rrcf
rrcf 是一个专为流式数据设计的开源 Python 库,实现了鲁棒随机切割森林(RRCF)算法,用于高效检测数据中的异常点。在实时监控、物联网传感器网络或金融交易流等场景中,数据往往持续涌入且维度较高,传统方法难以兼顾速度与准确性,而 rrcf 正是为了解决这一痛点而生。
该工具特别适合数据科学家、算法研究人员以及需要处理实时数据流的开发者使用。它能够优雅地应对高维数据,自动降低无关维度的干扰,并能有效识别被大量重复数据掩盖的罕见异常值。与其他黑盒模型不同,rrcf 提供的异常评分机制具有清晰的统计学意义,基于“共谋位移”(CoDisp)概念:如果插入一个新点显著增加了模型的复杂度,则该点极有可能是异常值。
此外,rrcf 支持动态增删数据点,无需重新训练整个模型,非常适合资源受限或要求低延迟的在线应用场景。只需几行代码,用户即可构建随机切割树,实时插入新观测值并获取异常评分,是探索流数据异常检测的理想选择。
使用场景
某大型电商平台的实时风控团队正在处理每秒数万条的用户交易流,急需从海量正常订单中瞬间识别出罕见的欺诈行为。
没有 rrcf 时
- 传统静态模型难以适应交易数据的实时流动,必须定期停机重新训练,导致新出现的欺诈模式存在数小时的检测盲区。
- 面对包含用户设备、地理位置、行为习惯等几十维特征的高维数据,常规算法容易受无关维度干扰,误报率居高不下。
- 大量重复的正常交易(如批量采购)会掩盖少数异常点,导致基于密度的检测方法失效,漏掉精心伪装的团伙作弊。
- 缺乏明确的统计解释,运维人员面对报警只能凭经验猜测,无法量化某个订单为何被判定为异常。
使用 rrcf 后
- rrcf 专为流数据设计,支持动态插入和删除节点,无需重训即可实时同化新交易,将欺诈识别延迟降低至毫秒级。
- 其鲁棒随机切割机制自动降低无关维度的权重,在高维特征空间中依然能精准锁定真正的异常轨迹。
- 算法天然免疫重复数据干扰,即使面对海量相似的正常订单,也能敏锐捕捉到那些试图混入其中的离群欺诈点。
- 提供的“共谋位移”(CoDisp)评分具有清晰的统计学含义,让开发人员能直接依据分数阈值解释报警原因,大幅缩短排查时间。
rrcf 通过其独特的流式处理能力与统计可解释性,将原本滞后的离线风控升级为实时、精准且透明的智能防御体系。
运行环境要求
未说明
未说明

快速开始
rrcf 🌲🌲🌲

![]()
![]()


由 Guha 等人 (2016) 提出的用于异常检测的 鲁棒随机切割森林算法 的实现。
S. Guha, N. Mishra, G. Roy, & O. Schrijvers,《基于鲁棒随机切割森林的流式数据异常检测》,载于第33届国际机器学习会议论文集,纽约,纽约州,2016年(第2712–2721页)。
关于
鲁棒随机切割森林(RRCF)算法是一种用于检测流式数据中离群点的集成方法。RRCF 具有许多竞争性异常检测算法所不具备的功能。具体而言,RRCF:
- 专为处理流式数据而设计。
- 在高维数据上表现良好。
- 减少无关维度的影响。
- 能够优雅地处理重复和近似重复的数据,这些数据可能会掩盖离群点的存在。
- 拥有一个具有明确统计意义的异常评分算法。
本仓库提供了 RRCF 算法及其核心数据结构的开源实现,旨在促进实验研究,并为 RRCF 算法的未来扩展提供支持。
文档
请在此处阅读文档 📖[链接]。
安装
使用 pip 通过 pypi 安装 rrcf:
$ pip install rrcf
目前仅支持 Python 3。
依赖项
安装和使用 rrcf 需要以下依赖项:
- numpy(>= 1.15)
运行文档中示例所需的以下可选依赖项:
- pandas(>= 0.23)
- scipy(>= 1.2)
- scikit-learn(>= 0.20)
- matplotlib(>= 3.0)
列出的版本号已经过测试并确认可用(但这并不排除较旧版本的可能性)。
鲁棒随机切割树
鲁棒随机切割树(RRCT)是一种二叉搜索树,可用于检测点集中的离群点。RRCT 可以从点集实例化。也可以向 RRCT 中添加或删除点。
创建树
import numpy as np
import rrcf
# 可以从点集(n x d)实例化一棵(鲁棒)随机切割树
X = np.random.randn(100, 2)
tree = rrcf.RCTree(X)
# 随机切割树也可以在没有点的情况下实例化
tree = rrcf.RCTree()
插入点
tree = rrcf.RCTree()
for i in range(6):
x = np.random.randn(2)
tree.insert_point(x, index=i)
─+
├───+
│ ├───+
│ │ ├──(0)
│ │ └───+
│ │ ├──(5)
│ │ └──(4)
│ └───+
│ ├──(2)
│ └──(3)
└──(1)
删除点
tree.forget_point(2)
─+
├───+
│ ├───+
│ │ ├──(0)
│ │ └───+
│ │ ├──(5)
│ │ └──(4)
│ └──(3)
└──(1)
异常评分
一个点是离群点的可能性由其协同位移(CoDisp)来衡量:如果加入一个新的点会显著改变模型复杂度(即位深),那么该点更有可能是离群点。
# 使用零均值、正态分布的数据初始化树
X = np.random.randn(100,2)
tree = rrcf.RCTree(X)
# 生成一个内点和一个离群点
inlier = np.array([0, 0])
outlier = np.array([4, 4])
# 插入树中
tree.insert_point(inlier, index='inlier')
tree.insert_point(outlier, index='outlier')
tree.codisp('inlier')
>>> 1.75
tree.codisp('outlier')
>>> 39.0
批量异常检测
此示例展示了如何使用鲁棒随机切割森林在批量环境中检测离群点。离群点对应于较大的 CoDisp 值。
import numpy as np
import pandas as pd
import rrcf
# 设置参数
np.random.seed(0)
n = 2010
d = 3
num_trees = 100
tree_size = 256
# 生成数据
X = np.zeros((n, d))
X[:1000,0] = 5
X[1000:2000,0] = -5
X += 0.01*np.random.randn(*X.shape)
# 构建森林
forest = []
while len(forest) < num_trees:
# 从点集中均匀随机选择子集
ixs = np.random.choice(n, size=(n // tree_size, tree_size),
replace=False)
# 将采样的树添加到森林中
trees = [rrcf.RCTree(X[ix], index_labels=ix) for ix in ixs]
forest.extend(trees)
# 计算平均 CoDisp
avg_codisp = pd.Series(0.0, index=np.arange(n))
index = np.zeros(n)
for tree in forest:
codisp = pd.Series({leaf : tree.codisp(leaf) for leaf in tree.leaves})
avg_codisp[codisp.index] += codisp
np.add.at(index, codisp.index.values, 1)
avg_codisp /= index
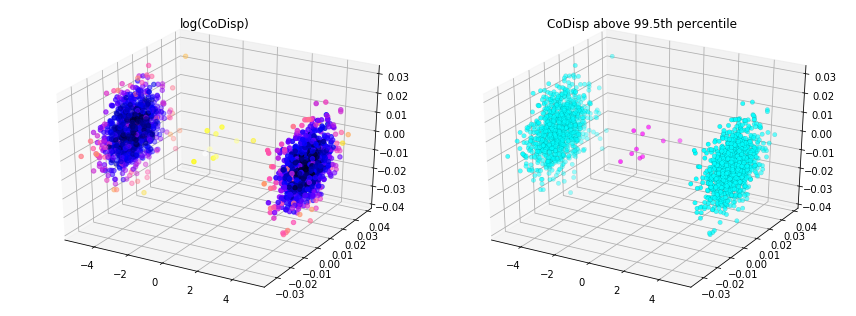
流式异常检测
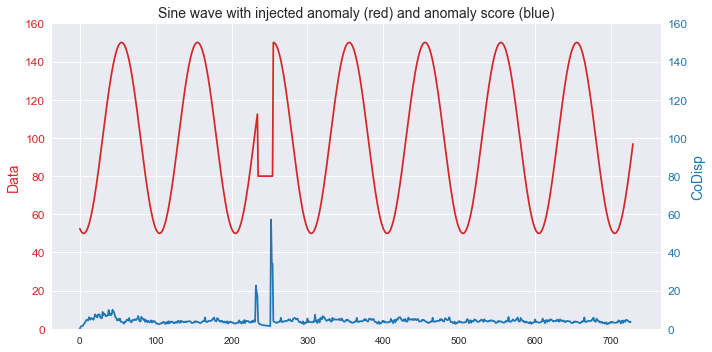
此示例展示了如何使用该算法检测流式时间序列数据中的异常。
import numpy as np
import rrcf
# 生成数据
n = 730
A = 50
center = 100
phi = 30
T = 2*np.pi/100
t = np.arange(n)
sin = A*np.sin(T*t-phi*T) + center
sin[235:255] = 80
# 设置树的参数
num_trees = 40
shingle_size = 4
tree_size = 256
# 创建一个空树的森林
forest = []
for _ in range(num_trees):
tree = rrcf.RCTree()
forest.append(tree)
# 使用“shingle”生成器创建滚动窗口
points = rrcf.shingle(sin, size=shingle_size)
# 创建一个字典存储每个点的异常评分
avg_codisp = {}
# 对于每一个 shingle...
for index, point in enumerate(points):
# 对于森林中的每一棵树...
for tree in forest:
# 如果树的叶子数量超过允许的最大值,则移除最老的叶子(FIFO)
if len(tree.leaves) > tree_size:
tree.forget_point(index - tree_size)
# 将新点插入树中
tree.insert_point(point, index=index)
# 计算新点的 CoDisp,并取所有树的平均值
if not index in avg_codisp:
avg_codisp[index] = 0
avg_codisp[index] += tree.codisp(index) / num_trees
获取特征重要性
此示例展示了如何在计算 CoDisp 时,利用切割维度来估计特征的重要性。
import numpy as np
import pandas as pd
import rrcf
# 设置参数
np.random.seed(0)
n = 2010
d = 3
num_trees = 100
tree_size = 256
# 生成数据
X = np.zeros((n, d))
X[:1000,0] = 5
X[1000:2000,0] = -5
X += 0.01*np.random.randn(*X.shape)
# 构建森林
forest = []
while len(forest) < num_trees:
# 从点集中均匀随机选择子集
ixs = np.random.choice(n, size=(n // tree_size, tree_size),
replace=False)
# 将采样的树加入森林
trees = [rrcf.RCTree(X[ix], index_labels=ix) for ix in ixs]
forest.extend(trees)
# 计算每个点在切割维度上的平均CoDisp
dim_codisp = np.zeros([n,d],dtype=float)
index = np.zeros(n)
for tree in forest:
for leaf in tree.leaves:
codisp,cutdim = tree.codisp_with_cut_dimension(leaf)
dim_codisp[leaf,cutdim] += codisp
index[leaf] += 1
avg_codisp = dim_codisp.sum(axis=1)/index
# 根据CoDisp异常阈值计算各特征的平均值
feature_importance_anomaly = np.mean(dim_codisp[avg_codisp>50,:],axis=0)
# 创建包含特征重要性的数据框
df_feature_importance = pd.DataFrame(feature_importance_anomaly,columns=['feature_importance'])
df_feature_importance

贡献说明
我们欢迎对 rrcf 仓库的贡献。如需贡献,请向 dev 分支提交一个 拉取请求。
贡献类型
以下是一些建议的贡献类型:
- 修复 bug
- 改进文档
- 提升性能
- 扩展算法功能
请查看问题跟踪器,了解是否有需要帮助的具体问题。如果您在使用 rrcf 时遇到问题,或有扩展功能的想法,欢迎随时提交问题。
贡献者指南
在向代码库贡献时,请遵循以下指南:
- 确保所有新增的方法、函数或类都包含文档字符串。文档字符串应包括代码描述、输入参数和输出结果的说明。建议提供示例用法(可参考现有方法)。
- 为任何新代码编写单元测试,并确保所有测试都能通过且无警告。请确保整体代码覆盖率不低于80%。
运行单元测试
要运行单元测试,首先确保已安装 pytest 和 pytest-cov:
$ pip install pytest pytest-cov
然后导航到仓库的根目录并运行:
$ pytest --cov=rrcf/
引用说明
如果您在论文或其他出版物中使用了本代码库并希望引用它,请使用 Journal of Open Source Software 文章。
M. Bartos, A. Mullapudi, & S. Troutman, rrcf: Implementation of the Robust Random Cut Forest algorithm for anomaly detection on streams, in: Journal of Open Source Software, The Open Journal, 第4卷第35期. 2019
@article{bartos_2019_rrcf,
title={{rrcf: Implementation of the Robust Random Cut Forest algorithm for anomaly detection on streams}},
authors={Matthew Bartos and Abhiram Mullapudi and Sara Troutman},
journal={{The Journal of Open Source Software}},
volume={4},
number={35},
pages={1336},
year={2019}
}
版本历史
0.4.42023/03/150.4.32020/06/100.4.12020/05/230.42020/01/010.3.22019/05/260.3.12019/03/280.32019/03/26常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备