CoreML-Models
CoreML-Models 是一个专为苹果生态打造的机器学习模型资源库,汇集了众多已转换并优化好的 Core ML 格式模型。它主要解决了开发者在 iOS、macOS 等平台应用机器学习功能时,面临模型格式转换复杂、适配难度大以及缺乏高质量现成模型的痛点。
无论是图像分类、目标检测(涵盖 YOLO 系列)、人像分割,还是超分辨率重建、低光增强、风格迁移乃至 Stable Diffusion 文生图,CoreML-Models 都提供了丰富的预训练模型选择。其独特的技术亮点在于将原本复杂的开源模型直接转换为苹果原生框架支持的格式,让开发者无需自行处理繁琐的转换流程,即可通过简单的下载和拖拽操作,将先进的 AI 能力集成到 Xcode 项目中。
这套资源库非常适合 iOS /macOS 应用开发者、希望快速验证算法原型的科研人员,以及对移动端 AI 感兴趣的设计师使用。对于普通用户而言,虽然不能直接运行模型,但许多基于此库开发的 App 能带来更智能的拍照、修图及交互体验。如果你希望在苹果设备上高效落地前沿 AI 技术,CoreML-Models 无疑是一个值得信赖的起点。
使用场景
一位 iOS 开发者正在为一款旅行摄影 App 开发“实时智能背景虚化”功能,希望在不依赖云端服务器的情况下,让用户在拍摄瞬间即可享受专业级的人像效果。
没有 CoreML-Models 时
- 模型转换门槛高:开发者需自行寻找开源算法(如 MobileSAM 或 RMBG),并耗费数天时间配置复杂的 Python 环境进行格式转换,极易因版本兼容问题失败。
- 端侧性能难优化:直接移植的通用模型体积庞大,导致 App 安装包激增,且在旧款 iPhone 上运行帧率低下,无法实现流畅的实时预览。
- 集成调试周期长:缺乏针对 Xcode 优化的示例代码,开发者需从零编写 Core ML 推理逻辑,排查内存泄漏与算力瓶颈耗时耗力。
- 功能迭代受限:由于技术验证成本过高,团队被迫放弃尝试更先进的分割算法,只能使用效果平庸的传统图像处理方案。
使用 CoreML-Models 后
- 即取即用高效集成:直接从仓库下载已预训练并转换好的
MobileSAM或RMBG1.4模型文件,拖入 Xcode 项目即可调用,省去了繁琐的转换环节。 - 原生性能极致发挥:这些模型专为 Apple 神经引擎优化,在保持高精度的同时大幅降低延迟,确保即使在 iPhone 11 等老设备上也能维持 30fps+ 的实时流畅度。
- 参考示例加速开发:利用仓库提供的 Sample Project 快速理解 API 调用方式,将原本需要一周的集成调试工作压缩至半天内完成。
- 前沿算法轻松落地:能够低成本尝试最新的分割与生成式模型,迅速上线竞品难以企及的创意滤镜功能,显著提升产品竞争力。
CoreML-Models 通过将复杂的模型工程标准化,让 iOS 开发者能专注于业务创新,真正实现了高端 AI 能力在移动端的普惠与即时落地。
运行环境要求
- macOS
- iOS
未说明
未说明
快速开始
CoreML-模型
转换后的Core ML模型库。

Core ML是苹果公司推出的一款机器学习框架。 如果你是一名iOS开发者,就可以轻松地在你的Xcode项目中使用机器学习模型。
使用方法
浏览这个模型库,如果你找到了想要的CoreML模型, 可以从Google Drive链接下载该模型,并将其打包到你的项目中。 或者,如果该模型附有示例项目链接,可以尝试运行一下,看看如何在项目中使用这个模型。 你可以选择是否这样做。
如果你喜欢这个仓库,请给我点个赞,这样我就能更加努力地维护它了。
章节链接
稳定扩散 :文本到图像
如何获取模型
你可以通过Google Drive链接获取已转换为CoreML格式的模型。 关于如何在Xcode中使用这些模型,请参阅下方章节。 每个模型的许可证均遵循其原始项目的许可证。
图像分类器
Efficientnet
| Google Drive链接 | 大小 | 数据集 | 原始项目 | 许可证 |
|---|---|---|---|---|
| Efficientnetb0 | 22.7 MB | ImageNet | TensorFlowHub | Apache2.0 |
Efficientnetv2
| Google Drive链接 | 大小 | 数据集 | 原始项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| Efficientnetv2 | 85.8 MB | ImageNet | Google/autoML | Apache2.0 | 2021 |
VisionTransformer
一张图片胜过16x16个单词:大规模图像识别中的Transformer。
| Google Drive链接 | 大小 | 数据集 | 原始项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| VisionTransformer-B16 | 347.5 MB | ImageNet | google-research/vision_transformer | Apache2.0 | 2021 |
Conformer
局部特征耦合全局表示用于视觉识别。

| Google Drive 链接 | 大小 | 数据集 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| Conformer-tiny-p16 | 94.1 MB | ImageNet | pengzhiliang/Conformer | Apache2.0 | 2021 |
DeiT
数据高效的图像Transformer

| Google Drive 链接 | 大小 | 数据集 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| DeiT-base384 | 350.5 MB | ImageNet | facebookresearch/deit | Apache2.0 | 2021 |
RepVGG
让VGG风格的卷积神经网络再次伟大
| Google Drive 链接 | 大小 | 数据集 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| RepVGG-A0 | 33.3 MB | ImageNet | DingXiaoH/RepVGG | MIT | 2021 |
RegNet
设计网络设计空间
| Google Drive 链接 | 大小 | 数据集 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| regnet_y_400mf | 16.5 MB | ImageNet | TORCHVISION.MODELS | MIT | 2020 |
MobileViTv2
CVNets:用于训练计算机视觉网络的库
| Google Drive 链接 | 大小 | 数据集 | 原项目 | 许可证 | 年份 | 转换脚本 |
|---|---|---|---|---|---|---|
| MobileViTv2 | 18.8 MB | ImageNet | apple/ml-cvnets | 苹果 | 2022 |
目标检测
D-FINE

| 下载链接 | 大小 | 输出 | 原项目 | 许可证 | 备注 | 示例项目 |
|---|---|---|---|---|---|---|
| dfine-n-coco | 13MB | 置信度(Float32 300 × 80 的多维数组),坐标(Float32 300 × 4 的多维数组) | Peterande/D-FINE | Apache 2.0 | 输入为640×640。坐标归一化为cxcywh。无NMS——按置信度阈值筛选。 | peaceofcake DFINEDemo |
RF-DETR

| 下载链接 | 大小 | 输出 | 原项目 | 许可证 | 备注 | 示例项目 |
|---|---|---|---|---|---|---|
| rfdetr-n-coco | 95MB | 置信度(Float32 300 × 91 的多维数组),坐标(Float32 300 × 4 的多维数组) | roboflow/rf-detr | Apache 2.0 | 输入为384×384。91个类别(索引0为背景,1-90为COCO类别ID)。坐标归一化为cxcywh。无NMS。 | peaceofcake DFINEDemo |
YOLOv5s
| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 备注 | 示例项目 |
|---|---|---|---|---|---|---|
| YOLOv5s | 29.3MB | 置信度(Double 0 × 80 的多维数组),坐标(Double 0 × 4 的多维数组) | ultralytics/yolov5 | GNU | 已添加非极大值抑制。 | CoreML-YOLOv5 |
YOLOv7
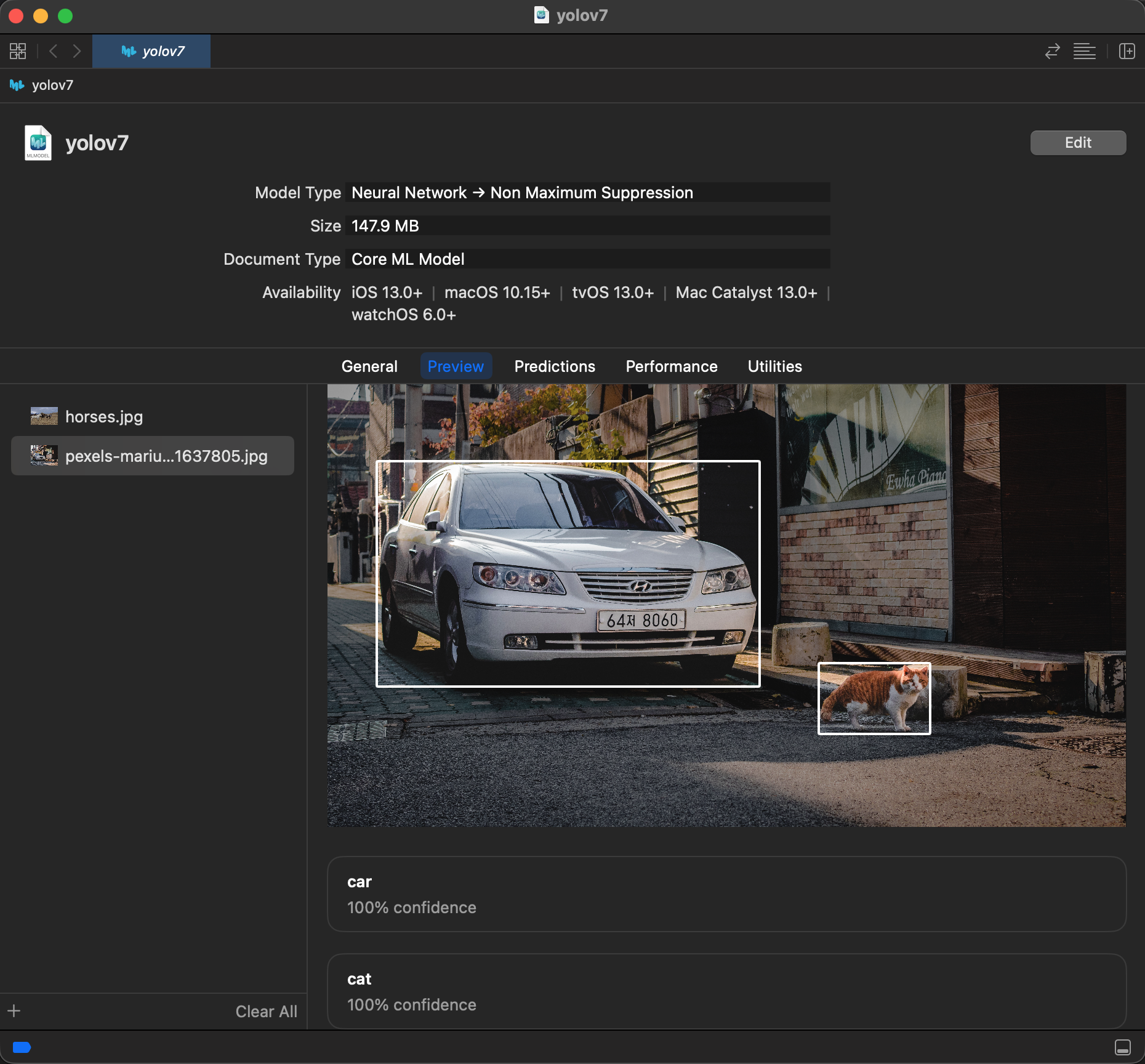
| Google Drive 链接 | 大小 | 输出 | 原始项目 | 许可证 | 备注 | 示例项目 | 转换脚本 |
|---|---|---|---|---|---|---|---|
| YOLOv7 | 147.9MB | 置信度(多维数组 (Double 0 × 80)),坐标(多维数组 (Double 0 × 4)) | WongKinYiu/yolov7 | GNU | 已添加非极大值抑制。 | CoreML-YOLOv5 |
YOLOv8
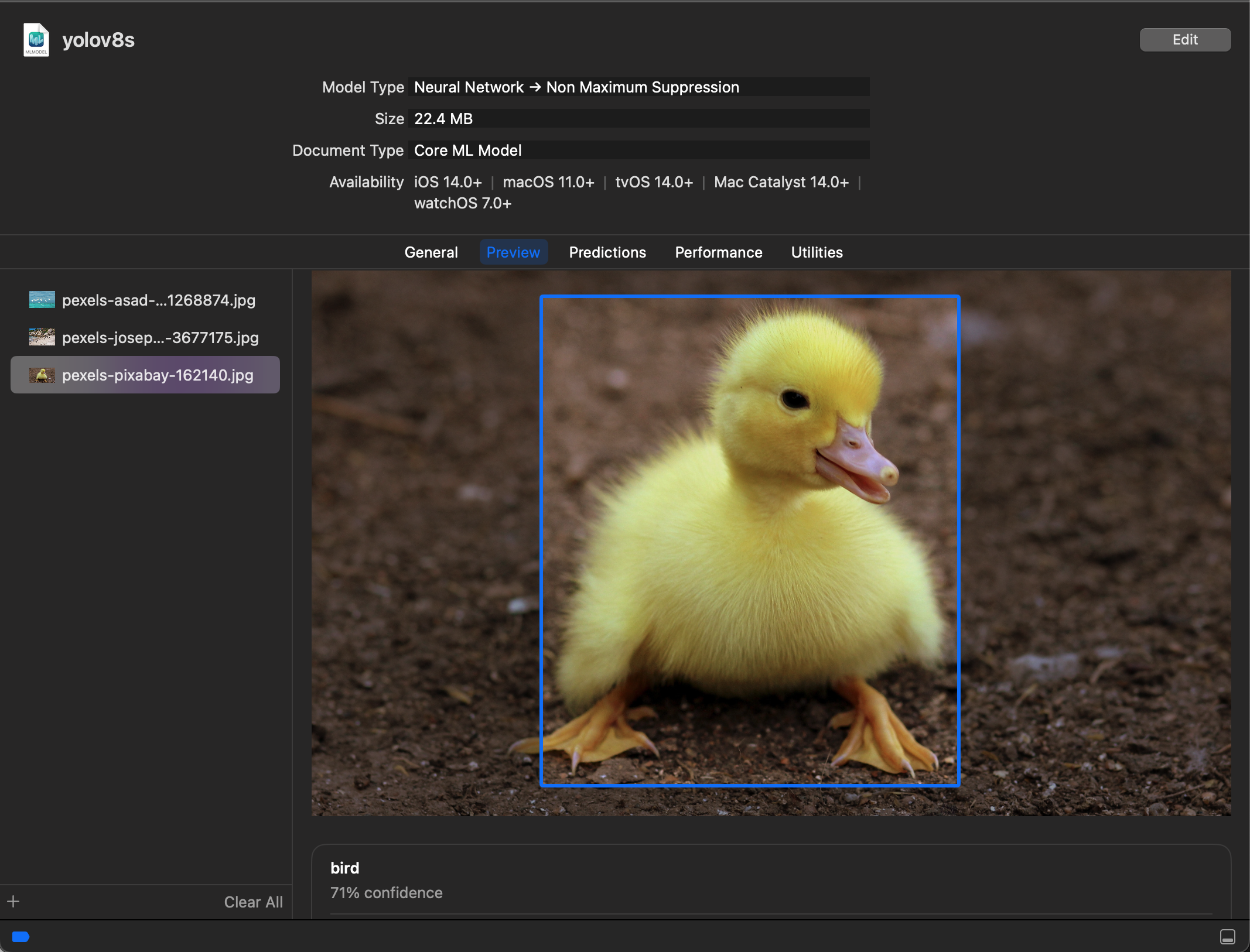
| Google Drive 链接 | 大小 | 输出 | 原始项目 | 许可证 | 备注 | 示例项目 |
|---|---|---|---|---|---|---|
| YOLOv8s | 45.1MB | 置信度(多维数组 (Double 0 × 80)),坐标(多维数组 (Double 0 × 4)) | ultralytics/ultralytics | GNU | 已添加非极大值抑制。 | CoreML-YOLOv5 |
YOLOv9
YOLOv9:使用可编程梯度信息学习你想学的内容。采用 PGI 和 GELAN 架构实现高效的目标检测。
| 下载链接 | 大小 | 输出 | 原始项目 | 许可证 | 年份 | 备注 | 示例项目 |
|---|---|---|---|---|---|---|---|
| yolov9s.mlpackage.zip | 14 MB | 置信度(多维数组(Double 0 × 80)),坐标(多维数组(Double 0 × 4)) | WongKinYiu/yolov9 | GPL-3.0 | 2024 | 已添加非极大值抑制。 | YOLOv9Demo |
YOLOv10
YOLOv10:实时端到端目标检测。采用一致的双重分配无 NMS 架构——无需后处理。
| 下载链接 | 大小 | 输出 | 原始项目 | 许可证 | 年份 | 备注 | 示例项目 |
|---|---|---|---|---|---|---|---|
| yolov10s.mlpackage.zip | 14 MB | 多维数组(1 × 300 × 6) | THU-MIG/yolov10 | AGPL-3.0 | 2024 | 无 NMS 的端到端检测。 | YOLO26Demo |
YOLO11
YOLO11:Ultralytics 最新的 YOLO,改进了骨干和颈部架构。参数比 YOLOv8 少 22%,mAP 更高。
| 下载链接 | 大小 | 输出 | 原始项目 | 许可证 | 年份 | 备注 | 示例项目 |
|---|---|---|---|---|---|---|---|
| yolo11s.mlpackage.zip | 18 MB | 置信度(多维数组(Double 0 × 80)),坐标(多维数组(Double 0 × 4)) | ultralytics/ultralytics | AGPL-3.0 | 2024 | 已添加非极大值抑制。 | YOLOv9Demo |
YOLO26
YOLO26:边缘优先的视觉 AI,具有无 NMS 的端到端检测功能。与 YOLO11 相比,CPU 推理速度最高快 43%,并移除了 DFL 和 ProgLoss。

| 下载链接 | 大小 | 输出 | 原始项目 | 许可证 | 年份 | 备注 | 示例项目 |
|---|---|---|---|---|---|---|---|
| yolo26s.mlpackage.zip | 18 MB | 多维数组(1 × 300 × 6) | ultralytics/ultralytics | AGPL-3.0 | 2026 | 无 NMS 的端到端检测。 | YOLO26Demo |
YOLO-World
YOLO-World:实时开放词汇目标检测。输入任意文本查询即可检测,无需固定类别列表。使用 CLIP 文本编码器进行开放词汇匹配。

| 下载链接 | 大小 | 描述 | 原始项目 | 许可证 | 年份 | 示例项目 |
|---|---|---|---|---|---|---|
| yoloworld_detector.mlpackage.zip | 25 MB | YOLO-World V2-S 视觉检测器 | AILab-CVC/YOLO-World | GPL-3.0 | 2024 | YOLOWorldDemo |
| clip_text_encoder.mlpackage.zip | 121 MB | CLIP ViT-B/32 文本编码器 | openai/CLIP | MIT | 2021 | — |
| clip_vocab.json.zip | 1.6 MB | BPE 词汇表用于分词器 | — | — | — | — |
分割
U2Net
| Google Drive 链接 | 大小 | 输出 | 原始项目 | 许可证 |
|---|---|---|---|---|
| U2Net | 175.9 MB | 图像(灰度,320 × 320) | xuebinqin/U-2-Net | Apache |
| U2Netp | 4.6 MB | 图像(灰度,320 × 320) | xuebinqin/U-2-Net | Apache |
IS-Net




| Google Drive 链接 | 大小 | 输出 | 原始项目 | 许可证 | 年份 | 转换脚本 |
|---|---|---|---|---|---|---|
| IS-Net | 176.1 MB | 图像(灰度,1024 × 1024) | xuebinqin/DIS | Apache | 2022 | |
| IS-Net-General-Use | 176.1 MB | 图像(灰度,1024 × 1024) | xuebinqin/DIS | Apache | 2022 |
RMBG1.4
RMBG1.4 - 经过我们独特的训练方案和专有数据集增强的 IS-Net。


| 下载链接 | 大小 | 输出 | 原始项目 | 许可证 | 年份 | 示例项目 | 转换脚本 |
|---|---|---|---|---|---|---|---|
| RMBG_1_4.mlpackage.zip | 42 MB(INT8) | Alpha 透明度图 1024×1024 | briaai/RMBG-1.4 | 知识共享 | 2024 | RMBGDemo | convert_rmbg.py |
face-Parsing


| Google Drive 链接 | 大小 | 输出 | 原始项目 | 许可证 | 示例项目 |
|---|---|---|---|---|---|
| face-Parsing | 53.2 MB | 多维数组(1 x 512 × 512) | zllrunning/face-parsing.PyTorch | MIT | CoreML-face-parsing |
Segformer
使用 Transformer 的简单高效语义分割设计


| Google Drive 链接 | 大小 | 输出 | 原始项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| SegFormer_mit-b0_1024x1024_cityscapes | 14.9 MB | 多维数组(512 × 1024) | NVlabs/SegFormer | NVIDIA | 2021 |
BiSeNetV2
用于实时语义分割的引导聚合双边网络


| Google Drive 链接 | 大小 | 输出 | 原始项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| BiSeNetV2_1024x1024_cityscapes | 12.8 MB | 多维数组 | ycszen/BiSeNet | Apache2.0 | 2021 |
DNL
解耦非局部神经网络


| Google Drive 链接 | 大小 | 输出 | 数据集 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|---|
| dnl_r50-d8_512x512_80k_ade20k | 190.8 MB | MultiArray[512x512] | ADE20K | yinmh17/DNL-Semantic-Segmentation | Apache2.0 | 2020 |
ISANet
用于语义分割的交错稀疏自注意力机制


| Google Drive 链接 | 大小 | 输出 | 数据集 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|---|
| isanet_r50-d8_512x512_80k_ade20k | 141.5 MB | MultiArray[512x512] | ADE20K | openseg-group/openseg.pytorch | MIT | ArXiv'2019/IJCV'2021 |
FastFCN
重新思考骨干网络中的空洞卷积在语义分割中的应用


| Google Drive 链接 | 大小 | 输出 | 数据集 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|---|
| fastfcn_r50-d32_jpu_aspp_512x512_80k_ade20k | 326.2 MB | MultiArray[512x512] | ADE20K | wuhuikai/FastFCN | MIT | ArXiv'2019 |
GCNet
非局部网络与挤压激励网络的结合及其扩展


| Google Drive 链接 | 大小 | 输出 | 数据集 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|---|
| gcnet_r50-d8_512x512_20k_voc12aug | 189 MB | MultiArray[512x512] | PascalVOC | xvjiarui/GCNet | Apache License 2.0 | ICCVW'2019/TPAMI'2020 |
DANet
用于场景分割的双注意力网络(CVPR2019)


| Google Drive 链接 | 大小 | 输出 | 数据集 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|---|
| danet_r50-d8_512x1024_40k_cityscapes | 189.7 MB | MultiArray[512x1024] | CityScapes | junfu1115/DANet | MIT | CVPR2019 |
Semantic-FPN
全景特征金字塔网络


| Google Drive 链接 | 大小 | 输出 | 数据集 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|---|
| fpn_r50_512x1024_80k_cityscapes | 108.6 MB | MultiArray[512x1024] | CityScapes | facebookresearch/detectron2 | Apache License 2.0 | 2019 |
cloths_segmentation
用于各种衣物二值分割的代码。


| Google Drive 链接 | 大小 | 输出 | 数据集 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|---|
| clothSegmentation | 50.1 MB | 图像(灰度 640x960) | fashion-2019-FGVC6 | facebookresearch/detectron2 | MIT | 2020 |
easyportrait
EasyPortrait - 人脸解析与人像分割数据集。


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 | Swift 示例 | 转换脚本 |
|---|---|---|---|---|---|---|---|
| easyportrait-segformer512-fp | 7.6 MB | 图像(灰度 512x512)* 9 | hukenovs/easyportrait | 知识共享 | 2023 | easyportrait-coreml |
MobileSAM
更快的 Segment Anything:面向移动应用的轻量级 SAM。MobileSAM 通过解耦的知识蒸馏,用轻量级的 ViT-Tiny 编码器替代了沉重的 ViT-H 图像编码器,使其体积缩小约 60 倍,速度提升约 40 倍,相比原始的 SAM。
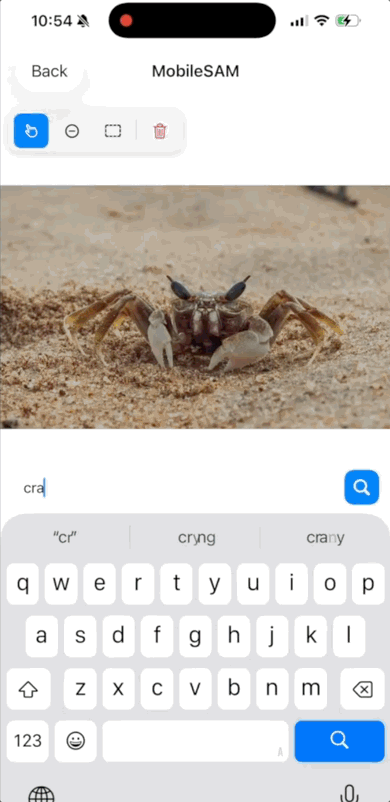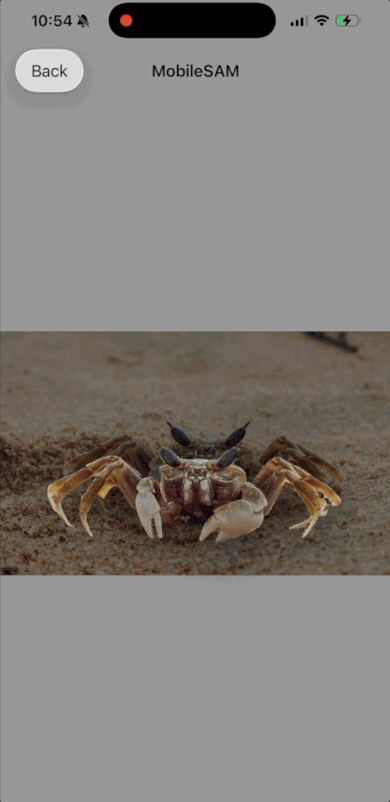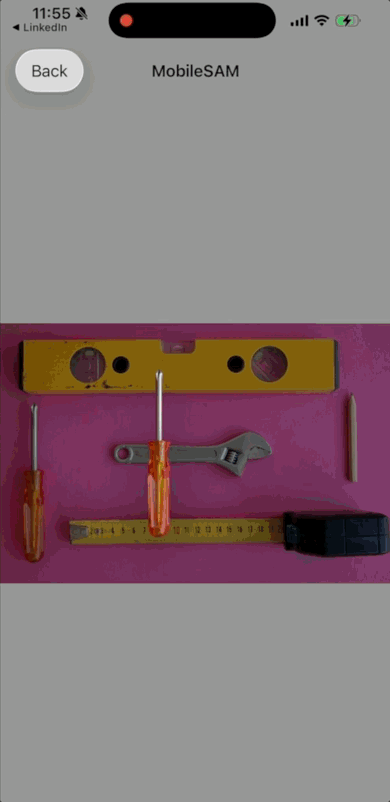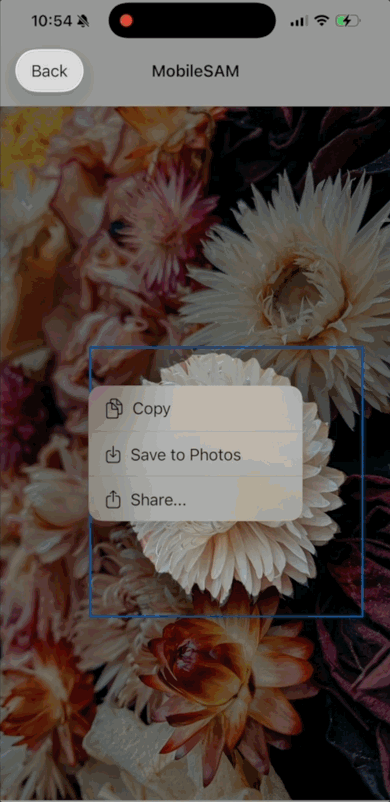 | 下载链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 | 示例项目 |
| ------------- | ------------- | ------------- | ------------- | ------------- | ------------- | ------------- |
| [MobileSAM.zip](https://github.com/john-rocky/SamKit/releases/download/v1.0.0/MobileSAM.zip) | 23 MB(编码器 13 MB + 解码器 9.8 MB) | 分割掩膜 | [ChaoningZhang/MobileSAM](https://github.com/ChaoningZhang/MobileSAM) | [Apache 2.0](https://github.com/ChaoningZhang/MobileSAM/blob/master/LICENSE) | 2023 | [SamKit](https://github.com/john-rocky/SamKit) |
| 下载链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 | 示例项目 |
| ------------- | ------------- | ------------- | ------------- | ------------- | ------------- | ------------- |
| [MobileSAM.zip](https://github.com/john-rocky/SamKit/releases/download/v1.0.0/MobileSAM.zip) | 23 MB(编码器 13 MB + 解码器 9.8 MB) | 分割掩膜 | [ChaoningZhang/MobileSAM](https://github.com/ChaoningZhang/MobileSAM) | [Apache 2.0](https://github.com/ChaoningZhang/MobileSAM/blob/master/LICENSE) | 2023 | [SamKit](https://github.com/john-rocky/SamKit) |
SAM2-Tiny
SAM 2:对图像和视频进行任意分割。SAM 2 使用带有记忆功能的流式架构,将可提示分割从图像扩展到视频。Tiny 变体采用 Hiera-T 主干网络,以实现高效的设备端推理。
| 下载链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 | 示例项目 |
|---|---|---|---|---|---|---|
| SAM2Tiny.zip | 76 MB(图像编码器 64 MB + 提示编码器 2 MB + 掩膜解码器 9.8 MB) | 分割掩膜 | facebookresearch/sam2 | Apache 2.0 | 2024 | SamKit |
视频抠图
MatAnyone
pq-yang/MatAnyone(CVPR 2025)—— 具有对象级记忆传播的时序一致视频抠图。给定第一帧的掩膜,该网络会跟踪并细化整段视频中的 Alpha 抠图,能够比逐帧抠图基线更好地保持清晰的边缘(如头发、半透明区域)。它基于 Cutie 视频目标分割主干网络构建,并配备了专门用于抠图的掩膜解码器。
CoreML 版本将网络拆分为 5 个无状态模块,以便每帧的记忆状态机可以在 Swift 中运行,而 CoreML 则负责繁重的计算任务。端到端 Alpha 抠图与官方 PyTorch 参考实现的对比结果显示:MAE < 2e-4,相关系数在 18 帧中超过 0.9999,其中包括 3 个记忆周期。
示例应用程序使用 Vision 的 VNGeneratePersonSegmentationRequest 自动生成第一帧的掩膜——选择一段视频,点击“移除背景”,即可将前景合成到选定的背景颜色上。
| 下载链接 | 大小 | 输入 | 输出 | 原项目 | 许可证 | 年份 | 示例项目 | 转换脚本 |
|---|---|---|---|---|---|---|---|---|
| MatAnyone(5 个 mlpackage,FP16 总大小约 111 MB) | 111 MB | 图像 [1,3,432,768](每帧状态由 Swift 维护) | alpha 抠图 [1,1,432,768] | pq-yang/MatAnyone | NTU S-Lab 1.0 | 2025 | MatAnyoneDemo | convert_matanyone.py |
有关每帧状态机、5 模块拆分及转换细节,请参阅 sample_apps/MatAnyoneDemo/README.md。
超分辨率
Real ESRGAN


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| Real ESRGAN4x | 66.9 MB | 图像(RGB 2048x2048) | xinntao/Real-ESRGAN | BSD 3-Clause 许可证 | 2021 |
| Real ESRGAN Anime4x | 66.9 MB | 图像(RGB 2048x2048) | xinntao/Real-ESRGAN | BSD 3-Clause 许可证 | 2021 |
GFPGAN
利用生成式面部先验实现真实世界的盲态人脸修复


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| GFPGAN | 337.4 MB | 图像(RGB 512x512) | TencentARC/GFPGAN | Apache2.0 | 2021 |
BSRGAN


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| BSRGAN | 66.9 MB | 图像(RGB 2048x2048) | cszn/BSRGAN | 2021 |
A-ESRGAN


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 | 转换脚本 |
|---|---|---|---|---|---|---|
| A-ESRGAN | 63.8 MB | 图像(RGB 1024x1024) | aesrgan/A-ESRGANN | BSD 3-Clause 许可证 | 2021 |
Beby-GAN
用于高细节图像超分辨率的最佳伙伴GANs


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| Beby-GAN | 66.9 MB | 图像(RGB 2048x2048) | dvlab-research/Simple-SR | MIT | 2021 |
RRDN
用于图像超分辨率的残差级联密集网络。


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| RRDN | 16.8 MB | 图像(RGB 2048x2048) | idealo/image-super-resolution | Apache2.0 | 2018 |
Fast-SRGAN
快速SRGAN。


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| Fast-SRGAN | 628 KB | 图像(RGB 1024x1024) | HasnainRaz/Fast-SRGAN | MIT | 2019 |
ESRGAN
增强版SRGAN。


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| ESRGAN | 66.9 MB | 图像(RGB 2048x2048) | xinntao/ESRGAN | Apache 2.0 | 2018 |
UltraSharp
预训练:4倍ESRGAN


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| UltraSharp | 34 MB | 图像(RGB 1024x1024) | Kim2019/ | CC-BY-NC-SA-4.0 | 2021 |
SRGAN
使用生成对抗网络实现照片级真实感单张图像超分辨率。


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| SRGAN | 6.1 MB | 图像(RGB 2048x2048) | dongheehand/SRGAN-PyTorch | 2017 |
SRResNet
基于生成对抗网络的逼真单张图像超分辨率。


| Google Drive 链接 | 大小 | 输出 | 原始项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| SRResNet | 6.1 MB | 图像(RGB 2048x2048) | dongheehand/SRGAN-PyTorch | 2017 |
LESRCNN
基于增强CNN的轻量级图像超分辨率。


| Google Drive 链接 | 大小 | 输出 | 原始项目 | 许可证 | 年份 | 转换脚本 |
|---|---|---|---|---|---|---|
| LESRCNN | 4.3 MB | 图像(RGB 512x512) | hellloxiaotian/LESRCNN | 2020 |
MMRealSR
基于度量学习的真实世界交互式调制超分辨率


| Google Drive 链接 | 大小 | 输出 | 原始项目 | 许可证 | 年份 | 转换脚本 |
|---|---|---|---|---|---|---|
| MMRealSRGAN | 104.6 MB | 图像(RGB 1024x1024) | TencentARC/MM-RealSR | BSD 3-Clause | 2022 | |
| MMRealSRNet | 104.6 MB | 图像(RGB 1024x1024) | TencentARC/MM-RealSR | BSD 3-Clause | 2022 |
DASR
“用于盲超分辨率的无监督退化表征学习”在 CVPR 2021 中的 PyTorch 实现


| Google Drive 链接 | 大小 | 输出 | 原始项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| DASR | 12.1 MB | 图像(RGB 1024x1024) | The-Learning-And-Vision-Atelier-LAVA/DASR | MIT | 2022 |
SinSR
wyf0912/SinSR — 单步扩散式超分辨率(CVPR 2024,约1.13亿参数)。从 ResShift 中提炼而来,实现一步4倍放大。采用 Swin Transformer UNet 结合 VQ-VAE 隐空间。

左:双三次4倍放大,右:SinSR单步扩散超分辨率(128x128 → 512x512)
包含3个 CoreML 模型:VQ-VAE 编码器、Swin-UNet 去噪器(单步)以及带有向量量化功能的 VQ-VAE 解码器。
| 下载链接 | 大小 | 输入 | 输出 | 原始项目 | 许可证 | 年份 | 示例项目 | 转换脚本 |
|---|---|---|---|---|---|---|---|---|
| SinSR_Encoder.mlpackage.zip | 39 MB | 图像 [1,3,1024,1024] | 隐变量 [1,3,256,256] | wyf0912/SinSR | S-Lab | 2024 | SinSRDemo | convert_sinsr.py |
| SinSR_Denoiser.mlpackage.zip | 420 MB | 输入 [1,6,256,256] | 预测的隐变量 [1,3,256,256] | |||||
| SinSR_Decoder.mlpackage.zip | 58 MB | 隐变量 [1,3,256,256] | 图像 [1,3,1024,1024] |
推理流程及转换细节请参阅 sample_apps/SinSRDemo/README.md。
低光增强
StableLLVE
从单张图像中学习时间一致性以进行低光视频增强。


| Google Drive 链接 | 大小 | 输出 | 原始项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| StableLLVE | 17.3 MB | 图像(RGB 512x512) | zkawfanx/StableLLVE | MIT | 2021 |
Zero-DCE
无参考深度曲线估计用于低光图像增强


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 | 转换脚本 |
|---|---|---|---|---|---|---|
| Zero-DCE | 320KB | 图像(RGB 512x512) | Li-Chongyi/Zero-DCE | 查看仓库 | 2021 |
Retinexformer
Retinexformer:基于 Retinex 的单阶段 Transformer 用于低光图像增强


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 | 转换脚本 |
|---|---|---|---|---|---|---|
| ZRetinexformer FiveK | 3.4MB | 图像(RGB 512x512) | caiyuanhao1998/Retinexformer | MIT | 2023 | |
| ZRetinexformer NTIRE | 3.4MB | 图像(RGB 512x512) | caiyuanhao1998/Retinexformer | MIT | 2023 |
图像修复
MPRNet
多阶段渐进式图像修复。
去模糊


去噪
去雨


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| MPRNetDebluring | 137.1 MB | 图像(RGB 512x512) | swz30/MPRNet | MIT | 2021 |
| MPRNetDeNoising | 108 MB | 图像(RGB 512x512) | swz30/MPRNet | MIT | 2021 |
| MPRNetDeraining | 24.5 MB | 图像(RGB 512x512) | swz30/MPRNet | MIT | 2021 |
MIRNetv2
用于快速图像修复与增强的特征学习模型。
去噪


超分辨率


对比度增强


低光增强


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 | 转换脚本 |
|---|---|---|---|---|---|---|
| MIRNetv2Denoising | 42.5 MB | 图像(RGB 512×512) | swz30/MIRNetv2 | 学术公共许可证 | 2022 | |
| MIRNetv2SuperResolution | 42.5 MB | 图像(RGB 512×512) | swz30/MIRNetv2 | 学术公共许可证 | 2022 | |
| MIRNetv2ContrastEnhancement | 42.5 MB | 图像(RGB 512×512) | swz30/MIRNetv2 | 学术公共许可证 | 2022 | |
| MIRNetv2LowLightEnhancement | 42.5 MB | 图像(RGB 512×512) | swz30/MIRNetv2 | 学术公共许可证 | 2022 |
图像生成
MobileStyleGAN


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 示例项目 |
|---|---|---|---|---|---|
| MobileStyleGAN | 38.6MB | 图像(彩色 1024 × 1024) | bes-dev/MobileStyleGAN.pytorch | Nvidia 源代码许可证-非商业用途 | CoreML-StyleGAN |
DCGAN

| Google Drive 链接 | 大小 | 输出 | 原项目 |
|---|---|---|---|
| DCGAN | 9.2MB | 多维数组 | TensorFlowCore |
图像到图像转换
Anime2Sketch


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 使用方法 |
|---|---|---|---|---|---|
| Anime2Sketch | 217.7MB | 图像(彩色 512 × 512) | Mukosame/Anime2Sketch | MIT 许可证 | 拖入一张图片即可预览 |
AnimeGAN2Face_Paint_512_v2
用于快速图像修复与增强的特征学习。
去噪
超分辨率
对比度增强
低光增强
| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 | 转换脚本 |
|---|---|---|---|---|---|---|
| MIRNetv2Denoising | 42.5 MB | 图像(RGB 512x512) | swz30/MIRNetv2 | 学术公共许可证 | 2022 | |
| MIRNetv2SuperResolution | 42.5 MB | 图像(RGB 512x512) | swz30/MIRNetv2 | 学术公共许可证 | 2022 | |
| MIRNetv2ContrastEnhancement | 42.5 MB | 图像(RGB 512x512) | swz30/MIRNetv2 | 学术公共许可证 | 2022 | |
| MIRNetv2LowLightEnhancement | 42.5 MB | 图像(RGB 512x512) | swz30/MIRNetv2 | 学术公共许可证 | 2022 |
图像生成
MobileStyleGAN
| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 示例项目 |
|---|---|---|---|---|---|
| MobileStyleGAN | 38.6MB | 图像(彩色 1024 × 1024) | bes-dev/MobileStyleGAN.pytorch | Nvidia 源代码许可证-NC | CoreML-StyleGAN |
DCGAN
| Google Drive 链接 | 大小 | 输出 | 原项目 |
|---|---|---|---|
| DCGAN | 9.2MB | 多维数组 | TensorFlowCore |
图像到图像
Anime2Sketch
| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 使用方法 |
|---|---|---|---|---|---|
| Anime2Sketch | 217.7MB | 图像(彩色 512 × 512) | Mukosame/Anime2Sketch | MIT | 拖放一张图片即可预览 |
AnimeGAN2Face_Paint_512_v2
| Google Drive 链接 | 大小 | 输出 | 原项目 | 转换脚本 |
|---|---|---|---|---|
| AnimeGAN2Face_Paint_512_v2 | 8.6MB | 图像(彩色 512 × 512) | bryandlee/animegan2-pytorch |
Photo2Cartoon


| Google Drive 链接 | 大小 | 输出 | 原始项目 | 许可证 | 备注 |
|---|---|---|---|---|---|
| Photo2Cartoon | 15.2 MB | 图像(彩色 256 × 256) | minivision-ai/photo2cartoon | MIT | 输出与原始模型略有不同,原因是部分操作被手动替换。 |
AnimeGANv2_Hayao


| Google Drive 链接 | 大小 | 输出 | 原始项目 | 示例 |
|---|---|---|---|---|
| AnimeGANv2_Hayao | 8.7MB | 图像(256 x 256) | TachibanaYoshino/AnimeGANv2 | AnimeGANv2-iOS |
AnimeGANv2_Paprika


| Google Drive 链接 | 大小 | 输出 | 原始项目 |
|---|---|---|---|
| AnimeGANv2_Paprika | 8.7MB | 图像(256 x 256) | TachibanaYoshino/AnimeGANv2 |
WarpGAN 卡通化

| Google Drive 链接 | 大小 | 输出 | 原始项目 |
|---|---|---|---|
| WarpGAN 卡通化 | 35.5MB | 图像(256 x 256) | seasonSH/WarpGAN |
UGATIT selfie2anime


| Google Drive 链接 | 大小 | 输出 | 原始项目 |
|---|---|---|---|
| UGATIT selfie2anime | 266.2MB(量化版) | 图像(256x256) | taki0112/UGATIT |
CartoonGAN
| Google Drive 链接 | 大小 | 输出 | 原始项目 |
|---|---|---|---|
| CartoonGAN_Shinkai | 44.6MB | 多数组 | mnicnc404/CartoonGan-tensorflow |
| CartoonGAN_Hayao | 44.6MB | 多数组 | mnicnc404/CartoonGan-tensorflow |
| CartoonGAN_Hosoda | 44.6MB | 多数组 | mnicnc404/CartoonGan-tensorflow |
| CartoonGAN_Paprika | 44.6MB | 多数组 | mnicnc404/CartoonGan-tensorflow |
快速神经风格迁移






| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| fast-neural-style-transfer-cuphead | 6.4MB | 图像(RGB 960x640) | eriklindernoren/Fast-Neural-Style-Transfer | MIT | 2019 |
| fast-neural-style-transfer-starry-night | 6.4MB | 图像(RGB 960x640) | eriklindernoren/Fast-Neural-Style-Transfer | MIT | 2019 |
| fast-neural-style-transfer-mosaic | 6.4MB | 图像(RGB 960x640) | eriklindernoren/Fast-Neural-Style-Transfer | MIT | 2019 |
白盒卡通化
使用白盒卡通表示学习卡通化


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| White_box_Cartoonization | 5.9MB | 图像(1536x1536) | SystemErrorWang/White-box-Cartoonization | creativecommons | CVPR2020 |
人脸卡通化
白盒人脸图像卡通化


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 |
|---|---|---|---|---|---|
| FacialCartoonization | 8.4MB | 图像(256x256) | SystemErrorWang/FacialCartoonization | creativecommons | 2020 |
图像修复
AOT-GAN用于图像修复

| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 备注 | 示例项目 |
|---|---|---|---|---|---|---|
| AOT-GAN-for-Inpainting | 60.8MB | MLMultiArray(3,512,512) | researchmm/AOT-GAN-for-Inpainting | Apache2.0 | 使用时请参考示例。 | john-rocky/Inpainting-CoreML |
Lama

| Google Drive 链接 | 大小 | 输入 | 输出 | 原项目 | 许可证 | 备注 | 示例项目 | 转换脚本 |
|---|---|---|---|---|---|---|---|---|
| Lama | 216.6MB | 图像(彩色 800 × 800),图像(灰度 800 × 800) | 图像(彩色 800 × 800) | advimman/lama | Apache2.0 | 使用时请参考示例。 | john-rocky/lama-cleaner-iOS | mallman/CoreMLaMa |
单目深度估计
MiDaS
迈向鲁棒的单目深度估计:混合数据集实现零样本跨数据集迁移


| Google Drive 链接 | 大小 | 输出 | 原项目 | 许可证 | 年份 | 转换脚本 |
|---|---|---|---|---|---|---|
| MiDaS_Small | 66.3MB | MultiArray(1x256x256) | isl-org/MiDaS | MIT | 2022 |
稳定扩散
Hyper-SD
ByteDance/Hyper-SD — 通过轨迹分段一致性蒸馏从 SD1.5 中提炼出的单步文生图模型。字节跳动报告称,在单步情况下,用户对 Hyper-SD 的偏好是 SD-Turbo 的两倍。结合 Apple 的 ml-stable-diffusion(Split-Einsum 注意力机制、分块 UNet、6 位调色板量化),该模型在 iPhone 15 及更高版本上能够以可接受的速度和质量运行。

iPhone 上的单步生成,512×512 分辨率。提示词:戴太阳镜的猫、赛博朋克城市、日式庭院、骑马的宇航员。
包含 4 个 CoreML 模型(总大小约 947 MB):CLIP 文本编码器 + Swin 风格分块 UNet(6 位调色板量化)+ VAE 解码器。使用 TCD 调度器进行单步推理。
| 下载链接 | 大小 | 输入 | 输出 | 原始项目 | 许可证 | 年份 | 示例项目 | 转换脚本 |
|---|---|---|---|---|---|---|---|---|
| HyperSDTextEncoder.mlpackage.zip | 235 MB | input_ids [1,77] | encoder_hidden_states [1,77,768] | ByteDance/Hyper-SD | OpenRAIL++ | 2024 | HyperSDDemo | convert_hypersd.py |
| HyperSDUnetChunk1.mlpackage.zip | 318 MB | latent + encoder_hs + timestep | 第一半中间结果 | |||||
| HyperSDUnetChunk2.mlpackage.zip | 299 MB | 第一半输出 + 跳跃连接 | noise_pred [2,4,64,64] | |||||
| HyperSDVAEDecoder.mlpackage.zip | 95 MB | latent [1,4,64,64] | image [1,3,512,512] |
有关 LoRA 融合、分块 UNet 调色板量化以及 TCD 调度器的详细信息,请参阅 sample_apps/HyperSDDemo/README.md。
stable-diffusion-v1-5
| Google Drive 链接 | 原始模型 | 原始项目 | 许可证 | 在 Mac 上运行 | 转换脚本 | 年份 |
|---|---|---|---|---|---|---|
| stable-diffusion-v1-5 | runwayml/stable-diffusion-v1-5 | runwayml/stable-diffusion | Open RAIL M 许可证 | godly-devotion/MochiDiffusion | godly-devotion/MochiDiffusion | 2022 |
pastel-mix
Pastel Mix - 一种风格化的潜在扩散模型。该模型旨在仅通过少量提示词就能生成高质量、细节丰富的动漫风格图像。
| Google Drive 链接 | 原始模型 | 许可证 | 在 Mac 上运行 | 转换脚本 | 年份 |
|---|---|---|---|---|---|
| pastelMixStylizedAnime_pastelMixPrunedFP16 | andite/pastel-mix | Fantasy.ai | godly-devotion/MochiDiffusion | godly-devotion/MochiDiffusion | 2023 |
Orange Mix
| Google Drive 链接 | 原始模型 | 许可证 | 在 Mac 上运行 | 转换脚本 | 年份 |
|---|---|---|---|---|---|
| AOM3_orangemixs | WarriorMama777/OrangeMixs | CreativeML OpenRAIL-M | godly-devotion/MochiDiffusion | godly-devotion/MochiDiffusion | 2023 |
Counterfeit
| Google Drive 链接 | 原始模型 | 许可证 | 在 Mac 上运行 | 转换脚本 | 年份 |
|---|---|---|---|---|---|
| Counterfeit-V2.5 | gsdf/Counterfeit-V2.5 | - | godly-devotion/MochiDiffusion | godly-devotion/MochiDiffusion | 2023 |
anything-v4
| Google Drive 链接 | 原始模型 | 许可证 | 是否可在 Mac 上运行 | 转换脚本 | 年份 |
|---|---|---|---|---|---|
| anything-v4.5 | andite/anything-v4.0 | Fantasy.ai | godly-devotion/MochiDiffusion | godly-devotion/MochiDiffusion | 2023 |
Openjourney
| Google Drive 链接 | 原始模型 | 许可证 | 是否可在 Mac 上运行 | 转换脚本 | 年份 |
|---|---|---|---|---|---|
| Openjourney | prompthero/openjourney | - | godly-devotion/MochiDiffusion | godly-devotion/MochiDiffusion | 2023 |
dreamlike-photoreal-2
| Google Drive 链接 | 原始模型 | 许可证 | 是否可在 Mac 上运行 | 转换脚本 | 年份 |
|---|---|---|---|---|---|
| dreamlike-photoreal-2.0 | dreamlike-art/dreamlike-photoreal-2.0 | CreativeML OpenRAIL-M | godly-devotion/MochiDiffusion | godly-devotion/MochiDiffusion | 2023 |
图像上色
DDColor Tiny
DDColor — 使用双解码器对灰度/黑白照片进行 AI 图像上色(ICCV 2023)。
| 输入 | 输出 |
|---|---|
 |
 |
| 下载链接 | 大小 | 输入 | 输出 | 原项目 | 许可证 | 年份 | 示例项目 | 转换脚本 |
|---|---|---|---|---|---|---|---|---|
| DDColor_Tiny.mlpackage.zip | 242 MB | 512×512 RGB | AB 通道(LAB) | piddnad/DDColor | Apache-2.0 | 2023 | DDColorDemo | convert_ddcolor.py |
人脸识别
AdaFace IR-18
AdaFace — 质量自适应的人脸识别。输出用于人脸验证和识别的 512 维嵌入向量。
| 下载链接 | 大小 | 输入 | 输出 | 原项目 | 许可证 | 年份 | 示例项目 | 转换脚本 |
|---|---|---|---|---|---|---|---|---|
| AdaFace_IR18.mlpackage.zip | 48 MB | 图像(112×112 的人脸) | 512 维 L2 归一化嵌入向量 | mk-minchul/AdaFace | MIT | 2022 | AdaFaceDemo | convert_adaface.py |
3D 人脸姿态估计
3DDFA_V2
3DDFA_V2 — 从单张人脸图像中进行 3D 人脸重建和头部姿态估计(偏航、俯仰、滚转)。

| 下载链接 | 大小 | 输入 | 输出 | 原项目 | 许可证 | 年份 | 示例项目 |
|---|---|---|---|---|---|---|---|
| 3DDFA_V2.mlpackage.zip | 6.3 MB | 图像(120×120 RGB) | 62 个参数(12 个姿态 + 40 个形状 + 10 个表情) | cleardusk/3DDFA_V2 | MIT | 2020 | Face3DDemo |
发言人分离
pyannote segmentation-3.0
pyannote 分割 — 最多支持 3 名同时发言者的发言人分离。能够识别谁在何时说话,并具备重叠检测和每位发言人的转录功能。
| 下载链接 | 大小 | 输入 | 输出 | 原项目 | 许可证 | 年份 | 示例项目 | 转换脚本 |
|---|---|---|---|---|---|---|---|---|
| SpeakerSegmentation.mlpackage.zip | 5.8 MB | 10 秒单声道 16kHz [1,1,160000] | [1, 589, 7] 发言人置信度分数 | pyannote/segmentation-3.0 | MIT | 2023 | DiarizationDemo | convert_diarization.py |
语音转换
OpenVoice V2
OpenVoice — 零样本语音转换。录制源语音和目标语音,在设备端进行转换。
| 下载链接 | 大小 | 输入 | 输出 | 原项目 | 许可证 | 年份 | 示例项目 | 转换脚本 |
|---|---|---|---|---|---|---|---|---|
| OpenVoice_SpeakerEncoder.mlpackage.zip | 1.7 MB | 频谱图 [1, T, 513] | 256维说话人嵌入 | myshell-ai/OpenVoice | MIT | 2024 | OpenVoiceDemo | convert_openvoice.py |
| OpenVoice_VoiceConverter.mlpackage.zip | 64 MB | 频谱图 + 说话人嵌入 | 波形音频(22050 Hz) |
音频分离
HTDemucs
混合Transformer Demucs — 将音乐分离为鼓、贝斯、人声和其他乐器4个音轨。
| 下载链接 | 大小 | 输入 | 输出 | 原项目 | 许可证 | 年份 | 示例项目 | 转换脚本 |
|---|---|---|---|---|---|---|---|---|
| HTDemucs_SourceSeparation_F32.mlpackage.zip | 80 MB | 音频波形 [1, 2, 343980],采样率44.1kHz | 4个音轨(鼓、贝斯、其他、人声)立体声 | facebookresearch/demucs | MIT | 2022 | DemucsDemo | convert_htdemucs.py |
视觉-语言模型
Florence-2-base
微软Florence-2 — 一个统一的视觉-语言模型,支持从单个模型完成图像描述、OCR和目标检测任务。已转换为3个CoreML模型(INT8):视觉编码器(DaViT)、文本编码器(BART)以及具有自回归生成能力的解码器。
| 下载链接 | 大小 | 输入 | 输出 | 原项目 | 许可证 | 年份 | 示例项目 | 转换脚本 |
|---|---|---|---|---|---|---|---|---|
| Florence2VisionEncoder / TextEncoder / Decoder | 260 MB(INT8,共3个模型) | 768×768 RGB图像 + 任务提示 | 生成的文本(描述、OCR等) | microsoft/Florence-2-base | MIT | 2024 | Florence2Demo | convert_florence2.py |
零样本图像分类
SigLIP ViT-B/16
谷歌SigLIP — 基于sigmoid的对比学习图像-文本模型,用于零样本分类。输入任意标签(如“猫、狗、汽车”),即可获得每个标签的概率。已转换为2个CoreML模型(INT8):图像编码器和文本编码器。
| 下载链接 | 大小 | 输入 | 输出 | 原项目 | 许可证 | 年份 | 示例项目 | 转换脚本 |
|---|---|---|---|---|---|---|---|---|
| SigLIP_ImageEncoder / TextEncoder | 386 MB(FP16,共2个模型) | 224×224 RGB图像 + 文本标签 | 每个标签的相似度分数(softmax) | google/siglip-base-patch16-224 | Apache-2.0 | 2024 | SigLIPDemo | convert_siglip.py |
文本转语音
心-82M
hexgrad/Kokoro-82M — hexgrad 开源的 8200 万参数 TTS 模型。基于 StyleTTS2 架构(BERT + 长度预测器 + iSTFTNet 声码器),能够根据每种声音的风格嵌入,生成 9 种语言、采样率为 24kHz 的语音。这是首个 CoreML 移植版本,支持 设备端双语(英语 + 日语)自由文本输入——运行时无需 MLX、MeCab、IPADic 或 Python G2P。
包含两个 CoreML 模型:一个灵活长度的 预测器(BERT + LSTM 长度头 + 文本编码器)和 三个固定形状的解码器桶(128 / 256 / 512 帧)。Swift 流水线会选取最合适的桶来匹配预测的总时长,对输入特征进行零填充,并裁剪输出音频。
| 下载链接 | 大小 | 输入 | 输出 | 原项目 | 许可证 | 年份 | 示例项目 | 转换脚本 |
|---|---|---|---|---|---|---|---|---|
| Kokoro_Predictor.mlpackage.zip | 75 MB | input_ids [1, T≤256] (int32) + ref_s_style [1, 128] | duration [1, T] + d_for_align [1, 640, T] + t_en [1, 512, T] | hexgrad/Kokoro-82M | Apache-2.0 | 2025 | KokoroDemo | convert_kokoro.py |
| Kokoro_Decoder_128.mlpackage.zip | 238 MB | en_aligned [1, 640, 128] + asr_aligned [1, 512, 128] + ref_s [1, 256] | audio [1, 76800] @ 24kHz | |||||
| Kokoro_Decoder_256.mlpackage.zip | 241 MB | en_aligned [1, 640, 256] + asr_aligned [1, 512, 256] + ref_s [1, 256] | audio [1, 153600] @ 24kHz | |||||
| Kokoro_Decoder_512.mlpackage.zip | 246 MB | en_aligned [1, 640, 512] + asr_aligned [1, 512, 512] + ref_s [1, 256] | audio [1, 307200] @ 24kHz |
有关设备端 G2P(英语 + 日语)、分桶解码策略及转换细节,请参阅 sample_apps/KokoroDemo/README.md。
异常检测
EfficientAD
EfficientAD(PDN-Small)— 一种轻量级的无监督工业质检异常检测模型。它将教师网络、学生网络和自编码器网络封装为单个模型,输出像素级异常热图和图像级别的异常分数。已在 MVTec AD 瓶子类别数据集上预训练。
| 下载链接 | 大小 | 输入 | 输出 | 原项目 | 许可证 | 年份 | 示例项目 | 转换脚本 |
|---|---|---|---|---|---|---|---|---|
| EfficientAD_Bottle.mlpackage.zip | 15 MB(FP16) | 256×256 RGB 图像 | anomaly_map [1,1,256,256] + anomaly_score [0-1] | nelson1425/EfficientAD | MIT | 2023 | EfficientADDemo | convert_efficientad.py |
音乐转录
Basic Pitch
spotify/basic-pitch — 一款多声部自动音乐转录工具。它可以将任何音频(任何乐器或人声)转换为带有音高弯曲检测的 MIDI 音符。仅需 1.7 万个参数 / 272 KB,即可在 iPhone 上通过 ANE 全速加速实时运行。
这是首个开源的 iOS 实现。它可以加载任意音频文件,在 2 秒滑动窗口中运行 CoreML 模型,随后在 Swift 中原生执行完整的 Python note_creation.py 流程(起音推断、贪婪逆向追踪、Melodia 技巧、音高弯曲提取)。检测到的音符会以钢琴卷帘的形式可视化,导出为标准 MIDI 文件,并通过内置的加法正弦合成器播放,以便与原始音频进行 A/B 对比。
| 下载链接 | 大小 | 输入 | 输出 | 原项目 | 许可证 | 年份 | 示例项目 |
|---|---|---|---|---|---|---|---|
| BasicPitch_nmp.mlpackage.zip | 272 KB | 音频波形 [1, 43844, 1] @ 22050 Hz 单声道 | note [1,172,88] + onset [1,172,88] + contour [1,172,264] | spotify/basic-pitch | Apache-2.0 | 2022 | BasicPitchDemo |
有关滑窗推理、后处理移植以及 iOS 特有的注意事项,请参阅 sample_apps/BasicPitchDemo/README.md。
文本到音乐生成
稳定音频开放小型模型
stabilityai/stable-audio-open-small — 文本到音乐生成(4.97亿参数)。该模型使用修正流扩散技术,可根据文本提示生成长达11.9秒的44.1kHz立体声音频。
包含4个CoreML模型:T5文本编码器、NumberEmbedder(秒数条件)、DiT(扩散Transformer)以及VAE解码器(Oobleck)。
| 下载链接 | 大小 | 输入 | 输出 | 原项目 | 许可证 | 年份 | 示例项目 | 转换脚本 |
|---|---|---|---|---|---|---|---|---|
| StableAudioT5Encoder.mlpackage.zip | 105 MB | input_ids [1, 64] | text_embeddings [1, 64, 768] | stabilityai/stable-audio-open-small | Stability AI Community | 2024 | StableAudioDemo | convert_stable_audio.py |
| StableAudioNumberEmbedder.mlpackage.zip | 396 KB | normalized_seconds [1] | seconds_embedding [1, 768] | |||||
| StableAudioDiT.mlpackage.zip | 326 MB | latent [1,64,256] + timestep + conditioning | velocity [1,64,256] | |||||
| StableAudioDiT_FP32.mlpackage.zip | 1.3 GB | latent [1,64,256] + timestep + conditioning | velocity [1,64,256] | |||||
| StableAudioVAEDecoder.mlpackage.zip | 149 MB | latent [1, 64, 256] | 立体声音频 [1, 2, 524288],采样率为44.1kHz |
有关INT8与FP32 DiT的选择及转换详情,请参阅sample_apps/StableAudioDemo/README.md。
非我本人转换的模型。
稳定扩散
如何在Xcode项目中使用。
方法一:实现Vision请求。
import Vision
lazy var coreMLRequest:VNCoreMLRequest = {
let model = try! VNCoreMLModel(for: modelname().model)
let request = VNCoreMLRequest(model: model, completionHandler: self.coreMLCompletionHandler)
return request
}()
let handler = VNImageRequestHandler(ciImage: ciimage,options: [:])
DispatchQueue.global(qos: .userInitiated).async {
try? handler.perform([coreMLRequest])
}
如果模型输出类型为Image:
let result = request?.results?.first as! VNPixelBufferObservation
let uiimage = UIImage(ciImage: CIImage(cvPixelBuffer: result.pixelBuffer))
否则,若模型输出类型为Multiarray:
要将MultiArray可视化为图像,Hollance先生的“CoreML Helpers”非常方便。 CoreML Helpers
使用CoreML Helpers将MultiArray转换为图像。
func coreMLCompletionHandler(request:VNRequest?、error:Error?){
let = coreMLRequest.results?.first as!VNCoreMLFeatureValueObservation
let multiArray = result.featureValue.multiArrayValue
let cgimage = multiArray?.cgImage(min:-1、max:1、channel:nil)
方法二:使用CoreGANContainer。您可以将模型拖放至容器项目中直接使用。
使模型更轻量化
如果您希望减小模型大小,可以通过量化来实现。 https://coremltools.readme.io/docs/quantization
位数越低,模型精度下降的风险越大。精度损失因模型而异。
import coremltools as ct
from coremltools.models.neural_network import quantization_utils
# 加载全精度模型
model_fp32 = ct.models.MLModel('model.mlmodel')
model_fp16 = quantization_utils.quantize_weights(model_fp32, nbits=16)
# nbits可以是16(模型大小减半)、8(四分之一)、4(八分之一)、2或1
量化后的示例(U2Net)
输入图像 / nbits=32(原版) / nbits=16 / nbits=8 / nbits=4




感谢
封面图片取自吉卜力免费素材。
在YOLOv5转换方面,dbsystel/yolov5-coreml-tools为我提供了极其智能的转换脚本。
以及所有原始项目的所有者。
作者
Daisuke Majima 自由职业工程师。iOS/机器学习/AR 我可以从事移动ML项目和AR项目。 欢迎联系:rockyshikoku@gmail.com
版本历史
moge2-v12026/04/08hypersd-v12026/04/06kokoro-v12026/04/07efficientad-v12026/04/04sinsr-v12026/04/05stable-audio-v12026/04/04siglip-v22026/04/03rmbg-v12026/04/03siglip-v12026/04/03florence2-v12026/04/03diarization-v12026/04/03ddcolor-v12026/04/03openvoice-v12026/04/03adaface-v12026/04/03face3d-v12026/04/02demucs-v12026/04/01yolo-models-v12026/03/30相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备