ColossalAI
ColossalAI 是一个致力于让大型人工智能模型训练与推理变得更经济、高效且易于获取的开源系统。它主要解决了大模型在开发过程中面临的显存受限、训练速度缓慢以及硬件成本高昂等核心痛点,通过先进的并行策略和系统优化,让用户能在有限的计算资源上运行参数量巨大的模型。
这款工具非常适合 AI 研究人员、算法工程师以及希望深入探索大模型技术的开发者使用。无论是进行前沿学术研究,还是构建企业级 AI 应用,ColossalAI 都能提供强有力的支持。其独特的技术亮点在于集成了多种高效的并行训练技术(如张量并行、流水线并行及序列并行),并针对主流硬件进行了深度适配与加速。此外,它还提供了丰富的预置示例和友好的文档,帮助用户快速上手,轻松实现从模型微调到大规模部署的全流程。借助 ColossalAI,用户无需从零构建复杂的底层架构,即可显著降低算力门槛,将更多精力聚焦于模型创新与应用落地。
使用场景
某金融科技公司算法团队需要在有限的预算下,基于开源基座模型训练一个拥有 700 亿参数、支持长上下文的专业风控大模型。
没有 ColossalAI 时
- 硬件门槛极高:传统并行策略无法将超大模型装入单卡显存,团队被迫采购昂贵的多节点 GPU 集群,初期投入成本激增。
- 开发周期漫长:手动编写分布式训练代码(如 ZeRO、流水线并行)耗时数周,且极易出现通信死锁或显存溢出错误,调试困难。
- 训练效率低下:由于缺乏优化的算子融合与通信调度,GPU 利用率长期低于 40%,原本预计两周的训练任务往往拖延至一个月以上。
- 长序列支持受限:面对金融研报等超长文本,现有框架难以高效处理长上下文,频繁报错或被迫截断关键信息。
使用 ColossalAI 后
- 低成本启动:利用其自动并行技术与显存优化机制,团队仅用少量消费级显卡即可启动 70B 模型训练,硬件成本降低 60%。
- 极速落地:通过几行配置代码即可开启 3D 并行训练,无需底层重构,模型上线时间从数周缩短至 2 天。
- 性能显著提升:内置的高效算子与通信优化使 GPU 利用率提升至 85% 以上,训练速度提升 3 倍,按期交付模型。
- 无缝长文处理:原生支持超长序列并行计算,轻松处理百万级 token 上下文,完整保留风控所需的细节特征。
ColossalAI 通过极致的系统优化,让中小团队也能以低廉成本和敏捷速度驾驭超大规模 AI 模型的训练与应用。
运行环境要求
- 未说明
需要 NVIDIA GPU(基准测试提及 H200, B200),支持多卡并行(8 卡/16 卡配置),显存需求视模型规模而定(7B 模型约 12GB+,70B 模型需更大显存或并行策略),CUDA 版本未明确说明
未说明

快速开始
Colossal-AI





在企业级GPU上即刻运行Colossal-AI
无需繁琐的配置。在HPC-AI云上,您即可访问强大且预配置好的Colossal-AI环境。
只需点击一下,即可训练您的模型并扩展AI工作负载!
- NVIDIA Blackwell B200s:体验下一代AI性能(查看基准测试结果)。现可在云端以低至每小时2.47美元的价格使用。
- 高性价比H200集群:按需租赁,仅需每小时1.99美元,即可享受顶级性能。

以半价畅享顶尖开源模型
省去麻烦。通过HPC-AI模型API,您可以无缝访问强大的长上下文LLM。
使用HPC-AI模型API构建您的AI智能体、聊天机器人和RAG应用吧!
最新最全模型:体验Kimi 2.5、MiniMax 2.5和GLM 5.1等最先进的性能。非常适合处理超过200万token的超大上下文窗口及复杂编码任务。
无与伦比的价格:不再为API端点支付过高费用。以比OpenRouter低至50%的价格获得顶级推理速度。

Colossal-AI基准测试
为验证这些性能提升在实际应用中的效果,我们使用Colossal-AI对类似Llama的模型进行了大规模语言模型训练基准测试。测试分别在8卡和16卡配置下进行,对应7B和70B规模的模型。
| GPU | GPUs | 模型大小 | 并行策略 | 每个数据并行组的批量大小 | 序列长度 | 吞吐量 | TFLOPS/GPU | 峰值显存(MiB) |
|---|---|---|---|---|---|---|---|---|
| H200 | 8 | 7B | zero2(dp8) | 36 | 4096 | 17.13 样本/秒 | 534.18 | 119040.02 |
| H200 | 16 | 70B | zero2 | 48 | 4096 | 3.27 样本/秒 | 469.1 | 150032.23 |
| B200 | 8 | 7B | zero1(dp2)+tp2+pp4 | 128 | 4096 | 25.83 样本/秒 | 805.69 | 100119.77 |
| H200 | 16 | 70B | zero1(dp2)+tp2+pp4 | 128 | 4096 | 5.66 样本/秒 | 811.79 | 100072.02 |
Colossal-AI基准测试的结果提供了极具实用价值的洞察。对于8卡上的7B模型,B200的吞吐量高出50%,且每GPU的TFLOPS显著提升。而对于16卡上的70B模型,B200同样展现出明显优势,其吞吐量和每GPU的TFLOPS均高出70%以上。这些数据表明,B200的性能提升能够直接转化为大规模模型更短的训练时间。
最新消息
- [2025/02] DeepSeek 671B 微调指南曝光——一键解锁升级版 DeepSeek 套件,AI 爱好者欣喜若狂!
- [2024/12] 视频生成模型的开发成本节省了50%!现提供开源解决方案,并附赠 H200 GPU 代金券 [代码] [代金券]
- [2024/10] 如何构建低成本的 Sora 类应用?为您提供的解决方案
- [2024/09] 新加坡初创公司 HPC-AI Tech 获得 5000 万美元 A 轮融资,用于打造视频生成 AI 模型和 GPU 平台
- [2024/09] 通过 FP8 混合精度训练升级,仅需一行代码即可将 AI 大模型训练成本降低 30%
- [2024/06] Open-Sora 继续开源:一键生成任意 16 秒 720p 高清视频,模型权重即用
- [2024/05] 大型 AI 模型推理速度翻倍,Colossal-Inference 开源发布
- [2024/04] Open-Sora 全面升级:拥抱开源,支持单次生成 16 秒、720p 分辨率视频
- [2024/04] 针对 LLaMA3 系列量身定制的最具性价比的推理、微调和预训练解决方案
目录
为什么选择 Colossal-AI

詹姆斯·德梅尔教授(加州大学伯克利分校):Colossal-AI 使 AI 模型的训练高效、简单且可扩展。
(返回顶部)
功能特性
Colossal-AI 为您提供一系列并行化组件。我们的目标是让您像在笔记本电脑上编写模型一样轻松地编写分布式深度学习模型。我们提供友好的工具,只需几行代码即可启动分布式训练和推理。
并行策略:
异构内存管理:
友好易用:
- 基于配置文件的并行化
(返回顶部)
Colossal-AI 在现实世界中的应用
Open-Sora
Open-Sora:揭秘完整模型参数、训练细节以及所有与Sora类似视频生成模型相关的内容 [代码] [博客] [模型权重] [演示] [GPU云平台] [OpenSora图像]

(返回顶部)
Colossal-LLaMA-2
7B:仅需几百美元、半天的训练,即可获得与主流大模型相当的效果,是一款开源且无商业限制的领域专用LLM解决方案。 [代码] [博客] [HuggingFace模型权重] [Modelscope模型权重]
13B:仅需5000美元,即可构建出性能优异的13B规模私有模型。 [代码] [博客] [HuggingFace模型权重] [Modelscope模型权重]
| 模型 | 主干网络 | 消耗的token数 | MMLU (5-shot) | CMMLU (5-shot) | AGIEval (5-shot) | GAOKAO (0-shot) | CEval (5-shot) |
|---|---|---|---|---|---|---|---|
| Baichuan-7B | - | 1.2T | 42.32 (42.30) | 44.53 (44.02) | 38.72 | 36.74 | 42.80 |
| Baichuan-13B-Base | - | 1.4T | 50.51 (51.60) | 55.73 (55.30) | 47.20 | 51.41 | 53.60 |
| Baichuan2-7B-Base | - | 2.6T | 46.97 (54.16) | 57.67 (57.07) | 45.76 | 52.60 | 54.00 |
| Baichuan2-13B-Base | - | 2.6T | 54.84 (59.17) | 62.62 (61.97) | 52.08 | 58.25 | 58.10 |
| ChatGLM-6B | - | 1.0T | 39.67 (40.63) | 41.17 (-) | 40.10 | 36.53 | 38.90 |
| ChatGLM2-6B | - | 1.4T | 44.74 (45.46) | 49.40 (-) | 46.36 | 45.49 | 51.70 |
| InternLM-7B | - | 1.6T | 46.70 (51.00) | 52.00 (-) | 44.77 | 61.64 | 52.80 |
| Qwen-7B | - | 2.2T | 54.29 (56.70) | 56.03 (58.80) | 52.47 | 56.42 | 59.60 |
| Llama-2-7B | - | 2.0T | 44.47 (45.30) | 32.97 (-) | 32.60 | 25.46 | - |
| Linly-AI/Chinese-LLaMA-2-7B-hf | Llama-2-7B | 1.0T | 37.43 | 29.92 | 32.00 | 27.57 | - |
| wenge-research/yayi-7b-llama2 | Llama-2-7B | - | 38.56 | 31.52 | 30.99 | 25.95 | - |
| ziqingyang/chinese-llama-2-7b | Llama-2-7B | - | 33.86 | 34.69 | 34.52 | 25.18 | 34.2 |
| TigerResearch/tigerbot-7b-base | Llama-2-7B | 0.3T | 43.73 | 42.04 | 37.64 | 30.61 | - |
| LinkSoul/Chinese-Llama-2-7b | Llama-2-7B | - | 48.41 | 38.31 | 38.45 | 27.72 | - |
| FlagAlpha/Atom-7B | Llama-2-7B | 0.1T | 49.96 | 41.10 | 39.83 | 33.00 | - |
| IDEA-CCNL/Ziya-LLaMA-13B-v1.1 | Llama-13B | 0.11T | 50.25 | 40.99 | 40.04 | 30.54 | - |
| Colossal-LLaMA-2-7b-base | Llama-2-7B | 0.0085T | 53.06 | 49.89 | 51.48 | 58.82 | 50.2 |
| Colossal-LLaMA-2-13b-base | Llama-2-13B | 0.025T | 56.42 | 61.80 | 54.69 | 69.53 | 60.3 |
ColossalChat

ColossalChat: 一个开源解决方案,用于克隆 ChatGPT,并配备完整的 RLHF 流程。 [代码] [博客] [演示] [教程]
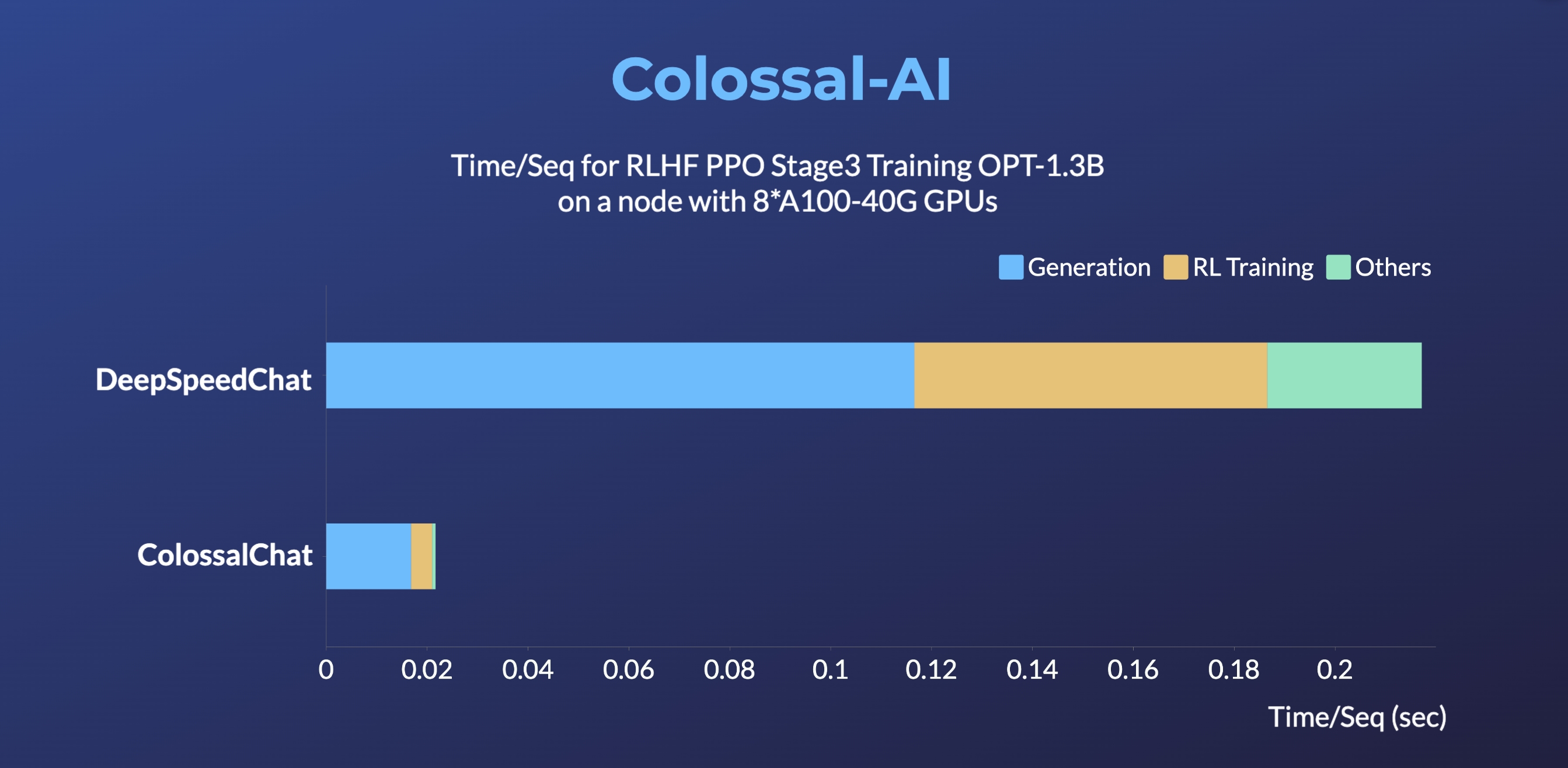
- RLHF PPO Stage3 训练速度最高可提升至10倍
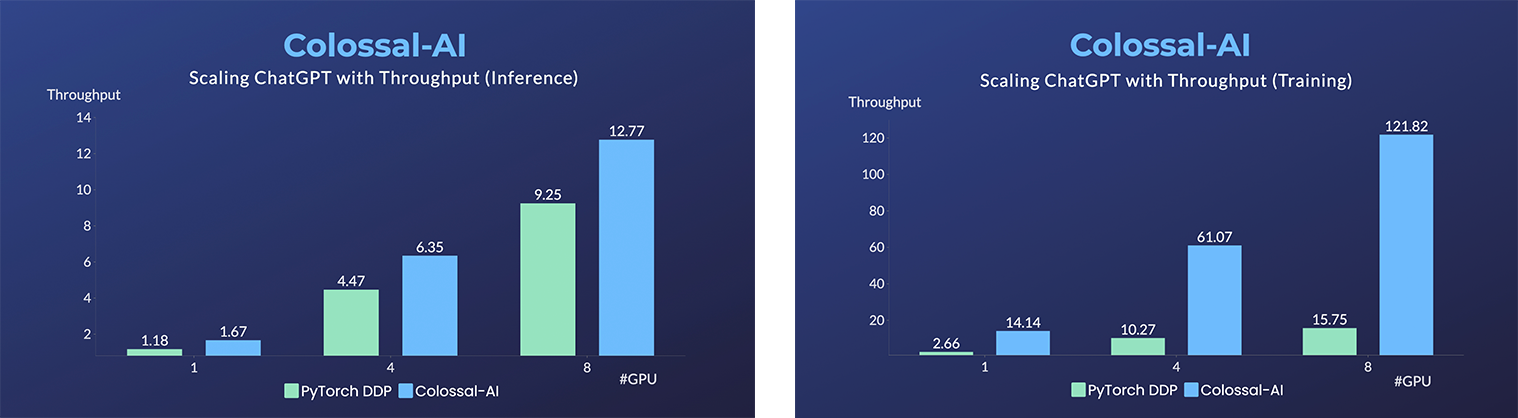
- 单服务器训练速度最高可提升至7.73倍,单GPU推理速度最高可提升至1.42倍
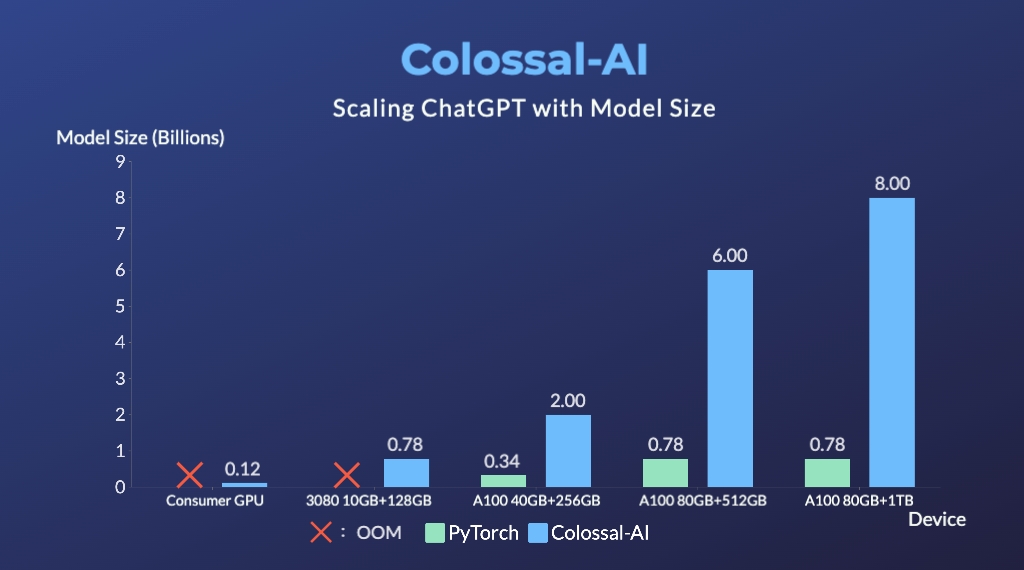
- 在单个GPU上,模型容量最高可增长10.3倍
- 一次小型演示训练过程仅需1.62GB显存(任何消费级GPU均可)
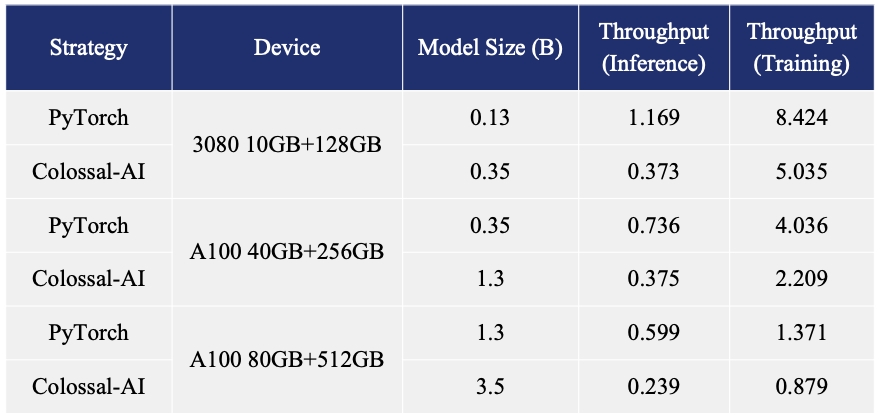
- 在单个GPU上,微调模型的容量最高可提升至3.7倍
- 同时保持足够高的运行速度
(返回顶部)
AIGC
加速AIGC(人工智能生成内容)模型,例如 Stable Diffusion v1 和 Stable Diffusion v2。
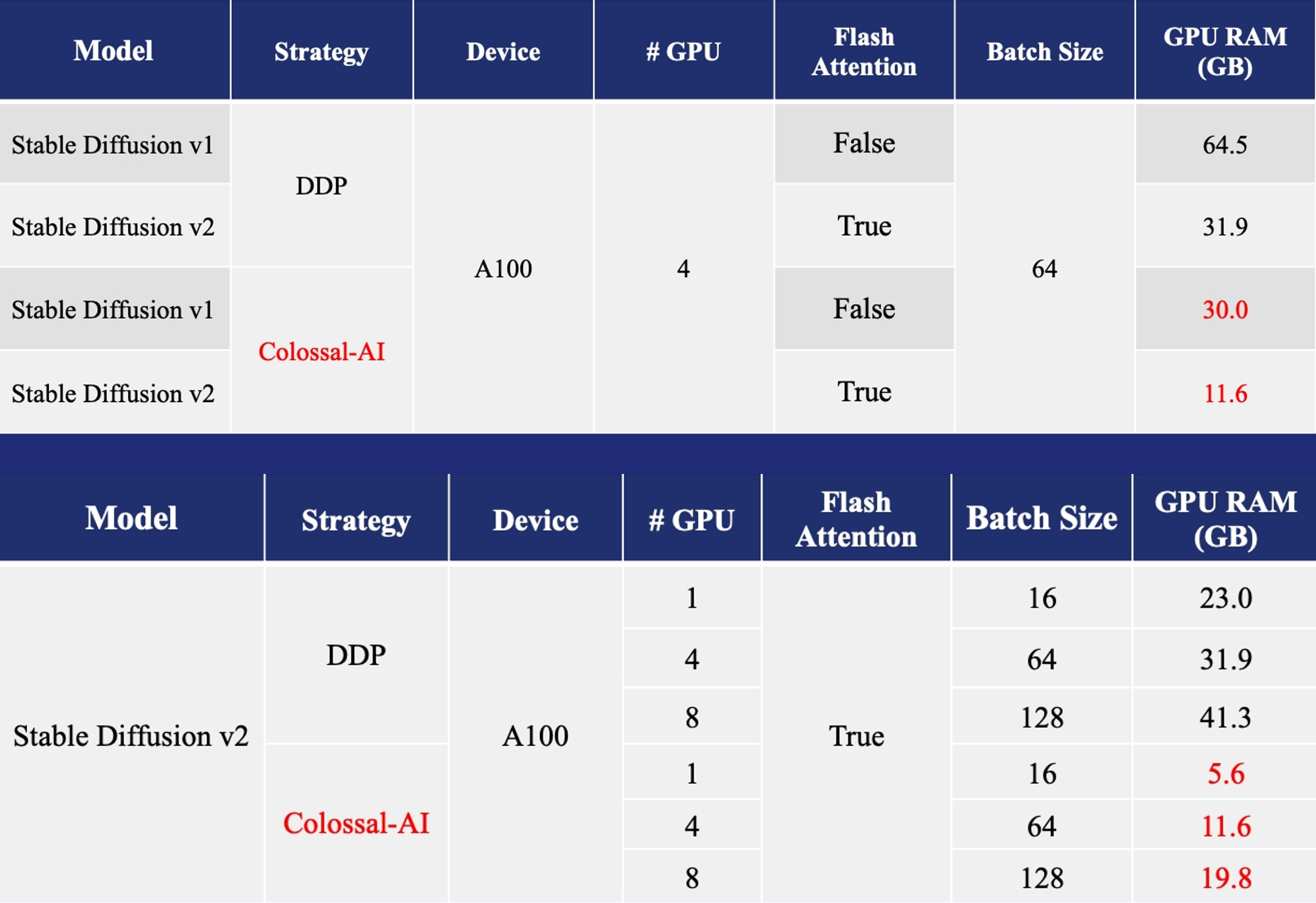
- 训练: 将Stable Diffusion的显存消耗降低至多5.6倍,硬件成本降低至多46倍(从A100降至RTX3060)。

- DreamBooth微调: 仅需3–5张目标对象的照片即可个性化您的模型。

- 推理: 将推理过程中的显存消耗减少2.5倍。
(返回顶部)
生物医药
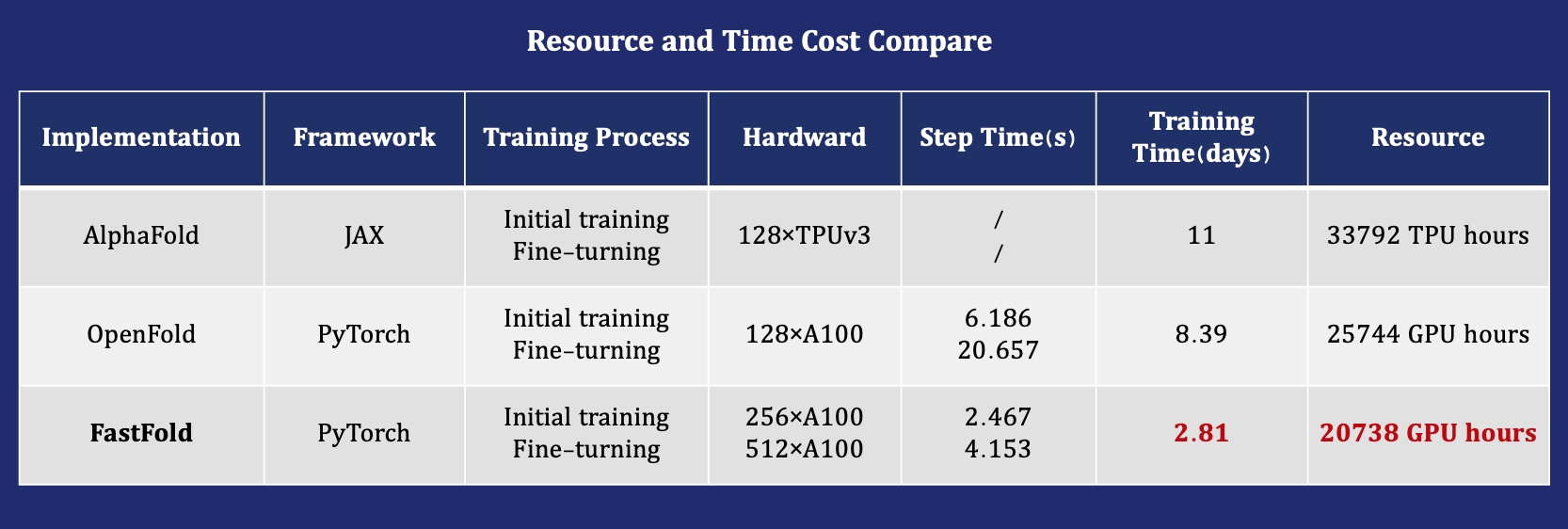
- FastFold: 加速GPU集群上的训练和推理,提升数据处理速度,支持超过10000个残基的序列推理。
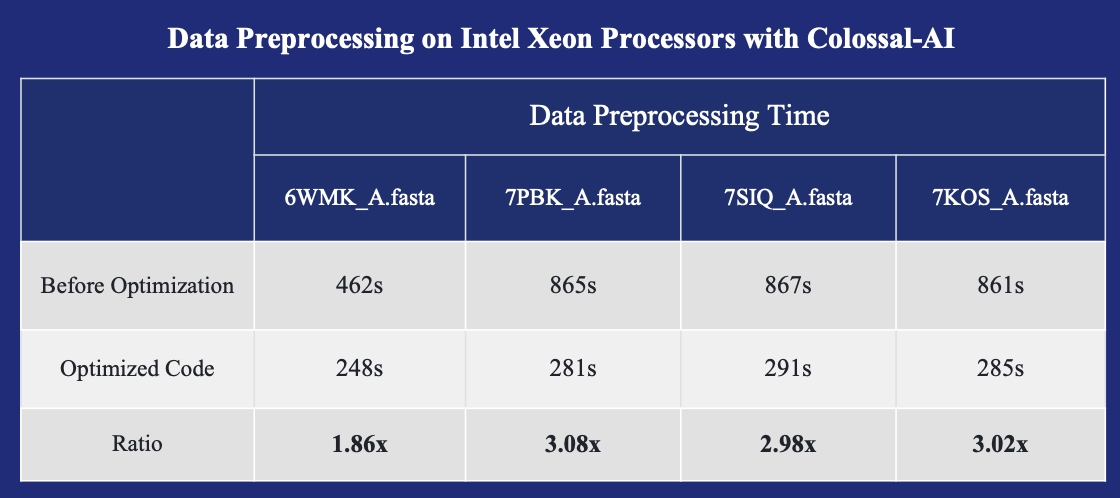
- FastFold与Intel结合: 推理速度提升3倍,成本降低39%。
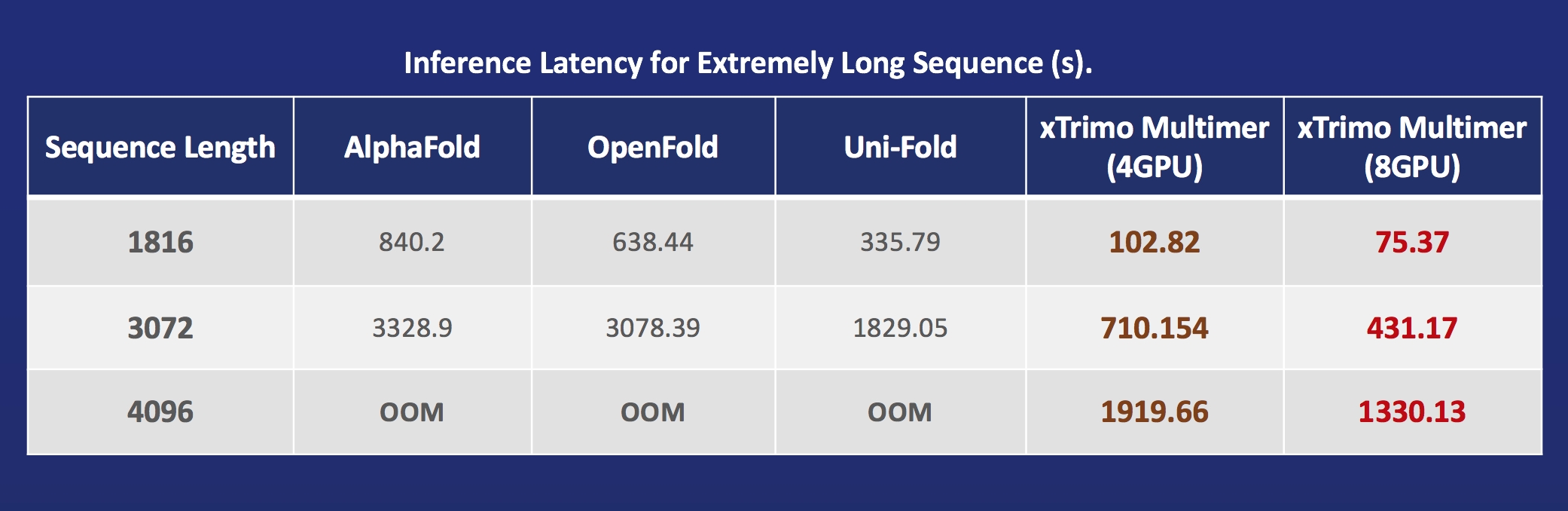
- xTrimoMultimer: 将蛋白质单体和多聚体的结构预测速度提升11倍。
(返回顶部)
并行训练演示
LLaMA3
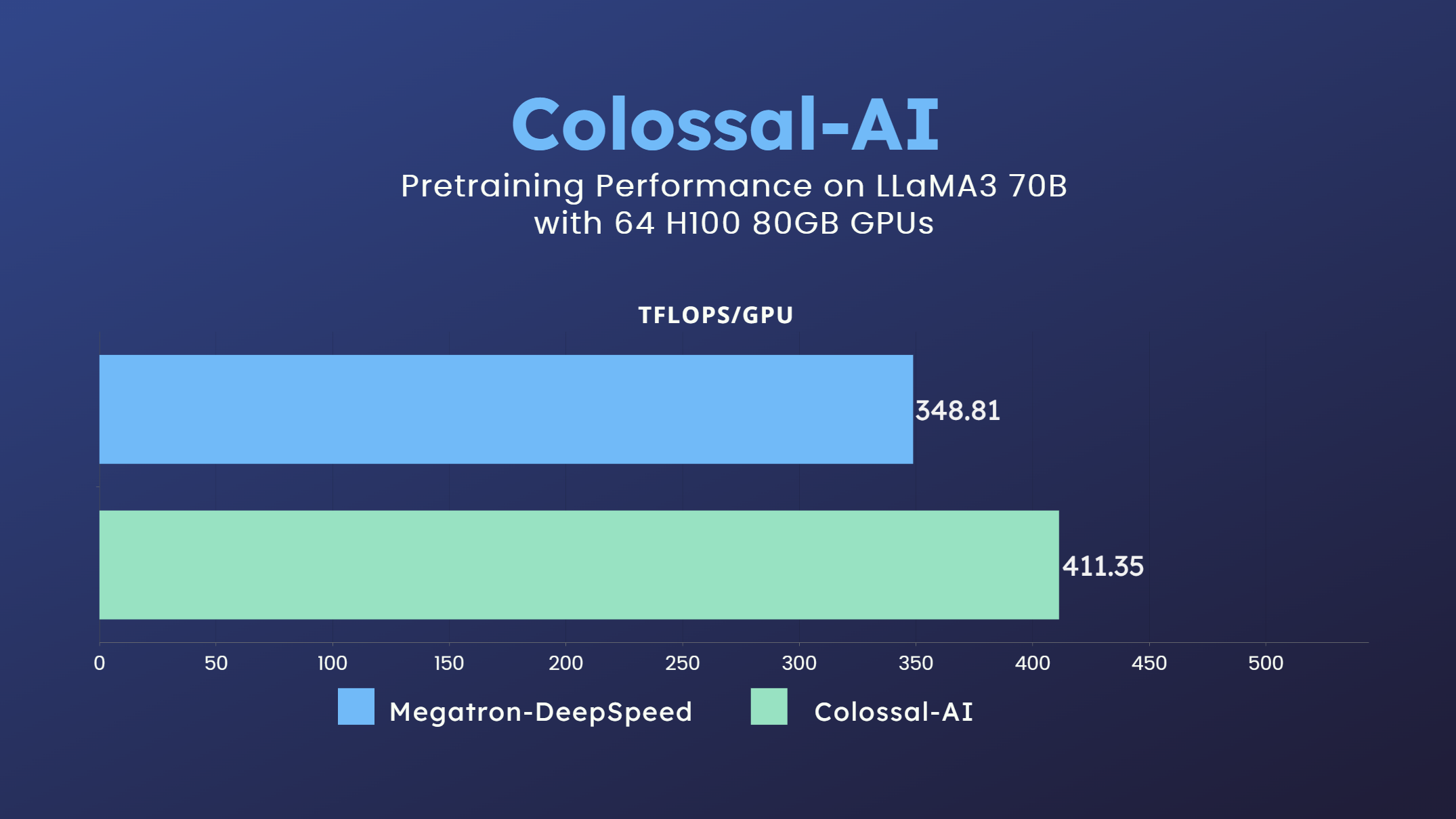
- 700亿参数的LLaMA3模型训练加速18% [代码] [GPU云平台] [LLaMA3图像]
LLaMA2
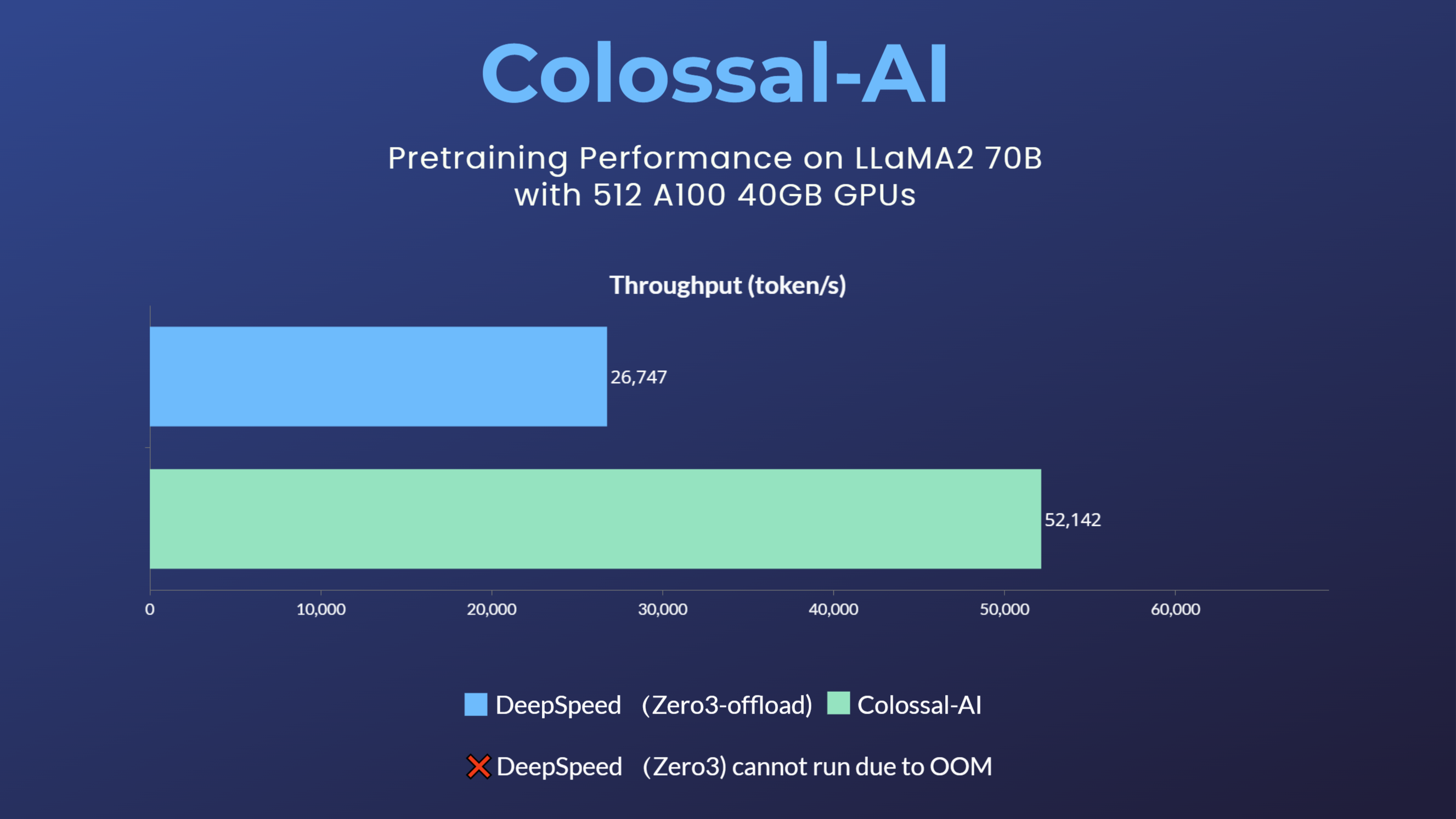
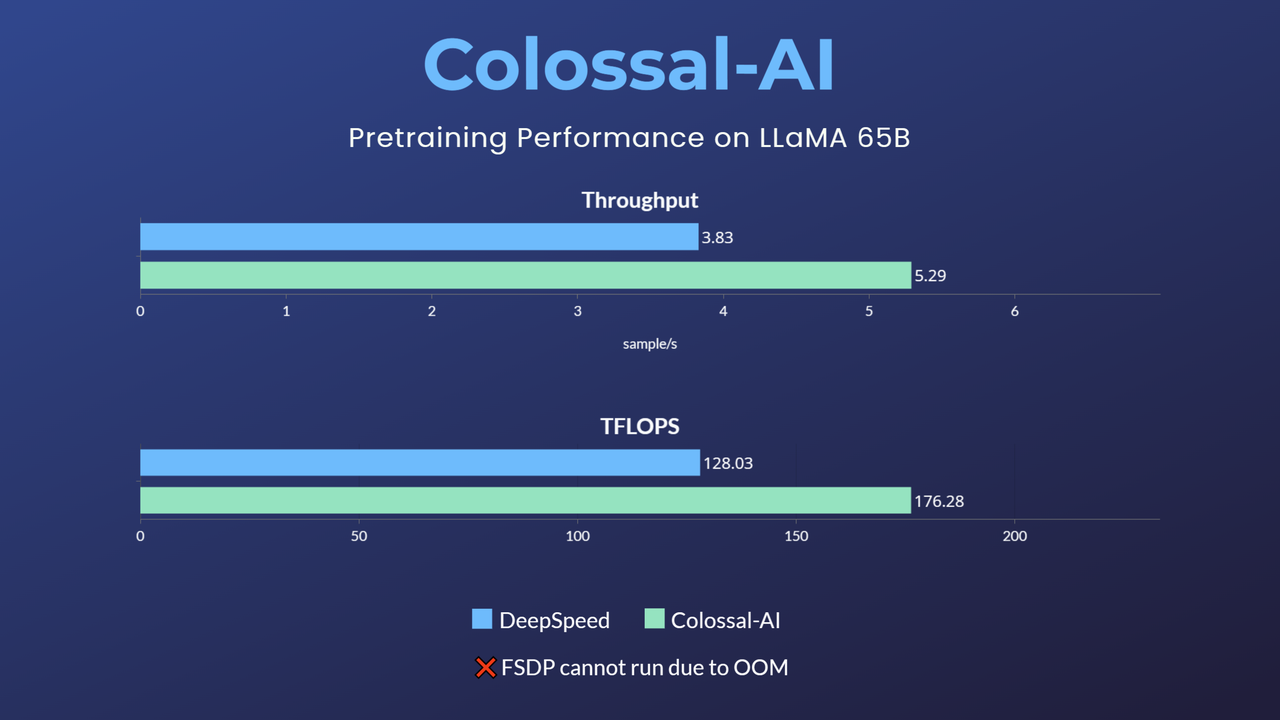
LLaMA1
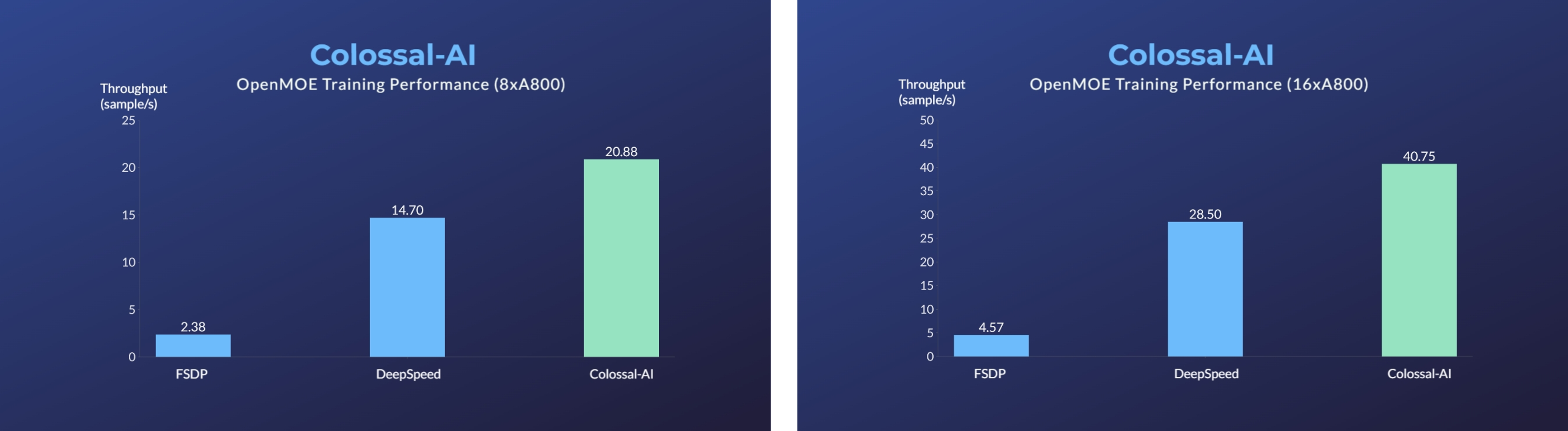
MoE
GPT-3
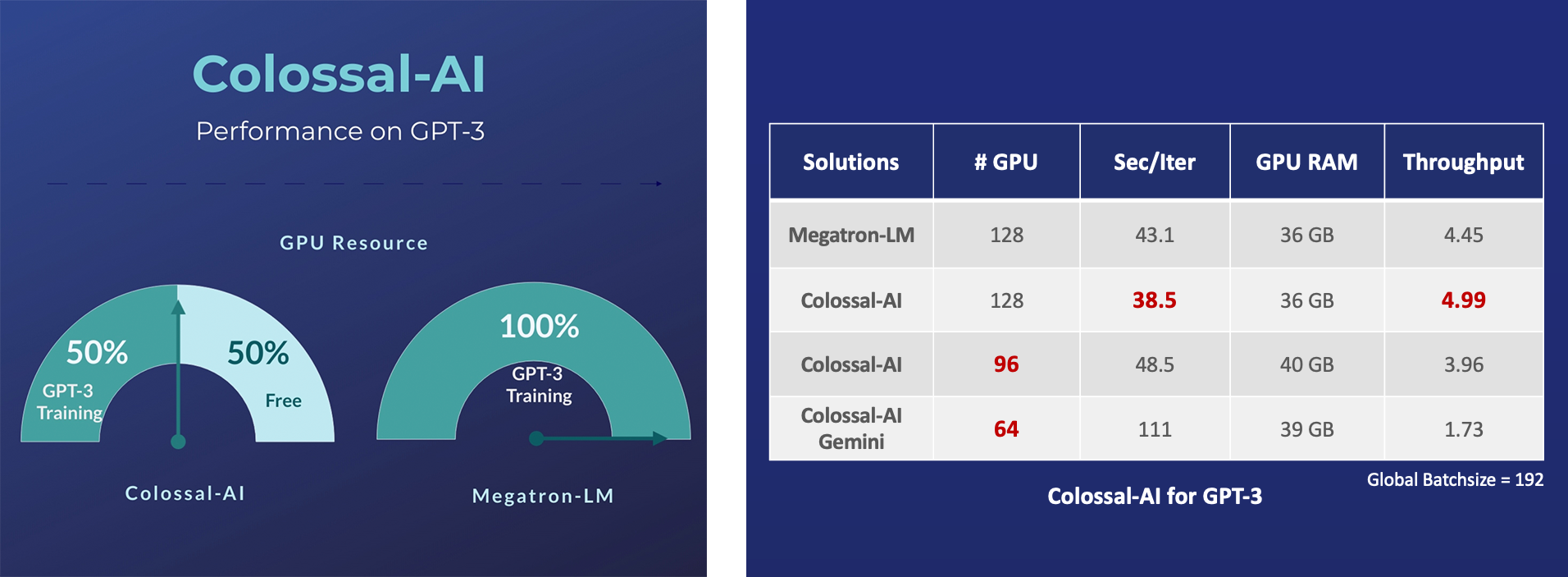
- 节省50%的GPU资源,并实现10.7%的加速
GPT-2
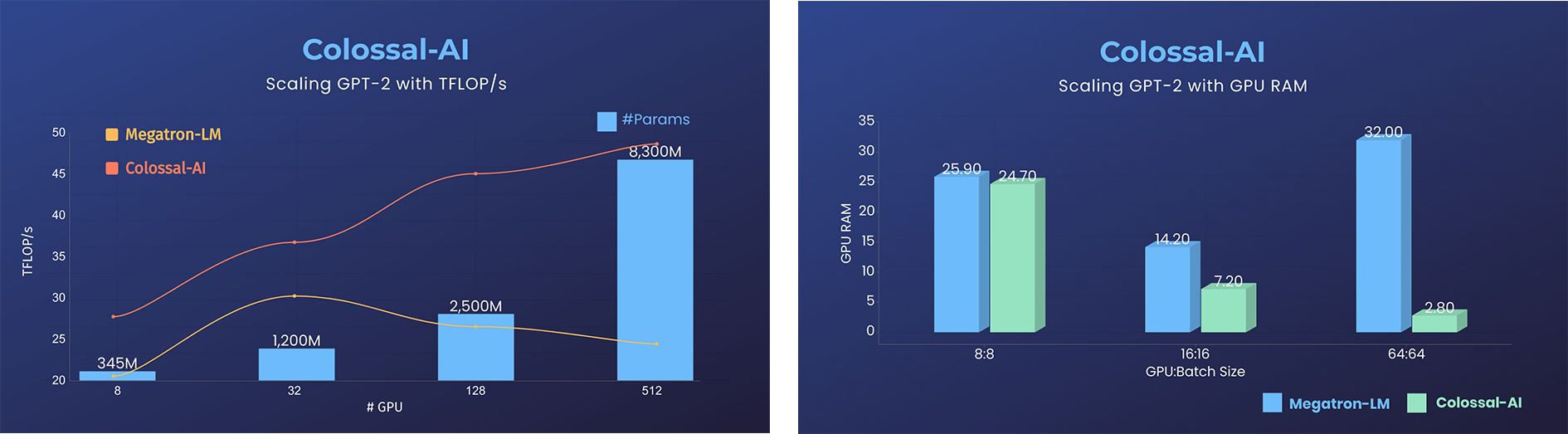
- 显存消耗降低11倍,且采用张量并行时具有超线性扩展效率
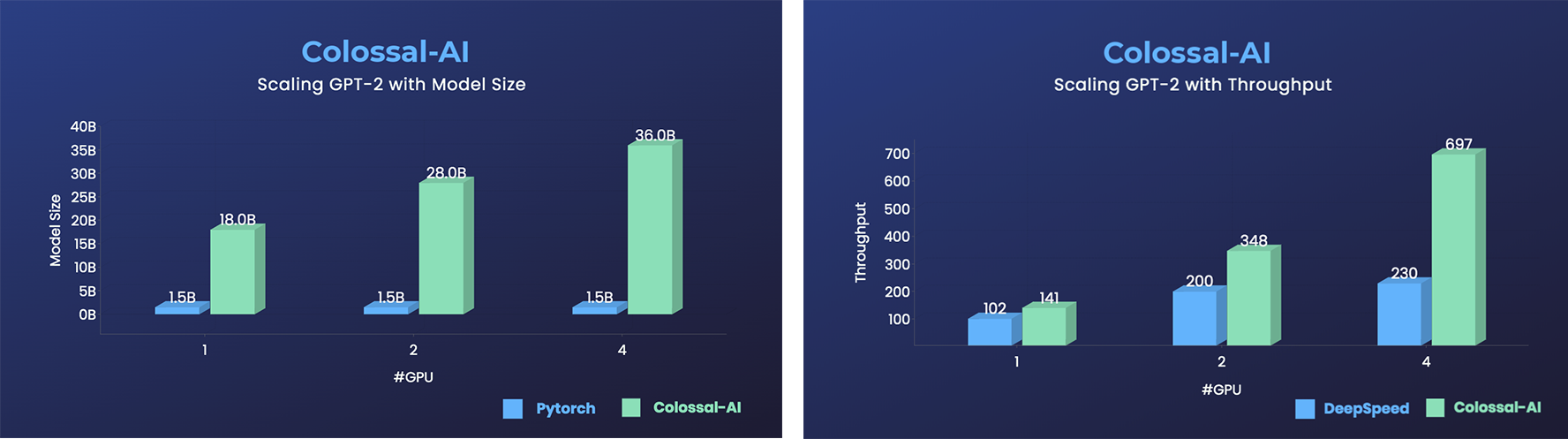
- 在相同硬件条件下,模型规模扩大24倍
- 加速超过3倍
BERT
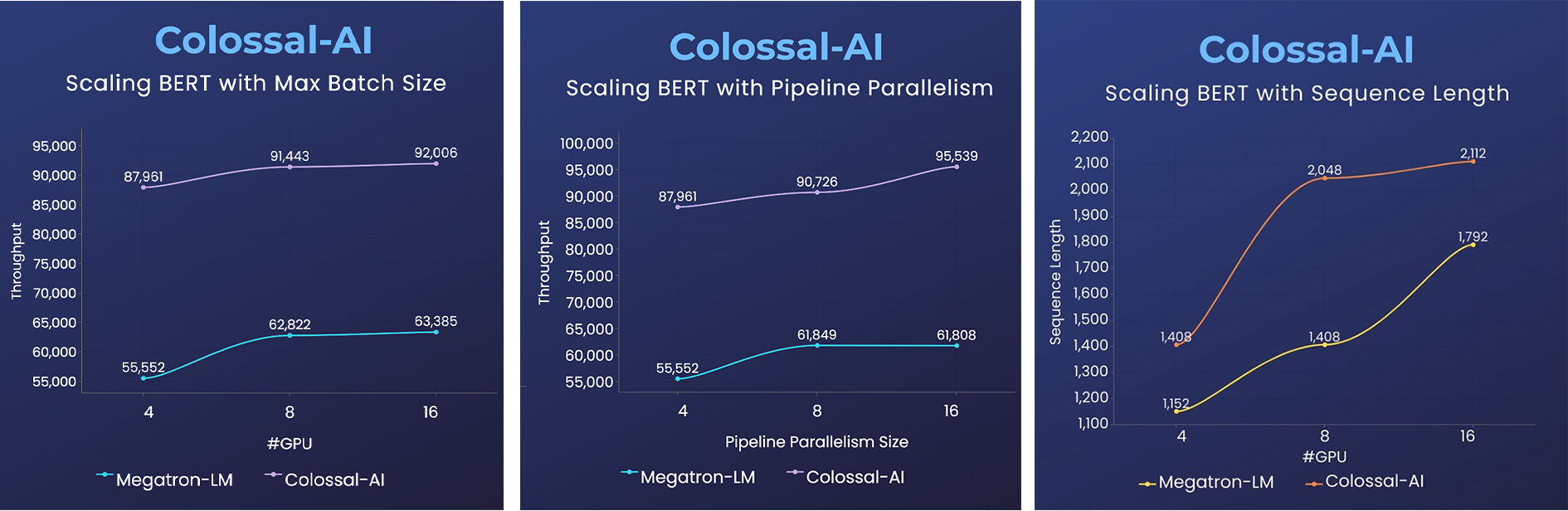
- 训练速度提升2倍,或序列长度延长50%
PaLM
- PaLM-colossalai:谷歌Pathways语言模型(PaLM)的可扩展实现。
OPT
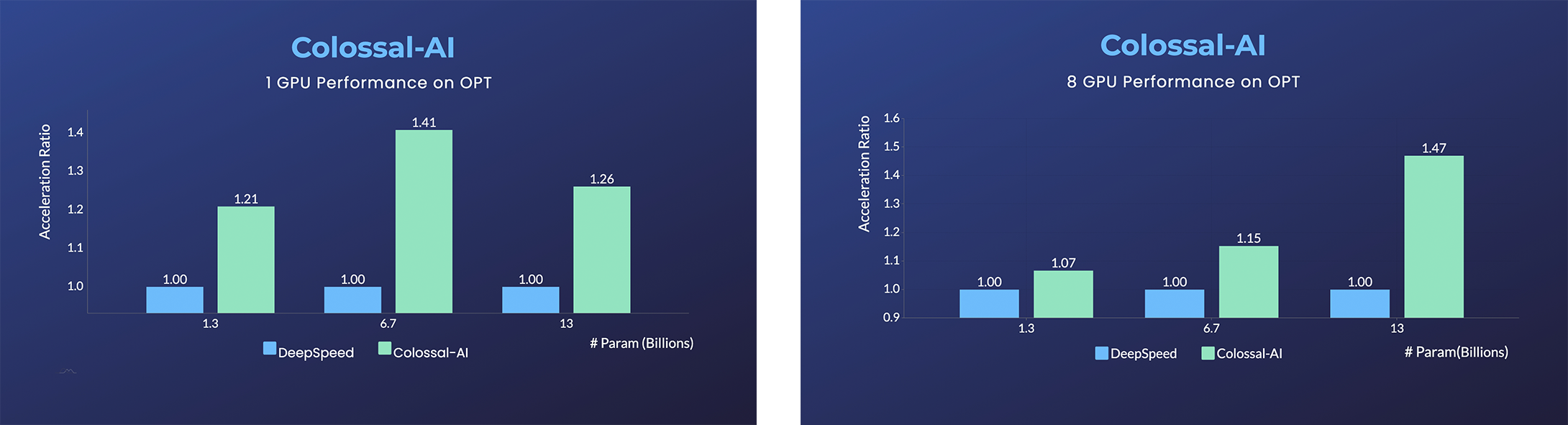
- Open Pretrained Transformer (OPT),由Meta发布的1750亿参数AI语言模型,其公开的预训练权重激发了AI开发者进行各种下游任务和应用部署。
- 以较低的代码成本实现OPT微调速度提升45%。[示例] [在线推理]
ViT
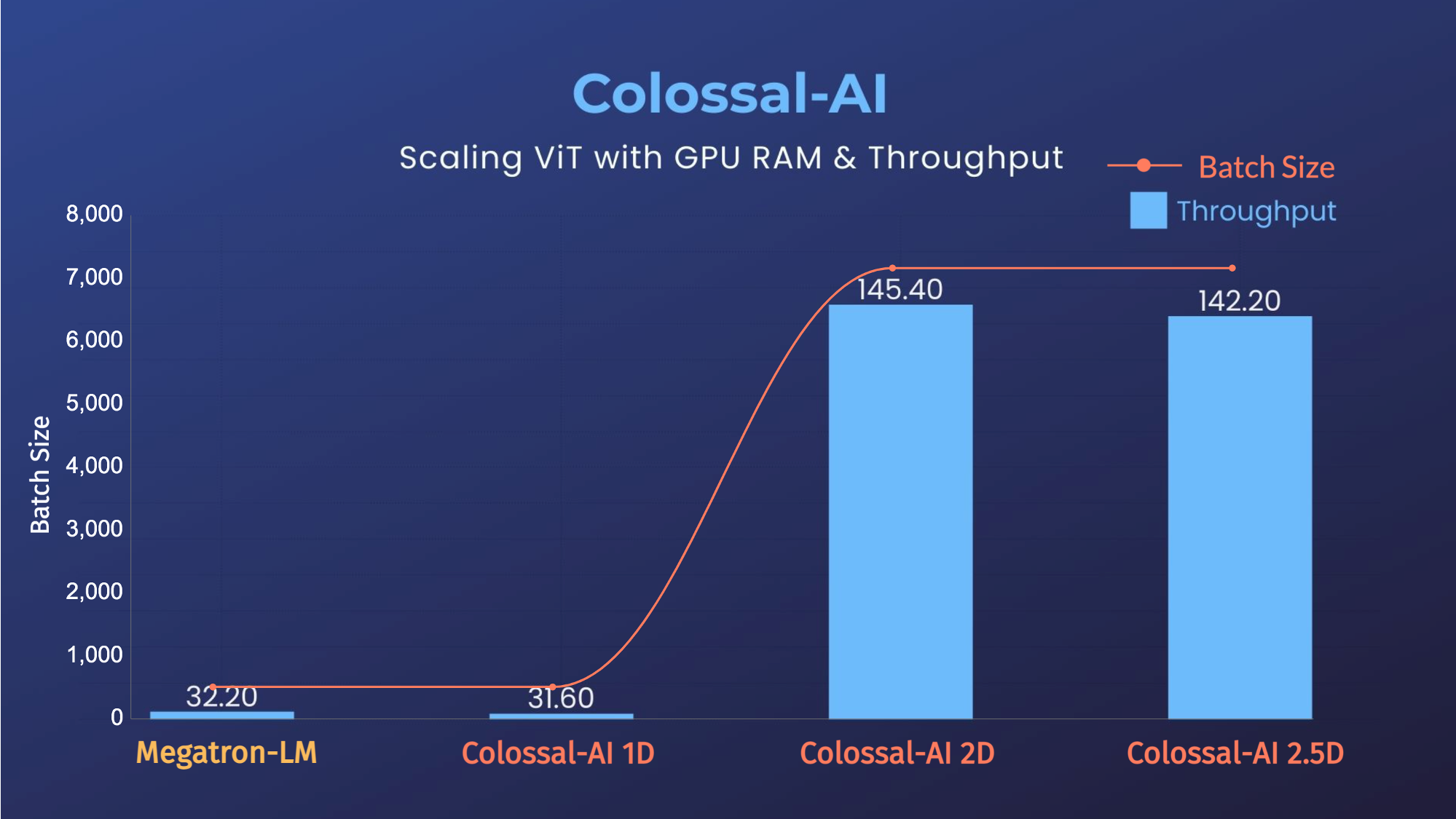
- 对于张量并行度为64的情况,批量大小扩大14倍,训练速度提升5倍。
推荐系统模型
- Cached Embedding,利用软件缓存技术,在较小的GPU显存预算下训练更大的嵌入表。
(返回顶部)
单GPU训练演示
GPT-2
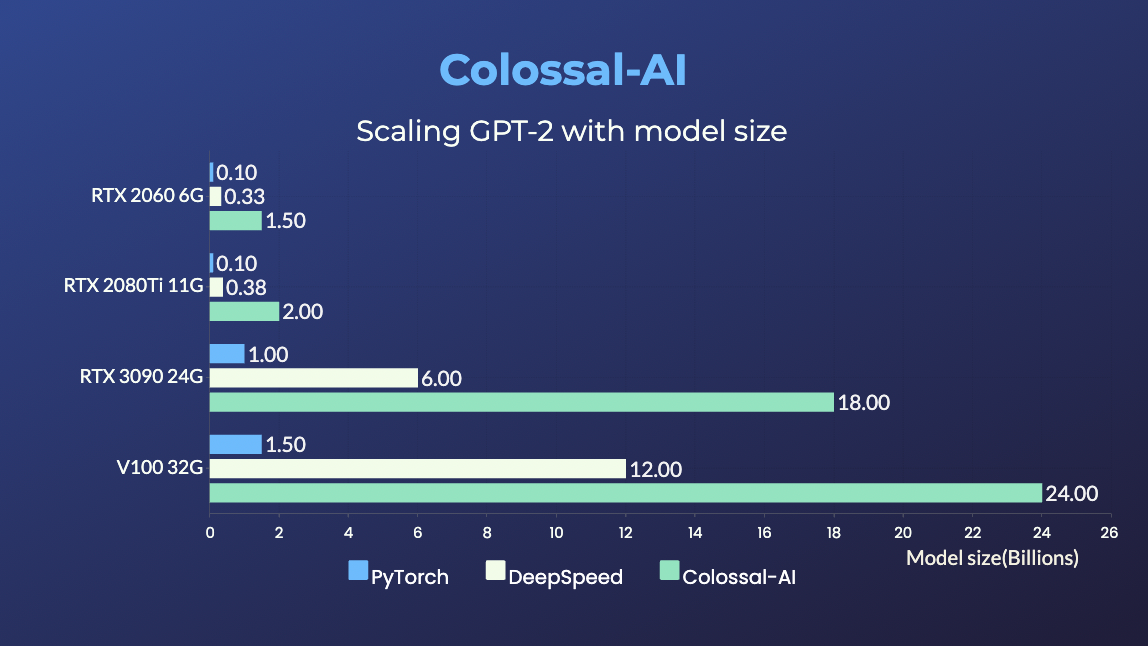
- 在相同硬件上,模型规模扩大20倍。
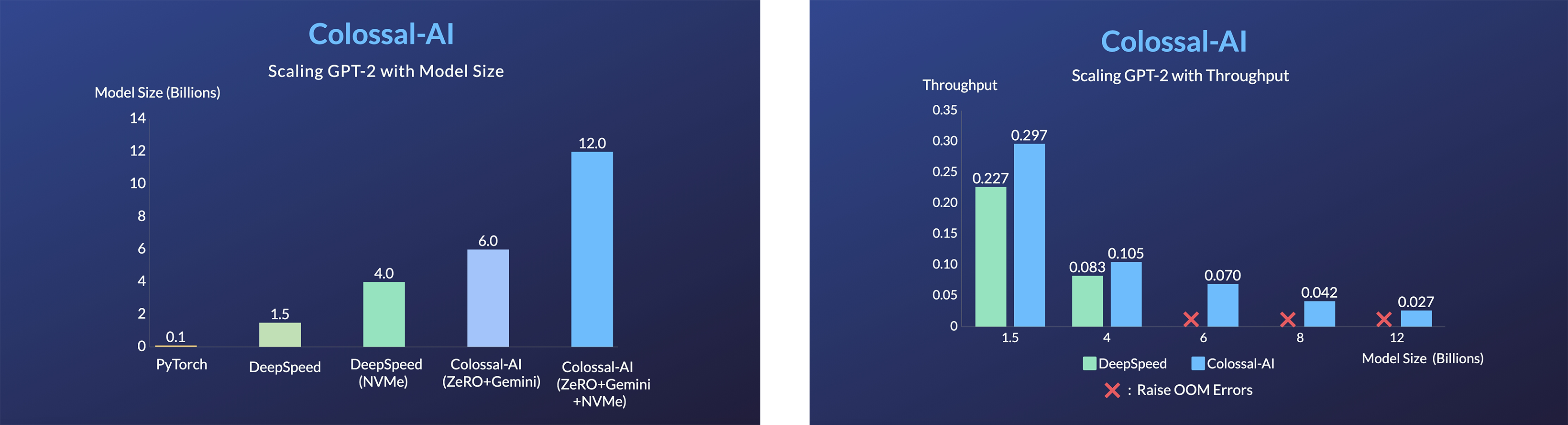
- 在相同硬件(RTX 3080)上,模型规模扩大120倍。
PaLM
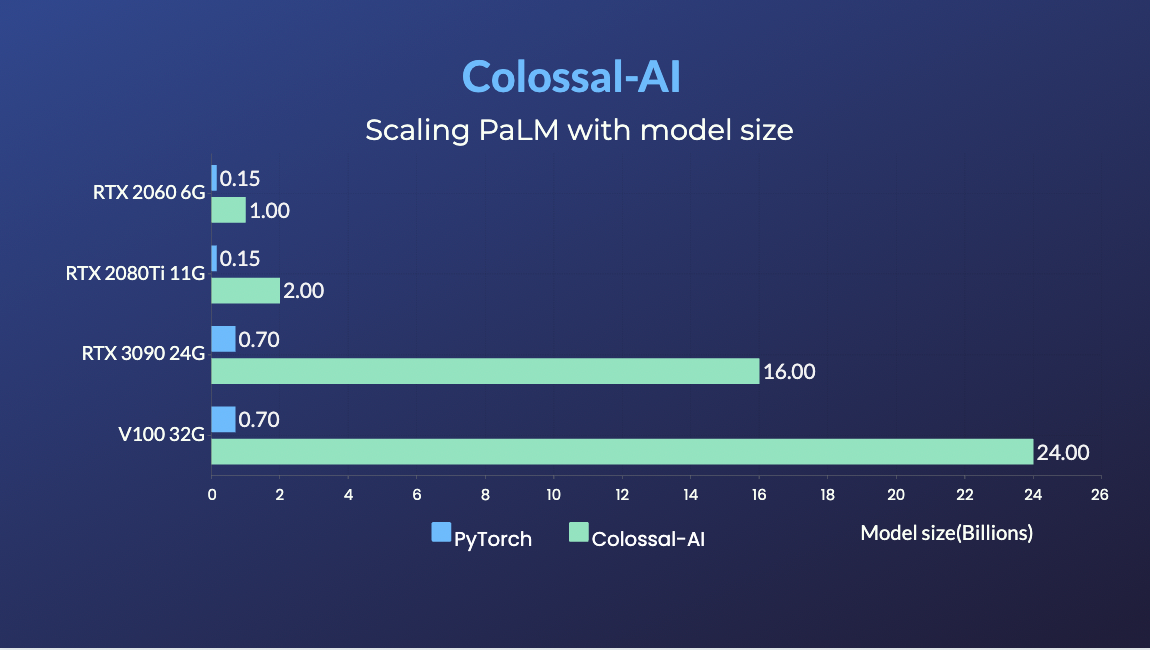
- 在相同硬件上,模型规模扩大34倍。
(返回顶部)
推理
Colossal-Inference
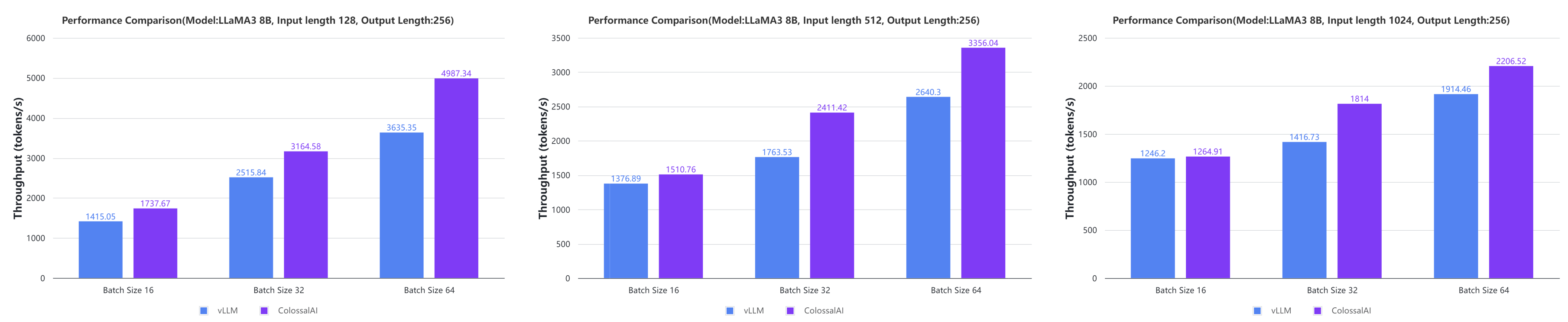
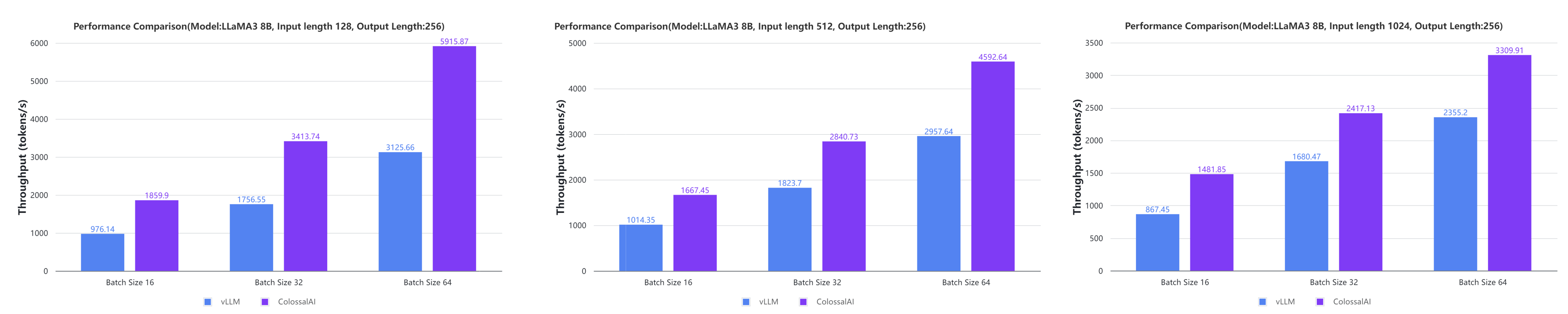
- 在某些情况下,大型AI模型的推理速度相比vLLM的离线推理性能提升了一倍。 [代码] [博客] [GPU云平台] [LLaMA3图像]
Grok-1
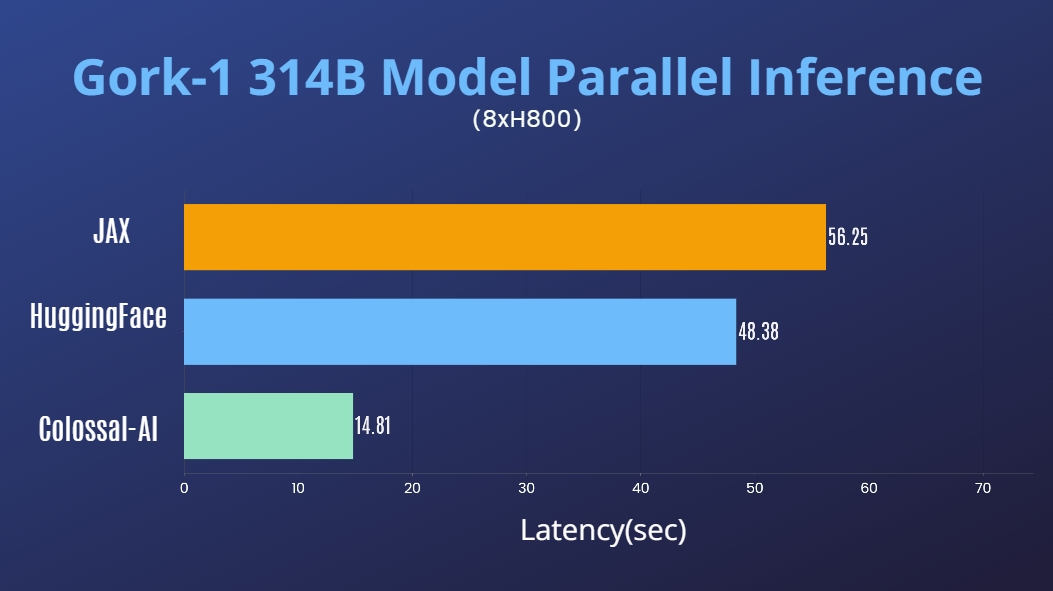
- 3140亿参数的Grok-1推理加速3.8倍,提供易于使用的Python + PyTorch + HuggingFace版本用于推理。
[代码] [博客] [HuggingFace Grok-1 PyTorch模型权重] [ModelScope Grok-1 PyTorch模型权重]
SwiftInfer
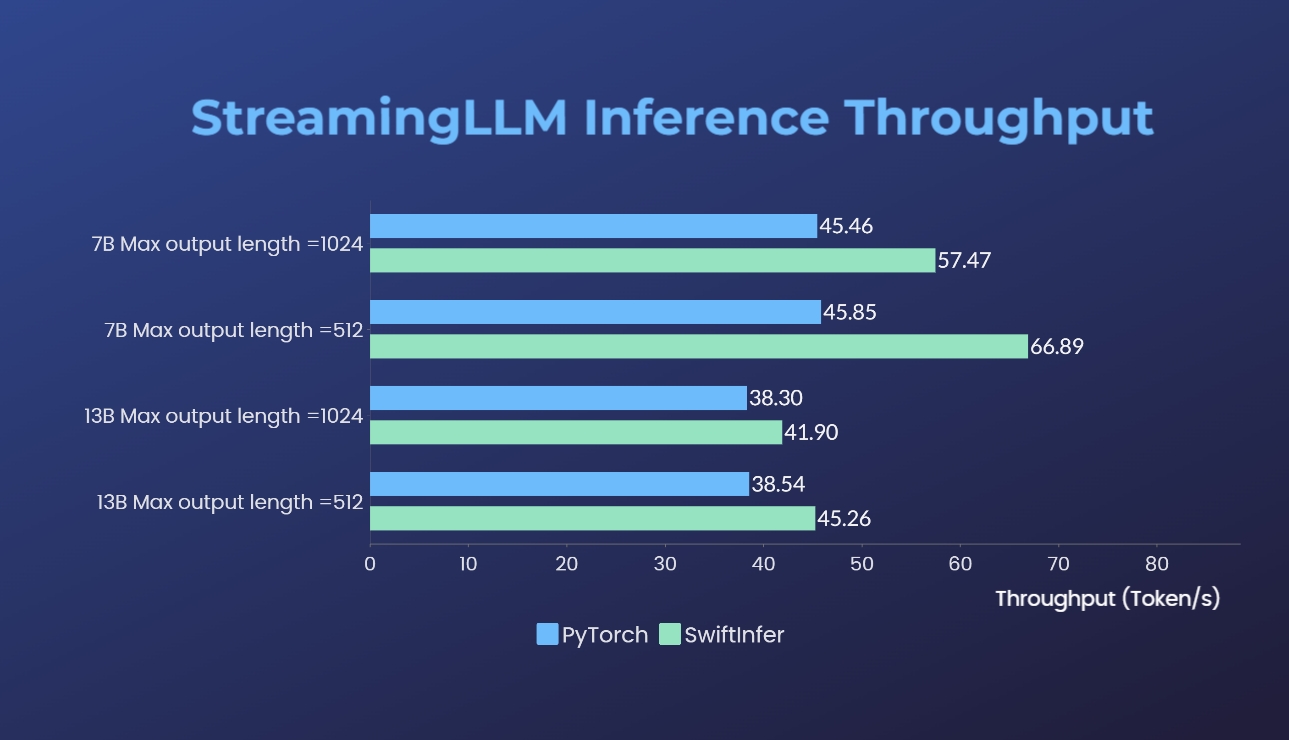
- SwiftInfer:推理性能提升46%,开源解决方案突破了LLM在多轮对话中的长度限制。
(返回顶部)
安装
要求:
- PyTorch ≥ 2.2
- Python ≥ 3.7
- CUDA ≥ 11.0
- NVIDIA GPU计算能力 ≥ 7.0(V100/RTX20及以上)
- Linux操作系统
如果在安装过程中遇到任何问题,您可以在本仓库中提交issue。
通过PyPI安装
您可以使用以下命令轻松安装Colossal-AI。默认情况下,我们在安装时不会构建PyTorch扩展。
pip install colossalai
注意:目前仅支持Linux系统。
然而,如果您希望在安装时构建PyTorch扩展,可以设置BUILD_EXT=1。
BUILD_EXT=1 pip install colossalai
否则,CUDA内核将在您实际需要时于运行时构建。
我们每周还会向PyPI发布夜间版本,使您能够体验主分支中尚未发布的功能和错误修复。 可通过以下命令进行安装:
pip install colossalai-nightly
从源码下载
Colossal-AI的版本将与仓库的主分支保持一致。如遇任何问题,请随时提出issue。:)
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI
# 安装colossalai
pip install .
默认情况下,我们不会编译CUDA/C++内核。ColossalAI会在运行时构建它们。 如果您希望安装并启用CUDA内核融合(使用融合优化器时必须安装):
BUILD_EXT=1 pip install .
对于使用CUDA 10.2的用户,仍然可以从源码构建ColossalAI。不过,您需要手动下载cub库并将其复制到相应目录。
# 克隆仓库
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI
# 下载cub库
wget https://github.com/NVIDIA/cub/archive/refs/tags/1.8.0.zip
unzip 1.8.0.zip
cp -r cub-1.8.0/cub/ colossalai/kernel/cuda_native/csrc/kernels/include/
# 安装
BUILD_EXT=1 pip install .
(返回顶部)
使用Docker
从DockerHub拉取
您可以直接从我们的DockerHub页面拉取Docker镜像。每次发布时,镜像都会自动上传。
Build On Your Own
Run the following command to build a docker image from Dockerfile provided.
Building Colossal-AI from scratch requires GPU support, you need to use Nvidia Docker Runtime as the default when doing
docker build. More details can be found here. We recommend you install Colossal-AI from our project page directly.
cd ColossalAI
docker build -t colossalai ./docker
Run the following command to start the docker container in interactive mode.
docker run -ti --gpus all --rm --ipc=host colossalai bash
Community
Join the Colossal-AI community on Forum, Slack, and WeChat(微信) to share your suggestions, feedback, and questions with our engineering team.
Contributing
Referring to the successful attempts of BLOOM and Stable Diffusion, any and all developers and partners with computing powers, datasets, models are welcome to join and build the Colossal-AI community, making efforts towards the era of big AI models!
You may contact us or participate in the following ways:
- Leaving a Star ⭐ to show your like and support. Thanks!
- Posting an issue, or submitting a PR on GitHub follow the guideline in Contributing
- Send your official proposal to email contact@hpcaitech.com
Thanks so much to all of our amazing contributors!

CI/CD
We leverage the power of GitHub Actions to automate our development, release and deployment workflows. Please check out this documentation on how the automated workflows are operated.
Cite Us
This project is inspired by some related projects (some by our team and some by other organizations). We would like to credit these amazing projects as listed in the Reference List.
To cite this project, you can use the following BibTeX citation.
@inproceedings{10.1145/3605573.3605613,
author = {Li, Shenggui and Liu, Hongxin and Bian, Zhengda and Fang, Jiarui and Huang, Haichen and Liu, Yuliang and Wang, Boxiang and You, Yang},
title = {Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training},
year = {2023},
isbn = {9798400708435},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3605573.3605613},
doi = {10.1145/3605573.3605613},
abstract = {The success of Transformer models has pushed the deep learning model scale to billions of parameters, but the memory limitation of a single GPU has led to an urgent need for training on multi-GPU clusters. However, the best practice for choosing the optimal parallel strategy is still lacking, as it requires domain expertise in both deep learning and parallel computing. The Colossal-AI system addressed the above challenge by introducing a unified interface to scale your sequential code of model training to distributed environments. It supports parallel training methods such as data, pipeline, tensor, and sequence parallelism and is integrated with heterogeneous training and zero redundancy optimizer. Compared to the baseline system, Colossal-AI can achieve up to 2.76 times training speedup on large-scale models.},
booktitle = {Proceedings of the 52nd International Conference on Parallel Processing},
pages = {766–775},
numpages = {10},
keywords = {datasets, gaze detection, text tagging, neural networks},
location = {Salt Lake City, UT, USA},
series = {ICPP '23}
}
Colossal-AI has been accepted as official tutorial by top conferences NeurIPS, SC, AAAI, PPoPP, CVPR, ISC, NVIDIA GTC ,etc.
版本历史
v0.5.02025/06/04v0.4.92025/03/04v0.4.82025/02/20v0.4.72025/01/03v0.4.62024/11/04v0.4.52024/10/21v0.4.42024/09/19v0.4.32024/09/10v0.4.22024/07/31v0.4.12024/07/17v0.4.02024/06/28v0.3.92024/06/20v0.3.82024/05/31v0.3.72024/04/27v0.3.62024/03/07v0.3.52024/02/23v0.3.42023/11/01v0.3.32023/09/22v0.3.22023/09/06v0.3.12023/08/01常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器