awesome-deep-vision
awesome-deep-vision 是一份专为计算机视觉领域打造的深度学习资源精选清单。它系统地整理了该方向的核心学术成果与实用资料,涵盖了从基础的图像分类、目标检测、跟踪,到高级的语义分割、人体姿态估计、图像生成以及图文跨模态理解等广泛主题。
在深度学习技术快速迭代的背景下,研究人员和开发者往往面临海量论文与信息过载的挑战,难以高效定位高质量文献。awesome-deep-vision 正是为了解决这一痛点而生,它将分散的资源按应用场景和技术细分领域进行了结构化梳理,帮助用户快速建立知识体系或追踪前沿进展。除了收录经典的学术论文(如 ResNet、GoogLeNet 等),清单还包含了相关的课程、书籍、视频教程、软件框架及博客文章,形成了完整的学习闭环。
这份资源特别适合计算机视觉领域的研究人员、算法工程师以及希望深入该专业的学生使用。虽然项目目前不再活跃维护,但其沉淀的经典文献目录依然具有极高的参考价值,是入门深造或开展科研工作的理想“导航图”。通过 awesome-deep-vision,用户可以更专注于技术本身,而非在信息海洋中盲目摸索。
使用场景
某初创公司的算法工程师小李正负责开发一款智能零售货架系统,需要快速复现最新的商品检测与超分辨率重建算法以优化监控画面。
没有 awesome-deep-vision 时
- 文献检索如大海捞针:在 arXiv 和 Google Scholar 上盲目搜索关键词,耗费数天筛选,却常遗漏像 ResNet 或 Batch Normalization 这类奠基性论文。
- 技术选型缺乏依据:面对物体检测、语义分割等细分领域,难以快速对比不同模型的优劣,导致选用了过时或不适配的架构。
- 学习资源分散零碎:寻找配套的代码框架、教程博客和公开课程需要在多个网站间跳转,知识体系难以构建,新人上手极慢。
- 重复造轮子风险高:因不了解已有的开源实现(Software 章节),团队花费大量时间重新编写本可复用的基础模块。
使用 awesome-deep-vision 后
- 核心资源一键直达:直接通过分类目录(如 Object Detection、Super-Resolution)定位到微软的 Deep Residual Learning 等关键论文及幻灯片,调研效率提升十倍。
- 技术路线清晰明确:依托整理好的细分领域列表,迅速锁定当前 SOTA(最先进)模型,为货架商品识别选择了最优的 CNN 架构。
- 全栈学习路径完整:从 Papers 到 Courses、Books 再到 Tutorials,团队成员能按图索骥建立系统的深度学习视觉知识树,缩短培训周期。
- 开源复用加速落地:利用 Software 章节提供的成熟框架和应用案例,直接集成现有工具,将原本两个月的原型开发期压缩至两周。
awesome-deep-vision 将散落的计算机视觉珍珠串成项链,让开发者从繁琐的搜集工作中解放,专注于核心算法的创新与落地。
运行环境要求
未说明
未说明

快速开始
令人惊叹的深度视觉 
一份精心整理的计算机视觉深度学习资源列表,灵感来源于 awesome-php 和 awesome-computer-vision。
维护者 - Jiwon Kim, Heesoo Myeong, Myungsub Choi, Jung Kwon Lee, Taeksoo Kim
该项目目前未处于积极维护状态。
贡献
欢迎通过 pull requests 添加论文。

分享
- [在 Twitter 上分享](http://twitter.com/home?status=http://jiwonkim.org/awesome-deep-vision%0ADeep Learning Resources for Computer Vision)
- 在 Facebook 上分享
- 在 Google Plus 上分享
- 在 LinkedIn 上分享
目录
论文
ImageNet 分类
 (摘自 Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton,《使用深度卷积神经网络进行 ImageNet 分类》,NIPS,2012年。)
(摘自 Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton,《使用深度卷积神经网络进行 ImageNet 分类》,NIPS,2012年。)
- 微软(深度残差学习)[论文][幻灯片]
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun,《用于图像识别的深度残差学习》,arXiv:1512.03385。
- 微软(PReLu/权重初始化)[论文]
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun,《深入研究修正线性单元:超越人类水平的 ImageNet 分类性能》,arXiv:1502.01852。
- 批量归一化 [论文]
- Sergey Ioffe, Christian Szegedy,《批量归一化:通过减少内部协变量偏移加速深度网络训练》,arXiv:1502.03167。
- GoogLeNet [论文]
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich,CVPR,2015年。
- VGG-Net [网页] [论文]
- Karen Simonyan 和 Andrew Zisserman,《用于大规模视觉识别的非常深的卷积网络》,ICLR,2015年。
- AlexNet [论文]
- Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton,《使用深度卷积神经网络进行 ImageNet 分类》,NIPS,2012年。
目标检测
 (摘自邵庆仁、何凯明、罗斯·吉尔希克、孙剑:《Faster R-CNN:基于区域建议网络的实时目标检测》,arXiv:1506.01497。)
(摘自邵庆仁、何凯明、罗斯·吉尔希克、孙剑:《Faster R-CNN:基于区域建议网络的实时目标检测》,arXiv:1506.01497。)
- PVANET [论文] [代码]
- 奎贤金、桑勋洪、炳锡卢、英在千、民哲朴:《PVANET:用于实时目标检测的深层但轻量级神经网络》,arXiv:1608.08021
- OverFeat,纽约大学 [论文]
- OverFeat:利用卷积网络实现集成式识别、定位与检测,ICLR,2014年。
- R-CNN,加州大学伯克利分校 [CVPR14论文] [arXiv14论文]
- 罗斯·吉尔希克、杰夫·多纳休、特雷弗·达雷尔、吉滕德拉·马利克:《用于精确目标检测和语义分割的丰富特征层次结构》,CVPR,2014年。
- SPP,微软研究院 [论文]
- 何凯明、张祥宇、邵庆仁、孙剑:《视觉识别中深度卷积网络的空间金字塔池化》,ECCV,2014年。
- Fast R-CNN,微软研究院 [论文]
- 罗斯·吉尔希克:《Fast R-CNN》,arXiv:1504.08083。
- Faster R-CNN,微软研究院 [论文]
- 邵庆仁、何凯明、罗斯·吉尔希克、孙剑:《Faster R-CNN:基于区域建议网络的实时目标检测》,arXiv:1506.01497。
- R-CNN minus R,牛津大学 [论文]
- 卡雷尔·伦茨、安德烈亚·韦达尔迪:《R-CNN minus R》,arXiv:1506.06981。
- 拥挤场景中的端到端人群检测 [论文]
- 罗素·斯图尔特、米哈伊洛·安德里卢卡:《拥挤场景中的端到端人群检测》,arXiv:1506.04878。
- You Only Look Once:统一的实时目标检测 [论文],[论文第2版],[C语言代码],[TensorFlow代码]
- 约瑟夫·雷德蒙、桑托什·迪瓦拉、罗斯·吉尔希克、阿里·法尔哈迪:《You Only Look Once:统一的实时目标检测》,arXiv:1506.02640
- 约瑟夫·雷德蒙、阿里·法尔哈迪(第2版)
- Inside-Outside Net [论文]
- 肖恩·贝尔、C·劳伦斯·齐特尼克、卡维塔·巴拉、罗斯·吉尔希克:《Inside-Outside Net:通过跳跃池化和循环神经网络在上下文中检测目标》
- 深度残差网络(当前最先进水平)[论文]
- 何凯明、张祥宇、邵庆仁、孙剑:《用于图像识别的深度残差学习》
- 弱监督目标定位与多折叠多实例学习 [论文]
- R-FCN [论文] [代码]
- 戴继峰、李毅、何凯明、孙剑:《R-FCN:基于区域的全卷积网络目标检测》
- SSD [论文] [代码]
- 刘伟1、德拉戈米尔·安格洛夫、杜米特鲁·埃尔汉、克里斯蒂安·塞格迪、斯科特·里德、程阳·傅、亚历山大·C·伯格:《SSD:单次多框检测器》,arXiv:1512.02325
- 现代卷积目标检测器的速度/精度权衡 [论文]
- 乔纳森·黄、维韦克·拉托德、陈孙、孟龙朱、阿努普·科拉蒂卡拉、阿里雷扎·法西、伊恩·费舍尔、兹比格涅夫·沃伊纳、杨松、塞尔吉奥·瓜达拉马、凯文·墨菲:谷歌研究院,《现代卷积目标检测器的速度/精度权衡》,arXiv:1611.10012
视频分类
- 尼古拉斯·巴拉斯、姚立、帕尔·克里斯、阿隆·库维尔:“深入卷积网络以学习视频表示”,ICLR 2016。[论文]
- 迈克尔·马修、卡米耶·库普里、扬·勒丘恩:“超越均方误差的深度多尺度视频预测”,ICLR 2016。[论文]
目标跟踪
- 晟勋洪、宅根尤、秀河郭、宝亨韩:《基于卷积神经网络学习判别性显著图的在线跟踪》,arXiv:1502.06796。[论文]
- 李翰熙、李毅和法提赫·波里克利:《DeepTrack:利用卷积神经网络学习判别性特征表示进行视觉跟踪》,BMVC,2014年。[论文]
- N Wang、DY Yeung:《为视觉跟踪学习深度紧凑的图像表示》,NIPS,2013年。[论文]
- 马超、黄家斌、杨晓康和杨明轩:《用于视觉跟踪的层次化卷积特征》,ICCV 2015 [论文] [代码]
- 王利军、欧阳万力、王小刚和陆虎川:《使用全卷积网络进行视觉跟踪》,ICCV 2015 [论文] [代码]
- 贤燮南和宝亨韩:《为视觉跟踪学习多领域卷积神经网络》,[论文] [代码] [项目页面]
低层视觉
超分辨率
- 迭代图像重建
- 超分辨率(SRCNN)[网页] [论文-ECCV14] [论文-arXiv15]
- 董超、陈昌立、何凯明、汤晓鸥:学习用于图像超分辨率的深度卷积网络,ECCV,2014年。
- 董超、陈昌立、何凯明、汤晓鸥:使用深度卷积网络进行图像超分辨率,arXiv:1501.00092。
- 极深超分辨率
- 金智源、李正权、李京穆:使用极深卷积网络实现精确的图像超分辨率,arXiv:1511.04587,2015年。[论文]
- 深度递归卷积网络
- 金智源、李正权、李京穆:用于图像超分辨率的深度递归卷积网络,arXiv:1511.04491,2015年。[论文]
- 分层稀疏编码网络
- 用于超分辨率的感知损失
- SRGAN
- 克里斯蒂安·莱迪格、卢卡斯·泰斯、费伦茨·胡萨尔、何塞·卡巴列罗、安德鲁·坎宁安、亚历杭德罗·阿科斯塔、安德鲁·艾特肯、阿利汗·特贾尼、约翰内斯·托茨、泽汉·王、温哲·史:使用生成对抗网络实现照片级真实感单幅图像超分辨率,arXiv:1609.04802v3,2016年。[论文]
- 其他
- 奥森多夫、克里斯蒂安、于贝尔·索耶和帕特里克·范德·斯马赫特:使用快速近似卷积稀疏编码进行图像超分辨率,ICONIP,2014年。[ICONIP-2014论文]
其他应用
- 光流(FlowNet)[论文]
- 菲利普·费舍尔、阿列克谢·多索维茨基、埃迪·伊尔格、菲利普·豪瑟、卡内尔·哈兹尔巴斯、弗拉基米尔·戈尔科夫、帕特里克·范德·斯马赫特、丹尼尔·克雷默斯、托马斯·布罗克斯:FlowNet:用卷积网络学习光流,arXiv:1504.06852。
- 压缩伪影去除[论文-arXiv15]
- 董超、邓宇斌、陈昌立、汤晓鸥:通过深度卷积网络去除压缩伪影,arXiv:1504.06993。
- 模糊去除
- 图像反卷积 [网页] [论文]
- 徐立、任志军、刘策、贾佳亚:用于图像反卷积的深度卷积神经网络,NIPS,2014年。
- 深度边缘感知滤波器 [论文]
- 徐立、任志军、严琼、廖仁杰、贾佳亚:深度边缘感知滤波器,ICML,2015年。
- 使用卷积神经网络计算立体匹配代价 [论文]
- 尤雷·日邦塔尔、扬·勒丘恩:使用卷积神经网络计算立体匹配代价,CVPR,2015年。
- 彩色图像着色 理查德·张、菲利普·伊索拉、阿列克谢·A·叶夫罗斯:ECCV,2016年 [论文],[代码]
- 瑞安·达尔,[博客]
- 通过修复学习特征[论文][代码]
- 迪帕克·帕塔克、菲利普·克拉亨布尔、杰夫·多纳休、特雷弗·达雷尔、阿列克谢·A·叶夫罗斯:上下文编码器:通过修复学习特征,CVPR,2016年。
边缘检测
 (来自盖达斯·贝尔塔修斯、施健博、洛伦佐·托雷萨尼:DeepEdge:一种用于自顶向下轮廓检测的多尺度分支深度网络,CVPR,2015年。)
(来自盖达斯·贝尔塔修斯、施健博、洛伦佐·托雷萨尼:DeepEdge:一种用于自顶向下轮廓检测的多尺度分支深度网络,CVPR,2015年。)
- 整体嵌套式边缘检测 [论文] [代码]
- 谢赛宁、涂卓文:整体嵌套式边缘检测,arXiv:1504.06375。
- DeepEdge [论文]
- 盖达斯·贝尔塔修斯、施健博、洛伦佐·托雷萨尼:DeepEdge:一种用于自顶向下轮廓检测的多尺度分支深度网络,CVPR,2015年。
- DeepContour [论文]
- 沈伟、王兴刚、王燕、白翔、张志江:DeepContour:一种通过正向共享损失学习的深度卷积特征,用于轮廓检测,CVPR,2015年。
语义分割
 (摘自戴继峰、何恺明、孙剑:BoxSup:利用边界框监督卷积网络进行语义分割,arXiv:1503.01640。)
(摘自戴继峰、何恺明、孙剑:BoxSup:利用边界框监督卷积网络进行语义分割,arXiv:1503.01640。)
- PASCAL VOC2012 挑战赛排行榜(2016年9月1日)
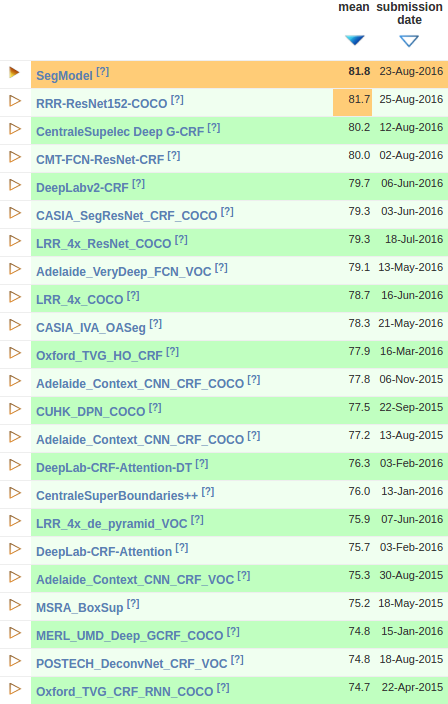 (摘自 PASCAL VOC2012 排行榜)
(摘自 PASCAL VOC2012 排行榜) - SEC:种子、扩展与约束
- 阿德莱德大学
- 深度解析网络(DPN)
- 刘子威、李晓晓、罗平、陈昌礼、唐晓鸥:基于深度解析网络的语义图像分割,arXiv:1509.02634 / ICCV 2015 [论文](在 VOC 2012 中排名第二)
- CentraleSuperBoundaries,INRIA [论文]
- 伊阿索纳斯·科基诺斯:利用深度学习超越人类的边界检测能力,arXiv:1411.07386(在 VOC 2012 中排名第四)
- BoxSup [论文]
- 戴继峰、何恺明、孙剑:BoxSup——利用边界框监督卷积网络进行语义分割,arXiv:1503.01640。(在 VOC2012 中排名第六)
- 浦项工科大学
- 条件随机场作为循环神经网络 [论文]
- 郑帅、萨迪普·贾亚苏马纳、贝尔纳迪诺·罗梅拉-帕雷德斯、维布哈夫·维尼特、朱志忠、杜达龙、黄昌、菲利普·H·S·托尔:条件随机场作为循环神经网络,arXiv:1502.03240。(在 VOC2012 中排名第八)
- DeepLab
- 陈亮杰、乔治·帕潘德里欧、凯文·墨菲、艾伦·L·尤伊尔:用于语义图像分割的弱监督与半监督 DCNN 学习,arXiv:1502.02734。[论文](在 VOC2012 中排名第九)
- 放大视野 [论文]
- 穆罕默德·雷扎·莫斯塔贾比、派曼·亚多拉胡尔、格雷戈里·沙赫纳罗维奇:具有放大视野特征的前馈语义分割,CVPR 2015
- 联合校准 [论文]
- 霍尔格·凯撒、贾斯珀·乌伊林斯、维托里奥·费拉里:用于语义分割的联合校准,arXiv:1507.01581。
- 用于语义分割的全卷积网络 [CVPR15 论文] [arXiv15 论文]
- 乔纳森·朗、埃文·谢尔哈默、特雷弗·达雷尔:用于语义分割的全卷积网络,CVPR 2015。
- 超柱 [论文]
- 巴拉特·哈里哈兰、巴勃罗·阿尔贝莱斯、罗斯·吉尔希克、吉滕德拉·马利克:用于目标分割和细粒度定位的超柱,CVPR 2015。
- 深度层次解析
- 阿比舍克·夏尔马、昂塞尔·图泽尔、大卫·W·雅各布斯:用于语义分割的深度层次解析,CVPR 2015。[论文]
- 用于场景标注的层次特征学习 [ICML12 论文] [PAMI13 论文]
- 克莱芒·法拉贝特、卡米耶·库普里、洛朗·纳伊曼、扬·勒丘恩:通过多尺度特征学习、纯度树和最优覆盖进行场景解析,ICML 2012。
- 克莱芒·法拉贝特、卡米耶·库普里、洛朗·纳伊曼、扬·勒丘恩:用于场景标注的层次特征学习,PAMI 2013。
- 剑桥大学 [网站]
- 维杰·巴德里纳拉扬、亚历克斯·肯德尔和罗伯托·西波拉:“SegNet:一种用于图像分割的深度卷积编码器-解码器架构。” arXiv 预印本 arXiv:1511.00561,2015。[论文]
- 亚历克斯·肯德尔、维杰·巴德里纳拉扬和罗伯托·西波拉:“贝叶斯 SegNet:场景理解中深度卷积编码器-解码器架构中的模型不确定性。” arXiv 预印本 arXiv:1511.02680,2015。[论文]
- 普林斯顿大学
- 费舍尔·余、弗拉德伦·科尔顿:“通过空洞卷积进行多尺度上下文聚合”,ICLR 2016,[论文]
- 华盛顿大学、艾伦人工智能研究所
- 哈米德·伊扎迪尼亚、费雷什特·萨德吉、桑托什·库马尔·迪瓦拉、叶津·崔、阿里·法拉迪:“用于语义分割、视觉蕴含和释义的片段-短语表”,ICCV 2015,[论文]
- INRIA
- 伊阿索纳斯·科基诺斯:“利用深度学习突破边界检测的极限”,ICLR 2016,[论文]
- 加州大学圣芭芭拉分校
- 尼鲁法尔·普里安、S·卡尔蒂凯扬和 B·S·曼朱纳特:“通过学习图像部件社区实现弱监督的基于图的语义分割”,ICCV 2015,[论文]
视觉注意力与显著性
 (摘自刘念、韩俊伟、张丁文、温世峰、刘天明,《利用卷积神经网络预测眼动注视点》,CVPR 2015。)
(摘自刘念、韩俊伟、张丁文、温世峰、刘天明,《利用卷积神经网络预测眼动注视点》,CVPR 2015。)
- Mr-CNN [论文]
- 刘念、韩俊伟、张丁文、温世峰、刘天明,《利用卷积神经网络预测眼动注视点》,CVPR 2015。
- 学习用于地标检测的序列搜索 [论文]
- Saurabh Singh、Derek Hoiem、David Forsyth,《学习用于地标检测的序列搜索》,CVPR 2015。
- 基于视觉注意力的多目标识别 [论文]
- Jimmy Lei Ba、Volodymyr Mnih、Koray Kavukcuoglu,《基于视觉注意力的多目标识别》,ICLR 2015。
- 视觉注意力的循环模型 [论文]
- Volodymyr Mnih、Nicolas Heess、Alex Graves、Koray Kavukcuoglu,《视觉注意力的循环模型》,NIPS 2014。
目标识别
- 基于卷积神经网络的弱监督学习 [论文]
- Maxime Oquab、Leon Bottou、Ivan Laptev、Josef Sivic,《目标定位是免费的吗?——基于卷积神经网络的弱监督学习》,CVPR 2015。
- FV-CNN [论文]
- Mircea Cimpoi、Subhransu Maji、Andrea Vedaldi,《用于纹理识别和分割的深度滤波器组》,CVPR 2015。
人体姿态估计
- Zhe Cao、Tomas Simon、Shih-En Wei 和 Yaser Sheikh,《基于部位亲和场的实时多人二维姿态估计》,CVPR 2017。
- Leonid Pishchulin、Eldar Insafutdinov、Siyu Tang、Bjoern Andres、Mykhaylo Andriluka、Peter Gehler 和 Bernt Schiele,《Deepcut:多人姿态估计中的子集划分与标注联合方法》,CVPR 2016。
- Shih-En Wei、Varun Ramakrishna、Takeo Kanade 和 Yaser Sheikh,《卷积姿态机器》,CVPR 2016。
- Alejandro Newell、Kaiyu Yang 和 Jia Deng,《用于人体姿态估计的堆叠沙漏网络》,ECCV 2016。
- Tomas Pfister、James Charles 和 Andrew Zisserman,《用于视频中人体姿态估计的流式卷积网络》,ICCV 2015。
- Jonathan J. Tompson、Arjun Jain、Yann LeCun、Christoph Bregler,《卷积网络与图模型联合训练用于人体姿态估计》,NIPS 2014。
理解卷积神经网络
 (摘自 Aravindh Mahendran、Andrea Vedaldi,《通过反演理解深层图像表示》,CVPR 2015。)
(摘自 Aravindh Mahendran、Andrea Vedaldi,《通过反演理解深层图像表示》,CVPR 2015。)
- Karel Lenc、Andrea Vedaldi,《通过测量图像表示的等变性和等价性来理解图像表示》,CVPR 2015。[论文]
- Anh Nguyen、Jason Yosinski、Jeff Clune,《深度神经网络极易被欺骗:对无法识别图像的高置信度预测》,CVPR 2015。[论文]
- Aravindh Mahendran、Andrea Vedaldi,《通过反演理解深层图像表示》,CVPR 2015。[论文]
- Bolei Zhou、Aditya Khosla、Agata Lapedriza、Aude Oliva、Antonio Torralba,《深度场景卷积神经网络中涌现的目标检测器》,ICLR 2015。[arXiv论文]
- Alexey Dosovitskiy、Thomas Brox,《用卷积网络反演视觉表示》,arXiv 2015。[论文]
- Matthrew Zeiler、Rob Fergus,《可视化与理解卷积网络》,ECCV 2014。[论文]
图像与语言
图像描述生成
 (摘自 Andrej Karpathy、李飞飞,《用于生成图像描述的深度视觉-语义对齐》,CVPR 2015。)
(摘自 Andrej Karpathy、李飞飞,《用于生成图像描述的深度视觉-语义对齐》,CVPR 2015。)
- UCLA / 百度 [论文]
- Junhua Mao, Wei Xu, Yi Yang, Jiang Wang, Alan L. Yuille, 使用多模态循环神经网络解释图像,arXiv:1410.1090。
- 多伦多 [论文]
- Ryan Kiros, Ruslan Salakhutdinov, Richard S. Zemel, 通过多模态神经语言模型统一视觉-语义嵌入,arXiv:1411.2539。
- 伯克利 [论文]
- Jeff Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Marcus Rohrbach, Subhashini Venugopalan, Kate Saenko, Trevor Darrell,用于视觉识别与描述的长期循环卷积网络,arXiv:1411.4389。
- 谷歌 [论文]
- Oriol Vinyals, Alexander Toshev, Samy Bengio, Dumitru Erhan,展示与讲述:一种神经图像字幕生成器,arXiv:1411.4555。
- 斯坦福 [网页] [论文]
- Andrej Karpathy, Li Fei-Fei,用于生成图像描述的深度视觉-语义对齐,CVPR 2015。
- UML / UT [论文]
- Subhashini Venugopalan, Huijuan Xu, Jeff Donahue, Marcus Rohrbach, Raymond Mooney, Kate Saenko,使用深度循环神经网络将视频翻译成自然语言,NAACL-HLT 2015。
- CMU / 微软 [论文-arXiv] [论文-CVPR]
- Xinlei Chen, C. Lawrence Zitnick,学习用于图像字幕生成的循环视觉表示,arXiv:1411.5654。
- Xinlei Chen, C. Lawrence Zitnick,心灵之眼:用于图像字幕生成的循环视觉表示,CVPR 2015。
- 微软 [论文]
- Hao Fang, Saurabh Gupta, Forrest Iandola, Rupesh Srivastava, Li Deng, Piotr Dollár, Jianfeng Gao, Xiaodong He, Margaret Mitchell, John C. Platt, C. Lawrence Zitnick, Geoffrey Zweig,从字幕到视觉概念再返回,CVPR 2015。
- 蒙特利尔大学 / 多伦多大学 [网页] [论文]
- Kelvin Xu, Jimmy Lei Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhutdinov, Richard S. Zemel, Yoshua Bengio,展示、注意与讲述:基于视觉注意力的神经图像字幕生成,arXiv:1502.03044 / ICML 2015。
- Idiap / EPFL / Facebook [论文]
- Remi Lebret, Pedro O. Pinheiro, Ronan Collobert,基于短语的图像字幕生成,arXiv:1502.03671 / ICML 2015。
- UCLA / 百度 [论文]
- Junhua Mao, Wei Xu, Yi Yang, Jiang Wang, Zhiheng Huang, Alan L. Yuille,像孩子一样学习:从图像的句子描述中快速学习新的视觉概念,arXiv:1504.06692。
- MS + 伯克利
- 阿德莱德 [论文]
- Qi Wu, Chunhua Shen, Anton van den Hengel, Lingqiao Liu, Anthony Dick,带有中间属性层的图像字幕生成,arXiv:1506.01144。
- 提尔堡 [论文]
- Grzegorz Chrupala, Akos Kadar, Afra Alishahi,通过图片学习语言,arXiv:1506.03694。
- 蒙特利尔大学 [论文]
- Kyunghyun Cho, Aaron Courville,Yoshua Bengio,利用基于注意力的编码器-解码器网络描述多媒体内容,arXiv:1507.01053。
- 康奈尔 [论文]
- Jack Hessel, Nicolas Savva, Michael J. Wilber,神经图像字幕生成中的图像表示与新领域,arXiv:1508.02091。
- MS + 香港城市大学 [论文]
- Ting Yao, Tao Mei 和 Chong-Wah Ngo,“通过排序典型相关分析学习查询与图像相似性”,ICCV 2015。
视频字幕生成
- 伯克利 [网页] [论文]
- Jeff Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Marcus Rohrbach, Subhashini Venugopalan, Kate Saenko, Trevor Darrell,用于视觉识别和描述的长期循环卷积网络,CVPR 2015。
- UT / UML / 伯克利 [论文]
- Subhashini Venugopalan, Huijuan Xu, Jeff Donahue, Marcus Rohrbach, Raymond Mooney, Kate Saenko,使用深度循环神经网络将视频翻译成自然语言,arXiv:1412.4729。
- 微软 [论文]
- Yingwei Pan, Tao Mei, Ting Yao, Houqiang Li, Yong Rui,联合建模嵌入与翻译以连接视频与语言,arXiv:1505.01861。
- UT / 伯克利 / UML [论文]
- Subhashini Venugopalan, Marcus Rohrbach, Jeff Donahue, Raymond Mooney,Trevor Darrell,Kate Saenko,序列到序列——视频转文字,arXiv:1505.00487。
- 蒙特利尔大学 / 舍布鲁克大学 [论文]
- Li Yao,Atousa Torabi,Kyunghyun Cho,Nicolas Ballas,Christopher Pal,Hugo Larochelle,Aaron Courville,通过利用时间结构描述视频,arXiv:1502.08029。
- MPI / 伯克利 [论文]
- Anna Rohrbach,Marcus Rohrbach,Bernt Schiele,电影描述的长短期故事,arXiv:1506.01698。
- 多伦多大学 / MIT [论文]
- Yukun Zhu,Ryan Kiros,Richard Zemel,Ruslan Salakhutdinov,Raquel Urtasun,Antonio Torralba,Sanja Fidler,通过对电影的观看和书籍的阅读来对齐书籍与电影:迈向类似故事的视觉解释,arXiv:1506.06724。
- 蒙特利尔大学 [论文]
- Kyunghyun Cho,Aaron Courville,Yoshua Bengio,利用基于注意力的编码器-解码器网络描述多媒体内容,arXiv:1507.01053。
- TAU / USC [论文]
- Dotan Kaufman,Gil Levi,Tal Hassner,Lior Wolf,用于视频标注与摘要的时间镶嵌,arXiv:1612.06950。
问答
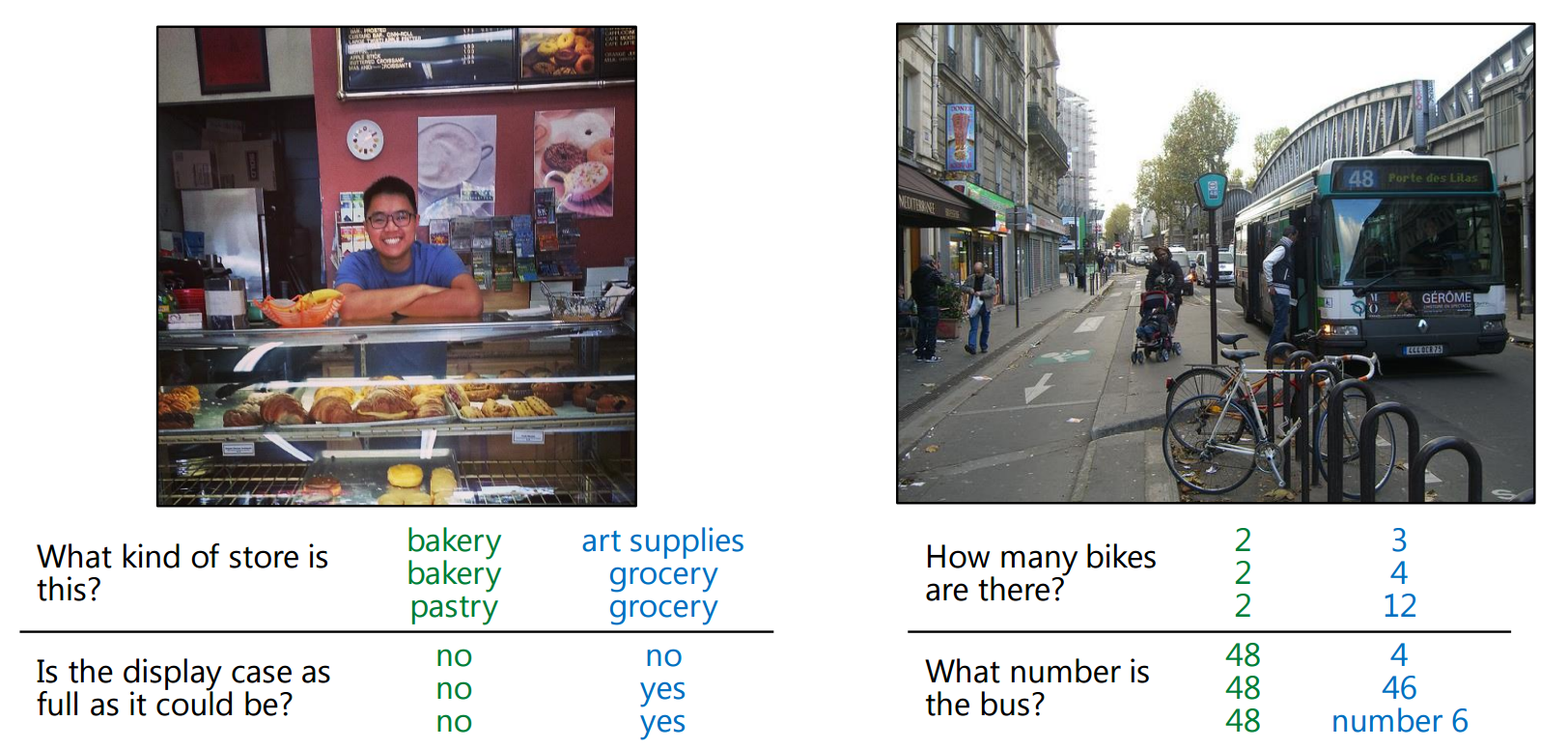 (来自 Stanislaw Antol,Aishwarya Agrawal,Jiasen Lu,Margaret Mitchell,Dhruv Batra,C. Lawrence Zitnick,Devi Parikh,VQA:视觉问答,CVPR 2015 SUNw:场景理解研讨会)
(来自 Stanislaw Antol,Aishwarya Agrawal,Jiasen Lu,Margaret Mitchell,Dhruv Batra,C. Lawrence Zitnick,Devi Parikh,VQA:视觉问答,CVPR 2015 SUNw:场景理解研讨会)
- 弗吉尼亚理工大学 / 微软研究院 [网页] [论文]
- 斯坦尼斯瓦夫·安托尔、艾什瓦里娅·阿格拉瓦尔、贾森·卢、玛格丽特·米切尔、德鲁夫·巴特拉、C·劳伦斯·齐特尼克、黛薇·帕里克,VQA:视觉问答,CVPR 2015 SUNw:场景理解研讨会。
- 马普所 / 伯克利 [网页] [论文]
- 马特乌什·马利诺夫斯基、马库斯·罗尔巴赫、马里奥·弗里茨,问问你的神经元:一种基于神经网络的图像问答方法,arXiv:1505.01121。
- 多伦多 [论文] [数据集]
- 孟也仁、瑞安·基罗斯、理查德·泽梅尔,图像问答:一种视觉语义嵌入模型及新数据集,arXiv:1505.02074 / ICML 2015 深度学习研讨会。
- 百度 / UCLA [论文] [数据集]
- 高怀远、毛俊华、周杰、黄志恒、王磊、徐伟,你在和机器对话吗?多语言图像问答的数据集与方法,arXiv:1505.05612。
- 浦项工科大学 [论文] [项目页面]
- 诺贤宇、保罗·洪淑·徐、韩宝亨,利用动态参数预测的卷积神经网络进行图像问答,arXiv:1511.05765
- 卡内基梅隆大学 / 微软研究院 [论文]
- 杨、何、高、邓、斯莫拉 (2015)。用于图像问答的堆叠注意力网络。arXiv:1511.02274。
- MetaMind [论文]
- 蔡明雄、史蒂芬·梅里蒂、理查德·索彻。“用于视觉和文本问答的动态记忆网络”。arXiv:1603.01417(2016)。
- 首尔大学 + NAVER [论文]
- 金镇华、李相佑、郭东贤、许敏旿、金正熙、河正宇、张炳卓,《面向视觉问答的多模态残差学习》,arXiv:1606.01455
- 加州大学伯克利分校 + 索尼 [论文]
- 阿基拉·福库伊、朴东赫、杨戴伦、安娜·罗尔巴赫、特雷弗·达雷尔、马库斯·罗尔巴赫,《用于视觉问答和视觉定位的多模态紧凑双线性池化》,arXiv:1606.01847
- 浦项工科大学 [论文]
- 诺贤宇和韩宝亨,《通过联合损失最小化训练循环式回答单元以用于VQA》,arXiv:1606.03647
- 首尔大学 + NAVER [论文]
- 金镇华、权京云、金正熙、河正宇、张炳卓,《低秩双线性池化的哈达玛积》,arXiv:1610.04325。
图像生成
- 卷积 / 循环网络
- 对抗网络
- 伊恩·J·古德费洛、让·普热-阿巴迪、梅迪·米尔扎、宾·徐、大卫·瓦尔德-法利、谢尔吉尔·奥扎伊尔、亚伦·库维尔、约书亚·本吉奥,生成对抗网络,NIPS 2014。[论文]
- 艾米莉·登顿、苏米思·钦塔拉、阿瑟·兹拉姆、罗布·费格斯,使用对抗网络拉普拉斯金字塔的深度生成图像模型,NIPS 2015。[论文]
- 卢卡斯·泰斯、阿龙·范登奥德、马蒂亚斯·贝特格,“关于生成模型评估的一点说明”,ICLR 2016。[论文]
- 甄文戴、安德烈亚斯·达米亚努、哈维尔·冈萨雷斯、尼尔·劳伦斯,“变分自编码的深度高斯过程”,ICLR 2016。[论文]
- 埃尔曼·曼西莫夫、埃米利奥·帕里索托、吉米·巴、鲁斯兰·萨拉胡丁诺夫,“通过注意力机制从描述生成图像”,ICLR 2016,[论文]
- 尤斯特·托比亚斯·施普林根贝格,“使用分类生成对抗网络进行无监督和半监督学习”,ICLR 2016,[论文]
- 哈里森·爱德华兹、阿莫斯·斯托基,“用对手审查表示”,ICLR 2016,[论文]
- 片桐武、前田信一、小山正典、中江健、石井真,“通过虚拟对抗训练进行分布平滑”,ICLR 2016,[论文]
- 朱俊彦、菲利普·克拉亨布尔、伊莱·谢赫特曼和阿列克谢·A·叶夫罗斯,“在自然图像流形上进行生成式视觉操控”,ECCV 2016。[论文] [代码] [视频]
- 卷积与对抗网络的结合
- 亚历克·拉德福德、卢克·梅茨、苏米思·钦塔拉,“使用深度卷积生成对抗网络进行无监督表征学习”,ICLR 2016。[论文]
其他主题
- 视觉类比 [论文]
- 斯科特·里德、张毅、张宇婷、李洪洛,深度视觉类比生成,NIPS,2015年
- 表面法线估计 [论文]
- 王晓龙、大卫·F·福黑、阿比纳夫·古普塔,面向表面法线估计的深度网络设计,CVPR,2015年。
- 动作检测 [论文]
- 乔治娅·吉奥克萨里、吉滕德拉·马利克,寻找动作管,CVPR,2015年。
- 人群计数 [论文]
- 张聪、李宏生、王晓刚、杨晓康,基于深度卷积神经网络的跨场景人群计数,CVPR,2015年。
- 3D形状检索 [论文]
- 王芳、康乐、李毅,使用卷积神经网络的基于草图的3D形状检索,CVPR,2015年。
- 弱监督分类
- 萨曼内·阿扎迪、冯嘉诗、施特法妮·耶格尔卡、特雷弗·达雷尔,“用于带有噪声标签的深度CNN的辅助图像正则化”,ICLR 2016,[论文]
- 艺术风格 [论文] [代码]
- 列昂·A·加蒂斯、亚历山大·S·埃克尔、马蒂亚斯·贝特格,艺术风格的神经算法。
- 人眼视线估计
- 人脸识别
- 面部关键点检测
课程
- 深度视觉
- [斯坦福] CS231n:用于视觉识别的卷积神经网络
- [香港中文大学] ELEG 5040:信号处理高级专题(深度学习导论)
- 更多深度学习
- [斯坦福] CS224d:自然语言处理中的深度学习
- [牛津大学] 由南多·德·弗雷塔斯教授讲授的深度学习
- [纽约大学] 由扬·勒丘恩教授讲授的深度学习
书籍
视频
软件
框架
- TensorFlow:由谷歌开发的开源数值计算软件库,采用数据流图技术 [官网]
- Torch7:基于Lua的深度学习库,被Facebook和Google DeepMind使用 [官网]
- 基于Torch的深度学习库:[torchnet],
- Caffe:由BVLC开发的深度学习框架 [官网]
- Theano:Python中的数学库,由LISA实验室维护 [官网]
- MatConvNet:用于MATLAB的卷积神经网络 [官网]
- MXNet:一种灵活高效的深度学习库,适用于异构分布式系统,并支持多种语言 [官网]
- Deepgaze:基于CNN的人机交互计算机视觉库 [官网]
应用程序
- 对抗训练
- “生成对抗网络”论文的代码及超参数 [官网]
- 理解与可视化
- CVPR 2015“通过反演理解深度图像表示”的源代码。[官网]
- 语义分割
- 超分辨率
- 动漫风格艺术的图像超分辨率 [官网]
- 边缘检测
教程
- [CVPR 2014] 计算机视觉中的深度学习教程
- [CVPR 2015] 使用Torch的计算机视觉深度学习应用教程
博客
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。