University1652-Baseline
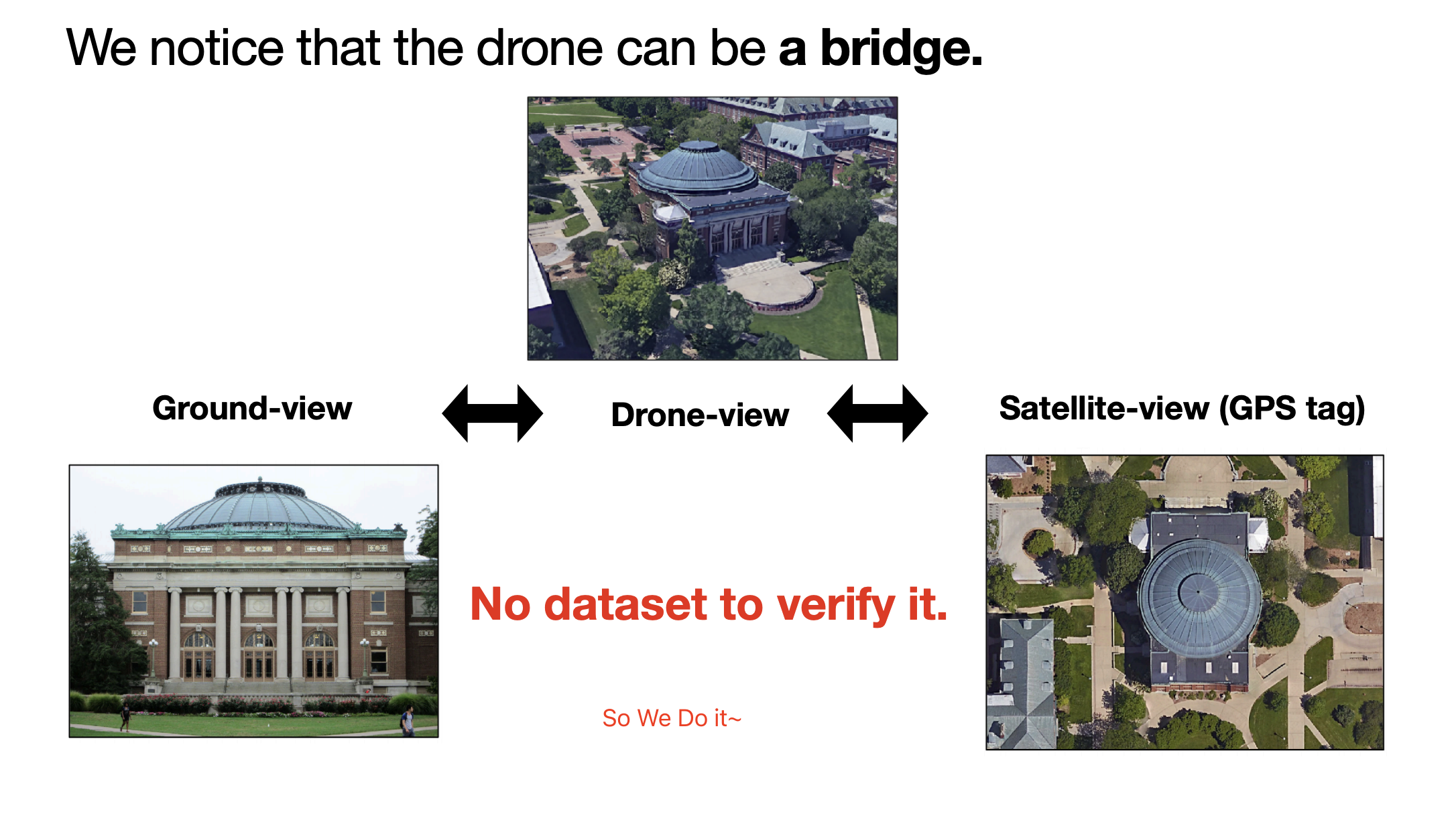
University1652-Baseline 是一个专注于无人机地理定位的开源基准项目,源自 ACM Multimedia 2020 的研究成果。它构建了一个涵盖全球 72 所大学、共计 1652 栋建筑的多视角数据集,整合了无人机航拍、卫星遥感及地面街景三种来源的图像数据。
该项目主要解决跨视角图像匹配难题,支持两大核心任务:一是“无人机视角目标定位”,即通过无人机拍摄的画面在卫星图中精准锁定建筑物位置;二是“无人机导航”,利用卫星图像引导无人机回溯其曾经过的具体地点。这种多源数据融合方案有效弥补了单一视角在复杂环境下的定位局限。
University1652-Baseline 特别适合计算机视觉领域的研究人员、算法开发者以及从事自动驾驶或无人机技术探索的专业人士使用。其独特亮点在于提供了高质量的标注数据与完整的基线代码,不仅包含详细的飞行路径和经纬度信息,还持续举办相关国际研讨会与挑战赛,推动社区在无人机定位领域的技术交流与模型迭代。无论是进行学术研究还是开发实际应用场景,它都是一个极具价值的参考资源。
使用场景
某智慧城市安防团队正在开发一套无人机自动巡检系统,需要在复杂城市环境中快速定位特定建筑物并规划返航路径。
没有 University1652-Baseline 时
- 数据获取困难:团队需自行采集全球不同视角的建筑图像,耗时数月仍难以覆盖多样化的光照和角度变化。
- 跨视角匹配精度低:缺乏标准的“无人机 - 卫星”配对数据训练模型,导致无人机拍摄画面无法准确对应到卫星地图上的具体位置。
- 导航回溯失败:当无人机需要依据卫星图找回曾飞越的地点时,因缺少多源视图基准,算法常迷失方向或定位偏差过大。
- 研发验证无标准:没有统一的评测基准,团队难以客观评估算法性能,也无法与学术界最新成果进行横向对比。
使用 University1652-Baseline 后
- 数据即拿即用:直接调用涵盖全球 72 所高校、1652 栋建筑的标准化数据集,立即启动包含卫星、无人机及地面三视角的模型训练。
- 定位精准度跃升:利用其提供的多视角配对数据优化算法,实现了从无人机实时视频到卫星地图的秒级高精度匹配。
- 智能返航无忧:基于"Satellite -> Drone"任务基准,无人机能根据历史飞行记录,准确识别并返回目标建筑上空。
- 对标国际前沿:依托 ACM Multimedia 认可的权威基准进行测试,快速迭代模型并在国际挑战赛中验证技术领先性。
University1652-Baseline 通过提供高质量的多视角地理定位基准,将原本需要数月构建的数据壁垒转化为即插即用的核心能力,极大加速了无人机自主导航系统的落地进程。
运行环境要求
- 未说明
必需,显存 >= 8GB,具体 CUDA 版本未说明(需匹配 PyTorch 版本)
未说明
快速开始
University1652-基准
卫星、无人机、地面
![]()
![]()


[论文] [幻灯片] [探索无人机视角数据] [探索卫星视角数据] [探索街景视角数据] [视频样本] [中文介绍] [建筑物名称列表] [经纬度] [飞行路径]
![[探索无人机视角数据]](https://github.com/layumi/University1652-Baseline/blob/master/docs/index_files/sample_drone.jpg?raw=true){kind=link}
![[探索卫星视角数据]](https://github.com/layumi/University1652-Baseline/blob/master/docs/index_files/sample_satellite.jpg?raw=true){kind=link}
![[探索街景视角数据]](https://github.com/layumi/University1652-Baseline/blob/master/docs/index_files/sample_street.jpg?raw=true){kind=link}
⭐ 觉得有用吗?请给我们点个赞! 帮助我们触达更多从事基于无人机地理定位研究的学者。🚀

按需下载[University-1652](通常我会在5分钟内回复您)。您可以使用请求模板。
本仓库包含我们论文《University-1652:用于无人机地理定位的多视角多源基准》(https://arxiv.org/abs/2002.12186,ACM多媒体2020)的数据集链接和代码。官方论文链接为https://dl.acm.org/doi/10.1145/3394171.3413896。我们收集了全球72所大学的1652栋建筑物。感谢您的关注。
任务1:无人机视角目标定位。 (无人机→卫星)给定一张无人机视角图像或视频,任务旨在找到最相似的卫星视角图像,以在卫星视图中定位目标建筑物。
任务2:无人机导航。 (卫星→无人机)给定一张卫星视角图像,无人机需要找到它曾经飞过的最相关位置(无人机视角图像)。根据其飞行历史,无人机可以导航回目标位置。
研讨会与挑战赛
ACM MM UAVM 2026:加入我们的第4次研讨会!详情。
2025研讨会和特别会议
- **ACM MM UAVM 2025**:加入我们的第3次研讨会。 - **挑战赛流程**: 1. 在University-1652上训练(无人机+卫星+街景)。 2. 从[OneDrive](https://www.zdzheng.xyz/ACMMM2025Workshop-UAV/)下载姓名已脱敏的测试集。 3. 使用您的模型提取特征。 4. 修改`demo.py`或`evaluate_gpu.py`以保存前10名画廊图像的名称(按查询顺序排列)。2024研讨会和特别会议
ACM MM UAVM研讨会2024 我们将在ACM MM 2024上举办第2次研讨会!请参阅https://www.zdzheng.xyz/ACMMM2024Workshop-UAV/以获取参考信息。
ACM ICMR研讨会2024 我们将在ACM ICMR 2024上举办关于多媒体对象再识别的研讨会。欢迎您分享您的见解。我们在泰国普吉岛见!😃 研讨会链接是https://www.zdzheng.xyz/MORE2024/ 。投稿截止日期为2024年4月15日。
ACM WWW研讨会2024 我们将在ACM WWW 2025上举办关于多媒体对象再识别的研讨会。欢迎您分享您的见解。我们在悉尼见!😃 研讨会链接是https://www.zdzheng.xyz/MORE2025/ 。投稿截止日期为2025年1月1日。
2023研讨会和特别会议
IEEE ITSC特别会议2023 我们将在IEEE智能交通系统大会(ITSC)上举办一场特别会议,主题涵盖对象再识别和点云技术。论文提交截止日期为2023年5月15日,结果通知将于2023年6月30日发布。请在提交时选择会议代码``w7r4a''。更多详情请参见特别会议网站。
遥感特别期号2023 我们自即日起至~~2023年6月16日~~2023年12月16日发起遥感特别期号(IF=5.3)。欢迎各位提交稿件至(https://www.mdpi.com/journal/remotesensing/special_issues/EMPK490239),但请注意开源费用问题。
目录
关于数据集
数据集的划分如下:
| 划分 | #图片 | #建筑物 | #大学 |
|---|---|---|---|
| 训练集 | 50,218 | 701 | 33 |
| 无人机查询集 | 37,855 | 701 | 39 |
| 卫星查询集 | 701 | 701 | 39 |
| 地面查询集 | 2,579 | 701 | 39 |
| 无人机图库集 | 51,355 | 951 | 39 |
| 卫星图库集 | 951 | 951 | 39 |
| 地面图库集 | 2,921 | 793 | 39 |
更详细的文件结构:
├── University-1652/
│ ├── readme.txt
│ ├── train/
│ ├── drone/ /* 无人机视角训练图像
│ ├── 0001
| ├── 0002
| ...
│ ├── street/ /* 街景视角训练图像
│ ├── satellite/ /* 卫星视角训练图像
│ ├── google/ /* 来自Google Image的噪声街景训练图像
│ ├── test/
│ ├── query_drone/
│ ├── gallery_drone/
│ ├── query_street/
│ ├── gallery_street/
│ ├── query_satellite/
│ ├── gallery_satellite/
│ ├── 4K_drone/
我们注意到,训练集中的33所大学与测试集中的39所大学之间没有重叠。 下载:请在此处申请数据集链接(5分钟内回复)。
新闻
2025年5月2日 我用PyTorch中合并的支持替换了apex,用于fp16和bf16。
2024年11月26日 无人机到BEV?您可以查看我们的新论文“Video2BEV: 将无人机视频转换为BEV以进行基于视频的地理定位”,网址为https://arxiv.org/abs/2411.13610。
2024年7月2日 文本引导的地理定位已被ECCV 2024接受。代码现已可用。
2023年1月26日 1652栋建筑名称列表可在这里找到。
2022年7月10日 雨天?夜晚?雾天?雪天?您可以查看我们的新论文“用于航拍地理定位的多环境自适应网络”,网址为https://github.com/wtyhub/MuseNet(已被Pattern Recognition'24接受)。
2021年12月1日 修复了由于最新版torchvision导致的问题,该版本不允许空子文件夹。请注意,部分建筑物没有Google图像。
2021年3月3日 添加了GeM池化。您可以通过--pool gem来使用它。
2021年1月21日 基于GNN的实时后处理代码GPU-Re-Ranking已在这里提供。
2020年8月21日 用于牛津和巴黎的迁移学习代码已在这里提供。
2020年7月27日 1652栋建筑的元数据,如经纬度,现已在Google Drive上可用。(您可以使用Google Earth Pro打开kml文件或使用vim查看数值)。我们还提供了螺旋飞行游览文件,可在Google Drive上找到。(您可以通过Google Earth Pro打开kml文件以启用飞行相机)。
2020年7月26日 论文已被ACM Multimedia 2020接受。
2020年7月12日 我将University-1652上的三元组损失(带软边界)基准公开在这里。
2020年3月12日 我添加了关于地理定位的最先进方法页面以及教程,这些内容将很快更新。
代码特性
目前我们支持:
- 使用原生PyTorch支持的Float16和BFloat16(替换apex)
- 多查询评估
- 重排序
- 随机擦除
- ResNet/VGG-16
- 可视化训练曲线
- 可视化排名结果
- 线性预热
先决条件
- Python 3.6+
- GPU内存 >= 8G
- Numpy > 1.12.1
- PyTorch 0.3+
开始使用
安装
- 从http://pytorch.org/安装PyTorch
- 安装所需包
pip install -r requirement.txt
- [可选] 通常PyTorch自带。从源码安装Torchvision(请查看README。或者直接通过anaconda安装即可)。
git clone https://github.com/pytorch/vision # 请检查版本以匹配PyTorch。
cd vision
python setup.py install
数据集与准备
按需下载[University-1652]。您可以使用申请模板。
对于CVUSA,我遵循(Liumouliu/OriCNN)中的训练/测试划分。
训练与评估
训练与评估University-1652
python train.py --name three_view_long_share_d0.75_256_s1_google --extra --views 3 --droprate 0.75 --share --stride 1 --h 256 --w 256 --fp16;
python test.py --name three_view_long_share_d0.75_256_s1_google
默认设置:无人机 -> 卫星 如果您想尝试其他评估设置,可以修改以下代码行:https://github.com/layumi/University1652-Baseline/blob/master/test.py#L217-L225
仅卫星与无人机的消融研究
python train_no_street.py --name two_view_long_no_street_share_d0.75_256_s1 --share --views 3 --droprate 0.75 --stride 1 --h 256 --w 256 --fp16;
python test.py --name two_view_long_no_street_share_d0.75_256_s1
设置三个视图,但将街景图像的损失权重设为零。
训练与评估CVUSA
python prepare_cvusa.py
python train_cvusa.py --name usa_vgg_noshare_warm5_lr2 --warm 5 --lr 0.02 --use_vgg16 --h 256 --w 256 --fp16 --batchsize 16;
python test_cvusa.py --name usa_vgg_noshare_warm5_lr2
展示检索到的前10名结果
python test.py --name three_view_long_share_d0.75_256_s1_google # 测试完成后
python demo.py --query_index 0 # 您想在查询集中查询哪张图片
系统会保存一张名为show.png的图片,其中包含前10名检索结果,存放在相应文件夹中。
训练好的模型
您可以在GoogleDrive或OneDrive下载训练好的模型。下载后,请将模型文件夹放入./model/目录下。
🌍 University-160k 测试——永久开放!
随时测试 —— 我们的评测服务器 永不结束!
University160k 是一个具有挑战性的跨视角地理定位测试集,模拟了真实世界的大规模场景。
它在 University-1652 的基础上扩展了 +167,486 张卫星视图干扰图像。
加入并提交 →
引用
以下论文使用并报告了基线模型的结果。您可以在自己的论文中引用它们。
@article{zheng2020university,
title={University-1652:基于无人机的多视角、多源地理定位基准数据集},
author={Zheng, Zhedong and Wei, Yunchao and Yang, Yi},
journal={ACM Multimedia},
year={2020}
}
@inproceedings{zheng2023uavm,
title={UAVM'23:2023年多媒体中的无人机研讨会——以全新视角捕捉世界},
author={Zheng, Zhedong and Shi, Yujiao and Wang, Tingyu and Liu, Jun and Fang, Jianwu and Wei, Yunchao and Chua, Tat-seng},
booktitle={第31届ACM国际多媒体会议论文集},
pages={9715--9717},
year={2023}
}
实例损失的定义见:
@article{zheng2017dual,
title={带有实例损失的双路径卷积图像-文本嵌入},
author={Zheng, Zhedong and Zheng, Liang and Garrett, Michael and Yang, Yi and Xu, Mingliang and Shen, Yi-Dong},
journal={ACM多媒体计算、通信与应用期刊(TOMM)},
doi={10.1145/3383184},
volume={16},
number={2},
pages={1--23},
year={2020},
publisher={ACM 纽约,纽约州,美国}
}
相关工作
版本历史
v1.22025/05/07v1.12021/12/16常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器