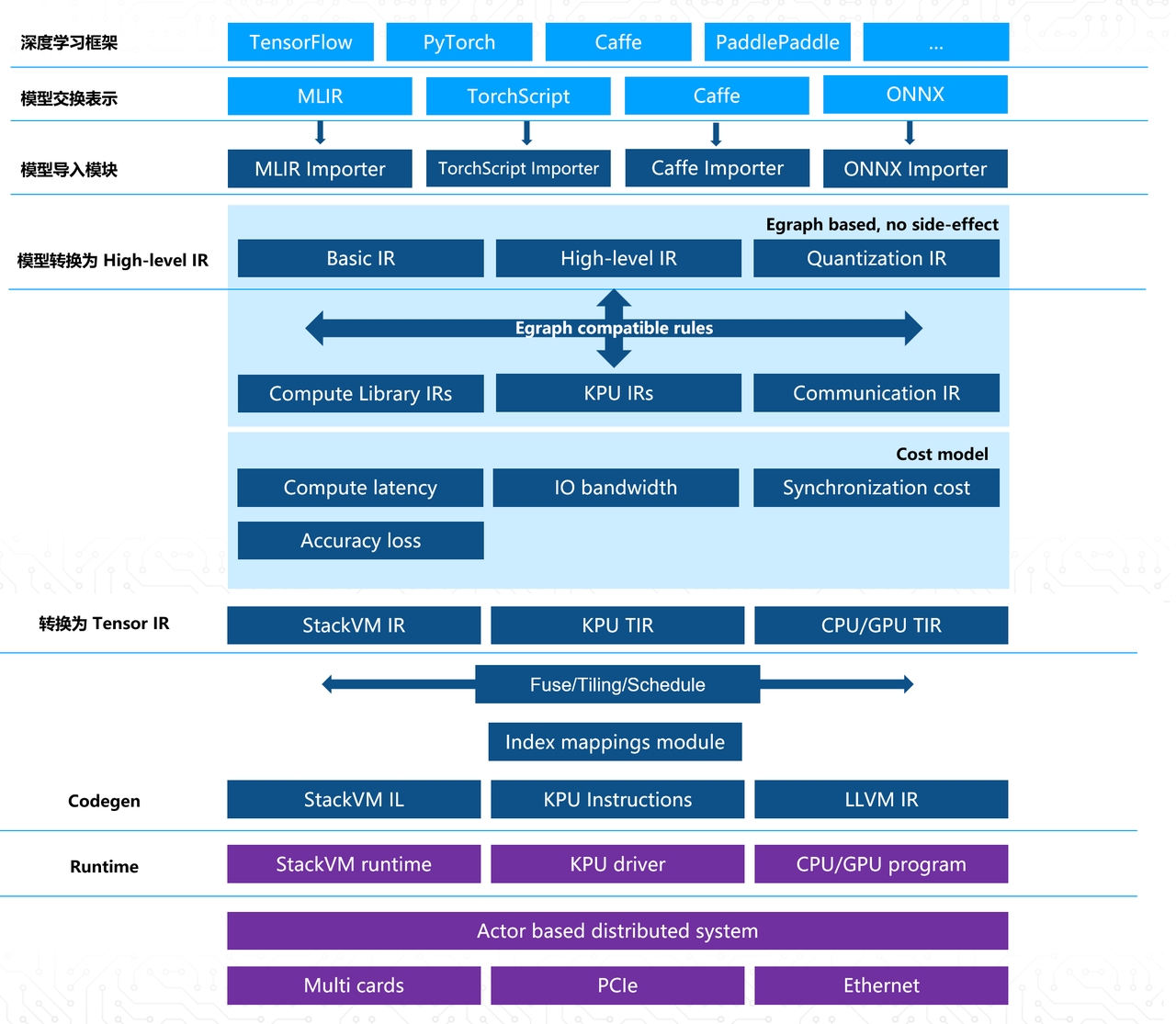
nncase
nncase 是一款专为 Kendryte 系列 AI 加速器(如 K230)打造的开源深度学习编译器。它的核心作用是将用户在主流框架(如 TensorFlow Lite、Caffe、ONNX)中训练好的神经网络模型,高效地编译并优化为能在特定硬件上流畅运行的格式,从而打通从算法模型到嵌入式设备部署的“最后一公里”。
对于希望在资源受限的边缘设备上落地 AI 应用的开发者而言,nncase 解决了模型兼容性差、推理速度慢以及精度损失大等痛点。它内置了强大的量化技术和算子融合策略,在显著提升了模型推理帧率(FPS)的同时,能够最大程度保持模型的原始识别准确率,确保在图像分类、目标检测和语义分割等任务中表现优异。
这款工具主要面向嵌入式 AI 工程师、算法研究人员以及物联网设备开发者。如果你正在使用嘉楠科技的芯片进行项目开发,或者需要将轻量级模型部署到边缘端,nncase 提供了完善的命令行工具和 Python 接口,支持 Linux 和 Windows 环境,并附带详细的文档与社区支持,能帮助你快速完成模型的转换、仿真测试与实际部署。
使用场景
某嵌入式开发团队正致力于将基于 YOLOv5 的目标检测算法部署到嘉楠科技 K230 AI 加速芯片上,用于智能安防摄像头的实时人流统计。
没有 nncase 时
- 模型兼容性差:直接从 PyTorch 导出的 ONNX 模型无法直接在 K230 硬件上运行,团队需手动重写底层算子或寻找不稳定的第三方转换脚本。
- 推理性能低下:未经针对硬件优化的浮点模型在边缘端运行帧率仅为 3-4 FPS,完全无法满足实时监控所需的流畅度。
- 精度损失不可控:自行尝试量化(Quantization)时缺乏校准工具,导致模型压缩后精度大幅下跌,误报率飙升。
- 调试周期漫长:缺乏统一的编译栈和仿真环境,每次修改参数都需烧录固件到开发板验证,严重拖慢迭代速度。
使用 nncase 后
- 一键模型编译:利用 nncase 直接导入 ONNX 模型,自动完成算子融合与硬件指令映射,无需手动修改网络结构即可生成可执行文件。
- 性能显著提升:通过 nncase 的量化感知训练与优化,模型在保持 u8/int8 精度的同时,推理速度提升至 23+ FPS,实现流畅实时检测。
- 精度高度对齐:内置的校准工具确保量化后的模型 mAP 指标与原始浮点模型误差控制在 1% 以内,保障了业务准确性。
- 高效仿真验证:借助 nncase 提供的模拟器,开发者可在 PC 端快速验证模型效果与性能,将“修改 - 验证”循环从小时级缩短至分钟级。
nncase 通过提供从模型导入、量化优化到硬件编译的一站式解决方案,彻底打通了通用深度学习模型到 Kendryte 专用加速器的高效落地路径。
运行环境要求
- Linux
- Windows
未说明 (该工具为 AI 加速器编译器,主要运行在 CPU 上进行模型编译,目标硬件为 K210/K510/K230 等 NPU)
未说明

快速开始


nncase 是一款面向 AI 加速器的神经网络编译器。
Telegram:nncase 社区 技术讨论 QQ 群:790699378 。答案:人工智能
K230
安装
Linux:
pip install nncase nncase-kpuWindows:
1. pip install nncase 2. 在下方链接中下载 `nncase_kpu-2.x.x-py2.py3-none-win_amd64.whl`。 3. pip install nncase_kpu-2.x.x-py2.py3-none-win_amd64.whl
nncase 和 nncase-kpu 的所有版本均可在 Release 中找到。