Bjornulf_custom_nodes
Bjornulf_custom_nodes 是一套专为 ComfyUI 打造的高效扩展插件包,集成了超过 160 个自定义节点,旨在全面提升用户在文本、图像、视频及 LoRA 模型处理上的工作流能力。它主要解决了原生 ComfyUI 在复杂逻辑控制、内容随机化生成以及多模态数据交互方面的局限性,让用户能够轻松实现循环操作、条件判断、手动流程暂停以及与 Ollama、文字转语音等外部 AI 工具的无缝对接。
这套工具特别适合希望突破基础绘图限制的设计师、需要构建复杂自动化流程的开发者,以及热衷于探索 AI 创作边界的进阶用户。其独特亮点在于提供了极其丰富的文本操控功能,从简单的字符替换、随机行选择,到专业的角色描述生成器和全局变量管理,应有尽有。此外,它还增强了可视化调试能力,支持多种数据类型(如 JSON、浮点数)的实时预览与笔记标注,让复杂的节点连接一目了然。作为一个持续快速迭代的项目,Bjornulf_custom_nodes 正不断引入新特性,帮助用户将创意更灵活、更精准地转化为现实作品。
使用场景
一位独立游戏开发者正在利用 ComfyUI 批量生成数百个具有独特背景故事和外观的 NPC 角色,以填充其开放世界游戏的世界观。
没有 Bjornulf_custom_nodes 时
- 工作流断裂:需要在外部文本编辑器手动编写角色描述,再复制粘贴到 ComfyUI,无法在节点图中直接编辑或预览文本内容。
- 随机性难以控制:缺乏原生的高级随机化工具,难以从预设列表中灵活抽取不同的性格特征或名字,导致生成的角色千篇一律。
- 逻辑判断缺失:无法根据性别或职业自动切换提示词(Prompt),必须为男性和女性角色分别搭建两套独立的复杂工作流。
- 调试效率低下:中间生成的文本变量无法直观显示,排查提示词错误时需要反复运行整个流程并查看后台日志。
使用 Bjornulf_custom_nodes 后
- 全流程可视化:利用
Advanced Write Text和Show (String/Text)节点,直接在画布上编写、修改并实时预览角色剧本,无需跳出界面。 - 智能内容混合:通过
Random line from input和Text scrambler节点,轻松从列表中提取随机姓名与特质,瞬间组合出千变万化的角色设定。 - 动态逻辑分支:借助
Text Switch On/Off和条件判断节点,单条工作流即可根据随机生成的性别自动切换对应的身体描述提示词,大幅简化结构。 - 即时调试反馈:使用
Note和各类预览节点随时监控数据流向,快速定位文本拼接错误,将迭代测试时间从小时级缩短至分钟级。
Bjornulf_custom_nodes 通过将文本处理、逻辑控制与随机化能力深度融入 ComfyUI,让大规模、高多样性的自动化内容生产变得简单且可控。
运行环境要求
- 未说明
未说明
未说明
快速开始
🔗 ComfyUI:Bjornulf_自定义节点 v1.1.8 🔗
适用于ComfyUI的170个自定义节点列表:用于显示、操作、创建和编辑文本、图像、视频、LoRA模型,生成角色等。您可以管理循环操作、生成随机内容、触发逻辑条件、暂停并手动控制工作流,甚至与外部AI工具(如Ollama或文本转语音)协同工作。
⚠️ 注意:开发非常活跃,仍在进行中。🏗
最新更新视频:
观看视频(快速概览28分钟)+ 视频播放列表中的更新:
咖啡评分:☕☕☕☕☕ 5/5
开发极其活跃,不断推出新节点、新功能、新创意和新可能性……如果您遇到任何问题,请随时告知我,这些问题必须为所有人解决!
请支持我、这个项目以及我其他的AI相关项目:❤️❤️❤️ https://ko-fi.com/bjornulf ❤️❤️❤️
☘ 该项目是我AI三部曲的一部分。☘
1 - 📝 文本/聊天AI生成:Bjornulf Lobe Chat Fork
2 - 🔊 语音AI生成:Bjornulf Text To Speech
3 - 🎨 图像AI生成: Bjornulf ComfyUI 自定义节点(您当前所在位置)
📋 节点菜单按类别划分
👁 显示与展示 👁
1. 👁 显示(文本、整数、浮点数)49. 📹👁 视频预览68. 🔢 添加行号71. 👁 显示(整数)72. 👁 显示(浮点数)73. 👁 显示(字符串/文本)74. 👁 显示(JSON)126. 📒 备注127. 🖼📒 图像备注(加载图像)128. 🖼👁 预览(第一张)图像130. 📥🖼📒 图像备注(加载图像)133. 🖼👁 预览1-4张图像(对比)
✒ 文本 ✒
2. ✒ 写入文本3. ✒🗔🅰️ 高级写入文本(+ 🎲 随机选项)4. 🔗 组合文本15. 💾 保存文本26. 🎲 从输入中随机选择一行28. 🔢🎲 带有随机种子的文本32. 🧑📝 角色描述生成器48. 🔀🎲 文本乱序器(🧑 角色)67. 📝➜✨ 文本转任意内容68. ✨➜📝 任意内容转文本75. 📝➜📝 替换文本111. ✨➜🔢 任意内容转整数112. ✨➜🔢 任意内容转浮点数113. 📝🔪 将文本分割为5份132. 📝🔪 将文本分割为10份115. 📥 从Bjornulf文件夹加载文本116. 📥 从路径加载文本117. 📝👈🅰️ 行选择器(🎲 或 ♻ 或 ♻📑)131. ✒👉 写入“Pick Me”链136. 🔛📝 文本开关(开/关)138. 📑👈 从列表中选择141. 🌎✒👉 全局“Pick Me”写入142. 🌎📥 加载全局“Pick Me”144 📊🔍 文本分析器
🔥 文本生成器 🔥
81. 🔥📝🖼 图像文本生成器 🖼📝🔥82. 👩🦰📝 文本生成器(女性角色)83. 👨🦰📝 文本生成器(男性角色)84. 👾📝 文本生成器(生物角色)85. 💃🕺📝 文本生成器(角色姿势)86. 🔧👨🔧📝 文本生成器(角色使用的物品)87. 🌄📝 文本生成器(场景)88. 🎨📝 文本生成器(风格)89. 👗 文本生成器(女性服装)90. 👚 文本生成器(男性服装)91. ♻🔥📝 列表循环器(文本生成器)92. ♻🌄📝 列表循环器(文本生成器场景)93. ♻🎨📝 列表循环器(文本生成器风格)94. ♻💃🕺📝 列表循环器(文本生成器姿势)95. ♻👨🦰👩🦰👾 列表循环器(文本生成器角色)96. ♻👚 列表循环器(文本生成器男性服装)97. ♻👗 列表循环器(文本生成器女性服装)
♻ 循环 ♻
6. ♻ 循环7. ♻ 循环文本8. ♻ 循环整数9. ♻ 循环浮点数10. ♻ 循环所有采样器11. ♻ 循环所有调度器12. ♻ 循环组合27. ♻ 循环(输入中的所有行)33. ♻ 循环(输入中的所有行,按行组合)38. ♻🖼 循环(图像)39. ♻ 循环(✒🗔🅰️ 高级写入文本)42. ♻ 循环(模型+CLIP+VAE)——即检查点/模型53. ♻ 循环加载检查点(模型选择器)54. ♻👑 循环LoRA选择器56. ♻📑 循环顺序(整数)57. ♻📑 循环顺序(输入行)90. ♻🔥📝 列表循环器(文本生成器)91. ♻🌄📝 列表循环器(文本生成器场景)92. ♻🎨📝 列表循环器(文本生成器风格)93. ♻💃🕺📝 列表循环器(文本生成器姿势)94. ♻👨🦰👩🦰📝 列表循环器(文本生成器角色)95. ♻👚 列表循环器(文本生成器男性服装)96. ♻👗 列表循环器(文本生成器女性服装)
🎲 随机化 🎲
3. ✒🗔🅰️ 高级写文本(+ 🎲 随机选项)5. 🎲 随机(文本)26. 🎲 从输入中随机选择一行28. 🔢🎲 带随机种子的文本37. 🎲🖼 随机图片40. 🎲 随机(模型+CLIP+VAE)——又称检查点/模型41. 🎲 随机加载检查点(模型选择器)48. 🔀🎲 文本乱序器(🧑 字符)55. 🎲👑 随机LoRA选择器117. 📝👈🅰️ 行选择器(🎲 或 ♻ 或 ♻📑)139. 🎲 随机整数140. 🎲 随机浮点数
🖼💾 保存图片/文本 💾🖼
16. 💾🖼💬 为Bjornulf LobeChat保存图片17. 💾🖼 将图片保存为tmp_api.png临时API18. 💾🖼📁 将图片保存到指定文件夹14. 💾🖼 保存精确名称123. 💾🅰️ 保存全局变量
🖼📥 加载图片/文本 📥🖼
29. 📥🖼 带透明度的图片▢43. 📥🖼📂 从输出文件夹加载图片124. 📥🅰️ 加载全局变量
🖼 图片 - 其他 🖼
13. 📏 调整图片大小22. 🔲 去除图片透明度(alpha通道)23. 🔲 将图片转为灰度(黑白)24. 🖼+🖼 叠加两张图片(背景+叠加层)25. 🟩➜▢ 绿幕转透明29. ⬇️🖼 带透明度的图片▢30. 🖼✂ 用遮罩裁剪图片37. 🎲🖼 随机图片38. ♻🖼 循环(图片)43. ⬇️📂🖼 从输出文件夹加载图片44. 🖼👈 选择一张图片,挑选46. 🖼🔍 图片详情47. 🖼 组合图片60. 🖼🖼 合并图片/视频📹📹(水平方向)61. 🖼🖼 合并图片/视频📹📹(垂直方向)62. 🦙👁 Ollama Vision70. 📏 按百分比调整图片大小80. 🩷 空latent选择器146 🖼📹🔪 分割图片/视频网格147 🖼📹🔨 重组图片/视频网格160. 🦙👁 Ollama Vision提示词选择器
🅰️ 变量 🅰️
3. ✒🗔🅰️ 高级写文本(+ 🎲 随机选项)117. 📝👈🅰️ 行选择器(🎲 或 ♻ 或 ♻📑)123. 💾🅰️ 保存全局变量124. 📥🅰️ 加载全局变量129. 📌🅰️ 从文本设置变量
🚀 加载检查点 🚀
40. 🎲 随机(模型+CLIP+VAE)——又称检查点/模型41. 🎲 随机加载检查点(模型选择器)42. ♻ 循环(模型+CLIP+VAE)——又称检查点/模型53. ♻ 循环加载检查点(模型选择器)125. 📝👈 模型-CLIP-VAE选择器(🎲 或 ♻ 或 ♻📑)
🚀 加载LoRA 🚀
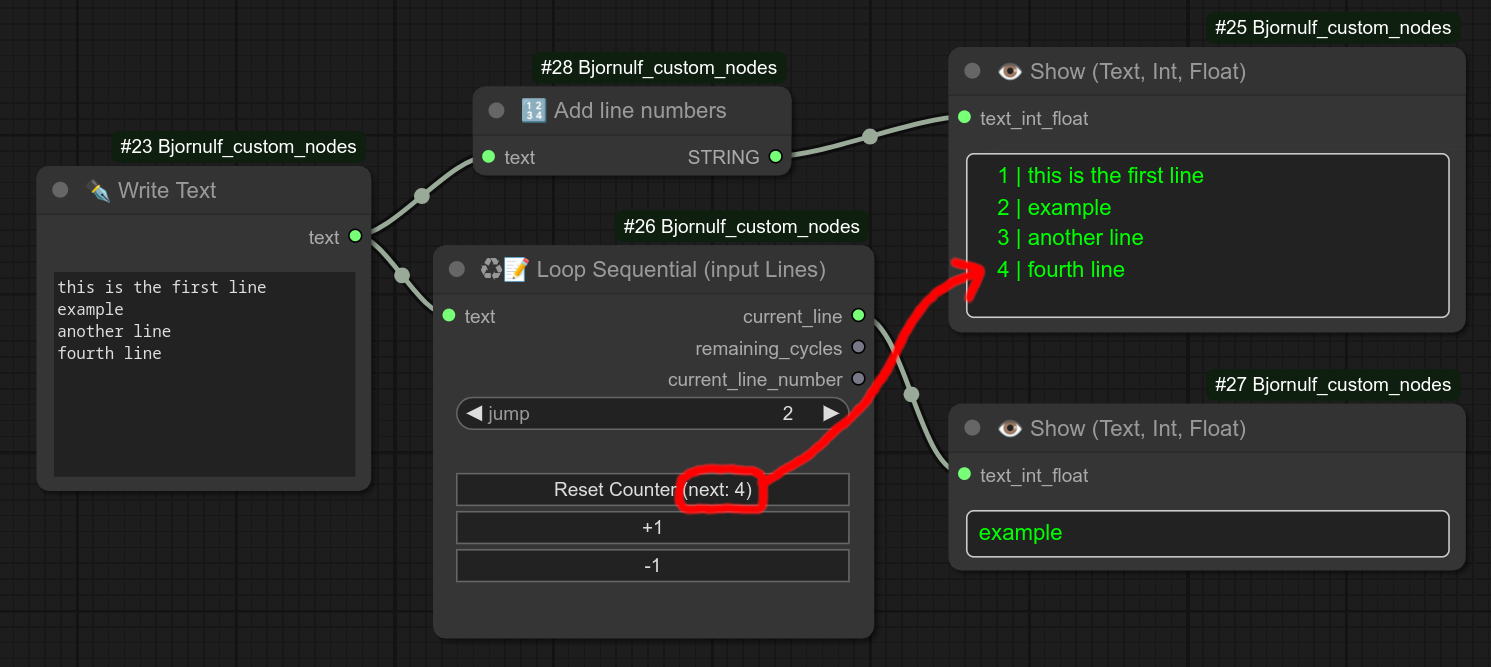
54. ♻ LoRA选择器循环55. 🎲 随机LoRA@选择器114. 📥👑 加载带有路径的LoRA122. 👑 组合LoRA,LoRA堆栈
☁ 图片生成:API / 云 / 远程 ☁
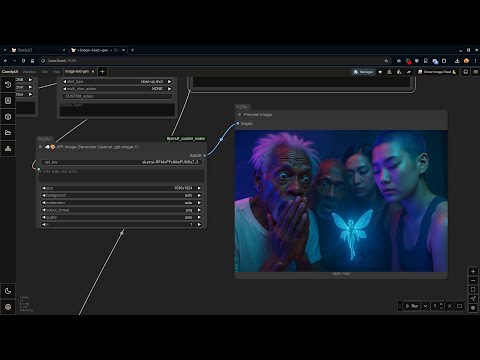
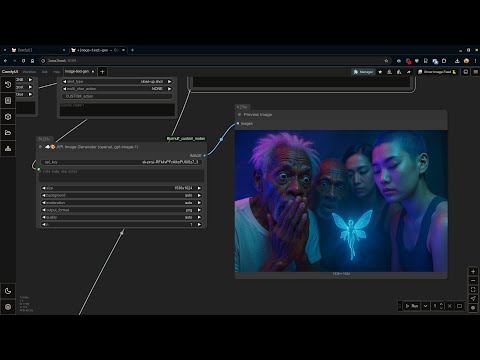
106. ☁🎨 API图片生成器(FalAI)☁107. ☁🎨 API图片生成器(CivitAI)☁108. ☁👑 添加LoRA(仅API - CivitAI)👑☁109. ☁🎨 API图片生成器(Black Forest Labs - Flux)☁110. ☁🎨 API图片生成器(Stability - Stable Diffusion)☁151 📥🕑🤖 加载CivitAI链接163 ☁🎨 API图片生成器(openai, gpt-image-1)
📥 从CivitAI / Hugging Face获取 📥
98. 📥 加载SD1.5检查点(+从CivitAi下载)99. 📥 加载SDXL检查点(+从CivitAi下载)100. 📥 加载Pony检查点(+从CivitAi下载)101. 📥 加载FLUX Dev检查点(+从CivitAi下载)102. 📥 加载FLUX Schnell检查点(+从CivitAi下载)103. 📥👑 加载SD1.5 LoRA(+从CivitAi下载)104. 📥👑 加载SDXL LoRA(+从CivitAi下载)105. 📥👑 加载Pony LoRA(+从CivitAi下载)119. 📥👑📹 加载Hunyuan Video LoRA(+从CivitAi下载)121. 💾 Hugging Face下载器
📹 视频 📹
20. 📹 视频乒乓球21. 🖼➜📹 图片转视频(FFmpeg 保存视频)49. 📹👁 视频预览50. 🖼➜📹 图片转视频路径(临时视频)51. 📹➜🖼 视频路径转图片52. 🔊📹 音频视频同步58. 📹🔗 视频拼接59. 📹🔊 合并视频+音频60. 🖼🖼 合并图片/视频 📹📹(水平方向)61. 🖼🖼 合并图片/视频 📹📹(垂直方向)76. ⚙📹 FFmpeg 配置 📹⚙77. 📹🔍 视频详情 ⚙78. 📹➜📹 转换视频79. 📹🔗 从列表拼接视频119. 📥👑📹 加载 Lora Hunyuan 视频(+从 CivitAi 下载)146 🖼📹🔪 分割图片/视频网格147 🖼📹🔨 重组图片/视频网格149 💾📹 保存视频(tmp_api.mp4/mkv/webm)⚠️💣
🤖 AI 🤖
19. 🦙💬 Ollama 对话31. 📝➜🔊 TTS - 文本转语音62. 🦙👁 Ollama 视觉63. 🦙 Ollama 配置 ⚙64. 🦙 Ollama 任务选择器 💼65. 🦙 Ollama 人物角色选择器 🧑66. 🔊➜📝 STT - 语音转文本118. 🔊 TTS 配置 ⚙160. 🦙👁 Ollama 视觉提示词选择器
🔊 音频 🔊
31. 📝➜🔊 TTS - 文本转语音52. 🔊📹 音频视频同步59. 📹🔊 合并视频+音频66. 🔊➜📝 STT - 语音转文本118. 🔊 TTS 配置 ⚙120. 📝➜🔊 Kokoro - 文本转语音134. 134 - 🔊▶ 播放音频145 🔊▶ 音频预览(音频播放器)148 💾🔊 保存音频(tmp_api.wav/mp3)⚠️💣
💻 通用 / 系统 💻
34. 🧹 释放 VRAM 的技巧137. 🌎🎲 全局种子管理器143 🧮 基础数学
🧍 手动用户控制 🧍
35. ⏸️ 暂停中。继续或停止,请选择👇36. ⏸️ 暂停中。选择输入,请选择👇117. 📝👈🅰️ 行选择器(🎲 或 ♻ 或 ♻📑)135. 🔛✨ 任意开关开启/关闭136. 🔛📝 文本开关开启/关闭
🧠 逻辑 / 条件运算 🧠
45. 🔀 如果-否则(输入/比较值)
【即将推出】—— 尚未归入上述分类...
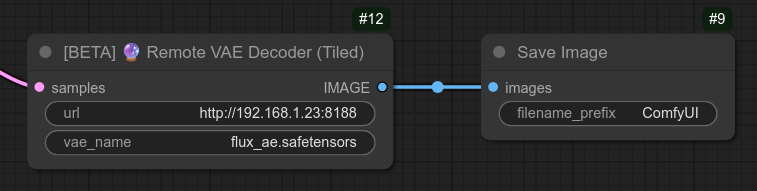
150 [即将推出] 🎨📜 风格选择器(🎲 或 ♻ 或 ♻📑)+ Civitai urn152 [即将推出] 💾 保存张量(tmp_api.pt)⚠️💣153 [即将推出] 📥 加载张量(tmp_api.pt)154 [即将推出] 🔮 远程 VAE 解码器155 [即将推出] 🔮 远程 VAE 解码器(分块)156 [即将推出] 📥🔮 从 Base64 加载157 [即将推出] 🔮⚡ 执行工作流158 [[即将推出] 📥🔮📝 文本管理 API(执行工作流)]](#)159 [即将推出] 🔥📝📹 视频文本生成器 📹📝🔥161 [即将推出] 🔧🧑 修复人脸162 [即将推出] 🧑 人脸设置【修复人脸】⚙
☁ 云端使用:
ComfyUI 非常适合本地使用,但有时我需要比自己设备更强的算力……
我有一台配备 4070 Super 显卡(12GB 显存)的电脑,运行 flux fp8 简单工作流大约需要 40 秒。而在云端使用 4090 显卡时,我可以以约 12 秒的时间运行 flux fp16。(当然也有一些工作流是我本地根本无法运行的。)
我的 Runpod 推荐链接:[https://runpod.io?ref=tkowk7g5](如果您通过该链接注册,我将获得佣金,但这对您没有任何额外费用。)
如果您想在云端使用我的节点和 ComfyUI,并且可以安装更多内容,我在 Runpod 上管理了一个优化过的开箱即用模板:[https://runpod.io/console/deploy?template=r32dtr35u1&ref=tkowk7g5]
模板名称:bjornulf-comfyui-allin-workspace,大约 3 分钟即可投入使用。(具体时间取决于您的 Pod、设置以及下载额外模型等未包含的内容。)
在使用之前,您需要创建并选择一个网络存储卷,大小由您决定。我选择了 50GB 存储空间,因为我只在云端使用 4090 显卡进行 Flux 或 LoRA 训练。(约 0.7 美元/小时)
⚠️ 当 Pod 准备好后,您需要在浏览器中打开终端(点击 Pod 的“连接”按钮后),然后使用以下命令手动启动 ComfyUI:cd /workspace/ComfyUI && python main.py --listen 0.0.0.0 --port 3000 或者使用别名 start_comfy(通过终端控制会更好,方便查看日志等)。
之后,您可以直接点击“连接到端口 3000”按钮。
文件管理方面,您可以使用内置的 JupyterLab,端口为 8888。
如果您遇到任何问题,请随时告诉我。
该模板会将所有内容管理在 Runpod 的网络存储中(/workspace/ComfyUI),因此您可以随时停止或启动云端 GPU 而不会丢失任何数据,也可以更换 GPU 等。
区域:我推荐 EU-RO-1,但您可以自行选择。
请至少充值 10 美元到您的 Runpod 账户才能开始使用。
⚠️ 注意:计费按分钟计算,因此不建议用于测试或学习 ComfyUI,请务必在本地完成!
只有在您已经准备好工作流时再启动云端 GPU。
建议:先使用廉价的 GPU 进行测试、下载模型或配置环境。
下载检查点或其他文件时,必须使用终端。
从 Hugging Face 下载时(在此处获取令牌:https://huggingface.co/settings/tokens)。
以下是运行 Flux 开发版所需的所有命令示例:
huggingface-cli login --token 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
huggingface-cli download black-forest-labs/FLUX.1-dev flux1-dev.safetensors --local-dir /workspace/ComfyUI/models/unet
huggingface-cli download comfyanonymous/flux_text_encoders clip_l.safetensors --local-dir /workspace/ComfyUI/models/clip
huggingface-cli download comfyanonymous/flux_text_encoders t5xxl_fp16.safetensors --local-dir /workspace/ComfyUI/models/clip
huggingface-cli download black-forest-labs/FLUX.1-dev ae.safetensors --local-dir /workspace/ComfyUI/models/vae
要使用 Flux,您只需在我的 GitHub 仓库中拖放 .json 文件到浏览器中的 ComfyUI 界面即可:workflows/FLUX_dev_troll.json,直接链接:[https://github.com/justUmen/ComfyUI-BjornulfNodes/blob/main/workflows/FLUX_dev_troll.json]。
从 Civitai 下载时(在此处获取令牌:https://civitai.com/user/account),只需复制粘贴您想要下载的检查点链接,并使用类似以下的命令,将您的令牌插入 URL 中:
CIVITAI="8b275fada679ba5812b3da2bf35016f6"
wget --content-disposition -P /workspace/ComfyUI/models/checkpoints "https://civitai.com/api/download/models/272376?type=Model&format=SafeTensor&size=pruned&fp=fp16&token=$CIVITAI"
如果您想下载整个输出文件夹,可以直接将其压缩:
cd /workspace/ComfyUI/output && tar -czvf /workspace/output.tar.gz .
然后您就可以通过 JupyterLab 文件管理器将其下载了。
如果您在使用这个 Runpod 模板时遇到任何问题,请随时告知我,我将竭诚为您提供帮助。😊
🏗 依赖项(无需在我提供的 Runpod 模板中操作)
请查看 requirements.txt 以获取最新的依赖项列表。
🪟🐍 Windows:在嵌入式 Python(便携版)上安装依赖项
首先,您需要找到这个嵌入式的 python.exe,然后在文件管理器中右键单击或按住 Shift 键并右键单击文件夹,即可在此处打开终端。
这是我存放的位置及所需命令:H:\ComfyUI_windows_portable\python_embeded> .\python.exe -m pip install ollama pydub opencv-python ffmpeg-python civitai-py fal_client sounddevice langdetect spacy textblob dill
如果需要安装其他内容,您可以重复使用相同的代码来安装所需的依赖项:.\python.exe -m pip install whateveryouwant
之后即可运行 ComfyUI。
🐧🐍 Linux:安装依赖项(无需虚拟环境,不推荐)
进入 custom_node 文件夹,执行:pip install -r requirements.txt
或者
pip install ollama(您也可以选择安装 Ollama:https://ollama.com/download) - 如果您不想使用我的 Ollama 节点,则无需真正安装它。(但您仍需运行pip install ollama)pip install pydub(用于 TTS 节点)pip install opencv-python- 等等……
🐧🐍 Linux:使用 Python 虚拟环境(venv)安装依赖项
如果您希望仅为 ComfyUI 使用 Python 虚拟环境,这是推荐的做法,您可以按照以下步骤操作(同时预先安装 pip):
sudo apt-get install python3-venv python3-pip
python3 -m venv /the/path/you/want/venv/bjornulf_comfyui
当您在这个新文件夹中创建好环境后,可以通过以下命令激活并安装依赖项:
source /the/path/you/want/venv/bjornulf_comfyui/bin/activate
cd custom_nodes/Bjornulf_custom_nodes
pip install -r requirements.txt
随后,您可以使用此环境启动 ComfyUI(请注意,每次启动 ComfyUI 时都需要重新激活环境):
cd /where/you/installed/ComfyUI && python main.py
📝 更改记录
- v0.2: 改进 Ollama 节点,加入系统提示和模型选择功能。
- v0.3: 新增节点:将图像保存到指定文件夹。
- v0.3: 为所有与图像相关的节点添加 ComfyUI 元数据/工作流支持。
- v0.4: 支持 WebM 格式的透明度选项及编码器设置,并新增音频流输入功能。
- v0.5: 新增节点:移除图像透明度(Alpha 通道)——用纯色填充 Alpha 通道。
- v0.5: 新增节点:将图像转换为灰度图(黑白)——将彩色图像转换为灰度图像。
- v0.6: 新增节点:合并图像(背景+叠加)——将两张图像合并为一张。
- v0.7: 将“保存 API”节点替换为“保存 Bjornulf Lobechat”节点。(用于我的自定义 Lobe-Chat)
- v0.8: 合并图像:新增选项,可将图像放置在顶部、底部或居中。
- v0.8: 合并文本:新增斜杠分隔符选项 /。
- v0.8: 新增基础节点,用于将绿幕背景转换为透明效果。
- v0.9: 新增节点:从输入中随机返回一行。
- v0.10: 新增节点:循环(输入中的所有行)——遍历输入文本中的每一行。
- v0.11: 新增节点:带随机种子的文本——生成随机种子及对应的文本。
- v0.12: 合并图像:新增垂直和水平移动选项。(范围从 -50% 到 150%)
- v0.13: 新增节点:加载带透明度(Alpha 通道)的图像——加载带有透明度的图像。
- v0.14: 新增节点:根据遮罩裁剪图像。
- v0.15: 新增两个节点:TTS——文本转语音,以及角色描述生成器。
- v0.16: 角色描述生成器的重大改动。
- v0.17: 新型循环节点,按行合并。
- v0.18: 新型循环节点,免费 VRAM 技巧。
- v0.19: 文件夹保存节点的更改:忽略缺失的图像文件名,自动使用已发现的最大编号加 1。
- v0.20: Lobechat 图像保存节点的更改:包含免费 VRAM 技巧代码,并忽略缺失的图像文件名。
- v0.21: 新增写入文本节点,同时在 ComfyUI 控制台显示文本内容(便于调试)。
- v0.22: 允许写入文本节点使用随机选择功能,例如 {hood|helmet} 将随机选择 hood 或 helmet。
- v0.23: 新增节点:暂停、恢复或停止工作流。
- v0.24: 新增节点:暂停、选择输入、随机选取一个。
- v0.25: 新增两个节点:循环图像和随机图像。
- v0.26: 新增节点:循环写入文本。同时增加大多数节点允许的输入数量。(并更新部分破坏性变更)
- v0.27: 新增两个节点:循环(模型+Clip+Vae)和随机(模型+Clip+Vae)——即检查点/模型。
- v0.28: 修复随机文本问题,并为多个节点添加大量截图示例。
- v0.29: 修复循环浮点节点的浮点数问题。
- v0.30: 更新基础循环节点,增加可选输入。
- v0.31: ❗抱歉,写入/显示文本节点发生重大变更,系统更简洁:一个为简单写入文本,另一个为高级版,带有控制台和特殊语法。此外,显示节点现在可以处理整数、浮点数和文本。
- v0.32: 快速重命名以避免破坏 loop_text 节点。
- v0.33: 在暂停节点上控制随机性,修复 Windows 系统下 pydub 音频权限问题。
- v0.34: 新增两个节点:从输出文件夹加载图像,以及选择图像、随机选取。
- v0.35: TTS 节点 31 号得到大幅改进,它还会将音频文件保存到 “ComfyUI/Bjornulf_TTS/” 文件夹中。——尚未在 Windows 上测试过——
- v0.36: 修复随机模型问题。
- v0.37: 新增节点:随机加载检查点(模型选择器)。作为随机检查点节点的替代方案。(不预先将所有检查点加载到内存中,切换检查点的速度较慢,但提供更多输出供你决定存储结果的位置。)
- v0.38: 新增节点:If-Else 逻辑。(input == compare_with),并提供不同潜在空间大小的示例。+修复一些反序列化问题。
- v0.39: 为高级写入文本节点添加变量管理功能。
- v0.40: 为循环高级写入文本节点添加变量管理功能。并在 README 中为所有节点添加菜单。
- v0.41: 新增两个节点:图像详情和合并图像。另外 ❗ If-Else 节点也进行了重大改动。(以及许多其他小改动)
- v0.42: 改进 README,按类别划分节点,并修改部分节点标题。
- v0.43: 为 Ollama 添加 control_after_generate 功能,允许在必要时将其保留在 VRAM 中 1 分钟。(用于快速连续生成)并添加回退到 0.0.0.0 的选项。
- v0.44: 允许 Ollama 使用自定义 URL,该 URL 存储在 ComfyUI 自定义节点文件夹下的
ollama_ip.txt文件中。进行了一些小改动,并在 README 中添加详细信息和更新内容。 - v0.45: 新增节点:字符乱码器——使用 ComfyUI 自定义节点文件夹中的
scrambler/scrambler_character.json文件随机更改文本。 - v0.46: ❗ 视频节点发生了大量变化。保存视频现在使用浮点数表示帧率,而非整数。(许多其他自定义节点也是如此……)新增预览视频节点,新增将视频路径转换为图像列表的节点,新增将图像列表转换为临时视频 + 视频路径的节点,新增同步音频与视频时长的节点。(对 MuseTalk 很有用)同时更新 TTS 节点,增加多项输出(“audio_path”、“full_path”、“duration”),以便与其他节点如 MuseTalk 共用;并将 TTS 输入名称改为“connect_to_workflow”,以避免误将文本发送给它。
- v0.47: 新增节点:循环加载检查点(模型选择器)。
- v0.48: 为 LoRA 新增两个节点:随机 LoRA 选择器和循环 LoRA 选择器。
- v0.49: 新增节点:顺序循环(整数)——按整数值范围循环。(但每个工作流仅运行一次),音频同步更加智能,会根据音频时长调整视频时长。
- v0.50: 允许音频进入“图像转视频路径”(临时视频)。新增三个节点:视频拼接、音视频合并以及顺序循环(输入行)。保存文本更改至 ComfyUI 文件夹内。修复从输入中随机抽取一行时输出为列表的问题。❗ 音频/视频同步节点发生重大变更,允许不同类型的输入。
- v0.51: 修复音频/视频同步节点的一些问题。新增两个节点:垂直和水平合并图像/视频。添加 requirements.txt 和 ollama_ip.txt 文件。
- v0.52-53: 将 Git 名称改回 Bjornulf_custom_nodes,与 Comfy 注册表保持一致。
- v0.54-55: 在 requirements.txt 中添加 opencv-python。
- v0.56: ❗重大变更:Ollama 节点简化,不再需要 ollama_ip.txt 文件,等待 Ollama 节点集合准备就绪。
- v0.57: ❗❗重大变革,全新 Ollama 节点“Ollama Chat”具备实际功能。共 5 个 Ollama 节点。(模型选择器 + 任务选择器 + 人格选择器 + Ollama Vision + Ollama Talk)Ollama Talk 可以使用上下文,并支持上下文文件。为顺序节点增加行数/当前计数器和下一个节点。新增 STT 节点。(依赖 faster_whisper)更好地管理选择器上的空 LoRA/检查点。(预设列表)为 TTS 节点添加“default_for_language”,即为每种语言选择默认语音(例如:fr/default.wav)。如果没有,则选择所选语言的第一条 WAV 文件。
- v0.58: 对模型选择器的默认值进行小幅修正。(默认设置为 None)
- v0.59: 大量修复 JavaScript 代码,以避免尺寸调整问题,并改善属性管理和恢复功能。
- v0.60: 恢复 ollama_talk 的原状(稍后实现 _user 模式 / 另一节点)。
- v0.61: 新增/修改一系列 Ffmpeg/视频节点。配备全局配置系统,并可切换使用 python-ffmpeg 或系统自带的版本。
- v0.62: 大规模更新,文本生成节点。(共 15 个节点)API 节点生成(civitai / black forest labs / fal.ai),CIVIT AI API 下载模型节点,LoRA。
- v0.63: 删除冗长且无用的文件。
- v0.64: 移除“import wget”,并在文本生成器中添加了一些关键词。
- v0.65: ❗重大变更:合并文本输入现均为可选(请重新制作您的节点,抱歉)。新增 6 个节点:any2int、any2float、从文件夹加载文本、从路径加载文本、从路径加载 LoRA。同时升级了保存文本节点。
- v0.66: 新增 hunyuan CIVIT AI 的 LoRA 并下载,新增 TTS 配置节点,编辑 requirements.txt。
- v0.67: 新增 kokoro TTS 节点。
- v0.68: 更新 kokoro TTS 节点,使其支持 connect_to_workflow,并采用与 XTTS 相同的输出。
- v0.69: 进行小幅修复。
- v0.70: ❗重大变更:“行选择器节点”现已成为“通用节点”:手动选择、随机选择以及循环+顺序选择。
文本替换现在支持多行正则表达式选项。(https://github.com/justUmen/Bjornulf_custom_nodes/issues/17)——可以从 Ollama 中移除
标签。 新增 8 个节点:“🖼👁 预览(第一张)图像”、“💾 Huggingface 下载器”、“👑 合并 LoRA,LoRA 堆栈”、“📥 加载全局变量”、“💾 保存全局变量”、“📝👈 模型-Clip-Vae 选择器(🎲 或 ♻ 或 ♻📑)”、“📒 笔记”、“🖼📒 图像笔记”。 修复各处大量代码,略微改进日志系统等……正在进行中:重写所有 FFMPEG 节点。(仍需改进和修复,将在 v0.71 中完成?)或许目前暂不使用这些节点…… - v0.71: ❗全局变量节点发生重大变更。(向全局变量系统中添加“filename”,即单独的全局变量文件。)修复语音转文本节点,新增 5 个节点 129-133。将合并文本限制提高至 100 行,改进保存图像到文件夹节点。
- v0.71-0.75: 多次修复 bug。CIVIT AI 节点已在 Windows 上正常运行。(编码、链接问题是否已解决?至少在我的设备上是这样……)
- v0.76: 由于与其他节点(如 Impact-Pack)存在冲突,且涉及旧版本的 numpy,因此从 requirements.txt 中移除 kokoro_onnx。(如果想使用此节点,需手动安装。)
为高级文本/行选择器推出新语法,例如:{left|right|middle|group=LMR}+{left|right|middle|group=LMR}+{left|right|middle|group=LMR},以及 {A(80%)|B(15%)|C(5%)}。
新增两个开关节点: 🔛✨ 任意事物开关开启/关闭(兼容合并图像) AND 🔛📝 文本开关开启/关闭(兼容合并文本)。
新增两个 Pick Me 全局节点,使用标识符代替链条: 🌎✒👉 全球写入 Pick Me AND 🌎📥 加载全球 Pick Me。
新增三个随机节点: 🌎🎲 全球随机种子、 🎲 随机整数、 🎲 随机浮点数(每个节点不仅返回其值,还返回相应的文本版本)。其中“种子节点”更为高级。
新增一个快速从列表中选择元素的节点: 📑👈 从列表中选择。
新增一个音频节点: 🔊▶ 播放音频(仅播放音频文件,默认为 bell.m4a,若未提供则使用该文件)。支持 AUDIO 格式或 audio_path。
❗重大变更。全面重写所有与 FFMPEG 相关的节点,并提供视频预览选项。(仍有少量改动待完成,将在下一版本中进行。) - v0.77: 为从文件夹加载图像节点添加刷新按钮。
为高级写入/行选择器添加新语法:2 个 {apple|orange|banana|static_group=FRUIT}s,左侧一个 {apple|orange|banana|static_group=FRUIT},右侧一个 {apple|orange|banana|static_group=FRUIT}。
修复 TTS 请求语音的问题。
❗重大变更。Ollama 新增视觉模型。
新增 20 个节点(143-162),包括文本分析器、基础数学、音频预览等……(其中 10 个尚未发布,但已纳入公开“路线图”中。)
对于使用 Python 3.13 的用户,从 requirements.txt 中移除 faster-whisper。(需手动安装。)
修复预览图像节点,以适配新的 ComfyUI 布局。
重写 FFMPEG 节点,完善配置和视频预览功能。
此外,还修复了许多其他节点的 bug,并进行了多项改进,感谢大家的反馈。 - v0.78: 修复行选择器重置按钮的 JavaScript 代码。(刷新时无法显示)
- v0.79: 修复 Ollama Talk。
- v0.780: gtp-image-1 API 节点。
📝 节点说明
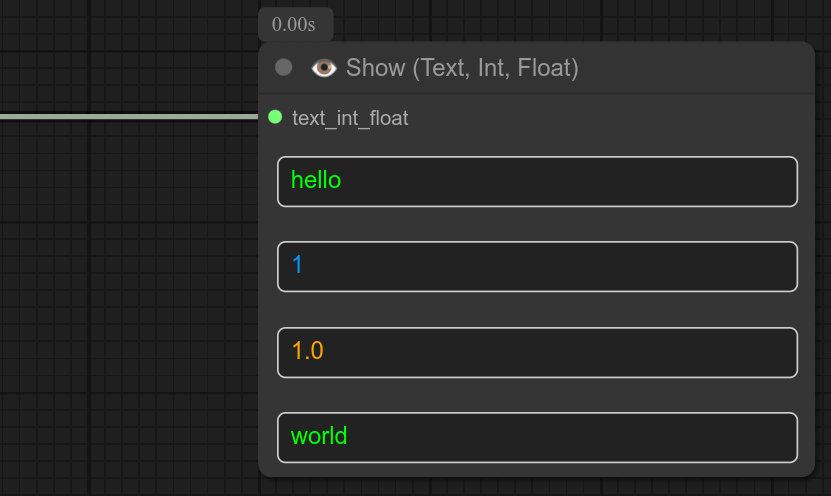
1 - 👁 显示(文本、整数、浮点数)
描述:
显示节点仅用于展示文本或多个文本的列表。(只读节点)
管理三种类型:绿色代表字符串类型,橙色代表浮点数类型,蓝色代表整数类型。我添加了颜色以便您不会尝试编辑它们。🤣
更新 0.61:现在您还有另外四个节点可用于显示特定格式的值:整数、浮点数、字符串和 JSON(字符串)。
这些节点非常方便,因为它们在拖放时会自动推荐。
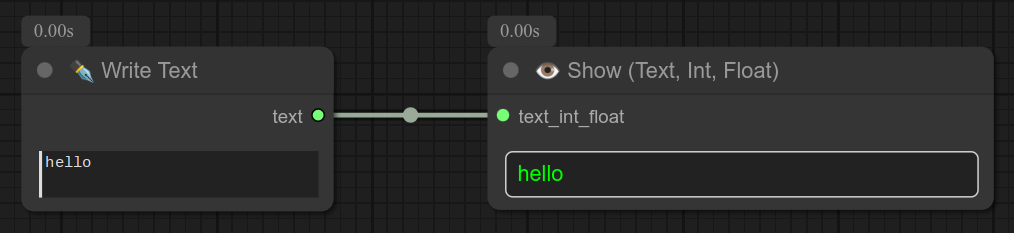
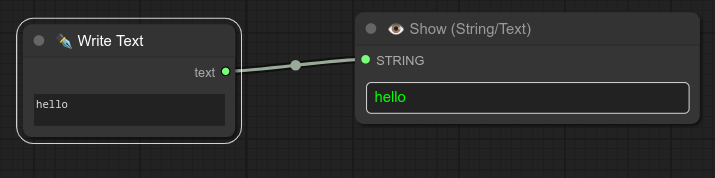
2 - ✒ 写入文本
描述:
一个简单的节点,用于写入文本或将文本发送到另一个节点。
以下是一个使用写入文本节点与显示节点的简单示例:
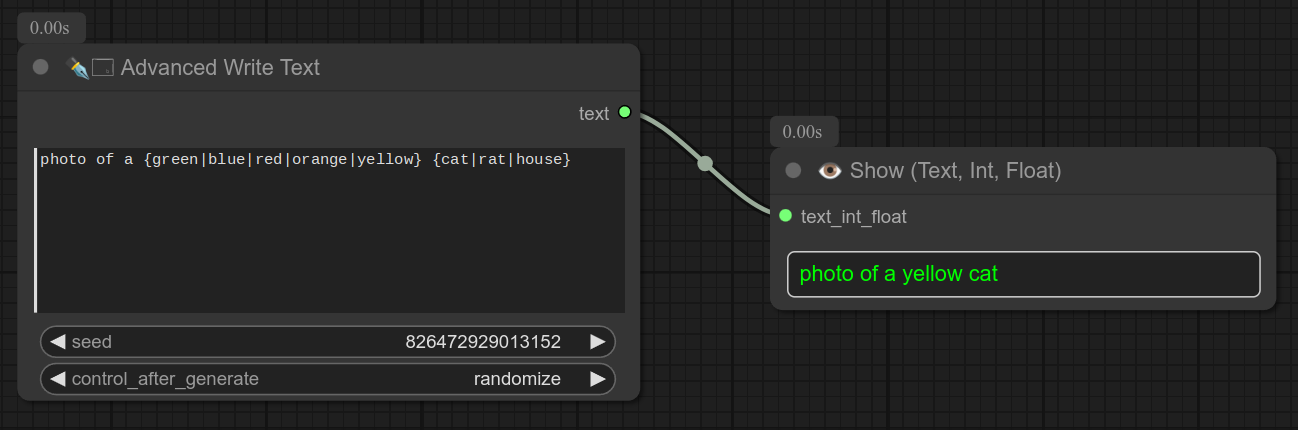
3 - ✒🗔🅰️ 高级写入文本(+ 🎲 随机选项)
描述:
高级写入文本节点允许使用特殊语法来接受随机变体,例如 {hood|helmet} 会随机选择 hood 或 helmet。
您还可以使用 seed 和 control_after_generate 来控制随机性。
它还会在 ComfyUI 控制台中显示文本。(对调试很有用)
控制台日志示例:
原始文本:一张{green|blue|red|orange|yellow} {cat|rat|house}的照片
选定文本:一张绿色房子的照片
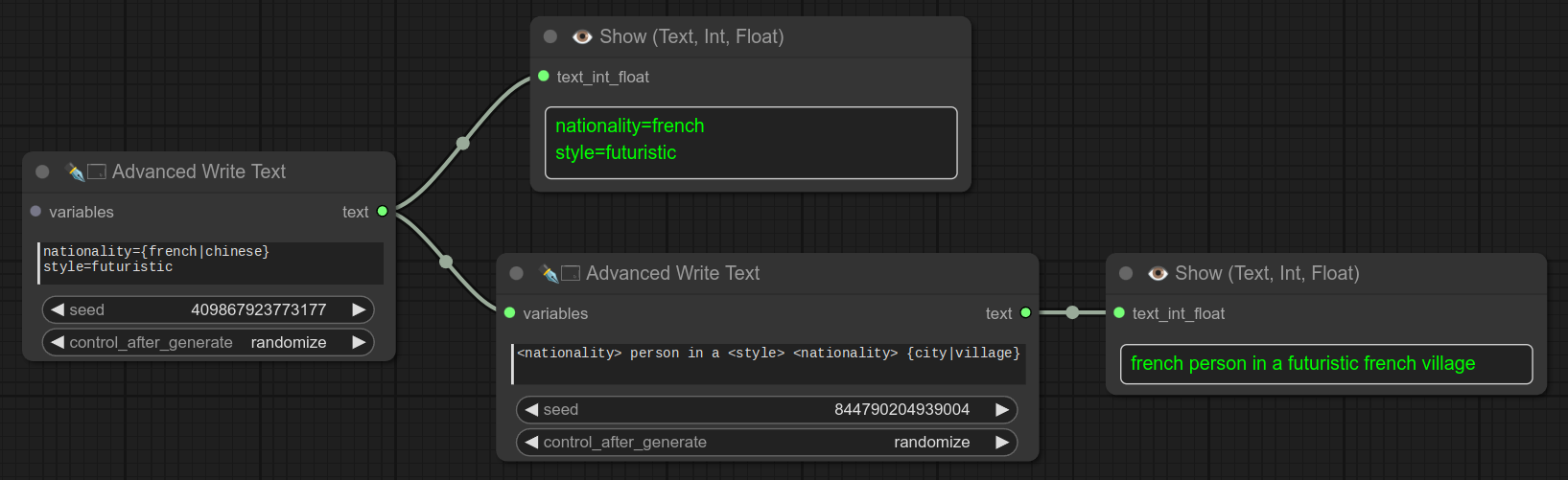
您也可以使用这种语法创建和重用变量:
使用示例:
❗ 0.76 - 新增语法:
分组,无重复,例如:{left|right|middle|group=LMR}+{left|right|middle|group=LMR}+{left|right|middle|group=LMR}
基于百分比的随机选择:{A(80%)|B(15%)|C(5%)}
❗ 0.77 - 新增语法:
2 个 {apple|orange|banana|static_group=FRUIT}s,左边一个 {apple|orange|banana|static_group=FRUIT},右边一个 {apple|orange|banana|static_group=FRUIT}
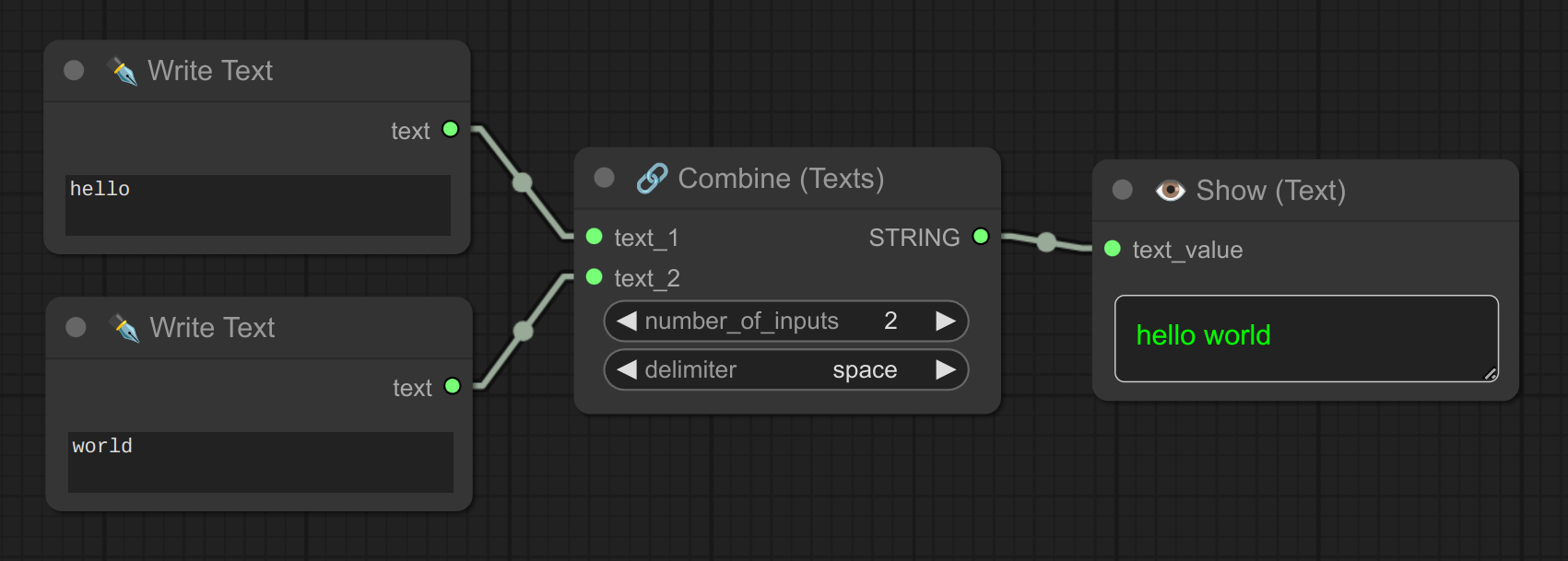
4 - 🔗 组合文本
描述:
将多个文本输入组合成一个输出。(可以选择以逗号、空格、换行符或不加任何分隔符的方式连接)
5 - 🎲 随机(文本)
描述:
从预定义的列表中生成并显示随机文本。非常适合创建随机提示词。
您还可以使用 control_after_generate 来控制随机性。
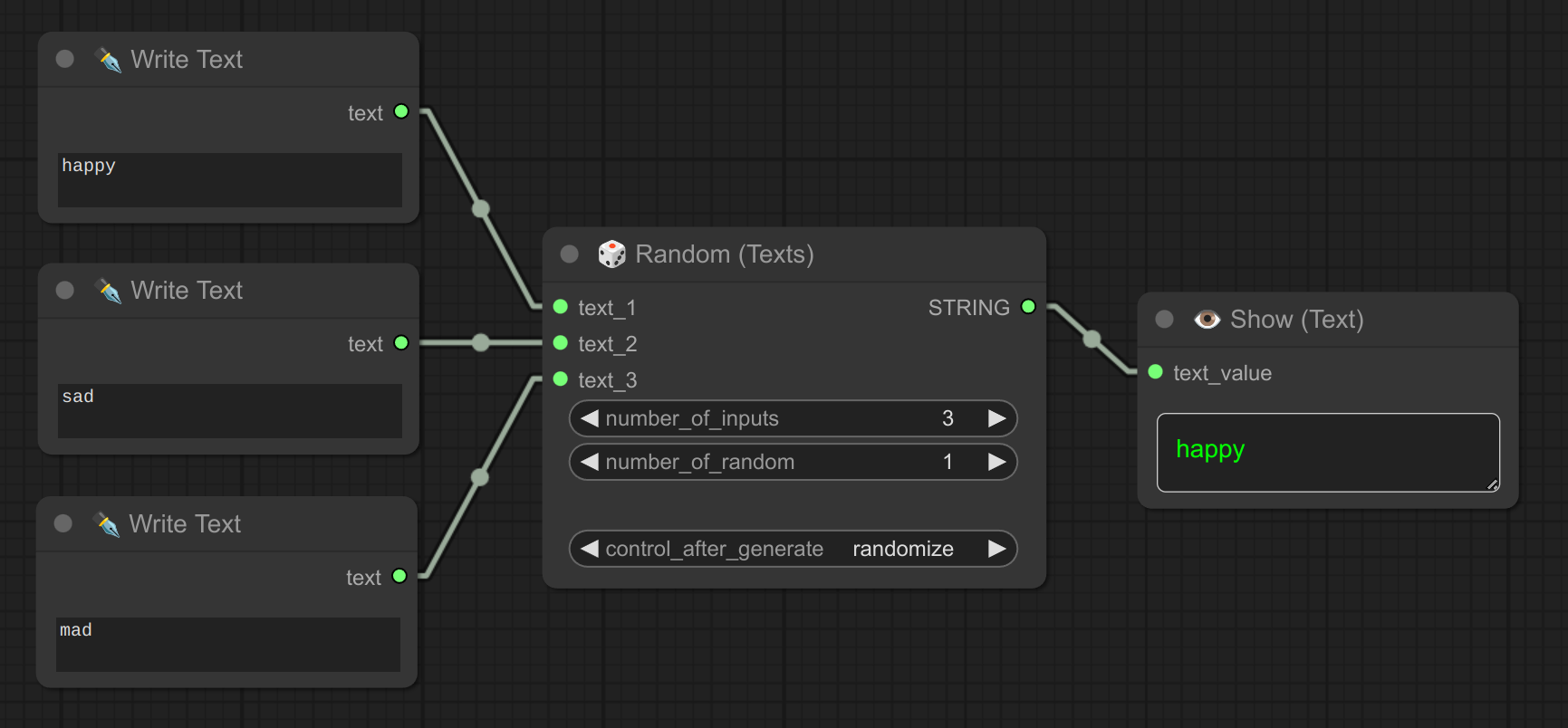
6 - ♻ 循环
描述:
⚠️ 注意:已弃用,此节点不再工作。
最新的 ComfyUI 版本拒绝输出两次相同的值。
通用循环节点,您可以将其连接到任何地方。
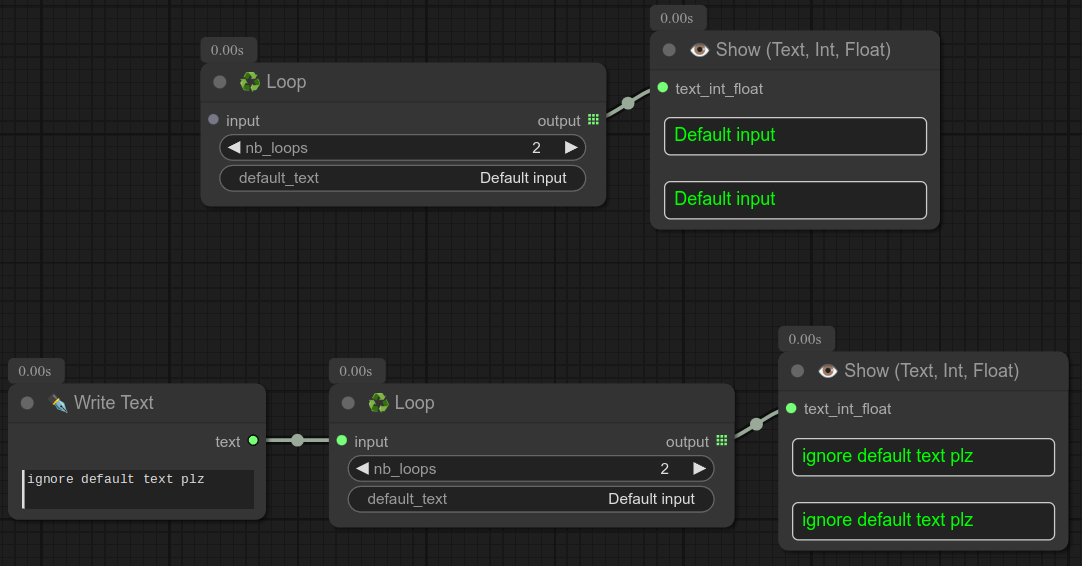
它有一个可选输入,如果没有输入,它会循环“if_no_input”字符串的值(您可以编辑)。
❗ 请注意,此节点接受所有类型的输入和输出,因此您可以将其与文本、整数、图像、掩码、分割等一起使用,但请确保输入和输出的一致性。
如果可以避免,请不要使用此循环节点。
这是一个与我的节点 28 结合使用的示例,用于为每次迭代强制使用不同的种子: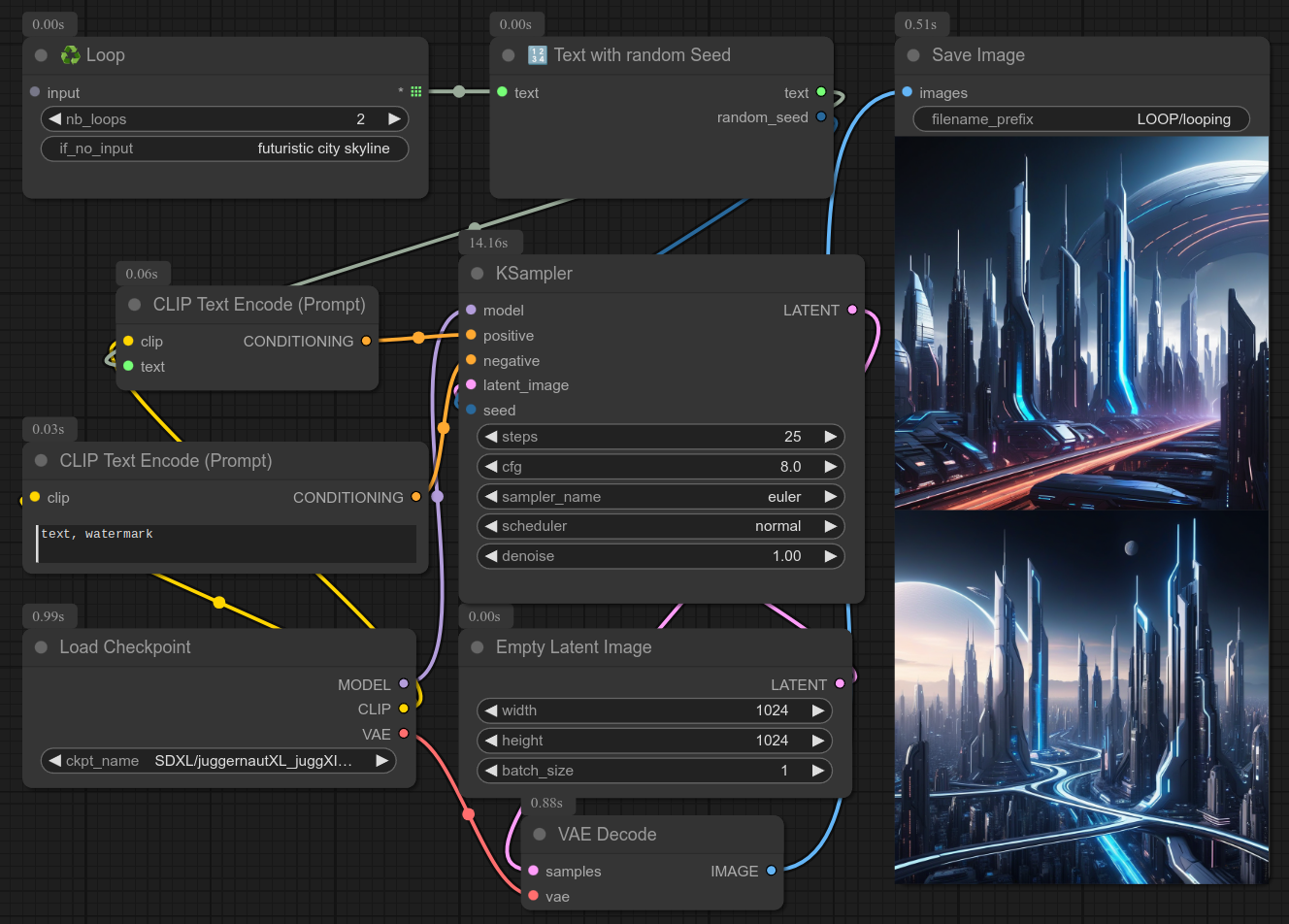
7 - ♻ 循环文本
描述:
循环遍历一组文本输入。
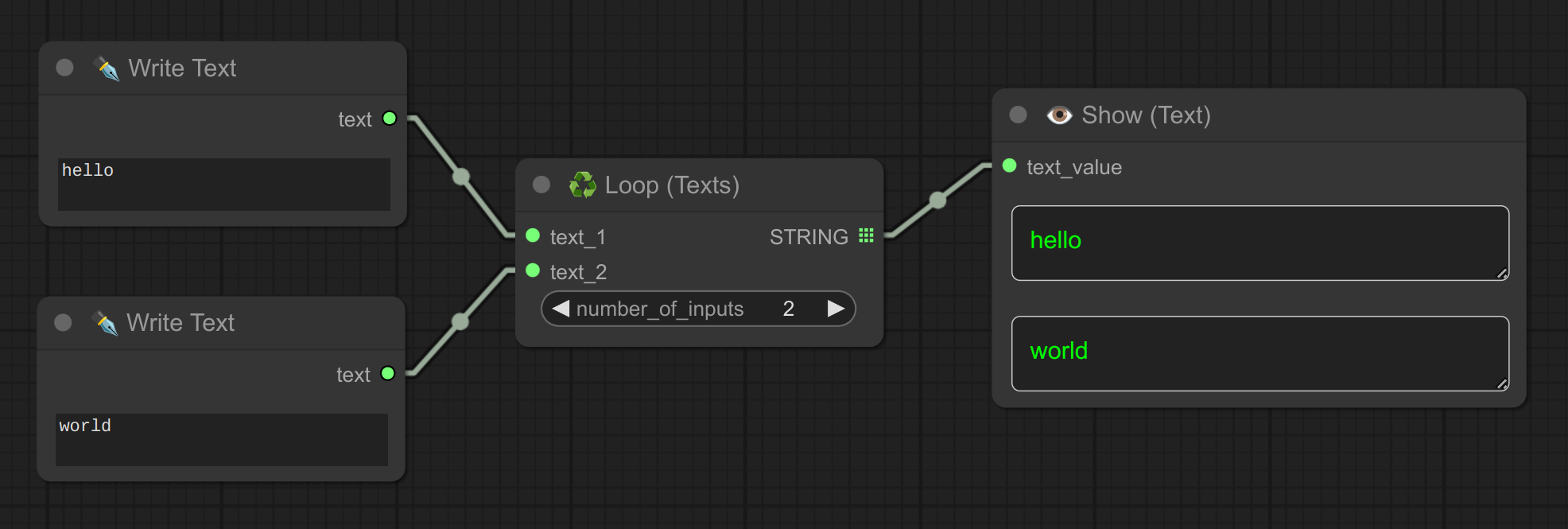
这里是一个结合组合文本和 flux 使用的示例: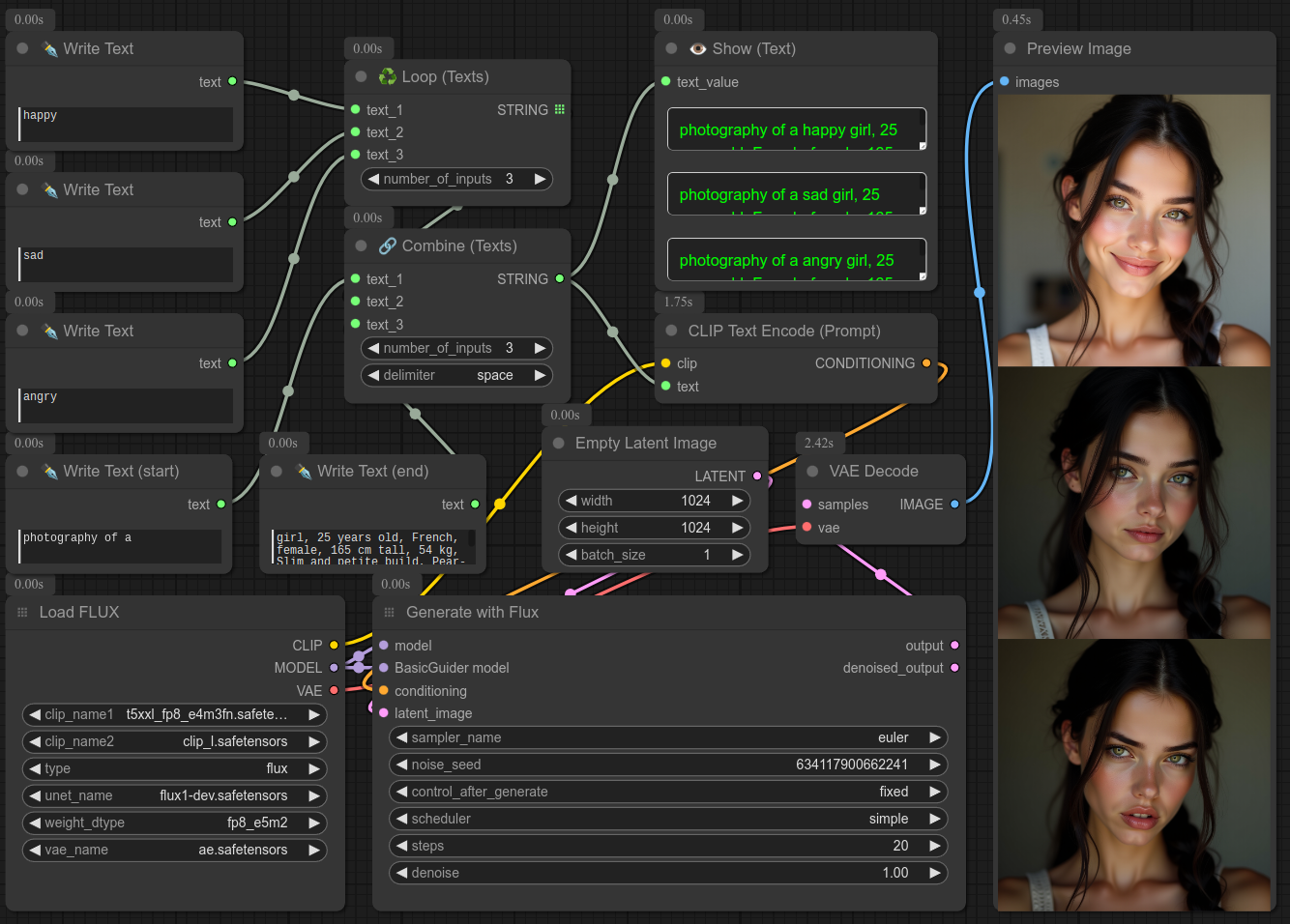
8 - ♻ 循环整数
描述:
迭代一个整数范围,适用于 ksampler 中的 steps 等参数。
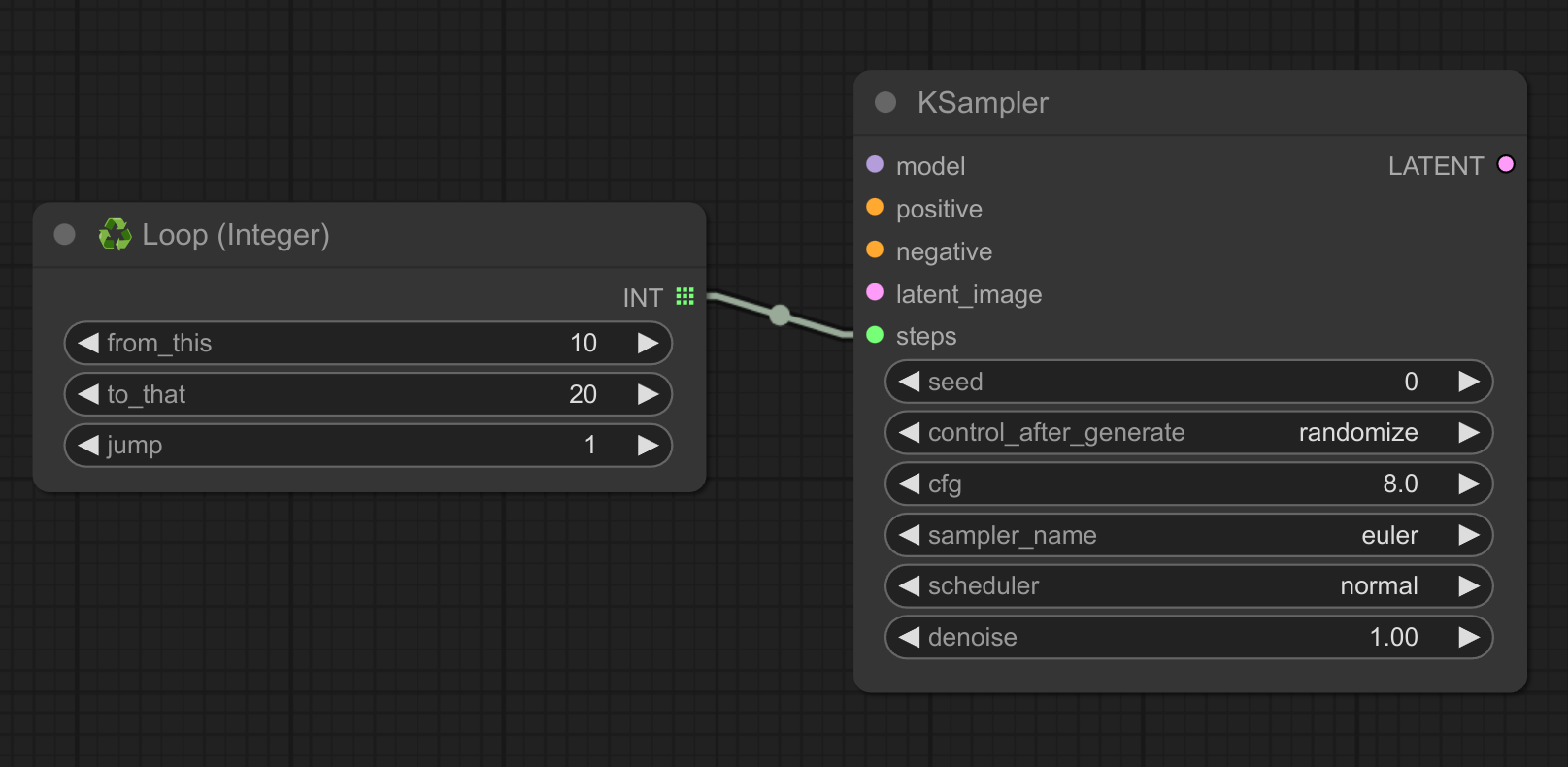
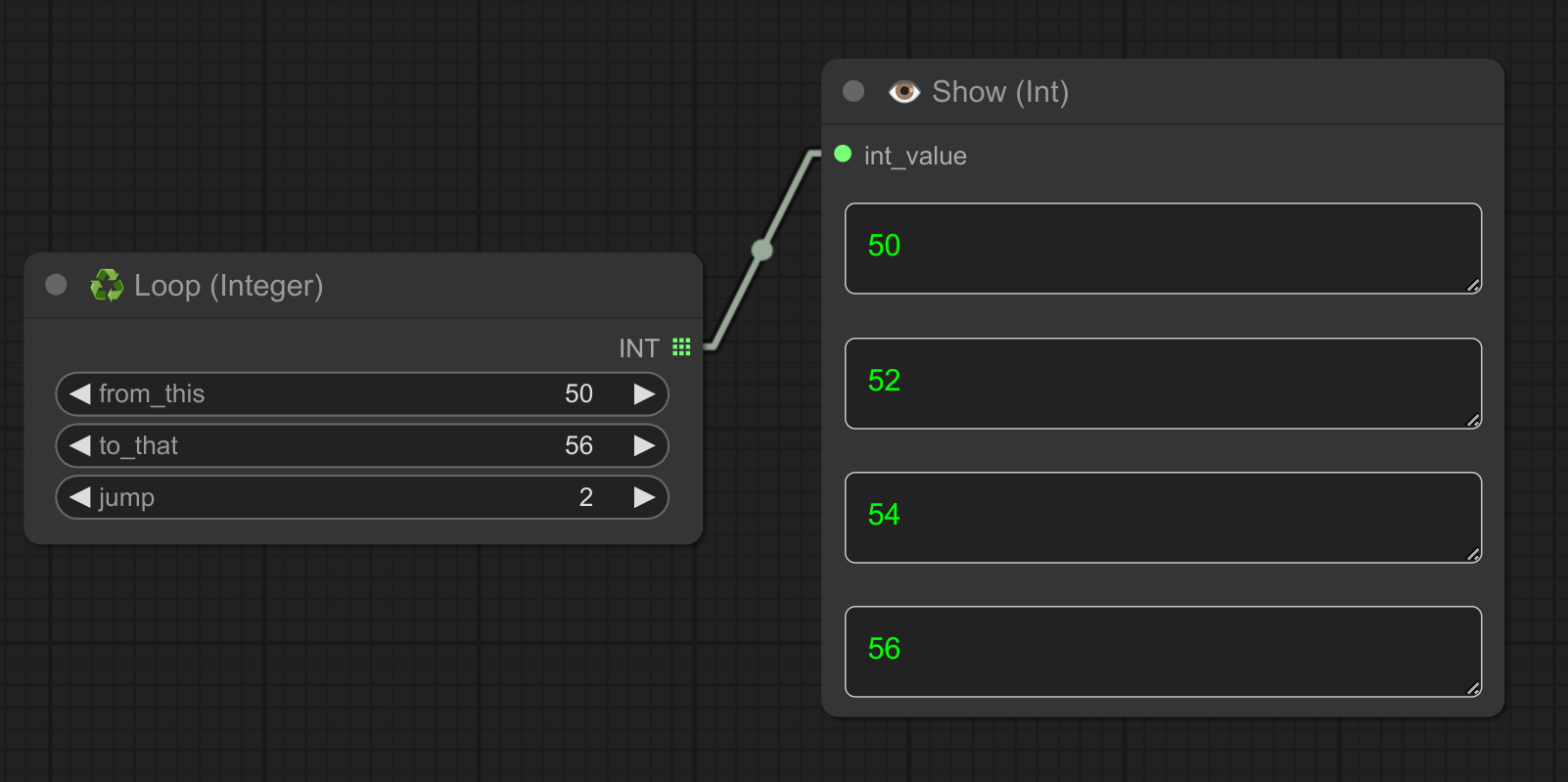
❗ 请记住,您可以通过右键单击 ksampler 节点将其小部件转换为输入: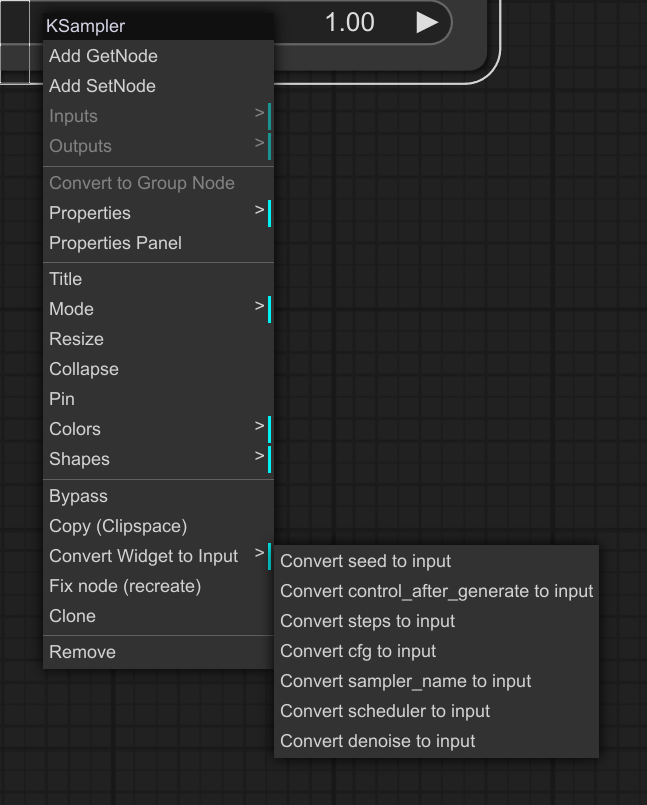
这里是一个使用 ksampler 的示例(请注意,对于“steps”参数,此节点并不优化,但足以进行快速测试):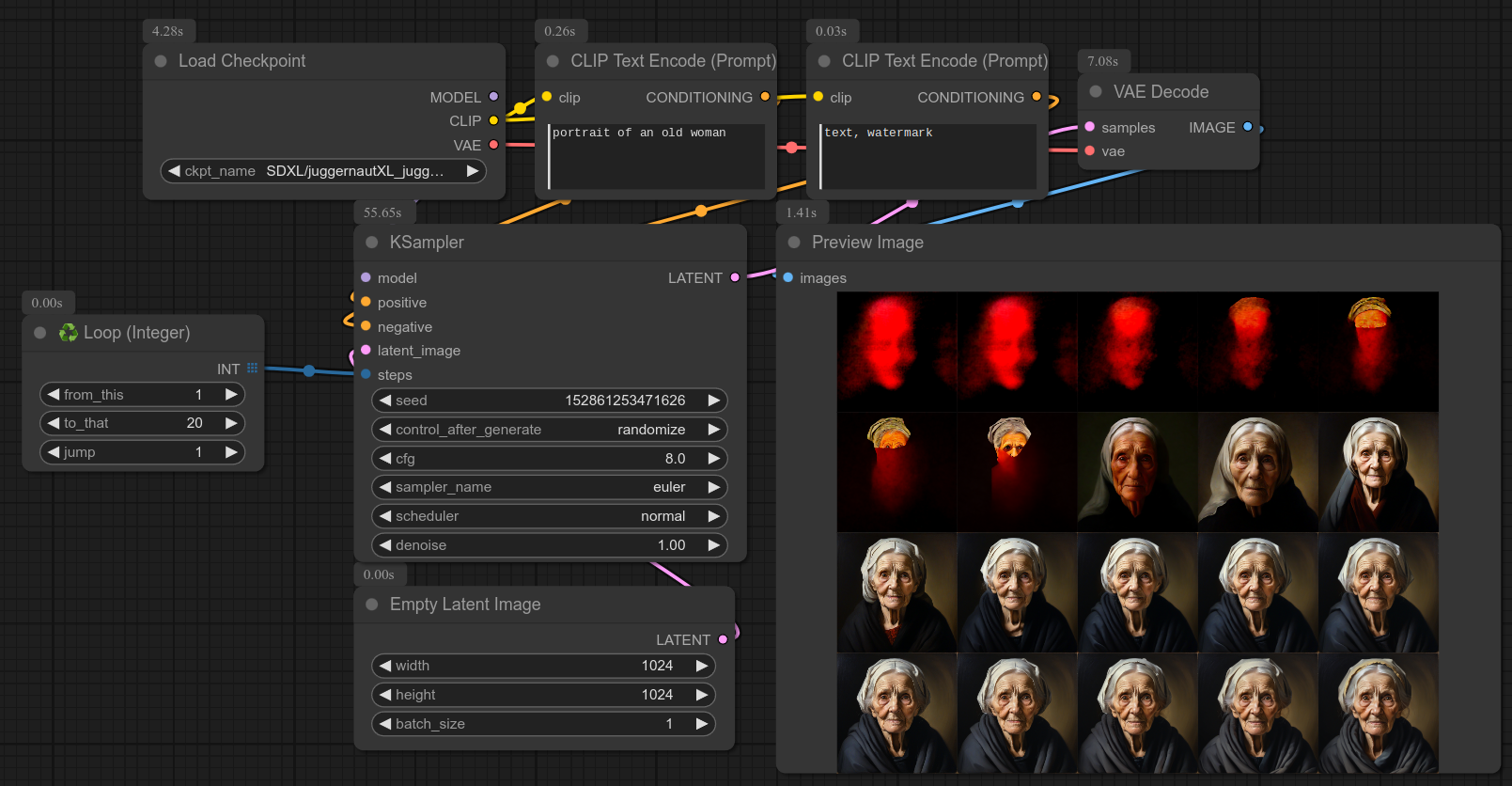
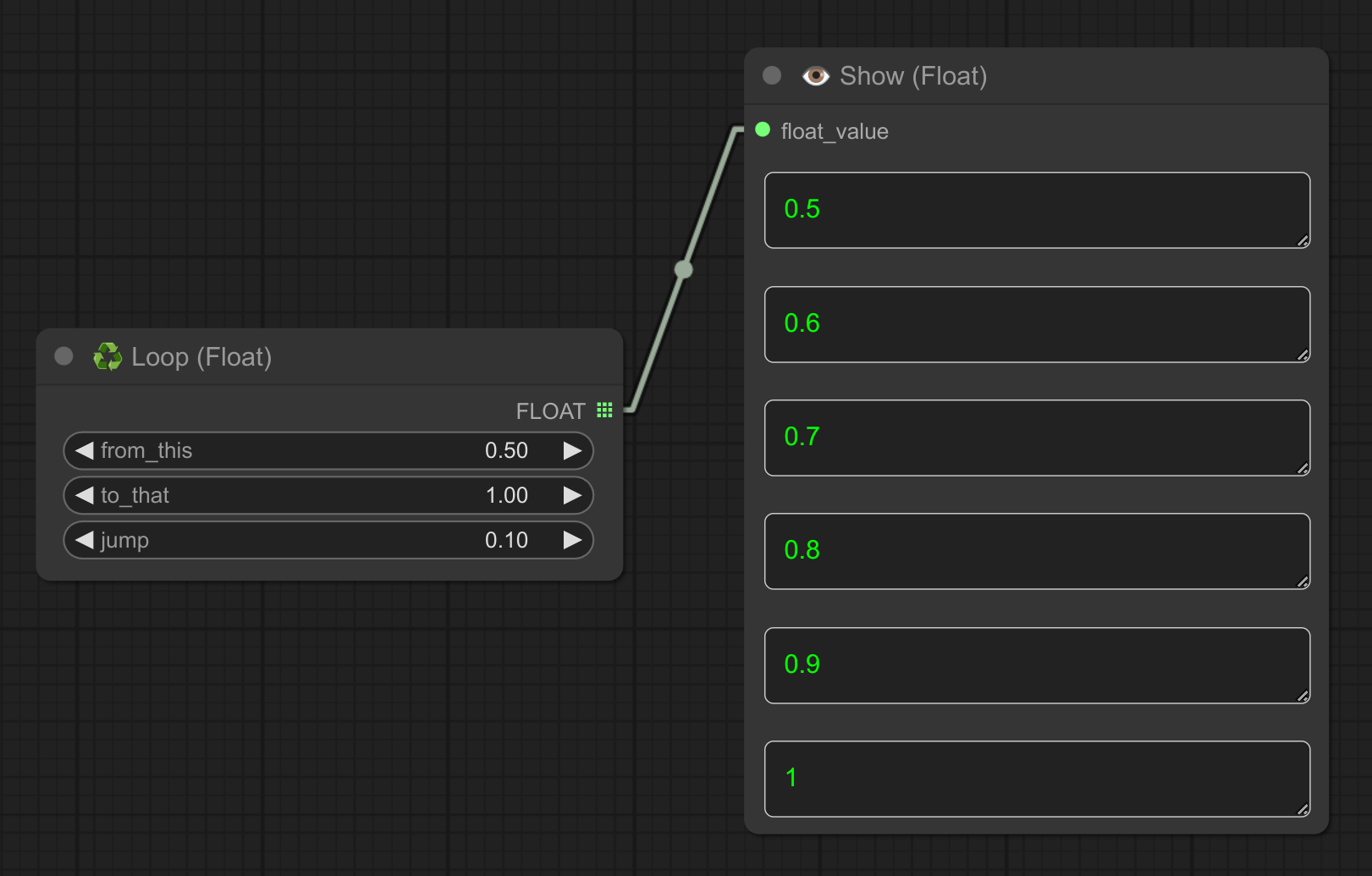
9 - ♻ 循环浮点数
描述:
循环遍历一个浮点数范围,适用于 cfg、denoise 等参数。
这里是一个使用 controlnet 的示例,尝试根据一只蓝色兔子生成一只红色猫: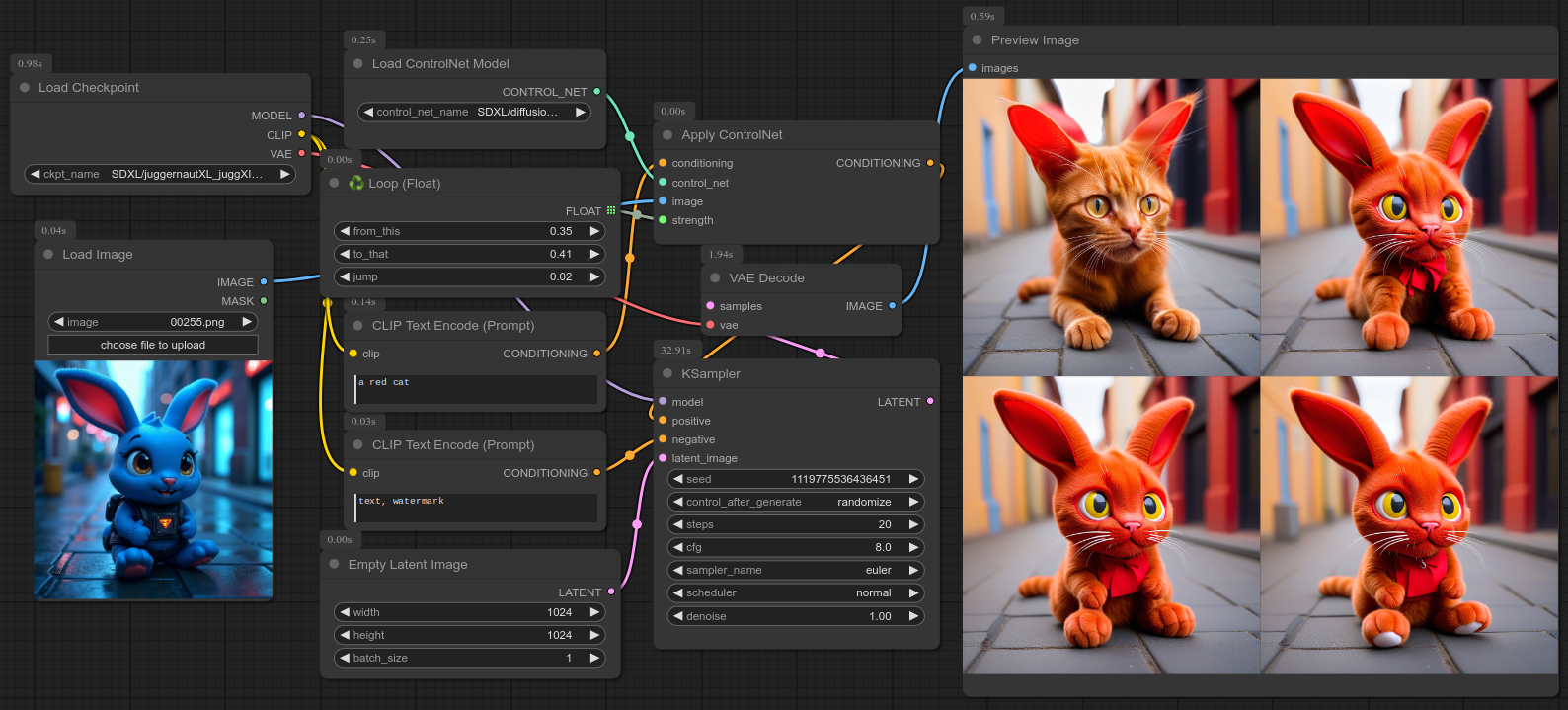
10 - ♻ 循环所有采样器
描述:
迭代所有可用的采样器,并逐一应用。非常适合测试。
这里是一个使用正常调度器循环所有采样器的示例:
11 - ♻ 循环所有调度器
描述:
迭代所有可用的调度器,并逐一应用。非常适合测试。(与上面的采样器类似,但针对调度器)
12 - ♻ 循环组合
描述:
从我自定义的一组组合(调度器+采样器)中生成循环,或者手动选择一个组合。
适合测试。
使用示例,以查看不同组合之间的差异: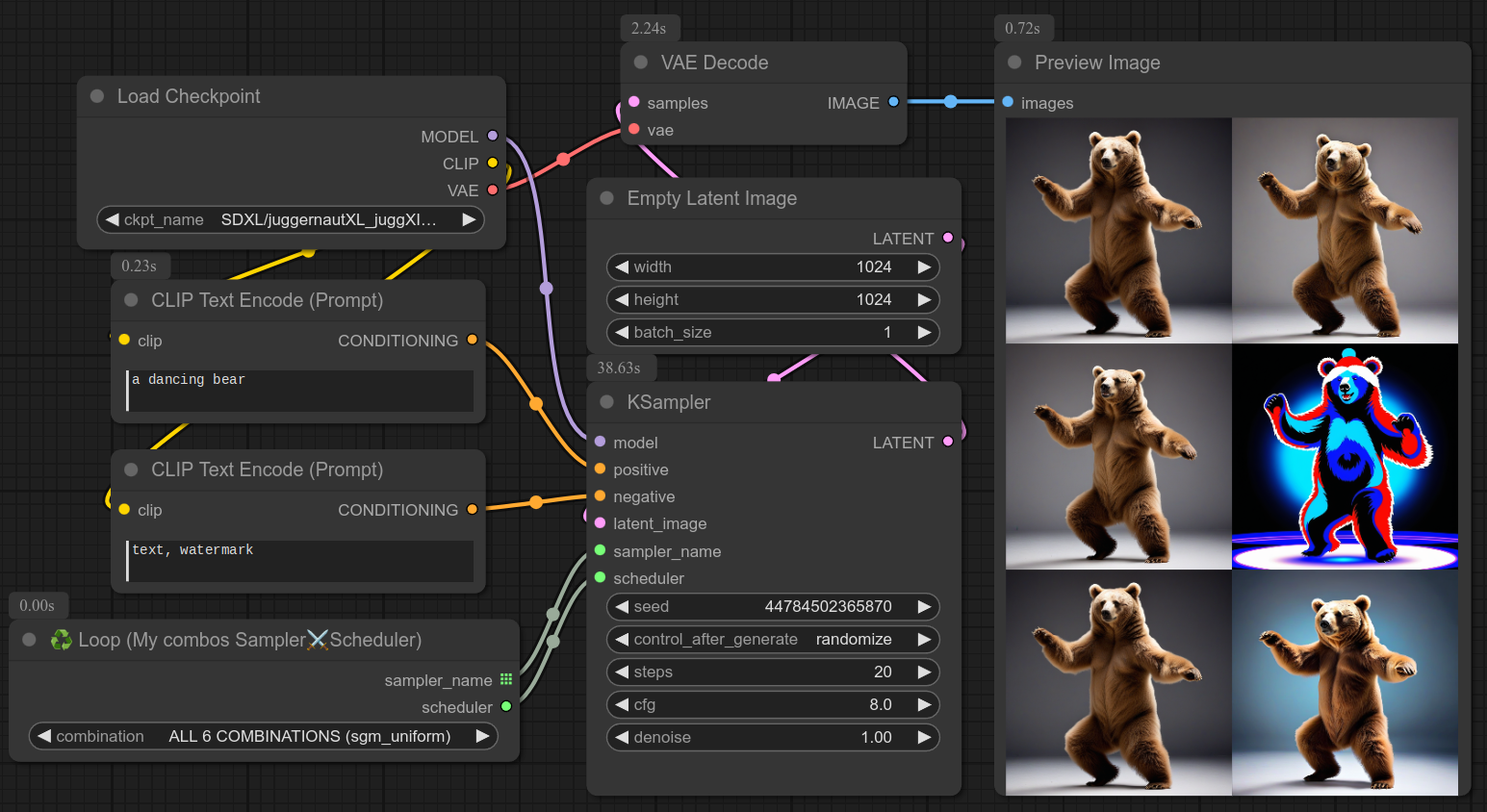
13/14 - 📏 + 🖼 调整大小并保存精确名称 ⚠️💣
描述:
将图像调整为精确的尺寸。如果高度或宽度设置为 0,则会保持宽高比。
另一个节点会将图像保存到指定路径。
⚠️💣 注意:如果文件已存在,将会被覆盖。
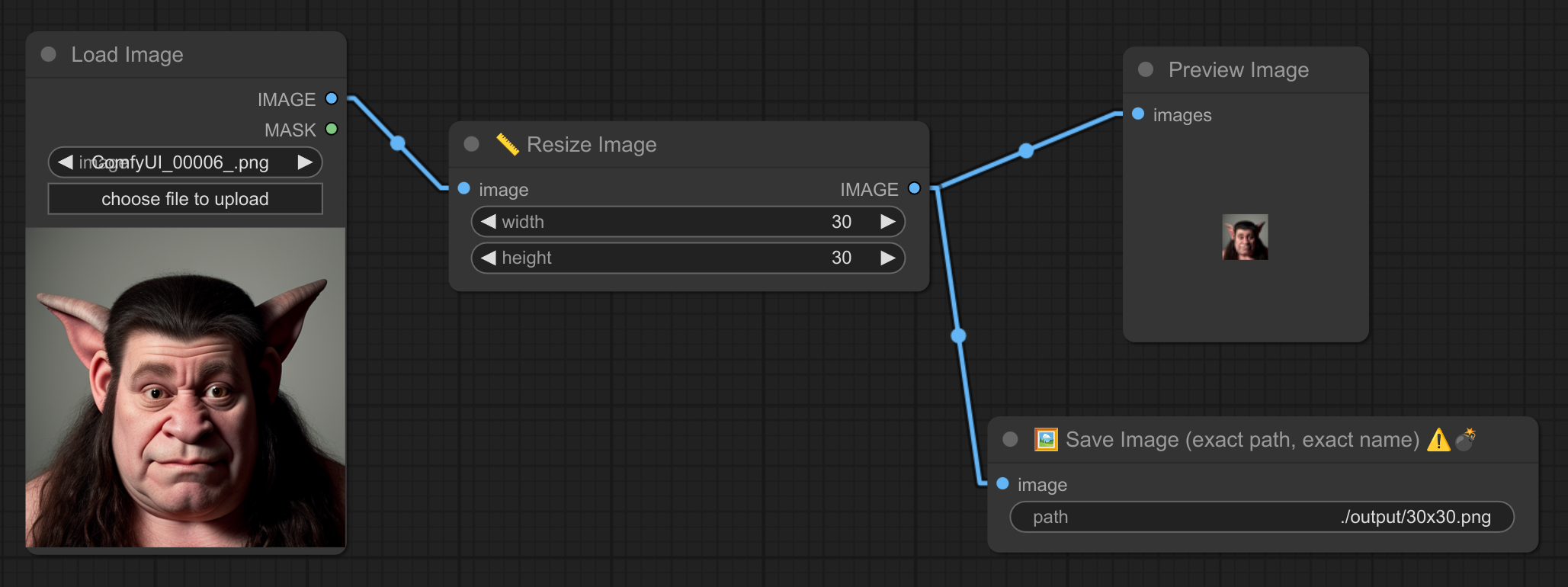
15 - 💾 保存文本
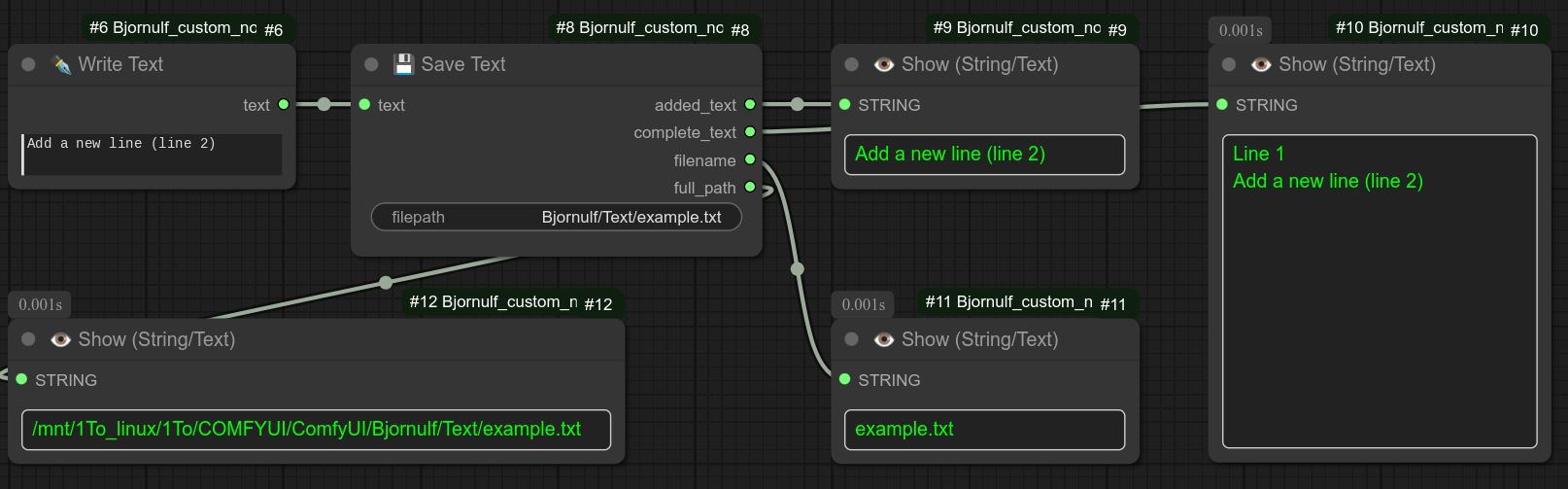
描述:
将给定的文本输入保存到文件中。适用于记录和存储文本数据。
如果文件已存在,文本将追加到文件末尾。
建议您将文件保存在“Bjornulf/Text”目录下(位于 Comfyui 文件夹中,紧邻 output 目录),因为节点 116 从文件夹加载文本 正是从该目录查找文本文件的。
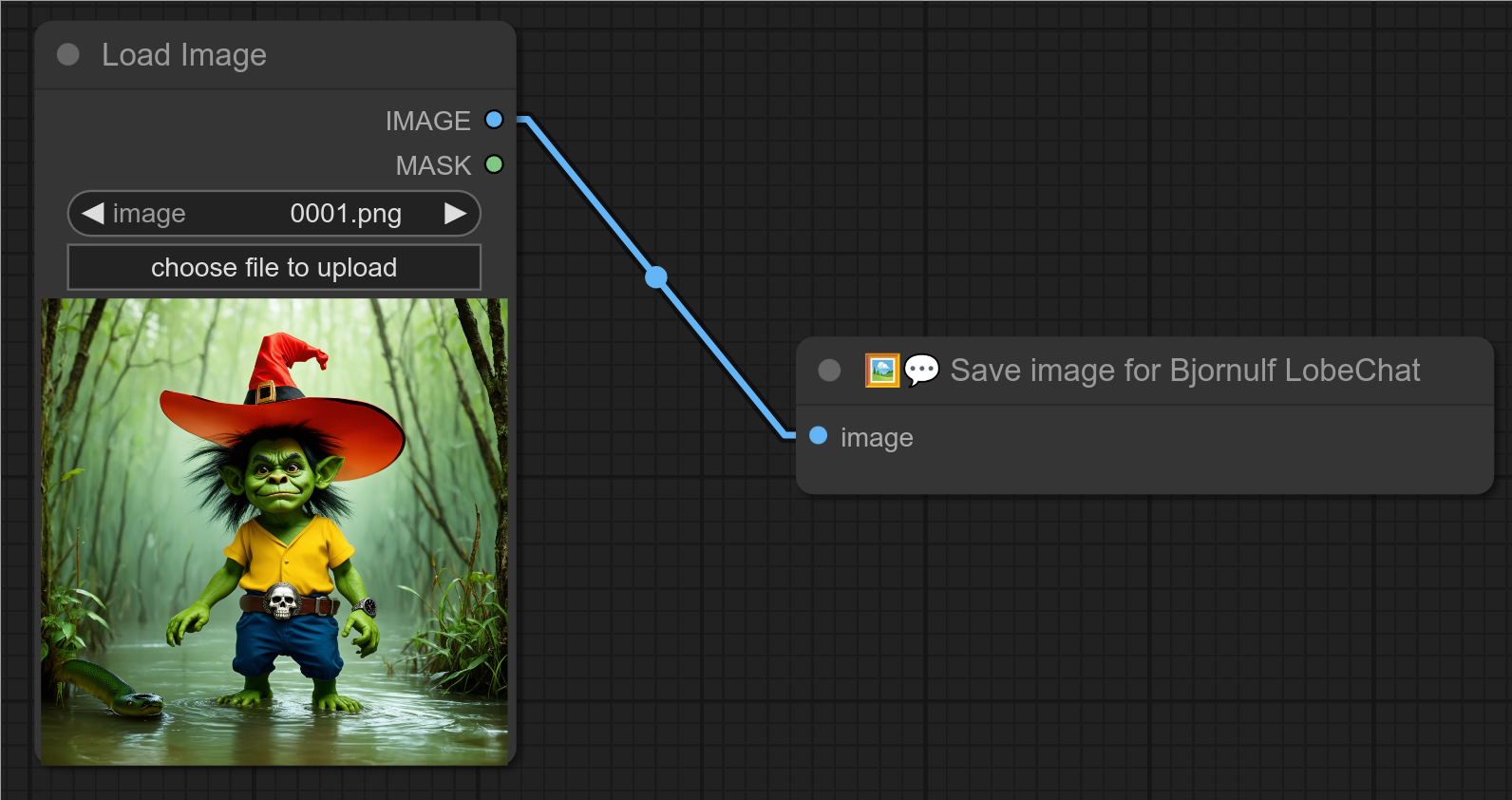
16 - 💾🖼💬 为 Bjornulf LobeChat 保存图像(❗专为我的自定义 lobe-chat 准备的❗)
描述:
❓ 我制作这个节点是为了让我的自定义 lobe-chat 能够通过 Comfyui API 发送和接收图像:lobe-chat
它会将图像保存到 output/BJORNULF_LOBECHAT/ 文件夹中。
文件名将从 api_00001.png 开始,然后是 api_00002.png,依此类推。
它还会在 output/BJORNULF_API_LAST_IMAGE.png 位置创建一个指向最新生成图像的链接。
这个链接将被我的自定义 lobe-chat 用来将图像复制到 lobe-chat 项目中。
17 - 💾🖼 以 tmp_api.png 临时 API 格式保存图像 ⚠️💣
描述:
保存图像以供短期使用:./output/tmp_api.png ⚠️💣
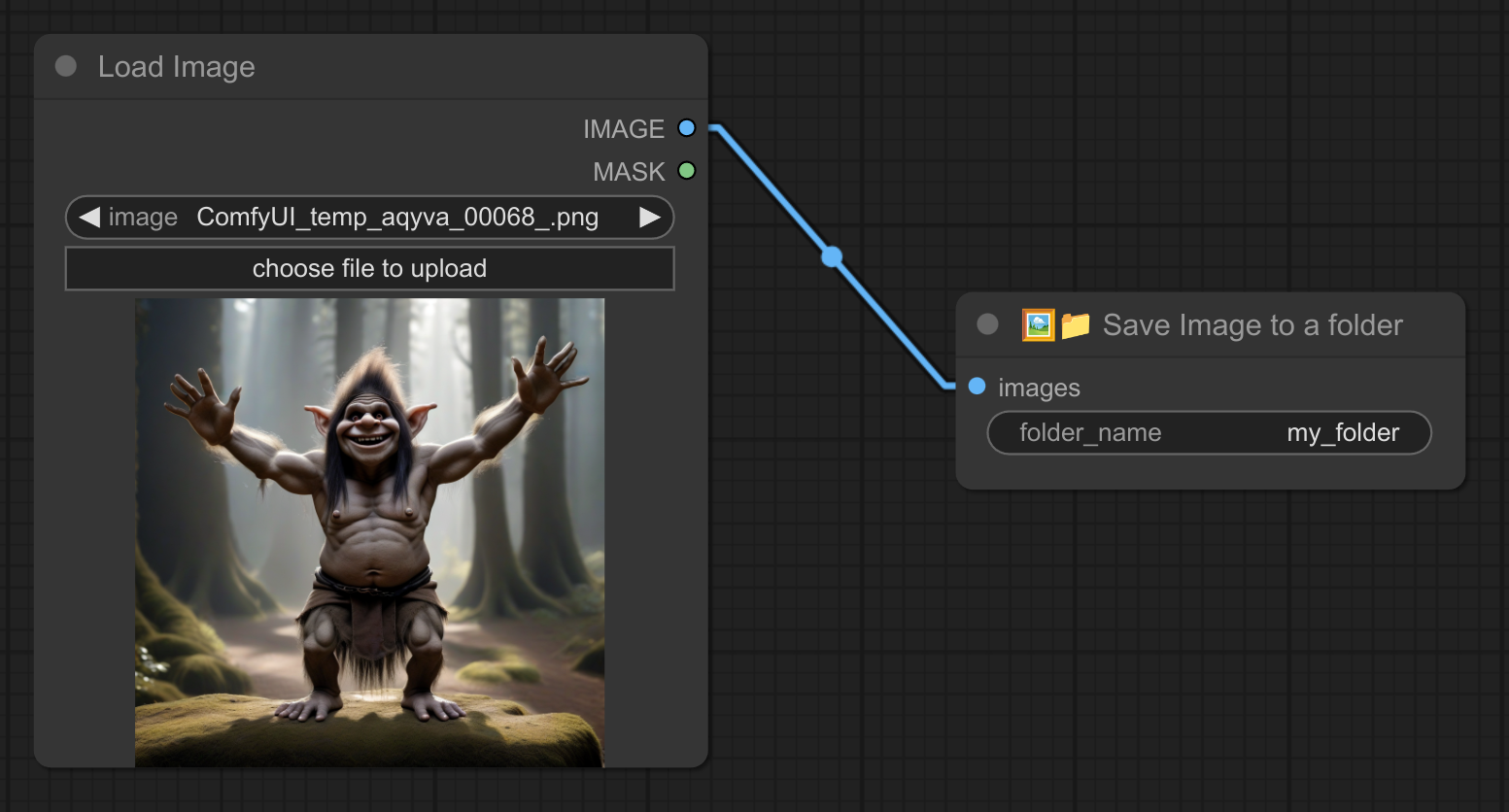
18 - 💾🖼📁 将图像保存到指定文件夹
描述:
将图像保存到特定文件夹中,例如 my_folder/00001.png、my_folder/00002.png 等。
同时支持多级嵌套文件夹,比如 animal/dog/small。
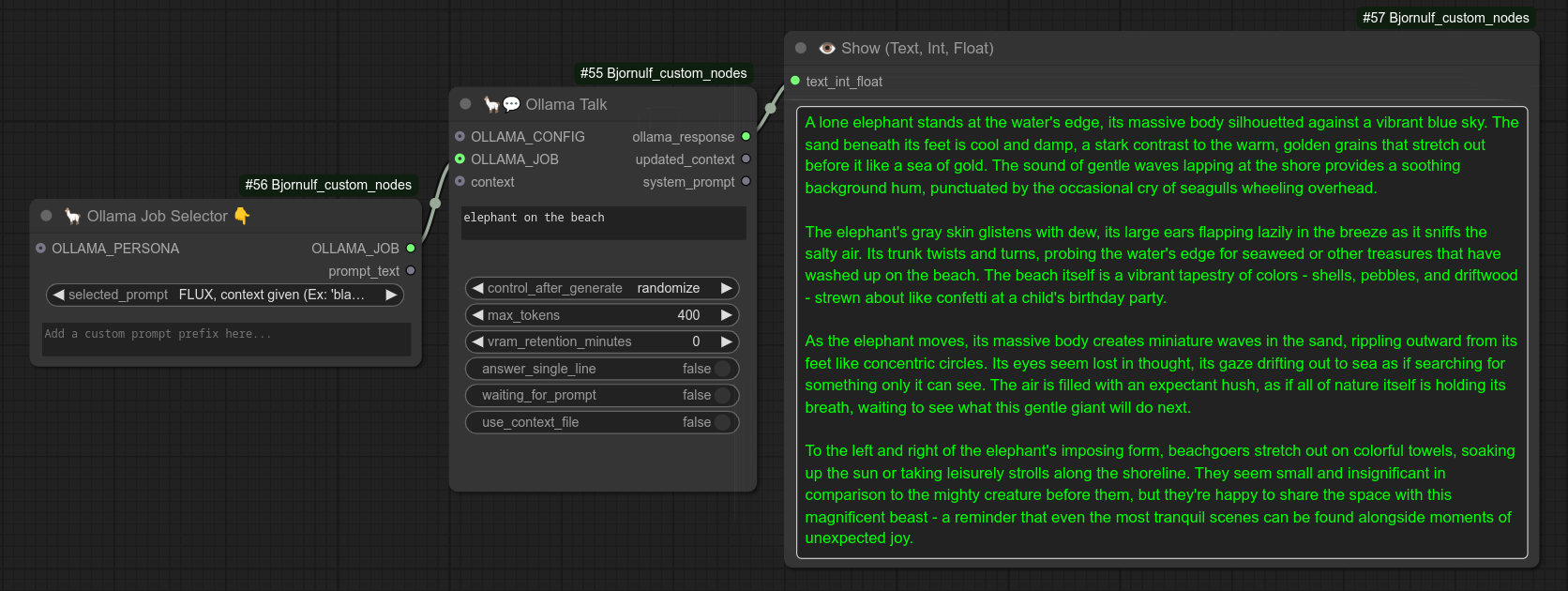
19 - 🦙💬 Ollama对话
描述:
在ComfyUI中使用Ollama。(需要已安装并正在运行的Ollama后端服务。)
默认使用模型 llama3.2:3b 和 URL http://0.0.0.0:11434。(自定义配置请使用节点63)
基本使用示例: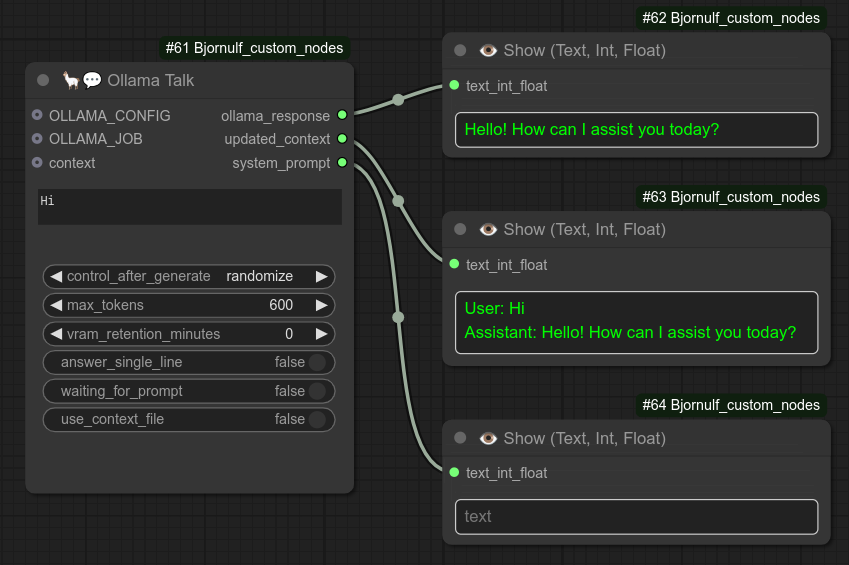
带上下文的使用示例,注意在有上下文的情况下可以继续之前的对话,“那里”显然指的是“布加勒斯特”: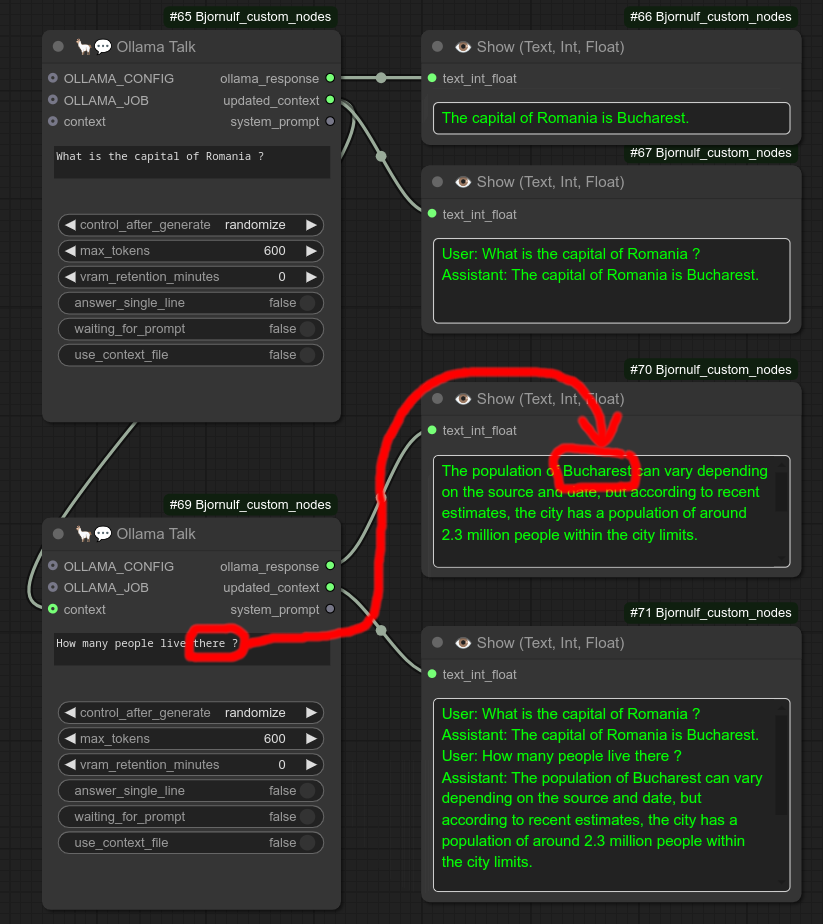
你还可以启用 use_context_file(设置为True),这会将上下文保存到文件中:ComfyUI/Bjornulf/ollama_context.txt。
这样你就可以在不连接多个节点的情况下继续使用上下文,只需多次运行同一个工作流即可。
使用上下文文件进行对话的三步示例
步骤1:注意目前上下文为空,因此它将成为 ComfyUI/Bjornulf/ollama_context.txt 中的第一条消息: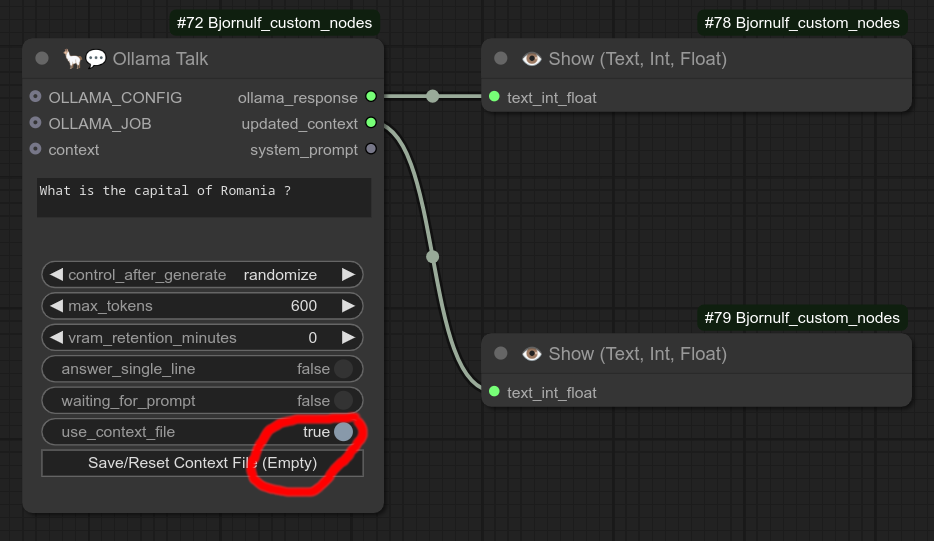
步骤2:注意现在上下文文件中的行数已经改变(这些与 updated_context 相同):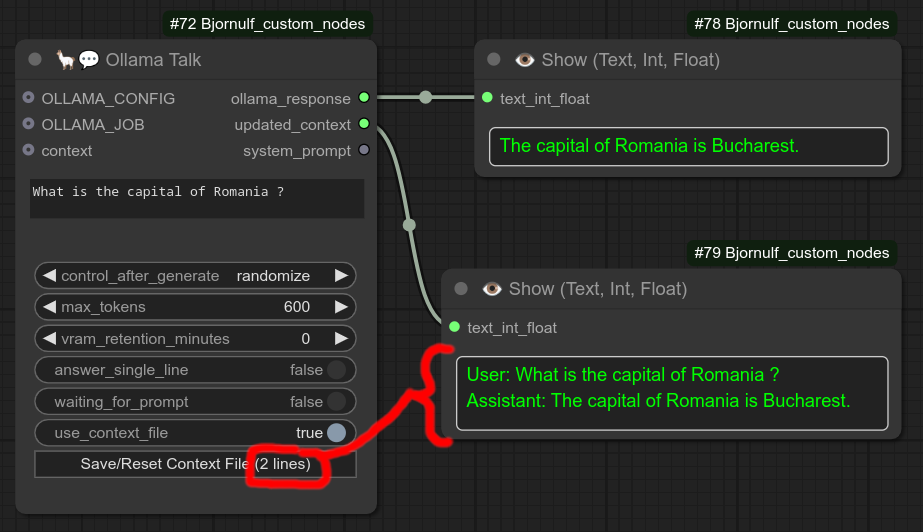
步骤3:注意行数持续增加。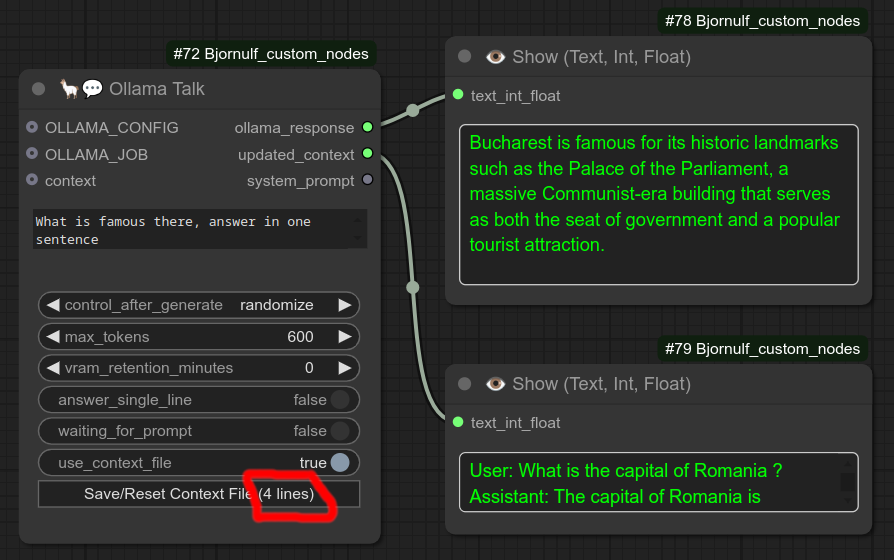
点击“重置按钮”时,它还会将上下文保存到:ComfyUI/Bjornulf/ollama_context_001.txt、ComfyUI/Bjornulf/ollama_context_002.txt 等。
⚠️ 如果你想进行“交互式”对话,可以启用 waiting_for_prompt 选项。
当设置为True时,会生成一个“恢复”按钮,使用该按钮解除节点暂停并处理提示。
使用 waiting_for_prompt 进行交互式对话的三步示例
步骤1:我运行工作流,注意到显示节点是空的,节点正在暂停工作流并等待你编辑提示。(此时它正在询问法国的首都。)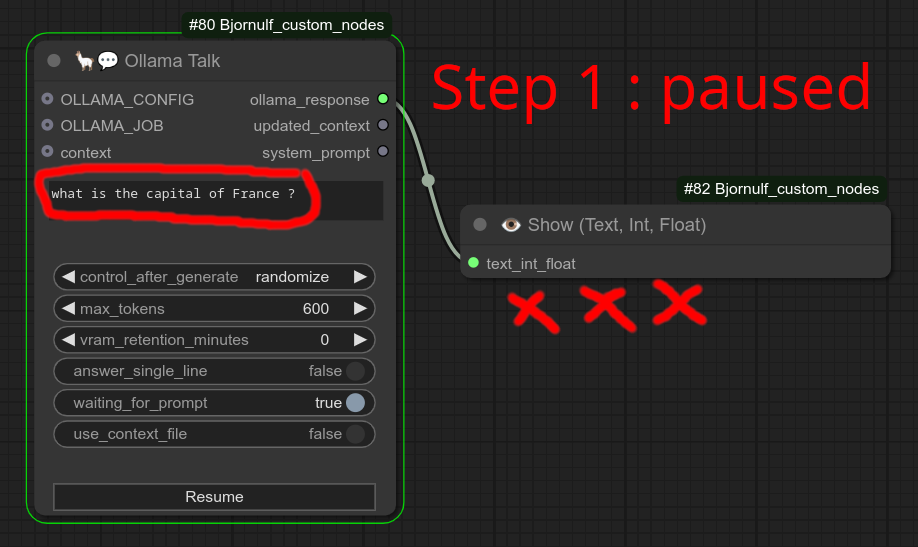
步骤2:我将提示中的“法国”改为“中国”,但节点不会处理请求,直到你点击“恢复”按钮。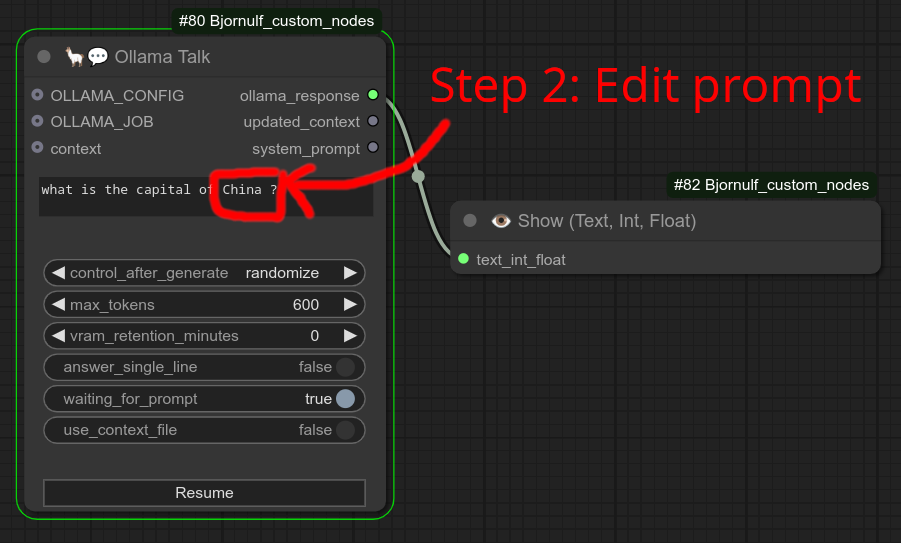
步骤3:我点击“恢复”按钮,这时请求才被处理。注意它使用的是“中国”而不是“法国”。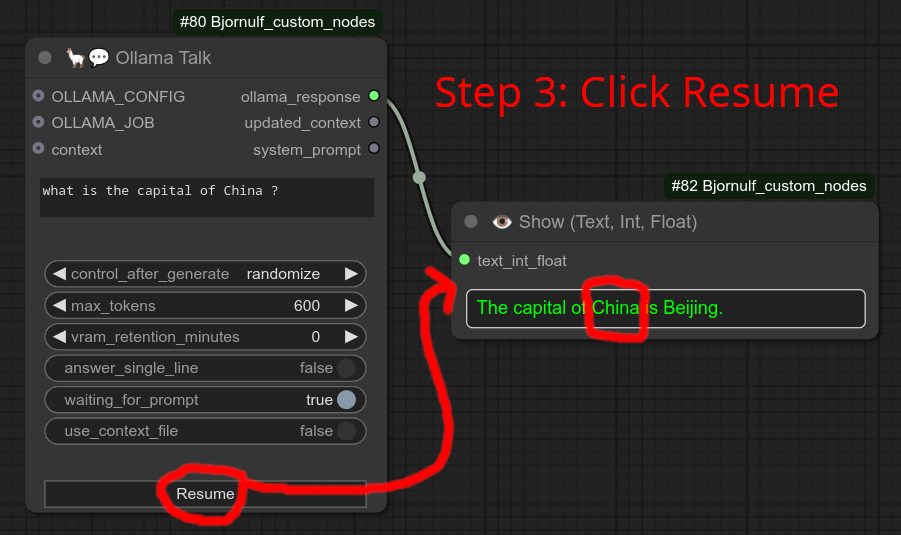
其他选项:
- 你还可以使用
control_after_generate来强制节点在每次运行工作流时都重新运行。(即使节点或其输入没有变化。) - 可以设置
max_tokens来减少回答的长度,一个token大约相当于3个英文字符。 - 可以强制答案只显示在一行上,这可能会很有用。
- 你可以选择将模型保留在显存中。(如果你计划用相同的提示多次生成内容)——每次运行都会显著加快速度,但不会释放显存供其他任务使用。
⚠️ 注意:使用 vram_retention_minutes 可能会对你的显存造成一定压力。请考虑是否真的需要它。通常情况下,在使用 vram_retention_minutes 时,你不应该同时进行图像生成或其他操作。
20 - 📹 视频乒乓
描述:
通过在到达最后一帧时反转播放方向,从一系列图像(来自视频)中创建乒乓效果。非常适合实现“无限循环”效果。
21 - 🖼➜📹 图片转视频(FFMPEG保存视频)
描述:
将一系列图像组合成一个视频文件。
❓ 我制作这个节点是因为它支持WebM格式的透明度。(rembg需要)
临时图像以及WAV音频文件都会存储在 ComfyUI/temp_images_imgs2video/ 文件夹中。
22 - 🔲 去除图像透明度(Alpha通道)
描述:
通过用纯色填充Alpha通道来去除图像的透明度。(黑色、白色或绿幕)
当然,它需要输入一张带有透明度的图像,比如来自rembg节点的图像。
对于一些不支持透明度的节点来说,这是必要的。
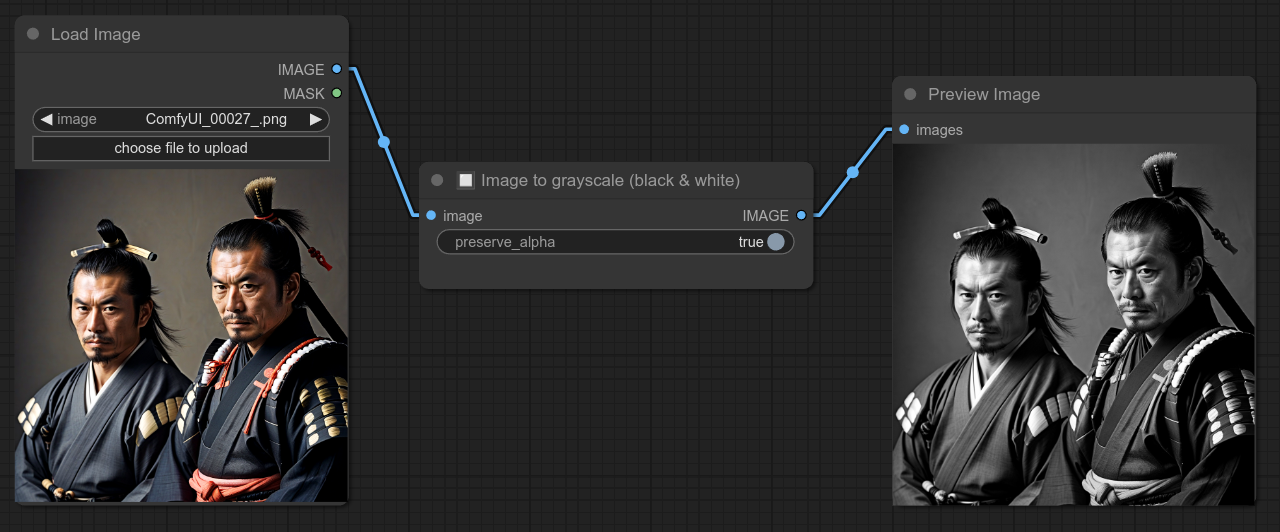
23 - 🔲 图像转灰度(黑白)
描述:
将图像转换为灰度(黑白)。
示例:我有时会将其与Ipadapter一起使用,以消除颜色的影响。
但有时你也可能想要一张黑白照片……
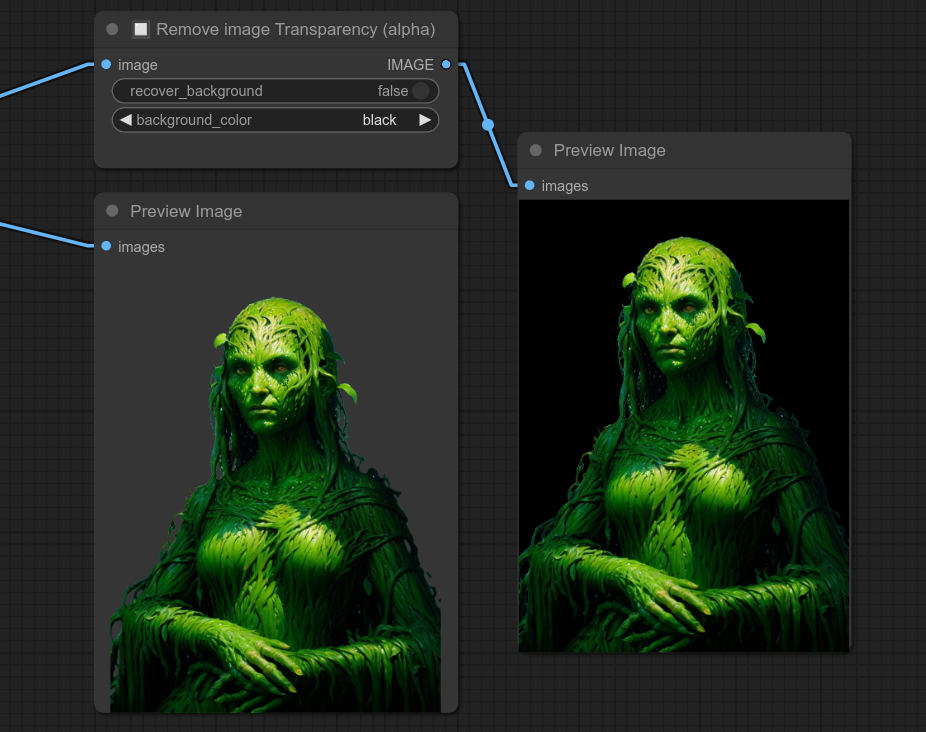
24 - 🖼+🖼 叠加两张图像(背景+叠加层)
描述:
将两张图像叠加成一张:一张背景图和一张或多张透明的叠加层。(也可以用于视频处理,只需发送所有帧并在之后重新组合。)
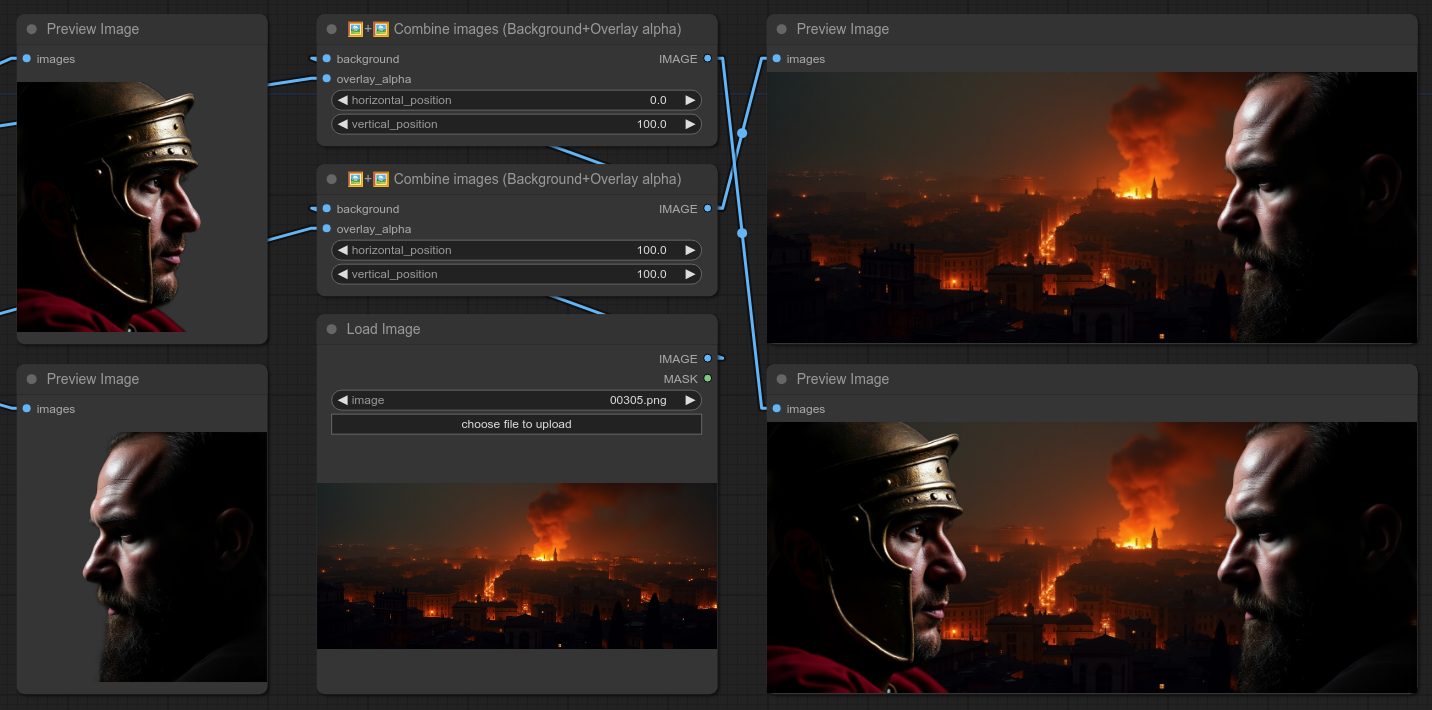
更新0.11:新增垂直和水平移动选项。(范围从-50%到150%)
❗ 注意:目前,背景 是一张静态图像。(以后也会支持视频。)
⚠️ 注意:如果你想直接加载带有透明度的图像,请使用我的节点 🖼 带透明度的图像加载 ▢ 而不是 加载图像 节点。
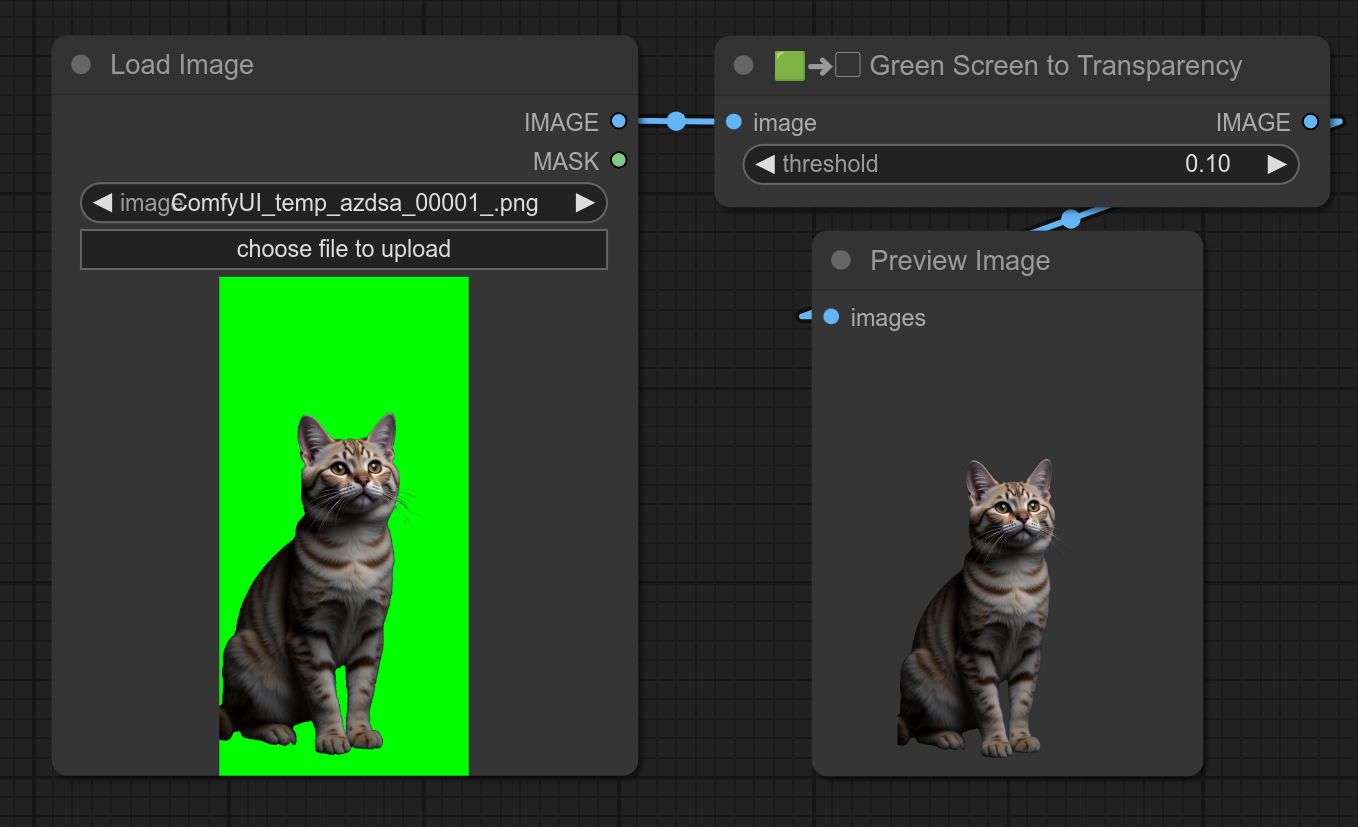
25 - 🟩➜▢ 绿幕转透明度
描述:
将绿幕转换为透明度。
当然,需要干净的绿幕。(可以调整阈值,但这是一个非常基础的节点。)
26 - 🎲 从输入中随机抽取一行
描述:
从输入文本中随机抽取一行。(例如,当你使用多个“写文本”节点时会很麻烦,这时你可以使用这个节点,只需从外部复制粘贴一个列表即可。)
你可以通过更改 control_after_generate 的固定/随机设置,让每次运行工作流时都得到不同的文本。(或者保持不变)
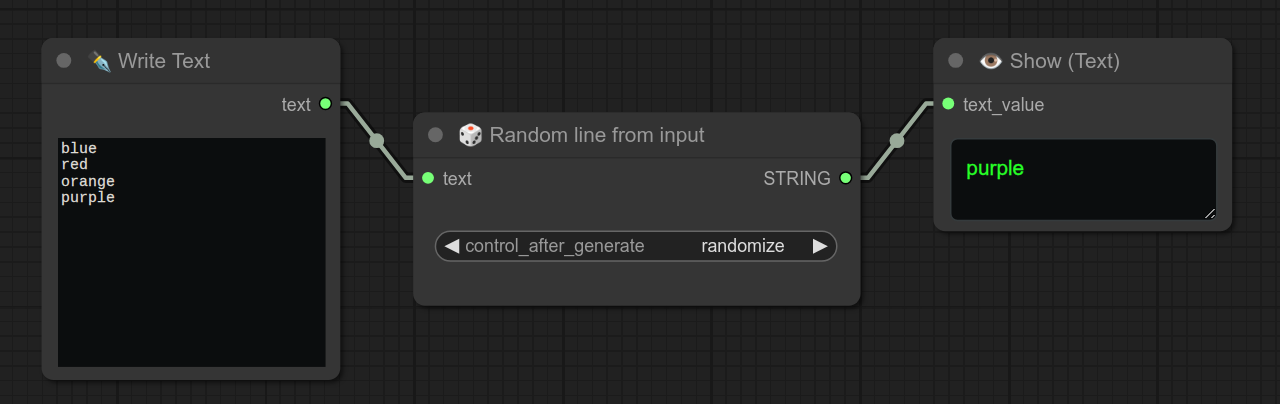
27 - ♻ 循环(输入中的所有行)
描述:
遍历输入文本中的所有行。(非常适合测试多行文本。)
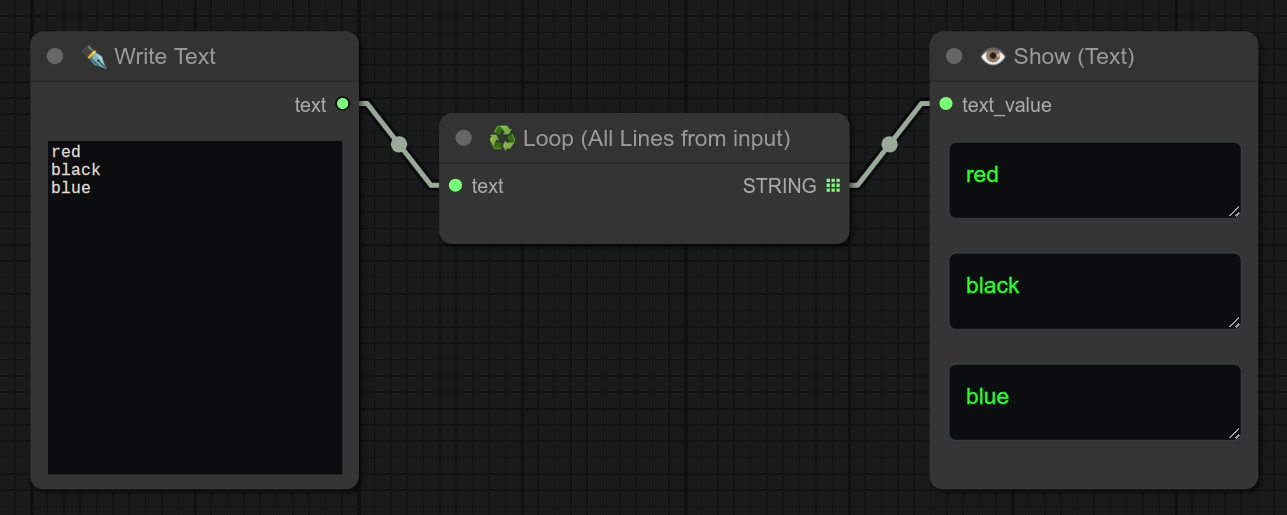
28 - 🔢 带随机种子的文本
描述:
❗ 此节点用于强制生成一个随机种子,并伴随文本一起输出。
但这到底是什么意思呢???
当你使用循环(♻)时,每次迭代都会使用相同的种子。(这就是它的目的——保持同一种子以便比较结果。)
即使在 control_after_generate 中启用了随机化功能,循环仍然会为每一次迭代使用同一个种子,只有在整个工作流完成后才会改变种子。
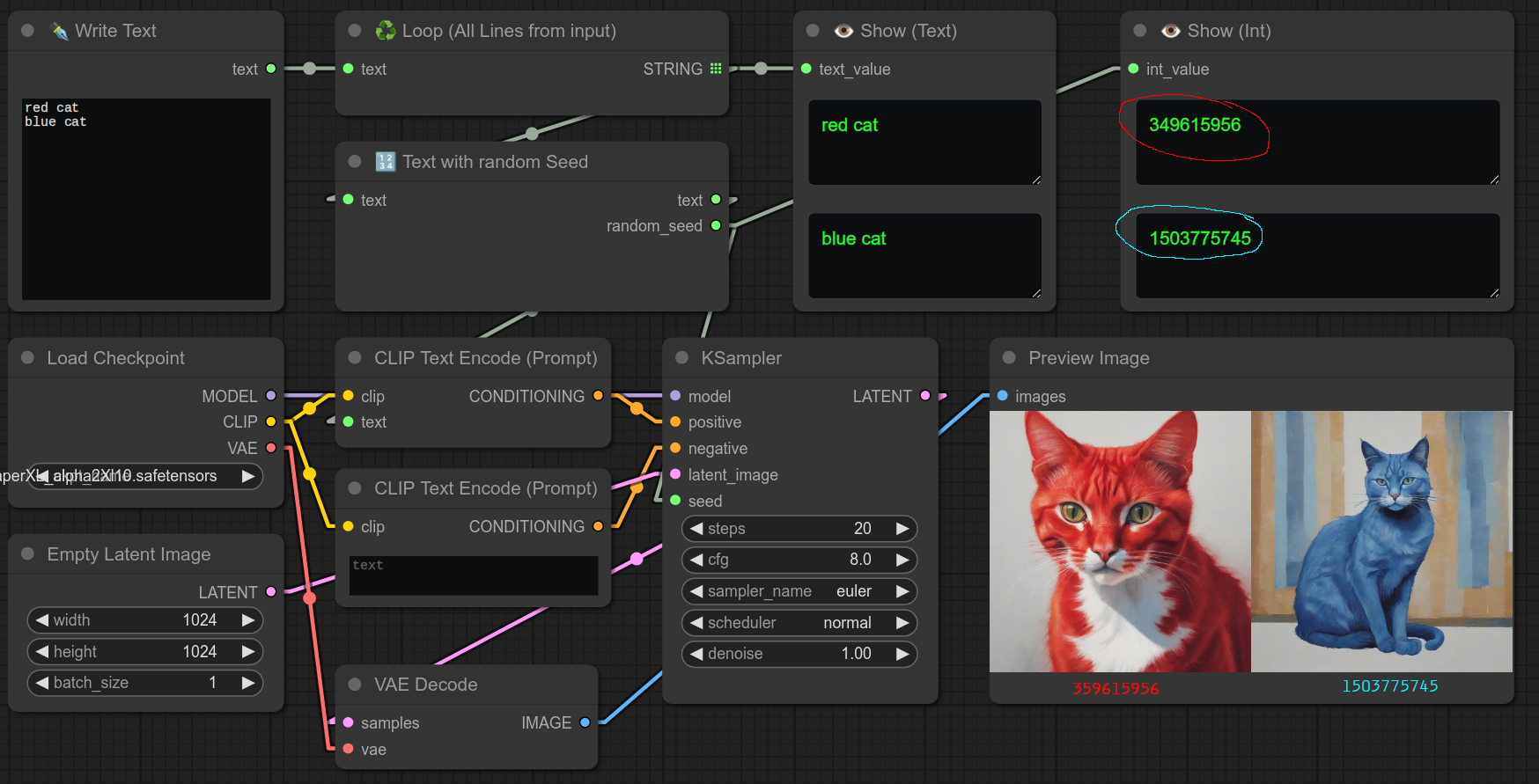
不使用随机种子节点的简单示例:(两张图片提示词不同,但种子相同)
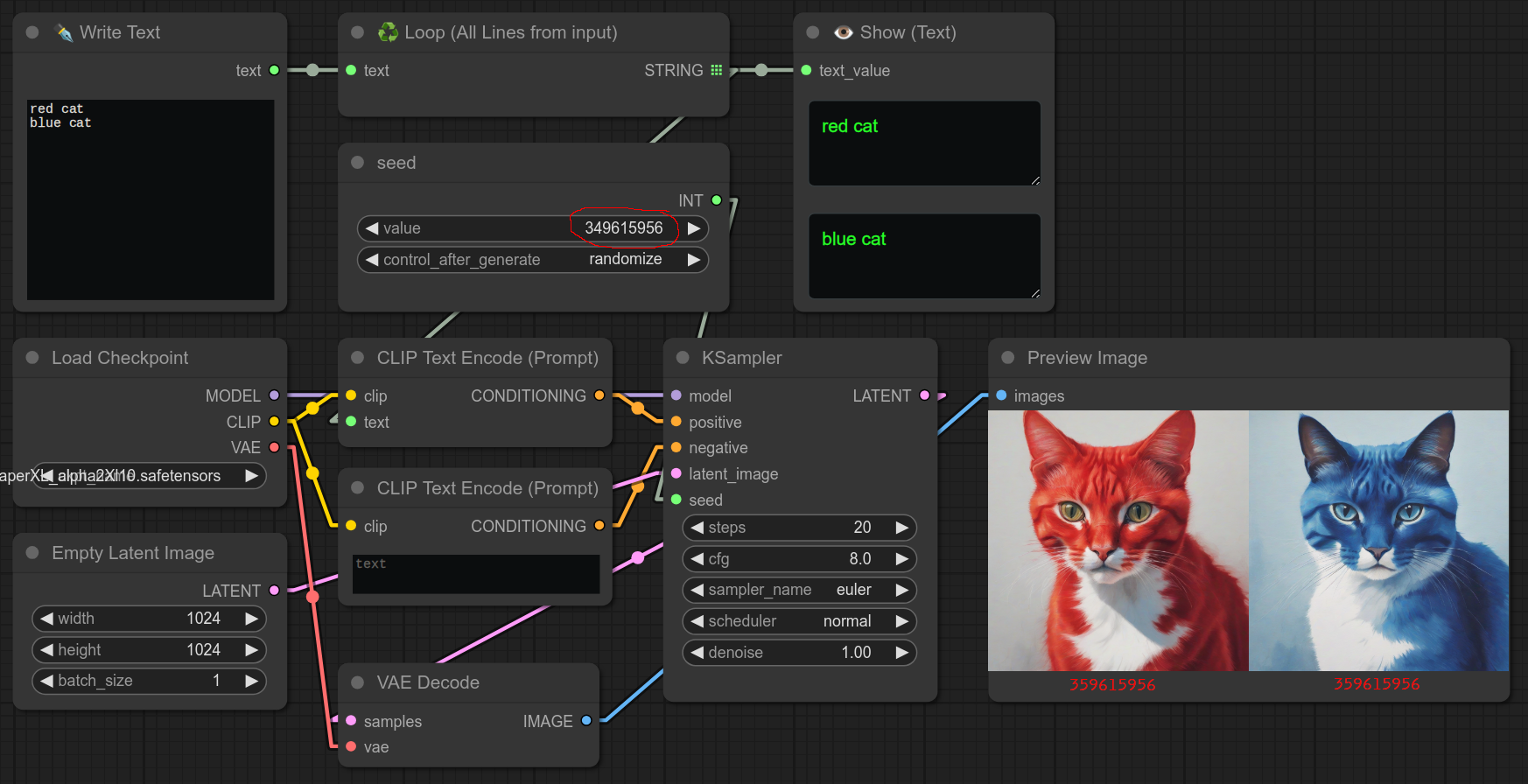
因此,如果你希望每次迭代都强制使用不同的种子,可以在循环中间使用此节点。
例如,如果你想每次都生成一张不同的图片。(即:你使用循环节点不是为了比较或测试结果,而是为了生成多张图片。)
可以这样使用:(两张图片提示词和种子都不同)
以下是 FLUX 在不同提示词(兜帽/头盔)但相同种子情况下可能出现相似性的示例:
以下是 SDXL 在不同提示词(蓝色/红色)但相同种子情况下可能出现相似性的示例:
FLUX:以下是左侧4张未使用随机种子节点的图片,右侧4张使用了随机种子节点的图片:

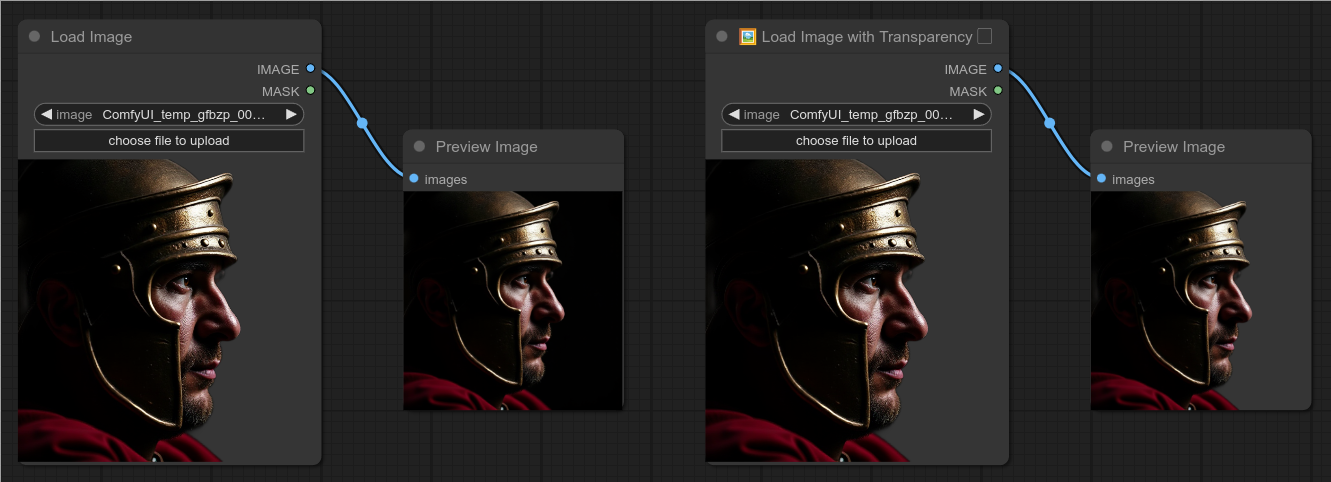
29 - 🖼 带透明度的图像加载 ▢
描述:
加载带有透明度的图像。
默认的 Load Image 节点不会加载透明度信息。
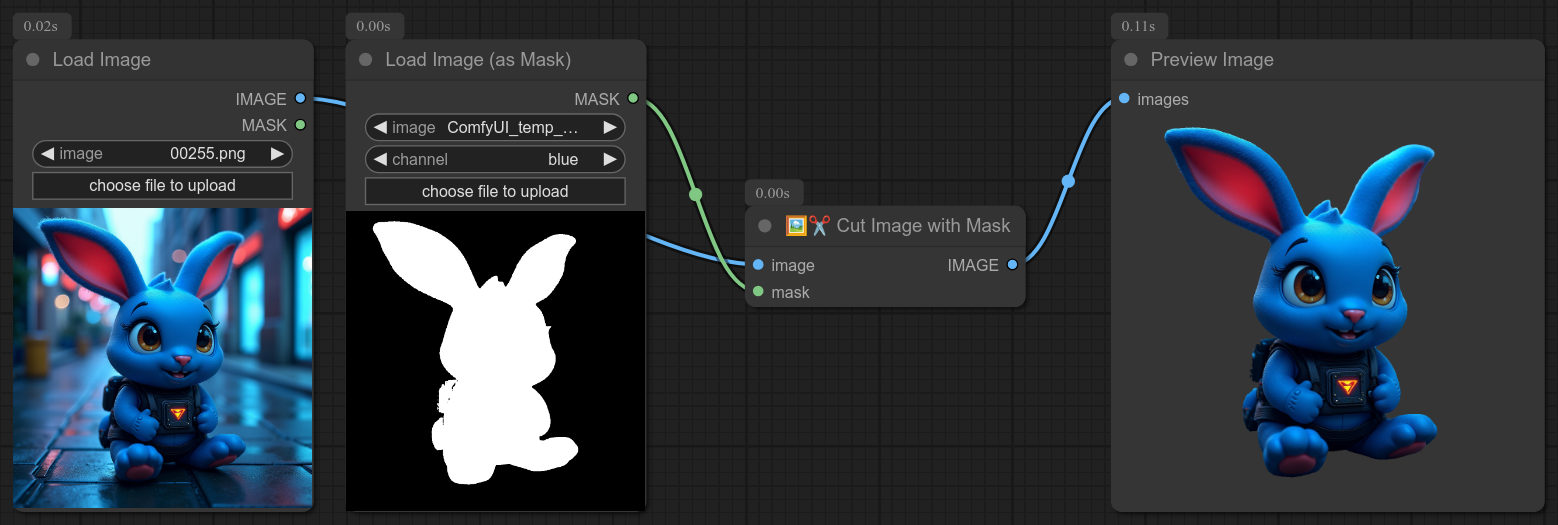
30 - 🖼✂ 使用遮罩裁剪图像
描述:
根据遮罩裁剪图像。
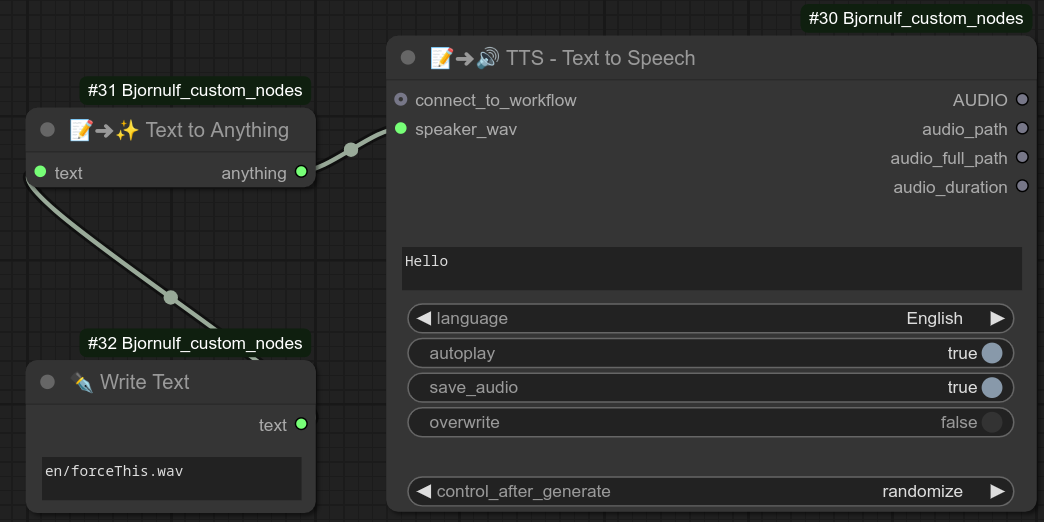
31 - 🔊 TTS - 文本转语音(100% 本地运行,任意声音、任意语言)
描述:
使用我的 TTS 服务器,根据任意声音和语言,将文本转换为高质量语音。
收听音频示例
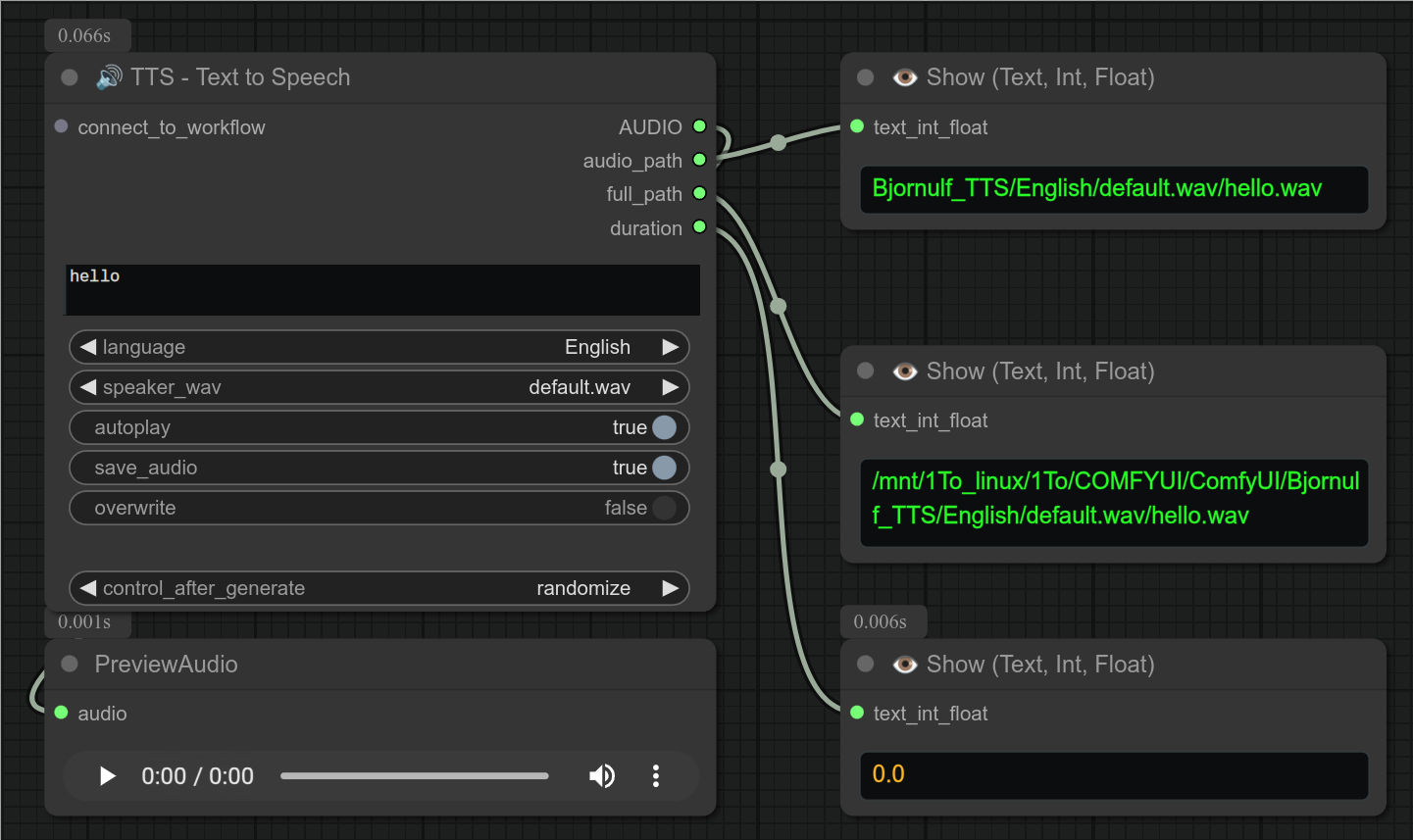
❗ 此节点目前仅在 Linux 上测试过,尚未在 Windows 上测试过。 ❗
使用基于 XTTS v2 的 TTS 服务器来生成文本到语音的转换。
❗ 当然,要使用这个 ComfyUI 节点(前端),你需要先运行我的 TTS 服务器(后端):https://github.com/justUmen/Bjornulf_XTTS
我为 https://github.com/justUmen/Bjornulf_lobe-chat 制作了这个后端,但也可以通过此节点与 ComfyUI 配合使用。
安装好 Bjornulf_XTTS 后,你需要在我的 ComfyUI 自定义节点文件夹中创建一个名为 speakers 的链接:ComfyUI/custom_nodes/Bjornulf_custom_nodes/speakers
该链接必须指向你存放用于 TTS 的语音样本的文件夹,例如 default.wav。
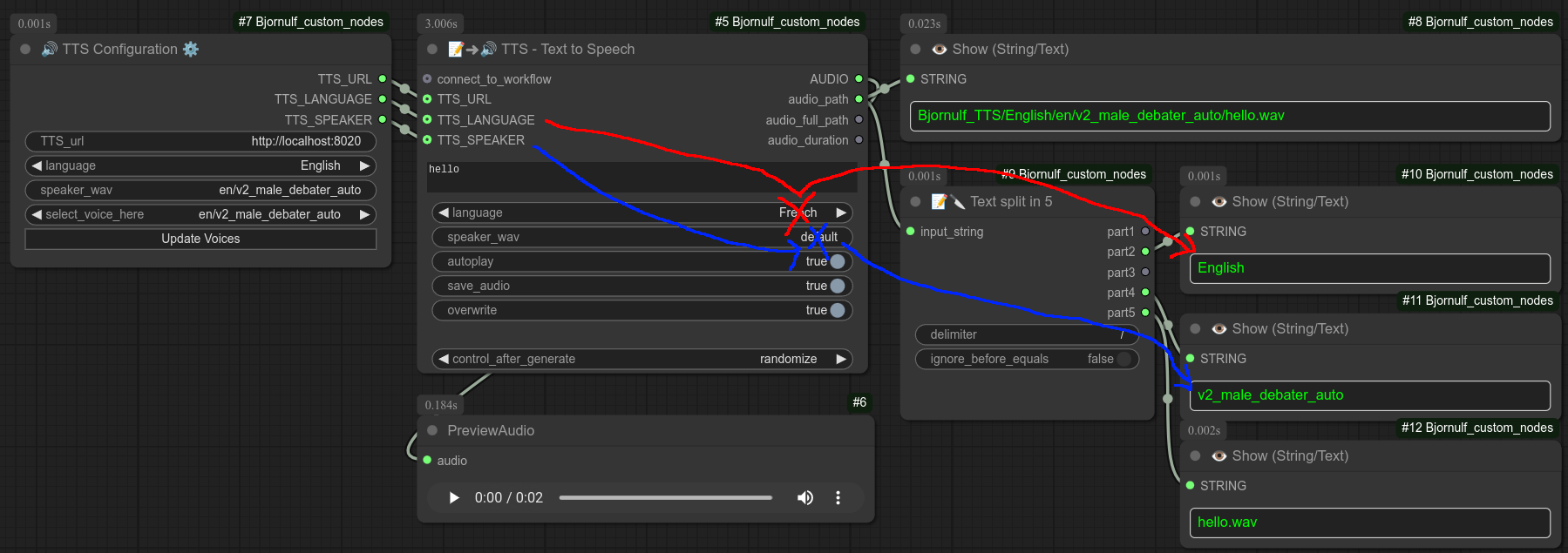
如果我的 TTS 服务器正在 8020 端口运行(你可以通过浏览器访问 http://localhost:8020/tts_stream?language=en&speaker_wav=default&text=Hello 测试),并且语音样本正常,就可以使用此节点将文本转换为语音。
细节
此节点应始终连接到核心节点:Preview audio。
我的节点会将音频文件保存在 ComfyUI/Bjornulf_TTS/ 文件夹中,路径依次为所选语言、语音样本名称和文本。
例如上图中的音频文件路径为:ComfyUI/Bjornulf_TTS/Chinese/default.wav/你吃了吗.wav
你可以注意到,你并不需要选择中文语音才能说中文。是的,你可以自己录制并用任何语言说话。
此外,当你选择类似 fr/fake_Bjornulf.wav 这样的语音时,系统会自动创建一个 fr 文件夹:ComfyUI/Bjornulf_TTS/English/fr/fake_Bjornulf.wav/hello_im_me.wav。很明显,你是在用法语语音样本录制英语内容。
control_after_generate 和往常一样,用于强制节点在每次工作流运行时重新执行。(即使节点或其输入没有变化。)overwrite 用于覆盖已存在的音频文件。(例如,如果你对生成结果不满意,只需将 overwrite 设置为 True 并再次运行工作流,直到得到满意的结果。之后可以将其改回 False。)autoplay 用于在节点执行时自动播放音频文件。(手动重播或保存则在 preview audio 节点中完成。)
所以……请注意,如果你已经准备好了一个音频文件,仍然可以使用我的节点,而无需运行我的 TTS 服务器。
只要能找到音频文件,我的节点就会直接播放,而不会尝试连接后端的 TTS 服务器。
假设你已经使用此节点创建了一个用阿滕伯勒声音说“工作流已完成”的音频文件:
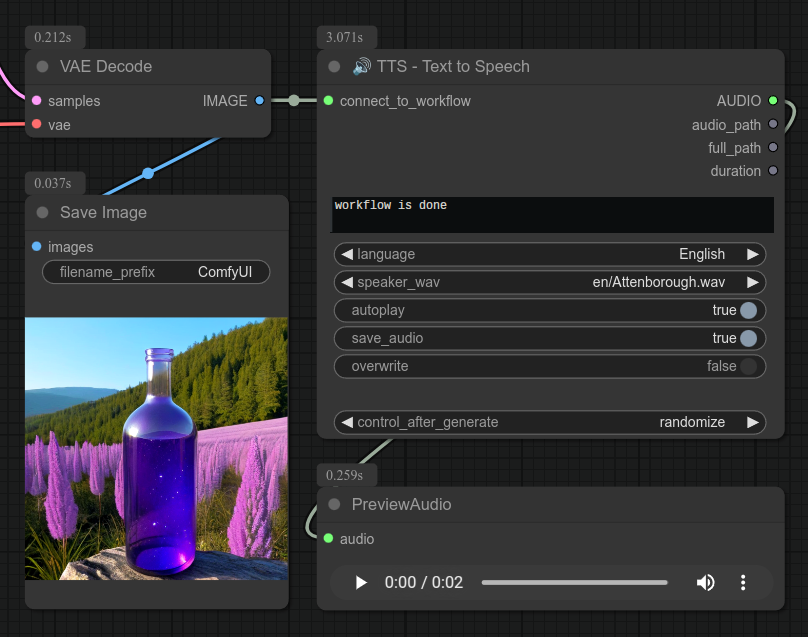
只要设置完全一致,它就不会调用我的服务器来播放音频文件!你可以放心地关闭 TTS 服务器,这样就不会占用宝贵的显存了。(TTS 服务器大约需要 3GB 显存。)
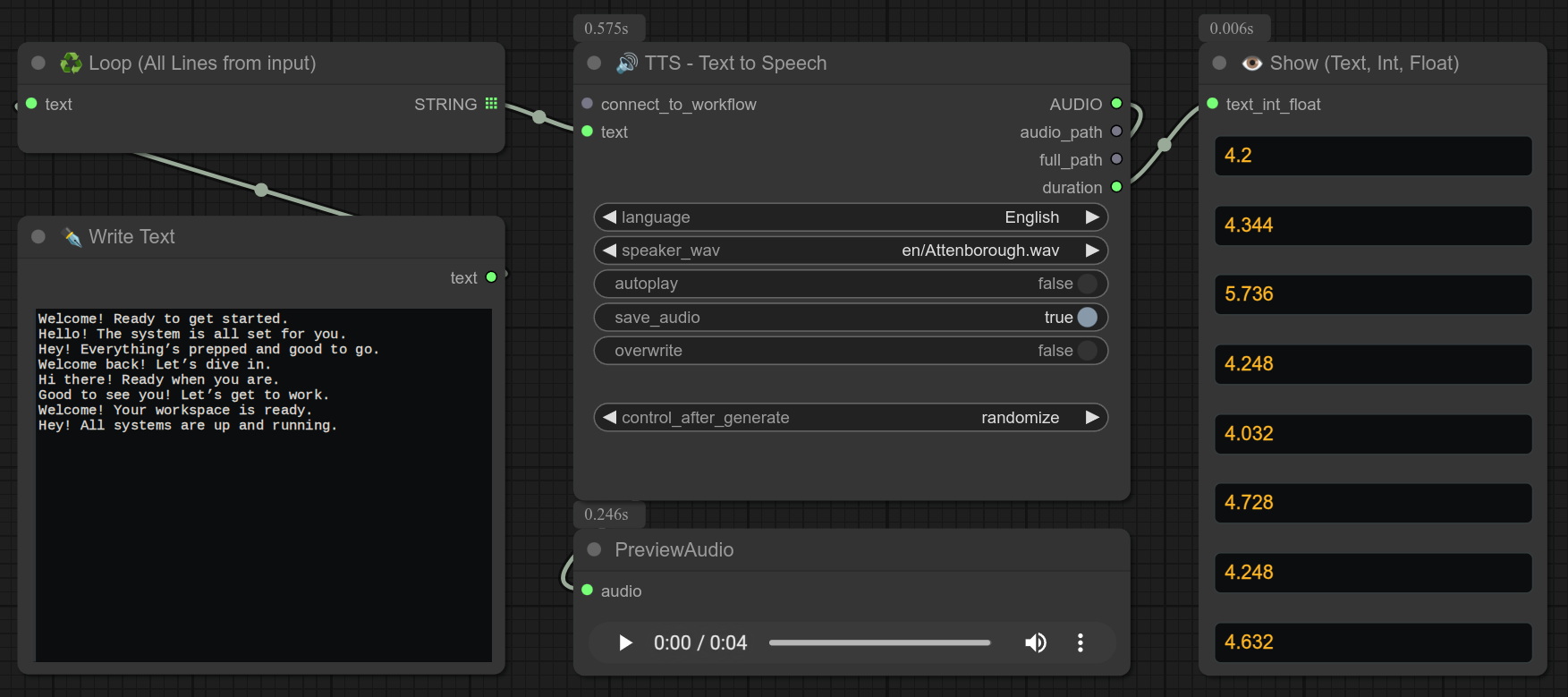
另外,connect_to_workflow 是可选的,这意味着你可以只用我的 TTS 节点创建一个工作流,预先生成你以后想要使用的句子的音频文件,例如:
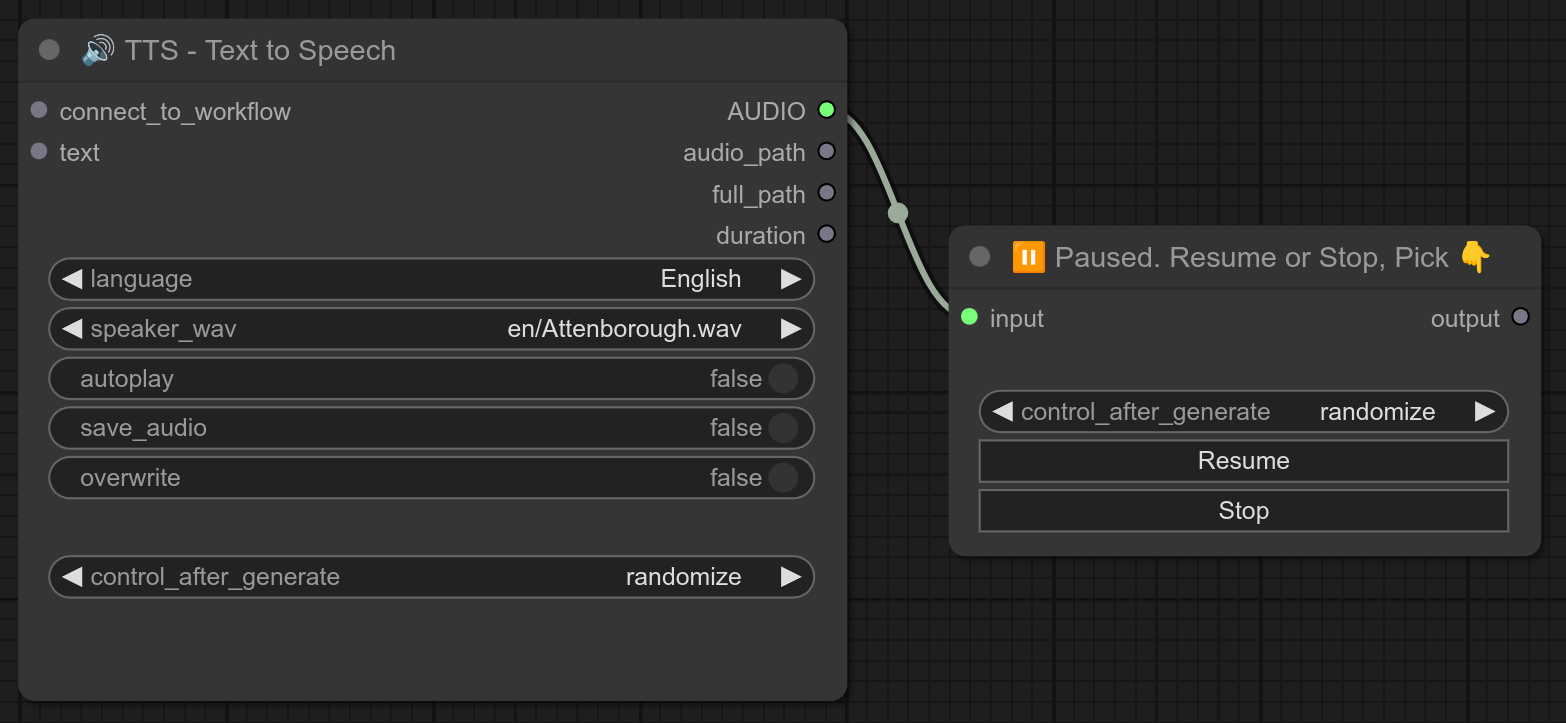
如果你希望在生成图像的同时运行我的 TTS 节点,建议使用我的 PAUSE 节点,以便在 TTS 节点完成后手动停止 TTS 服务器。当显存释放后,再点击 RESUME 按钮继续工作流。
如果你有能力同时运行两者,那当然很好,但在本地环境下,我无法同时运行 TTS 服务器和 FLUX,所以我采用了这种技巧:
32 - 🧑📝 角色描述生成器
描述:
根据 characters 文件夹中的 JSON 文件生成角色描述:ComfyUI/custom_nodes/Bjornulf_custom_nodes/characters
你可以自己制作包含角色信息的 JSON 文件,然后使用此节点生成描述。
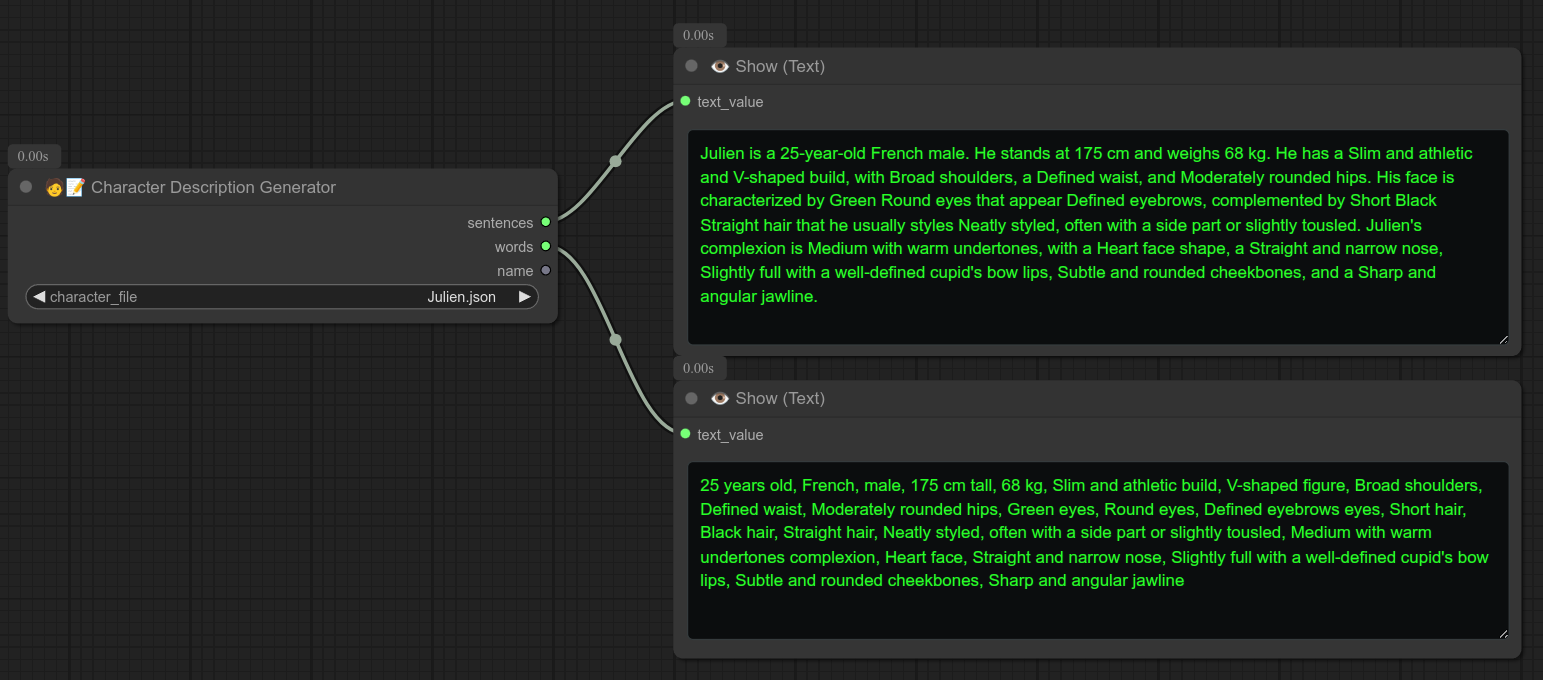
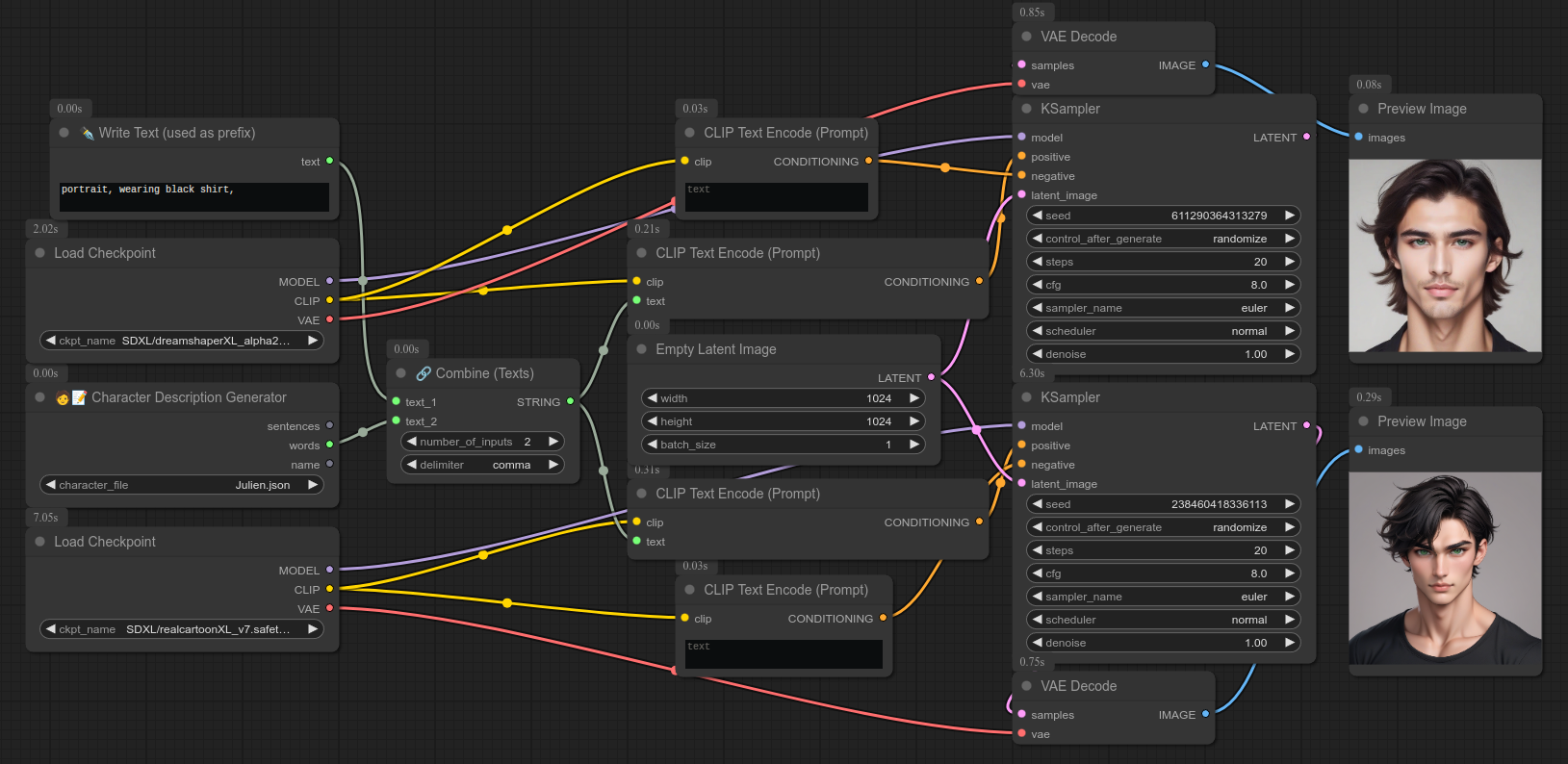
❗ 目前这是一个非常基础的节点,未来还会添加和修改许多功能!!!
某些细节对于部分检查点可能无法使用,目前仍处于开发阶段,JSON 结构也尚未固定。
其中包含了一些预设角色。
33 - ♻ 循环(将输入的所有行按行合并)
描述:
有时你希望对多个输入进行循环处理,但又希望将输出的不同行分开。
有了这个节点,你可以根据需要设置输入和输出的数量。请参阅使用示例。
34 - 🧹 免费VRAM修复小技巧
描述:
这是我尝试在使用后释放VRAM内存的方法,我还会继续优化它。
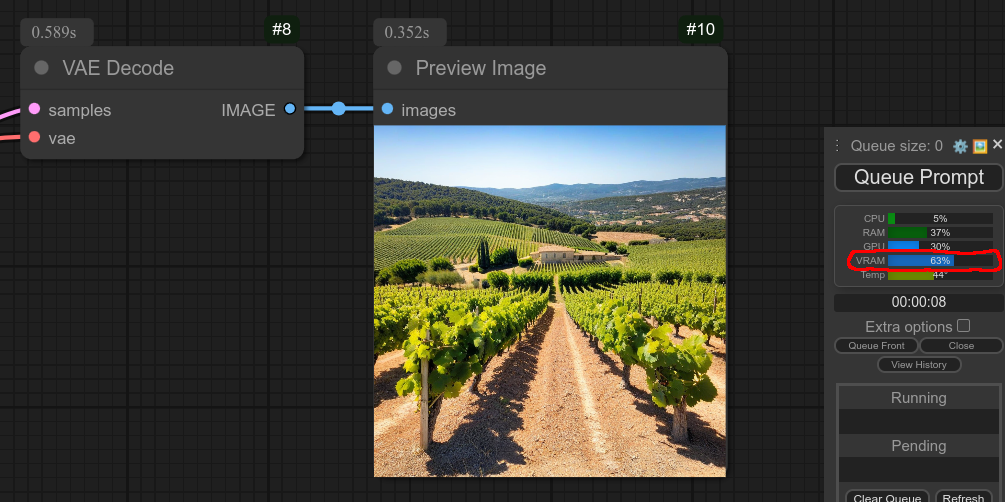
对我而言,ComfyUI启动时会占用180MB的VRAM,而在我使用这个清理节点之后,VRAM占用可以降低到376MB。
我觉得目前并没有一个干净的方式来实现这一点,所以只能用这种“hacky”的方法。
虽然不完美,但总比一直卡在6GB VRAM占用上要好——尤其是当我确定不会再用到这些资源时……
你只需把这个节点接入你的工作流中即可,它可以接收任何输入并原样输出。因此,你可以把它放在工作流中的任意位置。
❗ ComfyUI为了运行得更快会使用缓存(比如不会重复加载检查点),所以请仅在需要时使用这个释放VRAM的节点。
❗ 要使这个节点正常工作,你需要在ComfyUI中启用开发者/API模式。(可以在设置中完成)
此外,该节点会运行一个“空的/虚拟的”工作流来释放VRAM,因此在工作流结束后可能需要几秒钟才能生效。
35 - ⏸️ 暂停。恢复还是停止?
描述:
自动暂停工作流,并在暂停时发出铃声。(播放提供的bell.m4a音频文件)


随后,你可以通过点击节点上的按钮手动恢复或停止工作流。
例如,当我在进行一个非常耗时的超分辨率处理时,我会先检查输入是否合适再继续。有时我也会直接停止工作流,然后用另一个随机种子重新开始。
你可以将任何类型的节点连接到暂停节点上,上面的例子是文本节点,但你也可以发送图像或其他任何内容,因为节点的“输入=输出”。当然,输出必须连接到能够正确处理该格式的组件才行……
36 - ⏸️🔍 暂停。选择输入,挑选一个
描述:
自动暂停工作流,并在暂停时发出铃声。(播放提供的bell.m4a音频文件)
随后,你可以手动选择想要使用的输入,并用它来恢复工作流。
你可以把这个节点连接到任何你想处理的内容上,上面的例子是图像节点。不过,你也可以根据需要选择其他类型的数据,因为节点的“输入=输出”。
37 - 🎲🖼 随机图片
描述:
从一组图片中随机选取一张图片。
38 - ♻🖼 循环(图片)
描述:
对一组图片进行循环处理。
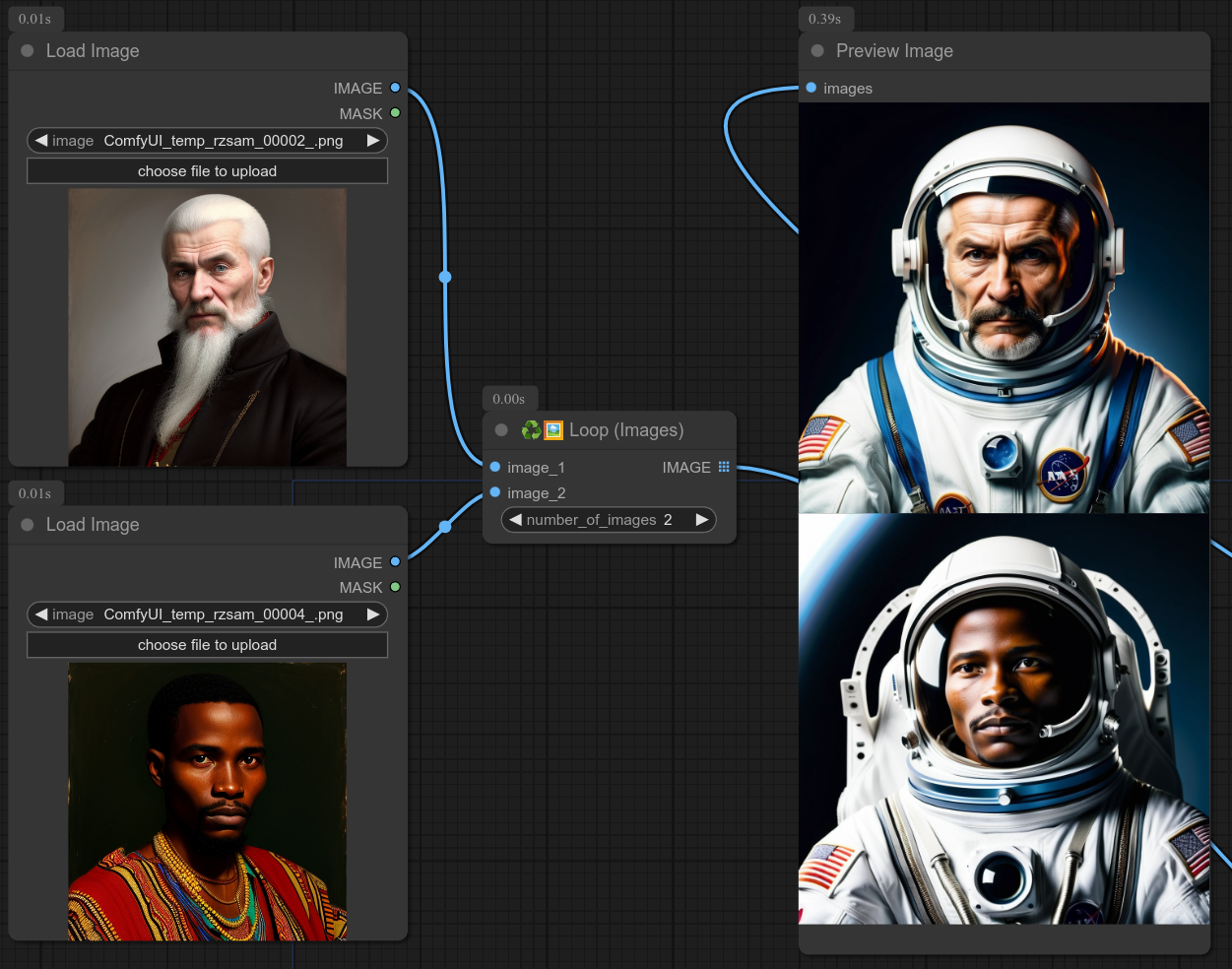
使用示例:如果你有一组图片,希望对每一张都应用相同的处理流程,就可以使用这个节点。
上面的例子展示了循环图片节点如何将这些图片送入一个Ipadapter工作流中。(当然,所有图片都会使用相同的随机种子。)
39 - ♻ 循环(✒🗔🅰️ 高级写文字)
描述:
如果你需要快速循环,但又不想使用复杂的循环节点,可以使用这个结合了高级写文字和循环功能的节点。
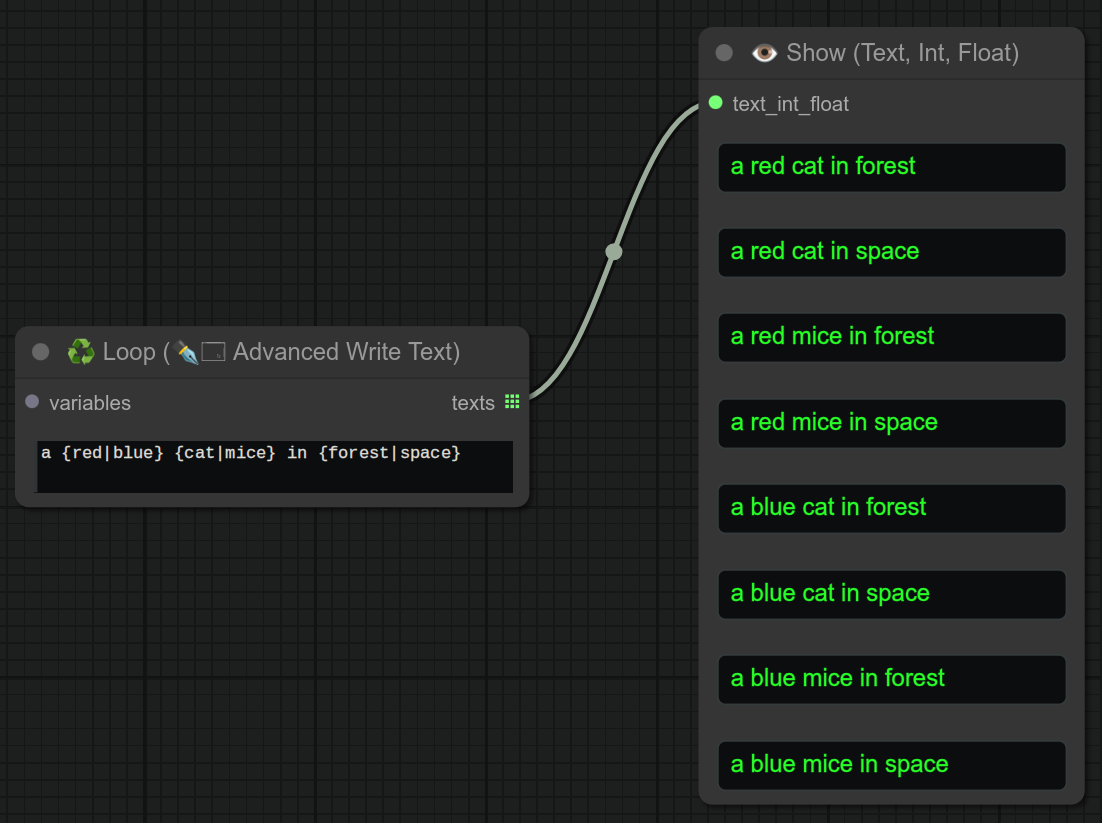
它会采用与高级写文字节点相同的特殊语法 {blue|red},但它会遍历所有可能的组合,而不是随机选择其中一个。
0.40:你还可以在循环中使用变量 <name>。
40 - 🎲 随机(模型+CLIP+VAE)- 即检查点/模型
描述:
简单地从一个加载检查点节点中随机抽取一组三件套。
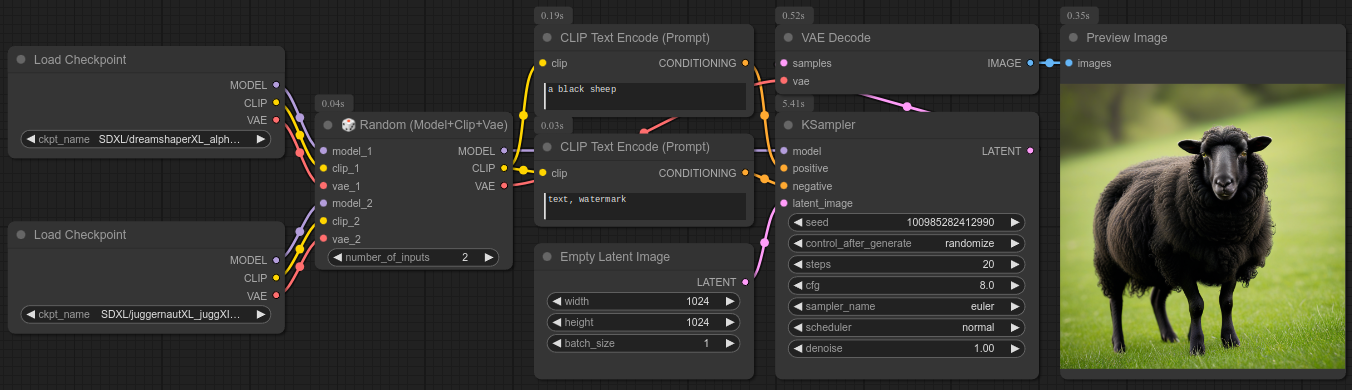
需要注意的是,它使用的是核心的加载检查点节点。这意味着所有的检查点都会被预先加载到内存中。
细节:
- 这种方式会占用更多的VRAM,但切换检查点的速度会更快。
- 它无法告诉你当前加载的是哪个检查点的名称。
在决定使用哪一种方法之前,请先查看第41个节点。
41 - 🎲 随机加载检查点(模型选择器)
描述:
这是另一种随机选择加载检查点节点的方式。
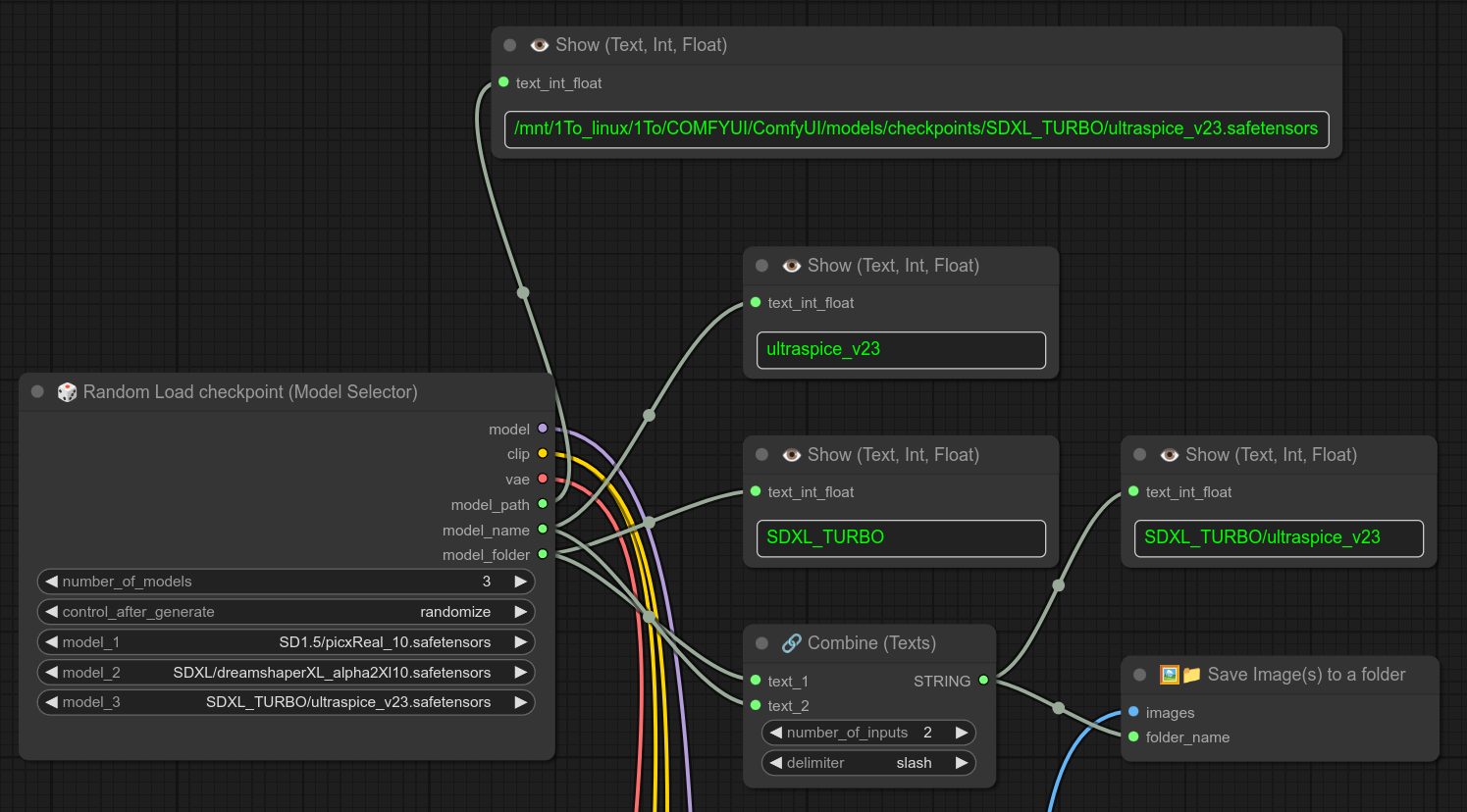
它不会将所有检查点预先加载到内存中,因此切换检查点的速度会稍慢。
不过,你可以利用更多的输出来决定结果的存储位置。(model_folder会返回检查点所属的最后一个文件夹名称。)
我通常会将检查点按照模型类型分别存放在不同的文件夹中,比如 SD1.5、SDXL 等等。因此,这种方式能帮助我快速获取这些信息。
细节:
- 与第40个节点相比,你无法为每个选定的检查点单独配置参数。(例如,针对特定模型设置 CLIP 的最后一层参数,或者使用不同的 VAE 或 CLIP。)也就是说,所有模型都会共享完全相同的工作流。
在决定使用哪一种方法之前,请先查看第40个节点。第53个节点则是这个节点的循环版本。
注意:如果你想只加载一个检查点,但又想提取其所属文件夹的名称(比如将检查点名称作为保存结果的文件夹名称,或者用于 if/else 条件判断),那么可以使用我的第41个节点,只是在里面放入一个检查点即可。(它会随机选择一个,所以实际上总是同一个检查点。)
42 - ♻ 循环(模型+CLIP+VAE)- 即检查点/模型
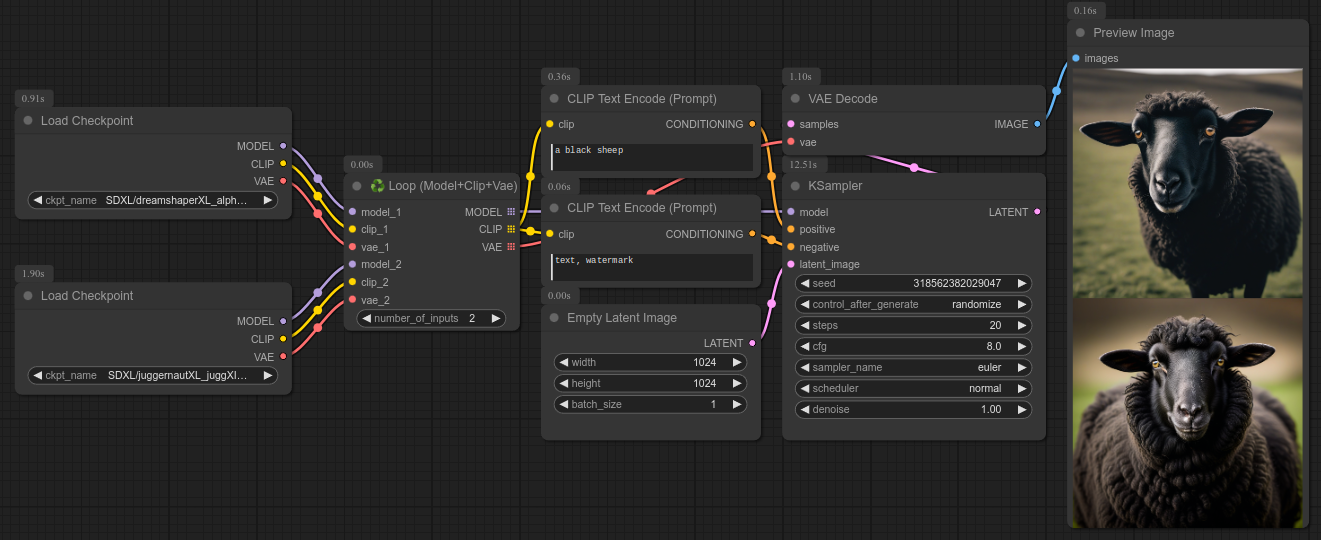
描述:
对多个检查点节点中的所有三件套进行循环处理。
43 - 📥🖼📂 从输出文件夹加载图片
描述:
快速从输出文件夹中的某个子文件夹内选择所有图片。(非递归方式。)
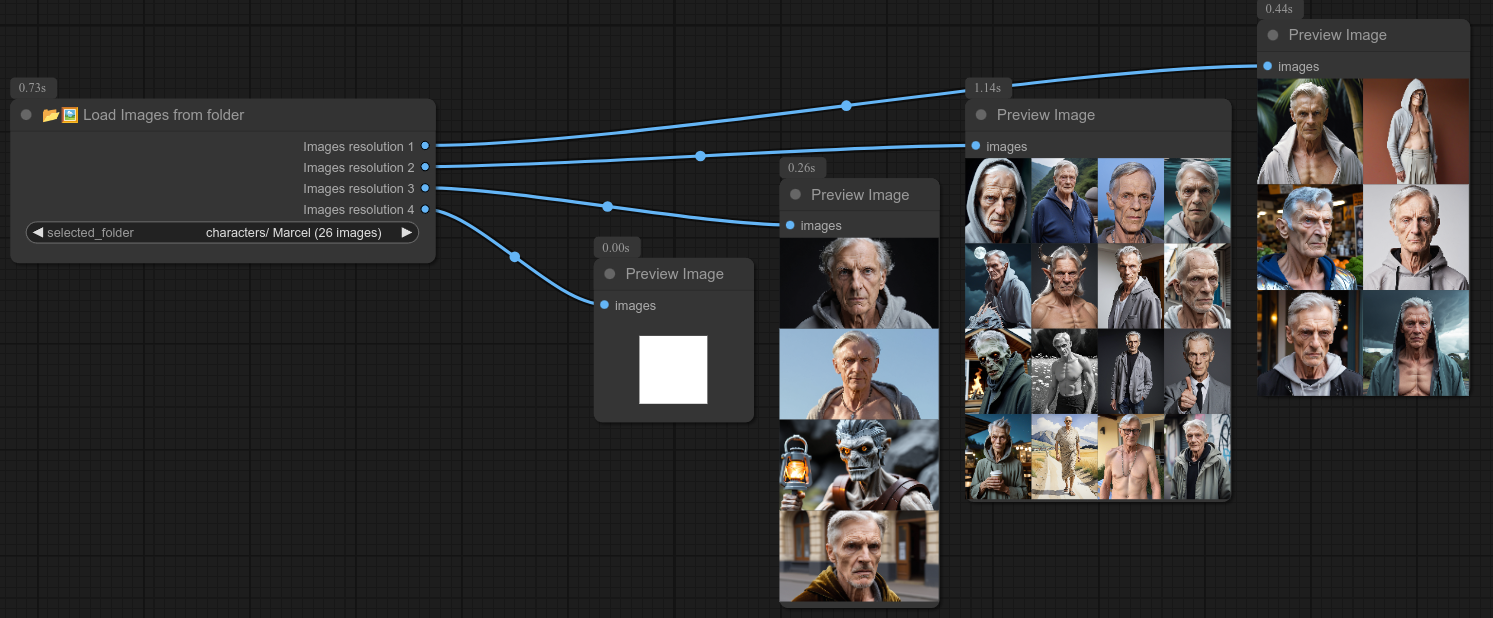
如你所见,截图中图片是按照分辨率进行分类的。
目前还无法动态调整输出数量,所以我直接设置为4个。
节点会根据图片的分辨率来分离它们,因此每个文件夹最多可以有4种不同的分辨率。(如果超过4种,可能就需要新建一个文件夹了……)
为了避免在文件夹中分辨率少于4种时出现错误或崩溃,节点会输出白色张量(即白色方块图像)。
所以这个节点现在还比较“hacky”,不过它确实能让我在一秒钟内选出不同的角色。
如果你想知道我是如何为特定角色保存图片的,以下是部分工作流示例(注意我在Linux系统上使用/作为路径分隔符):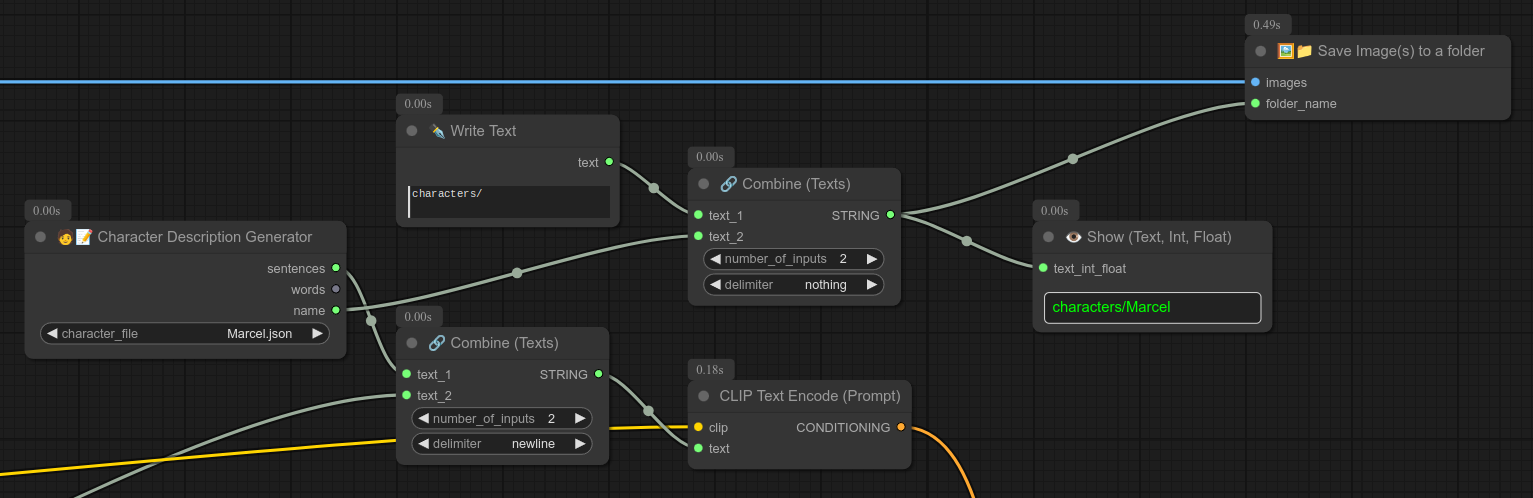
在这个例子中,我先输入字符串“character/”,再与“nothing”拼接;当然也可以先输入“character”,再加一个斜杠“/”。(我只是习惯在文件夹名后面加上斜杠……)
如果你对这种逻辑感到满意,可以选中这些节点,右键点击并选择“转换为组节点”,这样就能创建属于自己的自定义“保存角色节点”: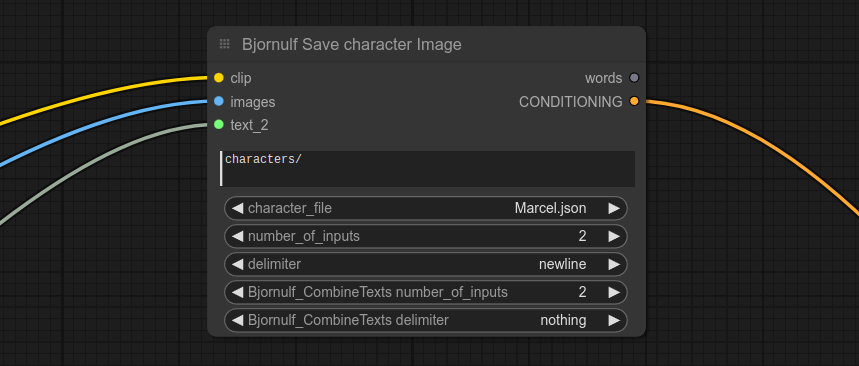
这里还有一个类似的例子,但去掉了保存文件夹的节点: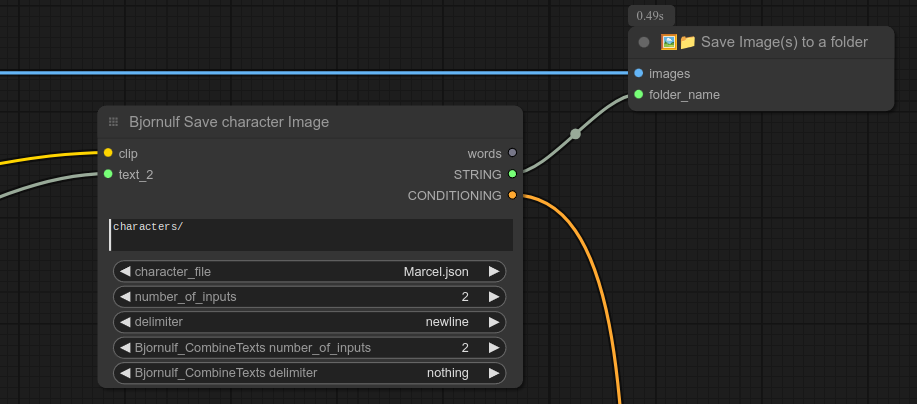
⚠️ 如果你真的想把所有图片整合到一个流程中,可以使用我的第47号节点“合并图片”将它们全部放在一起。
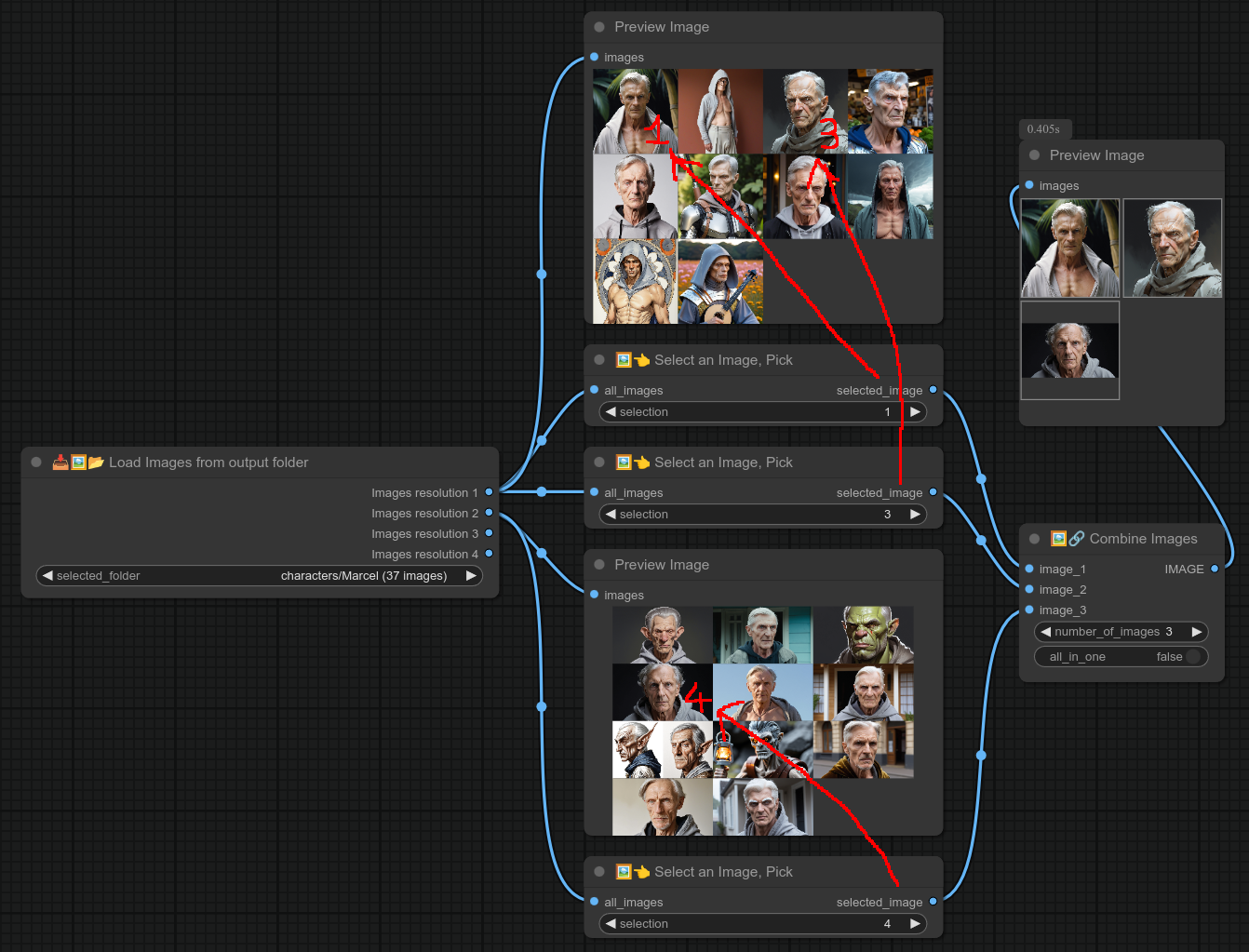
44 - 🖼👈 选择一张图片,挑选
描述:
从一组图片中选择一张。
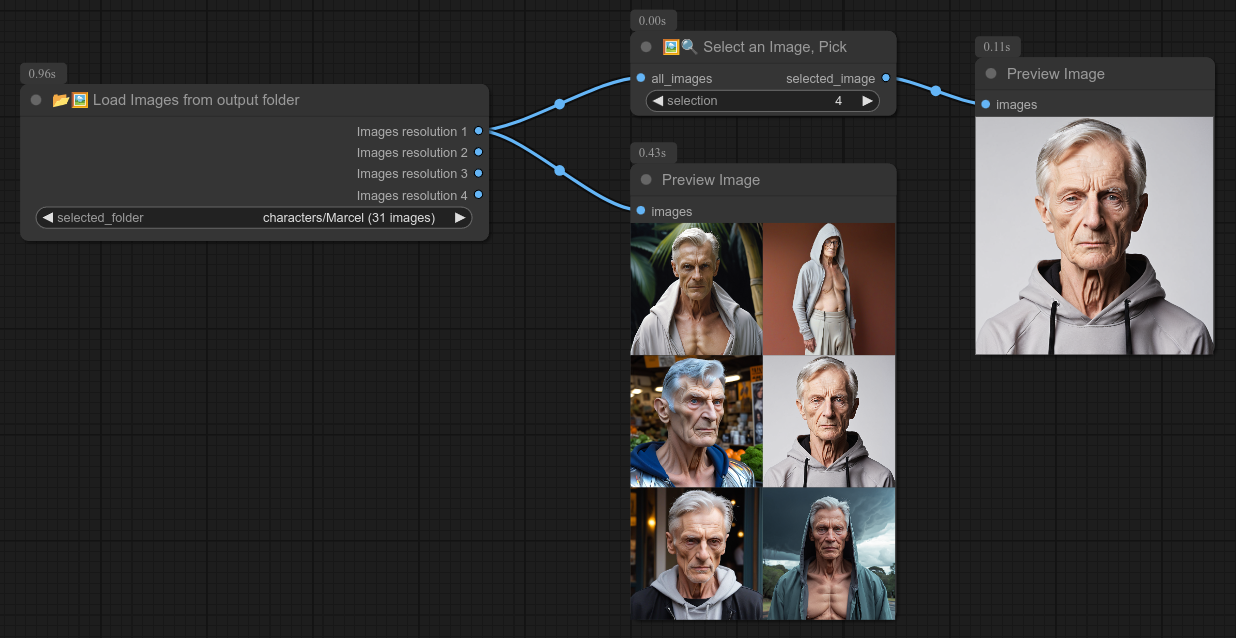
此节点与我的“从文件夹加载图片”和“预览图片”节点配合使用非常有用。
你当然也可以像上面的截图那样制作一个组节点: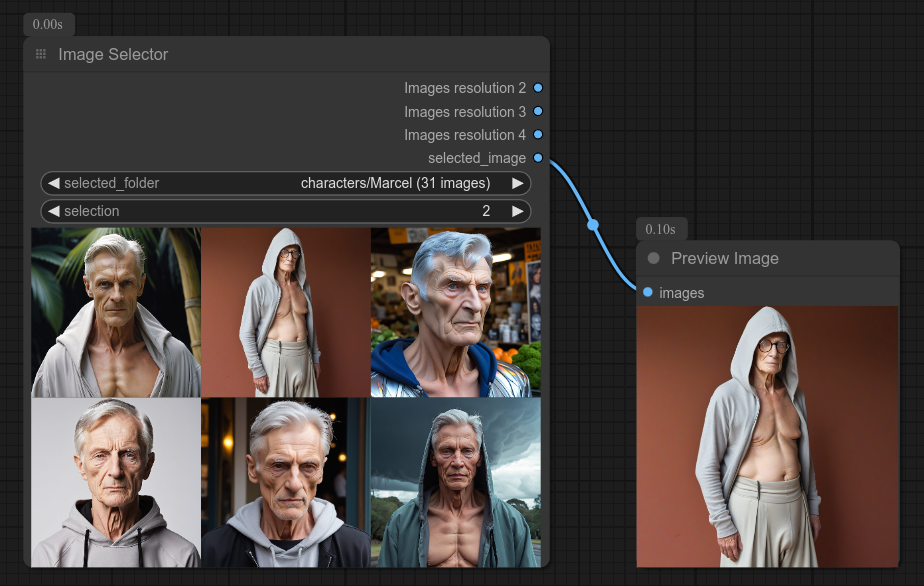
45 - 🔀 如果-否则(输入 / 比较值)
描述:
复杂的if/else逻辑节点系统。
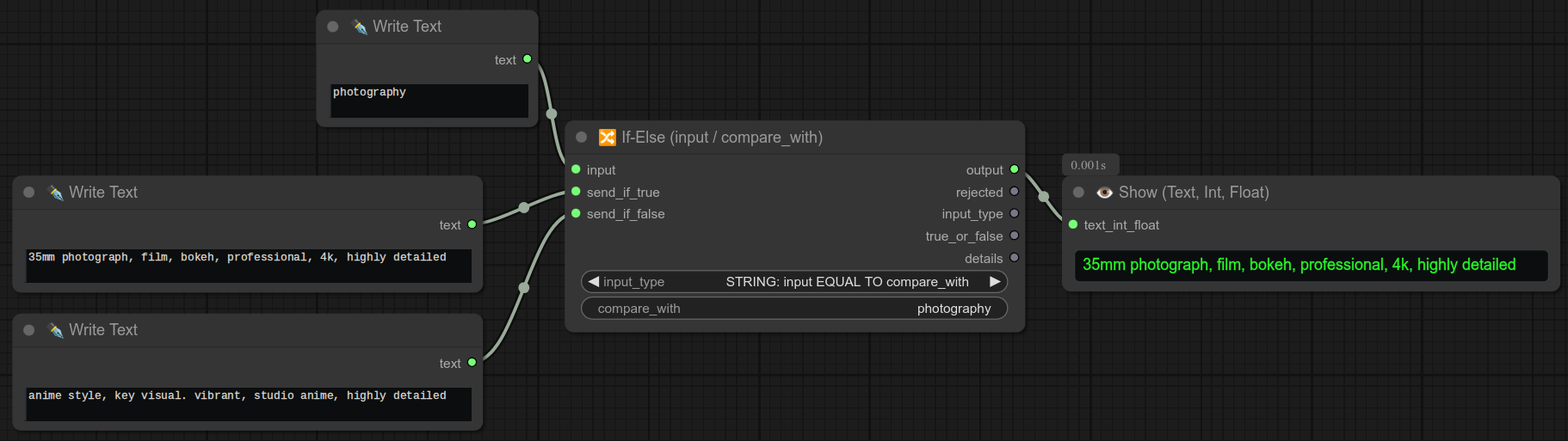
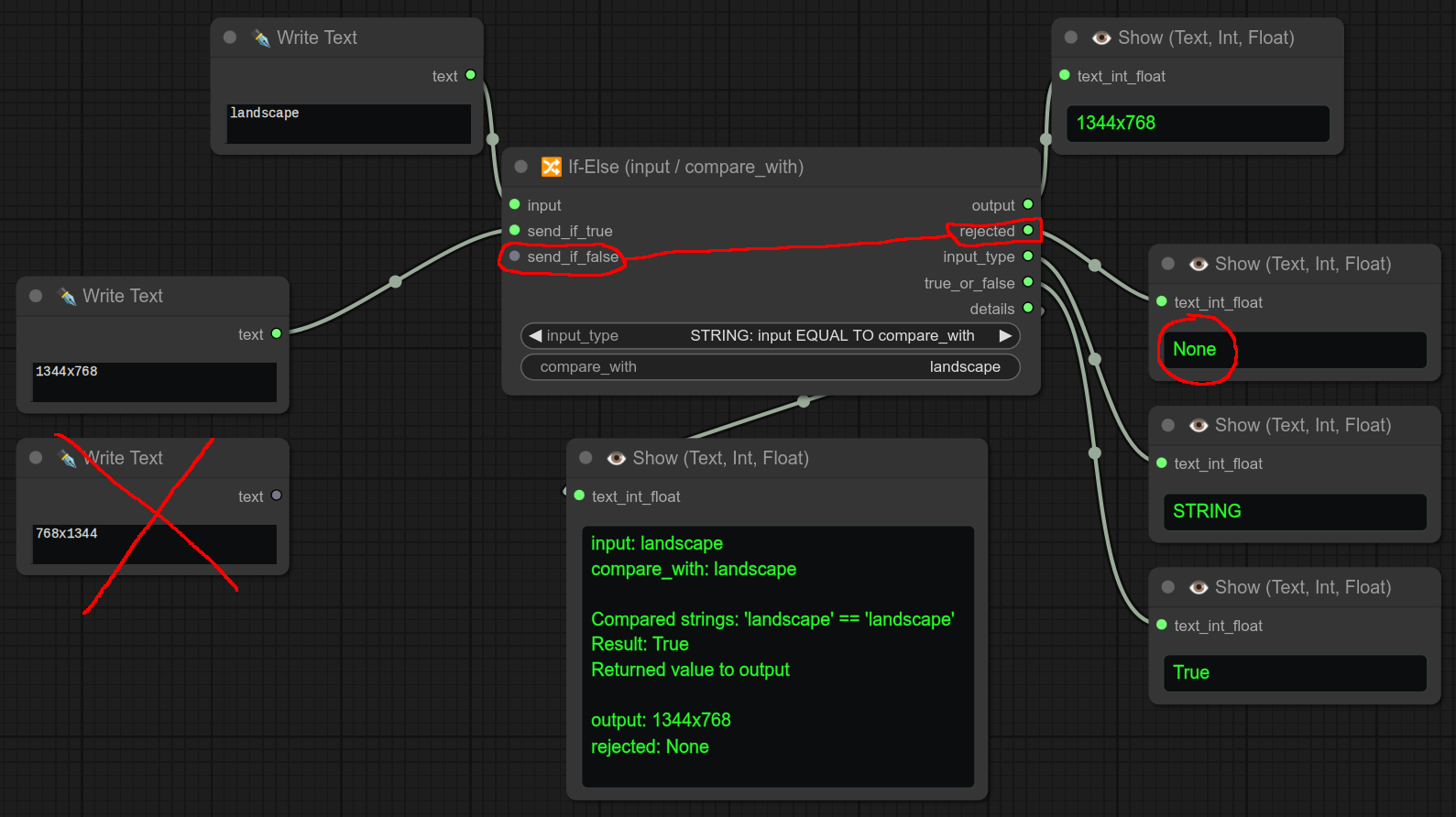
如果提供的输入等于小部件中设定的比较值,则会转发send_if_true;否则会转发send_if_false。(如果没有连接send_if_false,则返回None。)
你可以转发任何内容,下面是一个根据是否为SDXL模型来转发不同尺寸潜在空间的例子:
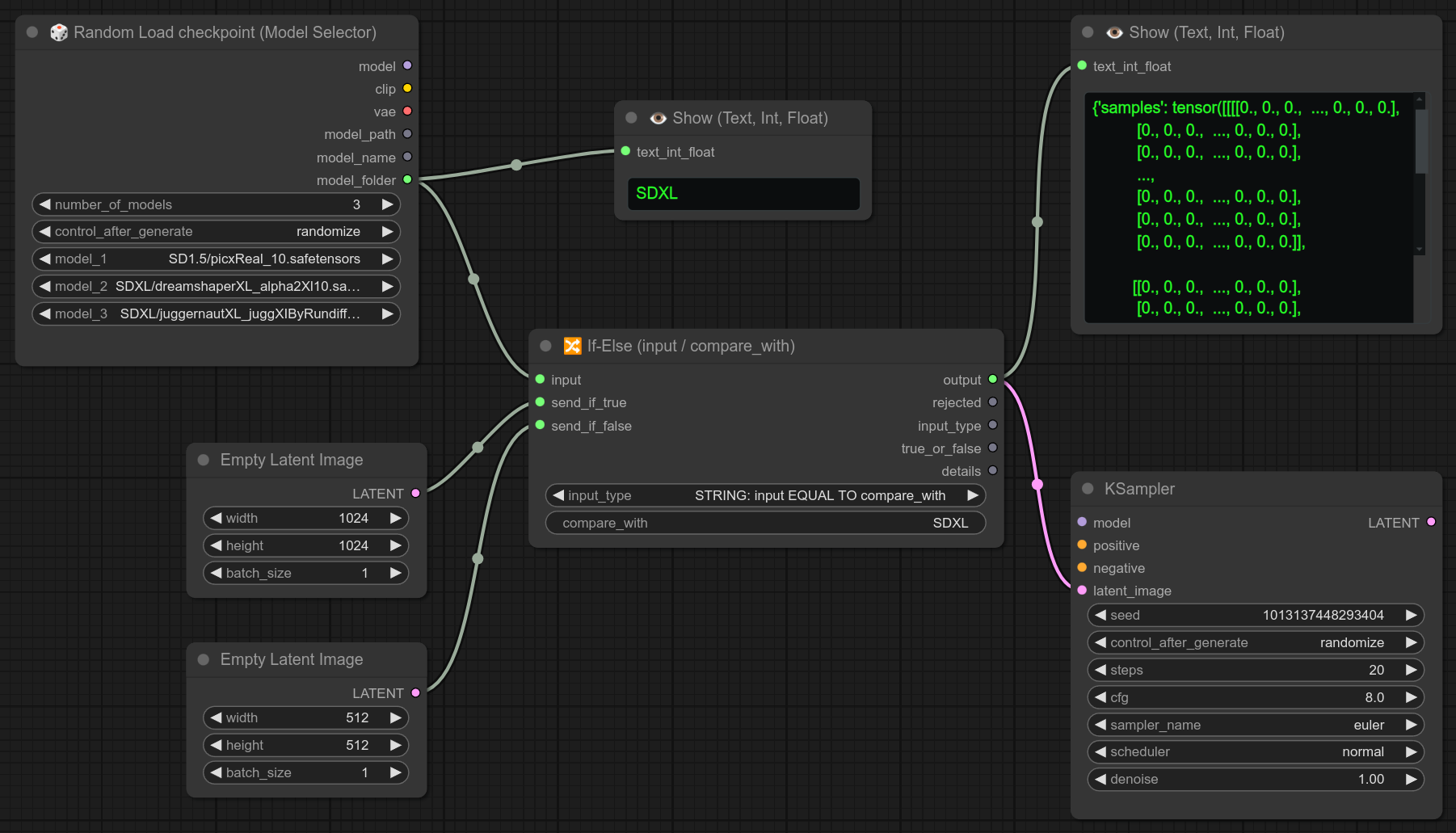
这里是该节点的一个完整示例,所有输出都通过“显示文本”节点展示出来:
send_if_false是可选的,如果不连接,将会被替换为None。
If-Else节点是可以串联使用的,只需将output连接到send_if_false即可。
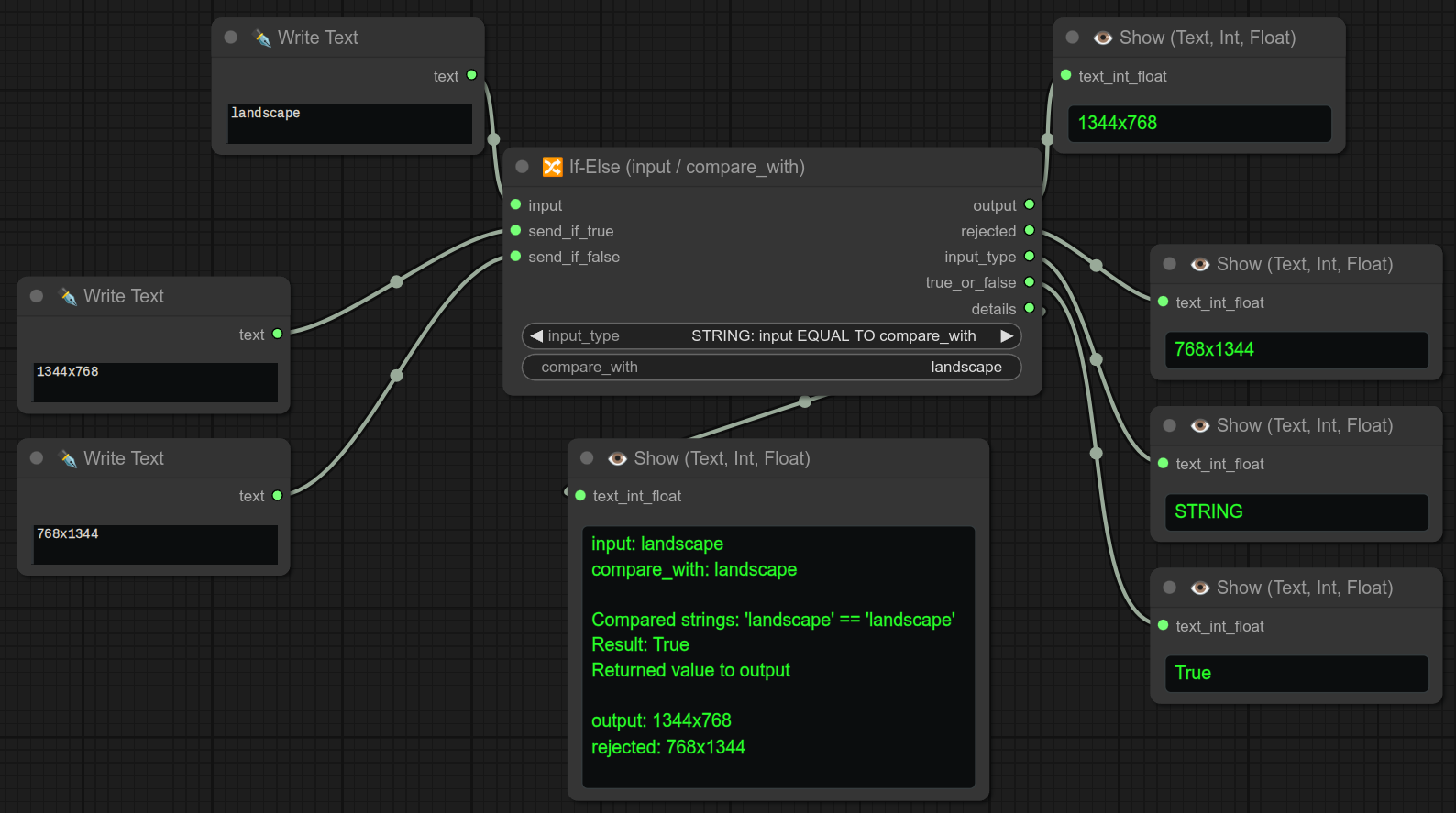
⚠️ 始终只需用compare_with测试input,并将期望的值连接到send_if_true。⚠️
这里有一个简单的例子,使用两个If-Else节点来选择三种不同的分辨率:
❗ 注意,同一个写文本节点同时连接到了两个If-Else节点的输入端:
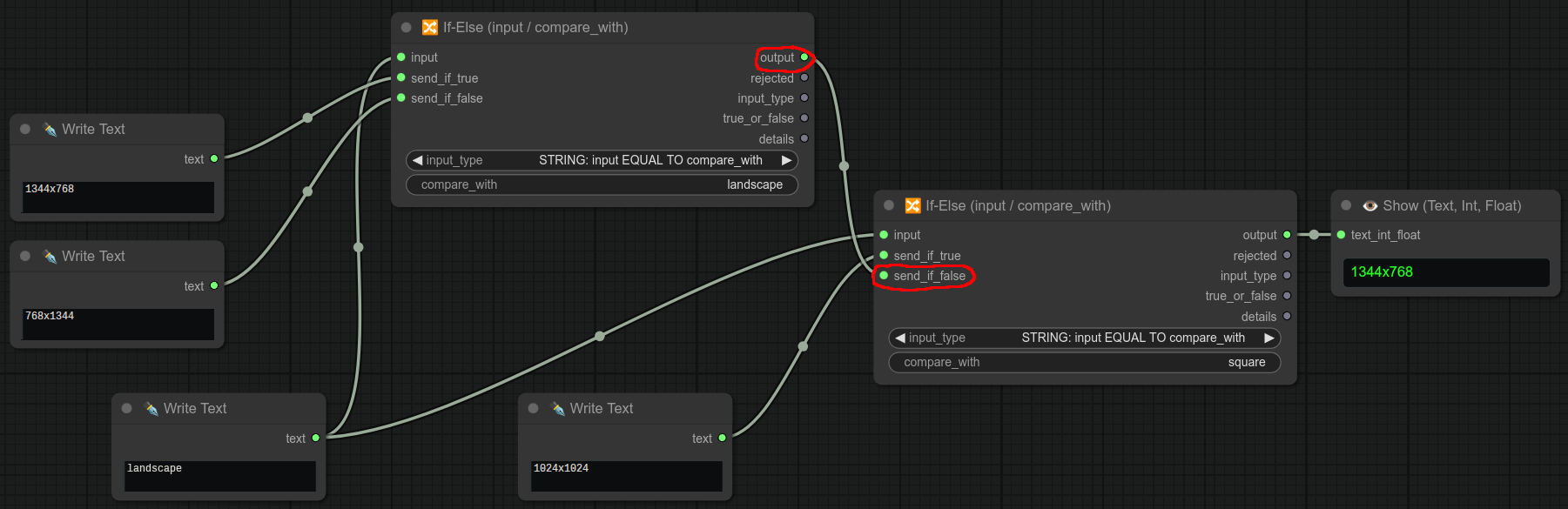
再来一个类似的例子,这次我们使用我的“循环写文本”节点一次性显示所有三种类型:
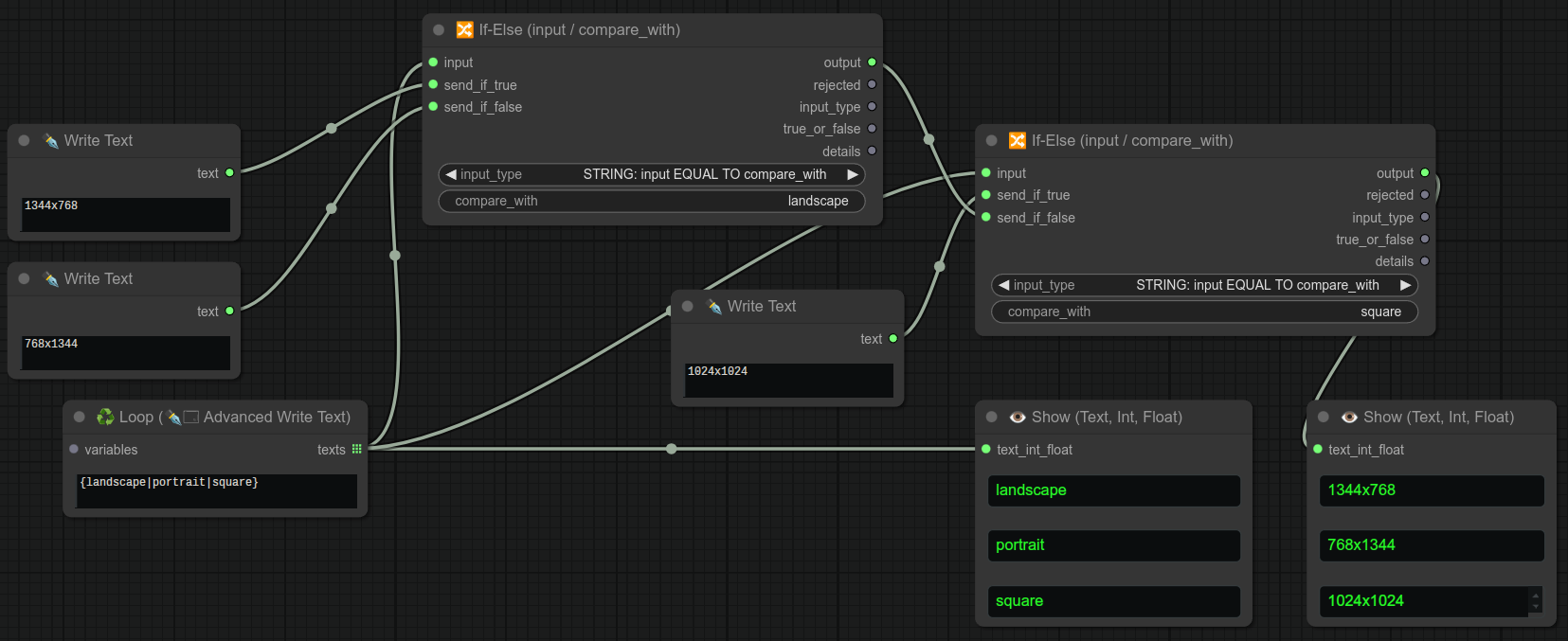
如果你已经理解了前面的例子,那么这里有一个完整的示例,它会生成三张图片:横版、竖版和正方形:
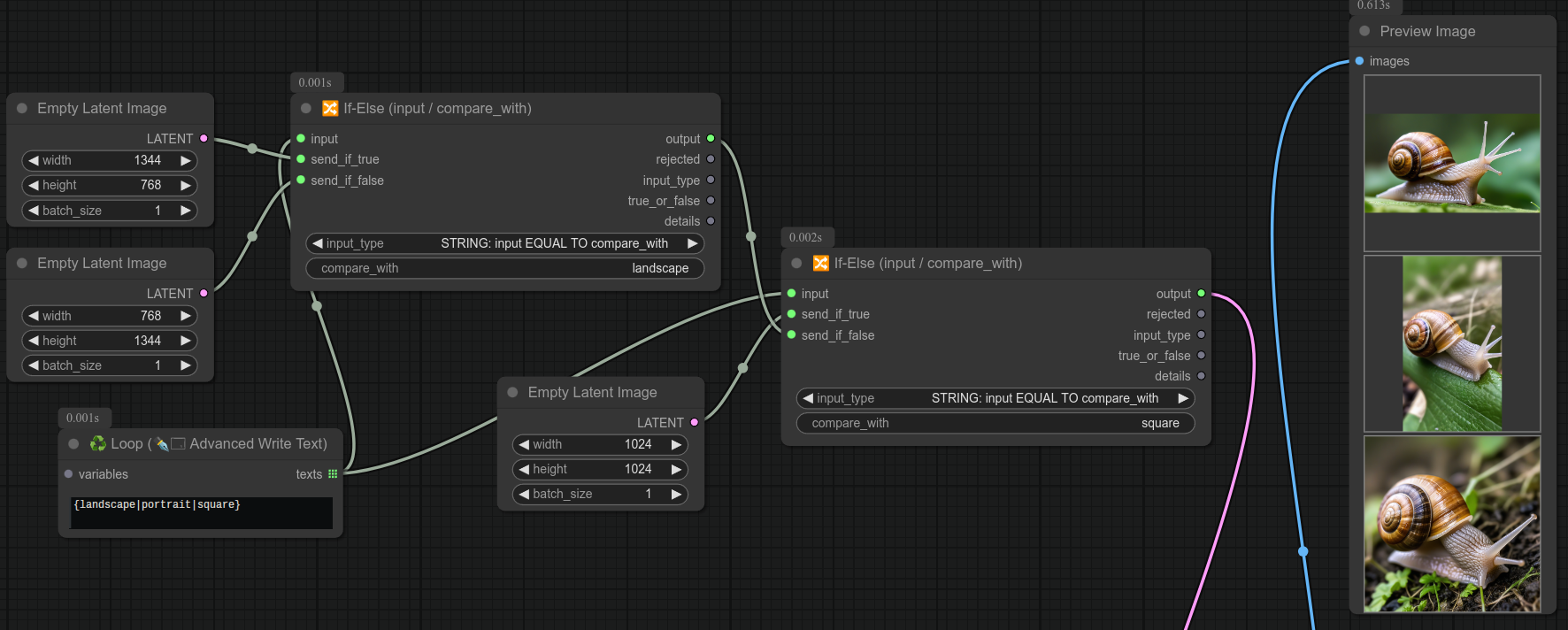
为了简化起见,工作流被隐藏了,但实际上非常简单——只需将潜在空间连接到Ksampler即可,没有特别复杂的地方。
你还可以将高级的循环写文本节点与我的“保存文件夹”节点相连,从而将横版/竖版/正方形的图片分别保存到不同的文件夹中,不过这就要看你自己的需求了……
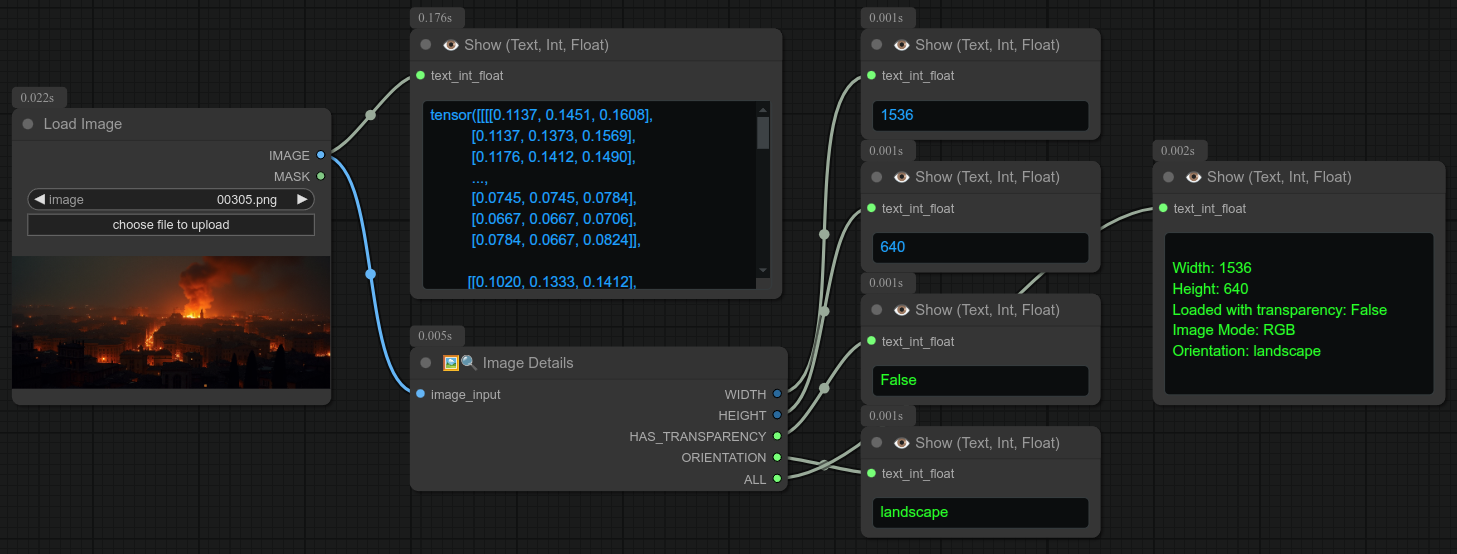
46 - 🖼🔍 图片详情
描述:
显示图片的详细信息。(宽度、高度、是否透明、方向、类型)RGBA被视为具有透明度,而RGB则不具有。orientation可以是“landscape”(横版)、“portrait”(竖版)或“square”(正方形)。
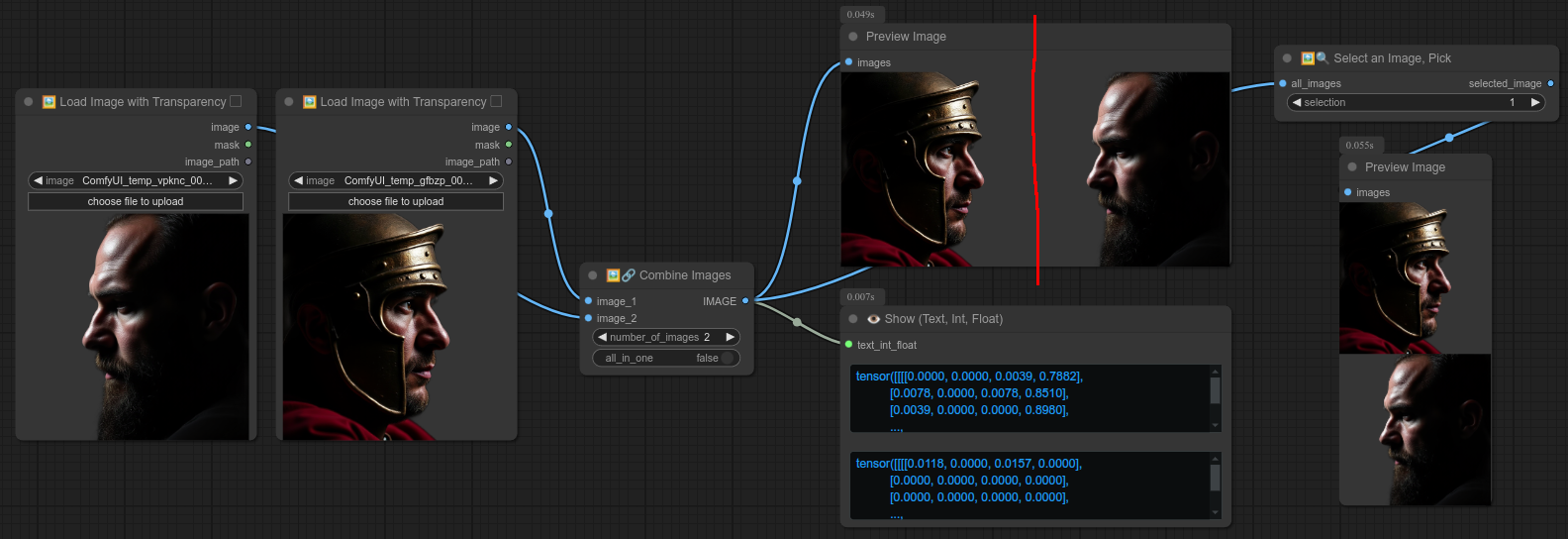
47 - 🖼🔗 合并图片
描述:
合并多张图片(单张图片或图片列表)。
如果你想将多张图片合并成一张,请查看第60或61号节点。
“合并图片”有两种逻辑模式。启用“all_in_one”后,所有图片会被合并成一个张量。
否则,图片会逐个发送。(请参阅下方示例):
这是一个禁用“all_in_one”选项的示例(注意这里有两张图片,它们并不是并排显示,而是被组合成了一个列表):
但例如,如果你想使用我的“选择一张图片,挑选”节点,就必须启用“all_in_one”,并且所有图片必须具有相同的分辨率。
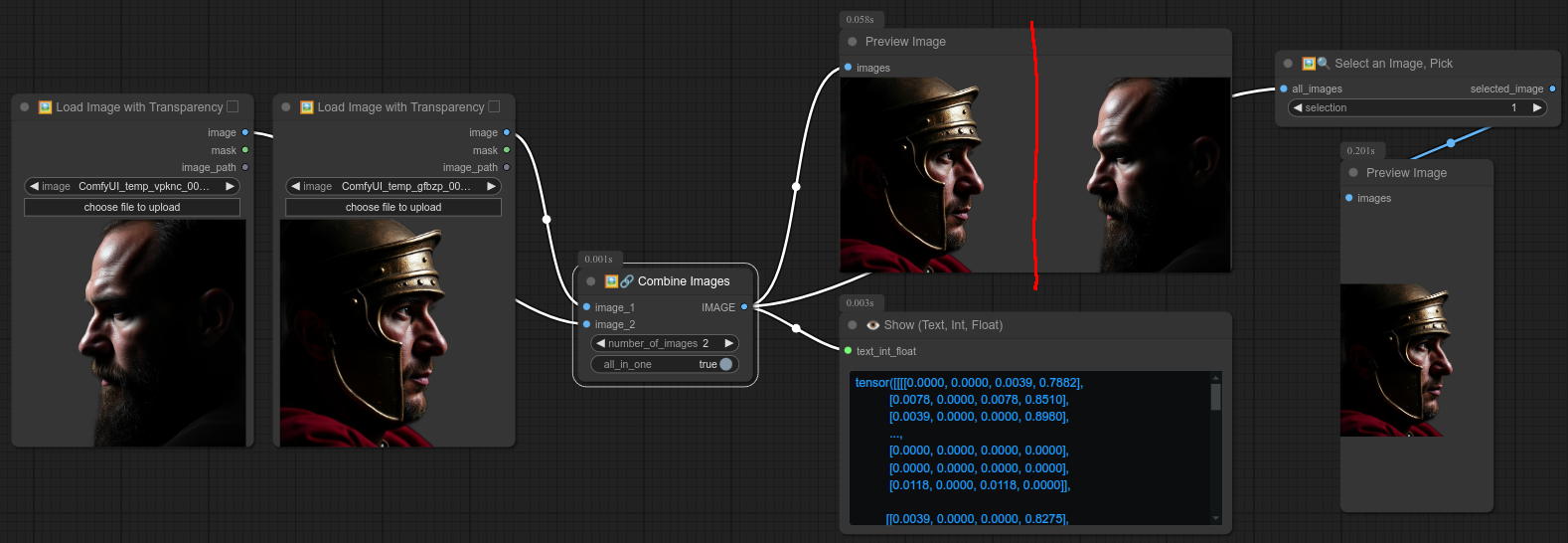
你会发现,在使用“all_in_one”模式时,结合“预览图片”节点并不会产生可见的变化。(这就是为什么我添加了“显示文本”节点——请注意,“显示文本”会让图像呈现蓝色,因为它是张量形式的图像。)
实际上,使用“合并图片”节点时,你也可以一次发送多张图片,它们都会被合并在一起。
以下是一个结合“从文件夹加载图片”节点、“图片详情”节点和“合并图片”节点的示例:(当然,在这种情况下不能启用“all_in_one”,因为图片的分辨率各不相同):
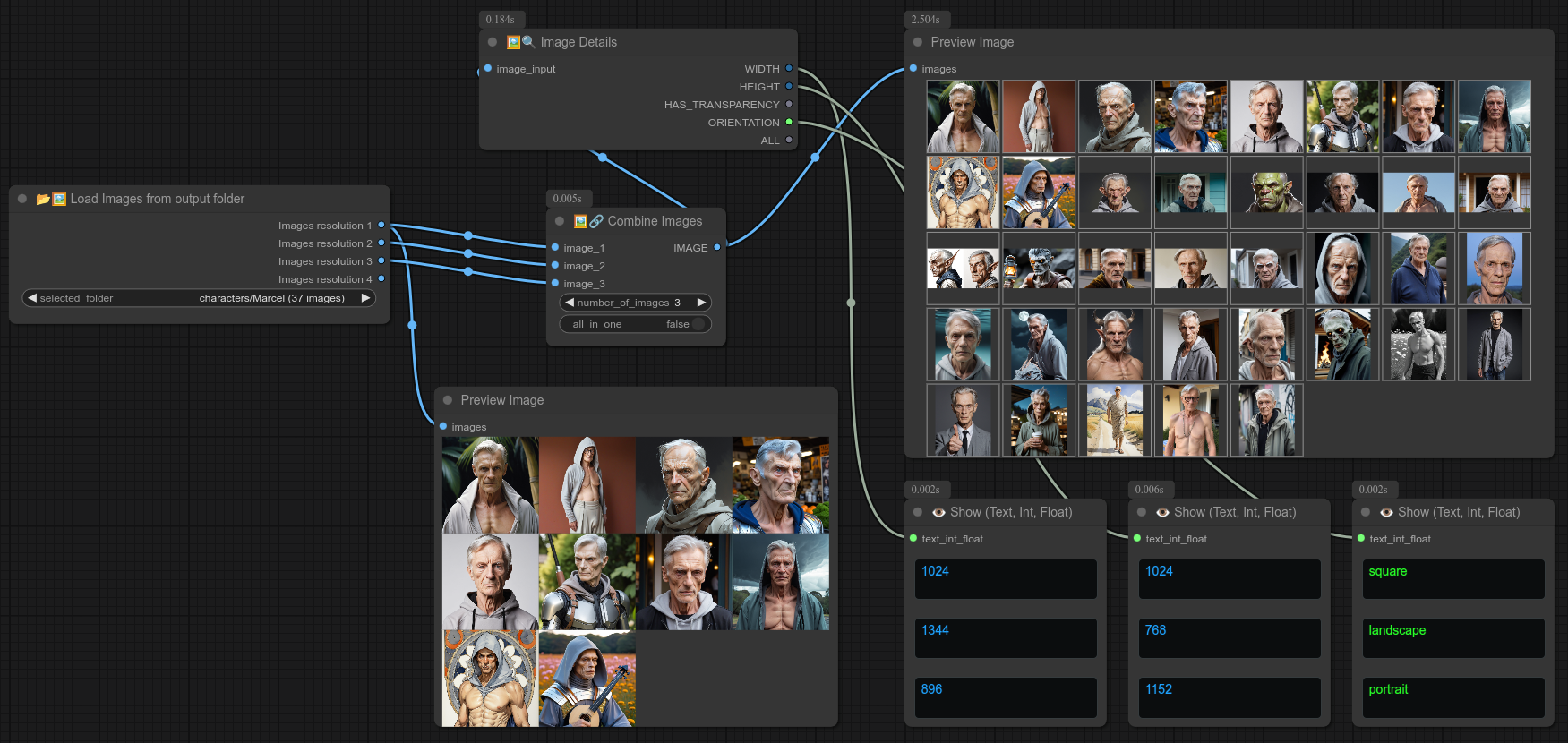
这里还有一个更简单的例子,从文件夹中选取几张图片并将其合并起来,以供后续处理使用:
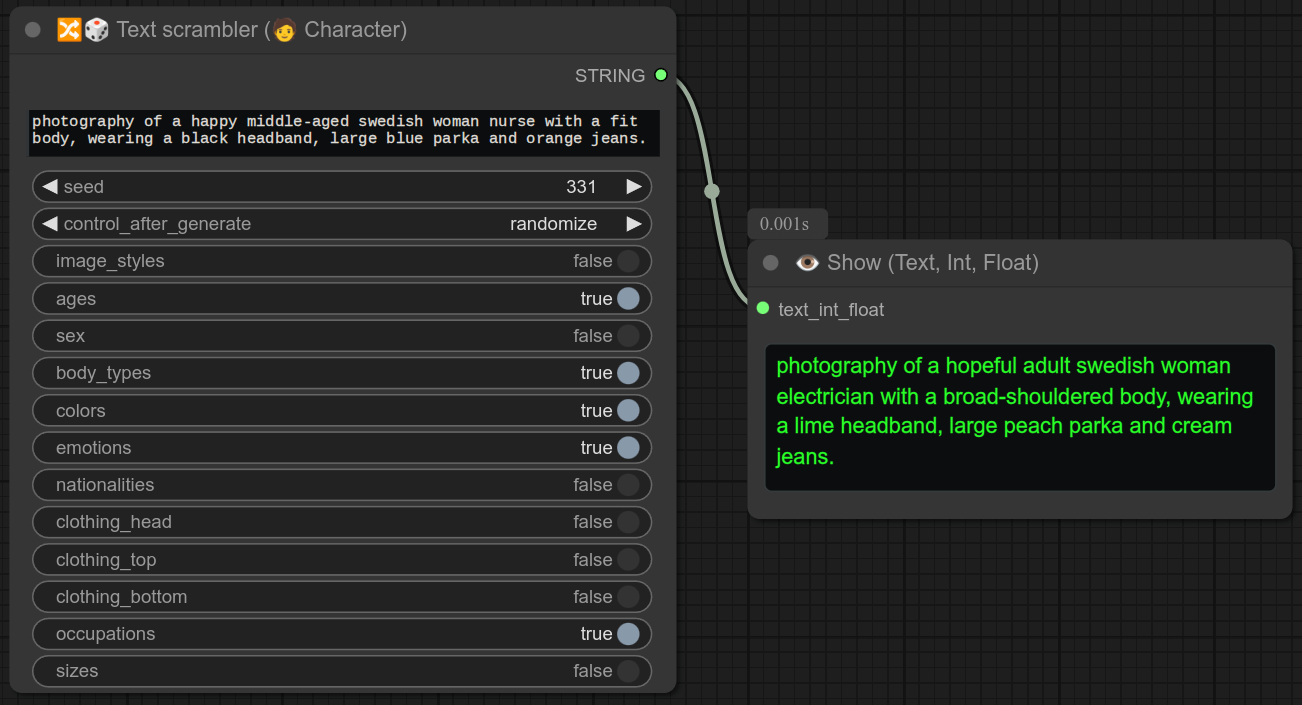
48 - 🔀🎲 文本乱序器(🧑 字符)
描述:
接收文本作为输入,并使用ComfyUI自定义节点文件夹中的scrambler/character_scrambler.json文件对文本进行随机打乱。
49 - 📹👁 视频预览
描述:
此节点接收视频路径作为输入,并播放该视频。
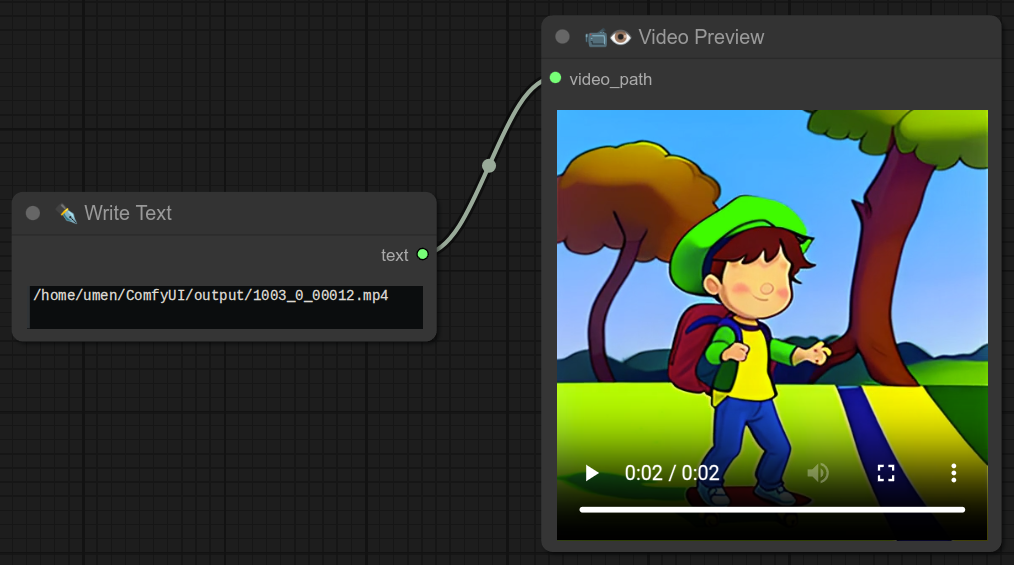
50 - 🖼➜📹 图片转视频路径(临时视频)
描述:
此节点会将一组图片转换为一个临时的视频文件。
❗ 更新0.50:现在可以向视频添加音频。(audio_path 或 audio TYPE)
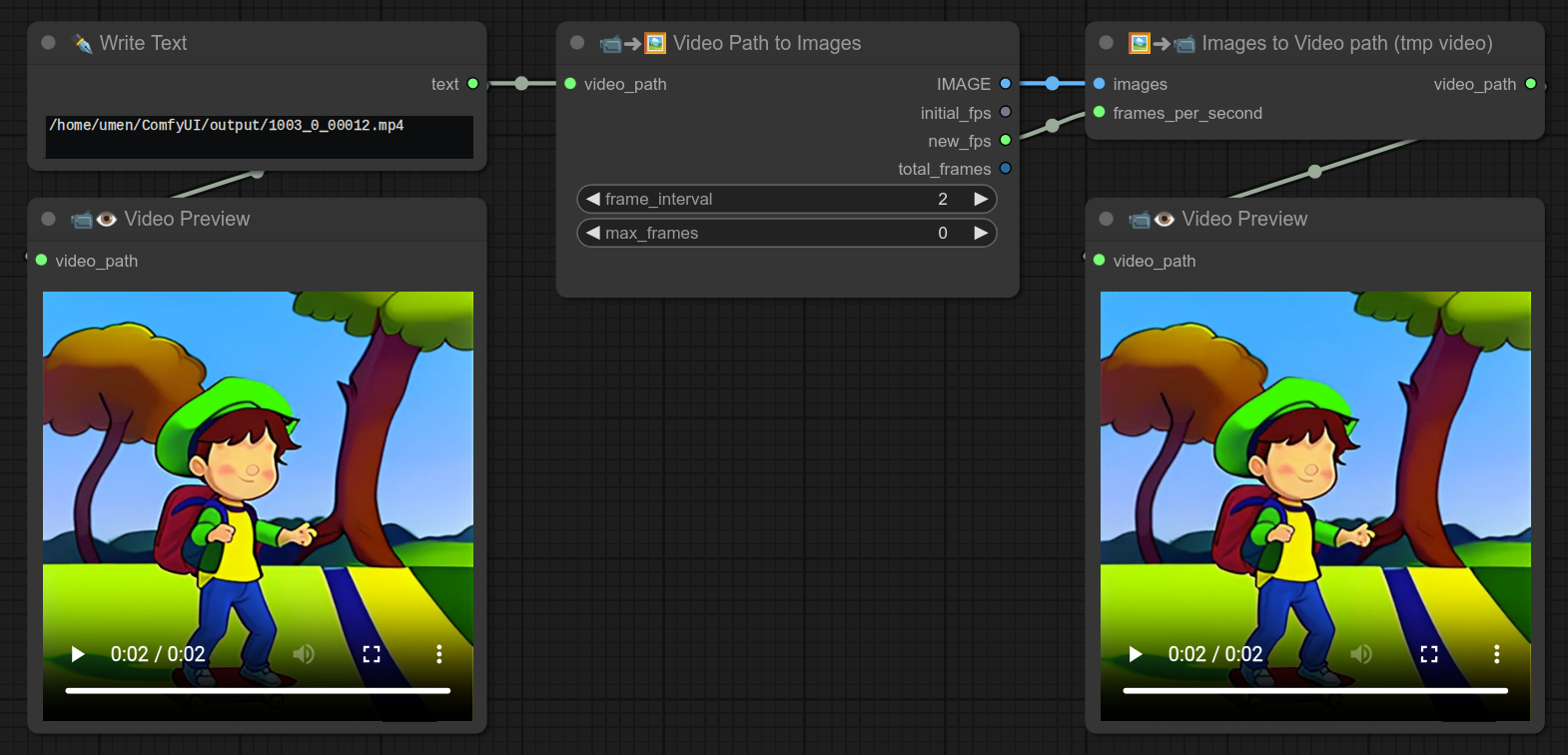
51 - 📹➜🖼 视频路径转图片
描述:
此节点会将视频路径作为输入,转换为一组图片。
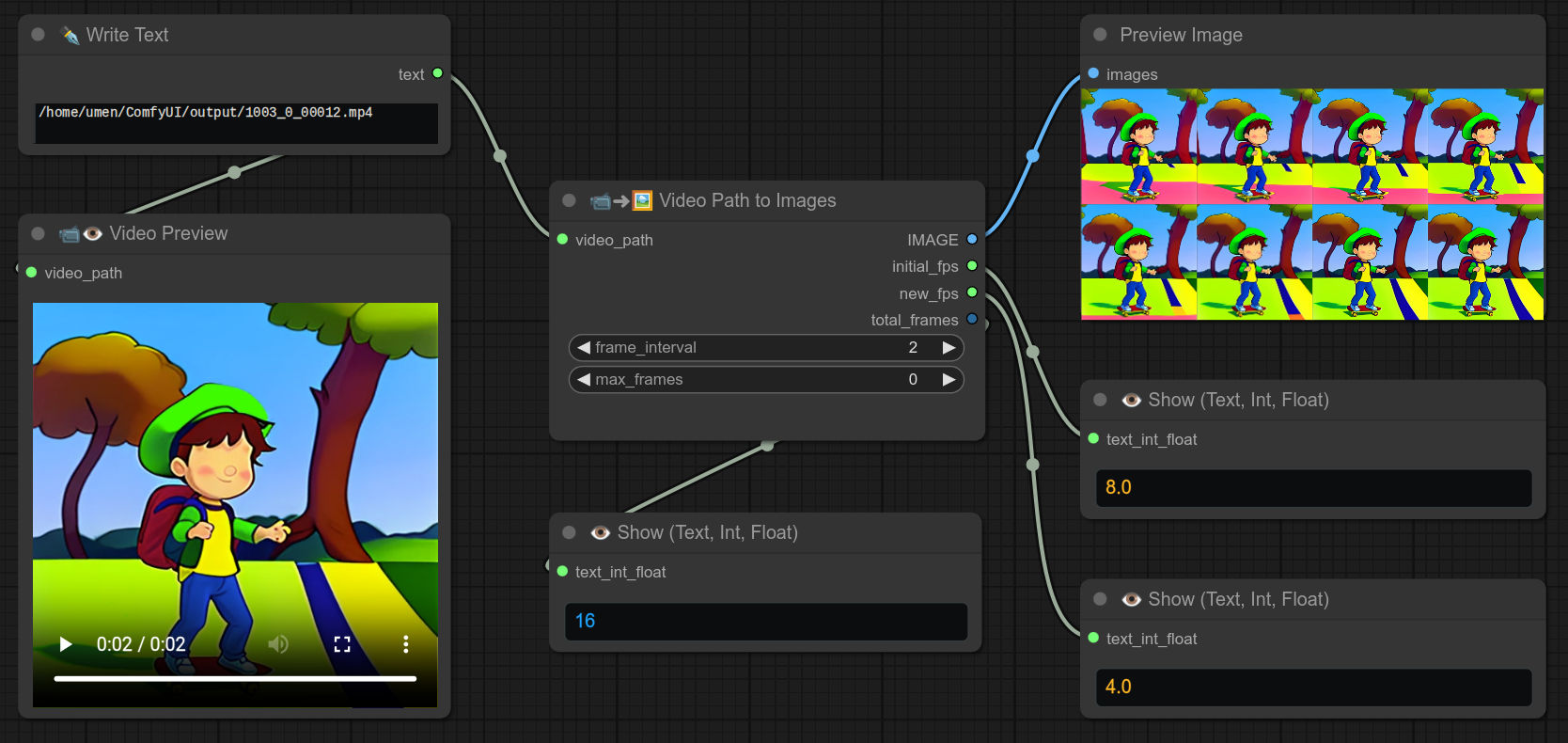
在上面的例子中,我还通过将frame_interval设置为2来只取一半的帧。
需要注意的是,原本有16帧,但在右上角的预览中只能看到8张图片。
52 - 🔊📹 音频视频同步
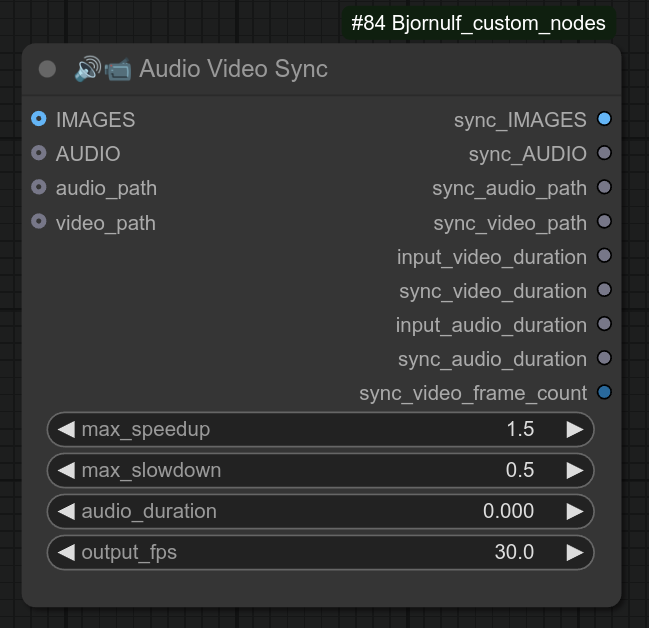
描述:
这个节点是一个过度设计的节点,旨在将音频文件的时长与视频文件的时长相匹配并同步。
❗ 视频理想情况下应为循环播放;如果需要,可以查看我的乒乓视频节点。
此次同步的主要目标是实现视频结尾与开头之间的平滑过渡(同一帧)。
随后,您可以串联多个视频,使它们之间实现流畅切换。
具体来说,此节点会执行以下操作:
- 如果视频稍长:在音频文件中添加静音部分。
- 如果视频过长:将视频速度降低至原速的0.5倍,并在音频中添加静音。(现已可编辑)
- 如果音频稍长:将视频速度提高至原速的1.5倍。(现已可编辑)
- 如果视频过长:将视频速度提高至原速的1.5倍,并在音频中添加静音。
它非常适合与MuseTalk等工具配合使用 https://github.com/chaojie/ComfyUI-MuseTalk。
以下是“音频视频同步”节点的一个示例,请注意,该节点还可以方便地获取视频的帧率,并将其传递给其他节点。(代码有点乱……凑合着用吧。😎 如果你不明白也没关系,可以直接测试一下。):
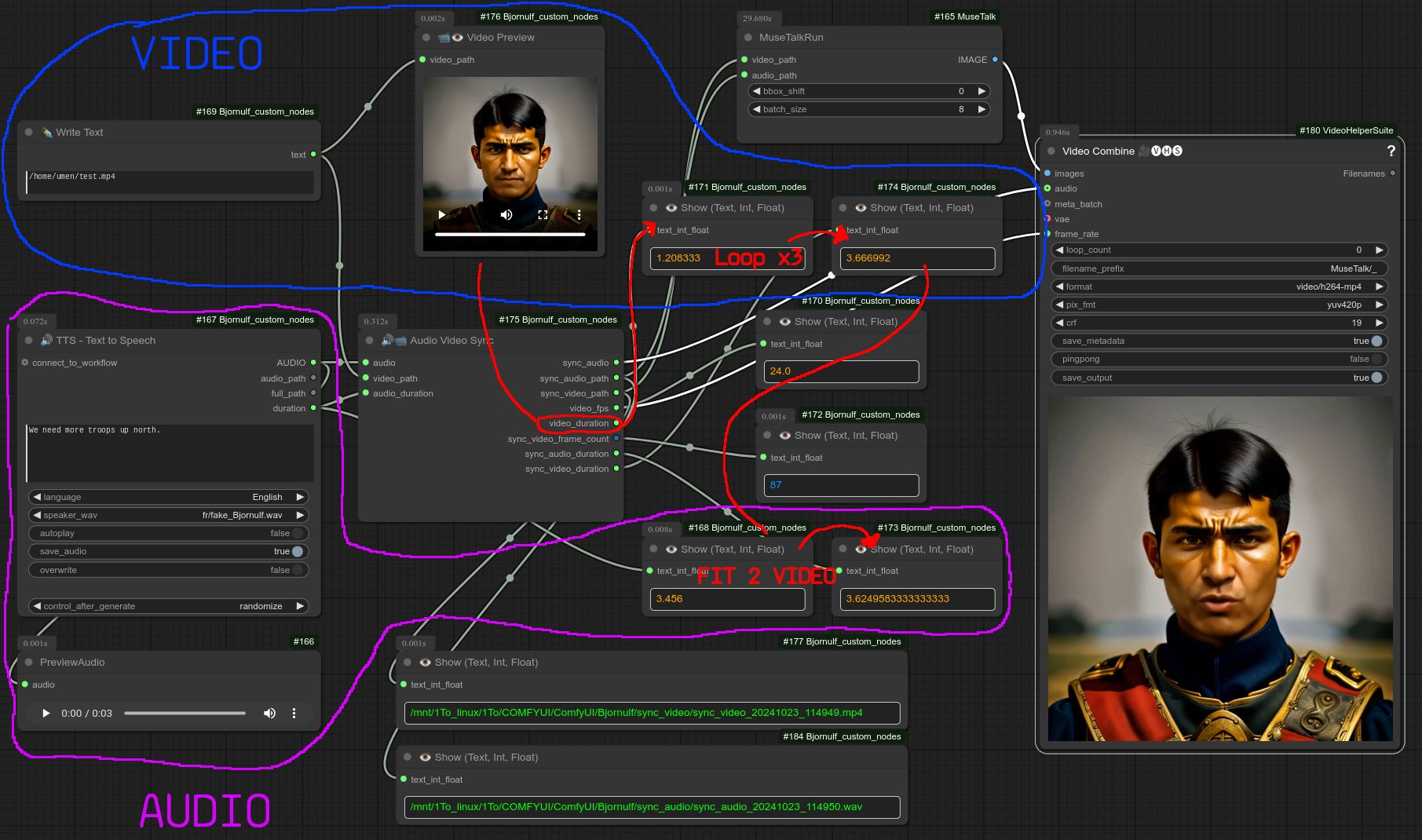
❗ 更新 0.50:audio_duration 现在是可选参数,如果不连接,将自动从音频文件中读取。
❗ 更新 0.50:现在既可以输入视频的图像列表,也可以直接提供视频路径;音频同样支持 AUDIO 或 audio_path 输入方式。
新版本 0.50 的布局,逻辑保持不变:
53 - ♻ 循环加载检查点(模型选择器)
描述:
这是节点41的循环版本。(详情请参考节点41)
它会依次循环遍历所有选定的检查点。
❗ 与节点41的最大区别在于,检查点会被预先加载到内存中,因此可以更快地一次性运行所有检查点。
这是一种快速测试多个检查点的好方法。
54 - ♻ 循环LoRA选择器
描述:
循环遍历所有选定的LoRA。
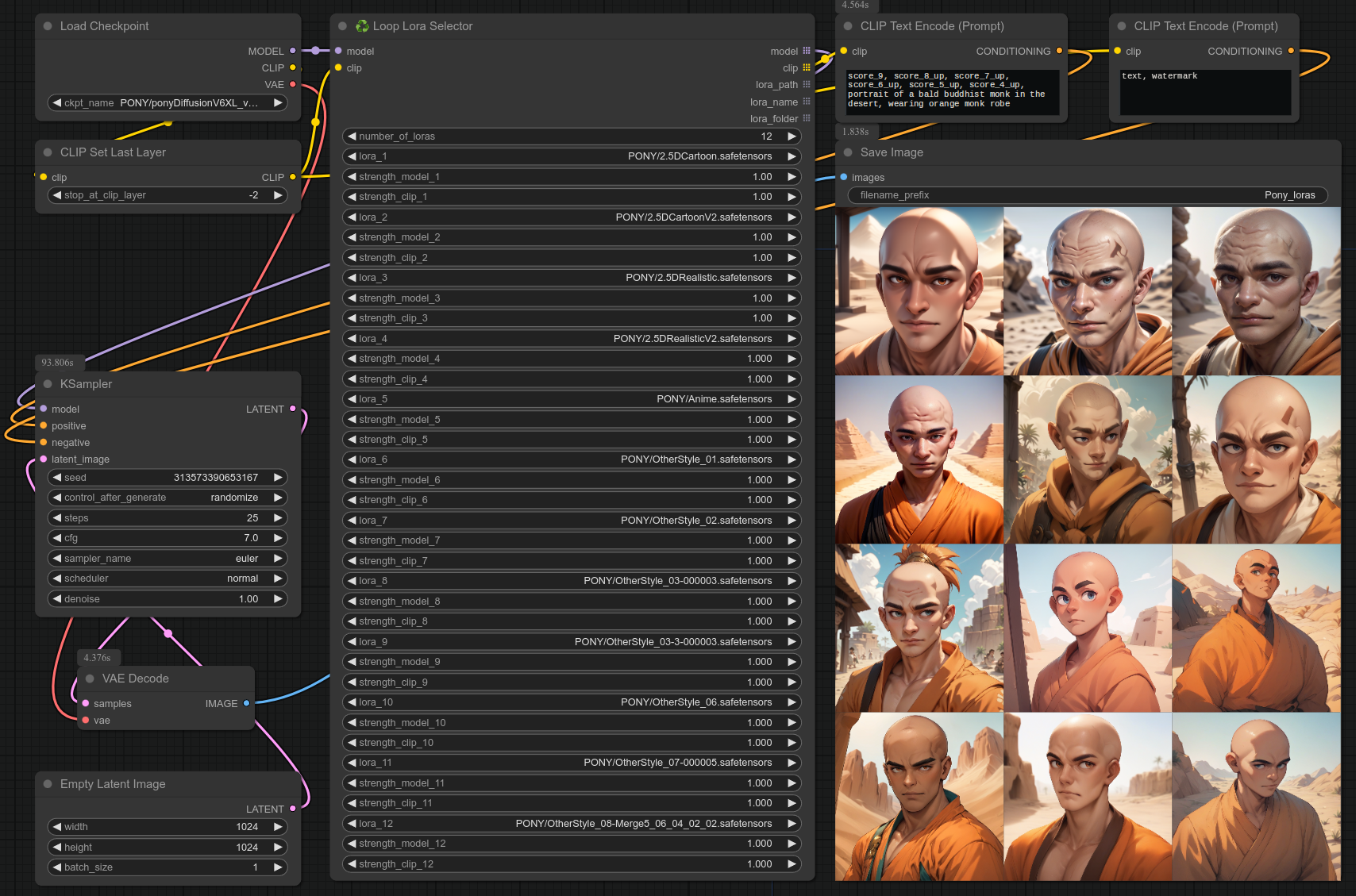
以上示例展示了Pony模型搭配多种风格的LoRA效果。
下面是一个使用Flux模型的示例,用于测试您的LoRA训练是否欠拟合、过拟合或恰到好处:

55 - 🎲 随机LoRA选择器
描述:
从一组LoRA中随机选取一个。
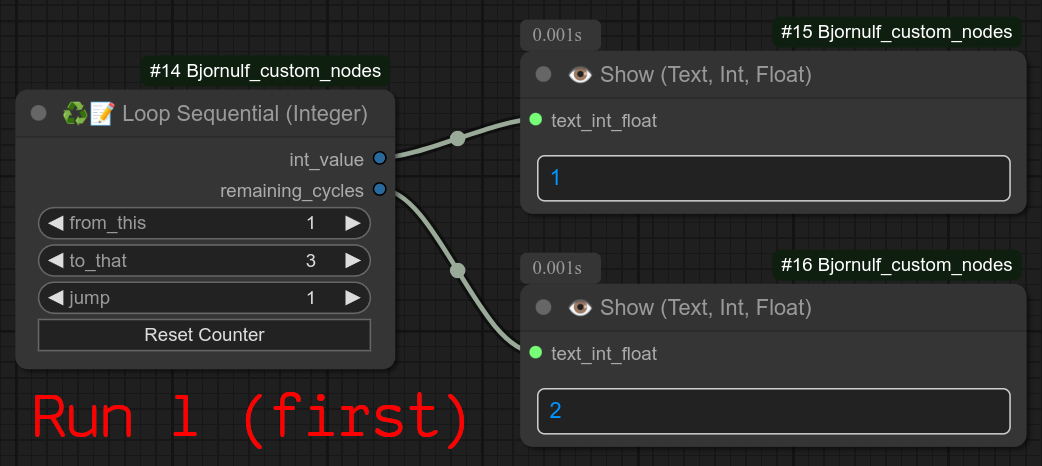
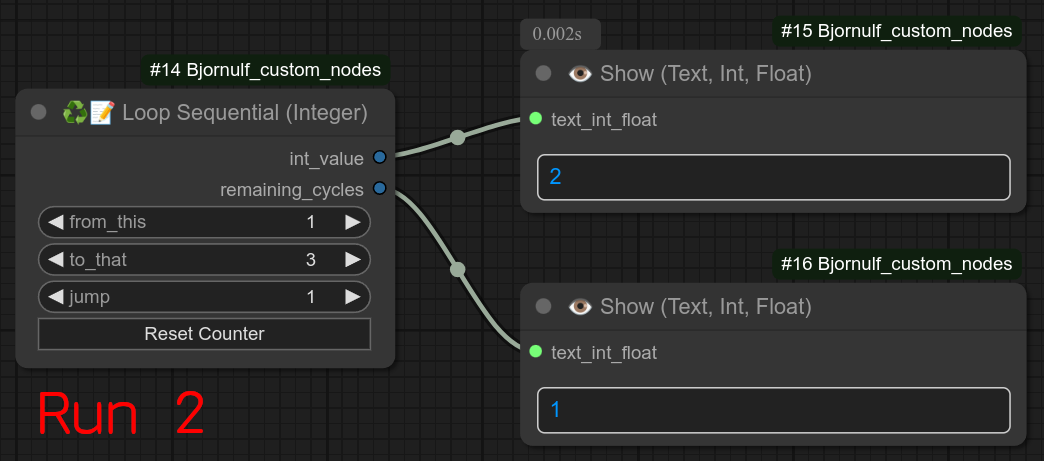
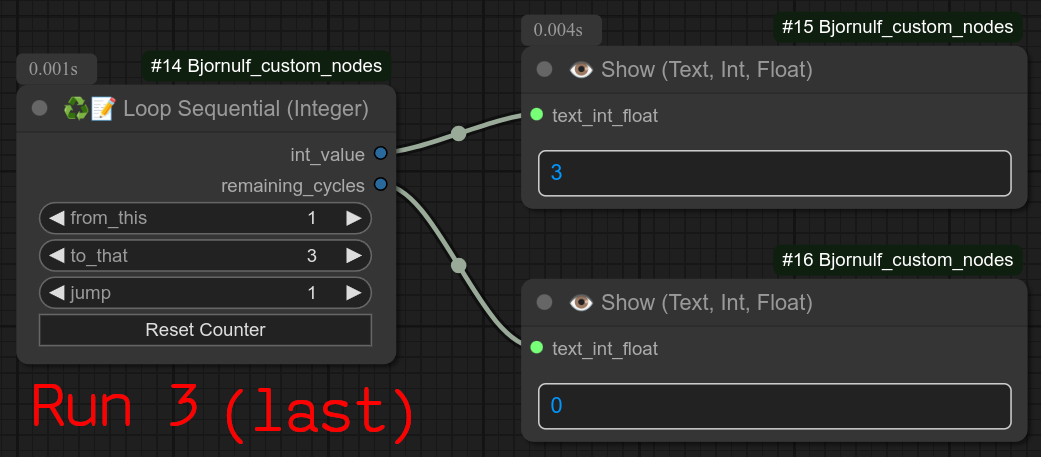
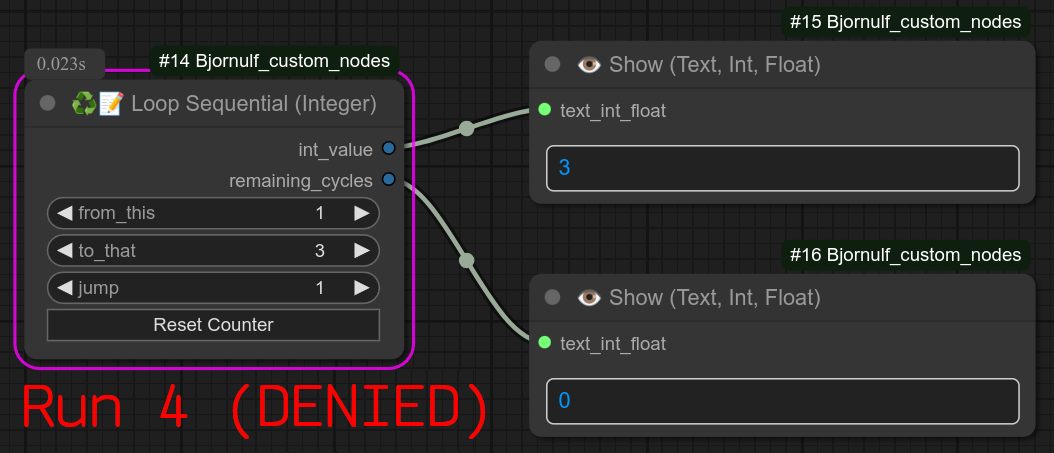
56 - ♻📑📝 循环顺序执行(整数)
描述:
此循环的工作方式与普通循环类似,但它是顺序执行的:每次工作流运行时,它只会输出一个整数!!!
第一次输出第一个整数,第二次输出第二个整数,依此类推……
当达到最后一个整数时,节点会停止整个工作流,防止后续步骤继续执行。
其内部实现依赖于 ComfyUI/Bjornulf 文件夹下的单个文件 counter_integer.txt。
❗ 请勿在一个工作流中使用超过一个此类节点,因为它们会共享同一个 counter_integer.txt 文件。(可能导致意外行为。)
更新 0.57:重置按钮现在也会显示下一个计数器值。
57 - ♻📑 循环顺序执行(输入行)
描述:
此循环的工作方式与普通循环类似,但它是顺序执行的:每次工作流运行时,它只会输出一行内容!!!
第一次输出第一行,第二次输出第二行,依此类推……
您还可以通过 +1 / -1 按钮来控制当前行号。
当到达最后一行时,节点会停止工作流,阻止后续步骤继续执行。
其内部实现依赖于 ComfyUI/Bjornulf 文件夹下的文件 counter_lines.txt。
以下是我的 TTS 节点的一个使用示例:当我有一组句子需要处理时,如果对某个版本不满意,只需点击 -1 按钮,在 TTS 节点上勾选“覆盖”选项,即可重新生成同一句话,直到满意为止。
❗ 请勿在一个工作流中使用超过一个此类节点,因为它们会共享同一个 counter_lines.txt 文件。(可能导致意外行为。)
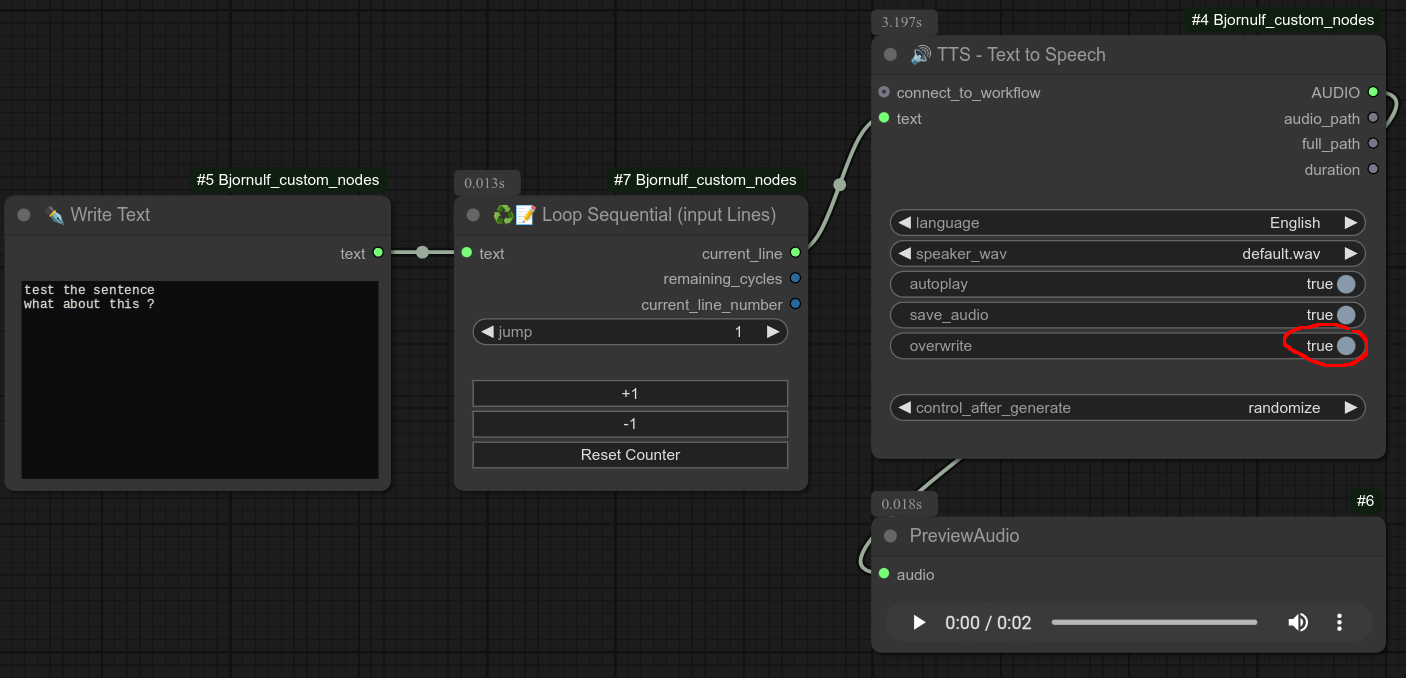
更新 0.57:重置按钮现在也会显示下一个计数器值。
如果您希望预测下一行内容,可以使用节点68为文本添加行号。
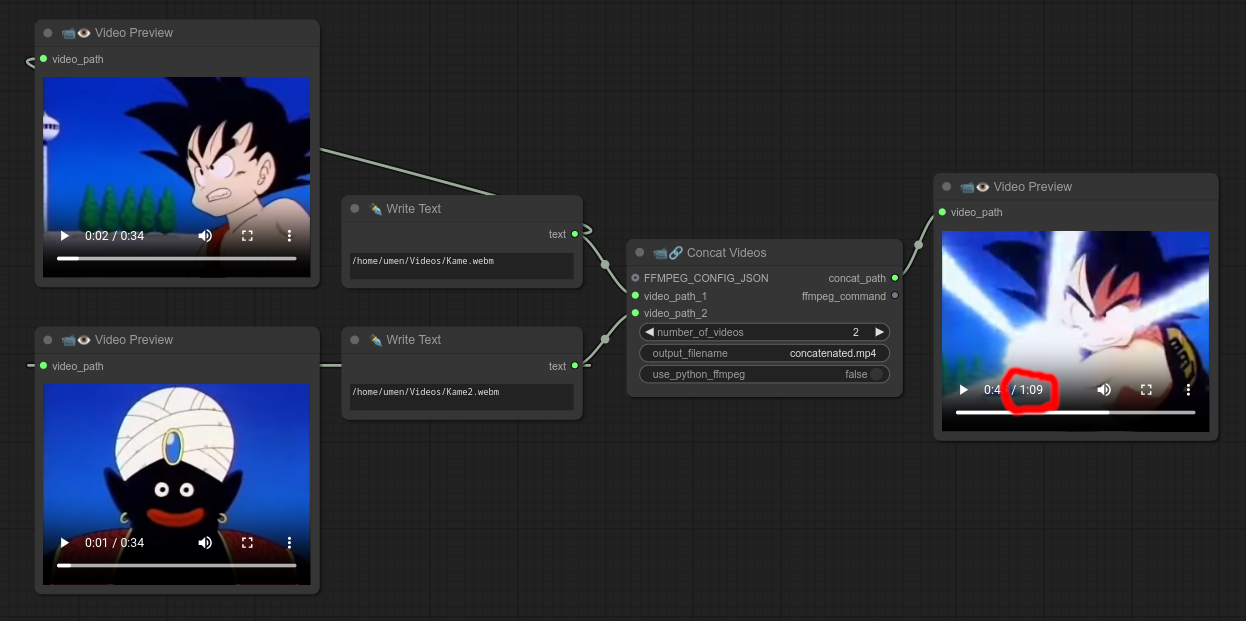
58 - 📹🔗 视频拼接
描述:
将两段视频拼接在一起(前后顺序排列在同一视频中)。
还可以对视频进行格式转换,支持使用 FFMPEG_CONFIG_JSON。(来自节点76/77)
59 - 📹🔊 视频与音频合并
描述:
简单地将视频和音频合并在一起。
视频:可以使用图像列表或视频路径。
音频:可以使用音频路径或直接输入音频数据。
60 - 🖼🖼 图像/视频水平合并 📹📹
描述:
将图像或视频沿水平方向合并。
以下是使用节点60和61对视频进行合并的一个可能示例:
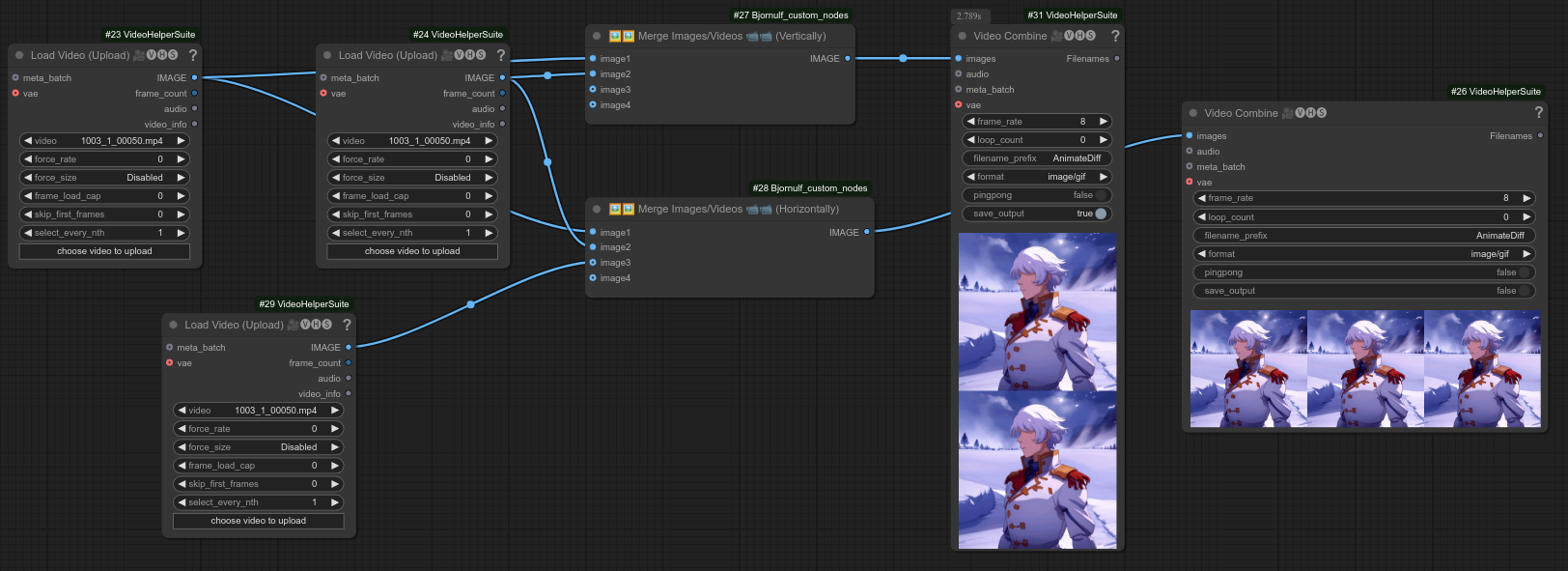
61 - 🖼🖼 图像/视频垂直合并 📹📹
描述:
将图像或视频沿垂直方向合并。
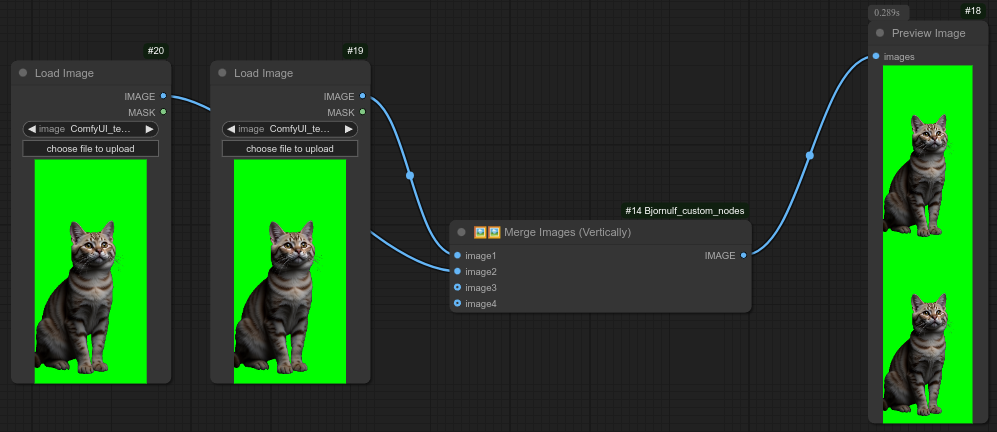
以下是使用节点60和61对视频进行合并的一个可能示例:
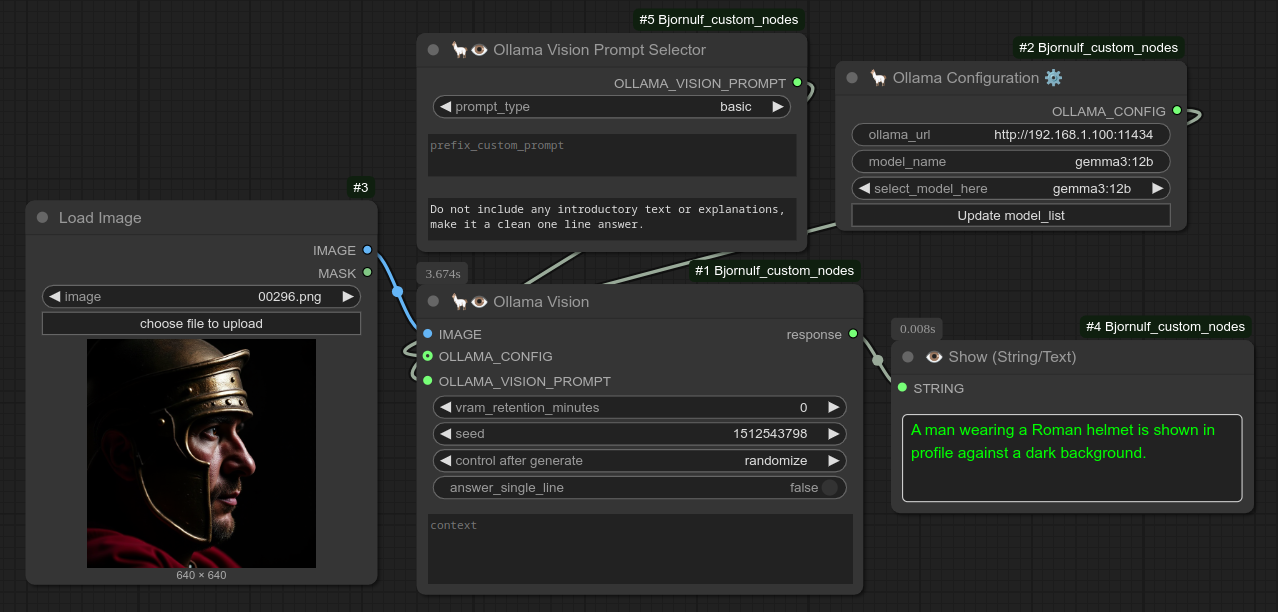
62 - 🦙👁 Ollama 视觉
描述:
以一张图片作为输入,对该图片进行描述。默认使用 moondream 模型,但可通过节点63选择其他模型,并借助节点161自定义提示词。
63 - 🦙 Ollama 配置 ⚙
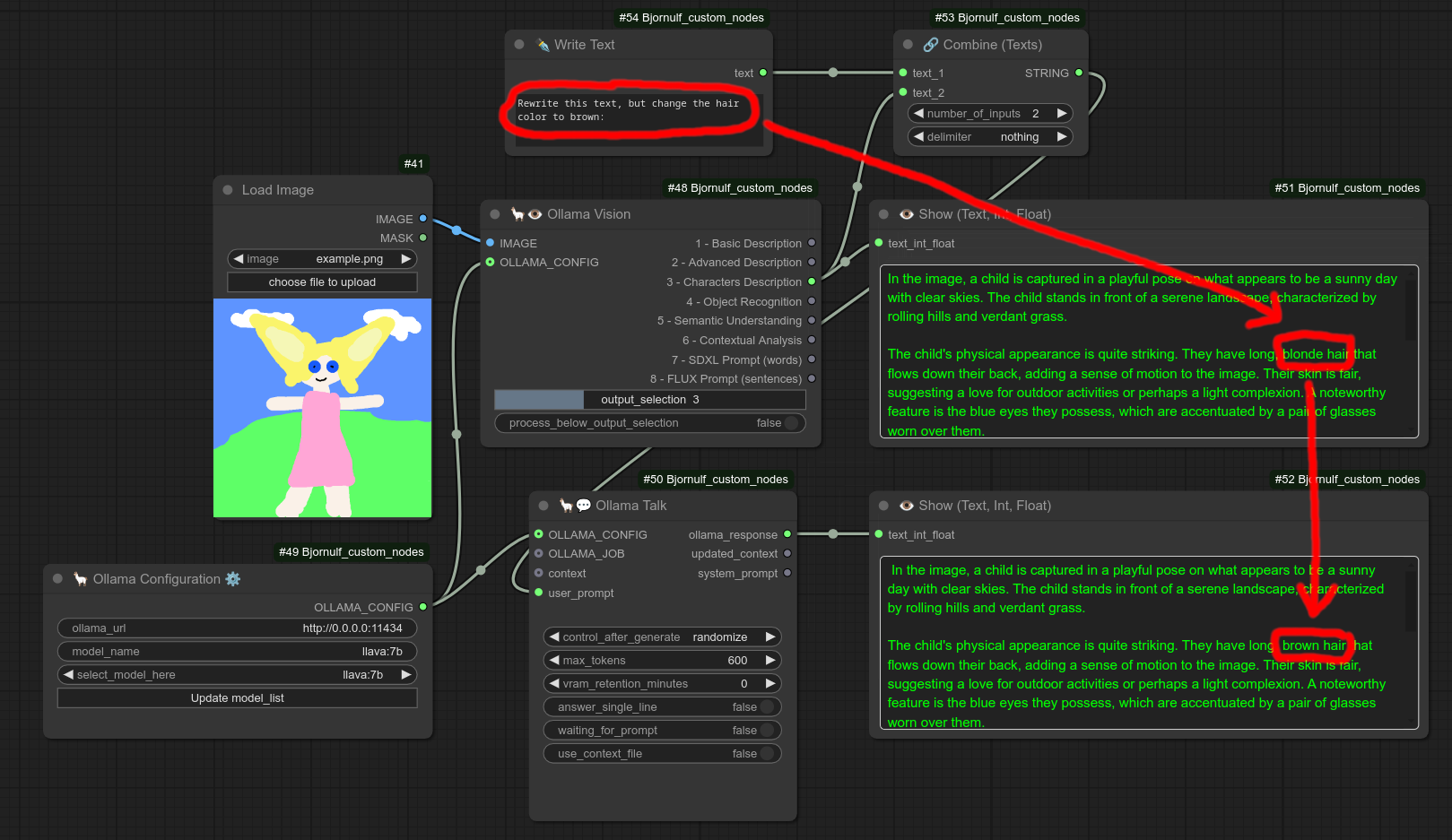
描述:
为 Ollama Talk 和 Vision 提供自定义配置。
您可以更改 Ollama 的 URL 以及使用的模型。
部分视觉模型在一定程度上也能处理文本任务。
以下是一个同时使用 Ollama 视觉节点 和 Ollama Talk 节点 的示例,二者共用同一个 Ollama 配置节点:
64 - 🦙 Ollama 工作角色选择 💼
描述:
为您的 Ollama Talk 节点选择一种角色,设置为 None 即可进行普通聊天。
如果您想自定义角色,只需将其设置为 None,然后在提示词前加上自定义内容。
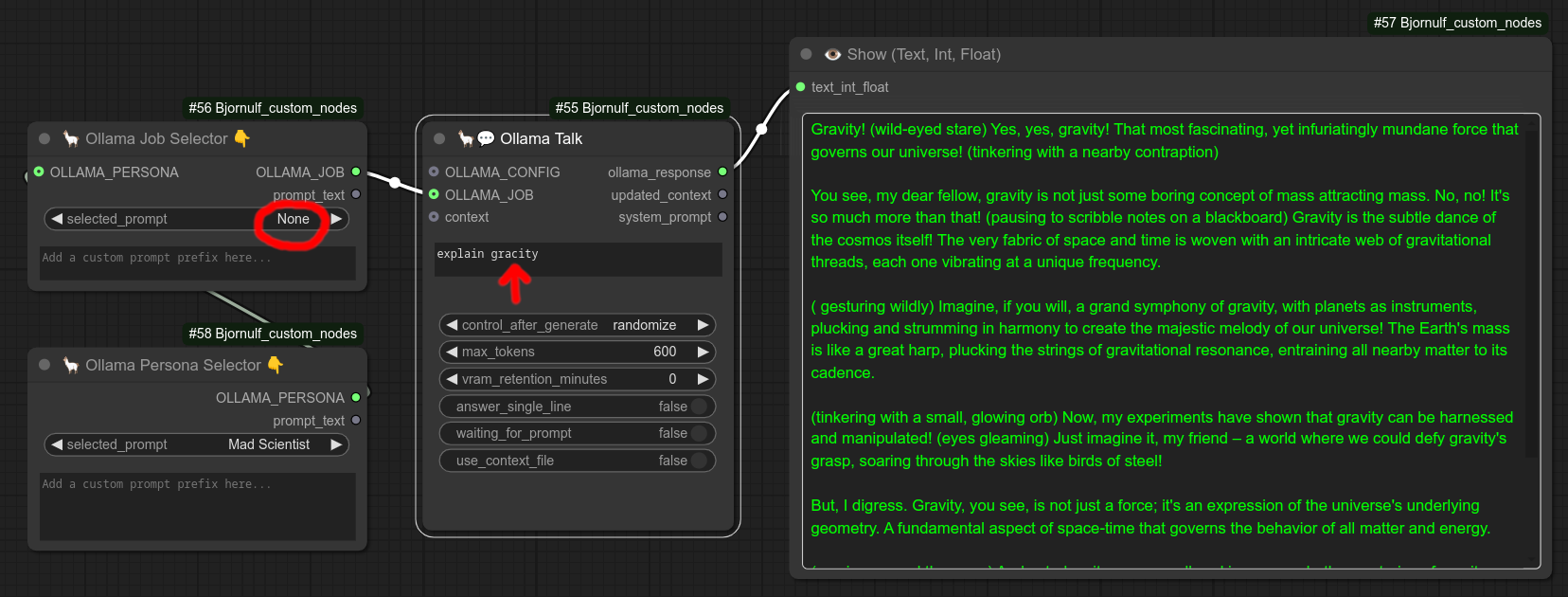
65 - 🦙 Ollama 人格选择 🧑
描述:
为您的 Ollama Talk 节点选择一种人格设定。
如果您想自定义人格,只需将其设置为 None,并在提示词前添加自定义内容。
以下是一个疯狂科学家解释引力的例子:(请注意,LLM 足够智能,能够理解其中的拼写错误):
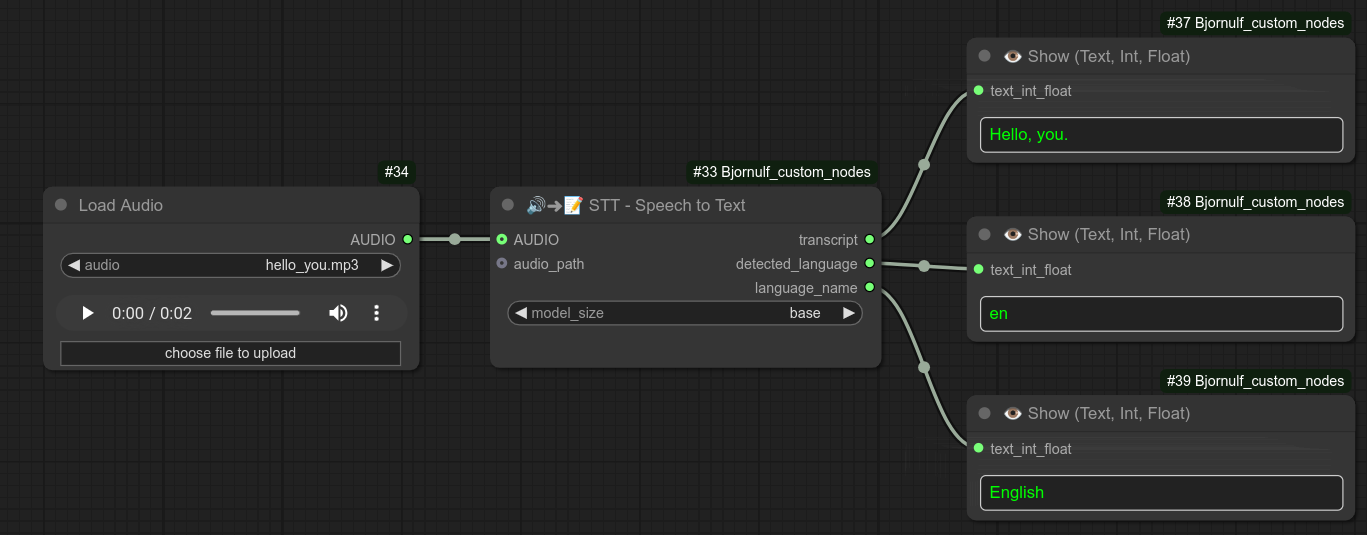
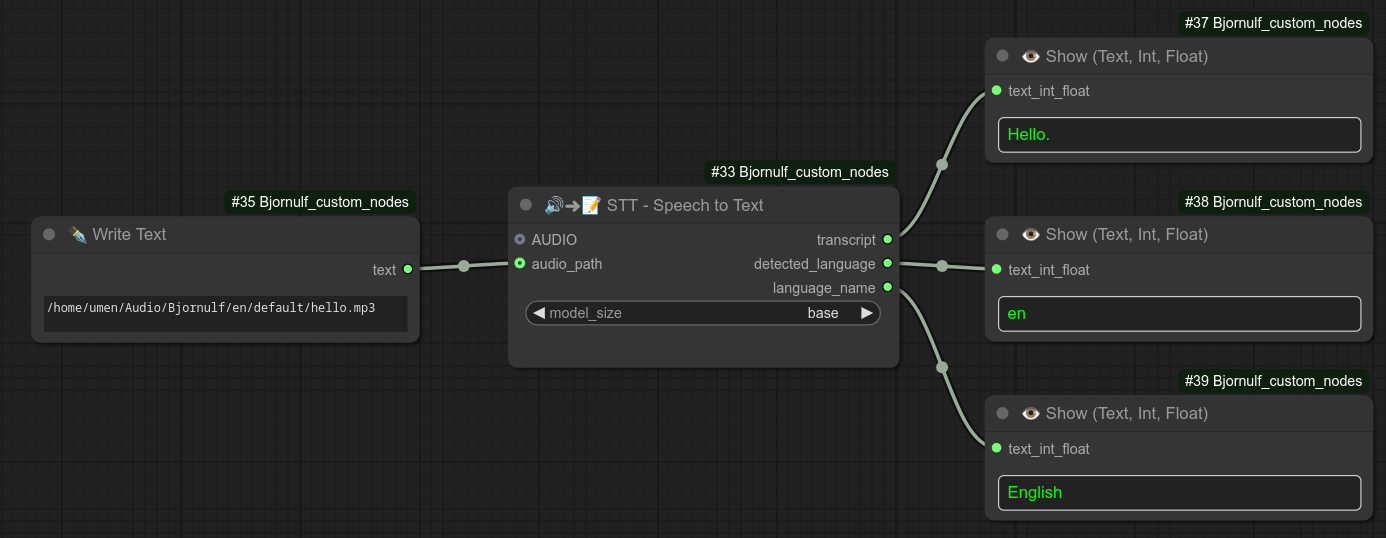
66 - 🔊➜📝 STT - 语音转文本
描述:
使用 faster-whisper 将 AUDIO 类型或音频路径转换为文本。(自动检测语言)
⚠️ 注意:此节点与 Python 3.13 不兼容,需使用 3.12。(通常来说,ComfyUI 生态系统仍然建议使用 3.12:https://github.com/comfyanonymous/ComfyUI?tab=readme-ov-file#manual-install-windows-linux。)
(faster-whisper 已从 requirements.txt 中移除,需手动安装。)
如果您确实想使用该节点,则需要自行安装:pip install faster-whisper。
67 - 📝➜✨ 文本转任意内容
描述:
有时您希望强制某个节点接受一个字符串。
例如,当节点的输入是列表时,就无法直接传入字符串。
此节点可以插入到流程中间,强制将字符串作为输入使用。
以下是结合我的 TTS 节点的一个示例。
68 - ✨➜📝 任意内容转文本
描述:
有时您希望将某种数据强制转换为字符串。
大多数输出确实是文本,尽管可能无法直接使用。
此节点会忽略这一点,直接将输入转换为简单的字符串。
69 - 🔢 添加行号
描述:
此节点会为文本添加行号。
在使用第 57 个节点(该节点会逐行处理输入)时非常有用。(您可以读取或预测下一行内容。)
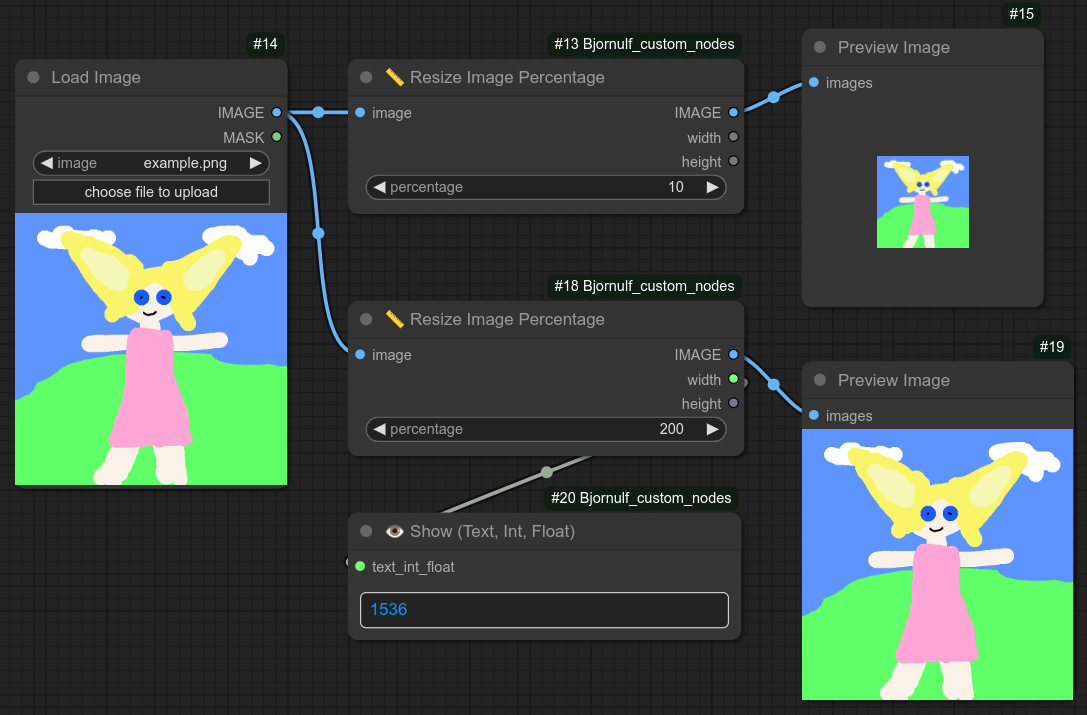
70 - 📏 按百分比调整图像大小
描述:
按百分比缩放图像。
71 - 👁 显示整数
描述:
基础节点,用于显示整数。(您可以直接拖拽任何整数节点,它会被自动推荐。)
72 - 👁 显示浮点数
描述:
基础节点,用于显示浮点数。(您可以直接拖拽任何浮点数节点,它会被自动推荐。)
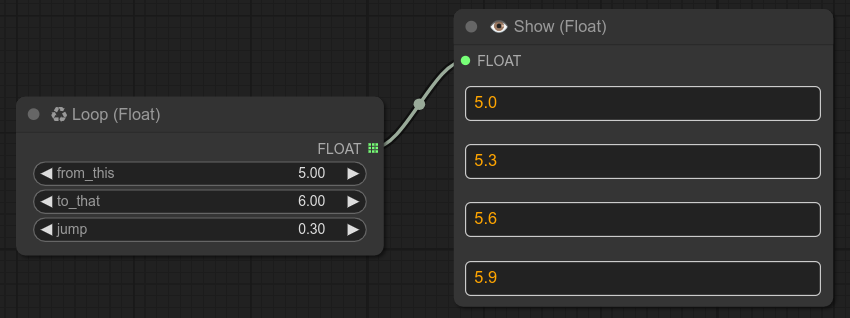
73 - 👁 显示字符串/文本
描述:
基础节点,用于显示字符串。(您可以直接拖拽任何字符串节点,它会被自动推荐。)
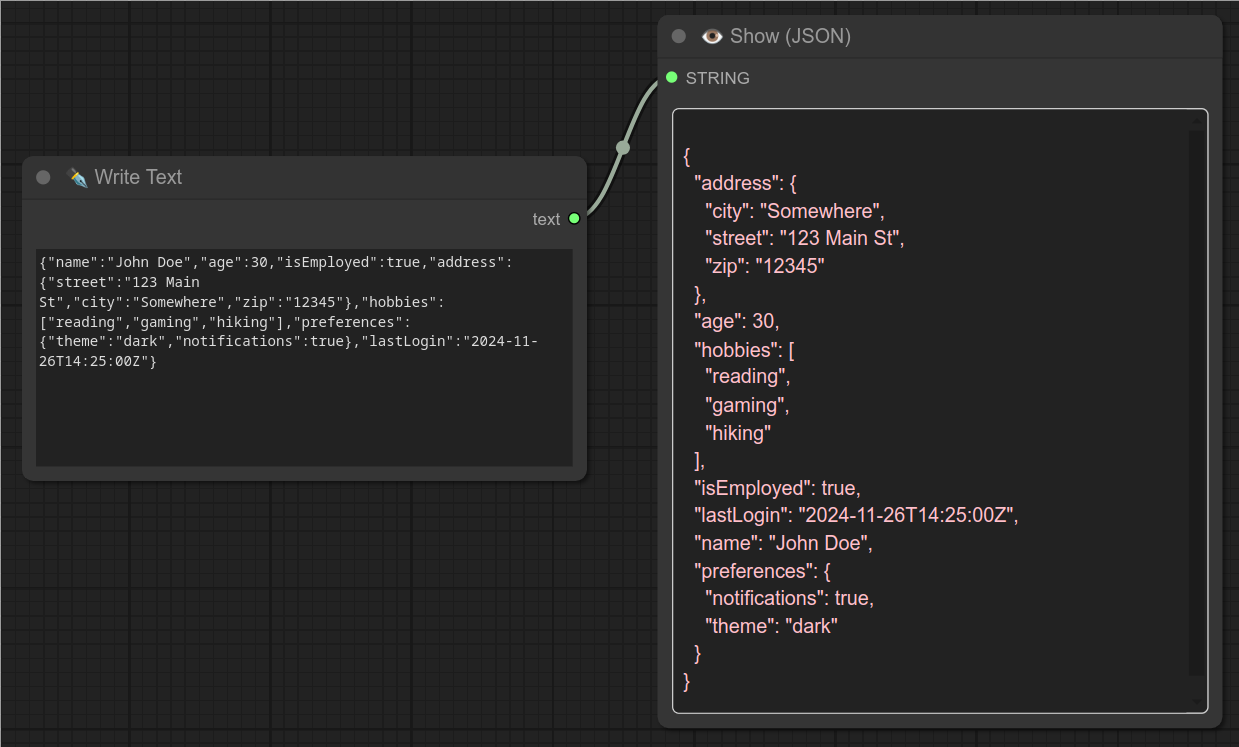
74 - 👁 显示 JSON
描述:
此节点会将字符串格式化为可读的 JSON。(并以粉色显示)
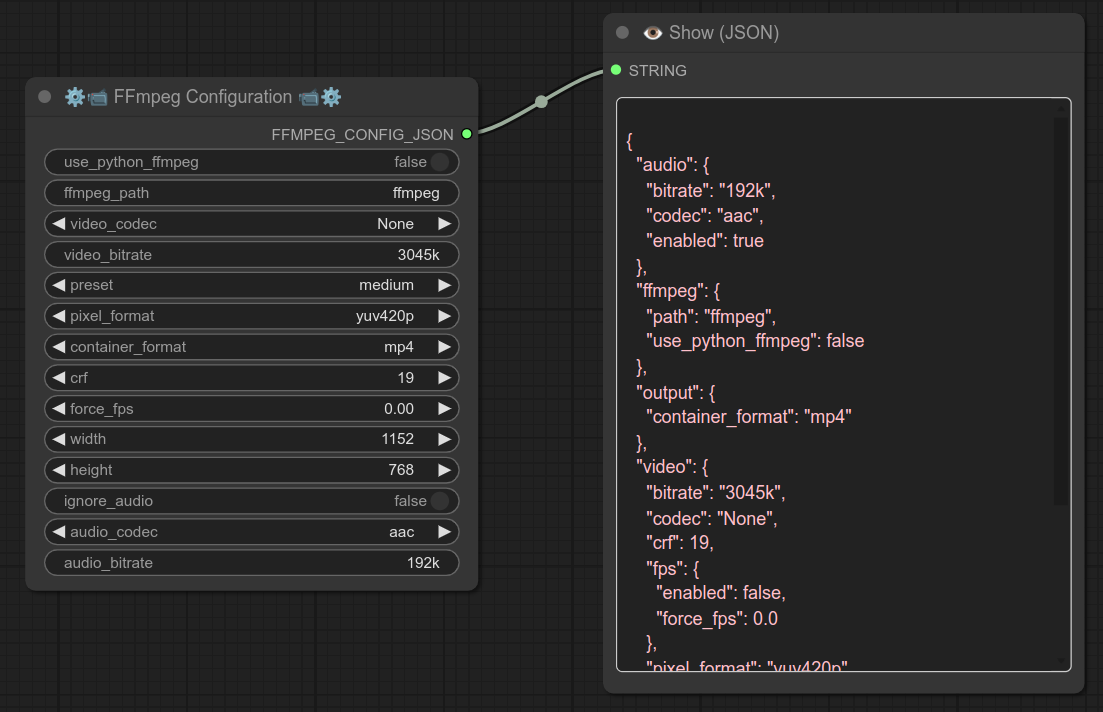
75 - 📝➜📝 替换文本
描述:
用另一种文本替换现有文本,支持正则表达式等多种选项,请参阅下方示例:
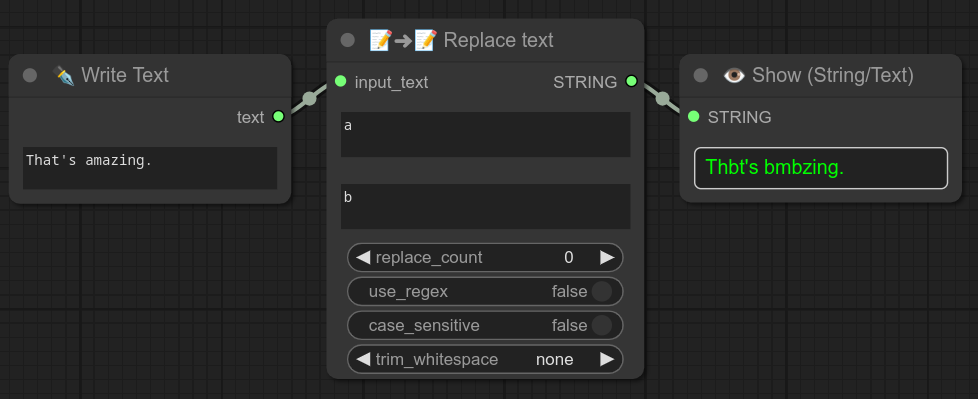
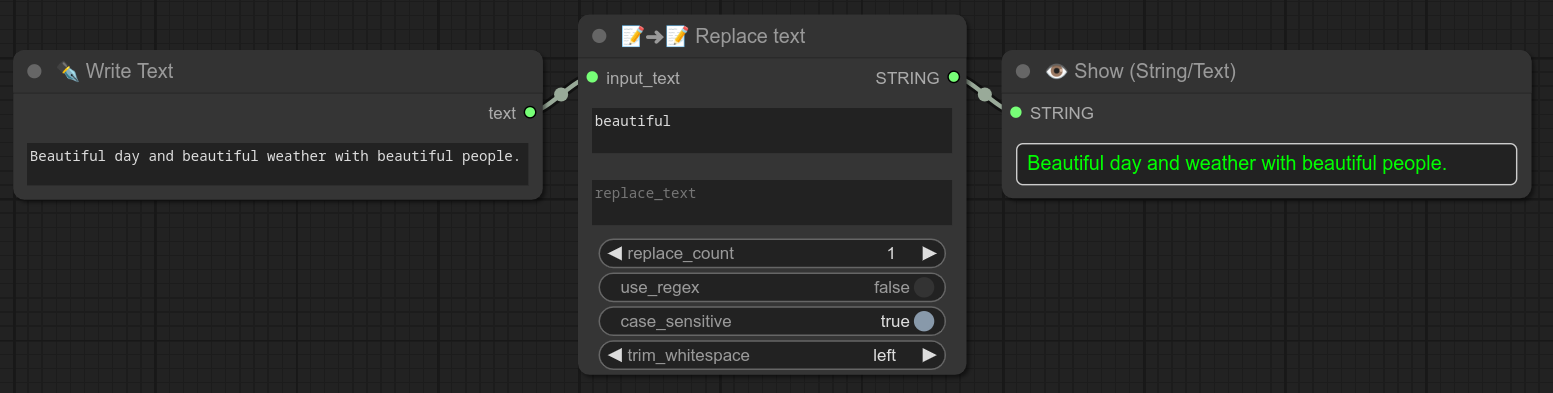
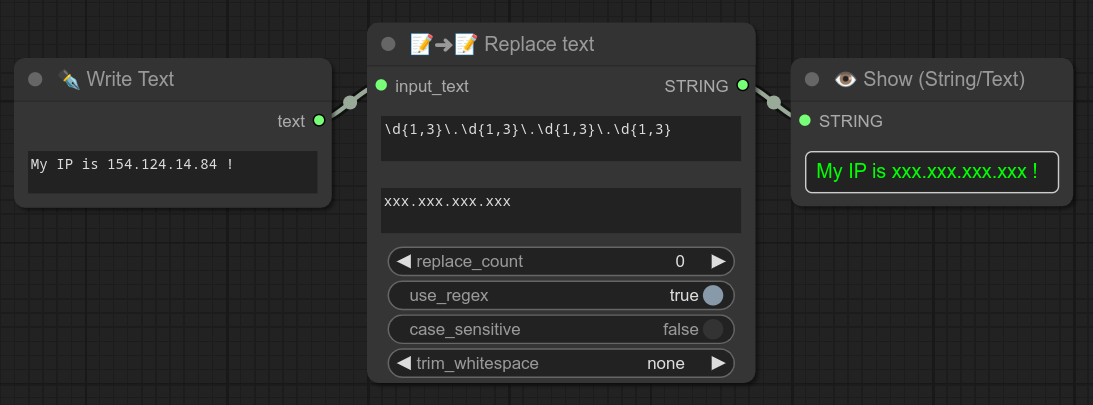
0.70:文本替换功能现已支持多行正则表达式。
76 - ⚙📹 FFmpeg 配置 📹⚙
描述:
创建一个 FFMPEG_CONFIG_JSON,其中包含可用于其他节点的 JSON 数据:
- 视频转换
- 视频拼接
- 从列表中拼接视频
77 - 📹🔍 视频详情 ⚙
描述:
从视频路径中提取详细信息。
您可以将一体化的 FFMPEG_CONFIG_JSON 与其他节点一起使用,也可以根据需要单独使用其他变量。
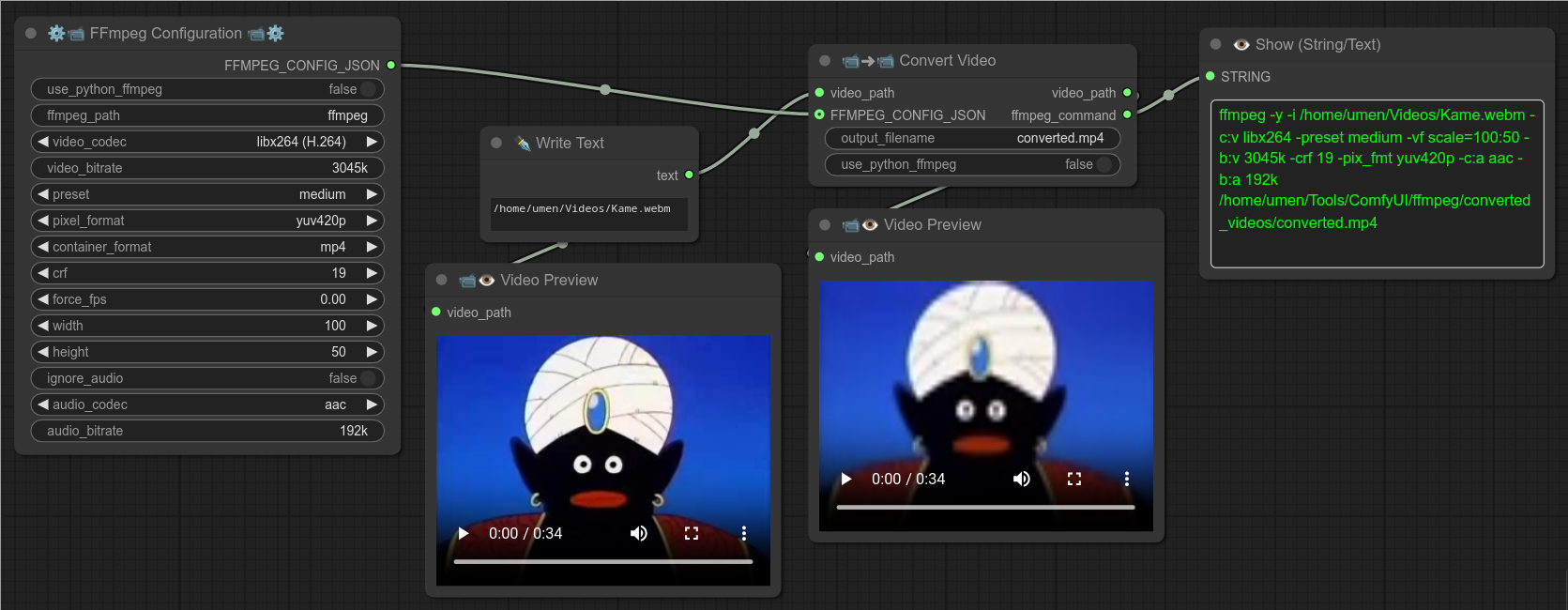
78 - 📹➜📹 视频转换
描述:
转换视频,可使用 FFMPEG_CONFIG_JSON。
79 - 📹🔗 从列表拼接视频
描述:
接收一个视频列表(每行一个视频),并将它们依次拼接成一个视频。
可使用来自第 76 或 77 个节点的 FFMPEG_CONFIG_JSON。
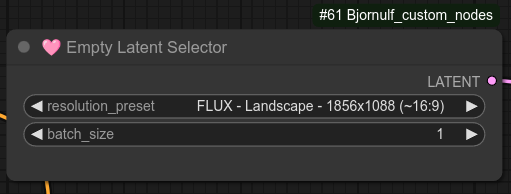
80 - 🩷 空潜变量选择器
描述:
厌倦了手动设置潜变量空间?
从我自定义的格式列表中选择一个。
只需将其连接到您的 KSampler 即可。
81 - 🔥📝🖼 图像文本生成器 🖼📝🔥
描述:
主要的文本生成节点,本身并不执行太多操作,仅负责“相机角度”和“多角色动作”。(例如:“……吃野餐,俯视视角。”)
但是,您可以将其他“文本生成节点”连接到它上。
⚠️ 关于“文本生成”的警告:此节点只是单纯地编写文本,随后由检查点模型(SD1.5、SDXL、Flux 等)解析文本并生成图像。
某些模型在某些方面表现较差,因此请不要期望您所编写的文本在所有检查点或 LoRA 上都能完美生效。(此节点的设计初衷是配合 Flux 模型使用。)
以下是我所有“文本生成节点”的使用教程,共分为 8 步:
第 1 步:使用主文本生成节点,编写图像的一般细节(此处为“相机角度”和“拍摄类型”)。目前我只是将文本与一个简单的“写文本”节点结合,后者会发送“沼泽怪物”: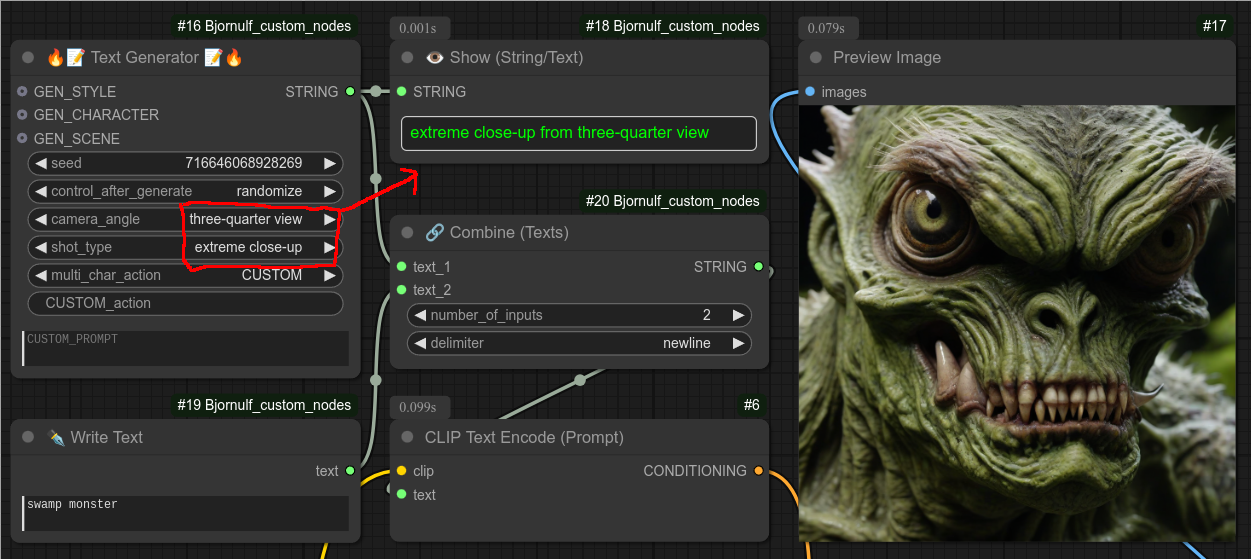
第 2 步:为图像添加特定风格: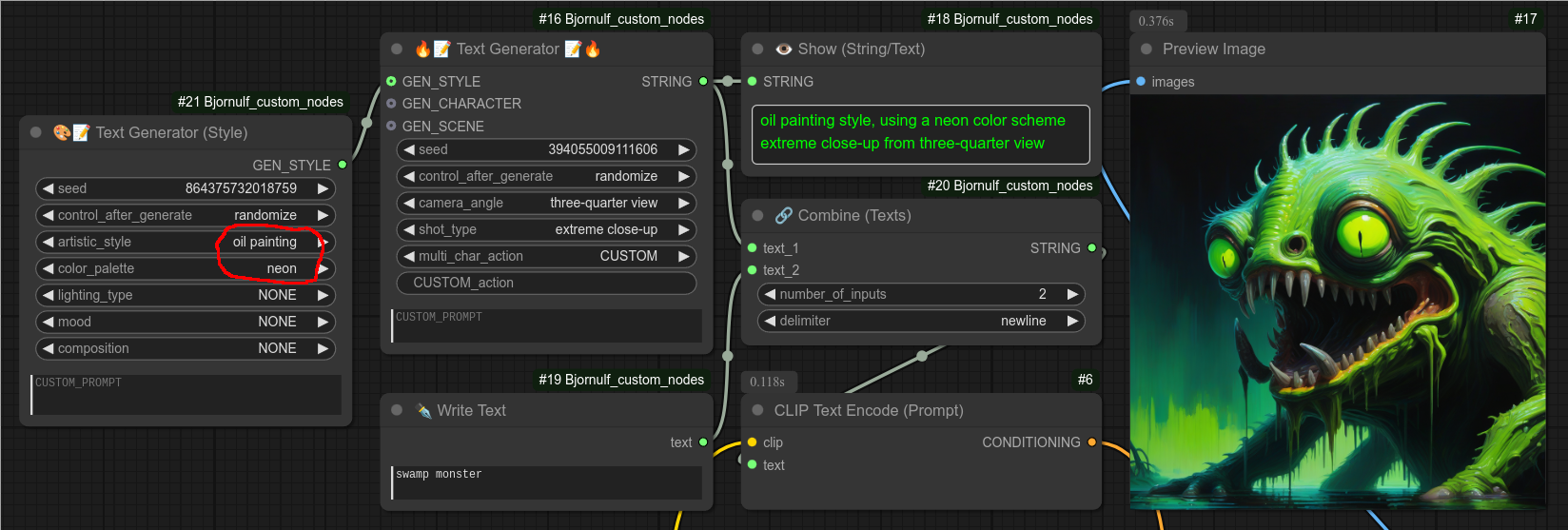
第 3 步:为图像添加场景/背景: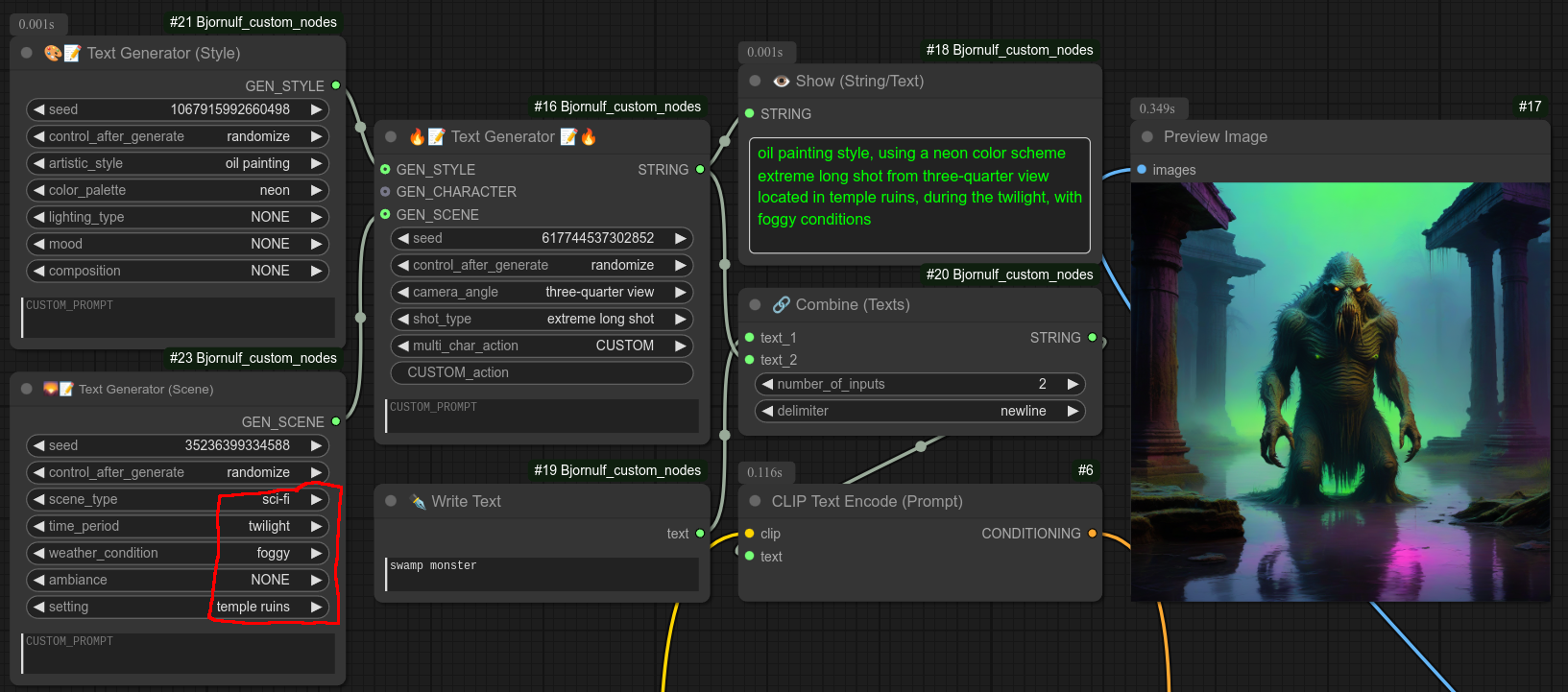
第 4 步:使用角色节点代替“写文本”节点,向场景中添加角色。
我将移除“写文本”节点中的“沼泽怪物”,改用我的角色节点,创建一只具有闪电能力的凶猛龙: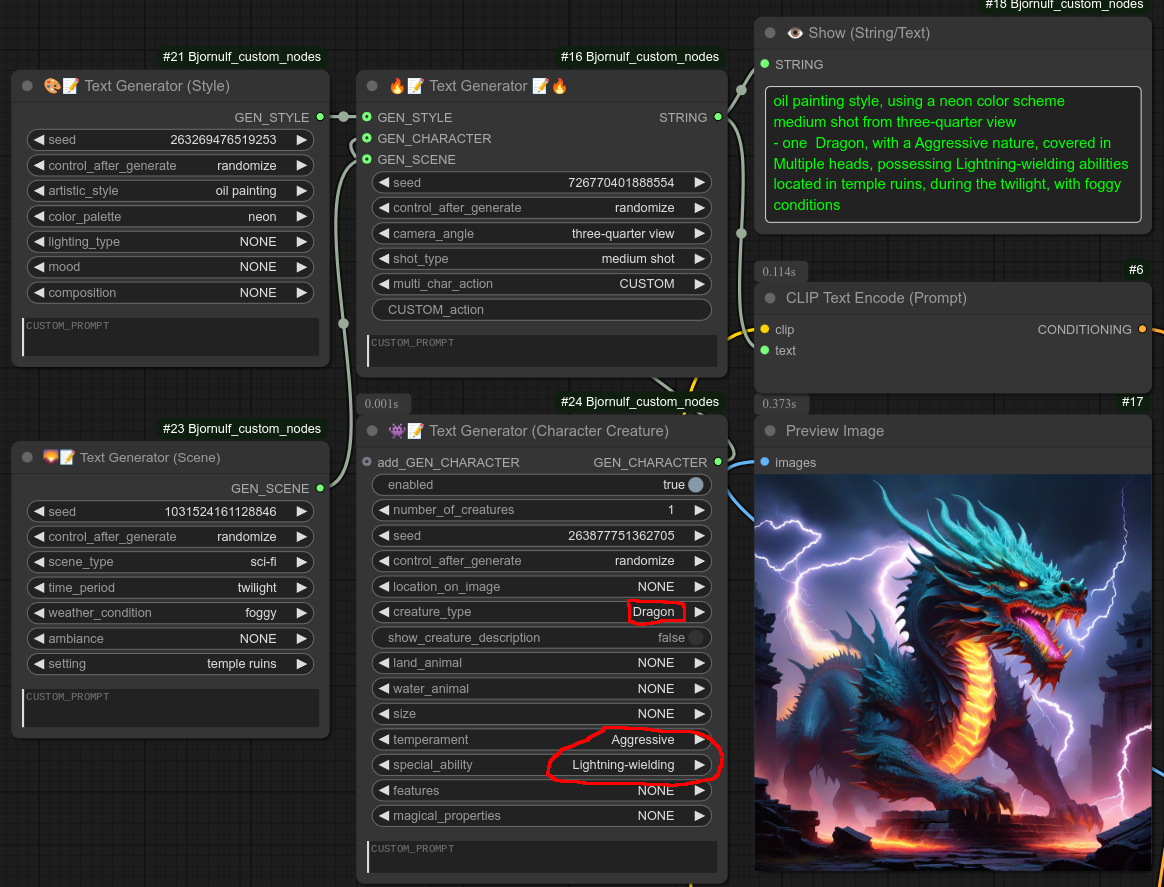
第 5 步:角色节点(男性/女性及生物)可以包含多个角色。(但这些角色将共享相同的特征。)
接下来,我移除了龙,并利用主节点中的“multi_char_action”创建了两个正在打斗的“男性角色”。(您也可以将其设置为自定义动作并自行编写。)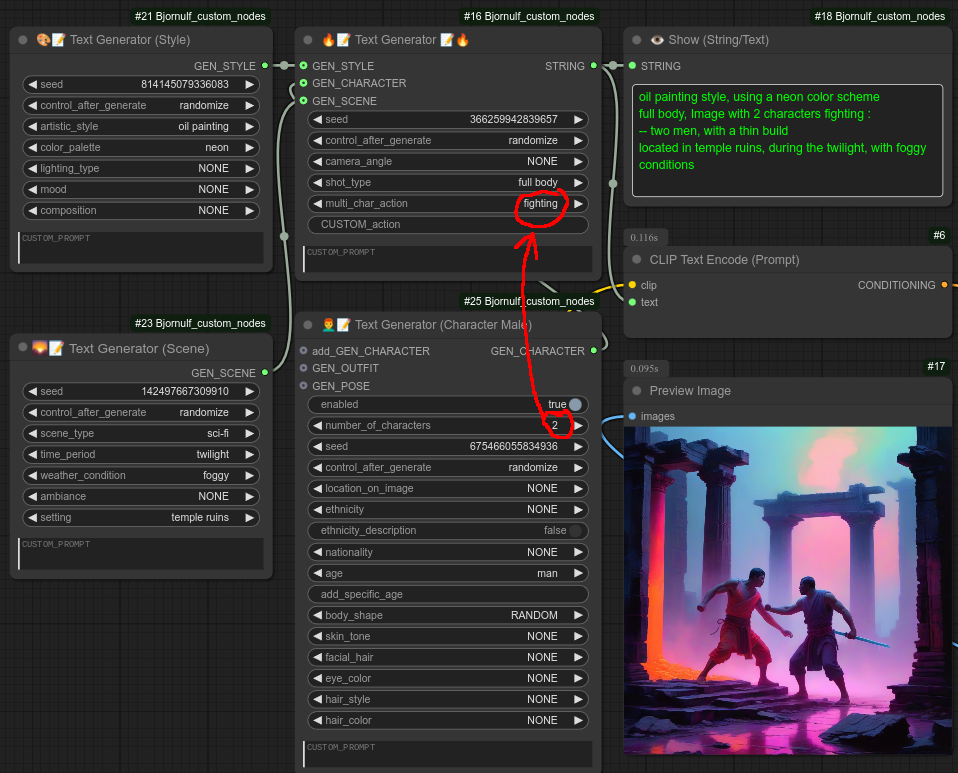
第 5 步:尝试为角色添加位置,我希望将其放置在图像左侧。然而,使用我一直使用的 SDXL 模型却失败了: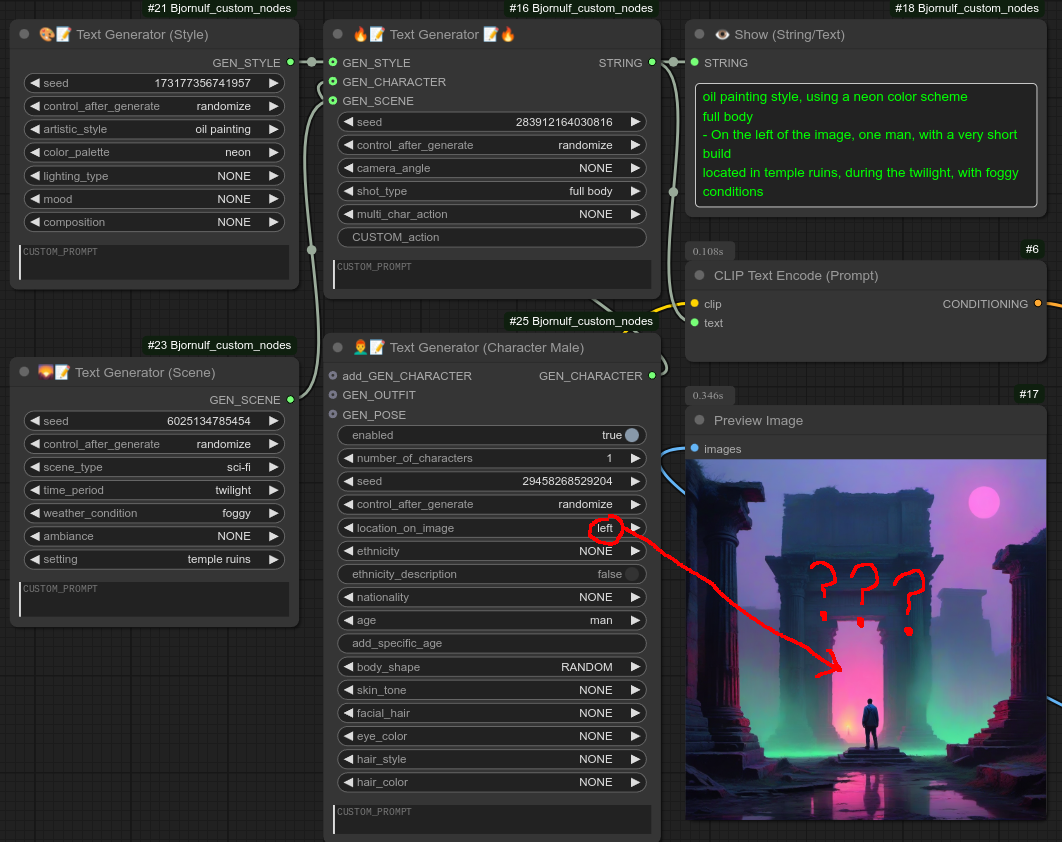
第 6 步:切换到 FLUX 模型,测试其“location_on_image”功能(该功能有效):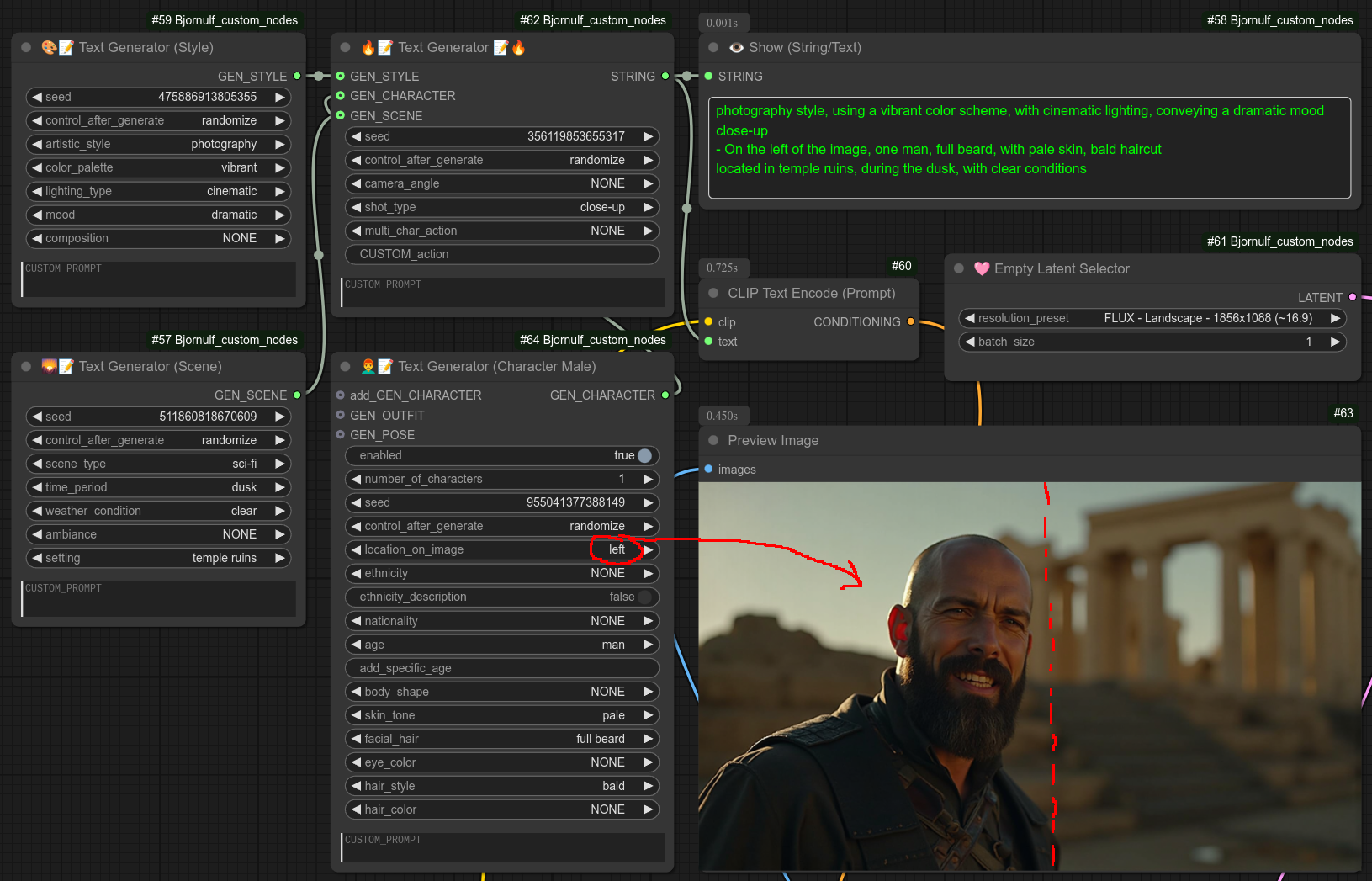
第 7 步:使用我的 API 自定义节点 109,切换至 Black Forest Lab 的 FLUX Ultra 模型。
如果您希望多个角色拥有不同的特征(如“location_on_image”或其他特性),可以将多个角色节点串联起来,彼此连接使用。
如下所示,我请求在图像左侧放置两只小恐龙,在右侧放置一只僵尸: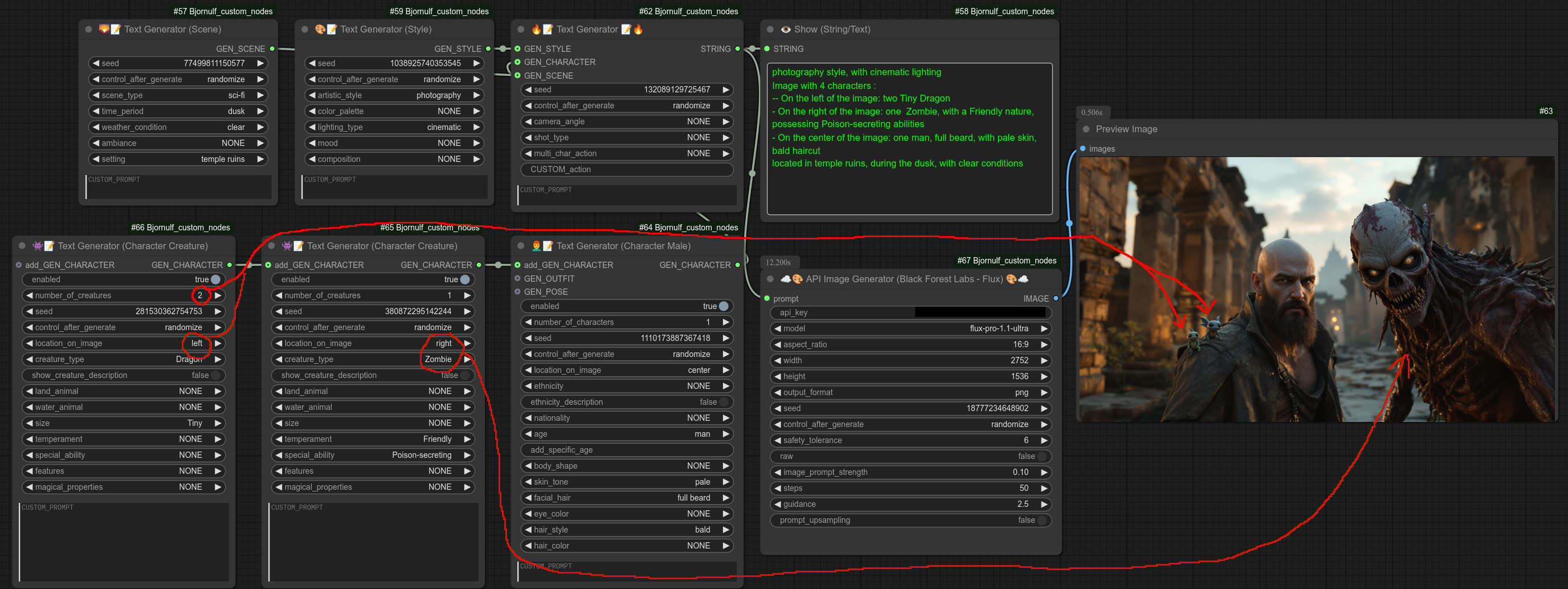
步骤8:最后,我将禁用僵尸角色,添加一套服装(这里是一套“花卉盔甲”),还会为角色添加一个“姿势”节点,并将该姿势节点连接到一个“物体”节点。(它们一起会让角色“拿着一本书”并把“手放在下巴上”)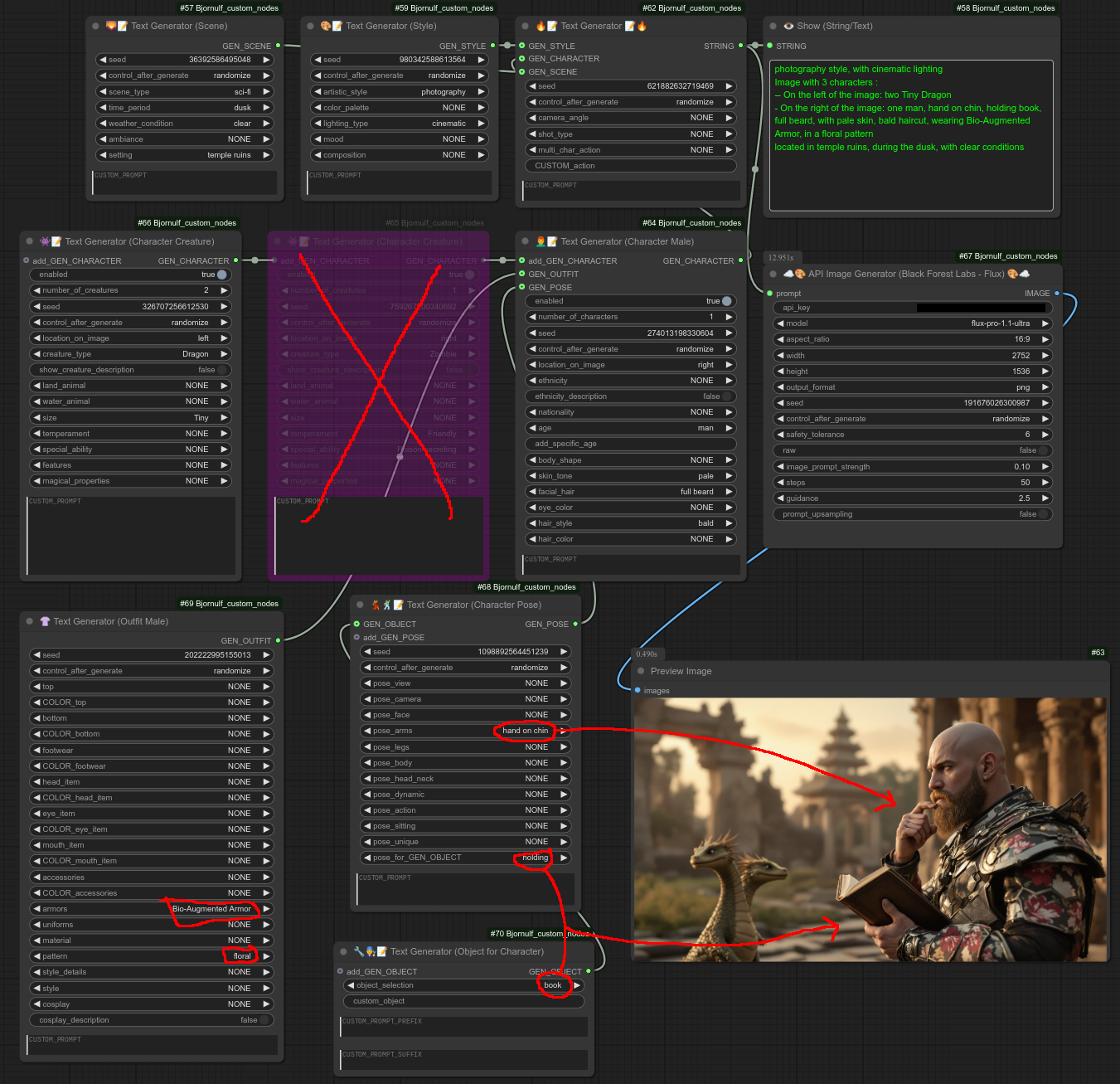
82 - 👩🦰📝 文本生成器(女性角色)
描述:
生成与女性角色相关的文本。
需要连接到“文本生成器”主节点。
⚠️ 关于“文本生成器”的教程,请参见节点81。
83 - 👨🦰📝 文本生成器(男性角色)
描述:
生成与男性角色相关的文本。
⚠️ 关于“文本生成器”的教程,请参见节点81。
84 - 👾📝 文本生成器(生物角色)
描述:
生成与生物角色相关的文本。
⚠️ 关于“文本生成器”的教程,请参见节点81。
85 - 💃🕺📝 文本生成器(角色姿势)
描述:
生成与角色姿势相关的文本。
⚠️ 关于“文本生成器”的教程,请参见节点81。
86 - 🔧👨🔧📝 文本生成器(角色相关物品)
描述:
生成与某个与角色姿势相连的物品相关的文本。
⚠️ 关于“文本生成器”的教程,请参见节点81。
87 - 🌄📝 文本生成器(场景)
描述:
生成与特定场景相关的文本,直接连接到主文本生成器。
⚠️ 关于“文本生成器”的教程,请参见节点81。
88 - 🎨📝 文本生成器(风格)
描述:
生成与特定风格相关的文本,直接连接到主文本生成器。
⚠️ 关于“文本生成器”的教程,请参见节点81。
89 - 👗 文本生成器(女性服装)
描述:
生成与特定女性服装相关的文本。
⚠️ 关于“文本生成器”的教程,请参见节点81。
90 - 👚 文本生成器(男性服装)
描述:
生成与特定男性服装相关的文本。
⚠️ 关于“文本生成器”的教程,请参见节点81。
91 - ♻🔥📝 列表循环器(文本生成器)
描述:
用于对主文本生成器节点中的元素进行循环的循环器。
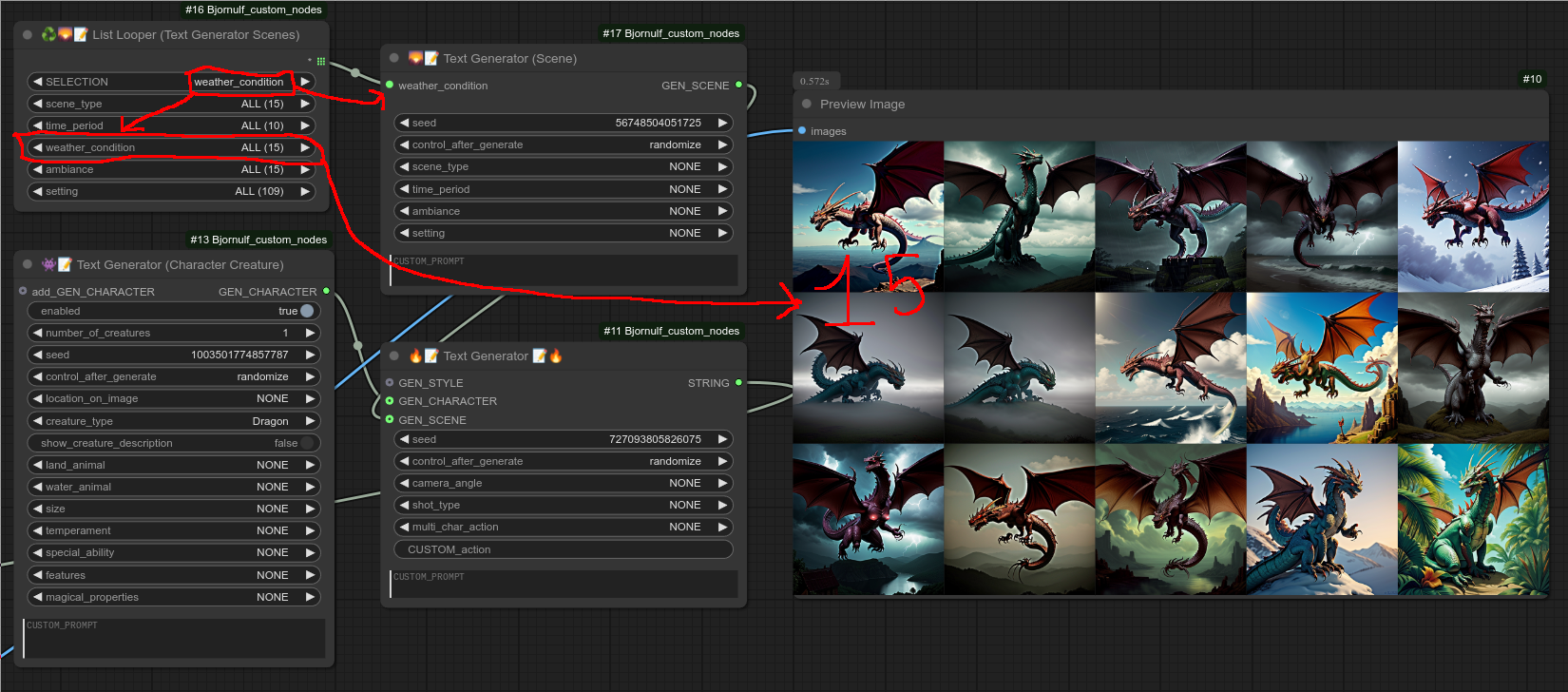
所有“列表循环器”节点都采用相同的逻辑,你可以以相同的方式使用它们。以下是节点92(场景列表循环器)的示例,它会遍历所有不同的“天气状况”:
⚠️ 注意,如果你想逐个循环元素,而不是一次性全部循环,请不要使用这些“列表循环器”节点!!你只需将想要的元素转换为输入,并双击创建一个新的节点,将其设置为“递增”。
例如,这里可以看到数值被“递增”了,也就是变成了列表中的下一个值;下一次运行时,它又会取列表中的下一个值(以此类推):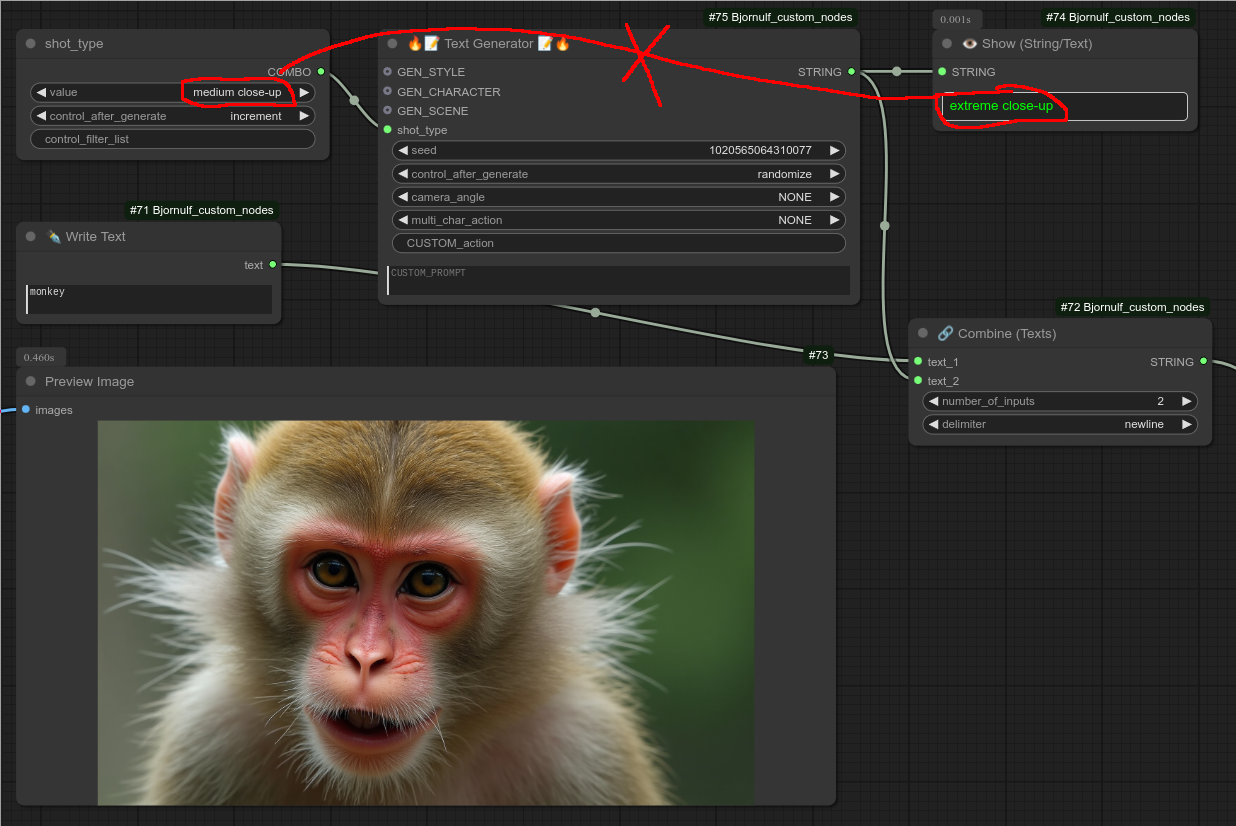
92 - ♻🌄📝 列表循环器(文本生成器场景)
描述:
用于对场景节点中的元素进行循环的循环器。
⚠️ 关于“列表循环器”的教程,请参见节点91。
93 - ♻🎨📝 列表循环器(文本生成器风格)
描述:
用于对风格节点中的元素进行循环的循环器。
⚠️ 关于“列表循环器”的教程,请参见节点91。
94 - ♻💃🕺📝 列表循环器(文本生成器姿势)
描述:
用于对姿势节点中的元素进行循环的循环器。
⚠️ 关于“列表循环器”的教程,请参见节点91。
95 - ♻👨🦰👩🦰👾 列表循环器(文本生成器角色)
描述:
用于对角色节点中的元素进行循环的循环器(包括男性、女性和生物角色)。
⚠️ 关于“列表循环器”的教程,请参见节点91。
96 - ♻👚 列表循环器(文本生成器男性服装)
描述:
用于对男性服装节点中的元素进行循环的循环器。
⚠️ 关于“列表循环器”的教程,请参见节点91。
97 - ♻👗 列表循环器(文本生成器女性服装)
描述:
用于对女性服装节点中的元素进行循环的循环器。
⚠️ 关于“列表循环器”的教程,请参见节点91。
98 - 📥 加载SD1.5检查点(+从CivitAI下载)
描述:
这与基础的“加载检查点”节点相同,但其模型列表来自CivitAI(而非本地文件夹)。
如果你的电脑上还没有该模型,它还会从CivitAI自动下载。(你需要从自己的账户获取API令牌——可在CivitAI.com的设置中找到。)
这是sd1.5版本,模型将被下载到:ComfyUI/models/checkpoints/Bjornulf_civitAI/sd1.5
下载完成后,你可以继续使用此节点来加载检查点,或者通过基础的“加载检查点”节点使用已下载的模型。
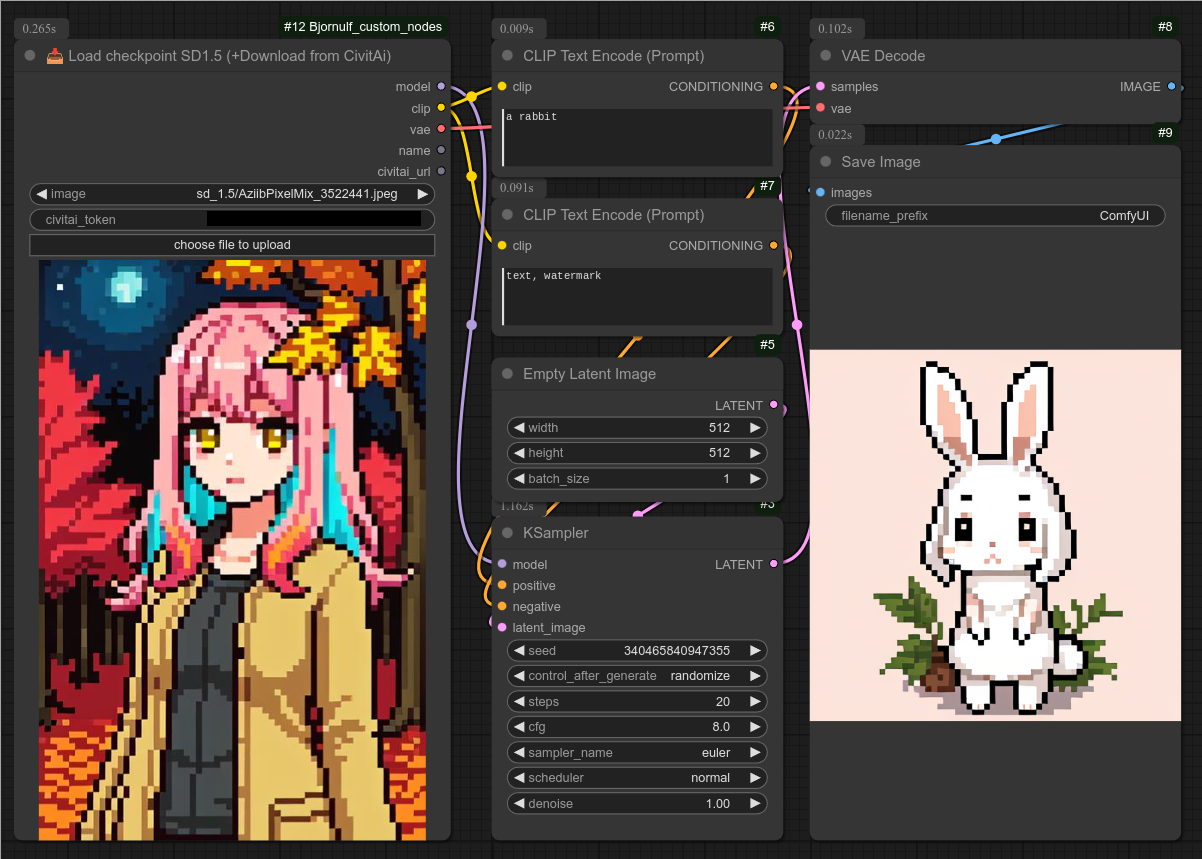
99 - 📥 加载SDXL检查点(+从CivitAI下载)
描述:
这与基础的“加载检查点”节点相同,但其模型列表来自CivitAI(而非本地文件夹)。
如果你的电脑上还没有该模型,它还会从CivitAI自动下载。(你需要从自己的账户获取API令牌——可在CivitAI.com的设置中找到。)
这是sdxl_1.0版本,模型将被下载到:ComfyUI/models/checkpoints/Bjornulf_civitAI/sdxl_1.0
下载完成后,你可以继续使用此节点来加载检查点,或者通过基础的“加载检查点”节点使用已下载的模型。
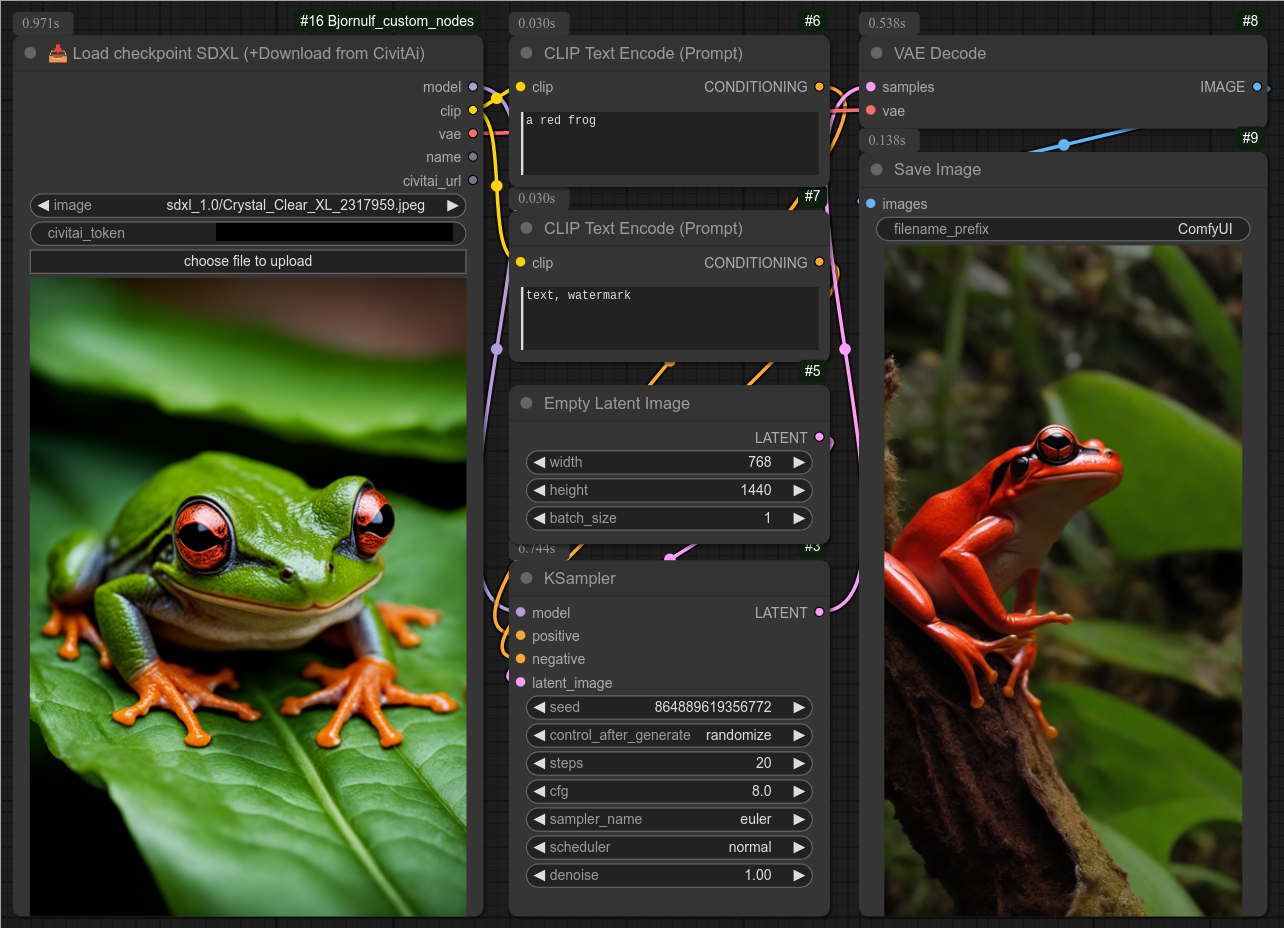
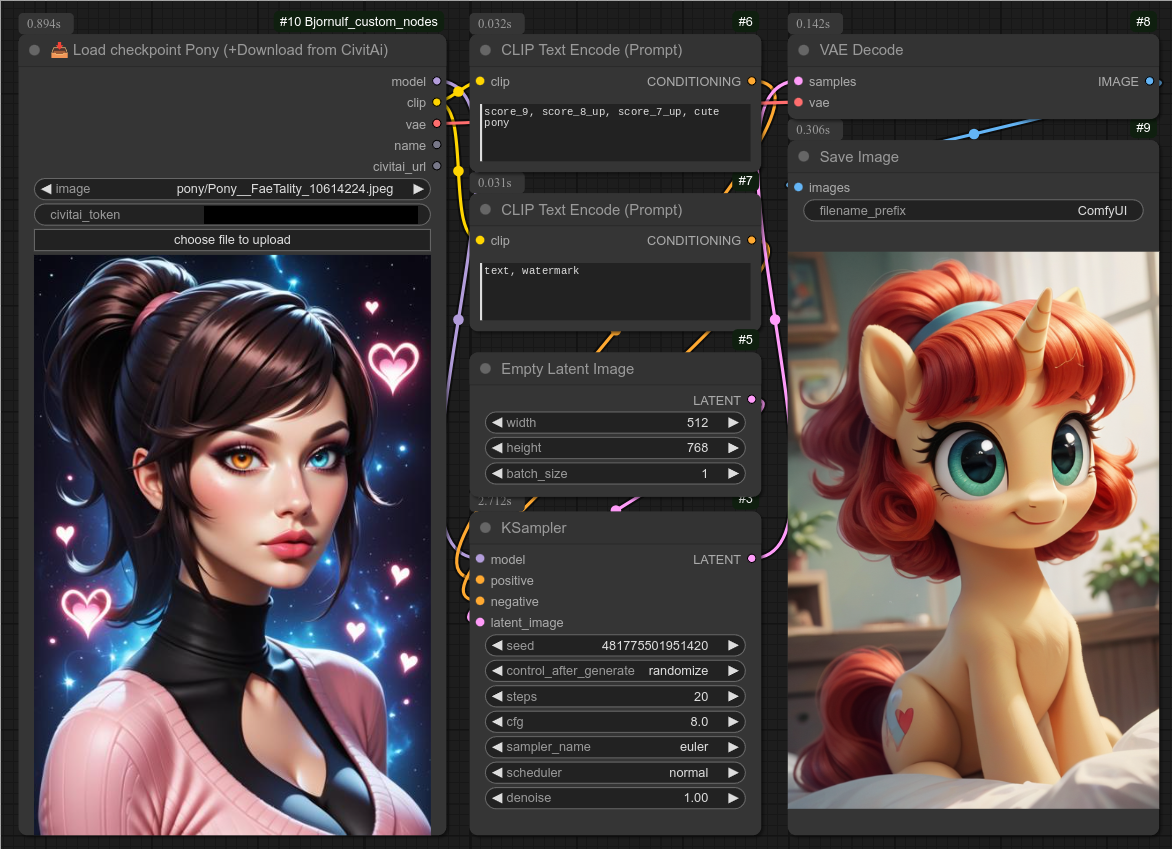
100 - 📥 加载Pony检查点(+从CivitAI下载)
描述:
这与基础的“加载检查点”节点相同,但其模型列表来自CivitAI(而非本地文件夹)。
如果你的电脑上还没有该模型,它还会从CivitAI自动下载。(你需要从自己的账户获取API令牌——可在CivitAI.com的设置中找到。)
这是pony版本,模型将被下载到:ComfyUI/models/checkpoints/Bjornulf_civitAI/pony
下载完成后,你可以继续使用此节点来加载检查点,或者通过基础的“加载检查点”节点使用已下载的模型。
101 - 📥 加载FLUX Dev检查点(+从CivitAI下载)
描述:
这与基础的“加载检查点”节点相同,但其模型列表来自CivitAI(而非本地文件夹)。
如果你的电脑上还没有该模型,它还会从CivitAI自动下载。(你需要从自己的账户获取API令牌——可在CivitAI.com的设置中找到。)
这是flux_d版本,模型将被下载到:ComfyUI/models/checkpoints/Bjornulf_civitAI/flux_d
下载完成后,你可以继续使用此节点来加载检查点,或者通过基础的“加载检查点”节点使用已下载的模型。
🚧 正在处理中,还需要手动清理列表、扩散器等……? 🚧
102 - 📥 加载FLUX Schnell检查点(+从CivitAI下载)
描述:
这与基础的“加载检查点”节点相同,但列表来自Civitai(而非本地文件夹)。
如果你的电脑上还没有该文件,它也会从Civitai下载。(你需要从你的账户获取API令牌——在civitai.com的设置中找到你的令牌。)
这是flux_s版本,它会将模型下载到:ComfyUI/models/checkpoints/Bjornulf_civitAI/flux_s
下载完成后,你可以继续使用此节点来加载你的检查点,也可以从一个基础的“加载检查点”节点中使用已下载的模型。
🚧 正在开发中,需要手动清理列表、diffusers等……? 🚧
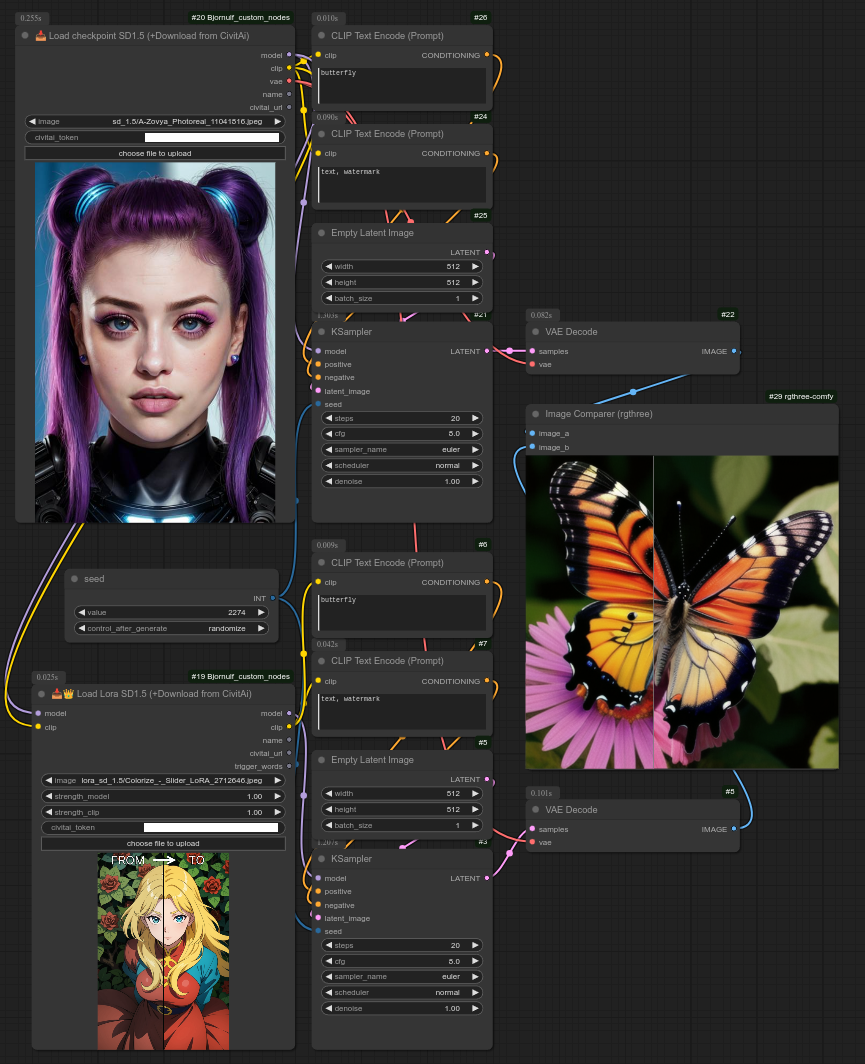
103 - 📥👑 加载Lora SD1.5(+从CivitAi下载)
描述:
这与基础的“加载Lora”节点相同,但列表来自Civitai(而非本地文件夹)。
如果你的电脑上还没有该文件,它也会从Civitai下载。(你需要从你的账户获取API令牌——在civitai.com的设置中找到你的令牌。)
这是sd_1.5版本,它将把Lora下载到:ComfyUI/models/loras/Bjornulf_civitAI/sd_1.5
下载完成后,你可以继续使用此节点来加载你的Lora,或者从一个基础的“加载Lora”节点中使用已下载的Lora。
以下是使用Lora“Colorize”的示例:
104 - 📥👑 加载Lora SDXL(+从CivitAi下载)
描述:
这与基础的“加载Lora”节点相同,但列表来自Civitai(而非本地文件夹)。
如果你的电脑上还没有该文件,它也会从Civitai下载。(你需要从你的账户获取API令牌——在civitai.com的设置中找到你的令牌。)
这是sdxl_1.0版本,它将把Lora下载到:ComfyUI/models/loras/Bjornulf_civitAI/sdxl_1.0
下载完成后,你可以继续使用此节点来加载你的Lora,或者从一个基础的“加载Lora”节点中使用已下载的Lora。
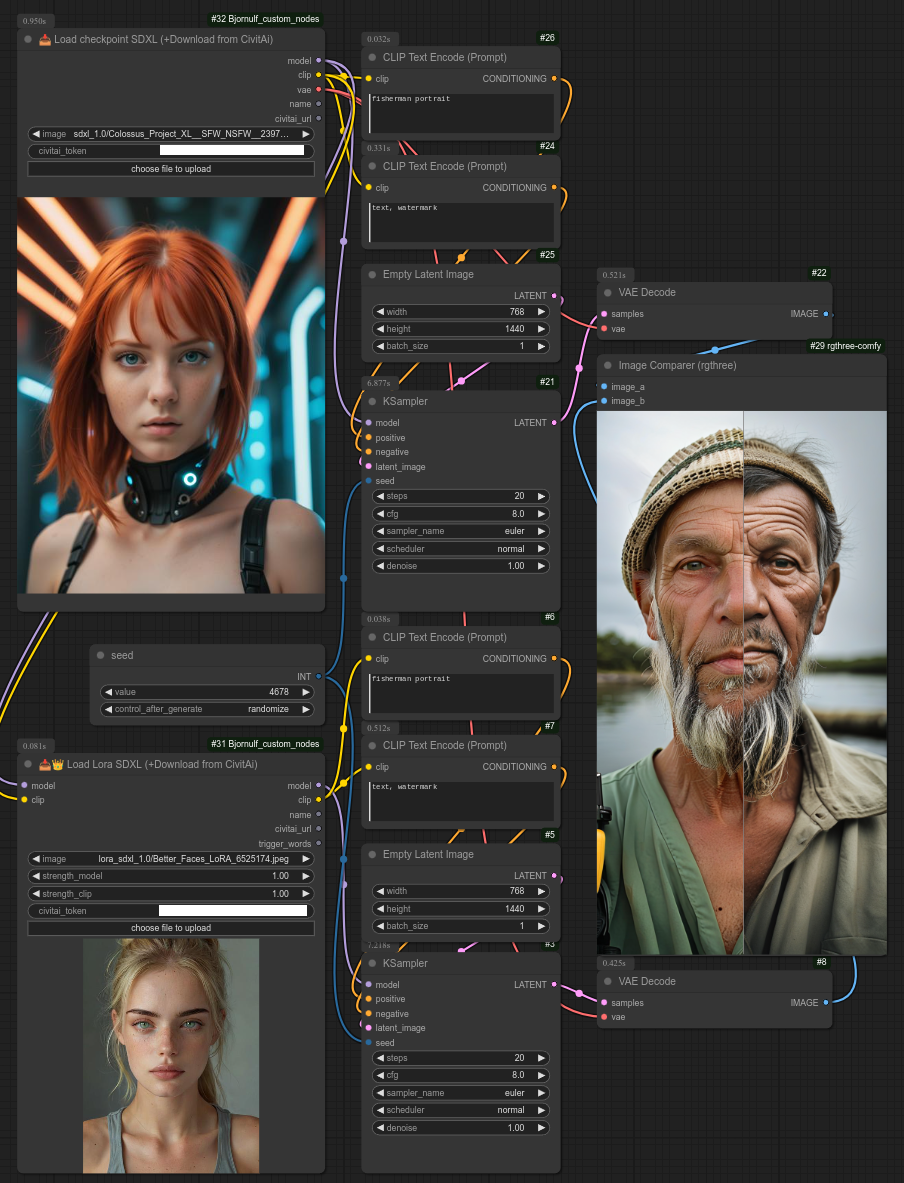
以下是使用Lora“Better faces”的示例:
105 - 📥👑 加载Lora Pony(+从CivitAi下载)
描述:
这与基础的“加载Lora”节点相同,但列表来自Civitai(而非本地文件夹)。
如果你的电脑上还没有该文件,它也会从Civitai下载。(你需要从你的账户获取API令牌——在civitai.com的设置中找到你的令牌。)
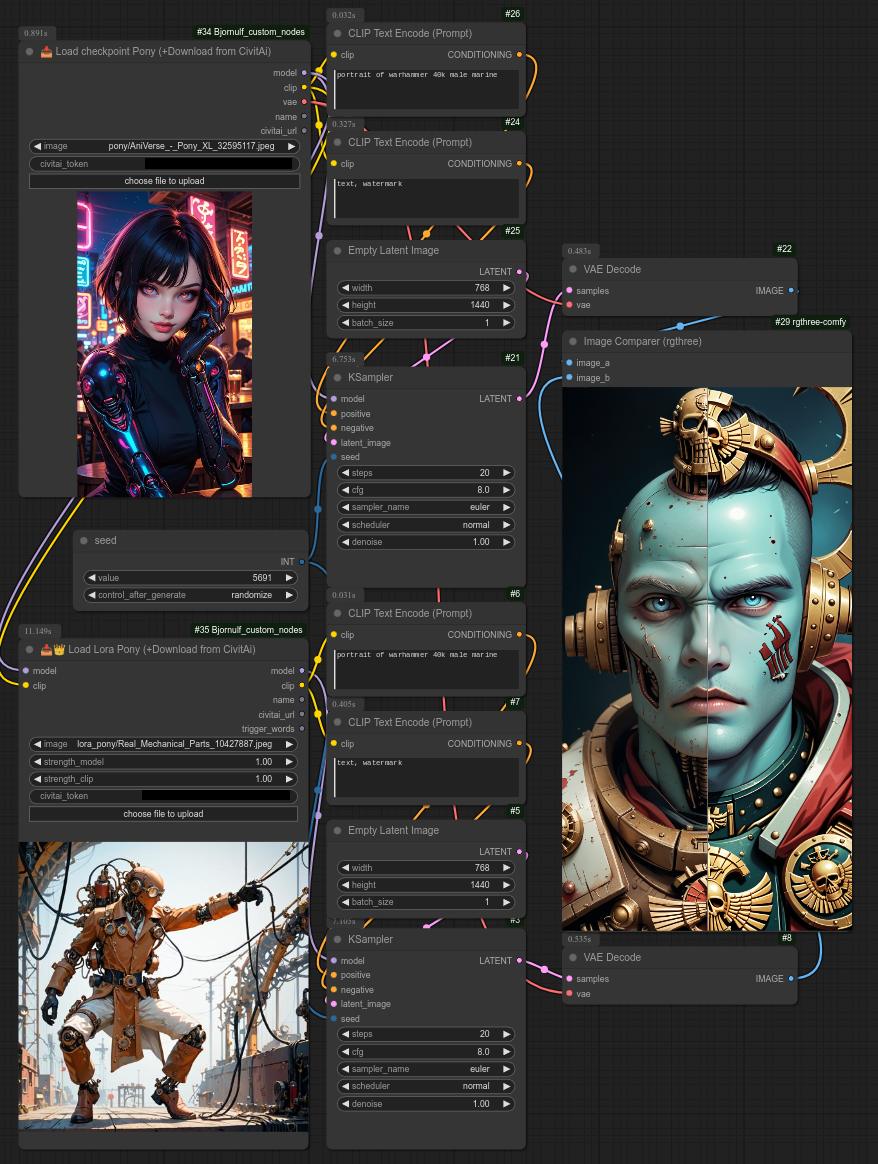
这是pony版本,它将把Lora下载到:ComfyUI/models/loras/Bjornulf_civitAI/pony
下载完成后,你可以继续使用此节点来加载你的Lora,或者从一个基础的“加载Lora”节点中使用已下载的Lora。
106 - ☁🎨 API图像生成器(FalAI)🎨☁
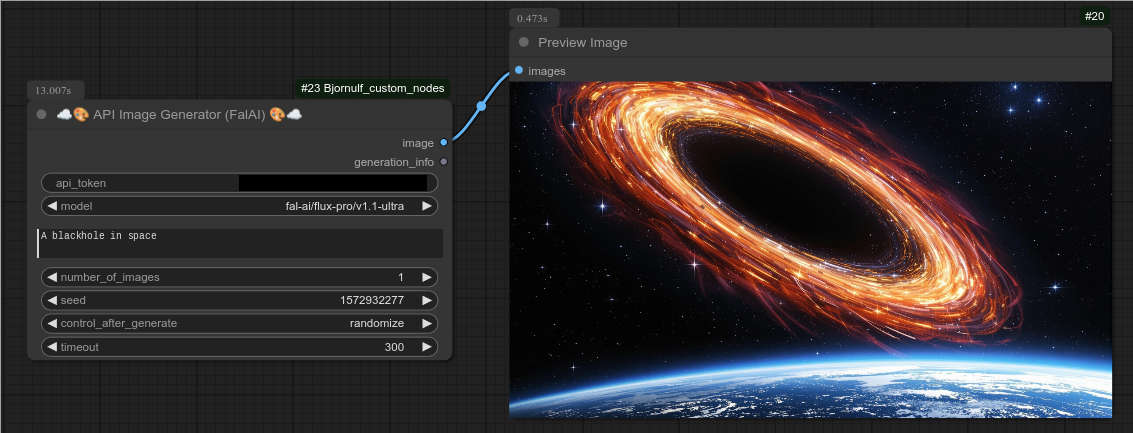
描述:
只需一个令牌即可生成图像。
这是fal.ai版本,生成的图像将保存在ComfyUI/output/API/CivitAI/目录下。
107 - ☁🎨 API图像生成器(CivitAI)🎨☁
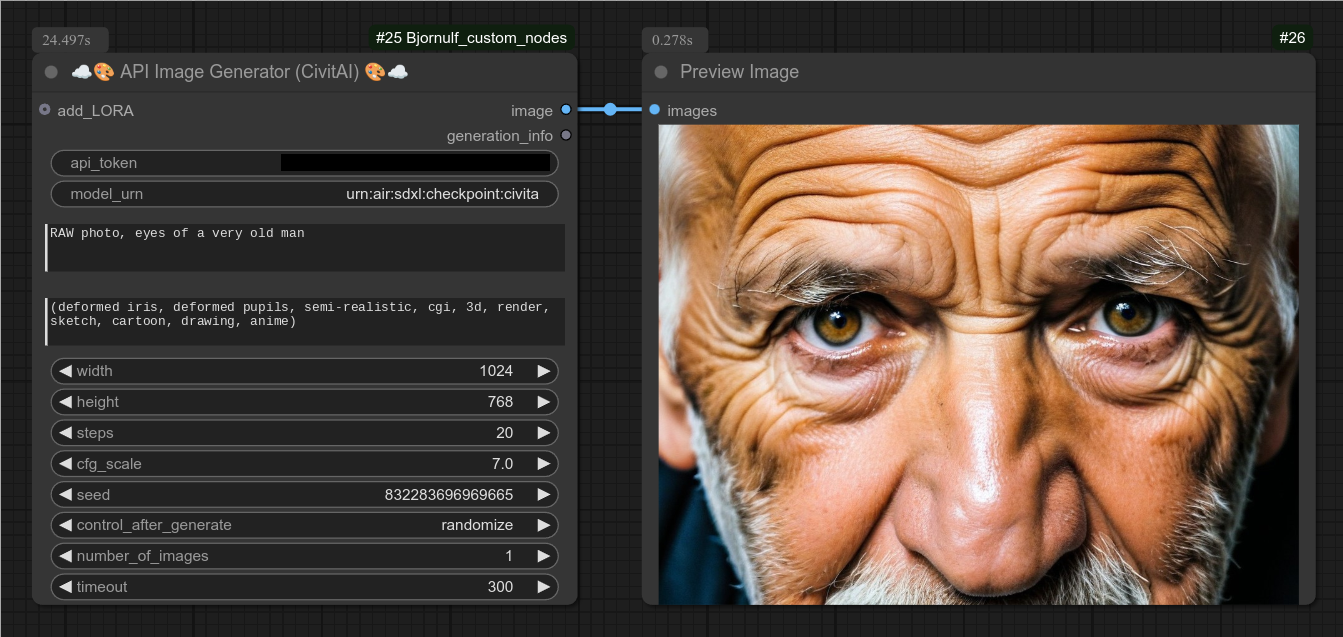
描述:
只需一个令牌即可生成图像。
这是civit.ai版本,生成的图像将保存在ComfyUI/output/API/CivitAI/目录下。
⚠️ 注意:Civitai并不是最可靠的API,有时无法响应,或响应时间过长,某些urn也比其他urn更不可靠等……
请自行承担风险使用,我不建议使用他们的API运行任何“昂贵”的任务,比如Flux Ultra等。(建议改用带有蓝色buzz的网站。)
此类API请求(如本节点中的请求)会消耗黄色buzz。
108 - ☁👑 添加Lora(仅限API - CivitAI)👑☁
描述:
通过API使用Lora,以下是一个示例,清晰地展示了使用和不使用Lora时的差异。
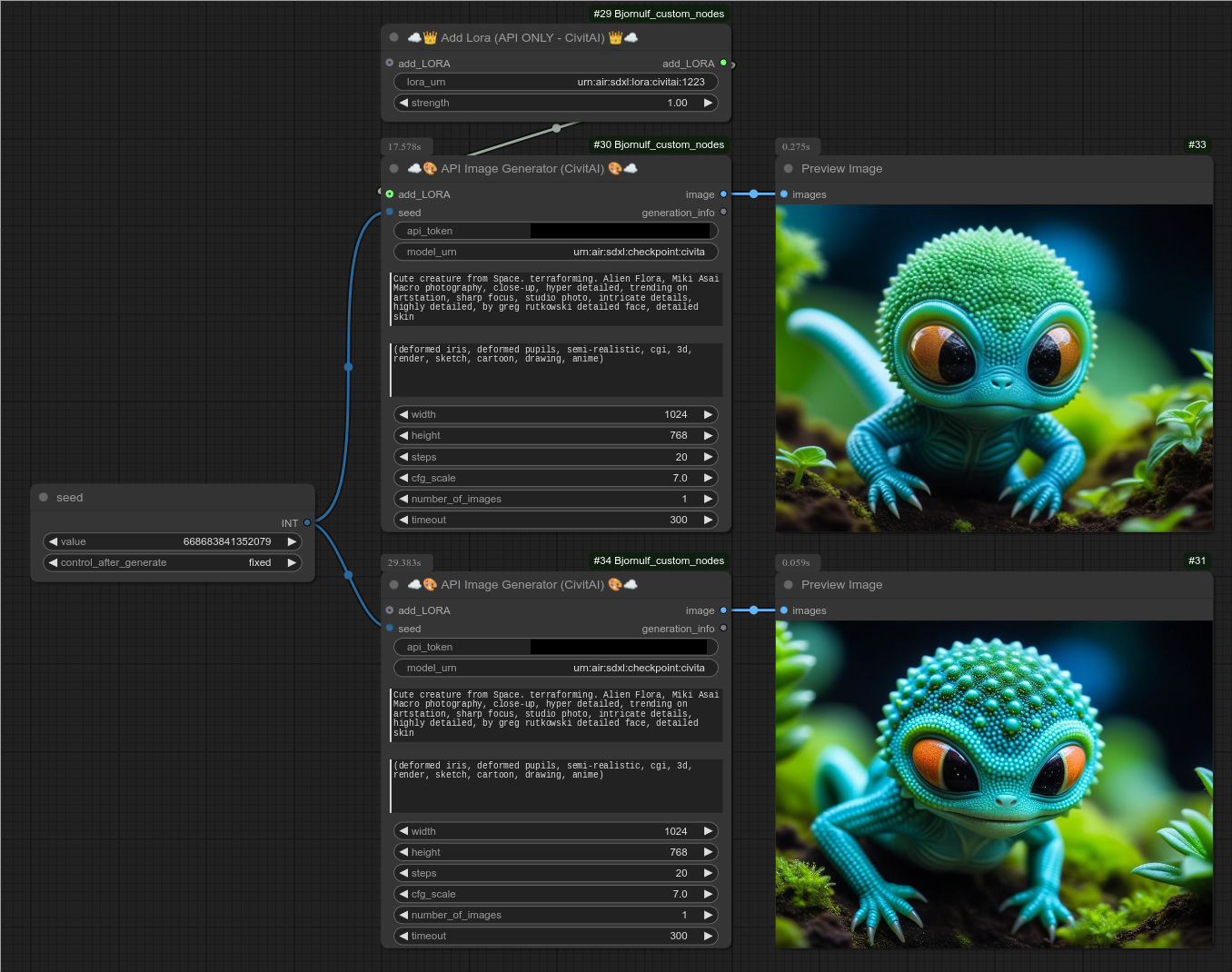
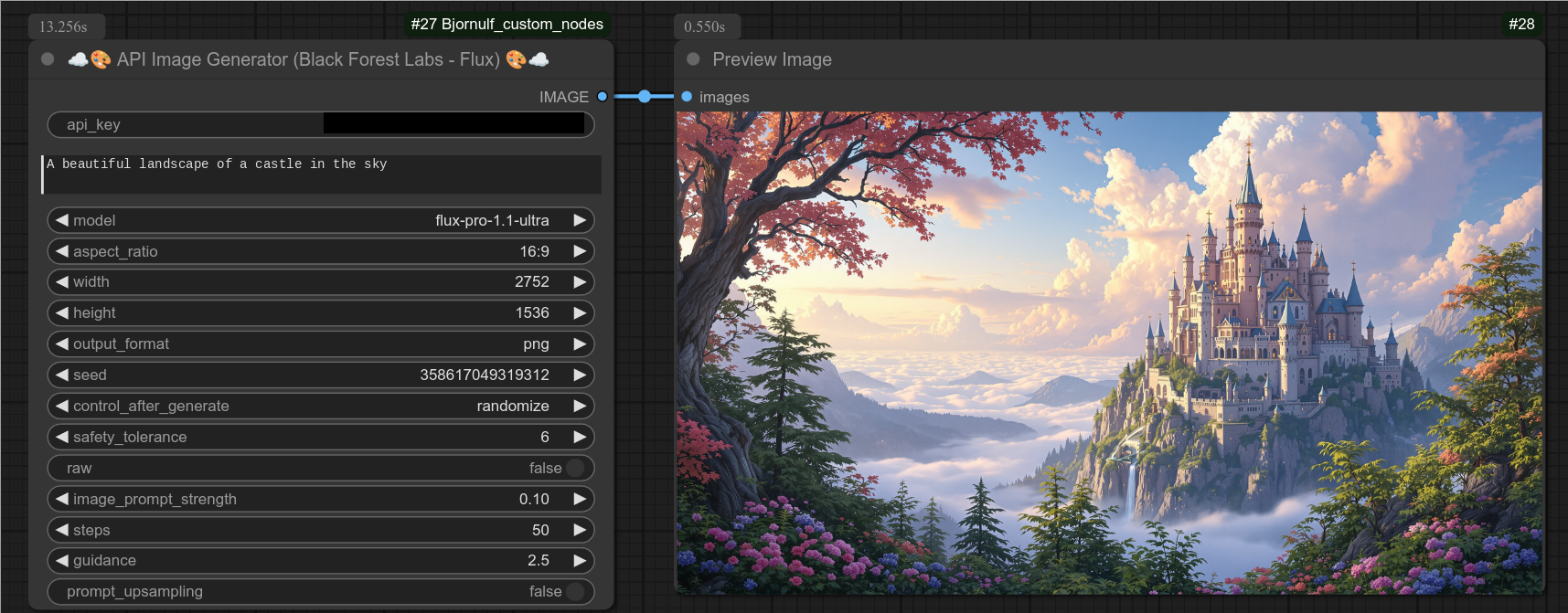
109 - ☁🎨 API图像生成器(Black Forest Labs - Flux)🎨☁
描述:
使用Black Forest Labs的API生成一张图像。(flux)
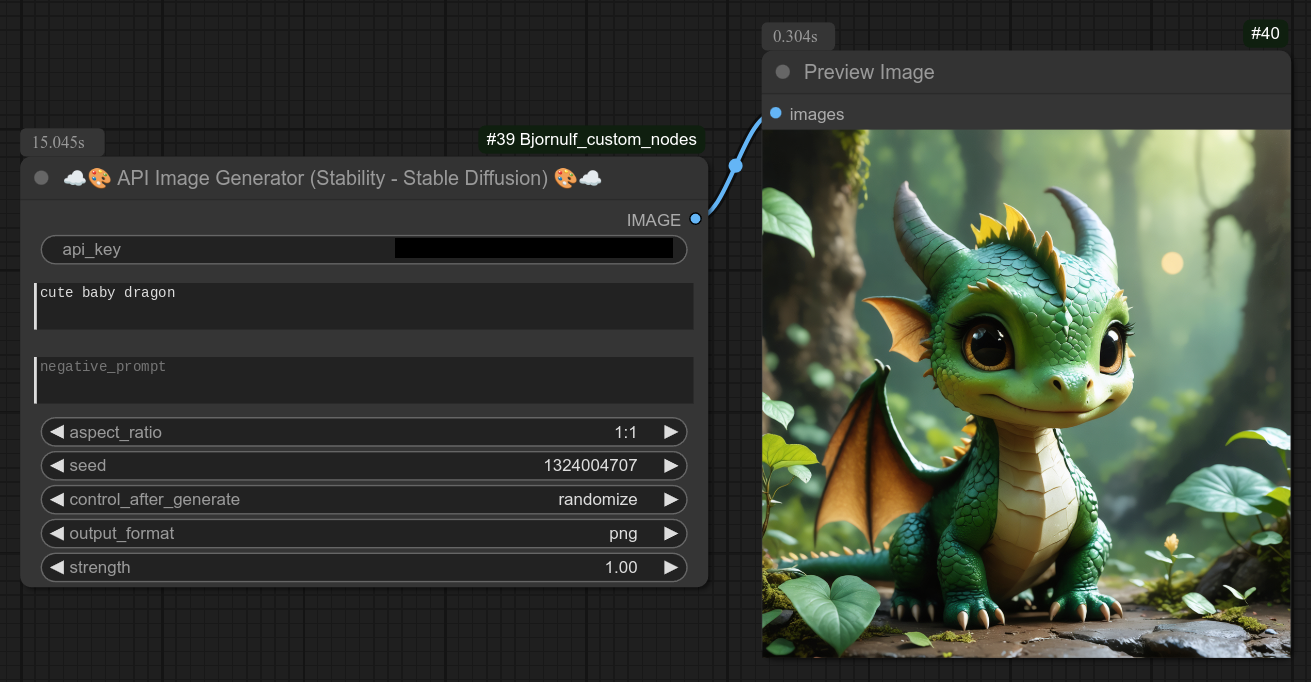
110 - ☁🎨 API图像生成器(Stability - Stable Diffusion)🎨☁
描述:
使用Stability的API生成一张图像。(sd3)
111 - ✨➜🔢 任意值转整数
描述:
只需将任意值转换为有效的整数。
112 - ✨➜🔢 任意值转浮点数
描述:
只需将任意值转换为有效的浮点数。
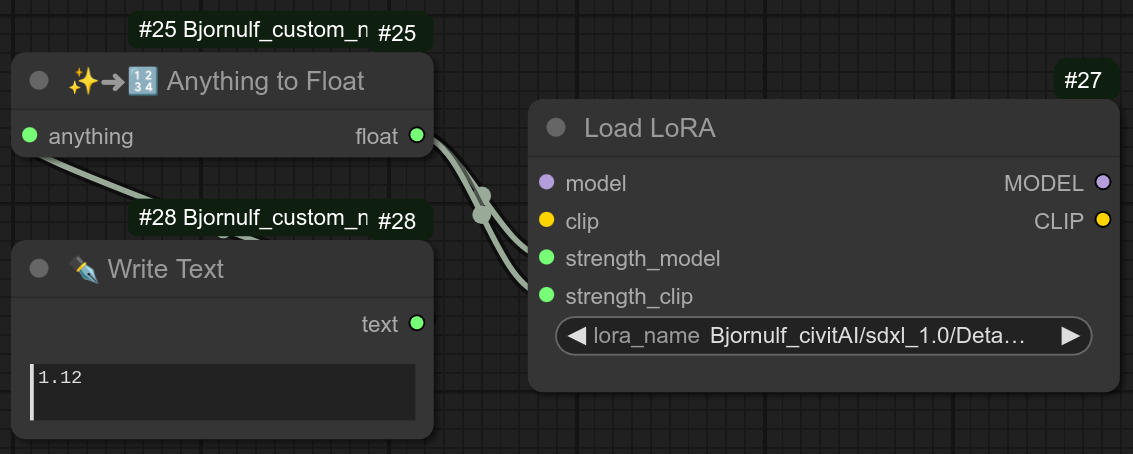
113 - 📝🔪 文本按5份分割
描述:
接收单个输入,并将其按分隔符(默认为换行符)分割成5份。
如果使用“变量类型格式”,它还可以忽略=符号左侧的所有内容。
114 - 📥👑 按路径加载Lora
描述:
通过指定路径加载Lora。
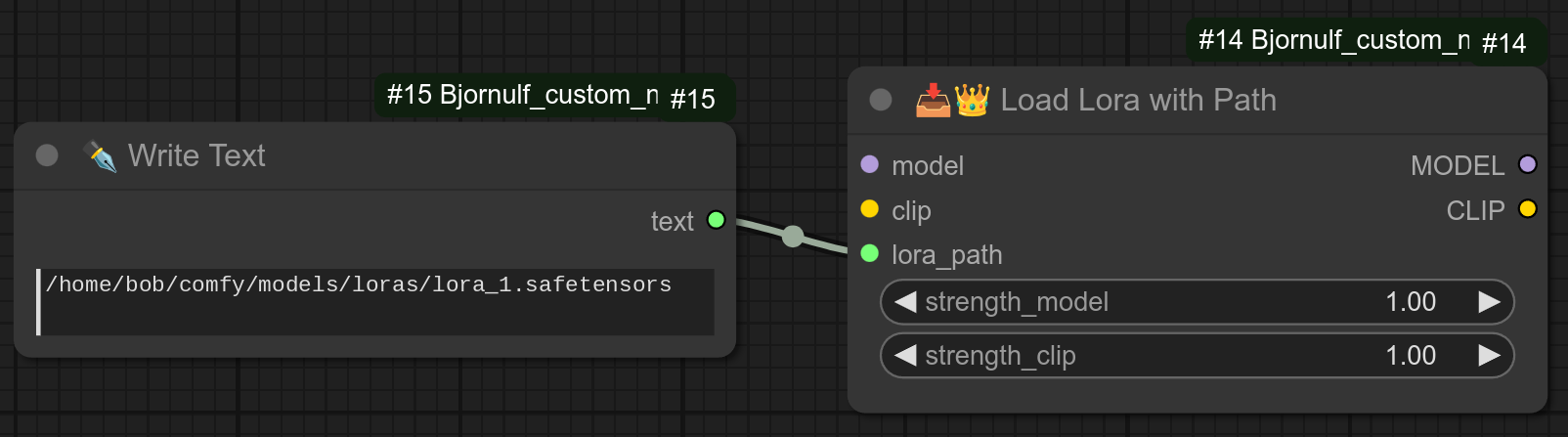
这里有一个结合节点113、114和112的复杂实际示例: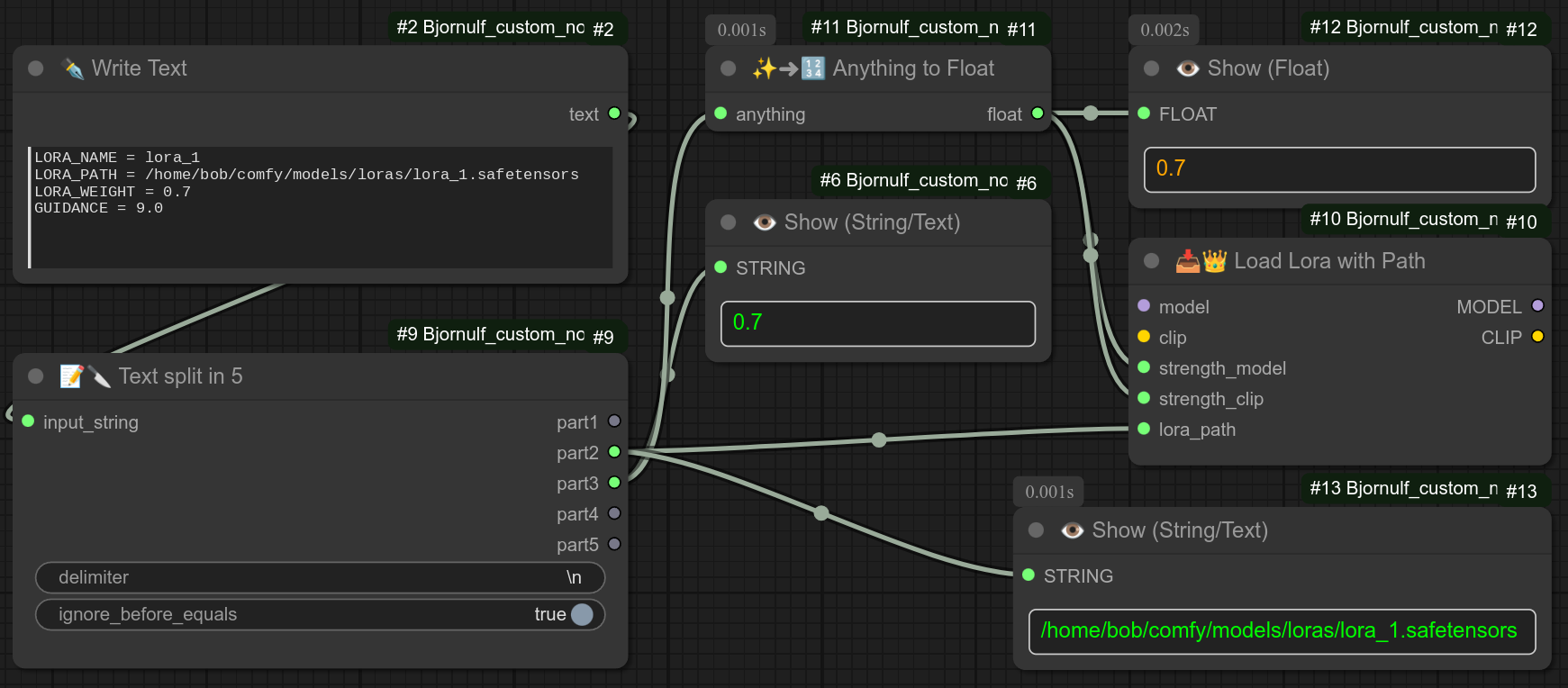
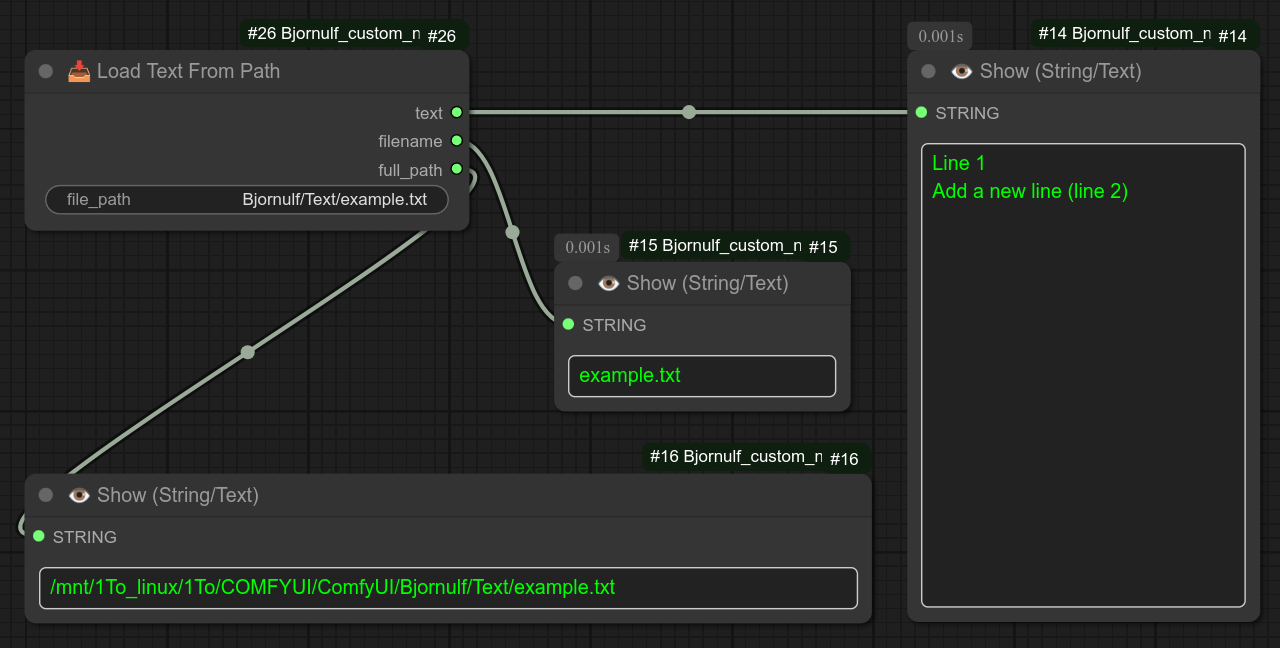
115 - 📥 从Bjornulf文件夹加载文本
描述:
只需从Bjornulf/Text文件夹中选择一个文件,即可恢复其内容。
它设计用于与节点15“保存文本”一起使用。
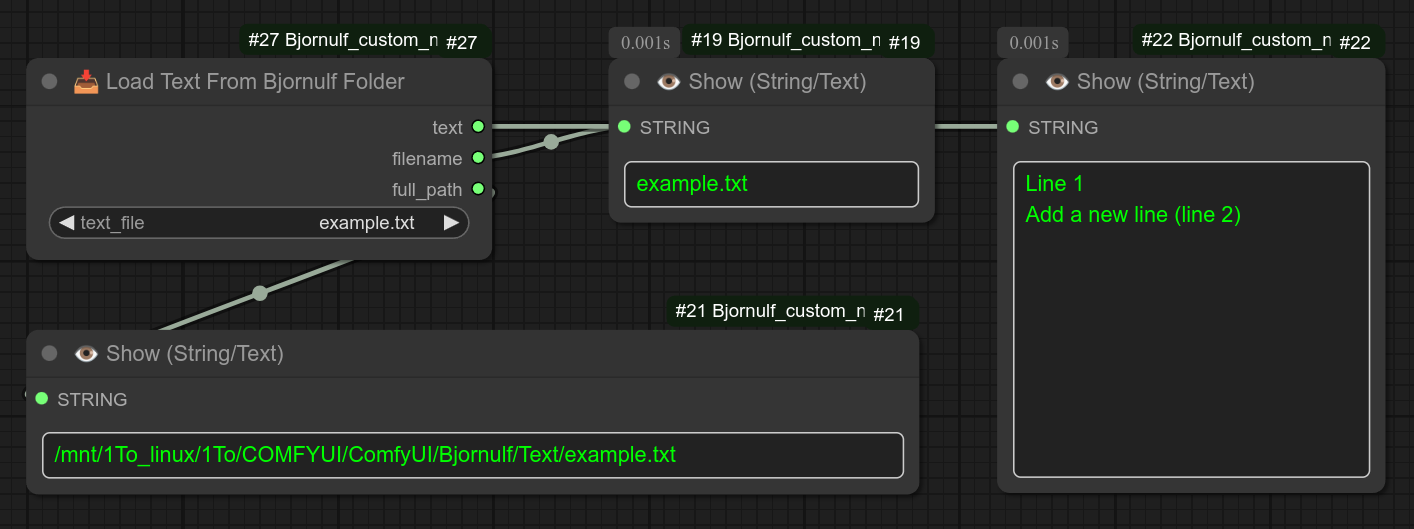
116 - 📥 从路径加载文本
描述:
只需提供文件的路径,即可恢复其内容。
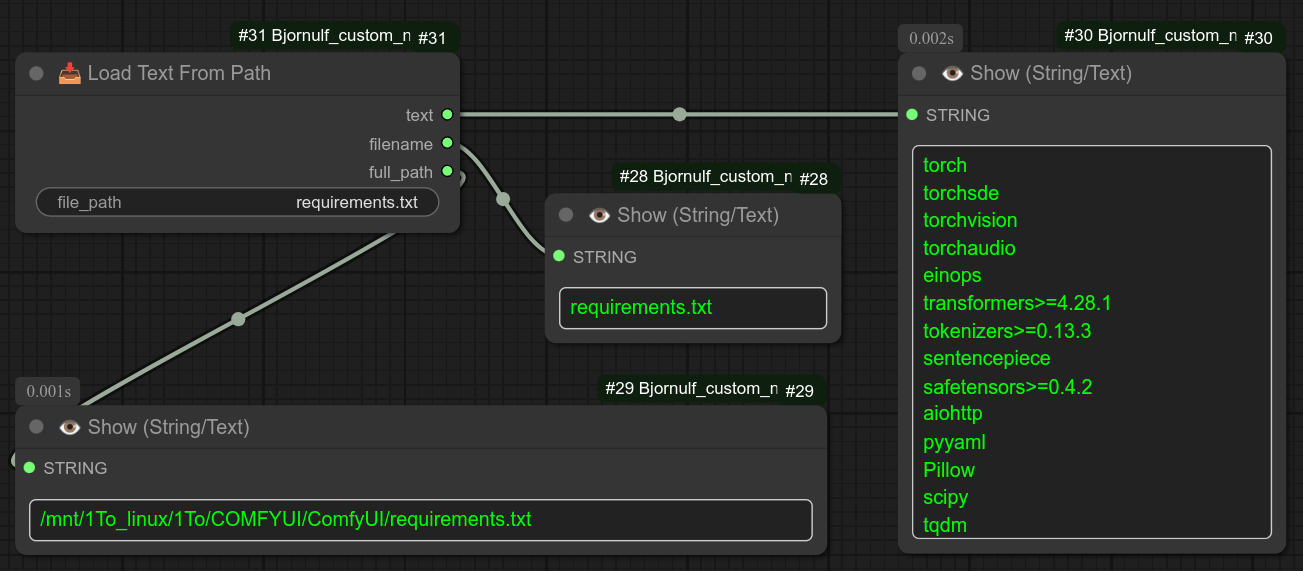
如果你愿意,使用“从路径加载文本”也可以通过添加路径来恢复“Bjornulf/Text”中的内容:
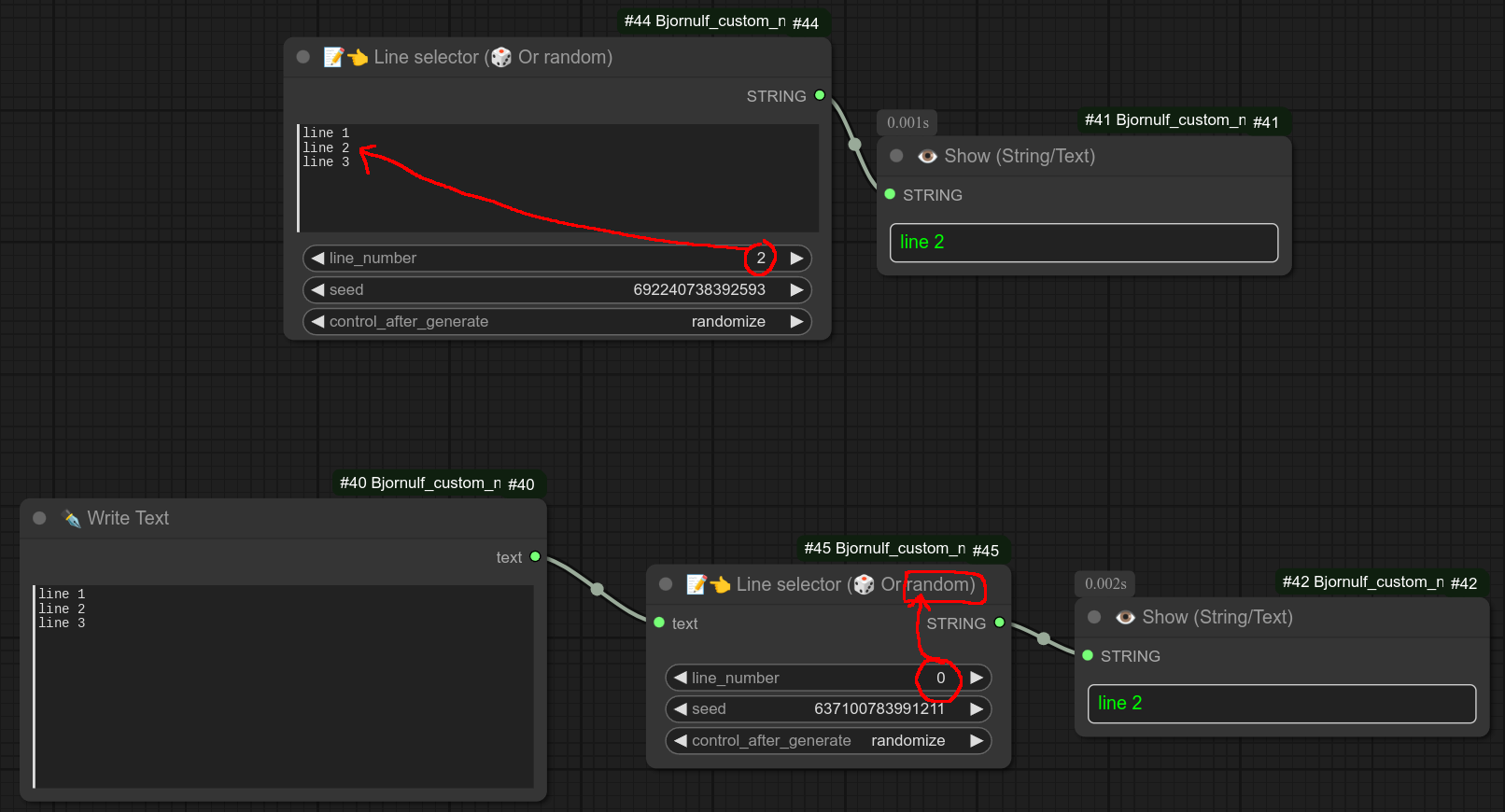
117 - 📝👈🅰️ 行选择器(🎲 或 ♻ 或 ♻📑)
描述:
从输入文本中选择一行。如果设置为0,则会随机选择一行。
如果随机选择的一行以#符号开头,则不会被选中。因此,如果你想跳过某一行,可以使用此功能。
❗ 0.76 - 新语法可用:
分组,无重复,例如:{left|right|middle|group=LMR}+{left|right|middle|group=LMR}+{left|right|middle|group=LMR}
基于百分比的随机:{A(80%)|B(15%)|C(5%)}
❗ 0.77 - 新语法可用:
2个{apple|orange|banana|static_group=FRUIT}s,左边一个{apple|orange|banana|static_group=FRUIT}, 右边一个{apple|orange|banana|static_group=FRUIT}
118 - 🔊 TTS配置⚙
描述:
一个新的可选配置节点,用于连接到TTS节点,它可以请求给定语言的扬声器列表,并在主TTS节点中替换:
- URL。
- 语言。
- 扬声器。
仅当你想用配置节点中的信息替换主TTS节点中的信息时,才进行连接。
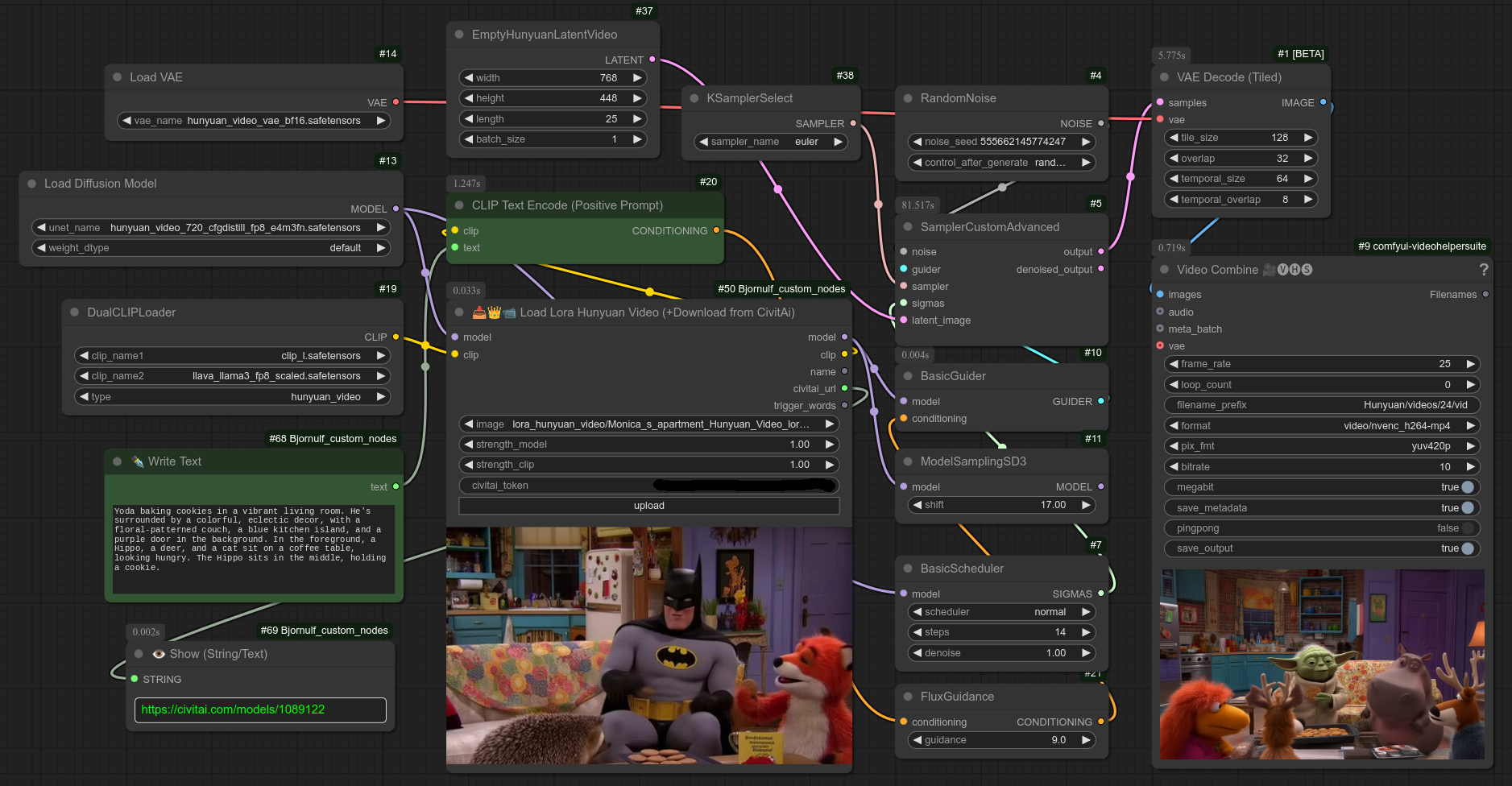
119 - 📥👑 加载Hunyuan Video的Lora(+从CivitAi下载)
描述:
使用CivitAI的Lora来配合Hunyuan使用。(当然,NSFW列表不在github上。)
以下工作流已包含:workflows/HUNYUAN_basic_lora.json):
120 - 📝➜🔊 Kokoro - 文本转语音
描述:
❗ 0.76 - 由于与其他自定义节点存在一些兼容性问题,现在若要使用该节点,需要手动安装:pip install kokoro_onnx
另一个基于Kokoro的文本转语音节点。: https://github.com/thewh1teagle/kokoro-onnx
轻量级、更简单、无需配置,并且完全集成到Comfyui中。(无需运行外部后端。)
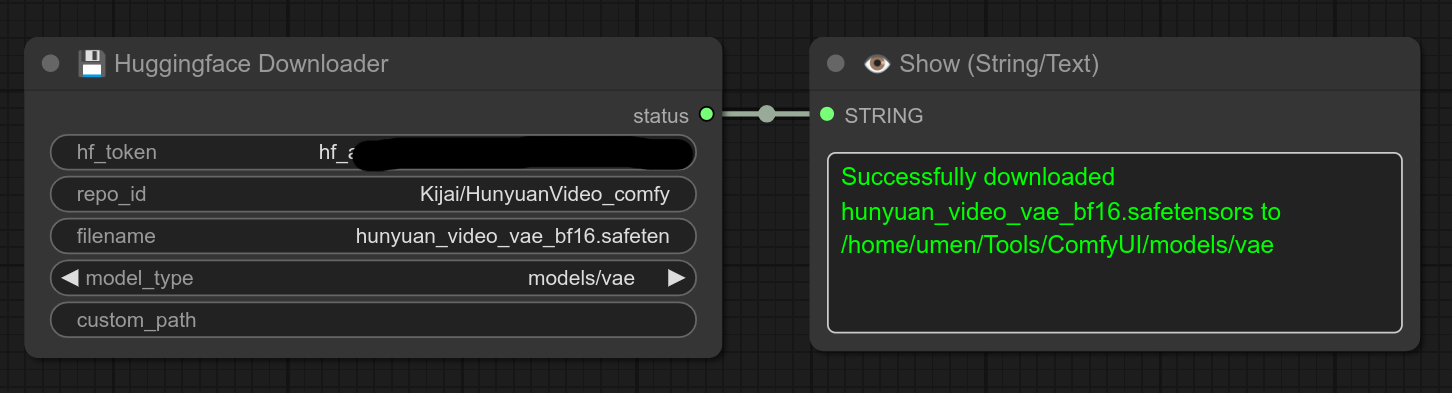
121 - 💾 Huggingface 下载器
描述:
此节点允许您使用访问令牌直接从Huggingface下载模型/VAE/UNet等。
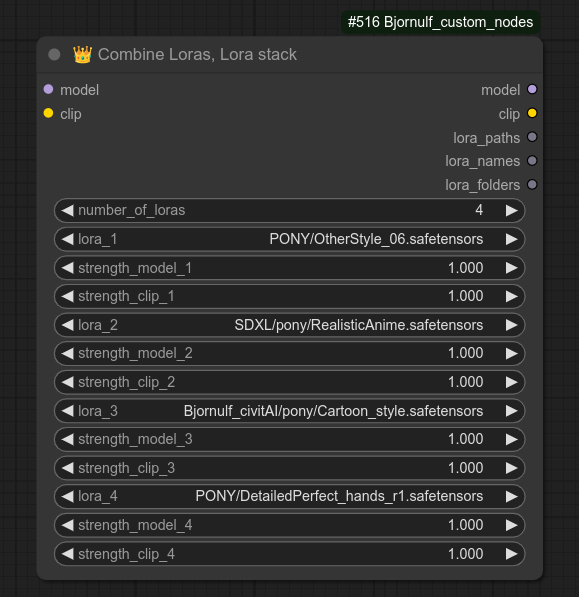
122 - 👑 合并LoRA,LoRA堆栈
描述:
如果您希望在一个节点中同时使用多个LoRA,那么这就是您需要的节点。
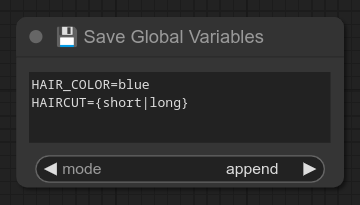
123 - 💾🅰️ 保存全局变量
描述:
如果您知道如何在我的节点中使用变量,那么这个节点可以让您创建全局变量。
这个节点非常简单,它只会追加(或覆盖)文件:Bjornulf/GlobalVariables.txt(如果您愿意,也可以手动编辑该文件。)
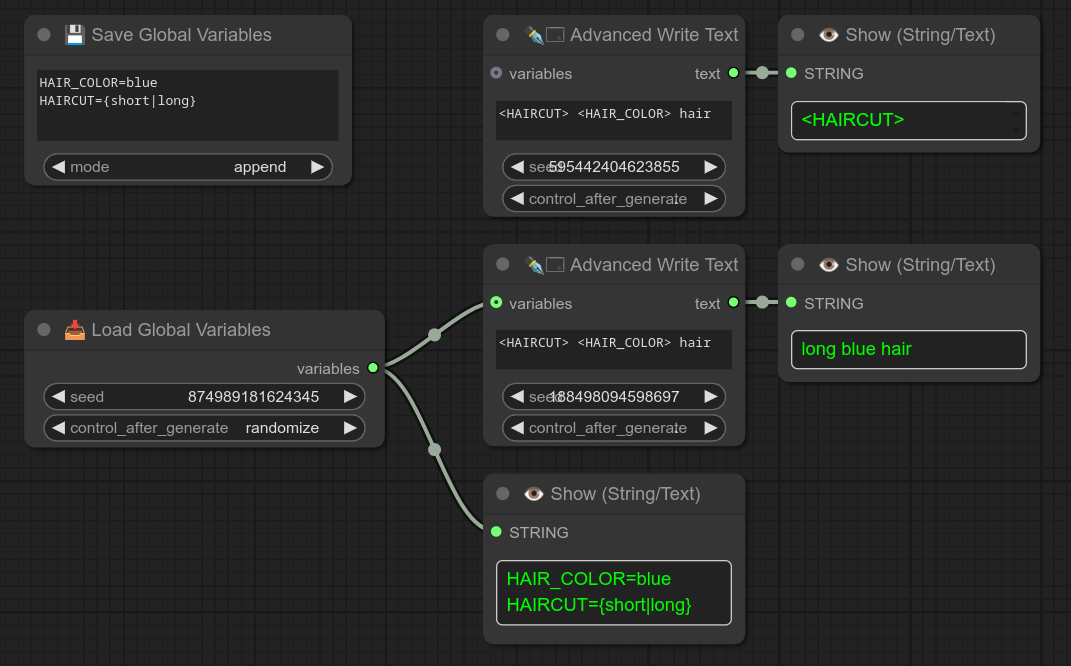
124 - 📥🅰️ 加载全局变量
描述:
此节点会从文件Bjornulf/GlobalVariables.txt中加载全局变量文本。
以下是保存和加载的使用示例:
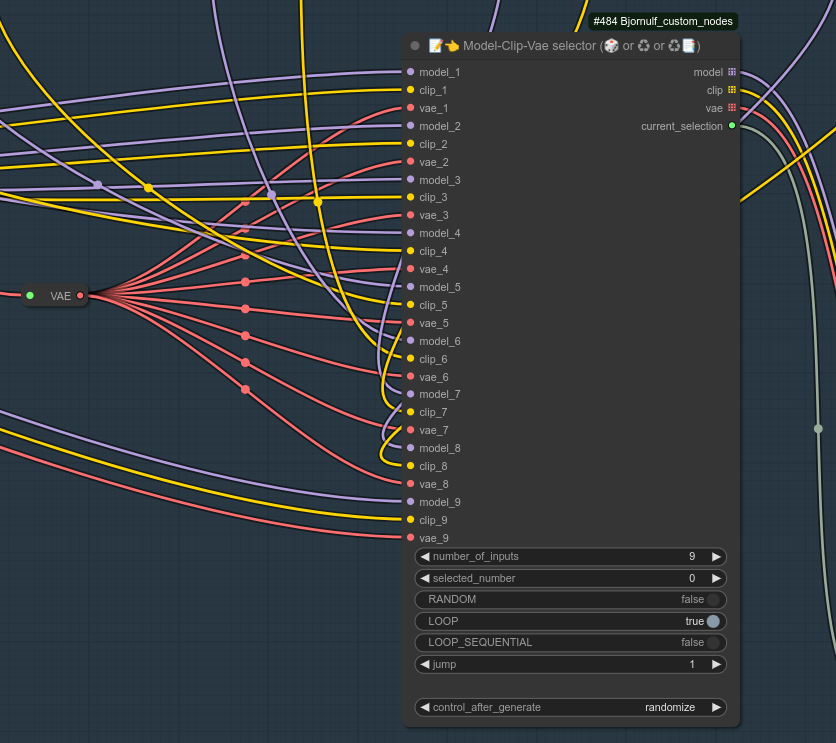
125 - 📝👈 模型-CLIP-VAE选择器(🎲 或 ♻ 或 ♻📑)
描述:
如果您想使用和管理多个模型/CLIP/VAE,那么这就是通用的选择器节点。
您可以将它们以循环模式运行,随机选择一个,按顺序循环(每次运行工作流时依次使用一个),甚至可以选择特定的一个。
126 - 📒 备注
描述:
有时我想添加一个备注,但又希望这个备注与特定的连接线关联在一起。
因此,您可以使用此节点来记录某个特定连接的详细信息,它会随着连接线一起移动。
当然,您也可以随意使用它,下面是一个关于HunYuan视频生成的例子。(您可以根据想要运行的内容,快速切换与其他部分的工作流连接。)
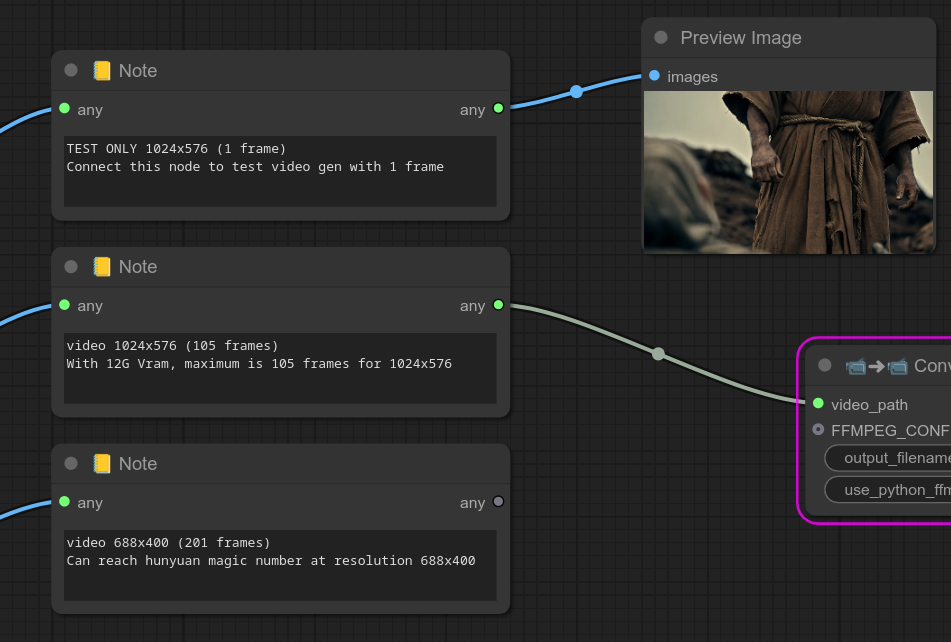
127 - 🖼📒 图像备注
描述:
您可以使用此节点来显示之前生成的一张图像以及一些自定义文本。(使用image_path或IMAGE类型。)
您可以用文本展示生成该图像所使用的提示词,例如。
它的行为类似于“预览图像”节点。(如果您想要类似“加载图像”的行为,请参阅第130个节点。)
有时我想要展示一张图像,以便直观地解释某件事的作用。(例如,一组LoRA叠加会有特定的风格。)
这里有一个复杂的例子,说明我是如何使用它的,用于展示一系列LoRA叠加效果。(然后我通过使用节点125 - 模型-CLIP-VAE选择器来“选择”一种风格。)
0.77 在较新的Comfyui版本中,多行文本+图像现在成为了一个问题。已被单行备注取代,因为找不到干净的JavaScript方法来解决布局问题……
128 - 🖼👁 预览(第一)张图像
描述:
此节点可以显示一张图像的预览……
- 但它也可以接收一组图像,并仅预览第一张图像。(这对于视频非常有用,它会提取第一帧。)
- 它还可以接受完整的图像路径作为输入。
- 但它同样可以接受视频路径作为输入,并从中提取第一帧。
在处理视频时进行测试时非常有用。
以下是刚才所述内容的可视化示例:
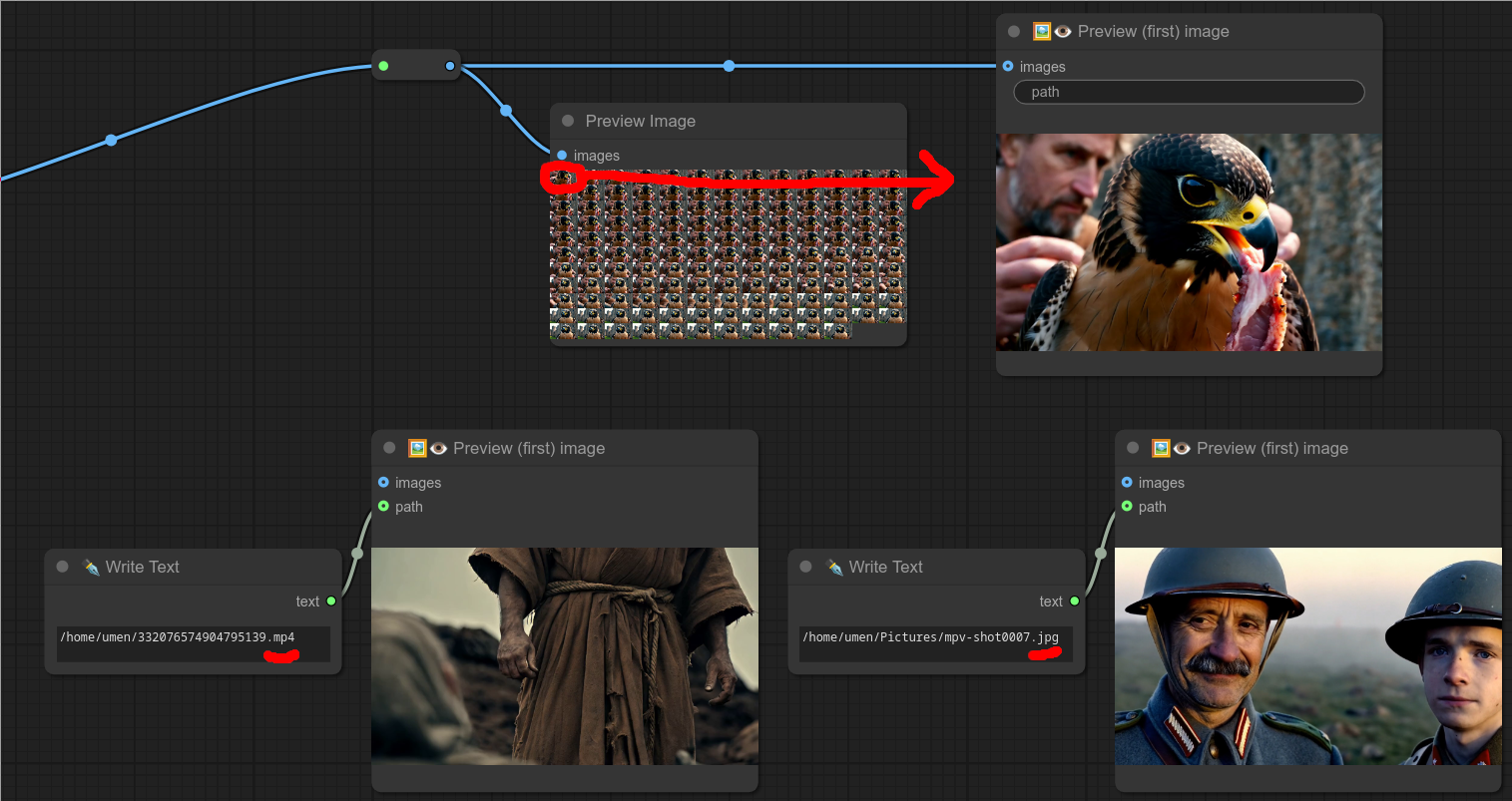
0.77 在较新的Comfyui版本中,多行文本+图像现在成为了一个问题。已被单行备注取代,因为找不到干净的JavaScript方法来解决布局问题……
129 - 📌🅰️ 从文本设置变量
描述:
此节点会快速将一段文本转换为另一种文本,这种文本可以被我的所有变量节点快速使用。
下面是一个使用“高级写文本”的例子,但您也可以将其用于其他所有节点,包括全局变量等。
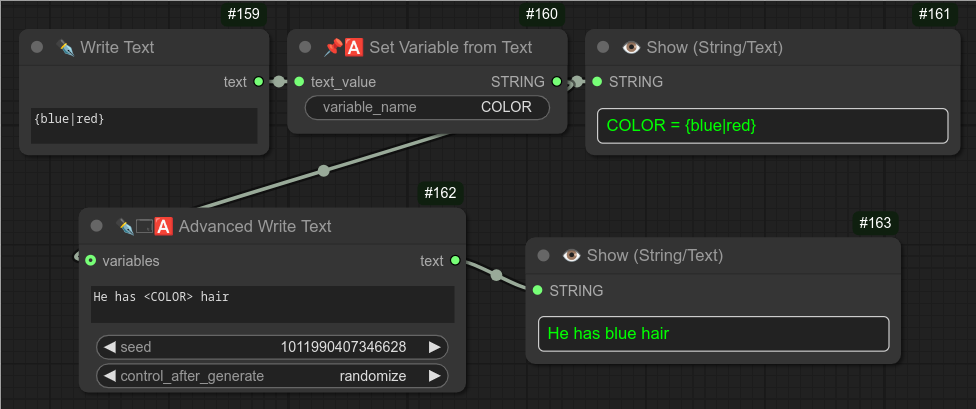
130 - 📥🖼📒 图像备注(加载图像)
描述:
此节点与第127个节点非常相似。但不同的是,它使用的是“加载图像”功能,而不是预览系统。
因此,如果您希望在启动工作流之前先进行一次“预览”,就可以使用此节点。
它的行为类似于“加载图像”节点。
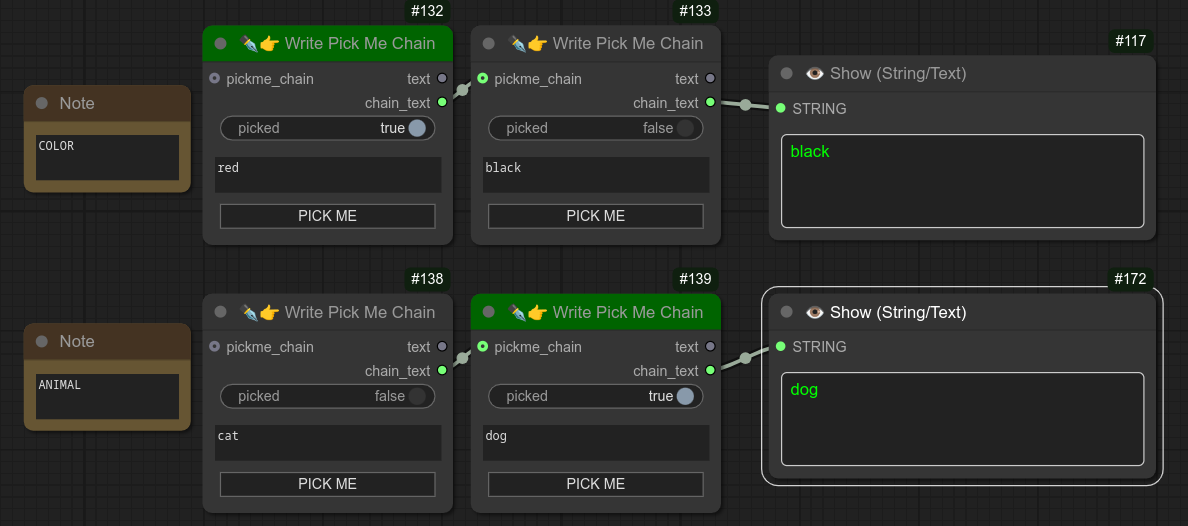
131 - ✒👉 写作挑选链
描述:
这是一个全新的“写文本”节点。
但有一点特别之处:您可以将这些节点相互连接起来,当您点击“PICK ME”按钮时,它会禁用链条中的其他所有“写文本”节点,只激活您点击的那个节点(该节点会变成绿色)。
因此,通过这个节点,您只需轻轻一按,就能在不同的提示词之间切换!
不限于一行,您还可以使用列表、变量等,但下面是一个简单的例子:
132 - 📝🔪 文本分成10份
描述:
与第113个节点相同,但这次是分成10份。
有一天我有6份,结果卡在了分成5份的节点上,所以我觉得有时候分成10份可能更有用,那就做一个分成10份的吧……
133 - 🖼👁 预览1-4张图像(比较)
描述:
这是一个很酷的节点,您可以用来比较几张图像。
中间有一个光标,您只需点击图像即可将其移动到任何位置。
下面是一个例子,在这个尺寸/分辨率下,25%的效果几乎与原始图像一样好。
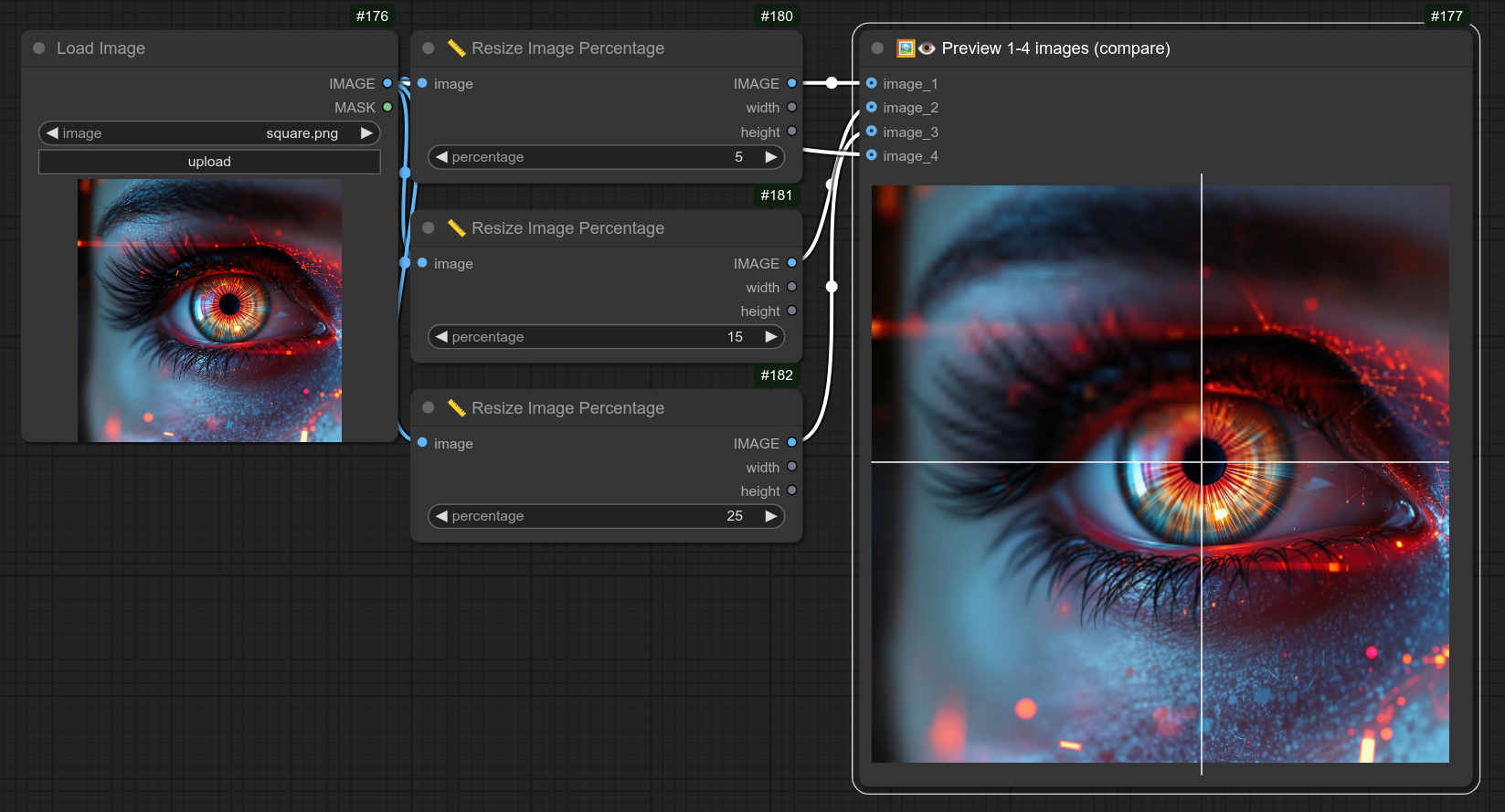
这里是同一张图像的放大图:

134 - 🔊▶ 播放音频
描述:
此节点只会播放一声铃声。
例如,如果您的工作流需要一段时间才能完成,而您希望每次完成时都能收到提醒。

您可以连接一个自定义的音频文件路径:

或者发送一个AUDIO类型的格式:
135 - 🔛✨ 任意开关开启/关闭
描述:
一个基本的开关,如果关闭则不会输出任何内容。
下面是一个与兼容的“合并图像节点”结合的例子,您可以看到顶部的图像被忽略了。
136 - 🔛📝 文本开关开启/关闭
描述:
是否厌倦了暂时断开不需要的节点?
也许你正在处理某个输入,但你的工作流尚未准备好接收它?
现在你可以快速启用或禁用它。(禁用时,节点会显示为红色。)
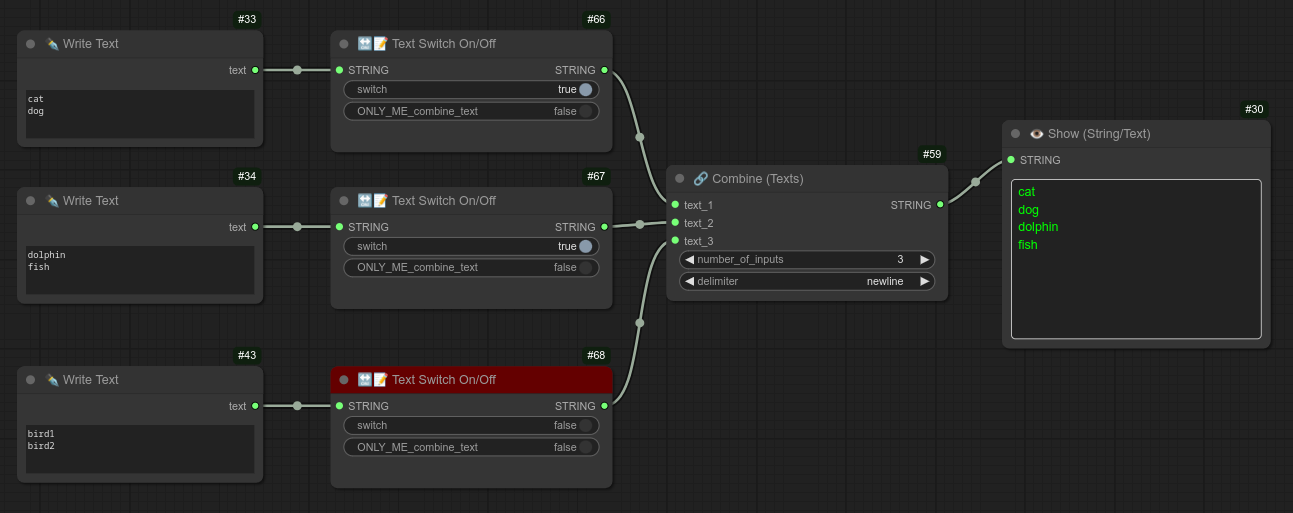
如果与我的文本合并节点连接,你可以使用一个特殊选项 ONLY_ME_combine_text,它会指示文本合并节点仅输出被选中的节点内容,而忽略其他所有节点。(此时该节点会显示为蓝色。):
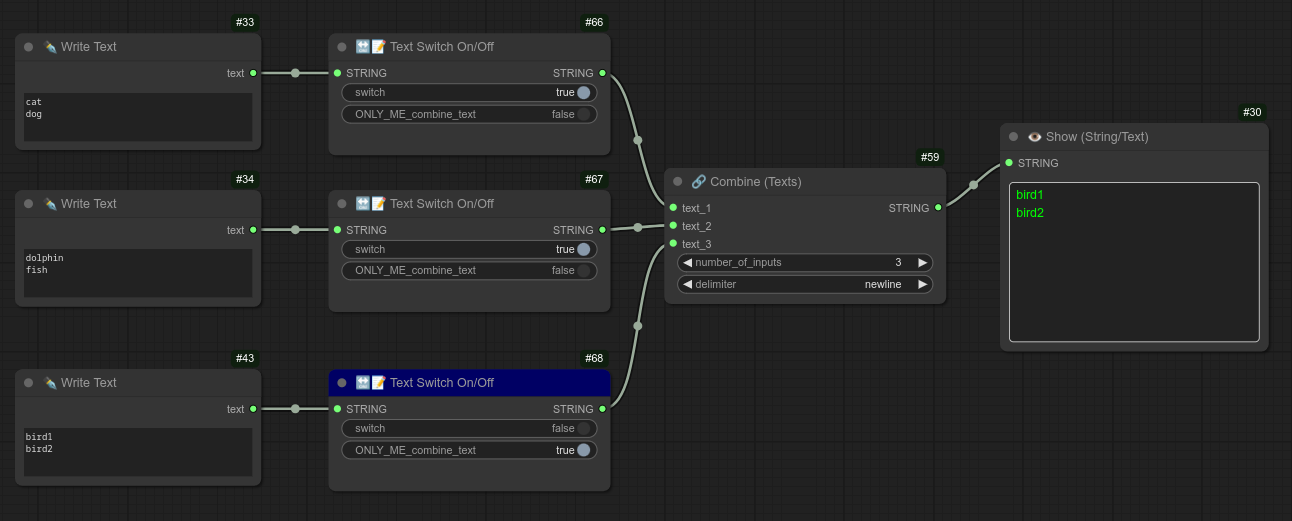
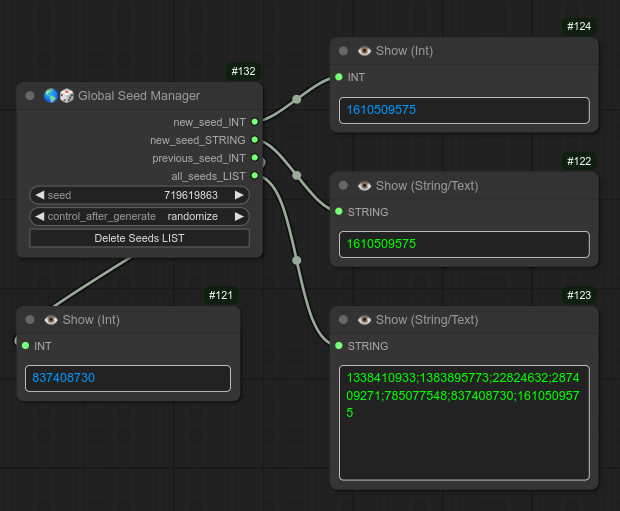
137 - 🌎🎲 全局种子管理器
描述:
种子管理器。
它的功能包括:
- 每次运行时生成一个随机种子。
- 返回当前种子作为字符串,供其他支持字符串格式的节点使用。
- 返回上一次使用的种子值。
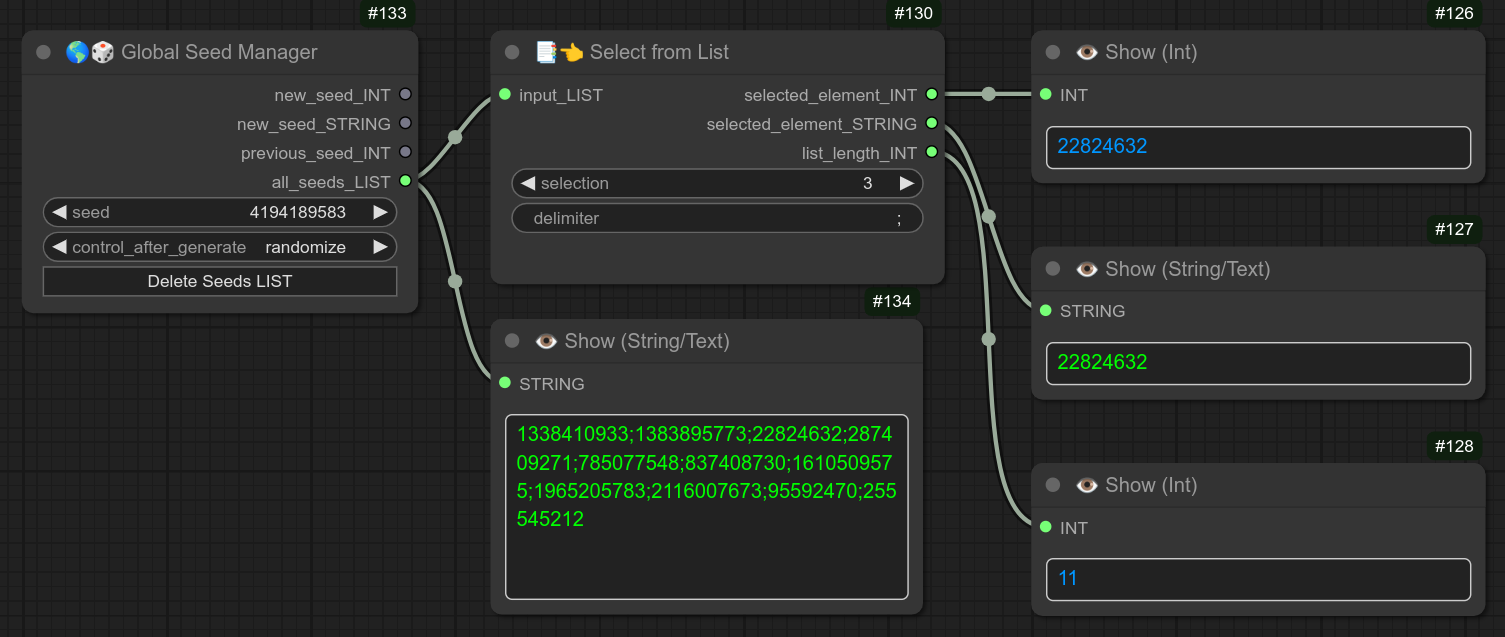
- 将所有已使用的种子保存到文件中(可通过按钮重置)。 若想从该列表中选择种子,请使用节点 138。
138 - 📑👈 从列表中选择
描述:
快速从列表中选择一个元素。(默认情况下,列表是以分号分隔的字符串。) 例如:a;b;c;d
以下示例展示了如何快速选择全局种子管理器所使用的第三个种子:
139 - 🎲 随机整数
描述:
简单地返回两个指定值之间的整数。
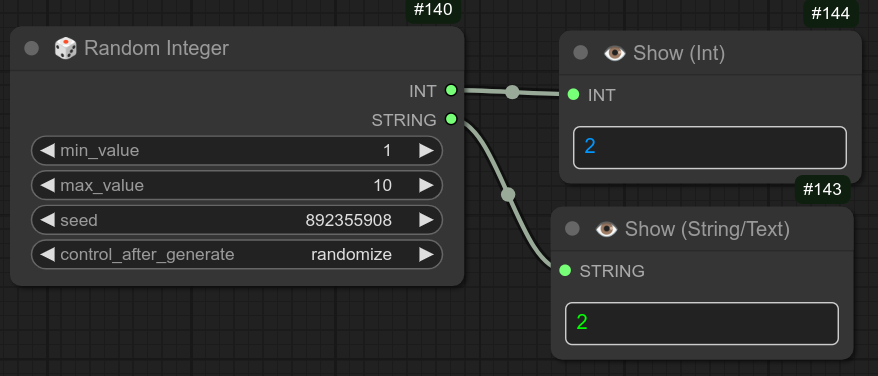
140 - 🎲 随机浮点数
描述:
简单地返回两个指定值之间的浮点数。
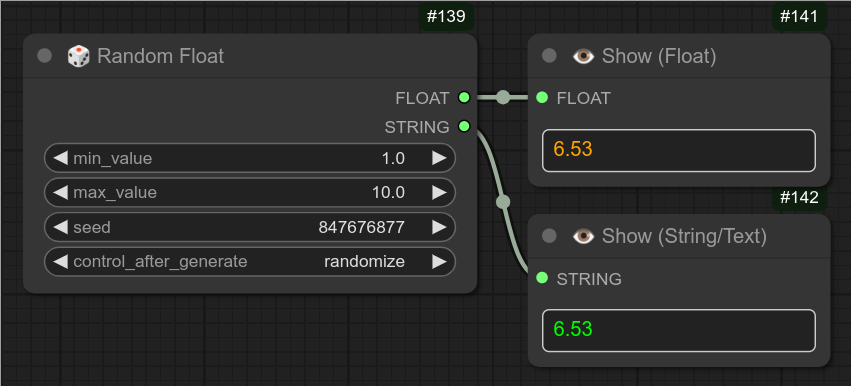
141 - 🌎✒👉 全局 Pick Me 写入
描述:
你喜欢使用 Pick Me 链式节点吗?
这个节点使用标识符(global_pickme_id)而非连接线来实现节点间的自动连接。只需为每个节点设置相同的 global_pickme_id,具有相同 ID 的节点就会自动相互连接。
以下是写入与加载的示例:
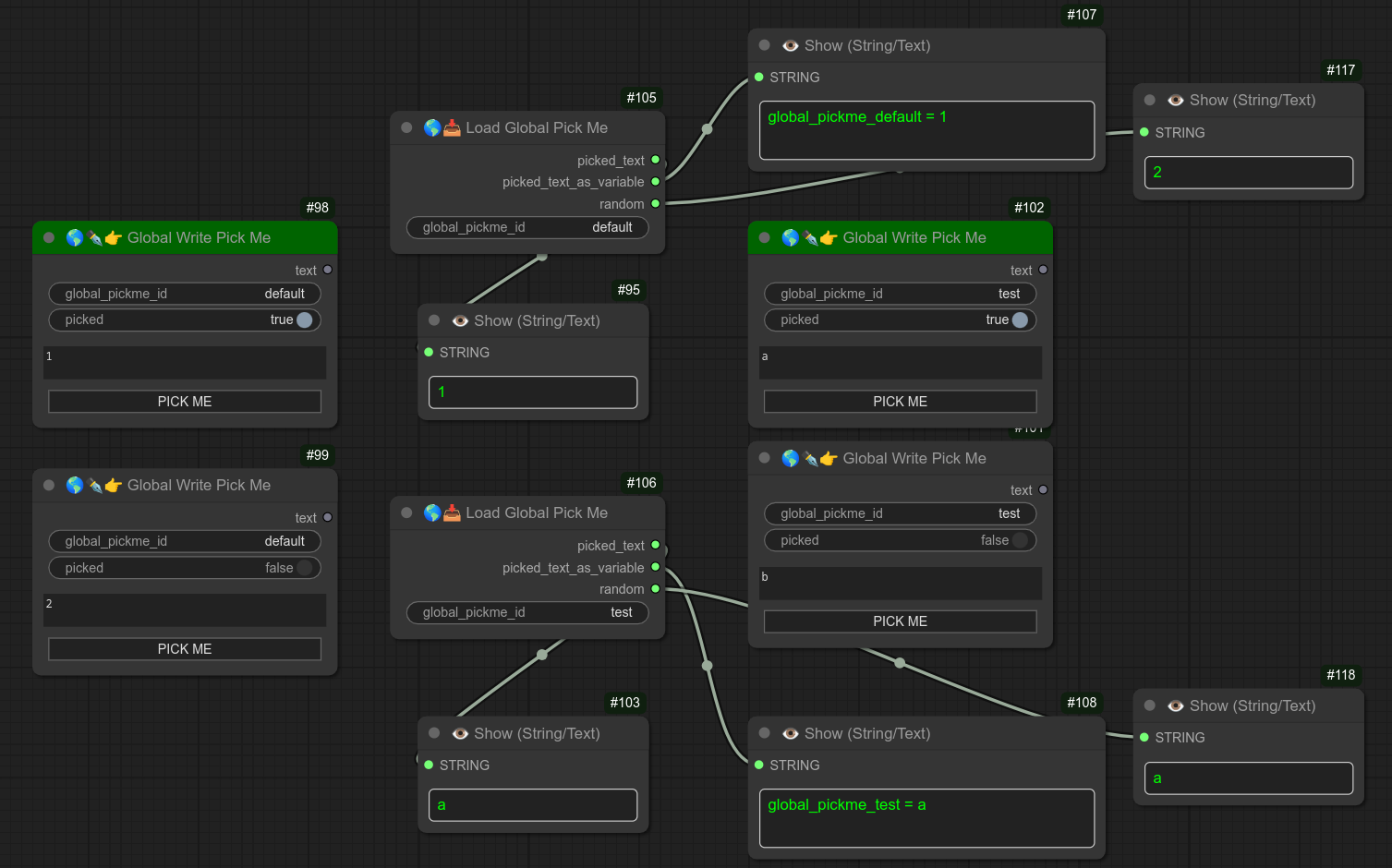
142 - 🌎📥 全局 Pick Me 加载
描述:
用于从全局 Pick Me 写入节点中恢复值的节点。
它会返回当前选定 global_pickme_id 对应的值。
此外,该节点还会自动从具有相同 global_pickme_id 的列表中随机返回一个值。
以下是写入与加载的示例:
143 - 🧮 基础数学
描述:
基础数学节点,可用于加法、乘法等运算。
以下示例是我用来检测某段视频相对于另一段视频“缺失”帧数的方法:
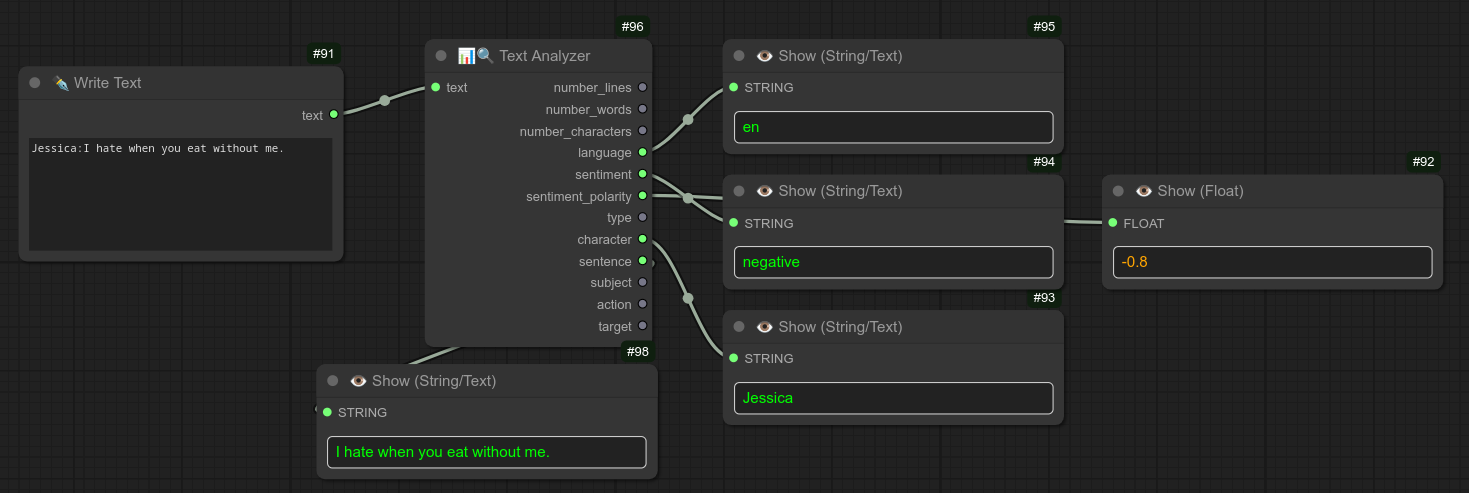
144 - 📊🔍 文本分析器
描述:
显示输入文本的详细信息。
你可以仅用它来获取字符数量,然后利用该数字避免提示过长导致内存溢出(OOM):
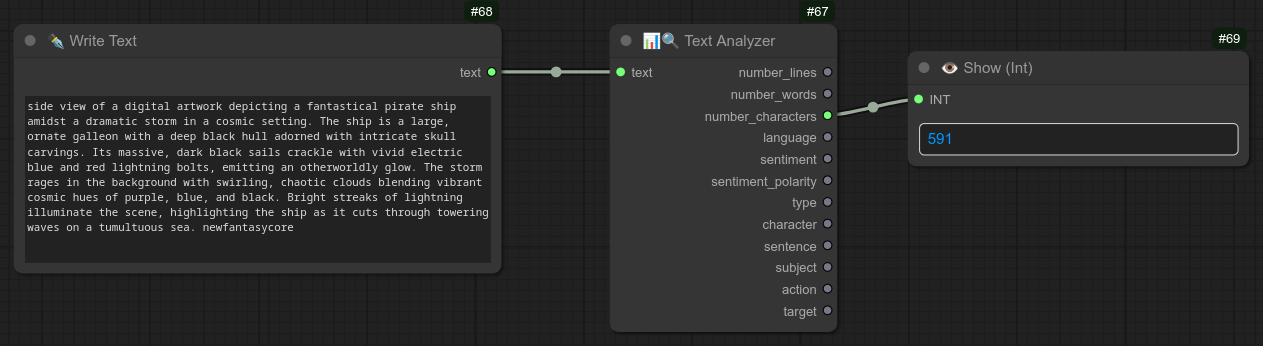
或者提取更多关于对话及其情感极性的细节。(例如,为正面、中性或负面情绪选择特定的 TTS 音色):
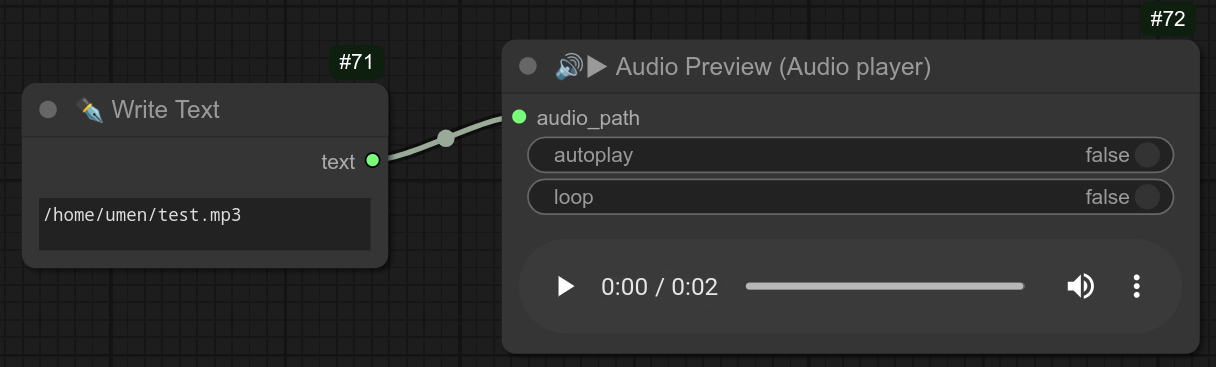
145 - 🔊▶ 音频预览(音频播放器)
描述:
一个简单的音频预览节点,可接受音频路径、MP3 或 WAV 格式的输入。
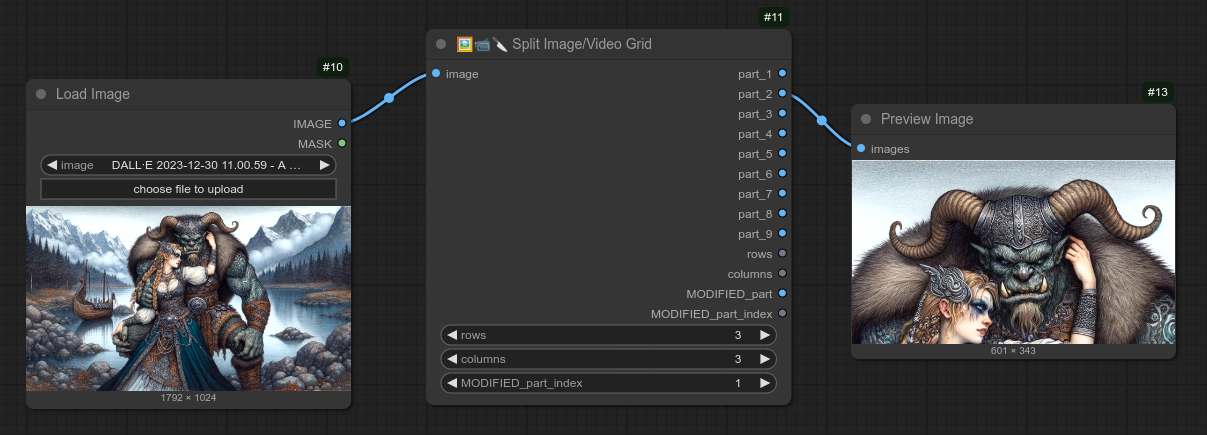
146 - 🖼📹🔪 图像/视频网格拆分
描述:
此节点会将图像或视频网格拆分为单独的图像或视频。
以下是一个包含 6 张图片的网格示例,它会将其拆分为 6 张独立的图片(3 行 × 3 列):
我为什么需要这个节点呢?有时一张图片或视频中会包含多个角色。
当我需要对某个角色应用口型同步时,就需要先将其拆分为单独的角色图像或视频,完成口型同步后再用节点 147 重新组合起来。
或者仅仅是为了节省显存,只处理图像中所需的部分。
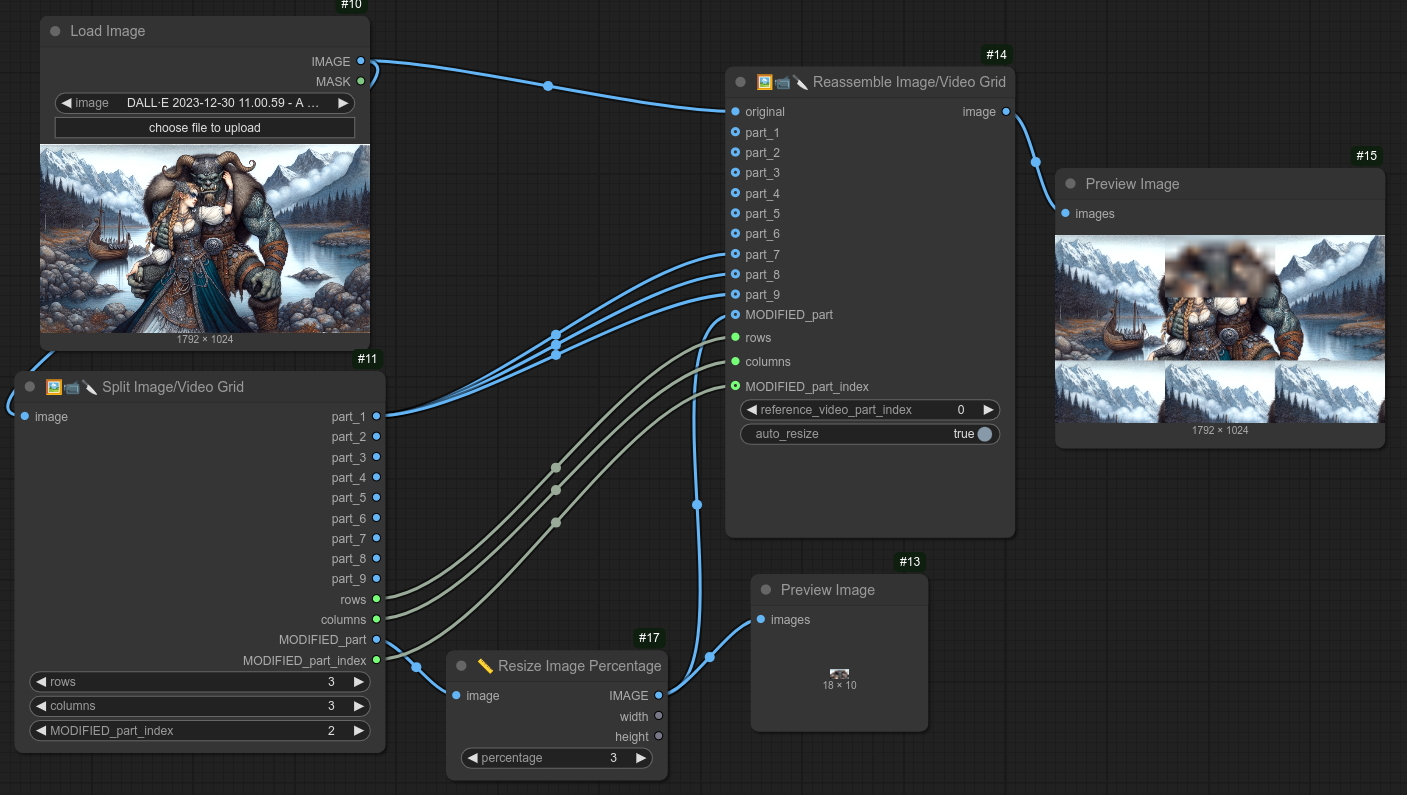
147 - 🖼📹🔨 图像/视频网格重组
描述:
将之前由节点 146 拆分的图像或视频网格重新组合成完整的图像或视频。
输入时需指定与拆分时相同的网格尺寸。
你可以对网格中的特定部分进行修改,然后再重新组合。
你可以单独选择每一部分,但还有一个“特殊”的部分,即“已修改”的部分。
这部分通过 MODIFIED_part 和 MODIFIED_part_index 来选择(part number,如果 index 设置为 2,则会使用 part_2)。
以下是一个修改 part_2 并重新组合的示例。(没有直接使用 part_2 的输出,而是通过将 MODIFIED_part_index 设置为 2 来选择 part_2):
你也可以直接操作 part_2,但采用这种设置可以快速切换不同部分,而无需更改节点布局。
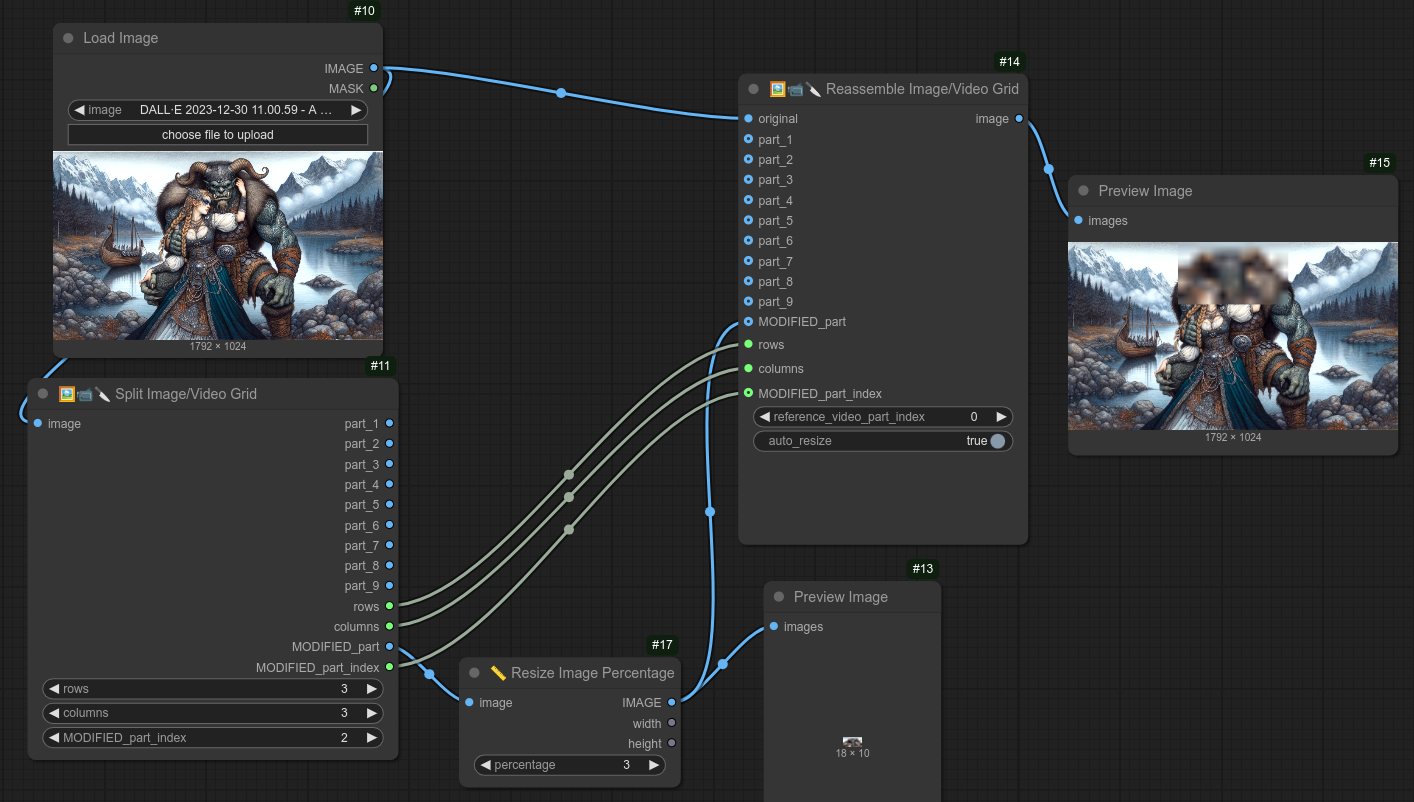
以下是一个展示如何手动影响不同部分的示例。(这里我只是将 part_1 替换掉 part 7、8、9。)
对于视频的重组可能会更复杂。
例如,如果你使用了节点 52 - 🔊📹 音频视频同步,那么修改后的部分可能会变短或变长,帧率也可能发生变化等。
如果修改后总时长发生了变化,你可以尝试重新同步所有部分。
在这种情况下,你需要使用 reference_video_part_index 来选择参考视频部分。(很可能与 MODIFIED_part_index 相同。)

148 - 💾🔊 保存音频(tmp_api.wav/mp3)⚠️💣
描述:
用于临时保存音频文件,格式为 MP3 或 WAV。
在多个 ComfyUI 实例之间通过 API 调用同步数据时非常有用。(我的 API 节点会在后台使用此节点,例如节点 157 🔮⚡ 执行工作流,用于交换音频文件——原始或处理后的——)
你可以发送音频路径(这将创建文件 tmp_api.mp3):

或者直接发送 AUDIO 类型的数据(这将创建文件 tmp_api.wav):
需要注意的是,如果你发送的是 AUDIO 类型的数据,此节点会将其保存为 WAV 文件。(即使你选择的是 MP3 文件。)
149 - 💾📹 保存视频(tmp_api.mp4/mkv/webm)⚠️💣
描述:
用于临时保存视频文件,格式为 MP4、MKV 或 WEBM。
在多个 ComfyUI 实例之间通过 API 调用同步数据时非常有用。(我的 API 节点会在后台使用此节点,例如节点 157 🔮⚡ 执行工作流,用于交换视频文件——原始或处理后的——)
150 - 🎨📜 风格选择器(🎲 或 ♻ 或 ♻📑)+ Civitai urn
描述:
一个新的通用风格选择节点。
同时包含一些关于 Civitai urn 的信息。(需要进一步测试,并建立更好的优质、快速模型数据库,建议您手动提交自己喜欢的 urn。)
以下是一个结合 CivitAI API 节点使用的示例:
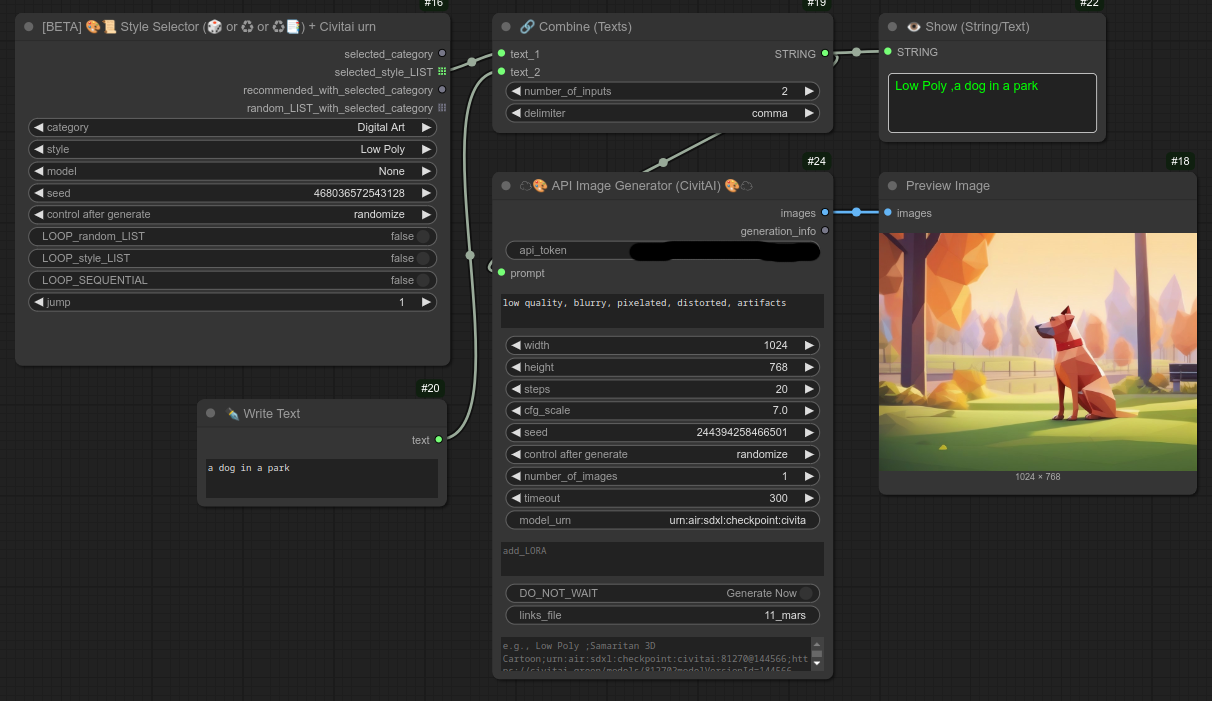
以下是一个使用模型 urns 的稍微复杂一些的例子:
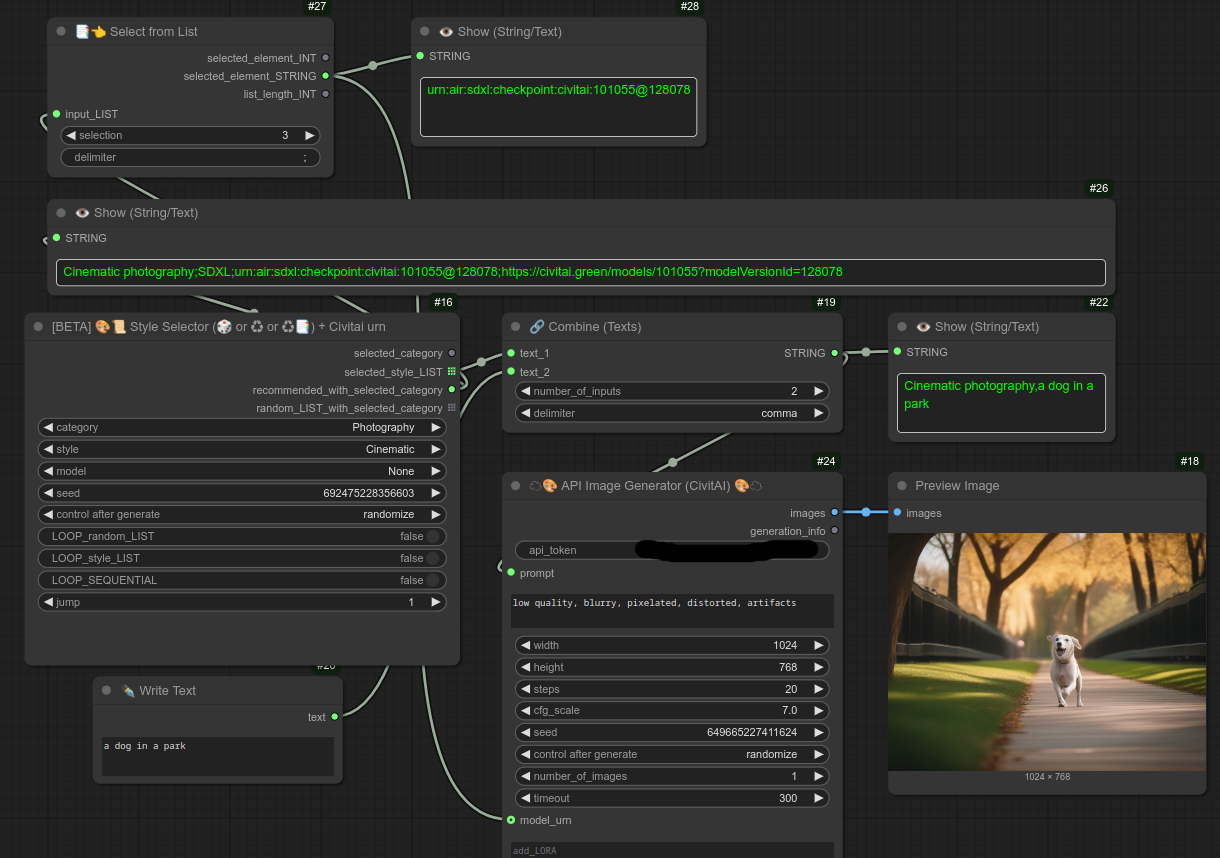
注意:CivitAI 可能会特别慢!!因此,您可以使用 DO_NOT_WAIT 选项,并配合一个可选的“links_file”。
它会创建一个包含链接的文件,以便稍后通过节点 151 恢复生成的图像。
这样您就可以发出任意数量的请求,然后在稍后的某个时间点使用该文本文件来恢复图像。
请注意,您也可以直接发送包含所有值的 LIST。
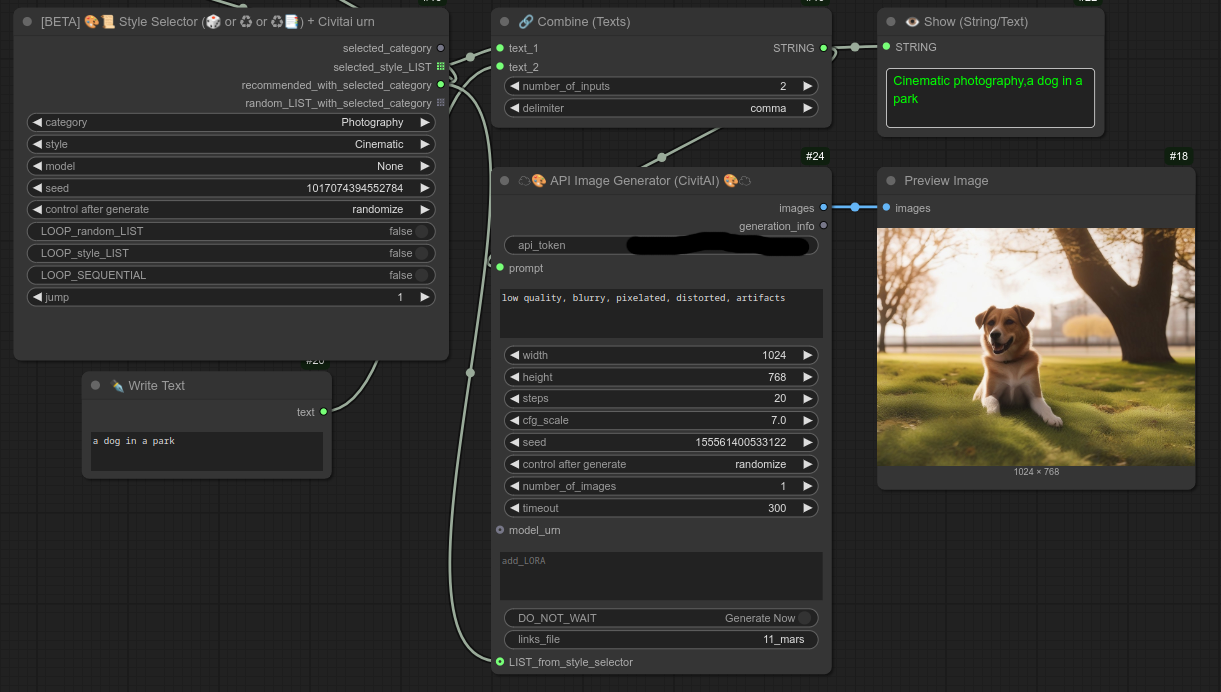
如果您这样做,稍后可以将这些值作为文本恢复,并使用节点 151 的“autosave”选项。
它会根据风格创建相应的文件夹。例如,从上图中可以看到:./ComfyUI/output/civitai_autosave/Cinematic_photography/
如果将节点 150 用作循环(LOOP),这将非常有用,因为您可以稍后恢复图像,并自动按照所选风格将它们整理到不同的文件夹中。
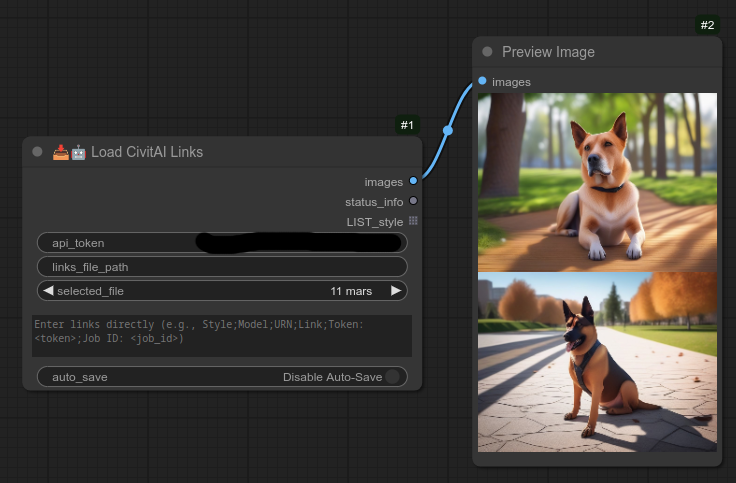
151 - 📥🕑🤖 加载 CivitAI 链接
描述:
此节点必须在使用节点 150 + DO_NOT_WAIT + links_file 之后使用。
当您从节点 150 中保存 DO_NOT_WAIT 和“links_file”时,它会在“ComfyUI/Bjornulf/civitai_links/”目录下创建一个文本文件,您可以使用此节点加载这些链接。
以下是来自“11_mars.txt”文件的已恢复图像:
如果您在节点 150 中使用了 LIST_from_style_selector,则稍后可以恢复这些值,并使用节点 151 的“autosave”选项。
它会根据风格创建相应的文件夹。例如,从上图中可以看到:./ComfyUI/output/civitai_autosave/Cinematic_photography/
如果将节点 150 用作循环(LOOP),这将非常有用,因为您可以稍后恢复图像,并自动按照所选风格将它们整理到不同的文件夹中。
152 - [即将推出] 💾 保存张量 (tmp_api.pt) ⚠️💣
描述:
此功能处于 BETA 阶段,它会将张量保存到文件中。
其目的是通过将张量保存到文件来优化显存使用。
153 - [即将推出] 📥 加载张量 (tmp_api.pt)
描述:
此功能处于 BETA 阶段,它会加载一个张量。
其目的是通过将张量保存到文件来优化显存使用。
154 - 🔮 远程 VAE 解码器
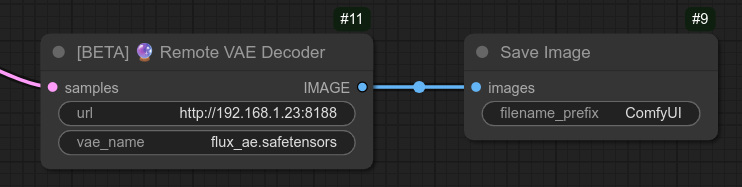
描述:
这是一个简单的节点,用于从远程机器解码 VAE 模型。
VAE 解码节点不必位于同一台机器上,因此如果您有一台远程机器并希望节省显存,就可以使用此节点。
远程机器也需要安装我的自定义节点。
155 - [即将推出] 🔮 远程 VAE 解码器(分块版)
描述:
与 154 相同,但采用分块版本。
156 - [即将推出] 📥🔮 从 Base64 加载
描述:
此功能处于 BETA 阶段,用于在不同 Comfyui 实例之间恢复某些值。
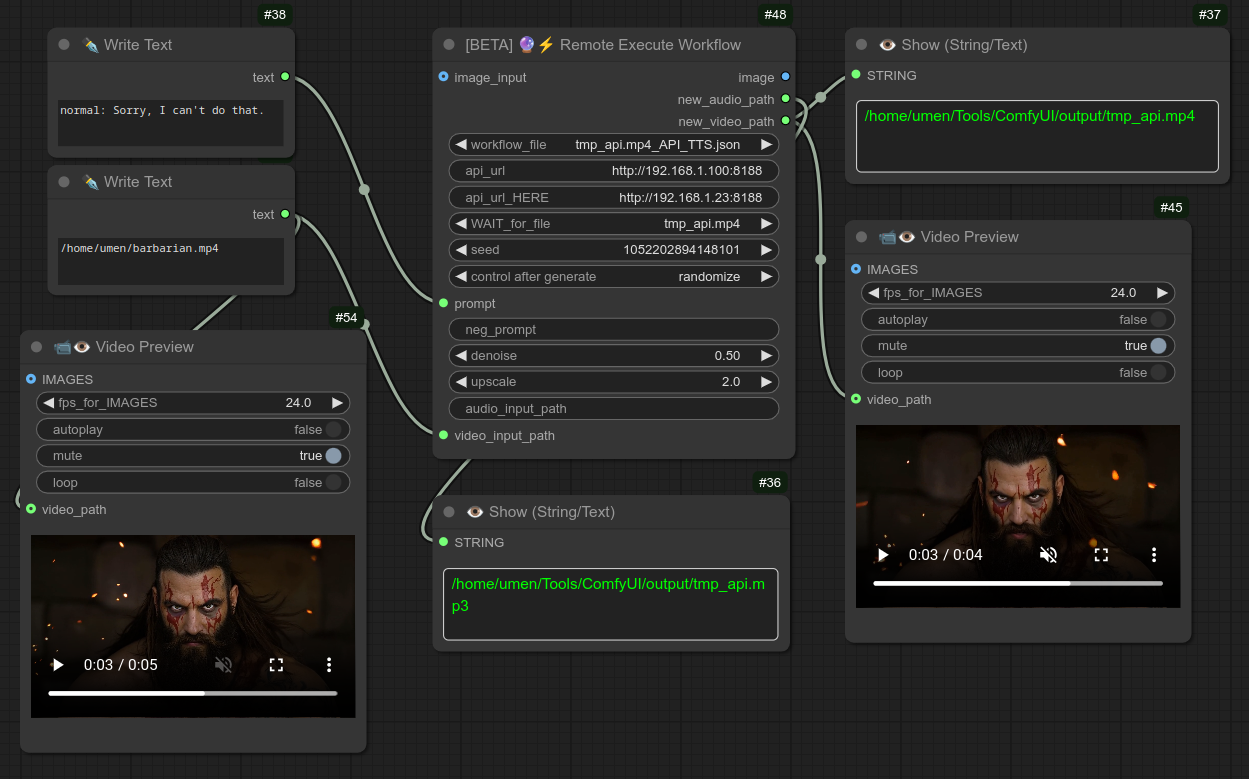
157 - [即将推出] 🔮⚡ 远程执行工作流
描述:
这是复杂新环境的开端,目前仍处于 BETA 阶段。
此节点的目标是在另一台 Comfyui 设备上运行工作流,并恢复生成的内容。
目前支持图像、声音和视频。
它可以完成任何常规工作流所能完成的任务。
例如,创建图像、制作视频、放大图像等。
请继续关注更多信息……正在开发中……
基本上就是可以在另一台机器上运行高负载的工作流,并恢复结果。
以下是一个我在另一台 Comfyui 设备上运行的唇形同步工作流示例。(目前仅限本地网络,但未来也会在 RunPod 上运行。)
我使用笔记本电脑(192.168.1.23)来接收来自我的“AI专用”台式机(192.168.1.100)的结果:
158 - [即将推出] 📥🔮📝 文本管理 API(执行工作流)
描述:
此功能处于 BETA 阶段。
此节点需要用于创建可与节点 157 配合使用的功能性工作流。
它会从另一个 Comfyui 实例与节点 157 进行通信。
159 - [即将推出] 🔥📝📹 视频文本生成器 📹📝🔥
描述:
此功能处于 BETA 阶段。
这是一个新的节点的开始,它将生成视频提示词。
其目标是类似于“文本生成器”节点,但针对视频。
原来的“文本生成器”主节点 81 现已被重命名为仅用于图像的节点:🔥📝🖼 图像文本生成器 🖼📝🔥。
160 - 🦙👁 Ollama 视觉提示选择器
描述:
Ollama 视觉的新布局提示选择器。
Ollama 视觉现在被分为两个独立的节点。
161 - [即将推出] 🔧🧑 修复人脸
描述:
此功能处于 BETA 阶段。
这是“修复图像”系列节点中的第一个。
可以快速修复、控制和编辑人脸(以及其他内容)。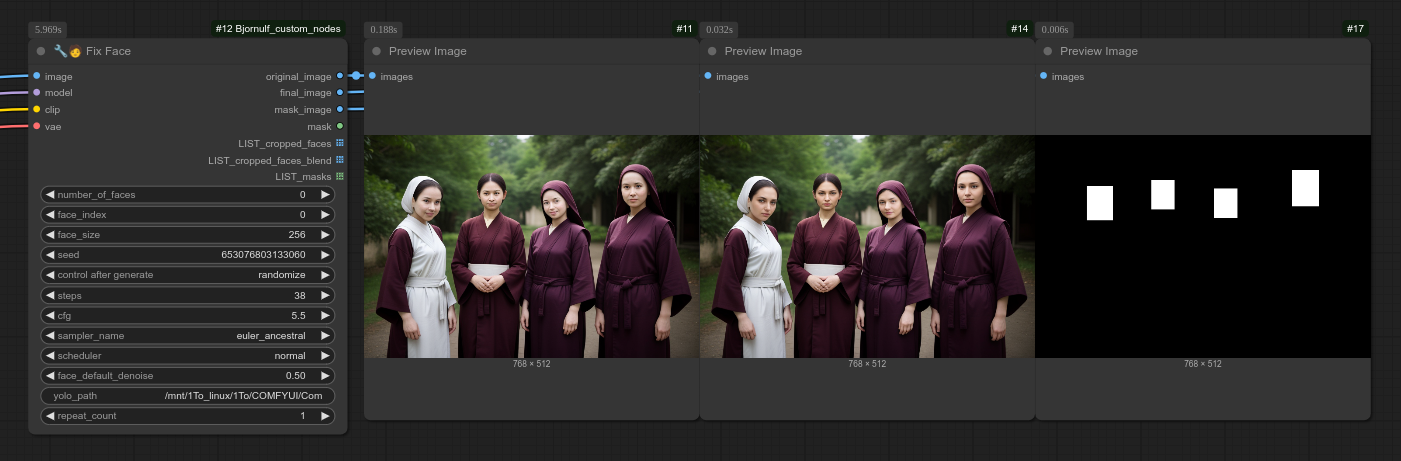
以下是其放大图:
您还可以为每张脸提供特定的文本和自定义去噪设置: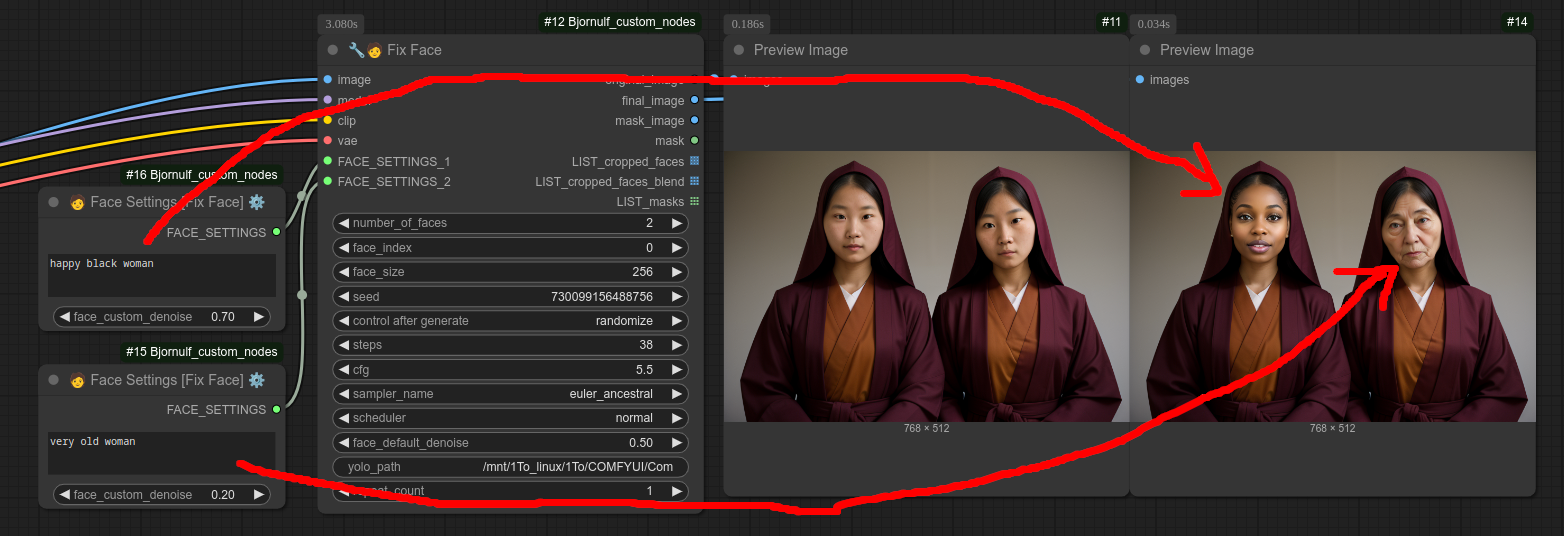
您还可以选择特定的脸部区域;如果设置为 0,则会对所有脸部进行处理,而下面我将其设置为 1: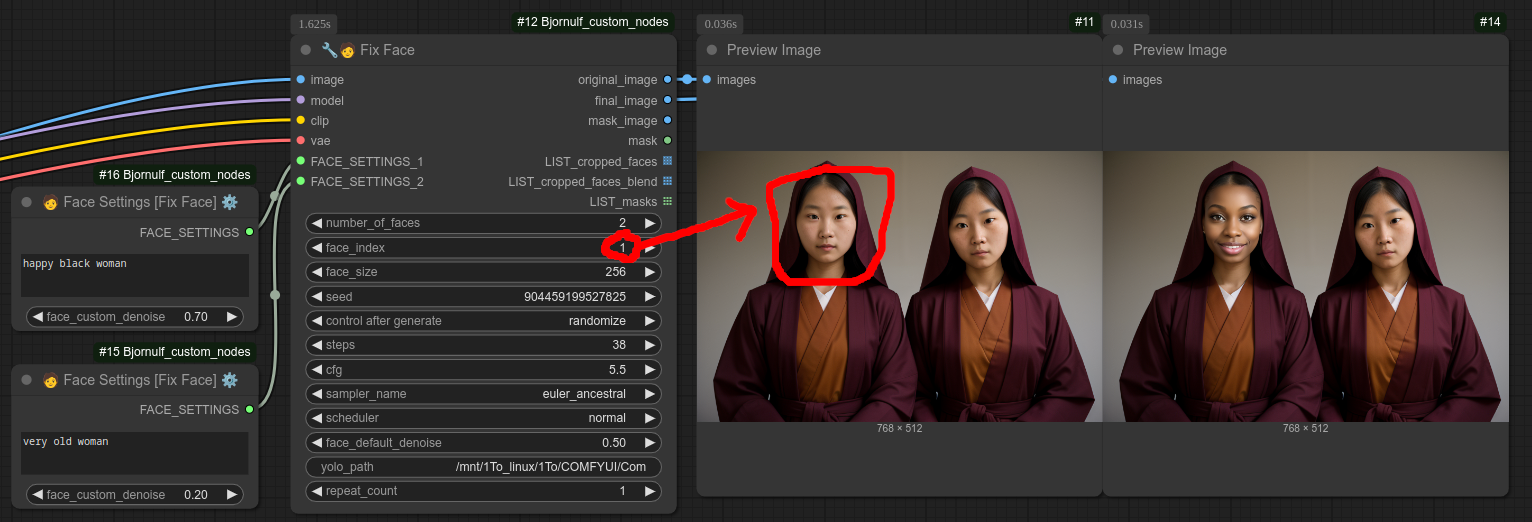
此节点也可以修复整个人物,但我可能会在稍后为此单独创建一个节点: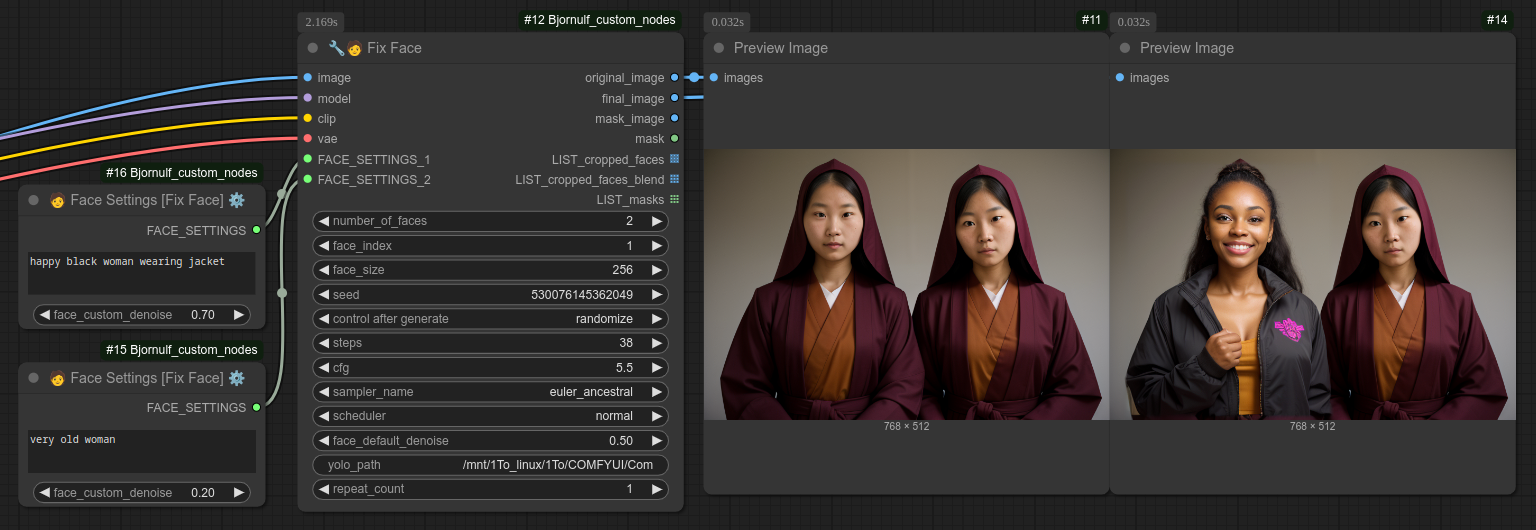
您可以通过我的预览图像节点很好地查看节点的效果。在这里,您可以清楚地看到被检测到的“人物”白色框: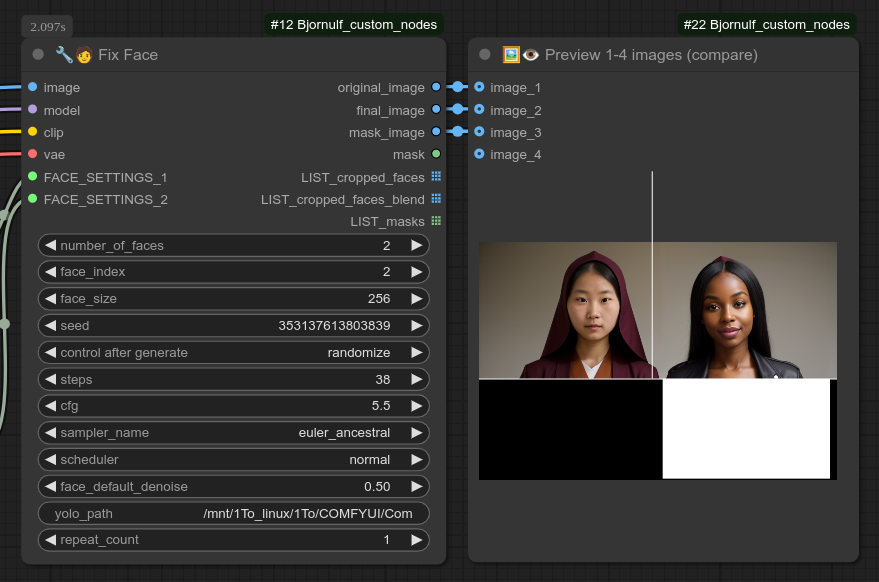
未来,我计划构建一个系统,用于“注入”特定的可重复使用角色,可能与 LoRA 或类似技术相关联。
162 - [即将推出] 🧑 人脸设置 [修复人脸] ⚙
描述:
与“修复人脸”节点连接,用于修改特定的脸部。
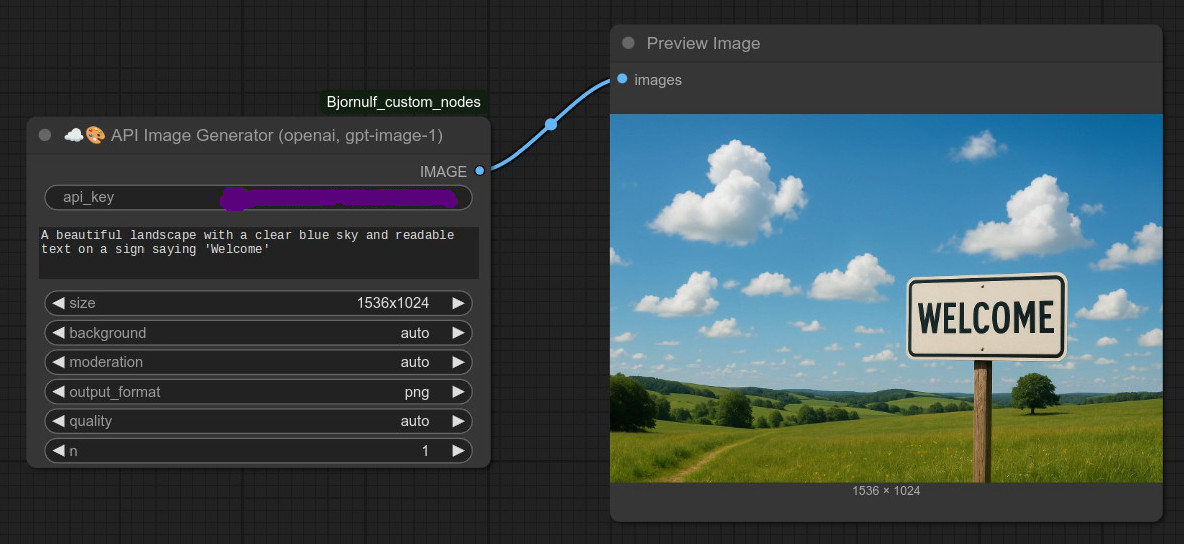
163 - ☁🎨 API 图像生成器 (openai, gpt-image-1)
描述:
使用 GPT-Image-1 API 创建图像。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。