ComfyUI-Impact-Pack
ComfyUI-Impact-Pack 是专为 ComfyUI 设计的一套强大自定义节点扩展包,旨在简化并增强图像生成与修复的工作流。它通过集成检测器(Detector)、细节修复器(Detailer)、超分辨率放大器(Upscaler)以及高效的管道连接(Pipe)等核心功能,帮助用户轻松实现人脸修复、局部重绘、高清放大及复杂区域控制,有效解决了原生工作流中操作繁琐、难以精准控制局部细节的痛点。
该工具特别适合希望深入定制 AI 绘图流程的设计师、高级爱好者及研究人员使用。对于需要精细调整生成结果(如修复崩坏的手指或面部)的用户,ComfyUI-Impact-Pack 提供了近乎自动化的解决方案。其技术亮点在于支持最新的 FLUX.1 模型与 SAM2 分割模型,并具备基于执行模型反转的开关逻辑,允许用户在单个工作流中灵活切换不同处理路径。此外,它还完美兼容 AnimateDiff 动态生成与控制网(ControlNet)的高级应用。虽然安装时需注意版本兼容性建议通过 ComfyUI-Manager 进行部署,但一旦配置完成,它将极大提升图像生成的质量与可控性,是构建专业级 ComfyUI 工作流不可或缺的组件。
使用场景
一位电商设计师正在批量生成模特展示图,需要确保人物面部清晰且服装细节完美,同时保持高分辨率以用于广告海报。
没有 ComfyUI-Impact-Pack 时
- 生成的人物面部经常模糊或五官扭曲,必须手动重绘数十次才能碰巧得到一张可用的脸。
- 想要修复手部或饰品细节时,缺乏自动遮罩功能,只能依靠繁琐的手动蒙版绘制或外部 PS 处理。
- 直接放大图片会导致画面出现伪影和噪点,无法在保持细节的前提下提升分辨率。
- 工作流节点连线极其复杂,调整一个参数需要断开并重连多条线,调试效率极低。
- 难以统一控制检测模型与修复模型的参数,导致批量出图时质量参差不齐。
使用 ComfyUI-Impact-Pack 后
- 利用 Detailer 节点自动检测并重绘人脸,无需反复重试,每张图的人物五官都自然清晰。
- 通过 Detector 自动识别身体、手部或特定衣物区域生成精准遮罩,实现局部细节的自动化修复。
- 集成专用 Upscaler 流程,在放大的同时智能补充纹理,直接输出可用于印刷的高清大图。
- 借助 Pipe 系列节点将复杂的模型参数打包传输,大幅简化连线,让工作流整洁且易于维护。
- 支持一键切换不同的检测模型(如 SAM2),确保在不同姿态下都能稳定锁定目标区域。
ComfyUI-Impact-Pack 将原本依赖运气的“抽卡式”生成,转变为可控、高效且高质量的工业化图像生产流程。
运行环境要求
- Windows
- Linux
- macOS
未说明(作为 ComfyUI 插件,依赖宿主环境的 GPU 配置以运行 SAM、YOLO 等检测模型)
未说明
快速开始
ComfyUI-Impact-Pack
ComfyUI 自定义节点包 此节点包通过检测器、细节增强器、超分辨率模型、管道等功能,帮助您便捷地增强图像。
注意:UltralyticsDetectorProvider 节点不属于 ComfyUI-Impact-Pack。如需使用 UltralyticsDetectorProvider 节点,请单独安装 ComfyUI-Impact-Subpack。
注意事项
- V8.24:由于 DifferentialDiffusion 的结构变化,此兼容性补丁需要 ComfyUI 0.3.63 或更高版本。
- V8.19:移除了旧版节点(如 mmdet 等)。
- V8.18:支持 facebookresearch/sam2 模型。
- V8.0:
Impact Subpack不再自动安装。如需使用UltralyticsDetectorProvider节点,请单独安装Impact Subpack。 - V7.6:不再支持自动安装。请使用 ComfyUI-Manager 进行安装,或手动安装 requirements.txt 并运行 install.py 完成安装。
- V7.0:支持基于执行模型反转的切换功能。
- V6.0:在 Impact KSampler、Detailers 和 PreviewBridgeLatent 中支持 FLUX.1 模型。
- V5.0:不再兼容 2024 年 4 月 8 日之前的 ComfyUI 版本。
- V4.87.4:请更新至 2024 年 4 月 8 日之后的 ComfyUI 版本,以确保正常运行。
- V4.85:与过时的 ComfyUI IPAdapter Plus 不兼容。(需使用 3 月 24 日或之后的版本。)
- V4.77:已应用兼容性补丁。要求 ComfyUI 版本为 10 月 8 日或之后。
- V4.73.3:ControlNetApply (SEGS) 支持 AnimateDiff。
- V4.20.1:由于
RegionalSampler功能更新,参数顺序发生了变化,导致之前创建的RegionalSamplers出现故障。请相应调整参数。 - V4.12:
MASKS已更改为MASK。 - V4.7.2 与旧版本的
ControlNet 辅助预处理器不兼容。如需使用MediaPipe FaceMesh to SEGS,请更新至最新版本(9 月 17 日)。 - 自 V3.16 起,选择权重语法已更改(: -> ::)。(教程)
- 自 V3.6 起,需要 ComfyUI 最新版本(8 月 8 日,9ccc965)。
- 在 V3.3.1 以下版本中,使用 UltralyticsDetectorProvider 后生成的图像质量存在问题。请务必升级到较新版本。
- 自 V3.0 起,与
mmdet相关的节点为可选节点,仅根据配置设置启用。- 通过 ComfyUI-Impact-Subpack,您可以利用 UltralyticsDetectorProvider 访问多种检测模型。
- 在 2.22 和 2.21 版本之间,Detailer 工作流存在部分兼容性损失。若继续使用现有工作流,执行时可能会出现错误。Detailer 相关节点新增了一个名为 “enhanced_alpha_list” 的输出。
- Impact Pack 安装过程中出现的 cv2 权限错误已在 2.21.4 版本中修复。但请注意,需要使用最新版本的 ComfyUI 和 ComfyUI-Manager。
- “PreviewBridge” 功能可能无法在 2023 年 7 月 1 日之前发布的 ComfyUI 版本上正常工作。
- 尝试在 2023 年 6 月 27 日之前发布的 ComfyUI 版本上加载 “ComfyUI-Impact-Pack”,将会失败。
- 随着 FaceDetailer 中通配符支持的加入,DETAILER_PIPE 相关节点和 Detailer 节点的结构发生了变化。使用现有工作流时可能出现故障。
安装方法
推荐方式
- 通过 ComfyUI-Manager 安装。
手动安装
- 在终端(cmd)中导航至
ComfyUI/custom_nodes。 - 使用以下命令将仓库克隆到
custom_nodes目录下:git clone https://github.com/ltdrdata/ComfyUI-Impact-Pack comfyui-impact-pack cd comfyui-impact-pack - 在您的 Python 环境中安装依赖项。
- 对于 Windows 可移植版,在
ComfyUI\custom_nodes\comfyui-impact-pack内运行以下命令:..\..\..\python_embeded\python.exe -m pip install -r requirements.txt - 如果使用 venv 或 conda,请先激活 Python 环境,然后运行:
pip install -r requirements.txt
- 对于 Windows 可移植版,在
伴侣包
- 如需使用
Ultralytics Detector Provider来访问各种 YOLO 检测模型,还应安装 ComfyUI-Impact-Subpack。
自定义节点
检测节点
SAMLoader (Impact)- 加载 SAM 模型。ONNXDetectorProvider- 加载 ONNX 模型以提供 BBOX_DETECTOR。CLIPSegDetectorProvider- CLIPSeg 的封装,用于提供 BBOX_DETECTOR。- 需要安装 ComfyUI-CLIPSeg 节点扩展。
SEGM Detector (combined)- 检测分割并从输入图像中返回掩码。BBOX Detector (combined)- 检测边界框并从输入图像中返回掩码。SAMDetector (combined)- 利用 SAM 技术,在输入图像上提取由输入 SEGS 指定位置的分割区域,并将其输出为统一的掩码。SAMDetector (Segmented)- 类似于SAMDetector (combined),但它会将检测到的分割区域分开并分别输出。对于同一检测区域,可能会找到多个分割区域,目前的策略是将它们任意地每三个一组进行分组。这一部分预计在未来会得到改进。- 因此,它会输出一个统一的
combined_mask掩码,以及以批次形式组合的多个batch_masks掩码。 - 虽然
batch_masks可能不会完全分离,但它提供了进行一定程度分割的功能。
- 因此,它会输出一个统一的
Simple Detector (SEGS)- 主要使用BBOX_DETECTOR运行,同时通过提供SAM_MODEL或SEGM_DETECTOR,该节点会在内部通过对 bbox 和 silhouette 进行掩码操作来生成更优的 SEGS。它是一个方便的工具,可以简化较为复杂的流程。Simple Detector for Video (SEGS)– 对由图像帧组成的视频进行检测。它不是使用单个掩码,而是对每一帧图像单独进行检测,并生成包含一批掩码的 SEGS 对象。SAM2 Video Detector (SEGS)– 类似于Simple Detector for Video (SEGS),但利用 SAM2 的视频跟踪技术生成包含一批掩码的 SEGS 对象。- 使用该节点时,必须在 SAMLoader 中选择一个 SAM2 模型。
ControlNet、IPAdapter
ControlNetApply (SEGS)- 若要在 SEGS 中应用 ControlNet,需要使用 Inspire Pack 中的 Preprocessor Provider 节点来配合使用此节点。- 可以选择性地应用
segs_preprocessor或control_image。如果提供了control_image,则会忽略segs_preprocessor。 - 如果设置为
control_image,可以通过SEGSPreview (CNET Image)预览裁剪后的 cnet 图像。由segs_preprocessor生成的图像应通过每个 Detailer 的cnet_images输出进行验证。 segs_preprocessor是在细化过程中基于裁剪后的图像实时进行预处理,而control_image则会被裁剪后作为输入传递给ControlNetApply (SEGS)。
- 可以选择性地应用
ControlNetClear (SEGS)- 清除 SEGS 中已应用的 ControlNet。IPAdapterApply (SEGS)- 若要在 SEGS 中应用 IPAdapter,同样需要使用 Inspire Pack 中的 Preprocessor Provider 节点来配合使用此节点。
掩码操作
Pixelwise(SEGS & SEGS)- 在两个 SEGS 之间执行“逐像素与”操作。Pixelwise(SEGS - SEGS)- 从一个 SEGS 中减去另一个 SEGS。Pixelwise(SEGS & MASK)- 在 SEGS 和 MASK 之间执行逐像素 AND 操作。Pixelwise(SEGS & MASKS ForEach)- 在 SEGS 和 MASKS 之间执行逐像素 AND 操作。- 请注意,此操作是对一批 MASKS 而非单个 MASK 进行的。
Pixelwise(MASK & MASK)- 在两个掩码之间执行“逐像素与”操作。Pixelwise(MASK - MASK)- 从一个掩码中减去另一个掩码。Pixelwise(MASK + MASK)- 将两个掩码合并。SEGM Detector (SEGS)- 检测分割并从输入图像中返回 SEGS。BBOX Detector (SEGS)- 检测边界框并从输入图像中返回 SEGS。Dilate Mask- 扩张掩码。- 支持使用负值进行腐蚀。
Gaussian Blur Mask- 对掩码应用高斯模糊。可用于掩码羽化。Mask Rect Area- 基于百分比创建矩形掩码,并可在预览画布上查看。Mask Rect Area (Advanced)- 基于像素和图像尺寸创建矩形掩码。
细化节点
Detailer (SEGS)- 根据 SEGS 对图像进行细化。Detailer (SEGS) with auto retry- 根据 SEGS 对图像进行细化,如果补丁全部为黑色,则会自动重试。DetailerDebug (SEGS)- 根据 SEGS 对图像进行细化。此外,它还提供了监控裁剪图像以及裁剪图像细化结果的能力。- 为了避免在使用“external_seed”时因每次种子不变而导致的重复生成,请在“Detailer…”节点中关闭“seed random generate”选项。
MASK to SEGS- 根据掩码生成 SEGS。MASK to SEGS For Video- 根据视频中的掩码生成 SEGS。(由MASK to SEGS For AnimateDiff更名而来)- 当使用单个掩码时,将其转换为 SEGS 以应用于整个帧。
- 当使用批量掩码时,轮廓填充功能将被禁用。
MediaPipe FaceMesh to SEGS- 从 MediaPipe 面部网格图像中分离出每个地标,创建带标签的 SEGS。- 通常,通过 MediaPipe 面部网格预处理器生成的图像会被缩小。它会将 MediaPipe 面部网格图像调整回原始大小,以便在处理过程中与 reference_image_opt 提供的参考图像尺寸匹配。
ToBinaryMask- 将使用 0 到 255 之间 alpha 值生成的掩码分离为 0 和 255。非零部分始终设置为 255。Masks to Mask List- 该节点将批量的 MASKS 转换为单个掩码列表。Mask List to Masks- 该节点将掩码列表转换为批量掩码形式。EmptySEGS- 提供一个空的 SEGS。MaskPainter- 提供绘制掩码的功能。FaceDetailer- 轻松检测人脸并进行优化。FaceDetailer (pipe)- 轻松检测人脸并进行优化(适用于多通道)。MaskDetailer (pipe)- 这是一个简单的 inpaint 节点,可将 Detailer 应用于掩码区域。FromDetailer (SDXL/pipe),BasicPipe -> DetailerPipe (SDXL),Edit DetailerPipe (SDXL)- 这些是用于 Detailer 的管道函数,旨在利用 SDXL 的细化模型。Any PIPE -> BasicPipe- 将其他自定义节点中并非 BASIC_PIPE,但内部结构与 BASIC_PIPE 相同的 PIPE 值转换为 BASIC_PIPE。如果应用了不兼容的类型,可能会导致运行时错误。
SEGS 操作节点
SEGSDetailer- 对 SEGS 进行细节处理,但不将其贴回原图。SEGSPaste- 将 SEGS 的处理结果贴回原图。- 如果提供了
ref_image_opt,则会忽略 SEGS 中包含的图像。取而代之的是,使用ref_image_opt中与 SEGS 裁剪区域对应的部分进行粘贴。ref_image_opt中的图像尺寸应与原图尺寸相同。 - 此节点可与 AnimateDiff 的处理结果结合使用。
- 如果提供了
SEGSPreview- 提供 SEGS 的预览。- 该选项用于在将改进后的图像合并回原图之前,通过
SEGSDetailer预览其效果。在经过SEGSDetailer处理前,SEGS 只包含掩码信息,而不包含图像信息。如果连接了fallback_image_opt作为原图,则 SEGS 将使用原图生成无图像信息的预览。然而,如果 SEGS 已经包含图像信息,则fallback_image_opt将被忽略。 - 此节点可与 AnimateDiff 的处理结果结合使用。
- 该选项用于在将改进后的图像合并回原图之前,通过
SEGSPreview (CNET Image)- 用于调试目的,显示通过ControlNetApply (SEGS)配置的图像。SEGSToImageList- 将 SEGS 转换为图像列表。SEGSToMaskList- 将 SEGS 转换为掩码列表。SEGS Filter (label)- 根据检测区域的标签对 SEGS 进行过滤。SEGS Filter (ordered)- 根据大小和位置对 SEGS 进行排序,并提取特定范围内的 SEG。SEGS Filter (range)- 仅从 SEGS 中提取尺寸和位置在特定范围内的 SEG。SEGS Filter (non max suppression)- 根据交并比(IoU)阈值,移除重叠度高的 SEG,仅保留置信度最高的检测结果。SEGS Filter (intersection)- 根据交集面积(IoA)阈值,从 segs1 中筛选出与 segs2 中任何 SEG 均无显著重叠的 SEG。SEGS Assign (label)- 按顺序为 SEGS 分配标签。此节点在与 FaceDetailer 的[LAB]结合使用时非常有用。SEGSConcat- 将 segs1 和 segs2 拼接在一起。如果 segs1 和 segs2 的源形状不同,则 segs2 将被忽略。SEGS Merge- SEGS 包含多个 SEG。SEGS Merge 可将多个 SEG 整合为一个合并后的 SEG。标签将变为merged,置信度则取最低值。应用的 ControlNet 和裁剪后的图像将被移除。Picker (SEGS)- 在输入的 SEGS 中,可通过对话框选择特定的 SEG。若未选择任何 SEG,则输出空的 SEGS。增加SEGSDetailer的 batch_size 可用于从候选中进行选择。Set Default Image For SEGS- 为 SEGS 设置默认图像。以这种方式设置图像的 SEGS 不再需要设置后备图像。当 override 设置为 false 时,将保留原图。Remove Image from SEGS- 移除通过 “Set Default Image for SEGS” 或SEGSDetailer配置的 SEGS 图像。移除 SEGS 的图像后,Detailer 节点将基于当前处理的图像而非 SEGS 运行。Make Tile SEGS- [实验性] 从图像创建瓦片形式的 SEGS,以便于使用 Detailer 进行分块放大实验。filter_in_segs_opt和filter_out_segs_opt是可选输入。如果提供了这些输入,在创建瓦片时,每个瓦片的掩码将通过与filter_in_segs_opt的掩码叠加,并排除与filter_out_segs_opt的掩码重叠来生成。掩码为空的瓦片将不会被创建为 SEGS。
Dilate Mask (SEGS)- 对 SEGS 中的掩码进行膨胀/腐蚀操作。Gaussian Blur Mask (SEGS)- 对 SEGS 中的掩码应用高斯模糊。SEGS_ELT Manipulation- 实验性节点DecomposeSEGS- 将 SEGS 分解,以便进行详细操作。AssembleSEGS- 将分解后的 SEGS 重新组装。From SEG_ELT- 从 SEG_ELT 中提取详细信息。Edit SEG_ELT- 修改 SEG_ELT 中的部分信息。Dilate SEG_ELT- 膨胀 SEG_ELT 的掩码。From SEG_ELTbbox - 从 SEG_ELT 中的 bbox 提取坐标。From SEG_ELTcrop_region - 从 SEG_ELT 中的 crop_region 提取坐标。
Count Elt in SEGS- 计算 SEGS 中的元素数量。
管道节点
ToDetailerPipe,FromDetailerPipe- 这些节点用于将 Detailer 中使用的多个输入(如模型、VAE 等)打包成一个 DETAILER_PIPE,或从 DETAILER_PIPE 中提取已打包的元素。ToBasicPipe,FromBasicPipe- 这些节点用于将模型、CLIP、VAE、正向条件和反向条件打包成一个 BASIC_PIPE,或从 BASIC_PIPE 中提取各个元素。EditBasicPipe,EditDetailerPipe- 这些节点用于替换 BASIC_PIPE 或 DETAILER_PIPE 中的部分元素。FromDetailerPipe_v2,FromBasicPipe_v2- 功能与FromDetailerPipe和FromBasicPipe相同,但额外提供了一个直接导出输入管道的输出。这在编辑 EditBasicPipe 和 EditDetailerPipe 时非常有用。Latent Scale (on Pixel Space)- 本节点将潜在空间转换为像素空间,对其进行放大,然后再转换回潜在空间。- 如果提供了 upscale_model_opt,则使用该模型对像素进行放大,随后使用 scale_method 中提供的插值方法将其缩小到目标分辨率。
PixelKSampleUpscalerProvider- 提供一种放大器,它使用 VAEDecode 将潜在空间转换为像素,执行放大操作,再使用 VAEEncode 将其转换回潜在空间,最后进行 k-sampling。这种放大器可以附加到Iterative Upscale等节点上使用。- 类似于
Latent Scale (on Pixel Space),如果提供了 upscale_model_opt,则会使用该模型进行像素放大。
- 类似于
PixelTiledKSampleUpscalerProvider- 与PixelKSampleUpscalerProvider类似,但它使用ComfyUI_TiledKSampler和 Tiled VAE 解码器/编码器,以避免在高分辨率下出现 GPU VRAM 问题。- 需要安装 BlenderNeko/ComfyUI_TiledKSampler 节点扩展。
PK_HOOK
DenoiseScheduleHookProvider- IterativeUpscale 提供了一个钩子,随着迭代步骤的推进,逐渐将去噪强度调整为目标去噪强度。CfgScheduleHookProvider- IterativeUpscale 提供了一个钩子,随着迭代步骤的推进,逐渐将 CFG 强度调整为目标 CFG 强度。StepsScheduleHookProvider- IterativeUpscale 提供了一个钩子,随着迭代步骤的推进,逐渐将采样步数调整为目标步数。NoiseInjectionHookProvider- 在 IterativeUpscale 的每次迭代过程中,会根据预设的时间表逐步调整噪声强度,并向潜在空间注入噪声。- 需要安装 BlenderNeko/ComfyUI_Noise 节点扩展。
- 种子用于生成初始噪声值,每次迭代时种子值会递增 1。
- 源参数决定了配置 CPU 噪声还是 GPU 噪声。
- 目前仅提供一种简单的时间表:在每次迭代过程中,噪声强度从 start_strength 逐渐变化到 end_strength。
UnsamplerHookProvider- 在每次迭代中应用 Unsampler。使用此节点前需先安装 ComfyUI_Noise 扩展。PixelKSampleHookCombine- 用于连接两个 PK_HOOK。首先执行 hook1,然后再执行 hook2。- 如果希望同时调整 CFG 和去噪强度,可以将 CfgScheduleHookProvider 和 PixelKSampleHookCombine 结合使用。
DETAILER_HOOK
NoiseInjectionDetailerHookProvider-detailer_hook是Detailer中的一个钩子,在处理每个 SEGS 的过程中注入噪声。UnsamplerDetailerHookProvider- 在每次循环中应用 Unsampler。使用此节点前需先安装 ComfyUI_Noise 扩展。DenoiseSchedulerDetailerHookProvider- 在循环进行的过程中,详细器的去噪强度会被调整至target_denoise。CoreMLDetailerHookProvider- CoreML 仅支持 512x512、512x768、768x512、768x768 尺寸的采样。CoreMLDetailerHookProvider 会精确地将裁剪区域的放大尺寸固定为这些规格。使用此钩子时,无论 guide_size 如何,都会始终选择上述尺寸。然而,如果 guide_size 过小,则可能会出现跳过的情况。DetailerHookCombine- 用于连接两个 DETAILER_HOOK。与 PixelKSampleHookCombine 类似。SEGSOrderedFilterDetailerHook、SEGSRangeFilterDetailerHook、SEGSLabelFilterDetailerHook- 这些是包装节点,通过创建 DETAILER_HOOK,为 FaceDetailer 或 Detector 提供 SEGSFilter 节点。PreviewDetailerHook- 连接此钩子节点有助于在每次完成 SEGS 详细化任务后查看预览效果。当处理大量 SEGS 时,例如制作拼贴 SEGS,它可以让用户逐步监控处理进度。- 由于该钩子是在最终粘贴回原始图像时应用的,因此对
SEGSDetailer等节点没有影响。
- 由于该钩子是在最终粘贴回原始图像时应用的,因此对
VariationNoiseDetailerHookProvider- 向详细器应用变异种子。可以通过组合方式分多个阶段应用。CustomSamplerDetailerHookProvider- 应用一个允许在 Detailer 节点中使用自定义采样器的钩子。当使用DetailerHookCombine时,会优先应用第一个钩子中的采样器。LamaRemoverDetailerHookProvider- 在详细化阶段,将 Lama Remover 应用于放大后的图像。如果设置skip_sampling为 True,则可单独使用 Lama Remover 而无需经过详细化阶段,直接移除检测到的区域。- 不适用于 AnimateDiff 详细器。使用
DetailerHookCombine时,只有当所有钩子都设置为True时,才会生效skip_sampling。 - 使用此节点前,需安装位于 Layer-norm/comfyui-lama-remover 的节点包。
- 不适用于 AnimateDiff 详细器。使用
迭代式放大节点
Iterative Upscale (Latent/on Pixel Space)- 该放大器接收输入放大器,并将缩放因子拆分为若干步骤,然后逐次进行放大操作。此节点以潜在空间作为输入,输出也为潜在空间。Iterative Upscale (Image)- 该放大器接收输入放大器,并将缩放因子拆分为若干步骤,然后逐次进行放大操作。此节点以图像作为输入,输出也为图像。- 内部实现上,该节点使用的是
Iterative Upscale (Latent)。
- 内部实现上,该节点使用的是
双采样器节点
TwoSamplersForMask- 该节点可以根据掩码区域应用两种不同的采样器。掩码值为 0 的区域使用 base_sampler,而掩码值为 1 的区域则使用 mask_sampler。- 注意:无法使用通过 VAEEncodeForInpaint 编码的潜在空间。
KSamplerProvider- 这是一个包装器,使 KSampler 能够在 TwoSamplersForMask 和 TwoSamplersForMaskUpscalerProvider 中使用。TiledKSamplerProvider- ComfyUI_TiledKSampler 是一个包装器,用于提供 KSAMPLER。- 需要安装 BlenderNeko/ComfyUI_TiledKSampler 节点扩展。
TwoAdvancedSamplersForMask- TwoSamplersForMask 与 TwoAdvancedSamplersForMask 类似,但它们的操作方式有所不同。TwoSamplersForMask 只有在基础区域的所有采样完成后,才会对掩码区域进行采样。而 TwoAdvancedSamplersForMask 则会在每一步中依次对基础区域和掩码区域进行采样。KSamplerAdvancedProvider- 这是一个包装器,使 KSampler 能够在 TwoAdvancedSamplersForMask 和 RegionalSampler 中使用。- sigma_factor:通过将去噪时间表乘以 sigma_factor,可以根据配置的去噪程度调整去噪量。
TwoSamplersForMaskUpscalerProvider- 这是一个放大器,扩展了 TwoSamplersForMask 的功能,使其能够在 Iterative Upscale 中使用。- TwoSamplersForMaskUpscalerProviderPipe - 是 TwoSamplersForMaskUpscalerProvider 的管道版本。
图像工具
PreviewBridge (image)- 此自定义节点可在使用 Clipspace 的 MaskEditor 功能时,与图像桥接一起使用。PreviewBridge (latent)- 此自定义节点可在使用 Clipspace 的 MaskEditor 功能时,与潜在图像桥接一起使用。- 如果输入的是带有掩码的潜在变量,则会显示该掩码。此外,掩码输出会提供在潜在变量中设置的掩码。
- 如果输入的是不带掩码的潜在变量,则会原样输出原始潜在变量,但掩码输出会将整个区域都视为掩码。
- 当通过 MaskEditor 设置掩码时,掩码会被应用到潜在变量上,并且输出中会包含存储的掩码。相同的掩码也会作为掩码输出。
- 当连接到
vae_opt时,其优先级高于preview_method。
ImageSender,ImageReceiver- 在 ImageSender 中生成的图像会自动发送到具有相同 link_id 的 ImageReceiver。LatentSender,LatentReceiver- 在 LatentSender 中生成的潜在变量会自动发送到具有相同 link_id 的 LatentReceiver。- 此外,LatentSender 是通过 PreviewLatent 实现的,它会将潜在变量以负载形式存储在图像缩略图中。
- 由于 ComfyUI 当前的结构限制,无法区分 SDXL 潜在变量和 SD1.5/SD2.1 潜在变量。因此,它会使用 SD1.5 方法对潜在变量进行解码并生成缩略图。
切换节点
Switch (image,mask),Switch (latent),Switch (SEGS)- 在多个输入中,选择由选择器指定的输入并输出。必须提供第一个输入,其他输入为可选。但是,如果选择器指定的输入未连接,可能会发生错误。Switch (Any)- 这是一个可以接受任意数量输入并产生单个输出的切换节点。其类型会在连接到任何节点时确定,连接更多输入会增加可用的连接槽位。Inversed Switch (Any)- 与Switch (Any)相反,它接受一个输入并从多个输出中选择一个。- 注意:请参阅此教程
通配符 节点
- 这些节点支持
__wildcard-name__形式的语法以及{a|b|c}等动态提示语法。 - 通配符文件可以通过将
.txt或.yaml文件放置在ComfyUI-Impact-Pack/wildcards或ComfyUI-Impact-Pack/custom_wildcards路径下使用。- 您可以下载并使用这种格式的 Wildcard YAML 文件。
- 首次执行后,您可以在创建的
ComfyUI-Impact-Pack/impact-pack.ini文件中的custom_wildcards条目中更改自定义通配符路径。
ImpactWildcardProcessor- 通过处理文本中的通配符来生成文本。如果模式设置为“填充”,则每次执行时都会生成动态提示,并将输入内容填充到第二个文本框中。如果模式设置为“固定”,则第二个文本框的内容保持不变。- 当以“固定”模式生成图像时,用于该特定生成的提示会存储在元数据中。
ImpactWildcardEncode- 类似于 ImpactWildcardProcessor,此节点提供了 LoRA 的加载功能(例如<lora:some_awesome_lora:0.7:1.2>)。在所有 LoRA 加载完成后,填充后的提示会使用 Clip 进行编码。- 如果安装了
Inspire Pack,您可以使用 Lora Block Weight,格式为LBW=lbw spec; <lora:chunli:1.0:1.0:LBW=B11:0,0,0,0,0,0,0,0,0,0,A,0,0,0,0,0,0;A=0.;>,<lora:chunli:1.0:1.0:LBW=0,0,0,0,0,0,0,0,0,0,A,B,0,0,0,0,0;A=0.5;B=0.2;>,<lora:chunli:1.0:1.0:LBW=SD-MIDD;>
- 如果安装了
区域采样
- 这些节点能够通过掩码划分区域并进行部分采样。与 TwoSamplersForMask 不同,每个区域的采样会在每一步中应用。
RegionalPrompt- 此节点结合用于指定区域的 掩码 和应用于每个区域的 采样器,以创建REGIONAL_PROMPTS。CombineRegionalPrompts- 将多个REGIONAL_PROMPTS组合在一起,形成一个单一的REGIONAL_PROMPTS。RegionalSampler- 此节点使用基础采样器和区域提示进行采样。基础采样器的采样会在每一步中执行,而每个区域的采样则通过绑定到该区域的采样器进行。- overlap_factor - 指定每个区域的重叠量,以便与掩码外部区域更好地融合。
- restore_latent - 在对每个区域进行采样时,将掩码外部的区域恢复到基础潜在变量,从而防止在区域采样过程中向掩码外部引入额外噪声。
RegionalSamplerAdvanced- 这是 RegionalSampler 的高级版本。您可以使用step而不是denoise来控制它。注意:
sde采样器和uni_pc采样器在采样的每一步中都会引入额外的噪声。为了缓解这一点,在对每个区域进行采样时,uni_pc采样器会额外应用dpmpp_fast,而 sde 采样器则会额外应用dpmpp_2m采样器。
Impact KSampler
- 这些采样器支持 basic_pipe 以及 AYS/OSS/GITS 调度器。
KSampler (pipe)- KSampler 的管道版本。KSampler (advanced/pipe)- KSampler Advanced 的管道版本。- 当将调度器小部件转换为输入时,请参考
Impact Scheduler Adapter节点以解决兼容性问题。 GITSScheduler Func Provider- GITSScheduler 的调度函数提供者。
批量/列表工具
Image Batch to Image List- 将图像批次转换为图像列表。- 您可以使用在多批次中生成的图像来处理它们。
Image List to Image Batch- 将图像列表转换为图像批次。Make Image List- 将多张图像转换成一个图像列表。Make Image Batch- 将多张图像转换成一个图像批次。- 图像输入可以根据需要进行扩展。
Masks to Mask List,Mask List to Masks,Make Mask List,Make Mask Batch- 这些节点的功能与上述节点相同,只是输入为掩码而非图像。Flatten Mask Batch- 将掩码批次展平为单个掩码。对于非二值掩码,不能保证正常运行。Make List (Any)- 创建包含任意值的列表。Select Nth Item (Any list)- 从列表中选择第 N 项。如果索引超出范围,则返回列表中的最后一项。
逻辑节点(实验性)
- 这些节点是实验性的,旨在实现循环和动态切换的逻辑。
ImpactCompare、ImpactConditionalBranch、ImpactConditionalBranchSelMode、ImpactInt、ImpactBoolean、ImpactValueSender、ImpactValueReceiver、ImpactImageInfo、ImpactMinMax、ImpactNeg、ImpactConditionalStopIterationImpactIsNotEmptySEGS- 该节点仅在输入的SEGS不为空时返回true。ImpactIfNone- 如果any_input为None,则返回true;否则返回false。Queue Trigger- 当此节点执行时,它会添加一个新的队列来协助重复性任务。只有当信号状态发生变化时,才会执行。Queue Trigger (Countdown)- 类似于Queue Trigger,它也会添加一个队列,但仅当计数大于1时才添加,并且每次运行时将计数减1。Sleep- 等待指定的时间(以秒为单位)。Set Widget Value- 此节点将可选输入之一设置为指定节点的控件值。如果类型不匹配,可能会发生错误。Set Mute State- 此节点更改特定节点的静音状态。Control Bridge- 此节点根据mode和behavior修改连接的控制节点的状态。如果有需要更改的节点,当前执行会被暂停,静音状态会被更新,并插入一个新的提示队列。- 当
mode为active时,无论行为如何,都会使连接的控制节点处于激活状态。 - 当
mode为Bypass/Mute时,会根据行为是Bypass还是Mute来改变连接节点的状态。 - 局限性:由于这些特性,当批次数量超过1时,该节点无法正常工作。此外,在Control Bridge之前,如果种子被随机化,或者节点状态被
Queue Trigger、Set Widget Value、Set Mute等操作改变,也无法保证其正常运行。 - 使用此节点时,请确保将
Queue Trigger、Set Widget Value、Set Mute State等操作安排在工作流的最后部分执行。 - 如果希望每次迭代都更改种子值,请确保在工作流的最后执行Set Widget Value,而不是使用随机化功能。
- 只要种子变化发生在Control Bridge部分之后,就不会有问题。
- 当
Remote Boolean (on prompt)、Remote Int (on prompt)- 在提示开始时,此节点会强制设置node_id的widget_value。如果目标控件类型不同,则会被忽略。- 您可以通过ComfyUI-Manager以
Badge: #ID Nickname的格式查看node_id。 - 用于实现循环功能的实验性节点集合(教程将在稍后提供 / 示例工作流)。
局限性
Impact Pack中的许多节点使用通配符类型,以允许任意的输入输出连接。一旦ComfyUI正式支持动态类型,这种方法将被取代。在此之前,虽然这些节点可以正常工作,但在类型验证时仍可能出现错误信息。
HuggingFace节点
- 这些节点基于HuggingFace仓库中的模型提供功能。
- 可以通过
HF_HOME环境变量更改HuggingFace模型缓存的存储路径。 HF Transformers Classifier Provider- 这是一个基于HuggingFace的transformers模型提供分类器的节点。- 参数
repo id应包含HuggingFace的仓库ID。当preset_repo_id设置为Manual repo id时,需在manual_repo_id中手动输入仓库ID。 - 例如,
rizvandwiki/gender-classification-2是一个提供性别分类模型的仓库。
- 参数
SEGS Classify- 此节点利用由HF Transformers Classifier Provider加载的TRANSFORMERS_CLASSIFIER对SEGS进行分类。- 参数
expr允许使用如label > number的形式,当preset_expr为Manual expr时,则使用manual_expr中输入的表达式。 - 例如,在
male <= 0.4的情况下,如果分类结果中male标签的得分小于或等于0.4,则将其归类为filtered_SEGS,否则归类为remained_SEGS。- 支持的标签请参考相应HuggingFace仓库的
config.json文件。
- 支持的标签请参考相应HuggingFace仓库的
#Female和#Male是用于方便起见而将多个标签(如Female, women, woman, ...)分组的符号,而非单个标签。
- 参数
其他节点
Impact Scheduler Adapter- 随着AYS加入Impact Pack和Inspire Pack的日程安排器中,在将现有日程安排器控件转换为输入时会出现兼容性问题。Impact Scheduler Adapter允许间接连接。StringListToString- 将字符串列表转换为字符串。WildcardPromptFromString- 从字符串创建用于detailer的带标签通配符。- 该节点与MakeTileSEGS配合使用效果良好。[链接]
String Selector- 选择并返回字符串的一部分。当multiline模式关闭时,它简单地返回选择器指向的那一行的字符串。当multiline模式开启时,它会根据以#开头的行分割字符串并返回。如果select值大于项目总数,它会从第一行重新开始计数并返回相应的结果。Combine Conditionings- 接受多个conditioning作为输入,并将它们合并为一个conditioning。Concat Conditionings- 接受多个conditioning作为输入,并将它们串联成一个conditioning。Negative Cond Placeholder- 像FLUX.1这样的模型不使用Negative Conditioning。这是一个为它们准备的占位符节点。您可以用此节点替换Impact KSampler、KSampler (Inspire)和Detailer中使用的Negative Conditioning,从而使用FLUX.1。Execution Order Controller- 一个辅助节点,可以强制控制节点的执行顺序。- 将应首先执行的节点的输出连接到信号,并使随后执行的节点的输入经过此节点。
List Bridge- 当列表输出通过此节点时,它会收集并整理数据后再转发,从而确保前一阶段的子工作流已完成。
功能
交互式 SAM 检测器(剪贴板空间)- 当您右键单击具有 'MASK' 和 'IMAGE' 输出的节点时,会打开一个上下文菜单。从此菜单中,您可以选择使用“在 SAM 检测器中打开”来创建 SAM Mask 的对话框,或者使用“复制(剪贴板空间)”复制内容(很可能是掩码数据),然后从剪贴板空间菜单中使用“Impact SAM 检测器”生成掩码,并使用“粘贴(剪贴板空间)”将其粘贴。- 提供检测功能,用于识别在样本执行过程中混合来自
SDXL Base、SDXL Refiner、SD1.x、SD2.x等检查点的模型和片段时出现的错误,并报告相应的错误信息。
如何安装?
通过 ComfyUI-Manager 安装(推荐)
- 在 ComfyUI-Manager 中搜索
ComfyUI Impact Pack,然后点击“安装”按钮。
手动安装(不推荐)
cd custom_nodesgit clone https://github.com/ltdrdata/ComfyUI-Impact-Packcd ComfyUI-Impact-Packpip install -r requirements.txt- 重要提示:
- 必须在运行 ComfyUI 的 Python 环境中进行安装。
- 对于便携版,请使用
<installed path>\python_embeded\python.exe -m pip而不是pip。对于venv,请先激活venv,然后再使用pip。
- 重要提示:
- 重启 ComfyUI
- 注意1:如果在安装过程中出现错误,请参阅故障排除页面以获取帮助。
- 注意2:您可以使用此 Colab 笔记本 colab notebook 来启动它。该笔记本会自动将 Impact Pack 下载到 custom_nodes 目录,安装经过测试的依赖项并运行它。
- 注意3:如果您在
ComfyUI/custom_nodes/目录中创建一个名为skip_download_model的空文件,那么在安装 Impact Pack 时将会跳过模型下载步骤。
软件包依赖(如果需要手动设置)
使用 pip 安装
- segment-anything
- scikit-image
- piexif
- opencv-python
- scipy
- numpy<2
- dill
- matplotlib
- (可选)onnxruntime
- (已弃用)openmim # 用于 mim
- (已弃用)pycocotools # 用于 mim
Linux 软件包(Ubuntu)
- libgl1-mesa-glx
- libglib2.0-0
配置示例
- 当您首次运行 Impact Pack 时,会在 Impact Pack 目录中自动生成一个
impact-pack.ini文件。您可以修改此配置文件以自定义默认行为。dependency_version- 不要修改此选项sam_editor_cpu- 使用 CPU 而不是 GPU 进行SAM 编辑器操作- sam_editor_model:指定 SAM 编辑器使用的 SAM 模型。
- 您可以通过 ComfyUI-Manager 下载各种 SAM 模型。
- SAM 模型路径:
ComfyUI/models/sams
[default]
sam_editor_cpu = False
sam_editor_model = sam_vit_b_01ec64.pth
其他资源(安装时自动下载)
- ComfyUI/models/sams <= https://dl.fbaipublicfiles.com/segment_anything/sam_vit_b_01ec64.pth
故障排除页面
使用方法(DDetailer 功能)
1. 基本的自动人脸检测与细化示例。
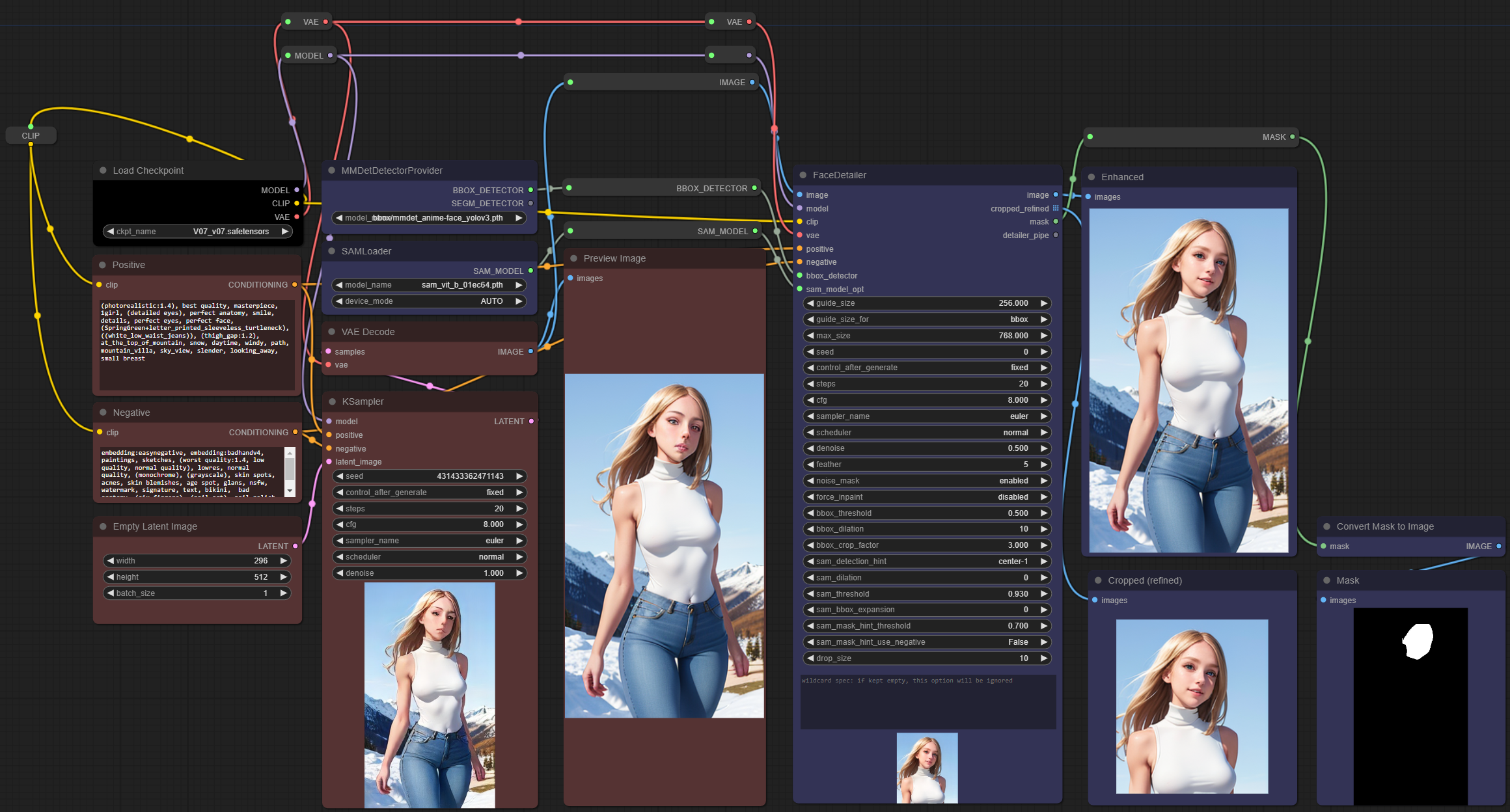
- 由于低分辨率导致损坏的人脸,通过生成和合成高分辨率图像来恢复细节。
- FaceDetailer 节点结合了用于人脸检测的 Detector 节点和用于图像增强的 Detailer 节点。更详细的说明请参阅高级教程。
- FaceDetailer 的 MASK 输出提供了检测和增强区域的可视化信息。


- 可以看到,左侧图像中的人脸细节在右侧图像中得到了显著提升。
2. 两步细化(修复严重损坏的人脸)
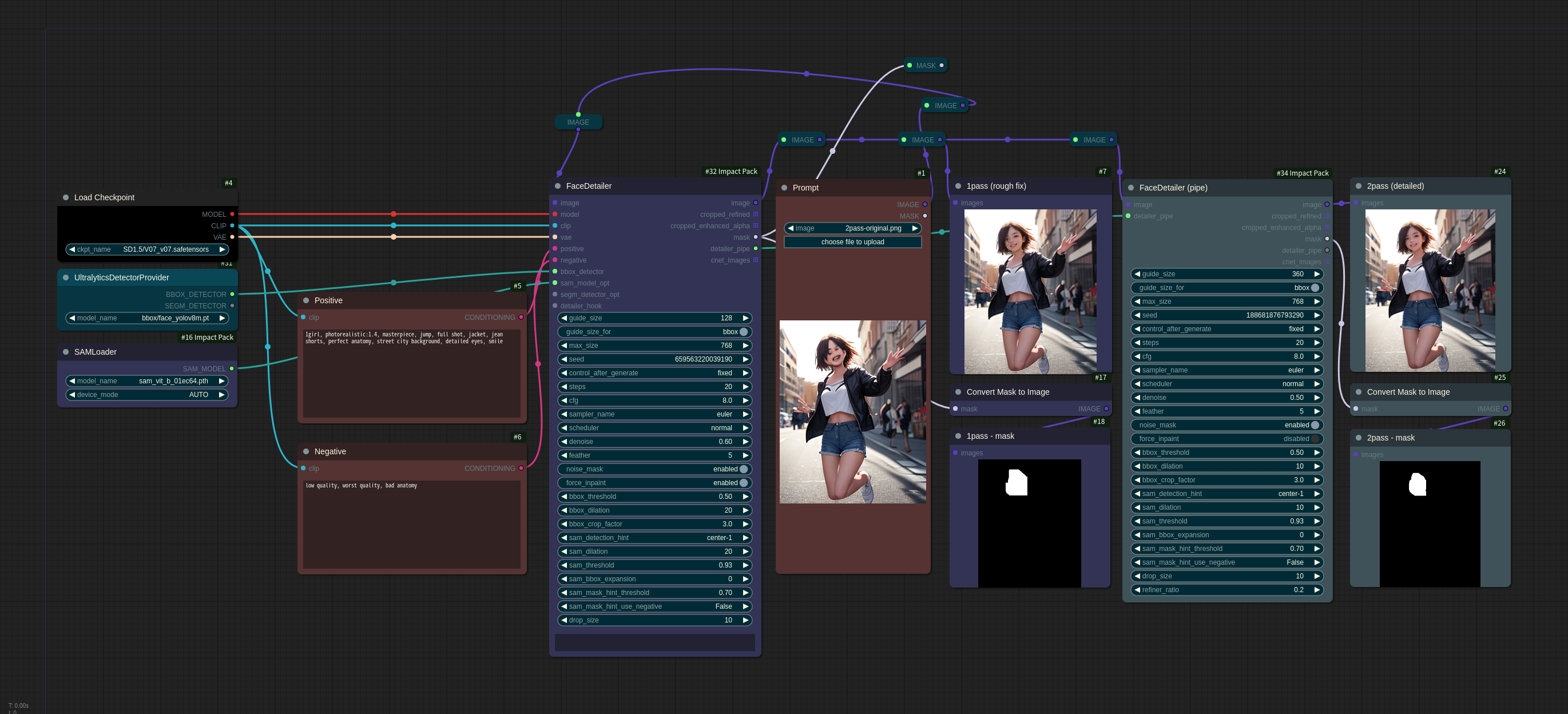
- 虽然可以将两个 FaceDetailer 节点串联起来实现两步处理,但也可以通过 DETAILER_PIPE 传递 KSampler 中常用的多种输入,因此使用 FaceDetailerPipe 可以更方便地进行配置。
- 在第一遍中,只需恢复大致轮廓,因此可以使用合理的分辨率和较低的选项进行修复。不过,如果此时增加膨胀值,不仅人脸会被纳入修复范围,周围的区域也会受到影响,因此在需要对脸部以外的部分进行重塑时会很有用。



- 第一阶段将严重损坏的人脸恢复到一定程度,第二阶段则进一步恢复细节。
3. 人脸边界框 + 人物轮廓分割(防止背景失真)



强调细节的人脸合成被精细地对齐到面部轮廓上,可以看出它并未影响到面部以外的图像部分。
BBoxDetectorForEach 节点用于检测人脸,而 SAMDetectorCombined 节点则用于找到与检测到的人脸相关的分割区域。通过将这两种方式获得的掩码输入到 Segs & Mask 节点中,可以生成基于分割精确相交的掩码。如果将此掩码输入到 DetailerForEach 节点中,则仅能对目标区域进行高分辨率重建并将其合成到原图中。
4. 迭代式放大
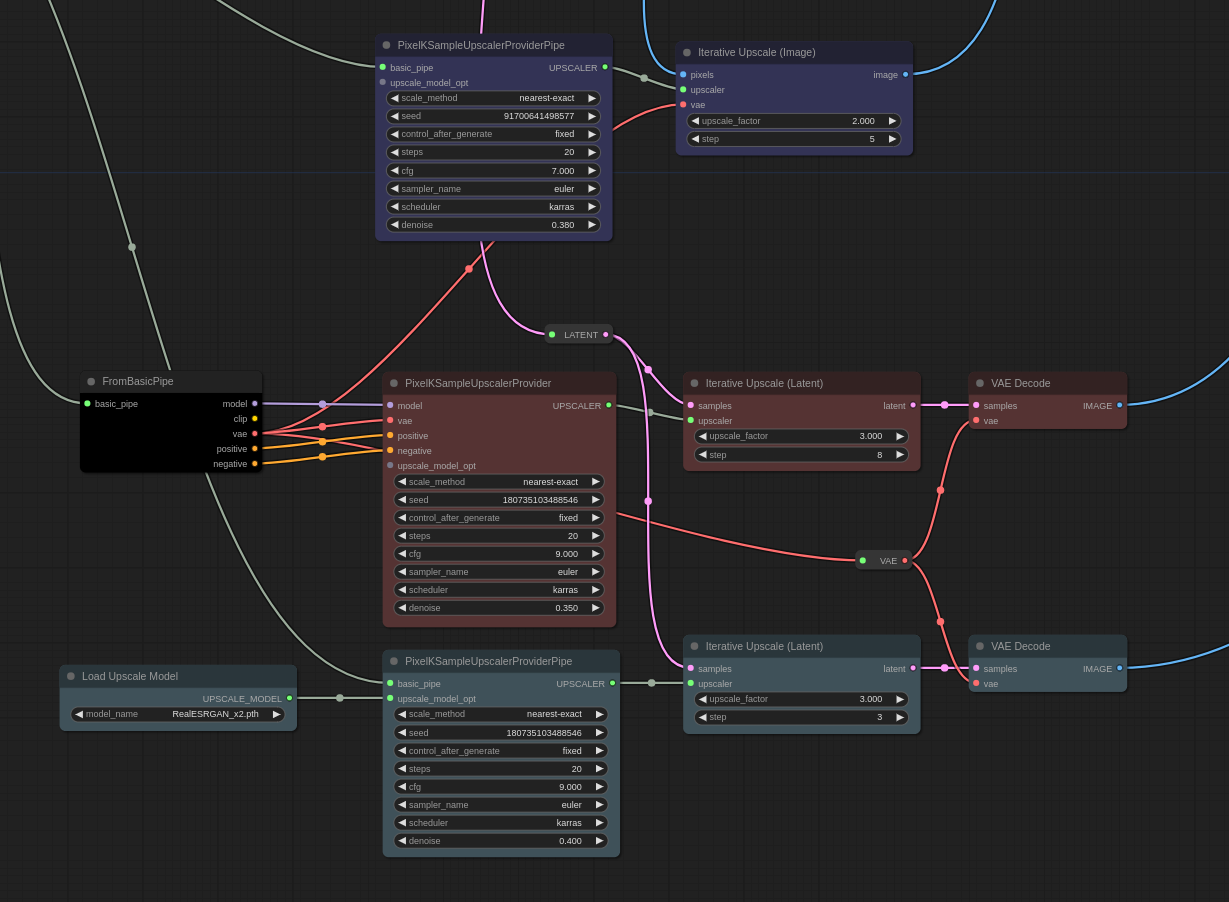
IterativeUpscale 节点是一个按 scale_factor 放大图像或潜在表示的节点。在此过程中,放大操作会分步骤逐步进行。
IterativeUpscale 接受一个类似于插件的 Upscaler 作为输入,并在每次迭代中使用它。PixelKSampleUpscalerProvider 是一种将潜在表示转换为像素空间并应用 ksampling 的放大器。
- upscale_model_opt 是一个可选参数,用于决定是否在模型基础具备放大功能时使用该功能。使用模型自带的放大功能可以显著减少所需的迭代次数。例如,如果使用 x2 放大器,图像或潜在表示会先被放大两倍,然后在每一步中再缩小到目标尺寸,之后才会继续进行后续处理。
下图是一张 304x512 像素的图像,以及使用 IterativeUpscale 将其放大至原尺寸三倍后的效果。


5. 交互式 SAM 检测器(Clipspace)
当您右键单击输出 'MASK' 和 'IMAGE' 的节点时,会出现一个名为“在 SAM 检测器中打开”的菜单,如图所示。点击该菜单会打开 SAM 功能中的对话框,允许您生成分割掩码。
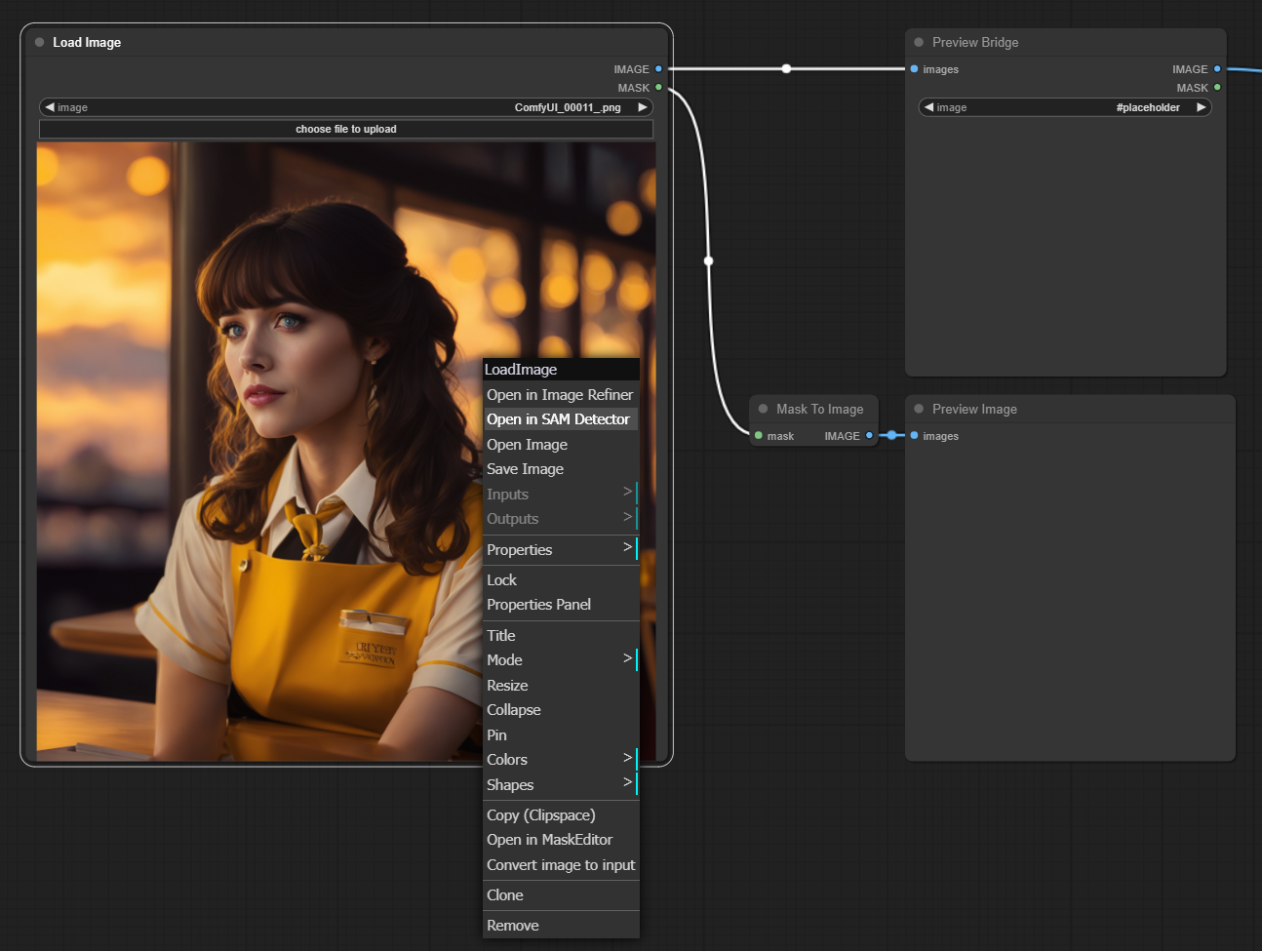
单击鼠标左键会在坐标处添加蓝色的正面提示,表示应包含的区域;单击鼠标右键则会添加红色的负面提示,表示应排除的区域。正面提示代表应包含的区域,而负面提示代表应排除的区域。
您可以通过“撤销”按钮移除已添加的点。选择好点位后,点击“检测”按钮即可生成掩码。此外,您还可以通过调整保真度滑块来控制掩码属于置信区的程度。
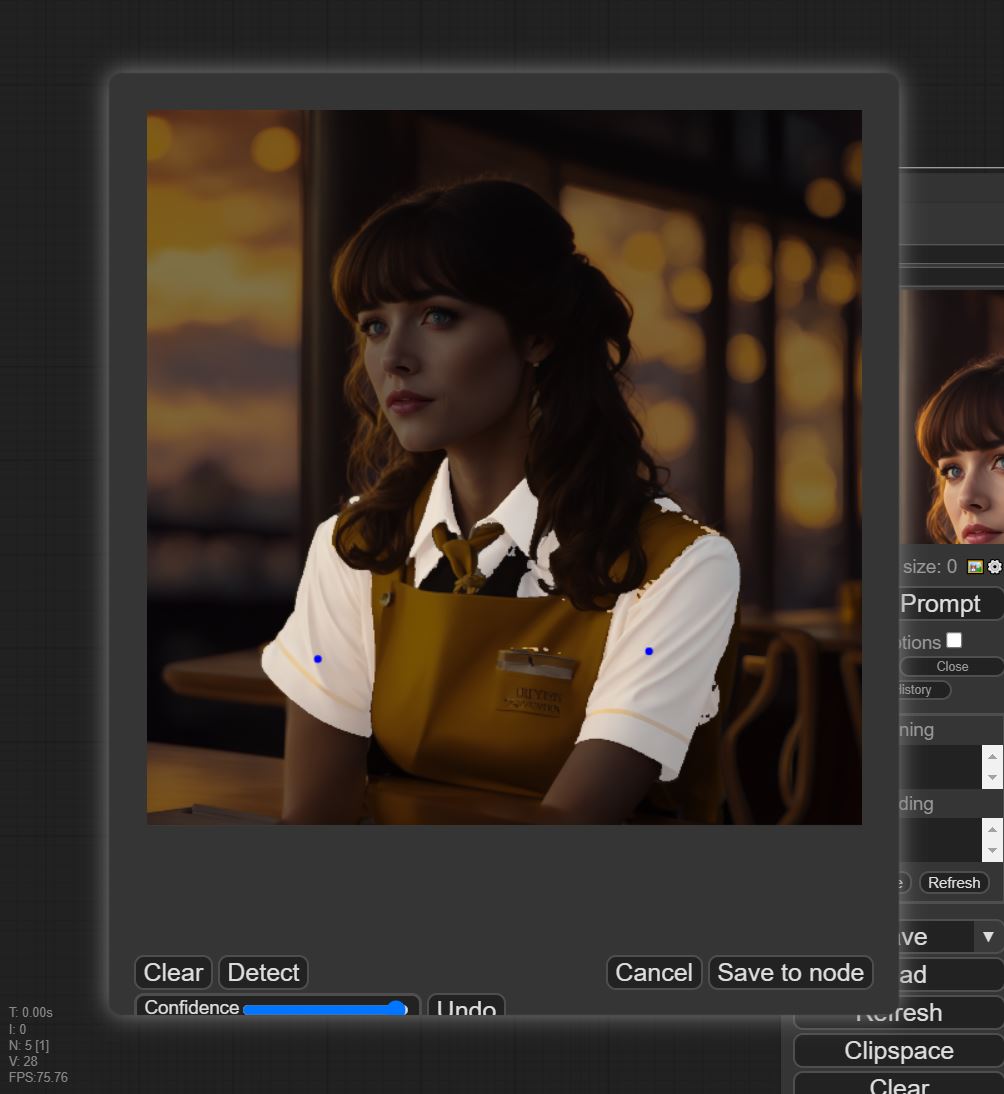
- 如果您是通过节点中的“在 SAM 检测器中打开”选项打开对话框的,则可以直接点击“保存到节点”按钮来应用更改。而如果通过“clipspace”菜单打开对话框,则需点击“保存”按钮将其保存到 clipspace 中。
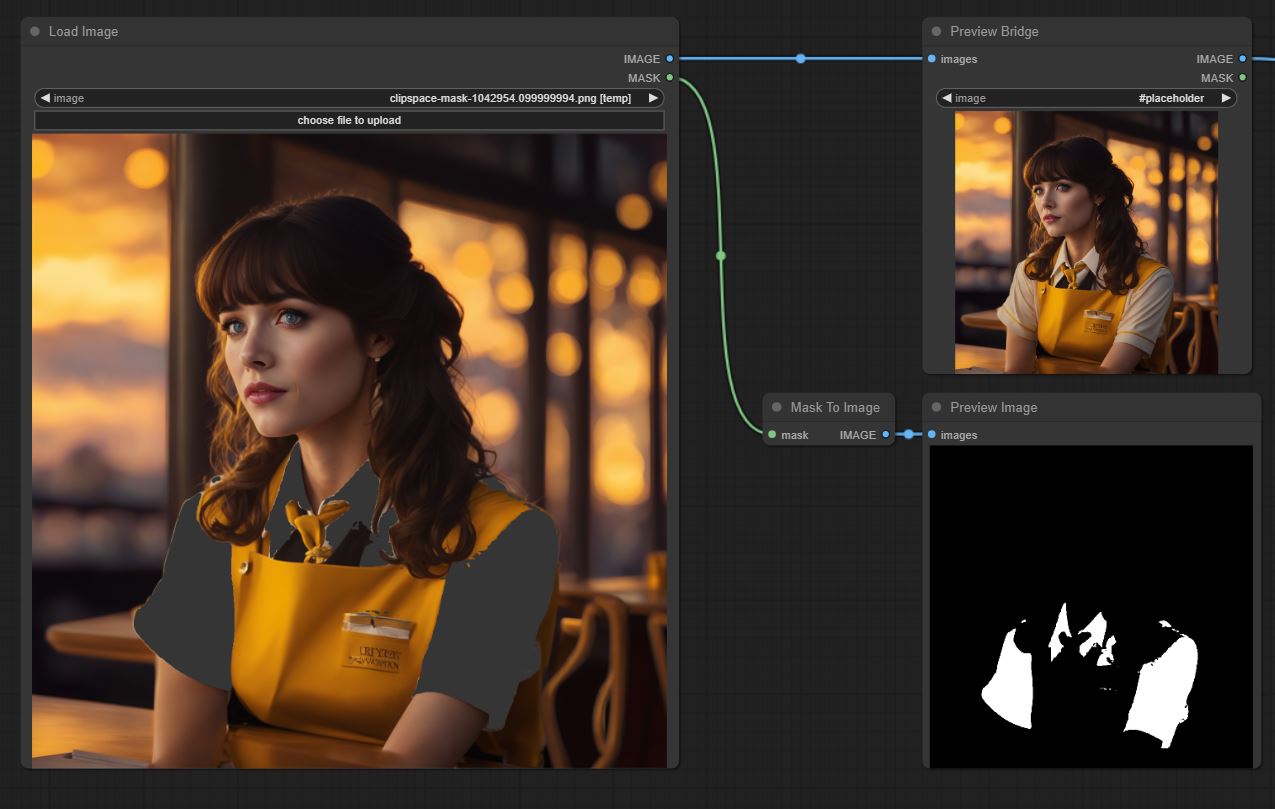
- 当您使用节点中反映的掩码执行操作时,可以看到图像和掩码会分别显示。
其他教程
- ComfyUI-extension-tutorials/ComfyUI-Impact-Pack - 在此页面上,您可以找到各种教程和工作流。
- 高级教程
- SAM 应用
- PreviewBridge
- Mask Pointer
- ONNX 教程
- CLIPSeg 教程
- 极端高分辨率放大
- TwoSamplersForMask
- TwoAdvancedSamplersForMask
- 高级迭代放大:PK_HOOK
- 高级迭代放大:TwoSamplersForMask 放大提供者
- 交互式 SAM + PreviewBridge
- ImageSender/ImageReceiver/LatentSender/LatentReceiver
- ImpactWildcardProcessor
致谢
ComfyUI/ComfyUI - 一个功能强大且模块化的稳定扩散 GUI。
dustysys/ddetailer - Stable-diffusion-webUI 扩展中的 DDetailer。
Bing-su/dddetailer - DDetailer 中使用的动漫人脸检测器已更新为兼容 mmdet 3.0.0,并且我们还为 DDetailer 的 pycocotools 依赖项在 Windows 环境中打上了补丁。
facebook/segment-anything - 分割一切!
hysts/anime-face-detector - anime-face_yolov3 的创建者,在多种艺术风格上表现出色。
open-mmlab/mmdetection - 目标检测工具集。dd-person_mask2former 是基于他们的 R-50 Mask2Former 实例分割模型 进行迁移学习训练的。
biegert/ComfyUI-CLIPSeg - 这是一个自定义节点,使 CLIPSeg 技术能够在 ComfyUI 中使用,该技术可以通过提示词来查找分割区域。
BlenderNeok/ComfyUI-TiledKSampler - 平铺采样器即使在 GPU 显存较低的情况下也能进行高分辨率采样。
BlenderNeok/ComfyUI_Noise - 噪声注入功能依赖于该函数以及 slerp 代码来实现噪声变化。
WASasquatch/was-node-suite-comfyui - ComfyUI 功能强大的自定义节点扩展。
Trung0246/ComfyUI-0246 - 一个不错的绕过技巧!
Layer-norm/comfyui-lama-remover - 使用 LamaRemoverDetailerHook 所需。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器