Deep_White_Balance
Deep_White_Balance 是 CVPR 2020 会议口头报告论文《Deep White-Balance Editing》的官方开源实现,由三星人工智能中心与约克大学联合研发。它主要解决数码摄影中常见的白平衡失衡问题,即照片因环境光线影响而出现偏色(如过黄或过蓝),导致色彩还原不准确。
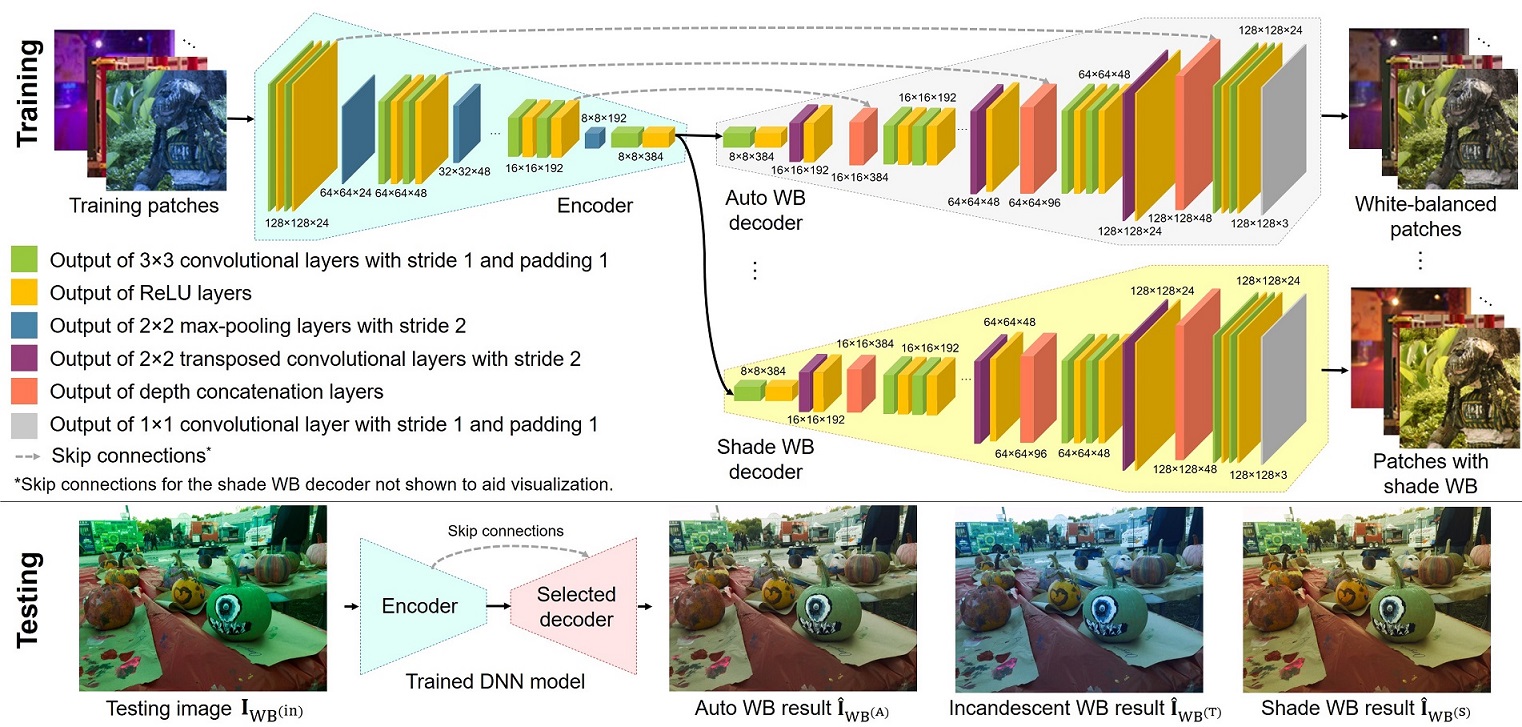
与传统仅能自动校正白平衡的方法不同,Deep_White_Balance 基于深度学习多任务框架,不仅能自动将图像调整至中性白平衡,还支持用户进行交互式编辑,灵活控制画面的冷暖色调风格。其核心技术亮点在于利用渲染生成的白平衡数据集进行训练,并通过端到端的神经网络架构,在保持图像细节的同时实现高质量的颜色迁移与校正。
该项目提供了成熟的 MATLAB 和 PyTorch 版本代码,包含完整的训练脚本、单图处理示例以及直观的图形界面(GUI)演示。因此,它非常适合计算机视觉领域的研究人员复现算法、开发者集成色彩校正功能,以及摄影师或设计师用于辅助后期调色工作。虽然普通用户也可通过 GUI 体验功能,但整体使用门槛仍偏向具备一定技术背景的专业人群。
使用场景
一位电商摄影师正在处理一批在混合光源(如橱窗自然光与室内暖黄射灯)下拍摄的服装产品图,急需统一色调以符合品牌视觉规范。
没有 Deep_White_Balance 时
- 手动调色效率极低:面对数百张不同色温的照片,设计师只能在 Photoshop 中逐张拖动色温滑块,耗时数小时且难以保持一致性。
- 色彩还原失真:传统自动白平衡算法在复杂混合光线下容易误判,导致白色衬衫偏蓝或肤色呈现病态的蜡黄,严重影响商品质感。
- 缺乏精细编辑能力:现有工具通常只能“校正”色偏,无法像后期修图师那样根据创意需求灵活调整画面冷暖氛围,限制了创作空间。
- 批次处理效果参差:使用简单的批量滤镜会导致部分过曝或欠曝区域色彩断裂,不得不重新返工进行局部蒙版修复。
使用 Deep_White_Balance 后
- 智能多任务一键处理:利用其深度学习框架,Deep_White_Balance 能自动识别场景光照并批量完成自动白平衡校正,将数小时的工作缩短至几分钟。
- 精准的色彩复原:基于 CVPR 2020 获奖算法,该工具在混合光源下仍能准确还原衣物本色,消除不自然的色偏,确保肤色和织物纹理真实自然。
- 灵活的创意编辑模式:除了自动校正,Deep_White_Balance 还提供“编辑”模式,允许用户在保持色彩连贯性的前提下,自由调节画面冷暖风格以满足营销需求。
- 高质量的输出稳定性:得益于多任务学习架构,即使在光影复杂的边缘区域,生成的图像也能保持平滑过渡,避免了传统方法常见的色彩断层和噪点。
Deep_White_Balance 通过 AI 驱动的精准色温控制,将繁琐且依赖经验的色彩校正工作转化为高效、标准化的自动化流程,显著提升了视觉内容的生产质量与速度。
运行环境要求
- 未说明
- PyTorch 版本需要 cudatoolkit(具体版本未说明,需匹配 PyTorch 1.2.0/1.5.0)
- Matlab 版本未明确要求 GPU
未说明

快速开始
深度白平衡编辑,CVPR 2020(口头报告)
Mahmoud Afifi1,2 和 Michael S. Brown1
1三星AI中心(SAIC)- 多伦多
2约克大学

论文参考代码:Deep White-Balance Editing。Mahmoud Afifi 和 Michael S. Brown,CVPR 2020。如果您使用此代码或我们的数据集,请引用我们的论文:
@inproceedings{afifi2020deepWB,
title={Deep White-Balance Editing},
author={Afifi, Mahmoud and Brown, Michael S},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2020}
}
训练数据
下载 Rendered WB 数据集。
将输入图像和真实标签图像分别复制到同一个目录中。每对输入/标签图像应采用以下命名格式:输入图像为
name_WB_picStyle.png,对应的标签图像为name_G_AS.png。这与 Rendered WB 数据集 中使用的文件名风格一致。请参阅dataset目录以获取示例。
代码
我们提供了 Matlab 和 PyTorch 平台的源代码。无法保证训练好的模型会生成完全相同的结果。
1. Matlab(推荐)
前提条件
- Matlab 2019b 或更高版本
- 深度学习工具箱
使用说明
运行 install_.m
示例:
- 运行
demo_single_image.m或demo_images.m分别处理单张图像或图像目录。可用任务包括 AWB、全部和编辑。如果运行demo_single_image.m,结果将保存在../result_images中,并输出如下图像:

- 运行
demo_GUI.m进行 GUI 演示。

训练代码:
运行 training.m 开始训练。在运行代码之前,您需要调整 datasetDir 变量中的训练图像目录。您可以在训练前修改 training.m 中的训练设置。
例如,您可以使用 epochs 和 miniBatch 变量分别更改训练轮数和小批量大小。如果将 fold = 0 和 trainingImgsNum = 0 设置,则训练将使用所有训练数据,不进行交叉验证。如果您希望将训练图像数量限制为 n 张,请将 trainingImgsNum 设置为 n。若要进行 3 折交叉验证,可将 fold 设置为 testing_fold。此时代码将在剩余折数上进行训练,并将选定的一折用于测试。
其他有用选项包括:patchsPerImg 用于选择每张图像的随机补丁数量,以及 patchSize 用于设置训练补丁的大小。要控制学习率下降的速率和因子,请查看位于 utilities 目录中的 get_training_options.m 函数。您可以使用 loadpath 变量从 .mat 格式的训练检查点继续训练。若要从头开始训练,请将 loadpath=[];。
训练开始后,会在 reports_and_checkpoints 目录下生成一个 .csv 文件,可用于可视化训练进度。如果您使用带有图形界面的 Matlab,并希望在训练过程中可视化部分输入/输出补丁,请在 此处 设置断点,并在命令窗口中输入以下代码:
close all; i = 1; figure; subplot(2,3,1);imshow(extractdata(Y(:,:,1:3,i))); subplot(2,3,2);imshow(extractdata(Y(:,:,4:6,i))); subplot(2,3,3);imshow(extractdata(Y(:,:,7:9,i))); subplot(2,3,4); imshow(gather(T(:,:,1:3,i))); subplot(2,3,5); imshow(gather(T(:,:,4:6,i))); subplot(2,3,6); imshow(gather(T(:,:,7:9,i)));
您可以通过更改上述代码中的 i 值来查看当前批次中的不同图像。该图将显示生成的补丁(第一行)及其对应的标签补丁(第二行)。对于无图形界面的情况,您可以编辑自定义代码 此处 来定期保存示例补丁。提示:您可能需要使用 持久变量 来控制这一过程。另一种方法是使用 自定义训练循环。
2. PyTorch
前置条件
Python 3.6
PyTorch(已测试版本:1.2.0 和 1.5.0)
torchvision(已测试版本:0.4.0 和 0.6.0)
cudatoolkit
tensorboard(可选)
numpy
Pillow
future
tqdm
matplotlib
scipy
scikit-learn
代码可能在指定版本之外的库版本上也能运行。
开始使用
示例:
- 运行
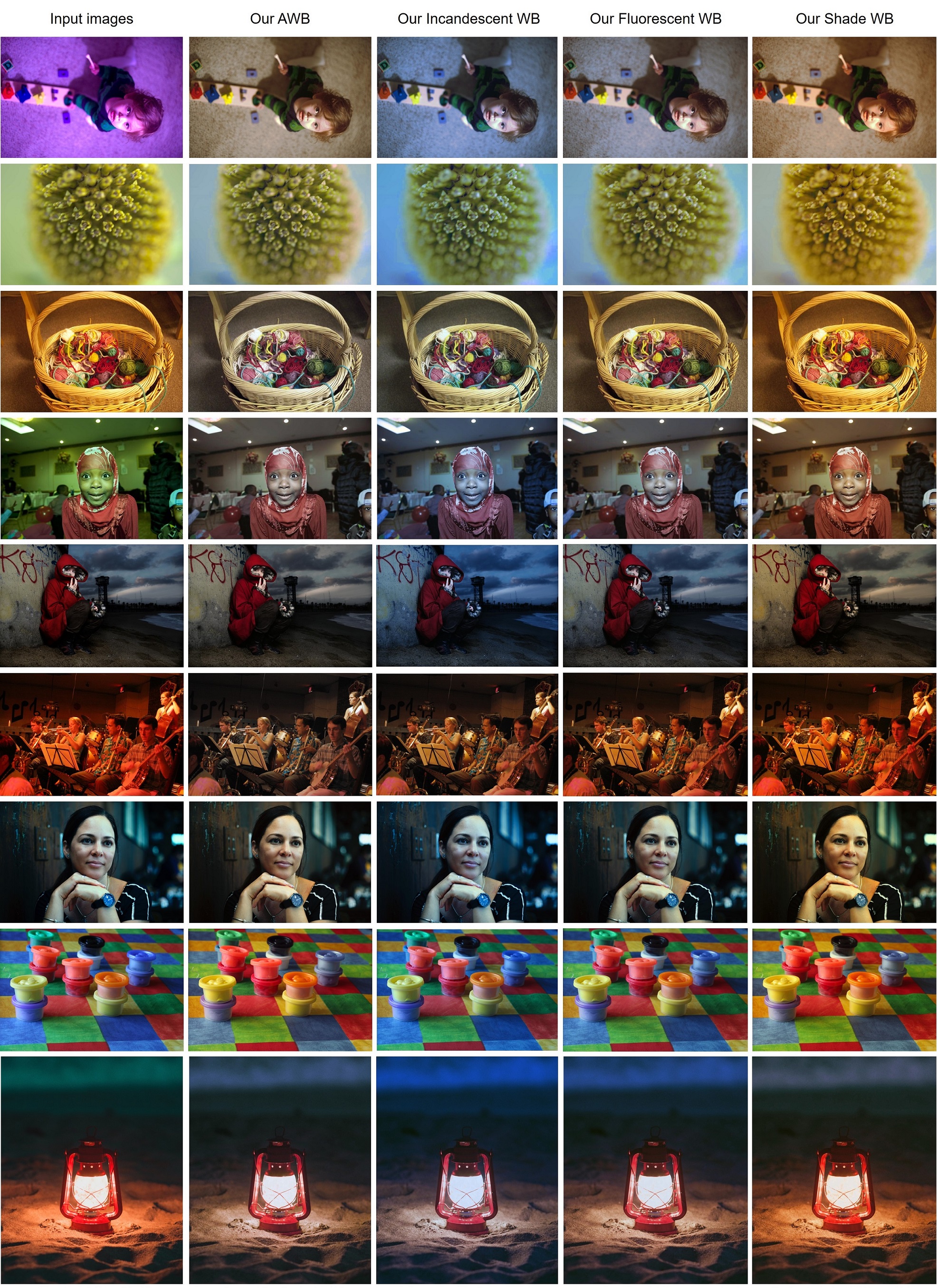
demo_single_image.py处理单张图片。 应用 AWB + 不同白平衡设置的示例:python demo_single_image.py --input_image ../example_images/00.jpg --output_image ../result_images --show。此示例应在../result_images中保存输出图像,并显示如下图像:

- 运行
demo_images.py处理图片目录。示例:python demo_images.py --input_dir ../example_images/ --output_dir ../result_images --task AWB。可用任务包括 AWB、all 和 editing。您也可以在demo_single_image.py示例中指定任务。
训练代码:
运行 training.py 开始训练。在运行代码之前,您应调整训练图像目录。
示例:CUDA_VISIBLE_DEVICE=0 python train.py --training_dir ../dataset/ --fold 0 --epochs 500 --learning-rate-drop-period 50 --num_training_images 0。在此示例中,fold = 0 和 num_training_images = 0 表示训练将使用所有训练数据,不进行交叉验证。如果您希望将训练图像数量限制为 n 张,请将 num_training_images 设置为 n。如果您希望进行 3 折交叉验证,请使用 fold = testing_fold。此时,代码将在剩余的折中进行训练,并将选定的折用于测试。
其他有用的选项包括:--patches-per-image 用于选择每张图像的随机补丁数量;--learning-rate-drop-period 和 --learning-rate-drop-factor 分别用于控制学习率下降的周期和因子;以及 --patch-size 用于设置训练补丁的大小。您可以使用 --load 选项从 .pth 训练检查点文件继续训练。
如果您机器上安装了 TensorBoard,在开始训练后运行 tensorboard --logdir ./runs 可以查看训练进度并可视化输入/输出补丁的样本。
结果


本软件仅用于研究目的,不得用于商业用途。
维护者:Mahmoud Afifi(m.3afifi@gmail.com)
相关研究项目
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。