normalizing_flows
normalizing_flows 是一个基于 PyTorch 的开源项目,集成了多种主流归一化流(Normalizing Flows)算法的实现,包括 BNAF、Glow、MAF、RealNVP 以及平面流等。它主要致力于解决复杂的概率密度估计与生成建模问题,能够将简单的已知分布(如高斯分布)通过可逆变换映射为复杂的数据分布,从而实现对数据的高效建模和样本生成。
该项目特别适合人工智能研究人员、算法工程师以及对生成模型感兴趣的高级开发者使用。无论是需要复现经典论文实验、验证新算法思路,还是希望深入理解可逆神经网络内部机制,normalizing_flows 都提供了清晰、模块化的代码参考。其技术亮点在于不仅涵盖了从基础的平面流到先进的 Glow(引入可逆 1x1 卷积)和 BNAF(块神经自回归流)等多种架构,还包含了在 2D 玩具数据集及 CelebA、MNIST 等真实图像数据上的完整训练与可视化示例。通过这些实现,用户可以直观地观察模型如何学习数据分布细节,并在稳定的训练过程中获得高质量的生成结果,是探索深度生成模型领域的实用工具库。
使用场景
某计算机视觉团队正在开发一个人脸属性编辑系统,需要基于 CelebA 数据集生成高质量且可精确控制的人脸图像。
没有 normalizing_flows 时
- 分布建模能力弱:传统 GAN 模型难以精确计算数据概率密度,导致生成的样本多样性不足,容易陷入模式崩溃,无法覆盖复杂的人脸特征分布。
- 属性编辑不可控:缺乏可逆映射机制,无法在潜在空间中进行精确的数学运算,修改“微笑”或“戴眼镜”等属性时往往伴随身份特征丢失或画面伪影。
- 训练稳定性差:对抗训练过程波动大,需要大量调参技巧才能收敛,且不同温度下的采样质量参差不齐,难以满足生产环境对稳定性的要求。
使用 normalizing_flows 后
- 精准密度估计:利用 Glow 算法的可逆 1x1 卷积特性,实现了对人脸数据分布的精确建模,生成的样本在多种温度设置下均保持高清晰度与自然度。
- 线性属性操纵:借助可逆流的双向特性,团队能在潜在空间中通过向量加减(如 $z_{new} = z + \Delta z$)精确调整特定属性,同时完美保留人物身份和其他细节。
- 训练高效稳定:基于最大似然估计的训练目标避免了博弈震荡,模型在 10 万次迭代内即可稳定收敛至 4.2 bits/dim,显著降低了运维成本。
normalizing_flows 通过引入可逆变换与精确密度估计,将原本黑盒式的生成过程转化为可控、可解释的数学流,彻底解决了复杂数据分布下的生成质量与编辑精度难题。
运行环境要求
- 未说明
- 训练 Glow 模型时建议使用多 GPU (通过 torch.distributed.launch),具体显存需求取决于模型大小和批次大小 (例如:74M 参数模型在单卡上使用 batch_size=16,更大模型需使用梯度检查点 --checkpoint_grads 以节省显存)
- 其他模型 (BNAF, MAF) 支持 CUDA 但未强制要求
未说明 (大模型训练如 Glow 的 190M 参数版本可能需要较大内存)
快速开始
归一化流
对以下论文中的密度估计算法进行了重新实现:
块神经自回归流
https://arxiv.org/abs/1904.04676
在玩具密度估计数据集上实现了 BNAF。
结果
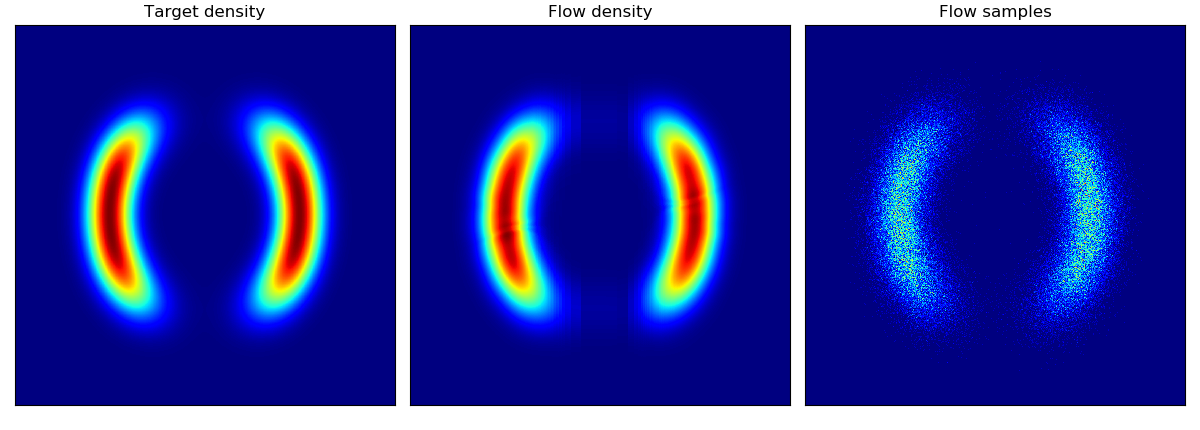
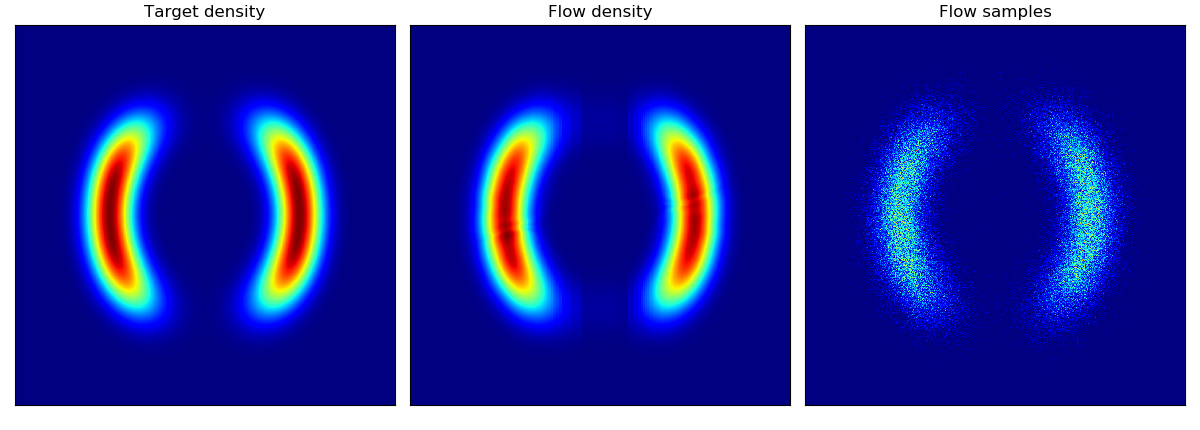
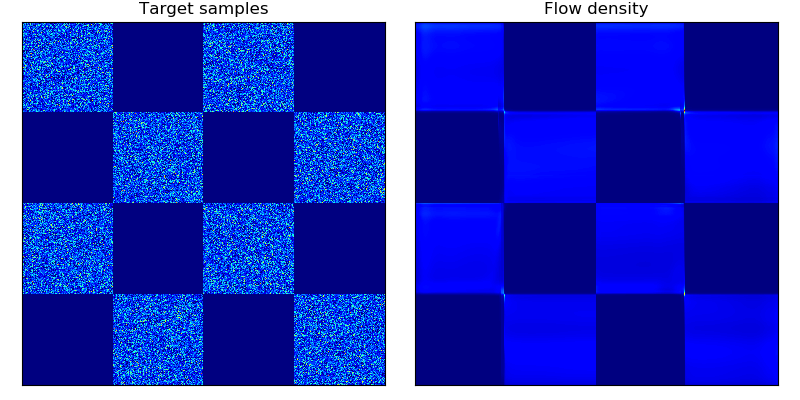
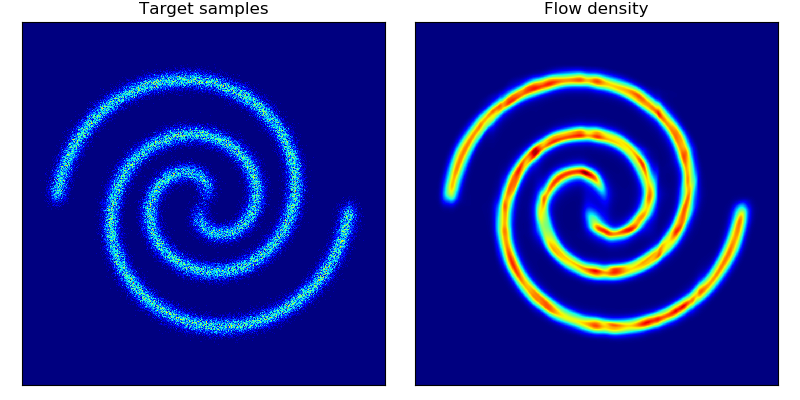
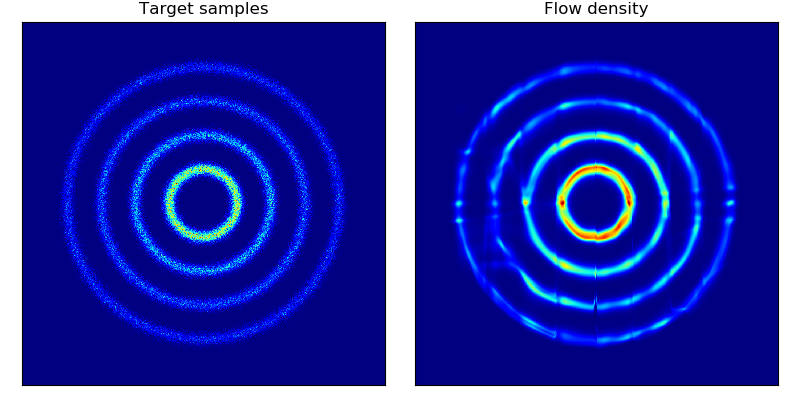
对二维玩具数据的密度估计以及对二维测试能量势能的密度估计(参见论文中的图 2 和图 3):
这些模型按照论文第 5 节中描述的架构和超参数训练了 20,000 步,除了 rings 数据集(右下角)使用了 5 层隐藏层。与 Rezende & Mohamed 中的平面流模型相比,BNAF 训练得更快且更加稳定;有趣的是,BNAF 对空间的拉伸方式不同,需要更多的测试点才能显示出平滑的势能。
| 二维能量势能上的密度匹配 | 二维玩具数据上的密度估计 |
|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
使用方法
训练模型:
python bnaf.py --train
--dataset # 可选 u1、u2、u3、u4、8gaussians、checkerboard、2spirals
--log_interval # 模型保存和结果可视化的频率
--n_steps # 训练步数
--n_hidden # 隐藏层数量
--hidden_dim # 隐藏层维度
--[其他选项]
其他选项包括:学习率、学习率衰减及耐心值、CUDA 设备 ID、批量大小。
绘制模型:
python bnaf.py --plot
--restore_file [路径到 .pt 检查点文件]
有用资源
Glow:带有可逆1×1卷积的生成流模型
https://arxiv.org/abs/1807.03039
在CelebA和MNIST数据集上实现Glow模型。
结果
我训练了两个模型:
- 模型A:3个层级,深度32,宽度512(约7400万参数)。在5位图像上训练,每张GPU上的批量大小为16,共进行了10万次迭代。
- 模型B:3个层级,深度24,宽度256(约2200万参数)。在4位图像上训练,每张GPU上的批量大小为32,共进行了10万次迭代。
在这两种情况下,梯度都被裁剪至范数50,学习率为1e-3,并在前2个epoch内从0线性预热。两者都达到了相似的结果,即4.2比特/维度。
不同温度下的采样结果
温度范围为0、0.25、0.5、0.6、0.7、0.8、0.9、1(行,从上到下):
| 模型A | 模型B |
|---|---|
 |
 |
温度为0.7时的采样结果:
| 模型A | 模型B |
|---|---|
 |
 |
模型A对分布内样本的属性操控:
对前3万个训练图像计算了嵌入向量,分别取正负属性的平均值并相减。得到的dz被归一化后应用于测试集中的一个图像(中间图表示未改变的真实数据点)。
| 属性 | dz 范围 [-2, -1, 0, 1, 2] |
|---|---|
| 棕色头发 |  |
| 男性 |  |
| 嘴微微张开 |  |
| 年轻 |  |
模型A对“分布外”样本(即我自己)的属性操控:
| 属性 | dz 范围 |
|---|---|
| 棕色头发 |  |
| 嘴微微张开 |  |
使用方法
使用PyTorch分布式包训练模型:
python -m torch.distributed.launch --nproc_per_node=NUM_GPUS_YOU_HAVE \
glow.py --train \
--distributed \
--dataset=celeba \
--data_dir=[数据源路径 ] \
--n_levels=3 \
--depth=32 \
--width=512 \
--batch_size=16 [这是每张GPU上的批量大小]
对于更大的模型或更高分辨率的图像,可以添加--checkpoint_grads选项来使用PyTorch库进行梯度检查点保存。我曾训练过一个3层/深度32/宽度512、批量大小为16且未使用梯度检查点的模型,以及一个4层/深度48/宽度512、批量大小为16的模型,后者约有1.9亿参数,因此必须使用梯度检查点(并且在8张GPU上运行时速度非常慢)。
评估模型:
python glow.py --evaluate \
--restore_file=[ .pt 检查点文件路径 ] \
--dataset=celeba \
--data_dir=[ 数据源路径 ] \
--[ 已保存模型的参数:n_levels、depth、width、batch_size ]
从已训练好的模型生成样本:
python glow.py --generate \
--restore_file=[ .pt 检查点文件路径 ] \
--dataset=celeba \
--data_dir=[ 数据源路径 ] \
--[ 已保存模型的参数:n_levels、depth、width、batch_size ] \
--z_std=[ 温度参数;若为空,则生成一系列样本 ]
可视化特定图像的操控效果(需已训练好模型):
python glow.py --visualize \
--restore_file=[ .pt 检查点文件路径 ] \
--dataset=celeba \
--data_dir=[ 数据源路径 ] \
--[ 已保存模型的参数:n_levels、depth、width、batch_size ] \
--z_std=[ 温度参数;若为空,则使用默认值 ] \
--vis_attrs=[ 需要操控的属性索引列表;若为空,则操控所有属性 ] \
--vis_alphas=[ 用于乘以`dz`的数值列表;默认为[-2,2] ] \
--vis_img=[ 需要操控的图像路径(注意:尺寸需与数据集一致);若为空,则使用测试集中的示例 ]
数据集
下载CelebA数据集,请按照此处的说明操作。这里有一个方便的脚本可以帮助简化下载和解压过程:https://github.com/nperraud/download-celebA-HQ/
参考文献
- 官方TensorFlow实现:https://github.com/openai/glow
掩码自回归流
https://arxiv.org/abs/1705.07057
在 UCI 数据集和 MNIST 上重新实现了 MADE、MAF、高斯混合 MADE、高斯混合 MAF 以及 RealNVP 模块。
结果
无条件/条件密度估计的平均测试对数似然(参考论文中的表 1 和表 2 以获取结果和参数;此处模型训练了 50 个 epoch):
| 模型 | POWER | GAS | HEPMASS | MINIBOONE | BSDS300 | MNIST(无条件) | MNIST(条件) |
|---|---|---|---|---|---|---|---|
| MADE | -3.10 ± 0.02 | 2.53 ± 0.02 | -21.13 ± 0.01 | -15.36 ± 15.06 | 146.42 ± 0.14 | -1393.67 ± 1.90 | -1340.98 ± 1.71 |
| MADE MOG | 0.37 ± 0.01 | 8.08 ± 0.02 | -15.70 ± 0.02 | -11.64 ± 0.44 | 153.56 ± 0.28 | -1023.13 ± 1.69 | -1013.75 ± 1.61 |
| RealNVP (5) | -0.49 ± 0.01 | 7.01 ± 0.06 | -19.96 ± 0.02 | -16.88 ± 0.21 | 148.34 ± 0.26 | -1279.76 ± 9.91 | -1276.33 ± 12.21 |
| MAF (5) | 0.03 ± 0.01 | 6.23 ± 0.01 | -17.97 ± 0.01 | -11.57 ± 0.21 | 153.53 ± 0.27 | -1272.70 ± 1.87 | -1268.24 ± 2.73 |
| MAF MOG (5) | 0.09 ± 0.01 | 7.96 ± 0.02 | -17.29 ± 0.02 | -11.27 ± 0.41 | 153.35 ± 0.26 | -1080.46 ± 1.53 | -1070.33 ± 1.53 |
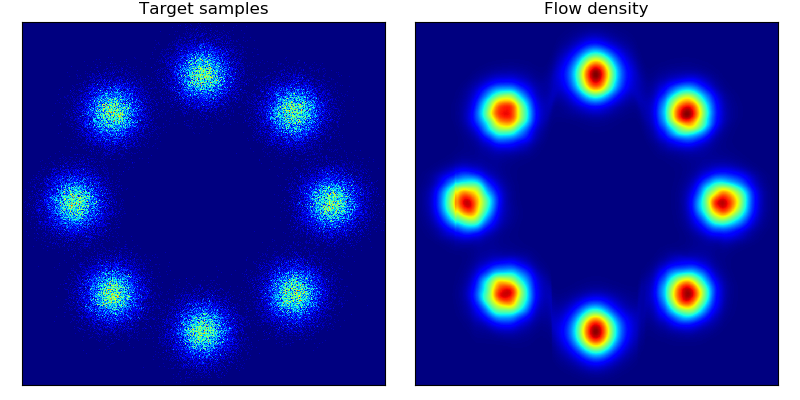
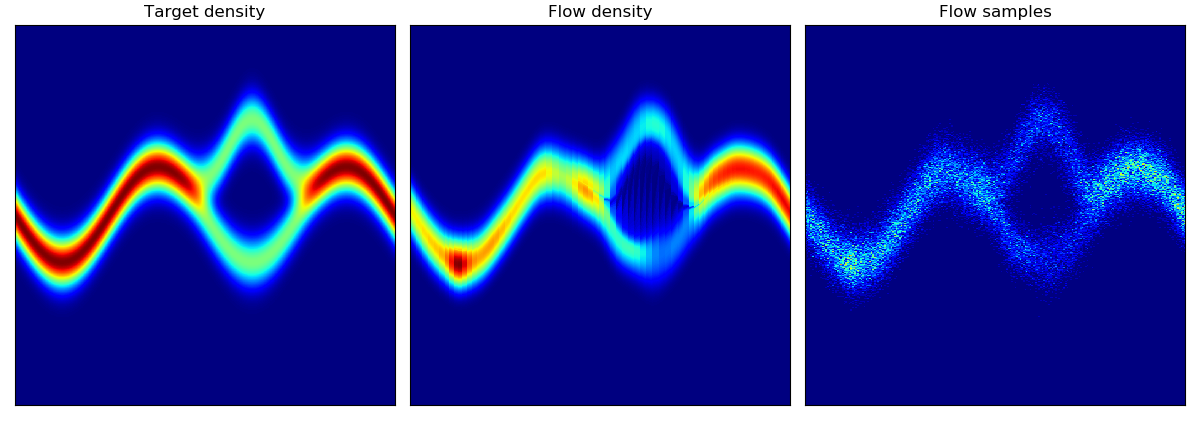
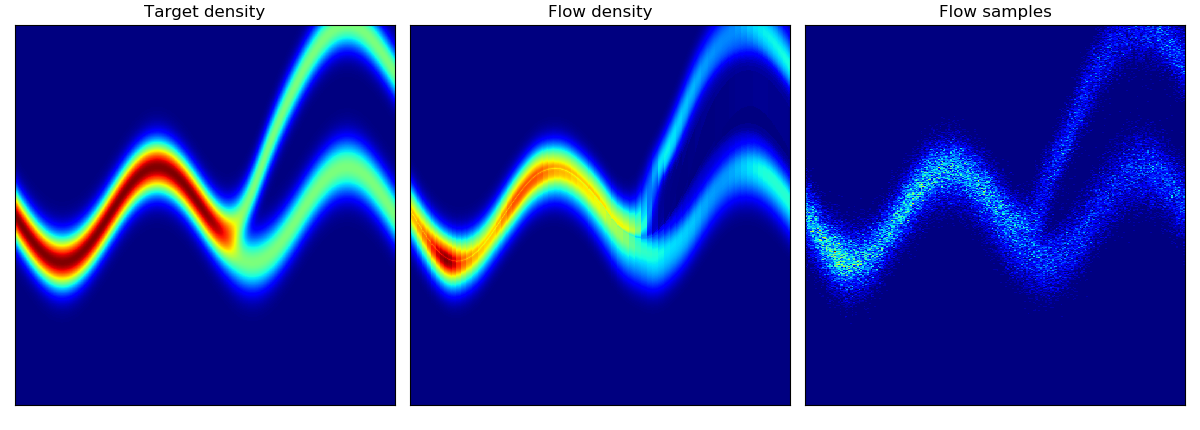
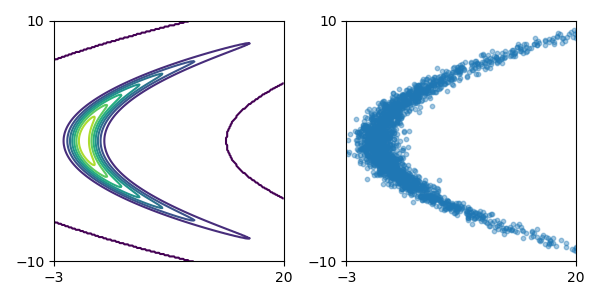
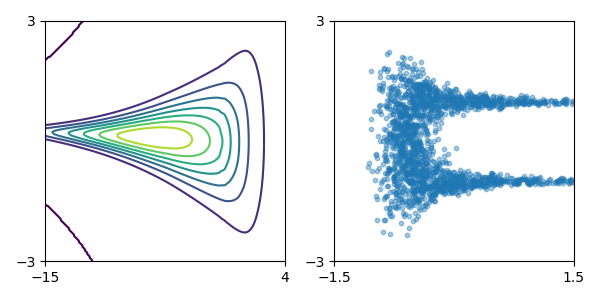
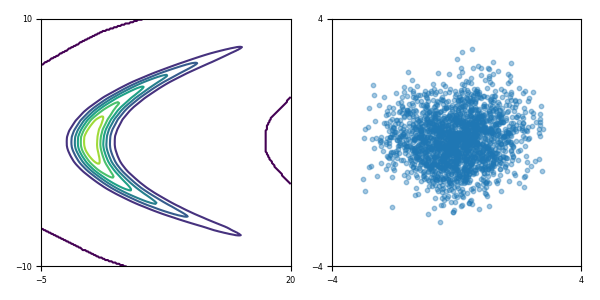
玩具密度模型(参考论文中的图 1):
| 目标密度 | 使用 MADE 及随机数驱动 MADE 学习到的密度 | 使用 MAF 5 层及随机数驱动 MAF 学习到的密度 |
|---|---|---|
 |
 |
 |
使用 MAF (5) 模型生成的 MNIST 类条件图像;生成数据按对数似然递减排序(参考论文中的图 3):

使用方法
训练模型:
python maf.py -- train \
-- model=['made' | 'mademog' | 'maf' | 'mafmog' | 'realnvp'] \
-- dataset=['POWER' | 'GAS' | 'HEPMASS' | 'MINIBOONE' | 'BSDS300' | MNIST'] \
-- n_blocks=[对于 maf/mafmog 和 realnvp,指定 MADE 块或耦合层的数量] \
-- n_components=[如果是高斯混合,则指定组件数量] \
-- conditional [如果是 MNIST,可以训练类条件对数似然] \
-- [更多选项请参阅 py 文件]
评估模型:
python maf.py -- evaluate \
-- restore_file=[.pt 检查点路径] \
-- [保存模型的选项:n_blocks、n_hidden、hidden_size、n_components、conditional]
从已训练模型生成数据(针对 MNIST 数据集):
python maf.py -- generate \
-- restore_file=[.pt 检查点路径] \
-- dataset='MNIST' \
-- [保存模型的选项:n_blocks、n_hidden、hidden_size、n_components、conditional]
数据集
数据集和预处理代码源自 MAF 作者的实现 这里。解压后的数据集应符号链接到 ./data 文件夹,或指定 data_dir 参数指向实际数据。
参考文献
基于归一化流的变分推断
实现了 基于归一化流的变分推断
结果
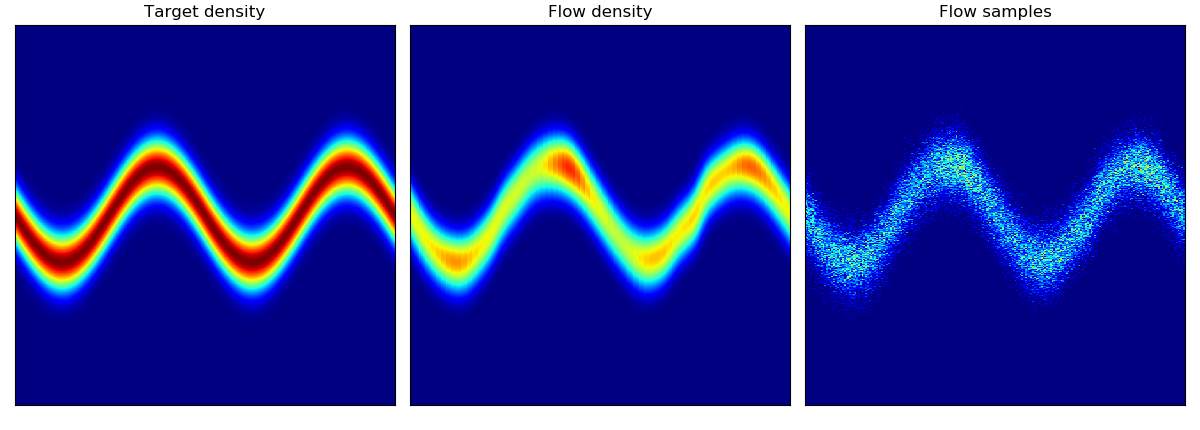
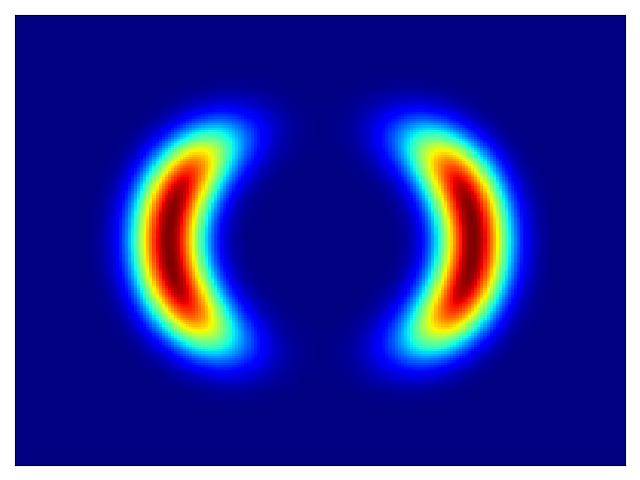
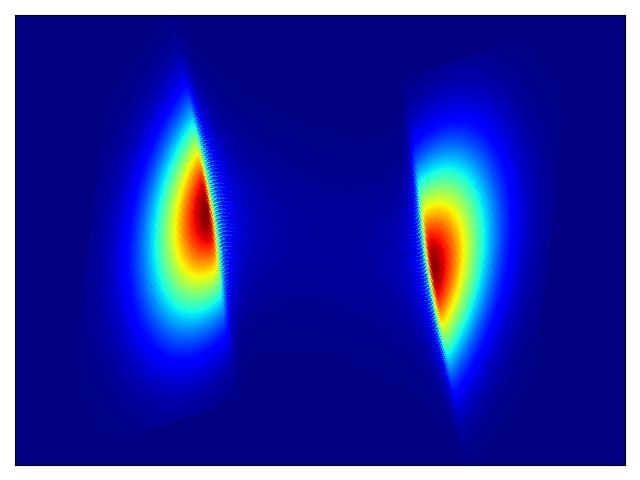
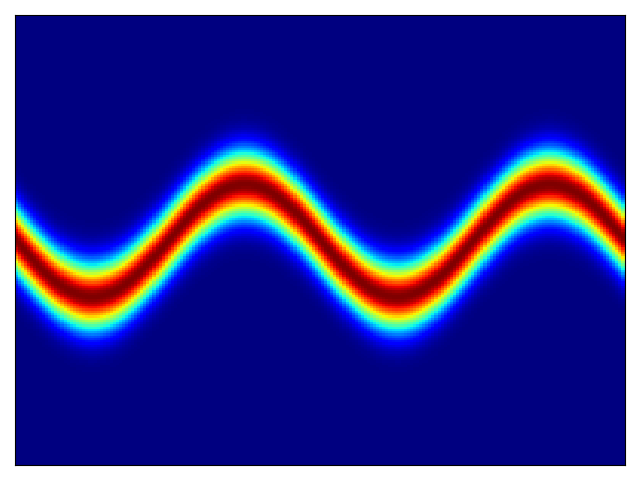
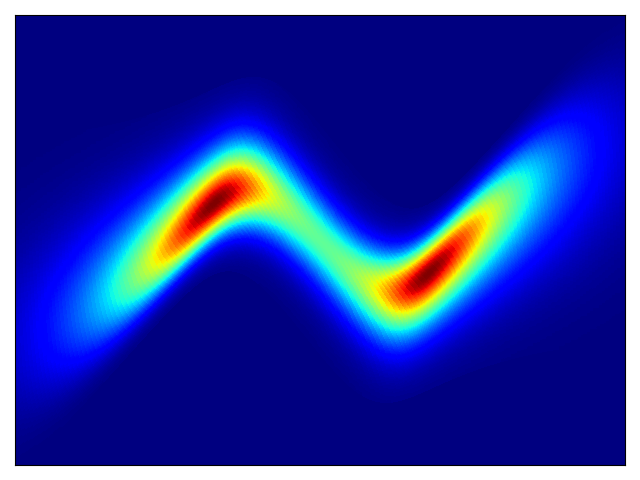
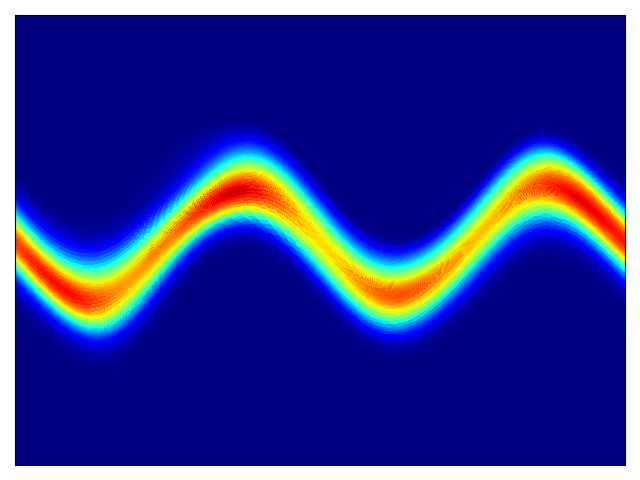
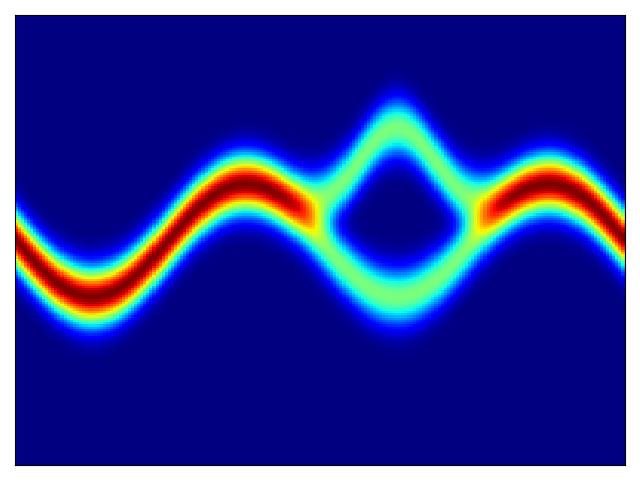
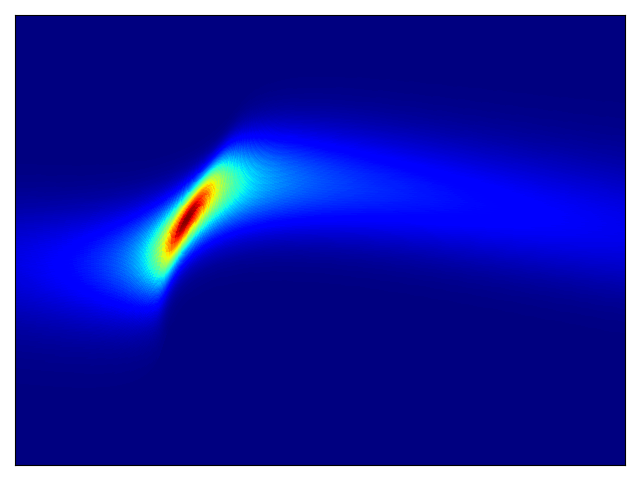
二维测试能量势的密度估计(参考论文中的表 1 和图 3)。
| 目标密度 | 流 K = 2 | 流 K = 32 | 训练参数 |
|---|---|---|---|
 |
 |
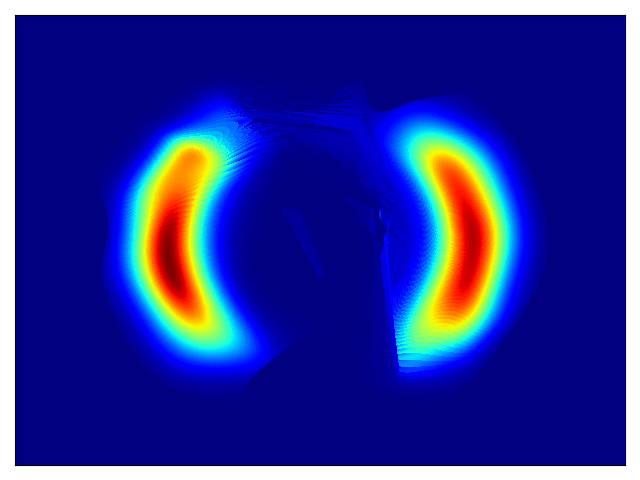 |
权重初始化为 N(0,1),基础分布尺度为 2 |
 |
 |
 |
权重初始化为 N(0,1),基础分布尺度为 1 |
 |
 |
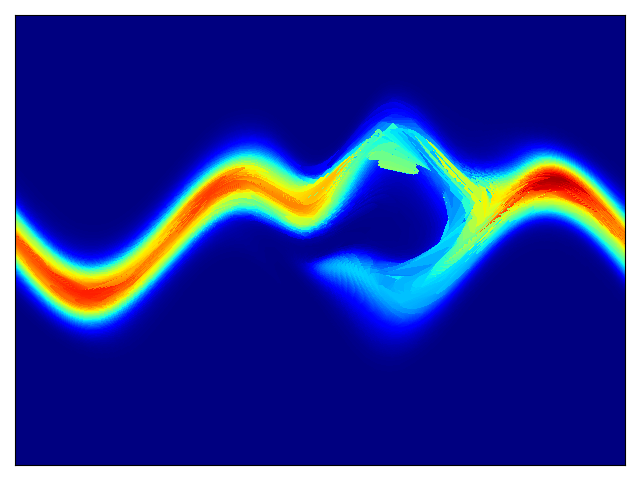 |
权重初始化为 N(0,1),基础分布尺度为 1,权重衰减为 1e-3 |
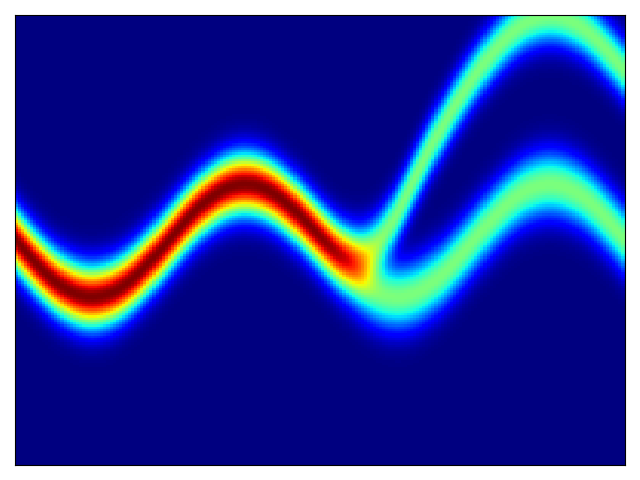 |
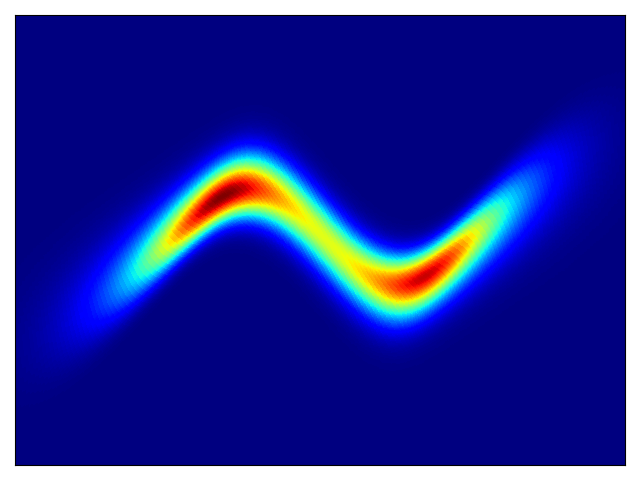 |
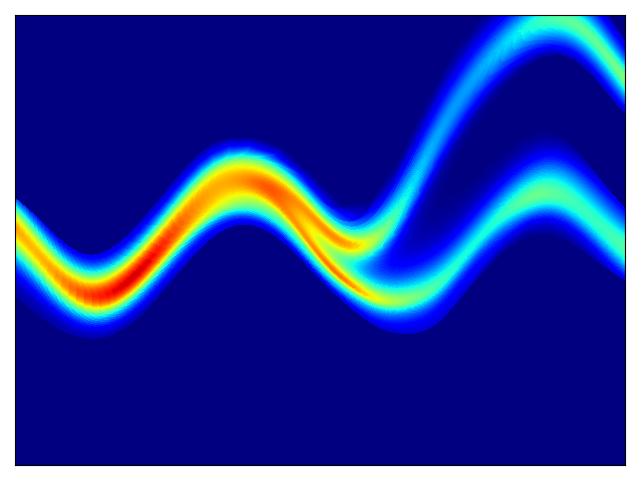 |
权重初始化为 N(0,1),基础分布尺度为 4,权重衰减为 1e-3 |
使用方法
训练模型:
python planar_flow.py -- train \
-- target_potential=[选择 u_z1 | u_z2 | u_z3 | u_z4] \
-- flow_length=[流的层数] \
-- [其他选项]
其他选项包括:基础分布(q0)的尺度、权重初始化的尺度、权重衰减以及可学习的第一层仿射变换(我没有发现添加仿射层有益)。
评估模型:
python planar_flow.py -- evaluate \
-- restore_file=[.pt 检查点路径]
有用资源
依赖项
- python 3.6
- pytorch 1.0
- numpy
- matplotlib
- tensorboardX
部分数据集还需要:
- pandas
- sklearn
- h5py
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器