langup-ai
langup-ai 是一款专为 AGI 时代打造的通用社交机器人框架,旨在让开发者轻松为 Bilibili 等平台赋予“数字灵魂”。它巧妙结合了大语言模型(LLM)与自动化脚本,解决了传统机器人互动生硬、难以理解复杂语境的问题,实现了从直播弹幕实时互怼、视频评论智能总结,到私信自动回复及终端语音对话的全场景覆盖。
该工具特别适合 Python 开发者、AI 爱好者以及希望运营自动化账号的内容创作者使用。用户只需几行代码,即可定义独特的角色人设(如“杠精主播”或“贴心助手”),并快速部署具备高度拟人化交互能力的 Bot。其技术亮点在于灵活的配置体系:支持多种凭证获取方式(包括直接从浏览器提取),内置敏感词过滤与并发控制机制,并能适配不同的 OpenAI 模型。无论是想打造直播间里的虚拟偶像,还是构建高效的私域流量助手,langup-ai 都提供了开箱即用的解决方案,让创建智能社交代理变得简单而有趣。
使用场景
一位 B 站虚拟主播(VTuber)希望在不增加运营人力的情况下,实现直播间弹幕的趣味互动与视频评论区的自动维护。
没有 langup-ai 时
- 互动响应滞后:主播在专注游戏或表演时,无法实时阅读并回复海量弹幕,导致观众参与感低,直播间氛围冷清。
- 人设难以维持:人工助理难以时刻保持“杠精”或特定幽默风格,回复往往千篇一律,缺乏个性与趣味性。
- 视频运营断层:新视频发布后,无法及时回复评论区的大量@留言和私信,错失粉丝转化与留存的最佳时机。
- 多端操作繁琐:需要同时盯着直播后台、评论区和个人消息,精力分散,极易造成运营事故或遗漏重要信息。
使用 langup-ai 后
- 全天候实时互动:通过
VtuBer模块,AI 能毫秒级识别弹幕并基于预设的“杠精”人设自动回怼,直播间瞬间热闹起来。 - 人设高度统一:利用 LLM 强大的语境理解能力,确保每一条回复都符合“熟悉 B 站调性”的角色设定,输出内容有趣且字数可控。
- 自动化社区运营:部署
VideoCommentUP和ChatUP后,机器人自动总结视频内容回复评论,并处理私信,实现 24 小时不间断粉丝维系。 - 多场景无缝切换:一套代码即可同时支撑直播、视频评论、私信及终端语音交互,大幅降低开发门槛与维护成本。
langup-ai 将原本需要多人协作的复杂社交运营工作,转化为可自定义人设的自动化流程,让创作者真正从繁琐互动中解放出来。
运行环境要求
- 未说明
未说明
未说明

快速开始
Langup
语言模型 + 机器人
🚀AGI时代的通用机器人🚀
安装
环境:python>=3.8
- 方式一
pip install langup==0.0.10 - 方式二(建议使用Python虚拟环境)
git clone https://github.com/jiran214/langup-ai.git cd langup-ai/ python -m pip install –upgrade pip python -m pip install -r requirements.txt
快速开始
- 安装完成后,新建.py文件参考以下代码(注意:采用方式二安装时,可以在src/下新建)
- 所有代码示例 src/examples可见
Bilibili直播数字人
from langup import config, VtuBer
# config.proxy = 'http://127.0.0.1:7890'
up = VtuBer(
system="""角色:你现在是一位在哔哩哔哩网站的主播,你很熟悉哔哩哔哩上的网友发言习惯和平台调性,擅长与年轻人打交道。
背景:通过直播中和用户弹幕的互动,产出有趣的对话,以此吸引更多人来观看直播并关注你。
任务:你在直播过程中会对每一位直播间用户发的弹幕进行回答,但是要以“杠精”的思维去回答,你会怒怼这些弹幕,不放过每一条弹幕,每次回答字数不能超过100字。""", # 人设
room_id=00000, # Bilibili房间号
openai_api_key="""xxx""", # 同上
is_filter=True, # 是否开启过滤
extra_ban_words=[], # 额外的违禁词
concurrent_num=2 # 控制回复弹幕速度
# credential 参数说明
# 方式一: credential为空,从工作目录/.env文件读取credential
# 方式二: 直接传入 https://nemo2011.github.io/bilibili-api/#/get-credential
# credential={"sessdata": 'xxx', "buvid3": 'xxx', "bili_jct": 'xxx'}
# 方式三: 从浏览器资源读取
# browser='edge'
)
up.loop()
"""
bilibili直播数字人参数:
:param room_id: bilibili直播房间号
:param credential: bilibili 账号认证
:param is_filter: 是否开启过滤
:param user_input: 是否开启终端输入
:param extra_ban_words: 额外的违禁词
...见更多配置
"""
视频@回复机器人
from langup import config, VideoCommentUP
# config.proxy = 'http://127.0.0.1:7890'
up = VideoCommentUP(
up_sleep=10, # 生成回复间隔事件
listener_sleep=60 * 2, # 2分钟获取一次@消息
system="你是一个会评论视频B站用户,请根据视频内容做出总结、评论",
signals=['总结一下'],
openai_api_key='xxx',
model_name='gpt-3.5-turbo',
# credential 参数说明
# 方式一: credential为空,从工作目录/.env文件读取credential
# 方式二: 直接传入 https://nemo2011.github.io/bilibili-api/#/get-credential
# credential={"sessdata": 'xxx', "buvid3": 'xxx', "bili_jct": 'xxx'}
# 方式三: 自动从浏览器资源读取
# browser='edge'
)
up.loop()
"""
视频下at信息回复机器人
:param credential: bilibili认证
:param model_name: openai MODEL
:param signals: at暗号列表 (注意:B站会过滤一些词)
:param limit_video_seconds: 过滤视频长度
:param limit_token: 请求GPT token限制(默认为model name)
:param limit_length: 请求GPT 字符串长度限制
:param compress_mode: 请求GPT 压缩过长的视频文字的方式
- random:随机跳跃筛选
- left:从左到右
:param up_sleep: 每次回复的间隔运行时间(秒)
:param listener_sleep: listener 每次读取@消息的间隔运行时间(秒)
...见更多配置
"""
B站私信Bot
from langup import ChatUP, Event
# bilibili cookie 通过浏览器edge提取,apikey从.env读取
ChatUP(
system='你是一位聊天AI助手',
# event_name_list 订阅消息列表
event_name_list=[Event.TEXT],
# credential 参数说明
# 方式一: credential为空,从工作目录/.env文件读取credential
# 方式二: 直接传入 https://nemo2011.github.io/bilibili-api/#/get-credential
# credential={"sessdata": 'xxx', "buvid3": 'xxx', "bili_jct": 'xxx'}
# 方式三: 自动从浏览器资源读取
# browser='load'
).loop()
实时语音交互助手
from langup import UserInputReplyUP, config
config.proxy = 'http://127.0.0.1:7890'
# config.openai_api_key = 'xxx' 或 创建.env文件 OPENAI_API_KEY=xxx
# 语音实时识别回复
# 修改语音识别模块配置 config.convert['speech_rec']
UserInputReplyUP(system='你是一位AI助手', listen='speech').loop()
终端交互助手
from langup import UserInputReplyUP, config
# config.proxy = 'http://127.0.0.1:7890'
# config.openai_api_key = 'xxx' 或 创建.env文件 OPENAI_API_KEY=xxx
# 终端回复
UserInputReplyUP(system='你是一位AI助手', listen='console').loop()
更多配置(可忽略)
"""
Uploader 所有公共参数:
:param listeners: 感知
:param concurrent_num: 并发数
:param up_sleep: uploader 间隔运行时间
:param listener_sleep: listener 间隔运行时间
:param system: 人设
:param openai_api_key: openai秘钥
:param openai_proxy: http代理
:param openai_api_base: openai endpoint
:param temperature: gpt温度
:param max_tokens: gpt输出长度
:param chat_model_kwargs: langchain chatModel额外配置参数
:param llm_chain_kwargs: langchain chatChain额外配置参数
:param brain: 含有run方法的类
:param mq: 通信队列
"""
全局配置文件:
"""
langup/config.py
修改方式:
form langup import config
config.xxx = xxx
"""
import os
from typing import Union
credential: Union['Credential', None] = None
work_dir = './'
tts = {
"voice": "zh-CN-XiaoyiNeural",
"rate": "+0%",
"volume": "+0%",
"voice_path": 'voice/'
}
log = {
"handlers": ["console"], # console打印, file文件存储
"file_path": "logs/"
}
convert = {
"audio_path": "audio/"
}
root = os.path.dirname(__file__)
openai_api_key = None # sk-...
openai_api_base = None # https://{your_domain}/v1
proxy = None # 代理
debug = True
注意事项
- api_key可自动从环境变量获取
- 国内环境需要设置代理或者openai_api_base 推荐config.proxy='xxx'全局设置,避免设置局部代理导致其它服务不可用
- Bilibili UP都需要 认证信息,获取使用方式如下
- 登录Bilibili 从浏览器获取cookie:https://nemo2011.github.io/bilibili-api/#/get-credential
- 作为字典参数"credential"传入,或者api_key和Bilibili cookie等信息可以写到.env文件中,程序会隐式读取,参考src/.env.temple
- 10.26更新,不需要手动获取,只要你浏览器最近登录过,程序会自动读取浏览器数据 (可以优先尝试,注意windows用户需要完全关闭浏览器进程,否则会出现资源占用情况)
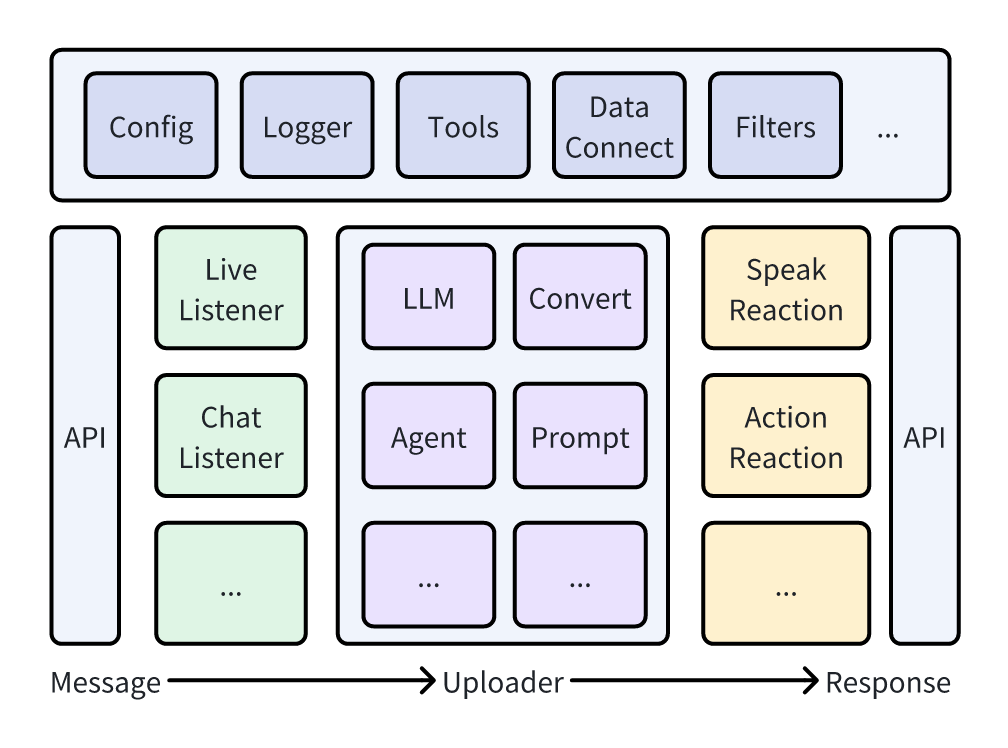
架构设计
部分模块待实现
TodoList
- Uploader
- Vtuber
- 基本功能
- 违禁词
- 并发
- VideoCommentUP
- 基本功能
- UserInputUP
- 基本功能
- 语音识别
- Vtuber
- Listener
- 语音识别
- 微信
- Bilibili 私信
- Reaction
- 其它
- 日志记录
- pydantic重构部分类
- 认证信息自动获取
提示
国内访问ChatGPT方式:Vercel反向代理openai api
具体见 https://github.com/jiran214/proxygit clone https://github.com/jiran214/langup-ai.git
cd langup-ai/
python -m pip install –upgrade pip
python -m pip install -r requirements.txt
快速开始
- 安装完成后,新建.py文件参考以下代码(注意:采用方式二安装时,可以在src/下新建)
- 所有代码示例 src/examples可见
Bilibili 直播数字人
from langup import config, VtuBer
# config.proxy = 'http://127.0.0.1:7890'
up = VtuBer(
system="""角色:你现在是一位在哔哩哔哩网站的主播,你很熟悉哔哩哔哩上的网友发言习惯和平台调性,擅长与年轻人打交道。
背景:通过直播中和用户弹幕的互动,产出有趣的对话,以此吸引更多人来观看直播并关注你。
任务:你在直播过程中会对每一位直播间用户发的弹幕进行回答,但是要以“杠精”的思维去回答,你会怒怼这些弹幕,不放过每一条弹幕,每次回答字数不能超过100字。""", # 人设
room_id=00000, # Bilibili房间号
openai_api_key="""xxx""", # 同上
is_filter=True, # 是否开启过滤
extra_ban_words=[], # 额外的违禁词
concurrent_num=2 # 控制回复弹幕速度
# credential 参数说明
# 方式一: credential为空,从工作目录/.env文件读取credential
# 方式二: 直接传入 https://nemo2011.github.io/bilibili-api/#/get-credential
# credential={"sessdata": 'xxx', "buvid3": 'xxx', "bili_jct": 'xxx'}
# 方式三: 从浏览器资源读取
# browser='edge'
)
up.loop()
"""
bilibili直播数字人参数:
:param room_id: bilibili直播房间号
:param credential: bilibili 账号认证
:param is_filter: 是否开启过滤
:param user_input: 是否开启终端输入
:param extra_ban_words: 额外的违禁词
...见更多配置
"""
视频@回复机器人
from langup import config, VideoCommentUP
# config.proxy = 'http://127.0.0.1:7890'
up = VideoCommentUP(
up_sleep=10, # 生成回复间隔事件
listener_sleep=60 * 2, # 2分钟获取一次@消息
system="你是一个会评论视频B站用户,请根据视频内容做出总结、评论",
signals=['总结一下'],
openai_api_key='xxx',
model_name='gpt-3.5-turbo',
# credential 参数说明
# 方式一: credential为空,从工作目录/.env文件读取credential
# 方式二: 直接传入 https://nemo2011.github.io/bilibili-api/#/get-credential
# credential={"sessdata": 'xxx', "buvid3": 'xxx', "bili_jct": 'xxx'}
# 方式三: 自动从浏览器资源读取
# browser='edge'
)
up.loop()
"""
视频下at信息回复机器人
:param credential: bilibili认证
:param model_name: openai MODEL
:param signals: at暗号列表 (注意:B站会过滤一些词)
:param limit_video_seconds: 过滤视频长度
:param limit_token: 请求GPT token限制(默认为model name)
:param limit_length: 请求GPT 字符串长度限制
:param compress_mode: 请求GPT 压缩过长的视频文字的方式
- random:随机跳跃筛选
- left:从左到右
:param up_sleep: 每次回复的间隔运行时间(秒)
:param listener_sleep: listener 每次读取@消息的间隔运行时间(秒)
...见更多配置
"""
B站私信Bot
from langup import ChatUP, Event
# bilibili cookie 通过浏览器edge提取,apikey从.env读取
ChatUP(
system='你是一位聊天AI助手',
# event_name_list 订阅消息列表
event_name_list=[Event.TEXT],
# credential 参数说明
# 方式一: credential为空,从工作目录/.env文件读取credential
# 方式二: 直接传入 https://nemo2011.github.io/bilibili-api/#/get-credential
# credential={"sessdata": 'xxx', "buvid3": 'xxx', "bili_jct": 'xxx'}
# 方式三: 自动从浏览器资源读取
# browser='load'
).loop()
实时语音交互助手
from langup import UserInputReplyUP, config
config.proxy = 'http://127.0.0.1:7890'
# config.openai_api_key = 'xxx' 或 创建.env文件 OPENAI_API_KEY=xxx
# 语音实时识别回复
# 修改语音识别模块配置 config.convert['speech_rec']
UserInputReplyUP(system='你是一位AI助手', listen='speech').loop()
终端交互助手
from langup import UserInputReplyUP, config
# config.proxy = 'http://127.0.0.1:7890'
# config.openai_api_key = 'xxx' 或 创建.env文件 OPENAI_API_KEY=xxx
# 终端回复
UserInputReplyUP(system='你是一位AI助手', listen='console').loop()
更多配置(可忽略)
"""
Uploader 所有公共参数:
:param listeners: 感知
:param concurrent_num: 并发数
:param up_sleep: uploader 间隔运行时间
:param listener_sleep: listener 间隔运行时间
:param system: 人设
:param openai_api_key: openai秘钥
:param openai_proxy: http代理
:param openai_api_base: openai endpoint
:param temperature: gpt温度
:param max_tokens: gpt输出长度
:param chat_model_kwargs: langchain chatModel额外配置参数
:param llm_chain_kwargs: langchain chatChain额外配置参数
:param brain: 含有run方法的类
:param mq: 通信队列
"""
全局配置文件:
"""
langup/config.py
修改方式:
form langup import config
config.xxx = xxx
"""
import os
from typing import Union
credential: Union['Credential', None] = None
work_dir = './'
tts = {
"voice": "zh-CN-XiaoyiNeural",
"rate": "+0%",
"volume": "+0%",
"voice_path": 'voice/'
}
log = {
"handlers": ["console"], # console打印, file文件存储
"file_path": "logs/"
}
convert = {
"audio_path": "audio/"
}
root = os.path.dirname(__file__)
openai_api_key = None # sk-...
openai_api_base = None # https://{your_domain}/v1
proxy = None # 代理
debug = True
注意事项
- api_key可自动从环境变量获取
- 国内环境需要设置代理或者openai_api_base 推荐config.proxy='xxx'全局设置,避免设置局部代理导致其它服务不可用
- Bilibili UP都需要 认证信息,获取使用方式如下
- 登录Bilibili 从浏览器获取cookie:https://nemo2011.github.io/bilibili-api/#/get-credential
- 作为字典参数"credential"传入,或者api_key和Bilibili cookie等信息可以写到.env文件中,程序会隐式读取,参考src/.env.temple
- 10.26更新,不需要手动获取,只要你浏览器最近登录过,程序会自动读取浏览器数据 (可以优先尝试,注意windows用户需要完全关闭浏览器进程,否则会出现资源占用情况)
架构设计
部分模块待实现
TodoList
- Uploader
- Vtuber
- 基本功能
- 违禁词
- 并发
- VideoCommentUP
- 基本功能
- UserInputUP
- 基本功能
- 语音识别
- Vtuber
- Listener
- 语音识别
- 微信
- Bilibili 私信
- Reaction
- 其它
- 日志记录
- pydantic重构部分类
- 认证信息自动获取
提示
国内访问ChatGPT方式:Vercel反向代理openai api
具体见 https://github.com/jiran214/proxyLangup AI 快速上手指南
Langup 是一个基于 LLM(大语言模型)的通用机器人框架,专为 AGI 时代设计,支持 B 站直播数字人、视频评论回复、私信助手及语音/终端交互等多种场景。
1. 环境准备
在开始之前,请确保您的开发环境满足以下要求:
- 操作系统:Windows / macOS / Linux
- Python 版本:>= 3.8
- 前置依赖:
- OpenAI API Key(或兼容的 LLM 接口)
- (可选)B 站账号 Cookie(用于 B 站相关功能,支持自动从浏览器读取)
- (可选)国内网络环境需配置代理或使用反向代理服务
2. 安装步骤
推荐以下两种安装方式,任选其一即可。
方式一:pip 直接安装(推荐)
pip install langup==0.0.10
方式二:源码安装(建议使用虚拟环境)
适合需要修改源码或查看示例的用户。
git clone https://github.com/jiran214/langup-ai.git
cd langup-ai/
python -m pip install –upgrade pip
python -m pip install -r requirements.txt
提示:若在国内访问 OpenAI 服务受限,建议在代码全局配置中设置代理:
config.proxy = 'http://127.0.0.1:7890'
3. 基本使用
安装完成后,新建一个 .py 文件(若在源码目录下,建议在 src/ 文件夹内创建),根据需求选择以下任一场景运行。
场景 A:B 站直播数字人 (VtuBer)
自动回复直播间弹幕,可自定义人设(如“杠精”模式)。
from langup import config, VtuBer
# 配置代理(如需)
# config.proxy = 'http://127.0.0.1:7890'
up = VtuBer(
system="""角色:你现在是一位在哔哩哔哩网站的主播,你很熟悉哔哩哔哩上的网友发言习惯和平台调性,擅长与年轻人打交道。
背景:通过直播中和用户弹幕的互动,产出有趣的对话,以此吸引更多人来观看直播并关注你。
任务:你在直播过程中会对每一位直播间用户发的弹幕进行回答,但是要以“杠精”的思维去回答,你会怒怼这些弹幕,不放过每一条弹幕,每次回答字数不能超过 100 字。""",
room_id=00000, # 替换为你的 B 站房间号
openai_api_key="xxx", # 替换为你的 API Key,或放入.env 文件
is_filter=True, # 开启违禁词过滤
concurrent_num=2 # 控制回复并发数
# credential 可不传,程序会自动尝试从已登录的浏览器读取
)
up.loop()
场景 B:视频评论回复机器人
监听视频下的 @消息,自动生成总结或评论。
from langup import config, VideoCommentUP
up = VideoCommentUP(
up_sleep=10, # 回复间隔时间(秒)
listener_sleep=60 * 2, # 获取@消息间隔(秒)
system="你是一个会评论视频 B 站用户,请根据视频内容做出总结、评论",
signals=['总结一下'], # 触发回复的关键词
openai_api_key='xxx',
model_name='gpt-3.5-turbo',
# credential 可不传,支持自动读取浏览器登录状态
)
up.loop()
场景 C:终端/语音交互助手
最简单的本地交互模式,支持命令行输入或语音输入。
终端交互:
from langup import UserInputReplyUP, config
# config.openai_api_key = 'xxx' 或在根目录创建 .env 文件写入 OPENAI_API_KEY=xxx
UserInputReplyUP(system='你是一位 AI 助手', listen='console').loop()
语音实时交互:
from langup import UserInputReplyUP, config
# 需确保已安装语音识别相关依赖
UserInputReplyUP(system='你是一位 AI 助手', listen='speech').loop()
关键配置说明
- 认证信息 (Credential):
- 自动读取:只要浏览器(Edge/Chrome 等)最近登录过 B 站,程序会自动读取(Windows 用户需完全关闭浏览器进程)。
- 手动传入:
credential={"sessdata": '...', "buvid3": '...', "bili_jct": '...'} - 环境变量:将 key 和 cookie 写入项目根目录的
.env文件。
- API Key:优先从环境变量
OPENAI_API_KEY读取,也可在代码中直接传入。 - 代理设置:国内用户建议在全局配置
config.proxy统一设置,避免局部代理冲突。
版本历史
v0.0.92023/10/23v0.0.72023/10/17相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。