index-tts
IndexTTS2 是一款工业级的零样本语音合成系统,致力于生成自然且可控的人声。它主要解决了现有自回归大模型在语音合成中难以精确控制时长的问题,这一痛点曾严重制约视频配音等需要严格音画同步的应用场景。通过创新的时长控制机制,IndexTTS2 既能指定生成 token 数量以精准把控语音时长,也能自由生成并完美复现参考音频的韵律特征。
该工具的独特亮点在于实现了情感表达与说话人身份的解耦。用户可以在零样本设置下,独立控制音色与情感:既准确还原目标音色,又完美复刻指定的情绪基调。此外,项目引入了基于文本描述的软指令机制(经 Qwen3 微调),让用户仅通过文字描述即可轻松引导语音的情感走向,大幅降低了情感控制的门槛。结合三阶段训练范式,IndexTTS2 在高度情感化的表达中依然保持了极高的清晰度和稳定性。
IndexTTS2 非常适合需要高质量语音生成的开发者、研究人员以及内容创作者。无论是用于开发视频自动配音工具、构建交互式语音助手,还是进行多情感语音合成的学术研究,它都能提供超越当前主流模型的词错率、说话人相似度和情感保真度表现。
使用场景
某短视频制作团队正在为一款情感类纪录片进行多语种配音,需要确保不同语言版本的旁白在语速、情绪和口型上严格同步。
没有 index-tts 时
- 口型对不上:传统 TTS 模型无法精确控制语音时长,导致生成的音频与视频画面中人物的嘴部动作严重错位,后期需人工逐帧调整,耗时极长。
- 情绪表达僵硬:难以在复刻特定说话人音色的同时,精准注入“悲伤”或“激昂”等复杂情感,声音听起来像毫无感情的读稿机器。
- 音色一致性差:切换不同语种配音时,说话人的音色特征发生漂移,观众感觉像是换了一个人在说话,破坏了角色连贯性。
- 试错成本高:为了找到合适的语速和情感组合,往往需要反复生成数十个版本并人工筛选,严重拖慢项目交付进度。
使用 index-tts 后
- 精准时长控制:利用 index-tts 的显式令牌数量指定功能,直接生成与视频片段毫秒级同步的音频,彻底解决了口型不同步的难题。
- 情感与音色解耦:通过独立的风格提示词,index-tts 能在完美保留原说话人音色的基础上,生动还原剧本要求的细腻情感,表现力大幅提升。
- 零样本跨语种复用:仅需一段参考音频,index-tts 即可在零样本设置下让同一“声音”流畅演绎多种语言,确保了多语种版本的角色统一性。
- 文本指令引导:借助基于 Qwen3 微调的软指令机制,制作人员只需输入“带着哽咽的语气”等自然语言描述,即可一次性生成高质量音频,无需反复试错。
index-tts 通过工业级的时长控制与情感解耦能力,将视频配音从繁琐的“手工修补”转变为高效的“精准生成”,极大提升了多媒体内容的生产质量与效率。
运行环境要求
- Linux
- Windows
- 需要 NVIDIA GPU,需安装 CUDA Toolkit 12.8 或更高版本以支持加速
- 支持 FP16 推理以降低显存占用(具体显存大小未说明,建议使用较大显存显卡)
未说明

快速开始

仓库历史已重置。请删除本地副本并重新克隆。
(仓库历史已重置。请删除本地副本并重新克隆。)
👉🏻 IndexTTS2 👈🏻
IndexTTS2:情感丰富且时长可控的自回归零样本文本转语音技术突破

摘要
现有的自回归大规模文本转语音(TTS)模型在语音自然度方面具有优势,但其逐字处理的生成机制使得精确控制合成语音的时长变得困难。这在需要严格音画同步的应用场景中,例如视频配音,成为显著的限制。
本文介绍了IndexTTS2,提出了一种新颖、通用且与自回归模型兼容的语音时长控制方法。
该方法支持两种生成模式:一种明确指定生成的音素数量以精确控制语音时长;另一种则无需指定音素数量,以自回归方式自由生成语音,同时忠实再现输入提示中的韵律特征。
此外,IndexTTS2实现了情感表达与说话人身份的解耦,从而能够独立控制音色和情感。在零样本场景下,模型可以准确地重建目标音色(来自音色提示),同时完美还原指定的情感基调(来自风格提示)。
为提升高度情感化表达下的语音清晰度,我们引入了GPT潜在表征,并设计了一种全新的三阶段训练范式,以增强生成语音的稳定性。另外,为了降低情感控制的门槛,我们基于通义千问的微调,设计了一套基于文本描述的软指令机制,有效引导生成符合预期情感倾向的语音。
最后,多组实验结果表明,IndexTTS2在词错误率、说话人相似度以及情感保真度等方面均优于当前最先进的零样本TTS模型。音频示例可在以下链接查看:IndexTTS2演示页。
提示:如需更详细的信息,请联系作者。商业使用及合作事宜,请发送邮件至indexspeech@bilibili.com。
感受IndexTTS2
IndexTTS2:语音的未来,现已生成

点击图片观看IndexTTS2介绍视频。
联系方式
QQ群:663272642(No.4) 1013410623(No.5)
Discord:https://discord.gg/uT32E7KDmy
邮箱:indexspeech@bilibili.com
欢迎大家加入我们的社区! 🌏
欢迎大家来交流讨论!
[!CAUTION] 感谢您对bilibili indextts项目的大力支持! 请注意,核心团队维护的唯一官方渠道是:https://github.com/index-tts/index-tts。 其他任何网站或服务均非官方,我们无法保证其安全性、准确性或及时性。 如需最新动态,请务必参考此官方仓库。
📣 更新
2025/09/08🔥🔥🔥 我们向全球发布IndexTTS-2!- 首个具备精确合成时长控制功能的自回归TTS模型,支持可控与不可控两种模式。本次发布尚未启用该功能。
- 该模型实现了高度情感化的语音合成,并通过多种输入模态实现了情感可控能力。
2025/05/14🔥🔥 我们发布了IndexTTS-1.5,显著提升了模型的稳定性和英语表现。2025/03/25🔥 我们发布了包含模型权重和推理代码的IndexTTS-1.0。2025/02/12🔥 我们将论文提交至arXiv,并公开了演示和测试数据集。
🖥️ 神经网络架构
我们最先进语音模型——IndexTTS2的架构概览:
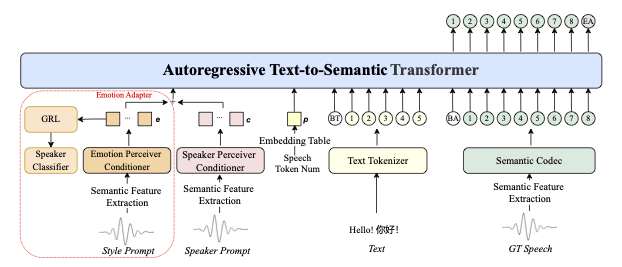
IndexTTS2的主要贡献总结如下:
- 我们提出了一种适用于自回归TTS模型的时长适配方案。IndexTTS2是首个将精确时长控制与自然时长生成相结合的自回归零样本TTS模型,且该方法可扩展应用于任何自回归大规模TTS模型。
- 将情感和说话人相关特征从输入提示中解耦,并设计了一种特征融合策略,以在情感丰富的表达中保持语义流畅和发音清晰。此外,我们还开发了一款利用自然语言描述进行情感控制的工具,方便用户操作。
- 针对缺乏高度情感化语音数据的问题,我们提出了一种有效的训练策略,显著提升了零样本TTS的情感表现力,达到当前最先进水平(SOTA)。
- 我们将公开代码和预训练权重,以促进未来的研究和实际应用。
模型下载
| HuggingFace | ModelScope |
|---|---|
| 😁 IndexTTS-2 | IndexTTS-2 |
| IndexTTS-1.5 | IndexTTS-1.5 |
| IndexTTS | IndexTTS |
使用说明
⚙️ 环境设置
同时,还需在当前用户账户中启用 Git-LFS 插件:
git lfs install
- 克隆本仓库:
git clone https://github.com/index-tts/index-tts.git && cd index-tts
git lfs pull # 下载大型文件
- 安装 uv 包管理器。 这是构建可靠、现代化开发环境的必要条件。
[!TIP] 快速简便的安装方法:
您可以通过多种方式在本地安装
uv命令行工具。请参阅上方链接以获取所有选项。或者,如果您希望采用更快速简便的方式,可以直接运行:pip install -U uv
[!WARNING] 我们仅支持使用
uv进行安装。其他工具如conda或pip并不能保证正确安装所需的依赖版本。如果不使用uv,您几乎肯定会遇到随机性错误、报错信息、缺失 GPU 加速以及其他各种问题。因此,请勿就非标准安装方式提出任何问题,因为这些问题大多属于无效范畴。
此外,uv 的安装速度比 pip 快达 115 倍(参考:BENCHMARKS.md),这也是选择这一行业新标准来管理 Python 项目的一大理由。
- 安装所需依赖:
我们使用 uv 来管理项目的依赖环境。以下命令将自动创建一个 .venv 目录,并安装正确版本的 Python 及所有必需的依赖项:
uv sync --all-extras
如果下载速度较慢,可以尝试使用国内镜像源,例如以下任一中国镜像:
uv sync --all-extras --default-index "https://mirrors.aliyun.com/pypi/simple"
uv sync --all-extras --default-index "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple"
[!TIP] 可选附加功能:
--all-extras:自动启用下方列出的所有附加功能。若需自定义安装内容,可移除该参数。--extra webui:添加 WebUI 支持(推荐)。--extra deepspeed:添加 DeepSpeed 支持(可能加速部分系统的推理过程)。
[!IMPORTANT] Windows 用户注意: 对于部分 Windows 用户而言,DeepSpeed 库的安装可能存在困难。您可以移除
--all-extras参数以跳过该组件。若仍希望启用其他附加功能,则可单独添加相应的标志。
Linux/Windows 用户注意: 如果在安装过程中出现关于 CUDA 的错误,请确保已在系统上安装 NVIDIA 的 CUDA Toolkit,且版本为 12.8 或更高。
- 通过
uv tool下载所需模型:
使用 huggingface-cli 下载:
uv tool install "huggingface-hub[cli,hf_xet]"
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
或使用 modelscope 下载:
uv tool install "modelscope"
modelscope download --model IndexTeam/IndexTTS-2 --local_dir checkpoints
[!IMPORTANT] 若上述命令无法执行,请仔细阅读
uv tool的输出信息。它会指导您如何将这些工具添加到系统路径中。
[!NOTE] 除了上述模型外,首次运行项目时还会自动下载一些小型模型。如果您的网络访问 HuggingFace 较为缓慢,建议在运行代码前先执行以下命令:
export HF_ENDPOINT="https://hf-mirror.com"
🖥️ 检查 PyTorch GPU 加速状态
若需诊断当前环境并查看已检测到的 GPU 设备,可使用我们提供的工具进行检查:
uv run tools/gpu_check.py
🔥 IndexTTS2 快速入门
🌐 网页演示
uv run webui.py
打开浏览器并访问 http://127.0.0.1:7860 即可查看演示。
你还可以调整设置,启用诸如 FP16 推理(降低显存占用)、DeepSpeed 加速、编译后的 CUDA 内核以提升速度等功能。所有可用选项可通过以下命令查看:
uv run webui.py -h
祝你玩得开心!
[!重要提示] 使用 FP16(半精度)推理会非常有帮助。它不仅速度更快,还能减少显存占用,且对音质的影响极小。
DeepSpeed 可能会在某些系统上加速推理,但也可能导致速度变慢。其性能影响高度依赖于你的具体硬件、驱动程序和操作系统。请尝试开启和关闭 DeepSpeed,以确定哪种方式在你的设备上效果最佳。
最后,请注意,所有
uv命令都会 自动激活 项目所需的正确虚拟环境。在运行uv命令之前,请勿手动激活任何虚拟环境,否则可能会导致依赖冲突!
📝 在 Python 中使用 IndexTTS2
要运行脚本,必须使用 uv run <file.py> 命令,以确保代码在当前的 “uv” 环境中执行。有时,你还需要将当前目录添加到 PYTHONPATH 中,以便找到 IndexTTS 模块。
通过 uv 运行脚本的示例:
PYTHONPATH="$PYTHONPATH:." uv run indextts/infer_v2.py
以下是几种在自定义脚本中使用 IndexTTS2 的示例:
- 使用单个参考音频文件合成新语音(语音克隆):
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(cfg_path="checkpoints/config.yaml", model_dir="checkpoints", use_fp16=False, use_cuda_kernel=False, use_deepspeed=False)
text = "Translate for me, what is a surprise!"
tts.infer(spk_audio_prompt='examples/voice_01.wav', text=text, output_path="gen.wav", verbose=True)
- 使用单独的情感参考音频文件来调节语音合成:
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(cfg_path="checkpoints/config.yaml", model_dir="checkpoints", use_fp16=False, use_cuda_kernel=False, use_deepspeed=False)
text = "酒楼丧尽天良,开始借机竞拍房间,哎,一群蠢货。"
tts.infer(spk_audio_prompt='examples/voice_07.wav', text=text, output_path="gen.wav", emo_audio_prompt="examples/emo_sad.wav", verbose=True)
- 当指定了情感参考音频时,你可以选择性地设置
emo_alpha来调整其对输出的影响程度。有效范围为0.0 - 1.0,默认值为1.0(100%):
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(cfg_path="checkpoints/config.yaml", model_dir="checkpoints", use_fp16=False, use_cuda_kernel=False, use_deepspeed=False)
text = "酒楼丧尽天良,开始借机竞拍房间,哎,一群蠢货。"
tts.infer(spk_audio_prompt='examples/voice_07.wav', text=text, output_path="gen.wav", emo_audio_prompt="examples/emo_sad.wav", emo_alpha=0.9, verbose=True)
- 也可以不提供情感参考音频,而是直接给出一个包含 8 个浮点数的列表,按顺序指定每种情感的强度:
[happy, angry, sad, afraid, disgusted, melancholic, surprised, calm]。此外,你还可以使用use_random参数来引入随机性;默认值为False,将其设置为True则会启用随机性:
[!注释] 启用随机采样会降低语音合成的克隆保真度。
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(cfg_path="checkpoints/config.yaml", model_dir="checkpoints", use_fp16=False, use_cuda_kernel=False, use_deepspeed=False)
text = "对不起嘛!我的记性真的不太好,但是和你在一起的事情,我都会努力记住的~"
tts.infer(spk_audio_prompt='examples/09.wav', text=text,output_path="gen.wav", emo_vector=[0, 0, 0.8, 0, 0, 0, 0, 0], use_random=False,verbose=True)
- 或者,你可以启用
use_emo_text,根据你提供的文本内容来引导情感。此时,文本将自动转换为情感向量。建议在使用文本情感模式时,将emo_alpha设置为 0.6 左右(或更低),以获得更自然的语音效果。你还可以通过use_random引入随机性(默认为False;设置为True则启用随机性):
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(cfg_path="checkpoints/config.yaml", model_dir="checkpoints", use_fp16=False,use_cuda_kernel=False,use_deepspeed=False)
text = "快躲起来!是他要来了!他要来抓我们了!"
tts.infer(spk_audio_prompt='examples/voice_12.wav', text=text,output_path="gen.wav”,emo_alpha=0.6,use_emo_text=True,use_random=False,verbose=True)
- 你也可以直接通过
emo_text参数提供特定的情感描述。系统会自动将该描述转换为情感向量,从而实现对文本内容和情感描述的独立控制:
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(cfg_path="checkpoints/config.yaml", model_dir="checkpoints", use_fp16=False,use_cuda_kernel=False,use_deepspeed=False)
text = "快躲起来!是他要来了!他要来抓我们了!"
emo_text = "你吓死我了!你是鬼吗?"
tts.infer(spk_audio_prompt='examples/voice_12.wav', text=text,output_path="gen.wav”,emo_alpha=0.6,use_emo_text=True,emo_text=emo_text,use_random=False,verbose=True)
[!提示] 拼音使用说明:
IndexTTS2 仍然支持汉字与拼音的混合建模。当你需要精确控制发音时,请提供带有具体拼音标注的文本,以激活拼音控制功能。请注意,拼音控制并非适用于所有辅音—元音组合;仅支持有效的中文拼音情况。完整支持的条目列表请参阅
checkpoints/pinyin.vocab。示例:
之前你做DE5很好,所以这一次也DEI3做DE2很好才XING2,如果这次目标完成得不错的话,我们就直接打DI1去银行取钱。
旧版:IndexTTS1 使用指南
你也可以通过导入不同的模块来使用我们之前的 IndexTTS1 模型:
from indextts.infer import IndexTTS
tts = IndexTTS(model_dir="checkpoints",cfg_path="checkpoints/config.yaml")
voice = "examples/voice_07.wav"
text = "大家好,我现在正在bilibili 体验 ai 科技,说实话,来之前我绝对想不到!AI技术已经发展到这样匪夷所思的地步了!比如说,现在正在说话的其实是B站为我现场复刻的数字分身,简直就是平行宇宙的另一个我了。如果大家也想体验更多深入的AIGC功能,可以访问 bilibili studio,相信我,你们也会吃惊的。"
tts.infer(voice, text, 'gen.wav')
如需更多信息,请参阅 README_INDEXTTS_1_5,或访问 IndexTTS1 仓库:index-tts:v1.5.0。
我们的发布与演示
IndexTTS2:[论文];[演示];[ModelScope];[HuggingFace]
IndexTTS1:[论文];[演示];[ModelScope];[HuggingFace]
致谢
Bilibili 的贡献者
我们衷心感谢 Bilibili 各个岗位的同事们,正是大家的共同努力才使得 IndexTTS 系列得以实现。
核心作者
- Wei Deng - 核心作者;发起并主导了 IndexTTS 项目,负责 IndexTTS1 数据流水线、模型架构设计与训练,以及 IndexTTS 系列模型的迭代优化工作,专注于基础能力构建与性能提升。
- Siyi Zhou – 核心作者;在 IndexTTS2 中,主导了模型架构设计与训练流水线优化,重点聚焦多语言及情感合成等核心功能。
- Jingchen Shu - 核心作者;参与整体架构设计、跨语言建模方案及训练策略优化,推动模型迭代。
- Xun Zhou - 核心作者;负责跨语言数据处理与实验,探索多语言训练策略,并为音频质量提升及稳定性评估作出贡献。
- Jinchao Wang - 核心作者;从事模型开发与部署工作,搭建推理框架并支持系统集成。
- Yiquan Zhou - 核心作者;参与模型实验与验证,并提出和实现了基于文本的情感控制方法。
- Yi He - 核心作者;参与模型实验与验证工作。
- Lu Wang – 核心作者;负责数据处理与模型评估,支持模型训练与性能验证。
技术支持人员
- Yining Wang - 支持性贡献者;参与开源代码的实现与维护,支持功能适配与社区发布。
- Yong Wu - 支持性贡献者;负责数据处理与实验支持,确保模型训练与迭代所需的数据质量和效率。
- Yaqin Huang – 支持性贡献者;参与系统的模型评估与效果跟踪,提供反馈以支持迭代改进。
- Yunhan Xu – 支持性贡献者;在录音与数据采集方面提供指导,同时从产品与运营角度提出反馈,以提升易用性和实际应用价值。
- Yuelang Sun – 支持性贡献者;在音频录制与数据采集方面提供专业支持,确保用于模型训练与评估的高质量数据。
- Yihuang Liang - 支持性贡献者;负责系统的模型评估与项目推广,帮助 IndexTTS 扩大影响力与用户参与度。
技术指导
- Huyang Sun - 为 IndexTTS 项目提供了强有力的支持,确保战略方向一致及资源保障。
- Bin Xia - 参与技术方案的评审、优化及后续跟进工作,重点关注模型的有效性。
📚 引用
🌟 如果您觉得我们的工作有所帮助,请为我们点亮星标并引用我们的论文。
IndexTTS2:
@article{zhou2025indextts2,
title={IndexTTS2:一种突破性的情感丰富且时长可控的自回归零样本文语转换系统},
author={Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, Jingchen Shu},
journal={arXiv 预印本 arXiv:2506.21619},
year={2025}
}
IndexTTS:
@article{deng2025indextts,
title={IndexTTS:一个工业级可控且高效的零样本文语转换系统},
author={Wei Deng, Siyi Zhou, Jingchen Shu, Jinchao Wang, Lu Wang},
journal={arXiv 预印本 arXiv:2502.05512},
year={2025},
doi={10.48550/arXiv.2502.05512},
url={https://arxiv.org/abs/2502.05512}
}
版本历史
v1.5.02025/09/01常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。