GeoChat
GeoChat 是首个专为遥感领域打造的地面化大型视觉语言模型,曾入选 CVPR 2024。它突破了通用视觉模型在专业领域的局限,能够深入理解高分辨率卫星及航空影像,不仅支持对整张图像的描述,更能精准定位并分析图像中的特定区域,实现“指哪打哪”的深度场景解读。
针对遥感图像数据复杂、通用模型缺乏领域知识导致识别不准的痛点,GeoChat 基于 LLaVA-1.5 架构,利用全新构建的大规模遥感多模态指令数据集进行微调。这使得它在零样本设置下,即可出色完成图像与区域描述、视觉问答、场景分类、接地对话以及参照物体检测等多种任务。
其核心技术亮点在于独特的“区域级推理”能力,能够将自然语言指令与图像中的具体地理坐标或区域紧密关联,大幅提升了人机交互的精确度。目前,GeoChat 已开源代码、模型权重及评估脚本,非常适合从事遥感技术研究的学者、开发地理信息系统的工程师,以及希望探索多模态大模型在垂直领域应用的开发者使用。通过 GeoChat,专业人士可以更高效地从海量遥感数据中提取关键信息,推动智能对地观测技术的发展。
使用场景
某城市规划局的遥感分析师正急需从最新的高分辨率卫星影像中,快速提取特定受灾区域的建筑物损毁情况并生成详细报告。
没有 GeoChat 时
- 分析师必须依赖通用视觉模型,这些模型缺乏对遥感影像特有视角的理解,常将阴影误判为水体或道路。
- 无法直接针对图像中的特定坐标区域进行提问,只能获取整张图的笼统描述,难以定位具体受损地块。
- 需要人工逐帧标注并结合传统 GIS 软件进行二次分析,耗时数小时才能完成单一场景的评估。
- 面对复杂的地理术语(如“不透水面”、“植被覆盖度”),通用模型往往无法准确理解指令意图,导致回答偏离专业需求。
使用 GeoChat 后
- GeoChat 凭借专为遥感训练的特性,能精准区分阴影与真实地物,显著降低了对高楼阴影和复杂地形的误判率。
- 支持区域级推理,分析师可直接框选受灾街区询问“该区域内有多少栋完全倒塌的建筑”,获得精确到坐标的回答。
- 实现了零样本下的多任务处理,一键生成包含场景分类、物体检测及自然语言描述的綜合报告,将分析时间缩短至分钟级。
- 能够流畅理解并运用专业地理术语进行多轮对话,如同拥有一位精通遥感知识的专家助手实时协同工作。
GeoChat 通过将通用的视觉语言能力深度“落地”于遥感领域,彻底改变了从卫星影像到决策信息的转化效率。
运行环境要求
- Linux
- 必需 NVIDIA GPU
- 训练推荐 3x A100 (40GB 显存)
- 依赖 flash-attn,通常仅支持 Linux 环境下的 NVIDIA 显卡
未说明 (建议根据模型大小配置充足内存,训练需大显存)

快速开始
GeoChat  :面向遥感的接地型大型视觉-语言模型 [CVPR-2024]
:面向遥感的接地型大型视觉-语言模型 [CVPR-2024]

Kartik Kuckreja*, Muhammad Sohail Danish*, Muzammal Naseer, Abhijit Das, Salman Khan 和 Fahad Khan
* 共同第一作者
穆罕默德·本·扎耶德人工智能大学、比尔拉理工学院与科学研究所、澳大利亚国立大学、林雪平大学
![]()
📢 最新动态
- 已接受论文的补充材料现已发布:Supplementary。
- 2024年2月28日:我们开源了代码、模型、数据集和评估脚本。
- 2024年2月27日:GeoChat已被 CVPR-24 接受 🎉。
- 2023年11月28日:GeoChat论文已发布 arxiv链接。🔥🔥
概述
GeoChat是首个专为遥感(RS)场景设计的接地型大型视觉-语言模型。与通用领域模型不同,GeoChat在处理高分辨率遥感图像方面表现出色,采用区域级推理来实现对场景的全面理解。借助新创建的遥感多模态数据集,GeoChat基于LLaVA-1.5架构进行了微调。这使得它在多种遥感任务中展现出强大的零样本性能,包括图像和区域描述、视觉问答、场景分类、视觉接地对话以及指代性目标检测。
目录
安装
- 克隆此仓库并进入GeoChat文件夹
git clone https://github.com/mbzuai-oryx/GeoChat.git
cd GeoChat
- 安装软件包
conda create -n geochat python=3.10 -y
conda activate geochat
pip install --upgrade pip # 启用PEP 660支持
pip install -e .
- 安装用于训练的额外软件包
pip install ninja
pip install flash-attn --no-build-isolation
升级到最新代码库
git pull
pip uninstall transformers
pip install -e .
GeoChat权重与演示
请查看我们的模型库,以获取所有公开的GeoChat检查点,并参阅LoRA.md,了解如何运行演示和进行训练。
训练
GeoChat的训练包括使用GeoChat_Instruct数据集进行视觉指令微调:318k条由Vicuna生成的多模态指令遵循数据,在LLaVA-v1.5的预训练权重基础上进行微调。
我们在3张配备40GB显存的A100 GPU上训练GeoChat。若使用较少的GPU进行训练,可相应降低per_device_train_batch_size并增加gradient_accumulation_steps。务必保持全局批次大小不变:per_device_train_batch_size × gradient_accumulation_steps × num_gpus。
超参数
我们在微调时采用了与Vicuna相似的超参数设置。以下同时列出了预训练和微调所使用的超参数。
| 超参数 | 全局批次大小 | 学习率 | 轮数 | 最大长度 | 权重衰减 |
|---|---|---|---|---|---|
| GeoChat-7B | 144 | 2e-5 | 1 | 2048 | 0 |
预训练(特征对齐)
我们使用LLaVAv1.5的预训练投影器,该投影器是在包含BLIP字幕的LAION-CC-SBU数据集558K子集上训练的。LLaVA-v1.5-7B大约需要3.5小时完成预训练。
--mm_projector_type mlp2x_gelu:两层MLP视觉-语言连接器。--vision_tower openai/clip-vit-large-patch14-336:CLIP ViT-L/14 336px。
视觉指令微调
- 准备数据
请下载我们指令微调数据最终混合体的标注文件GeoChat_Instruct.json,并从Hugging Face下载分割后的图像压缩包。将多个图像压缩包保存在一个文件夹中,然后运行以下命令将其合并:
cat images_parta* > images.zip
解压images.zip文件至一个文件夹,并将该文件夹路径输入到finetune_lora.sh中。
- 开始训练!
由于CLIP分辨率提升至504×504,视觉指令微调所需时间更长。在3张A100(40G)上微调GeoChat-7B大约需要~25小时。
使用DeepSpeed ZeRO-3的训练脚本:finetune_lora.sh。
需要注意的选项:
--mm_projector_type mlp2x_gelu:两层MLP视觉-语言连接器。--vision_tower openai/clip-vit-large-patch14-336:CLIP ViT-L/14 336px。--image_aspect_ratio pad:此选项会将非正方形图像填充为正方形,而不是裁剪它们;这样可以略微减少幻觉现象。--group_by_modality_length True:仅当您的指令微调数据集同时包含语言(例如ShareGPT)和多模态(例如LLaVA-Instruct)内容时才应使用此选项。
评估
我们基于一组多样化的7个基准测试对GeoChat进行了评估。为确保结果的可重复性,我们采用贪婪解码方式对模型进行评估。我们未使用束搜索进行评估,以使推理过程与实时输出的聊天演示保持一致。 详情请参阅Evaluation.md。
🏆 贡献
遥感多模态指令遵循数据集。 我们提出了一种新颖的数据生成流程,利用现有的目标检测数据集为图像生成简短描述,随后使用Vicuna-v1.5仅基于这些文本创建对话。此外,我们还引入了视觉问答和场景分类能力,并分别使用相应的数据集进行补充。最终,我们为遥感领域构建了一个包含318,000对指令的数据集。
GeoChat。 基于我们的数据集,我们对LLaVA-1.5进行了微调,从而创建了面向遥感领域的视觉-语言模型——GeoChat。我们的LoRA微调方法高效且不会遗忘全量微调的LLaVA模型中所嵌入的关键上下文信息;该模型的MLP投影层经过训练,能够将图像映射到LLM(Vicuna-v1.5)的词嵌入空间中。这使得GeoChat既能保留LLaVA的对话和指令遵循能力,又能将其领域知识扩展到遥感任务中。
评估基准。 我们还解决了现有视觉-语言模型在遥感对话任务上缺乏评估基准的问题。为此,我们制定了遥感场景下对话定位的评估协议,并设计了一系列任务,以便未来相关工作可以进行比较。我们展示了针对不同遥感任务的各种监督式及零样本评估结果,包括图像字幕生成、视觉问答和场景分类,以证明GeoChat这一对话型视觉-语言模型的泛化能力。
👁️💬 GeoChat:面向遥感的具身大型视觉-语言模型
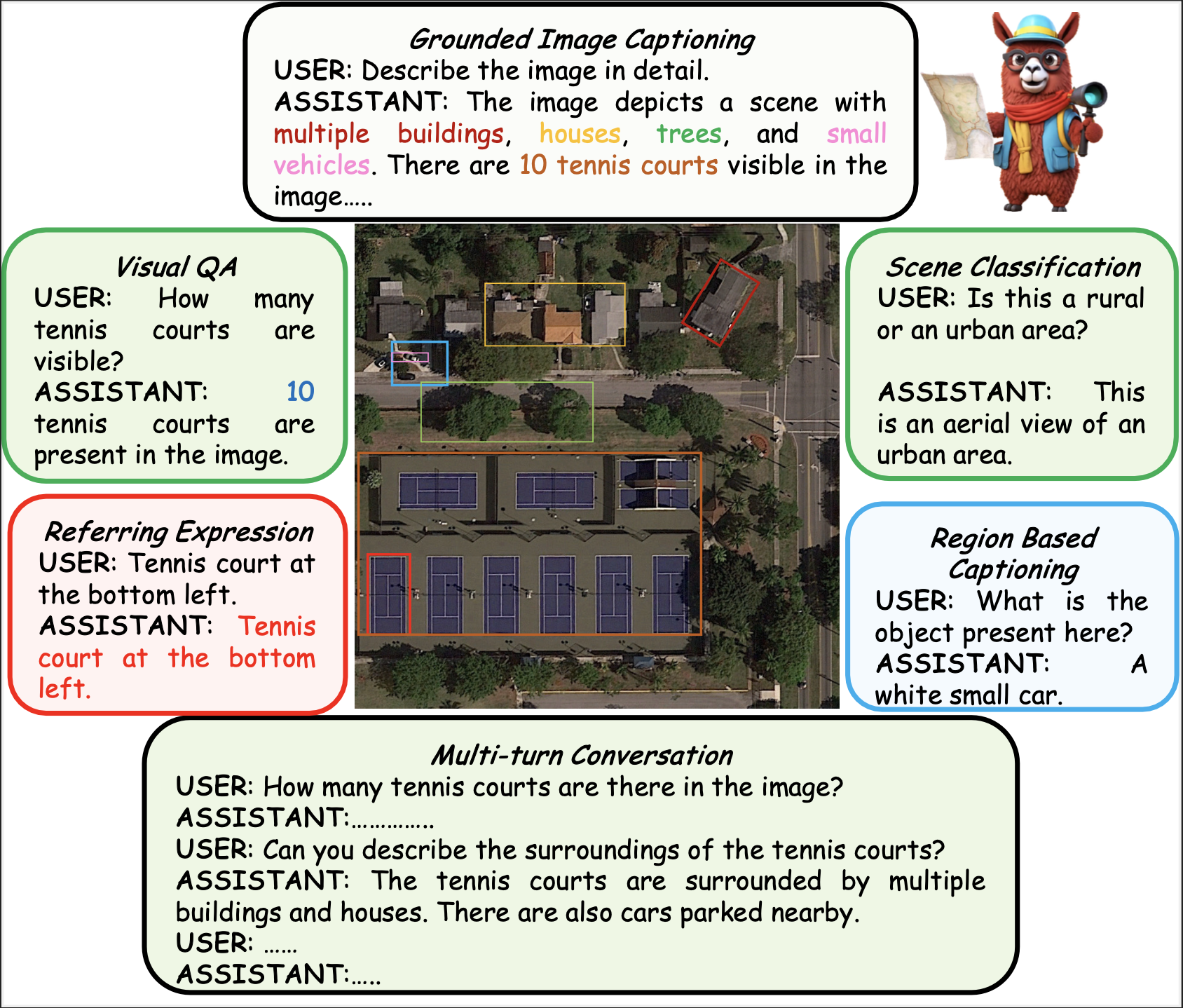
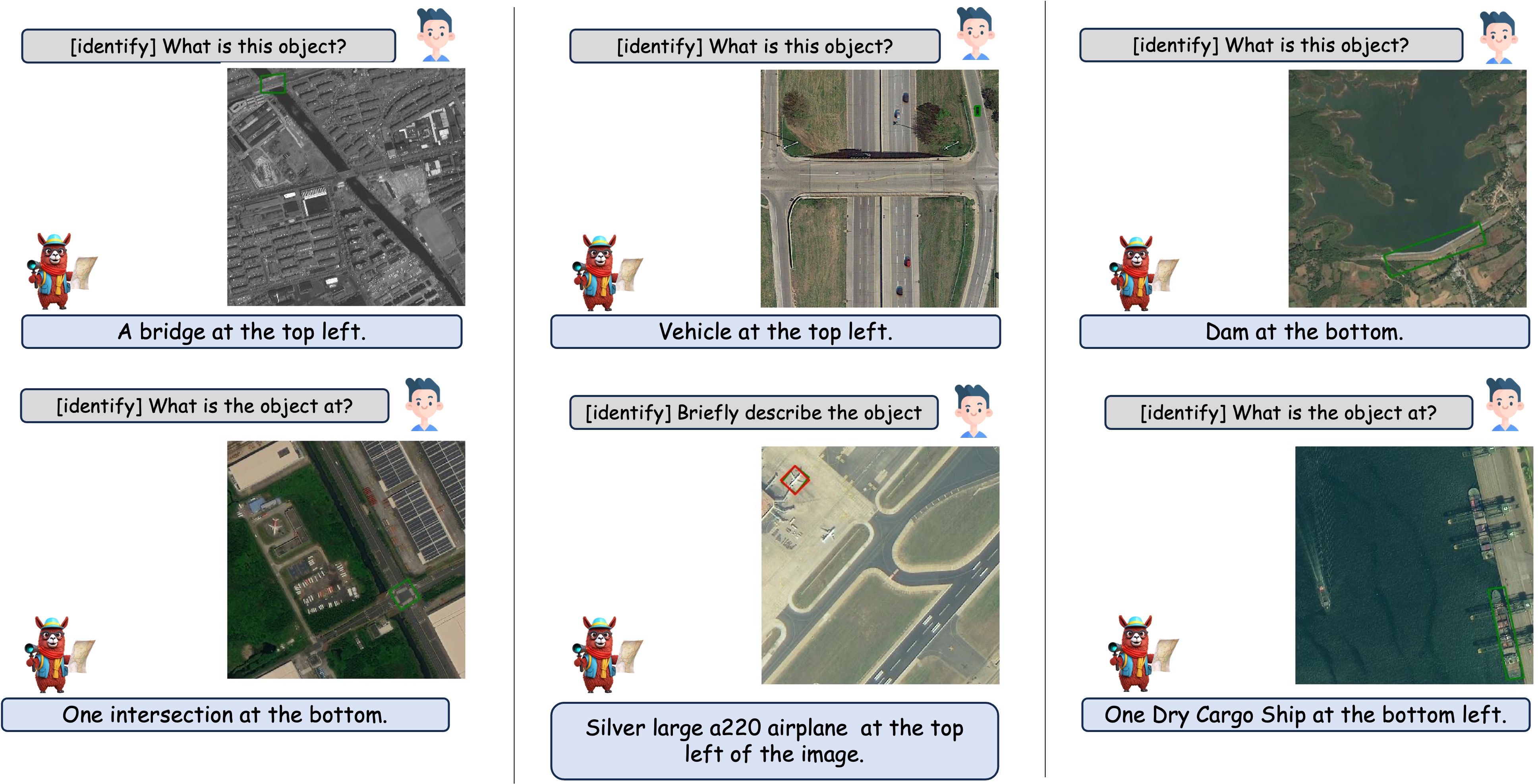
GeoChat能够在统一的框架内完成多项遥感图像理解任务。通过提供适当的任务标记和用户查询,该模型可以生成具有视觉定位的响应(文本中包含对应的目标位置,如图顶部所示)、针对图像及特定区域的视觉问答(分别位于左上角和右下角),以及场景分类(右上角)和常规自然语言对话(底部)。这使其成为首个具备具身能力的遥感视觉-语言模型。
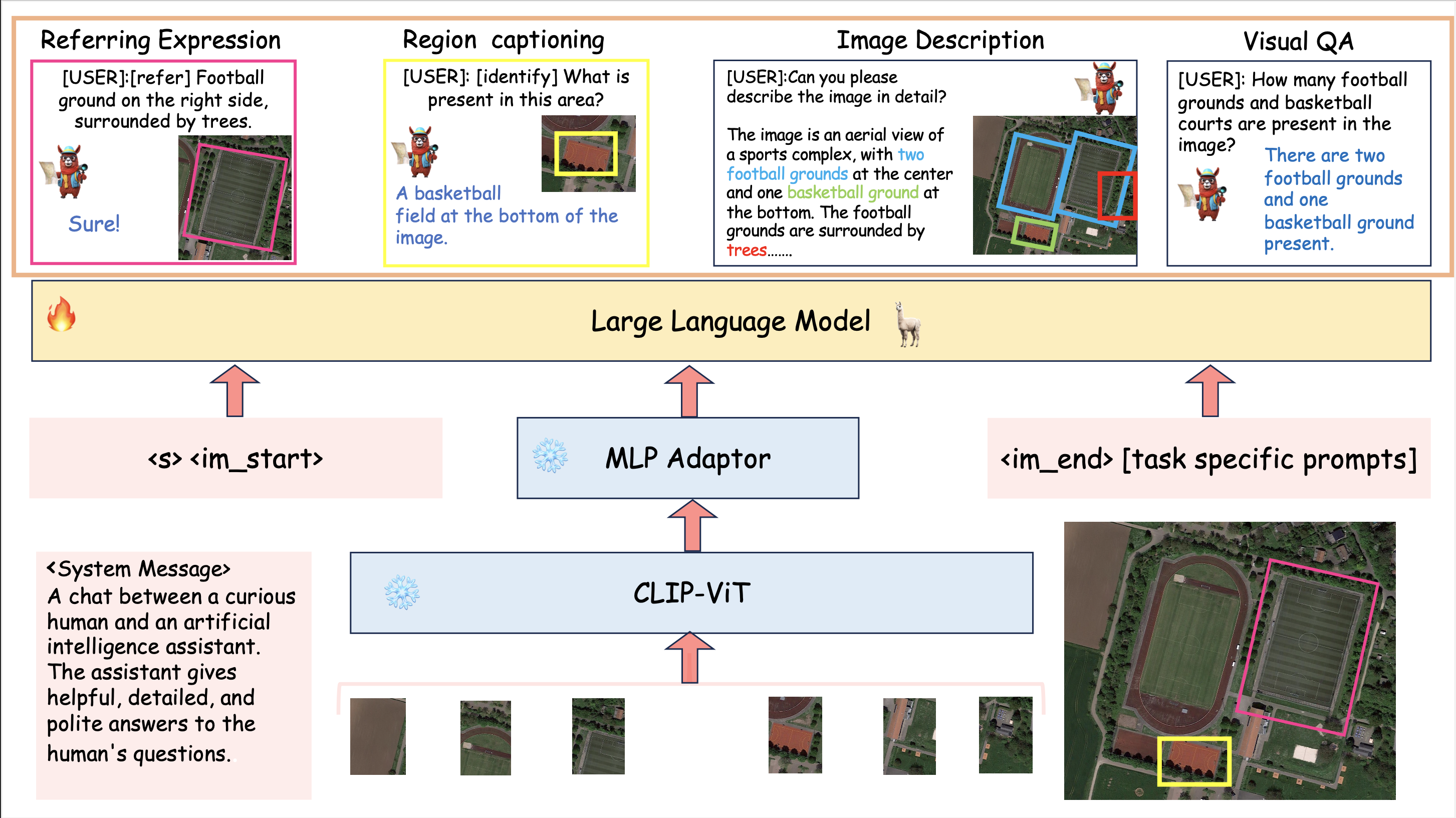
🛰️ GeoChat:架构
GeoChat的架构概览——这是首个面向遥感领域的具身大型视觉-语言模型。给定一张输入图像和用户查询后,首先会使用视觉骨干网络以更高分辨率编码补丁级特征,并通过插值位置编码来实现。随后,一个多层感知机(MLP)会将视觉特征适配到适合输入大型语言模型(Vicuna 1.5)的语言空间中。除了视觉输入外,还可以将区域位置与特定于任务的提示一同输入模型,以明确用户所需执行的任务类型。在此上下文中,语言模型能够生成自然语言响应,并将相应目标的位置信息穿插其中。如图顶部所示,GeoChat可执行多种任务,例如场景分类、图像/区域字幕生成、视觉问答以及具身对话。
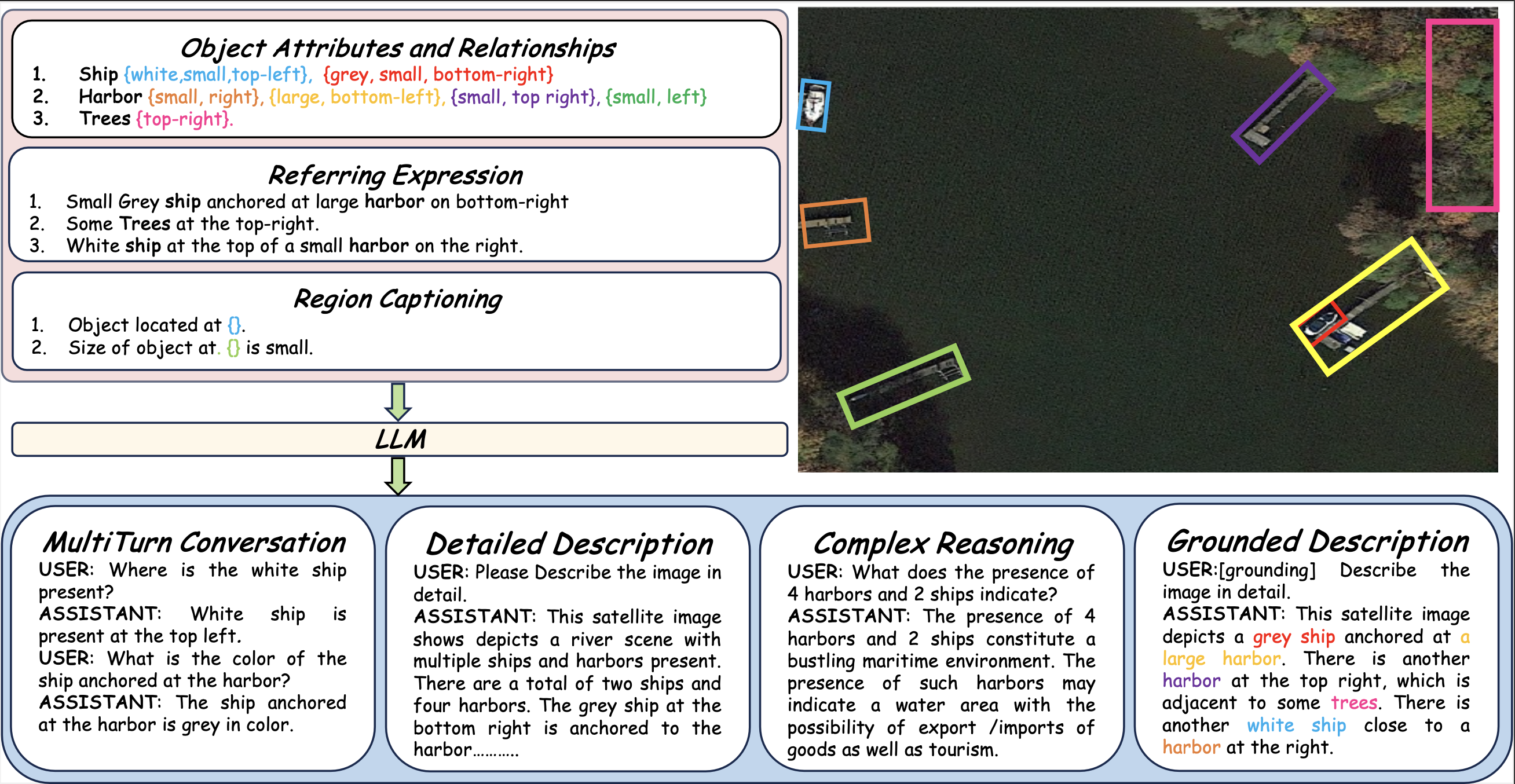
🔍 遥感多模态指令数据集
GeoChat指令集中包含的各类标注类型。对于给定的遥感图像,我们提取了对象属性与关系信息、指代表达和区域字幕,同时附带对应的区域标注(显示在图像上方)。这些结构化信息被用于构建丰富的指令集,总计包含318,000对图像-指令对。
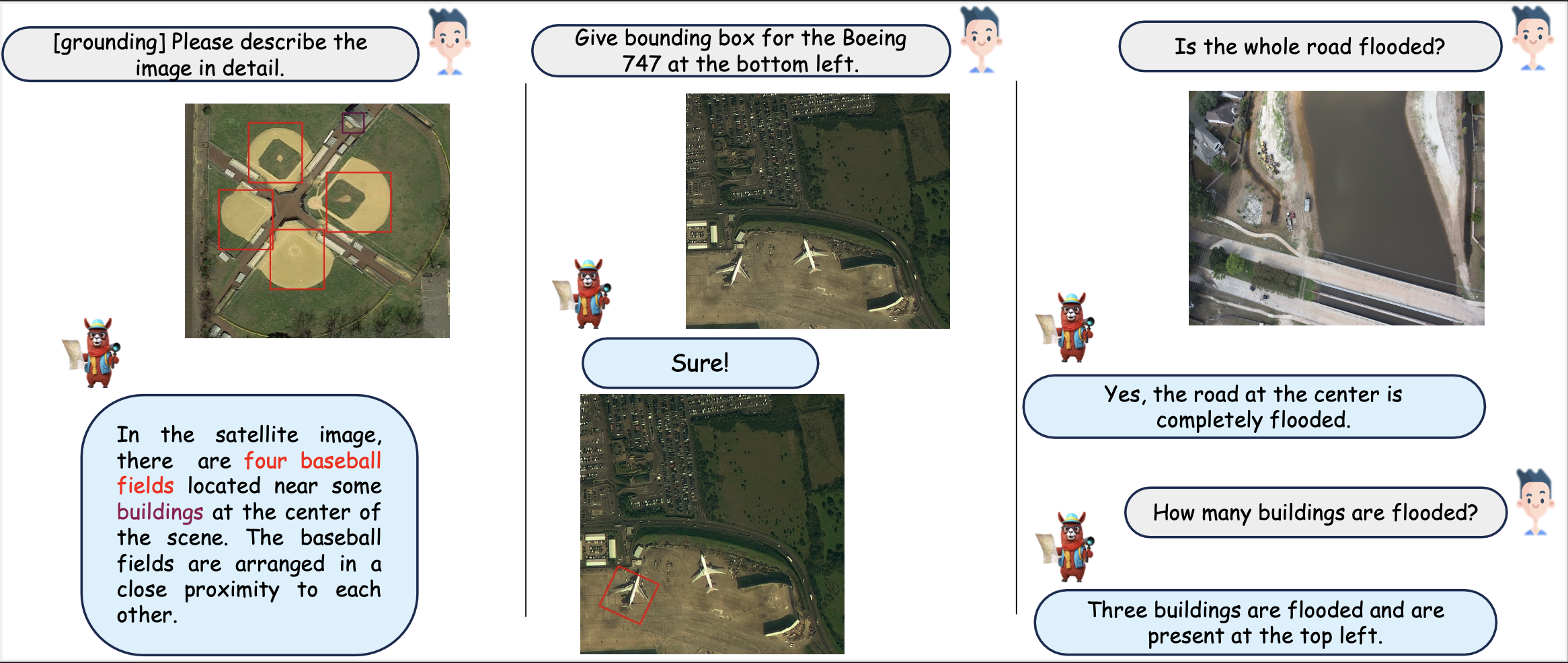
🤖 GeoChat 定性结果
GeoChat的定性结果。(从左至右)展示的内容包括场景定位、指代目标检测以及灾害/损伤检测。用户可以通过提供特定于任务的标记(例如[grounding])来引导模型生成符合需求的响应。模型可以生成纯文本响应(右图)、仅包含视觉定位的输出(中图),以及文本与目标定位信息交织的混合输出(左图)。此外,模型还能识别目标类型、数量、属性及相互关系。
🤖 视觉问答
视觉问答任务的定性示例。GeoChat能够根据不同类型的问题进行多轮对话,问题涵盖是否存在、数量统计、复杂比较等。它甚至可以在低分辨率图像上检测目标并展开对话。
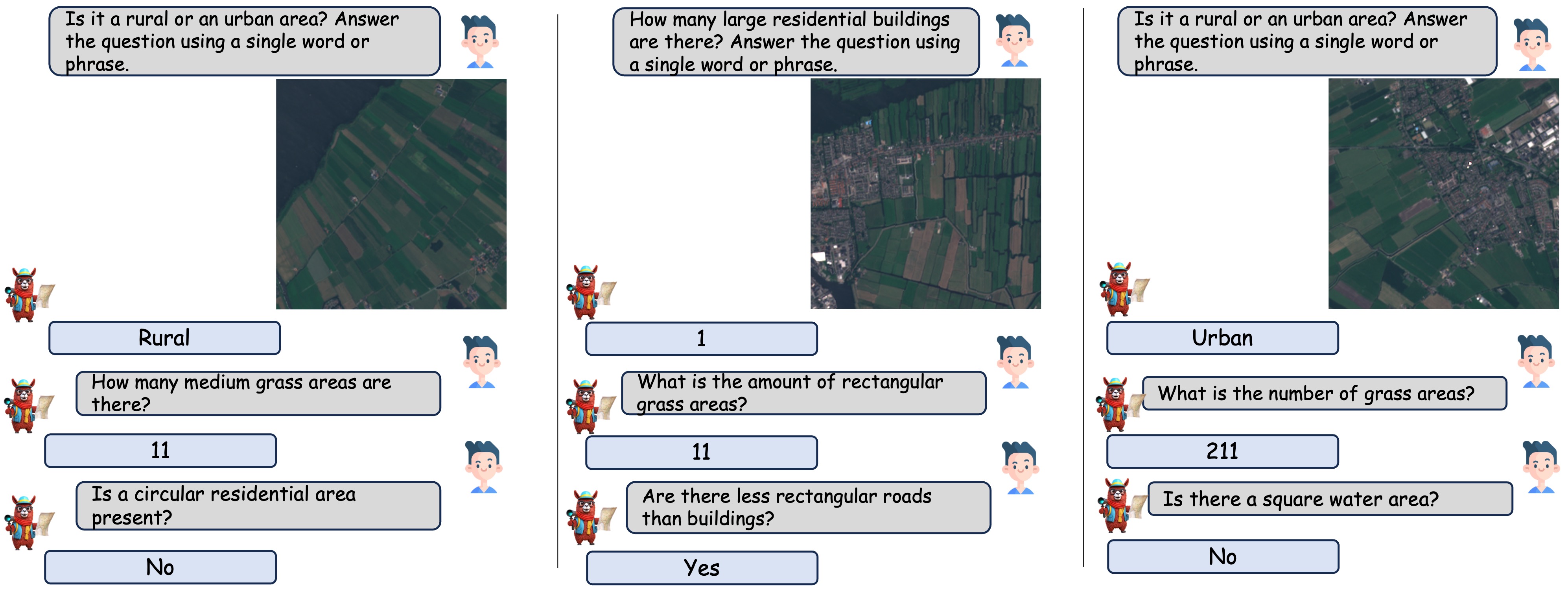
🤖 场景分类
场景分类任务的定性示例。我们向模型提供了数据集中所有的类别,并要求其从中选择一个。
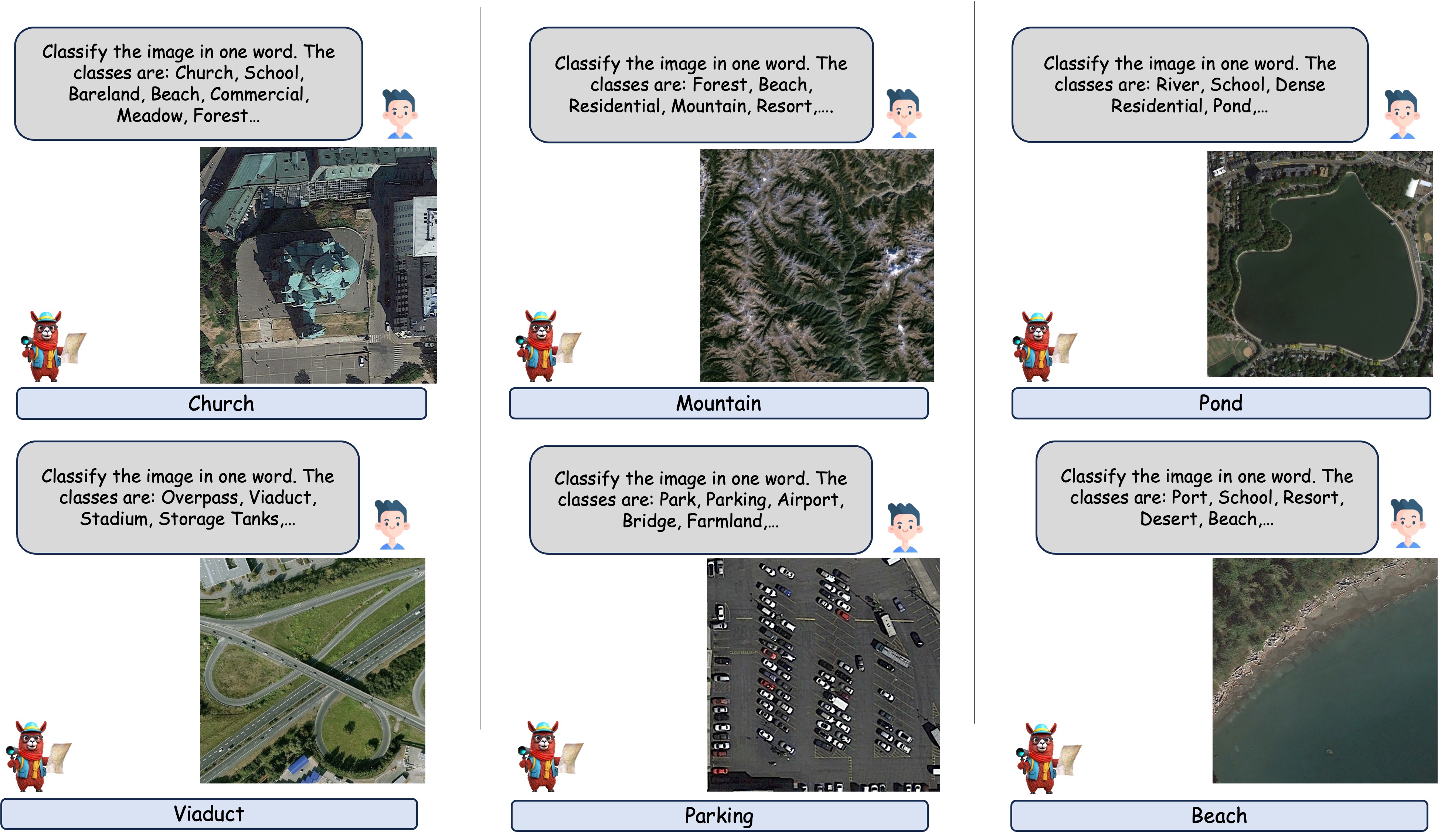
🤖 具身描述
当用户使用特殊标记“[grounding]”要求描述图像时,GeoChat不仅会生成图像描述,还会为所有检测到的物体绘制边界框。
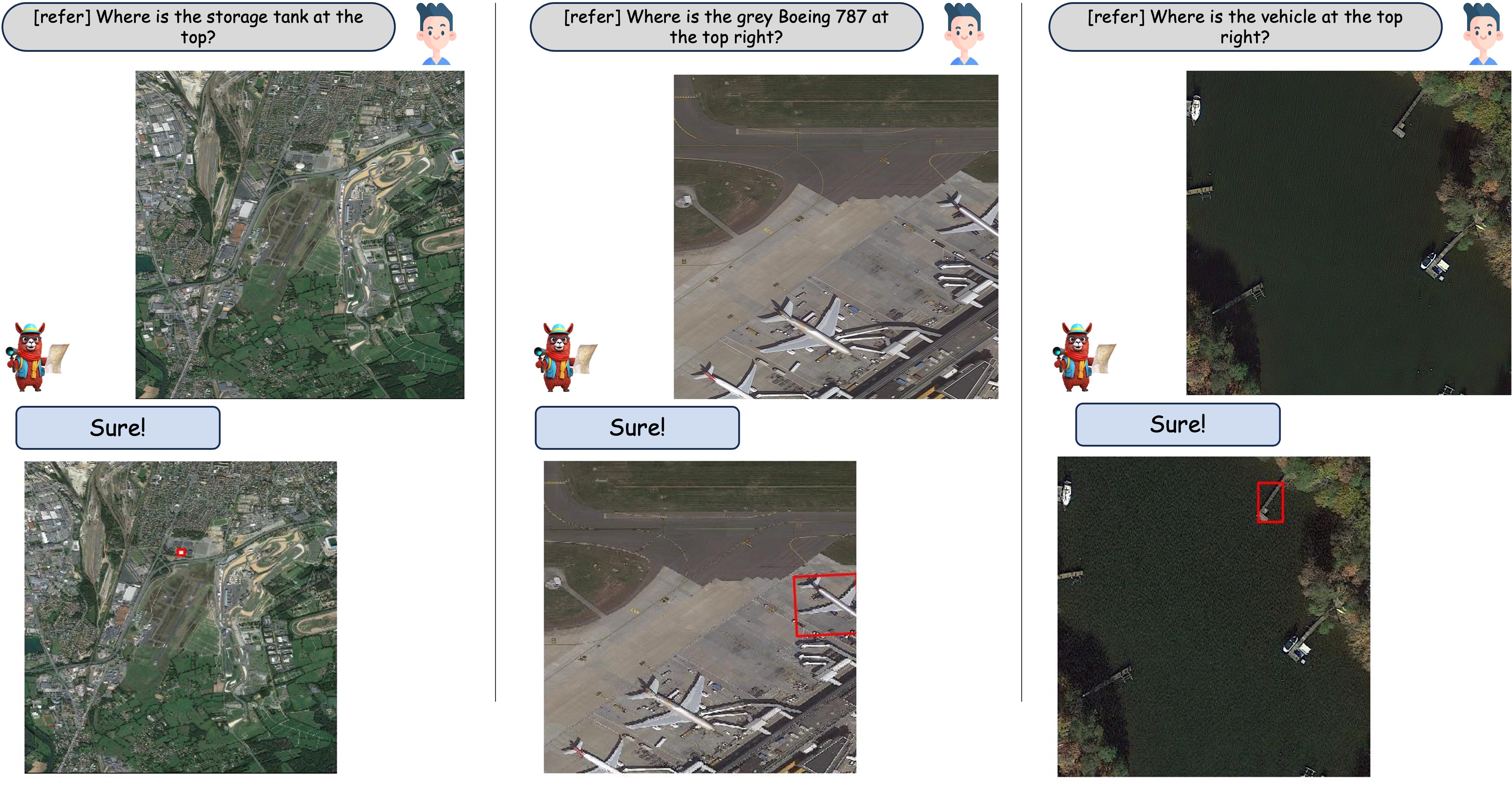
🤖 指代表达
当用户询问某个目标的指代表达时,GeoChat能够准确定位该目标,并为其绘制旋转的边界框。

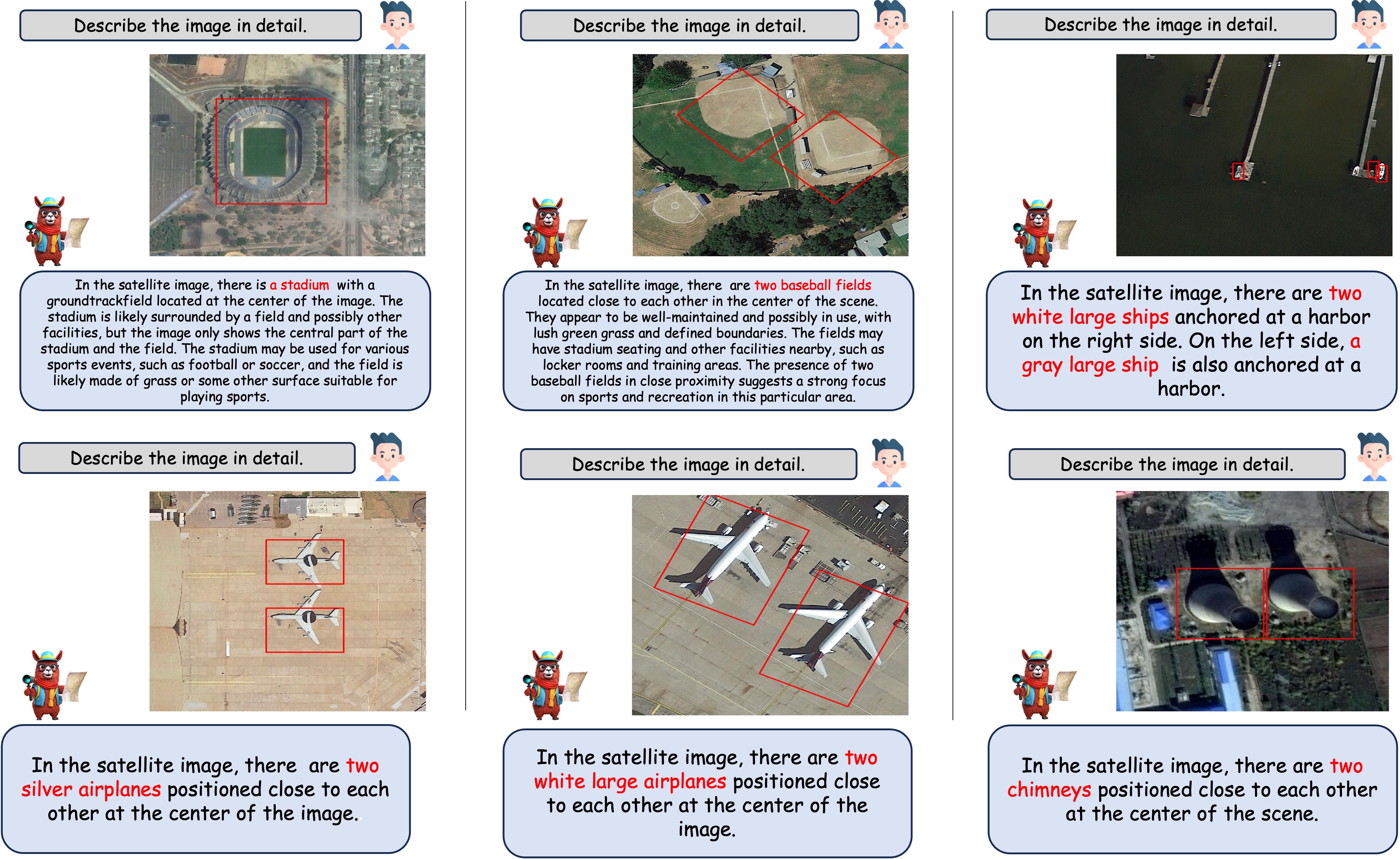
🤖 区域字幕
基于区域的字幕生成任务的定性示例。给定一个边界框,GeoChat能够为该区域或框内覆盖的对象提供简短描述。
📜 引用
@article{kuckreja2023geochat,
title={GeoChat: Grounded Large Vision-Language Model for Remote Sensing},
author={Kuckreja, Kartik and Danish, Muhammad S. and Naseer, Muzammal and Das, Abhijit and Khan, Salman and Khan, Fahad S.},
journal={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}
🙏 致谢
我们感谢LLaVA和Vicuna开放其模型和代码,作为开源贡献。



常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备