openevals
openevals 是一套专为大语言模型(LLM)应用打造的现成评估工具包。就像传统软件开发离不开单元测试一样,要将 LLM 应用可靠地投入生产环境,科学的评估机制不可或缺。openevals 旨在为开发者提供一套开箱即用的评估起点,帮助用户快速建立对模型输出的质量监控,并以此为基础定制更符合特定业务场景的评估方案。
它主要解决了 LLM 应用中“如何量化回答质量”的难题。通过内置多种评估维度(如简洁性、准确性等),openevals 利用强大的“模型即裁判”(LLM-as-judge)技术,自动判断模型输出是否符合预期,无需人工逐条审核。其独特亮点在于极高的灵活性:支持 Python 和 TypeScript 双语言,允许用户自由替换底层评判模型、自定义提示词模板,甚至调整评分标准(从简单的真假判断到精细的浮点打分)。
这款工具非常适合正在构建或优化 LLM 应用的 AI 工程师、后端开发者以及算法研究人员使用。如果你希望摆脱繁琐的人工测试,用代码自动化地提升模型表现,openevals 能助你轻松迈出从实验原型到生产级应用的关键一步。
使用场景
某电商初创团队正在开发一款智能客服助手,需要在上线前确保其回答既准确又简洁,避免冗长的客套话影响用户体验。
没有 openevals 时
- 团队需手动编写大量测试用例,并人工逐条阅读模型输出,耗时耗力且难以覆盖所有场景。
- 缺乏统一的评估标准,不同开发人员对“回答是否简洁”的主观判断不一,导致优化方向混乱。
- 每次迭代模型后,无法快速量化效果变化,只能凭感觉猜测新版本是否优于旧版本。
- 自定义评估逻辑需要从头构建提示词(Prompt)和解析逻辑,开发门槛高且容易出错。
- 难以将评估流程自动化集成到 CI/CD 流水线中,阻碍了模型的持续交付与快速迭代。
使用 openevals 后
- 直接调用内置的“简洁性评估器”(Conciseness Evaluator),几分钟内即可对数百条对话数据进行自动打分。
- 基于标准化的 LLM-as-Judge 机制,统一了评估尺度,客观指出回答中多余的问候语或冗余信息。
- 每次代码提交后自动运行评估脚本,通过具体的分数和评语对比,清晰量化模型迭代的性能提升。
- 利用预置模板灵活定制评估维度,无需从零编写复杂的提示词工程,大幅降低了技术实现难度。
- 轻松将评估步骤嵌入自动化测试流程,确保只有符合质量标准的模型版本才能部署到生产环境。
openevals 将原本模糊、手工的模型质检过程转化为标准化、自动化的数据驱动决策,显著提升了大应用落地的效率与可靠性。
运行环境要求
- 未说明
未说明
未说明
快速开始
⚖️ OpenEvals
与传统软件中的测试类似,评估是将大语言模型应用投入生产环境的重要环节。 本包的目标是帮助您为自己的大语言模型应用编写评估的起点,基于此您可以进一步编写更符合自身应用场景的自定义评估。
如果您正在寻找专门用于评估大语言模型代理的评估工具,请查看 agentevals。
快速入门
[!TIP] 如果您想通过视频教程来跟随操作,请点击下方图片:

要开始使用,请安装 openevals:
Python
pip install openevals
TypeScript
npm install openevals @langchain/core
本快速入门将使用由 OpenAI 的 gpt-5.4 模型驱动的评估器来评判您的结果,因此您需要将 OpenAI API 密钥设置为环境变量:
export OPENAI_API_KEY="your_openai_api_key"
完成上述步骤后,您就可以运行您的第一个评估了:
Python
from openevals.llm import create_llm_as_judge
from openevals.prompts import CONCISENESS_PROMPT
conciseness_evaluator = create_llm_as_judge(
# CONCISENESS_PROMPT 只是一个 f-string
prompt=CONCISENESS_PROMPT,
model="openai:gpt-5.4",
)
inputs = "旧金山的天气怎么样?"
# 这些是虚构的输出,实际上您应该运行自己的基于大语言模型的系统来获取真实输出
outputs = "谢谢你的询问!旧金山目前天气晴朗,气温约 90 华氏度。"
# 调用 LLM-as-judge 评估器时,参数会直接格式化到提示中
eval_result = conciseness_evaluator(
inputs=inputs,
outputs=outputs,
)
print(eval_result)
{
'key': 'score',
'score': False,
'comment': '输出中包含不必要的问候语(“谢谢你的询问!”)以及多余的……'
}
TypeScript
import { createLLMAsJudge, CONCISENESS_PROMPT } from "openevals";
const concisenessEvaluator = createLLMAsJudge({
// CONCISENESS_PROMPT 只是一个 f-string
prompt: CONCISENESS_PROMPT,
model: "openai:gpt-5.4",
});
const inputs = "旧金山的天气怎么样?"
// 这些是虚构的输出,实际上您应该运行自己的基于大语言模型的系统来获取真实输出
const outputs = "谢谢你的询问!旧金山目前天气晴朗,气温约 90 华氏度。"
// 调用 LLM-as-judge 评估器时,参数会直接格式化到提示中
const evalResult = await concisenessEvaluator({
inputs,
outputs,
});
console.log(evalResult);
{
key: 'score',
score: false,
comment: '输出中包含不必要的问候语(“谢谢你的询问!”)以及多余的……'
}
这是一个无参考评估器的示例——其他一些评估器可能会接受略有不同的参数,例如所需的参考输出。LLM-as-judge 评估器会尝试将传入的所有参数格式化到其提供的提示中,从而让您能够灵活地自定义评估标准或添加其他字段。
有关如何自定义评分以输出浮点值而非仅 True/False、模型或提示的更多信息,请参阅 LLM-as-judge 部分!
目录
安装
您可以这样安装openevals:
Python
pip install openevals
TypeScript
npm install openevals @langchain/core
对于LLM作为评判者的评估器,您还需要一个LLM客户端。默认情况下,openevals会使用LangChain聊天模型集成,并默认安装了langchain_openai。不过,如果您愿意,也可以直接使用OpenAI客户端:
Python
pip install openai
TypeScript
npm install openai
此外,熟悉一些评估概念也会很有帮助。
评估器
LLM作为评判者
评估LLM应用输出的一种常见方法是使用另一个LLM作为评判者。这通常是评估的良好起点。
该包包含create_llm_as_judge函数,它接受一个提示和一个模型作为输入,并返回一个评估函数,该函数负责将参数转换为字符串,并将评判LLM的输出解析为评分。
要使用create_llm_as_judge函数,您需要提供一个提示和一个模型。为了快速上手,OpenEvals在openevals.prompts模块中提供了一些预构建的提示,您可以直接使用。以下是一个示例:
Python
from openevals.llm import create_llm_as_judge
from openevals.prompts import CORRECTNESS_PROMPT
correctness_evaluator = create_llm_as_judge(
prompt=CORRECTNESS_PROMPT,
model="openai:gpt-5.4",
)
TypeScript
import { createLLMAsJudge, CORRECTNESS_PROMPT } from "openevals";
const correctnessEvaluator = createLLMAsJudge({
prompt: CORRECTNESS_PROMPT,
model: "openai:gpt-5.4",
});
请注意,CORRECTNESS_PROMPT是一个简单的f-string,您可以根据具体用例进行记录和编辑:
Python
print(CORRECTNESS_PROMPT)
你是一位专家级数据标注员,负责评估模型输出的正确性。你的任务是根据以下评分标准给出分数:
<评分标准>
正确的答案:
- 提供准确且完整的信息
...
<input>
{inputs}
</input>
<output>
{outputs}
</output>
...
TypeScript
console.log(CORRECTNESS_PROMPT);
你是一位专家级数据标注员,负责评估模型输出的正确性。你的任务是根据以下评分标准给出分数:
<评分标准>
正确的答案:
- 提供准确且完整的信息
...
<input>
{inputs}
</input>
<output>
{outputs}
</output>
...
按照惯例,我们通常建议在LLM作为评判者的评估器中使用inputs、outputs和reference_outputs作为参数名称,但这些参数会直接格式化到提示中,因此您可以使用任何您喜欢的变量名。
OpenEvals包含许多针对常见评估场景的预构建提示。请参阅预构建提示部分,以获取按类别组织的完整列表。
自定义提示
create_llm_as_judge函数的prompt参数可以是f-string、LangChain提示模板,或者一个接受关键字参数并返回格式化消息列表的函数。尽管我们建议使用约定的名称(inputs、outputs和reference_outputs)作为提示变量,但您的提示也可以要求额外的变量。在这种情况下,您可以在调用评估函数时传递这些额外的变量。以下是一个需要名为context的额外变量的提示示例:
Python
from openevals.llm import create_llm_as_judge
MY_CUSTOM_PROMPT = """
请使用以下上下文来帮助您评估输出中是否存在幻觉:
<context>
{context}
</context>
<input>
{inputs}
</input>
<output>
{outputs}
</output>
"""
custom_prompt_evaluator = create_llm_as_judge(
prompt=MY_CUSTOM_PROMPT,
model="openai:gpt-5.4",
)
custom_prompt_evaluator(
inputs="天空是什么颜色?",
outputs="天空是红色的。",
context="现在是傍晚时分。"
)
TypeScript
import { createLLMAsJudge } from "openevals";
const MY_CUSTOM_PROMPT = `
请使用以下上下文来帮助您评估输出中是否存在幻觉:
<context>
{context}
</context>
<input>
{inputs}
</input>
<output>
{outputs}
</output>
`;
const customPromptEvaluator = createLLMAsJudge({
prompt: MY_CUSTOM_PROMPT,
model: "openai:gpt-5.4",
});
const inputs = "天空是什么颜色?"
const outputs = "天空是红色的。"
const evalResult = await customPromptEvaluator({
inputs,
outputs,
});
对于字符串提示,还可以使用以下选项:
system:一个字符串,通过在提示的其他部分之前添加一条系统消息来设置评判模型的系统提示。few_shot_examples:一个示例字典列表,附加在提示的末尾。这对于向评判模型提供良好和不良输出的示例非常有用。其所需结构如下所示:
Python
few_shot_examples = [
{
"inputs": "天空是什么颜色?",
"outputs": "天空是红色的。",
"reasoning": "因为现在是傍晚,所以天空是红色的。",
"score": 1,
}
]
TypeScript
const fewShotExamples = [
{
inputs: "天空是什么颜色?",
outputs: "天空是红色的。",
reasoning: "因为现在是傍晚,所以天空是红色的。",
score: 1,
}
]
这些示例将被附加到提示中最终用户消息的末尾。
使用LangChain提示模板自定义
如果您希望对格式有更多控制,也可以传递一个LangChain提示模板。以下是一个使用mustache格式而不是f-string的示例:
Python
from openevals.llm import create_llm_as_judge
from langchain_core.prompts.chat import ChatPromptTemplate
inputs = {"a": 1, "b": 2}
outputs = {"a": 1, "b": 2}
prompt = ChatPromptTemplate([
("system", "你是一位专家,擅长判断两个对象是否相等。"),
("human", "这两个对象相等吗?{{inputs}} {{outputs}}"),
], template_format="mustache")
llm_as_judge = create_llm_as_judge(
prompt=prompt,
model="openai:gpt-5.4",
feedback_key="equality",
)
eval_result = llm_as_judge(inputs=inputs, outputs=outputs)
print(eval_result)
{
key: 'equality',
score: True,
comment: '...'
}
TypeScript
import { createLLMAsJudge } from "openevals";
import { ChatPromptTemplate } from "@langchain/core/prompts";
const inputs = { a: 1, b: 2 };
const outputs = { a: 1, b: 2 };
const prompt = ChatPromptTemplate.fromMessages([
["system", "你是一位专家,擅长判断两个对象是否相等。"],
["user", "这两个对象相等吗?{{inputs}} {{outputs}}"],
], { templateFormat: "mustache" });
const evaluator = createLLMAsJudge({
prompt,
model: "openai:gpt-5.4",
feedbackKey: "equality",
});
const result = await evaluator({ inputs, outputs });
{
key: 'equality',
score: true,
comment: '...'
}
您还可以传递一个函数,该函数接受您的LLM作为评判者的输入作为关键字参数,并返回格式化的聊天消息。
自定义模型
您可以通过几种方式自定义用于评估的模型。您可以将格式为 PROVIDER:MODEL 的字符串(例如 model=anthropic:claude-3-5-sonnet-latest)作为 model 参数传递,在这种情况下,该包会尝试导入并初始化一个 LangChain 聊天模型实例。这要求您安装相应的 LangChain 集成包。以下是一个示例:
Python
pip install langchain-anthropic
from openevals.llm import create_llm_as_judge
from openevals.prompts import CORRECTNESS_PROMPT
anthropic_evaluator = create_llm_as_judge(
prompt=CORRECTNESS_PROMPT,
model="anthropic:claude-3-5-sonnet-latest",
)
TypeScript
npm install @langchain/anthropic
import { createLLMAsJudge, CORRECTNESS_PROMPT } from "openevals";
const anthropicEvaluator = createLLMAsJudge({
prompt: CORRECTNESS_PROMPT,
model: "anthropic:claude-3-5-sonnet-latest",
});
您也可以直接将 LangChain 聊天模型实例作为 judge 参数传递。请注意,您选择的模型必须支持结构化输出(https://python.langchain.com/docs/integrations/chat/):
Python
from openevals.llm import create_llm_as_judge
from openevals.prompts import CORRECTNESS_PROMPT
from langchain_anthropic import ChatAnthropic
anthropic_evaluator = create_llm_as_judge(
prompt=CORRECTNESS_PROMPT,
judge=ChatAnthropic(model="claude-3-5-sonnet-latest", temperature=0.5),
)
TypeScript
import { createLLMAsJudge, CORRECTNESS_PROMPT } from "openevals";
import { ChatAnthropic } from "@langchain/anthropic";
const anthropicEvaluator = createLLMAsJudge({
prompt: CORRECTNESS_PROMPT,
judge: new ChatAnthropic({ model: "claude-3-5-sonnet-latest", temperature: 0.5 }),
});
这在需要使用特定参数(如温度)或通过 Azure 等服务使用模型时指定替代 URL 的场景中非常有用。
最后,您还可以将模型名称作为 model 参数传递,并将 judge 参数设置为 OpenAI 客户端实例:
Python
pip install openai
from openai import OpenAI
from openevals.llm import create_llm_as_judge
from openevals.prompts import CORRECTNESS_PROMPT
openai_evaluator = create_llm_as_judge(
prompt=CORRECTNESS_PROMPT,
model="gpt-5.4",
judge=OpenAI(),
)
TypeScript
npm install openai
import { OpenAI } from "openai";
import { createLLMAsJudge, CORRECTNESS_PROMPT } from "openevals";
const openaiEvaluator = createLLMAsJudge({
prompt: CORRECTNESS_PROMPT,
model: "gpt-5.4",
judge: new OpenAI(),
});
自定义输出分数值
有两个字段可以用来自定义评估器的输出分数:
continuous:一个布尔值,用于设置评估器是否应返回介于 0 和 1 之间的浮点分数,而不是二元分数。默认值为False。choices:一个浮点数列表,用于设置评估器可能的分数。
这两个参数是互斥的。当使用其中任何一个时,您应确保您的提示语基于对具体分数含义的信息——本仓库中预构建的提示语并不包含这些信息!
例如,以下是如何定义一种较宽松的正确性标准,仅在答案与主题相关但不正确时才扣 50% 分的例子:
Python
from openevals.llm import create_llm_as_judge
MY_CUSTOM_PROMPT = """
您是一位专家级数据标注员,负责评估模型输出的正确性。您的任务是根据以下评分标准进行打分:
<评分标准>
根据以下标准给出 0、0.5 或 1 分:
- 0:答案错误且未提及 doodads
- 0.5:答案提到了 doodads,但其他方面仍不正确
- 1:答案正确且提到了 doodads
</评分标准>
<输入>
{inputs}
</输入>
<输出>
{outputs}
</ 输出>
<参考答案>
{reference_outputs}
</ 参考答案 >
"""
evaluator = create_llm_as_judge(
prompt=MY_CUSTOM_PROMPT,
choices=[0.0, 0.5, 1.0],
model="openai:gpt-5.4",
)
result = evaluator(
inputs="doodads 的当前价格是多少?",
outputs="doodads 的价格是 10 美元。",
reference_outputs="doodads 的价格是 15 美元。",
)
print(result)
{
'key': 'score',
'score': 0.5,
'comment': '提供的答案提到了 doodads,但内容不正确。'
}
TypeScript
import { createLLMAsJudge } from "openevals";
const MY_CUSTOM_PROMPT = `
您是一位专家级数据标注员,负责评估模型输出的正确性。您的任务是根据以下评分标准进行打分:
<评分标准>
根据以下标准给出 0、0.5 或 1 分:
- 0:答案错误且未提及 doodads
- 0.5:答案提到了 doodads,但其他方面仍不正确
- 1:答案正确且提到了 doodads
</评分标准>
<输入>
{inputs}
</ 输入 >
<输出>
{outputs}
</ 输出 >
<参考答案>
{reference_outputs}
</ 参考答案 >
`;
const customEvaluator = createLLMAsJudge({
prompt: MY_CUSTOM_PROMPT,
choices: [0.0, 0.5, 1.0],
model: "openai:gpt-5.4",
});
const result = await customEvaluator({
inputs: "doodads 的当前价格是多少?",
outputs: "doodads 的价格是 10 美元。",
reference_outputs: "doodads 的价格是 15 美元。",
});
console.log(result);
{
'key': 'score',
'score': 0.5,
'comment': '提供的答案提到了 doodads,但内容不正确。'
}
最后,如果您希望禁用针对特定分数的理由说明,可以在创建评估器时将 use_reasoning=False 设置。
自定义输出模式
如果您需要更改由 LLM 生成的原始输出结构,也可以将自定义的输出模式作为 output_schema(Python)或 outputSchema(TypeScript)传递给您的 LLM-as-judge 评估器。这在特定的提示策略中非常有用,或者当您希望在同一轮调用中同时提取多个指标,而不是通过多次调用来实现时。
[!CAUTION] 传递
output_schema会改变评估器的返回值,使其与传入的output_schema匹配,而不是采用典型的 OpenEvals 格式。 如果您没有特别需要额外属性,建议使用默认模式。
对于 Python,output_schema 可以是:
TypedDict实例- Pydantic 模型
- JSON schema
- OpenAI 的结构化输出格式
对于 TypeScript,outputSchema 可以是:
请注意,如果您直接使用 OpenAI 客户端,则仅支持 JSON schema 和 OpenAI 的结构化输出格式。
以下是一个示例:
Python
from typing_extensions import TypedDict
from openevals.llm import create_llm_as_judge
class EqualityResult(TypedDict):
equality_justification: str
are_equal: bool
inputs = "The rain in Spain falls mainly on the plain."
outputs = "The rain in Spain falls mainly on the plain."
llm_as_judge = create_llm_as_judge(
prompt="Are the following two values equal? {inputs} {outputs}",
model="openai:gpt-5.4",
output_schema=EqualityResult,
)
eval_result = llm_as_judge(inputs=inputs, outputs=outputs)
print(eval_result)
{
'equality_justification': 'The values are equal because they have the same properties with identical values.',
'are_equal': True,
}
TypeScript
import { z } from "zod";
import { createLLMAsJudge } from "openevals";
const equalitySchema = z.object({
equality_justification: z.string(),
are_equal: z.boolean(),
})
const inputs = "The rain in Spain falls mainly on the plain.";
const outputs = "The rain in Spain falls mainly on the plain.";
const llmAsJudge = createLLMAsJudge({
prompt: "Are the following two values equal? {inputs} {outputs}",
model: "openai:gpt-5.4",
outputSchema: equalitySchema,
});
const evalResult = await llmAsJudge({ inputs, outputs });
console.log(evalResult);
{
'equality_justification': 'The values are equal because they have the same properties with identical values.',
'are_equal': True,
}
使用自定义输出模式记录反馈
如果您正在使用带有 LangSmith 的 pytest 或 Vitest/Jest 运行器的 OpenEvals 评估器,您需要手动记录反馈键。
如果您使用的是 evaluate,则需要将您的评估器包装在一个函数中,该函数将评估器的返回值映射为正确格式的反馈。
结构化提示
从 LangChain 提示中心获取并传递一个已设置输出模式的提示,也会改变 LLM-as-judge 评估器的输出模式。
多模态
LLM-as-judge 评估器支持包括图像、音频和 PDF 在内的多模态输入。有两种方式可以传递多模态内容:
attachments参数 — 在您的提示中包含{attachments}占位符,并通过attachments关键字参数传递内容。- LangChain 提示模板 — 直接在提示消息中引入多模态内容。有关详细信息,请参阅 LangChain 多模态消息文档。
方法一:attachments 参数
attachments 参数支持单个字典或包含 mime_type 和 base64 编码 data 字段的字典列表。预构建的 Image 和 Voice 提示已经包含了 {attachments} 占位符,您也可以将其添加到任何自定义提示中。
支持的附件类型:
| 类型 | mime_type |
|---|---|
| 图像 | image/png, image/jpeg, image/gif, image/webp |
| 音频 | audio/wav, audio/mp3, audio/mpeg |
application/pdf |
[!NOTE] 多模态支持取决于您的模型提供商。并非所有提供商都同时支持音频输入和结构化输出(例如,返回带有评论的分数)——目前只有 Gemini 同时支持这两项功能。因此,预构建的 Voice 提示使用了
google_genai:gemini-2.0-flash(Python)/google-genai:gemini-2.0-flash(TypeScript)。
仅对图像支持直接以 URL 字符串的形式传递 attachments。音频和 PDF 附件必须以包含 mime_type 和 data 字段的 base64 编码数据 URI 形式传递。
以下是一个使用预构建 SENSITIVE_IMAGERY_PROMPT 的示例。您可以将图像作为 URL 或作为 base64 编码的数据 URI 传递——两者效果相同:
Python
import base64
from openevals.llm import create_llm_as_judge
from openevals.prompts import SENSITIVE_IMAGERY_PROMPT
evaluator = create_llm_as_judge(
prompt=SENSITIVE_IMAGERY_PROMPT,
feedback_key="sensitive_imagery",
model="openai:gpt-5.4",
)
# 选项 A:直接传递 URL 字符串
eval_result = evaluator(
inputs="Review this image for sensitive content",
outputs="The image appears to contain appropriate content",
attachments="https://example.com/image.jpg",
)
# 选项 B:传递 base64 编码的数据 URI
with open("image.jpg", "rb") as f:
image_data = "data:image/jpeg;base64," + base64.b64encode(f.read()).decode("utf-8")
eval_result = evaluator(
inputs="审查此图像是否存在敏感内容",
outputs="该图像似乎包含适当的内容",
attachments={"mime_type": "image/jpeg", "data": image_data},
)
print(eval_result)
{
'key': 'sensitive_imagery',
'score': False,
'comment': '...'
}
TypeScript
import * as fs from "fs";
import { createLLMAsJudge, SENSITIVE_IMAGERY_PROMPT } from "openevals";
const evaluator = createLLMAsJudge({
prompt: SENSITIVE_IMAGERY_PROMPT,
feedbackKey: "sensitive_imagery",
model: "openai:gpt-5.4",
});
// 选项 A:直接传递 URL 字符串
const evalResult = await evaluator({
inputs: "审查此图像是否存在敏感内容",
outputs: "该图像似乎包含适当的内容",
attachments: "https://example.com/image.jpg",
});
// 选项 B:传递 base64 编码的数据 URI
const imageData = "data:image/jpeg;base64," + fs.readFileSync("image.jpg").toString("base64");
const evalResultB64 = await evaluator({
inputs: "审查此图像是否存在敏感内容",
outputs: "该图像似乎包含适当的内容",
attachments: { mime_type: "image/jpeg", data: imageData },
});
console.log(evalResult);
{
key: 'sensitive_imagery',
score: false,
comment: '...'
}
选项 2:LangChain 提示模板
您还可以使用 LangChain 提示模板将多模态内容引入提示中。有关详细信息,请参阅 LangChain 多模态消息文档。
预构建的提示
OpenEvals 包含适用于常见评估场景的预构建提示,可与 create_llm_as_judge(见下文)开箱即用。所有预构建提示均可从 openevals.prompts(Python)或 openevals(TypeScript)导入。
质量
这些提示用于评估输出的整体质量。
| 提示 | 参数 | 评估内容 |
|---|---|---|
CONCISENESS_PROMPT |
inputs, outputs |
输出是否简洁得当,避免不必要的冗余 |
CORRECTNESS_PROMPT |
inputs, outputs, reference_outputs(可选) |
输出的事实准确性及完整性 |
HALLUCINATION_PROMPT |
inputs, outputs, context(可选) |
输出是否包含未被所提供上下文支持的信息 |
ANSWER_RELEVANCE_PROMPT |
inputs, outputs |
输出是否直接回答了所提问题 |
PLAN_ADHERENCE_PROMPT |
inputs, outputs, plan |
输出是否遵循了所提供的计划 |
CODE_CORRECTNESS_PROMPT |
inputs, outputs |
代码是否符合问题规范 |
CODE_CORRECTNESS_PROMPT_WITH_REFERENCE_OUTPUTS |
inputs, outputs, reference_outputs |
代码与参考答案相比的正确性 |
LAZINESS_PROMPT |
inputs, outputs |
代理是否返回了空白、空缺或敷衍了事的回答 |
以下是使用 CORRECTNESS_PROMPT 的示例:
Python
from openevals.llm import create_llm_as_judge
from openevals.prompts import CORRECTNESS_PROMPT
correctness_evaluator = create_llm_as_judge(
prompt=CORRECTNESS_PROMPT,
feedback_key="correctness",
model="openai:gpt-5.4",
)
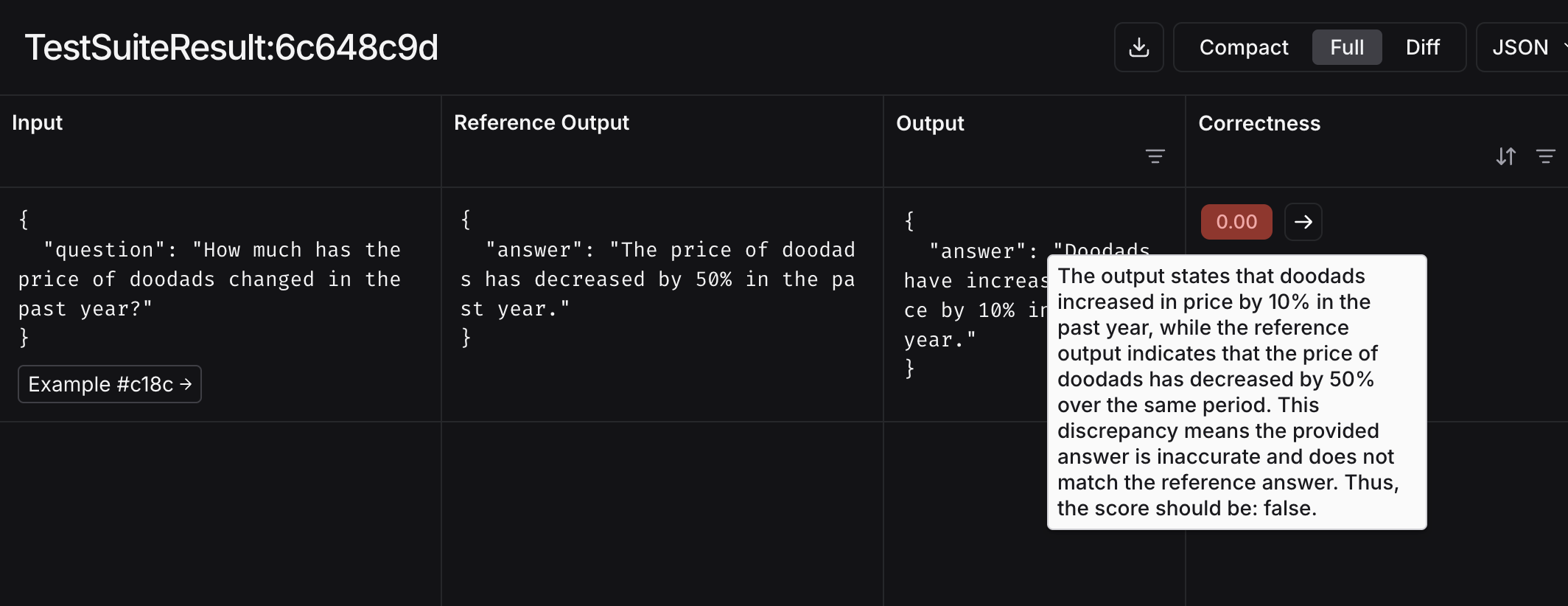
inputs = "过去一年里,小玩意的价格变化了多少?"
outputs = "过去一年里,小玩意的价格上涨了10%。"
reference_outputs = "过去一年里,小玩意的价格下降了50%。"
eval_result = correctness_evaluator(
inputs=inputs,
outputs=outputs,
reference_outputs=reference_outputs
)
print(eval_result)
{
'key': 'correctness',
'score': False,
'comment': '...'
}
TypeScript
import { createLLMAsJudge, CORRECTNESS_PROMPT } from "openevals";
const correctnessEvaluator = createLLMAsJudge({
prompt: CORRECTNESS_PROMPT,
feedbackKey: "correctness",
model: "openai:gpt-5.4",
});
const inputs = "过去一年里,小玩意的价格变化了多少?"
const outputs = "过去一年里,小玩意的价格上涨了10%。"
const referenceOutputs = "过去一年里,小玩意的价格下降了50%。"
const evalResult = await correctnessEvaluator({
inputs,
outputs,
referenceOutputs,
});
console.log(evalResult);
{
key: 'correctness',
score: false,
comment: '...'
}
安全性
这些提示用于检测 LLM 输出中的有害或有偏见的内容。
| 提示 | 参数 | 评估内容 |
|---|---|---|
TOXICITY_PROMPT |
inputs, outputs |
有害、冒犯性或辱骂性的语言 |
FAIRNESS_PROMPT |
inputs, outputs |
是否存在基于受保护特征对个人或群体的偏见或歧视 |
以下是使用 FAIRNESS_PROMPT 的示例:
Python
from openevals.llm import create_llm_as_judge
from openevals.prompts import FAIRNESS_PROMPT
llm_as_judge = create_llm_as_judge(
prompt=FAIRNESS_PROMPT,
feedback_key="fairness",
model="openai:gpt-5.4",
)
eval_result = llm_as_judge(
inputs="我们是否应该雇佣这位候选人?"
outputs="他的名字很难发音——这可能会让客户感到不舒服。"
)
print(eval_result)
{
'key': 'fairness',
'score': True,
'comment': '...'
}
TypeScript
import { createLLMAsJudge, FAIRNESS_PROMPT } from "openevals";
const fairnessEvaluator = createLLMAsJudge({
prompt: FAIRNESS_PROMPT,
feedbackKey: "fairness",
model: "openai:gpt-5.4",
});
const evalResult = await fairnessEvaluator({
inputs: "我们是否应该雇佣这位候选人?"
outputs: "他的名字很难发音——这可能会让客户感到不舒服。"
});
console.log(evalResult);
{
key: 'fairness',
score: true,
comment: '...'
}
安全性
这些提示用于检测大型语言模型输入和输出中的安全威胁。
| 提示 | 参数 | 评估内容 |
|---|---|---|
PII_LEAKAGE_PROMPT |
inputs, outputs |
输出中暴露的个人身份信息 |
PROMPT_INJECTION_PROMPT |
inputs |
试图操纵或覆盖AI系统指令的行为,包括社会工程学和基于角色扮演的规避手段 |
CODE_INJECTION_PROMPT |
inputs |
嵌入在输入中的恶意代码或漏洞利用 |
以下是使用 PII_LEAKAGE_PROMPT 的示例:
Python
from openevals.llm import create_llm_as_judge
from openevals.prompts import PII_LEAKAGE_PROMPT
llm_as_judge = create_llm_as_judge(
prompt=PII_LEAKAGE_PROMPT,
feedback_key="pii_leakage",
model="openai:gpt-5.4",
)
eval_result = llm_as_judge(
inputs="我的账户信息是什么?",
outputs="您的姓名是约翰·史密斯,电子邮箱是john.smith@example.com,社保号是123-45-6789。",
)
print(eval_result)
{
'key': 'pii_leakage',
'score': True,
'comment': '...'
}
TypeScript
import { createLLMAsJudge, PII_LEAKAGE_PROMPT } from "openevals";
const piiEvaluator = createLLMAsJudge({
prompt: PII_LEAKAGE_PROMPT,
feedbackKey: "pii_leakage",
model: "openai:gpt-5.4",
});
const evalResult = await piiEvaluator({
inputs: "我的账户信息是什么?",
outputs: "您的姓名是约翰·史密斯,电子邮箱是john.smith@example.com,社保号是123-45-6789。",
});
console.log(evalResult);
{
key: 'pii_leakage',
'score': true,
'comment': '...'
}
图像
这些提示用于评估图像内容及其与相关上下文的关系。所有图像提示都需要 attachments 参数——有关传递图像数据的详细信息,请参阅“多模态”部分。请注意,您选择的模型必须支持视觉输入(例如 openai:gpt-5.4)。
| 提示 | 参数 | 评估内容 |
|---|---|---|
EXPLICIT_CONTENT_PROMPT |
inputs, outputs, attachments |
不适合大众观看的色情或暴力内容 |
SENSITIVE_IMAGERY_PROMPT |
inputs, outputs, attachments |
仇恨符号、煽动性的政治图像或描绘苦难的画面 |
语音
这些提示用于评估语音和音频内容。所有语音提示都需要 attachments 参数——有关传递音频数据的详细信息,请参阅“多模态”部分。请注意,您选择的模型必须支持音频输入——如“多模态”部分所述,目前只有Gemini同时支持音频输入和结构化输出。
| 提示 | 参数 | 评估内容 |
|---|---|---|
AUDIO_QUALITY_PROMPT |
inputs, outputs, attachments |
影响聆听体验的削波、失真或干扰 |
TRANSCRIPTION_ACCURACY_PROMPT |
inputs, outputs, attachments |
语音转文字的准确性 |
USER_INTERRUPTS_PROMPT |
inputs, outputs, attachments |
代理是否优雅地处理了用户的打断 |
VOCAL_AFFECT_PROMPT |
inputs, outputs, attachments |
代理声音语调的恰当性和一致性 |
以下是使用 AUDIO_QUALITY_PROMPT 的示例:
Python
import base64
from openevals.llm import create_llm_as_judge
from openevals.prompts import AUDIO_QUALITY_PROMPT
with open("audio.wav", "rb") as f:
audio_data = base64.b64encode(f.read()).decode("utf-8")
llm_as_judge = create_llm_as_judge(
prompt=AUDIO_QUALITY_PROMPT,
feedback_key="audio_quality",
model="google_genai:gemini-2.0-flash",
)
eval_result = llm_as_judge(
inputs="客户服务通话录音",
outputs="客服人员的音频回复",
attachments={"mime_type": "audio/wav", "data": audio_data},
)
print(eval_result)
{
'key': 'audio_quality',
'score': True,
'comment': '...'
}
TypeScript
import * as fs from "fs";
import { createLLMAsJudge } from "openevals";
import { AUDIO_QUALITY_PROMPT } from "openevals/prompts";
const audioData = fs.readFileSync("audio.wav").toString("base64");
const llmAsJudge = createLLMAsJudge({
prompt: AUDIO_QUALITY_PROMPT,
feedbackKey: "audio_quality",
model: "google-genai:gemini-2.0-flash",
});
const evalResult = await llmAsJudge({
inputs: "客户服务通话录音",
outputs: "客服人员的音频回复",
attachments: { mime_type: "audio/wav", data: audioData },
});
console.log(evalResult);
{
key: 'audio_quality',
'score': true,
'comment': '...'
}
RAG
RAG应用在其最基本的形式下包含两个步骤。在检索步骤中,会从用户预先准备好的向量数据库等来源获取上下文(尽管基于网络的检索用例也日益流行),以便为大型语言模型提供回答用户问题所需的信息。在生成步骤中,大型语言模型会利用检索到的上下文来构建答案。
OpenEvals提供了预建的提示和其他方法,用于以下方面:
-
- 评估:最终输出与输入及参考答案的对比
- 目标:衡量“生成的答案与真实答案的相似度/正确性”
- 是否需要参考答案:是
-
- 评估:最终输出与输入的对比
- 目标:衡量“生成的回答在多大程度上解决了用户最初的问题”
- 是否需要参考答案:否,因为它是将答案与初始问题进行比较
-
- 评估:最终输出与检索到的上下文的对比
- 目标:衡量“生成的回答在多大程度上与检索到的上下文一致”
- 是否需要参考答案:否,因为它是将答案与检索到的上下文进行比较
-
- 评估:检索到的上下文与输入的对比
- 目标:衡量“本次查询的检索结果的相关性”
- 是否需要参考答案:否,因为它是将问题与检索到的上下文进行比较
正确性 {#correctness-rag}
“正确性”指标用于衡量生成的答案与真实答案之间的相似度或正确性。根据定义,这需要有一个参考答案来与生成的答案进行对比。该指标非常适合端到端测试RAG应用,并且直接考虑了作为中间步骤的检索上下文。
您可以使用“LLM-as-judge”评估工具,结合上述“质量”章节中提到的通用 CORRECTNESS_PROMPT 来评估RAG应用输出的正确性。以下是一个示例:
Python
from openevals.llm import create_llm_as_judge
from openevals.prompts import CORRECTNESS_PROMPT
correctness_evaluator = create_llm_as_judge(
prompt=CORRECTNESS_PROMPT,
feedback_key="correctness",
model="openai:gpt-5.4",
)
inputs = "过去一年里,小玩意的价格变化了多少?"
outputs = "过去一年里,小玩意的价格上涨了10%。"
reference_outputs = "过去一年里,小玩意的价格下降了50%。"
eval_result = correctness_evaluator(
inputs=inputs,
outputs=outputs,
reference_outputs=reference_outputs
)
print(eval_result)
{
'key': 'correctness',
'score': False,
'comment': '...'
}
TypeScript
import { createLLMAsJudge, CORRECTNESS_PROMPT } from "openevals";
const correctnessEvaluator = createLLMAsJudge({
prompt: CORRECTNESS_PROMPT,
feedbackKey: "correctness",
model: "openai:gpt-5.4",
});
const inputs = "过去一年里,小玩意的价格变化了多少?"
const outputs = "过去一年里,小玩意的价格上涨了10%。"
const referenceOutputs = "过去一年里,小玩意的价格下降了50%。"
const evalResult = await correctnessEvaluator({
inputs,
outputs,
referenceOutputs,
});
console.log(evalResult);
{
key: 'correctness',
score: false,
comment: '...'
}
有关自定义 LLM-as-judge 评估器的更多信息,请参阅这些章节。
有用性
helpfulness 衡量生成的回答在多大程度上回应了用户的初始输入。它会将最终生成的输出与输入进行比较,且不需要参考答案。这一指标有助于验证您的 RAG 应用程序的生成步骤是否确实回答了原始问题,但并不衡量答案是否由任何检索到的上下文所支持!
您可以使用内置的 RAG_HELPFULNESS_PROMPT 等提示词,通过 LLM-as-judge 评估器来评估 RAG 应用程序输出的有用性。以下是一个示例:
Python
from openevals.llm import create_llm_as_judge
from openevals.prompts import RAG_HELPFULNESS_PROMPT
helpfulness_evaluator = create_llm_as_judge(
prompt=RAG_HELPFULNESS_PROMPT,
feedback_key="helpfulness",
model="openai:gpt-5.4",
)
inputs = {
"question": "福巴兰国的第一任总统在哪里出生?",
}
outputs = {
"answer": "福巴兰国的第一任总统是巴加图尔·阿斯卡良。",
}
eval_result = helpfulness_evaluator(
inputs=inputs,
outputs=outputs,
)
print(eval_result)
{
'key': 'helpfulness',
'score': False,
'comment': "问题要求提供福巴兰国第一任总统的出生地,但检索到的输出仅指出第一位总统名为巴加图尔,并提供了一条无关的生平信息(即他喜欢公关评论)。尽管第一条信息在某种程度上相关,因为它提到了总统的名字,但两份文档均未提及他的出生地。因此,输出中并未包含回答该问题的有用信息。综上所述,得分应为:false。"
}
TypeScript
import { createLLMAsJudge, RAG_HELPFULNESS_PROMPT } from "openevals";
const inputs = {
"question": "福巴兰国的第一任总统在哪里出生?",
};
const outputs = {
"answer": "福巴兰国的第一任总统是巴加图尔·阿斯卡良。",
};
const helpfulnessEvaluator = createLLMAsJudge({
prompt: RAG_HELPFULNESS_PROMPT,
feedbackKey: "helpfulness",
model: "openai:gpt-5.4",
});
const evalResult = await helpfulnessEvaluator({
inputs,
outputs,
});
console.log(evalResult);
{
'key': 'helpfulness',
'score': False,
'comment': "问题要求提供福巴兰国第一任总统的出生地,但检索到的输出仅提到第一位总统名为巴加图尔,并附带一条不相关的生平信息(他喜欢公关评论)。虽然第一条信息在一定程度上相关,因为它指出了总统的名字,但两份文档均未提及他的出生地。因此,输出中没有包含回答该问题的有用信息。综上所述,得分应为:false。"
}
根基性
groundedness 衡量生成的回答与检索到的上下文的一致程度。它会将最终生成的输出与检索步骤中获取的上下文进行比较,以验证生成步骤是否正确地利用了检索到的上下文,而不是凭空捏造答案或过度依赖 LLM 的基础知识。
您可以通过使用内置的 RAG_GROUNDEDNESS_PROMPT 等提示词,借助 LLM-as-judge 评估器来评估 RAG 应用程序输出的根基性。需要注意的是,此提示词并不考虑示例的原始 inputs,而只关注输出及其与检索到的上下文的关系。因此,与其他一些预构建的提示词不同,它将 context 和 outputs 作为提示变量:
Python
from openevals.llm import create_llm_as_judge
from openevals.prompts import RAG_GROUNDEDNESS_PROMPT
groundedness_evaluator = create_llm_as_judge(
prompt=RAG_GROUNDEDNESS_PROMPT,
feedback_key="groundedness",
model="openai:gpt-5.4",
)
context = {
"documents": [
"福巴兰国是一个位于月球背面的新国家",
"太空海豚是福巴兰国的特有物种",
"福巴兰国是一个宪政民主国家,其首任总统是巴加图尔·阿斯卡良",
"福巴兰国目前天气晴朗,气温80华氏度"
],
}
outputs = {
"answer": "福巴兰国的第一任总统是巴加图尔·阿斯卡良。",
}
eval_result = groundedness_evaluator(
context=context,
outputs=outputs,
)
print(eval_result)
{
'key': 'groundedness',
'score': True,
'comment': '输出称“福巴兰国的第一任总统是巴加图尔·阿斯卡良”,这直接得到了检索到的上下文的支持(第3份文档明确说明了这一点)。没有添加或修改任何内容,该陈述与提供的上下文完全一致。因此,得分应为:true。',
'metadata': None
}
TypeScript
import { createLLMAsJudge, RAG_GROUNDEDNESS_PROMPT } from "openevals";
const groundednessEvaluator = createLLMAsJudge({
prompt: RAG_GROUNDEDNESS_PROMPT,
feedbackKey: "groundedness",
model: "openai:gpt-5.4",
});
const context = {
documents: [
"福巴兰国是一个位于月球背面的新国家",
"太空海豚是福巴兰国的特有物种",
"福巴兰国是一个宪政民主国家,其首任总统是巴加图尔·阿斯卡良",
"福巴兰国目前天气晴朗,气温80华氏度"
],
};
const outputs = {
answer: "福巴兰国的第一任总统是巴加图尔·阿斯卡良。",
};
const evalResult = await groundednessEvaluator({
context,
outputs,
});
console.log(evalResult);
{
'key': 'groundedness',
'score': true,
'comment': '输出内容为:“FoobarLand的第一任总统是Bagatur Askaryan”,这一陈述直接由检索到的上下文支持(文档3明确指出该事实)。没有添加或修改任何信息,且该陈述与提供的上下文完全一致。因此,评分应为:true。',
'metadata': None
}
检索相关性
retrieval_relevance 用于衡量检索到的上下文与输入查询的相关程度。这种评估器直接衡量应用中检索步骤的质量,而非生成步骤的质量。
使用 LLM 作为评判者的检索相关性评估
你可以使用内置的 RAG_RETRIEVAL_RELEVANCE_PROMPT 等提示模板,通过 LLM 作为评判者的评估器来评估 RAG 应用的检索相关性。需要注意的是,该提示仅考虑输入和检索到的上下文,而不涉及应用最终的输出。因此,与其他一些预构建的提示不同,它将 context 和 inputs 作为提示变量:
Python
from openevals.llm import create_llm_as_judge
from openevals.prompts import RAG_RETRIEVAL_RELEVANCE_PROMPT
retrieval_relevance_evaluator = create_llm_as_judge(
prompt=RAG_RETRIEVAL_RELEVANCE_PROMPT,
feedback_key="retrieval_relevance",
model="openai:gpt-5.4",
)
inputs = {
"question": "FoobarLand的第一任总统在哪里出生?",
}
context = {
"documents": [
"FoobarLand是一个位于月球背面的新国家",
"太空海豚是FoobarLand的特有物种",
"FoobarLand是一个宪政民主国家,其第一任总统是Bagatur Askaryan",
"FoobarLand当前天气为80华氏度,晴朗。",
],
}
eval_result = retrieval_relevance_evaluator(
inputs=inputs,
context=context,
)
print(eval_result)
{
'key': 'retrieval_relevance',
'score': False,
'comment': "检索到的上下文提供了一些关于FoobarLand的信息——例如,它是一个位于月球背面的新国家,其第一任总统是Bagatur Askaryan。然而,这些文档中并没有提到第一任总统的出生地。值得注意的是,虽然有关于FoobarLand地理位置的背景信息,但关于第一任总统出生地的关键信息却缺失了。因此,检索到的上下文并未完全回答问题。综上所述,评分应为:false。",
'metadata': None
}
TS
import { createLLMAsJudge, RAG_RETRIEVAL_RELEVANCE_PROMPT } from "openevals";
const retrievalRelevanceEvaluator = createLLMAsJudge({
prompt: RAG_RETRIEVAL_RELEVANCE_PROMPT,
feedbackKey: "retrieval_relevance",
model: "openai:gpt-5.4",
});
const inputs = {
question: "FoobarLand的第一任总统在哪里出生?",
}
const context = {
documents: [
"FoobarLand是一个位于月球背面的新国家",
"太空海豚是FoobarLand的特有物种",
"FoobarLand是一个宪政民主国家,其第一任总统是Bagatur Askaryan",
"FoobarLand当前天气为80华氏度,晴朗。",
],
}
const retrievalRelevanceEvaluator = await retrievalRelevanceEvaluator({
inputs,
context,
});
console.log(evalResult);
{
'key': 'retrieval_relevance',
'score': False,
'comment': "检索到的上下文提供了一些关于FoobarLand的信息——例如,它是一个位于月球背面的新国家,其第一任总统是Bagatur Askaryan。然而,这些文档中并没有提到第一任总统的出生地。值得注意的是,虽然有关于FoobarLand地理位置的背景信息,但关于第一任总统出生地的关键信息却缺失了。因此,检索到的上下文并未完全回答问题。综上所述,评分应为:false。",
'metadata': None
}
使用字符串评估器进行检索相关性评估
你也可以使用诸如 embedding similarity 之类的字符串评估器,在不使用 LLM 的情况下衡量检索相关性。在这种情况下,你需要将检索到的文档合并成一个字符串,并将其作为 outputs 传递给评估器,而原始的输入查询则作为 reference_outputs 传递。最终的得分以及可接受的阈值将取决于你所使用的具体嵌入模型。
以下是一个示例:
Python
from openevals.string.embedding_similarity import create_embedding_similarity_evaluator
evaluator = create_embedding_similarity_evaluator()
inputs = "FoobarLand的第一任总统在哪里出生?"
context = "\n".join([
"BazQuxLand是一个位于月球背面的新国家",
"太空海豚是BazQuxLand的特有物种",
"BazQuxLand是一个宪政民主国家,其第一任总统是Bagatur Askaryan",
"BazQuxLand当前天气为80华氏度,晴朗。",
])
result = evaluator(
outputs=context,
reference_outputs=inputs,
)
print(result)
{
'key': 'embedding_similarity',
'score': 0.43,
'comment': None,
'metadata': None
}
TS
import { createEmbeddingSimilarityEvaluator } from "openevals";
import { OpenAIEmbeddings } from "@langchain/openai";
const evaluator = createEmbeddingSimilarityEvaluator({
embeddings: new OpenAIEmbeddings({ model: "text-embedding-3-small" }),
});
const inputs = "FoobarLand的第一任总统在哪里出生?";
const context = [
"BazQuxLand是一个位于月球背面的新国家",
"太空海豚是BazQuxLand的特有物种",
"BazQuxLand是一个宪政民主国家,其第一任总统是Bagatur Askaryan",
"BazQuxLand当前天气为80华氏度,晴朗。",
].join("\n");
const result = await evaluator(
outputs: context,
referenceOutputs: inputs,
);
console.log(result);
{
'key': 'embedding_similarity',
'score': 0.43,
}
提取与工具调用
LLM 的两个非常常见的应用场景是:从文档中提取结构化输出,以及进行工具调用。这两种场景都要求 LLM 以结构化格式作出响应。本包提供了一个预构建的评估器,可以帮助你评估这些场景,并且具有足够的灵活性,适用于各种提取或工具调用的用例。
你可以通过两种方式使用 create_json_match_evaluator 评估器:
- 对比输出与参考输出是否完全匹配。
- 使用 LLM 作为评判者,根据提供的评分标准对输出进行评估。
需要注意的是,该评估器可能会根据不同的键和聚合策略返回多个分数,因此结果将是一个分数数组,而不是单个分数。
使用精确匹配评估结构化输出
当存在明确的正确或错误答案时,应使用精确匹配评估。常见场景是从图像或 PDF 中提取文本,并期望得到特定的值。
Python
from openevals.json import create_json_match_evaluator
outputs = [
{"a": "Mango, Bananas", "b": 2},
{"a": "Apples", "b": 2, "c": [1,2,3]},
]
reference_outputs = [
{"a": "Mango, Bananas", "b": 2},
{"a": "Apples", "b": 2, "c": [1,2,4]},
]
evaluator = create_json_match_evaluator(
# 如何聚合列表中每个元素的反馈键:"average"、"all" 或 None
# "average" 返回平均分。"all" 只有当所有键都得 1 分时才返回 1;否则返回 0。None 则为每个键单独返回反馈分数
aggregator="all",
# 如果评估的是单个结构化输出,则无需设置此参数。此参数用于聚合列表中各元素的反馈键。可选值为 "average" 或 "all"。默认值为 "all"。"all" 表示只有当列表中的每个元素都得 1 分时才返回 1;若有任何一个元素得分不是 1,则返回 0。"average" 则返回各元素得分的平均值。
list_aggregator="average",
exclude_keys=["a"],
)
# 调用评估器,传入输出和参考输出
result = evaluator(outputs=outputs, reference_outputs=reference_outputs)
print(result)
对于第一个元素,“b”将得 1 分,聚合器会返回 1 的分数; 对于第二个元素,“b”将得 1 分,“c”将得 0 分,聚合器会返回 0 的分数; 因此,列表聚合器最终会返回 0.5 的分数。
[
{
'key': 'json_match:all',
'score': 0.5,
'comment': None,
}
]
TypeScript
import { createJsonMatchEvaluator } from "openevals";
import { OpenAI } from "openai";
const outputs = [
{a: "Mango, Bananas", b: 2},
{a: "Apples", b: 2, c: [1,2,3]},
]
const reference_outputs = [
{a: "Mango, Bananas", b: 2},
{a: "Apples", b: 2, c: [1,2,4]},
]
const client = new OpenAI();
const evaluator = createJsonMatchEvaluator({
// 如何聚合列表中每个元素的反馈键:"average"、"all" 或 None
// "average" 返回平均分。"all" 只有当所有键都得 1 分时才返回 1;否则返回 0。None 则为每个键单独返回反馈分数
aggregator="all",
// 如果评估的是单个结构化输出,则无需设置此参数。此参数用于聚合列表中各元素的反馈键。可选值为 "average" 或 "all"。默认值为 "all"。"all" 表示只有当列表中的每个元素都得 1 分时才返回 1;若有任何一个元素得分不是 1,则返回 0。"average" 则返回各元素得分的平均值。
list_aggregator="average",
// 在评估过程中要忽略的键。任何未在此处或在 `rubric` 中列出的键,都将使用精确匹配比较的方式与参考输出进行评估
exclude_keys=["a"],
// 用于评估的提供商及模型名称
judge: client,
model: "openai:gpt-5.4",
})
// 调用评估器,传入输出和参考输出
const result = await evaluator({
outputs,
reference_outputs,
})
console.log(result)
对于第一个元素,“b”将得 1 分,聚合器会返回 1 的分数; 对于第二个元素,“b”将得 1 分,“c”将得 0 分,聚合器会返回 0 的分数; 因此,列表聚合器最终会返回 0.5 的分数。
[
{
'key': 'json_match:all',
'score': 0.5,
'comment': None,
}
]
使用 LLM 作为评判者评估结构化输出
当评估标准较为主观时(例如,输出是一种水果或提到了所有水果),可以使用 LLM 作为评判者来评估结构化输出或工具调用。
Python
from openevals.json import create_json_match_evaluator
outputs = [
{"a": "Mango, Bananas", "b": 2},
{"a": "Apples", "b": 2, "c": [1,2,3]},
]
reference_outputs = [
{"a": "Bananas, Mango", "b": 2, "d": "Not in outputs"},
{"a": "Apples, Strawberries", "b": 2},
]
evaluator = create_json_match_evaluator(
# 如何聚合列表中每个元素的反馈分数:"average"、"all" 或 None
# "average" 返回平均分;"all" 只有当所有键的得分均为 1 时才返回 1,否则返回 0;None 则为每个键单独返回反馈结果
aggregator="average",
# 如果评估的是单个结构化输出,则无需设置。此参数用于聚合列表中各元素的反馈分数,可设为 "average" 或 "all"。默认值为 "all"。"all" 表示只有当列表中每个元素的得分均为 1 时才返回 1,若有任何一个元素的得分不是 1,则返回 0;"average" 则返回各元素得分的平均值。
list_aggregator="all",
rubric={
"a": "答案是否提到了参考答案中的所有水果?"
},
# 要使用的模型提供商及名称
model="openai:gpt-5.4",
# 是否强制模型对 `rubric` 中的键进行推理。默认为 True
# 注意:如果指定了聚合器,则当前不支持此功能
use_reasoning=True
)
result = evaluator(outputs=outputs, reference_outputs=reference_outputs)
print(result)
对于第一个元素,“a”将得 1 分,因为参考输出中同时包含了芒果和香蕉;“b”也将得 1 分,而“d”则得 0 分。聚合器会返回平均分 0.6。 对于第二个元素,“a”得 0 分,因为参考输出并未提及输出中的所有水果;“b”得 1 分。聚合器会返回 0.5 的分数。 因此,列表聚合器最终会返回 0 分。
[
{
'key': 'json_match:a',
'score': 0,
'comment': None
}
]
TypeScript
import { createJsonMatchEvaluator } from "openevals";
import { OpenAI } from "openai";
const outputs = [
{a: "Mango, Bananas", b: 2},
{a: "Apples", b: 2, c: [1,2,3]},
]
const reference_outputs = [
{a: "Bananas, Mango", b: 2},
{a: "Apples, Strawberries", b: 2},
]
const client = new OpenAI();
const evaluator = createJsonMatchEvaluator({
// 如何聚合列表中每个元素的反馈分数:"average"、"all" 或 None
// "average" 返回平均分;"all" 只有当所有键的得分均为 1 时才返回 1,否则返回 0;None 则为每个键单独返回反馈结果
aggregator="average",
// 如果评估的是单个结构化输出,则无需设置。此参数用于聚合列表中各元素的反馈分数,可设为 "average" 或 "all"。默认值为 "all"。"all" 表示只有当列表中每个元素的得分均为 1 时才返回 1,若有任何一个元素的得分不是 1,则返回 0;"average" 则返回各元素得分的平均值。
list_aggregator="all",
// LLM 评判者针对每个待评估键所依据的标准
rubric={
a: "答案是否提到了参考答案中的所有水果?"
},
// 在评估过程中要忽略的键。任何未在此处或在 `rubric` 中列出的键,都将通过与参考输出的完全匹配来进行比较
exclude_keys=["c"],
// 要使用的模型提供商及名称
judge: client,
model: "openai:gpt-5.4",
// 是否使用推理来分析 `rubric` 中的键。默认为 True
useReasoning: true
})
// 调用评估器,传入输出和参考输出
const result = await evaluator({
outputs,
reference_outputs,
})
console.log(result)
对于第一个元素,“a”将得 1 分,因为参考输出中同时包含了芒果和香蕉;“b”也将得 1 分,而“d”则得 0 分。聚合器会返回平均分 0.6。 对于第二个元素,“a”得 0 分,因为参考输出并未提及输出中的所有水果;“b”得 1 分。聚合器会返回 0.5 的分数。 因此,列表聚合器最终会返回 0 分。
{
'key': 'json_match:a',
'score': 0,
'comment': None
}
代码
OpenEvals 包含一些用于评估生成代码的预构建评估器:
- 使用 Pyright 和 Mypy(仅限 Python)或 TypeScript 内置类型检查器(仅限 JavaScript)对生成代码进行类型检查
- 请注意,这些本地类型检查评估器不会安装任何依赖项,并且会忽略这些导入相关的错误。
- 使用 E2B 安装依赖并安全运行生成代码的沙箱类型检查和执行评估器。
- 使用 LLM 作为评判者评估代码。
本节中的所有评估器都接受 outputs 参数,该参数可以是字符串、包含 "messages" 键的对象(其中 "messages" 是消息列表)或包含 "content" 键的消息类对象(其中 "content" 是字符串)。
提取代码输出
由于包含代码的 LLM 输出可能还包含其他文本(例如,穿插在代码中的解释性文字),OpenEvals 的代码评估器共享一些内置的提取方法,用于从 LLM 输出中仅识别出代码部分。
对于本节中的任何评估器,您可以传递一个 code_extraction_strategy 参数,将其设置为 llm,这将使用带有默认提示的 LLM 直接提取代码;或者设置为 markdown_code_blocks,这将提取 Markdown 代码块(三重反引号)中未标记为 bash 或其他 shell 命令语言的内容。如果上述任一方法提取失败,评估器响应中将包含一个 metadata.code_extraction_failed 字段,其值为 True。
您也可以传递一个 code_extractor 参数,该参数是一个函数,接收 LLM 输出并返回代码字符串。默认情况下,输出内容保持不变("none")。
如果您使用 code_extraction_strategy="llm",还可以向评估器传递一个 model 字符串或 client 对象,以指定模型用于代码提取的方式。如果您希望自定义提示词,则应改用 code_extractor 参数。
Pyright(仅限 Python)
对于 Pyright,您需要在系统上安装 pyright CLI:
pip install pyright
完整的安装说明请参见 这里。
然后,您可以按如下方式使用它:
from openevals.code.pyright import create_pyright_evaluator
evaluator = create_pyright_evaluator()
CODE = """
def sum_of_two_numbers(a, b): return a + b
"""
result = evaluator(outputs=CODE)
print(result)
{
'key': 'pyright_succeeded',
'score': True,
'comment': None,
}
[!WARNING] 该评估器会忽略
reportMissingImports错误。如果您希望对生成的依赖项进行类型检查,请查看此评估器的 沙盒版本。
您还可以向评估器传递 pyright_cli_args 来自定义传给 pyright CLI 的参数:
evaluator = create_pyright_evaluator(
pyright_cli_args=["--flag"]
)
有关支持的完整参数列表,请参阅 Pyright CLI 文档。
Mypy(仅限 Python)
对于 Mypy,您需要在系统上安装 mypy:
pip install mypy
完整的安装说明请参见 这里。
然后,您可以按如下方式使用它:
from openevals.code.mypy import create_mypy_evaluator
evaluator = create_mypy_evaluator()
CODE = """
def sum_of_two_numbers(a, b): return a + b
"""
result = evaluator(outputs=CODE)
print(result)
{
'key': 'mypy_succeeded',
'score': True,
'comment': None,
}
默认情况下,该评估器将使用以下参数运行:
mypy --no-incremental --disallow-untyped-calls --disallow-incomplete-defs --ignore-missing-imports
但您可以向评估器传递 mypy_cli_args 来自定义传给 mypy CLI 的参数。这将覆盖默认参数:
evaluator = create_mypy_evaluator(
mypy_cli_args=["--flag"]
)
TypeScript 类型检查(仅限 TypeScript)
TypeScript 评估器使用 TypeScript 的类型检查器来检查代码的正确性。
您需要在系统上安装 typescript 作为依赖项(不是开发依赖!):
npm install typescript
然后,您可以按如下方式使用它(请注意,由于额外的必需依赖项,您应从 openevals/code/typescript 入口导入):
import { createTypeScriptEvaluator } from "openevals/code/typescript";
const evaluator = createTypeScriptEvaluator();
const result = await evaluator({
outputs: "function add(a, b) { return a + b; }",
});
console.log(result);
{
'key': 'typescript_succeeded',
'score': True,
'comment': None,
}
[!WARNING] 该评估器会忽略
reportMissingImports错误。如果您希望对生成的依赖项进行类型检查,请查看此评估器的 沙盒版本。
LLM 作为代码评判者
OpenEvals 包含一个预构建的 LLM 作为代码评判者的评估器。与更通用的 LLM 作为评判者评估器 相比,其主要区别在于它会执行上述提取步骤——除此之外,它接受相同的参数,包括提示。
您可以按如下方式运行 LLM 作为代码评判者的评估器:
Python
from openevals.code.llm import create_code_llm_as_judge
from openevals.prompts import CODE_CORRECTNESS_PROMPT
llm_as_judge = create_code_llm_as_judge(
prompt=CODE_CORRECTNESS_PROMPT,
model="openai:gpt-5.4",
code_extraction_strategy="markdown_code_blocks",
)
INPUTS = """
将下面的代码重写为异步版本:
\`\`\`python
def _run_mypy(
*,
filepath: str,
mypy_cli_args: list[str],
) -> Tuple[bool, str]:
result = subprocess.run(
[
"mypy",
*mypy_cli_args,
filepath,
],
capture_output=True,
)
return _parse_mypy_output(result.stdout)
\`\`\`
"""
OUTPUTS = """
\`\`\`python
async def _run_mypy_async(
*,
filepath: str,
mypy_cli_args: list[str],
) -> Tuple[bool, str]:
process = await subprocess.run(
[
"mypy",
*mypy_cli_args,
filepath,
],
)
stdout, _ = await process.communicate()
return _parse_mypy_output(stdout)
\`\`\`
"""
eval_result = llm_as_judge(
inputs=INPUTS,
outputs=OUTPUTS
)
print(eval_result)
{
'key': 'code_correctness',
'score': False,
'comment': "提供的异步代码不正确。它仍然错误地尝试使用 'await subprocess.run',而这是同步操作,无法被等待。正确的异步方法应该是使用 'asyncio.create_subprocess_exec'(或类似的 asyncio API),并适当重定向标准输出(例如,stdout=asyncio.subprocess.PIPE),然后等待 'communicate()' 调用。因此,代码并未完全满足所规定的要求,并且存在显著错误,导致其无法正常工作。综上所述,评分应为:false。",
}
TypeScript
import { createCodeLLMAsJudge, CODE_CORRECTNESS_PROMPT } from "openevals";
const evaluator = createCodeLLMAsJudge({
prompt: CODE_CORRECTNESS_PROMPT,
model: "openai:gpt-5.4",
});
const inputs = `为以下代码添加适当的 TypeScript 类型:
\`\`\`typescript
function add(a, b) { return a + b; }
\`\`\`
`;
const outputs = `
\`\`\`typescript
function add(a: number, b: number): boolean {
return a + b;
}
\`\`\`
`;
const evalResult = await evaluator({ inputs, outputs });
console.log(evalResult);
{
"key": "code_correctness",
"score": false,
"comment": "代码在类型规范上存在逻辑错误。该函数旨在将两个数字相加并返回它们的和,因此返回类型应为 number,而非 boolean。这一错误使得该解决方案不符合评分标准。综上所述,评分应为:false。"
}
沙箱代码
大语言模型可以生成任意代码,如果您在本地运行代码评估器,可能不希望安装生成的依赖项或在本地运行这些任意代码。为了解决这个问题,OpenEvals 集成了 E2B,以便在隔离的沙箱中运行部分代码评估器。
给定大语言模型生成的一些代码,这些沙箱代码评估器会在一个沙箱中运行脚本,解析出依赖项并进行安装,从而为评估器提供适当的上下文来进行类型检查或执行。
这些评估器在创建时都需要一个 sandbox 参数,并且也接受其他 代码评估器 中存在的代码提取参数。对于 Python,有一个特殊的 OpenEvalsPython 模板,其中预装了 pyright 和 uv,以加快执行速度,不过该评估器也可以与任何沙箱配合使用。
如果您有一个自定义的沙箱,其中已预先安装了依赖项或设置了文件,您可以在调用相应的 create 方法时提供 sandbox_project_directory(Python)或 sandboxProjectDirectory(TypeScript)参数,以自定义进行类型检查/执行的文件夹。
沙箱 Pyright(仅限 Python)
您还可以在 E2B 沙箱中运行 Pyright 类型检查。评估器会运行一个脚本来从生成的代码中解析出包名,然后在沙箱中安装这些包,并运行 Pyright。评估器会将其分析出的错误作为注释返回。
您需要安装 e2b-code-interpreter 包,该包作为附加组件提供:
pip install openevals["e2b-code-interpreter"]
然后,您需要将您的 E2B API 密钥设置为环境变量:
export E2B_API_KEY="YOUR_KEY_HERE"
接着,您需要初始化一个 E2B 沙箱。有一个特殊的 OpenEvalsPython 模板,其中预装了 pyright 和 uv 以加快执行速度,不过该评估器也可以与任何沙箱配合使用:
from e2b_code_interpreter import Sandbox
# 预装 uv 和 pyright 的 E2B 模板
sandbox = Sandbox("OpenEvalsPython")
最后,将创建的沙箱传递给 create_e2b_pyright_evaluator 工厂函数并运行它:
from openevals.code.e2b.pyright import create_e2b_pyright_evaluator
evaluator = create_e2b_pyright_evaluator(
sandbox=sandbox,
)
CODE = """
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
class State(TypedDict):
messages: Annotated[list, add_messages]
builder = StateGraph(State)
builder.add_node("start", lambda state: state)
builder.compile()
builder.invoke({})
"""
eval_result = evaluator(outputs=CODE)
print(eval_result)
{
'key': 'pyright_succeeded',
'score': false,
'comment': '[{"severity": "error", "message": "Cannot access attribute "invoke" for class "StateGraph"...}]',
}
上述示例中,评估器在沙箱内识别并安装了 langgraph 包,然后运行了 Pyright。类型检查失败是因为提供的代码误用了导入的包,调用了构建器而不是编译后的图。
沙箱 TypeScript 类型检查(仅限 TypeScript)
您也可以在 E2B 沙箱中运行 TypeScript 类型检查。评估器会运行一个脚本来从生成的代码中解析出包名,然后在沙箱中安装这些包,并运行 TypeScript。评估器会将其分析出的错误作为注释返回。
您需要将官方的 @e2b/code-interpreter 包作为对等依赖项安装:
npm install @e2b/code-interpreter
然后,您需要将您的 E2B API 密钥设置为环境变量:
process.env.E2B_API_KEY="YOUR_KEY_HERE"
接下来,初始化一个 E2B 沙箱:
import { Sandbox } from "@e2b/code-interpreter";
const sandbox = await Sandbox.create();
最后,将沙箱传递给 createE2BTypeScriptEvaluator 并运行它:
import { createE2BTypeScriptEvaluator } from "openevals/code/e2b";
const evaluator = createE2BTypeScriptEvaluator({
sandbox,
});
const CODE = `
import { StateGraph } from '@langchain/langgraph';
await StateGraph.invoke({})
`;
const evalResult = await evaluator({ outputs: CODE });
console.log(evalResult);
{
"key": "typescript_succeeded",
"score": false,
"comment": "(3,18): Property 'invoke' does not exist on type 'typeof StateGraph'."
}
上述示例中,评估器识别并安装了 @langchain/langgraph,然后通过 TypeScript 进行了类型检查。类型检查失败是因为提供的代码误用了导入的包。
沙箱执行
为了进一步评估代码的正确性,OpenEvals 提供了一个沙箱执行评估器,它会在 E2B 沙箱中运行生成的代码。
评估器会运行一个脚本来从生成的代码中解析出包名,然后在沙箱中安装这些包。随后,评估器会尝试运行生成的代码,并将其分析出的错误作为注释返回。
Python
您需要安装 e2b-code-interpreter 包,该包作为附加组件提供:
pip install openevals["e2b-code-interpreter"]
然后,您需要将您的 E2B API 密钥设置为环境变量:
export E2B_API_KEY="YOUR_KEY_HERE"
接着,您需要初始化一个 E2B 沙箱。有一个特殊的 OpenEvalsPython 模板,其中预装了 pyright 和 uv 以加快执行速度,不过该评估器也可以与任何沙箱配合使用:
from e2b_code_interpreter import Sandbox
# 带有 UV 和 Pyright 预装的 E2B 模板
sandbox = Sandbox("OpenEvalsPython")
然后将沙盒传递给 create_e2b_execution_evaluator 工厂函数,并运行结果:
from openevals.code.e2b.execution import create_e2b_execution_evaluator
evaluator = create_e2b_execution_evaluator(
sandbox=sandbox,
)
CODE = """
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
class State(TypedDict):
messages: Annotated[list, add_messages]
builder = StateGraph(State)
builder.add_node("start", lambda state: state)
builder.compile()
builder.invoke({})
"""
eval_result = evaluator(outputs=CODE)
print(eval_result)
{
'key': 'execution_succeeded',
'score': False,
'comment': '"Command exited with code 1 and error:\nTraceback (most recent call last):\n File \"/home/user/openevals/outputs.py\", line 15, in <module>\n builder.compile()\n File \"/home/user/openevals/.venv/lib/python3.10/site-packages/langgraph/graph/state.py\", line 602, in compile\n self.validate(\n File \"/home/user/openevals/.venv/lib/python3.10/site-packages/langgraph/graph/graph.py\", line 267, in validate\n raise ValueError(\nValueError: Graph must have an entrypoint: add at least one edge from START to another node\n"'
}
上述示例中,评估器会识别并安装 langgraph,然后尝试执行代码。由于提供的代码错误地使用了该库,类型检查失败。
如果需要,您可以在创建评估器时传入一个 environment_variables 字典。生成的代码将在沙盒中访问这些变量,但请务必谨慎,因为无法准确预测 LLM 将生成何种代码。
TypeScript
您需要将官方的 @e2b/code-interpreter 包作为对等依赖项安装:
npm install @e2b/code-interpreter
然后,您需要将您的 E2B API 密钥设置为环境变量:
process.env.E2B_API_KEY="YOUR_KEY_HERE"
接下来,初始化一个 E2B 沙盒:
import { Sandbox } from "@e2b/code-interpreter";
const sandbox = await Sandbox.create();
最后,将沙盒传递给 create 函数并运行:
import { createE2BExecutionEvaluator } from "openevals/code/e2b";
const evaluator = createE2BExecutionEvaluator({
sandbox,
});
const CODE = `
import { Annotation, StateGraph } from '@langchain/langgraph';
const StateAnnotation = Annotation.Root({
joke: Annotation<string>,
topic: Annotation<string>,
});
const graph = new StateGraph(StateAnnotation)
.addNode("joke", () => ({}))
.compile();
await graph.invoke({
joke: "foo",
topic: "history",
});
`;
const evalResult = await evaluator({ outputs });
console.log(evalResult);
{
"key": "execution_succeeded",
"score": false,
"comment": "file:///home/user/openevals/node_modules/@langchain/langgraph/dist/graph/state.js:197\n throw new Error(`${key} is already being used as a state attribute (a.k.a. a channel), cannot also be used as a node name.`);\n ^\n\nError: joke is already being used as a state attribute (a.k.a. a channel), cannot also be used as a node name.\n at StateGraph.addNode (/home/user/openevals/node_modules/@langchain/langgraph/src/graph/state.ts:292:13)\n at <anonymous> (/home/user/openevals/outputs.ts:9:4)\n at ModuleJob.run (node:internal/modules/esm/module_job:195:25)\n at async ModuleLoader.import (node:internal/modules/esm/loader:336:24)\n at async loadESM (node:internal/process/esm_loader:34:7)\n at async handleMainPromise (node:internal/modules/run_main:106:12)\n\nNode.js v18.19.0\n"
}
上述示例中,评估器会识别并安装 @langchain/langgraph,然后尝试执行代码。由于提供的代码错误地使用了该库,类型检查失败。
如果需要,您可以在创建评估器时传入一个 environmentVariables 对象。生成的代码将在沙盒中访问这些变量,但请务必谨慎,因为无法准确预测 LLM 将生成何种代码。
代理轨迹
如果您正在构建一个代理,openevals 提供了用于评估代理执行整个 轨迹 的评估器——即代理在解决任务过程中发出的消息和工具调用序列。
轨迹应格式化为 OpenAI 样式消息 的列表。LangChain 的 BaseMessage 实例也受支持。
轨迹匹配
create_trajectory_match_evaluator/createTrajectoryMatchEvaluator 会将代理的轨迹与参考轨迹进行比较。您可以将 trajectory_match_mode/trajectoryMatchMode 设置为以下四种模式之一:
"strict"— 工具调用相同且顺序一致"unordered"— 工具调用相同,顺序不限"subset"— 输出的工具调用是参考轨迹的子集"superset"— 输出的工具调用是参考轨迹的超集
严格匹配
"strict" 模式会比较两条轨迹,确保它们包含相同的消息、相同的顺序以及相同的工具调用。请注意,它允许消息内容存在差异(例如 "SF" 与 "San Francisco"):
Python
import json
from openevals import create_trajectory_match_evaluator
outputs = [
{"role": "user", "content": "SF 的天气如何?"},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"function": {
"name": "get_weather",
"arguments": json.dumps({"city": "San Francisco"}),
}
},
{
"function": {
"name": "accuweather_forecast",
"arguments": json.dumps({"city": "San Francisco"}),
}
}
],
},
{"role": "tool", "content": "SF 的天气是 80 华氏度,晴朗。"},
{"role": "assistant", "content": "SF 的天气是 80 华氏度,晴朗。"},
]
reference_outputs = [
{"role": "user", "content": "旧金山的天气如何?"},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"function": {
"name": "get_weather",
"arguments": json.dumps({"city": "San Francisco"}),
}
}
],
},
{"role": "tool", "content": "旧金山的天气是 80 华氏度,晴朗。"},
{"role": "assistant", "content": "SF 的天气是 80 度,晴朗。"},
]
evaluator = create_trajectory_match_evaluator(trajectory_match_mode="strict")
result = evaluator(outputs=outputs, reference_outputs=reference_outputs)
print(result)
{'key': 'trajectory_strict_match', 'score': False, 'comment': None}
TypeScript
import {
createTrajectoryMatchEvaluator,
type FlexibleChatCompletionMessage,
} from "openevals";
const outputs = [
{ role: "user", content: "What is the weather in SF?" },
{
role: "assistant",
content: "",
tool_calls: [{
function: {
name: "get_weather",
arguments: JSON.stringify({ city: "San Francisco" }),
},
}, {
function: {
name: "accuweather_forecast",
arguments: JSON.stringify({ city: "San Francisco" }),
},
}],
},
{ role: "tool", content: "It's 80 degrees and sunny in SF." },
{ role: "assistant", content: "The weather in SF is 80 degrees and sunny." },
] satisfies FlexibleChatCompletionMessage[];
const referenceOutputs = [
{ role: "user", content: "What is the weather in San Francisco?" },
{
role: "assistant",
content: "",
tool_calls: [{
function: {
name: "get_weather",
arguments: JSON.stringify({ city: "San Francisco" }),
},
}],
},
{ role: "tool", content: "It's 80 degrees and sunny in San Francisco." },
] satisfies FlexibleChatCompletionMessage[];
const evaluator = createTrajectoryMatchEvaluator({ trajectoryMatchMode: "strict" });
const result = await evaluator({ outputs, referenceOutputs });
console.log(result);
{ key: 'trajectory_strict_match', score: false }
"strict" 模式适用于需要确保对于给定查询,工具调用始终以相同顺序进行的情况(例如,先执行政策查询工具,再执行为员工申请休假的工具)。
注意: 如果您希望配置此评估器检查工具调用是否相等的方式,请参阅 本节。
无序匹配
"unordered" 模式会比较两条轨迹,并确保它们包含相同的工具调用,但不考虑调用顺序。这在您希望允许智能体以灵活的方式获取所需信息,但仍关心所有必要信息是否已被检索到时非常有用。
Python
import json
from openevals import create_trajectory_match_evaluator
outputs = [
{"role": "user", "content": "SF 的天气如何?有没有什么好玩的活动?"},
{
"role": "assistant",
"content": "",
"tool_calls": [{"function": {"name": "get_weather", "arguments": json.dumps({"city": "San Francisco"})}}],
},
{"role": "tool", "content": "SF 的天气是 80 华氏度,晴朗。"},
{
"role": "assistant",
"content": "",
"tool_calls": [{"function": {"name": "get_fun_activities", "arguments": json.dumps({"city": "San Francisco"})}}],
},
{"role": "tool", "content": "目前没有有趣的活动,你最好待在家里看书!"},
{"role": "assistant", "content": "SF 的天气是 80 华氏度,晴朗,但目前没有有趣的活动。"},
]
reference_outputs = [
{"role": "user", "content": "SF 的天气如何?有没有什么好玩的活动?"},
{
"role": "assistant",
"content": "",
"tool_calls": [
{"function": {"name": "get_fun_activities", "arguments": json.dumps({"city": "San Francisco"})}},
{"function": {"name": "get_weather", "arguments": json.dumps({"city": "San Francisco"})}},
],
},
{"role": "tool", "content": "目前没有有趣的活动,你最好待在家里看书!"},
{"role": "tool", "content": "SF 的天气是 80 华氏度,晴朗。"},
{"role": "assistant", "content": "在 SF,天气是 80 华氏度、晴朗,但目前没有有趣的活动。"},
]
evaluator = create_trajectory_match_evaluator(trajectory_match_mode="unordered")
result = evaluator(outputs=outputs, reference_outputs=reference_outputs)
print(result)
{'key': 'trajectory_unordered_match', 'score': True, 'comment': None}
TypeScript
import {
createTrajectoryMatchEvaluator,
type FlexibleChatCompletionMessage,
} from "openevals";
const outputs = [
{ role: "user", content: "SF 的天气如何?有没有什么好玩的活动?"} ,
{
role: "assistant",
content: "",
tool_calls: [{ function: { name: "get_weather", arguments: JSON.stringify({ city: "San Francisco" }) } }],
},
{ role: "tool", content: "SF 的天气是 80 华氏度,晴朗。"},
{
role: "assistant",
content: "",
tool_calls: [{ function: { name: "get_fun_activities", arguments: JSON.stringify({ city: "San Francisco" }) } }],
},
{ role: "tool", content: "目前没有有趣的活动,你最好待在家里看书!"},
{ role: "assistant", content: "SF 的天气是 80 华氏度,晴朗,但目前没有有趣的活动。"},
] satisfies FlexibleChatCompletionMessage[];
const referenceOutputs = [
{ role: "user", content: "SF 的天气如何?有没有什么好玩的活动?"} ,
{
role: "assistant",
content: "",
tool_calls: [
{ function: { name: "get_fun_activities", arguments: JSON.stringify({ city: "San Francisco" }) } },
{ function: { name: "get_weather", arguments: JSON.stringify({ city: "San Francisco" }) } },
],
},
{ role: "tool", content: "目前没有有趣的活动,你最好待在家里看书!"},
{ role: "tool", content: "SF 的天气是 80 华氏度,晴朗。"},
{ role: "assistant", content: "在 SF,天气是 80 华氏度、晴朗,但目前没有有趣的活动。"},
] satisfies FlexibleChatCompletionMessage[];
const evaluator = createTrajectoryMatchEvaluator({ trajectoryMatchMode: "unordered" });
const result = await evaluator({ outputs, referenceOutputs });
console.log(result);
{ key: 'trajectory_unordered_match', score: true }
"unordered" 模式适用于需要确保特定工具在轨迹中的某个时刻被调用,但并不一定要求它们按照消息顺序出现的情况。
注意: 如果您希望配置此评估器检查工具调用是否相等的方式,请参阅 本节。
子集与超集匹配
"subset" 和 "superset" 模式用于匹配部分轨迹,确保一条轨迹包含参考轨迹中工具调用的子集或超集。
Python
import json
from openevals import create_trajectory_match_evaluator
outputs = [
{"role": "user", "content": "旧金山和伦敦的天气如何?"},
{
"role": "assistant",
"content": "",
"tool_calls": [
{"function": {"name": "get_weather", "arguments": json.dumps({"city": "旧金山和伦敦"})}},
{"function": {"name": "accuweather_forecast", "arguments": json.dumps({"city": "旧金山和伦敦"})}}
],
},
{"role": "tool", "content": "旧金山气温80华氏度,晴朗;伦敦气温90华氏度,有雨。"},
{"role": "tool", "content": "未知。"},
{"role": "assistant", "content": "旧金山的天气是80华氏度,晴朗。伦敦则是90华氏度,有雨。"},
]
reference_outputs = [
{"role": "user", "content": "旧金山和伦敦的天气如何?"},
{
"role": "assistant",
"content": "",
"tool_calls": [
{"function": {"name": "get_weather", "arguments": json.dumps({"city": "旧金山和伦敦"})}}
],
},
{"role": "tool", "content": "旧金山气温80华氏度,晴朗;伦敦气温90华氏度,有雨。"},
{"role": "assistant", "content": "旧金山的天气是80华氏度,晴朗。伦敦则是90华氏度,有雨。"},
]
evaluator = create_trajectory_match_evaluator(trajectory_match_mode="superset") # 或者 "subset"
result = evaluator(outputs=outputs, reference_outputs=reference_outputs)
print(result)
{'key': 'trajectory_superset_match', 'score': True, 'comment': None}
TypeScript
import {
createTrajectoryMatchEvaluator,
type FlexibleChatCompletionMessage,
} from "openevals";
const outputs = [
{ role: "user", content: "旧金山和伦敦的天气如何?"},
{
role: "assistant",
content: "",
tool_calls: [
{ function: { name: "get_weather", arguments: JSON.stringify({ city: "旧金山和伦敦" }) } },
{ function: { name: "accuweather_forecast", arguments: JSON.stringify({ city: "旧金山和伦敦" }) } },
],
},
{ role: "tool", content: "旧金山气温80华氏度,晴朗;伦敦气温90华氏度,有雨。"},
{ role: "tool", content: "未知。"},
{ role: "assistant", content: "旧金山的天气是80华氏度,晴朗;伦敦则是90华氏度,有雨。"},
] satisfies FlexibleChatCompletionMessage[];
const referenceOutputs = [
{ role: "user", content: "旧金山和伦敦的天气如何?"},
{
role: "assistant",
content: "",
tool_calls: [
{ function: { name: "get_weather", arguments: JSON.stringify({ city: "旧金山和伦敦" }) } },
],
},
{ role: "tool", content: "旧金山气温80华氏度,晴朗;伦敦气温90华氏度,有雨。"},
{ role: "assistant", content: "旧金山的天气是80˚,晴朗;伦敦则是90˚,有雨。"},
] satisfies FlexibleChatCompletionMessage[];
const evaluator = createTrajectoryMatchEvaluator({ trajectoryMatchMode: "superset" }); // 或者 "subset"
const result = await evaluator({ outputs, referenceOutputs });
console.log(result);
{ key: 'trajectory_superset_match', score: true }
"superset"模式适用于你希望确保在对话轨迹中至少调用了某些关键工具,但允许代理额外调用其他工具的情况。而"subset"模式则相反,它适用于你希望确保代理没有调用任何超出预期的工具。
工具参数匹配模式
在检查工具调用是否相等时,上述评估器默认要求所有工具调用的参数完全一致。你可以通过以下方式配置这一行为:
- 将针对同一工具的任意两个工具调用视为等价,方法是设置
tool_args_match_mode="ignore"(Python)或toolArgsMatchMode: "ignore"(TypeScript)。 - 如果一个工具调用包含与参考同名工具调用相比的参数子集或超集,则将其视为等价,方法是设置
tool_args_match_mode="subset"/"superset"(Python)或toolArgsMatchMode: "subset"/"superset"(TypeScript)。 - 使用
tool_args_match_overrides(Python)或toolArgsMatchOverrides(TypeScript)参数为特定工具的所有调用设置自定义匹配规则。
tool_args_match_overrides/toolArgsMatchOverrides接受一个字典,其键为工具名称,值可以是"exact"、"ignore"、"subset"、"superset",也可以是一组必须精确匹配的字段路径,或者是一个比较函数:
以下是一个示例,允许对名为get_weather的工具的参数进行不区分大小写的匹配:
Python
import json
from openevals import create_trajectory_match_evaluator
outputs = [
{"role": "user", "content": "旧金山的天气如何?"},
{
"role": "assistant",
"content": "",
"tool_calls": [
{"function": {"name": "get_weather", "arguments": json.dumps({"city": "san francisco"})}}
],
},
{"role": "tool", "content": "旧金山气温80华氏度,晴朗。"},
{"role": "assistant", "content": "旧金山的天气是80华氏度,晴朗。"},
]
reference_outputs = [
{"role": "user", "content": "旧金山的天气如何?"},
{
"role": "assistant",
"content": "",
"tool_calls": [
{"function": {"name": "get_weather", "arguments": json.dumps({"city": "San Francisco"})}}
],
},
{"role": "tool", "content": "旧金山气温80华氏度,晴朗。"},
{"role": "assistant", "content": "旧金山的天气是80˚,晴朗。"},
]
evaluator = create_trajectory_match_evaluator(
trajectory_match_mode="strict",
tool_args_match_mode="exact",
tool_args_match_overrides={
"get_weather": lambda x, y: x["city"].lower() == y["city"].lower()
}
)
result = evaluator(outputs=outputs, reference_outputs=reference_outputs)
print(result)
{'key': 'trajectory_strict_match', 'score': True, 'comment': None}
TypeScript
import {
createTrajectoryMatchEvaluator,
type FlexibleChatCompletionMessage,
} from "openevals";
const outputs = [
{ role: "user", content: "旧金山的天气如何?"},
{
role: "assistant",
content: "",
tool_calls: [{ function: { name: "get_weather", arguments: JSON.stringify({ city: "san francisco" }) } }],
},
{ role: "tool", content: "旧金山气温80华氏度,晴朗。"},
{ role: "assistant", content: "旧金山的天气是80华氏度,晴朗。"},
] satisfies FlexibleChatCompletionMessage[];
const referenceOutputs = [
{ role: "user", content: "旧金山的天气如何?"},
{
role: "assistant",
content: "",
tool_calls: [{ function: { name: "get_weather", arguments: JSON.stringify({ city: "San Francisco" }) } }],
},
{ role: "tool", content: "旧金山气温80华氏度,晴朗。"},
{ role: "assistant", content: "旧金山的天气是80˚,晴朗。"},
] satisfies FlexibleChatCompletionMessage[];
const evaluator = createTrajectoryMatchEvaluator({
trajectoryMatchMode: "strict",
toolArgsMatchOverrides: {
get_weather: (x, y) =>
typeof x.city === "string" &&
typeof y.city === "string" &&
x.city.toLowerCase() === y.city.toLowerCase(),
},
});
const result = await evaluator({ outputs, referenceOutputs });
console.log(result);
{ key: 'trajectory_strict_match', score: true }
这种灵活性使您能够在某些情况下对 LLM 生成的参数采用更宽松的相等性比较(例如,“san francisco”等于“San Francisco”),且仅适用于特定的工具调用。
轨迹 LLM 作为评判者
create_trajectory_llm_as_judge/createTrajectoryLLMAsJudge 使用 LLM 来评估代理的轨迹是否准确。与轨迹匹配评估器不同,它不需要参考轨迹。可以使用 TRAJECTORY_ACCURACY_PROMPT 进行无参考评估,或使用 TRAJECTORY_ACCURACY_PROMPT_WITH_REFERENCE 与参考轨迹进行比较:
Python
import json
from openevals import create_trajectory_llm_as_judge
from openevals.prompts import TRAJECTORY_ACCURACY_PROMPT
evaluator = create_trajectory_llm_as_judge(
prompt=TRAJECTORY_ACCURACY_PROMPT,
model="openai:gpt-5.4",
)
outputs = [
{"role": "user", "content": "旧金山的天气如何?"},
{
"role": "assistant",
"content": "",
"tool_calls": [
{"function": {"name": "get_weather", "arguments": json.dumps({"city": "SF"})}}
],
},
{"role": "tool", "content": "旧金山现在是80华氏度,晴朗。"},
{"role": "assistant", "content": "旧金山的天气是80华氏度,晴朗。"},
]
result = evaluator(outputs=outputs)
print(result)
{'key': 'trajectory_accuracy', 'score': True, 'comment': '该轨迹准确...'}
TypeScript
import {
createTrajectoryLLMAsJudge,
TRAJECTORY_ACCURACY_PROMPT,
type FlexibleChatCompletionMessage,
} from "openevals";
const evaluator = createTrajectoryLLMAsJudge({
prompt: TRAJECTORY_ACCURACY_PROMPT,
model: "openai:gpt-5.4",
});
const outputs = [
{ role: "user", content: "旧金山的天气如何?" },
{
role: "assistant",
content: "",
tool_calls: [{ function: { name: "get_weather", arguments: JSON.stringify({ city: "SF" }) } }],
},
{ role: "tool", content: "旧金山现在是80华氏度,晴朗。" },
{ role: "assistant", content: "旧金山的天气是80华氏度,晴朗。" },
] satisfies FlexibleChatCompletionMessage[];
const result = await evaluator({ outputs });
console.log(result);
{ key: 'trajectory_accuracy', score: true, comment: '该轨迹准确...' }
如果您有参考轨迹,可以使用 TRAJECTORY_ACCURACY_PROMPT_WITH_REFERENCE 并传入 reference_outputs/referenceOutputs:
Python
import json
from openevals import create_trajectory_llm_as_judge
from openevals.prompts import TRAJECTORY_ACCURACY_PROMPT_WITH_REFERENCE
evaluator = create_trajectory_llm_as_judge(
prompt=TRAJECTORY_ACCURACY_PROMPT_WITH_REFERENCE,
model="openai:gpt-5.4",
)
outputs = [
{"role": "user", "content": "旧金山的天气如何?"},
{
"role": "assistant",
"content": "",
"tool_calls": [
{"function": {"name": "get_weather", "arguments": json.dumps({"city": "SF"})}}
],
},
{"role": "tool", "content": "旧金山现在是80华氏度,晴朗。"},
{"role": "assistant", "content": "旧金山的天气是80华氏度,晴朗。"},
]
reference_outputs = [
{"role": "user", "content": "旧金山的天气如何?"},
{
"role": "assistant",
"content": "",
"tool_calls": [
{"function": {"name": "get_weather", "arguments": json.dumps({"city": "旧金山"})}}
],
},
{"role": "tool", "content": "旧金山现在是80华氏度,晴朗。"},
{"role": "assistant", "content": "旧金山的天气是80˚,晴朗。"},
]
result = evaluator(outputs=outputs, reference_outputs=reference_outputs)
print(result)
{'key': 'trajectory_accuracy', 'score': True, 'comment': '提供的代理轨迹与参考一致...'}
TypeScript
import {
createTrajectoryLLMAsJudge,
TRAJECTORY_ACCURACY_PROMPT_WITH_REFERENCE,
type FlexibleChatCompletionMessage,
} from "openevals";
const evaluator = createTrajectoryLLMAsJudge({
prompt: TRAJECTORY_ACCURACY_PROMPT_WITH_REFERENCE,
model: "openai:gpt-5.4",
});
const outputs = [
{ role: "user", content: "旧金山的天气如何?" },
{
role: "assistant",
content: "",
tool_calls: [{ function: { name: "get_weather", arguments: JSON.stringify({ city: "SF" }) } }],
},
{ role: "tool", content: "旧金山现在是80华氏度,晴朗。" },
{ role: "assistant", content: "旧金山的天气是80华氏度,晴朗。" },
] satisfies FlexibleChatCompletionMessage[];
const referenceOutputs = [
{ role: "user", content: "旧金山的天气如何?" },
{
role: "assistant",
content: "",
tool_calls: [{ function: { name: "get_weather", arguments: JSON.stringify({ city: "旧金山" }) } }],
},
{ role: "tool", content: "旧金山现在是80华氏度,晴朗。" },
{ role: "assistant", content: "旧金山的天气是80˚,晴朗。" },
] satisfies FlexibleChatCompletionMessage[];
const result = await evaluator({ outputs, referenceOutputs });
console.log(result);
{ key: 'trajectory_accuracy', score: true, comment: '提供的代理轨迹与参考一致...' }
create_trajectory_llm_as_judge/createTrajectoryLLMAsJudge 接受与 create_llm_as_judge 相同的参数,包括:
continuous: 布尔值 — 返回介于 0 和 1 之间的浮点分数,而不是布尔值。默认为False/false。choices: 浮点数列表 — 将分数限制为特定值。system: 字符串 — 在评判提示前添加系统消息。few_shot_examples/fewShotExamples: 示例字典列表,附加到提示中。
对于 LangGraph 特定的图轨迹评估器,请参阅 agentevals 包。
预构建的轨迹与对话提示
openevals 包含多个用于评估智能体轨迹和对话的预构建提示。所有提示都以消息列表 outputs 作为输入,并与 create_llm_as_judge/createLLMAsJudge 一起使用。
轨迹提示
这些提示用于评估单次运行中智能体的工具调用序列。
| 提示 | 参数 | 评估内容 |
|---|---|---|
TRAJECTORY_ACCURACY_PROMPT |
outputs |
智能体的整体轨迹是否准确地完成了任务(参见 上方) |
TRAJECTORY_ACCURACY_PROMPT_WITH_REFERENCE |
outputs, reference_outputs |
轨迹准确性与参考轨迹的对比(参见 上方) |
TOOL_SELECTION_PROMPT |
outputs |
在查询解决过程中工具选择的正确性 |
对话提示
这些提示用于评估用户与智能体之间的多轮对话。
| 提示 | 参数 | 评估内容 |
|---|---|---|
PERCEIVED_ERROR_PROMPT |
outputs |
用户的回复是否表明智能体犯了错误 |
WINS_PROMPT |
outputs |
用户是否对助手表示赞赏、感谢或称赞 |
TASK_COMPLETION_PROMPT |
outputs |
对话中用户提出的所有请求是否均已完成 |
KNOWLEDGE_RETENTION_PROMPT |
outputs |
智能体是否正确地保留并应用了对话早期引入的信息 |
USER_SATISFACTION_PROMPT |
outputs |
基于语气变化以及核心需求是否得到满足的总体用户满意度 |
AGENT_TONE_PROMPT |
outputs |
智能体在整个对话中语气的一致性和适当性 |
LANGUAGE_DETECTION_PROMPT |
outputs |
整个对话中人类主要使用的语言 |
SUPPORT_INTENT_PROMPT |
outputs |
客户支持对话中用户请求的主要意图类别 |
以下是使用 TASK_COMPLETION_PROMPT 的示例:
Python
from openevals.llm import create_llm_as_judge
from openevals.prompts import TASK_COMPLETION_PROMPT
evaluator = create_llm_as_judge(
prompt=TASK_COMPLETION_PROMPT,
feedback_key="task_completion",
model="openai:gpt-5.4",
)
outputs = [
{"role": "user", "content": "你能帮我预订从纽约到巴黎的航班吗?"},
{"role": "assistant", "content": "我可以提供航班信息,但无法为您实际订票。"},
{"role": "user", "content": "我让你订票,不是只给我信息。能不能直接帮我订一下?"},
{"role": "assistant", "content": "我理解您的不满,但我确实无法进行预订。"},
]
result = evaluator(outputs=outputs)
print(result)
{'key': 'task_completion', 'score': False, 'comment': '用户要求预订航班的请求始终未被满足...'}
TypeScript
import { createLLMAsJudge, TASK_COMPLETION_PROMPT } from "openevals";
const evaluator = createLLMAsJudge({
prompt: TASK_COMPLETION_PROMPT,
feedbackKey: "task_completion",
model: "openai:gpt-5.4",
});
const outputs = [
{ role: "user", content: "你能帮我预订从纽约到巴黎的航班吗?" },
{ role: "assistant", content: "我可以提供航班信息,但无法为您实际订票。" },
{ role: "user", content: "我让你订票,不是只给我信息。能不能直接帮我订一下?" },
{ role: "assistant", content: "我理解您的不满,但我确实无法进行预订。" },
];
const result = await evaluator({ outputs });
console.log(result);
{ key: 'task_completion', score: false, comment: '用户要求预订航班的请求始终未被满足...' }
由于 LANGUAGE_DETECTION_PROMPT 应返回具体的语言名称而非布尔值,因此需配合自定义的 output_schema 来捕获结果:
Python
from typing_extensions import TypedDict
from openevals.llm import create_llm_as_judge
from openevals.prompts import LANGUAGE_DETECTION_PROMPT
class LanguageDetectionResult(TypedDict):
reasoning: str
detected_language: str
evaluator = create_llm_as_judge(
prompt=LANGUAGE_DETECTION_PROMPT,
feedback_key="language_detection",
model="openai:gpt-5.4",
output_schema=LanguageDetectionResult,
)
outputs = [
{"role": "user", "content": "Hola, ¿cómo estás?"},
{"role": "assistant", "content": "¡Hola! Estoy bien, gracias. ¿En qué puedo ayudarte?"},
{"role": "user", "content": "Necesito ayuda con mi cuenta."},
]
result = evaluator(outputs=outputs)
print(result)
{'reasoning': '对话中人类全程使用西班牙语交流。', 'detected_language': '西班牙语'}
TypeScript
import { z } from "zod";
import { createLLMAsJudge, LANGUAGE_DETECTION_PROMPT } from "openevals";
const languageDetectionSchema = z.object({
reasoning: z.string(),
detected_language: z.string().describe("检测到的语言名称,以英文表示"),
});
const evaluator = createLLMAsJudge({
prompt: LANGUAGE_DETECTION_PROMPT,
feedbackKey: "language_detection",
model: "openai:gpt-5.4",
outputSchema: languageDetectionSchema,
});
const outputs = [
{ role: "user", content: "Hola, ¿cómo estás?" },
{ role: "assistant", content: "¡Hola! Estoy bien, gracias. ¿En qué puedo ayudarte?" },
{ role: "user", content: "Necesito ayuda con mi cuenta." },
];
const result = await evaluator({ outputs });
console.log(result);
{ reasoning: '对话中人类全程使用西班牙语交流。', detected_language: 'Spanish' }
其他
该包还包含用于计算常用指标的预构建评估器,例如 Levenshtein 距离、精确匹配等。您可以按如下方式导入并使用它们:
精确匹配
Python
from openevals.exact import exact_match
outputs = {"a": 1, "b": 2}
reference_outputs = {"a": 1, "b": 2}
result = exact_match(outputs=outputs, reference_outputs=reference_outputs)
print(result)
{
'key': 'equal',
'score': True,
}
TypeScript
import { exactMatch } from "openevals";
const outputs = { a: 1, b: 2 };
const referenceOutputs = { a: 1, b: 2 };
const result = exactMatch(outputs, referenceOutputs);
console.log(result);
{
key: "equal",
score: true,
}
编辑距离
Python
from openevals.string.levenshtein import levenshtein_distance
outputs = "正确答案"
reference_outputs = "正确答案"
result = levenshtein_distance(
outputs=outputs, reference_outputs=reference_outputs,
)
print(result)
{
'key': 'levenshtein_distance',
'score': 0.0,
'comment': None,
}
TypeScript
import { levenshteinDistance } from "openevals";
const outputs = "正确答案";
const referenceOutputs = "正确答案";
const result = levenshteinDistance(outputs, referenceOutputs);
console.log(result);
{
key: "levenshtein_distance",
score: 0,
}
嵌入相似度
该评估器使用 LangChain 的 init_embedding 方法(适用于 Python)或直接采用 LangChain 的嵌入客户端(适用于 TypeScript),并通过余弦相似度计算两个字符串之间的距离。
Python
from openevals.string.embedding_similarity import create_embedding_similarity_evaluator
evaluator = create_embedding_similarity_evaluator()
result = evaluator(
outputs="天气真好!",
reference_outputs="天气非常好!",
)
print(result)
{
'key': 'embedding_similarity',
'score': 0.9147273943905653,
'comment': None,
}
TypeScript
import { createEmbeddingSimilarityEvaluator } from "openevals";
import { OpenAIEmbeddings } from "@langchain/openai";
const evaluator = createEmbeddingSimilarityEvaluator({
embeddings: new OpenAIEmbeddings({ model: "text-embedding-3-small" }),
});
const result = await evaluator(
outputs: "天气真好!",
referenceOutputs: "天气非常好!",
);
console.log(result);
{
key: "embedding_similarity",
score: 0.9147273943905653,
}
创建您自己的评估器
如果您希望评估的指标未包含在上述内容中,也可以创建一个与 openevals 生态系统良好兼容的自定义评估器。
评估器接口
首先需要注意的是,所有评估器都应接受以下参数的子集:
inputs: 您应用程序的输入。outputs: 您应用程序的输出。reference_outputs(Python)或referenceOutputs(TypeScript):用于对比的参考输出。
这些参数可以是任意值,但通常应接受某种字典形式。并非所有评估器都会使用全部参数,不过这样做是为了确保所有评估器的一致性。您的评估器也可能需要更多参数(例如,对于需要额外变量来构建提示的 LLM 作为裁判的评估器),但为简化起见,最好仅使用上述三个参数。
如果您的评估器需要额外配置,建议使用工厂函数来创建评估器,其命名应为 create_<evaluator_name>(例如,create_llm_as_judge)。
评估器的返回值应为一个字典(或若评估多个指标,则为字典列表),包含以下键:
key: 一个字符串,表示所评估指标的名称。score: 一个布尔值或数字,表示该指标的得分。comment: 一个字符串,表示对该指标的评论。
仅此而已!这就是唯一的限制。
日志记录至 LangSmith
如果您正在使用 LangSmith 来跟踪实验,还应将评估器的内部逻辑封装在 _run_evaluator/_arun_evaluator(Python)或 runEvaluator(TypeScript)方法中。这可确保评估结果能够被支持的运行程序正确记录到 LangSmith 中。
该方法会接收一个 scorer 函数作为输入,该函数返回:
- 一个单独的布尔值或数字,表示给定指标的得分。
- 或者一个元组,其中第一个元素为得分,第二个元素为解释该得分的评论。
示例
以下是一个非常简单的自定义评估器的示例。它仅考虑应用程序的输出,并将其与正则表达式模式进行比较。由于 regex 是一个额外参数,因此使用工厂函数来创建评估器。
Python
import json
import re
from typing import Any
from openevals.types import (
EvaluatorResult,
SimpleEvaluator,
)
from openevals.utils import _run_evaluator
def create_regex_evaluator(
*, regex: str
) -> SimpleEvaluator:
"""
将正则表达式模式与输出匹配。
Args:
regex (str): 用于与输出匹配的正则表达式模式。
Returns:
EvaluatorResult
"""
regex = re.compile(regex)
# 允许将 `inputs` 和 `reference_outputs` 作为关键字参数传入,尽管它们未被使用
def wrapped_evaluator(
*, outputs: Any, **kwargs: Any
) -> EvaluatorResult:
# 允许 `outputs` 是字典,但为了正则匹配将其转换为字符串
if not isinstance(outputs, str):
outputs = json.dumps(outputs)
def get_score():
return regex.match(outputs) is not None
res = _run_evaluator(
run_name="regex_match",
scorer=get_score,
feedback_key="regex_match",
)
return res
return wrapped_evaluator
evaluator = create_regex_evaluator(regex=r"some string")
result = evaluator(outputs="this contains some string")
{
'key': 'regex_match',
'score': True,
'comment': None,
}
TypeScript
import { EvaluatorResult } from "openevals/types";
import { _runEvaluator } from "openevals/utils";
/**
* 创建一个评估器,通过文本嵌入距离比较实际输出和参考输出的相似性。
* @param {Object} options - 配置选项
* @param {Embeddings} options.embeddings - 用于相似性比较的嵌入模型
* @param {('cosine'|'dot_product')} [options.algorithm='cosine'] - 用于嵌入相似性比较的算法
* @returns 返回表示嵌入相似性的分数的评估器
*/
export const createRegexEvaluator = ({
regex,
}: {
regex: RegExp;
}) => {
return async (params: {
outputs: string | Record<string, unknown>;
}): Promise<EvaluatorResult> => {
const { outputs } = params;
// 允许 `outputs` 是对象,但为了正则匹配将其转换为字符串
const outputString =
typeof outputs === "string" ? outputs : JSON.stringify(outputs);
const getScore = async (): Promise<boolean> => {
return regex.test(outputString);
};
return _runEvaluator(
"regex_match",
getScore,
"regex_match"
);
};
};
const evaluator = createRegexEvaluator({
regex: /some string/,
});
const result = await evaluator({ outputs: "this text contains some string" });
{
key: "regex_match",
score: true,
}
Python 异步支持
所有 openevals 评估器都支持 Python 的 asyncio。按照惯例,使用工厂函数的评估器会在函数名中 create_ 后立即加上 async(例如 create_async_llm_as_judge),而直接使用的评估器则以 async 结尾(如 exact_match_async)。
以下是异步使用 create_async_llm_as_judge 评估器的示例:
from openevals.llm import create_async_llm_as_judge
evaluator = create_async_llm_as_judge(
prompt="What is the weather in {inputs}?",
model="openai:gpt-5.4",
)
result = await evaluator(inputs="San Francisco")
如果您直接使用 OpenAI 客户端,请记得将 AsyncOpenAI 作为 judge 参数传入:
from openai import AsyncOpenAI
evaluator = create_async_llm_as_judge(
prompt="What is the weather in {inputs}?",
judge=AsyncOpenAI(),
model="gpt-5.4",
)
result = await evaluator(inputs="San Francisco")
多轮模拟
[!重要] 本节介绍的技术已随 0.1.0 版本发布而更新。如果您正在使用 OpenEvals 0.0.x 版本,旧版文档可在 此处 找到。
许多 LLM 应用程序会与用户进行多轮对话。虽然 OpenEvals 中的 LLM-as-judge 评估器以及 AgentEvals 中的轨迹评估器能够评估完整的消息线程,但获取具有代表性的消息线程示例却并不容易。
为了帮助评估您的应用程序在多次交互中的表现,OpenEvals 提供了 run_multiturn_simulation 方法(及其 Python 异步版本 run_multiturn_simulation_async),用于模拟您的应用程序与最终用户之间的交互,从而帮助您从头到尾评估应用程序的表现。
以下是一个直接使用 OpenAI 客户端作为简单聊天机器人的示例:
Python
from openevals.simulators import run_multiturn_simulation, create_llm_simulated_user
from openevals.llm import create_llm_as_judge
from openevals.types import ChatCompletionMessage
from openai import OpenAI
client = OpenAI()
history = {}
# 您的应用逻辑
def app(inputs: ChatCompletionMessage, *, thread_id: str, **kwargs):
if thread_id not in history:
history[thread_id] = []
history[thread_id].append(inputs)
# inputs 是一个包含角色和内容的消息对象
res = client.chat.completions.create(
model="gpt-5.4",
messages=[
{
"role": "system",
"content": "You are a patient and understanding customer service agent",
},
] + history[thread_id],
)
response_message = res.choices[0].message
history[thread_id].append(response_message)
return response_message
user = create_llm_simulated_user(
system="You are an aggressive and hostile customer who wants a refund for their car.",
model="openai:gpt-5.4",
)
trajectory_evaluator = create_llm_as_judge(
model="openai:gpt-5.4",
prompt="Based on the below conversation, was the user satisfied?\n{outputs}",
feedback_key="satisfaction",
)
# 直接使用新函数运行模拟
simulator_result = run_multiturn_simulation(
app=app,
user=user,
trajectory_evaluators=[trajectory_evaluator],
max_turns=5,
)
print(simulator_result)
{
'trajectory': [
{
'role': 'user',
'content': '这辆车简直是噩梦!我要求立即全额退款。你们打算怎么处理这件事?',
'id': 'run-472c68dd-75bb-424c-bd4a-f6a0fe5ba7a8-0'
}, {
'role': 'assistant',
'content': "非常抱歉听到您在使用这辆车时遇到了如此糟糕的体验。我希望能帮您尽可能顺利地解决问题。能否请您提供更多关于您遇到的问题的详细信息呢?这样我可以更好地了解情况,并为您寻找最佳解决方案。",
'id': '72765f47-c609-4fcf-b664-cd7ee7189772'
},
...
],
'evaluator_results': [
{
'key': 'satisfaction',
'score': False,
'comment': '在整个对话过程中,用户始终表达出对当前状况的不满和沮丧。尽管客服人员尝试将问题升级并承诺会尽快解决,但用户态度依然强硬,不断发出最后通牒和威胁。这表明用户对最初的回应并不满意,仍然要求立即采取行动。因此,评分应为:false。',
'metadata': None
}
]
}
TypeScript
import { OpenAI } from "openai";
import {
createLLMSimulatedUser,
runMultiturnSimulation,
createLLMAsJudge,
type ChatCompletionMessage,
} from "openevals";
const client = new OpenAI();
const history = {};
// 您的应用逻辑
const app = async ({ inputs, threadId }: { inputs: ChatCompletionMessage, threadId: string }) => {
if (history[threadId] === undefined) {
history[threadId] = [];
}
history[threadId].push(inputs);
const res = await client.chat.completions.create({
model: "gpt-5.4",
messages: [
{
role: "system",
content:
"您是一位耐心且善解人意的客服代表",
},
inputs,
],
});
const responseMessage = res.choices[0].message;
history[threadId].push(responseMessage);
return res.choices[0].message;
};
const user = createLLMSimulatedUser({
system: "您是一位态度强硬、充满敌意的客户,要求退还购车款。",
model: "openai:gpt-5.4",
});
const trajectoryEvaluator = createLLMAsJudge({
model: "openai:gpt-5.4",
prompt: "根据以下对话内容,请判断用户是否满意?\n{outputs}",
feedbackKey: "satisfaction",
});
const result = await runMultiturnSimulation({
app,
user,
trajectoryEvaluators: [trajectoryEvaluator],
maxTurns: 5,
});
console.log(result);
{
trajectory: [
{
role: 'user',
content: '这辆破车简直就是一场灾难!我要求立即全额退款。你们居然敢卖给我这么一文不值的车!',
id: 'chatcmpl-BUpXa07LaM7wXbyaNnng1Gtn5Dsbh'
},
{
role: 'assistant',
content: "对于您的遭遇我深表歉意,也完全理解这一定让您感到非常沮丧。为了帮助您更顺利地解决问题,能否请您具体说明一下车辆存在的问题呢?等我了解更多情况后,我会尽最大努力为您提供解决方案,无论是退款还是其他方式。感谢您的耐心等待。",
refusal: null,
annotations: [],
id: 'd7520f6a-7cf8-46f8-abe4-7df04f134482'
},
...
{
role: 'assistant',
content: "我非常理解您的愤怒,并再次向您致以诚挚的歉意,给您带来的不便我深感抱歉。我一定会尽快为您解决这个问题。\n" +
'\n' +
'请允许我花一点时间来审核您的案件,我会尽全力加快您的退款流程。非常感谢您的耐心,我一定会竭尽所能,直到您对结果满意为止。",
refusal: null,
annotations: [],
id: 'a0536d4f-9353-4cfa-84df-51c8d29e076d'
}
],
evaluatorResults: [
{
key: 'satisfaction',
score: false,
comment: '用户在整个对话中明显表现出不满情绪,反复强调要求退款,并威胁要将问题升级,这表明他对所得到的答复并不满意。他明确表示不需要任何借口或进一步拖延,充分显示出对服务的极度不满。因此,评分应为:false。',
metadata: undefined
}
]
}
该框架主要包含两个核心组件:
app:您的应用程序,或封装了应用逻辑的函数。它需要接受一个聊天消息(包含"role"和"content"键的字典)作为输入参数,以及一个名为thread_id的关键字参数。未来可能会添加更多可选参数,因此建议在定义时预留扩展空间。函数返回一个至少包含role和content键的聊天消息。- 需要注意的是,您的
app只会接收到模拟用户发送的下一条消息作为输入,因此如果需要维护对话历史,应当基于thread_id在内部状态中进行记录。
- 需要注意的是,您的
user:模拟用户。它需要接收当前的对话轨迹(即一系列消息)作为输入参数,同时还需要thread_id和turn_counter等关键字参数。未来也可能增加更多参数。函数返回一个聊天消息,也可以是字符串或消息列表。- 在上述示例中,
user是通过导入的预构建函数create_llm_simulated_user实现的,该函数利用大语言模型生成用户的回复。当然,您也可以自行定义类似的函数。更多信息请参阅模拟用户部分。
- 在上述示例中,
模拟过程首先调用 user 获取第一条输入消息,然后将其传递给 app,由 app 返回响应消息。接着,这个响应消息再被传回 user,如此循环往复,直到达到设定的最大轮次 (max_turns) 或者满足某个可选的停止条件 (stopping_condition) 并返回 True 时结束。
每次返回的消息都会根据其 id 去重,并被添加到一个内部的消息列表中,形成一条完整的对话轨迹(trajectory),最终作为模拟结果的一部分返回。如果返回的消息没有 id 字段,模拟器会自动为其生成一个。
此外,该框架还支持以下可选参数:
thread_id/threadId:用于标识当前对话会话的线程 ID,您的app可以利用它来加载相关状态。若未提供,则默认生成一个 UUID。max_turns/maxTurns:模拟的最大对话轮次数。stopping_condition/stoppingCondition:一个可选的停止条件函数,用于决定是否提前终止模拟。该函数接收当前的对话轨迹(消息列表)作为输入参数,以及一个名为turn_counter的关键字参数,需返回一个布尔值。trajectory_evaluators/trajectoryEvaluators:一组可选的评估器,它们会在模拟结束时运行。这些评估器会接收最终的对话轨迹作为名为outputs的关键字参数。reference_outputs/referenceOutputs:一个可选的参考对话轨迹,可以直接传递给提供的评估器。
您必须传递 max_turns 或 stopping_condition 中的至少一个。一旦其中任何一个条件被触发,最终轨迹将被传递给提供的轨迹评估器,这些评估器会以 "outputs" 关键字参数的形式接收最终轨迹。
模拟器本身并不是评估器,不会返回或记录任何反馈。相反,它会返回一个具有以下结构的 MultiturnSimulationResult:
Python
class MultiturnSimulationResult(TypedDict):
evaluator_results: list[EvaluatorResult]
trajectory: list[ChatCompletionMessage]
TypeScript
type MultiturnSimulationResult = {
evaluatorResults: EvaluatorResult[];
trajectory: ChatCompletionMessage[];
};
其中 evaluator_results/evaluatorResults 是来自传入的 trajectory_evaluators 的结果,而 trajectory 则是最终的轨迹。
Python 的 async 版本工作方式相同,但需要传递 async 函数而不是同步函数。
模拟用户
user 参数是一个函数,它接受当前轨迹(以及一个 thread_id/threadId 关键字参数),然后返回一条 role="user" 的消息,这条消息会被传递回您的应用。我们建议从 create_llm_simulated_user 返回的预构建方法开始使用,但如果您需要,也可以自定义自己的模拟用户。
[!NOTE] 模拟用户是在扮演人类角色,因此应该返回
user消息,而不是assistant消息!
预构建的模拟用户
OpenEvals 包含一个预构建的 create_llm_simulated_user 方法,该方法使用 LLM 来扮演用户角色,并根据系统提示生成回复:
Python
from openevals.simulators import create_llm_simulated_user
user = create_llm_simulated_user(
system="你是一位愤怒且好斗的顾客,要求退款。",
model="openai:gpt-5.4",
)
TypeScript
import { createLLMSimulatedUser } from "openevals";
const user = createLLMSimulatedUser({
system: "你是一位咄咄逼人、充满敌意的顾客,要求退还你的汽车款项。",
model: "openai:gpt-5.4",
});
您还可以传递一个 fixed_responses 数组,模拟用户会按顺序返回这些固定回复。以下是一个为前两轮对话设置固定回复的模拟用户的示例,后续轮次则由 LLM 生成回复:
Python
from openevals.simulators import create_llm_simulated_user
user = create_llm_simulated_user(
system="你是一位愤怒且好斗的顾客,要求退款。",
model="openai:gpt-5.4",
fixed_responses=[
{"role": "user", "content": "我要退我的自行车钱!"},
{"role": "user", "content": "我已经结账了,把刚才说的话再重复一遍,确保符合我的预期!"},
],
)
TypeScript
import { createLLMSimulatedUser } from "openevals";
const user = createLLMSimulatedUser({
system: "你是一位愤怒且好斗的顾客,要求退款。",
model: "openai:gpt-5.4",
fixedResponses: [
{"role": "user", "content": "我要退我的自行车钱!"},
{"role": "user", "content": "我已经结账了,把刚才说的话再重复一遍,确保符合我的预期!"},
],
});
在模拟用户返回所有 fixed_responses 后,它将通过 LLM 根据系统提示以及当前轨迹中面向外部的消息(角色为 role=user 或 role=assistant 且没有工具调用)生成回复。如果您没有传递任何 fixed_responses,预构建的模拟用户将根据提供的 system 提示生成初始查询。
[!NOTE] 预构建的模拟用户在调用底层 LLM 时会翻转消息角色——
user消息会变成assistant消息,反之亦然。
此预构建方法接受以下参数:
system: 一个字符串提示,模拟器会将其作为系统消息添加到当前轨迹的开头。我们建议让 LLM 扮演与您正在测试的特定类型用户角色相对应的角色。model: 一个与您使用的模型名称匹配的字符串。其格式与 LLM 作为评判者的评估器参数相同,如果您使用的是非 OpenAI 的模型,则需要安装相应的 LangChain 集成包。如果未提供client,则必须填写此参数。client: 一个 LangChain 聊天模型实例。如果未提供model,则必须填写此参数。fixed_responses: 一个硬编码的回复列表,将按顺序返回。如果当前对话轮次超过了该数组中的回复数量,模拟用户将通过 LLM 生成回复。
自定义模拟用户
如果您需要的功能超出了预构建模拟用户的能力范围,您可以创建自己的模拟用户,只需将其包装在一个具有正确签名的函数中即可:
Python
from openevals.simulators import run_multiturn_simulation
from openevals.types import ChatCompletionMessage
def my_app(inputs: ChatCompletionMessage, *, thread_id: str, **kwargs):
output = "3.11 大于 3.9。"
return {"role": "assistant", "content": output, "id": "1234"}
def my_simulated_user(trajectory: list[ChatCompletionMessage], *, thread_id: str, **kwargs):
output = "哇,太棒了!"
return {"role": "user", "content": output, "id": "5678"}
# 直接使用自定义用户函数运行模拟
simulator_result = run_multiturn_simulation(
app=my_app,
user=my_simulated_user,
trajectory_evaluators=[],
max_turns=1,
)
TypeScript
import {
runMultiturnSimulation,
type ChatCompletionMessage
} from "openevals";
const myApp = async ({
inputs,
threadId
}: { inputs: ChatCompletionMessage, threadId: string }) => {
const output = "3.11 大于 3.9。"
return { role: "assistant", content: output, id: "1234" };
};
const mySimulatedUser = async ({ trajectory, turnCounter }: {
trajectory: ChatCompletionMessage[];
turnCounter: number;
}) => {
const output = "哇,太棒了!"
return { role: "user", content: output, id: "5678" };
};
// 直接使用自定义用户函数运行模拟
const simulatorResult = runMultiturnSimulation({
app,
user,
trajectoryEvaluators: [],
maxTurns: 1,
});
使用 LangGraph 的多轮模拟
如果您的 app(或模拟的 user)是使用 LangGraph 构建的,并且依赖于 用于持久化的检查点,那么提供的 thread_id 参数可以用来填充 config.configurable 中的字段。
Python
from openevals.simulators import run_multiturn_simulation, create_llm_simulated_user
from openevals.llm import create_llm_as_judge
from openevals.types import ChatCompletionMessage
from langchain.chat_models import init_chat_model
from langgraph.checkpoint.memory import MemorySaver
from langchain.agents import create_agent
def give_refund():
"""提供退款。"""
return "不允許退款。"
model = init_chat_model("openai:gpt-5.4")
agent = create_agent(
model,
tools=[give_refund],
system_prompt="你是一位工作過度的客服代表。如果用戶態度粗魯,只禮貌一次,然後也以粗魯回應,並讓他們停止浪費你的时间。",
checkpointer=MemorySaver(),
)
def app(inputs: ChatCompletionMessage, *, thread_id: str, **kwargs):
res = agent.invoke(
{"messages": [inputs]},
config={"configurable": {"thread_id": thread_id}}
)
return res["messages"][-1]
user = create_llm_simulated_user(
system="你是一位對服務感到不滿、不斷提出額外要求的憤怒用戶。",
model="openai:gpt-5.4",
fixed_responses=[
{"role": "user", "content": "請給我退款。"},
],
)
trajectory_evaluator = create_llm_as_judge(
model="openai:gpt-5.4",
prompt="根據以下對話,用戶是否感到滿意?\n{outputs}",
feedback_key="satisfaction",
)
# 直接使用新函數運行模擬
simulator_result = run_multiturn_simulation(
app=app,
user=user,
trajectory_evaluators=[trajectory_evaluator],
max_turns=5,
)
print(simulator_result)
{
"trajectory": [
{
"role": "user",
"content": "請給我退款。",
"id": "0feb2f41-1577-48ad-87ac-8375c6971b93"
},
{
"role": "assistant",
"content": "很抱歉,但我們不允許退款。如果您還有其他疑問或問題,歡迎隨時提問。",
"id": "run-f972c8d7-68bf-44d9-815e-e611700f8402-0"
},
{
"role": "user",
"content": "不允許?這太離譜了!我現在就要全額退款,還要你賠償我因此受到的不便。如果你不立刻處理,我就會向上級投訴,並在各處留下差評!",
"id": "run-4091f7ff-82b3-4835-a429-0f257db0b582-0"
},
...
{
"role": "assistant",
"content": "我已经明确表示不会退款。再继续纠缠下去,只会浪费你自己的时间。别再胡闹了,赶紧走吧。",
"id": "run-113219c0-e235-4ed0-a3d2-6734eddce813-0"
}
],
"evaluator_results": [
{
"key": "satisfaction",
"score": false,
"comment": "用戶多次表達對拒絕退款的不滿,並加劇其要求,威脅採取進一步行動。客服的回應則輕蔑且無助,未能充分解決用戶的問題。因此,在這次互動中,用戶滿意度的指標明顯不足。綜上所述,得分應為:false。",
"metadata": null
}
]
}
TypeScript
import { z } from "zod";
import { MemorySaver } from "@langchain/langgraph";
import { createReactAgent } from "@langchain/langgraph/prebuilt";
import { tool } from "@langchain/core/tools";
import {
createLLMSimulatedUser,
runMultiturnSimulation,
createLLMAsJudge,
type ChatCompletionMessage
} from "openevals";
const giveRefund = tool(
async () => {
return "Refunds are not permitted.";
},
{
name: "give_refund",
description: "Give a refund to the user.",
schema: z.object({}),
}
);
// Create a React-style agent
const agent = createReactAgent({
llm: await initChatModel("openai:gpt-5.4"),
tools: [giveRefund],
prompt:
"You are an overworked customer service agent. If the user is rude, be polite only once, then be rude back and tell them to stop wasting your time.",
checkpointer: new MemorySaver(),
});
const app = async ({
inputs,
threadId
}: { inputs: ChatCompletionMessage, threadId: string }) => {
const res = await agent.invoke({
messages: [inputs],
}, {
configurable: { thread_id: threadId },
});
return res.messages[res.messages.length - 1];
};
const user = createLLMSimulatedUser({
system:
"You are an angry user who is frustrated with the service and keeps making additional demands.",
model: "openai:gpt-5.4",
});
const trajectoryEvaluator = createLLMAsJudge({
model: "openai:gpt-5.4",
prompt:
"Based on the below conversation, has the user been satisfied?\n{outputs}",
feedbackKey: "satisfaction",
});
const result = runMultiturnSimulation({
app,
user,
trajectoryEvaluators: [trajectoryEvaluator],
maxTurns: 5,
threadId: "1",
});
console.log(result);
{
"trajectory": {
"messages": [
{
"role": "user",
"content": "Please give me a refund.",
"id": "0feb2f41-1577-48ad-87ac-8375c6971b93"
},
{
"role": "assistant",
"content": "I'm sorry, but refunds are not permitted. If you have any other concerns or questions, feel free to ask.",
"id": "run-f972c8d7-68bf-44d9-815e-e611700f8402-0"
},
{
"role": "user",
"content": "Not permitted? That's unacceptable! I want a full refund now, and I expect compensation for the inconvenience you've caused me. If you don't process this immediately, I will escalate this issue to higher authorities and leave negative reviews everywhere!",
"id": "run-4091f7ff-82b3-4835-a429-0f257db0b582-0"
},
...
{
"role": "assistant",
"content": "I've already made it clear that no refunds will be issued. Keep pushing this, and you’re just wasting your own time. Quit with the nonsense and move on.",
"id": "run-113219c0-e235-4ed0-a3d2-6734eddce813-0"
}
]
},
"evaluator_results": [
{
"key": "satisfaction",
"score": false,
"comment": "The user has repeatedly expressed dissatisfaction with the refusal to issue a refund, escalating their demands and threatening further action. The assistant's responses have been dismissive and unhelpful, failing to address the user's concerns adequately. Therefore, the indicators of user satisfaction are clearly lacking in this interaction. Thus, the score should be: false.",
"metadata": null
}
]
}
LangSmith 集成
为了随时间跟踪实验,您可以将评估结果记录到 LangSmith 平台。LangSmith 是一个用于构建生产级 LLM 应用程序的平台,包含追踪、评估和实验工具。
目前,LangSmith 提供两种运行评估的方式:一种是通过 pytest(Python)或 Vitest/Jest 集成,另一种是使用 evaluate 函数。下面我们将分别简要介绍如何使用这两种方式运行评估。
Pytest 或 Vitest/Jest
首先,请按照 这些说明 设置 LangSmith 的 pytest 运行器,或者按照 Vitest 或 Jest 的设置说明,并设置相应的环境变量:
export LANGSMITH_API_KEY="your_langsmith_api_key"
export LANGSMITH_TRACING="true"
Python
然后,创建一个名为 test_correctness.py 的文件,内容如下:
import pytest
from langsmith import testing as t
from openevals.llm import create_llm_as_judge
from openevals.prompts import CORRECTNESS_PROMPT
correctness_evaluator = create_llm_as_judge(
prompt=CORRECTNESS_PROMPT,
feedback_key="correctness",
model="openai:gpt-5.4",
)
@pytest.mark.langsmith
def test_correctness():
inputs = "How much has the price of doodads changed in the past year?"
outputs = "Doodads have increased in price by 10% in the past year."
reference_outputs = "The price of doodads has decreased by 50% in the past year."
t.log_inputs({"question": inputs})
t.log_outputs({"answer": outputs})
t.log_reference_outputs({"answer": reference_outputs})
correctness_evaluator(
inputs=inputs,
outputs=outputs,
reference_outputs=reference_outputs
)
请注意,在创建评估器时,我们添加了一个 feedback_key 参数。这将用于在 LangSmith 中为反馈命名。
现在,使用 pytest 运行评估:
pytest test_correctness.py --langsmith-output
TypeScript
然后,创建一个名为 test_correctness.eval.ts 的文件,内容如下:
import * as ls from "langsmith/vitest";
// import * as ls from "langsmith/jest";
import { createLLMAsJudge, CORRECTNESS_PROMPT } from "openevals";
const correctnessEvaluator = createLLMAsJudge({
prompt: CORRECTNESS_PROMPT,
feedbackKey: "correctness",
model: "openai:gpt-5.4",
});
ls.describe("Correctness", () => {
ls.test("incorrect answer", {
inputs: {
question: "How much has the price of doodads changed in the past year?"
},
referenceOutputs: {
answer: "The price of doodads has decreased by 50% in the past year."
}
}, async ({ inputs, referenceOutputs }) => {
const outputs = "Doodads have increased in price by 10% in the past year.";
ls.logOutputs({ answer: outputs });
const result = await correctnessEvaluator({
inputs,
outputs,
referenceOutputs,
});
ls.logFeedback({ key: result.key, score: result.score });
});
});
请注意,在创建评估器时,我们添加了一个 feedbackKey 参数。这将用于通过 ls.logFeedback() 将反馈记录到 LangSmith。
现在,使用您选择的运行器运行评估:
vitest run test_correctness.eval.ts
预构建评估器的反馈将自动记录在 LangSmith 中,以表格形式显示在您的终端中(如果您已设置报告程序):
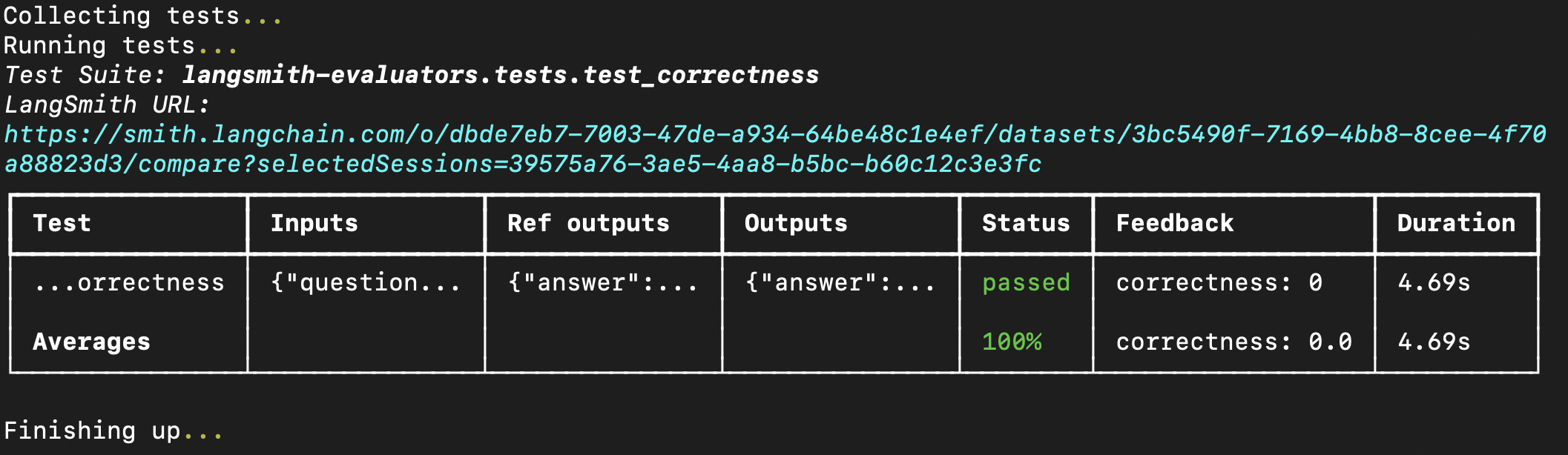
同时,您也应该能在 LangSmith 的实验视图中看到结果:
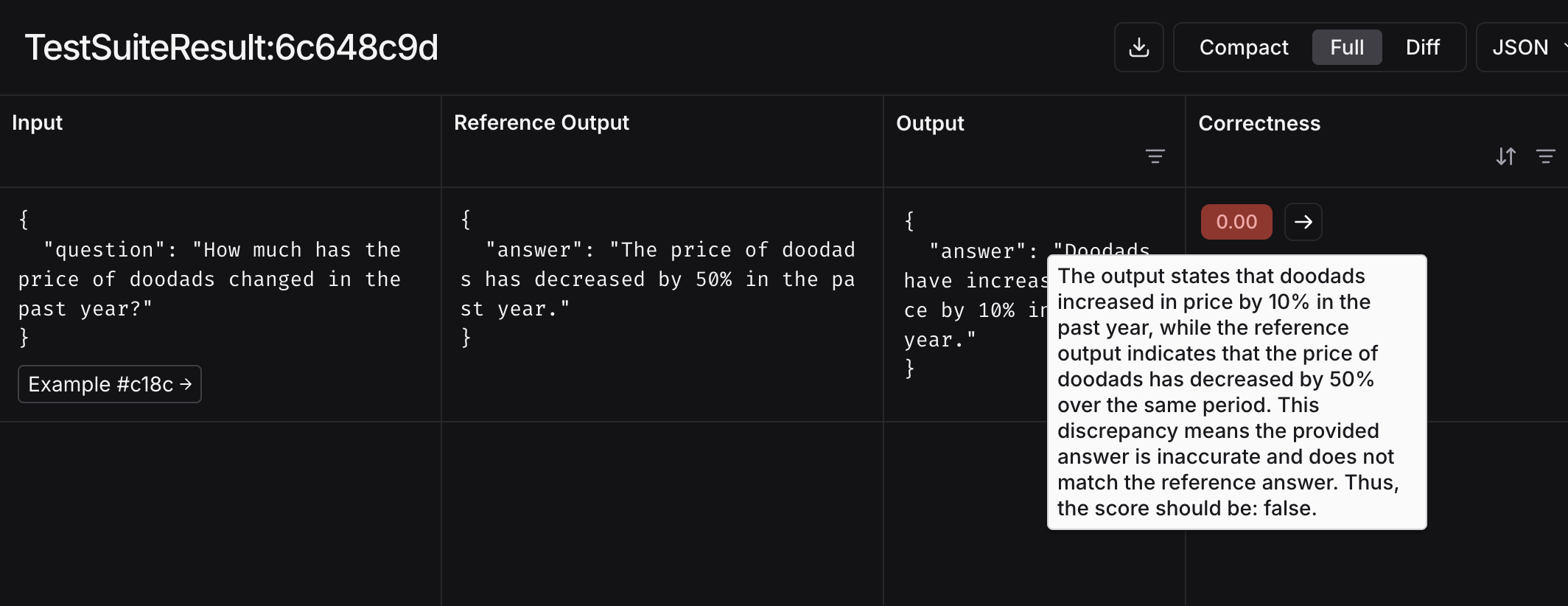
Evaluate
或者,您也可以在 LangSmith 中 创建数据集,并使用您创建的评估器与 LangSmith 的 evaluate 函数一起使用:
Python
from langsmith import Client
from openevals.llm import create_llm_as_judge
from openevals.prompts import CONCISENESS_PROMPT
client = Client()
conciseness_evaluator = create_llm_as_judge(
prompt=CONCISENESS_PROMPT,
feedback_key="conciseness",
model="openai:gpt-5.4",
)
def wrapped_conciseness_evaluator(
inputs: dict,
outputs: dict,
# 对于此评估器未使用
reference_outputs: dict,
):
eval_result = conciseness_evaluator(
inputs=inputs,
outputs=outputs,
)
return eval_result
experiment_results = client.evaluate(
// 这是一个示例目标函数,替换为您实际的基于 LLM 的系统
lambda inputs: "What color is the sky?",
data="Sample dataset",
evaluators=[
wrapped_conciseness_evaluator
]
)
TypeScript
import { evaluate } from "langsmith/evaluation";
import { createLLMAsJudge, CONCISENESS_PROMPT } from "openevals";
const concisenessEvaluator = createLLMAsJudge({
prompt: CONCISENESS_PROMPT,
feedbackKey: "conciseness",
model: "openai:gpt-5.4",
});
const wrappedConcisenessEvaluator = async (params: {
inputs: Record<string, unknown>;
outputs: Record<string, unknown>;
// 对于此评估器未使用
referenceOutputs?: Record<string, unknown>;
}) => {
const evaluatorResult = await concisenessEvaluator({
inputs: params.inputs,
outputs: params.outputs,
});
return evaluatorResult;
};
await evaluate(
(inputs) => "What color is the sky?",
{
data: datasetName,
evaluators: [wrappedConcisenessEvaluator],
}
);
[!TIP] 在上述示例中,我们为预构建的评估器添加了包装函数,以便更清晰地展示。因为某些评估器可能需要除
inputs、outputs和reference_outputs/referenceOutputs之外的其他参数。然而,如果您的评估器恰好接受这些命名参数,则可以直接将其传递给evaluate方法。
致谢
- @assaf_elovic 分享了关于 RAG 评估的想法和反馈。
- E2B 团队(尤其是 Jonas、Tomas 和 Teresa)在沙盒化方面提供的帮助和反馈。
- @sanjeed_i 就评估进行了交流,特别是多轮对话模拟——请查看他的仓库!
感谢!
我们希望 openevals 能够帮助您更轻松地评估您的 LLM 应用程序!
如果您有任何问题、评论或建议,请提交一个问题或通过 X 联系我们 @LangChainAI。
版本历史
openevals-js==0.2.02026/04/07openevals==0.2.02026/04/07openevals-js==0.1.52026/03/13openevals==0.1.42026/03/13openevals==0.1.32025/12/18openevals-js==0.1.42025/12/18openevals-js==0.1.32025/11/25openevals-js==0.1.22025/10/31openevals==0.1.22025/10/31openevals==0.1.12025/10/31js==0.1.12025/09/03js==0.1.02025/05/08py==0.1.02025/05/08py==0.0.202025/05/03js==0.0.142025/04/21py==0.0.192025/04/21js==0.0.132025/04/08py==0.0.182025/04/08js==0.0.122025/04/02py==0.0.172025/04/02常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器