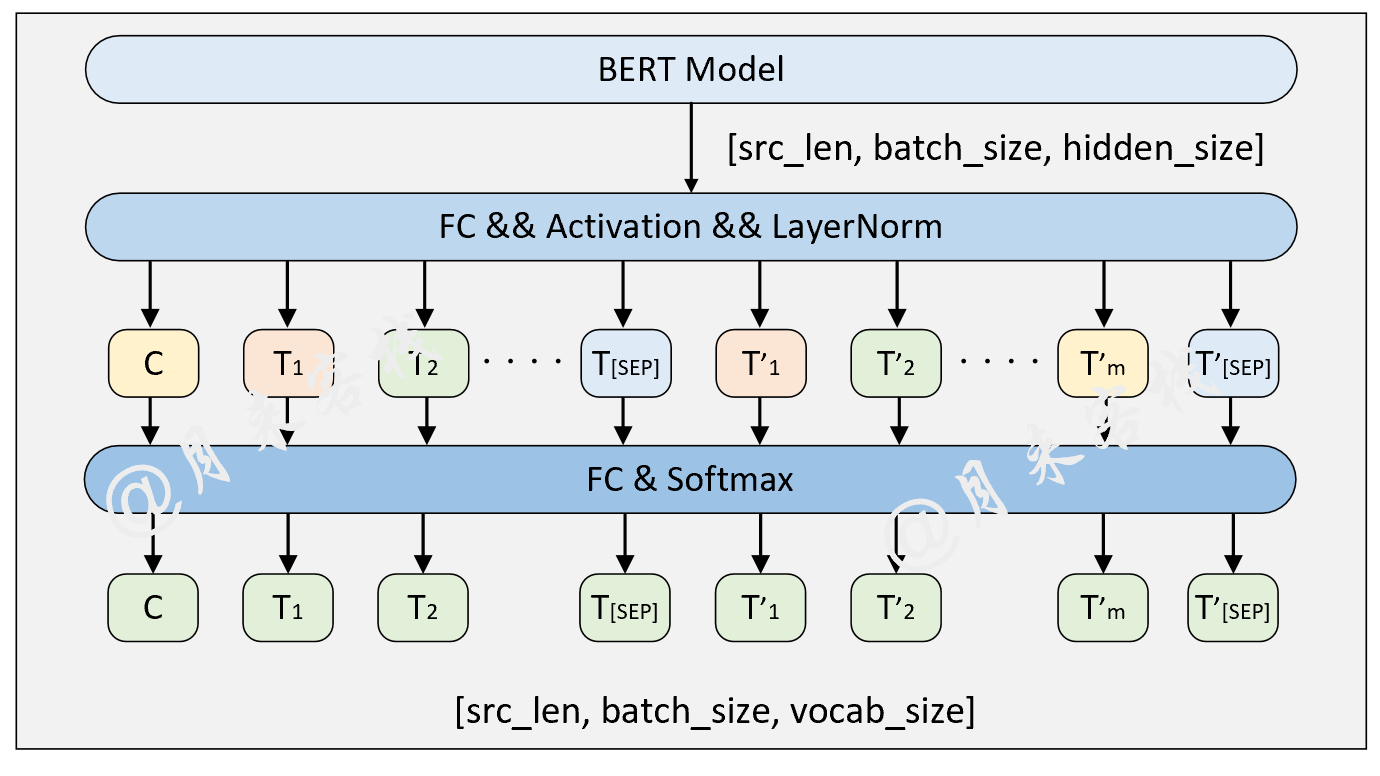
if __name__ == '__main__':
config = ModelConfig()
train(config)
sentences_1 = ["I no longer love her, true, but perhaps I love her.",
"Love is so short and oblivion so long."]
sentences_2 = ["我住长江头,君住长江尾。",
"日日思君不见君,共饮长江水。",
"此水几时休,此恨何时已。",
"只愿君心似我心,定不负相思意。"]
inference(config, sentences_2, masked=False, language='zh')
结果:
- INFO: ## 成功载入已有模型进行推理……
- INFO: ### 原始:我住长江头,君住长江尾。
- INFO: ## 掩盖:我住长江头,[MASK]住长[MASK]尾。
- INFO: ## 预测:我住长江头,君住长河尾。
- INFO: ====================
- INFO: ### 原始:日日思君不见君,共饮长江水。
- INFO: ## 掩盖:日日思君不[MASK]君,共[MASK]长江水。
- INFO: ## 预测:日日思君不见君,共饮长江水。
# ......
2.6 命名实体识别任务
模型结构与数据处理:
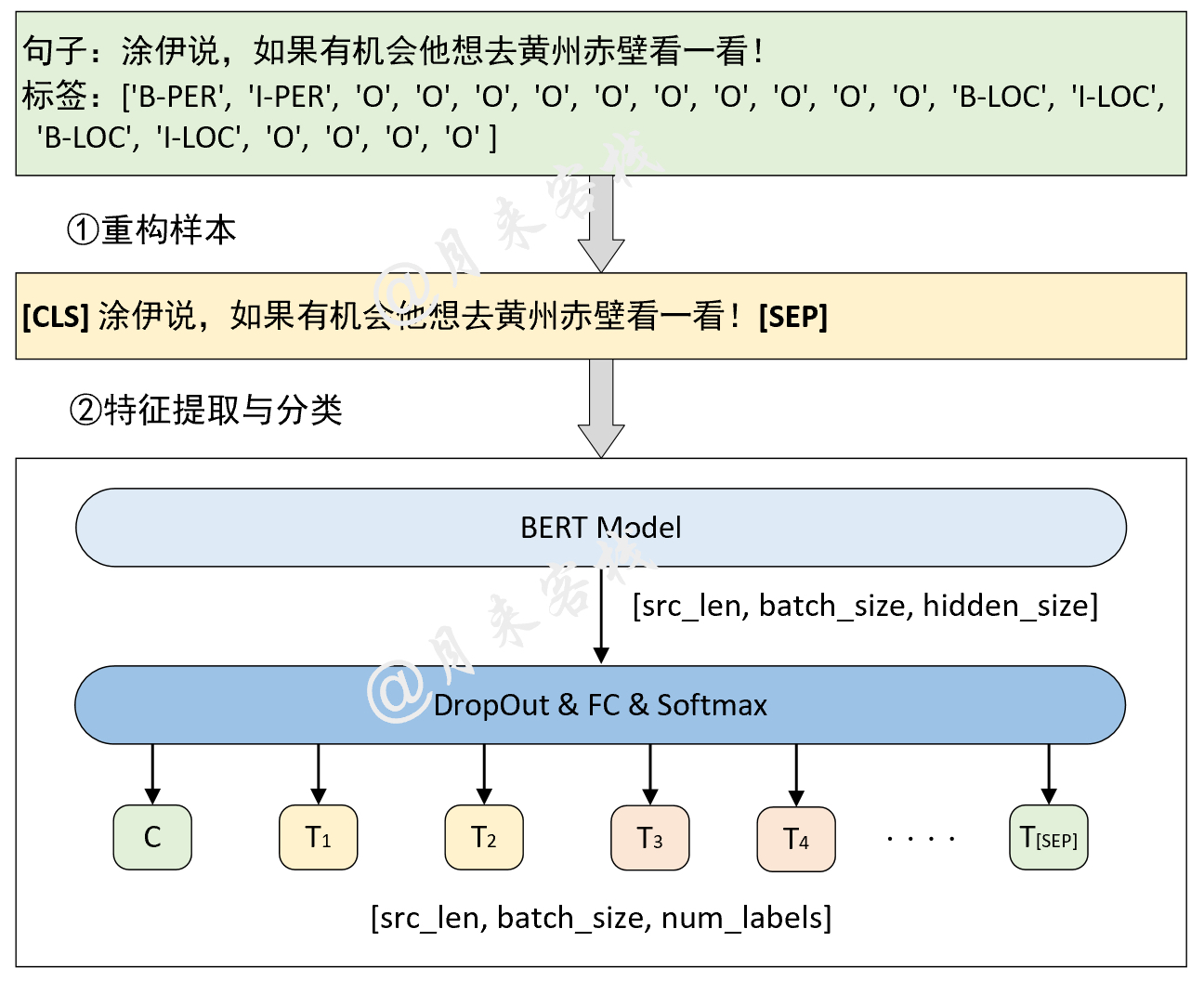
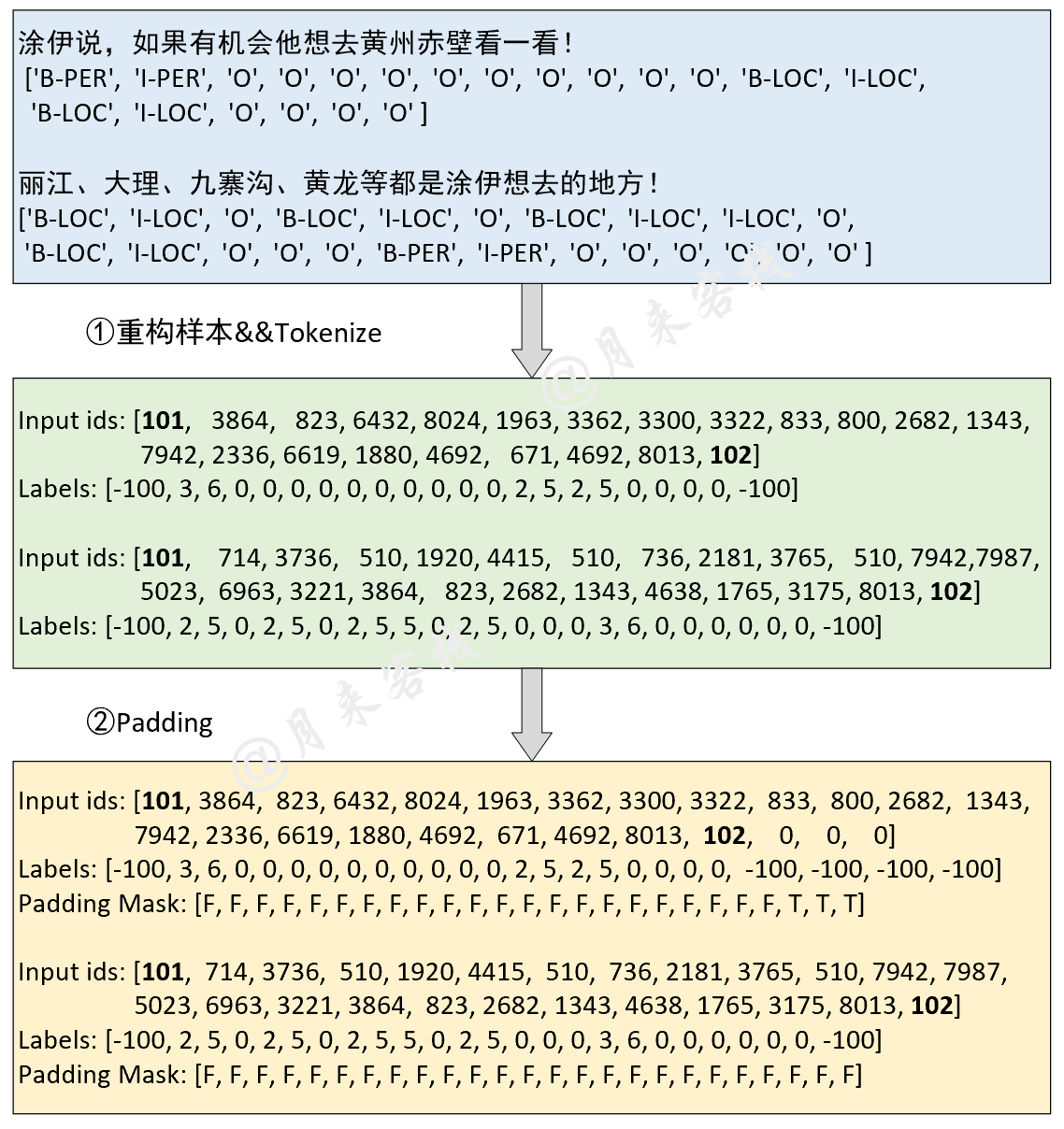
if __name__ == '__main__':
config = ModelConfig()
train(config)
sentences = ['智光拿出石壁拓文为乔峰详述事情始末,乔峰方知自己原本姓萧,乃契丹后族。',
'当乔峰问及带头大哥时,却发现智光大师已圆寂。',
'乔峰、阿朱相约找最后知情人康敏问完此事后,就到塞外骑马牧羊,再不回来。']
inference(config, sentences)
训练结果:
- INFO: 第[1/10]轮, 第[620/1739]批, 训练损失:0.115, 训练准确率:0.96386
- INFO: 第[1/10]轮, 第[240/1739]批, 训练损失:0.098, 训练准确率:0.96466
- INFO: 第[1/10]轮, 第[660/1739]批, 训练损失:0.087, 训练准确率:0.96435
......
- INFO: 句子:在澳大利亚等西方国家改变反倾销政策中对中国的划分后,不少欧盟人士也认识到,此种划分已背离中国经济迅速发展的现实。
- INFO: 澳大利亚: LOC
- INFO: 中国: LOC
- INFO: 欧盟: LOC
- INFO: 中国: LOC
......
precision recall f1-score support
O 1.00 0.99 1.00 97640
B-ORG 0.86 0.93 0.89 984
B-LOC 0.94 0.93 0.94 1934
B-PER 0.97 0.97 0.97 884
I-ORG 0.90 0.96 0.93 3945
I-LOC 0.91 0.95 0.93 2556
I-PER 0.99 0.98 0.98 1714
accuracy 0.99 109657
macro avg 0.94 0.96 0.95 109657
weighted avg 0.99 0.99 0.99 109657
推理结果:
- INFO: 句子:智光拿出石壁拓文为乔峰详述事情始末,乔峰方知自己原本姓萧,乃契丹后族。
- INFO: 智光: PER
- INFO: 乔峰: PER
- INFO: 乔峰: PER
- INFO: 萧: PER
- INFO: 丹: PER
......
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备