TFC-pretraining
TFC-pretraining 是一款专为时间序列数据设计的自监督对比学习预训练框架。它核心解决了时间序列分析中普遍存在的难题:不同数据集之间因传感器差异、采样不规则或语义不同导致的“域偏移”问题,使得在一个场景训练的模型难以直接迁移到其他场景。
该工具特别适合人工智能研究人员和开发者使用,尤其是那些需要在手势识别、故障检测或癫痫分析等多样化场景中构建高精度模型,但面临标注数据稀缺困境的团队。TFC-pretraining 的独特技术亮点在于其提出的“时频一致性”(Time-Frequency Consistency)理念。受信号处理中傅里叶定理的启发,它认为同一样本在时域和频域的表征应当在潜在空间中彼此靠近。通过在无标签的大规模数据上进行自监督预训练,强制模型学习这种跨域的共同模式,TFC-pretraining 能够提取出极具泛化能力的特征。用户只需将预训练模型在少量特定任务数据上进行微调,即可显著提升下游分类任务的表现,大幅降低了对昂贵标注数据的依赖。
使用场景
某工业预测性维护团队正试图利用振动传感器数据,提前识别旋转机械的潜在故障,但面临标注数据稀缺且工况多变的挑战。
没有 TFC-pretraining 时
- 标注依赖严重:传统监督学习需要大量人工标记的故障样本,而实际生产中故障罕见,导致模型因训练数据不足而无法收敛。
- 泛化能力薄弱:在不同转速或负载下采集的数据分布差异巨大,在一个工况训练的模型换到另一台设备上准确率断崖式下跌。
- 特征提取片面:单独使用时域或频域分析容易丢失关键信息,难以捕捉振动信号中时间动态与频率成分之间的内在一致性关联。
- 冷启动成本高:每接入新类型的传感器或新场景,都需要重新收集数据并从头训练模型,部署周期长达数周。
使用 TFC-pretraining 后
- 实现无监督预训练:利用海量未标注的原始振动数据,通过时频一致性对比学习预先提取通用特征,大幅降低对故障标签的依赖。
- 跨域迁移能力强:模型学到了时间序列底层的共性模式,只需少量目标场景数据进行微调,即可适应不同设备或变工况下的故障检测。
- 表征更加鲁棒:强制时域嵌入与频域嵌入在潜在空间靠近,使模型能同时捕捉瞬态冲击与频谱规律,显著提升了复杂噪声下的识别精度。
- 快速落地新场景:基于预训练权重进行微调,将新产线的模型开发周期从数周缩短至几天,实现了高效的“预训练 + 微调”工作流。
TFC-pretraining 通过挖掘时间序列独有的时频一致性,成功解决了工业场景下小样本、多变量导致的模型泛化难题,让预测性维护真正具备规模化落地能力。
运行环境要求
未说明
未说明

快速开始
基于时频一致性的自监督对比预训练用于时间序列
作者:张翔 (xiang.alan.zhang@gmail.com)、赵子源(ziyuanzhao@college.harvard.edu),
西奥多罗斯·齐利加里迪斯(ttsili@ll.mit.edu)、马林卡·齐特尼克 (marinka@hms.harvard.edu)
项目网站
TF-C 论文:NeurIPS 2022、预印本
概述
本仓库包含八个经过处理的数据集,以及为论文《基于时频一致性的自监督对比预训练用于时间序列》开发的 TF-C 预训练模型代码(连同基线模型)。我们提出了 TF-C,这是一种新颖的预训练方法,用于学习可跨不同时间序列数据集迁移的通用特征。我们在八个具有不同传感器测量和语义含义的时间序列数据集上,针对四个真实世界应用场景进行了评估。下图概述了我们的 TF-C 方法背后的思想及其广泛的适用性。该思想如 (a) 所示:给定一个时间序列样本,在潜在的时频空间中,基于时间的嵌入与基于频率的嵌入被拉近。应用场景如 (b) 所示:通过在时间序列中利用 TF-C,我们可以将预训练模型泛化到手势识别、故障检测和癫痫发作分析等多种场景。
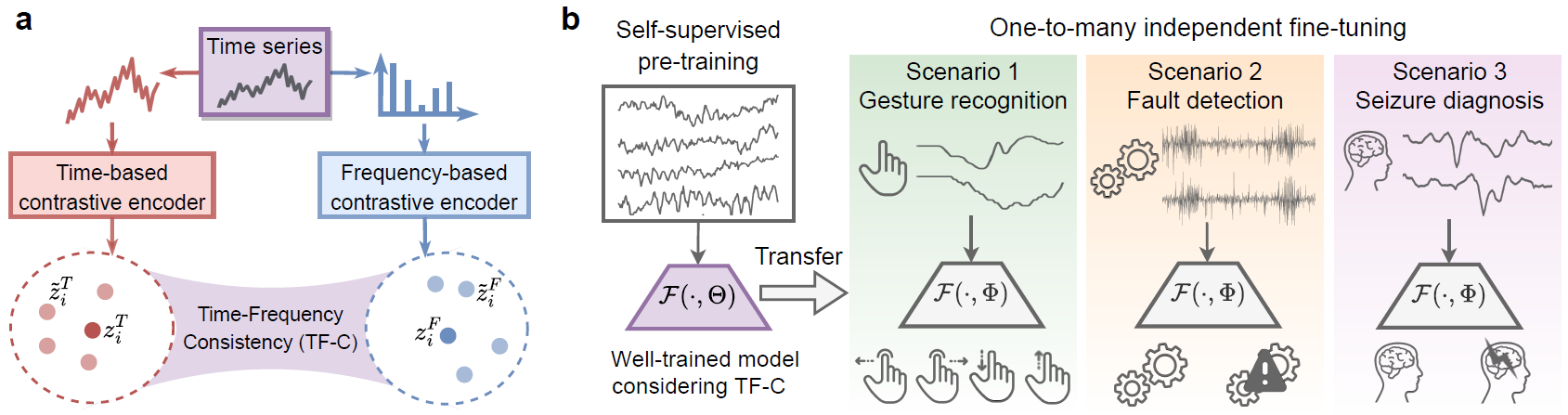
TF-C 的核心思想
我们的模型在大规模预训练时间序列数据集中捕捉了时间序列的可泛化特性——时频一致性(TF-C)。所谓时频一致性,是指从同一时间序列样本中学习到的基于时间和基于频率的表示,在联合时频空间中彼此更接近;而如果这些表示来自不同的时间序列样本,则会更加远离。通过建模这种专属于时间序列的特性,所开发的模型能够捕捉时间序列中的底层共性模式,并进一步促进知识在不同时间序列数据集之间的迁移。这些不同的时间序列数据集往往存在复杂性,例如各数据集之间的时间动态变化巨大、语义含义各异、采样不规则、系统因素(如不同设备或受试者)等。
此外,所开发的模型采用对比学习框架,实现了自监督预训练(无需预训练数据集中的标签)。我们的 TF-C 方法如下图所示。
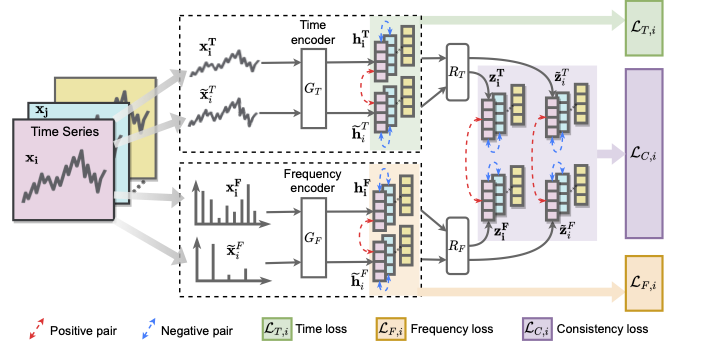
TF-C 方法概述。 我们的模型由四个组件组成:时间编码器、频率编码器,以及两个跨空间投影器,分别将基于时间的表示和基于频率的表示映射到同一个时频空间。这四个组件共同作用,可以将输入的时间序列嵌入到潜在的时频空间中,使基于时间的嵌入与基于频率的嵌入相互靠近。 通过促进潜在时频空间中基于时间和基于频率的表示对齐,TF-C 特性得以实现,从而为将训练好的模型迁移到未曾见过的目标数据集提供了途径。
数据集
我们准备了八个数据集,用于四个不同的场景,以此比较我们的方法与基线模型。这些场景包括电诊断测试、人类日常活动识别、机械故障检测和身体状态监测。
原始数据
(1). SleepEEG 包含 153 个整夜睡眠脑电图(EEG)记录,由睡眠监测仪采集。数据来自 82 名健康受试者。单导联 EEG 信号以 100 Hz 采样率采集。我们将 EEG 信号分割成无重叠的片段(窗口大小为 200),每个片段构成一个样本。每个样本对应五种睡眠模式/阶段之一:清醒(W)、非快速眼动睡眠(N1、N2、N3)和快速眼动睡眠(REM)。分割后,我们得到 371,055 个 EEG 样本。该 原始数据集 依据开放数据共享署名许可协议 v1.0 发布。
(2). 癫痫 数据集包含500名受试者的单通道脑电图测量数据。对于每位受试者,其脑活动被记录了23.6秒。随后,数据集被分割并打乱(以减少样本与受试者之间的关联),形成11,500个1秒长的样本,采样频率为178 Hz。原始数据集包含5个不同的分类标签,分别对应受试者的不同状态或测量位置:睁眼、闭眼、健康脑区的脑电图、肿瘤所在区域的脑电图,以及正在发作癫痫的受试者。为了突出癫痫阳性与阴性样本之间的区别,我们将前4类合并为一类,每个时间序列样本都带有二元标签,用于描述相关受试者是否正在发作癫痫。整个数据集共有11,500个脑电图样本。为了评估预训练模型在小规模微调数据集上的性能,我们选择了一个小型子集(60个样本;每类30个)进行微调,并使用验证集(20个样本;每类10个)对模型进行评估。表现最佳的模型将用于对测试集(剩余的11,420个样本)进行预测。原始数据集 依据知识共享署名4.0协议(CC-BY)发布。
(3), (4). FD-A 和 FD-B 是从 FD 数据集中提取的子集,该数据集来自一个机电驱动系统,用于监测滚动轴承的状态并检测其损坏情况。数据集包含四个在不同工况下采集的子集,这些工况的参数包括转速、负载扭矩和径向力。每个滚动轴承可能处于完好、内圈损坏或外圈损坏状态,因此总共分为三类。我们分别将对应工况A和工况B的子集称为故障检测工况A(FD-A)和故障检测工况B(FD-B)。每段原始记录为单通道,采样频率为64 kHz,持续时间为4秒。为处理较长的时长,我们遵循Eldele等人的方法,即使用5,120个观测值的滑动窗口,步长分别为1,024或4,096,以使最终各分类下的样本数量相对均衡。原始数据集 依据知识共享署名-非商业性使用4.0国际许可协议发布。
(5). HAR 数据集包含30名健康志愿者执行六种日常活动的记录,包括步行、上楼梯、下楼梯、坐下、站立和躺下。预测标签即为这六种活动。智能手机上的可穿戴传感器以50 Hz的频率测量三轴线加速度和三轴角速度。经过预处理并从身体加速度中分离出重力加速度后,共得到九个通道。为了使语义域与微调实验中使用的Gesture数据集中的通道保持一致,我们仅保留身体线加速度的三个通道。原始数据集 按“原样”提供,作者及其所属机构对其使用或误用不承担任何明示或暗示的责任。禁止任何商业用途。
(6). Gesture 数据集包含八种简单手势的加速度计测量数据,这些手势根据手部运动轨迹的不同而有所区分。这八种手势是:左手划动、右手划动、向上划动、向下划动、逆时针划圆、顺时针划圆、划方形以及划右箭头。分类标签即为这八种不同类型的手势。原始论文报告称包含了4,480次手势测量,但通过UCR数据库我们仅恢复了440次测量。该数据集每类有55个样本,分布均衡,且规模适于我们的微调实验目的。原始论文未明确报告采样频率,但推测为100 Hz。数据集使用三个通道,分别对应线加速度的三个坐标方向。原始数据集 公开可用。
(7). ECG 是2017年PhysioNet挑战赛的一个子集,该挑战赛专注于心电图记录的分类。单导联心电图用于测量四种不同的心脏节律异常状况。具体而言,这些类别对应于正常窦性心律、心房颤动(AF)、交替性心律以及其他(噪声过大无法分类)的记录。记录的采样频率为300 Hz。此外,数据集存在不平衡问题,心房颤动和噪声过大的类别样本数量远少于其他两类。为了预处理数据集,我们采用CLOCS论文中的代码,即使用固定长度为1,500个观测值的窗口,将长时间记录分割成5秒钟的短样本,这些样本仍具有生理意义。原始数据集 依据开放数据知识共享署名许可证v1.0发布。
(8). 肌电图(EMG)用于测量肌肉在神经刺激下的电活动响应,可用于诊断某些肌营养不良症和神经病变。EMG 数据集由三名志愿者的胫前肌单通道肌电图记录组成,这三名志愿者分别健康、患有神经病变和患有肌病。记录的采样频率为4 kHz。每位患者及其所患疾病被视为一个独立的分类类别。随后,记录被分割成时间序列样本,使用固定长度为1,500个观测值的窗口。原始数据集 依据开放数据知识共享署名许可证v1.0发布。
下表总结了所有八个数据集的统计信息:
| 场景编号 | 数据集 | 样本数量 | 通道数 | 类别数 | 长度 | 频率 (Hz) | |
|---|---|---|---|---|---|---|---|
| 1 | 预训练 | SleepEEG | 371,055 | 1 | 5 | 200 | 100 |
| 微调 | Epilepsy | 60/20/11,420 | 1 | 2 | 178 | 174 | |
| 2 | 预训练 | FD-A | 8,184 | 1 | 3 | 5,120 | 64K |
| 微调 | FD-B | 60/21/13,559 | 1 | 3 | 5,120 | 64K | |
| 3 | 预训练 | HAR | 10,299 | 9 | 6 | 128 | 50 |
| 微调 | Gesture | 320/120/120 | 3 | 8 | 315 | 100 | |
| 4 | 预训练 | ECG | 43,673 | 1 | 4 | 1,500 | 300 |
| 微调 | EMG | 122/41/41 | 1 | 3 | 1,500 | 4,000 |
处理后的数据
我们在此详细说明数据预处理过程,并突出一些关键步骤以确保清晰。更多细节请参阅论文附录。总体而言,我们的数据处理分为两个阶段。首先,对于过长的时间序列记录,我们会将其分段。对于微调(目标)数据集,我们将数据集划分为训练集、验证集和测试集。在可能的情况下,我们会尽量将属于同一记录的所有样本分配到同一个分区,以避免测试集中的数据泄露到训练集中;但对于已预处理的数据集,如癫痫数据集,则无法做到这一点。训练集与验证集的比例约为3:1,并且我们尽可能为每个类别分配均衡的样本数量。所有未包含在训练和验证分区中的剩余样本都会被放入测试分区,以便更准确地评估模型的性能指标。完成第一阶段后,我们为每个数据集生成了三个对应于三个分区的*.pt*文件(PyTorch格式)。每个文件包含一个字典,键分别为samples和labels,对应的值则是存储数据的PyTorch张量。对于样本,张量的维度分别对应样本数量、通道数以及每个时间序列样本的长度。这是TS-TCC模型以及我们的TF-C实现可以直接读取的标准格式。
第二步是将每个数据集的三个*.pt*文件转换为各基线模型所接受的输入格式,并将其放置到与负责预训练和微调流程的脚本相对应的正确目录中。我们为此准备了简单的脚本,但并未将其自动化。为了进一步减少仓库中的文件杂乱,我们选择不在基线文件夹中包含这些脚本。此外,请注意,在一对多预训练的第二个实验中,微调数据集会被进一步裁剪,使其长度与sleepEEG数据集相同。
第一步 处理后的数据集可以通过以下链接手动下载。
- wget -O SleepEEG.zip https://figshare.com/ndownloader/articles/19930178/versions/1
- wget -O Epilepsy.zip https://figshare.com/ndownloader/articles/19930199/versions/2
- wget -O FD-A.zip https://figshare.com/ndownloader/articles/19930205/versions/1
- wget -O FD-B.zip https://figshare.com/ndownloader/articles/19930226/versions/1
- wget -O HAR.zip https://figshare.com/ndownloader/articles/19930244/versions/1
- wget -O Gesture.zip https://figshare.com/ndownloader/articles/19930247/versions/1
- wget -O ECG.zip https://figshare.com/ndownloader/articles/19930253/versions/1
- wget -O EMG.zip https://figshare.com/ndownloader/articles/19930250/versions/1
然后需要将这些文件放置到data/dataset_name下的相应文件夹中(例如data/SleepEEG):
处理完善的数据集将在论文接收后发布(在FigShare上)。
或者,您也可以使用download_datasets.sh脚本自动下载并解压所有数据集到各自的目录中,从而立即完成预处理的第一步。
第二步
现在我们详细说明第二步。首先,TS-TCC和TS-SD(以及我们的TF-C模型)作为TS-TCC代码库的一部分,可以直接使用上一步下载的数据集。剩下的工作只是在TS-TCC/data/dataset_name下创建相应的子目录,并将数据集放入其中。这由shell脚本data_processing/TS-TCC.sh完成,它会创建文件夹和指向下载文件的软链接。
对于TS2Vec,它使用的{train,test}_{input,output}.npy文件格式与Mixing-up完全相同,因此我们可以只对下载的数据集进行一次处理,并将其用于这两种模型。数据格式的唯一区别在于标签张量是二维的,因此我们需要为每个这样的张量插入一个新的维度。这一操作在data_processing/Mixing-up.py中完成,随后我们可以运行data_processing/TS2vec.sh来为处理后的文件创建别名。
接下来,对于CLOCS,我们需要构建一个更为复杂的嵌套字典,其中包含时间序列和标签。此外,由于CLOCS假设我们在数据预处理过程中已经丢弃了通道信息,因此时间序列样本现在以二维张量的形式存储,即去除了通道维度。同样,最终的数据集应放置在正确的位置,格式为CLOCS/data/dataset_name。然而,由于别名问题,实际使用的名称可能与我们在论文中命名的数据集不一致。请使用Python脚本data_processing/CLOCS.py自动完成上述步骤。
最后,对于SimCLR,我们没有单独的数据文件夹,而是直接将文件放置在SimCLR/dataset_name目录下。关于数据本身,需要注意的是,存储时间序列的张量其第二和第三维(分别对应通道和观测值)与初始文件相比发生了互换。此外,标签不能是数值形式,而必须采用独热编码格式。这些操作都在data_processing/SimCLR.py脚本中完成,以方便操作。
当然,我们还提供了一个快捷脚本,只需在Git仓库的根目录下运行process_all.sh即可完成以上所有步骤。在运行这些脚本之前,请确保您处于baseline_requirements.yml中指定的正确环境中。
实验设置
我们在两种不同的设置下评估了我们的模型,并将其与八种基线方法进行了对比。这些基线包括六种可用于时间序列迁移学习的最先进模型,以及两种非预训练模型(一种非深度学习方法,此处为KNN;另一种是随机初始化的模型)。这两种不同的设置如下:
设置1:一对一预训练。 我们在一个预训练数据集上对模型进行预训练,然后仅在单个目标数据集上进行微调。我们分别在四个独立场景中测试了所提出的模型:神经阶段检测、机械设备诊断、活动识别和身体状态监测。例如,在场景1(神经阶段检测)中,我们使用SleepEEG数据集进行预训练,然后在Epilepsy数据集上进行微调。尽管这两个数据集都描述的是单通道脑电图信号,但它们来自头皮上的不同通道/位置,监测的是不同的生理过程(睡眠与癫痫),并且采集自不同的患者。这种设置模拟了实际应用中广泛存在的场景:当存在领域差距且微调数据集较小时,迁移学习可能非常有用。
设置2:一对多预训练。 我们使用一个数据集进行预训练,随后在多个目标数据集上分别进行微调,而不从头开始重新预训练。我们选择SleepEEG作为预训练数据集,因为它数据量大且具有复杂的时序动态。然后我们在来自其他三个场景的Epilepsy、FD-B和EMG数据集上进行微调。这一次,预训练数据集与三个微调数据集之间的领域差距更大,因此该设置用于检验我们模型在迁移学习中的通用性。
环境要求
TF-C已在Python >=3.5环境下进行过测试。
对于基线模型,由于原始实现差异较大,我们未能统一运行环境。因此,您需要搭建三个不同的环境来覆盖所有六个深度学习基线。对于ts2vec,请使用ts2vec_requirements.yml文件;对于SimCLR,由于Tang等人使用的是TensorFlow框架,因此请使用simclr_requirements.yml文件;对于其余四家基线,则使用baseline_requirements.yml文件。要通过Conda使用这些文件安装本项目所需的依赖项,请运行以下命令:
conda env create -f XXX_requirements.yml
代码运行
复现我们的TF-C 请将处理好的数据集下载到code/data/SleepEEG文件夹中,并确保文件夹名称与数据集名称一致。有三个关键参数:training_mode有两个选项,分别为pre_train和fine_tune_test;pretrain_dataset有四个选项,分别是SleepEEG、FD_A、HAR和ECG;target_dataset也有四个选项,分别是Epilepsy、FD_B、Gesture和EMG。模型的超参数可在config_files文件夹中的配置文件中找到。例如,当您在SleepEEG数据集上预训练模型并在Epilepsy数据集上进行微调时,请运行:
python main.py --training_mode pre_train --pretrain_dataset SleepEEG --target_dataset Epilepsy
python main.py --training_mode fine_tune_test --pretrain_dataset SleepEEG --target_dataset Epilepsy
复现基线模型 建议您尽可能按照各基线作者在其README.md文件中描述的命令行模式,从code/baselines/下的相应文件夹中运行模型。需要注意的是,在Mixing-up和SimCLR的情况下,预训练和微调是通过直接运行train_model.py和finetune_model.py完成的,无需传递参数。同样地,对于CLOCS,必须手动修改主文件(此处为run_experiments.py)中的超参数设置。如果您对这些基线模型的超参数设置有任何疑问,请联系其原作者。最后,对于每种基线,在不同的数据集组合上,迁移学习的效果会因超参数的选择而有所不同。我们已手动尝试了多种组合,并选择了在保持各基线模型复杂度相当的同时,能够获得最佳性能的参数配置。我们会在相应基线的文件夹中提供表格,详细列出针对不同数据集所使用的具体超参数组合,以便于复现我们的实验结果。请注意,某些基线是专为时间序列的表示学习设计的(而非预训练),我们将这些基线置于与我们的模型相同的实验设置中,以确保结果的可比性。
引用
如果您发现TF-C对您的研究有所帮助,请考虑引用本文:
```
@inproceedings{zhang2022self,
title = {Self-Supervised Contrastive Pre-Training For Time Series via Time-Frequency Consistency},
author = {Zhang, Xiang and Zhao, Ziyuan and Tsiligkaridis, Theodoros and Zitnik, Marinka},
booktitle = {Proceedings of Neural Information Processing Systems, NeurIPS},
year = {2022}
}
```
更新于2023年1月
我们在以下几个方面对所提出的TF-C模型的实现进行了更新:
- 修复了错误、清理了代码,并添加了注释以提高可读性。新上传的TF-C代码位于路径
TFC-pretraining/code/TFC下。该文件夹中提供了运行所需的所有必要文件。 - 对于时域和频域中的对比编码器,我们将原有的三层卷积神经网络块替换为两层Transformer。我们发现,虽然性能并未提升(甚至略有下降),但模型的稳定性有所改善。
- 在下游分类器部分,我们在原有的两层MLP分类器之外,新增了一个KNN分类器。初步实验表明,MLP的性能会因不同的设置和超参数而波动。因此,在本版本中,我们同时提供了两种分类器:两层MLP和KNN(K=5)。然而,导致性能波动的具体原因仍不明确,有待进一步研究。
- 为了便于复现,我们在此提供一个预训练模型的示例。模型权重位于路径
TFC-pretraining/code/experiments_logs/SleepEEG_2_Epilepsy/run1/pre_train_seed_42_2layertransformer/saved_models/ckp_last.pt。该模型路径与代码中使用的路径一致,因此您可以直接克隆或下载整个仓库,并运行TFC-pretraining/code/TFC/main.py文件。- 该模型是在“SleepEEG到Epilepsy”场景下预训练的(本次更新的所有调试均基于此设置)。具体而言,将训练模式设置为
pre_train,预训练数据集设置为SleepEEG。在SleepEEG_Configs.py中,所有超参数均未更改,即学习率lr=0.0005,预训练轮数为200(而微调轮数为20)。随机种子设置为42。 - 在Epilepsy数据集上的微调阶段(学习率lr=0.0005,轮数20,批次大小60),微调集仍为60个样本(30个阳性+30个阴性)。验证集包含20个样本,测试集则有11420个样本。不过,为了测试模型的稳定性,我们重新划分了Epilepsy数据集(即重新生成了60个微调样本)。重新划分的代码位于
TFC-pretraining/code/TFC/Data_split.py,划分后的数据集已上传至本仓库的TFC-pretraining/datasets/Epilepsy/目录下,并同步至Figshare。 - 在上述设置下,借助TF-C框架,微调集上的最佳测试性能为F1约0.88(由MLP实现,优于KNN);而在未进行TF-C预训练的情况下,该指标仅为约0.60。请注意,为便于快速调试,该模型是在SleepEEG数据集的一个子集上预训练的(仅1280个样本,占整个数据集不到1%)。因此,我们认为,若使用更多预训练样本,模型性能仍有较大提升空间。
- 该模型是在“SleepEEG到Epilepsy”场景下预训练的(本次更新的所有调试均基于此设置)。具体而言,将训练模式设置为
- 我们希望在后续工作中分享更多可能改进TF-C框架的想法:
- 可根据具体任务调整两层Transformer的结构(例如,针对复杂的时间序列增加层数)。对主干网络的优化可能会有所帮助。另外,切换到Transformer后,我们并未对超参数进行调优,采用更优的超参数组合(如层数、Transformer的维度、MLP隐藏层的维度等)可能会带来更好的效果。
- 在基于时间的编码器和基于频率的编码器中使用不同的架构。由于信号在频域和时域中的特性差异较大,采用专门的编码器架构有助于更好地捕捉信息。
- 探索更多频域增强方法。目前我们主要通过添加或移除频率成分来进行增强,未来可以尝试设计更多扰动方式(如带通滤波)。
- 在频域中,我们仅利用了幅度信息,而相位同样非常重要。因此,未来的重要研究方向是充分挖掘频域中的信息。
- 改进投影机制。目前我们将时域和频域的嵌入投影到一个共享的时频域中,所使用的投影器结构为两层MLP,较为简单。欢迎探索更强大、更有帮助的投影方法。
- 还有许多其他想法有待补充。
其他说明
如果您对代码和/或算法有任何疑问,请发送邮件至 xiang.alan.zhang@gmail.com。
许可证
TF-C代码库采用MIT许可证发布。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备