GLIP
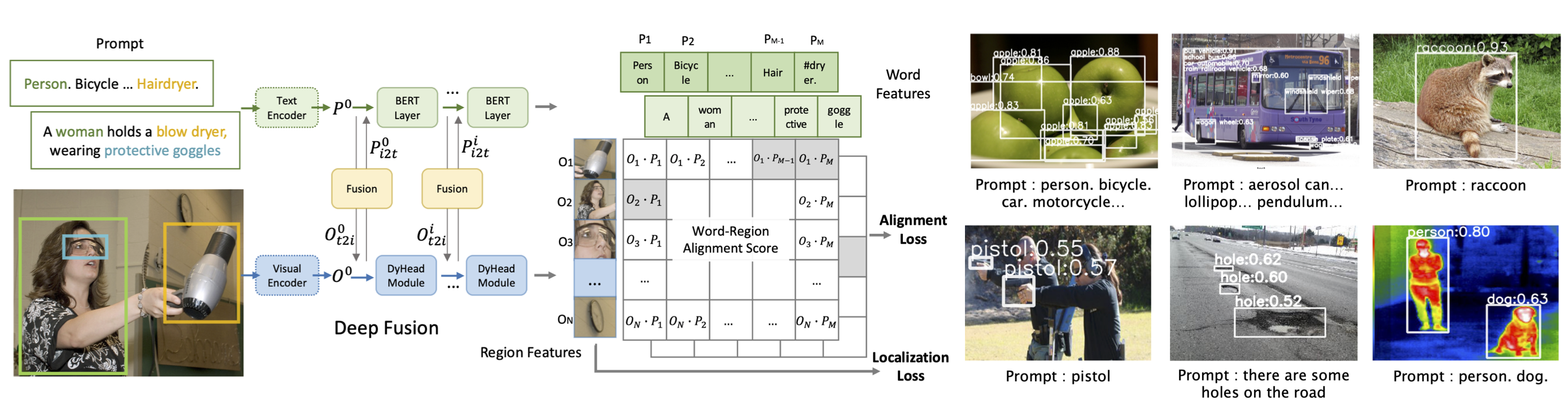
GLIP 是一款创新的开源人工智能模型,全称为“基于语言 - 图像预训练的定位模型”(Grounded Language-Image Pre-training)。它的核心能力是将自然语言理解与视觉目标检测深度融合,让用户能够直接用文字描述来查找图片中的特定物体,而无需预先针对这些物体进行专门的训练。
传统检测模型通常只能识别固定类别的对象,一旦遇到训练数据中未出现的新类别便束手无策。GLIP 有效解决了这一局限,展现出强大的“零样本”和“少样本”迁移能力。这意味着即使面对从未见过的物体类别,只要用语言描述清楚,GLIP 也能精准定位。它在多个权威基准测试中表现卓越,甚至在未见过的数据集上也能超越许多经过监督训练的模型。
该工具特别适合计算机视觉研究人员、AI 开发者以及需要处理开放集检测任务的技术团队使用。对于希望构建灵活识别系统或探索多模态大模型应用的从业者而言,GLIP 提供了宝贵的预训练代码、微调方案及评测基准。其独特的技术亮点在于统一了检测与接地(Grounding)任务,实现了从“图像到概念”的高效映射,并曾入选 CVPR 2022 最佳论文候选,代表了当前开放词汇目标检测领域的前沿水平。
使用场景
某电商初创公司的算法团队正急需构建一个能识别海量长尾商品(如特定款式的手办、小众设计师家具)的自动上架系统,但面临标注数据极度匮乏的困境。
没有 GLIP 时
- 冷启动成本极高:面对成千上万种未见过的商品类别,团队必须人工收集并逐帧标注数千张图片才能训练基础检测模型,耗时数周。
- 泛化能力严重不足:传统监督学习模型一旦遇到训练集中未包含的新品类(Zero-shot 场景),完全无法识别,导致新业务线无法快速展开。
- 迭代响应迟缓:每当运营部门提出新增一个细分品类(如“复古露营灯”),算法团队都需要重新经历数据采集、标注、训练的全流程,开发周期长达数天。
- 语义理解割裂:模型仅能识别预定义的类别 ID,无法直接理解自然语言描述(如“红色的、带轮子的行李箱”),难以支持灵活的搜索式检测需求。
使用 GLIP 后
- 实现零样本检测:利用 GLIP 强大的图文预训练能力,团队无需任何新图片标注,直接输入商品名称文本即可在图像中精准定位从未见过的长尾商品。
- 即时响应新需求:针对新增品类,只需修改输入的自然语言提示词(Prompt),模型即可实时生效,将新业务上线时间从“周级”缩短至“分钟级”。
- 支持自然语言交互:GLIP 原生支持接地(Grounding)任务,开发人员可直接用复杂语句(如“找出桌面上所有未包装的易碎品”)进行检索,大幅提升了系统的灵活性。
- 小样本微调即达 SOTA:对于极少数需要高精度的核心品类,仅需提供少量示例图片进行微调,GLIP 的性能即可超越以往全监督训练的大型模型。
GLIP 通过将语言理解与视觉检测深度融合,彻底打破了传统目标检测对大规模标注数据的依赖,让开放集物体识别变得像搜索引擎一样简单高效。
运行环境要求
- Linux
- 必需 NVIDIA GPU
- 官方训练示例使用 32GB 显存的 V100 显卡(GLIP-T 需 2 节点共 32 卡,GLIP-L 需 4 节点共 64 卡)
- 推理/评估需求未明确说明,但建议使用高显存显卡
- 支持 CUDA 10.2 或 CUDA 11.3(取决于选择的 Docker 镜像)
未说明(鉴于分布式训练配置,建议服务器级大内存)

快速开始
GLIP:接地型语言-图像预训练
更新
2023年1月17日:从图像理解到开放集接地的图像生成?请查看GLIGEN(接地型语言到图像生成)
- GLIGEN:(框, 概念) $\rightarrow$ 图像 || GLIP: 图像 $\rightarrow$ (框, 概念)
2022年9月19日:GLIPv2已被NeurIPS 2022接收(更新版本)。
2022年9月18日:组织ECCV研讨会野外计算机视觉(CVinW),其中举办了两项挑战赛,用于评估预训练视觉模型在下游任务中的零样本、少样本和全样本性能:
- [``野外图像分类(ICinW)''](https://eval.ai/web/challenges/challenge-page/1832/overview) 挑战赛评估了20个图像分类任务。
- [``野外目标检测(ODinW)''](https://eval.ai/web/challenges/challenge-page/1839/overview) 挑战赛评估了35个目标检测任务。
$\qquad$  [研讨会] $\qquad$
[研讨会] $\qquad$  [IC挑战]
$\qquad$
[IC挑战]
$\qquad$  [OD挑战]
[OD挑战]
2022年9月13日:更新了HuggingFace演示! 欢迎大家试用!!!
- 致谢:非常感谢@HuggingFace的帮助,他们升级了Space的GPU以支持GLIP演示!
2022年6月21日:GLIP被选为CVPR 2022最佳论文决赛入围者!
2022年6月16日:ODinW基准发布!GLIP-T A&B发布!
2022年6月13日:GLIPv2已上线Arxiv https://arxiv.org/abs/2206.05836!
2022年4月30日:更新了Colab演示!
2022年4月14日:GLIP已被CVPR 2022接受为口头报告!首次发布了代码和预训练模型!
2021年12月6日:GLIP论文上线arxiv https://arxiv.org/abs/2112.03857。
2021年11月23日:项目页面搭建完毕。
简介
本仓库是GLIP的项目页面。GLIP在各种对象级识别任务中表现出强大的零样本和少样本迁移能力。
- 直接在COCO和LVIS数据集上评估时(未见过COCO中的任何图像),GLIP分别取得了49.8 AP和26.9 AP的成绩,超越了许多有监督基线。
- 在COCO数据集上进行微调后,GLIP在验证集上达到了60.8 AP,在测试集上达到了61.5 AP,超过了之前的最先进水平。
- 当迁移到13个下游目标检测任务时,少样本的GLIP表现可与完全有监督的Dynamic Head相媲美。
我们提供了以下内容的代码:
- 预训练 GLIP,使用检测和接地数据;
- 零样本评估 GLIP在标准基准(COCO、LVIS、Flickr30K)以及自定义COCO格式数据集上的表现;
- 微调 GLIP在标准基准(COCO)以及自定义COCO格式数据集上的表现;
- 一个Colab演示;
- 用于**野外目标检测基准(ODinW)**的工具包,包含35个下游检测任务。
请参阅相应章节获取详细说明。
演示
请参阅链接中的Colab演示!
安装与设置
环境
本仓库需要Pytorch>=1.9和torchvision。我们建议使用docker来搭建环境。您可以根据自己的GPU选择使用以下预构建的docker镜像之一:docker pull pengchuanzhang/maskrcnn:ubuntu18-py3.7-cuda10.2-pytorch1.9 或 docker pull pengchuanzhang/pytorch:ubuntu20.04_torch1.9-cuda11.3-nccl2.9.9。
然后安装以下软件包:
pip install einops shapely timm yacs tensorboardX ftfy prettytable pymongo
pip install transformers
python setup.py build develop --user
骨干网络检查点。 将ImageNet预训练的骨干网络检查点下载到MODEL文件夹中。
mkdir MODEL
wget https://penzhanwu2bbs.blob.core.windows.net/data/GLIPv1_Open/models/swin_tiny_patch4_window7_224.pth -O swin_tiny_patch4_window7_224.pth
wget https://penzhanwu2bbs.blob.core.windows.net/data/GLIPv1_Open/models/swin_large_patch4_window12_384_22k.pth -O swin_large_patch4_window12_384_22k.pth
模型 zoo
检查点主机迁移。 检查点链接已过期。我们正在将检查点迁移到 https://huggingface.co/harold/GLIP/tree/main。目前大多数检查点都可用。我们正尽快托管剩余的检查点。
| 模型 | COCO [1] | LVIS [2] | LVIS [3] | ODinW [4] | 预训练数据 | 配置 | 权重 |
|---|---|---|---|---|---|---|---|
| GLIP-T (A) | 42.9 / 52.9 | - | 14.2 | ~28.7 | O365 | 配置 | 权重 |
| GLIP-T (B) | 44.9 / 53.8 | - | 13.5 | ~33.2 | O365 | 配置 | 权重 |
| GLIP-T (C) | 46.7 / 55.1 | 14.3 | 17.7 | 44.4 | O365,GoldG | 配置 | 权重 |
| GLIP-T [5] | 46.6 / 55.2 | 17.6 | 20.1 | 42.7 | O365,GoldG,CC3M,SBU | 配置 [6] | 权重 |
| GLIP-L [7] | 51.4 / 61.7 [8] | 29.3 | 30.1 | 51.2 | FourODs,GoldG,CC3M+12M,SBU | 配置 [9] | 权重 |
[1] 在 COCO val2017 上的零样本和微调性能。
[2] 使用最后一个预训练检查点在 LVIS minival(APr)上的零样本性能。
[3] 在 LVIS 上,模型在预训练过程中可能会出现轻微过拟合。因此,我们在 LVIS 上报告了两个数值:最后一个检查点的性能(LVIS[2])以及预训练过程中最佳检查点的性能(LVIS[3])。
[4] 在 13 个 ODinW 数据集上的零样本性能。GLIP 论文中报告的数字来自预训练过程中的最佳检查点,这可能略高于发布的最后一个检查点的数字,类似于 LVIS 的情况。
[5] 本仓库中发布的 GLIP-T 是在 Conceptual Captions 3M 和 SBU captions 上进行预训练的。它在论文的表 1 和附录 C.3 中有提及。其下游性能与主论文中的 GLIP-T 略有不同。我们将在下一次更新中发布支持使用 CC3M 和 SBU captions 数据进行预训练的功能。
[6] 此配置仅用于零样本评估和微调。支持使用 CC3M 和 SBU captions 数据进行预训练的配置将会更新。
[7] 本仓库中发布的 GLIP-L 是在 Conceptual Captions 3M+12M 和 SBU captions 上进行预训练的。它的性能略优于主论文中的 GLIP-L,因为用于标注这些 caption 数据的模型相比主论文有所改进。我们将在下一次更新中发布支持使用 CC3M+12M 和 SBU captions 数据进行预训练的功能。
[8] 使用了多尺度测试。
[9] 此配置仅用于零样本评估和微调。支持使用 CC3M+12M 和 SBU captions 数据进行预训练的配置将会更新。
预训练
所需数据。 按照 DATA.md 准备 Objects365、Flickr30K 和 MixedGrounding 数据。支持使用 caption 数据(Conceptual Captions 和 SBU captions)进行训练的功能将很快推出。
命令。
使用以下命令进行预训练(请相应地更改配置文件;请查看模型 zoo 获取对应的配置;将 {output_dir} 更改为您希望的输出目录):
python -m torch.distributed.launch --nnodes 2 --nproc_per_node=16 tools/train_net.py \
--config-file configs/pretrain/glip_Swin_T_O365_GoldG.yaml \
--skip-test --use-tensorboard --override_output_dir {output_dir}
对于训练 GLIP-T 模型,我们使用 nnodes = 2,nproc_per_node=16,在 32GB V100 机器上进行。对于训练 GLIP-L 模型,我们使用 nnodes = 4,nproc_per_node=16,在 32GB V100 机器上进行。请根据您的本地机器相应地设置环境。
(零样本)评估
COCO 评估
按照 DATA.md 准备 COCO/val2017 数据。根据 模型 zoo 设置 {config_file}、{model_checkpoint};将 {output_dir} 设置为存储评估结果的文件夹。
python tools/test_grounding_net.py --config-file {config_file} --weight {model_checkpoint} \
TEST.IMS_PER_BATCH 1 \
MODEL.DYHEAD.SCORE_AGG "MEAN" \
TEST.EVAL_TASK detection \
MODEL.DYHEAD.FUSE_CONFIG.MLM_LOSS False \
OUTPUT_DIR {output_dir}
LVIS 评估
我们遵循 MDETR 的方法,使用 FixedAP 标准进行评估。根据 模型 zoo 设置 {config_file}、{model_checkpoint}。按照 DATA.md 准备 COCO/val2017 数据。
python -m torch.distributed.launch --nproc_per_node=4 \
tools/test_grounding_net.py \
--config-file {config_file} \
--task_config configs/lvis/minival.yaml \
--weight {model_checkpoint} \
TEST.EVAL_TASK detection OUTPUT_DIR {output_dir}
TEST.CHUNKED_EVALUATION 40 TEST.IMS_PER_BATCH 4 SOLVER.IMS_PER_BATCH 4 TEST.MDETR_STYLE_AGGREGATE_CLASS_NUM 3000 MODEL.RETINANET.DETECTIONS_PER_IMG 300 MODEL.FCOS.DETECTIONS_PER_IMG 300 MODEL.ATSS.DETECTIONS_PER_IMG 300 MODEL.ROI_HEADS.DETECTIONS_PER_IMG 300
如果您希望在 Val 1.0 上进行评估,请将 --task_config 设置为 configs/lvis/val.yaml。
ODinW / 自定义数据集评估
GLIP 支持在自定义数据集上轻松进行评估。目前,代码支持对 COCO 格式的数据集进行评估。
我们将以 ODinW 中的 Aquarium 数据集为例,展示如何在自定义的 COCO 格式数据集上进行评估。
从 RoboFlow 下载 COCO 格式的原始数据集,并将其存放在
DATASET/odinw/Aquarium目录下。每个训练/验证/测试划分都对应一个annotation文件和一个image文件夹。从标注文件中移除背景类。这可以通过打开
_annotations.coco.json文件,将categories中id:0的条目删除来实现。为方便起见,我们提供了 Aquarium 数据集的修改后的标注文件:wget https://penzhanwu2bbs.blob.core.windows.net/data/GLIPv1_Open/odinw/Aquarium/Aquarium%20Combined.v2-raw-1024.coco/test/annotations_without_background.json -O DATASET/odinw/Aquarium/Aquarium\ Combined.v2-raw-1024.coco/test/annotations_without_background.json wget https://penzhanwu2bbs.blob.core.windows.net/data/GLIPv1_Open/odinw/Aquarium/Aquarium%20Combined.v2-raw-1024.coco/train/annotations_without_background.json -O DATASET/odinw/Aquarium/Aquarium\ Combined.v2-raw-1024.coco/train/annotations_without_background.json wget https://penzhanwu2bbs.blob.core.windows.net/data/GLIPv1_Open/odinw/Aquarium/Aquarium%20Combined.v2-raw-1024.coco/valid/annotations_without_background.json -O DATASET/odinw/Aquarium/Aquarium\ Combined.v2-raw-1024.coco/valid/annotations_without_background.json然后创建一个 YAML 文件,如
configs/odinw_13/Aquarium_Aquarium_Combined.v2-raw-1024.coco.yaml。YAML 文件中需要注意的几个字段:DATASET.CAPTION_PROMPT允许手动更改提示词(默认提示词只是将所有类别拼接在一起);MODELS.*.NUM_CLASSES需要设置为数据集中类别的数量(包括背景类)。例如,Aquarium 数据集有 7 个非背景类别,因此MODELS.*.NUM_CLASSES设置为 8;运行以下命令来评估该数据集。根据“模型库”设置
{config_file}和{model_checkpoint}。将{odinw_configs}设置为我们刚刚准备的任务 YAML 文件路径。
python tools/test_grounding_net.py --config-file {config_file} --weight {model_checkpoint} \
--task_config {odinw_configs} \
TEST.IMS_PER_BATCH 1 SOLVER.IMS_PER_BATCH 1 \
TEST.EVAL_TASK detection \
DATASETS.TRAIN_DATASETNAME_SUFFIX _grounding \
DATALOADER.DISTRIBUTE_CHUNK_AMONG_NODE False \
DATASETS.USE_OVERRIDE_CATEGORY True \
DATASETS.USE_CAPTION_PROMPT True
Flickr30K 评估
按照 DATA.md 中的说明准备 Flickr30K 数据。根据“模型库”设置 {config_file} 和 {model_checkpoint}。
python tools/test_grounding_net.py \
--config-file {config_file} \
--task_config configs/flickr/test.yaml,configs/flickr/val.yaml \
--weight {model_checkpoint} \
OUTPUT_DIR {output_dir} TEST.IMS_PER_BATCH 1 SOLVER.IMS_PER_BATCH 1 TEST.MDETR_STYLE_AGGREGATE_CLASS_NUM 100 TEST.EVAL_TASK grounding MODEL.DYHEAD.FUSE_CONFIG.MLM_LOSS False
微调
COCO 微调
按照 DATA.md 中的说明准备 COCO 数据。根据“模型库”设置 {config_file} 和 {model_checkpoint}。
以下是微调 Tiny 模型的脚本:
python -m torch.distributed.launch --nproc_per_node=16 tools/train_net.py \
--config-file {config_file} \
--skip-test \
MODEL.WEIGHT {model_checkpoint} \
DATASETS.TRAIN '("coco_grounding_train", )' \
MODEL.BACKBONE.FREEZE_CONV_BODY_AT -1 SOLVER.IMS_PER_BATCH 32 SOLVER.USE_AMP True SOLVER.MAX_EPOCH 24 TEST.DURING_TRAINING False TEST.IMS_PER_BATCH 16 SOLVER.FIND_UNUSED_PARAMETERS False SOLVER.BASE_LR 0.00001 SOLVER.LANG_LR 0.00001 SOLVER.STEPS \(0.67,0.89\) DATASETS.DISABLE_SHUFFLE True MODEL.DYHEAD.SCORE_AGG "MEAN" TEST.EVAL_TASK detection
对于评估,请遵循“COCO 评估”中的说明。用于微调 Large 模型的脚本将很快发布。
ODinW / 自定义数据集微调
按照“ODinW / 自定义数据集评估”中的说明准备数据集。
完整模型微调
对于 1/3/5/10 抽样微调,分别将 {custom_shot_and_epoch_and_general_copy} 设置为 “1_200_8”、“3_200_4”、“5_200_2”、“10_200_1”。
对于使用全部数据的微调,将 {custom_shot_and_epoch_and_general_copy} 设置为 “0_200_1”;将 SOLVER.STEP_PATIENCE 设置为 2;将 SOLVER.AUTO_TERMINATE_PATIENCE 设置为 4。
python -m torch.distributed.launch --nproc_per_node=4 tools/finetune.py \
--config-file {config_file} --ft-tasks {configs} --skip-test \
--custom_shot_and_epoch_and_general_copy {custom_shot_and_epoch_and_general_copy} \
--evaluate_only_best_on_test --push_both_val_and_test \
MODEL.WEIGHT {model_checkpoint} \
SOLVER.USE_AMP True TEST.DURING_TRAINING True TEST.IMS_PER_BATCH 4 SOLVER.IMS_PER_BATCH 4 SOLVER.WEIGHT_DECAY 0.05 TEST.EVAL_TASK detection DATASETS.TRAIN_DATASETNAME_SUFFIX _grounding MODEL.BACKBONE.FREEZE_CONV_BODY_AT 2 MODEL.DYHEAD.USE_CHECKPOINT True SOLVER.FIND_UNUSED_PARAMETERS False SOLVER.TEST_WITH_INFERENCE True SOLVER.USE_AUTOSTEP True DATASETS.USE_OVERRIDE_CATEGORY True SOLVER.SEED 10 DATASETS.SHUFFLE_SEED 3 DATASETS.USE_CAPTION_PROMPT True DATASETS.DISABLE_SHUFFLE True \
SOLVER.STEP_PATIENCE 3 SOLVER.CHECKPOINT_PER_EPOCH 1.0 SOLVER.AUTO_TERMINATE_PATIENCE 8 SOLVER.MODEL_EMA 0.0 SOLVER.TUNING_HIGHLEVEL_OVERRIDE full
提示词微调
按照“完整模型微调”的命令执行。但需设置以下超参数:
SOLVER.WEIGHT_DECAY 0.25 \
SOLVER.BASE_LR 0.05 \
SOLVER.TUNING_HIGHLEVEL_OVERRIDE language_prompt_v2
野外目标检测基准测试


ODinW 最早由 GLIP 提出,并在 ELEVATER 中得到进一步完善和规范化。GLIP 使用了 13 个下游任务,而完整的 ODinW 则包含 35 个下游任务。该基准测试将以挑战赛的形式在 2022 年 ECCV 野外计算机视觉研讨会上举办。我们希望我们的代码能够激励社区积极参与这一挑战!
ODinW 最初在 GLIP 中被引入,当时仅包含 13 个数据集。随后,我们通过纳入更多来自 RoboFlow 的数据集对其进行了扩展,最终版本共包含 35 个数据集。
为了区分这两个版本,我们将 GLIP 所使用的版本称为 ODinW-13,而 CVinW 研讨会所使用的版本则称为 ODinW-35。
本仓库还提供了在 ODinW 上进行训练和评估所需的相关代码。具体说明如下。
下载 ODinW
RoboFlow 托管了所有原始数据集。我们也在本地托管这些数据集,并提供了一个简单的脚本用于一次性下载全部数据。
python odinw/download_datasets.py
configs/odinw_35 包含所有数据集的元信息。configs/odinw_13 则是 GLIP 所使用的数据集。每个数据集均采用 COCO 目标检测格式。
所有 ODinW 数据集都采用 COCO 格式;因此,我们可以直接使用类似的脚本,将预训练模型适配并评估于 ODinW 上。以下是简要回顾。
(零样本)评估
odinw_configs 可以是 configs/odinw_14 或 configs/odinw_35 中的任意配置文件。
python tools/test_grounding_net.py --config-file {config_file} --weight {model_checkpoint} \
--task_config {odinw_configs} \
TEST.IMS_PER_BATCH 1 SOLVER.IMS_PER_BATCH 1 \
TEST.EVAL_TASK detection \
DATASETS.TRAIN_DATASETNAME_SUFFIX _grounding \
DATALOADER.DISTRIBUTE_CHUNK_AMONG_NODE False \
DATASETS.USE_OVERRIDE_CATEGORY True \
DATASETS.USE_CAPTION_PROMPT True
全模型微调
对于 1/3/5/10 抽样微调,分别将 {custom_shot_and_epoch_and_general_copy} 设置为 “1_200_8”、“3_200_4”、“5_200_2” 和 “10_200_1”。
对于使用全部数据进行微调,将 {custom_shot_and_epoch_and_general_copy} 设置为 “0_200_1”;同时将 SOLVER.STEP_PATIENCE 设为 2,SOLVER.AUTO_TERMINATE_PATIENCE 设为 4。
python -m torch.distributed.launch --nproc_per_node=4 tools/finetune.py \
--config-file {config_file} --ft-tasks {odinw_configs} --skip-test \
--custom_shot_and_epoch_and_general_copy {custom_shot_and_epoch_and_general_copy} \
--evaluate_only_best_on_test --push_both_val_and_test \
MODEL.WEIGHT {model_checkpoint} \
SOLVER.USE_AMP True TEST.DURING_TRAINING True TEST.IMS_PER_BATCH 4 SOLVER.IMS_PER_BATCH 4 SOLVER.WEIGHT_DECAY 0.05 TEST.EVAL_TASK detection DATASETS.TRAIN_DATASETNAME_SUFFIX _grounding MODEL.BACKBONE.FREEZE_CONV_BODY_AT 2 MODEL.DYHEAD.USE_CHECKPOINT True SOLVER.FIND_UNUSED_PARAMETERS False SOLVER.TEST_WITH_INFERENCE True SOLVER.USE_AUTOSTEP True DATASETS.USE_OVERRIDE_CATEGORY True SOLVER.SEED 10 DATASETS.SHUFFLE_SEED 3 DATASETS.USE_CAPTION_PROMPT True DATASETS.DISABLE_SHUFFLE True \
SOLVER.STEP_PATIENCE 3 SOLVER.CHECKPOINT_PER_EPOCH 1.0 SOLVER.AUTO_TERMINATE_PATIENCE 8 SOLVER.MODEL_EMA 0.0 SOLVER.TUNING_HIGHLEVEL_OVERRIDE full
提示词微调
对于 1/3/5/10 抽样微调,分别将 {custom_shot_and_epoch_and_general_copy} 设置为 “1_200_8”、“3_200_4”、“5_200_2” 和 “10_200_1”。
对于使用全部数据进行微调,将 {custom_shot_and_epoch_and_general_copy} 设置为 “0_200_1”;同时将 SOLVER.STEP_PATIENCE 设为 2,SOLVER.AUTO_TERMINATE_PATIENCE 设为 4。
按照“全模型微调”的命令执行即可。但需设置以下超参数:
SOLVER.WEIGHT_DECAY 0.25 \
SOLVER.BASE_LR 0.05 \
SOLVER.TUNING_HIGHLEVEL_OVERRIDE language_prompt_v2
线性探测
对于 1/3/5/10 抽样微调,分别将 {custom_shot_and_epoch_and_general_copy} 设置为 “1_200_8”、“3_200_4”、“5_200_2” 和 “10_200_1”。
对于使用全部数据进行微调,将 {custom_shot_and_epoch_and_general_copy} 设置为 “0_200_1”;同时将 SOLVER.STEP_PATIENCE 设为 2,SOLVER.AUTO_TERMINATE_PATIENCE 设为 4。
按照“全模型微调”的命令执行即可。但需设置以下超参数:
SOLVER.TUNING_HIGHLEVEL_OVERRIDE linear_prob
知识增强推理
GLIP 还支持知识增强推理。详情请参阅我们的论文 [https://arxiv.org/pdf/2204.08790.pdf]。这里我们提供一个如何使用外部知识的示例。请下载专门用于知识增强推理的 GLIP-A 模型:wget https://penzhanwu2bbs.blob.core.windows.net/data/GLIPv1_Open/models/glip_a_tiny_o365_knowledge.pth -O MODEL/glip_a_tiny_o365_knowledge.pth。
python tools/test_grounding_net.py --config-file configs/pretrain/glip_A_Swin_T_O365.yaml --weight MODEL/glip_a_tiny_o365_knowledge.pth \
--task_config {odinw_configs} \
TEST.IMS_PER_BATCH 1 SOLVER.IMS_PER_BATCH 1 \
TEST.EVAL_TASK detection \
DATASETS.TRAIN_DATASETNAME_SUFFIX _grounding \
DATALOADER.DISTRIBUTE_CHUNK_AMONG_NODE False \
DATASETS.USE_OVERRIDE_CATEGORY True \
DATASETS.USE_CAPTION_PROMPT True \
GLIPKNOW.KNOWLEDGE_FILE knowledge/odinw_benchmark35_knowledge_and_gpt3.yaml GLIPKNOW.KNOWLEDGE_TYPE gpt3_and_wiki GLIPKNOW.PARALLEL_LANGUAGE_INPUT True GLIPKNOW.LAN_FEATURE_AGG_TYPE first MODEL.DYHEAD.FUSE_CONFIG.USE_LAYER_SCALE True GLIPKNOW.GPT3_NUM 3 GLIPKNOW.WIKI_AND_GPT3 True
提交您的结果至 ODinW 排行榜
鼓励参赛团队将他们的结果上传至 EvalAI 上的 ODinW 排行榜。从数据标注成本的角度来看,降低对数据的需求能够支持更多应用场景。本次挑战设置了多个赛道:零样本、少样本和全样本。有关各阶段的详细信息,请参阅 ODinW 官网。
- 对于零样本/全样本设置,预测 JSON 文件的格式要求为:
{
"数据集名称(例如 'WildFireSmoke')":
[value]: value 需遵循 COCO 的结果格式,即包含 ["image_id":xxx, "category_id":xxx, "bbox":xxx, "score":xxx]
}
请参阅提供的零样本预测文件示例:all_predictions_zeroshot.json,以及全样本预测文件示例:all_predictions_fullshot.json。
- 对于少样本(根据挑战说明为 3 抽样)设置,将使用随机种子 [3, 30, 300] 分别生成三个训练-验证子集。预测 JSON 文件的格式要求为:
{
"数据集名称(例如 'WildFireSmoke')":{
"随机种子编号(例如 '30')":
[value]: value 需遵循 COCO 的结果格式,即包含 ["image_id":xxx, "category_id":xxx, "bbox":xxx, "score":xxx]
}
}
请参阅提供的少样本预测文件示例:all_predictions_3_shot.json。
参考文献
如果您使用了我们的代码,请考虑引用以下论文:
@inproceedings{li2021grounded,
title={接地式语言-图像预训练},
author={Liunian Harold Li* 和 Pengchuan Zhang* 和 Haotian Zhang* 和 Jianwei Yang 和 Chunyuan Li 和 Yiwu Zhong 和 Lijuan Wang 和 Lu Yuan 和 Lei Zhang 和 Jenq-Neng Hwang 和 Kai-Wei Chang 和 Jianfeng Gao},
year={2022},
booktitle={CVPR},
}
@article{zhang2022glipv2,
title={GLIPv2:统一目标定位与视觉-语言理解},
author={Zhang, Haotian* 和 Zhang, Pengchuan* 和 Hu, Xiaowei 和 Chen, Yen-Chun 和 Li, Liunian Harold 和 Dai, Xiyang 和 Wang, Lijuan 和 Yuan, Lu 和 Hwang, Jenq-Neng 和 Gao, Jianfeng},
journal={arXiv 预印本 arXiv:2206.05836},
year={2022}
}
@article{li2022elevater,
title={ELEVATER:用于评估语言增强型视觉模型的基准和工具包},
author={Li*, Chunyuan 和 Liu*, Haotian 和 Li, Liunian Harold 和 Zhang, Pengchuan 和 Aneja, Jyoti 和 Yang, Jianwei 和 Jin, Ping 和 Lee, Yong Jae 和 Hu, Houdong 和 Liu, Zicheng 等},
journal={arXiv 预印本 arXiv:2204.08790},
year={2022}
}
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。