offensive-ai-compilation
offensive-ai-compilation 是一份精心整理的开源资源清单,专注于“进攻性人工智能”(Offensive AI)领域。它旨在帮助安全从业者系统性地理解人工智能模型面临的潜在威胁与攻击手段,从而更好地构建防御体系。
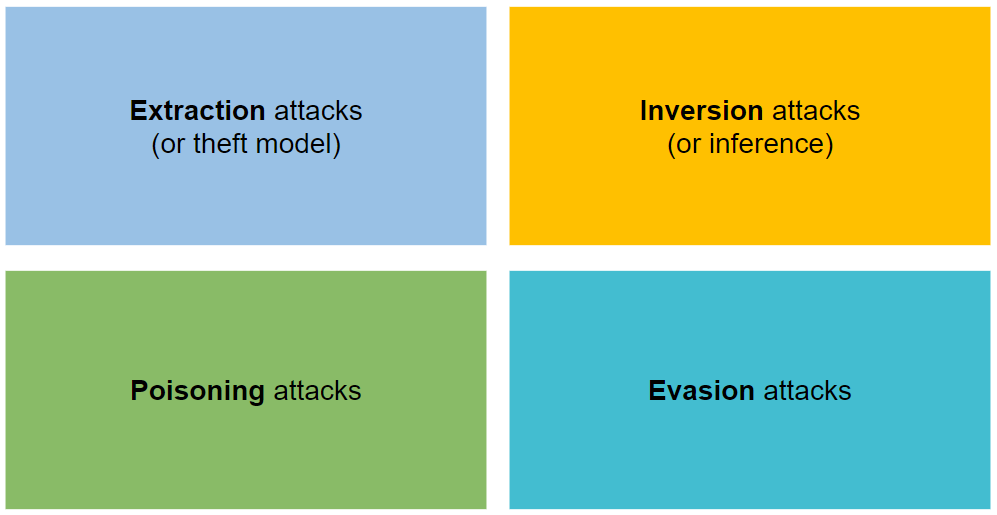
该资源库解决了 AI 安全学习中资料分散、分类不清的痛点。它将复杂的对抗性机器学习攻击梳理为四大核心类型:模型提取(窃取参数)、反演攻击(推断数据)、投毒攻击(污染训练数据)以及 evasion 攻击(绕过检测)。此外,它还涵盖了生成式 AI 在音频、图像、视频及文本领域的滥用风险,并提供了相应的检测方法与防御策略。
offensive-ai-compilation 特别适合网络安全研究人员、AI 开发者、渗透测试工程师以及对 AI 伦理与安全感兴趣的学生使用。其独特亮点在于不仅罗列了 Cleverhans、ART 等专业攻击工具,还针对每种攻击方式提供了具体的防御动作建议和学术文献链接,实现了从“攻击原理”到“防御实践”的闭环。无论是希望评估模型鲁棒性的开发者,还是致力于研究对抗样本的学者,都能从中获得极具价值的参考指引,共同提升人工智能系统的安全性。
使用场景
某金融科技公司安全团队正在对内部部署的信贷审批 AI 模型进行红队测试,旨在评估其抗攻击能力并防止核心算法泄露。
没有 offensive-ai-compilation 时
- 资源搜集零散低效:团队成员需花费数天在 GitHub、arXiv 和各类博客中手动搜索对抗样本生成、模型提取等攻击技术,难以确认资料的时效性与权威性。
- 防御策略缺乏系统性:面对潜在的“模型窃取”风险,团队仅知道概念,却找不到如 PRADA 或自适应误导等具体的防御架构实现方案,导致防护方案停留在理论层面。
- 工具选型盲目:在寻找用于模拟攻击的开源工具(如 ART 或 Cleverhans)时,因缺乏对比指引,容易集成过时或不兼容的库,增加了测试环境的搭建成本。
- 知识盲区明显:对于数据投毒、推理反转等高级攻击手段了解不足,无法全面覆盖测试场景,留下了严重的安全隐患。
使用 offensive-ai-compilation 后
- 一站式获取权威资源:团队直接利用该清单中分类整理的“对抗性机器学习”板块,几分钟内即可锁定最新的攻击论文与案例研究,大幅缩短调研周期。
- 精准落地防御措施:针对模型提取风险,团队迅速参考清单中提供的差分隐私、集成学习及特定防御架构链接,快速制定了可落地的加固方案。
- 高效集成测试工具:通过清单推荐的经过验证的工具列表,团队直接部署了成熟的攻击框架进行模拟演练,确保了测试环境的专业性与稳定性。
- 全覆盖风险排查:借助清单对攻击类型(提取、反转、投毒、规避)的系统化梳理,团队构建了完整的测试矩阵,有效识别并修复了此前被忽视的逻辑漏洞。
offensive-ai-compilation 将分散的攻防知识转化为结构化的行动指南,帮助安全团队从“盲目摸索”转变为“精准防御”,显著提升了 AI 系统的安全性评估效率。
运行环境要求
未说明
未说明
快速开始
攻击性人工智能合集
一份精选的实用资源列表,涵盖攻击性人工智能领域。
📁 目录 📁
🚫 滥用 🚫
利用人工智能模型的漏洞进行攻击。
🧠 对抗机器学习 🧠
对抗机器学习旨在评估这些模型的弱点,并提供相应的防御措施。
⚡ 攻击 ⚡
攻击主要分为四类:提取、还原、毒化和规避。
🔒 提取 🔒
通过发送请求以最大化信息提取量,试图窃取模型的参数和超参数。
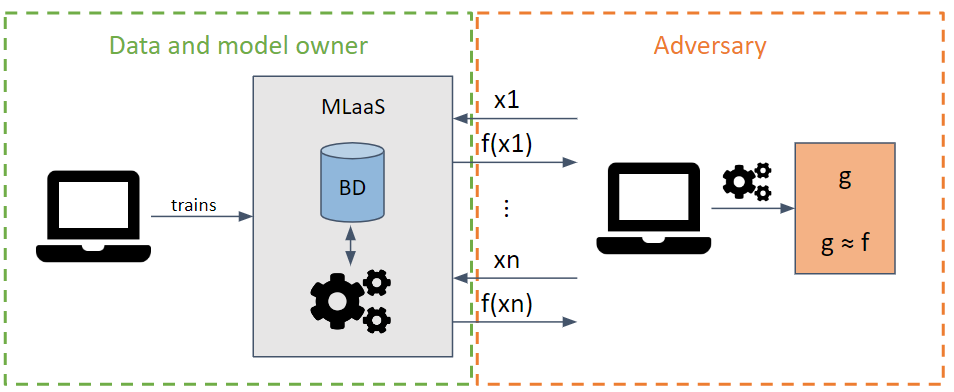
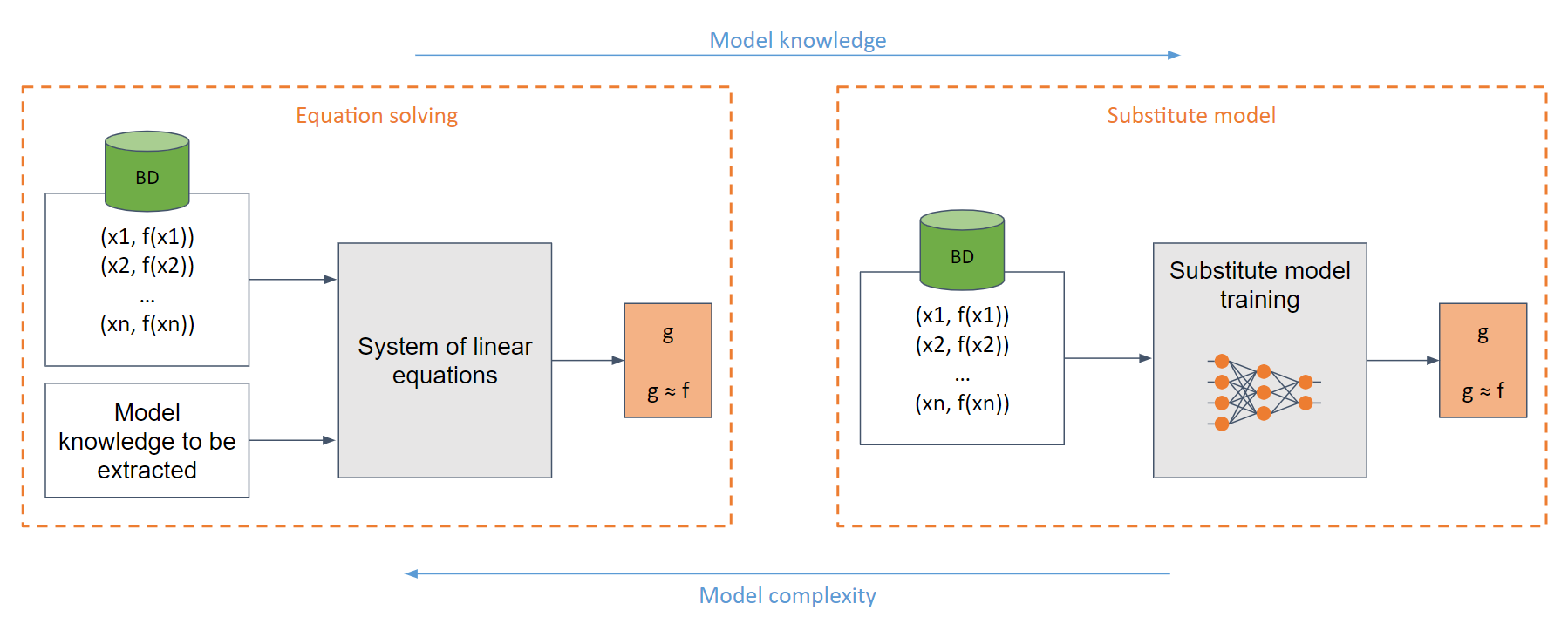
根据攻击者对目标模型的了解程度,可以进行白盒攻击和黑盒攻击。
在最简单的白盒情况下(当攻击者完全了解模型结构时,例如一个Sigmoid函数),可以建立一组易于求解的线性方程。
而在一般情况下,即对模型了解不足时,则会使用替代模型。该模型通过对原始模型发出的请求进行训练,以模仿原始模型的功能。
⚠️ 局限性 ⚠️
训练替代模型在很多情况下等同于从头开始训练一个新模型。
计算成本非常高。
攻击者在被检测之前,能够发出的请求数量有限。
🛡️ 防御措施 🛡️
🔗 有用链接 🔗
- 通过预测API窃取机器学习模型
- 窃取机器学习中的超参数
- 仿冒网络:通过随机未标记数据诱使供述来窃取黑盒模型的功能
- MLaaS范式下的模型提取警告
- 模仿CNN:通过说服供述并结合随机未标记数据窃取知识
- 预测毒化:迈向防御深度神经网络模型窃取攻击的方法
- 通过时间侧信道窃取神经网络
- 针对归纳图神经网络的模型窃取攻击
- 高精度与高保真度的神经网络提取
- 毒化大规模训练数据集是可行的
- 多项式时间密码分析法提取神经网络模型
- 针对文本到图像生成模型的提示特异性毒化攻击
- 优秀数据毒化与后门攻击资源库:一份精心整理的论文及资源列表,涉及数据毒化、后门攻击及其防御措施。

- BackdoorBox:一个开源的Python工具箱,用于后门攻击与防御。

- 窃取部分生产级语言模型
- 硬标签密码分析法提取神经网络模型
- https://www.anthropic.com/news/detecting-and-preventing-distillation-attacks
⬅️ 还原(或推断)⬅️
其目的是逆转机器学习模型的信息流。
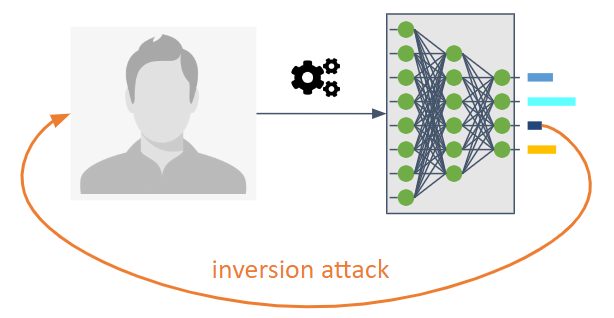
这类攻击使攻击者能够了解原本并未打算公开的模型内部信息。
它们还可以帮助我们获取训练数据或作为模型统计特征的信息。
主要有三种类型:
成员身份推断攻击(MIA):攻击者试图确定某个样本是否曾被用于训练过程。
属性推断攻击(PIA):攻击者旨在提取那些在训练阶段并未明确编码为特征的统计特性。
重构:攻击者尝试从训练集中重建一个或多个样本及其对应的标签。也称为还原。
🛡️ 防御措施 🛡️
🔗 有用链接 🔗
- 针对机器学习模型的成员推理攻击
- 利用置信度信息的模型逆向攻击及基本防御措施
- 记住过多信息的机器学习模型
- ML-Leaks:独立于模型和数据的成员推理攻击及其在机器学习模型上的防御
- GAN下的深度模型:协作式深度学习中的信息泄露
- LOGAN:针对生成模型的成员推理攻击
- 过拟合、鲁棒性与恶意算法:机器学习中潜在隐私风险原因的研究
- 深度学习的全面隐私分析:被动与主动白盒推理攻击下的独立及联邦学习
- 针对协作学习的推理攻击
- 秘密分享者:评估与测试神经网络中的意外记忆
- 迈向机器学习中的安全与隐私科学
- MemGuard:通过对抗样本防御黑盒成员推理攻击
- 从大型语言模型中提取训练数据
- 利用置换不变表示对全连接神经网络进行属性推理攻击
- 从扩散模型中提取训练数据
- 基于人类脑活动的潜在扩散模型高分辨率图像重建
- 在低误报条件下窃取并绕过恶意软件分类器和杀毒软件
- 基于对抗方法的真实指纹呈现攻击
- 主动对抗测试:提升对抗鲁棒性评估的信心。

- GPT越狱状态:关于OpenAI GPT语言模型越狱状态的更新。

- LLM成员推理的速度提升一个数量级
- GPT-oss泄露的关于OpenAI训练数据的信息
- 关于联邦学习中主动梯度反转攻击的可检测性
💉 毒化 💉
其目标是通过使机器学习模型的准确性降低来破坏训练集。
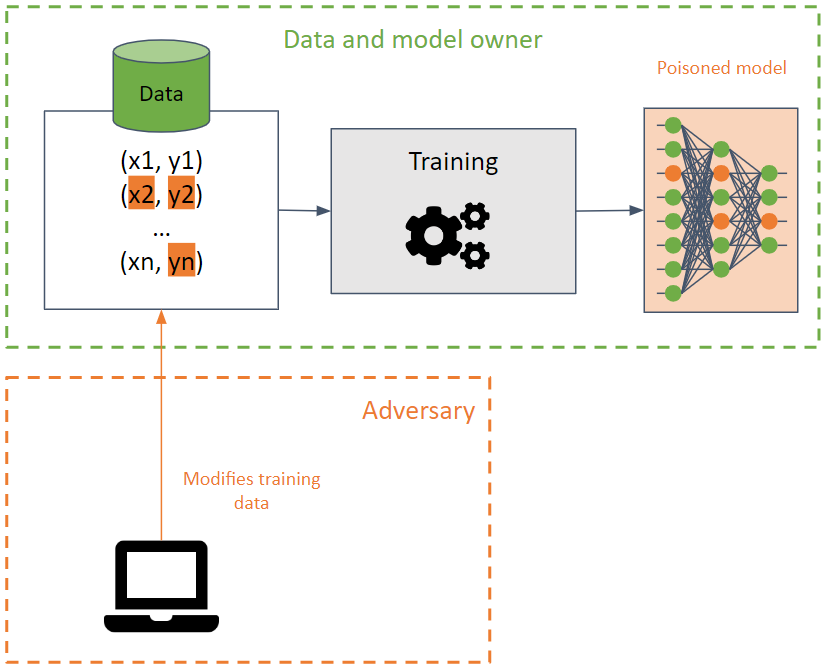
这种攻击在对训练数据实施时很难被发现,因为攻击可以在使用相同训练数据的不同模型之间传播。
攻击者试图通过修改决策边界来破坏模型的可用性,从而产生错误的预测,或者在模型中创建后门。在后一种情况下,模型在大多数情况下表现正常(返回预期的预测结果),但当遇到攻击者专门设计的某些输入时,却会产生非预期的结果。攻击者可以操纵预测结果,并借此发动未来的攻击。
🔓 后门 🔓
BadNets是机器学习模型中最简单的后门类型。此外,即使将模型重新训练用于与原始模型不同的任务(迁移学习),BadNets仍然能够保留在模型中。
需要注意的是,公开的预训练模型可能包含后门。
🛡️ 防御措施 🛡️
检测受污染的数据,并结合数据净化技术。
鲁棒的训练方法。
特定的防御措施。
🔗 有用链接 🔗
- 针对支持向量机的投毒攻击
- 利用数据投毒对深度学习系统进行定向后门攻击
- 神经网络中的木马攻击
- 精细剪枝:防御针对深度神经网络的后门攻击
- 毒蛙!针对神经网络的定向清洁标签投毒攻击
- 后门攻击中的频谱特征
- 深度神经网络中的隐性后门攻击
- Regula Sub-rosa:深度神经网络中的隐性后门攻击
- 隐藏触发器后门攻击
- 深度神经网络中可迁移的清洁标签投毒攻击
- TABOR:一种高度精确的方法,用于检测和修复人工智能系统中的木马后门
- 通过反向梯度优化实现深度学习算法的投毒
- 机器学习何时会失效?逃避与投毒攻击的广义可迁移性
- 针对数据投毒攻击的认证防御
- 输入感知的动态后门攻击
- 如何对联邦学习植入后门
- 在机器学习模型中植入难以检测的后门
- 愚弄AI!:黑客可以使用后门污染训练数据,使AI模型错误分类图像。了解IBM研究人员如何判断数据是否被投毒,并猜测这些数据集中隐藏了哪些后门。你能猜出后门吗?
- 后门工具箱:一个用于后门攻击与防御的紧凑工具箱。

- LaserGuider:一种基于激光的针对深度神经网络的物理后门攻击
- 通过海绵投毒实施的能量-延迟攻击
- ShadowCoT:用于LLM中隐蔽推理后门的认知劫持
- 少量样本即可投毒任何规模的LLM
🏃♂️ 逃避攻击 🏃♂️
攻击者会在机器学习模型的输入上添加微小的扰动(以噪声的形式),使其分类错误(示例攻击者)。
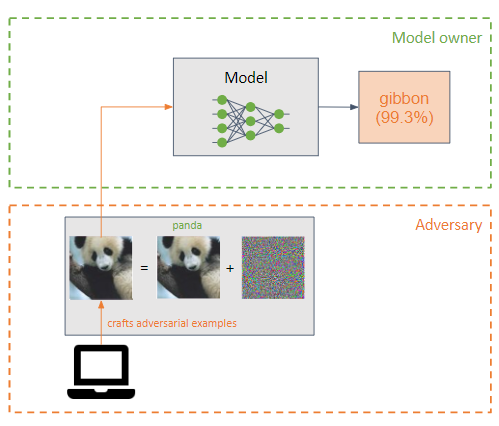
它们类似于投毒攻击,但主要区别在于,逃避攻击试图利用模型在推理阶段的弱点。
攻击者的目标是让对抗样本对人类来说几乎无法察觉。
根据对手期望的输出,可以执行两种类型的攻击:
定向攻击:攻击者旨在获得自己选择的预测结果。
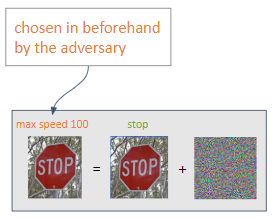
非定向攻击:攻击者意图实现错误分类。

最常见的攻击是白盒攻击:
🛡️ 防御措施 🛡️
- 对抗训练,即在训练过程中生成对抗样本,使模型学会识别对抗样本的特征,从而提高其对这类攻击的鲁棒性。
- 对输入进行变换。
- 梯度掩蔽/正则化。效果不佳。
- 弱防御措施。
- 提示注入防御:所有实用且提出的提示注入防御措施。

- Lakera PINT基准测试:提示注入测试(PINT)基准提供了一种中立的方式来评估提示注入检测系统的性能,例如Lakera Guard,而无需依赖这些工具可能用来优化评估表现的已知公开数据集。

- 恶魔推理:一种通过观察Phi-3 Instruct模型在特定输入下的注意力分布来对抗性地评估该模型的方法。这种方法促使模型采取“恶魔心态”,从而生成暴力性质的输出。

- 空中对抗攻击检测:从数据集到防御
- 利用双曲几何检测并净化有害提示
🔗 有用链接 🔗
- 针对机器学习的实用黑盒攻击
- 深度学习在对抗性环境中的局限性
- 迈向评估神经网络的鲁棒性
- 蒸馏作为防御深度神经网络对抗扰动的方法
- 物理世界中的对抗样本
- 集成对抗训练:攻击与防御
- 迈向抗对抗攻击的深度学习模型
- 神经网络的有趣性质
- 解释并利用对抗样本
- 深入研究可迁移的对抗样本与黑盒攻击
- 大规模的对抗性机器学习
- 有限查询与信息下的黑盒对抗攻击
- 特征挤压:检测深度神经网络中的对抗样本
- 基于决策的对抗攻击:对黑盒机器学习模型的可靠攻击
- 通过动量增强对抗攻击
- 可迁移对抗样本的空间
- 利用输入变换对抗对抗图像
- Defense-GAN:使用生成模型保护分类器免受对抗攻击
- 合成鲁棒的对抗样本
- 通过随机化缓解对抗效应
- 关于检测对抗扰动的研究
- 对抗补丁
- PixelDefend:利用生成模型理解并防御对抗样本
- 仅用一个像素即可愚弄深度神经网络的攻击
- 高效防御对抗攻击的方法
- 深度学习视觉分类任务中针对物理世界的鲁棒攻击
- 针对深度神经网络的对抗扰动用于恶意软件分类
- 超越点云的三维对抗攻击
- 对抗扰动可欺骗深度伪造检测器
- 对抗性深度伪造:评估深度伪造检测器对对抗样本的脆弱性
- 语音控制系统漏洞综述
- FastWordBug:一种快速生成针对NLP应用的对抗性文本的方法
- ADAS的幽灵:保护高级驾驶辅助系统免受瞬间幽灵攻击
- llm-attacks:对齐语言模型的通用且可迁移攻击。

- AI模型攻击:提示注入 vs 供应链中毒
- 针对集成LLM的应用程序的提示注入攻击
- garak:LLM漏洞扫描工具。

- promptfoo:开源LLM红队工具,包含100多种攻击类型。用于LLM的红队演练、渗透测试及漏洞扫描。

- PyTorch中的简单对抗变换
- ChatGPT插件:通过图片和跨插件请求伪造进行数据外泄
- 图像劫持:对抗图像可在运行时控制生成模型
- 多重攻击:多张图片+相同的对抗攻击→多个目标标签
- ACTIVE:迈向高度可迁移的3D物理伪装,实现车辆的通用且鲁棒规避
- GPTs的LLM红队:提示泄漏、API泄漏、文档泄漏
- 人类可制作的对抗样本
- 大型语言模型中的多语言越狱挑战
- 利用视觉对抗样本滥用大型语言模型中的工具
- AutoDAN:针对大型语言模型的可解释梯度基对抗攻击
- Multimodal Injection:(滥用)图像和声音,在多模态LLM中进行间接指令注入。

- JailbreakingLLMs:在二十次查询内越狱黑箱大型语言模型。

- 攻击之树:自动越狱黑箱LLM
- GPTs:泄露的GPTs提示。

- AI Exploits:负责任披露漏洞的真实世界AI/ML漏洞集合。

- LLM代理可自主入侵网站
- Cloudflare宣布推出AI防火墙
- PromptInject:以模块化方式组装提示的框架,用于定量分析LLM对对抗性提示攻击的鲁棒性。

- LLM红队:对抗、编程和语言学方法 vs ChatGPT、Claude、Mistral、Grok、LLAMA和Gemini
- 指令层级:训练LLM优先处理特权指令
- 银行LLM代理(GPT-4,Langchain)的提示注入/越狱
- GitHub Copilot聊天:从提示注入到数据外泄
- 对抗样本在扩散模型流形中存在错位
- 图转文逻辑越狱:你的想象力可以帮助你做任何事
- 缓解“密钥骨架”——一种新型生成式AI越狱技术
- 图像混淆基准:该仓库包含用于评估模型在图像混淆基准上表现的代码,该基准首次发表于《对抗性图像混淆的鲁棒性基准测试》(https://arxiv.org/abs/2301.12993)。[](https://github.com/google-deepmind/image_obfuscation_benchmark)
- 利用符号数学越狱大型语言模型
- 越狱时刻的对抗性推理
- 我们如何评估AI系统中提示注入攻击的风险
- 生成式AI的对抗性滥用
- 通过设计抵御提示注入
- 采用分层防御策略缓解提示注入攻击
- 逻辑层提示控制注入(LPCI):代理系统中的一种新型安全漏洞类别
- 针对攻击者的提示注入工程:利用GitHub Copilot
- 对抗性提示的现状
- TransferBench:基于集成的黑盒迁移攻击基准测试
- 注意力追踪器:检测LLM中的提示注入攻击
- 攻击者后手出击:更强的自适应攻击可绕过针对LLM越狱和提示注入的防御措施
- 将日历邀请武器化:对Google Gemini的语义攻击
- GTIG AI威胁追踪器:提炼、实验与(持续)整合AI用于对抗性用途
- Cline是如何被攻陷的:Cline供应链攻击中的提示注入和悬空提交
- Aguara:AI代理技能与MCP服务器的安全扫描工具
🛠️ 工具 🛠️
| 名称 | 类型 | 支持的算法 | 支持的攻击类型 | 攻击/防御 | 支持的框架 | 流行度 |
|---|---|---|---|---|---|---|
| Cleverhans | 图像 | 深度学习 | 欺骗 | 攻击 | Tensorflow, Keras, JAX |  |
| Foolbox | 图像 | 大量学习 | 欺骗 | 攻击 | Tensorflow, PyTorch, JAX |  |
| ART | 任意类型(图像、表格数据、音频等) | 深度学习、SVM、LR等 | 任意(提取、推理、投毒、欺骗) | 双方 | Tensorflow、Keras、Pytorch、Scikit Learn |  |
| TextAttack | 文本 | 深度学习 | 欺骗 | 攻击 | Keras、HuggingFace |  |
| Advertorch | 图像 | 深度学习 | 欺骗 | 双方 | --- |  |
| AdvBox | 图像 | 深度学习 | 欺骗 | 双方 | PyTorch、Tensorflow、MxNet |  |
| DeepRobust | 图像、图 | 深度学习 | 欺骗 | 双方 | PyTorch |  |
| Counterfit | 任意 | 任意 | 欺骗 | 攻击 | --- |  |
| Adversarial Audio Examples | 音频 | DeepSpeech | 欺骗 | 攻击 | --- |  |
ART
对抗鲁棒性工具箱,简称ART,是一个开源的对抗机器学习库,用于测试机器学习模型的鲁棒性。

它使用Python开发,实现了提取、逆向、投毒和欺骗等攻击与防御方法。
ART支持最流行的框架:Tensorflow、Keras、PyTorch、MxNet以及ScikitLearn等众多框架。
它不仅限于处理以图像为输入的模型,还支持其他类型的数据,如音频、视频、表格数据等。
Cleverhans
Cleverhans是一个用于执行欺骗攻击并测试图像模型深度学习鲁棒性的库。

它使用Python开发,并与Tensorflow、Torch和JAX框架集成。
它实现了多种攻击方法,如L-BFGS、FGSM、JSMA、C&W等。
🔧 使用 🔧
人工智能被用于完成恶意任务并增强传统攻击手段。
🕵️♂️ 渗透测试 🕵️♂️
- GyoiThon: 新一代渗透测试工具,用于Web服务器的情报收集工具。

- Cochise: 使用LLM代理对微软Windows Active Directory进行自主渗透测试(以GOAD为测试平台)。
- HackingBuddyGPT: 大型语言模型与渗透测试的结合。

- Deep Exploit: 基于深度强化学习的全自动渗透测试工具。

- AutoPentest-DRL: 利用深度强化学习实现自动化渗透测试。

- DeepGenerator: 利用遗传算法和生成对抗网络,全自动生成用于Web应用评估的注入代码。
- Eyeballer: Eyeballer适用于大规模网络渗透测试,能够在海量Web主机中快速找到“有趣”的目标。

- Nebula: 基于AI的道德黑客助手。

- AI-OPS: 基于开源大型语言模型的渗透测试AI助手。

- LLM能否攻陷企业网络?: 自主模拟入侵的Active Directory网络渗透测试
- LLM代理团队可利用零日漏洞
- 开源LLM漏洞扫描器的洞察与当前不足:比较分析
- AI代理与网络安全专业人员在真实渗透测试中的对比
- CAI: 一款开放且适合漏洞赏金计划的网络安全AI。

- Shannon: Shannon Lite是一款针对Web应用和API的自主白盒AI渗透测试工具。它会分析你的源代码,识别攻击向量,并执行真实的漏洞利用来证明潜在漏洞,从而防止它们在生产环境中被利用。

🦠 恶意软件 🦠
- DeepLocker: IBM实验室在Black Hat大会上展示的利用AI锁匠技术隐藏定向攻击的方法。
- 恶意软件中使用的人工智能概述: 精选的AI恶意软件资源列表。
- DeepObfusCode: 通过序列到序列网络进行源代码混淆。
- AutoCAT: 利用强化学习自动探索缓存定时攻击。
- 基于AI的僵尸网络: 一种基于博弈论的AI驱动僵尸网络攻击防御方法。
- SECML_Malware: 用于对Windows恶意软件检测器发起对抗性攻击的Python库。

- Transcendent-release: 使用共形评估检测影响恶意软件检测的概念漂移。

🗺️ OSINT 🗺️


📧 钓鱼邮件 📧
- DeepDGA: DeepDGA的实现:对抗性调优的域名生成与检测。

- 诈骗代理:AI代理如何模拟人类水平的诈骗电话
🕵 威胁情报 🕵
⚙️ 逆向工程 ⚙️
- 我们在约40MB的二进制文件中隐藏了后门,并让AI+Ghidra去寻找它们
- 恶意软件逆向工程不再是人类的任务!
- [GhidraMCP](Ghidra的MCP服务器。

- [ghidra-mcp](生产级Ghidra MCP服务器——包含179个MCP工具、147个GUI端点和172个无头端点,集成Ghidra服务器,支持跨二进制文档传输、批量操作、AI文档工作流,并可通过Docker部署实现AI驱动的逆向工程。

🌀 侧信道 🌀
- SCAAML: 机器学习辅助的侧信道攻击。

👨🎤 生成式AI 👨🎤
🔊 音频 🔊
🛠️ 工具 🛠️
- deep-voice-conversion: 基于 TensorFlow 的深度神经网络语音转换(语音风格迁移)工具。

- tacotron: Google Tacotron 语音合成的 TensorFlow 实现,包含预训练模型(非官方)。

- Real-Time-Voice-Cloning: 在 5 秒内克隆一段声音,实时生成任意语音。

- mimic2: 基于 Tacotron 架构的文本转语音引擎,最初由 Keith Ito 实现。

- Neural-Voice-Cloning-with-Few-Samples: 百度发表的少样本神经网络语音克隆研究论文的实现。

- Vall-E: 音频语言模型 VALL-E 的非官方 PyTorch 实现。

- voice-changer: 实时语音变换器。

- Retrieval-based-Voice-Conversion-WebUI: 基于 VITS 的易用型语音转换框架。

- Audiocraft: Audiocraft 是一个用于音频处理与生成的深度学习库。它包含最先进的 EnCodec 音频压缩器/分词器,以及 MusicGen——一种简单可控、可通过文本和旋律条件生成音乐的语言模型。

- VALL-E-X: 微软 VALL-E X 零样本 TTS 模型的开源实现。

- OpenVoice: MyShell 提供的即时语音克隆服务。

- MeloTTS: MyShell.ai 推出的高质量多语言文本转语音库,支持英语、西班牙语、法语、中文、日语和韩语。

- VoiceCraft: 零样本语音编辑及野外环境下的文本转语音技术。

- Parler-TTS: 高质量 TTS 模型的推理与训练库。

- ChatTTS: 用于日常对话的生成式语音模型。

💡 应用场景 💡
- Lip2Wav: 仅通过唇部动作生成高质量语音。

- AudioLDM:基于潜在扩散模型的文本到音频生成
- deepvoice3_pytorch:基于卷积神经网络的文本到语音合成模型的PyTorch实现。

- 🎸 Riffusion:用于实时音乐生成的稳定扩散模型。

- whisper.cpp:OpenAI Whisper模型的C/C++移植版本。

- TTS:🐸💬——一个在研究和生产中久经考验的深度学习文本到语音工具包。

- YourTTS:面向所有人的零样本多说话者TTS及零样本语音转换技术。

- TorToiSe:一款以质量为重训练的多语音TTS系统。

- DiffSinger:基于浅层扩散机制的歌声合成(SVS与TTS)。

- WaveNet声码器:WaveNet声码器的实现,可根据语言学或声学特征生成高质量的原始语音样本。

- Deepvoice3_pytorch:基于卷积神经网络的文本到语音合成模型的PyTorch实现。
- eSpeak NG 文本转语音:eSpeak NG是一款开源语音合成器,支持超过一百种语言和口音。

- RealChar:实时创建、自定义并与你的AI角色/伙伴对话(一体化代码库!)。使用LLM OpenAI GPT3.5/4、Anthropic Claude2、Chroma向量数据库、Whisper语音转文本以及ElevenLabs文本转语音,在任何地方(移动端、网页端和终端)与AI进行自然流畅的对话。

- 少量样本下的神经语音克隆
- NAUTILUS:多功能语音克隆系统
- 学习流利地说外语:多语言语音合成与跨语言语音克隆
- 当善变恶时:利用智能手表推断按键输入
- KeyListener:通过声学信号推断触摸屏QWERTY键盘上的按键输入
- 这个声音并不存在:关于语音合成、音频深度伪造及其检测
- AudioSep:分离你所描述的任何内容。

- stable-audio-tools:用于条件音频生成的生成模型。

- GPT-SoVITS-WebUI:只需1分钟的语音数据即可训练出优秀的TTS模型!(少样本语音克隆)。

- Hybrid-Net:实时音频源分离,生成歌词、和弦和节拍。

- CosyVoice:多语言大型语音生成模型,提供推理、训练和部署的全栈能力。

- EasyVolcap:加速神经体积视频研究。

🔎 检测 🔎
- fake-voice-detection:利用时间卷积检测音频深度伪造。

- 基于新型CLS-LBP特征和LSTM的鲁棒语音欺骗检测系统
- 语音欺骗检测器:统一的反欺骗框架
- 保护语音驱动界面免受虚假(克隆)音频攻击
- DeepSonar:迈向有效且鲁棒的AI合成虚假语音检测
- 以AI对抗AI:利用深度学习检测虚假语音
- 现代音频深度伪造检测方法综述:挑战与未来方向
📷 图像 📷
🛠️ 工具 🛠️
- StyleGAN: StyleGAN - 官方 TensorFlow 实现。

- StyleGAN2: StyleGAN2 - 官方 TensorFlow 实现。
- stylegan2-ada-pytorch: StyleGAN2-ADA - 官方 PyTorch 实现。
- StyleGAN-nada: 基于 CLIP 的图像生成器领域自适应。

- StyleGAN3: StyleGAN3 的官方 PyTorch 实现。
- Imaginaire: Imaginaire 是一个 PyTorch 库,包含了 NVIDIA 研发的多种图像和视频合成方法的优化实现。

- ffhq-dataset: Flickr-Faces-HQ 数据集 (FFHQ)。

- DALLE2-pytorch: OpenAI 更新的文本到图像合成神经网络 DALL-E 2 的 PyTorch 实现。

- ImaginAIry: AI 想象的图像。Python 风格的稳定扩散图像生成工具。

- Lama Cleaner: 基于 SOTA AI 模型的图像修复工具。可以移除照片中的任何不需要的对象、瑕疵或人物,也可以擦除并替换照片中的内容(基于稳定扩散模型)。

- Invertible-Image-Rescaling: 论文《可逆图像缩放》的 PyTorch 实现。

- DifFace: 基于扩散误差收缩的盲人面部修复(PyTorch)。

- CodeFormer: 基于码本查找变换器的鲁棒盲人面部修复。

- Custom Diffusion: 文本到图像扩散模型的多概念自定义。

- Diffusers: 🤗 Diffusers:用于图像和音频生成的最先进扩散模型,基于 PyTorch。

- Stable Diffusion: 使用潜在扩散模型进行高分辨率图像合成。

- InvokeAI: InvokeAI 是 Stable Diffusion 模型领域的领先创作引擎,赋能专业人士、艺术家和爱好者使用最新的 AI 驱动技术生成和创作视觉媒体。该解决方案提供行业领先的 WebUI,支持通过 CLI 进行终端操作,并作为多个商业产品的基础。

- Stable Diffusion web UI: Stable Diffusion 的 Web 界面。

- Stable Diffusion Infinity: 在无限画布上使用 Stable Diffusion 进行扩展绘画。

- Fast Stable Diffusion: 快速稳定扩散 + DreamBooth。

- GET3D: 一种从图像中学习的高质量 3D 纹理形状生成模型。

- Awesome AI Art Image Synthesis: 一份关于 AI 艺术和图像合成的优秀工具、创意、提示工程工具、合作项目、模型和辅助资源的列表。涵盖 Dalle2、MidJourney、StableDiffusion 以及开源工具。

- Stable Diffusion: 一种潜在的文本到图像扩散模型。

- Weather Diffusion: “利用基于补丁的去噪扩散模型恢复恶劣天气条件下的视觉”相关代码。

- DF-GAN: 一种简单而有效的文本到图像合成基线。

- Dall-E Playground: 一个使用 Stable Diffusion(过去曾使用 DALL-E Mini)根据任意文本提示生成图像的平台。

- MM-CelebA-HQ-Dataset: 一个大规模人脸图像数据集,可用于文本到图像生成、文本引导的图像编辑、素描到图像生成、用于人脸生成和编辑的 GAN、图像描述以及 VQA。

- Deep Daze: 一个简单的命令行工具,使用 OpenAI 的 CLIP 和 Siren(隐式神经表示网络)进行文本到图像生成。

- StyleMapGAN: 利用 GAN 中潜在空间的维度实现实时图像编辑。

- Kandinsky-2: 多语言文本到图像潜在扩散模型。

- DragGAN: 在生成式图像流形上进行交互式的基于点的操作。

- Segment Anything: 该仓库提供了运行 SegmentAnything Model (SAM) 推理的代码、下载训练好的模型检查点的链接,以及展示如何使用该模型的示例笔记本。

- Segment Anything 2: 该仓库提供了运行 Meta Segment Anything Model 2 (SAM 2) 推理的代码、下载训练好的模型检查点的链接,以及展示如何使用该模型的示例笔记本。

- MobileSAM: 这是 MobileSAM 项目的官方代码,旨在使 SAM 更轻量级,适用于移动应用及其他场景!

- FastSAM: 快速分割一切。

- Infinigen: 使用程序化生成创建无限逼真的世界。

- DALL·E 3
- StreamDiffusion: 一种面向管道级别的实时交互式生成解决方案。

- AnyDoor: 零样本对象级图像定制。
- DiT: 基于 Transformer 的可扩展扩散模型。

- BrushNet: 一种即插即用的图像修复模型,采用分解的双分支扩散机制。

- OOTDiffusion: 基于潜在扩散的可控虚拟试穿融合。

- VAR: “视觉自回归建模:通过下一尺度预测实现可扩展图像生成”的官方实现。

- Imagine Flash: 加速 Emu 扩散模型的反向蒸馏
- StyleGAN2: StyleGAN2 - 官方 TensorFlow 实现。



💡 应用 💡
- ArtLine:基于深度学习的线稿肖像生成项目。

- Depix:从像素化截图中恢复密码。

- 让老照片重焕生机:老照片修复(官方 PyTorch 实现)。

- Rewriting:交互式工具,可直接编辑 GAN 的规则,以合成添加、删除或修改对象的场景。例如将 StyleGANv2 改造为拥有夸张眉毛或戴帽子的马匹。

- Fawkes:用于对抗人脸识别系统的隐私保护工具。

- Pulse:通过探索生成模型的潜在空间实现自监督照片超分辨率。

- HiDT:论文《无需领域标签的高分辨率白天图像转换》的官方仓库。

- 3D Photo Inpainting:使用上下文感知分层深度修复技术进行 3D 摄影。

- SteganoGAN:一种利用对抗训练生成隐写图像的工具。

- Stylegan-T:释放 GAN 力量,实现快速的大规模文本到图像合成。

- MegaPortraits:一次性生成百万像素级神经网络头像。

- eg3d:高效的几何感知 3D 生成对抗网络。

- TediGAN:TediGAN 的 PyTorch 实现:文本引导的多样化人脸图像生成与操控。

- DALLE-pytorch:OpenAI 的文本到图像 Transformer DALL-E 在 PyTorch 中的实现/复现。

- StyleNeRF:这是 ICLR2022 论文《StyleNeRF:用于高分辨率图像合成的基于风格的 3D 感知生成器》的开源实现。

- DeepSVG:论文《DeepSVG:面向矢量图形动画的层次化生成网络》的官方代码。包含用于 SVG 数据深度学习的 PyTorch 库。

- NUWA:统一的 3D 变换器流水线,用于视觉合成。

- Image-Super-Resolution-via-Iterative-Refinement:PyTorch 非官方实现的迭代细化超分辨率方法。

- Lama:🦙 LaMa 图像修复,采用傅里叶卷积实现对大尺寸遮罩的稳健修复。

- Person_reID_baseline_pytorch:PyTorch ReID:一个轻量、友好且强大的目标再识别基准实现。

- instruct-pix2pix:InstructPix2Pix 的 PyTorch 实现,这是一种基于指令的图像编辑模型。

- GFPGAN:GFPGAN 致力于开发适用于现实世界的人脸修复实用算法。

- DeepVecFont:通过双模态学习合成高质量矢量字体。

- Stargan v2 Tensorflow:官方 TensorFlow 实现。

- StyleGAN2 蒸馏:成对的图像到图像翻译任务,基于 StyleGAN2 生成的合成数据进行训练,在图像操控方面优于现有方法。

- 从扩散模型中提取训练数据
- Mann-E - Mann-E(波斯语:مانی)是一个艺术生成模型,基于 Stable Diffusion 1.5 的权重以及从 Pinterest 上收集的艺术素材
- 端到端训练的 CNN 编码器-解码器网络用于图像隐写术
- Grounded-Segment-Anything:将 Grounding DINO 与 Segment Anything、Stable Diffusion、Tag2Text、BLIP、Whisper 和 ChatBot 相结合——能够自动检测、分割并根据图像、文本和音频输入生成任何内容。

- AnimateDiff:无需特定调优即可为您的个性化文本到图像扩散模型添加动画效果。

- BasicSR:用于超分辨率、去噪、去模糊等任务的开源图像和视频修复工具箱。目前包括 EDSR、RCAN、SRResNet、SRGAN、ESRGAN、EDVR、BasicVSR、SwinIR、ECBSR 等,并支持 StyleGAN2 和 DFDNet。[
 ](https://github.com/XPixelGroup/
BasicSR)
](https://github.com/XPixelGroup/
BasicSR) - Real-ESRGAN:Real-ESRGAN 致力于开发通用图像/视频修复的实用算法。

- ESRGAN:增强版 SRGAN。在 PIRM 感知超分辨率挑战赛中夺冠。

- MixNMatch:用于条件图像生成的多因子解耦与编码。

- Clarity-upscaler:为所有人重新构想的图像超分辨率工具。

- 一步扩散与分布匹配蒸馏
- 隐形缝合:通过深度修复生成平滑的 3D 场景。

- SSR:单视图高保真形状与纹理的 3D 场景重建。

- InvSR:通过扩散反演实现任意步数的图像超分辨率。

- REPARO:通过可微分的 3D 布局对齐生成组合式 3D 资产。

- Gen3DSR:从单视图出发,通过分治法实现可推广的 3D 场景重建。

- ml-sharp:在不到一秒钟内完成清晰的单目视图合成。

- Depix:从像素化截图中恢复密码。
🔎 检测 🔎
- stylegan3-detector: StyleGAN3 合成图像检测。
- stylegan2-projecting-images: 使用 StyleGAN2 将图像投影到潜在空间。

- FALdetector: 通过脚本化 Photoshop 检测经过 Photoshop 处理的人脸。

- B-Free: 一种无偏见的训练范式,用于更通用的 AI 生成图像检测。

- 多模态模型生成图像的检测

](https://github.com/google-deepmind/image_obfuscation_benchmark)](https://arxiv.org/abs/2301.12993)%E3%80%82%5B!%5Bstars%5D(https://oss.gittoolsai.com/images/jiep_offensive-ai-compilation_readme_e73077a5a2bf.png)%5D(https://github.com/google-deepmind/image_obfuscation_benchmark)){kind=link}
🎥 视频 🎥
🛠️ 工具 🛠️
- DeepFaceLab: DeepFaceLab 是领先的深度伪造制作软件。

- faceswap: 适用于所有人的深度伪造软件。

- dot: 深度伪造攻击工具包。

- SimSwap: 一个基于单一训练模型的任意人脸交换框架,可用于图像和视频!

- faceswap-GAN: 一种去噪自编码器 + 对抗损失和注意力机制的人脸交换方法。

- Celeb DeepFakeForensics: 一个大规模且具有挑战性的深度伪造取证数据集。

- VGen: 基于扩散模型构建的综合性视频生成生态系统。

- MuseV: 基于视觉条件并行去噪技术,实现无限长度、高保真度的虚拟人视频生成。

- GLEE: 面向图像和视频的大规模通用对象基础模型。

- T-Rex: 通过文本-视觉提示协同作用实现通用目标检测。

- DynamiCrafter: 利用视频扩散先验对开放域图像进行动画化处理。

- Mora: 更接近 Sora 的通用视频生成模型。

💡 应用 💡
- face2face-demo: 基于人脸关键点学习并将其转换为面部的pix2pix演示。

- Faceswap-Deepfake-Pytorch: 使用PyTorch实现的人脸交换或深度伪造。

- Point-E: 用于3D模型合成的点云扩散模型。

- EGVSR: 高效且通用的视频超分辨率技术。

- STIT: 时间拼接:基于GAN的真实视频人脸编辑。

- BackgroundMattingV2: 实时高分辨率背景抠图。

- MODNet: 无需三元图的实时人像抠图解决方案。

- Background-Matting: 背景抠图:世界即你的绿幕。

- First Order Model: 该仓库包含论文《用于图像动画的一阶运动模型》的源代码。

- Articulated Animation: 该仓库包含CVPR'2021论文《关节动画的运动表示》的源代码。

- Real Time Person Removal: 使用TensorFlow.js在网页浏览器中实时从复杂背景中移除人物。

- AdaIN-style: 使用自适应实例归一化实现实时任意风格迁移。

- Frame Interpolation: 大运动帧插值。

- Awesome-Image-Colorization: 📚 基于深度学习的图像着色和视频着色论文集。

- SadTalker: 学习用于风格化音频驱动单张图片说话人脸动画的真实3D运动系数。

- roop: 一键式深度伪造(人脸交换)。

- StableVideo: 文本驱动的一致性感知扩散视频编辑。

- MagicEdit: 高保真、时间一致的视频编辑。

- Rerender_A_Video: 零样本文本引导的视频到视频翻译。

- DreamEditor: 基于神经场的文本驱动3D场景编辑。

- DreamEditor: 4K分辨率下的实时4D视图合成。

- AnimateAnyone: 用于角色动画的一致且可控的图像到视频合成。

- Moore-AnimateAnyone: 该仓库复现了AnimateAnyone。

- audio2photoreal: 从音频到照片级逼真化身:在对话中合成人类形象。

- MagicVideo-V2: 多阶段高美学视频生成
- LWM: 一种通用的大上下文多模态自回归模型。它使用RingAttention在大量多样化的长视频和书籍数据上训练,能够进行语言、图像和视频的理解与生成。

- AniPortrait: 音频驱动的写实人像动画合成。

- Champ: 基于3D参数化指导的可控且一致的人像动画。

- Streamv2v: 借助特征库实现的流式视频到视频翻译。

- Deep-Live-Cam: 仅需一张图片即可实现实时人脸交换和一键式视频深度伪造。

- Sapiens: 人类视觉模型的基础。

- ViVid-1-to-3: 利用视频扩散模型进行新颖视图合成。

- VGGT: 视觉几何基础Transformer。

- LayerPano3D: 分层3D全景图,用于超沉浸式场景生成。

- RealmDreamer: 基于文本驱动的3D场景生成,结合修复和深度扩散技术。

- Faceswap-Deepfake-Pytorch: 使用PyTorch实现的人脸交换或深度伪造。
🔎 检测 🔎
- FaceForensics++: FaceForensics 数据集。

- DeepFake-Detection: 致力于真正有效的深度伪造检测。

- fakeVideoForensics: 检测深度伪造视频。

- Deepfake-Detection: 基于 Faceforensics++ 的 PyTorch 实现的深度伪造检测。

- SeqDeepFake: SeqDeepFake 的 PyTorch 代码:检测并恢复序列式深度伪造篡改。

- PCL-I2G: 非官方实现:学习自一致性以进行深度伪造检测。

- DFDC 深度伪造挑战赛: DFDC 挑战赛的获奖解决方案。

- POI-Forensics: 音频-视觉感兴趣人物的深度伪造检测。

- 标准化深度伪造检测:专家为何认为其重要
- 想识别深度伪造吗?看看他们眼睛里的“星星”
- 适合实际应用吗?现实世界中的深度伪造检测
📄 文本 📄
🛠️ 工具 🛠️
- GLM-130B: 一个开源的双语预训练模型。

- LongtermChatExternalSources: 具有长期记忆和外部信息源的GPT-3聊天机器人。

- sketch: 一款能够理解数据内容的AI代码编写助手。

- LangChain: ⚡ 通过可组合性构建大型语言模型应用 ⚡。

- ChatGPT Wrapper: 使用Python和Shell与ChatGPT交互的API。

- openai-python: OpenAI Python库为使用Python语言编写的应用程序提供了便捷的OpenAI API访问接口。

- Beto: BERT模型的西班牙语版本。

- GPT-Code-Clippy: GPT-Code-Clippy (GPT-CC) 是GitHub Copilot的开源版本,基于GPT-3的语言模型,称为GPT-Codex。

- GPT Neo: 使用mesh-tensorflow库实现的模型并行GPT-2和GPT-3风格模型。

- ctrl: 用于可控生成的条件Transformer语言模型。

- Llama: LLaMA模型的推理代码。

- Llama2
- Llama Guard 3
- UL2 20B: 一个开源的统一语言学习模型
- burgpt: 一个Burp Suite扩展,集成了OpenAI的GPT,用于执行额外的被动扫描以发现高度定制化的漏洞,并支持对任何类型的流量进行分析。

- Ollama: 在本地快速启动并运行Llama 2及其他大型语言模型。

- SneakyPrompt: 突破文本到图像生成模型的安全限制。

- Copilot-For-Security: 一种由生成式AI驱动的安全解决方案,旨在以机器速度和规模提升防御者的效率和能力,从而改善安全成果,同时遵守负责任的AI原则。

- Copilot-For-Security: 一种由生成式AI驱动的安全解决方案,旨在以机器速度和规模提升防御者的效率和能力,从而改善安全成果,同时遵守负责任的AI原则。
- LM Studio: 发现、下载并运行本地大型语言模型
- Bypass GPT: 将AI文本转换为人类风格的内容
- MGM: 该框架支持从2B到34B的一系列密集型和MoE大型语言模型(LLMs),同时具备图像理解、推理和生成能力。

- Secret Llama: 完全私密的LLM聊天机器人,完全在浏览器中运行,无需服务器。支持Mistral和LLama 3。

- Llama3: Meta Llama 3的官方GitHub站点。

- Unsloth: 以80%更少的内存,将Llama 3.3、Mistral、Phi-4、Qwen 2.5及Gemma 2的速度提升2倍!

🔎 检测 🔎
- Detecting Fake Text: 巨型语言模型测试室。

- Grover: 用于防御神经网络假新闻的代码。

- Rebuff.ai: 提示注入检测器。

- 用于指示AI撰写文本的新AI分类器
- 揭秘四种神奇方法来检测AI生成文本(包括ChatGPT)
- GPTZero
- AI内容检测器(beta版)
- 大型语言模型的水印技术
- 能否可靠地检测出AI生成的文本?
- GPT检测器对非英语母语写作者存在偏见
- 用ChatGPT,还是不用ChatGPT?这就是问题所在!
- 语言学家能否区分ChatGPT/人工智能与人类写作?——一项关于研究伦理和学术出版的研究
- ChatGPT就是胡扯
💡 应用 💡
- handwrite: Handwrite 根据你的手写样本生成自定义字体。

- GPT Sandbox: 该项目的目标是让用户仅用几行 Python 代码,就能利用新发布的 OpenAI GPT-3 API 创建酷炫的网页演示。

- PassGAN: 一种基于深度学习的密码猜测方法。

- GPT Index: GPT Index 是一个由一系列数据结构组成的项目,旨在使大型外部知识库更容易与 LLM 结合使用。

- nanoGPT: 训练/微调中等规模 GPT 的最简单、最快的仓库。

- whatsapp-gpt

- ChatGPT Chrome 扩展: 一款 ChatGPT Chrome 扩展程序。将 ChatGPT 集成到互联网上的每一个文本框中。
- Unilm: 跨任务、跨语言和跨模态的大规模自监督预训练。

- minGPT: OpenAI GPT(生成式预训练 Transformer)训练的极简 PyTorch 重实现。

- CodeGeeX: 一个开源的多语言代码生成模型。

- OpenAI Cookbook: 使用 OpenAI API 的示例和指南。

- 🧠 Awesome ChatGPT Prompts: 该仓库包含 ChatGPT 提示词精选,帮助用户更好地使用 ChatGPT。

- Alice: 让 ChatGPT 获得真正的终端访问权限。

- 使用 ChatGPT 进行安全代码审查
- 用户在 AI 助手的帮助下是否会编写更不安全的代码?
- 使用 ChatGPT 绕过 Gmail 的垃圾邮件过滤器
- 用于增强物联网密码安全性的循环 GAN 密码破解器
- PentestGPT: 一款由 GPT 驱动的渗透测试工具。

- GPT Researcher: 基于 GPT 的自主智能体,可针对任何给定主题进行在线全面研究。

- GPT Engineer: 指定你想要构建的内容,AI 会请求澄清,然后完成构建。

- localpilot: 在你的 Macbook 上一键本地使用 GitHub Copilot!

- WormGPT: 新型 AI 工具使网络犯罪分子能够发起复杂的网络攻击
- PoisonGPT: 我们如何在 Hugging Face 上隐藏一台被“切除前额叶”的 LLM 来传播假新闻
- PassGPT:使用大型语言模型进行密码建模和(引导式)生成
- DeepPass — 通过深度学习寻找密码
- GPTFuzz: 使用自动生成的越狱提示对大型语言模型进行红队测试。

- Open Interpreter: OpenAI 的 Code Interpreter 在你的终端中本地运行。

- Eureka: 通过大型语言模型编程实现人类级别的奖励设计。

- MetaCLIP: 揭秘 CLIP 数据。

- LLM OSINT: 利用 LLM 从互联网上收集信息,并基于这些信息执行任务的概念验证方法。

- HackingBuddyGPT: LLM 与渗透测试结合。
- ChatGPT-Jailbreaks: ChatGPT(GPT-3.5)的官方越狱方法。在与 ChatGPT 对话开始时发送一条长消息,即可获得具有攻击性、不道德、激进且接近人类的回答,支持英语和意大利语。

- Magika: 使用深度学习检测文件内容类型。

- Jan: 一个开源的 ChatGPT 替代品,在你的电脑上 100% 离线运行。

- LibreChat: 增强版 ChatGPT 克隆:支持 OpenAI、Assistants API、Azure、Groq、GPT-4 Vision、Mistral、Bing、Anthropic、OpenRouter、Vertex AI、Gemini,可切换 AI 模型、支持消息搜索、LangChain、DALL-E-3、ChatGPT 插件、OpenAI Functions、安全的多用户系统、预设功能,完全开源,可自行托管。

- Lumina-T2X: 一个统一的框架,用于文本到任意模态的生成。

- GPT Sandbox: 该项目的目标是让用户仅用几行 Python 代码,就能利用新发布的 OpenAI GPT-3 API 创建酷炫的网页演示。
📚 杂项 📚
- Awesome GPT + Security: 一个精选的安全工具、实验案例及其他与大语言模型或GPT相关有趣内容的列表。

- 🚀 Awesome Reinforcement Learning for Cyber Security: 一个专注于强化学习在网络安全领域应用的资源精选列表。

- Awesome Machine Learning for Cyber Security: 一个关于机器学习在网络安全中应用的超赞工具和资源精选列表。

- Hugging Face扩散模型课程: Hugging Face扩散模型课程的相关资料。

- Awesome-AI-Security: 一个AI安全资源的精选列表。

- 面向黑客的机器学习: 与《面向黑客的机器学习》一书配套的代码。

- Awful AI: Awful AI是一个精选列表,用于追踪当前令人担忧的AI使用案例,旨在提高公众意识。

- NIST AI风险管理框架手册
- SoK:面向计算机安全应用的可解释机器学习
- 谁来评估评估者?——关于评估基于AI的攻击性代码生成器的自动化指标
- 漏洞优先级排序:一种进攻性安全方法
- MITRE ATLAS™(人工智能系统对抗威胁态势图)
- 强化学习安全性及其在自动驾驶中的应用综述
- 如何避免机器学习陷阱:学术研究人员指南
- AI安全与隐私相关活动精选列表
- NIST AI 100-2 E2025:对抗性机器学习。攻击与缓解措施的分类与术语。
- 🇪🇸 RootedCon 2023 - 进攻性人工智能 - 我们该如何做好准备?
- AI系统的安全性:基础——对抗性深度学习
- 超越安全措施:探索ChatGPT的安全风险
- AI攻击面地图 v1.0
- 大型AI模型不可能的安全性
- 前沿AI监管:管理新兴公共安全风险
- 针对AI的良好网络安全实践多层框架
- 谷歌推出安全AI框架
- OWASP大型语言模型十大风险
- Awesome LLM Security: 一个关于LLM安全的优秀工具、文档和项目的精选列表。

- 一个在企业中安全使用LLM的框架。第1部分:风险概述。第2部分:风险管理。第3部分:保护ChatGPT和GitHub Copilot。
- 大型语言模型代码生成的鲁棒性和可靠性研究
- 使用SynthID识别AI生成的图像
- 大型语言模型审计:三层方法
- 解决短期与长期AI风险之争
- FraudGPT:ChatGPT的反派化身
- AI风险——Schneier谈安全
- LLM用于非法目的:威胁、预防措施及漏洞
- AI红队并非解决AI危害的一站式方案:关于利用红队进行AI问责制的建议
- 人工智能可信度分类体系
- 快速进步时代下的AI风险管理
- 谷歌——践行我们对安全可靠AI的承诺
- 进攻性ML手册
- 揭秘生成式AI 🤖——一位安全研究员的笔记
- GenAI-Security-Adventures: 一个开源项目,分享笔记、演示文稿以及用Jupyter Notebook呈现的多样化实验,旨在帮助你掌握大型语言模型的核心概念,并探索安全与自然语言处理之间引人入胜的交叉点。

- AI安全营将你与研究负责人联系起来,共同开展项目——看看你的工作如何助力确保未来AI的安全。
- 安全AI系统开发指南
- 人工智能与网络安全的方法。最佳实践报告
- 斯坦福安全、可靠且值得信赖的AI行政命令14110跟踪表
- Awesome ML Security: 一个精选的机器学习安全参考文献、指南、工具等资源列表。

- AI的可预测路径:2024年及以后AI的7个预期发展
- 人工智能与网络安全(西班牙语版)
- Vigil: 检测提示注入、越狱以及其他潜在危险的大语言模型输入。

- 生成式AI模型——对行业和当局的机遇与风险
- 安全部署AI系统。部署安全且有弹性的AI系统的最佳实践
- NIST AI 600-1:人工智能风险管理框架——生成式人工智能配置文件
- :fr: ANSSI:生成式AI系统的安全建议
- PyRIT: 生成式AI的Python风险识别工具(PyRIT)是一个开放访问的自动化框架,旨在赋能安全专业人士和机器学习工程师主动发现其生成式AI系统中的风险。

- OWASP智能体AI: 致力于制定OWASP智能体AI十大安全风险(AI代理安全)。

- 迈向保证安全的AI:确保稳健可靠AI系统的框架
- 定义真正的AI风险
- 生成式AI的安全方法
- 大型语言模型在网络安全中的应用
- 嘿,那是我的模型!介绍Chain & Hash:一种LLM指纹识别技术
- 生成式AI的滥用:基于真实数据的战术分类与洞察
- AI风险库
- 重新审视AI红队
- 德法两国关于使用AI编程助手的建议
- 用于识别大型语言模型输出的可扩展水印技术
- 从100款生成式AI产品红队测试中汲取的经验教训
- LLM红队指南
- 多智能体安全领域的开放挑战:迈向安全的交互式AI代理系统
- LLM解锁了利用漏洞获利的新途径
- 揭露真相:利用CPU缓存侧信道从大型语言模型中泄露令牌
- 利用大型语言模型增强自动修复代码漏洞的能力
- 你的大脑在ChatGPT面前:使用AI助手完成论文写作任务时的认知债务累积
- AIRTBench:衡量语言模型中自主AI红队能力
- Slopsquatting
- SP 800-53控制叠加用于保护AI系统概念文件
- 双主体规则:AI代理安全的实用方法
- ETSI EN 304 223 V2.1.1 (2025-12):人工智能安全保障(SAI);AI模型和系统的基本网络安全要求
- 评估AGENTS.md:仓库级别的上下文文件对编码代理有帮助吗?
- 数字人脸操纵与检测手册
- 人工智能代理的安全考量
- 🚀 Awesome Reinforcement Learning for Cyber Security: 一个专注于强化学习在网络安全领域应用的资源精选列表。
📊 调查研究 📊
- 组织面临的攻击性人工智能威胁
- 网络空间中的人工智能:进攻与防御
- 对抗攻击与防御的综述
- 对抗深度学习:图像分类中的对抗攻击与防御机制综述
- 机器学习中的隐私攻击综述
- 迈向深度学习系统的安全威胁:综述
- 机器学习的安全威胁与防御技术综述:数据驱动视角
- SoK:机器学习中的安全与隐私
- 对抗机器学习:人工智能赋能犯罪的兴起及其在垃圾邮件过滤器规避中的作用
- 基于机器学习系统的威胁、漏洞与控制措施:综述与分类
- 对抗攻击与防御:综述
- 安全问题:对抗机器学习综述
- 用于恶意软件分析的对抗攻击综述
- 图像分类中的对抗机器学习:面向防御者的综述
- 模式识别中鲁棒对抗训练的综述:基础、理论与方法
- 大型语言模型中的隐私:攻击、防御及未来方向
🗣 维护者 🗣
 Miguel Hernández |
 José Ignacio Escribano |
©️ 许可证 ©️
![]()
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器