RD-Agent
RD-Agent 是一款由微软开源的智能研发助手,旨在利用人工智能自动化高价值的研发流程,真正实现“用数据驱动的 AI 来驱动 AI 研发”。在当前的 AI 时代,研发的核心往往集中在数据处理与模型优化上,RD-Agent 正是为了解决这些环节耗时费力、依赖人工经验的问题而生。它能够自主执行从数据探索、特征工程到模型构建与迭代的全链路任务,显著提升工业生产力。
这款工具特别适合 AI 研究人员、机器学习工程师以及量化交易领域的开发者使用。无论是希望加速实验迭代的科研团队,还是寻求策略优化的金融技术专家,都能从中获益。RD-Agent 的独特亮点在于其强大的通用性与自适应能力,它不仅支持多种大语言模型后端(如 LiteLLM),还配备了直观的 Web 界面供用户实时交互与追踪任务进度。值得一提的是,RD-Agent 目前在权威的 MLE-bench 评测中表现卓越,成为领先的机器学习工程智能体,其相关研究成果也已获 NeurIPS 2025 收录。通过 RD-Agent,繁琐的重复性工作被交给智能体处理,让专业人士能更专注于核心创新。
使用场景
某量化对冲基金的算法团队正致力于从海量另类数据中挖掘新的 Alpha 因子,以优化其高频交易策略。
没有 RD-Agent 时
- 人工试错效率低:研究员需手动编写代码清洗数据、构建特征并回测,一个因子的验证周期长达数天,难以覆盖广阔的搜索空间。
- 知识复用困难:过往成功的建模经验散落在不同人员的笔记中,无法系统化地转化为可迭代的逻辑,导致重复造轮子。
- 创新瓶颈明显:面对复杂的市场非线性关系,人类直觉容易陷入局部最优,难以自主发现反直觉但高收益的数据组合模式。
- 工程维护成本高:大量的临时脚本缺乏统一标准,随着实验数量增加,代码库变得混乱且难以复现结果。
使用 RD-Agent 后
- 自动化闭环研发:RD-Agent 自主完成从数据加载、特征工程、模型训练到回测评估的全流程,将单个因子的探索时间压缩至小时级。
- 自我进化能力:它能自动分析失败案例,提取通用规律并生成新的假设,像资深研究员一样不断迭代优化策略逻辑。
- 突破人类认知局限:通过大规模并行搜索与深度推理,RD-Agent 成功挖掘出多个传统方法忽略的高夏普比率因子,显著提升策略收益。
- 标准化产出:所有实验过程自动生成文档与结构化代码,确保每一步决策可追溯、可复现,大幅降低团队协作成本。
RD-Agent 让 AI 自主驱动数据驱动的 AI 研发,将量化团队从繁琐的工程实现中解放出来,专注于更高维度的战略决策。
运行环境要求
- Linux
未说明
未说明

快速开始

🖥️ 在线演示 | 🎥 演示视频 ▶️YouTube | 📖 文档 | 📄 技术报告 | 📃 论文
![]()
![]()
![]()
![]()
![]()




![]()

![]()
![]()
📰 新闻
| 🗞️ 新闻 | 📝 描述 |
|---|---|
| Web UI 发布 | 我们发布了一个新的前端界面,可以通过 rdagent server_ui 构建并提供服务,用于实时交互和追踪查看,目前暂不包括 data_science 场景。 |
| NeurIPS 2025 录用 | 我们非常高兴地宣布,我们的论文 R&D-Agent-Quant 已被 NeurIPS 2025 接收 |
| 技术报告发布 | 整体框架描述及 MLE-bench 上的结果 |
| R&D-Agent-Quant 发布 | 将 R&D-Agent 应用于量化交易 |
| MLE-Bench 结果公布 | R&D-Agent 目前在 MLE-bench 上以 [最佳机器学习工程代理] 的身份领先 |
| 支持 LiteLLM 后端 | 我们现在完全支持 LiteLLM 作为默认后端,以便与多个 LLM 提供商集成。 |
| 通用数据科学代理 | 数据科学代理 |
| Kaggle 场景发布 | 我们发布了 Kaggle 代理,快来体验新功能吧! |
| 官方微信群发布 | 我们创建了一个微信群,欢迎大家加入! (🗪二维码) |
| 官方 Discord 发布 | 我们在 Discord 上推出了第一个聊天频道 (🗪 |
| 首次发布 | R&D-Agent 在 GitHub 上首次发布 |
🏆 最佳机器学习工程代理!
MLE-bench 是一个全面的基准测试,用于评估 AI 代理在机器学习工程任务中的表现。它使用来自 75 个 Kaggle 竞赛的数据集,为 AI 系统在真实世界 ML 工程场景中的能力提供了可靠的评估。
R&D-Agent 目前在 MLE-bench 上以最佳机器学习工程代理的身份领先:
| 代理 | 低 == 轻量级 (%) | 中等 (%) | 高 (%) | 总计 (%) |
|---|---|---|---|---|
| R&D-Agent o3(R)+GPT-4.1(D) | 51.52 ± 6.9 | 19.3 ± 5.5 | 26.67 ± 0 | 30.22 ± 1.5 |
| R&D-Agent o1-preview | 48.18 ± 2.49 | 8.95 ± 2.36 | 18.67 ± 2.98 | 22.4 ± 1.1 |
| AIDE o1-preview | 34.3 ± 2.4 | 8.8 ± 1.1 | 10.0 ± 1.9 | 16.9 ± 1.1 |
注释:
- O3(R)+GPT-4.1(D):此版本旨在通过无缝整合研究代理(o3)与开发代理(GPT-4.1),既减少每次循环的平均时间,又利用经济高效的后端 LLM 组合。
- AIDE o1-preview:代表了原始 MLE-bench 论文中报道的先前在 MLE-bench 上的最佳公开结果。
- R&D-Agent o1-preview 的平均值和标准差结果基于 5 个独立种子,而 R&D-Agent o3(R)+GPT-4.1(D) 的结果则基于 6 个种子。
- 根据 MLE-Bench 的分类,这 75 个竞赛被分为三个复杂度级别:如果我们估计一位经验丰富的 ML 工程师可以在不到 2 小时内提出合理的解决方案(不包括训练任何模型的时间),则归为 低 == 轻量级;如果需要 2 到 10 小时,则为 中等;如果需要超过 10 小时,则为 高。
您可以在网上查看上述结果的详细运行记录。
如需在 MLE-bench 上运行 R&D-Agent,请参阅 MLE-bench 指南:通过 MLE-bench 运行 ML 工程
🥇 首个以数据为中心的量化多智能体框架!
量化金融研发智能体,简称 RD-Agent(Q),是首个以数据为中心的多智能体框架,旨在通过协调一致的因子-模型联合优化,实现量化策略全栈研发的自动化。
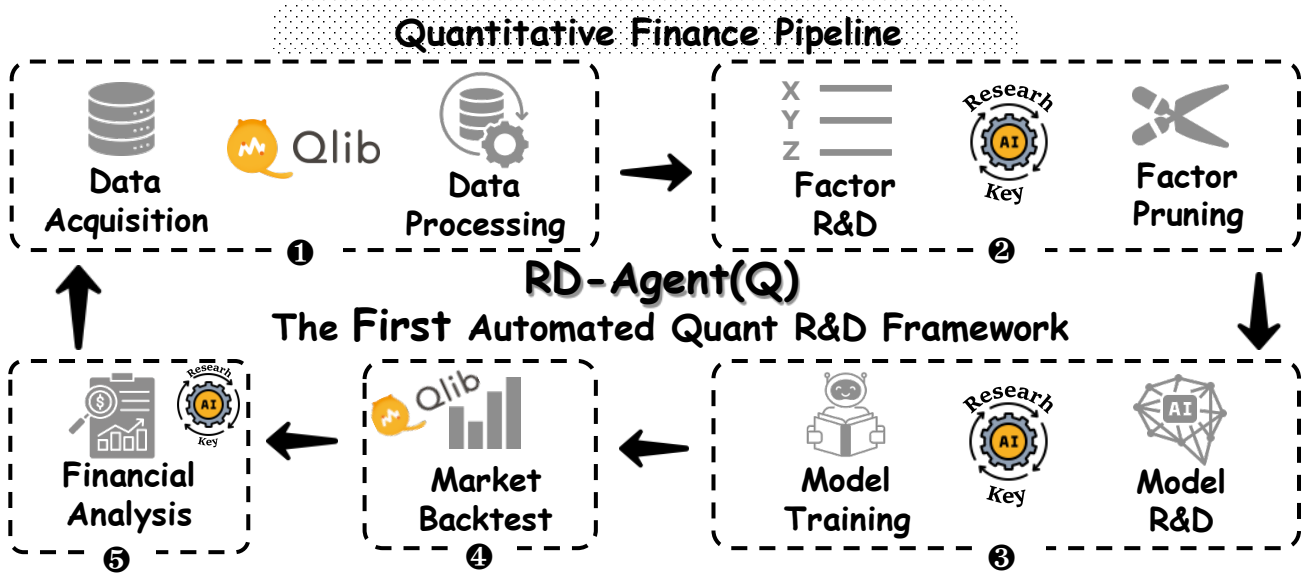
在真实股票市场中的大量实验表明,在成本低于10美元的情况下,RD-Agent(Q) 的年化收益率(ARR)比基准因子库高出约2倍,同时使用的因子数量减少了70%以上。此外,在资源预算较小的情况下,它也超越了当前最先进的深度时间序列模型。其交替进行的因子与模型优化机制,进一步实现了预测精度与策略稳健性之间的良好权衡。
您可以通过 论文 了解 RD-Agent(Q) 的更多细节,并通过 文档 进行复现。
数据科学智能体预览
请观看我们的演示视频,了解正在开发中的数据科学智能体的最新进展:
https://github.com/user-attachments/assets/3eccbecb-34a4-4c81-bce4-d3f8862f7305
🌟 简介
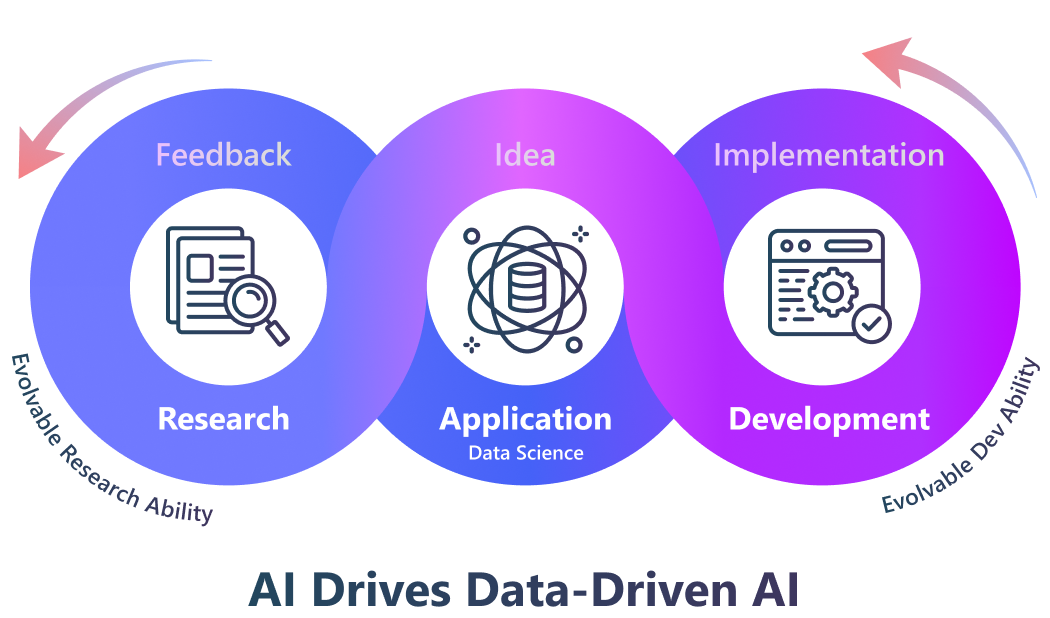
R&D-Agent 致力于自动化工业研发流程中最为关键和有价值的环节,我们首先聚焦于数据驱动型场景,以简化模型与数据的开发过程。 从方法论上看,我们确定了一个包含两个核心组件的框架:“R”代表提出新想法,“D”代表将这些想法付诸实施。 我们相信,研发过程的自动化演进将带来具有重大工业价值的解决方案。
R&D 是一个非常通用的场景。随着 R&D-Agent 的出现,它可以成为您的:
- 💰 自动量化工厂 (🎥演示视频|▶️YouTube)
- 🤖 数据挖掘智能体: 迭代式地提出数据与模型方案(🎥演示视频 1|▶️YouTube)(🎥演示视频 2|▶️YouTube),并通过从数据中获取知识来加以实现。
- 🦾 研究助手: 自动阅读科研论文(🎥演示视频|▶️YouTube) / 财务报告(🎥演示视频|▶️YouTube),并据此实现模型结构或构建数据集。
- 🤖 Kaggle 智能体: 自动进行模型调优与特征工程(🎥演示视频即将发布...),并在竞赛中加以应用以取得更好的成绩。
- …
您可以点击上方链接观看演示视频。我们正不断为该项目添加更多方法和场景,以优化您的研发流程并提升生产力。
此外,您还可以在我们的 🖥️ 实时演示 中查看更多示例。
⚡ 快速入门
RD-Agent 目前仅支持 Linux 系统。
您可以通过运行以下命令来尝试上述演示:
🐳 Docker 安装。
大多数场景的运行都需要先安装 Docker,请务必确保已正确安装。安装说明请参考 官方 🐳Docker 页面。
请确保当前用户无需使用 sudo 即可执行 Docker 命令。您可以通过运行 docker run hello-world 来验证这一点。
🐍 创建 Conda 环境
- 使用 Python 创建一个新的 Conda 环境(我们在 CI 测试中对 Python 3.10 和 3.11 进行了充分验证):
conda create -n rdagent python=3.10 - 激活该环境:
conda activate rdagent
🛠️ 安装 R&D-Agent
对于普通用户
- 您可以直接从 PyPI 安装 R&D-Agent 包:
pip install rdagent
对于开发者
- 如果您想体验最新版本或参与 RD-Agent 的开发,可以从源代码安装并按照开发环境配置步骤操作:
git clone https://github.com/microsoft/RD-Agent cd RD-Agent make dev
更多详细信息请参阅 开发环境设置。
💊 健康检查
- rdagent 提供一项健康检查功能,目前主要检测两方面:
- Docker 是否成功安装。
- rdagent UI 所使用的默认端口是否已被占用。
rdagent health_check --no-check-env
⚙️ 配置
本示例需要以下能力:
- ChatCompletion
- json_mode
- embedding query
您可以通过以下方式设置聊天模型和嵌入模型:
🔥 注意:我们现在提供对 DeepSeek 模型的实验性支持!您可以使用 DeepSeek 的官方 API 进行经济高效且高性能的推理。请参阅下方的 DeepSeek 配置示例。
使用 LiteLLM(默认):我们现在支持 LiteLLM 作为后端,以集成多个 LLM 提供商。您可以通过多种方式进行配置:
选项 1:两种模型共用统一的 API 基础地址
配置示例:
OpenAI设置:cat << EOF > .env # 设置为 LiteLLM 支持的任意模型。 CHAT_MODEL=gpt-4o EMBEDDING_MODEL=text-embedding-3-small # 配置统一的 API 基础地址 OPENAI_API_BASE=<your_unified_api_base> OPENAI_API_KEY=<replace_with_your_openai_api_key>配置示例:
Azure OpenAI设置:在使用此配置之前,请提前确认您的
Azure OpenAI API 密钥是否支持嵌入模型。cat << EOF > .env EMBEDDING_MODEL=azure/<支持嵌入的模型部署名称> CHAT_MODEL=azure/<您的部署名称> AZURE_API_KEY=<replace_with_your_openai_api_key> AZURE_API_BASE=<your_unified_api_base> AZURE_API_VERSION=<azure api 版本>选项 2:聊天模型和嵌入模型分别使用不同的 API 基础地址
cat << EOF > .env # 设置为 LiteLLM 支持的任意模型。 # 分别配置聊天和嵌入模型的 API 基础地址 # 聊天模型: CHAT_MODEL=gpt-4o OPENAI_API_BASE=<your_chat_api_base> OPENAI_API_KEY=<replace_with_your_openai_api_key> # 嵌入模型: # 以 Siliconflow 为例,您也可以使用其他提供商。 # 注意:嵌入需要添加 litellm_proxy 前缀 EMBEDDING_MODEL=litellm_proxy/BAAI/bge-large-en-v1.5 LITELLM_PROXY_API_KEY=<replace_with_your_siliconflow_api_key> LITELLM_PROXY_API_BASE=https://api.siliconflow.cn/v1配置示例:
DeepSeek设置:由于许多用户在配置 DeepSeek 时会遇到错误,这里提供一个完整的 DeepSeek 配置示例:
cat << EOF > .env # 聊天模型:使用 DeepSeek 官方 API CHAT_MODEL=deepseek/deepseek-chat DEEPSEEK_API_KEY=<replace_with_your_deepseek_api_key> # 嵌入模型:由于 DeepSeek 没有嵌入模型,因此使用 SiliconFlow 提供的嵌入服务。 # 注意:嵌入需要添加 litellm_proxy 前缀 EMBEDDING_MODEL=litellm_proxy/BAAI/bge-m3 LITELLM_PROXY_API_KEY=<replace_with_your_siliconflow_api_key> LITELLM_PROXY_API_BASE=https://api.siliconflow.cn/v1注意:如果您使用的推理模型会在响应中包含思考过程(例如
<think>标签),则需要设置以下环境变量:REASONING_THINK_RM=True如果您仅直接使用
OpenAI API或Azure OpenAI,也可以使用已弃用的后端。有关此弃用设置及更多配置信息,请参阅 文档。如果您的环境配置已完成,请执行以下命令以检查配置是否有效。此步骤是必要的。
rdagent health_check
🚀 运行应用
🖥️ 实时演示 由以下命令实现(每项代表一个演示,您可以选择自己喜欢的):
运行 自动化量化交易与迭代因子模型联合进化:Qlib 自循环因子与模型方案及实现应用
rdagent fin_quant运行 自动化量化交易与迭代因子进化:Qlib 自循环因子方案及实现应用
rdagent fin_factor运行 自动化量化交易与迭代模型进化:Qlib 自循环模型方案及实现应用
rdagent fin_model运行 自动化量化交易与财报中因子提取:基于财务报表运行 Qlib 因子提取与实现应用
# 1. 一般情况下,您可以通过以下命令运行此场景: rdagent fin_factor_report --report-folder=<您的财报文件夹路径> # 2. 具体来说,您需要先准备一些财务报表。可以按照以下具体示例操作: wget https://github.com/SunsetWolf/rdagent_resource/releases/download/reports/all_reports.zip unzip all_reports.zip -d git_ignore_folder/reports rdagent fin_factor_report --report-folder=git_ignore_folder/reports运行 自动化模型研发协作助手:模型提取与实现应用
# 1. 一般情况下,您可以通过以下命令运行自己的论文/报告: rdagent general_model <您的论文URL> # 2. 具体操作如下。更多详细信息和额外的论文示例,请使用 `rdagent general_model -h`: rdagent general_model "https://arxiv.org/pdf/2210.09789"运行 自动化医学预测模型进化:医学自循环模型方案及实现应用
# 一般情况下,您可以通过以下命令运行数据科学项目: rdagent data_science --competition <您的竞赛名称> # 具体来说,您需要创建一个用于存放竞赛文件的文件夹(例如竞赛说明文件、竞赛数据集等),并在环境中配置该文件夹的路径。此外,在下载竞赛说明时,您还需要使用 chromedriver,具体操作可参考以下示例: # 1. 下载数据集,并将其解压到目标文件夹。 wget https://github.com/SunsetWolf/rdagent_resource/releases/download/ds_data/arf-12-hours-prediction-task.zip unzip arf-12-hours-prediction-task.zip -d ./git_ignore_folder/ds_data/ # 2. 在 `.env` 文件中配置环境变量 dotenv set DS_LOCAL_DATA_PATH "$(pwd)/git_ignore_folder/ds_data" dotenv set DS_CODER_ON_WHOLE_PIPELINE True dotenv set DS_IF_USING_MLE_DATA False dotenv set DS_SAMPLE_DATA_BY_LLM False dotenv set DS_SCEN rdagent.scenarios.data_science.scen.DataScienceScen # 3. 运行应用 rdagent data_science --competition arf-12-hours-prediction-task注意:有关数据集的更多信息,请参阅 文档。
运行 自动化 Kaggle 模型调优与特征工程:自循环模型方案及特征工程实现应用
以 tabular-playground-series-dec-2021 为例。
# 一般情况下,您可以通过以下命令运行 Kaggle 竞赛程序: rdagent data_science --competition <您的竞赛名称> # 1. 在 `.env` 文件中配置环境变量 mkdir -p ./git_ignore_folder/ds_data dotenv set DS_LOCAL_DATA_PATH "$(pwd)/git_ignore_folder/ds_data" dotenv set DS_CODER_ON_WHOLE_PIPELINE True dotenv set DS_IF_USING_MLE_DATA True dotenv set DS_SAMPLE_DATA_BY_LLM True dotenv set DS_SCEN rdagent.scenarios.data_science.scen.KaggleScen # 2. 运行应用 rdagent data_science --competition tabular-playground-series-dec-2021
🖥️ 监控应用结果
Streamlit UI
使用 Streamlit UI 查看运行日志,尤其是 data_science 场景的日志。
rdagent ui --port 19899 --log-dir <您的日志文件夹,如 "log/"> --data-science
关于 data_science 参数:如果您想查看数据科学场景的日志,请将 data_science 参数设置为 True;否则设置为 False。
Web UI
我们还在 web/ 中提供了一个独立的 Web 前端,用于由 server_ui 启动的 Flask 后端。
注意:此 Web UI 与 rdagent ui 不同。目前的 Web UI 尚不支持 data_science 场景。对于 data_science 场景,请继续使用 rdagent ui --data-science。
cd web
npm install
为了构建 Flask 后端的前端,将静态资源生成到 server_ui 默认使用的目录中:
cd web
npm run build:flask
默认情况下,server_ui 会从 ./git_ignore_folder/static 提供静态文件。如果您需要其他位置,请在启动后端之前设置 UI_STATIC_PATH 环境变量。
启动 Flask 后端,并将构建好的前端与实时 API 一起提供:
rdagent server_ui --port 19899
之后,在浏览器中打开 http://127.0.0.1:19899。
常见注意事项
上述示例中使用了端口 19899。在启动任何 UI 之前,请检查该端口是否已被占用。如果已被占用,请更换为其他可用端口。
您可以通过运行以下命令来检查端口是否被占用:
rdagent health_check --no-check-env --no-check-docker
🏭 场景
我们已将 R&D-Agent 应用于多个有价值的以数据驱动的工业场景。
🎯 目标:数据驱动研发的智能体
在本项目中,我们的目标是构建一个用于自动化数据驱动研发的智能体,它能够:
- 📄 阅读真实世界中的材料(报告、论文等),并提取关键公式、感兴趣的特征和模型的描述,这些正是数据驱动研发的核心组成部分。
- 🛠️ 将提取出的公式(如特征、因子和模型)实现为可运行的代码。
- 由于大语言模型一次性实现的能力有限,我们将构建一个演进式流程,使智能体能够通过学习反馈和知识不断提升性能。
- 💡 基于现有知识和观察提出新想法。
📈 场景/演示
在数据驱动场景的两个关键领域——模型实现和数据构建——我们的系统旨在扮演两种主要角色:🦾协作助手和🤖智能体。
- 🦾协作助手会根据人类指令自动执行重复性任务。
- 🤖智能体则更具自主性,能够主动提出改进方案,以获得更好的结果。
支持的场景如下:
| 场景/目标 | 模型实现 | 数据构建 |
|---|---|---|
| 💹 金融 | 🤖 迭代提出想法并演进▶️YouTube | 🤖 迭代提出想法并演进 ▶️YouTube 🦾 自动阅读报告并实现▶️YouTube |
| 🩺 医疗 | 🤖 迭代提出想法并演进▶️YouTube | - |
| 🏭 通用 | 🦾 自动阅读论文并实现▶️YouTube 🤖 自动Kaggle模型调优 |
🤖自动Kaggle特征工程 |
- 路线图:目前,我们正努力为Kaggle场景添加新功能。
不同场景的入口和配置有所不同。请参阅场景文档中的详细设置教程。
这里提供一组成功探索案例(其中5个案例可在**🖥️在线演示**中查看)。您可以使用文档中的此命令下载并查看执行轨迹。
更多场景详情,请参阅**📖readthedocs_scen**。
⚙️ 框架
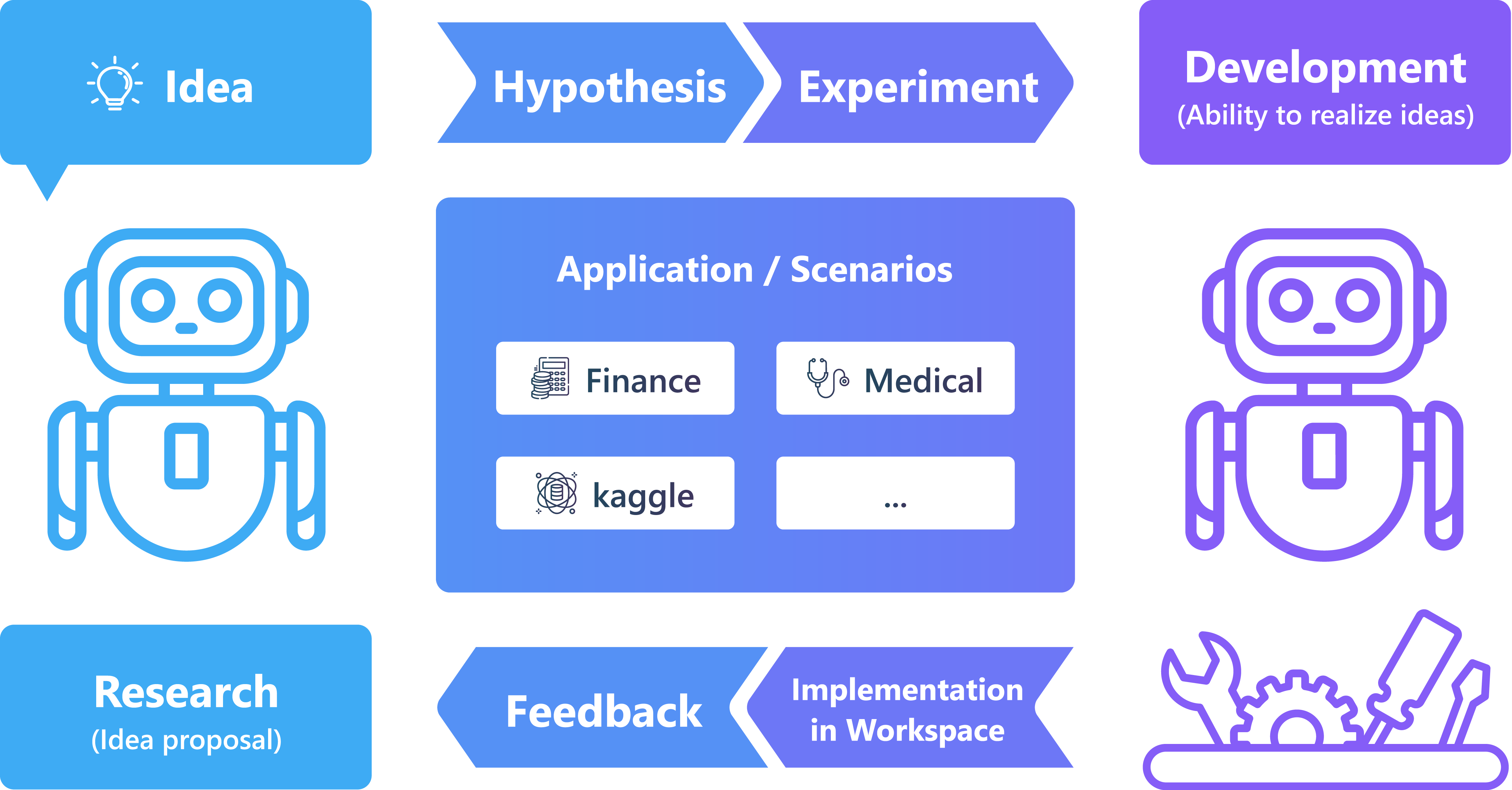
自动化数据科学领域的研发过程是一项极具价值但尚未充分开发的课题。我们提出了一套框架,旨在推动这一重要研究领域的边界。
该框架下的研究问题可分为三大类:
| 研究领域 | 论文/工作列表 |
|---|---|
| 评估研发能力 | 基准测试 |
| 想法提出: 探索新思路或优化现有思路 | 研究 |
| 实现能力: 将想法付诸实践并执行 | 开发 |
我们认为,提供高质量解决方案的关键在于不断进化研发能力。智能体应像人类专家一样学习,持续提升其研发技能。
更多文档请参见**📖 readthedocs**。
📃 论文/工作列表
总体技术报告
@misc{yang2025rdagentllmagentframeworkautonomous,
title={R&D-Agent: An LLM-Agent Framework Towards Autonomous Data Science},
author={Xu Yang and Xiao Yang and Shikai Fang and Yifei Zhang and Jian Wang and Bowen Xian and Qizheng Li and Jingyuan Li and Minrui Xu and Yuante Li and Haoran Pan and Yuge Zhang and Weiqing Liu and Yelong Shen and Weizhu Chen and Jiang Bian},
year={2025},
eprint={2505.14738},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2505.14738},
}
📊 基准测试
@misc{chen2024datacentric,
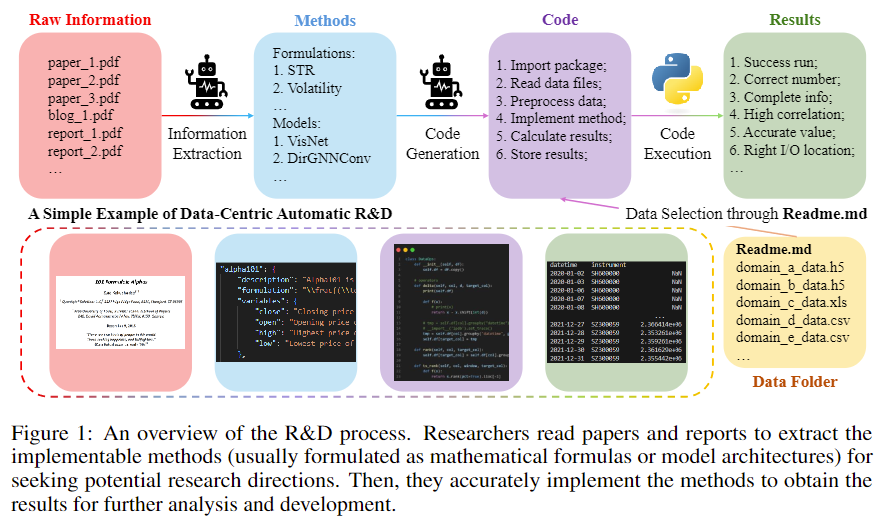
title={Towards Data-Centric Automatic R&D},
author={Haotian Chen and Xinjie Shen and Zeqi Ye and Wenjun Feng and Haoxue Wang and Xiao Yang and Xu Yang and Weiqing Liu and Jiang Bian},
year={2024},
eprint={2404.11276},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
🔍 研究
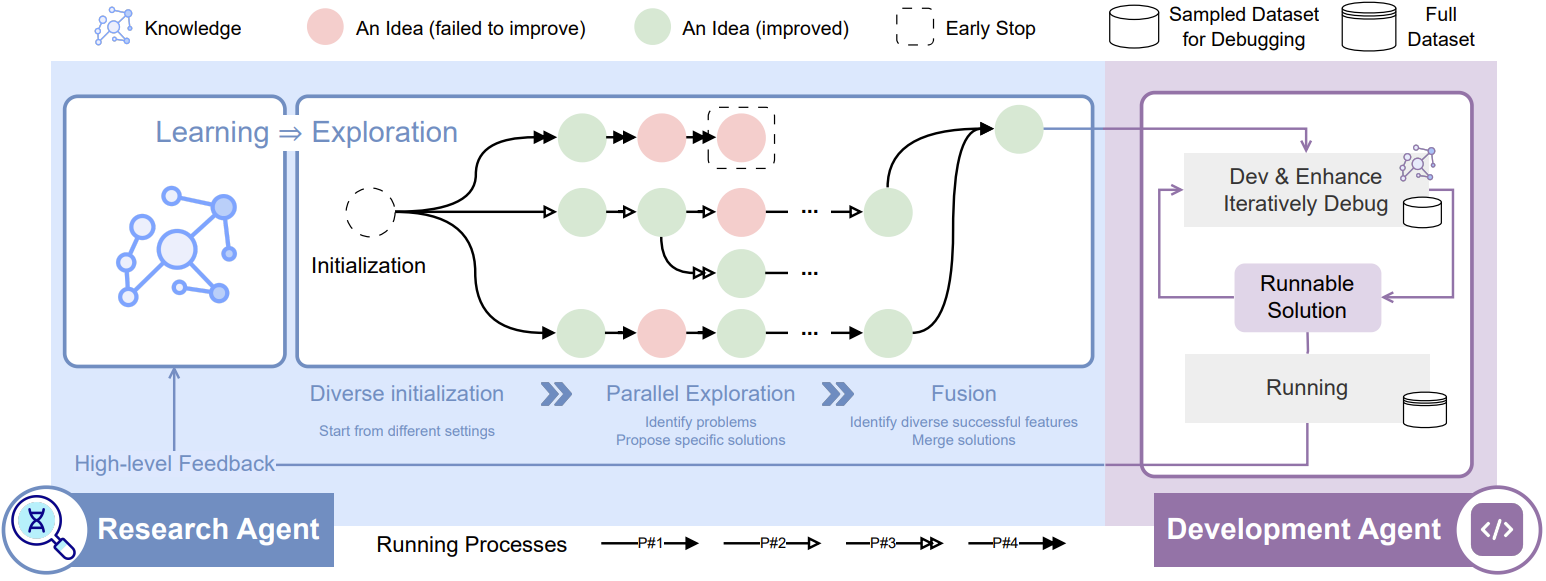
在数据挖掘专家的日常研发过程中,他们会提出假设(例如,RNN这样的模型结构可以捕捉时间序列数据中的模式)、设计实验(比如金融数据包含时间序列,可以在该场景下验证假设)、将实验转化为代码实现(如PyTorch模型结构),然后执行代码以获取反馈(如指标、损失曲线等)。专家们会根据反馈进行调整,并在下一轮迭代中改进。
基于上述原则,我们建立了一个基础方法框架,能够持续提出假设、验证假设,并从实际应用中获取反馈。这是首个支持与现实验证相结合的科学研究自动化框架。
欲了解更多详情,请访问我们的**🖥️在线演示页面**。
🛠️ Development
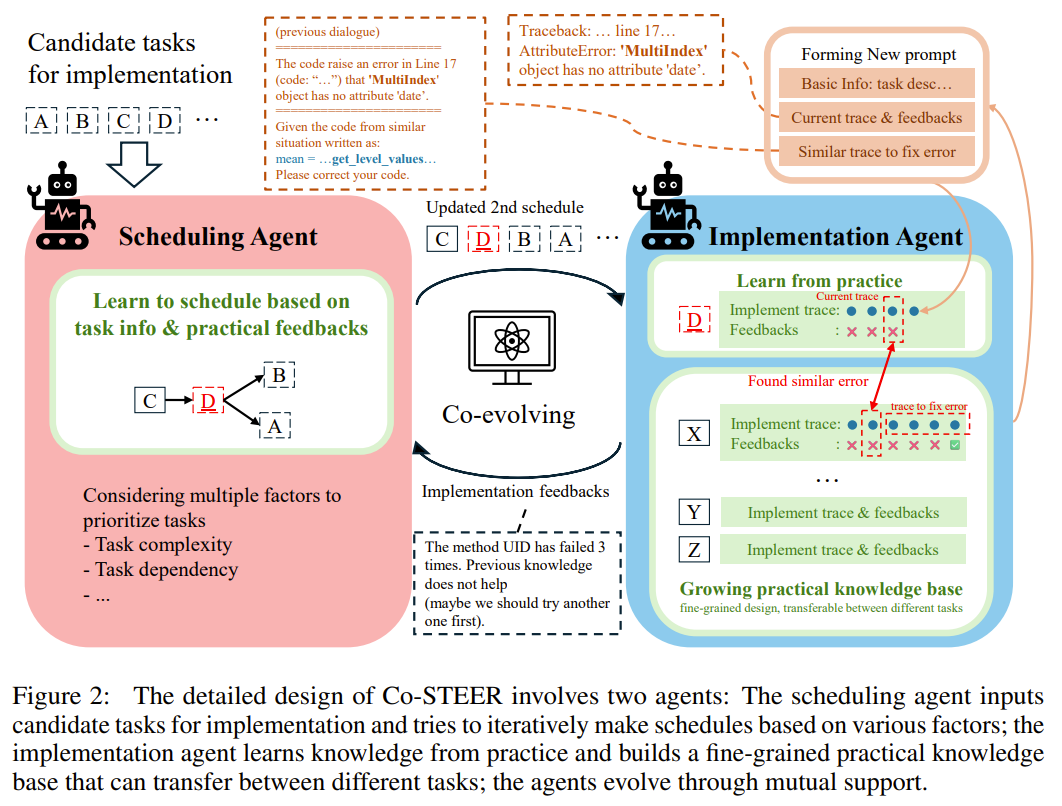
@misc{yang2024collaborative,
title={Collaborative Evolving Strategy for Automatic Data-Centric Development},
author={Xu Yang and Haotian Chen and Wenjun Feng and Haoxue Wang and Zeqi Ye and Xinjie Shen and Xiao Yang and Shizhao Sun and Weiqing Liu and Jiang Bian},
year={2024},
eprint={2407.18690},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
Deep Application in Diverse Scenarios
@misc{li2025rdagentquantmultiagentframeworkdatacentric,
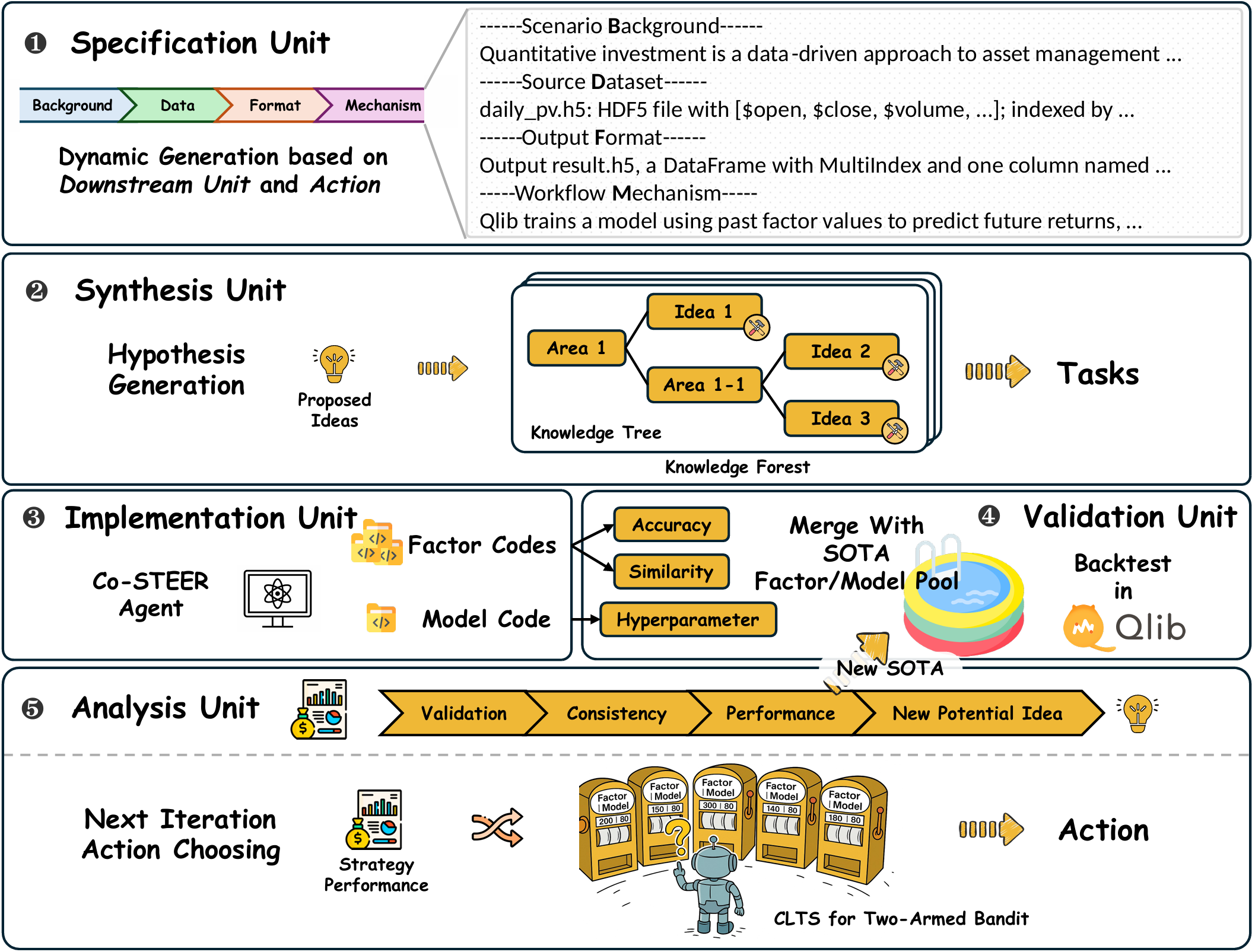
title={R&D-Agent-Quant: A Multi-Agent Framework for Data-Centric Factors and Model Joint Optimization},
author={Yuante Li and Xu Yang and Xiao Yang and Minrui Xu and Xisen Wang and Weiqing Liu and Jiang Bian},
year={2025},
eprint={2505.15155},
archivePrefix={arXiv},
primaryClass={q-fin.CP},
url={https://arxiv.org/abs/2505.15155},
}
🤝 Contributing
We welcome contributions and suggestions to improve R&D-Agent. Please refer to the Contributing Guide for more details on how to contribute.
Before submitting a pull request, ensure that your code passes the automatic CI checks.
📝 Guidelines
This project welcomes contributions and suggestions. Contributing to this project is straightforward and rewarding. Whether it's solving an issue, addressing a bug, enhancing documentation, or even correcting a typo, every contribution is valuable and helps improve R&D-Agent.
To get started, you can explore the issues list, or search for TODO: comments in the codebase by running the command grep -r "TODO:".


Before we released R&D-Agent as an open-source project on GitHub, it was an internal project within our group. Unfortunately, the internal commit history was not preserved when we removed some confidential code. As a result, some contributions from our group members, including Haotian Chen, Wenjun Feng, Haoxue Wang, Zeqi Ye, Xinjie Shen, and Jinhui Li, were not included in the public commits.
⚖️ Legal disclaimer
The RD-agent is provided “as is”, without warranty of any kind, express or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose and noninfringement. The RD-agent is aimed to facilitate research and development process in the financial industry and not ready-to-use for any financial investment or advice. Users shall independently assess and test the risks of the RD-agent in a specific use scenario, ensure the responsible use of AI technology, including but not limited to developing and integrating risk mitigation measures, and comply with all applicable laws and regulations in all applicable jurisdictions. The RD-agent does not provide financial opinions or reflect the opinions of Microsoft, nor is it designed to replace the role of qualified financial professionals in formulating, assessing, and approving finance products. The inputs and outputs of the RD-agent belong to the users and users shall assume all liability under any theory of liability, whether in contract, torts, regulatory, negligence, products liability, or otherwise, associated with use of the RD-agent and any inputs and outputs thereof.
版本历史
v0.8.02025/11/03v0.7.02025/07/08v0.6.12025/06/28v0.6.02025/06/26v0.5.02025/06/18v0.4.02025/04/04v0.3.02024/10/21v0.2.12024/09/10v0.2.02024/09/07v0.1.02024/08/09v0.0.12024/08/08常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。