Mooncake
Mooncake 是月之暗面(Moonshot AI)为其旗舰大模型服务 Kimi 打造的高性能推理平台,现已开源核心组件。它主要解决大模型在高并发场景下的显存瓶颈与数据传输延迟问题,通过一种“以 KVCache 为中心”的分离式架构,将计算与显存管理解耦。这种设计让多张显卡甚至多台服务器能高效共享关键缓存数据,大幅减少重复计算,显著提升长文本处理和复杂任务时的响应速度与吞吐量。
Mooncake 特别适合从事大模型基础设施开发的工程师、追求极致推理性能的研究人员,以及需要部署大规模 LLM 服务的企业团队。其技术亮点在于自研的 Transfer Engine(传输引擎)和 Mooncake Store,它们实现了跨设备、跨节点的低延迟数据搬运,并支持动态显存池化。目前,Mooncake 已深度集成至 PyTorch 生态,并被 SGLang、vLLM 等主流推理框架采纳,用于优化多模态嵌入缓存及分离式推理流程。如果你正在构建需要处理海量上下文或高流量请求的 AI 应用,Mooncake 提供了一个经过工业级验证的可靠解决方案,帮助你在有限的硬件资源下释放更大的模型潜能。
使用场景
某大型多模态内容平台在高峰期面临海量用户并发请求,需同时处理长文本对话与高分辨率图像理解,导致推理集群负载不均且响应延迟飙升。
没有 Mooncake 时
- 显存资源浪费严重:每个推理实例独立维护 KVCache,相同的前缀提示词(如系统指令或长文档)在不同节点被重复计算和存储,大幅降低显存利用率。
- 跨节点通信瓶颈:在多机部署架构下,缺乏高效的状态迁移机制,导致请求在不同 GPU 间调度时数据传输延迟高,首字生成时间(TTFT)波动剧烈。
- 弹性扩缩容困难:由于推理状态与计算节点强绑定,动态增减实例时难以平滑迁移正在进行的会话,常引发服务中断或需要昂贵的全量重计算。
- 多模态处理冗余:处理视频或多图输入时,视觉编码器(ViT)生成的嵌入向量无法在集群内共享,导致相同的视觉特征被反复提取,浪费大量算力。
使用 Mooncake 后
- 全局缓存共享:Mooncake 的解耦架构实现了 KVCache 的全局池化管理,相同前缀只需计算一次即可被集群内所有实例复用,显存效率提升数倍。
- 高速状态迁移:依托 Mooncake Transfer Engine,推理状态可在毫秒级内在不同设备或机器间无损传输,显著降低 TTFT 并消除长尾延迟。
- 无感弹性伸缩:计算与存储分离使得会话状态可自由漂移,扩容新节点时可瞬间接管现有请求,实现真正的零中断平滑扩缩容。
- 跨实例视觉复用:通过全局多模态嵌入缓存,ViT 提取的特征向量可在不同推理任务间直接共享,彻底避免了对同一视觉输入的重复计算。
Mooncake 通过以 KVCache 为核心的解耦架构,将大模型服务从“单点计算”升级为“集群协同”,在保障极致低延迟的同时大幅降低了算力成本。
运行环境要求
- Linux
- 需要 NVIDIA GPU(支持 RDMA),具体型号未说明但提及生产环境使用 H100/H200
- 支持 CUDA <=12.9 及 CUDA 13.0/13.1
未说明

快速开始






Mooncake 是  Kimi 的推理服务平台,Kimi 是由
Kimi 的推理服务平台,Kimi 是由  Moonshot AI 提供的领先大模型服务。目前,Transfer Engine 和 Mooncake Store 均已开源!本仓库还托管了其技术报告以及开源的数据追踪文件。
Moonshot AI 提供的领先大模型服务。目前,Transfer Engine 和 Mooncake Store 均已开源!本仓库还托管了其技术报告以及开源的数据追踪文件。
🔄 最新动态
- 2026年3月19日: TorchSpec: 大规模推测解码训练 已 开源,利用 Mooncake 通过高效的隐藏状态管理实现推理与训练的解耦。
- 2026年3月5日: LightX2V 现已支持基于 Mooncake 的分离式部署,借助 Mooncake Transfer Engine 实现编码器/Transformer 服务的解耦,从而实现高性能的跨设备、跨机器数据传输。
- 2026年2月25日: SGLang 合并了 Encoder Global Cache Manager,引入由 Mooncake 提供支持的全局多模态嵌入缓存,实现 ViT 嵌入在不同实例间的共享,避免重复的 GPU 计算。
- 2026年2月24日: vLLM-Omni 引入了分离式推理连接器,同时支持
MooncakeStoreConnector和MooncakeTransferEngineConnector,用于多节点全模态流水线。 - 2026年2月12日: Mooncake 加入 PyTorch 生态系统 我们非常高兴地宣布,Mooncake 已正式加入 PyTorch 生态系统!
- 2026年1月28日: FlexKV,由腾讯和 NVIDIA 联合社区开发的分布式 KV 存储与缓存系统,现已支持使用 Mooncake Transfer Engine 进行 分布式 KVCache 复用。
- 2025年12月27日: 与 ROLL 达成合作!论文请见 这里。
- 2025年12月23日: SGLang 引入了 Encode-Prefill-Decode (EPD) 分离,以 Mooncake 作为传输后端。该集成允许将计算密集型多模态编码器(如 Vision Transformer)从语言模型节点中解耦,并利用 Mooncake 的 RDMA 引擎实现大型多模态嵌入的零拷贝传输。
- 2025年12月19日: Mooncake Transfer Engine 已被 集成到 TensorRT LLM 中,用于 PD 分离式推理中的 KVCache 传输。
- 2025年12月19日: Mooncake Transfer Engine 已直接集成到 vLLM v1 中,作为 PD 分离式设置中的 KV 连接器。
- 2025年11月7日: RBG + SGLang HiCache + Mooncake,一种基于角色的云原生部署开箱即用解决方案,具备弹性、可扩展性和高性能。
- 2025年9月18日: Mooncake Store 为 vLLM Ascend 提供支持,作为 分布式 KV 缓存池后端。
- 2025年9月10日: SGLang 正式支持 Mooncake Store 作为 层次化 KV 缓存存储后端。该集成将 RadixAttention 扩展至跨设备、主机及远程存储层的多级 KV 缓存存储。
- 2025年9月10日: Mooncake P2P Store 的官方高性能版本已作为 checkpoint-engine 开源。它已成功应用于 K1.5 和 K2 的生产训练中,在数千张 GPU 上以约 20 秒的时间更新 Kimi-K2 模型(1T 参数)。
- 2025年8月23日: xLLM 高性能推理引擎基于 Mooncake 构建混合 KV 缓存管理方案,支持全局 KV 缓存管理,并具备智能卸载与预取功能。
- 2025年8月18日: vLLM-Ascend 集成 Mooncake Transfer Engine 用于 KV 缓存注册和分离式预填充,从而实现 Ascend NPU 上的高效分布式推理。
- 2025年7月20日: Mooncake 支持 Kimi K2 的部署 在 128 张 H200 GPU 上采用 PD 分离和大规模专家并行技术,实现了 224k tokens/sec 的预填充吞吐量和 288k tokens/sec 的解码吞吐量。
- 2025年6月20日: Mooncake 成为 LMDeploy 的 PD 分离式 后端。
- 2025年5月9日: NIXL 正式支持 Mooncake Transfer Engine 作为 后端插件。
- 2025年5月8日: Mooncake x LMCache 联手,开创以 KVCache 为中心的 LLM 服务系统。
- 2025年5月5日: 在 Mooncake 团队的支持下,SGLang 发布了 指南,介绍如何在 96 张 H100 GPU 上使用 PD 分离部署 DeepSeek。
- 2025年4月22日: LMCache 正式支持 Mooncake Store 作为 远程连接器。
- 2025年4月10日: SGLang 正式支持 Mooncake Transfer Engine,用于分离式预填充和 KV 缓存传输。
- 2025年3月7日: 我们开源了 Mooncake Store,这是一个基于 Transfer Engine 的分布式 KVCache。基于 Mooncake Store 的 vLLM xPyD 分离式预填充和解码功能即将发布。
- 2025年2月25日: Mooncake 在 FAST 2025 上荣获 最佳论文奖!
- 2025年2月21日: 我们发布了用于 FAST'25 论文的更新版 trace 数据。
- 2024年12月16日: vLLM 正式支持 Mooncake Transfer Engine,用于分离式预填充和 KV 缓存传输。
- 2024年11月28日: 我们开源了 Transfer Engine,这是 Mooncake 的核心组件。同时提供了两个关于 Transfer Engine 的演示:P2P Store 和 vLLM 集成。
- 2024年7月9日: 我们将 trace 以 JSONL 文件 的形式开源。
- 2024年6月27日: 我们发布了一系列中文博客,进一步探讨相关内容,详见 知乎 1、2、3、4、5、6、7。
- 2024年6月26日: 初步技术报告发布。
🎉 概述
Mooncake 采用以 KVCache 为中心的解耦架构,将预填充和解码集群分离。同时,它充分利用 GPU 集群中未充分使用的 CPU、DRAM 和 SSD 资源,构建了一个分布式 KVCache 池。
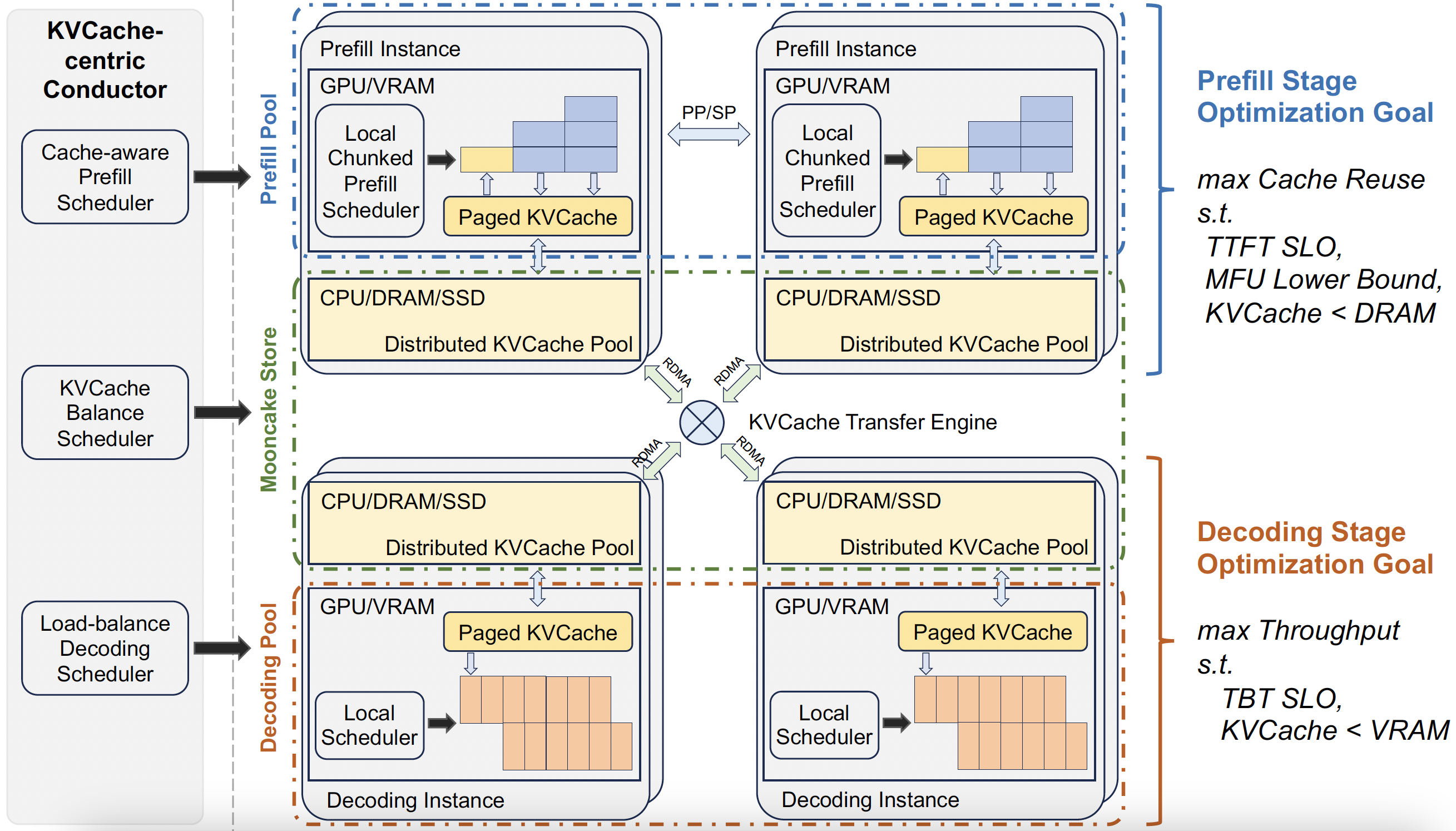
Mooncake 的核心是其基于 KVCache 的调度器,能够在满足延迟相关的服务等级目标(SLO)的同时,最大化整体有效吞吐量。与传统研究假设所有请求都会被处理不同,Mooncake 面临着高负载场景下的挑战。为此,我们开发了一种基于预测的早期拒绝策略。实验表明,Mooncake 在长上下文场景中表现尤为出色。与基准方法相比,在某些模拟场景中,Mooncake 可以在遵守 SLO 的前提下,将吞吐量提升高达 525%。而在实际工作负载下,Mooncake 的创新架构使 Kimi 能够处理多出 75% 的请求。
🧩 组件
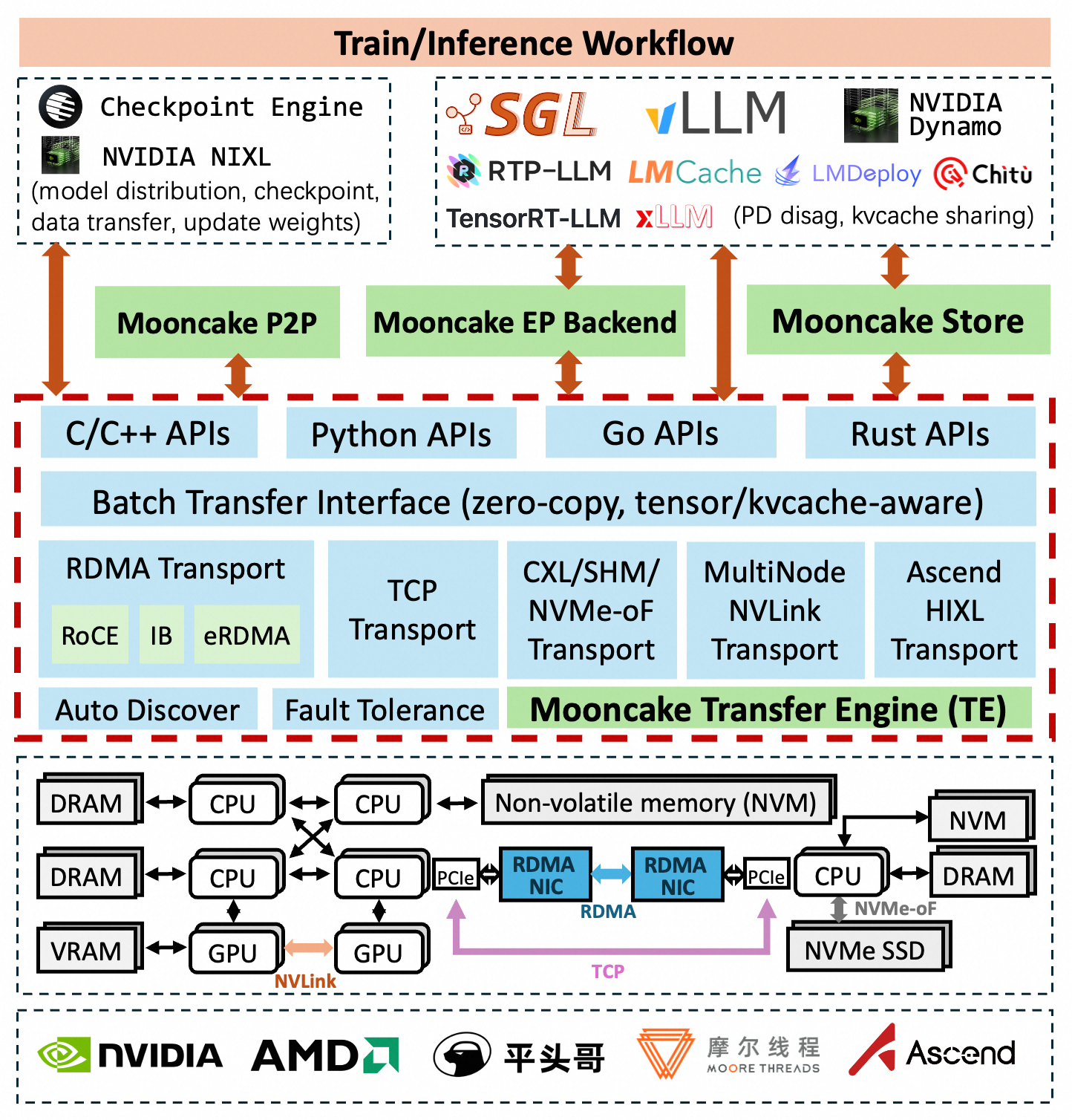
Mooncake 核心组件:传输引擎(TE) Mooncake 的核心是传输引擎(TE),它为跨多种存储设备和网络链路的批量数据传输提供统一接口。TE 支持 TCP、RDMA、CXL/共享内存以及 NVMe over Fabric(NVMe-of)等多种协议,旨在为 AI 工作负载实现快速可靠的数据传输。与 Distributed PyTorch 使用的 Gloo 以及传统 TCP 相比,TE 的 I/O 延迟显著更低,是高效数据传输的更优解决方案。
P2P 存储与 Mooncake 存储 P2P 存储和 Mooncake 存储均基于传输引擎构建,分别针对不同场景提供键值缓存功能。P2P 存储专注于在集群节点间共享临时对象(如检查点文件),从而避免单台机器带宽饱和。而 Mooncake 存储则支持分布式池化 KVCache,专为 XpYd 解耦设计,以提升资源利用率和系统性能。
Mooncake 与主流 LLM 推理系统的集成 Mooncake 已与多个流行的大语言模型(LLM)推理系统无缝集成。通过与 vLLM 和 SGLang 团队的合作,Mooncake 现已正式支持预填充-解码解耦。借助 RDMA 设备的高效通信能力,Mooncake 在预填充-解码解耦场景中显著提升了推理效率,为大规模分布式推理任务提供了强大的技术支持。 此外,Mooncake 还成功集成了 SGLang 的分层 KV 缓存、vLLM 的预填充服务以及 LMCache,从而增强了大规模推理场景下的 KV 缓存管理能力。
弹性专家并行支持 Mooncake 为 MoE 模型推理增加了弹性和容错支持,使推理系统在 GPU 故障或资源配置变化时仍能保持响应并恢复运行。该功能包括自动检测故障 Rank,并可与 EPLB 模块协同工作,在推理过程中将 Token 动态路由到健康的 Rank 上。
以 Tensor 为中心的生态系统 Mooncake 构建了一个全栈式的、面向 Tensor 的 AI 基础设施,其中 Tensor 是基础的数据载体。该生态系统从加速异构存储(DRAM/VRAM/NVMe)间 Tensor 数据移动的传输引擎,到用于分布式管理 Tensor 对象(如检查点和 KVCache)的 P2P 存储和 Mooncake 存储,再到支持基于 Tensor 的弹性分布式计算的 Mooncake 后端,层层递进。这一架构旨在最大限度地提高大规模模型推理和训练中的 Tensor 处理效率。
🔥 案例展示
单独使用传输引擎(指南)
传输引擎是一个高性能的数据传输框架。它提供统一的接口来传输来自 DRAM、VRAM 或 NVMe 的数据,同时隐藏了与硬件相关的技术细节。传输引擎支持多种通信协议,包括 TCP、RDMA(InfiniBand/RoCEv2/eRDMA/NVIDIA GPUDirect)、NVMe over Fabric(NVMe-of)、NVLink、HIP、CXL 和 Ascend 等。当与相应运行时环境结合使用时,传输引擎还能检测并路由 CUDA、MUSA、HIP 和寒武纪 MLU 设备上的加速器显存。有关支持的完整协议列表和配置指南,请参阅 支持的协议文档。
亮点
高效利用多张 RDMA 网卡。 传输引擎支持使用多张 RDMA 网卡,实现 传输带宽的聚合。
拓扑感知路径选择。 传输引擎能够根据源和目标的位置(NUMA 亲和性等) 选择最优设备。
对临时网络故障更具鲁棒性。 一旦传输失败,传输引擎会自动尝试使用替代路径进行数据交付。
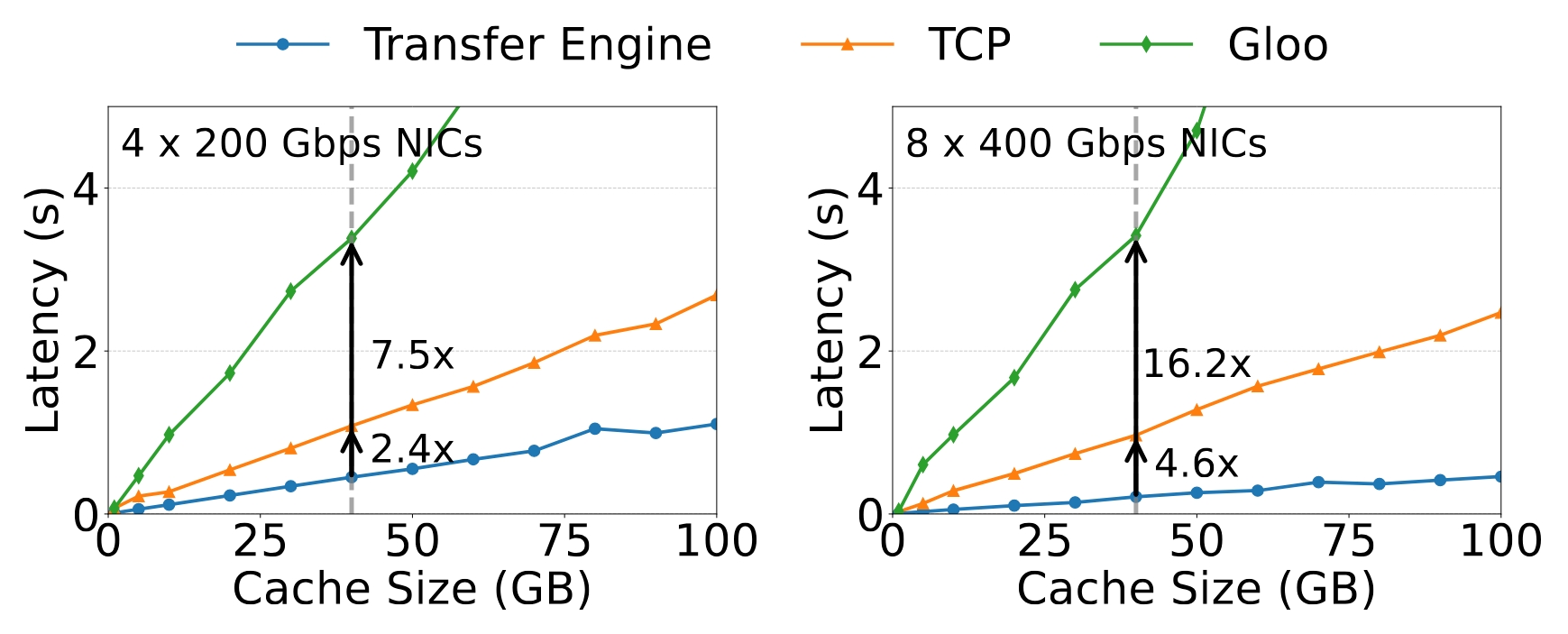
性能
在 4×200 Gbps 和 8×400 Gbps RoCE 网络中,对于 40 GB 的数据(相当于 LLaMA3-70B 模型中 12.8 万个 Token 生成的 KVCache 大小),Mooncake 传输引擎分别可达到 87 GB/s 和 190 GB/s 的带宽,这比 TCP 协议快约 2.4 倍和 4.6 倍。
P2P Store (指南)
P2P Store 构建于 Transfer Engine 之上,支持在集群中的对等节点间共享临时对象。P2P Store 非常适合检查点传输等场景,在这些场景中需要在集群内快速高效地共享数据。 P2P Store 已被用于 Moonshot AI 的检查点传输服务中。
亮点
去中心化架构。 P2P Store 采用纯客户端架构,全局元数据由 etcd 服务管理。
高效的数据分发。 为提升大规模数据分发效率而设计,P2P Store 避免了带宽饱和问题,允许副本节点直接共享数据。这降低了数据提供者(例如训练器)的 CPU 和 RDMA 网卡压力。
Mooncake Store (指南)
Mooncake Store 是一个基于 Transfer Engine 的分布式 KVCache 存储引擎,专为 LLM 推理而设计。它是以 KVCache 为中心的分离式架构的核心组件。Mooncake Store 的目标是在推理集群中的各个位置存储可重用的 KVCache。Mooncake Store 已被 SGLang 的分层 KV 缓存、vLLM 的预填充服务所支持,并且现在已与 LMCache 集成,以提供更强大的 KVCache 管理能力。
亮点
多副本支持:Mooncake Store 支持为同一对象存储多个数据副本,从而有效缓解访问压力的热点问题。
高带宽利用率:Mooncake Store 支持大型对象的条带化和并行 I/O 传输,充分利用多网卡聚合带宽进行高速数据读写。
SGLang 集成 (指南)
SGLang 官方将 Mooncake Store 作为 HiCache 存储后端正式支持。这一集成使得大规模 LLM 服务场景能够实现可扩展的 KVCache 保留和高性能访问。
亮点
- 分层 KV 缓存:Mooncake Store 在 SGLang 的 HiCache 系统中作为外部存储后端,通过设备、主机和远程存储层的多级 KVCache 存储扩展了 RadixAttention。
- 灵活的缓存管理:支持多种缓存策略,包括直写、选择性直写和回写模式,并配备智能预取策略以实现最佳性能。
- 全面优化:具备先进的数据平面优化功能,包括页面优先的内存布局以提高 I/O 效率、减少内存开销的零拷贝机制、加速 CPU-GPU 传输的 GPU 辅助 I/O 核心,以及在计算执行时并发加载 KVCache 的分层重叠技术。
- 弹性专家并行:Mooncake 的集体通信后端和专家并行核已被集成到 SGLang 中,以实现容错的专家并行推理(sglang#11657)。
- 显著的性能提升:多轮基准测试表明,相比非 HiCache 设置,性能有了大幅提高。更多详情请参阅我们的 基准测试报告。
- 社区反馈:有效的 KV 缓存显著减少了 TTFT,消除了冗余且昂贵的重新计算。将 SGLang HiCache 与 Mooncake 服务集成,可以实现可扩展的 KVCache 保留和高性能访问。在我们的评估中,我们使用内部在线请求,从通用 QA 场景中采样,对 PD 分离式部署下的 DeepSeek-R1-671B 模型进行了测试。平均而言,缓存命中使 TTFT 相比完全重新计算降低了 84%。——蚂蚁集团
vLLM 集成 (指南 v0.2)
为了优化 LLM 推理,vLLM 社区正在努力支持 分离式预填充(PR 10502)。该特性允许将 预填充 阶段与 解码 阶段分离到不同的进程。vLLM 默认使用 nccl 和 gloo 作为传输层,但目前还无法在不同机器上高效地解耦这两个阶段。
我们已经实现了 vLLM 集成,该集成使用 Transfer Engine 作为网络层,而非 nccl 和 gloo,以支持 节点间 KVCache 传输 (PR 10884)。Transfer Engine 提供更简单的接口和更高效的 RDMA 设备使用方式。
我们很快将发布基于 Mooncake Store 的新 vLLM 集成,该集成支持 xPyD 预填充/解码分离。
更新[2024年12月16日]:以下是基于 vLLM 主分支的最新 vLLM 集成(指南 v0.2)。
性能
通过支持拓扑感知路径选择和多卡带宽聚合,使用 Transfer Engine 的 vLLM 的平均 TTFT 比传统的基于 TCP 的传输方式低多达 25%。 未来,我们将通过 GPUDirect RDMA 和零拷贝进一步改善 TTFT。
| 后端/设置 | 输出 Token 吞吐量 (tok/s) | 总 Token 吞吐量 (tok/s) | 平均 TTFT (ms) | 中位数 TTFT (ms) | P99 TTFT (ms) |
|---|---|---|---|---|---|
| Transfer Engine (RDMA) | 12.06 | 2042.74 | 1056.76 | 635.00 | 4006.59 |
| TCP | 12.05 | 2041.13 | 1414.05 | 766.23 | 6035.36 |
- 点击 这里 查看详细的基准测试结果。
更多高级功能即将推出,请继续关注!
🚀 快速入门
使用 Mooncake 之前
Mooncake 专为高速 RDMA 网络设计并进行了优化。尽管 Mooncake 支持仅使用 TCP 的数据传输,但我们强烈建议用户在具备 RDMA 网络支持的环境中评估 Mooncake 的功能和性能。
在运行 Mooncake 的任何组件之前,需要先安装以下内容:
- RDMA 驱动程序及 SDK,例如 Mellanox OFED。
- Python 3.10,建议使用虚拟环境。
- CUDA 12.1 及以上版本,包括 NVIDIA GPUDirect Storage 支持;如果软件包是通过
-DUSE_CUDA标志构建的(默认未启用)。您可从 此处 安装所需工具。 - Cambricon Neuware;如果软件包是通过
-DUSE_MLU标志构建的。默认情况下,Mooncake 会在NEUWARE_HOME或/usr/local/neuware路径下查找 Neuware。
使用 Python 包
使用 Mooncake Transfer Engine 最简单的方式是通过 pip:
对于启用了 CUDA 的系统:
- CUDA < 13.0
pip install mooncake-transfer-engine
- CUDA ≥ 13.0
pip install mooncake-transfer-engine-cuda13
对于非 CUDA 系统:
pip install mooncake-transfer-engine-non-cuda
[!重要提示]
- 含有 CUDA 的版本(
mooncake-transfer-engine)包含 Mooncake-EP 和 GPU 拓扑检测功能,因此需要 CUDA 12.1 及以上版本。- 非 CUDA 版本(
mooncake-transfer-engine-non-cuda)适用于没有 CUDA 依赖的环境。- 目前 MLU 支持仅可通过源码构建实现(需指定
-DUSE_MLU=ON),暂无专门的预编译 MLU wheel 文件。- 如果用户遇到诸如缺少
lib*.so文件等问题,请先卸载已安装的包,然后手动重新编译二进制文件。
使用 Docker 镜像
Mooncake 支持基于 Docker 的部署,详细信息请参阅构建指南。
若要构建一个从源码编译 Mooncake、通过 scripts/build_wheel.sh 生成 wheel 文件,并将该 wheel 安装到容器内的镜像,可以使用 build-wheel.dockerfile:
docker build -f docker/mooncake.Dockerfile \
--build-arg PYTHON_VERSION=3.10 \
--build-arg EP_TORCH_VERSIONS="2.9.1" \
-t mooncake:from-source .
生成的镜像已在 /opt/venv 路径下创建了虚拟环境,并安装了新构建的 wheel 文件。根据需要以 GPU 或 RDMA 访问权限启动容器,例如:
docker run --gpus all --network host -it mooncake:from-source /bin/bash
[!注意] 请确保从仓库根目录构建镜像,以便 Git 元数据和子模块能够在构建上下文中被正确读取。
构建和使用二进制文件
以下是构建 Mooncake 的额外依赖项:
- 构建必备工具,包括 gcc、g++(9.4+)和 cmake(3.16+)。
- Go 1.20+,如果你希望使用
-DWITH_P2P_STORE、-DUSE_ETCD(默认启用以使用 etcd 作为元数据服务器)或-DSTORE_USE_ETCD(将 etcd 用于存储主节点的故障转移)进行构建。 - CUDA 12.1 及以上版本,包含 NVIDIA GPUDirect Storage 支持,如果软件包是使用
-DUSE_CUDA构建的。这并未包含在dependencies.sh脚本中。你可以从 这里 安装。 - Cambricon Neuware,如果你希望使用
-DUSE_MLU进行构建。这并未包含在dependencies.sh脚本中。 Mooncake 默认会从NEUWARE_HOME或/usr/local/neuware中解析,同时也支持在 CMake 配置时覆盖MLU_INCLUDE_DIR/MLU_LIB_DIR。 - [可选] Rust 工具链,如果你希望使用
-DWITH_RUST_EXAMPLE进行构建。这并未包含在dependencies.sh脚本中。 - [可选]
hiredis,如果你希望使用-DUSE_REDIS将 Redis 作为元数据服务器,而非 etcd。 - [可选]
curl,如果你希望使用-DUSE_HTTP将 HTTP 作为元数据服务器,而非 etcd。
构建和安装步骤如下:
从 GitHub 仓库获取源代码
git clone https://github.com/kvcache-ai/Mooncake.git cd Mooncake安装依赖项
bash dependencies.sh编译 Mooncake 和示例程序
mkdir build cd build cmake .. make -j sudo make install # 可选,使系统准备好被 vLLM/SGLang 使用
对于 Cambricon MLU 的构建,请在配置 CMake 时添加 -DUSE_MLU=ON。例如:
mkdir build
cd build
cmake .. -DUSE_MLU=ON -DNEUWARE_ROOT=/usr/local/neuware
make -j
🛣️ 即将到来的里程碑
- Mooncake 首次发布,并与最新的 vLLM 集成
- 在多个推理引擎之间共享 KV 缓存
- 用户和开发者文档
📦 开源追踪数据
{
"timestamp": 27482,
"input_length": 6955,
"output_length": 52,
"hash_ids": [46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 2353, 2354]
}
{
"timestamp": 30535,
"input_length": 6472,
"output_length": 26,
"hash_ids": [46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 2366]
}
以上展示了我们追踪数据集中的两个样本。该追踪数据包含了请求到达的时间、输入 token 的数量、输出 token 的数量以及重新映射后的块哈希值。为了保护客户的隐私,我们在保留数据集用于模拟评估价值的同时,应用了多种机制来移除与用户相关的信息。关于追踪数据的更多描述(例如高达 50% 的缓存命中率),请参阅技术报告的第 4 节。
更新[2025年2月21日]:我们在 FAST'25 论文中使用的更新版 追踪数据 已经发布!更多信息请参阅论文附录(见 这里)。
📑 引用
如果你认为我们的论文或追踪数据有用,请引用:@article{qin2025mooncake_tos,
author = {Qin Ruoyu and Li Zheming and He Weiran and Cui Jialei and Tang Heyi and Ren Feng and Ma Teng and Cai Shangming and Zhang Yineng and Zhang Mingxing and Wu Yongwei and Zheng Weimin and Xu Xinran},
title = {Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving},
year = {2025},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
issn = {1553-3077},
url = {https://doi.org/10.1145/3773772},
doi = {10.1145/3773772},
journal = {ACM Trans. Storage},
month = {nov},
keywords = {Machine learning system, LLM serving, KVCache},
}
@inproceedings{qin2025mooncake,
author = {Ruoyu Qin and Zheming Li and Weiran He and Jialei Cui and Feng Ren and Mingxing Zhang and Yongwei Wu and Weimin Zheng and Xinran Xu},
title = {Mooncake: Trading More Storage for Less Computation {\textemdash} A {KVCache-centric} Architecture for Serving {LLM} Chatbot},
booktitle = {23rd USENIX Conference on File and Storage Technologies (FAST 25)},
year = {2025},
isbn = {978-1-939133-45-8},
address = {Santa Clara, CA},
pages = {155--170},
url = {https://www.usenix.org/conference/fast25/presentation/qin},
publisher = {USENIX Association},
month = {feb},
}
@article{qin2024mooncake_arxiv,
title = {Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving},
author = {Ruoyu Qin and Zheming Li and Weiran He and Mingxing Zhang and Yongwei Wu and Weimin Zheng and Xinran Xu},
year = {2024},
url = {https://arxiv.org/abs/2407.00079},
}
版本历史
v0.3.10.post12026/04/01v0.3.102026/03/19v0.3.92026/02/05v0.3.8.post12026/01/09v0.3.82025/12/26v0.3.7.post22025/11/04v0.3.7.post12025/11/03v0.3.72025/10/25v0.3.6.post12025/09/20v0.3.62025/09/10v0.3.52025/07/25v0.3.4.post22025/06/25v0.3.4.post12025/06/23v0.3.42025/06/20v0.3.3.post22025/06/16v0.3.3.post12025/06/15v0.3.32025/06/14v0.3.2.post12025/05/26v0.3.22025/05/25v0.3.12025/05/19常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器