hagrid
HaGRID 是一个专为手势识别系统打造的大规模开源图像数据集。它旨在解决现有数据在多样性、场景覆盖及动态手势识别能力上的不足,为开发视频会议、智能家居控制及车载交互等应用提供坚实的数据基础。
该数据集非常适合计算机视觉领域的研究人员、算法工程师及开发者使用。其核心亮点在于庞大的规模与丰富的内容:HaGRIDv2 版本包含超过 108 万张全高清 RGB 图像,涵盖 33 种手势类别及独特的“无手势”自然姿态类。数据源自近 6.6 万名不同受试者,覆盖了多变的室内光照、极端逆光环境以及 0.5 至 4 米的拍摄距离,极大地提升了模型的泛化能力。
此外,项目团队还发布了一种创新的动态手势识别算法。该算法的独特之处在于仅使用静态图像训练,却能有效识别动态手势,打破了传统方法对视频序列数据的依赖。配合官方提供的预训练模型和详细的划分策略(按用户 ID 区分训练、验证与测试集),HaGRID 能帮助开发者高效构建高精度、实时的手势交互系统。
使用场景
某智能会议软件团队正在开发一款无需触控的“手势静音/举手”功能,旨在让用户在视频会议中通过简单挥手即可控制麦克风状态。
没有 hagrid 时
- 数据多样性严重不足:团队自行采集的数据仅覆盖少数人和单一光照环境,导致模型在用户背光或距离摄像头较远(如 2 米外)时完全失效。
- 误触率极高:缺乏自然的“无手势”样本训练,模型常将用户托腮、整理头发等日常动作误判为控制指令,频繁意外静音。
- 动态识别开发受阻:团队难以获取足够标注数据来训练动态手势算法,只能依赖昂贵的静态图像堆叠,导致手势响应延迟高、不流畅。
- 泛化能力差:由于训练集中人物种族和手部形态单一,系统对不同肤色或手型的用户识别准确率波动巨大,引发公平性质疑。
使用 hagrid 后
- 全场景鲁棒性提升:利用 hagrid 中 108 万张涵盖 6.5 万人、多种光照及 0.5-4 米距离的 FullHD 图像,模型在极端背光和远距离下依然保持高精度识别。
- 精准过滤无效动作:引入 hagrid 特有的"no_gesture"类别(含 20 多万自然手部姿态样本),有效区分控制手势与日常动作,误触率降低 90%。
- 实现实时动态交互:基于 hagrid 训练的专用算法,仅需静态图像数据即可实现流畅的动态手势识别,让用户挥手操作如原生般丝滑。
- 全球用户无缝适配:得益于数据集包含的多样化人种和独特场景,系统上线即具备强大的泛化能力,无需针对不同地区用户单独调优。
hagrid 凭借海量高质量标注数据和创新的动态识别算法,将原本需数月打磨的手势交互功能缩短至数周落地,并显著提升了用户体验的稳定性与包容性。
运行环境要求
- 未说明
未明确说明具体型号,但提供 YOLOv10x 等深度学习模型及多 GPU 训练支持,隐含需要 NVIDIA GPU 以进行高效训练和推理
未说明(鉴于数据集高达 1.5TB 且包含百万级 FullHD 图像,建议大容量内存)

快速开始
HaGRID - 手势识别图像数据集

我们推出了一套大型图像数据集 HaGRIDv2(HAnd Gesture Recognition Image Dataset),用于手势识别(HGR)系统。您可以将其用于图像分类或目标检测任务。该数据集有助于构建可在视频会议服务(Zoom、Skype、Discord、Jazz 等)、智能家居系统、汽车行业等领域应用的手势识别系统。此外,我们还发布了一种动态手势识别算法,并在论文中进行了详细描述。该模型完全基于 HaGRIDv2 训练而成,能够在仅使用静态手势训练的情况下实现动态手势的识别。您可以在我们的 仓库 中找到相关代码。
HaGRIDv2 的总大小为 1.5TB,包含 1,086,158 张 FullHD 分辨率的 RGB 图像,分为 33 个手势类别,以及一个全新的“no_gesture”类别,其中包含了特定领域的自然手部姿态。此外,部分图像也标注为“no_gesture”,当画面中存在另一只未做手势的手时即归入此类。这一额外类别共包含 2,164 个样本。数据按用户 user_id 进行划分,训练集占 76%,验证集占 9%,测试集占 15%,具体数量分别为:训练集 821,458 张,验证集 99,200 张,测试集 165,500 张。

该数据集涵盖了 65,977 名不同的个体,至少对应相同数量的独特场景。参与者均为 18 岁以上的人群。数据主要在室内采集,光照条件变化较大,包括人工光源和自然光。此外,数据集中还包括一些极端条件下的图像,例如面向或背对窗户拍摄的情况。参与者需要在距离摄像头 0.5 至 4 米的范围内展示手势。
示例样本及其标注:

更多信息请参阅我们在 arXiv 上发表的论文 链接。
🔥 更新日志
2025/02/27:我们发布了 动态手势识别算法。 🙋- 提出了一种创新算法,能够在仅使用静态手势训练的情况下实现动态手势识别。
- 模型完全基于 HaGRIDv2-1M 数据集训练而成。
- 专为实时应用场景设计,适用于视频会议、智能家居控制、汽车系统等。
- 开源实现,并在仓库中提供了预训练模型。
2024/09/24:我们发布了 HaGRIDv2。 🙏- HaGRID 数据集新增了 15 个手势类别,其中包括双手手势。
- 新增“no_gesture”类别,包含领域特定的自然手部姿态(共 2,164 个样本,按训练/验证/测试分别划分为 1,464、200、500 张)。
- “no_gesture”类别共包含 200,390 个边界框。
- 增加了手势检测、手部检测以及全帧分类的新模型。
- 数据集总大小为 1.5TB。
- 共有 1,086,158 张 FullHD RGB 图像。
- 按用户
user_id划分的训练/验证/测试比例为:821,458 张(76%)/ 99,200 张(9%)/ 165,500 张(15%)。 - 包含 65,977 名不同个体。
2023/09/21:我们发布了 HaGRID 2.0。 ✌️- 所有训练和测试文件被合并到一个目录中。
- 数据进一步清理并补充了新样本。
- 支持多 GPU 训练和测试。
- 增加了新的检测模型和全帧分类模型。
- 数据集总大小为 723GB。
- 共有 554,800 张 FullHD RGB 图像(清理并更新了类别,增加了种族多样性)。
- “no_gesture”类别新增 120,105 个样本。
- 按用户
user_id划分的训练/验证/测试比例为:410,800 张(74%)/ 54,000 张(10%)/ 90,000 张(16%)。 - 包含 37,583 名不同个体。
2022/06/16:HaGRID(初始数据集) 💪- 数据集总大小为 716GB。
- 共有 552,992 张 FullHD RGB 图像,分为 18 个手势类别。
- “no_gesture”类别包含 123,589 个样本。
- 按用户
user_id划分的训练/测试比例为:509,323 张(92%)/ 43,669 张(8%)。 - 包含 34,730 名 18 至 65 岁之间的不同个体。
- 参与者需在距离摄像头 0.5 至 4 米的范围内进行手势展示。
安装
克隆项目并安装所需的 Python 包:
git clone https://github.com/hukenovs/hagrid.git
# 或镜像链接:
cd hagrid
# 使用 conda 或 venv 创建虚拟环境
conda create -n gestures python=3.11 -y
conda activate gestures
# 安装依赖
pip install -r requirements.txt
下载
由于数据量庞大,我们将训练数据集按手势类别拆分为 34 个压缩包。请从以下链接下载并解压:
数据集
| 手势 | 大小 | 手势 | 大小 | 手势 | 大小 |
|---|---|---|---|---|---|
call |
37.2 GB | peace |
41.4 GB | grabbing |
48.7 GB |
dislike |
40.9 GB | peace_inverted |
40.5 GB | grip |
48.6 GB |
fist |
42.3 GB | rock |
41.7 GB | hand_heart |
39.6 GB |
four |
43.1 GB | stop |
41.8 GB | hand_heart2 |
42.6 GB |
like |
42.2 GB | stop_inverted |
41.4 GB | holy |
52.7 GB |
mute |
43.2 GB | three |
42.2 GB | little_finger |
48.6 GB |
ok |
42.5 GB | three2 |
40.2 GB | middle_finger |
50.5 GB |
one |
42.7 GB | two_up |
41.8 GB | point |
50.4 GB |
palm |
43.0 GB | two_up_inverted |
40.9 GB | take_picture |
37.3 GB |
three3 |
54 GB | three_gun |
50.1 GB | thumb_index |
62.8 GB |
thumb_index2 |
24.8 GB | timeout |
39.5 GB | xsign |
51.3 GB |
no_gesture |
493.9 MB |
dataset annotations: annotations
HaGRIDv2 512px - 轻量版完整数据集,包含 min_side = 512p 的 119.4 GB
或者使用 Python 脚本:
python download.py --save_path <PATH_TO_SAVE> \
--annotations \
--dataset
运行以下命令并使用 --dataset 参数下载数据集图像。通过 --annotations 参数下载选定阶段的标注文件。
usage: download.py [-h] [-a] [-d] [-t TARGETS [TARGETS ...]] [-p SAVE_PATH]
下载数据集...
可选参数:
-h, --help 显示此帮助信息并退出
-a, --annotations 下载标注文件
-d, --dataset 下载数据集
-t TARGETS [TARGETS ...], --targets TARGETS [TARGETS ...]
下载训练集的目标
-p SAVE_PATH, --save_path SAVE_PATH
保存路径
下载完成后,可以使用以下命令解压压缩包:
unzip <PATH_TO_ARCHIVE> -d <PATH_TO_SAVE>
数据集的结构如下:
├── hagrid_dataset <PATH_TO_DATASET_FOLDER>
│ ├── call
│ │ ├── 00000000.jpg
│ │ ├── 00000001.jpg
│ │ ├── ...
├── hagrid_annotations
│ ├── train <PATH_TO_JSON_TRAIN>
│ │ ├── call.json
│ │ ├── ...
│ ├── val <PATH_TO_JSON_VAL>
│ │ ├── call.json
│ │ ├── ...
│ ├── test <PATH_TO_JSON_TEST>
│ │ ├── call.json
│ │ ├── ...
模型
我们提供了一些在HaGRIDv2数据集上预训练的模型,作为手势分类、手势检测和手部检测任务的经典骨干网络架构基线。
| 手势检测器 | mAP |
|---|---|
| YOLOv10x | 89.4 |
| YOLOv10n | 88.2 |
| SSDLiteMobileNetV3Large | 72.7 |
此外,如果您需要检测手部,可以使用在HaGRIDv2数据集上预训练的YOLO检测模型。
| 手部检测器 | mAP |
|---|---|
| YOLOv10x | 88.8 |
| YOLOv10n | 87.9 |
然而,如果您只需要识别单个手势,可以使用预训练的全帧分类器,而不是检测器。 要使用全帧模型,请移除no_gesture类别。
| 全帧分类器 | F1得分 |
|---|---|
| MobileNetV3_small | 86.7 |
| MobileNetV3_large | 93.4 |
| VitB16 | 91.7 |
| ResNet18 | 98.3 |
| ResNet152 | 98.6 |
| ConvNeXt base | 96.4 |
训练
您可以使用下载的预训练模型,或者在configs文件夹中选择参数进行训练。
要训练模型,请执行以下命令:
单GPU:
python run.py -c train -p configs/<config>
多GPU:
bash ddp_run.sh -g 0,1,2,3 -c train -p configs/<config>
其中-g是GPU ID列表。
每一步的当前损失、学习率等值都会被记录到TensorBoard中。
通过打开命令行查看所有保存的指标和参数(这将打开一个网页,地址为localhost:6006):
tensorboard --logdir=<workdir>
测试
通过运行以下命令来测试您的模型:
单GPU:
python run.py -c test -p configs/<config>
多GPU:
bash ddp_run.sh -g 0,1,2,3 -c test -p configs/<config>
其中-g是GPU ID列表。
演示
python demo.py -p <PATH_TO_CONFIG> --landmarks
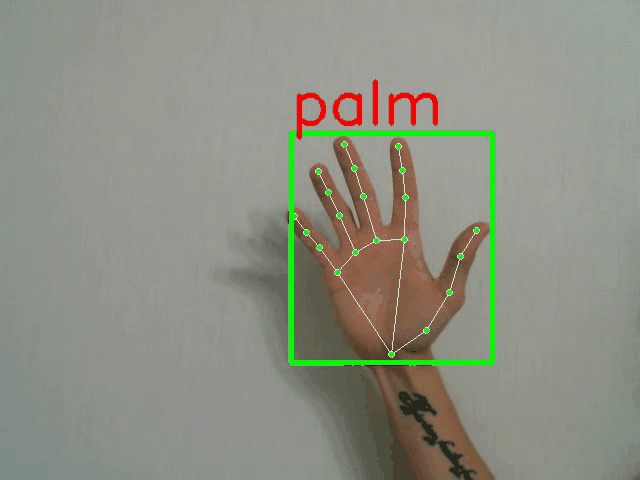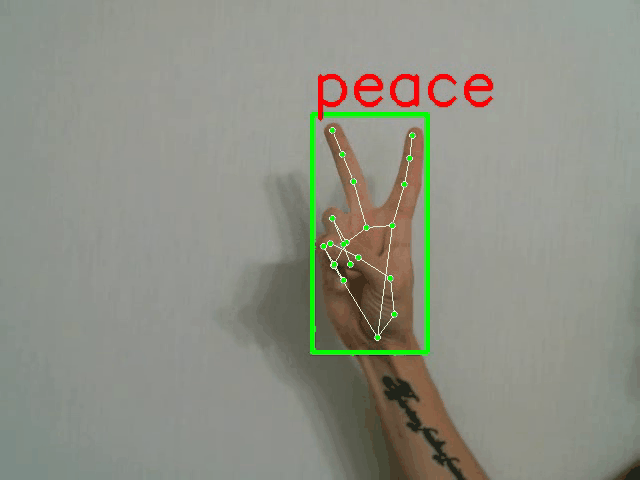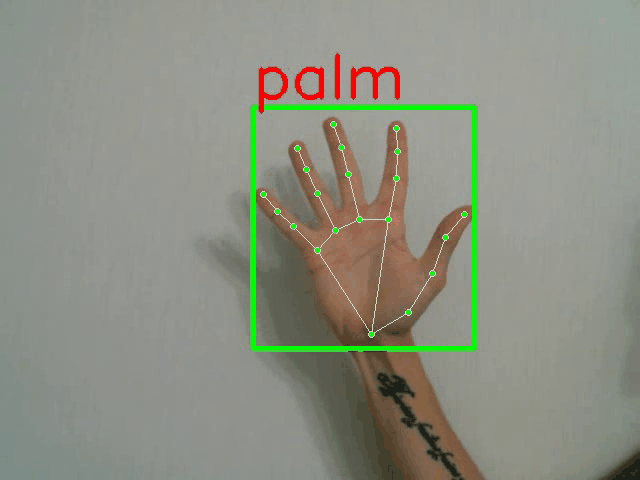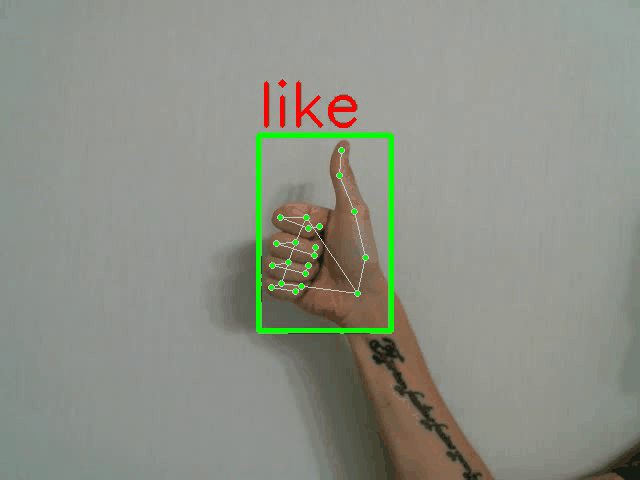
全帧分类器演示
python demo_ff.py -p <PATH_TO_CONFIG>
标注
标注由COCO格式的手部和手势边界框组成,格式为[左上角X坐标,左上角Y坐标,宽度,高度],并附有手势标签。我们提供了user_id字段,允许您自行划分训练/验证/测试数据集;此外,元信息包含自动标注的年龄、性别和种族。
"04c49801-1101-4b4e-82d0-d4607cd01df0": {
"bboxes": [
[0.0694444444, 0.3104166667, 0.2666666667, 0.2640625],
[0.5993055556, 0.2875, 0.2569444444, 0.2760416667]
],
"labels": [
"thumb_index2",
"thumb_index2"
],
"united_bbox": [
[0.0694444444, 0.2875, 0.7868055556, 0.2869791667]
],
"united_label": [
"thumb_index2"
],
"user_id": "2fe6a9156ff8ca27fbce8ada318c592b",
"hand_landmarks": [
[
[0.37233507701702123, 0.5935673528948108],
[0.3997604810145188, 0.5925499847441514],
...
],
[
[0.37388438145820907, 0.47547576284667353],
[0.39460467775730607, 0.4698847093520443],
...
]
]
"meta": {
"age": [24.41],
"gender": ["female"],
"race": ["White"]
}
- 键:图像名称,不含扩展名
- Bboxes:每个手的归一化边界框列表
[左上角X坐标,左上角Y坐标,宽度,高度] - Labels:每个手的类别标签列表,例如
like、stop、no_gesture - United_bbox:对于双手手势(如“hand_heart”、“hand_heart2”、“thumb_index2”、“timeout”、“holy”、“take_picture”、“xsign”),是两个手框的合并;对于单手手势,则为
null - United_label:双手手势时的联合类别标签,单手手势时为
null - User ID:受试者ID(可用于将数据划分为训练/验证子集)
- Hand_landmarks:使用MediaPipe地标自动标注的每只手的特征点
- Meta:由FairFace和MiVOLO神经网络自动标注的元信息,包括年龄、性别和种族
边界框
| 对象 | 训练集 | 验证集 | 测试集 | 总计 |
|---|---|---|---|---|
| 手势 | 980 924 | 120 003 | 200 006 | 1 300 933 |
| 无手势 | 154 403 | 19 411 | 29 386 | 203 200 |
| 总框数 | 1 135 327 | 139 414 | 229 392 | 1 504 133 |
特征点
| 对象 | 训练集 | 验证集 | 测试集 | 总计 |
|---|---|---|---|---|
| 总手数(带特征点) | 983 991 | 123 230 | 201 131 | 1 308 352 |
转换工具
Yolo
我们提供了一个脚本,用于将标注转换为 YOLO 格式。要进行标注转换,请运行以下命令:
python -m converters.hagrid_to_yolo --cfg <CONFIG_PATH> --mode <'hands' or 'gestures'>
转换完成后,您需要将原始的 img2labels 定义(位于 yolov7 仓库)修改为:
def img2label_paths(img_paths):
img_paths = list(img_paths)
# 根据图像路径定义标签路径
if "train" in img_paths[0]:
return [x.replace("train", "train_labels").replace(".jpg", ".txt") for x in img_paths]
elif "test" in img_paths[0]:
return [x.replace("test", "test_labels").replace(".jpg", ".txt") for x in img_paths]
elif "val" in img_paths[0]:
return [x.replace("val", "val_labels").replace(".jpg", ".txt") for x in img_paths]
Coco
此外,我们还提供了一个脚本,用于将标注转换为 Coco 格式。要进行标注转换,请运行以下命令:
python -m converters.hagrid_to_coco --cfg <CONFIG_PATH> --mode <'hands' or 'gestures'>
许可证

本作品采用一种变体的 知识共享 署名-相同方式共享 4.0 国际许可协议。
具体许可协议请参阅 此处。
作者与致谢
- Alexander Kapitanov
- Andrey Makhlyarchuk
- Karina Kvanchiani
- Aleksandr Nagaev
- Roman Kraynov
- Anton Nuzhdin
链接
引用
您可以使用以下 BibTeX 条目引用该论文:
@misc{nuzhdin2024hagridv21mimagesstatic,
title={HaGRIDv2: 1M 图像用于静态和动态手势识别},
author={Anton Nuzhdin、Alexander Nagaev、Alexander Sautin、Alexander Kapitanov、Karina Kvanchiani},
year={2024},
eprint={2412.01508},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2412.01508},
}
@InProceedings{Kapitanov_2024_WACV,
author = {Kapitanov, Alexander、Kvanchiani, Karina、Nagaev, Alexander、Kraynov, Roman、Makhliarchuk, Andrei},
title = {HaGRID -- 手势识别图像数据集},
booktitle = {IEEE/CVF 冬季计算机视觉应用会议(WACV)论文集},
month = {一月},
year = {2024},
pages = {4572-4581}
}
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器