semantic-draw
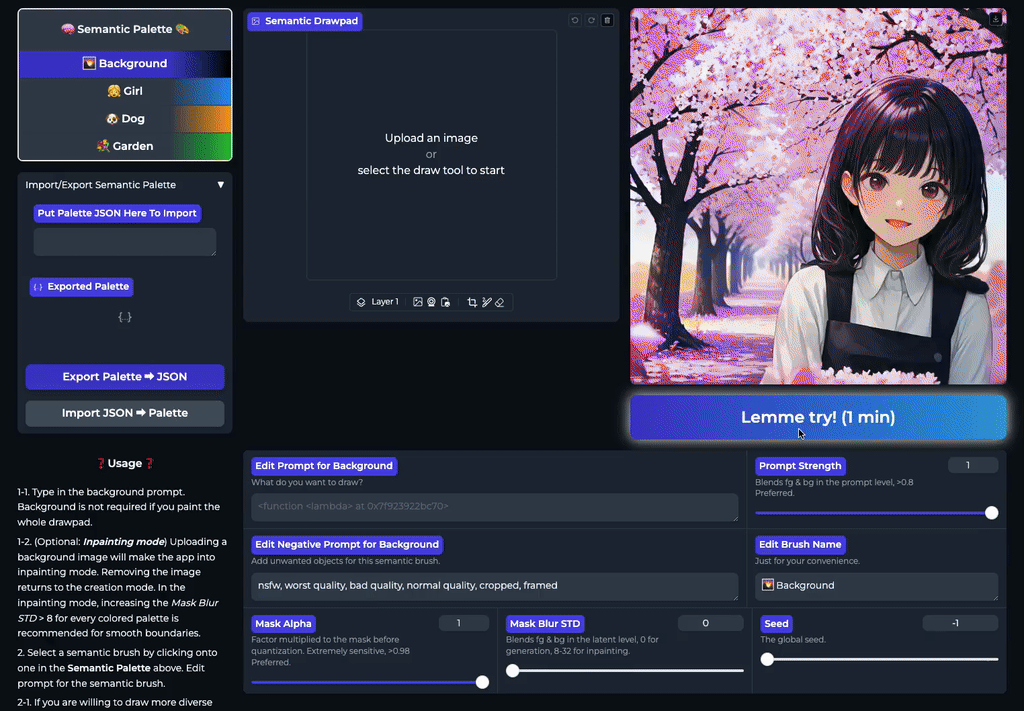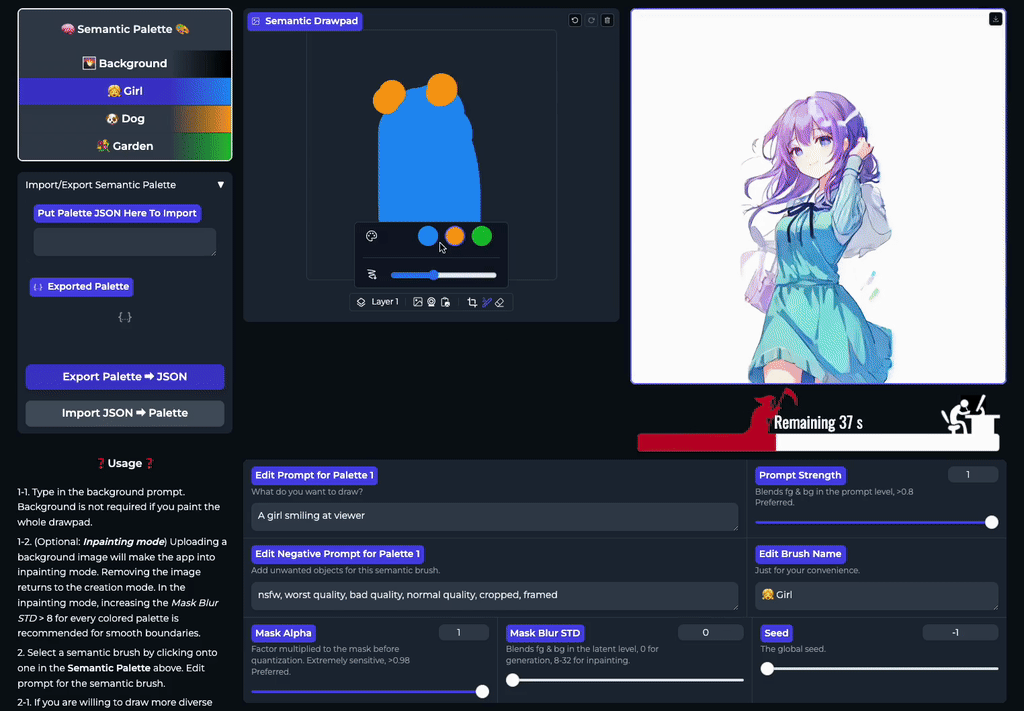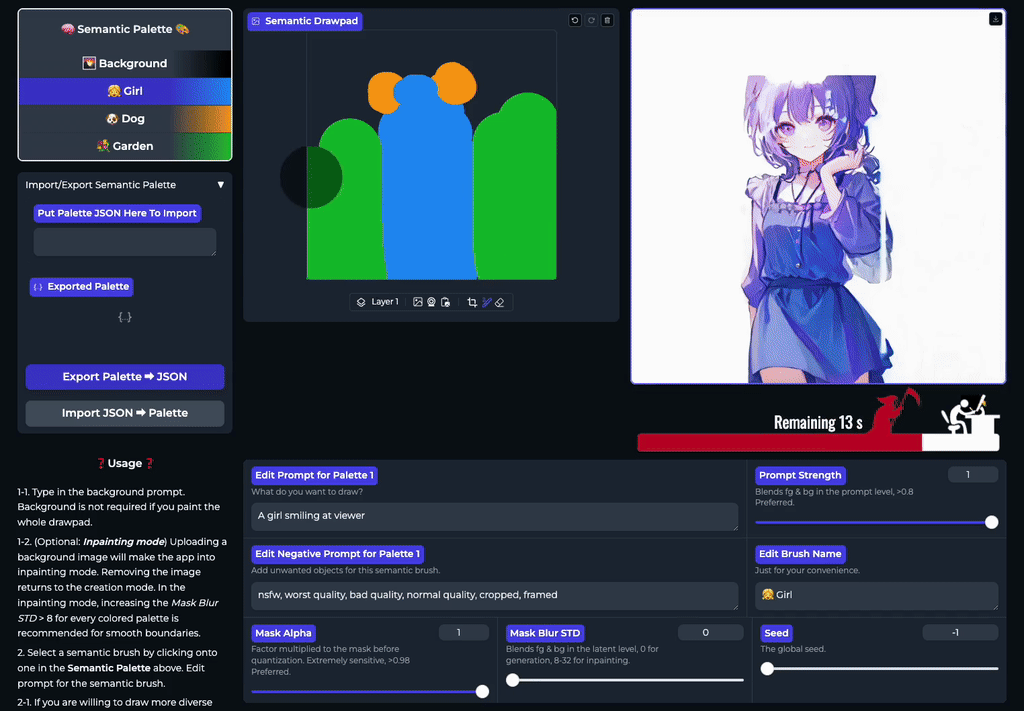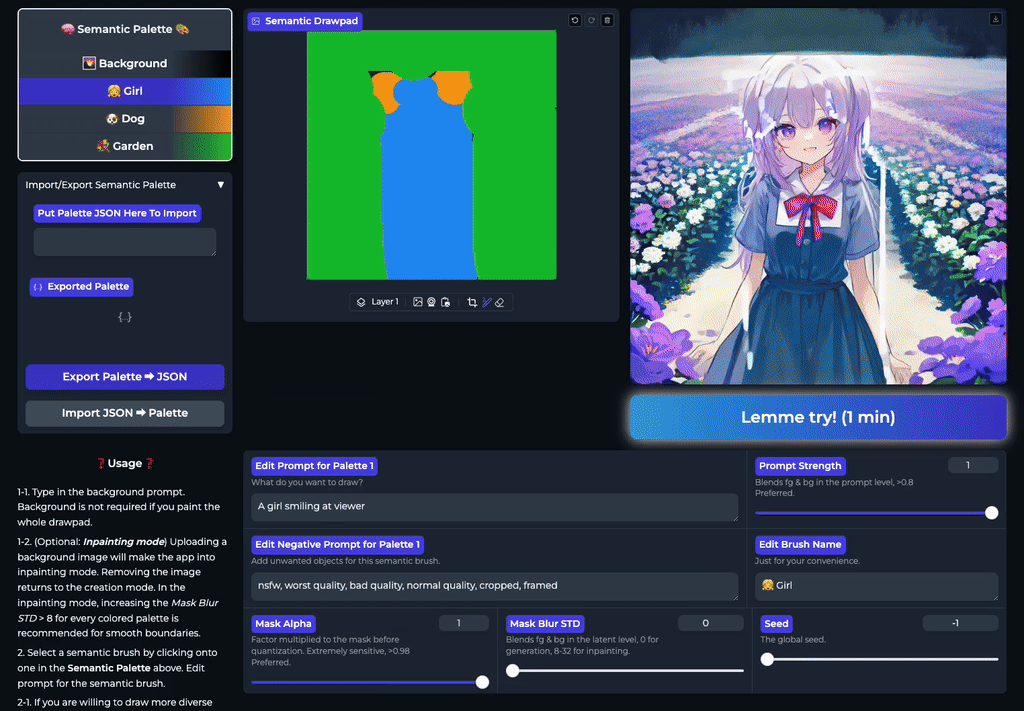
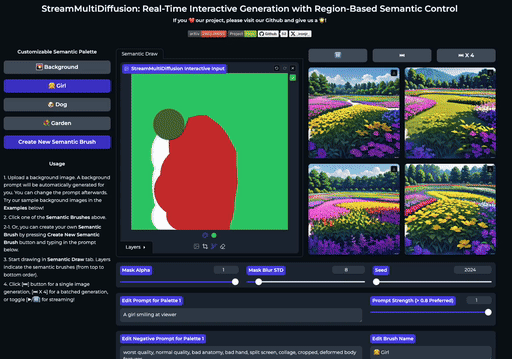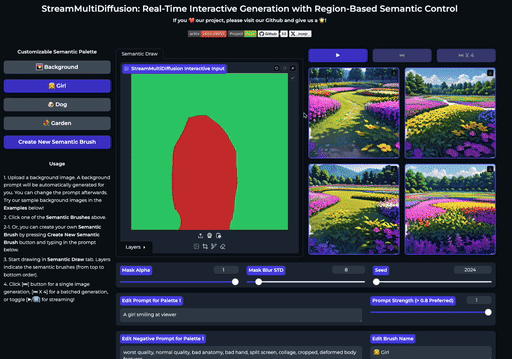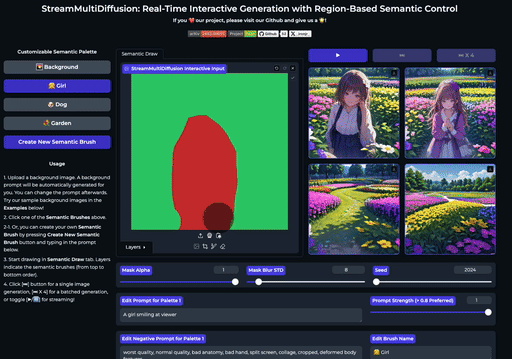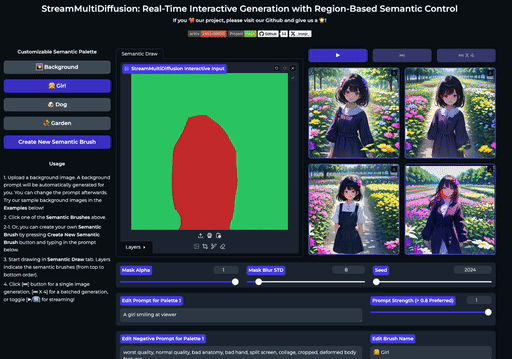
SemanticDraw 是一款源自 CVPR 2025 论文的开源框架,旨在实现基于图像扩散模型的实时交互式内容创作。它允许用户像画家一样,在画布上使用“语义画笔”直接绘制不同区域的蒙版,并为每个区域指定独立的文本提示词,从而精准控制生成内容的布局与细节。
传统文生图工具往往难以精确控制物体位置,或是在修改局部时影响整体画面。SemanticDraw 通过区域化的语义控制技术,有效解决了这一痛点:它不仅支持在大画布上自由绘制多个提示词区域,确保不同内容互不干扰,还能实现毫秒级的实时编辑反馈。用户每落下一笔,画面即刻更新,真正做到了“所见即所得”的流畅创作体验。
该工具特别适合需要精细构图控制的设计师、插画师,以及研究可控生成技术的开发者与科研人员。其技术亮点在于继承了前作 StreamMultiDiffusion 的流式生成优势,并进一步优化了交互延迟,同时兼容 Stable Diffusion 1.5、SDXL 乃至最新的 SD3 模型。无论是快速构思草图,还是进行复杂的场景合成,SemanticDraw 都能让创意不再受限于繁琐的参数调整,让绘画过程回归直观与自然。
使用场景
一位游戏概念设计师正在为新的奇幻场景快速绘制草图,需要在画布上灵活调整不同区域的元素(如天空、山脉、建筑),并实时查看生成效果以激发灵感。
没有 semantic-draw 时
- 迭代效率低下:每次修改局部内容(如把“森林”改成“沙漠”)都需要重新输入完整提示词并等待漫长的全图生成,打断创作心流。
- 区域控制困难:难以精确指定生成范围,常出现“想要山顶有雪,结果山脚也结冰”或不同语义区域内容相互渗透混合的情况。
- 交互体验割裂:无法像传统绘画软件那样“边画边看”,必须在“绘制蒙版 - 提交任务 - 等待结果 - 再次修改”的循环中反复切换,耗时费力。
- 创意验证缓慢:在头脑风暴阶段,因技术等待时间过长,导致大量瞬间的创意火花在未及可视化前就已流失。
使用 semantic-draw 后
- 实时流式生成:利用语义画笔在画布上涂抹的同时,图像即刻随笔触变化呈现,实现真正的“所画即所得”,创作过程流畅无中断。
- 精准语义隔离:通过独立的提示词 - 蒙版对控制不同区域,确保“左侧是火山”绝不会影响“右侧的海洋”,彻底杜绝内容混淆。
- 直观交互式编辑:支持在大画布上随意增删修改多个语义区域,像使用 Photoshop 图层一样自然,随时调整构图与细节。
- 即时创意反馈:设计师可在一分钟内尝试数十种场景组合方案,快速验证视觉构想,极大提升了概念设计的产出密度与质量。
semantic-draw 将原本滞后的文本生成图像过程转化为实时的交互式绘画体验,让创作者真正实现了用“语义”直接作画。
运行环境要求
- 未说明
- 必需 NVIDIA GPU
- 最低要求:8GB 显存(适用于 512x512 分辨率)
- 推荐:11GB 显存(适用于更高分辨率,已在 GTX 1080 Ti 上测试)
未说明
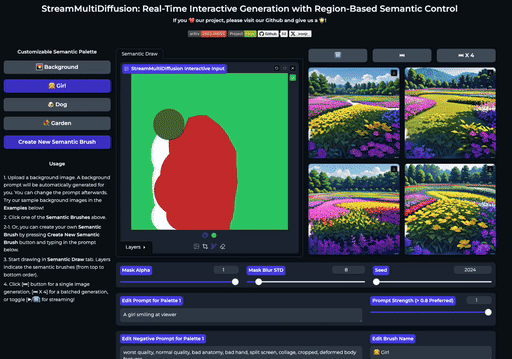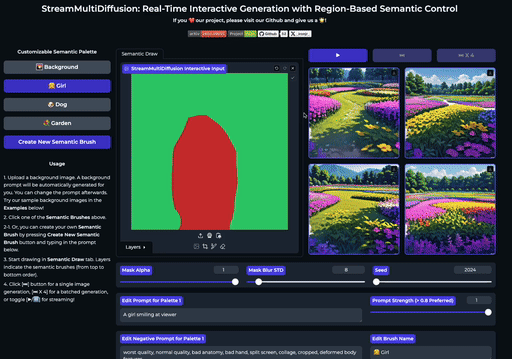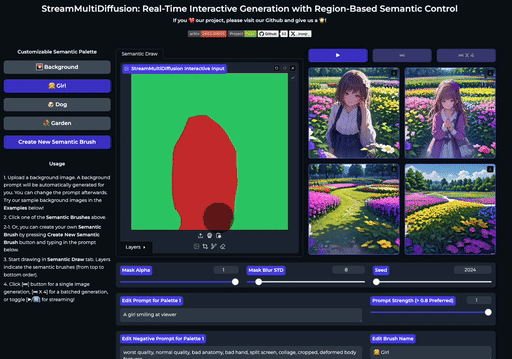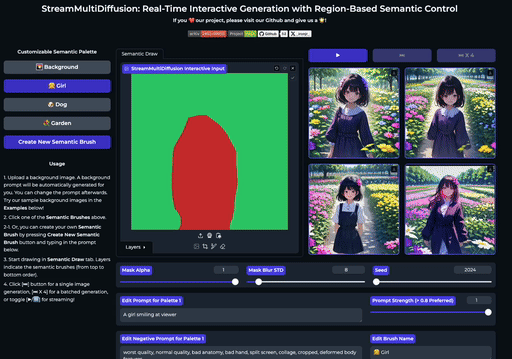
快速开始
SemanticDraw:基于图像扩散模型的实时交互式内容创作
CVPR 2025
此前曾发表过 StreamMultiDiffusion:基于区域语义控制的实时交互式生成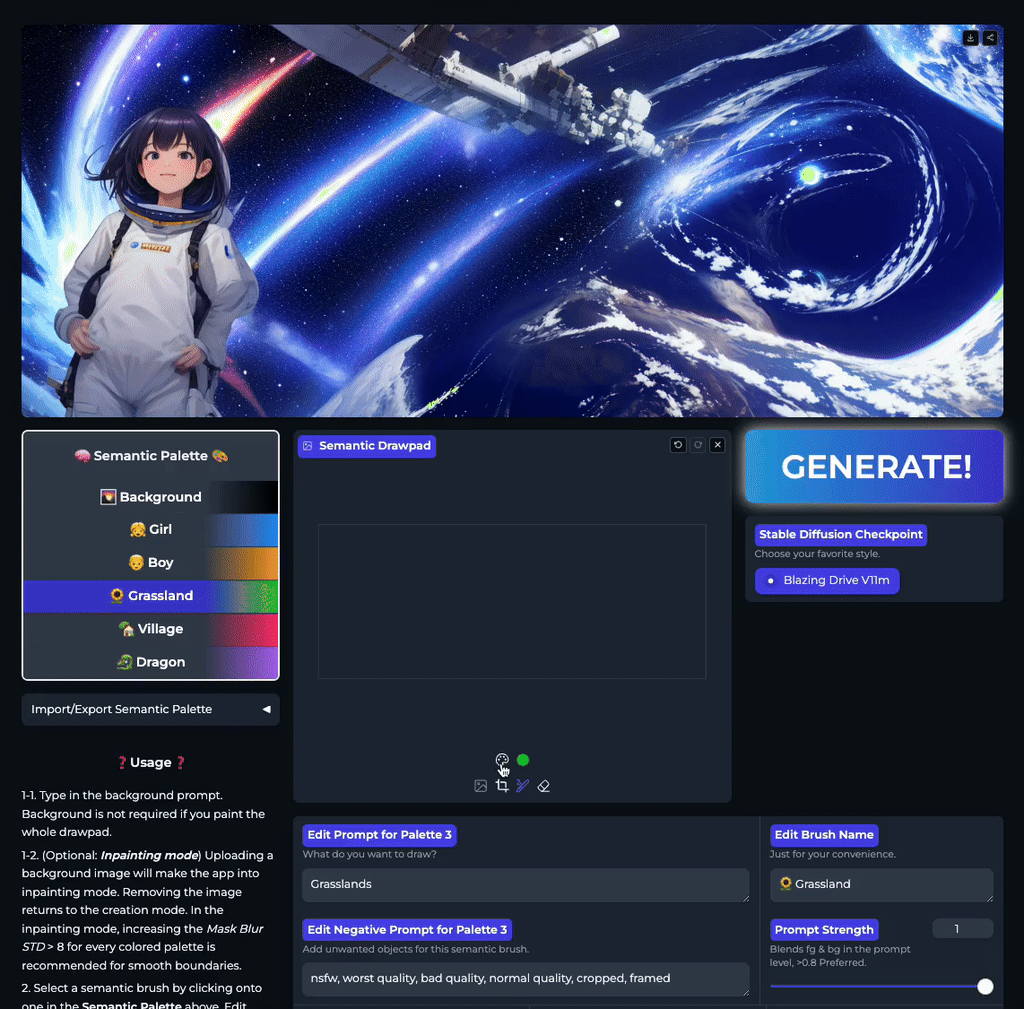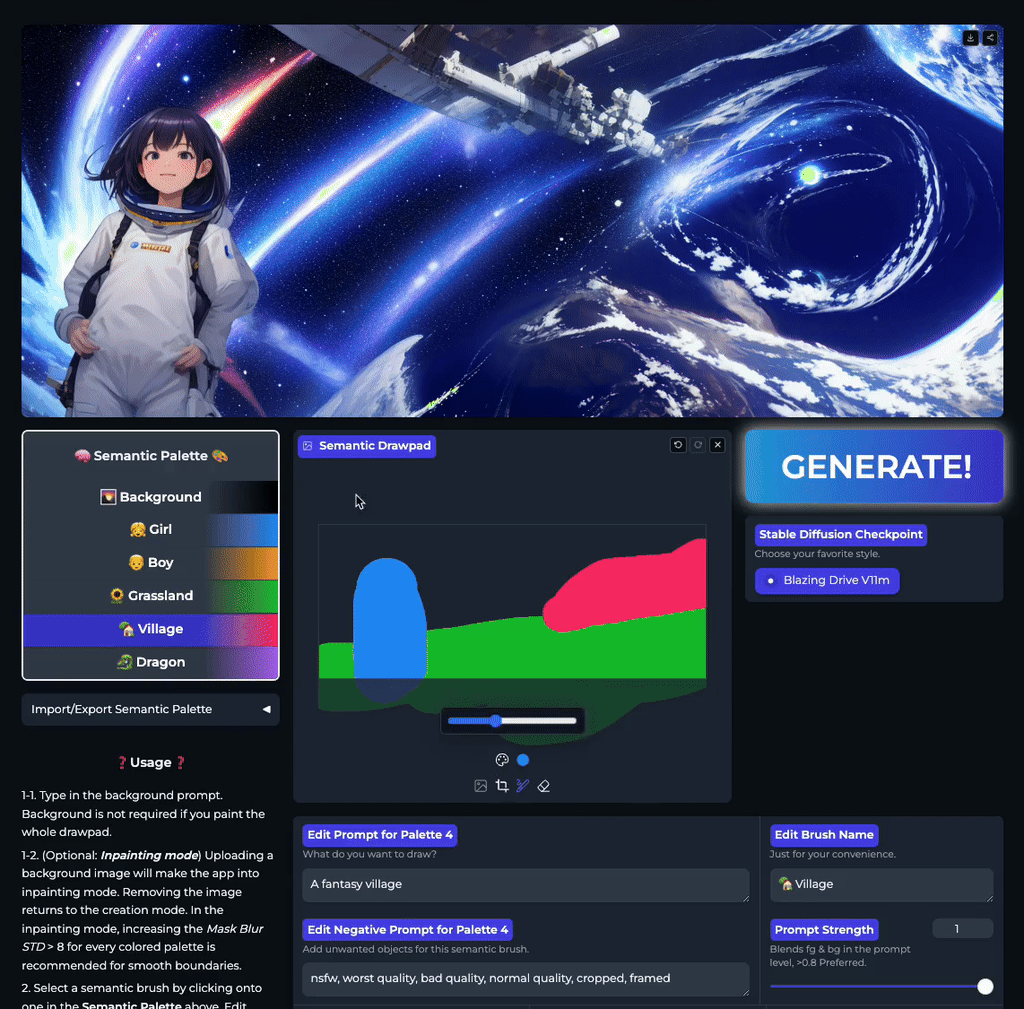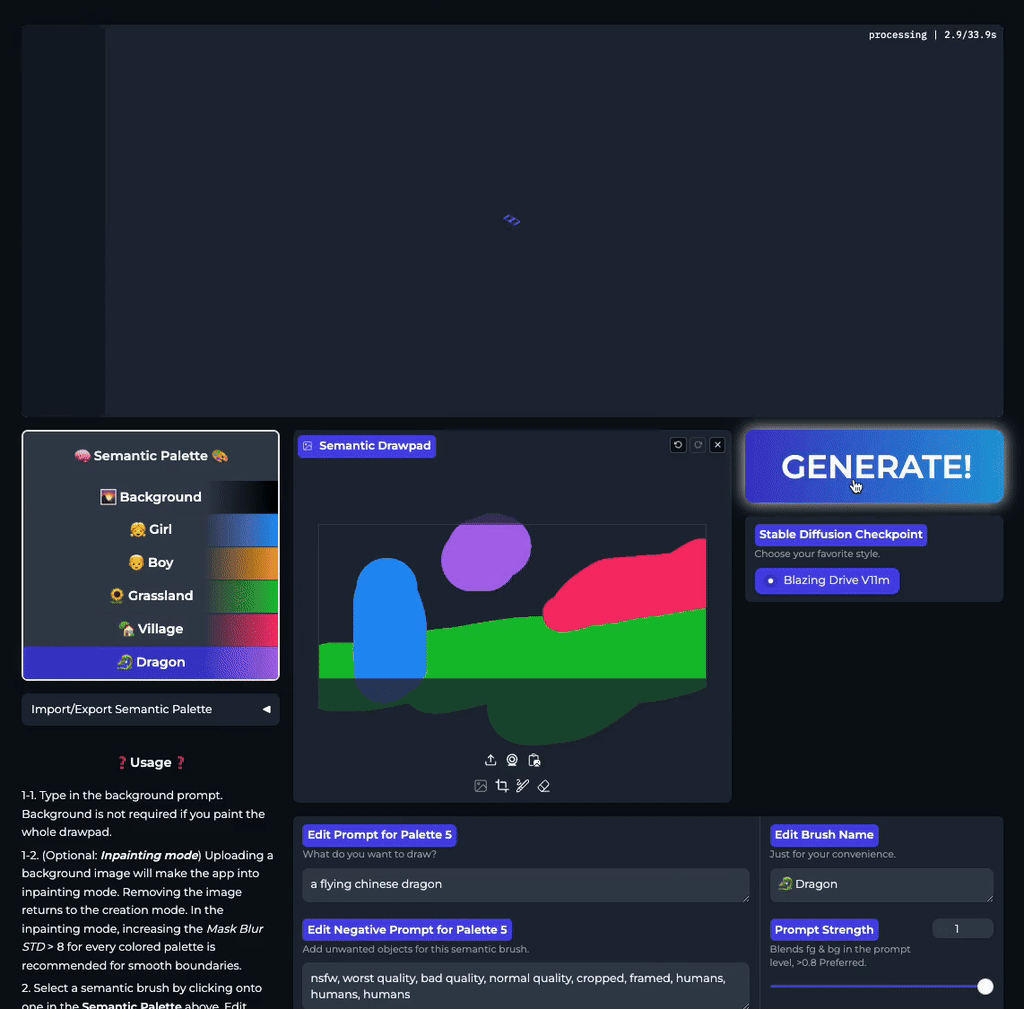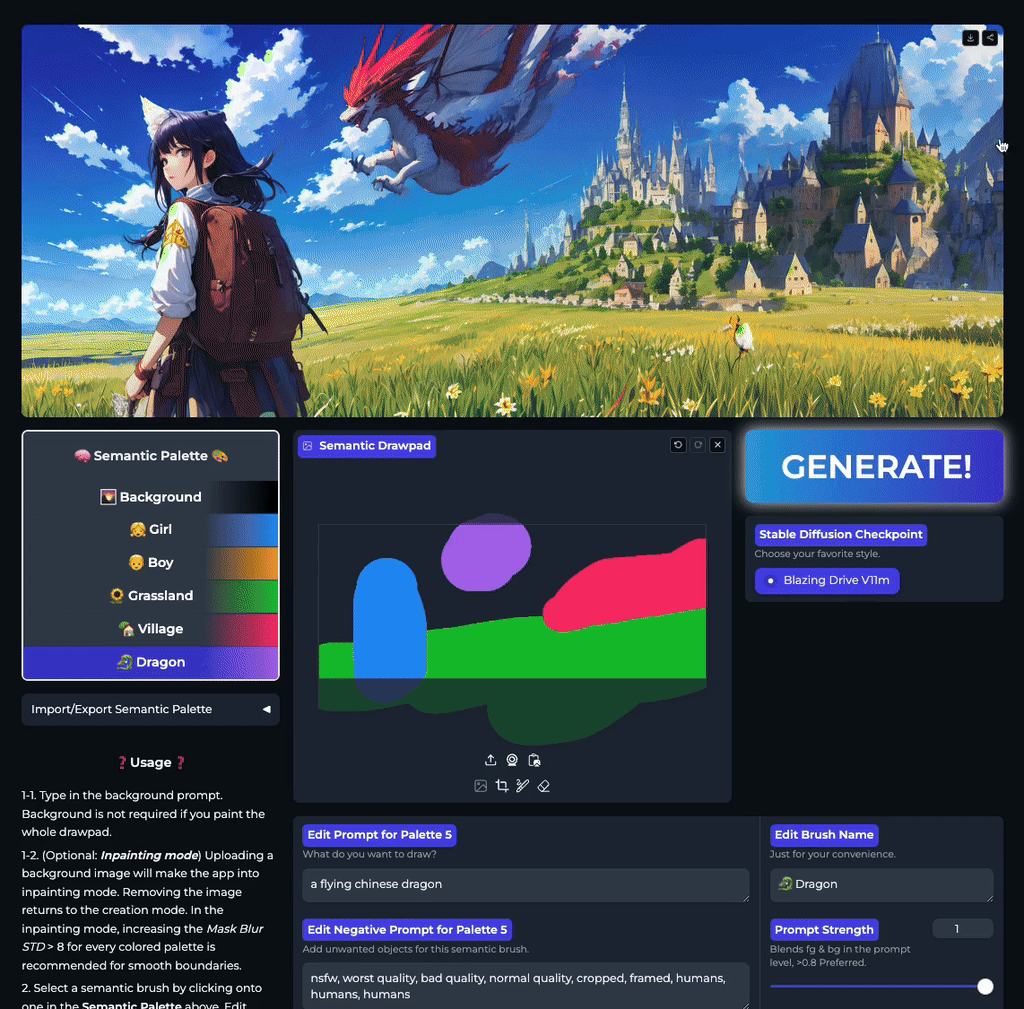 |
 |
|---|---|
| 在大画布上绘制多个提示掩码 | 实时创作 |
Jaerin Lee · Daniel Sungho Jung · Kanggeon Lee · Kyoung Mu Lee



![]()
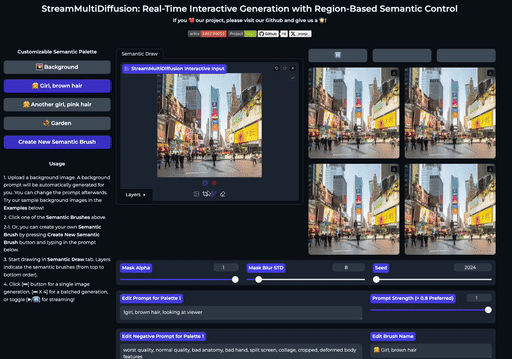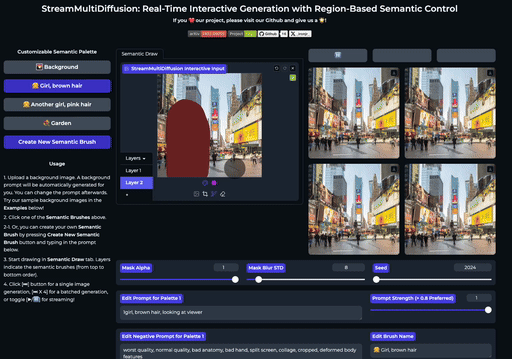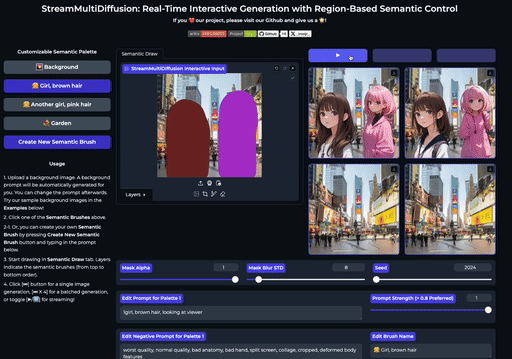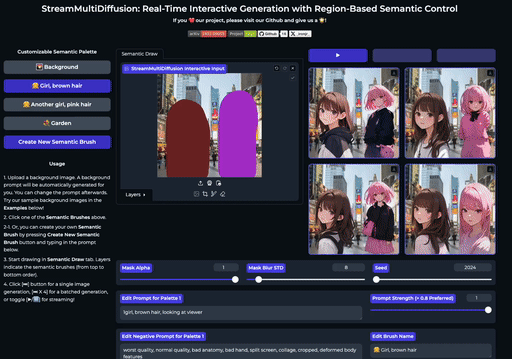
SemanticDraw 是一个实时交互式的文本到图像生成框架,它允许你使用语义画笔 🖌️ 来 带有意义地绘画 🧠。

🚀 快速入门
# 安装
conda create -n semdraw python=3.12 && conda activate semdraw
git clone https://github.com/ironjr/semantic-draw
cd semantic-draw
pip install -r requirements.txt
# 运行流式演示
cd demo/stream
python app.py --model "runwayml/stable-diffusion-v1-5" --port 8000
# 在浏览器中打开 http://localhost:8000
若要支持 SD3,还需额外运行:
pip install git+https://github.com/initml/diffusers.git@clement/feature/flash_sd3
注意:这已在 requirements.txt 中默认包含。
📚 目录
⭐ 功能
| 交互式绘图 | 提示分离 | 实时编辑 |
|---|---|---|
 |
 |
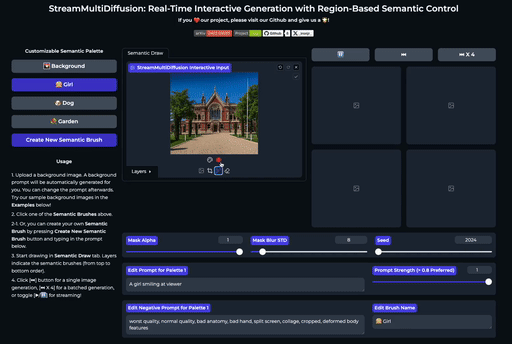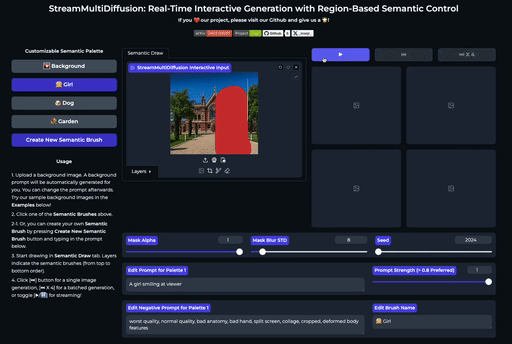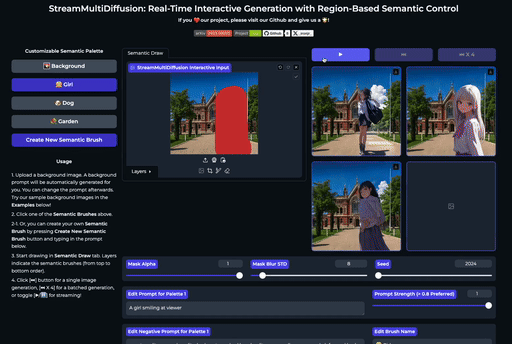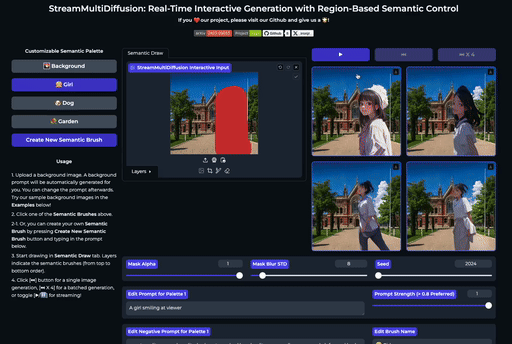 |
| 使用语义画笔作画 | 不混入无关内容 | 实时编辑图片 |
🔧 安装
基本安装
conda create -n smd python=3.12 && conda activate smd
git clone https://github.com/ironjr/StreamMultiDiffusion
cd StreamMultiDiffusion
pip install -r requirements.txt
支持 Stable Diffusion 3
pip install git+https://github.com/initml/diffusers.git@clement/feature/flash_sd3
🎨 演示应用
我们提供了几个具有不同功能和模型支持的演示应用:
1. StreamMultiDiffusion(主演示)
具备语义绘图能力的实时流媒体界面。
cd demo/stream
python app.py --model "your-model" --height 512 --width 512 --port 8000
选项
| 选项 | 描述 | 默认值 |
|---|---|---|
--model |
SD1.5 检查点路径(HF 或本地 .safetensors) | 无 |
--height |
画布高度 | 768 |
--width |
画布宽度 | 1920 |
--bootstrap_steps |
语义区域分离(建议 1–3 步) | 1 |
--seed |
随机种子 | 2024 |
--device |
GPU 设备编号 | 0 |
--port |
Web 服务器端口 | 8000 |
2. Semantic Palette
针对不同 SD 版本的简化界面:
SD 1.5 版本
cd demo/semantic_palette
python app.py --model "runwayml/stable-diffusion-v1-5" --port 8000
SDXL 版本
cd demo/semantic_palette_sdxl
python app.py --model "your-sdxl-model" --port 8000
SD3 版本
cd demo/semantic_palette_sd3
python app.py --port 8000
使用自定义模型 (.safetensors)
- 将你的
.safetensors文件放入演示的checkpoints文件夹 - 运行:
python app.py --model "your-model.safetensors"
💻 使用示例
Python API
基本生成
import torch
from model import StableMultiDiffusionPipeline
# 初始化
device = torch.device('cuda:0')
smd = StableMultiDiffusionPipeline(device, hf_key='runwayml/stable-diffusion-v1-5')
# 生成
image = smd.sample('多洛米蒂山脉的照片')
image.save('output.png')
基于区域的生成
import torch
from model import StableMultiDiffusionPipeline
from util import seed_everything
# 设置
seed_everything(2024)
device = torch.device('cuda:0')
smd = StableMultiDiffusionPipeline(device)
# 定义提示和掩码
prompts = ['背景:城市', '前景:一只猫', '前景:一只狗']
masks = load_masks() # 你的掩码加载逻辑
# 生成
image = smd(prompts, masks=masks, height=768, width=768)
image.save('output.png')
流式生成
from model import StreamMultiDiffusion
# 初始化流式管道
smd = StreamMultiDiffusion(device, height=512, width=512)
# 注册图层
smd.update_single_layer(idx=0, prompt='背景', mask=bg_mask)
smd.update_single_layer(idx=1, prompt='物体', mask=obj_mask)
# 流式生成
while True:
image = smd()
display(image)
Jupyter 笔记本
在我们的 notebooks 目录中探索交互式示例:
- 基本用法教程
- 高级区域控制
- SD3 示例
- 自定义模型集成
📖 文档
详细指南
论文
🙋 常见问题解答
什么是语义调色板?
语义调色板允许您使用文本提示而非颜色进行绘画。每支画笔都携带一个语义(提示),能够实时生成相应的内容。
支持哪些模型?
- ✅ Stable Diffusion 1.5 及其变体
- ✅ SDXL 及其变体(配合 Lightning LoRA)
- ✅ Stable Diffusion 3
- ✅ 自定义 .safetensors 检查点
硬件要求是什么?
- 最低配置:8GB 显存的 GPU(用于 512x512 分辨率)
- 推荐配置:11GB 显存的 GPU(用于更高分辨率)(已测试 1080 ti)。
🚩 最新更新
- 🔥 2025年6月:在 CVPR 2025 上发表
- ✅ 2024年6月:通过 Flash Diffusion 支持 SD3
- ✅ 2024年4月:StreamMultiDiffusion v2,配备响应式用户界面
- ✅ 2024年3月:通过 Lightning LoRA 支持 SDXL
- ✅ 2024年3月:发布首个版本
完整历史记录请参阅 README_old.md。
🌏 引用
@inproceedings{lee2025semanticdraw,
title="{SemanticDraw:} Towards Real-Time Interactive Content Creation from Image Diffusion Models",
author={Lee, Jaerin and Jung, Daniel Sungho and Lee, Kanggeon and Lee, Kyoung Mu},
booktitle={CVPR},
year={2025}
}
🤗 致谢
本项目基于 StreamDiffusion、MultiDiffusion 和 LCM 构建。特别感谢 Hugging Face 团队及各模型贡献者。
📧 联系方式
请发送邮件至 jarin.lee@gmail.com 或 提交 issue。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。