pytorch-widedeep
pytorch-widedeep 是一个基于 PyTorch 构建的灵活深度学习包,专为处理多模态数据而设计。它核心解决了传统机器学习模型难以同时高效融合表格数据、文本和图像的痛点,让用户能够轻松将结构化数据与非结构化数据结合进行联合建模。
该工具基于谷歌经典的"Wide & Deep"算法并进行了多模态扩展:利用"Wide"部分记忆特征交互,通过"Deep"部分学习复杂非线性关系,从而显著提升预测精度。其独特亮点在于模块化架构,不仅支持自定义表格数据处理(deeptabular),还内置了推荐系统模块(rec),并能无缝集成预训练的文本和图像编码器,极大降低了多模态深度学习的实现门槛。
pytorch-widedeep 非常适合数据科学家、AI 研究人员以及需要处理复杂混合数据的深度学习开发者使用。无论是构建高精度的推荐系统,还是解决涉及多维信息的分类与回归问题,它都能提供简洁高效的代码接口,帮助用户快速验证想法并部署模型,是探索表格数据与多模态融合领域的得力助手。
使用场景
某电商公司的数据科学团队正致力于构建一个精准的商品推荐系统,需要同时处理用户画像表格、商品描述文本以及商品展示图片。
没有 pytorch-widedeep 时
- 多模态融合困难:工程师需手动编写大量底层代码来对齐表格、文本和图像特征,不同数据源的维度匹配极易出错。
- 模型架构僵化:难以灵活实现 Google 的 Wide & Deep 算法,无法有效兼顾记忆历史规则(Wide 部分)与泛化新特征(Deep 部分)的能力。
- 开发周期漫长:从数据预处理到搭建完整的 PyTorch 训练流水线耗时数周,且维护自定义的多输入模型极其繁琐。
- 调优成本高昂:缺乏统一的接口管理多种模态的嵌入层和激活函数,导致超参数搜索和实验复现效率低下。
使用 pytorch-widedeep 后
- 一键多模态集成:利用其内置组件,仅需几行配置即可将结构化用户数据与非结构化图文数据无缝拼接,自动处理特征交叉。
- 架构灵活可配:直接调用预置的 Wide & Deep 架构,轻松调整“宽”侧的记忆能力与“深”侧的泛化深度,快速适配业务需求。
- 研发效率倍增:标准化的 API 屏蔽了复杂的底层实现,团队在几天内即可完成从原型验证到生产级模型的部署。
- 实验迭代加速:统一的训练循环和评估模块让多模态超参数调优变得简单可控,显著提升了模型最终的点击率预测精度。
pytorch-widedeep 通过标准化多模态深度学习流程,让团队能以最低成本释放表格、文本与图像数据的联合价值。
运行环境要求
- 未说明
未说明
未说明

快速开始
![]()
![]()
![]()

![]()
![]()
![]()
![]()
![]()

pytorch-widedeep
一个灵活的多模态深度学习包,用于在 PyTorch 中结合表格数据、文本和图像,采用 Wide 和 Deep 模型。
文档: https://pytorch-widedeep.readthedocs.io
配套文章与教程: infinitoml
实验及与 LightGBM 的对比: TabularDL vs LightGBM
Slack: 如果您想参与贡献或只是想与我们交流,请加入 slack。
本文档的内容组织如下:
简介
pytorch-widedeep 基于 Google 的 Wide and Deep 算法,并针对多模态数据集进行了调整。
广义上讲,pytorch-widedeep 是一个用于将深度学习应用于表格数据的工具包。具体而言,它旨在通过 Wide 和 Deep 模型,方便地将文本和图像与相应的表格数据相结合。基于这一目标,该库支持多种架构的实现。这些架构的主要组成部分如图所示:
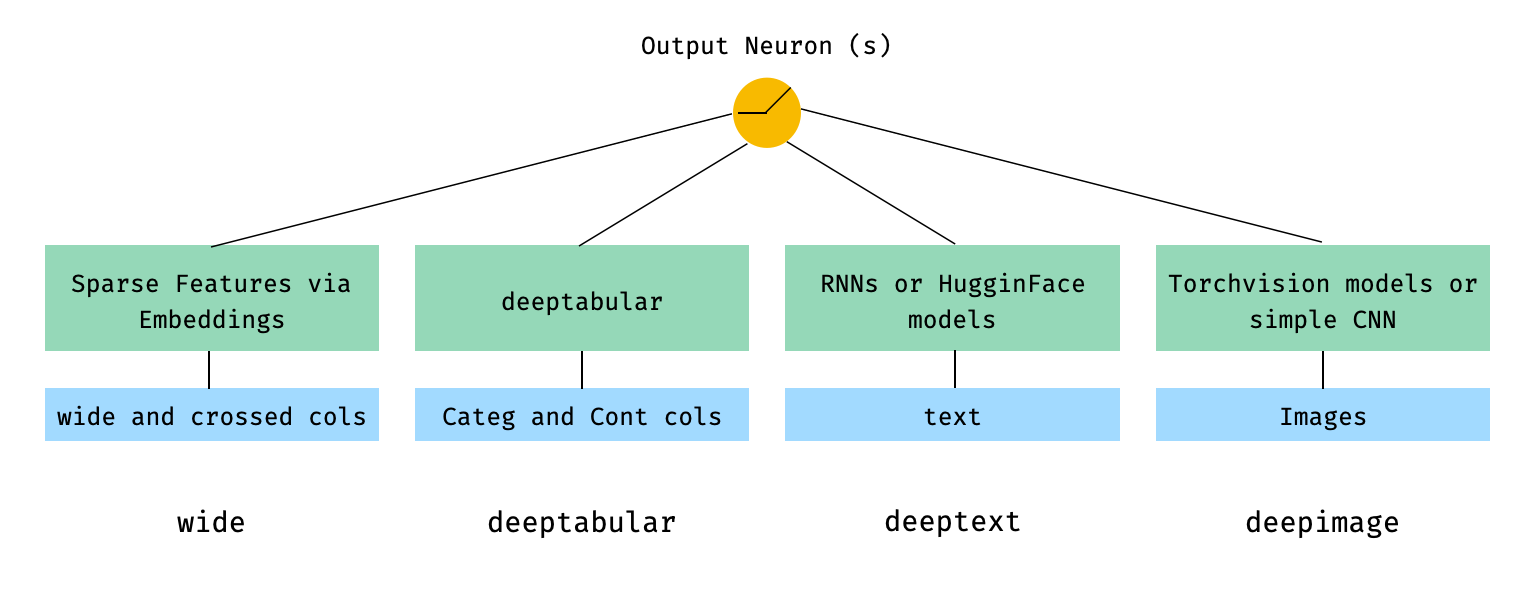
从数学角度来看,按照论文中的符号约定(论文链接),不含 deephead 组件的架构表达式可写为:
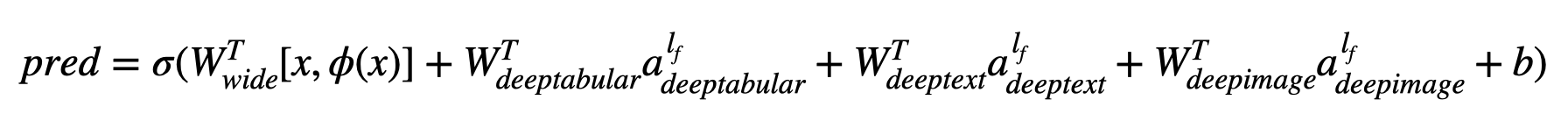
其中 σ 表示 sigmoid 函数,'W' 是应用于 Wide 模型以及 Deep 模型最终激活层的权重矩阵,'a' 是这些最终激活值,φ(x) 是对原始特征 'x' 进行的交叉乘积变换,而 'b' 则是偏置项。如果您好奇“交叉乘积变换”是什么,这里直接引用论文中的一段话:“对于二值特征,交叉乘积变换(例如‘AND(性别=女性, 语言=en)’)仅当其组成特征(‘性别=女性’和‘语言=en’)均为 1 时才为 1,否则为 0。”
当然,也可以使用自定义模型(而不局限于库中提供的模型),只要这些自定义模型具备名为 output_dim 的属性,表示最后一层激活的维度,以便能够构建 WideDeep 模型即可。有关如何使用自定义组件的示例,可在 Examples 文件夹及下文找到。
架构
pytorch-widedeep 库提供了多种不同的架构。在这一节中,我们将以最简单的形式(即大多数情况下使用默认参数值)展示其中的一些架构,并附上相应的代码片段。请注意,所有以下代码片段都应在本地运行。如需对各个组件及其参数的更详细说明,请参阅文档。
对于下面的示例,我们将使用一个如下生成的玩具数据集:
import os
import random
import numpy as np
import pandas as pd
from PIL import Image
from faker import Faker
def create_and_save_random_image(image_number, size=(32, 32)):
if not os.path.exists("images"):
os.makedirs("images")
array = np.random.randint(0, 256, (size[0], size[1], 3), dtype=np.uint8)
image = Image.fromarray(array)
image_name = f"image_{image_number}.png"
image.save(os.path.join("images", image_name))
return image_name
fake = Faker()
cities = ["New York", "Los Angeles", "Chicago", "Houston"]
names = ["Alice", "Bob", "Charlie", "David", "Eva"]
data = {
"city": [random.choice(cities) for _ in range(100)],
"name": [random.choice(names) for _ in range(100)],
"age": [random.uniform(18, 70) for _ in range(100)],
"height": [random.uniform(150, 200) for _ in range(100)],
"sentence": [fake.sentence() for _ in range(100)],
"other_sentence": [fake.sentence() for _ in range(100)],
"image_name": [create_and_save_random_image(i) for i in range(100)],
"target": [random.choice([0, 1]) for _ in range(100)],
}
df = pd.DataFrame(data)
这将创建一个包含100行的DataFrame,并在您的本地文件夹中生成一个名为images的目录,其中包含100张随机图像(或仅包含噪声的图像)。
也许最简单的架构就是单独使用wide、deeptabular、deeptext或deepimage中的某一个组件,这也是可行的。不过,我们还是从标准的Wide and Deep架构开始示例。在此之后,构建仅由一个组件组成的模型就会变得非常直观。
需要注意的是,以下示例几乎可以使用库中提供的任何模型来实现。例如,TabMlp可以被替换为TabResnet、TabNet、TabTransformer等。同样地,BasicRNN也可以被替换为AttentiveRNN、StackedAttentiveRNN,或者在使用Hugging Face模型时,替换为HFModel,并相应调整其参数和预处理器。
1. Wide和Tabular组件(即deeptabular)
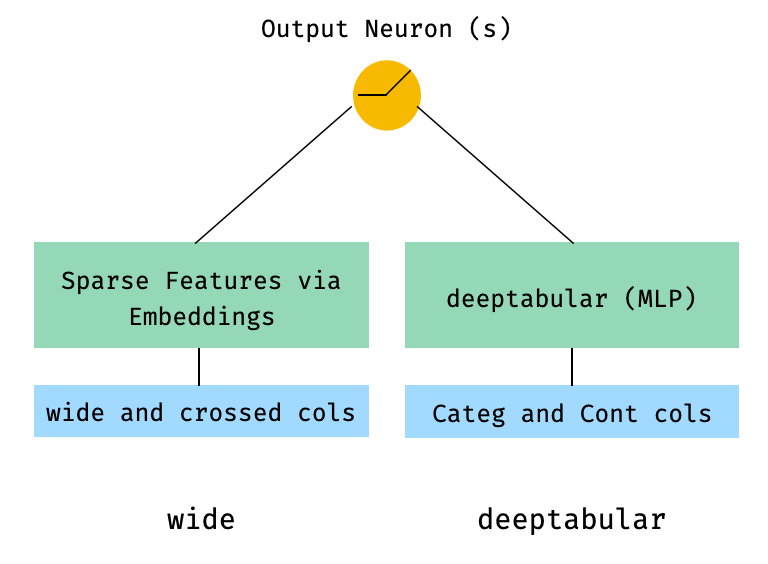
from pytorch_widedeep.preprocessing import TabPreprocessor, WidePreprocessor
from pytorch_widedeep.models import Wide, TabMlp, WideDeep
from pytorch_widedeep.training import Trainer
# Wide
wide_cols = ["city"]
crossed_cols = [("city", "name")]
wide_preprocessor = WidePreprocessor(wide_cols=wide_cols, crossed_cols=crossed_cols)
X_wide = wide_preprocessor.fit_transform(df)
wide = Wide(input_dim=np.unique(X_wide).shape[0])
# Tabular
tab_preprocessor = TabPreprocessor(
embed_cols=["city", "name"], continuous_cols=["age", "height"]
)
X_tab = tab_preprocessor.fit_transform(df)
tab_mlp = TabMlp(
column_idx=tab_preprocessor.column_idx,
cat_embed_input=tab_preprocessor.cat_embed_input,
continuous_cols=tab_preprocessor.continuous_cols,
mlp_hidden_dims=[64, 32],
)
# WideDeep
model = WideDeep(wide=wide, deeptabular=tab_mlp)
# 训练
trainer = Trainer(model, objective="binary")
trainer.fit(
X_wide=X_wide,
X_tab=X_tab,
target=df["target"].values,
n_epochs=1,
batch_size=32,
)
2. Tabular和Text数据
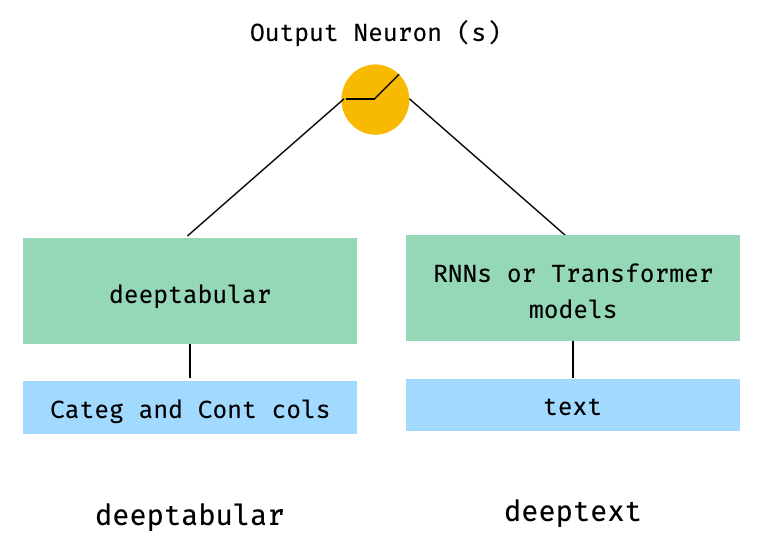
from pytorch_widedeep.preprocessing import TabPreprocessor, TextPreprocessor
from pytorch_widedeep.models import TabMlp, BasicRNN, WideDeep
from pytorch_widedeep.training import Trainer
# Tabular
tab_preprocessor = TabPreprocessor(
embed_cols=["city", "name"], continuous_cols=["age", "height"]
)
X_tab = tab_preprocessor.fit_transform(df)
tab_mlp = TabMlp(
column_idx=tab_preprocessor.column_idx,
cat_embed_input=tab_preprocessor.cat_embed_input,
continuous_cols=tab_preprocessor.continuous_cols,
mlp_hidden_dims=[64, 32],
)
# Text
text_preprocessor = TextPreprocessor(
text_col="sentence", maxlen=20, max_vocab=100, n_cpus=1
)
X_text = text_preprocessor.fit_transform(df)
rnn = BasicRNN(
vocab_size=len(text_preprocessor.vocab.itos),
embed_dim=16,
hidden_dim=8,
n_layers=1,
)
# WideDeep
model = WideDeep(deeptabular=tab_mlp, deeptext=rnn)
# 训练
trainer = Trainer(model, objective="binary")
trainer.fit(
X_tab=X_tab,
X_text=X_text,
target=df["target"].values,
n_epochs=1,
batch_size=32,
)
3. Tabular和text,并通过WideDeep中的head_hidden_dims参数在其顶部添加一个全连接层
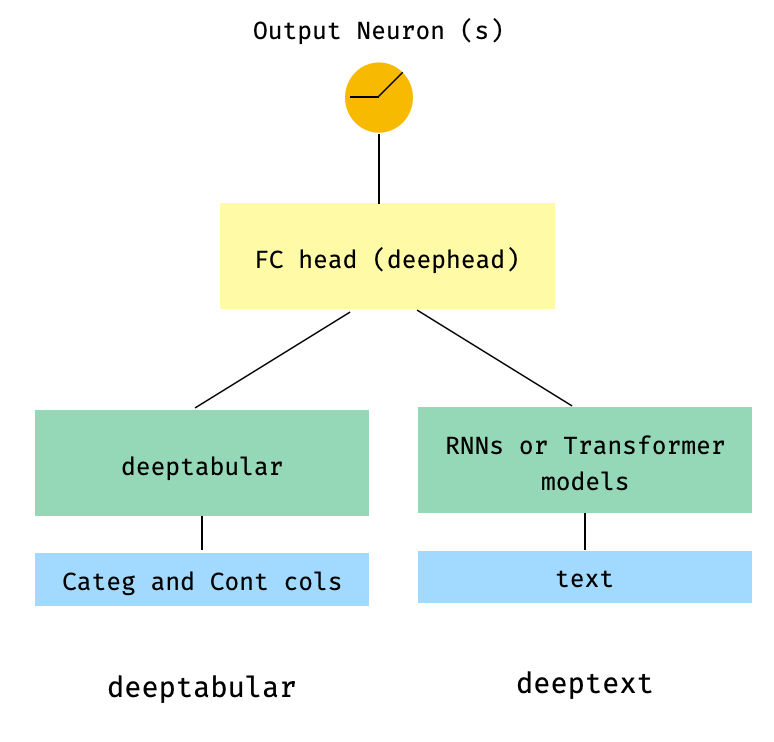
from pytorch_widedeep.preprocessing import TabPreprocessor, TextPreprocessor
from pytorch_widedeep.models import TabMlp, BasicRNN, WideDeep
from pytorch_widedeep.training import Trainer
# Tabular
tab_preprocessor = TabPreprocessor(
embed_cols=["city", "name"], continuous_cols=["age", "height"]
)
X_tab = tab_preprocessor.fit_transform(df)
tab_mlp = TabMlp(
column_idx=tab_preprocessor.column_idx,
cat_embed_input=tab_preprocessor.cat_embed_input,
continuous_cols=tab_preprocessor.continuous_cols,
mlp_hidden_dims=[64, 32],
)
# Text
text_preprocessor = TextPreprocessor(
text_col="sentence", maxlen=20, max_vocab=100, n_cpus=1
)
X_text = text_preprocessor.fit_transform(df)
rnn = BasicRNN(
vocab_size=len(text_preprocessor.vocab.itos),
embed_dim=16,
hidden_dim=8,
n_layers=1,
)
# WideDeep
model = WideDeep(deeptabular=tab_mlp, deeptext=rnn, head_hidden_dims=[32, 16])
# 训练
trainer = Trainer(model, objective="binary")
trainer.fit(
X_tab=X_tab,
X_text=X_text,
target=df["target"].values,
n_epochs=1,
batch_size=32,
)
4. Tabular和多个text列,直接传递给WideDeep
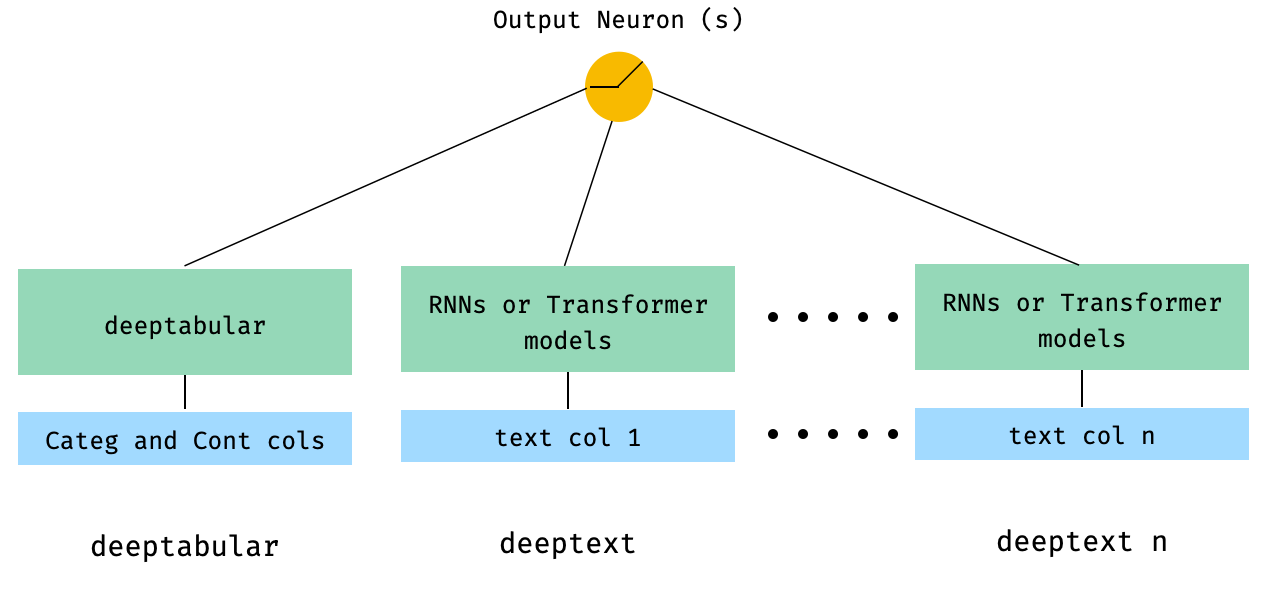
from pytorch_widedeep.preprocessing import TabPreprocessor, TextPreprocessor
from pytorch_widedeep.models import TabMlp, BasicRNN, WideDeep
from pytorch_widedeep.training import Trainer
# Tabular
tab_preprocessor = TabPreprocessor(
embed_cols=["city", "name"], continuous_cols=["age", "height"]
)
X_tab = tab_preprocessor.fit_transform(df)
tab_mlp = TabMlp(
column_idx=tab_preprocessor.column_idx,
cat_embed_input=tab_preprocessor.cat_embed_input,
continuous_cols=tab_preprocessor.continuous_cols,
mlp_hidden_dims=[64, 32],
)
# 文本
text_preprocessor_1 = TextPreprocessor(
text_col="sentence", maxlen=20, max_vocab=100, n_cpus=1
)
X_text_1 = text_preprocessor_1.fit_transform(df)
text_preprocessor_2 = TextPreprocessor(
text_col="other_sentence", maxlen=20, max_vocab=100, n_cpus=1
)
X_text_2 = text_preprocessor_2.fit_transform(df)
rnn_1 = BasicRNN(
vocab_size=len(text_preprocessor_1.vocab.itos),
embed_dim=16,
hidden_dim=8,
n_layers=1,
)
rnn_2 = BasicRNN(
vocab_size=len(text_preprocessor_2.vocab.itos),
embed_dim=16,
hidden_dim=8,
n_layers=1,
)
# WideDeep
model = WideDeep(deeptabular=tab_mlp, deeptext=[rnn_1, rnn_2])
# 训练
trainer = Trainer(model, objective="binary")
trainer.fit(
X_tab=X_tab,
X_text=[X_text_1, X_text_2],
target=df["target"].values,
n_epochs=1,
batch_size=32,
)
5. 表格数据与多个文本列,通过库中的 ModelFuser 类进行融合
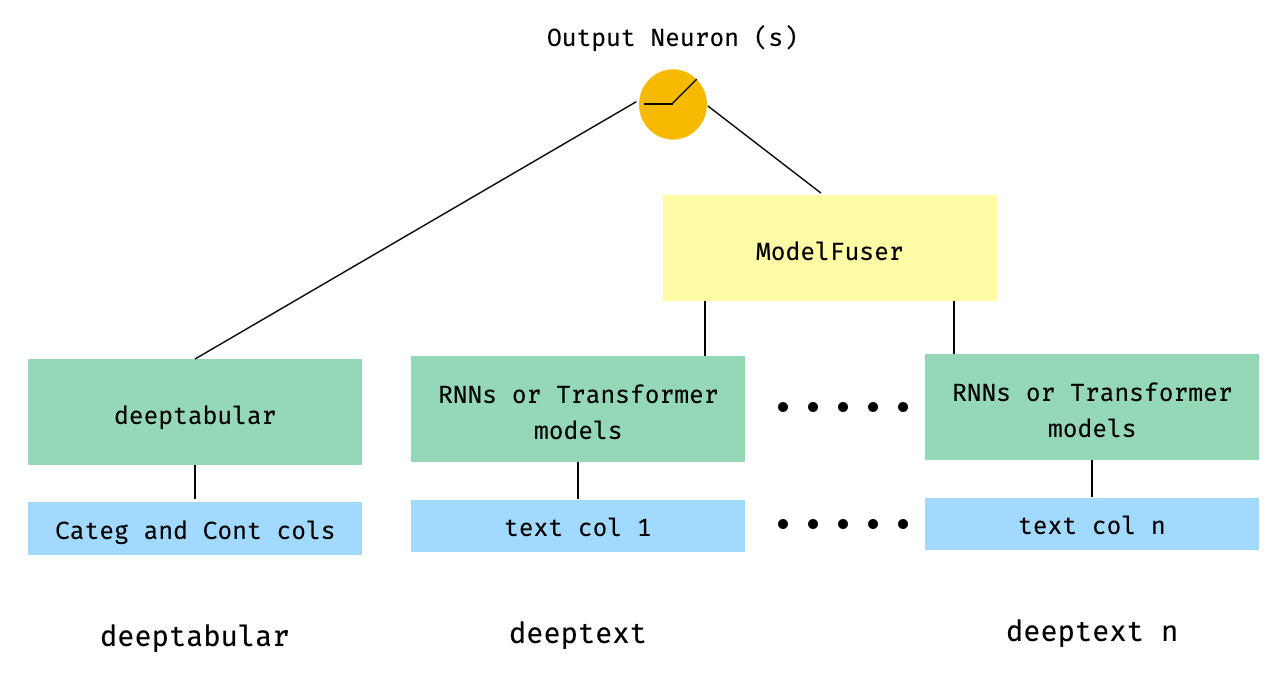
from pytorch_widedeep.preprocessing import TabPreprocessor, TextPreprocessor
from pytorch_widedeep.models import TabMlp, BasicRNN, WideDeep, ModelFuser
from pytorch_widedeep import Trainer
# 表格数据
tab_preprocessor = TabPreprocessor(
embed_cols=["city", "name"], continuous_cols=["age", "height"]
)
X_tab = tab_preprocessor.fit_transform(df)
tab_mlp = TabMlp(
column_idx=tab_preprocessor.column_idx,
cat_embed_input=tab_preprocessor.cat_embed_input,
continuous_cols=tab_preprocessor.continuous_cols,
mlp_hidden_dims=[64, 32],
)
# 文本数据
text_preprocessor_1 = TextPreprocessor(
text_col="sentence", maxlen=20, max_vocab=100, n_cpus=1
)
X_text_1 = text_preprocessor_1.fit_transform(df)
text_preprocessor_2 = TextPreprocessor(
text_col="other_sentence", maxlen=20, max_vocab=100, n_cpus=1
)
X_text_2 = text_preprocessor_2.fit_transform(df)
rnn_1 = BasicRNN(
vocab_size=len(text_preprocessor_1.vocab.itos),
embed_dim=16,
hidden_dim=8,
n_layers=1,
)
rnn_2 = BasicRNN(
vocab_size=len(text_preprocessor_2.vocab.itos),
embed_dim=16,
hidden_dim=8,
n_layers=1,
)
models_fuser = ModelFuser(models=[rnn_1, rnn_2], fusion_method="mult")
# WideDeep
model = WideDeep(deeptabular=tab_mlp, deeptext=models_fuser)
# 训练
trainer = Trainer(model, objective="binary")
trainer.fit(
X_tab=X_tab,
X_text=[X_text_1, X_text_2],
target=df["target"].values,
n_epochs=1,
batch_size=32,
)
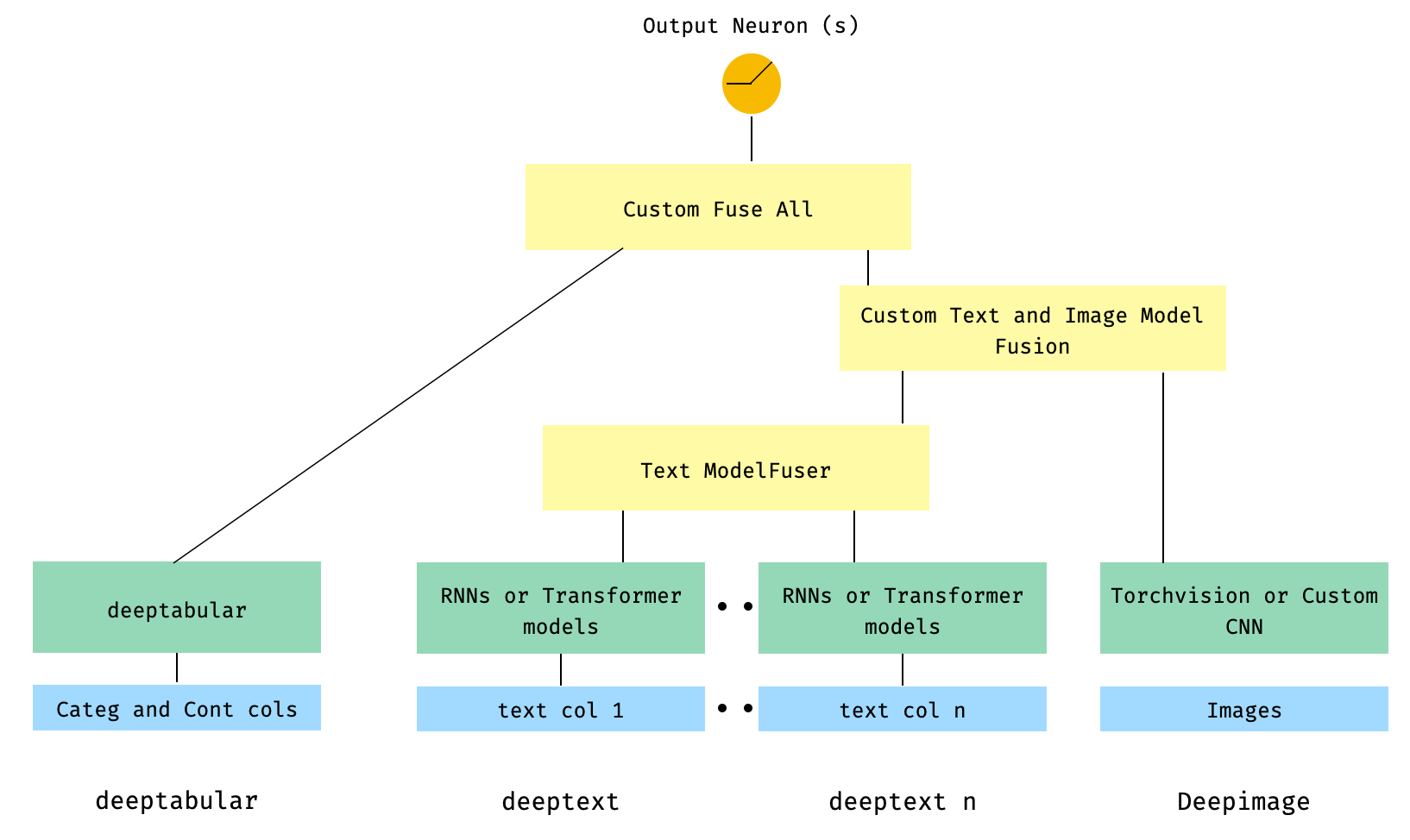
6. 表格数据、多个文本列以及一张图像列。文本列先通过库中的 ModelFuser 进行融合,再通过 WideDeep 中的 deephead 参数(由用户自定义的 ModelFuser)将所有模态进一步融合
这种方法可能稍显不够优雅,因为它涉及用户自定义组件以及对“输入”张量的切片操作。未来我们将推出专门的 TextAndImageModelFuser,以使这一流程更加简便。不过,这其实并不复杂,也是一个很好的示例,展示了如何在 pytorch-widedeep 中使用自定义组件。
需要注意的是,自定义组件的唯一要求是必须具备一个名为 output_dim 的属性,用于返回最后一层激活的维度。换句话说,它并不需要继承自 BaseWDModelComponent。这个基类的作用只是检查该属性是否存在,从而在内部避免一些类型错误。
import torch
from pytorch_widedeep.preprocessing import TabPreprocessor, TextPreprocessor, ImagePreprocessor
from pytorch_widedeep.models import TabMlp, BasicRNN, WideDeep, ModelFuser, Vision
from pytorch_widedeep.models._base_wd_model_component import BaseWDModelComponent
from pytorch_widedeep import Trainer
# 表格数据
tab_preprocessor = TabPreprocessor(
embed_cols=["city", "name"], continuous_cols=["age", "height"]
)
X_tab = tab_preprocessor.fit_transform(df)
tab_mlp = TabMlp(
column_idx=tab_preprocessor.column_idx,
cat_embed_input=tab_preprocessor.cat_embed_input,
continuous_cols=tab_preprocessor.continuous_cols,
mlp_hidden_dims=[16, 8],
)
# 文本数据
text_preprocessor_1 = TextPreprocessor(
text_col="sentence", maxlen=20, max_vocab=100, n_cpus=1
)
X_text_1 = text_preprocessor_1.fit_transform(df)
text_preprocessor_2 = TextPreprocessor(
text_col="other_sentence", maxlen=20, max_vocab=100, n_cpus=1
)
X_text_2 = text_preprocessor_2.fit_transform(df)
rnn_1 = BasicRNN(
vocab_size=len(text_preprocessor_1.vocab.itos),
embed_dim=16,
hidden_dim=8,
n_layers=1,
)
rnn_2 = BasicRNN(
vocab_size=len(text_preprocessor_2.vocab.itos),
embed_dim=16,
hidden_dim=8,
n_layers=1,
)
models_fuser = ModelFuser(
models=[rnn_1, rnn_2],
fusion_method="mult",
)
# 图像数据
image_preprocessor = ImagePreprocessor(img_col="image_name", img_path="images")
X_img = image_preprocessor.fit_transform(df)
vision = Vision(pretrained_model_setup="resnet18", head_hidden_dims=[16, 8])
# deephead(自定义模型融合器)
class MyModelFuser(BaseWDModelComponent):
"""
只是在文本和图像之上添加一个线性层加ReLU的序列,随后再接一个
线性层 -> ReLU -> 线性层的结构,用于将张量中的表格切片与文本和图像序列模型的输出进行拼接。
"""
def __init__(
self,
tab_incoming_dim: int,
text_incoming_dim: int,
image_incoming_dim: int,
output_units: int,
):
super(MyModelFuser, self).__init__()
self.tab_incoming_dim = tab_incoming_dim
self.text_incoming_dim = text_incoming_dim
self.image_incoming_dim = image_incoming_dim
self.output_units = output_units
self.text_and_image_fuser = torch.nn.Sequential(
torch.nn.Linear(text_incoming_dim + image_incoming_dim, output_units),
torch.nn.ReLU(),
)
self.out = torch.nn.Sequential(
torch.nn.Linear(output_units + tab_incoming_dim, output_units * 4),
torch.nn.ReLU(),
torch.nn.Linear(output_units * 4, output_units),
)
def forward(self, X: torch.Tensor) -> torch.Tensor:
tab_slice = slice(0, self.tab_incoming_dim)
text_slice = slice(
self.tab_incoming_dim, self.tab_incoming_dim + self.text_incoming_dim
)
image_slice = slice(
self.tab_incoming_dim + self.text_incoming_dim,
self.tab_incoming_dim + self.text_incoming_dim + self.image_incoming_dim,
)
X_tab = X[:, tab_slice]
X_text = X[:, text_slice]
X_img = X[:, image_slice]
X_text_and_image = self.text_and_image_fuser(torch.cat([X_text, X_img], dim=1))
return self.out(torch.cat([X_tab, X_text_and_image], dim=1))
@property
def output_dim(self):
return self.output_units
deephead = MyModelFuser(
tab_incoming_dim=tab_mlp.output_dim,
text_incoming_dim=models_fuser.output_dim,
image_incoming_dim=vision.output_dim,
output_units=8,
)
# WideDeep
model = WideDeep(
deeptabular=tab_mlp,
deeptext=models_fuser,
deepimage=vision,
deephead=deephead,
)
# 训练
trainer = Trainer(model, objective="binary")
trainer.fit(
X_tab=X_tab,
X_text=[X_text_1, X_text_2],
X_img=X_img,
target=df["target"].values,
n_epochs=1,
batch_size=32,
)
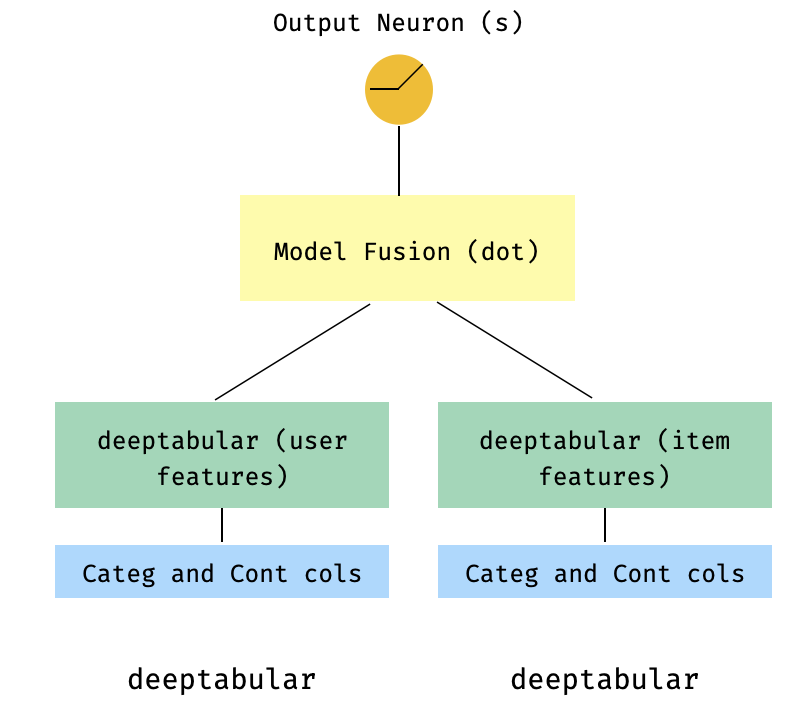
7. 双塔模型
这是一种在推荐系统中非常流行的模型。假设我们有一个由三元组(用户特征、物品特征、目标)组成的表格数据集。我们可以构建一个双塔模型,其中用户特征和物品特征分别通过两个独立的模型处理,然后通过点积进行“融合”。
import numpy as np
import pandas as pd
from pytorch_widedeep import Trainer
from pytorch_widedeep.preprocessing import TabPreprocessor
from pytorch_widedeep.models import TabMlp, WideDeep, ModelFuser
# 让我们创建交互数据集
# 用户特征数据框
np.random.seed(42)
user_ids = np.arange(1, 101)
ages = np.random.randint(18, 60, size=100)
genders = np.random.choice(["male", "female"], size=100)
locations = np.random.choice(["city_a", "city_b", "city_c", "city_d"], size=100)
user_features = pd.DataFrame(
{"id": user_ids, "age": ages, "gender": genders, "location": locations}
)
# 物品特征数据框
item_ids = np.arange(1, 101)
prices = np.random.uniform(10, 500, size=100).round(2)
colors = np.random.choice(["red", "blue", "green", "black"], size=100)
categories = np.random.choice(["electronics", "clothing", "home", "toys"], size=100)
item_features = pd.DataFrame(
{"id": item_ids, "price": prices, "color": colors, "category": categories}
)
# 交互数据框
interaction_user_ids = np.random.choice(user_ids, size=1000)
interaction_item_ids = np.random.choice(item_ids, size=1000)
purchased = np.random.choice([0, 1], size=1000, p=[0.7, 0.3])
interactions = pd.DataFrame(
{
"user_id": interaction_user_ids,
"item_id": interaction_item_ids,
"purchased": purchased,
}
)
user_item_purchased = interactions.merge(
user_features, left_on="user_id", right_on="id"
).merge(item_features, left-on="item_id", right-on="id")
# 用户
tab_preprocessor_user = TabPreprocessor(
cat_embed_cols=["gender", "location"],
continuous_cols=["age"],
)
X_user = tab_preprocessor_user.fit_transform(user_item_purchased)
tab_mlp_user = TabMlp(
column_idx=tab_preprocessor_user.column_idx,
cat_embed_input=tab_preprocessor_user.cat_embed_input,
continuous_cols=["age"],
mlp_hidden_dims=[16, 8],
mlp_dropout=[0.2, 0.2],
)
# 物品
tab_preprocessor_item = TabPreprocessor(
cat_embed_cols=["color", "category"],
continuous_cols=["price"],
)
X_item = tab_preprocessor_item.fit_transform(user_item_purchased)
tab_mlp_item = TabMlp(
column_idx=tab_preprocessor_item.column_idx,
cat_embed_input=tab_preprocessor_item.cat_embed_input,
continuous_cols=["price"],
mlp_hidden_dims=[16, 8],
mlp_dropout=[0.2, 0.2],
)
two_tower_model = ModelFuser([tab_mlp_user, tab_mlp_item], fusion_method="dot")
model = WideDeep(deeptabular=two_tower_model)
trainer = Trainer(model, objective="binary")
trainer.fit(
X_tab=[X_user, X_item],
target=interactions.purchased.values,
n_epochs=1,
batch_size=32,
)
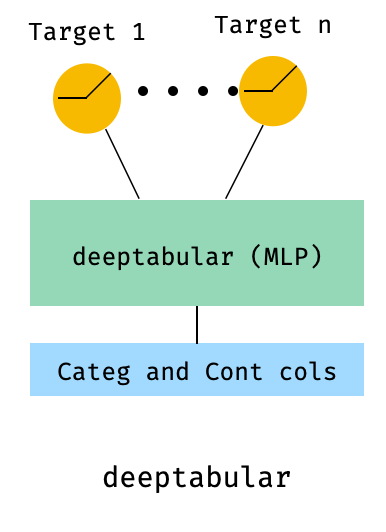
8. 具有多目标损失的表格数据
这个例子更像是一个“附加内容”,用来展示多目标损失的使用,而不是真正意义上的不同架构。
from pytorch_widedeep.preprocessing import TabPreprocessor, TextPreprocessor, ImagePreprocessor
from pytorch_widedeep.models import TabMlp, BasicRNN, WideDeep, ModelFuser, Vision
from pytorch_widedeep.losses_multitarget import MultiTargetClassificationLoss
from pytorch_widedeep.models._base_wd_model_component import BaseWDModelComponent
from pytorch_widedeep import Trainer
# 让我们在数据框中添加第二个目标
df["target2"] = [random.choice([0, 1]) for _ in range(100)]
# 表格数据
tab_preprocessor = TabPreprocessor(
embed_cols=["city", "name"], continuous_cols=["age", "height"]
)
X_tab = tab_preprocessor.fit_transform(df)
tab_mlp = TabMlp(
column_idx=tab_preprocessor.column_idx,
cat_embed_input=tab_preprocessor.cat_embed_input,
continuous_cols=tab_preprocessor.continuous_cols,
mlp_hidden_dims=[64, 32],
)
# 'pred_dim=2' 因为我们有两个二分类目标。对于其他类型的目标,
# 请参阅文档
model = WideDeep(deeptabular=tab_mlp, pred_dim=2)。
loss = MultiTargetClassificationLoss(binary_config=[0, 1], reduction="mean")
# 当使用多目标损失时,'custom_loss_function' 不得为 None。
# 参阅文档
trainer = Trainer(model, objective="multitarget", custom_loss_function=loss)
trainer.fit(
X_tab=X_tab,
target=df[["target", "target2"]].values,
n_epochs=1,
batch_size=32,
)
deeptabular 组件
需要再次强调的是,wide、deeptabular、deeptext 和 deepimage 这四个组件可以独立使用。例如,用户可以选择仅使用 wide 组件,它实际上就是一个线性模型。事实上,pytorch-widedeep 最有趣的功能之一就是单独使用 deeptabular 组件,也就是通常所说的面向表格数据的深度学习。目前,该组件提供了以下几种模型:
- Wide:一个简单的线性模型,通过之前提到的交叉项变换来捕捉非线性关系。
- TabMlp:一个简单的多层感知机,接收表示分类特征的嵌入向量,并将其与连续特征拼接起来;连续特征也可以被嵌入。
- TabResnet:与前一种模型类似,但嵌入向量会先经过一系列由全连接层构建的 ResNet 块处理。
- TabNet:关于 TabNet 的详细信息可在 TabNet: 用于表格数据的可解释注意力机制学习 中找到。
此外,还有两种基于注意力机制的简化模型,我们分别称为:
- ContextAttentionMLP:在 MLP 的基础上增加了一种基于 用于文档分类的层次化注意力网络 的注意力机制。
- SelfAttentionMLP:在 MLP 中引入了一种简化的自注意力机制,类似于我们称之为“查询-键自注意力”的 Transformer 块。
接下来是针对表格数据的 Transformer 系列模型:
- TabTransformer:关于 TabTransformer 的详细信息可在 TabTransformer:利用上下文嵌入进行表格数据建模 中找到。
- SAINT:关于 SAINT 的详细信息可在 SAINT:通过行级注意力和对比学习预训练改进表格数据神经网络 中找到。
- FT-Transformer:关于 FT-Transformer 的详细信息可在 重新审视用于表格数据的深度学习模型 中找到。
- TabFastFormer:将 FastFormer 模型适配到表格数据场景中。关于 FastFormer 的详细信息可在 FastFormers:用于自然语言理解的高度高效的 Transformer 模型 中找到。
- TabPerceiver:将 Perceiver 模型适配到表格数据场景中。关于 Perceiver 的详细信息可在 Perceiver:基于迭代注意力的通用感知模型 中找到。
此外,还有基于 神经网络中的权重不确定性 的概率深度学习模型,适用于表格数据:
- BayesianWide:对
Wide模型的概率化改造。 - BayesianTabMlp:对
TabMlp模型的概率化改造。
需要注意的是,虽然 TabTransformer、SAINT 和 FT-Transformer 都有相关的学术论文发表,但 TabFastFormer 和 TabPerceiver 是我们团队针对表格数据对这些算法所做的改编。
另外,所有 deeptabular 模型都可以使用自监督预训练方法,除了 TabPerceiver 之外。自监督预训练可以通过两种方式实现,我们称之为编码器-解码器方法和对比去噪方法。有关此功能及其他库内选项的详细信息,请参阅文档和示例。
rec 模块
该模块作为现有组件的扩展被引入,旨在解决推荐系统相关的问题。尽管目前仍在积极开发中,但它已经包含了一些强大的推荐模型。
值得注意的是,此前该库已支持使用现有组件实现多种推荐算法。例如,Wide & Deep、Two-Tower 或神经协同过滤等模型都可以通过库的核心功能轻松构建。
rec 模块中包含的推荐算法如下:
- AutoInt:基于自注意力神经网络的自动特征交互学习
- DeepFM:基于因子分解机的神经网络CTR预测模型
- (Deep)Field Aware Factorization Machine (FFM):这是 真实在线广告系统中的领域感知因子分解机 中提出的算法的深度学习版本。
- xDeepFM:结合显式与隐式特征交互的推荐系统
- 用于点击率预测的深度兴趣网络
- 用于广告点击预测的深度与交叉网络
- DCN V2:改进的深度与交叉网络及大规模排序学习系统的实践经验
- 迈向更深层、更轻量且可解释的点击率预测
- 一种基于 Transformer 的基础推荐模型,将问题视为序列建模任务。
有关如何使用这些模型的详细信息,请参阅示例。
文本与图像处理
对于文本处理组件 deeptext,该库提供了以下几种模型:
- BasicRNN:一个简单的循环神经网络。
- AttentiveRNN:基于 用于文档分类的层次化注意力网络 的带有注意力机制的 RNN。
- StackedAttentiveRNN:多层 AttentiveRNN 的堆叠结构。
- HFModel:一个封装了 Hugging Face 基于 Transformer 模型的接口。目前仅支持 BERT、RoBERTa、DistilBERT、ALBERT 和 ELECTRA 等系列模型。这是因为该库主要针对分类和回归任务设计,而这些模型是最为流行的仅编码器架构,已被证明在这些任务中表现最佳。如果未来有需求,其他模型也将被纳入支持范围。
对于图像处理组件 deepimage,该库支持以下模型家族:
'resnet'、'shufflenet'、'resnext'、'wide_resnet'、'regnet'、'densenet'、'mobilenetv3'、'mobilenetv2'、'mnasnet'、'efficientnet' 和 'squeezenet'。这些模型通过 torchvision 提供,并被封装在 Vision 类中。
安装
使用 pip 安装:
pip install pytorch-widedeep
或者直接从 GitHub 安装:
pip install git+https://github.com/jrzaurin/pytorch-widedeep.git
开发者安装
# 克隆仓库
git clone https://github.com/jrzaurin/pytorch-widedeep
cd pytorch-widedeep
# 以开发模式安装
pip install -e .
快速入门
以下是一个使用 Wide 和 DeepDense 模型,并采用默认设置,对 adult 数据集 进行二分类的端到端示例。
使用 pytorch-widedeep 构建一个宽(线性)模型和深度模型:
import numpy as np
import torch
from sklearn.model_selection import train_test_split
from pytorch_widedeep import Trainer
from pytorch_widedeep.preprocessing import WidePreprocessor, TabPreprocessor
from pytorch_widedeep.models import Wide, TabMlp, WideDeep
from pytorch_widedeep.metrics import Accuracy
from pytorch_widedeep.datasets import load_adult
df = load_adult(as_frame=True)
df["income_label"] = (df["income"].apply(lambda x: ">50K" in x)).astype(int)
df.drop("income", axis=1, inplace=True)
df_train, df_test = train_test_split(df, test_size=0.2, stratify=df.income_label)
# 定义特征列配置
wide_cols = [
"education",
"relationship",
"workclass",
"occupation",
"native-country",
"gender",
]
crossed_cols = [("education", "occupation"), ("native-country", "occupation")]
cat_embed_cols = [
"workclass",
"education",
"marital-status",
"occupation",
"relationship",
"race",
"gender",
"capital-gain",
"capital-loss",
"native-country",
]
continuous_cols = ["age", "hours-per-week"]
target = "income_label"
target = df_train[target].values
# 准备数据
wide_preprocessor = WidePreprocessor(wide_cols=wide_cols, crossed_cols=crossed_cols)
X_wide = wide_preprocessor.fit_transform(df_train)
tab_preprocessor = TabPreprocessor(
cat_embed_cols=cat_embed_cols, continuous_cols=continuous_cols # type: ignore[arg-type]
)
X_tab = tab_preprocessor.fit_transform(df_train)
# 构建模型
wide = Wide(input_dim=np.unique(X_wide).shape[0], pred_dim=1)
tab_mlp = TabMlp(
column_idx=tab_preprocessor.column_idx,
cat_embed_input=tab_preprocessor.cat_embed_input,
continuous_cols=continuous_cols,
)
model = WideDeep(wide=wide, deeptabular=tab_mlp)
# 训练和验证
trainer = Trainer(model, objective="binary", metrics=[Accuracy])
trainer.fit(
X_wide=X_wide,
X_tab=X_tab,
target=target,
n_epochs=5,
batch_size=256,
)
# 在测试集上进行预测
X_wide_te = wide_preprocessor.transform(df_test)
X_tab_te = tab_preprocessor.transform(df_test)
preds = trainer.predict(X_wide=X_wide_te, X_tab=X_tab_te)
# 保存和加载
# 选项1:如果使用了 LRHistory 回调函数,还会保存训练历史和学习率历史
trainer.save(path="model_weights", save_state_dict=True)
# 选项2:像保存其他 PyTorch 模型一样保存
torch.save(model.state_dict(), "model_weights/wd_model.pt")
# 从这里开始,选项1和选项2是等价的。假设用户已经准备好了数据并定义了新的模型组件:
# 1. 构建模型
model_new = WideDeep(wide=wide, deeptabular=tab_mlp)
model_new.load_state_dict(torch.load("model_weights/wd_model.pt"))
# 2. 实例化训练器
trainer_new = Trainer(model_new, objective="binary")
# 3. 可以开始训练,也可以直接进行预测
preds = trainer_new.predict(X_wide=X_wide, X_tab=X_tab, batch_size=32)
当然,你还可以做 更多 的事情。请查看 Examples 文件夹、文档或配套文章,以便更好地理解该包的内容及其功能。
测试
pytest tests
如何贡献
请查看 CONTRIBUTING 页面。
致谢
本库借鉴了多个其他库的经验,因此我认为在 README 中提及这些库是公平的(代码中也有具体说明)。
Callbacks 和 Initializers 的结构和代码灵感来源于 torchsample 库,而后者又部分受到 Keras 的启发。
本库中的 TextProcessor 类使用了 fastai 的 Tokenizer 和 Vocab。位于 utils.fastai_transforms 的代码是对它们的轻微改编,使其能在本库中正常工作。根据我的经验,他们的 Tokenizer 是同类产品中的佼佼者。
本库中的 ImageProcessor 类则使用了 Adrian Rosebrock 所著的精彩书籍 Deep Learning for Computer Vision(DL4CV)中的代码。
许可证
本作品采用 Apache 2.0 和 MIT 双重许可(或任何后续版本)。您在使用本作品时可以选择其中一种许可证。
SPDX-License-Identifier: Apache-2.0 AND MIT
引用
BibTex
@article{Zaurin_pytorch-widedeep_A_flexible_2023,
author = {Zaurin, Javier Rodriguez and Mulinka, Pavol},
doi = {10.21105/joss.05027},
journal = {Journal of Open Source Software},
month = jun,
number = {86},
pages = {5027},
title = {{pytorch-widedeep: A flexible package for multimodal deep learning}},
url = {https://joss.theoj.org/papers/10.21105/joss.05027},
volume = {8},
year = {2023}
}
APA
Zaurin, J. R., & Mulinka, P. (2023). pytorch-widedeep: A flexible package for multimodal deep learning. Journal of Open Source Software, 8(86), 5027.
https://doi.org/10.21105/joss.05027
版本历史
v.1.7.02025/09/27v.1.6.52024/11/06v.1.6.42024/09/24v.1.6.32024/08/26v.1.6.12024/06/17v1.6.02024/06/15v1.5.12024/04/10v.1.5.02024/02/17v.1.4.02023/11/17v.1.3.22023/08/06v1.3.12023/07/31v1.3.02023/07/21joss_paper_package_version_v1.2.02023/05/31v1.2.22023/01/20v.1.2.12022/10/07v1.2.02022/09/01v1.1.22022/08/29v1.1.02022/03/10v1.0.102021/10/07v1.0.92021/09/07常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器