optimum-quanto
Optimum Quanto 是专为 Hugging Face Optimum 生态打造的 PyTorch 量化后端,旨在帮助开发者轻松压缩大型 AI 模型。它主要解决了大模型在推理时显存占用高、运行速度慢的难题,通过降低权重和激活值的精度(支持 int2/4/8 及 float8 等格式),在几乎不损失模型准确率的前提下,显著减少内存需求并提升推理效率。
这款工具特别适合需要部署大语言模型(如 Llama 系列)或图像生成模型的 AI 研究人员与工程开发者。其独特亮点在于极高的易用性与兼容性:无需修改模型结构或进行复杂的图追踪,即可在 eager 模式下直接运行;它能自动插入量化算子,并无缝支持从动态到静态量化的完整工作流。此外,Optimum Quanto 针对 CUDA 设备提供了加速矩阵乘法内核,并兼容 PyTorch 原生权重格式及 Safetensors,让模型的量化、保存与加载变得像调用普通 API 一样简单。
需要注意的是,目前该项目已进入维护模式,不再添加重大新功能。对于追求最新特性或生产级高强度需求的用户,官方建议关注 bitsandbytes 或 torchAO 等活跃项目,但 Optimum Quanto 依然是理解和使用基础量化技术的优秀入门选择。
使用场景
某初创团队需要在消费级显卡(如 RTX 3090)上部署 Meta-Llama-3-8B 大模型,以构建低成本的内部知识库问答系统。
没有 optimum-quanto 时
- 显存严重不足:原始 BF16 精度的 8B 模型占用约 16GB 显存,加上推理时的激活值开销,极易导致单卡显存溢出(OOM),无法运行。
- 量化流程繁琐:手动编写量化脚本需要处理复杂的算子替换和权重转换,且难以兼容非标准模型结构,调试成本极高。
- 推理速度受限:缺乏针对特定硬件优化的混合精度矩阵乘法内核,即使强行量化,推理延迟也往往高于全精度模型,得不偿失。
- 部署灵活性差:生成的量化模型往往绑定特定后端,难以在不同设备(如 CUDA 或 MPS)间无缝迁移或保存为标准格式。
使用 optimum-quanto 后
- 显存占用减半:通过
qint4权重量化,模型显存占用降低至原来的 1/4 左右,轻松在单张消费级显卡上流畅运行。 - 工作流极简:仅需几行代码调用
QuantizedModelForCausalLM.quantize,即可自动插入量化/反量化桩并冻结权重,支持动态到静态的平滑过渡。 - 推理性能提升:自动启用 CUDA 上的加速矩阵乘法内核(如 bf16-int4),在保持精度几乎无损的前提下,显著降低了生成延迟。
- 生态兼容性强:量化后的模型可直接通过
save_pretrained保存为 safetensors 格式,并能在任何支持 PyTorch 的设备上直接加载推理。
optimum-quanto 让开发者能以极低的代码成本,将大型语言模型高效压缩并部署到资源受限的边缘设备上。
运行环境要求
- Linux
- macOS
- 可选但推荐
- 支持 CUDA (NVIDIA) 和 MPS (Apple Silicon)
- 若需加速矩阵乘法(如 int8-int8, fp16-int4 等),需要支持相应算子的 NVIDIA GPU
- 具体显存大小取决于模型规模,未明确最低要求
未说明

快速开始
Optimum Quanto
该项目目前处于维护模式。我们仅接受用于修复小错误、改进文档及其他维护任务的拉取请求。重大的新功能或破坏性更改不太可能被合并。对于生产就绪的量化功能或活跃的开发工作,请考虑使用其他项目,例如 bitsandbytes 或 torchAO。
🤗 Optimum Quanto 是一个用于 optimum 的 PyTorch 量化后端。
它在设计时充分考虑了通用性和简洁性:
- 所有功能均可在 eager 模式下使用(适用于不可跟踪的模型);
- 量化后的模型可以部署到任何设备上(包括 CUDA 和 MPS);
- 自动插入量化和反量化的桩代码;
- 自动插入量化后的函数操作;
- 自动插入量化模块(支持的模块列表见下文);
- 提供从浮点模型到动态量化再到静态量化的无缝工作流;
- 序列化与 PyTorch 的
weight_only格式及 🤗safetensors兼容; - 在 CUDA 设备上加速矩阵乘法运算(int8-int8、fp16-int4、bf16-int8、bf16-int4);
- 支持 int2、int4、int8 和 float8 权重;
- 支持 int8 和 float8 激活值。
尚未实现的功能:
- 动态激活平滑处理;
- 所有混合精度矩阵乘法的内核在所有设备上的实现;
- 与 PyTorch 编译器(即 dynamo)的兼容性。
性能
简而言之:
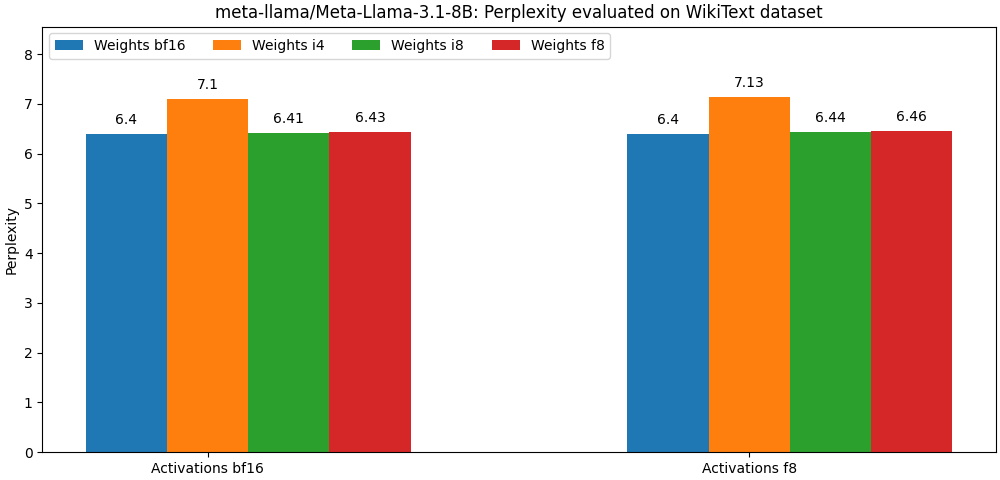
- 准确性:使用
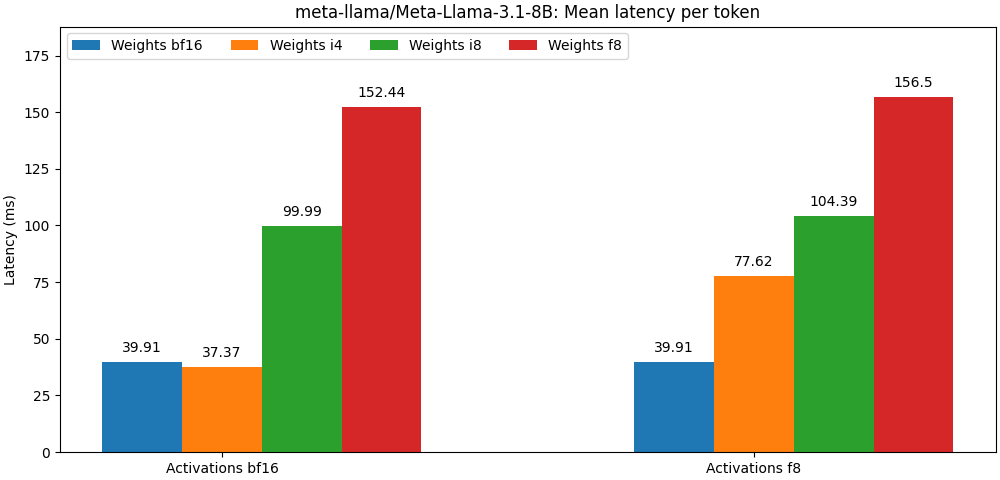
int8/float8权重和float8激活值编译的模型,其性能非常接近全精度模型; - 延迟:在存在优化内核的情况下,仅对模型权重进行量化时,量化模型的推理延迟可与全精度模型相媲美;
- 设备内存:大约为浮点位数除以整数位数。
以下段落仅为示例。有关按模型用例划分的详细结果,请参阅 bench 文件夹。
meta-llama/Meta-Llama-3.1-8B
安装
Optimum Quanto 可通过 pip 包管理器安装。
pip install optimum-quanto
Hugging Face 模型的量化流程
optimum-quanto 提供了辅助类,用于量化、保存和重新加载 Hugging Face 量化模型。
LLM 模型
第一步是量化模型:
from transformers import AutoModelForCausalLM
from optimum.quanto import QuantizedModelForCausalLM, qint4
model = AutoModelForCausalLM.from_pretrained('meta-llama/Meta-Llama-3-8B')
qmodel = QuantizedModelForCausalLM.quantize(model, weights=qint4, exclude='lm_head')
注意:量化后的模型权重将被冻结。如果希望保持权重未冻结以便继续训练,则需要直接使用 optimum.quanto.quantize 方法。
量化后的模型可以使用 save_pretrained 方法保存:
qmodel.save_pretrained('./Llama-3-8B-quantized')
之后可以通过 from_pretrained 方法重新加载:
from optimum.quanto import QuantizedModelForCausalLM
qmodel = QuantizedModelForCausalLM.from_pretrained('Llama-3-8B-quantized')
Diffusers 模型
您可以对 Diffusers 流水线中的任意子模型进行量化,并随后无缝地将其集成到另一个流水线中。这里我们对 Pixart 流水线中的 transformer 进行量化:
from diffusers import PixArtTransformer2DModel
from optimum.quanto import QuantizedPixArtTransformer2DModel, qfloat8
model = PixArtTransformer2DModel.from_pretrained("PixArt-alpha/PixArt-Sigma-XL-2-1024-MS", subfolder="transformer")
qmodel = QuantizedPixArtTransformer2DModel.quantize(model, weights=qfloat8)
qmodel.save_pretrained("./pixart-sigma-fp8")
稍后,我们可以重新加载量化后的模型并重建流水线:
from diffusers import PixArtTransformer2DModel
from optimum.quanto import QuantizedPixArtTransformer2DModel
transformer = QuantizedPixArtTransformer2DModel.from_pretrained("./pixart-sigma-fp8")
transformer.to(device="cuda")
pipe = PixArtSigmaPipeline.from_pretrained(
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS",
transformer=None,
torch_dtype=torch.float16,
).to("cuda")
pipe.transformer = transformer
适用于原生 PyTorch 模型的量化工作流(低层级 API)
使用低层级 Quanto API 时,需要注意的一点是:默认情况下,模型权重会进行动态量化;必须显式调用“冻结”操作来固定已量化的权重。
典型的量化工作流包括以下步骤:
1. 量化
第一步将标准的浮点模型转换为动态量化模型。
from optimum.quanto import quantize, qint8
quantize(model, weights=qint8, activations=qint8)
在此阶段,仅修改模型的推理过程,以动态量化权重。
2. 校准(可选,若未量化激活值则无需校准)
Quanto 支持校准模式,允许在通过代表性样本运行量化模型时记录激活值范围。
from optimum.quanto import Calibration
with Calibration(momentum=0.9):
model(samples)
这会自动启用量化模块中激活值的量化。
3. 微调,即量化感知训练(可选)
如果模型性能下降过多,可以对其进行几个 epoch 的微调,以恢复接近浮点模型的性能。
import torch
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data).dequantize()
loss = torch.nn.functional.nll_loss(output, target)
loss.backward()
optimizer.step()
4. 冻结整数量化权重
冻结模型时,其浮点权重会被替换为量化的整数量化权重。
from optimum.quanto import freeze
freeze(model)
5. 序列化量化模型
量化后的模型权重可以序列化为 state_dict,并保存到文件中。支持 pickle 和 safetensors(推荐)两种格式。
from safetensors.torch import save_file
save_file(model.state_dict(), 'model.safetensors')
为了能够重新加载这些权重,还需要存储量化模型的量化映射。
import json
from optimum.quanto import quantization_map
with open('quantization_map.json', 'w') as f:
json.dump(quantization_map(model), f)
6. 重新加载量化模型
可以通过 state_dict 和 quantization_map 使用 requantize 辅助函数重新加载序列化的量化模型。请注意,首先需要实例化一个空模型。
import json
from safetensors.torch import load_file
from optimum.quanto import requantize
state_dict = load_file('model.safetensors')
with open('quantization_map.json', 'r') as f:
quantization_map = json.load(f)
# 根据你的建模代码创建一个空模型,并对其进行重新量化
with torch.device('meta'):
new_model = ...
requantize(new_model, state_dict, quantization_map, device=torch.device('cuda'))
有关该工作流的具体实现,请参阅 示例。
设计概览
张量
Quanto 的核心是一个张量子类,它对应于:
- 将源张量投影到给定目标类型的最优范围内;
- 将投影后的值映射到目标类型。
对于浮点目标类型,映射由原生 PyTorch 的类型转换完成(即 Tensor.to())。
对于整数目标类型,映射则是一个简单的四舍五入操作(即 torch.round())。
投影的目标是通过减少以下情况的数量来提高转换精度:
- 饱和值(即被映射到目标类型的最小值或最大值);
- 被清零的值(因为它们低于目标类型所能表示的最小数值)。
投影方式根据数据类型而有所不同:对于 int8 和 float8,采用逐张量或逐通道对称投影;而对于更低的位宽,则采用分组仿射投影(带有偏移量或“零点”)。
使用较低位宽表示的一个好处是,可以利用针对目标类型加速的运算,通常比高精度版本更快。
Quanto 不支持使用混合目标类型对张量进行转换。
模块
Quanto 提供了一种通用机制,用于将 torch 模块替换为能够处理 Quanto 张量的 optimum-quanto 模块。
optimum-quanto 模块会在模型冻结之前动态转换其权重,这会略微降低推理速度,但如果需要对模型进行微调,则这是必要的。
权重通常按通道沿第一维度(输出特征)进行量化。
偏置不进行转换,以保持典型 addmm 运算的精度。
解释:为了与未量化算术运算保持一致,偏置需要以等于输入和权重尺度乘积的尺度进行量化,这会导致尺度小得离谱,从而需要非常高的位宽才能避免截断。例如,当输入和权重为 int8 时,偏置至少需要以 12 位进行量化,即 int16。由于大多数偏置目前都是 float16,这样做实际上并无意义。
激活值则按张量动态量化,使用静态尺度(默认范围为 [-1, 1])。
为保持精度,需要对模型进行校准,以评估最佳的激活尺度(使用动量参数)。
以下模块可以被量化:
- Linear(QLinear)。权重始终量化,偏置不量化。输入和输出均可量化。
- Conv2d(QConv2D)。权重始终量化,偏置不量化。输入和输出均可量化。
- LayerNorm,权重和偏置 不 量化。输出可以量化。
量化激活值时需避免的陷阱
激活值始终按张量整体进行量化,这是因为模型图中的大多数线性代数运算都不支持按轴输入:你无法对不同基数表示的数值进行加法运算(“不能把苹果和橘子相加”)。
与此相反,参与矩阵乘法的权重则始终沿其第一个轴进行量化,这是因为所有输出特征都是独立计算的。
无论如何,即使激活值已被量化,量化后的矩阵乘法结果仍会先被反量化,原因如下:
- 结果的累加值采用的位宽远高于激活值的位宽(通常为
int32或float32,而激活值通常是int8或float8); - 这些值还可能与一个
float类型的偏置项相加。
如果对应的张量中包含较大的异常值,将激活值按张量整体量化为 int8 格式,可能会导致严重的量化误差。典型情况下,这会使量化后的张量中大部分值都被置为零,仅保留那些异常值。
解决这一问题的一种方法是像 SmoothQuant 所示,对激活值进行静态平滑处理。你可以在 external/smoothquant 目录下找到用于平滑某些模型架构的脚本。
更好的选择则是使用 float8 来表示激活值。
版本历史
v0.2.72025/03/06v0.2.62024/10/29v0.2.52024/10/01v0.2.42024/07/26v0.2.32024/07/25v0.2.22024/06/28v0.2.12024/05/31v0.2.02024/05/24v0.1.02024/03/13v0.0.132024/02/23v0.0.122024/02/160.0.112024/01/190.0.102024/01/190.0.92023/12/150.0.82023/12/080.0.72023/12/010.0.62023/10/270.0.52023/10/190.0.42023/10/090.0.12023/10/02常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。