Awesome-Efficient-LLM
Awesome-Efficient-LLM 是一个专为高效大语言模型(LLM)打造的精选资源库,旨在汇集学术界与工业界在模型轻量化领域的最新成果。随着大模型规模日益庞大,其高昂的计算成本、显存占用及推理延迟成为落地应用的主要瓶颈。Awesome-Efficient-LLM 通过系统性地整理前沿论文、开源代码及技术综述,为开发者提供了一套完整的优化解决方案。
该资源库覆盖了从模型训练到部署的全链路优化技术,包括网络剪枝、知识蒸馏、量化压缩、推理加速、混合专家模型(MoE)优化、KV 缓存压缩以及低秩分解等核心方向。此外,它还特别关注硬件适配、高效微调及新兴的高效推理模型研究,并定期更新高引用的推荐论文。
无论是致力于算法创新的研究人员,还是需要将大模型部署到资源受限环境的工程师,都能在这里快速找到所需的技术路径和参考实现。通过追踪这一动态更新的列表,用户可以轻松掌握如何在不显著牺牲模型性能的前提下,大幅降低算力需求,推动大模型在更多场景下的高效应用。
使用场景
某初创团队试图将开源的 70B 参数大语言模型部署到仅有单张消费级显卡的边缘服务器上,以构建低成本的智能客服系统。
没有 Awesome-Efficient-LLM 时
- 选型迷茫:面对海量的模型压缩论文(如剪枝、量化、蒸馏),团队花费数周盲目试错,难以判断哪些技术适合当前硬件。
- 显存爆炸:直接加载全精度模型导致显存瞬间溢出,无法进行任何推理,且缺乏针对 KV Cache 压缩的有效方案。
- 推理迟缓:勉强运行的模型响应延迟高达数秒,完全无法满足客服场景对实时互动的要求。
- 微调成本过高:尝试全量微调时,因缺乏高效微调(Efficient Fine-tuning)指导,训练资源消耗超出预算十倍。
使用 Awesome-Efficient-LLM 后
- 精准导航:团队通过"Quantization"和"Hardware/Serving"分类,迅速锁定了适合消费级显卡的 4-bit 量化方案及推理加速框架。
- 显存优化:参考"KV Cache Compression"板块的最新论文,成功将长上下文对话的显存占用降低了 60%,模型顺利加载。
- 极速响应:应用"Inference Acceleration"列表中的优化算子,将首字生成延迟从 3 秒压缩至 200 毫秒,体验流畅自然。
- 低成本适配:利用"Efficient Fine-tuning"推荐的 LoRA 等策略,仅用少量数据即可完成领域适配,训练成本降低 90%。
Awesome-Efficient-LLM 充当了高效大模型落地的“技术雷达”,帮助开发者在有限的算力约束下,以最低成本实现高性能的模型部署与应用。
运行环境要求
未说明
未说明

快速开始
令人惊叹的高效大语言模型
一份精选的高效大语言模型列表
完整列表
请根据您感兴趣的子领域查看所有论文。在本主页上,仅展示过去90天内发布的论文。
🚀 更新
- 2025年4月15日:我们新增了一个针对高效推理模型的精选列表!
- 2024年5月29日:这个优秀的列表已经推出一年了 :smiling_face_with_three_hearts:!
- 2023年9月6日:新增子目录project/,用于整理高效的LLM项目。
- 2023年7月11日:创建了一个新的子目录efficient_plm/,用于存放适用于PLM的论文。
💮 贡献
如果您希望将您的论文加入列表,或者需要更新会议信息、代码链接等细节,请随时提交拉取请求。您可以通过填写generate_item.py中的信息并运行python generate_item.py来生成每篇论文所需的Markdown格式。我们非常感谢您对本列表的贡献。此外,您也可以通过邮件将您的论文和代码链接发送给我,我会尽快将您的论文添加到列表中。
:star: 推荐论文
针对每个主题,我们都精选了一些获得了大量GitHub星标或引用的推荐论文。
2024年9月30日至今的论文(完整列表自2023年5月22日起见这里)
快速链接
网络剪枝 / 稀疏化
| 标题与作者 | 简介 | 链接 |
|---|---|---|
 :star: SparseGPT: 大规模语言模型可一次性准确剪枝 Elias Frantar, Dan Alistarh |
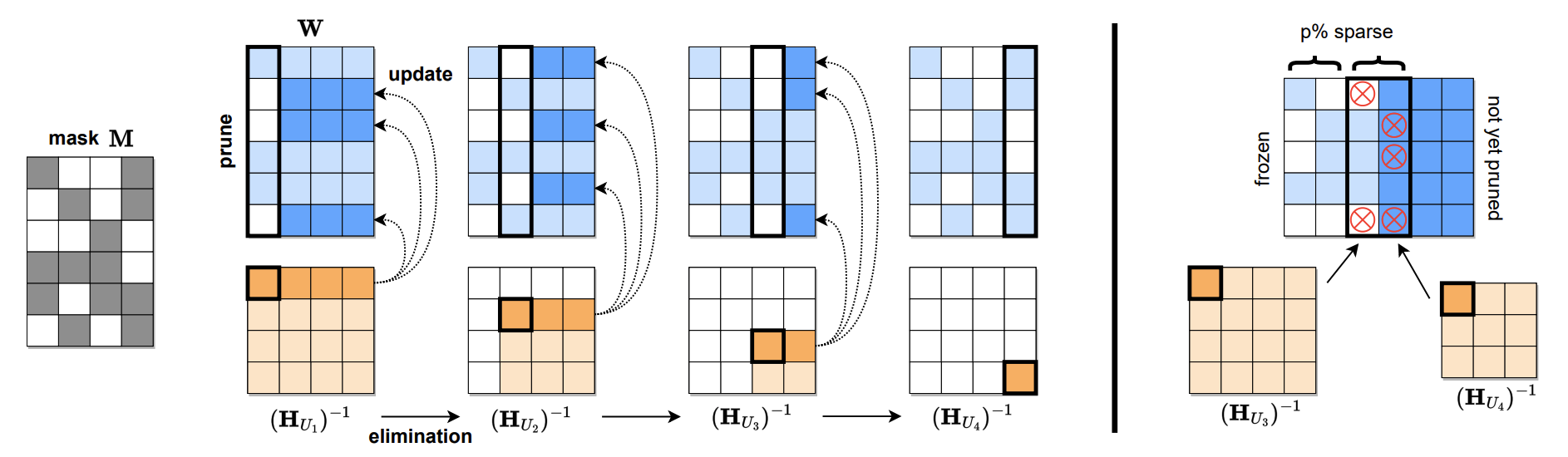 |
Github paper |
 :star: LLM-Pruner: 关于大型语言模型的结构化剪枝 Xinyin Ma, Gongfan Fang, Xinchao Wang |
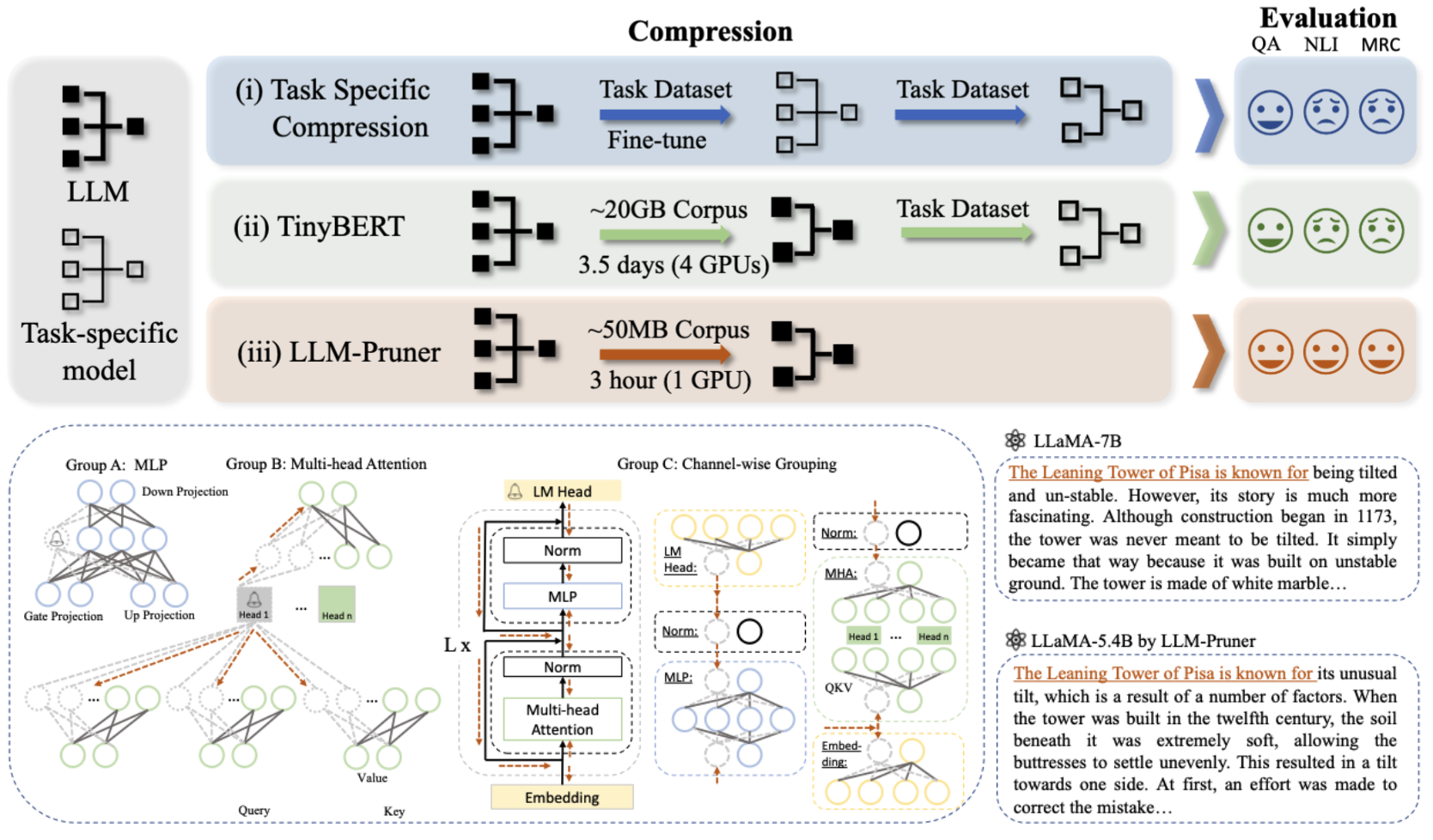 |
Github paper |
 :star: 一种简单有效的大型语言模型剪枝方法 Mingjie Sun, Zhuang Liu, Anna Bair, J. Zico Kolter |
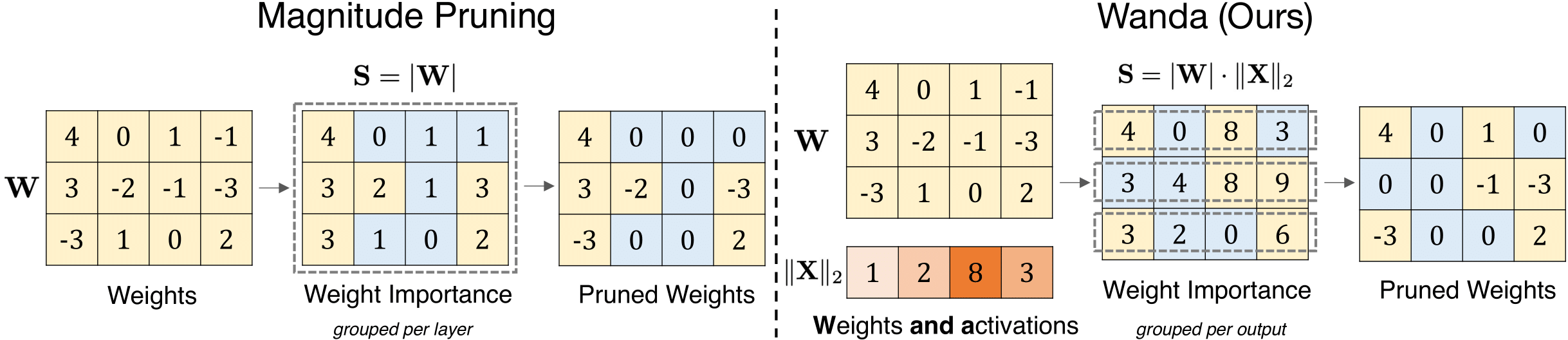 |
Github Paper |
 :star: Sheared LLaMA: 通过结构化剪枝加速语言模型预训练 Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, Danqi Chen |
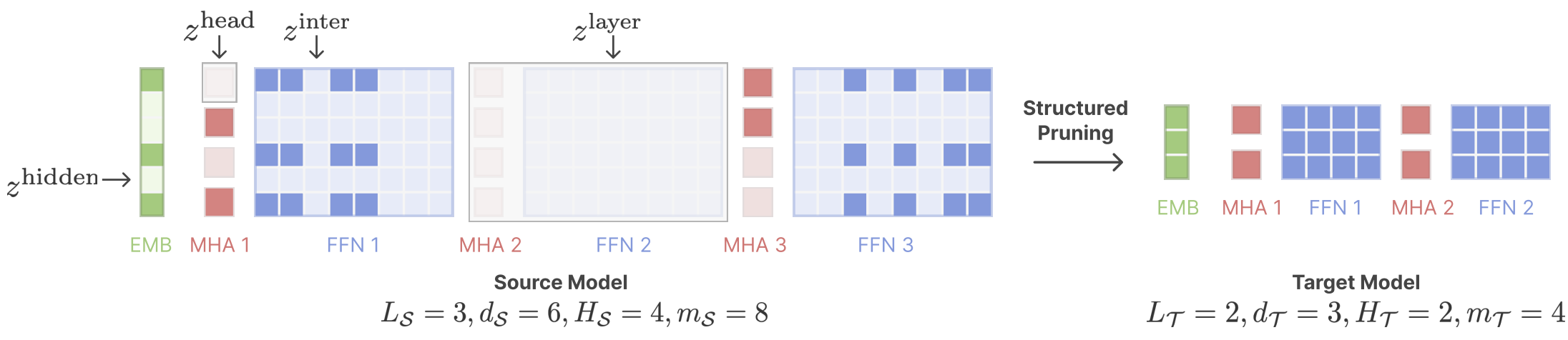 |
Github Paper |
 :star: MaskLLM: 可学习的半结构化稀疏性用于大型语言模型 Gongfan Fang, Hongxu Yin, Saurav Muralidharan, Greg Heinrich, Jeff Pool, Jan Kautz, Pavlo Molchanov, Xinchao Wang |
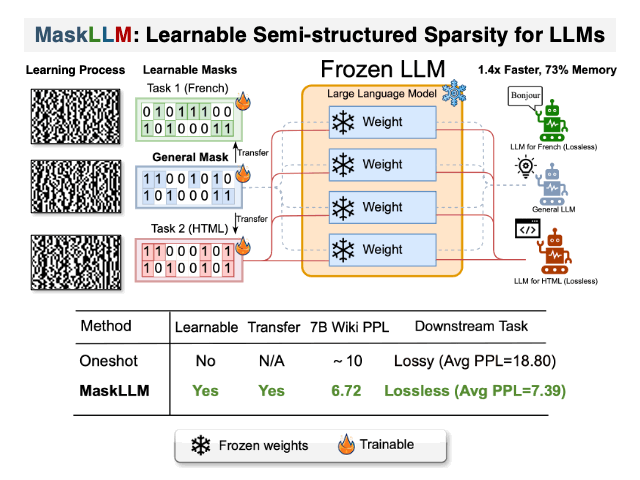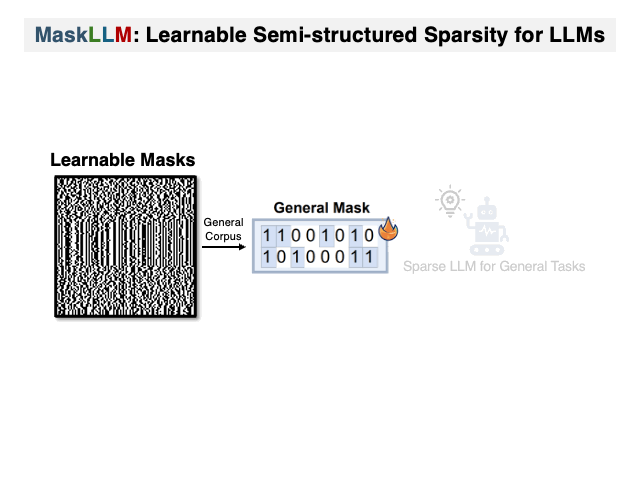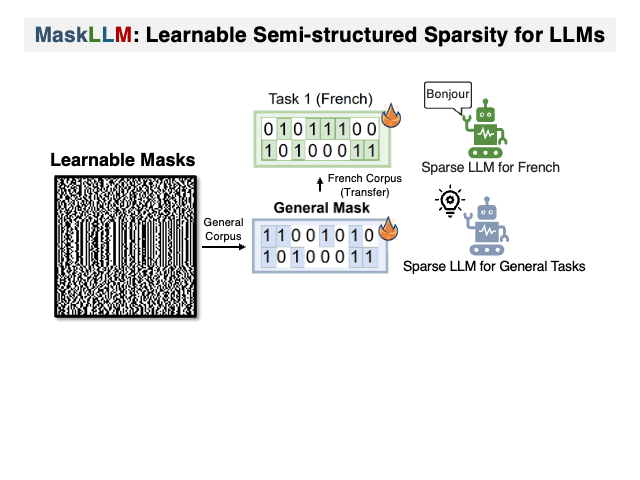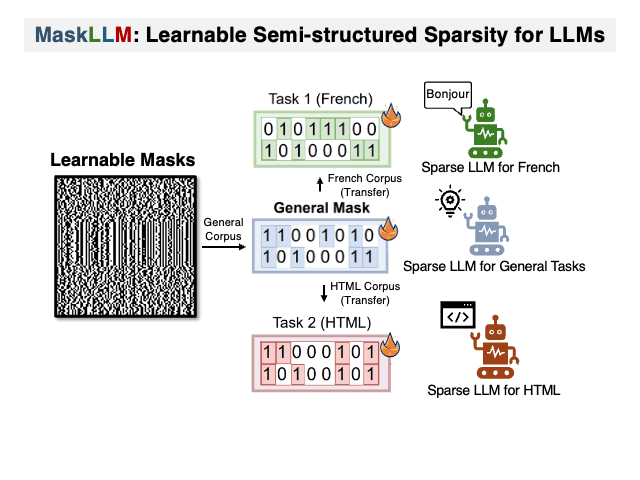 |
Github Paper |
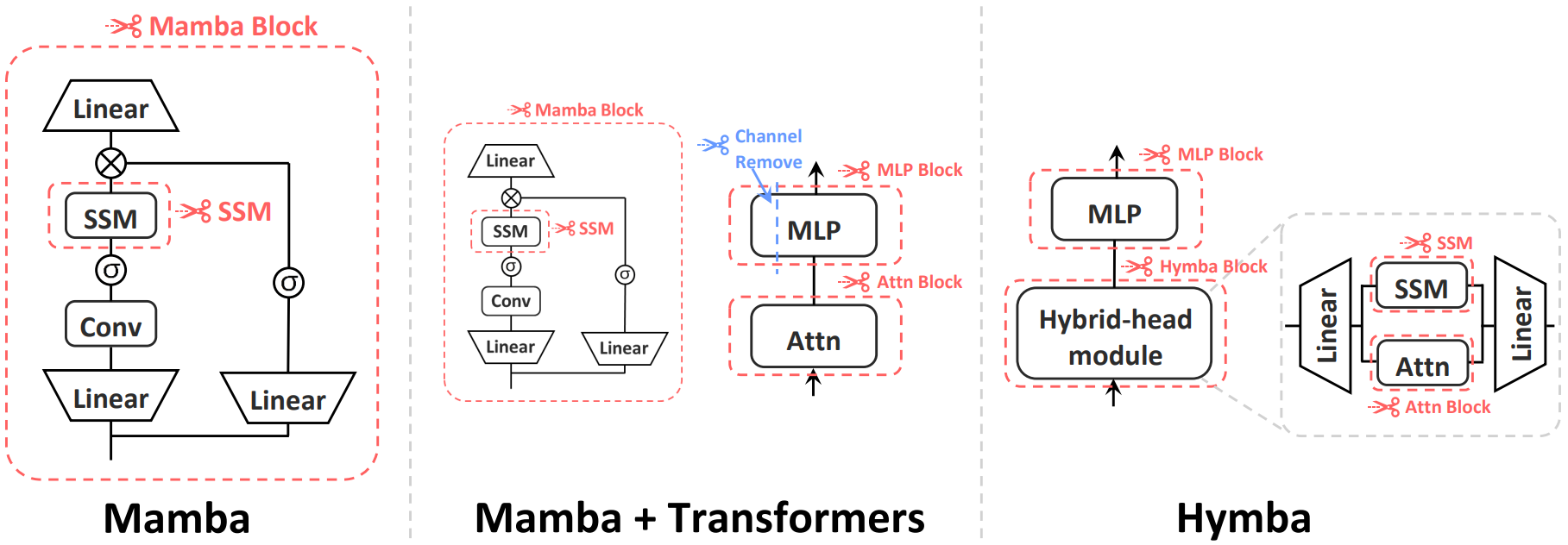
 Mamba-Shedder: 转换器后压缩,用于高效的有选择性结构化状态空间模型 Juan Pablo Munoz, Jinjie Yuan, Nilesh Jain |
 |
Github Paper |
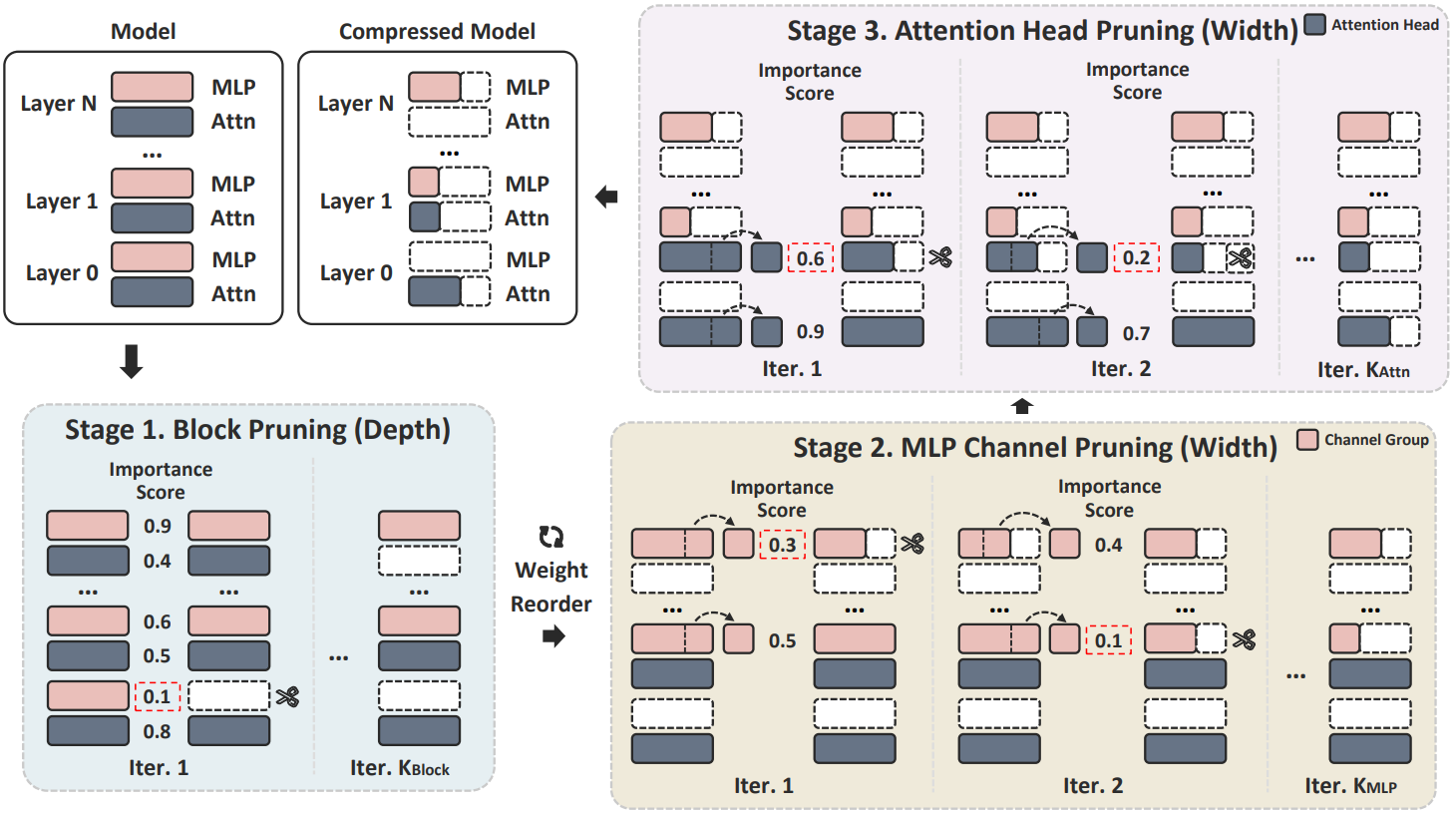
| MultiPruner: 基础模型中的均衡结构移除 Juan Pablo Munoz, Jinjie Yuan, Nilesh Jain |
 |
Github Paper |
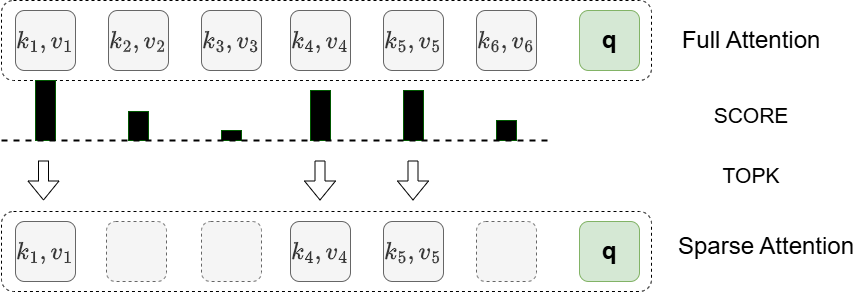
| HashAttention: 语义稀疏性以实现更快的推理 Aditya Desai, Shuo Yang, Alejandro Cuadron, Ana Klimovic, Matei Zaharia, Joseph E. Gonzalez, Ion Stoica |
 |
Paper |
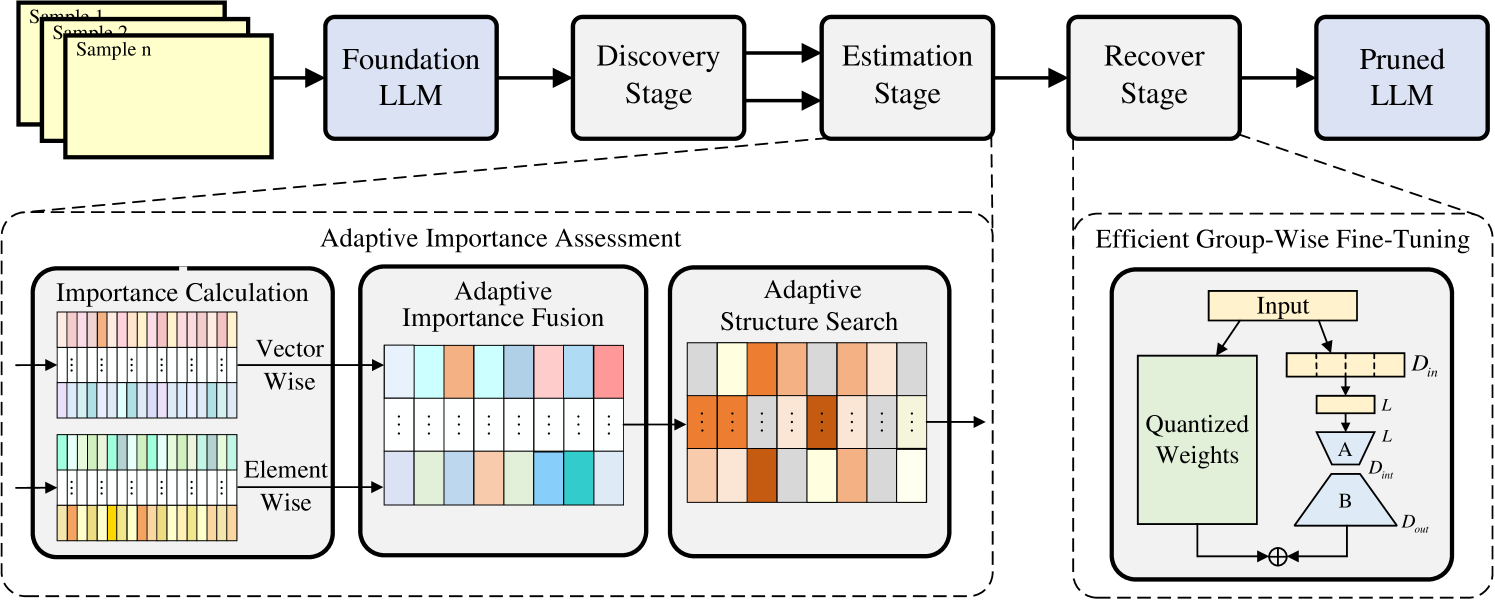
| 具有结构重要性感知的大型语言模型自适应剪枝 Haotian Zheng, Jinke Ren, Yushan Sun, Ruichen Zhang, Wenbo Zhang, Zhen Li, Dusit Niyato, Shuguang Cui, Yatong Han |
 |
Paper |
| SlimGPT: 大型语言模型的逐层结构化剪枝 Gui Ling, Ziyang Wang, Yuliang Yan, Qingwen Liu |
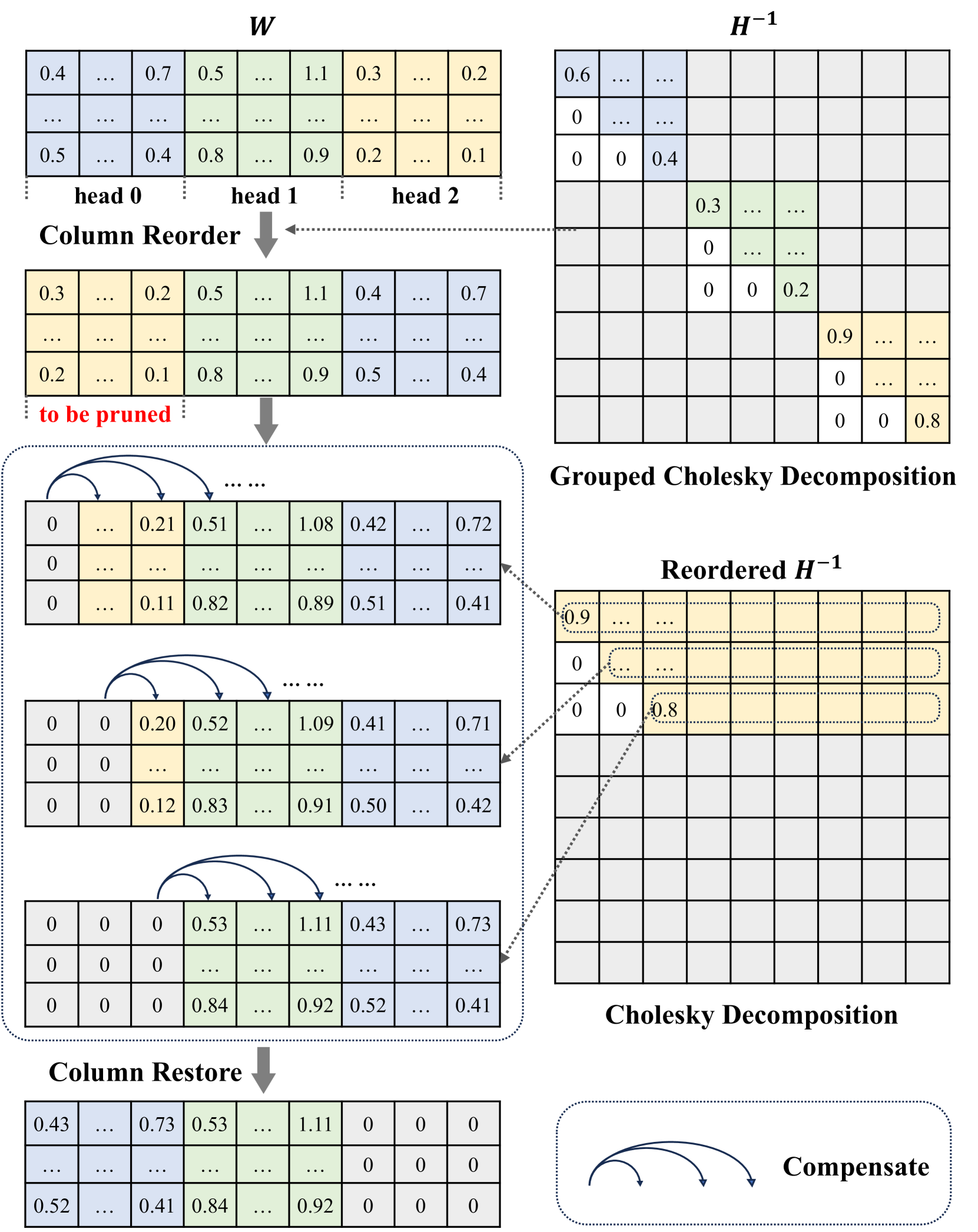 |
Paper |
| 少即是多:通过统一的结构化剪枝迈向绿色代码大型语言模型 Guang Yang, Yu Zhou, Xiangyu Zhang, Wei Cheng, Ke Liu, Xiang Chen, Terry Yue Zhuo, Taolue Chen |
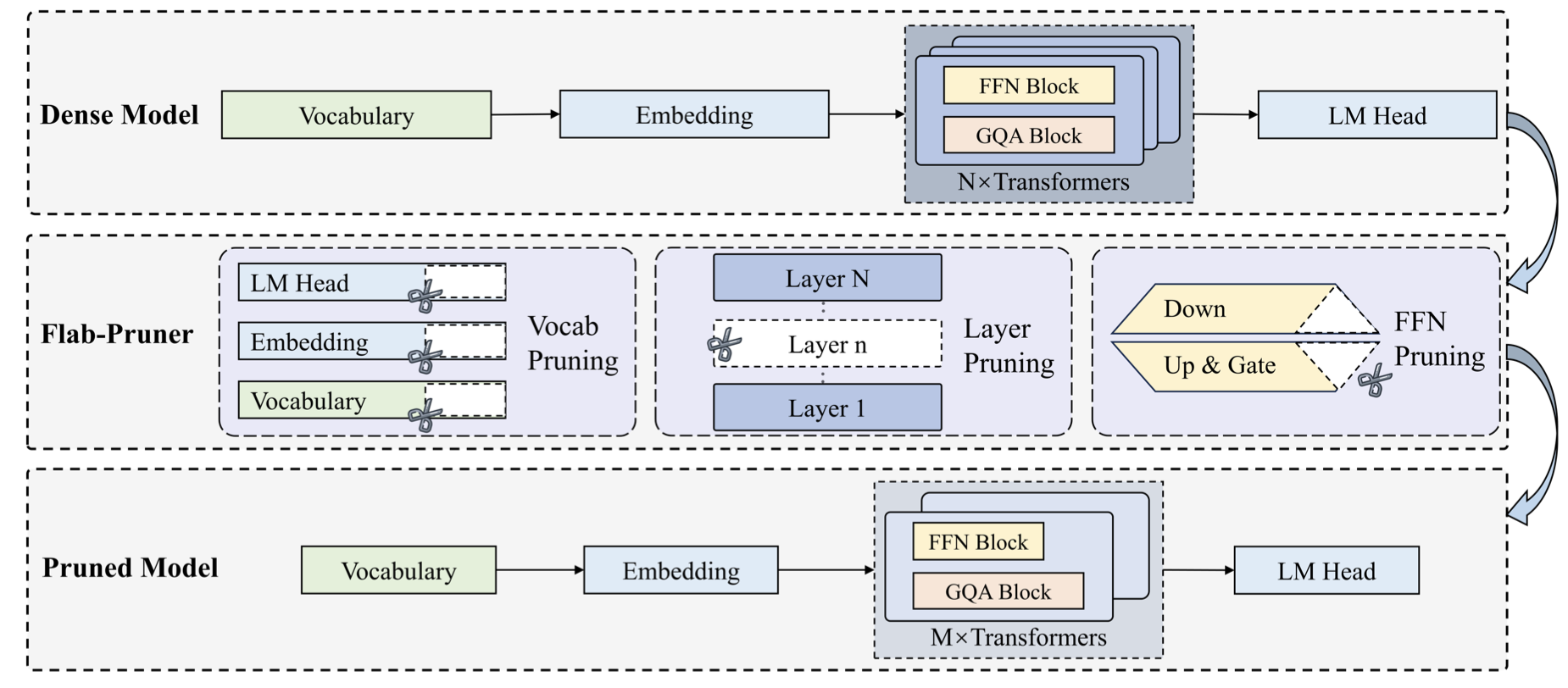 |
Paper |
| 利用动态输入剪枝和缓存感知掩码实现高效LLM推理 Marco Federici, Davide Belli, Mart van Baalen, Amir Jalalirad, Andrii Skliar, Bence Major, Markus Nagel, Paul Whatmough |
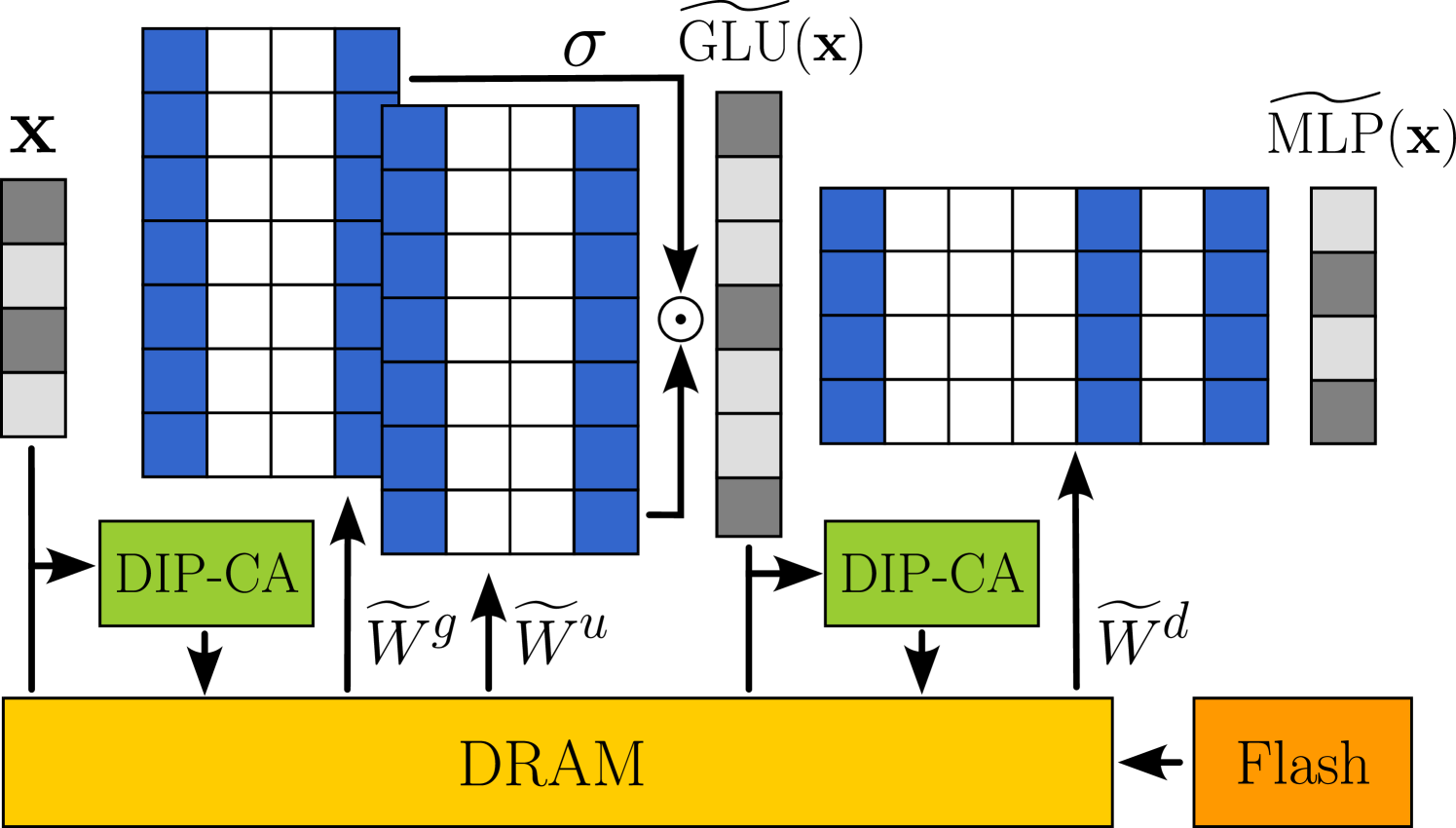 |
Paper |
| Puzzle: 基于蒸馏的NAS,用于优化推理的LLM Akhiad Bercovich, Tomer Ronen, Talor Abramovich, Nir Ailon, Nave Assaf, Mohammad Dabbah等 |
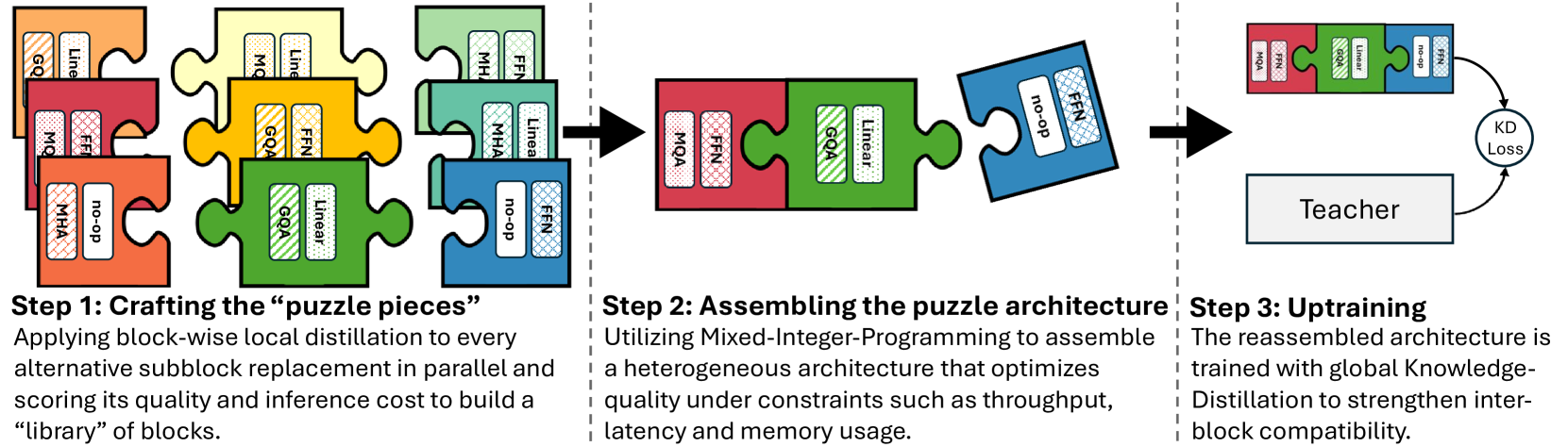 |
Paper |
 重新评估LLM中的层剪枝:新见解与方法 Yao Lu, Hao Cheng, Yujie Fang, Zeyu Wang, Jiaheng Wei, Dongwei Xu, Qi Xuan, Xiaoniu Yang, Zhaowei Zhu |
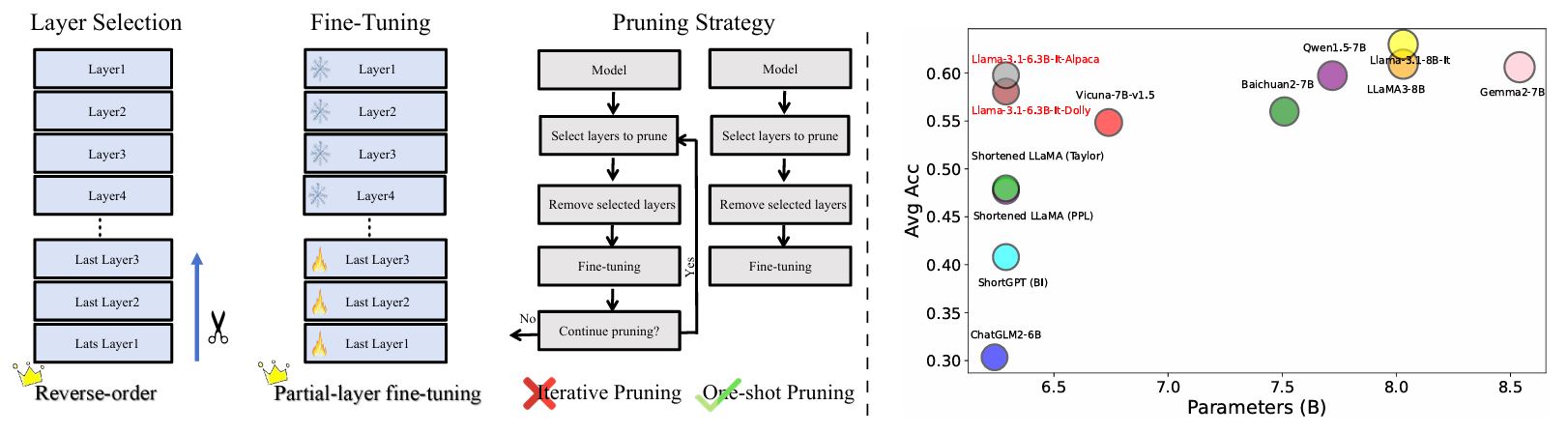 |
Github Paper |
| 通过增强激活方差-稀疏性分析大型语言模型中的层重要性和幻觉现象 Zichen Song, Sitan Huang, Yuxin Wu, Zhongfeng Kang |
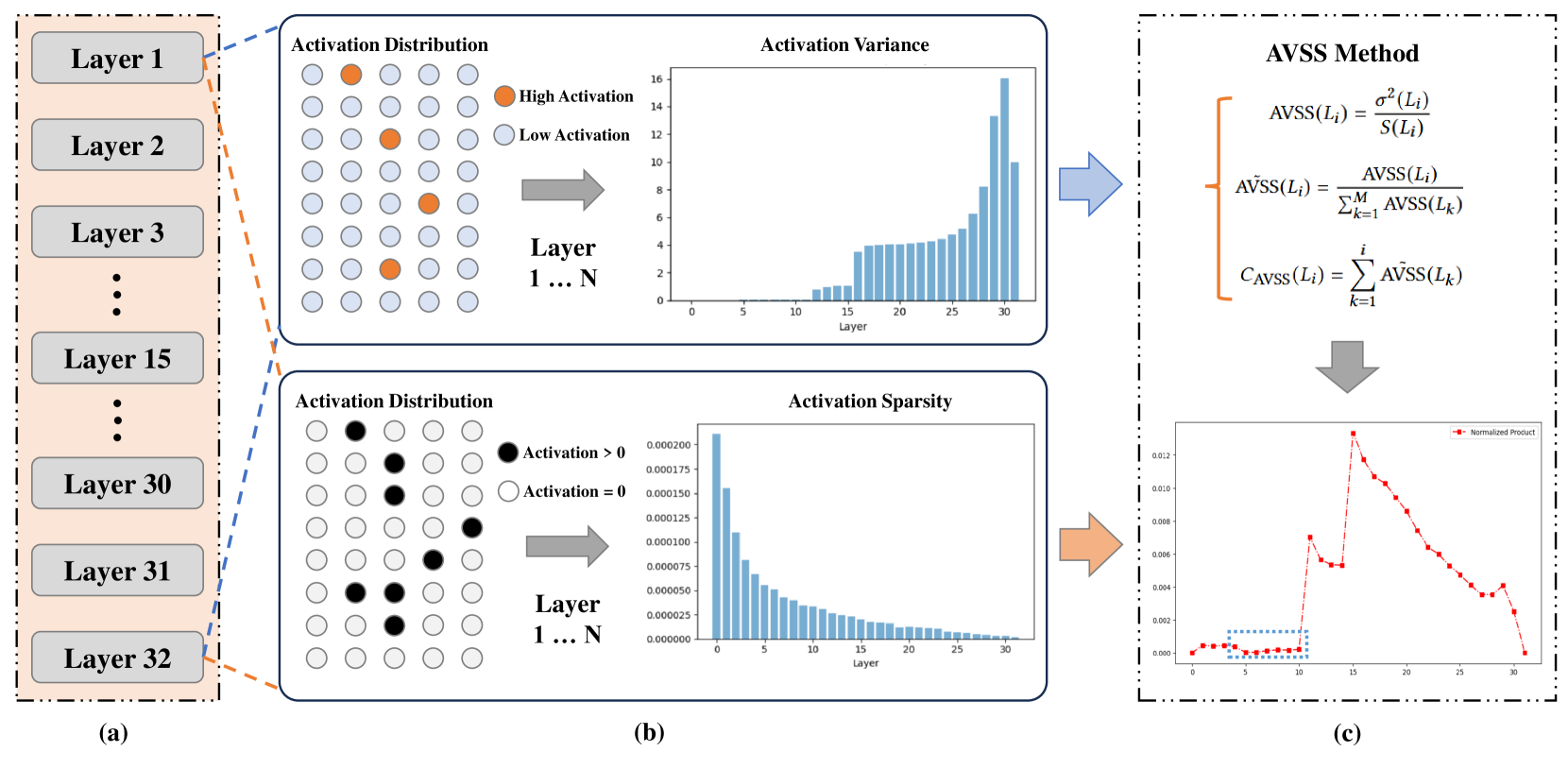 |
Paper |
 AmoebaLLM: 构建任意形状的大语言模型,以实现高效即时部署 Yonggan Fu, Zhongzhi Yu, Junwei Li, Jiayi Qian, Yongan Zhang, Xiangchi Yuan, Dachuan Shi, Roman Yakunin, Yingyan Celine Lin |
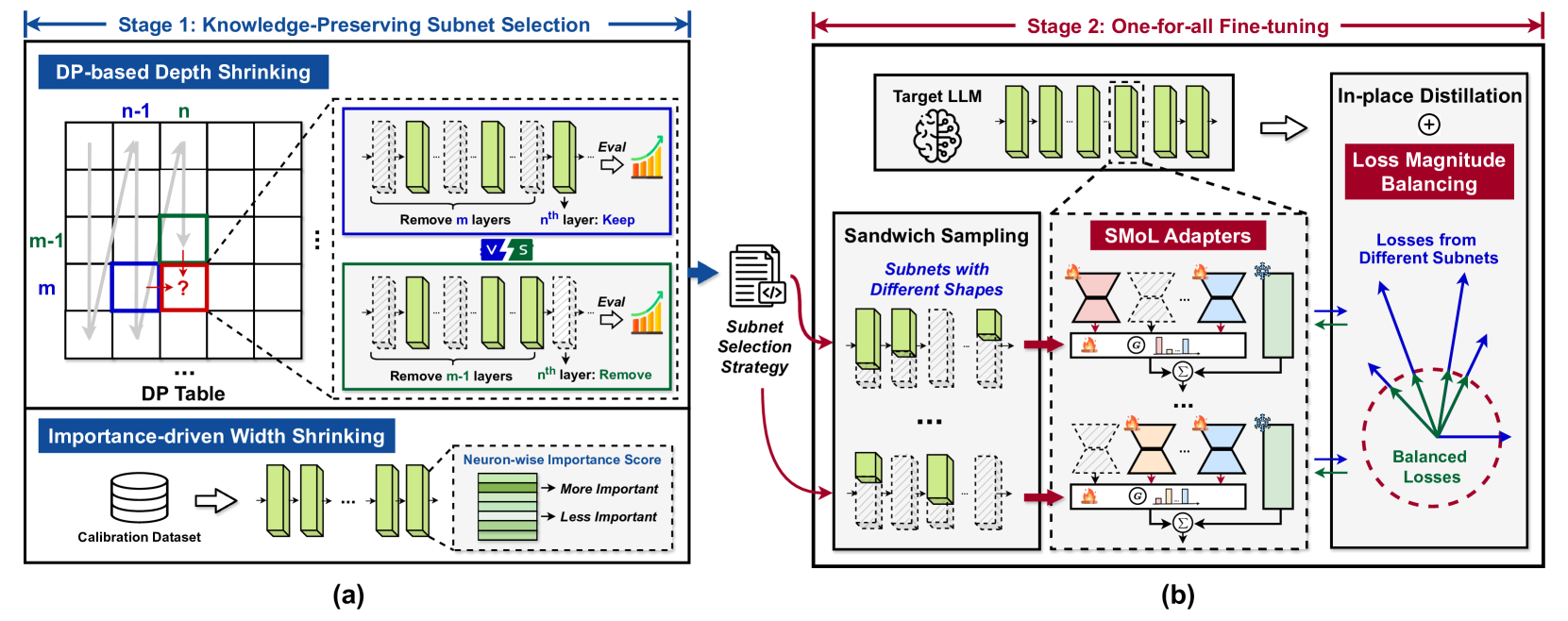 |
Github Paper |
| 模型剪枝后的训练后缩放定律 Xiaodong Chen, Yuxuan Hu, Jing Zhang, Xiaokang Zhang, Cuiping Li, Hong Chen |
Paper | |
 DRPruning: 通过分布鲁棒优化实现高效的大语言模型剪枝 Hexuan Deng, Wenxiang Jiao, Xuebo Liu, Min Zhang, Zhaopeng Tu |
 |
Github Paper |
 Sparsing Law: 朝着更高激活稀疏性的大型语言模型迈进 Yuqi Luo, Chenyang Song, Xu Han, Yingfa Chen, Chaojun Xiao, Zhiyuan Liu, Maosong Sun |
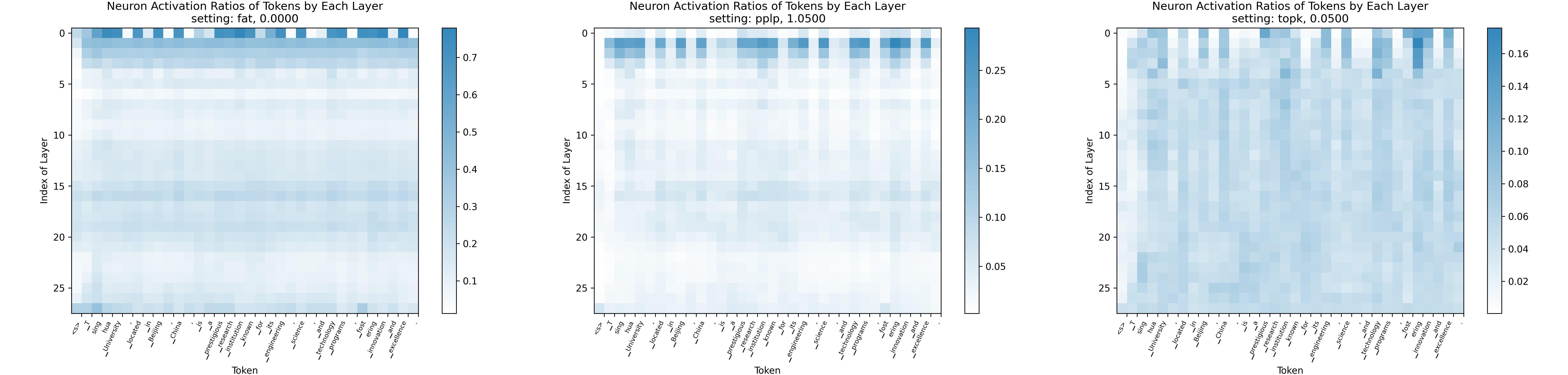 |
Github Paper |
| AVSS: 通过激活方差-稀疏性分析评估大型语言模型中的层重要性 Zichen Song, Yuxin Wu, Sitan Huang, Zhongfeng Kang |
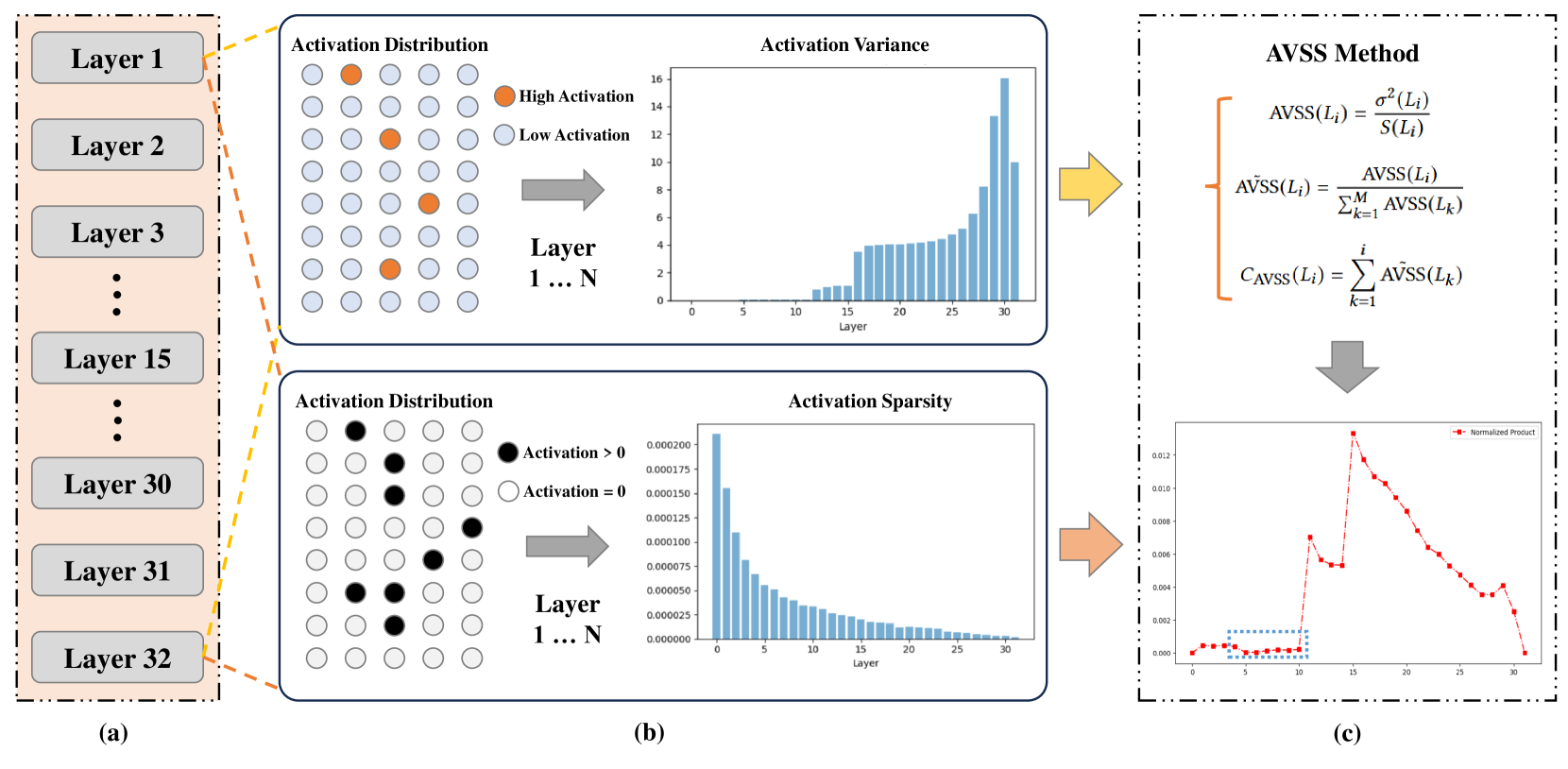 |
Paper |
| Tailored-LLaMA: 使用特定任务提示优化剪枝后的LLaMA模型中的少量样本学习 Danyal Aftab, Steven Davy |
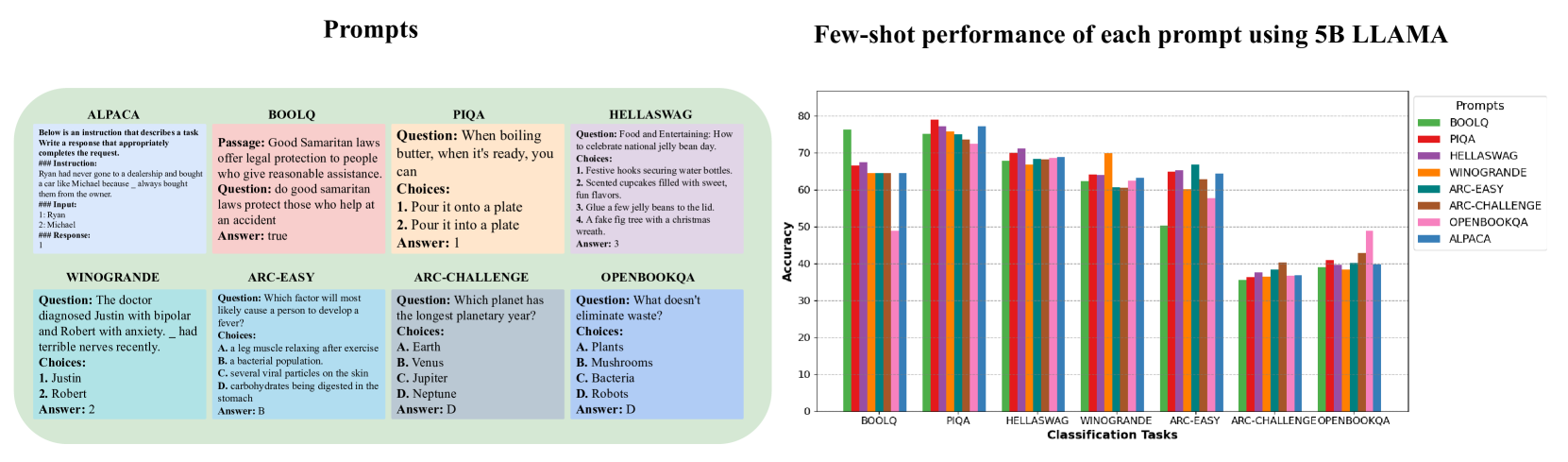 |
Paper |
 LLMCBench: 为高效部署而进行的大型语言模型压缩基准测试 Ge Yang, Changyi He, Jinyang Guo, Jianyu Wu, Yifu Ding, Aishan Liu, Haotong Qin, Pengliang Ji, Xianglong Liu |
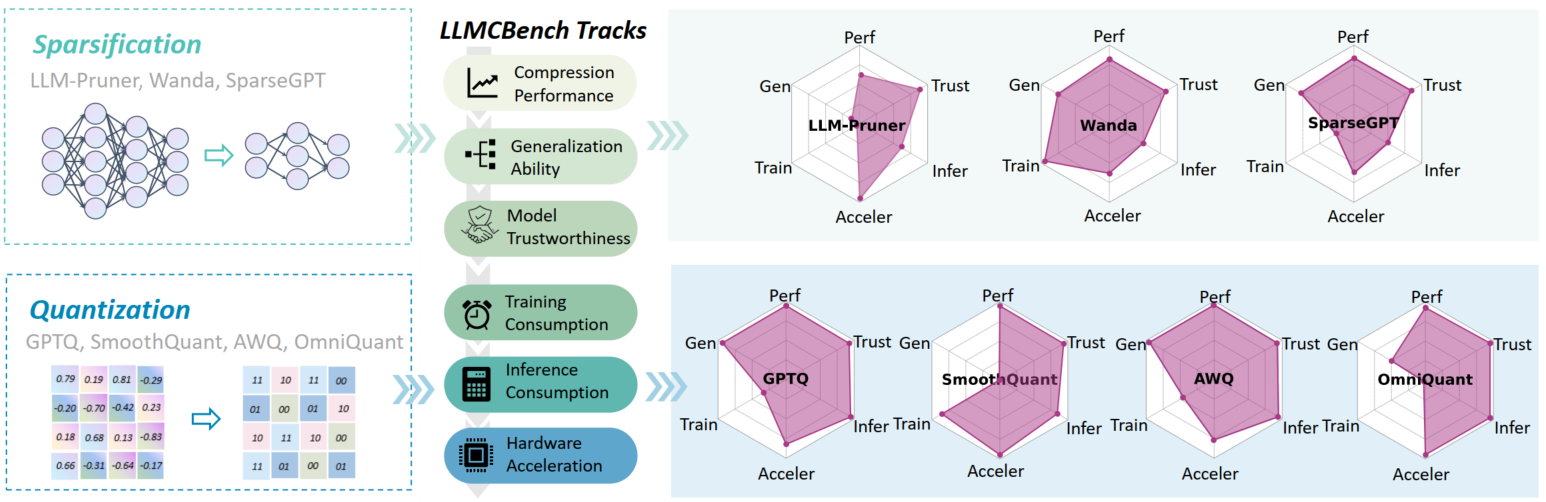 |
Github Paper |
| 超越2:4:探索V:N:M稀疏性以在GPU上高效推理Transformer Kang Zhao, Tao Yuan, Han Bao, Zhenfeng Su, Chang Gao, Zhaofeng Sun, Zichen Liang, Liping Jing, Jianfei Chen |
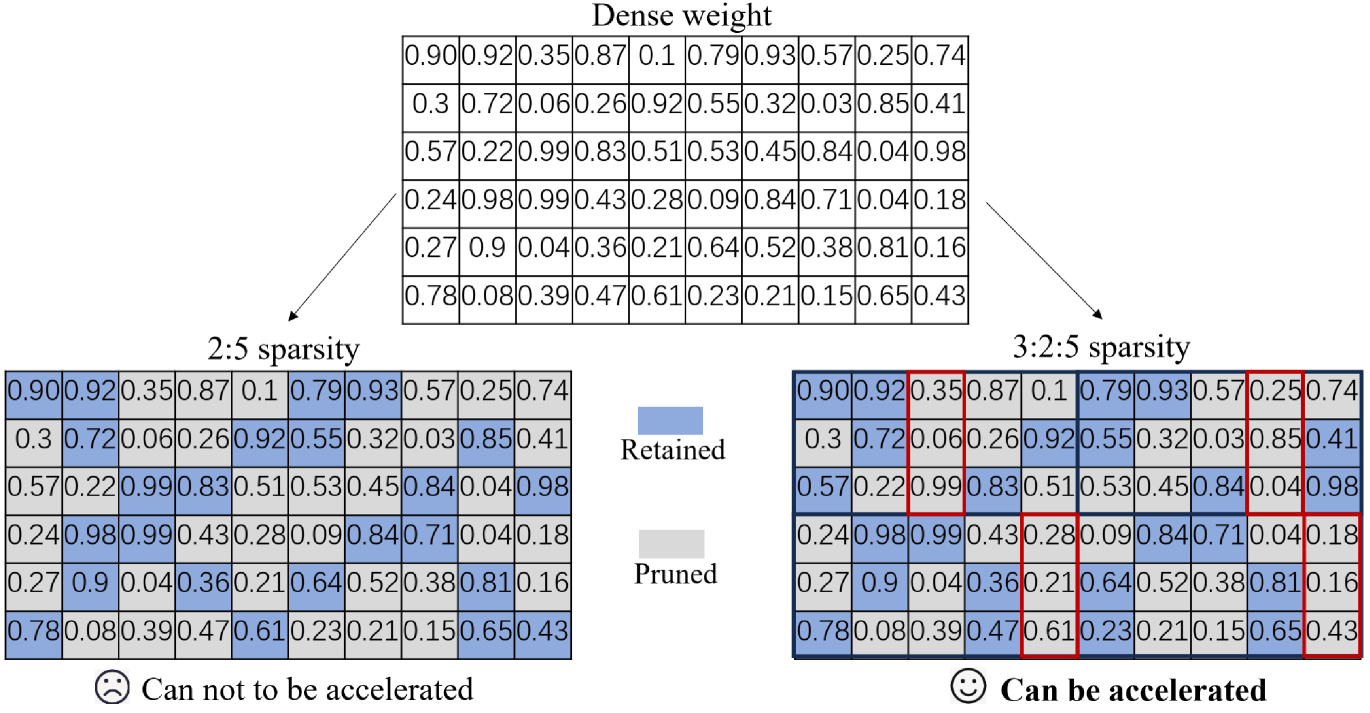 |
Paper |
 EvoPress: 通过进化搜索迈向最优动态模型压缩 Oliver Sieberling, Denis Kuznedelev, Eldar Kurtic, Dan Alistarh |
 |
Github Paper |
| FedSpaLLM: 大型语言模型的联邦剪枝 Guangji Bai, Yijiang Li, Zilinghan Li, Liang Zhao, Kibaek Kim |
 |
Paper |
 无需再训练即可实现高精度的基础模型剪枝 Pu Zhao, Fei Sun, Xuan Shen, Pinrui Yu, Zhenglun Kong, Yanzhi Wang, Xue Lin |
Github Paper |
|
| 语言模型量化和剪枝的自校准 Miles Williams, George Chrysostomou, Nikolaos Aletras |
 |
Paper |
| 警惕用于大型语言模型剪枝的校准数据 Yixin Ji, Yang Xiang, Juntao Li, Qingrong Xia, Ping Li, Xinyu Duan, Zhefeng Wang, Min Zhang |
Paper | |
 AlphaPruning: 利用重尾自正则化理论改进大型语言模型的逐层剪枝 Haiquan Lu, Yefan Zhou, Shiwei Liu, Zhangyang Wang, Michael W. Mahoney, Yaoqing Yang |
 |
Github Paper |
| 超越线性近似:注意力矩阵的一种新型剪枝方法 Yingyu Liang, Jiangxuan Long, Zhenmei Shi, Zhao Song, Yufa Zhou |
 |
Paper |
 DISP-LLM: 不受维度限制的大型语言模型结构化剪枝 Shangqian Gao, Chi-Heng Lin, Ting Hua, Tang Zheng, Yilin Shen, Hongxia Jin, Yen-Chang Hsu |
 |
Github Paper |
自我数据蒸馏以恢复剪枝后大型语言模型的质量 Vithursan Thangarasa, Ganesh Venkatesh, Nish Sinnadurai, Sean Lie |
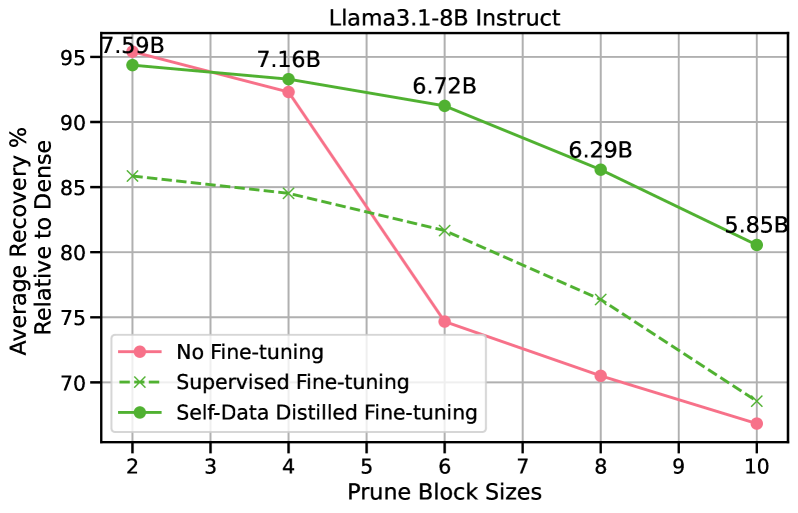 |
Paper |
| LLM-Rank: 一种基于图论的大型语言模型剪枝方法 David Hoffmann, Kailash Budhathoki, Matthaeus Kleindessner |
 |
Paper |
 C4数据集是否最适合剪枝?关于LLM剪枝校准数据的调查 Abhinav Bandari, Lu Yin, Cheng-Yu Hsieh, Ajay Kumar Jaiswal, Tianlong Chen, Li Shen, Ranjay Krishna, Shiwei Liu |
 |
Github Paper |
| 通过神经元剪枝缓解上下文学习中的复制偏差 Ameen Ali, Lior Wolf, Ivan Titov |
 |
Paper |
SQFT: 低成本模型适配,适用于低精度稀疏基础模型 Juan Pablo Munoz, Jinjie Yuan, Nilesh Jain |
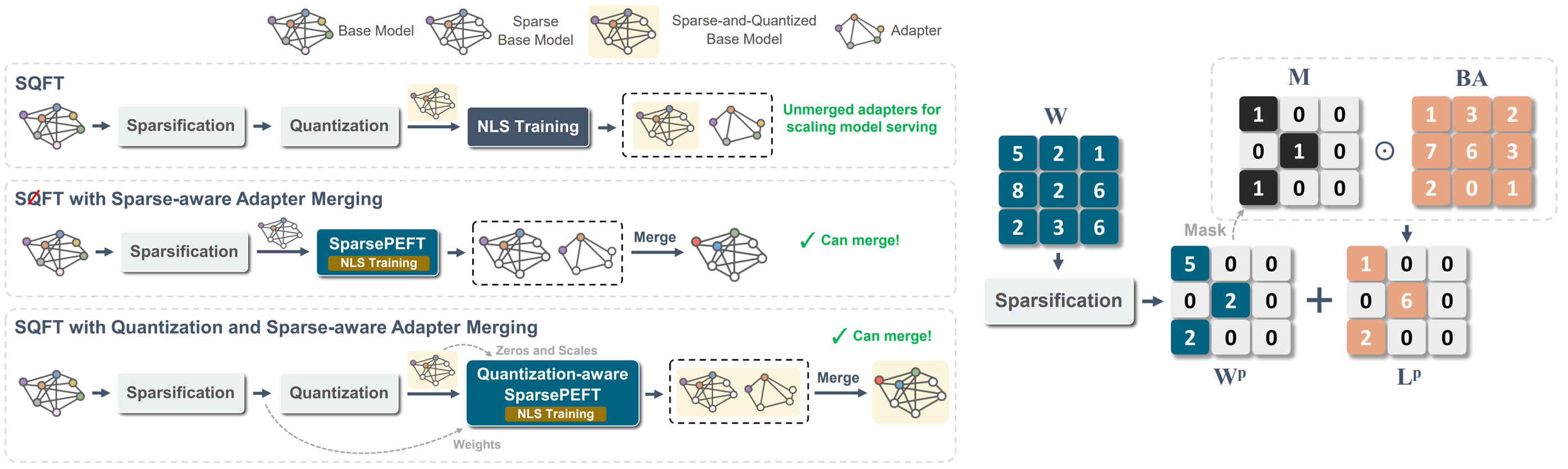 |
Github Paper |
 稀疏前沿:Transformer LLM中的稀疏注意力权衡 Piotr Nawrot, Robert Li, Renjie Huang, Sebastian Ruder, Kelly Marchisio, Edoardo M. Ponti |
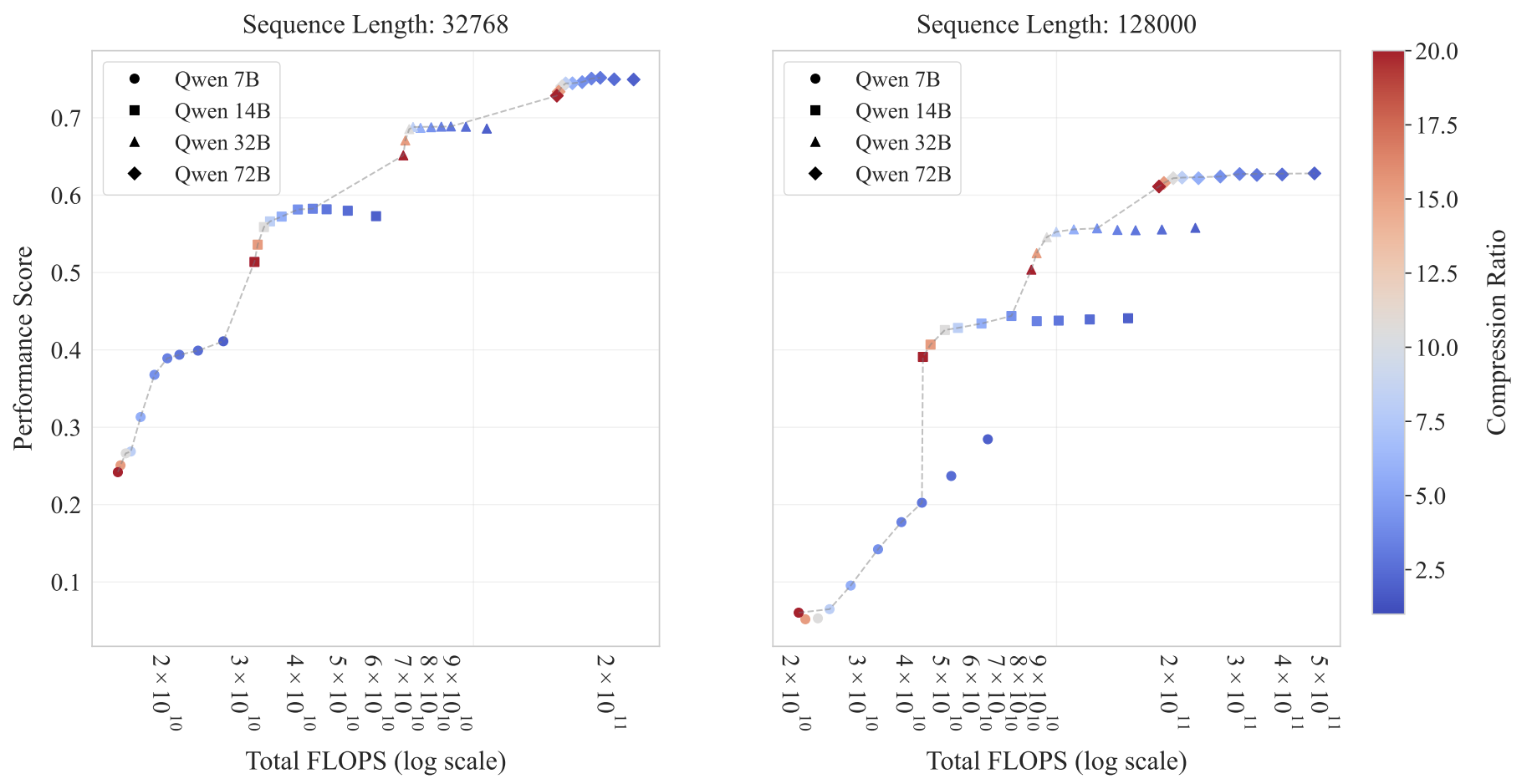 |
Github Paper |
 稀疏化状态空间模型是高效的高速公路网络 Woomin Song, Jihoon Tack, Sangwoo Mo, Seunghyuk Oh, Jinwoo Shin |
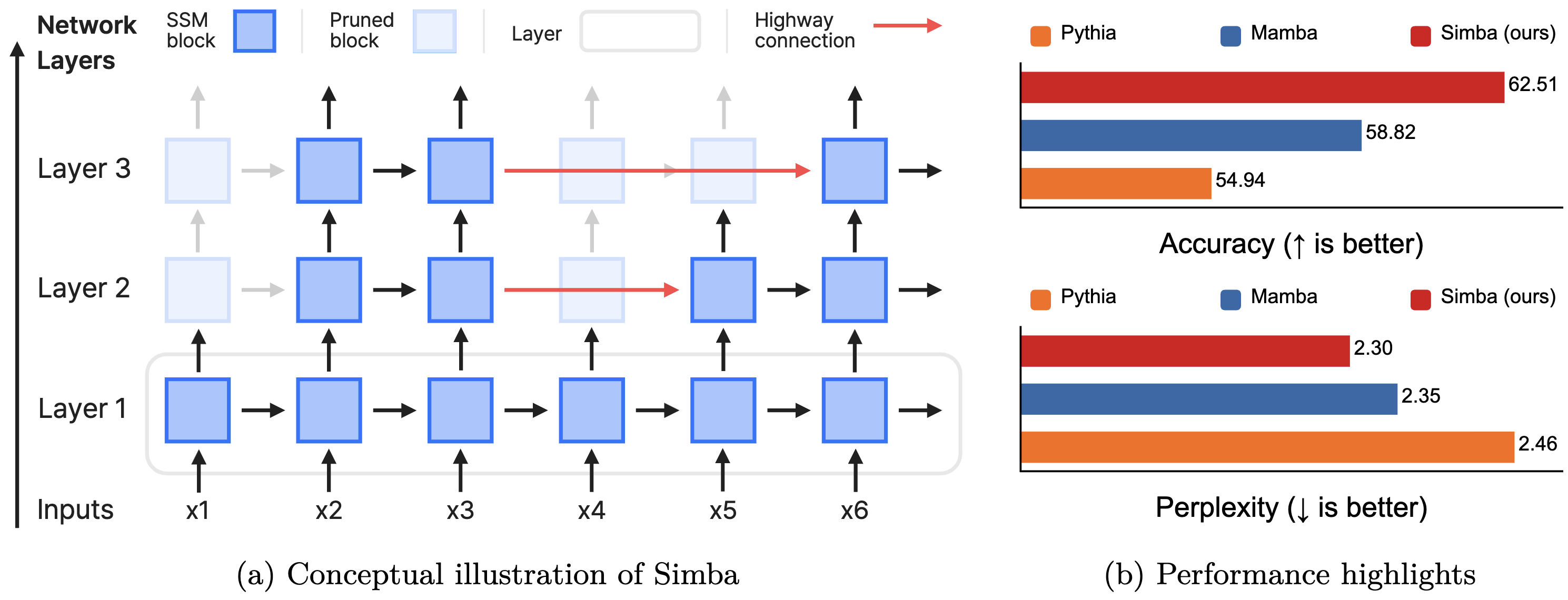 |
Github Paper |
知识蒸馏
| 标题与作者 | 简介 | 链接 |
|---|---|---|
| :star: 大型语言模型的知识蒸馏 顾宇贤、董力、魏福鲁、黄民烈 |
 |
Github 论文 |
基于LLM的机器翻译的自我进化知识蒸馏 宋云成、丁亮、赞昌通、黄树坚 |
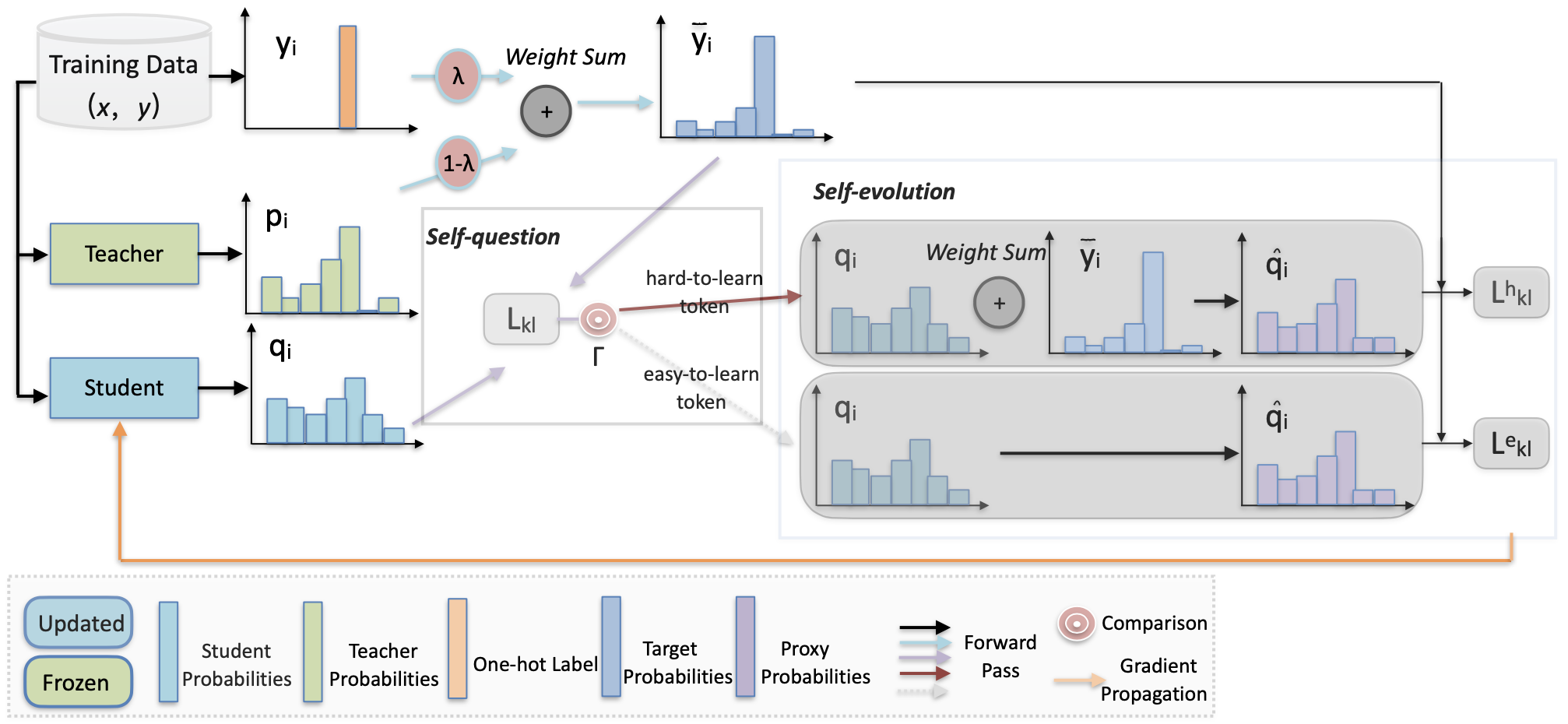 |
论文 |
| 通过低秩特征蒸馏压缩大型语言模型 亚亚·西、克里斯托夫·塞里萨拉、伊琳娜·伊利娜 |
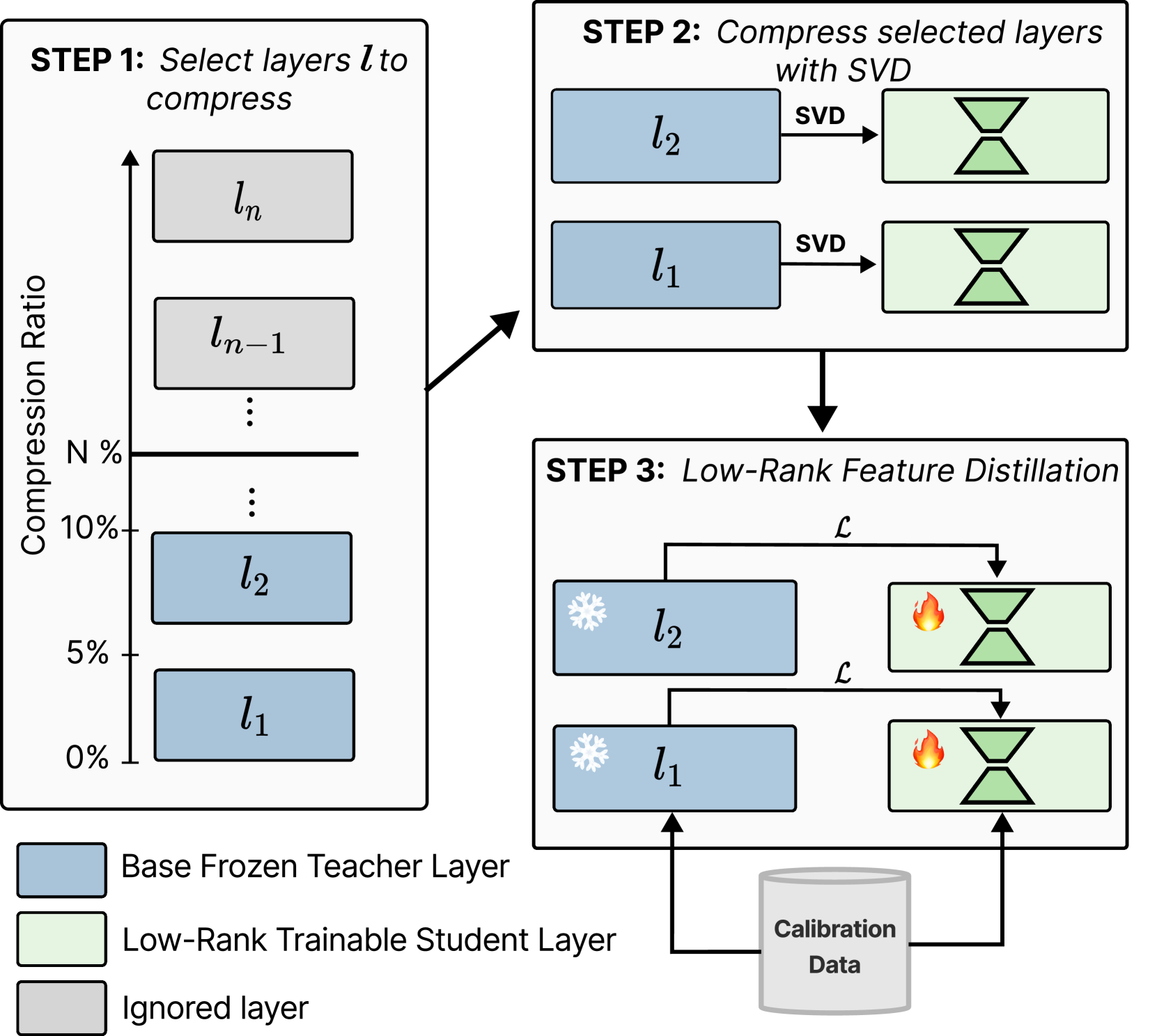 |
论文 |
 从大型语言模型中蒸馏细粒度的情感理解 张一策、谢光宇、徐洪玲、侯凯恒、鲍建竹、王乾龙、陈世伟、许瑞峰 |
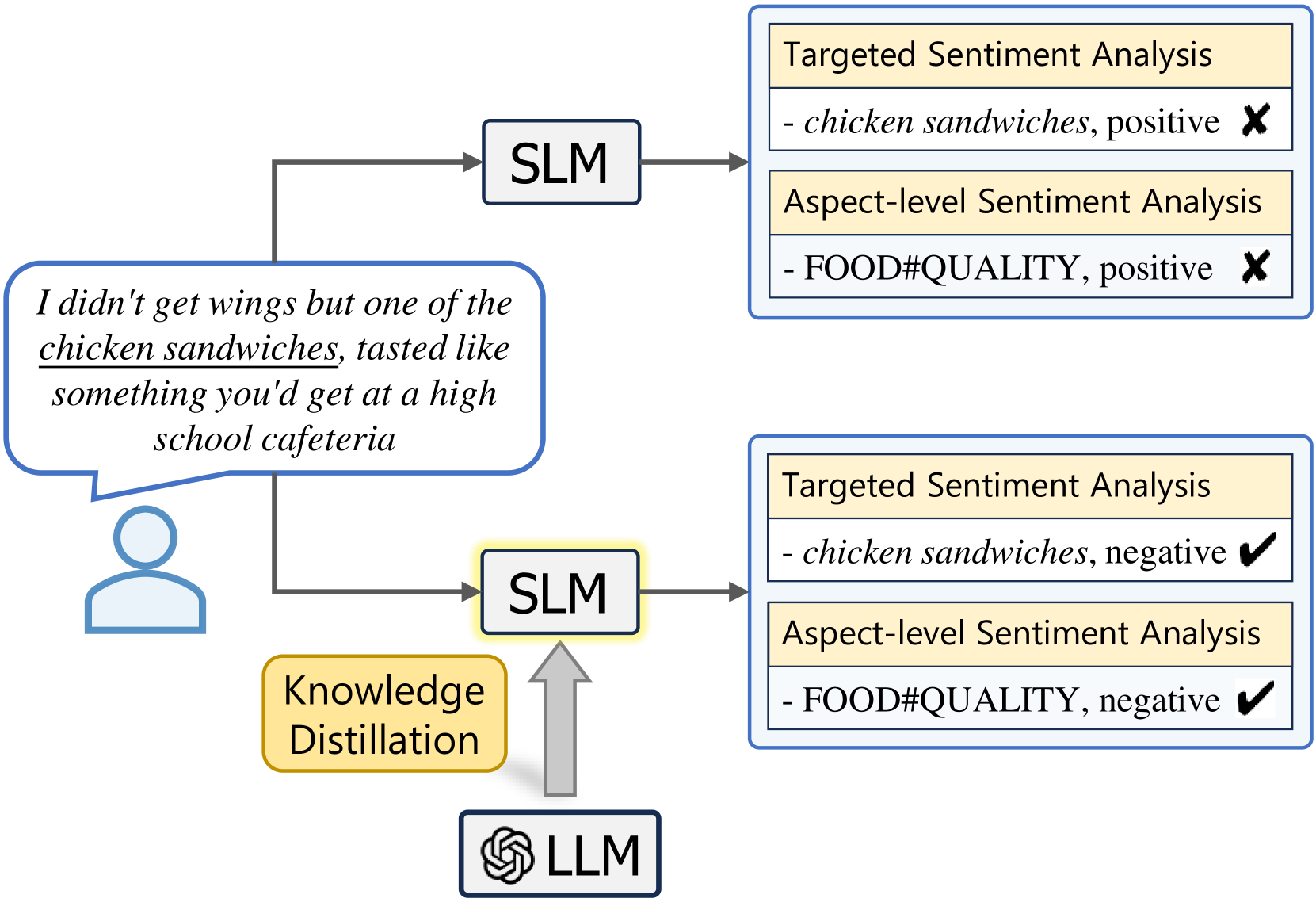 |
Github 论文 |
 利用响应引导提示增强LLM的知识蒸馏 维杰·戈亚尔、穆斯塔法·汗、阿普拉梅亚·提鲁帕蒂、哈维尔·赛尼、迈克尔·拉姆、凯文·朱 |
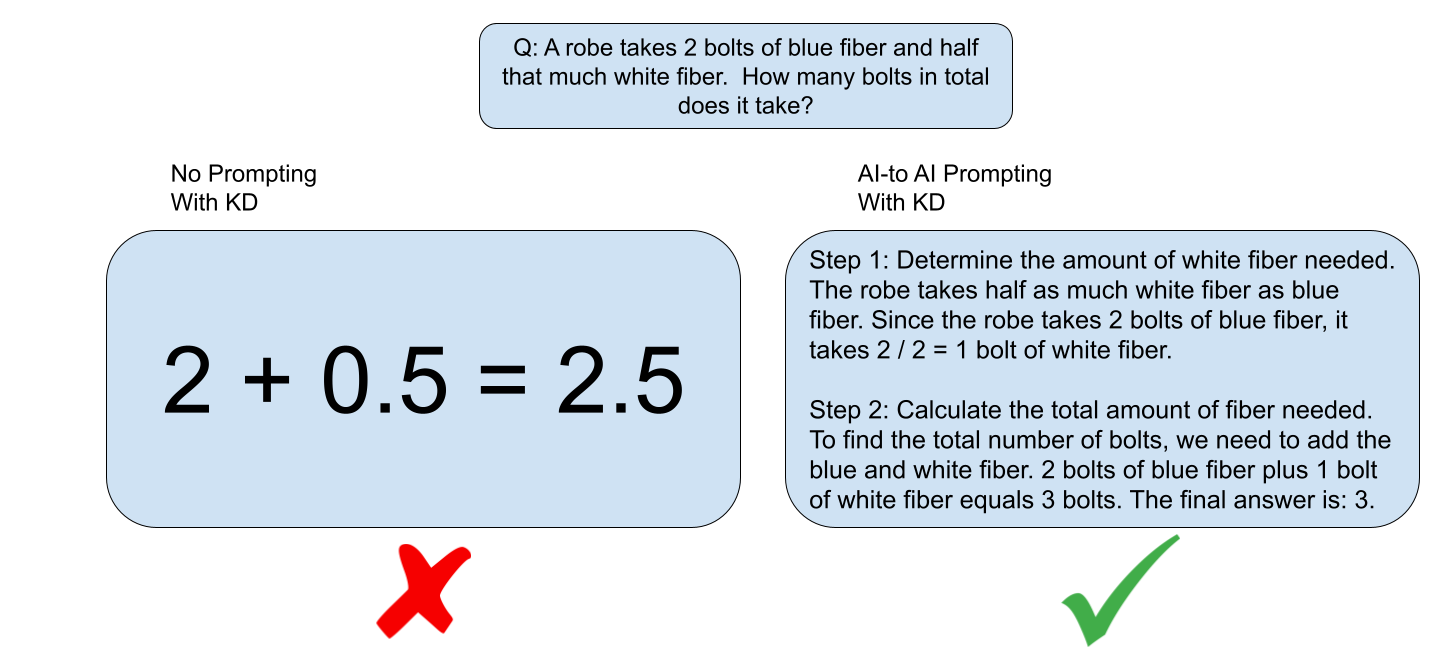 |
Github 论文 |
| 通过反馈驱动的蒸馏提升小型语言模型的数学推理能力 朱勋宇、李健、马灿、王卫平 |
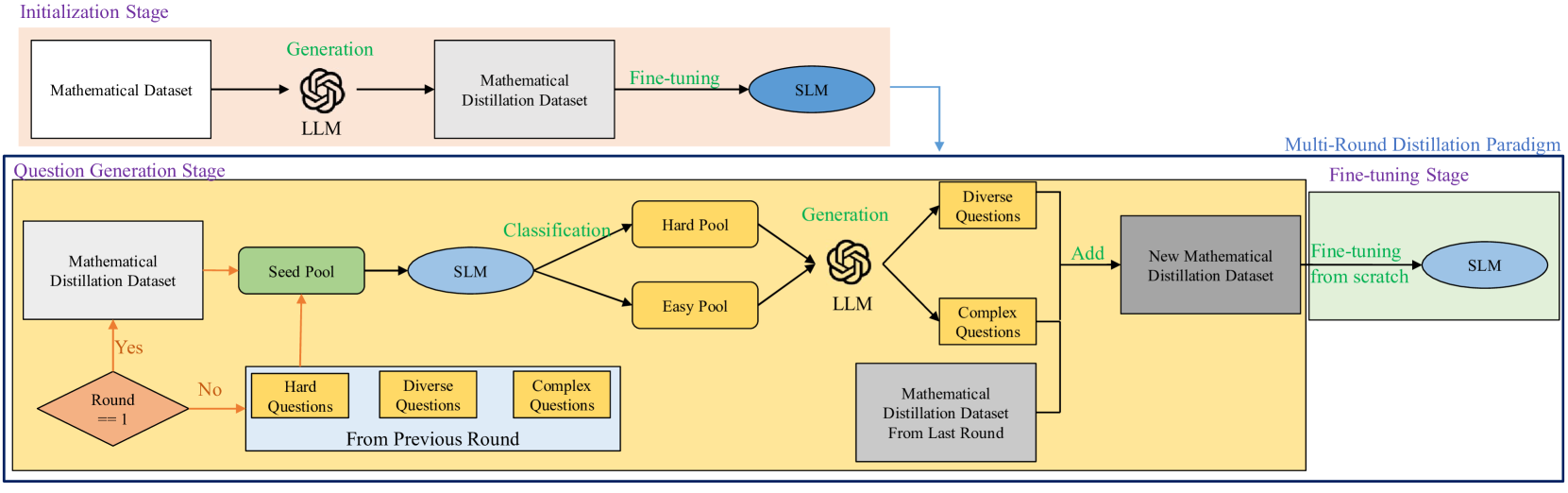 |
论文 |
 生成式提示内化 申河彬、季磊、龚叶云、金成东、崔恩菲、徐敏俊 |
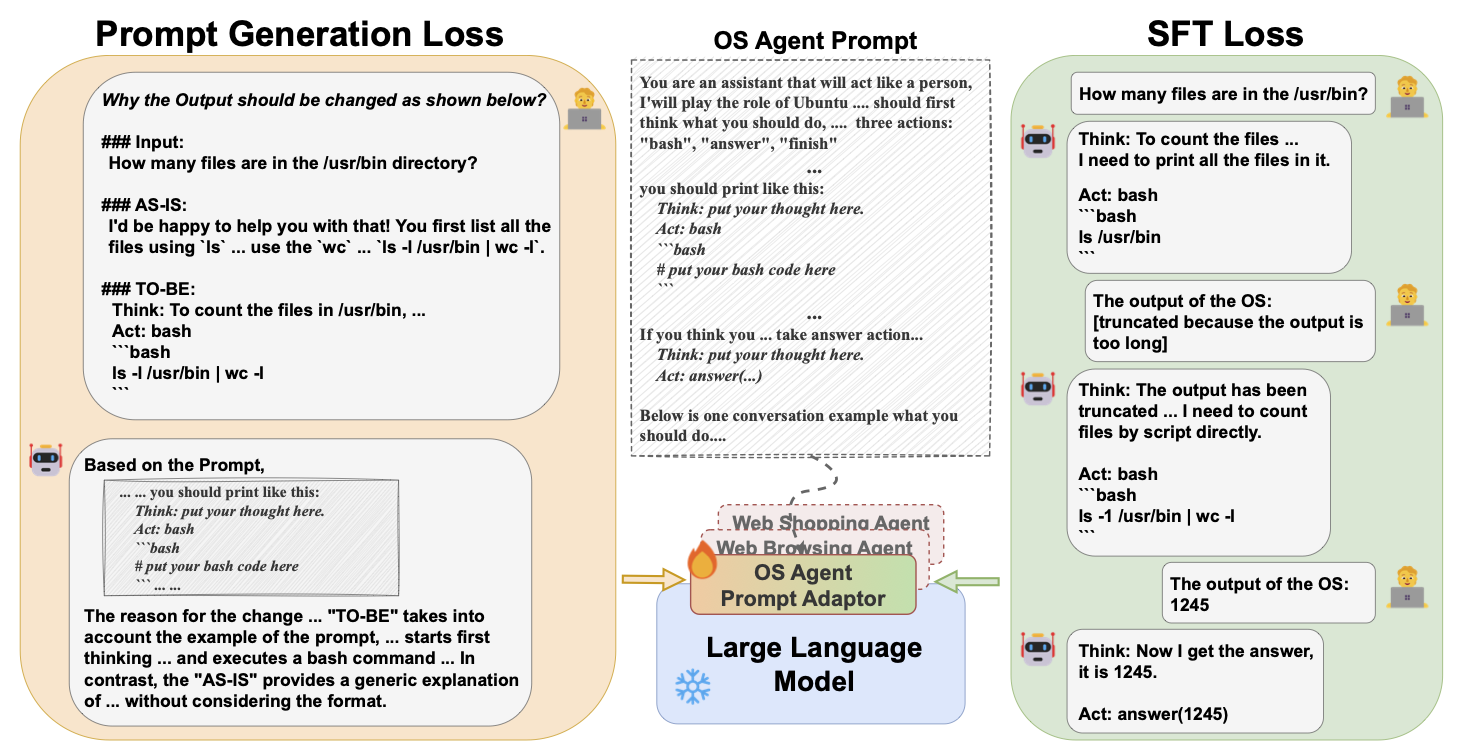 |
Github 论文 |
| SWITCH:与教师一起学习以进行大型语言模型的知识蒸馏 具在贤、黄艺琳、金永日、姜泰冠、裴贤京、郑教民 |
 |
论文 |
 超越自回归:通过时间自蒸馏实现快速LLM 贾斯汀·德舍诺、卡格拉尔·古尔切赫雷 |
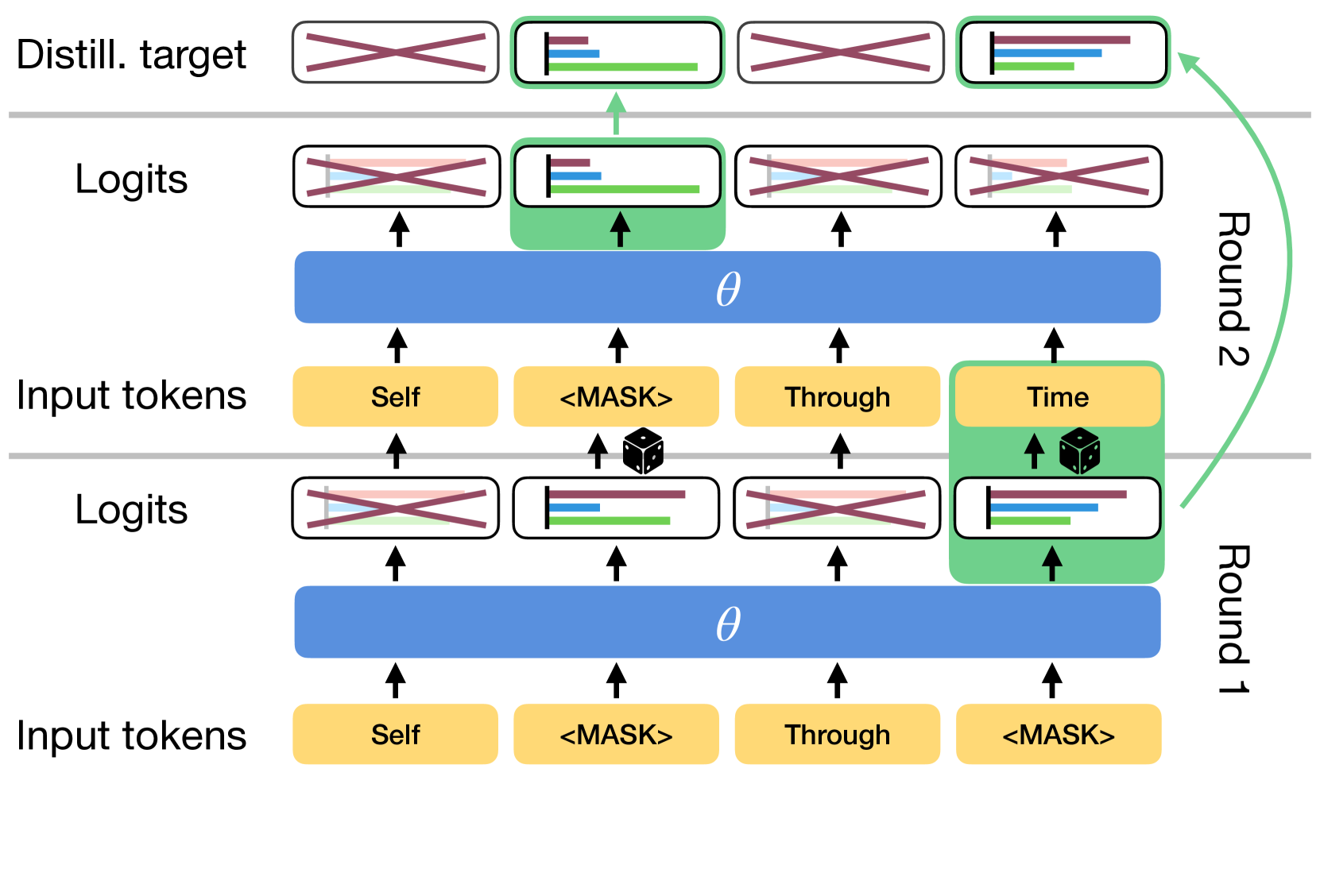 |
Github 论文 |
| 大型语言模型预训练蒸馏:设计空间探索 彭浩、吕欣、白宇诗、姚子俊、张佳杰、侯磊、李娟子 |
论文 | |
 MiniPLM:用于预训练语言模型的知识蒸馏 顾宇贤、周浩、孟凡东、周杰、黄民烈 |
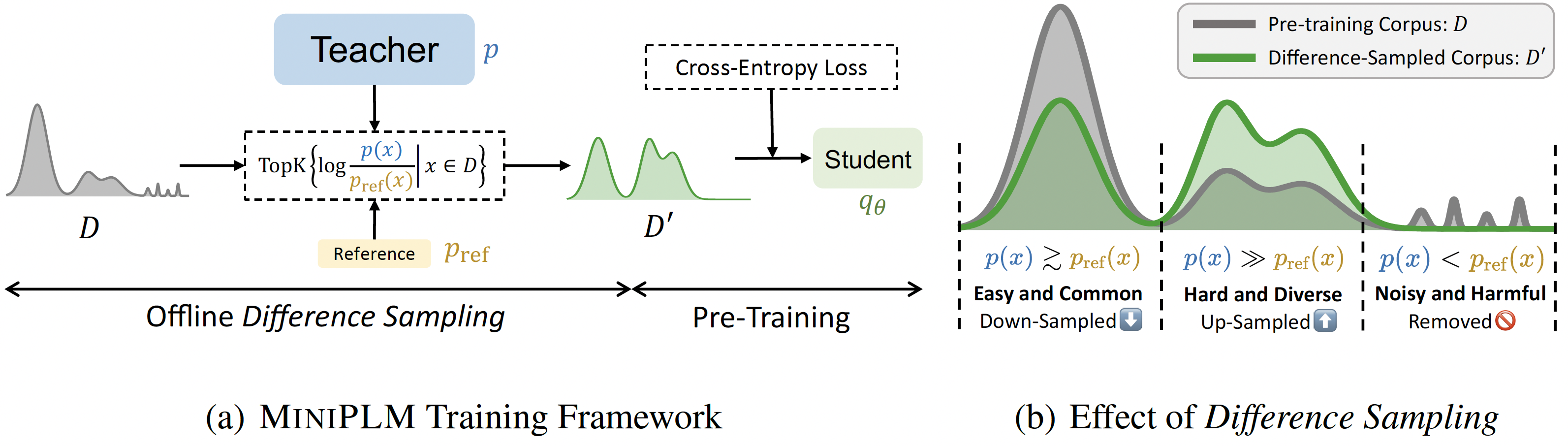 |
Github 论文 |
| 推测性知识蒸馏:通过交错采样弥合师生差距 徐文达、韩如军、王子峰、黎隆T、马德卡·德鲁夫、李磊、威廉·杨·王、里沙布·阿加瓦尔、李辰宇、托马斯·普菲斯特 |
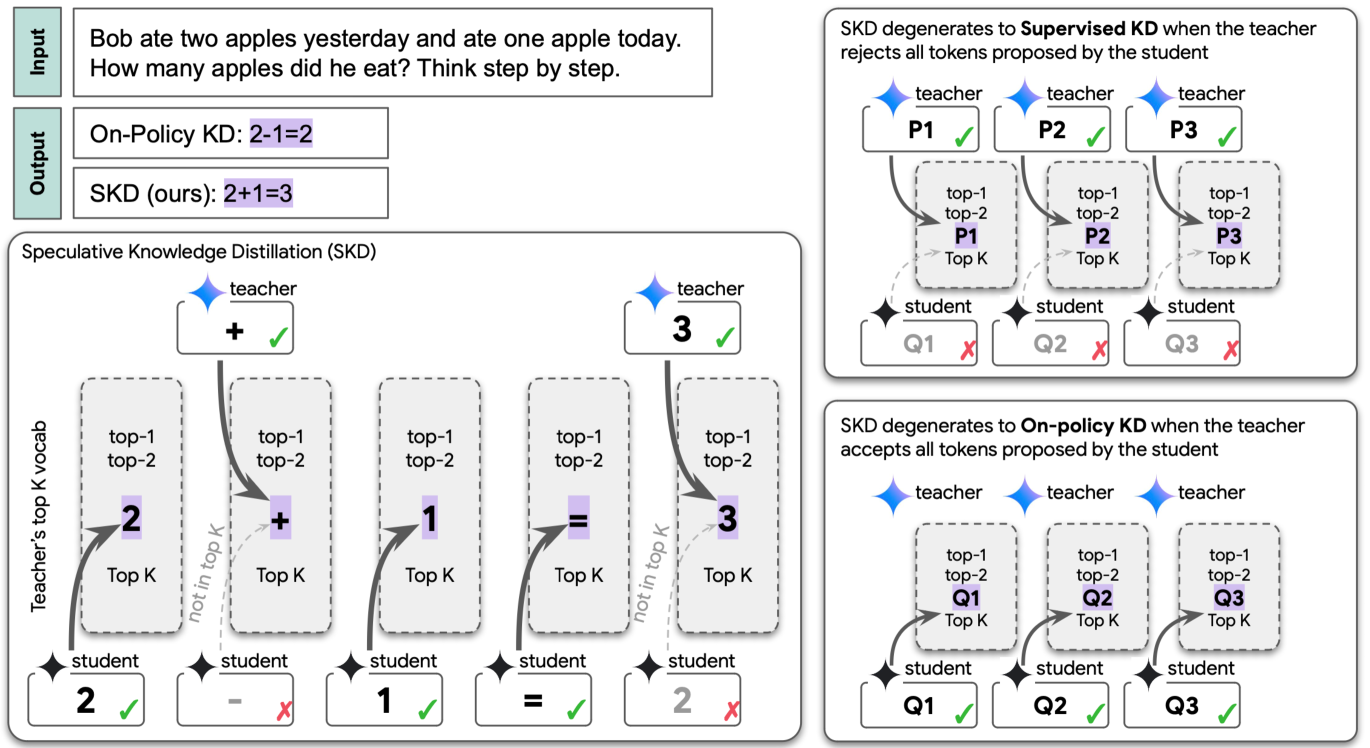 |
论文 |
| 用于语言模型对齐的进化对比蒸馏 朱利安·卡茨-萨缪尔斯、李正、尹孝根、尼甘·普里扬卡、徐毅、佩特里切克·瓦茨拉夫、殷兵、奇林比·特里舒尔 |
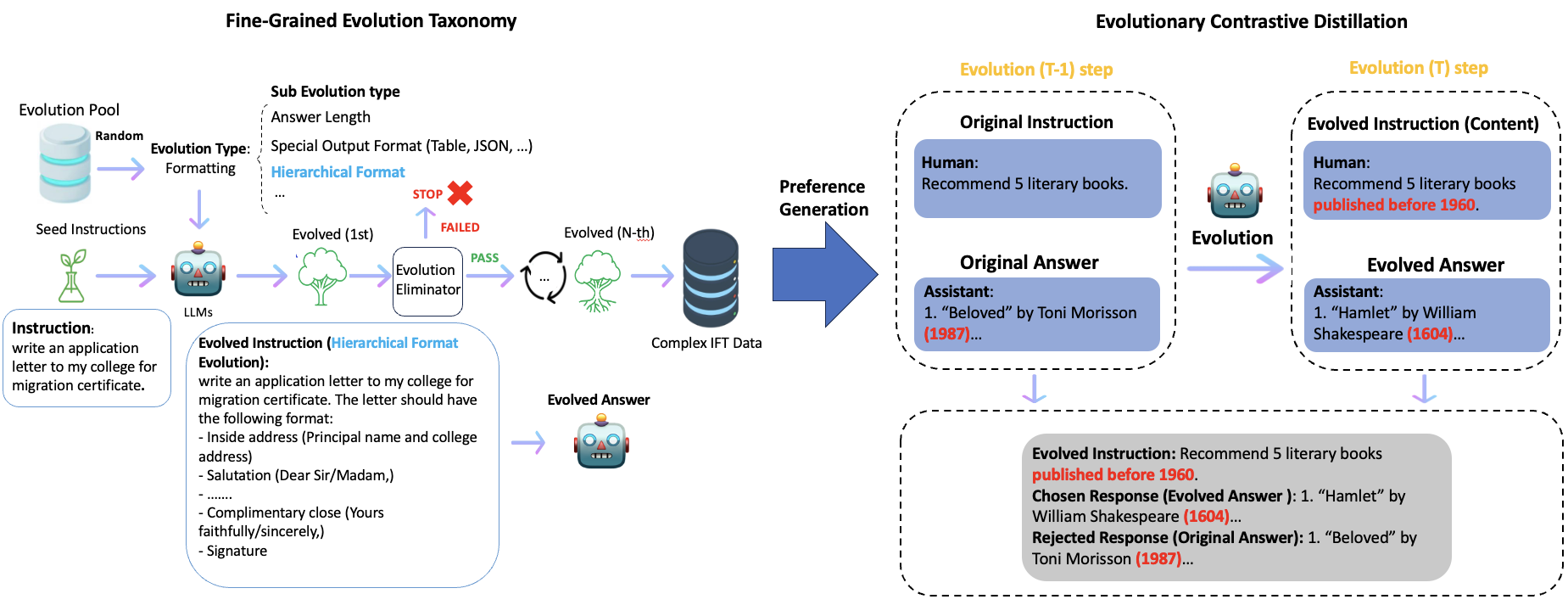 |
论文 |
量化
| 标题与作者 | 简介 | 链接 |
|---|---|---|
 :star: GPTQ: 用于生成式预训练 Transformer 的高精度后训练量化 Elias Frantar, Saleh Ashkboos, Torsten Hoefler, Dan Alistarh |
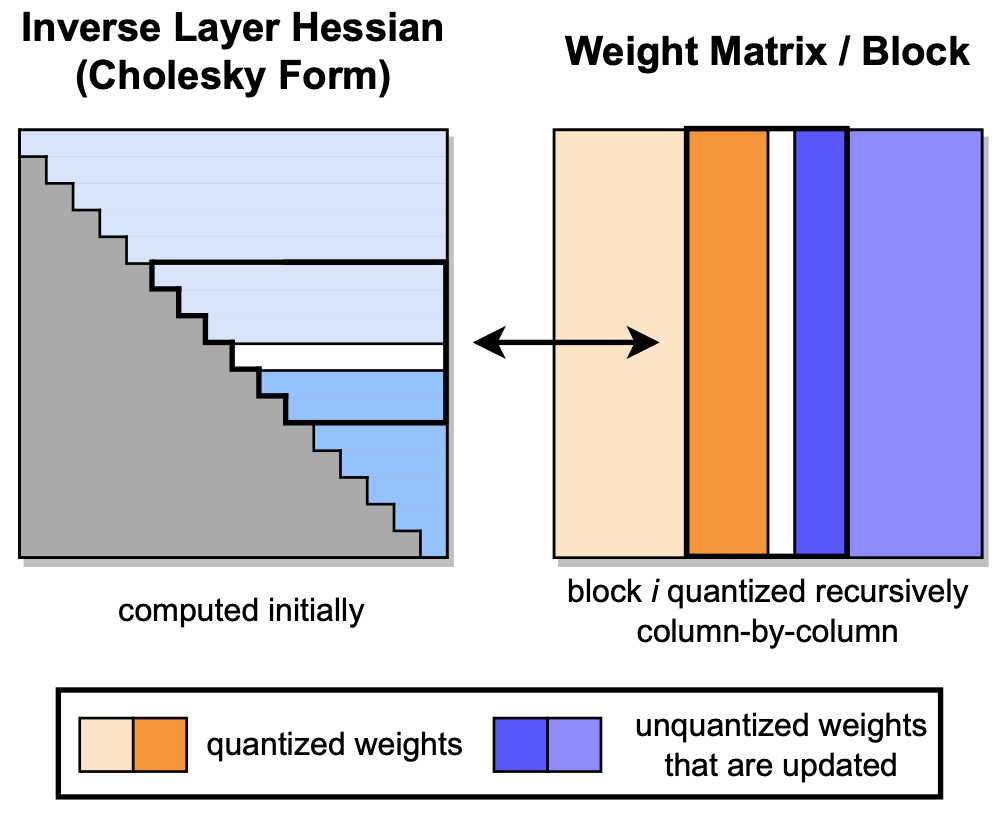 |
Github Paper |
 :star: SmoothQuant: 大型语言模型的精确高效后训练量化 Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, Song Han |
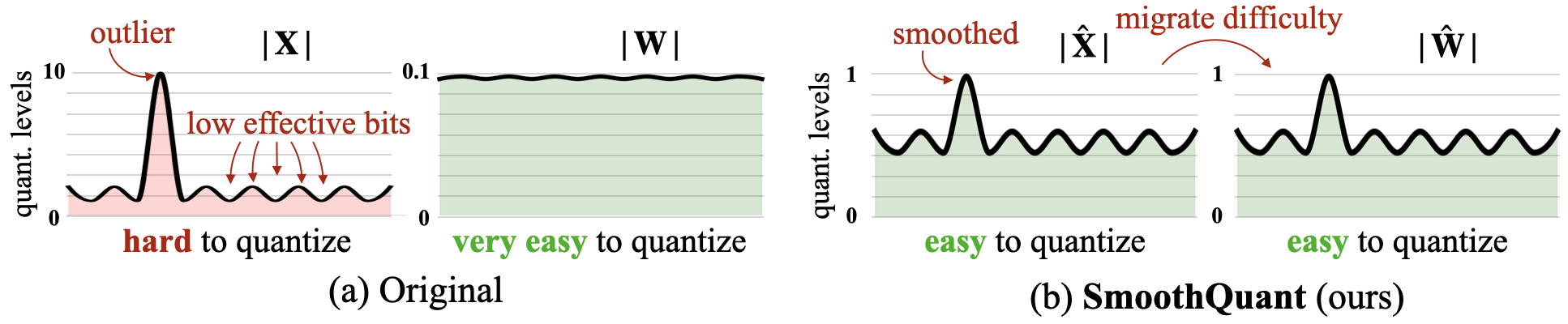 |
Github Paper |
 :star: AWQ: 面向 LLM 压缩与加速的激活感知权重量化 Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, Song Han |
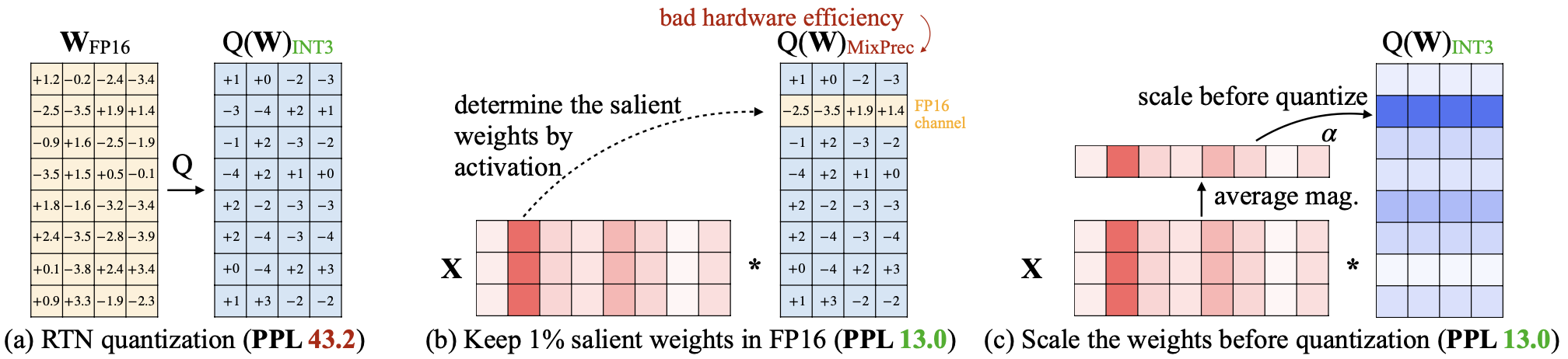 |
Github Paper |
 :star: OmniQuant: 大型语言模型的全方位校准量化 Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, Ping Luo |
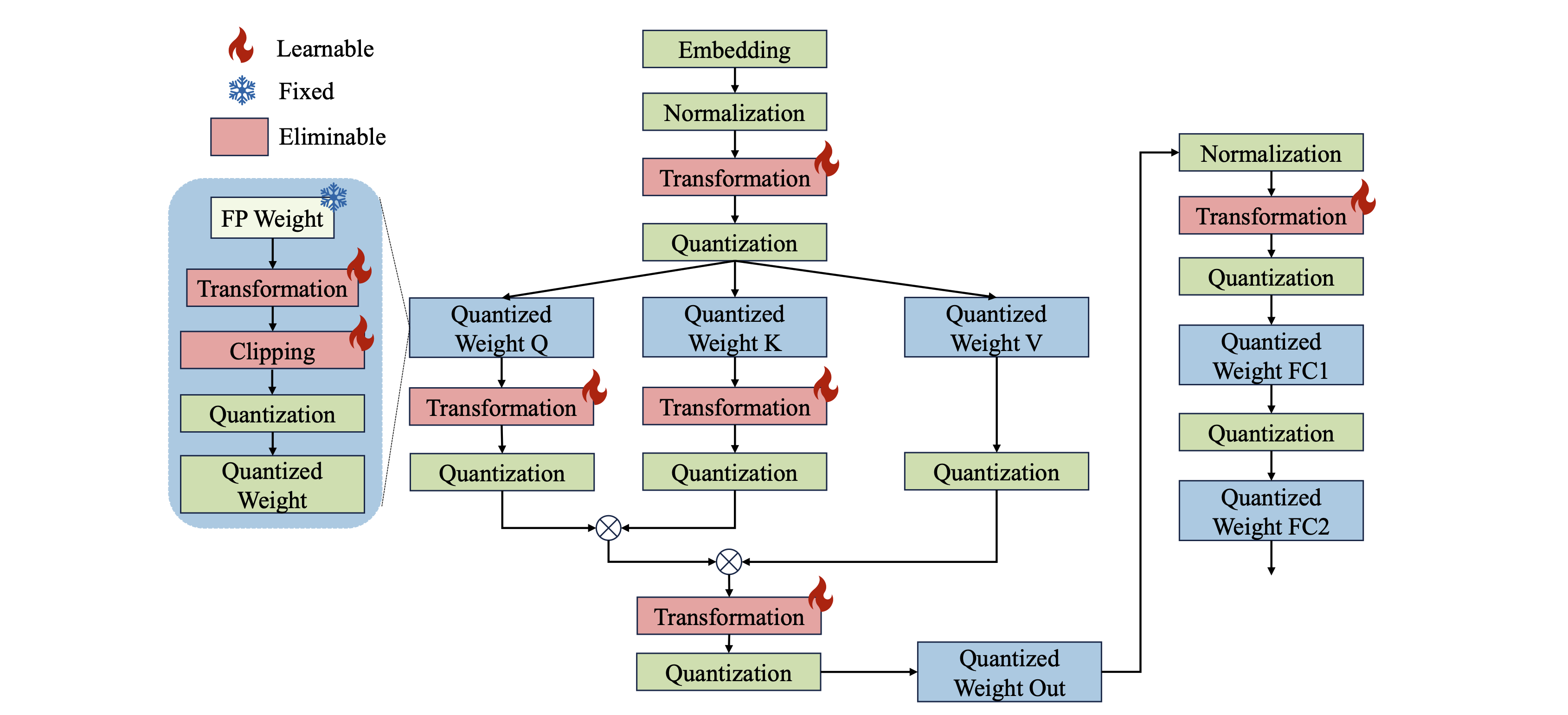 |
Github Paper |
 ResQ: 基于低秩残差的大语言模型混合精度量化 Utkarsh Saxena, Sayeh Sharify, Kaushik Roy, Xin Wang |
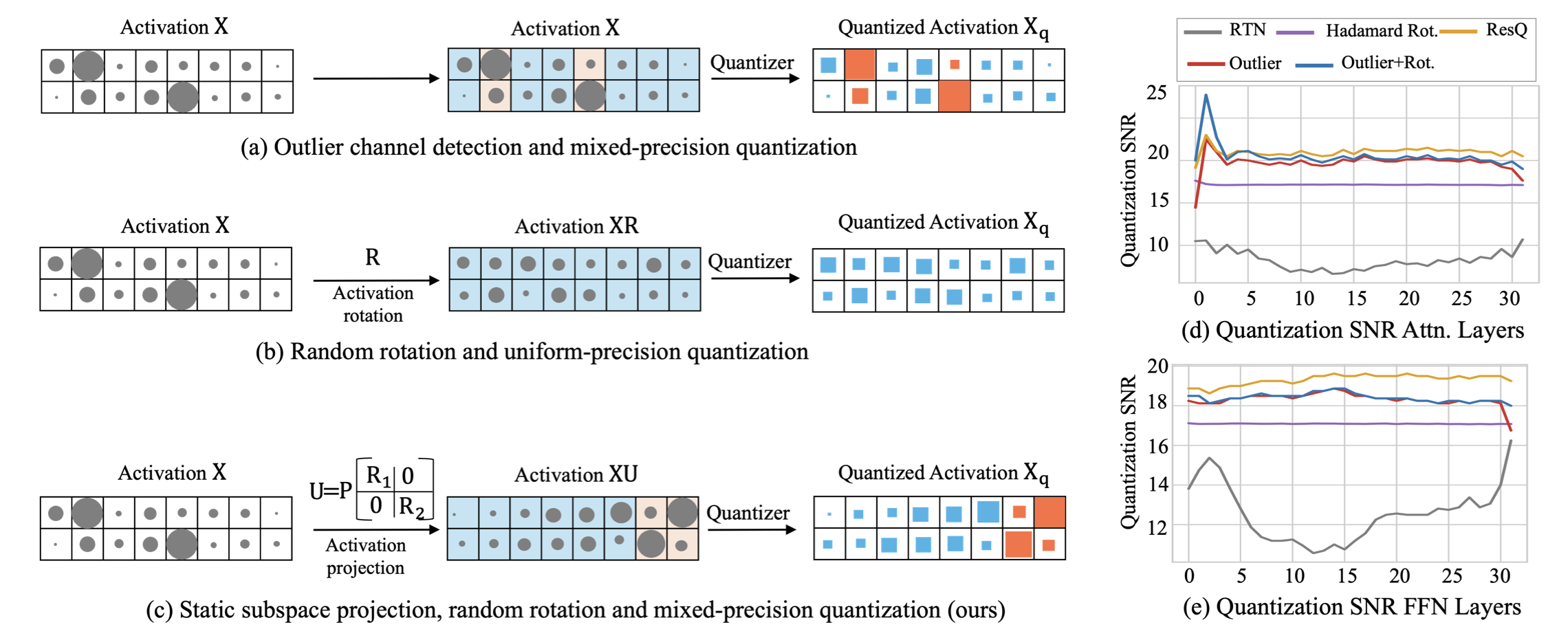 |
Github Paper |
| MixLLM: 输出特征间全局混合精度的 LLM 量化及高效系统设计 Zhen Zheng, Xiaonan Song, Chuanjie Liu |
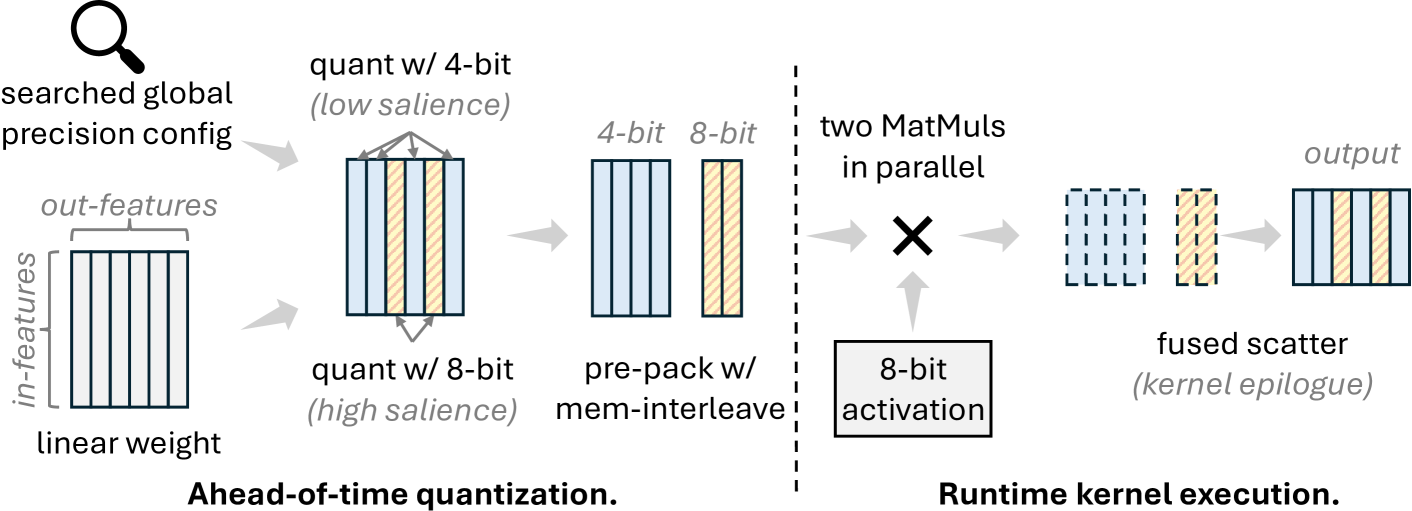 |
Paper |
| GQSA: 用于加速大型语言模型推理的分组量化与稀疏化 Chao Zeng, Songwei Liu, Shu Yang, Fangmin Chen, Xing Mei, Lean Fu |
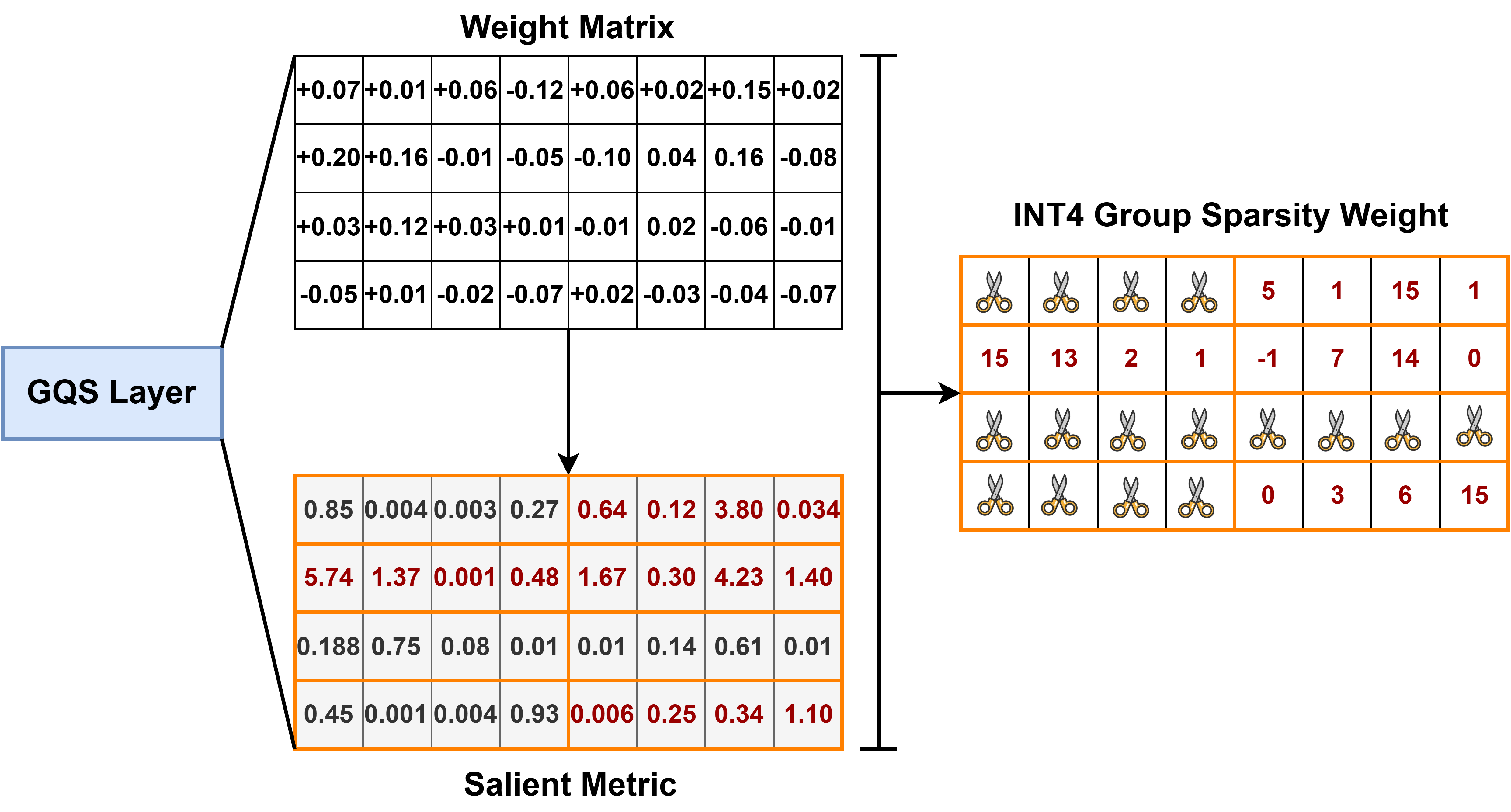 |
Paper |
| LSAQ: 针对大型语言模型部署的层特定自适应量化 Binrui Zeng, Bin Ji, Xiaodong Liu, Jie Yu, Shasha Li, Jun Ma, Xiaopeng Li, Shangwen Wang, Xinran Hong |
 |
Paper |
| SKIM: 超越后训练量化的任意比特量化 Runsheng Bai, Qiang Liu, Bo Liu |
 |
Paper |
| CPTQuant -- 大型语言模型的一种新型混合精度后训练量化技术 Amitash Nanda, Sree Bhargavi Balija, Debashis Sahoo |
 |
Paper |
Anda: 通过可变长度分组激活数据格式解锁高效的 LLM 推理 Chao Fang, Man Shi, Robin Geens, Arne Symons, Zhongfeng Wang, Marian Verhelst |
 |
Paper |
| MixPE: 面向高效 LLM 推理的量化与硬件协同设计 Yu Zhang, Mingzi Wang, Lancheng Zou, Wulong Liu, Hui-Ling Zhen, Mingxuan Yuan, Bei Yu |
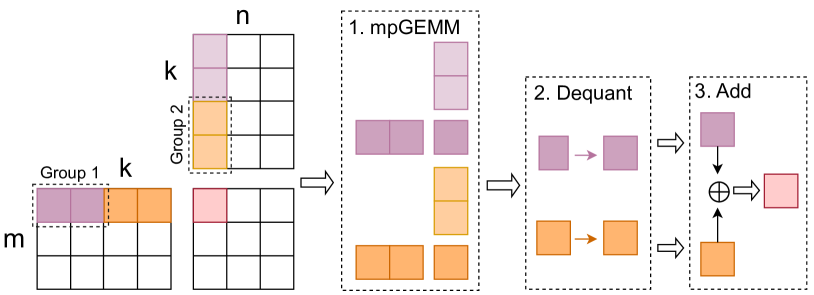 |
Paper |
 BitMoD: 比特串混合数据类型 LLM 加速 Yuzong Chen, Ahmed F. AbouElhamayed, Xilai Dai, Yang Wang, Marta Andronic, George A. Constantinides, Mohamed S. Abdelfattah |
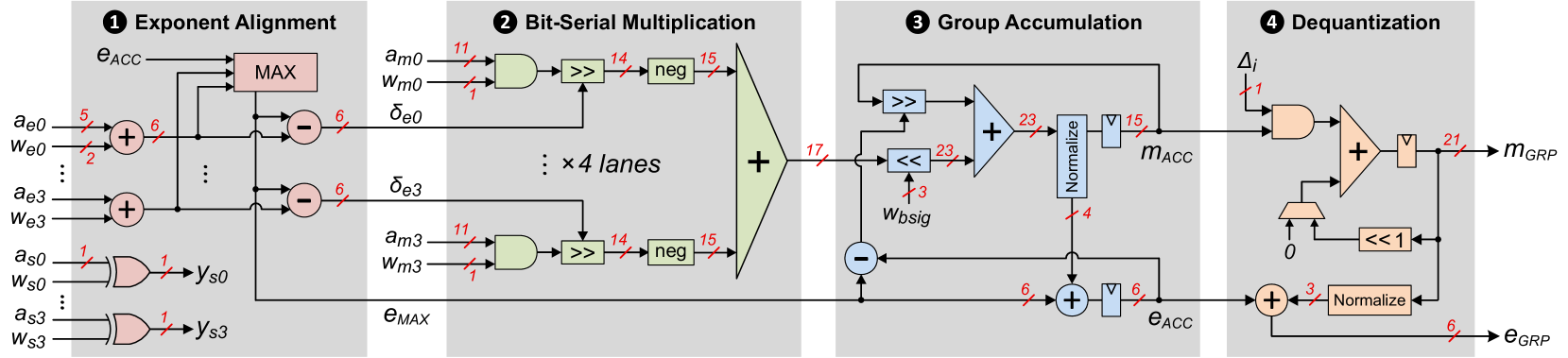 |
Github Paper |
| AMXFP4: 使用非对称微尺度浮点数驯服激活异常值,实现 4 位 LLM 推理 Janghwan Lee, Jiwoong Park, Jinseok Kim, Yongjik Kim, Jungju Oh, Jinwook Oh, Jungwook Choi |
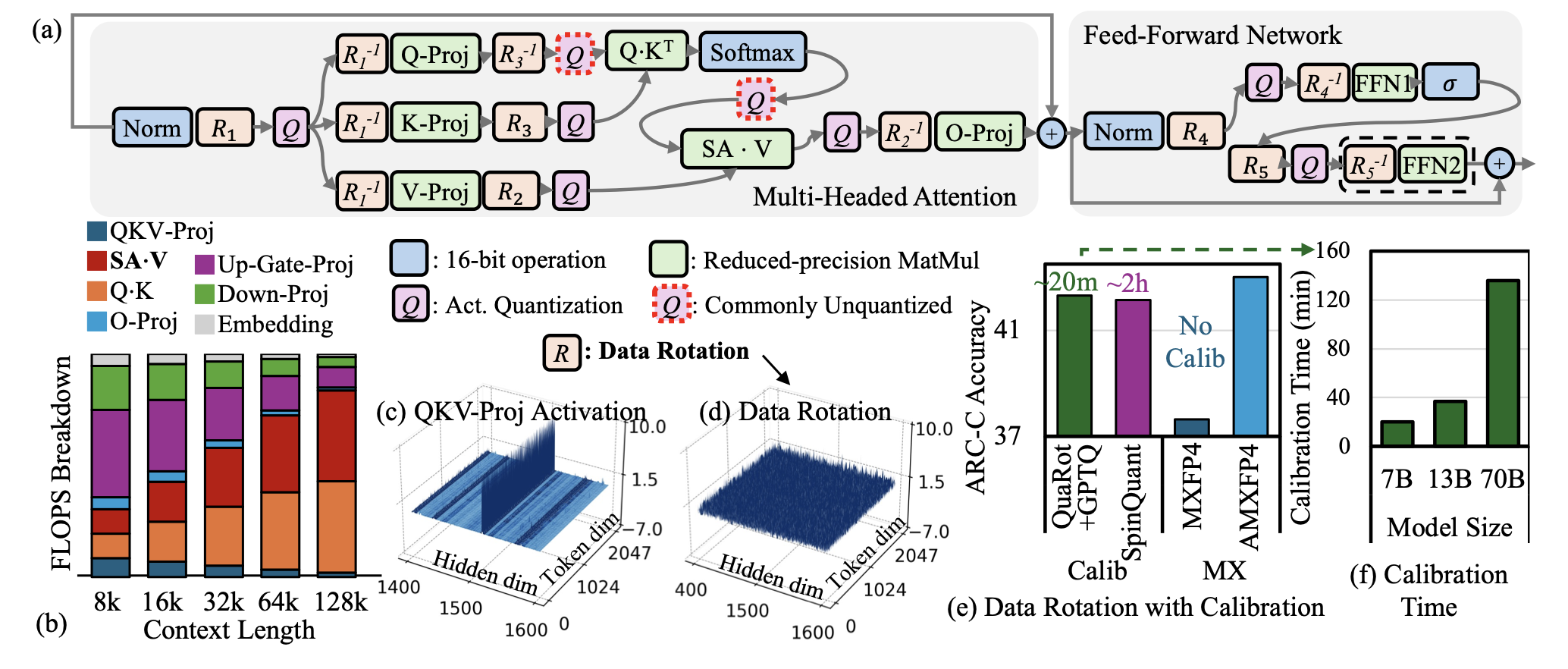 |
Paper |
| Bi-Mamba: 向精确的 1 位状态空间模型迈进 Shengkun Tang, Liqun Ma, Haonan Li, Mingjie Sun, Zhiqiang Shen |
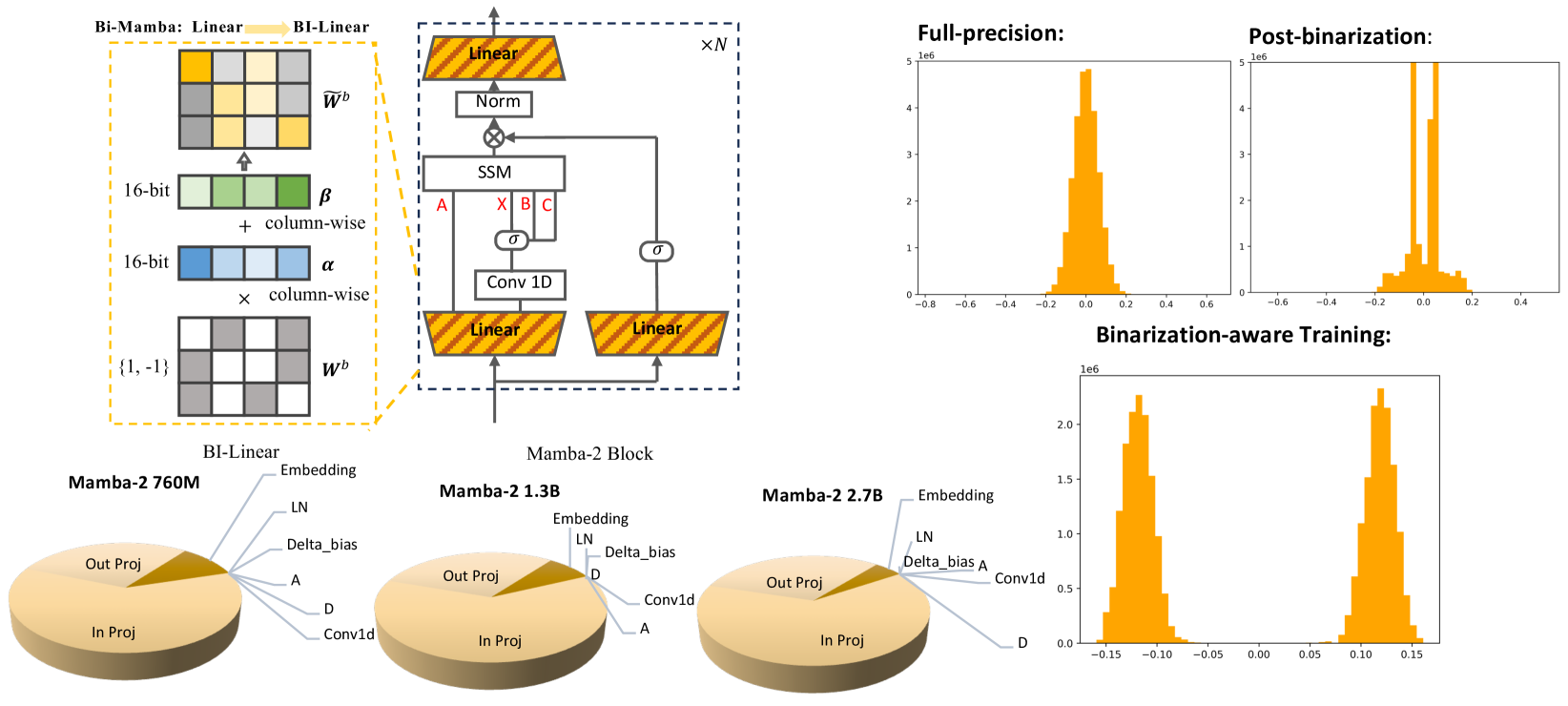 |
Paper |
| "给我 BF16 还是让我死"? LLM 量化中的准确率-性能权衡 Eldar Kurtic, Alexandre Marques, Shubhra Pandit, Mark Kurtz, Dan Alistarh |
Paper | |
| GWQ: 面向大型语言模型的梯度感知权重量化 Yihua Shao, Siyu Liang, Xiaolin Lin, Zijian Ling, Zixian Zhu 等 |
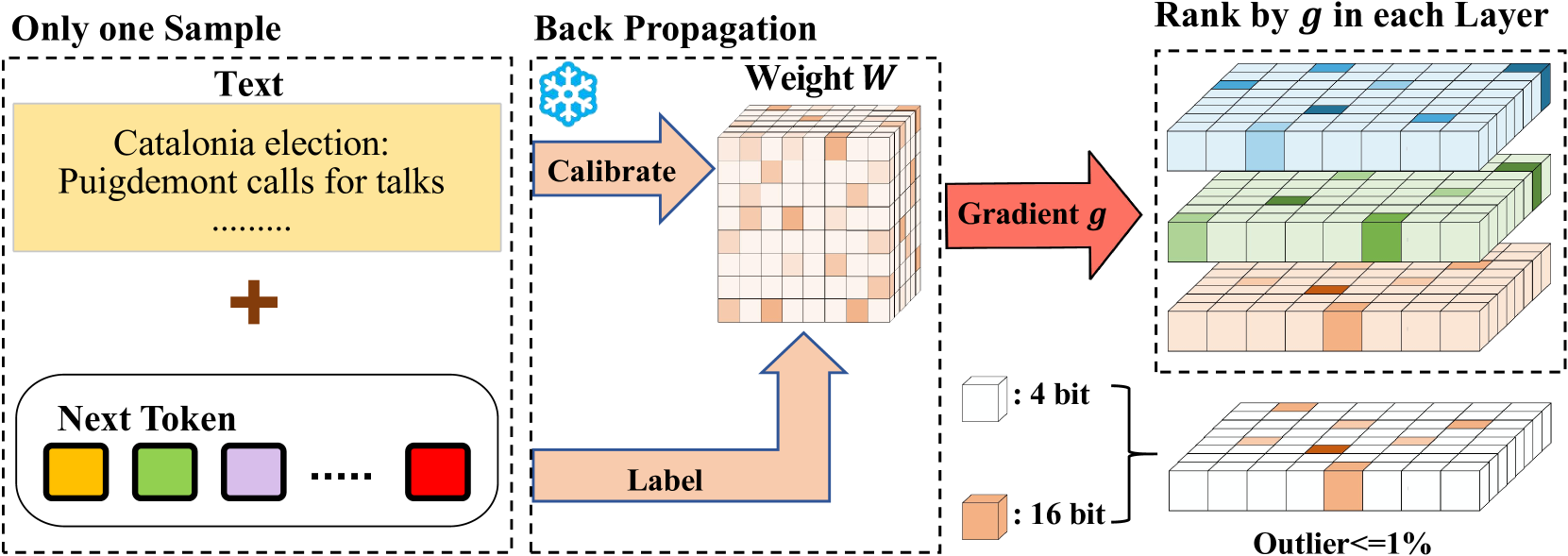 |
Paper |
| 大型语言模型量化技术综合研究 Jiedong Lang, Zhehao Guo, Shuyu Huang |
Paper | |
| BitNet a4.8: 用于 1 位 LLM 的 4 位激活 Hongyu Wang, Shuming Ma, Furu Wei |
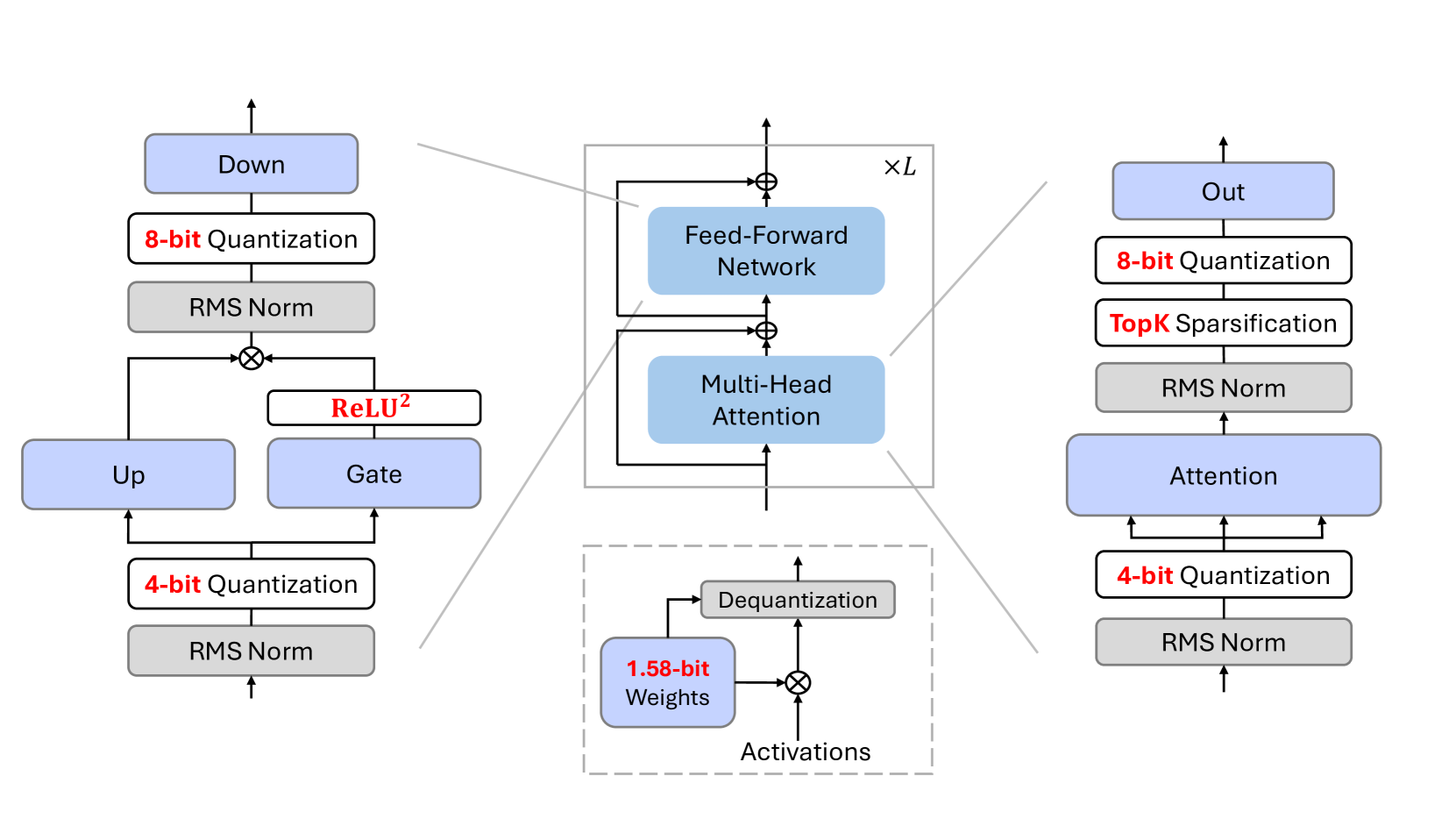 |
Paper |
 TesseraQ: 基于块重建的超低比特 LLM 后训练量化 Yuhang Li, Priyadarshini Panda |
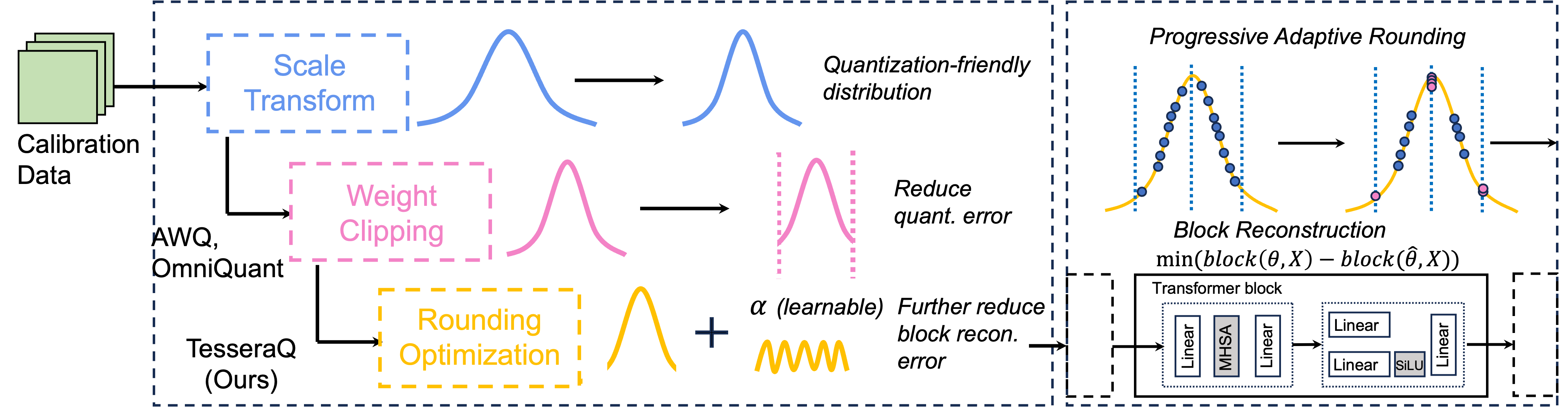 |
Github Paper |
 BitStack: 在可变内存环境下压缩大型语言模型的细粒度尺寸控制 Xinghao Wang, Pengyu Wang, Bo Wang, Dong Zhang, Yunhua Zhou, Xipeng Qiu |
 |
Github Paper |
| 推理加速策略对 LLM 偏见的影响 Elisabeth Kirsten, Ivan Habernal, Vedant Nanda, Muhammad Bilal Zafar |
Paper | |
| 理解大型语言模型低精度后训练量化的难度 Zifei Xu, Sayeh Sharify, Wanzin Yazar, Tristan Webb, Xin Wang |
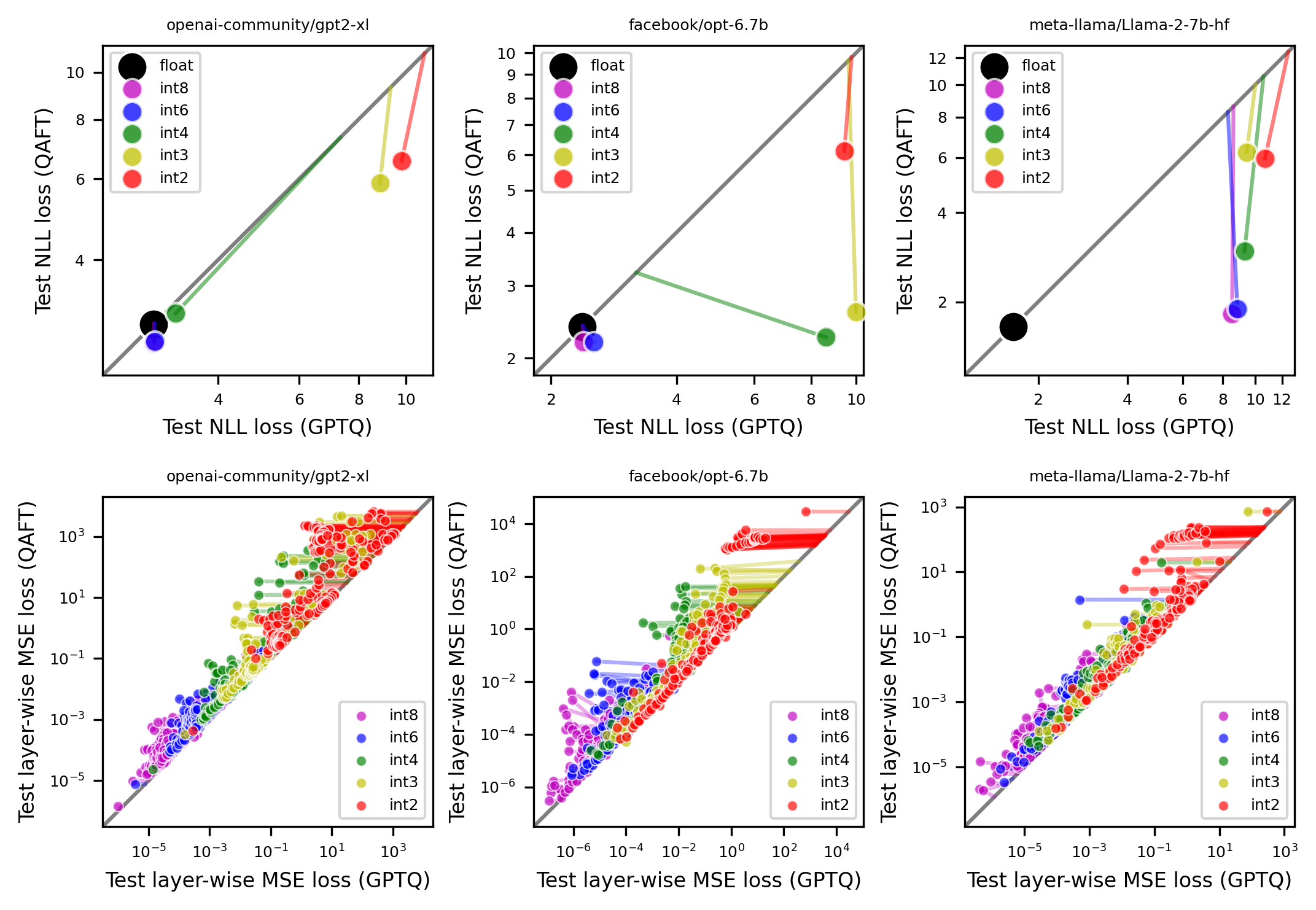 |
Paper |
 1 位 AI 基础设施: 第 1.1 部分,CPU 上快速无损的 BitNet b1.58 推理 Jinheng Wang, Hansong Zhou, Ting Song, Shaoguang Mao, Shuming Ma, Hongyu Wang, Yan Xia, Furu Wei |
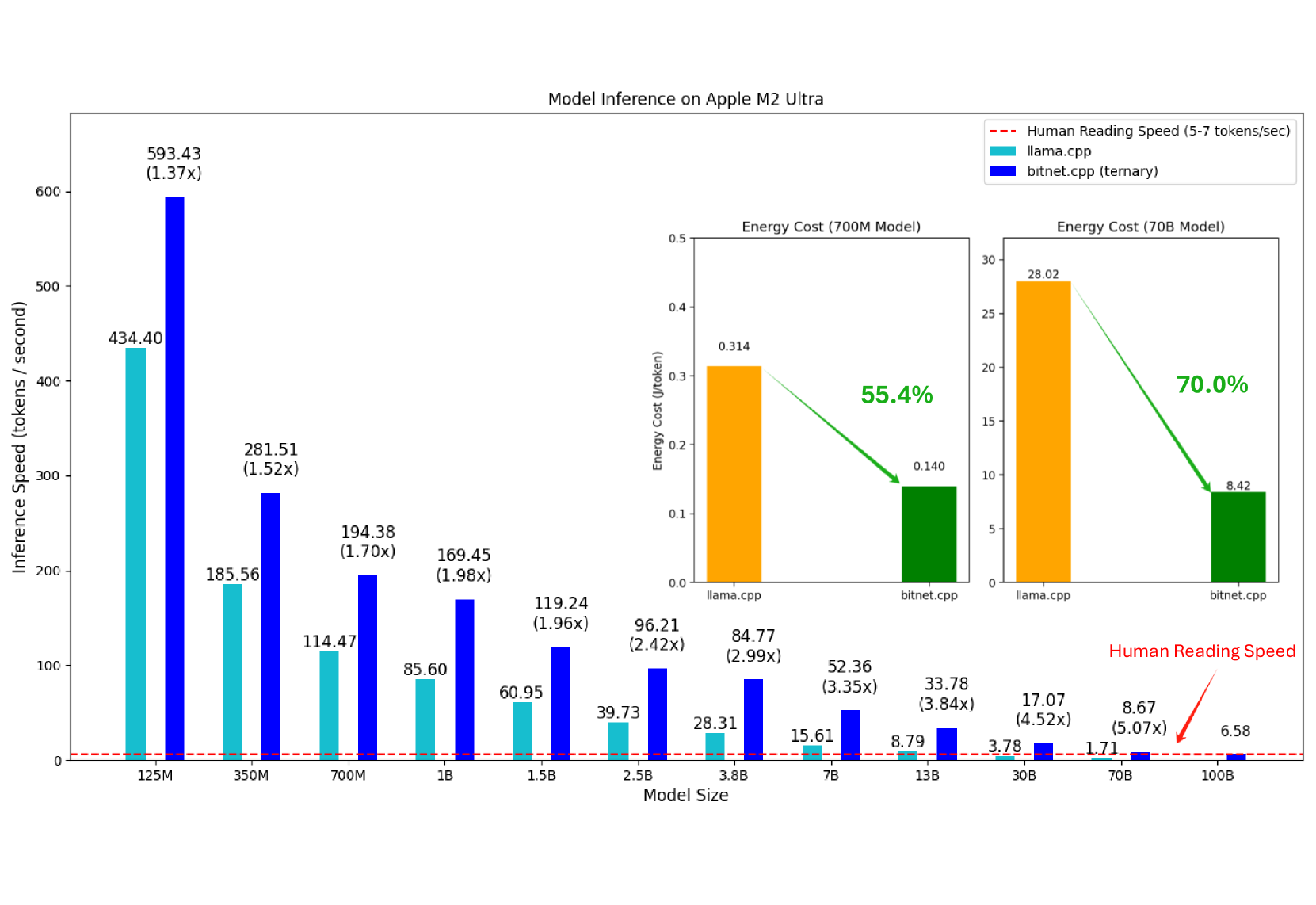 |
Github Paper |
| QuAILoRA: 面向 LoRA 的量化感知初始化 Neal Lawton, Aishwarya Padmakumar, Judith Gaspers, Jack FitzGerald, Anoop Kumar, Greg Ver Steeg, Aram Galstyan |
Paper | |
| 在低资源语言基准上评估量化大型语言模型的代码生成能力 Enkhbold Nyamsuren |
Paper | |
 :star: SqueezeLLM: 密集与稀疏量化 Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, Kurt Keutzer |
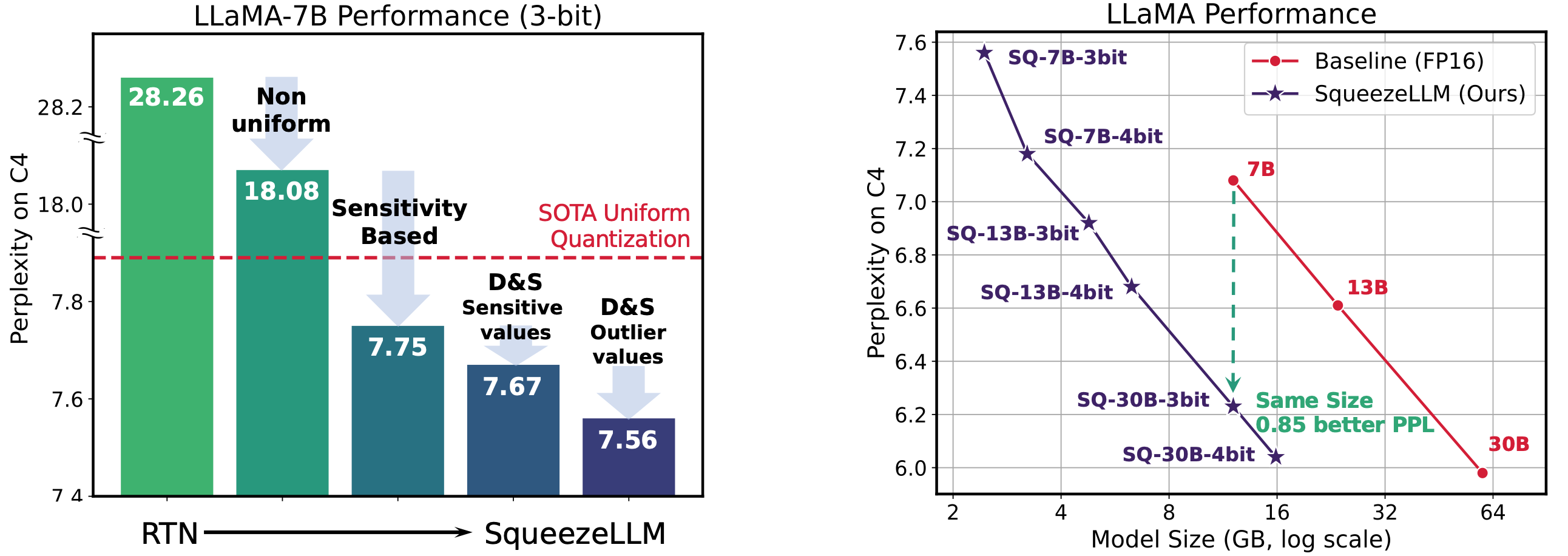 |
Github Paper |
| 金字塔向量量化应用于 LLM Tycho F. A. van der Ouderaa, Maximilian L. Croci, Agrin Hilmkil, James Hensman |
 |
Paper |
| SeedLM: 将 LLM 权重压缩为伪随机数生成器种子 Rasoul Shafipour, David Harrison, Maxwell Horton, Jeffrey Marker, Houman Bedayat, Sachin Mehta, Mohammad Rastegari, Mahyar Najibi, Saman Naderiparizi |
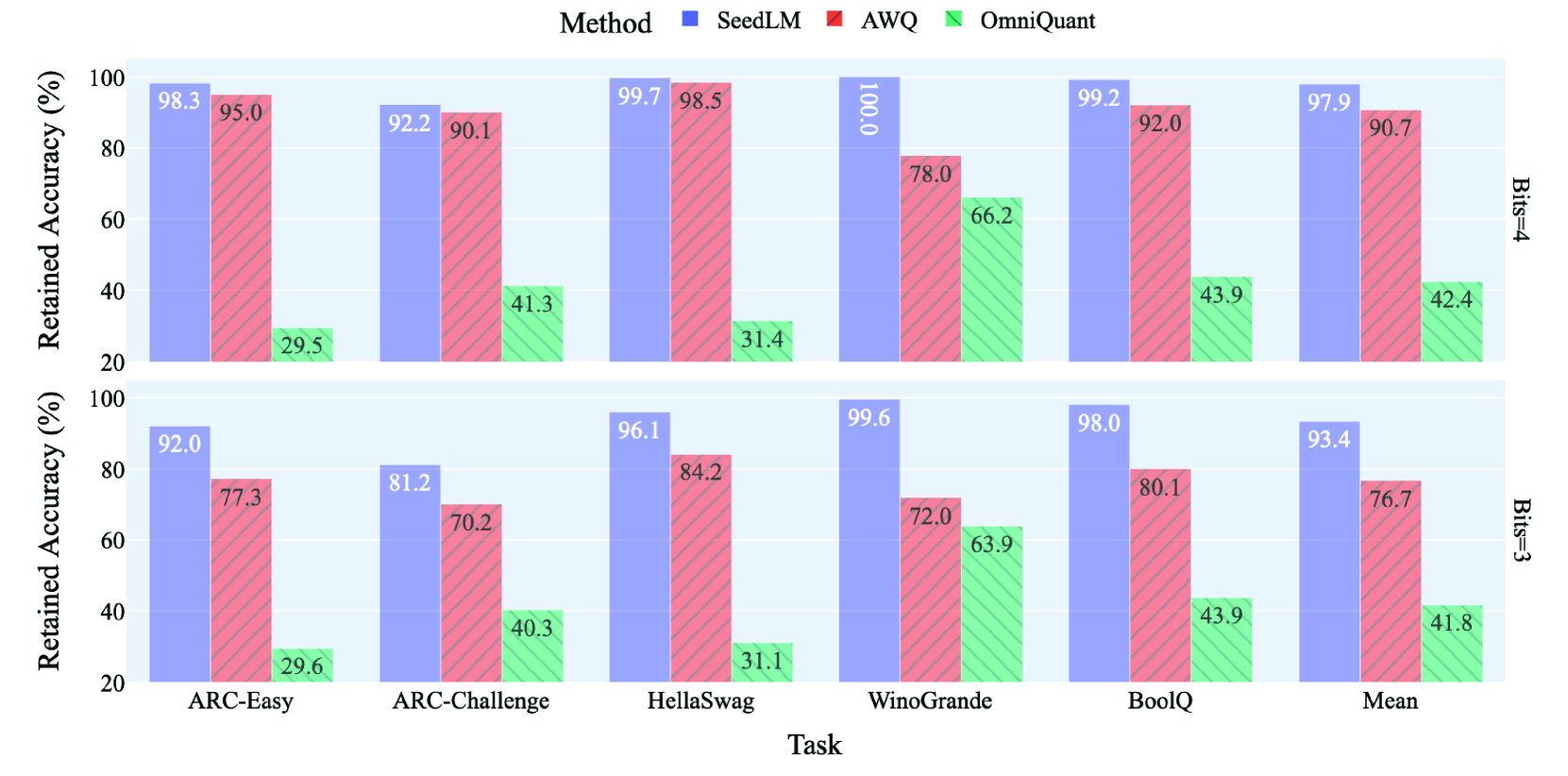 |
Paper |
 FlatQuant: 平坦性对 LLM 量化至关重要 Yuxuan Sun, Ruikang Liu, Haoli Bai, Han Bao, Kang Zhao, Yuening Li, Jiaxin Hu, Xianzhi Yu, Lu Hou, Chun Yuan, Xin Jiang, Wulong Liu, Jun Yao |
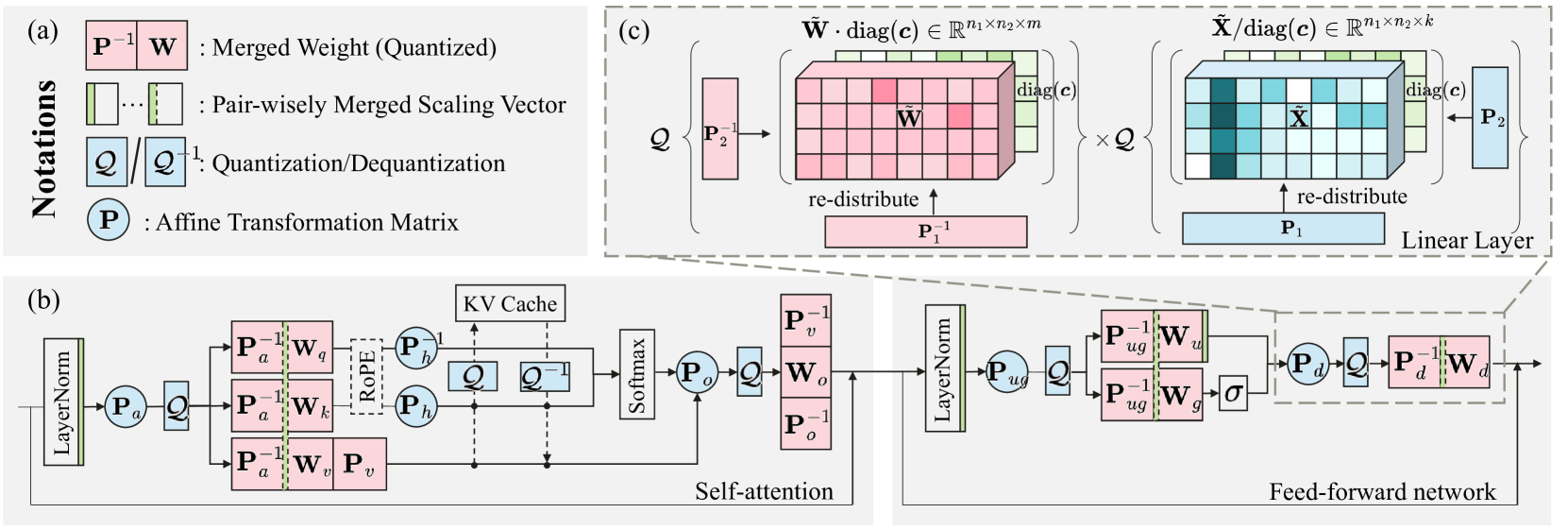 |
Github Paper |
 SLiM: LLM 的一次性量化稀疏加低秩近似 Mohammad Mozaffari, Maryam Mehri Dehnavi |
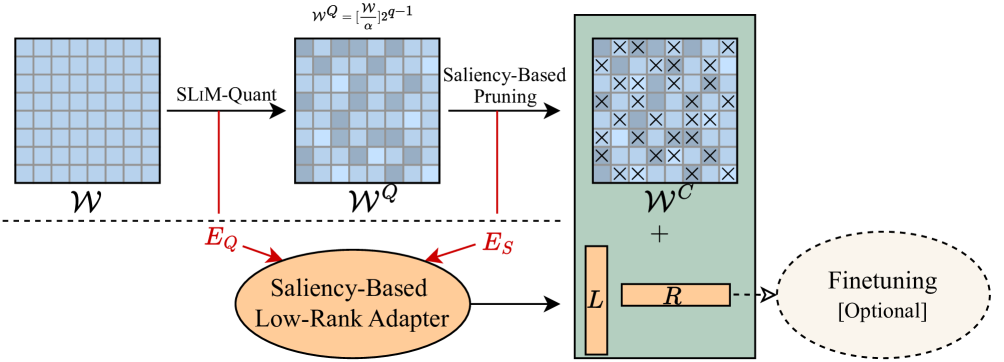 |
Github Paper |
| 后训练量化大型语言模型的规模法则 Zifei Xu, Alexander Lan, Wanzin Yazar, Tristan Webb, Sayeh Sharify, Xin Wang |
 |
Paper |
| 连续近似用于改进 LLM 的量化感知训练 He Li, Jianhang Hong, Yuanzhuo Wu, Snehal Adbol, Zonglin Li |
Paper | |
 DAQ: 面向 LLM 的密度感知仅权重后训练量化 Yingsong Luo, Ling Chen |
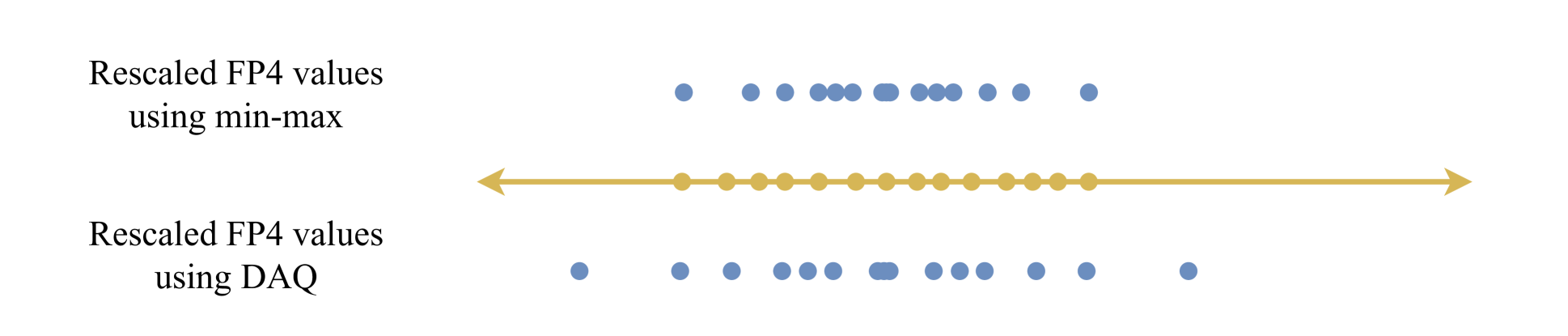 |
Github Paper |
 Quamba: 一种针对选择性状态空间模型的后训练量化配方 Hung-Yueh Chiang, Chi-Chih Chang, Natalia Frumkin、Kai-Chiang Wu、Diana Marculescu |
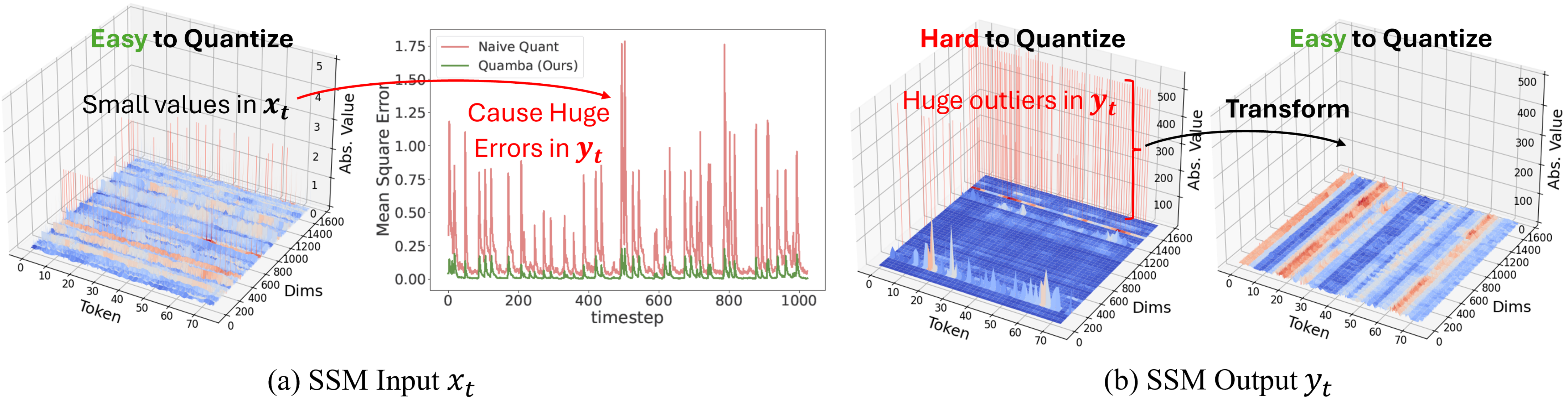 |
Github Paper |
| AsymKV: 通过逐层非对称量化配置实现 KV 缓存的 1 位量化 Qian Tao, Wenyuan Yu, Jingren Zhou |
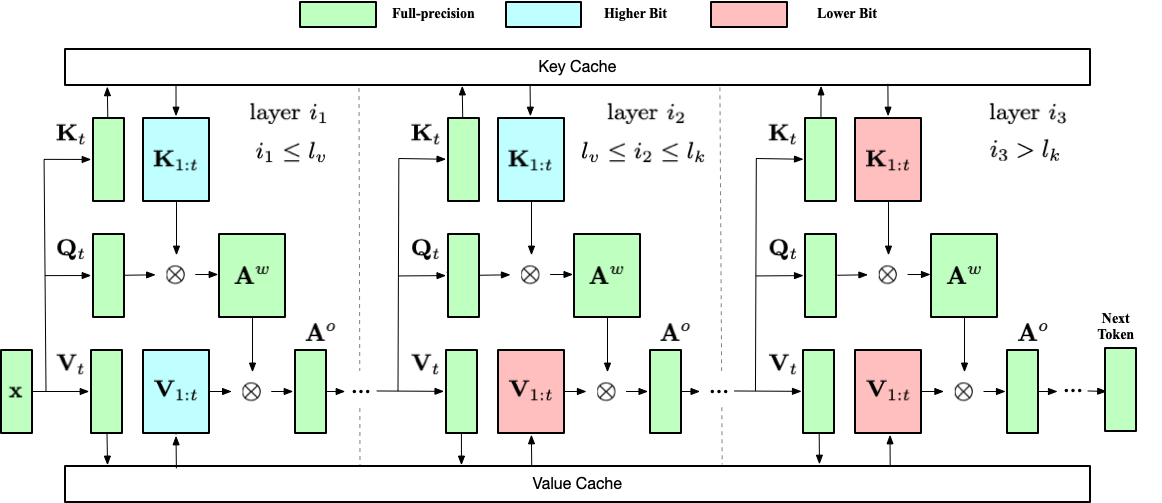 |
Paper |
| 面向大型语言模型的通道级混合精度量化 Zihan Chen, Bike Xie, Jundong Li, Cong Shen |
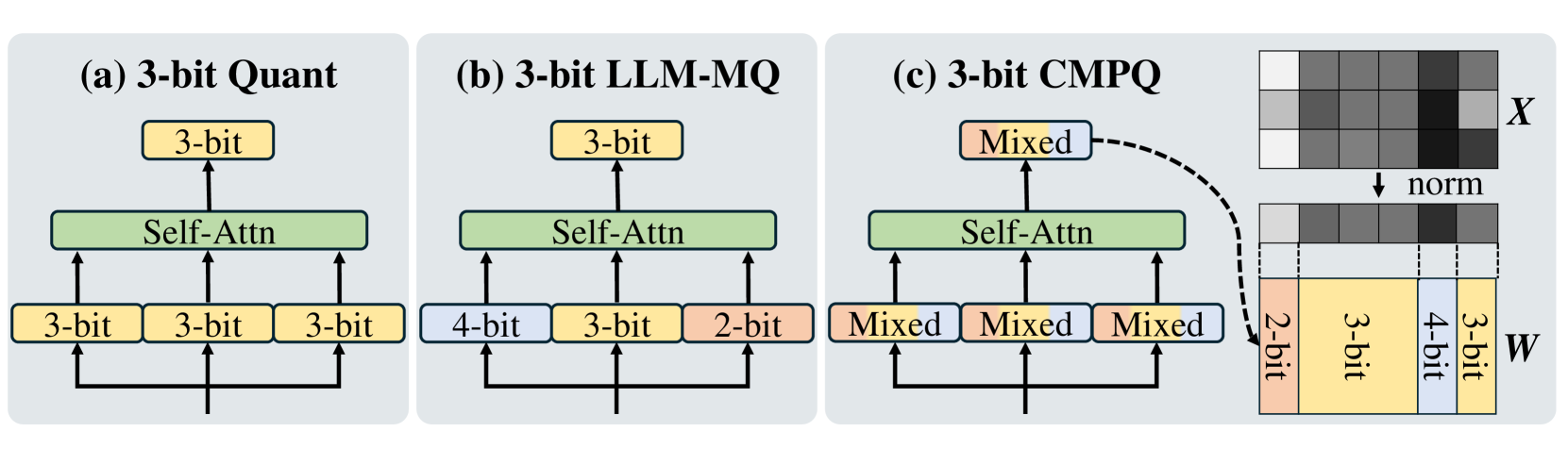 |
Paper |
| 渐进式混合精度解码用于高效 LLM 推理 Hao Mark Chen, Fuwen Tan, Alexandros Kouris、Royson Lee、Hongxiang Fan、Stylianos I. Venieris |
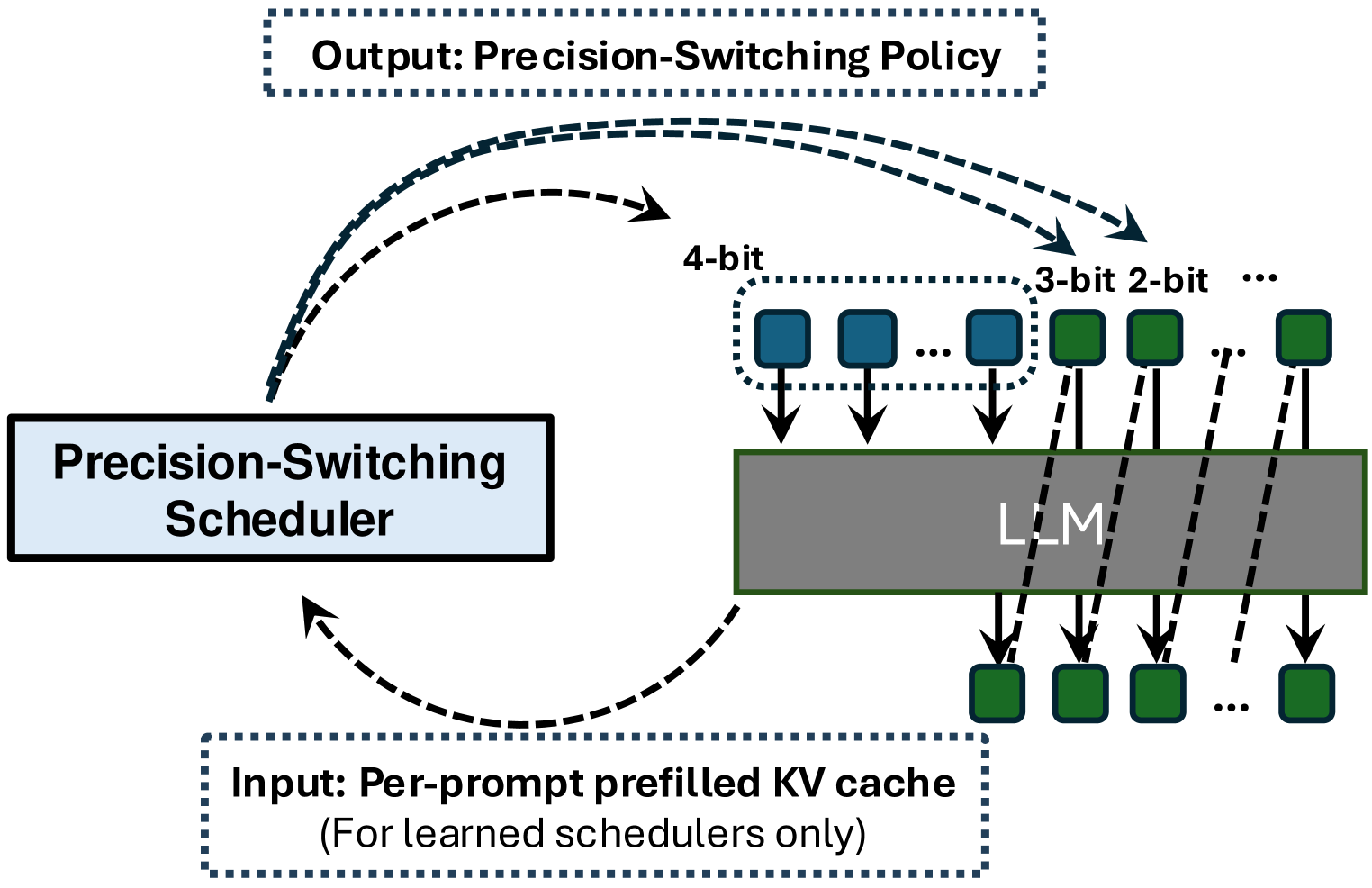 |
Paper |
 EXAQ: 指数感知量化用于加速 LLM Moran Shkolnik, Maxim Fishman、Brian Chmiel、Hilla Ben-Yaacov、Ron Banner、Kfir Yehuda Levy |
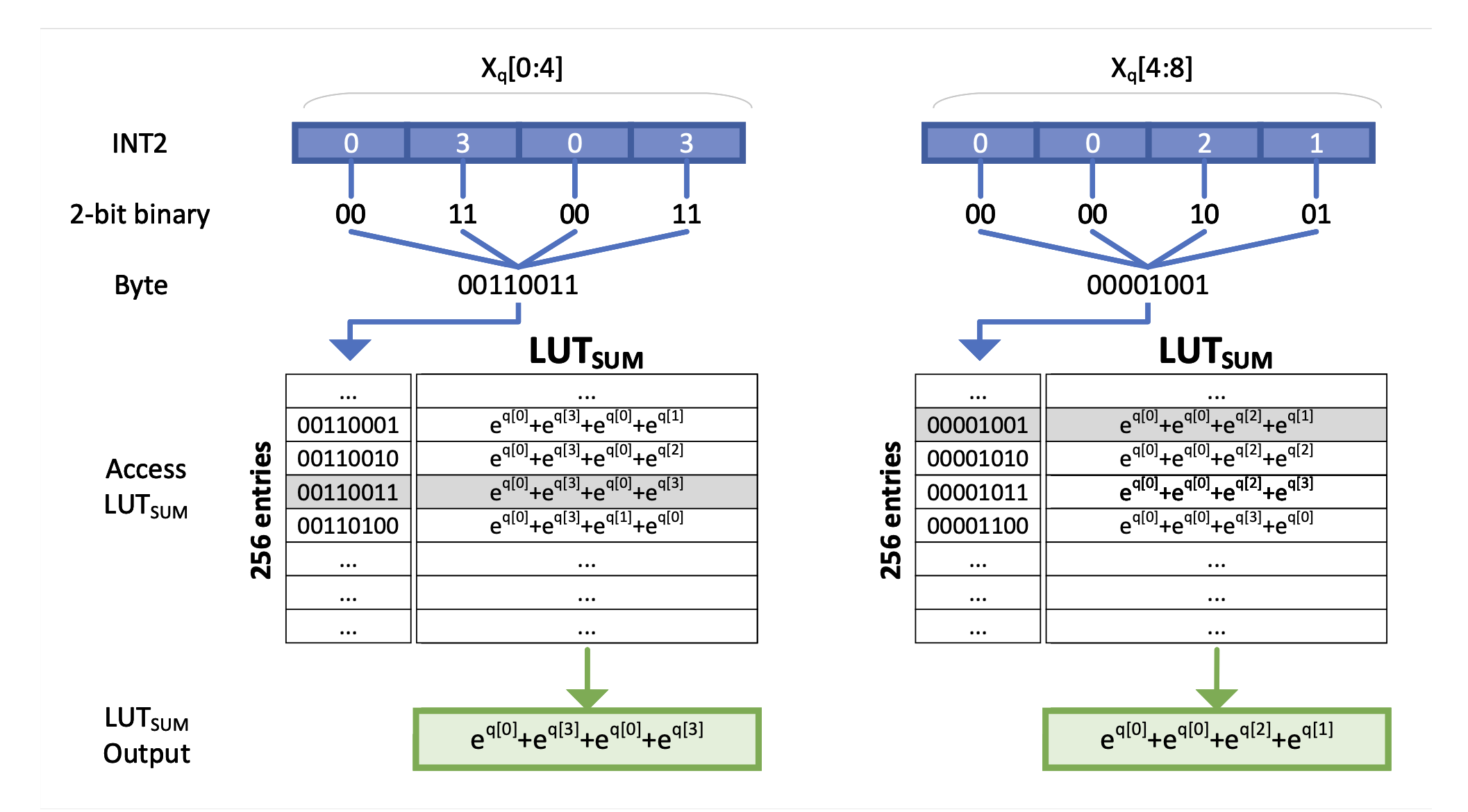 |
Github Paper |
 PrefixQuant: 静态量化胜过动态量化,通过 LLM 中的前缀异常值实现 Mengzhao Chen、Yi Liu、Jiahao Wang、Yi Bin、Wenqi Shao、Ping Luo |
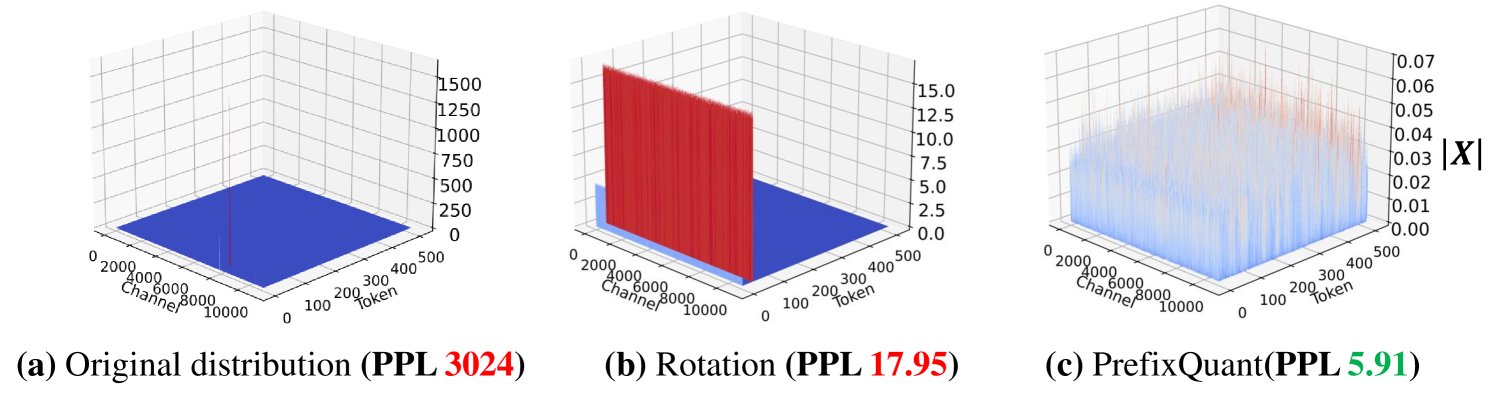 |
Github Paper |
 :star: 通过加法量化实现大型语言模型的极致压缩 Vage Egiazarian、Andrei Panferov、Denis Kuznedelev、Elias Frantar、Artem Babenko、Dan Alistarh |
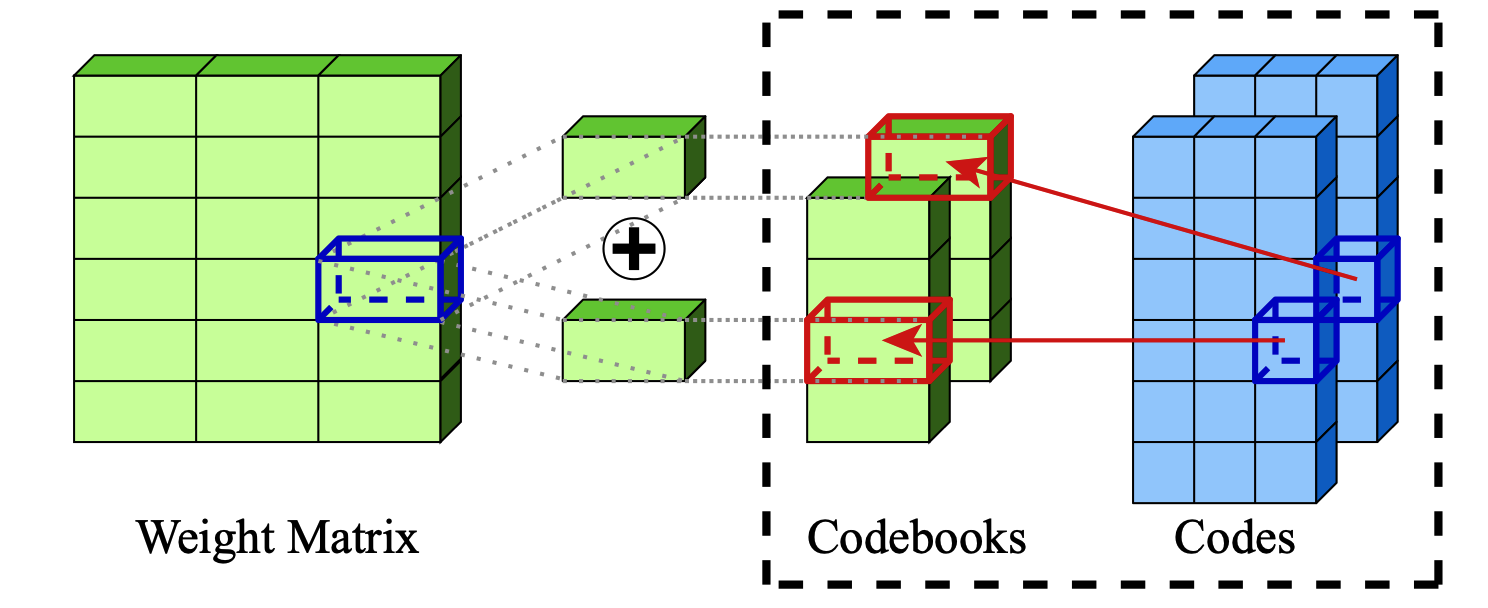 |
Github Paper |
| 大型语言模型中混合量化的规模法则 Zeyu Cao、Cheng Zhang、Pedro Gimenes、Jianqiao Lu、Jianyi Cheng、Yiren Zhao |
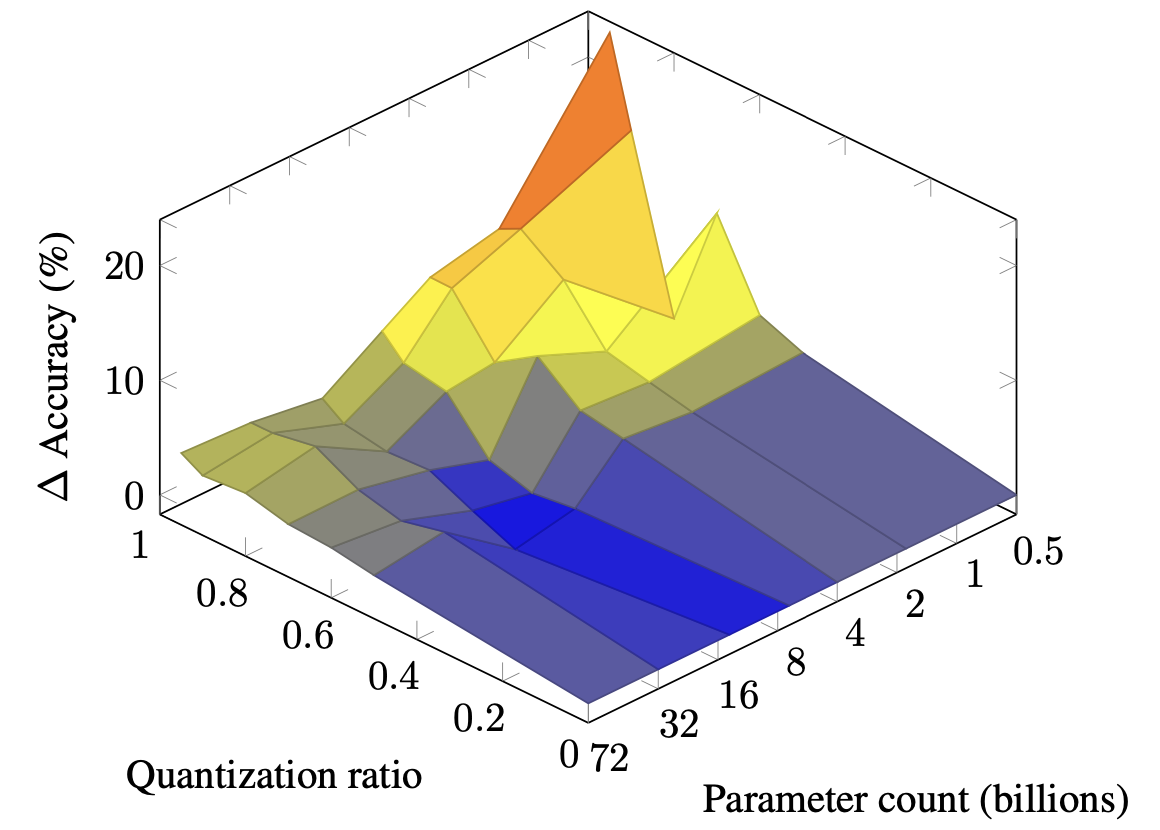 |
Paper |
| PalmBench: 移动平台上压缩大型语言模型的综合基准测试 Yilong Li、Jingyu Liu、Hao Zhang、M Badri Narayanan、Utkarsh Sharma、Shuai Zhang、Pan Hu、Yijing Zeng、Jayaram Raghuram、Suman Banerjee |
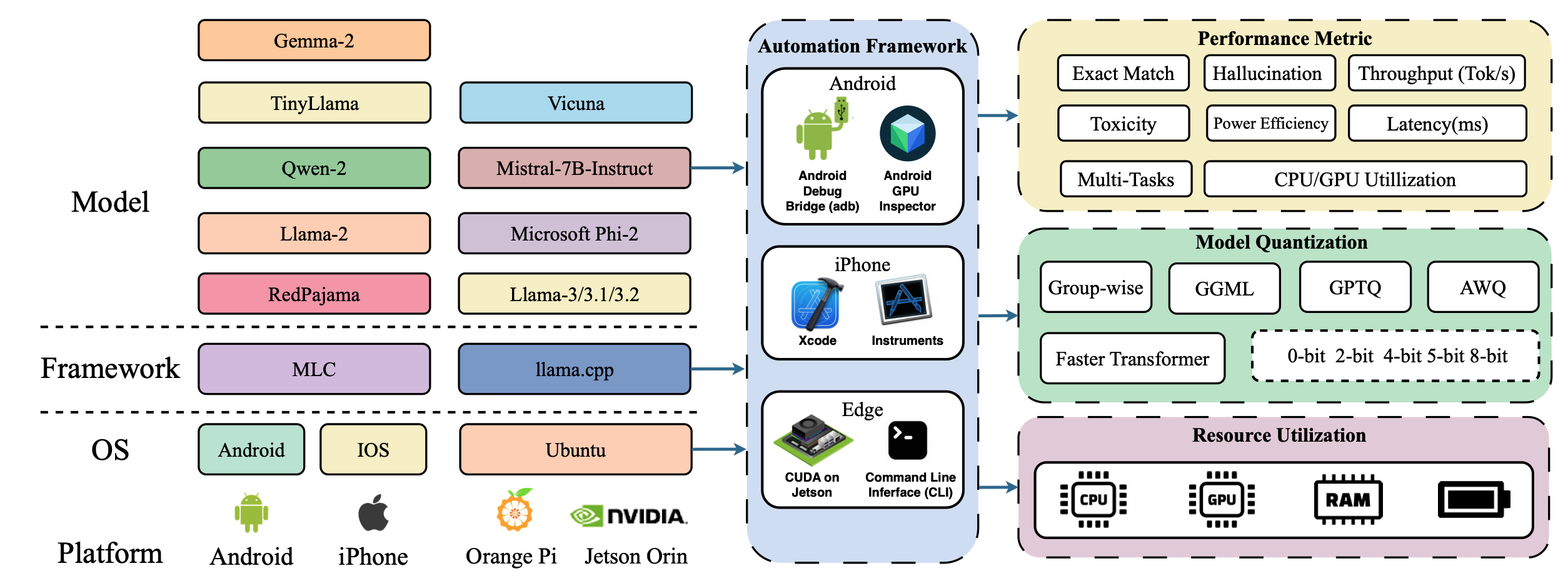 |
Paper |
| CrossQuant: 一种具有更小量化核的后训练量化方法,用于精确压缩大型语言模型 Wenyuan Liu、Xindian Ma、Peng Zhang、Yan Wang |
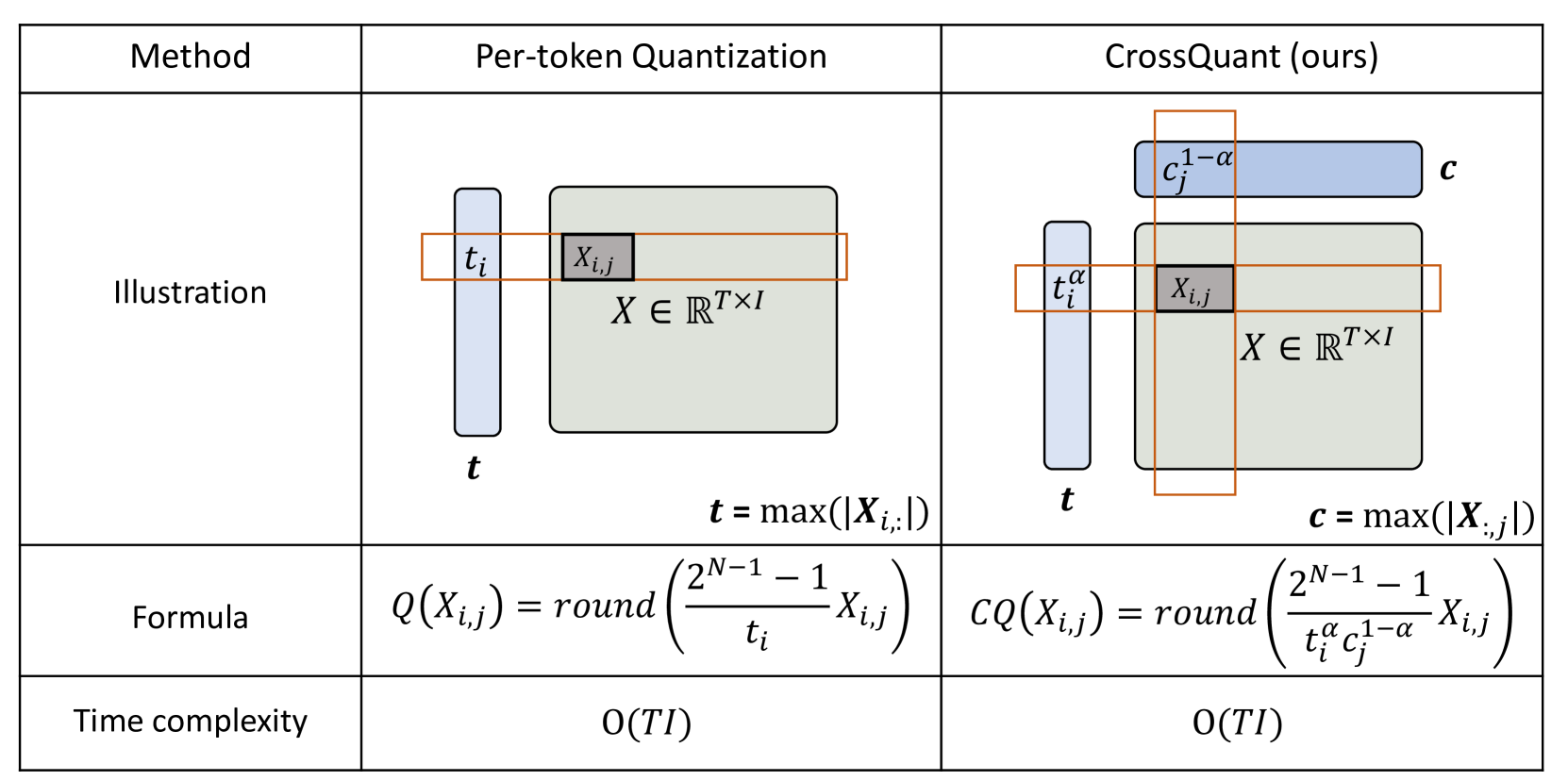 |
Paper |
| SageAttention: 准确的 8 位注意力机制,用于即插即用的推理加速 Jintao Zhang、Jia wei、Pengle Zhang、Jun Zhu、Jianfei Chen |
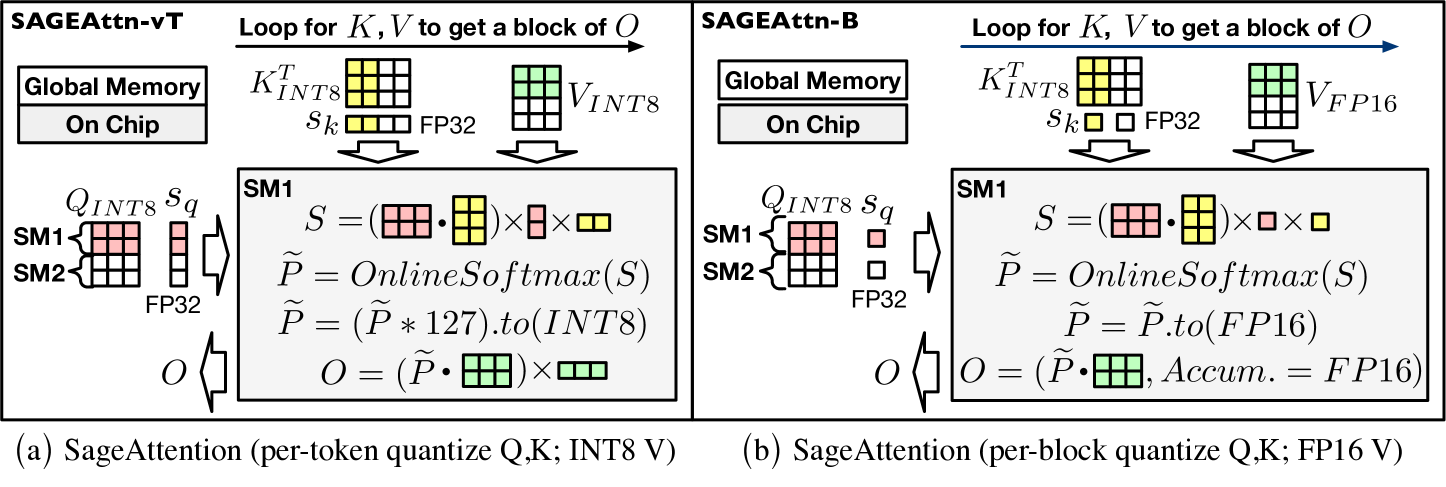 |
Paper |
| 对于节能语言模型,只需加法就够了 Hongyin Luo、Wei Sun |
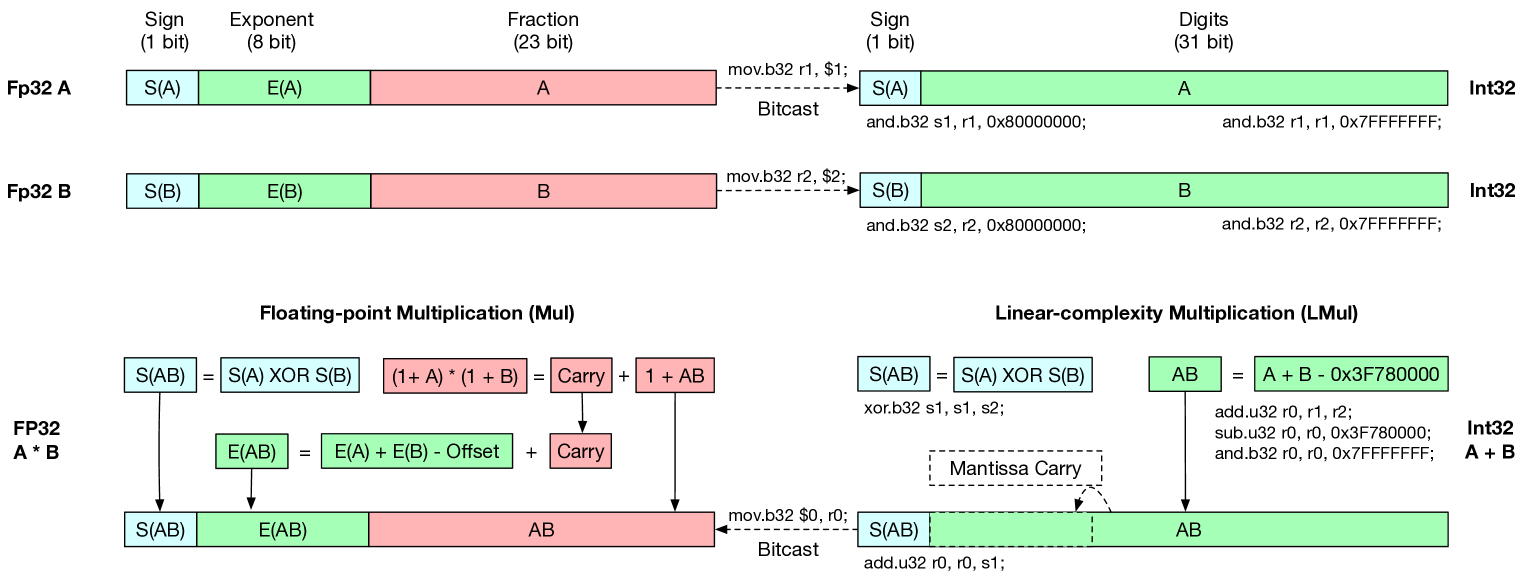 |
Paper |
 GuidedQuant: 利用末端损失指导进行大型语言模型量化 Jinuk Kim、Marwa El Halabi、Wonpyo Park、Clemens JS Schaefer、Deokjae Lee、Yeonhong Park、Jae W. Lee、Hyun Oh Song |
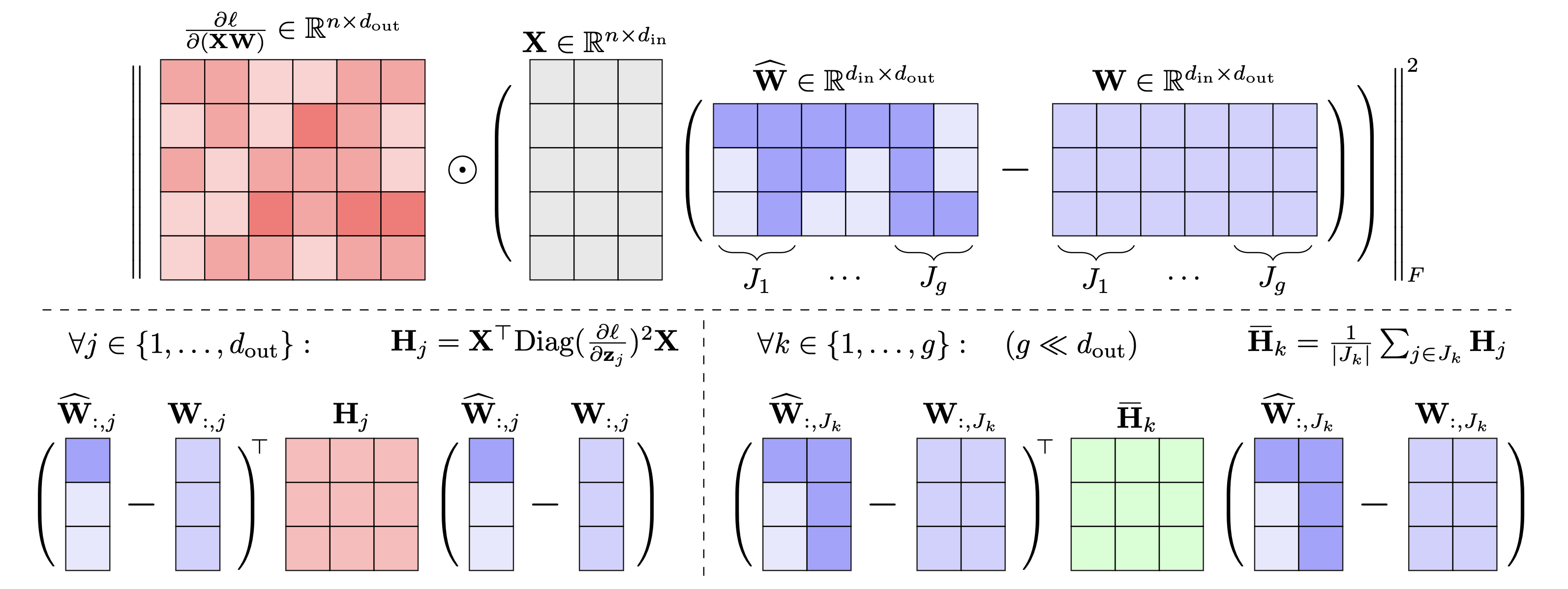 |
Github Paper |
推理加速
| 标题与作者 | 简介 | 链接 |
|---|---|---|
 :star: Deja Vu: 上下文稀疏性用于推理时高效的LLM 刘子畅, 王珏, 特里·道, 周天一, 袁彬航, 宋昭, 安舒马利·施里瓦斯塔瓦, 张策, 田元东, 克里斯托弗·雷, 陈贝迪 |
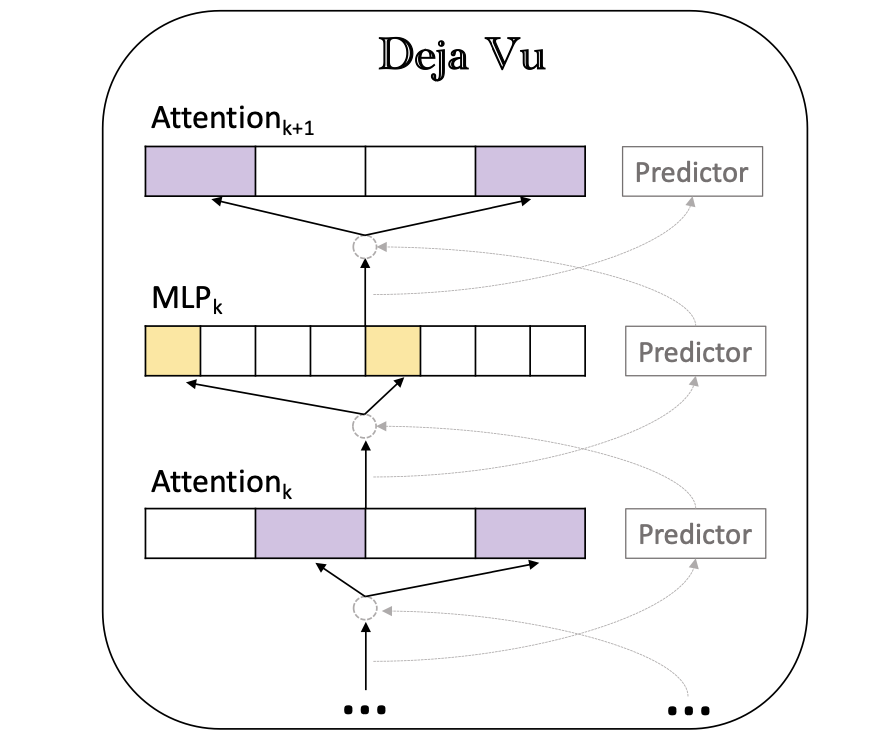 |
Github Paper |
 :star: SpecInfer: 利用推测式推理和标记树验证加速生成式LLM服务 缪旭鹏, 加布里埃莱·奥利亚罗, 张志浩, 程新浩, 王泽宇, 黄锐颖, 陈卓明, 阿尔芬·戴亚安, 雷娜·阿布扬卡尔, 贾志浩 |
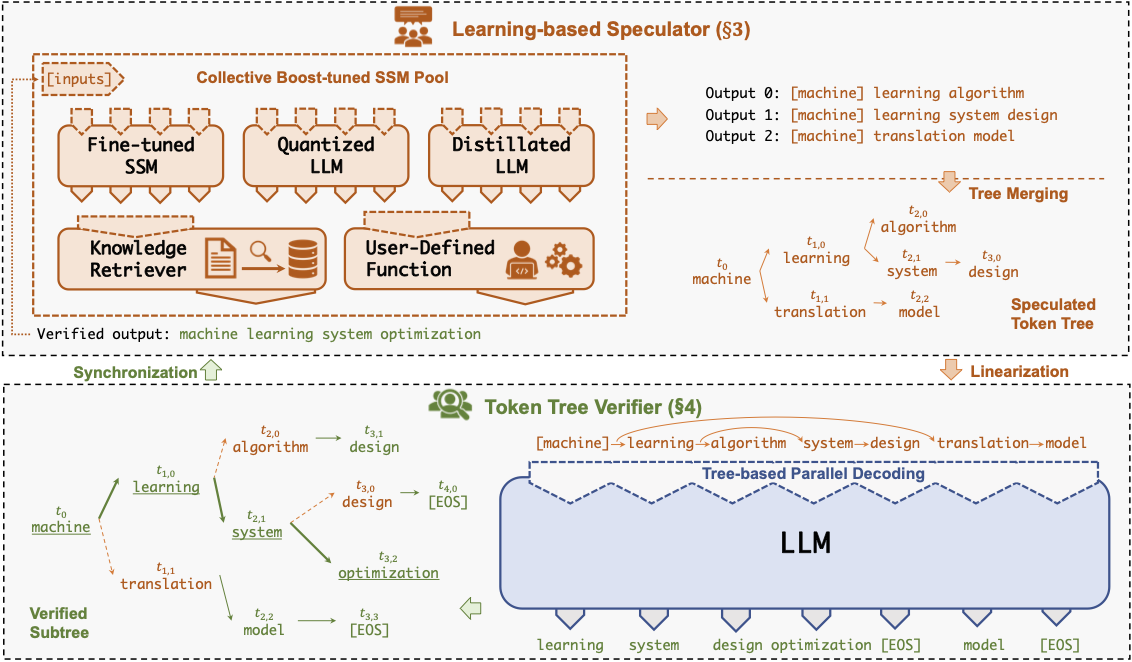 |
Github paper |
 :star: 利用注意力汇流实现高效流式语言模型 肖广轩, 田元东, 陈贝迪, 韩松, 迈克·刘易斯 |
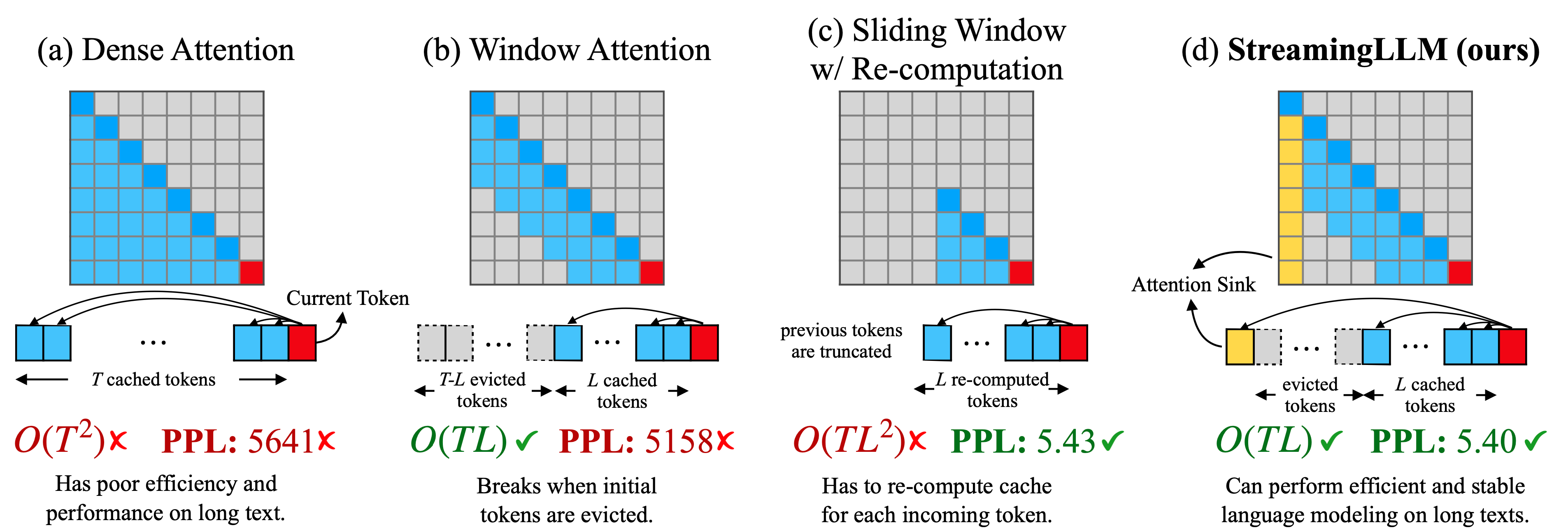 |
Github Paper |
 :star: EAGLE: 通过特征外推实现LLM解码的无损加速 李宇辉, 张超, 张洪洋 |
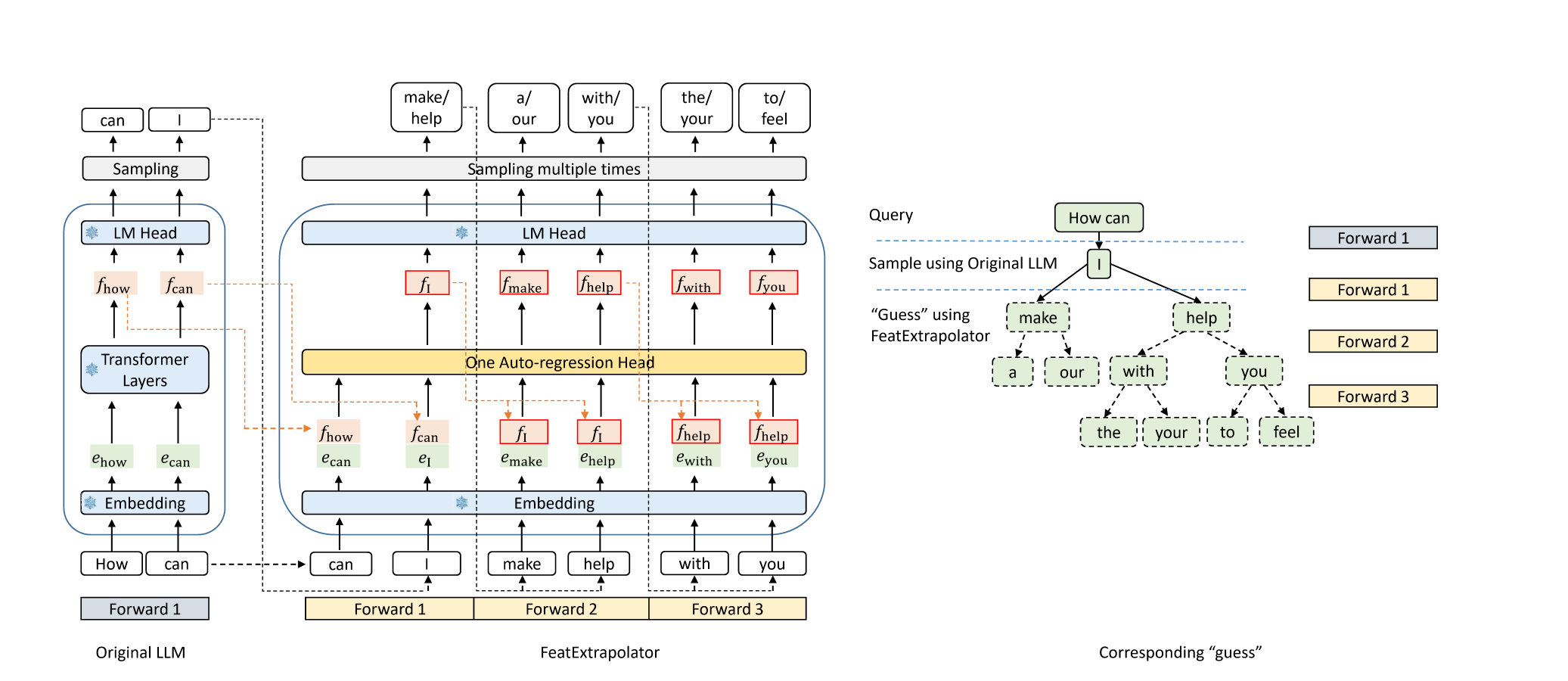 |
Github Blog |
 :star: Medusa: 带有多解码头的简单LLM推理加速框架 蔡天乐, 李宇宏, 耿正阳, 彭洪武, 杰森·D·李, 陈德明, 特里·道 |
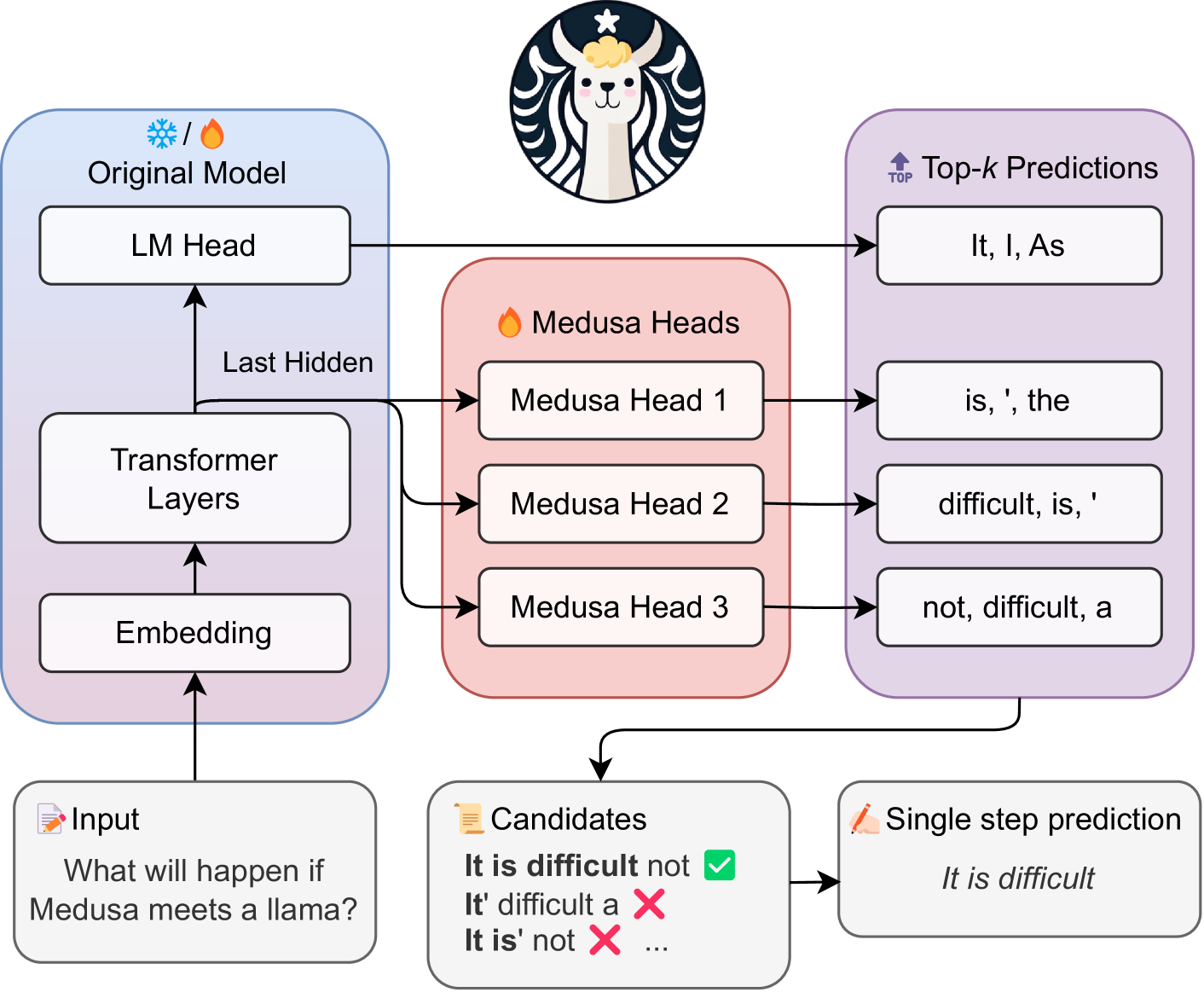 |
Github Paper |
| 基于CTC的草稿模型进行推测式解码以加速LLM推理 文卓凡, 桂尚通, 冯洋 |
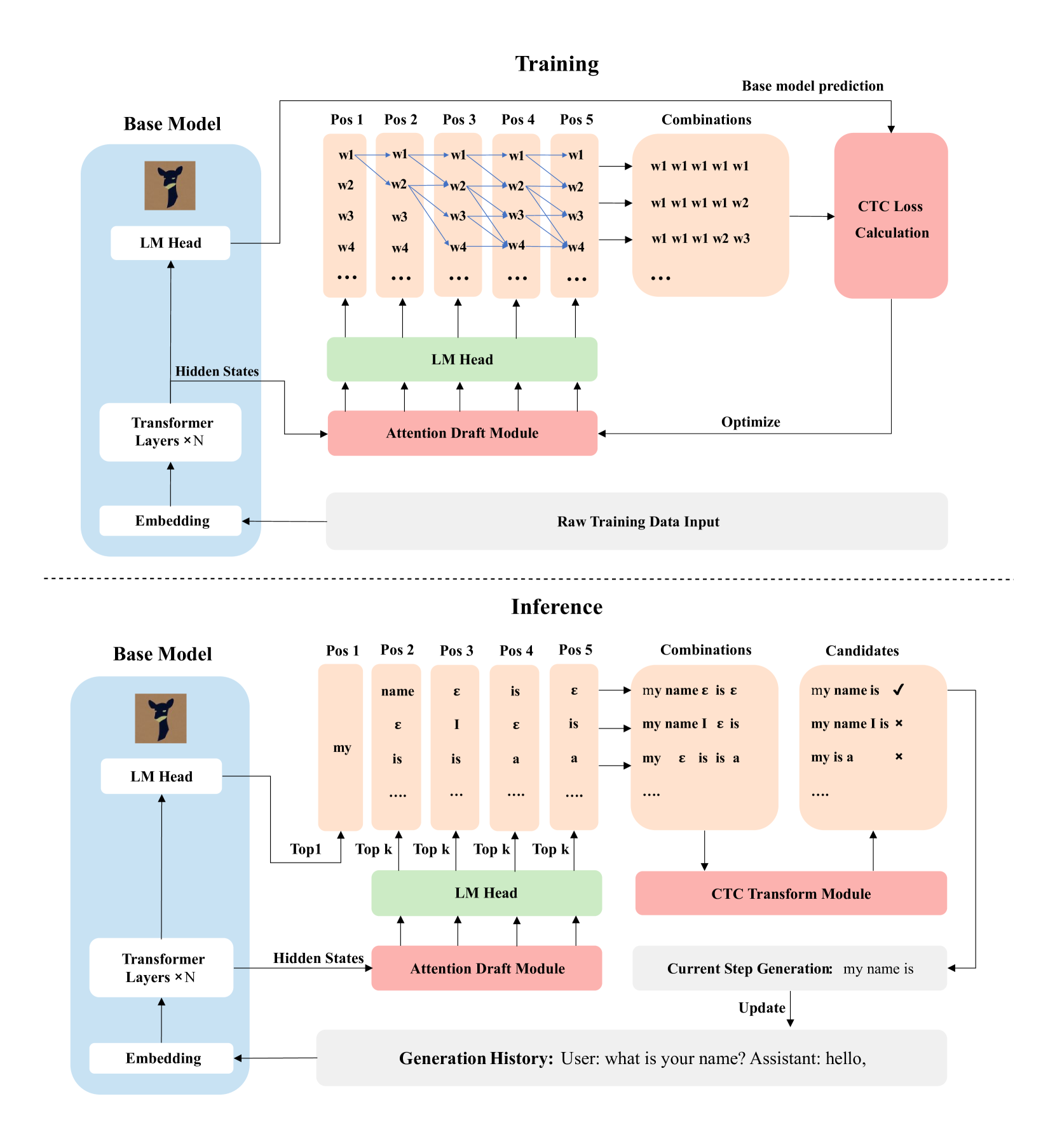 |
Paper |
| PLD+: 利用语言模型产物加速LLM推理 施韦塔·索马桑达拉姆, 阿尼鲁德·普卡恩, 阿普尔夫·萨克塞纳 |
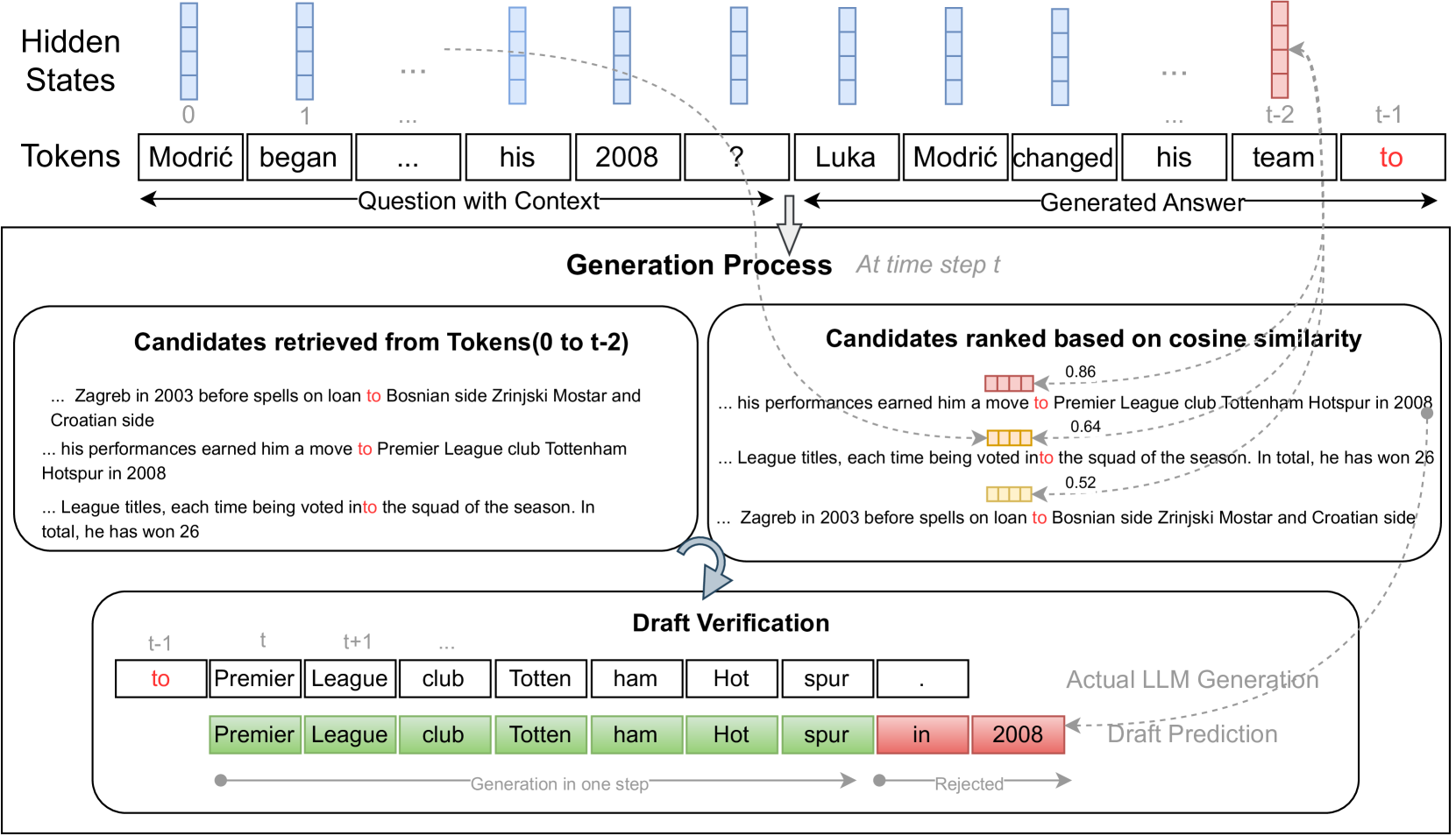 |
Paper |
FastDraft: 如何训练你的草稿 奥菲尔·扎弗里尔, 伊戈尔·马古利斯, 多林·什泰曼, 盖伊·鲍杜赫 |
Paper | |
 SMoA: 利用稀疏混合代理改进多智能体大型语言模型 李大伟, 谭振, 钱佩嘉, 李一帆, 库马尔·萨特维克·乔杜里, 胡丽洁, 沈佳怡 |
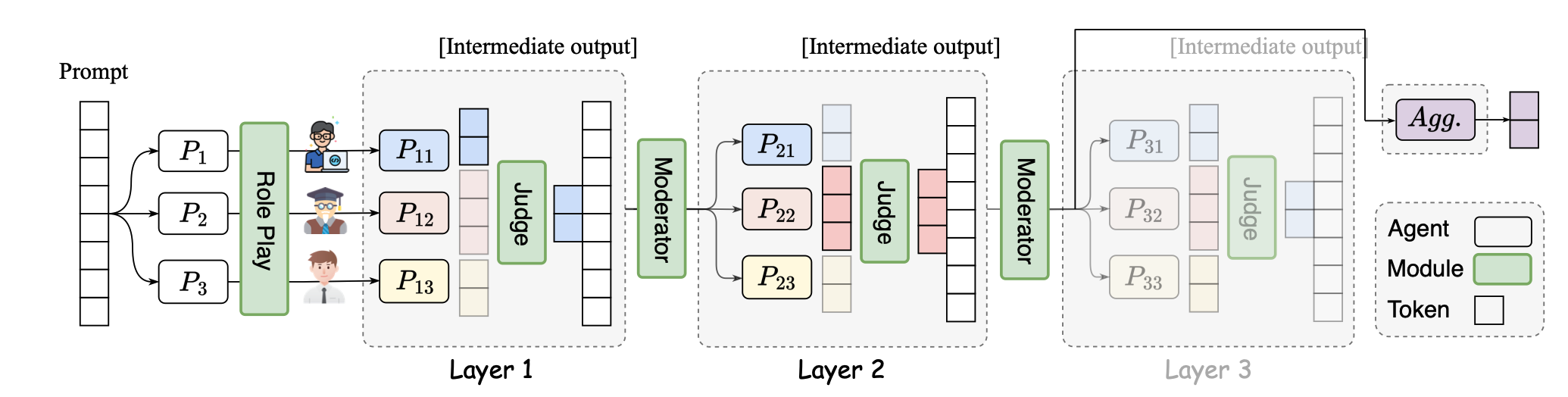 |
Github Paper |
| The N-Grammys: 利用无学习批处理推测加速自回归推理 劳伦斯·斯图尔特, 马修·特拉格, 苏詹·库马尔·戈努贡德拉, 斯特法诺·索阿托 |
Paper | |
| 通过动态执行方法加速AI推理 海姆·巴拉德, 雅沙·阿赫特贝格, 周天培, 于珍 |
Paper | |
| SuffixDecoding: 一种无需模型的方法来加速大型语言模型推理 加布里埃莱·奥利亚罗, 贾志浩, 丹尼尔·坎波斯, 奥里克·乔奥 |
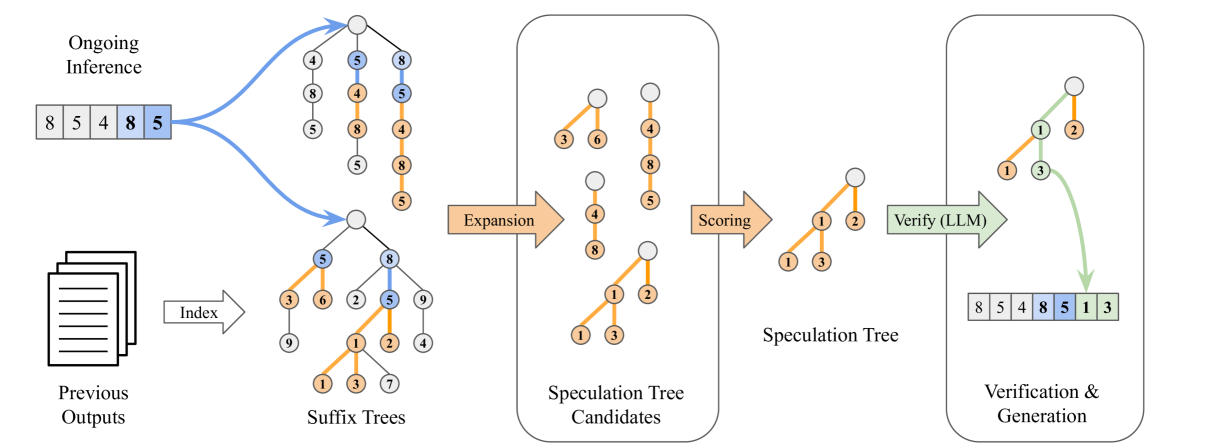 |
Paper |
| 针对大型语言模型高效问答的动态策略规划 坦迈·帕雷克, 普拉迪奥特·普拉卡什, 亚历山大·拉多维奇, 阿克谢·舍克哈尔, 丹尼斯·萨文科夫 |
 |
Paper |
 MagicPIG: LSH采样用于高效LLM生成 陈卓明, 拉纳乔伊·萨杜坎, 叶志豪, 周阳, 张建宇, 尼克拉斯·诺尔特, 田元东, 马蒂伊斯·杜兹, 莱昂·博图, 贾志浩, 陈贝迪 |
 |
Github Paper |
| 利用张量分解提升多标记预测能力,从而加快语言模型速度 阿尔乔姆·巴沙林, 安德烈·切尔特科夫, 伊万·奥塞列杰茨 |
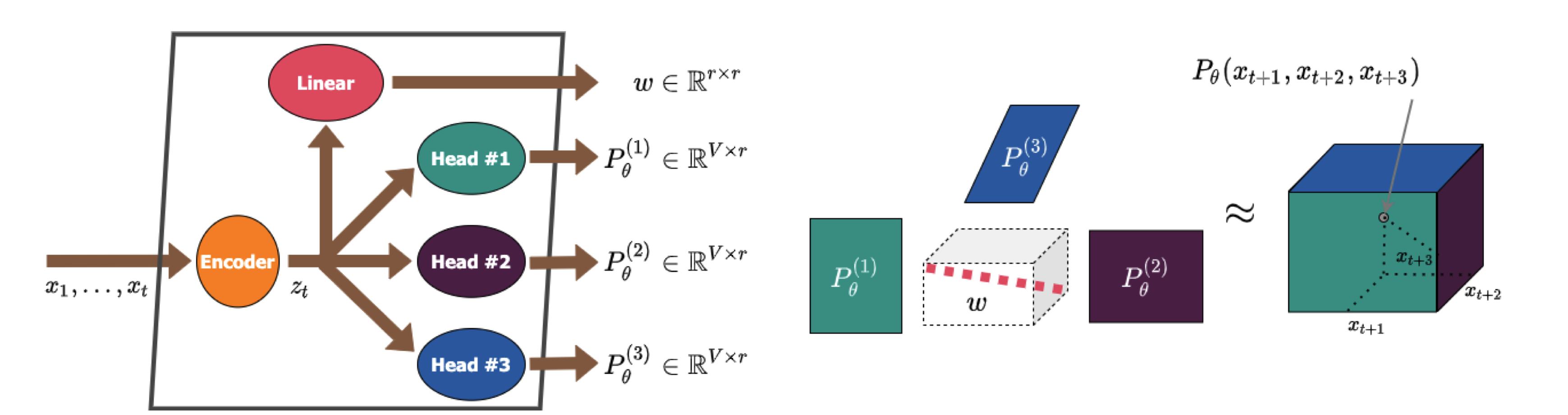 |
Paper |
| 增强型大型语言模型的高效推理 拉娜·沙胡特, 梁聪, 辛世基, 劳千茹, 崔勇, 余敏兰, 米歇尔·米岑马赫尔 |
 |
Paper |
 早期退出LLM中的动态词汇修剪 乔特·文森蒂, 卡里姆·阿卜杜勒·萨德克, 乔安·维尔哈, 马泰奥·努利, 梅托德·雅兹贝克 |
 |
Github Paper |
 CoreInfer: 利用语义启发的自适应稀疏激活加速大型语言模型推理 王钦思, 萨伊德·瓦希迪安, 叶汉成, 顾建阳, 张建毅, 陈怡然 |
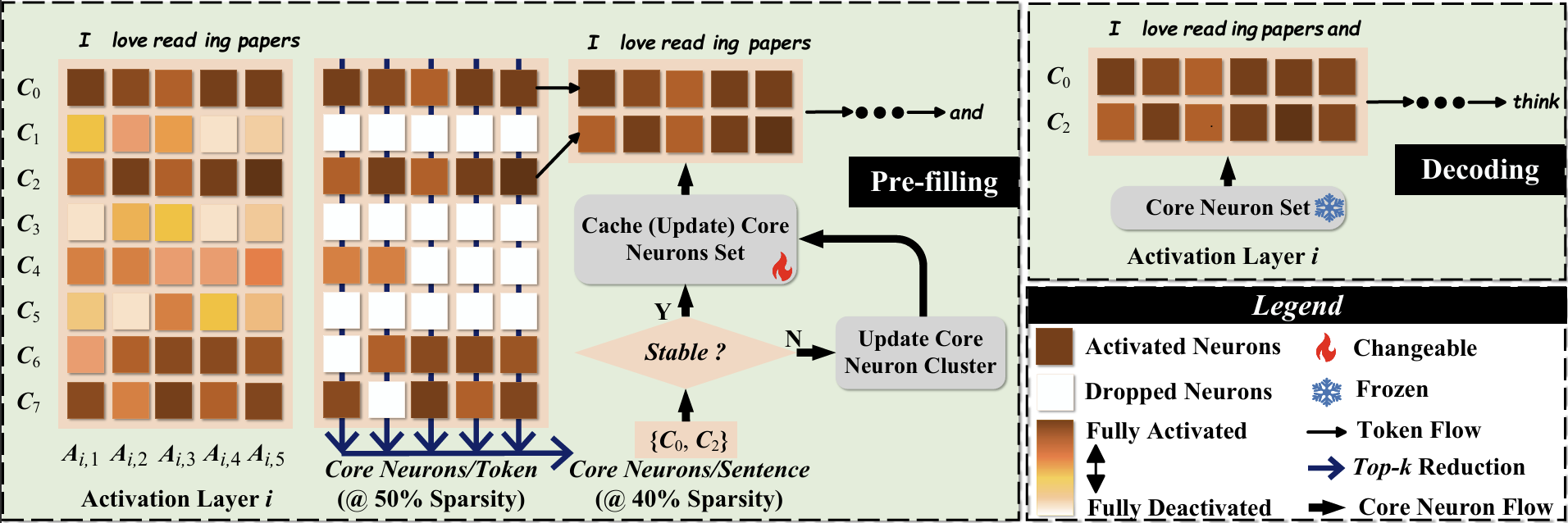 |
Github Paper |
 DuoAttention: 带有检索和流式头部的高效长上下文LLM推理 肖广轩, 唐家明, 左景威, 郭俊贤, 杨尚, 唐浩天, 傅瑶, 韩松 |
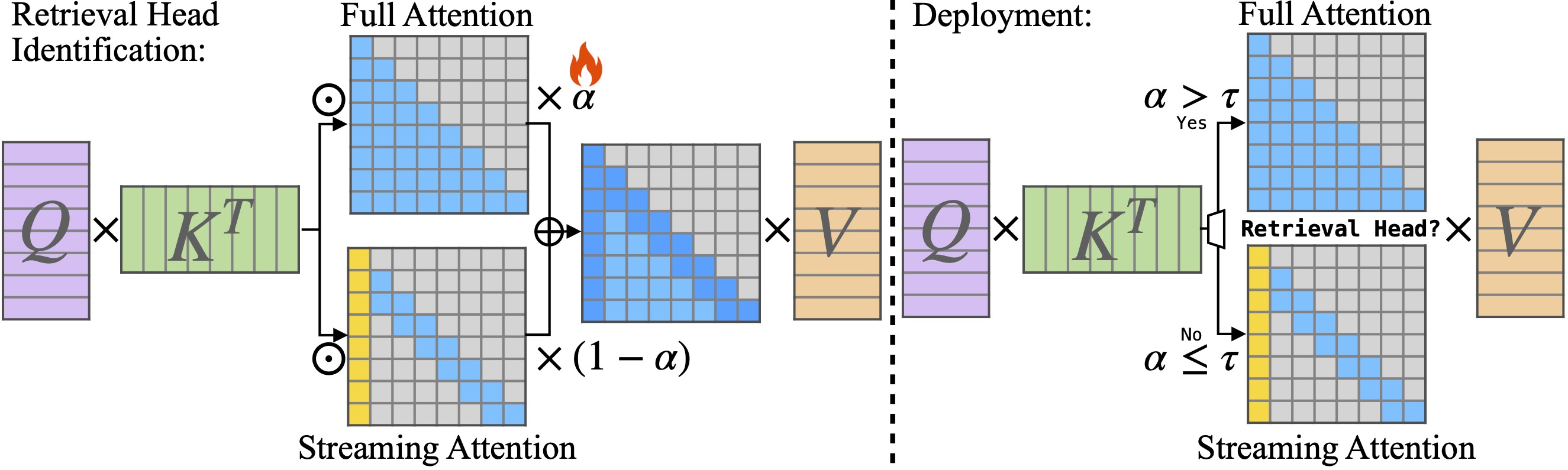 |
Github Paper |
| DySpec: 借助动态标记树结构实现更快的推测式解码 熊云帆, 张若雨, 李彦增, 吴天昊, 邹磊 |
 |
Paper |
| QSpec: 带有互补量化方案的推测式解码 赵俊涛, 陆文浩, 王盛, 孔令鹏, 吴川 |
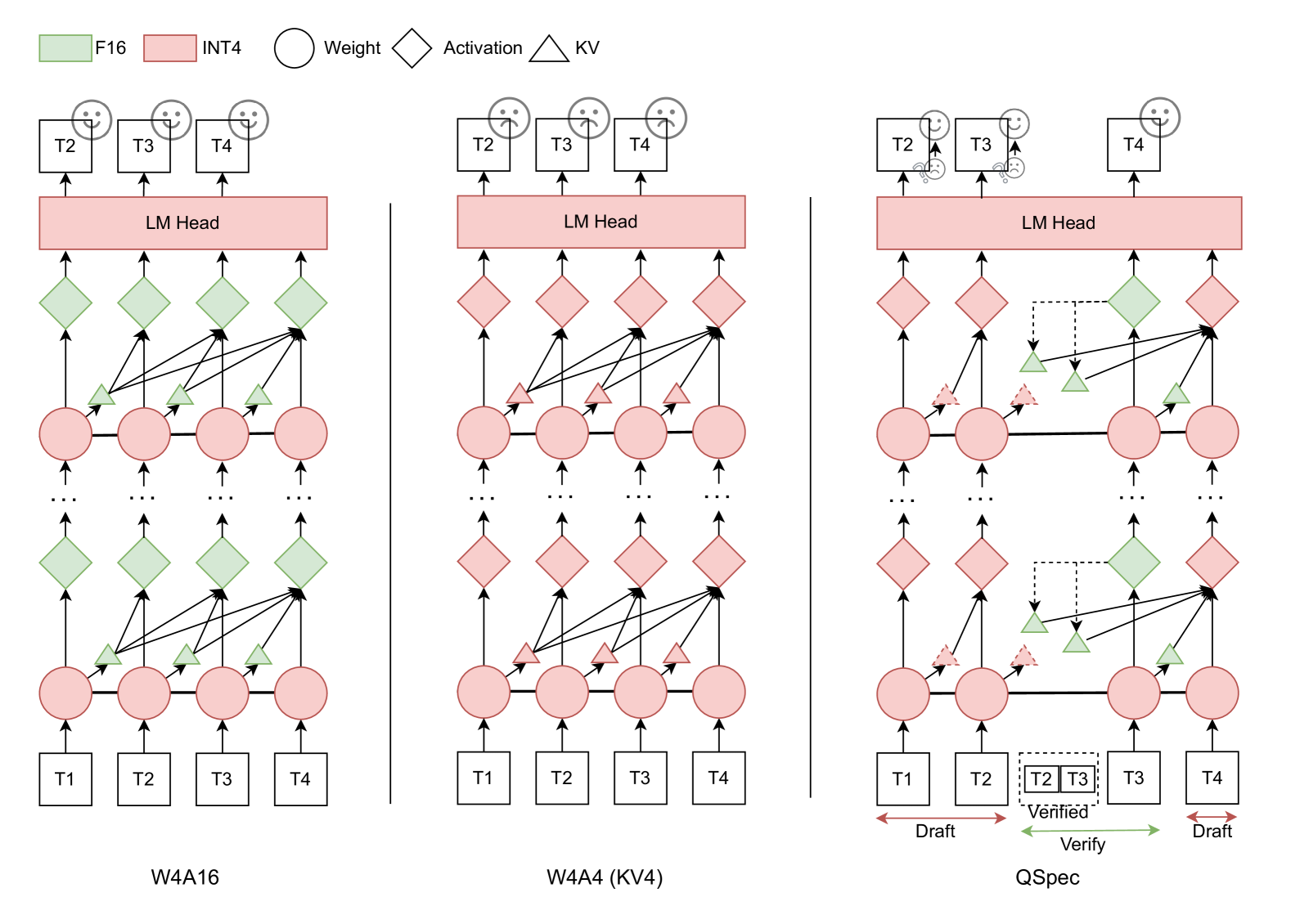 |
Paper |
| TidalDecode: 借助位置持久化稀疏注意力实现快速且准确的LLM解码 杨丽洁, 张志浩, 陈卓夫, 李子坤, 贾志浩 |
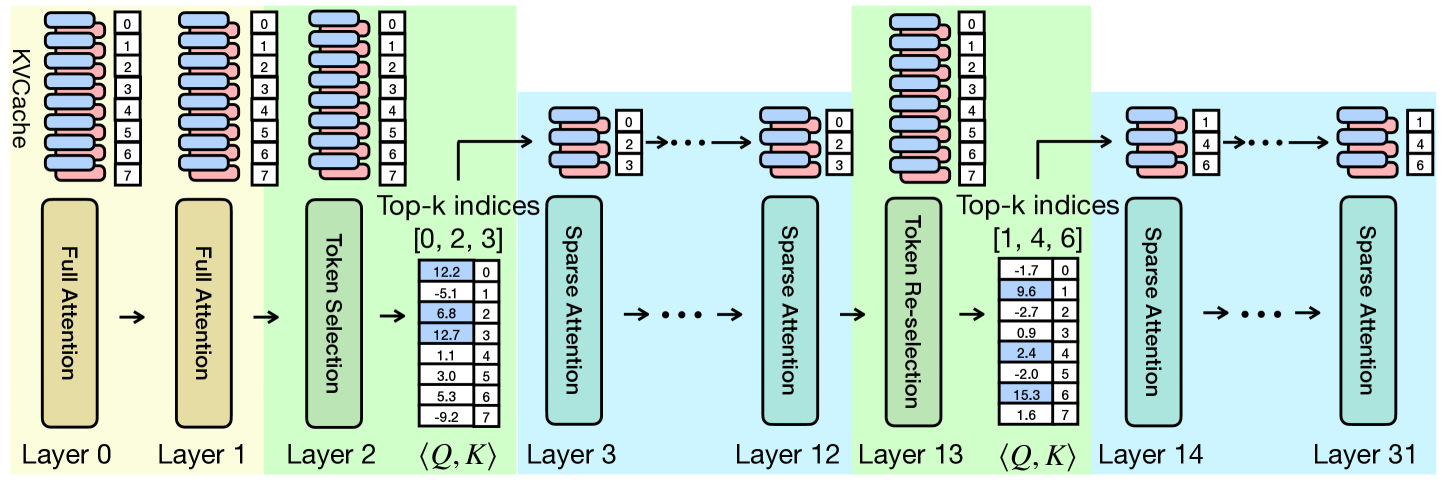 |
Paper |
| ParallelSpec: 并行草稿器用于高效推测式解码 肖子林, 张鸿明, 葛涛, 欧阳思儒, 奥尔多涅斯·比森特, 于东 |
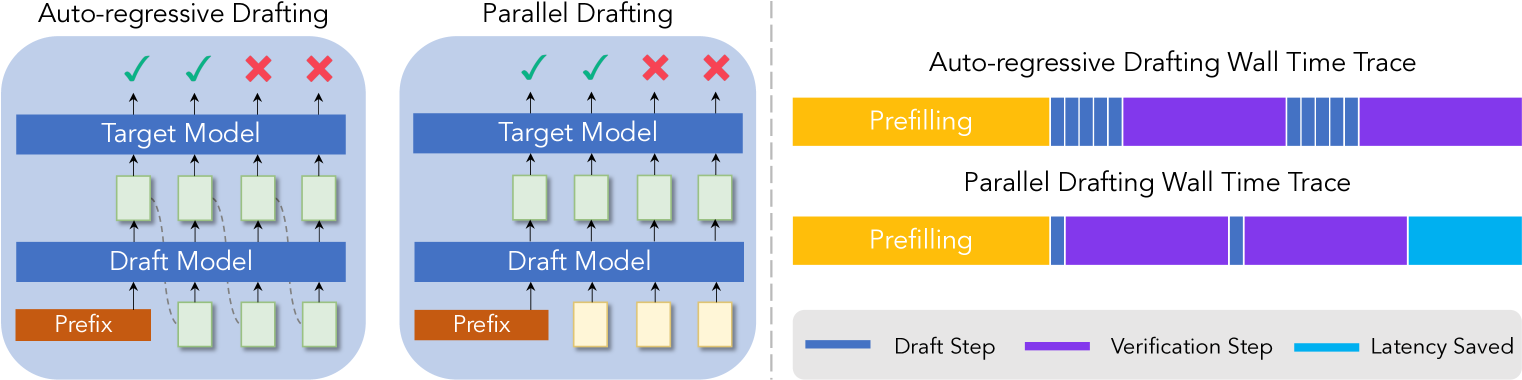 |
Paper |
 SWIFT: 用于LLM推理加速的即时自推测式解码 夏海明, 李永奇, 张军, 杜存晓, 李文杰 |
 |
Github Paper |
 TurboRAG: 利用预计算KV缓存加速分块文本的检索增强生成 陆松硕, 王华, 荣玉田, 陈志, 唐耀华 |
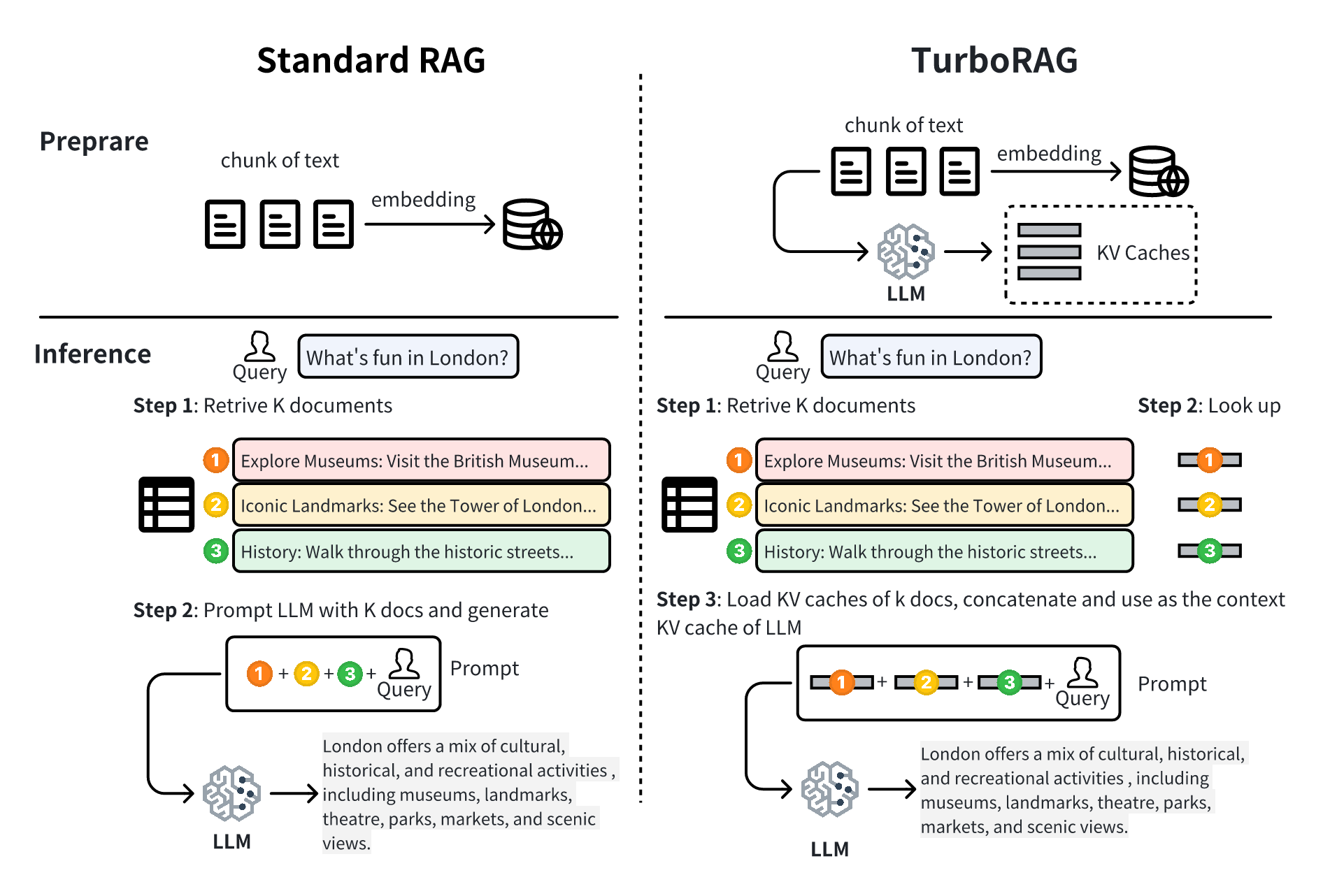 |
Github Paper |
| 点滴之力,成就非凡:利用部分上下文实现高效的长上下文训练与推理 葛苏宇, 林锡辉, 张宇楠, 韩家伟, 彭浩 |
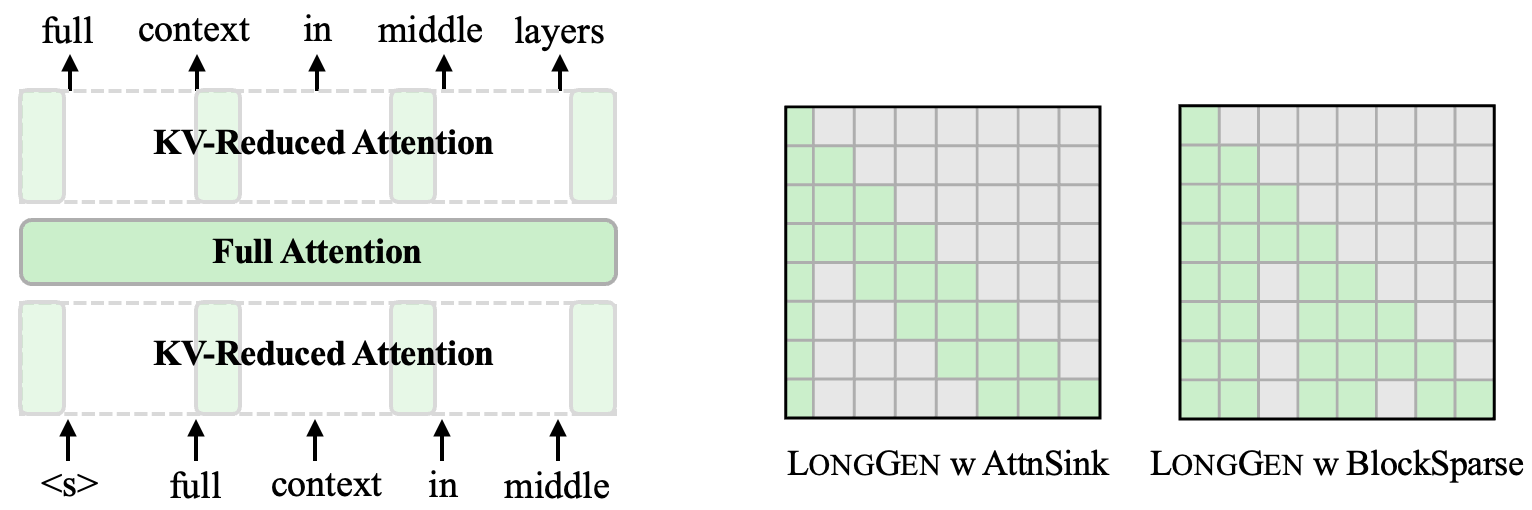 |
Paper |
Cache-Craft: 管理分块缓存以实现高效的检索增强生成 舒巴姆·阿加瓦尔, 赛·孙达雷桑, 苏布拉塔·米特拉, 德布拉塔·马哈帕特拉, 阿奇特·古普塔, 劳纳克·夏尔马, 尼尔马尔·约书亚·卡普, 佟宇, 希夫·赛尼 |
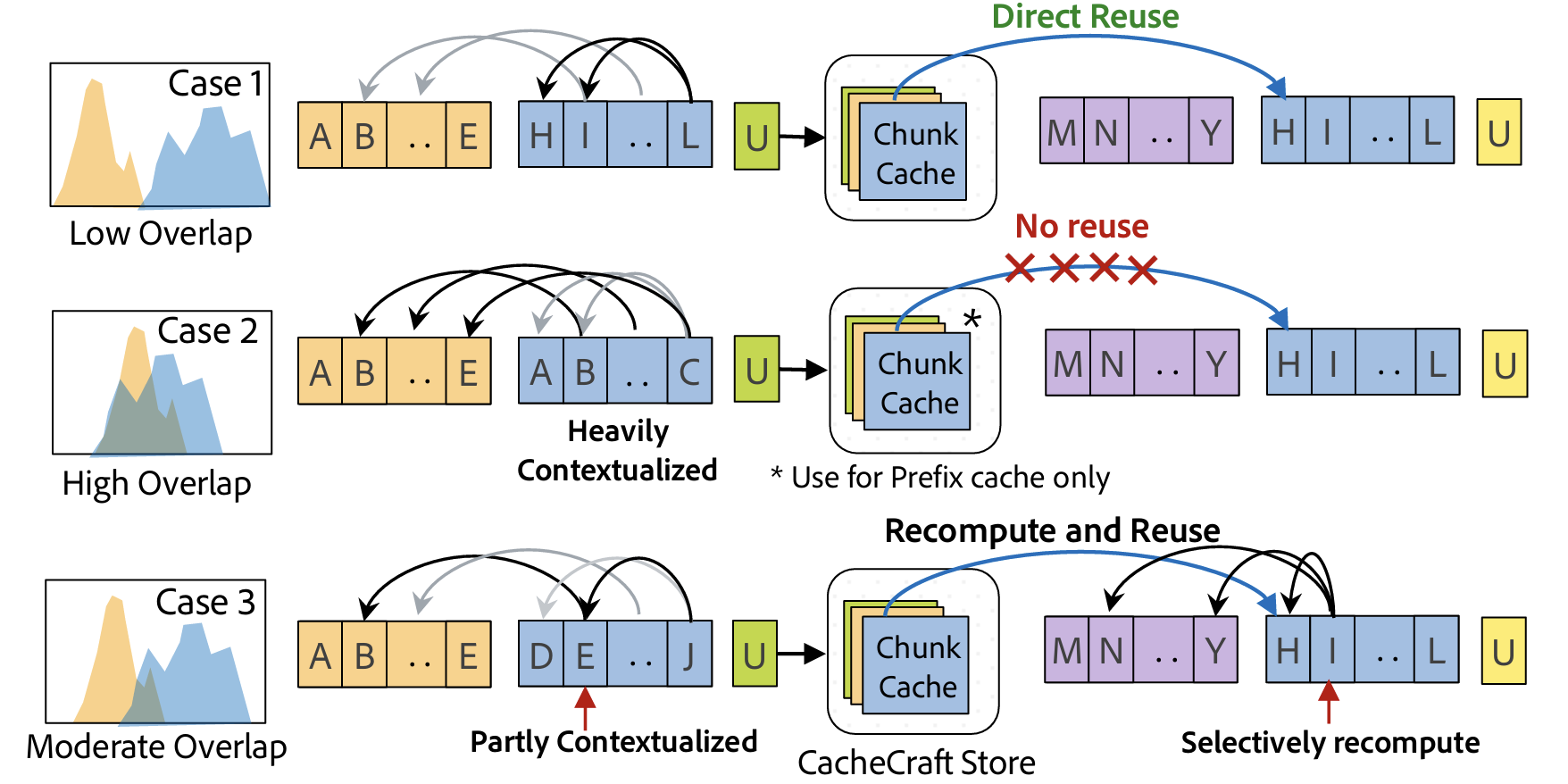 |
Paper |
| Mamba草稿器用于推测式解码 代源崔, 欧胜赫, 萨凯特·丁利瓦尔, 塔克·智勋, 金奎荣, 宋宇民, 金瑞珍, 韩仁洙, 申镇宇, 阿拉姆·加尔斯蒂安, 卡蒂亚尔·舒巴姆, 波达帕蒂·斯拉万·巴布 |
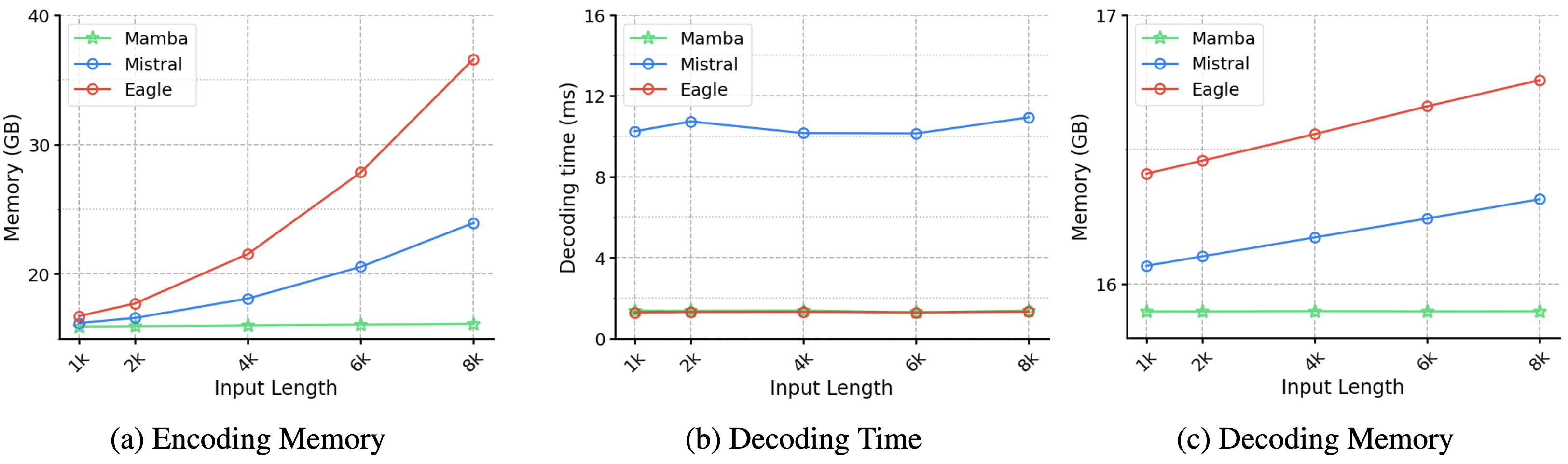 |
Paper |
| 利用无模型推测采样加速测试时缩放 宋宇民, 丁利瓦尔·萨凯特, 杰扬提·赛·穆拉利达尔, 加内什·巴哈瓦纳, 申镇宇, 加尔斯蒂安·阿拉姆, 波达帕蒂·斯拉万·巴布 |
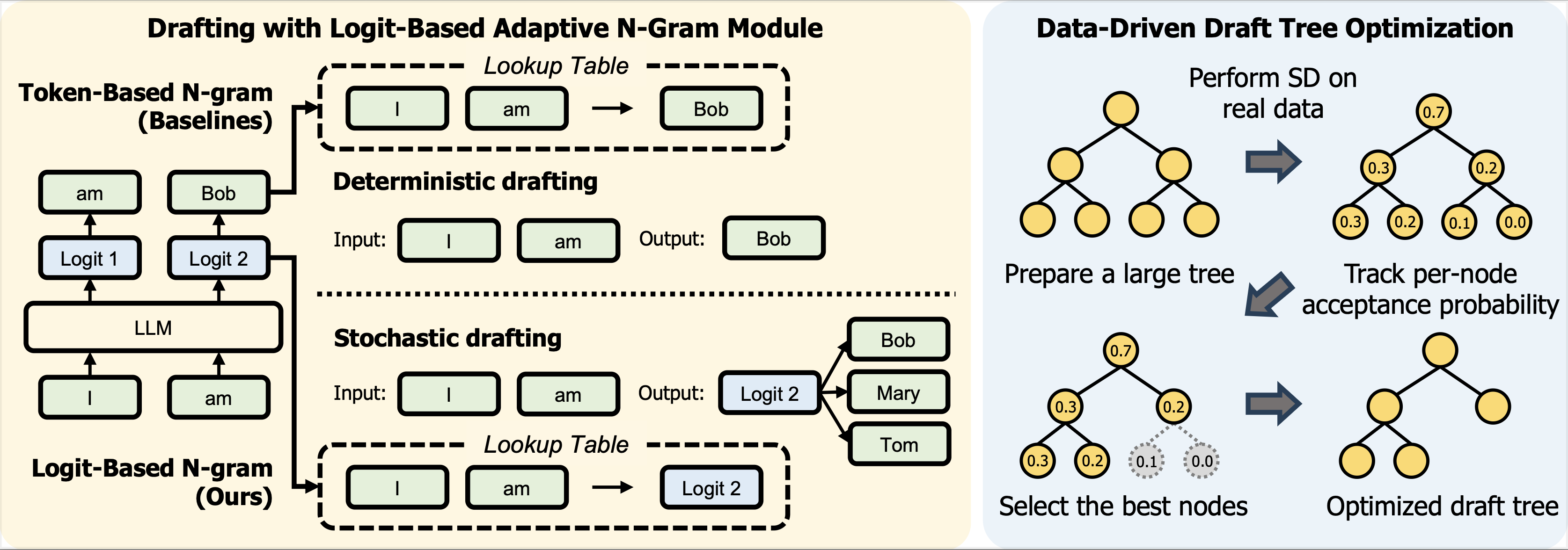 |
Paper |
高效的混合专家模型
| 标题与作者 | 简介 | 链接 |
|---|---|---|
 :star: 通过卸载实现混合专家语言模型的快速推理 阿尔乔姆·埃利塞耶夫,丹尼斯·马祖尔 |
 |
Github 论文 |
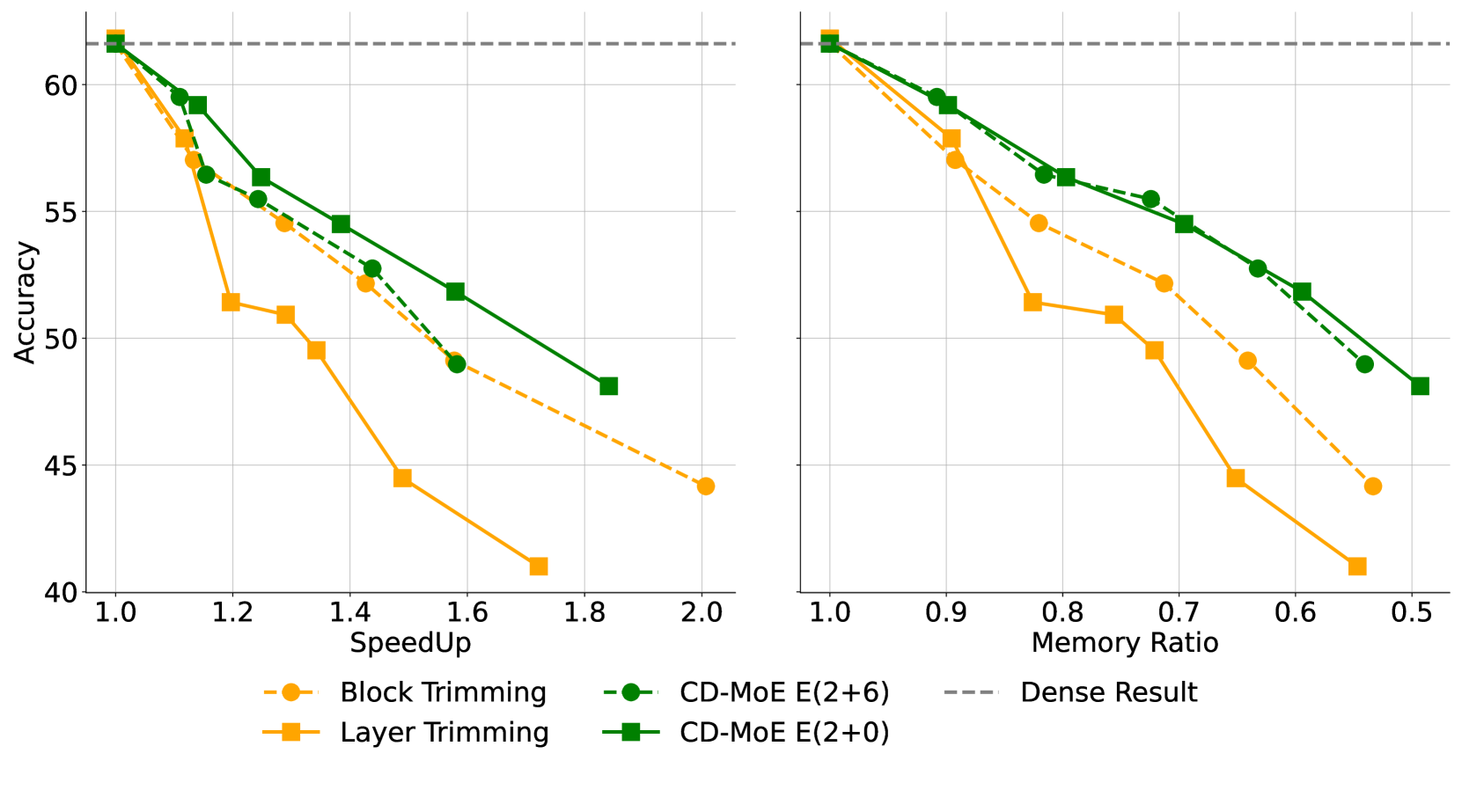
 精简而非单纯剪枝:提升混合专家层剪枝的效率与性能 曹明宇,李根,季杰,张佳琪,马晓龙,刘士伟,尹璐 |
 |
Github 论文 |
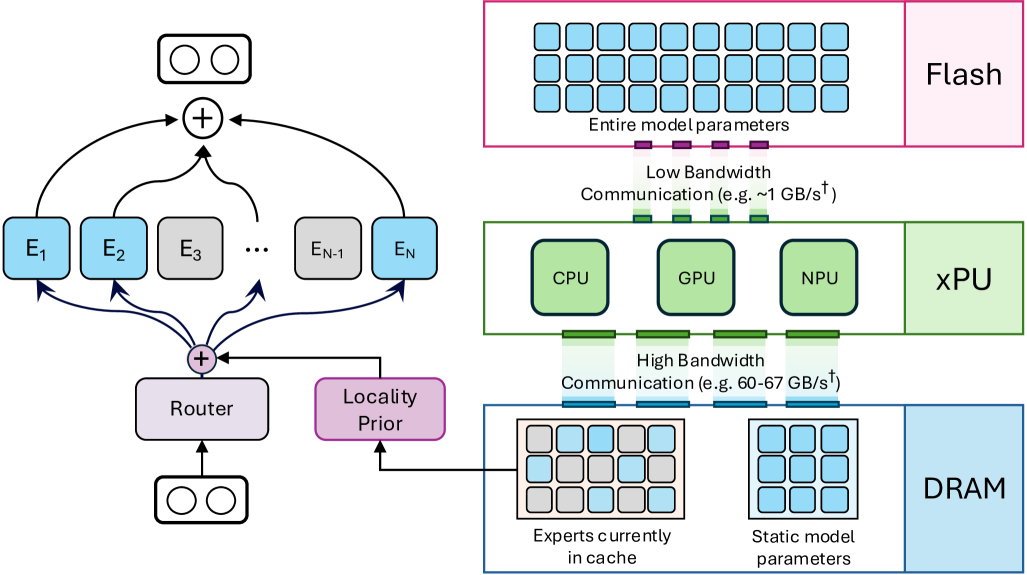
| 用于高效移动设备推理的缓存条件混合专家模型 安德里伊·斯克利亚尔,蒂斯·范·罗曾达尔,罗曼·勒佩尔特,托多尔·博伊诺夫斯基,马特·范·巴伦,马库斯·纳格尔,保罗·沃特莫夫,巴巴克·埃赫特沙米·贝琼迪 |
 |
论文 |
 MoNTA:基于网络流量感知的并行优化加速混合专家训练 郭景明,刘燕,孟宇,陶志伟,刘邦兰,陈刚,李翔 |
 |
Github 论文 |
 MoE-I2:通过专家间剪枝和专家内低秩分解压缩混合专家模型 杨成,隋洋,肖金奇,黄凌毅,龚宇,段元林,贾文琪,尹淼,程宇,袁博 |
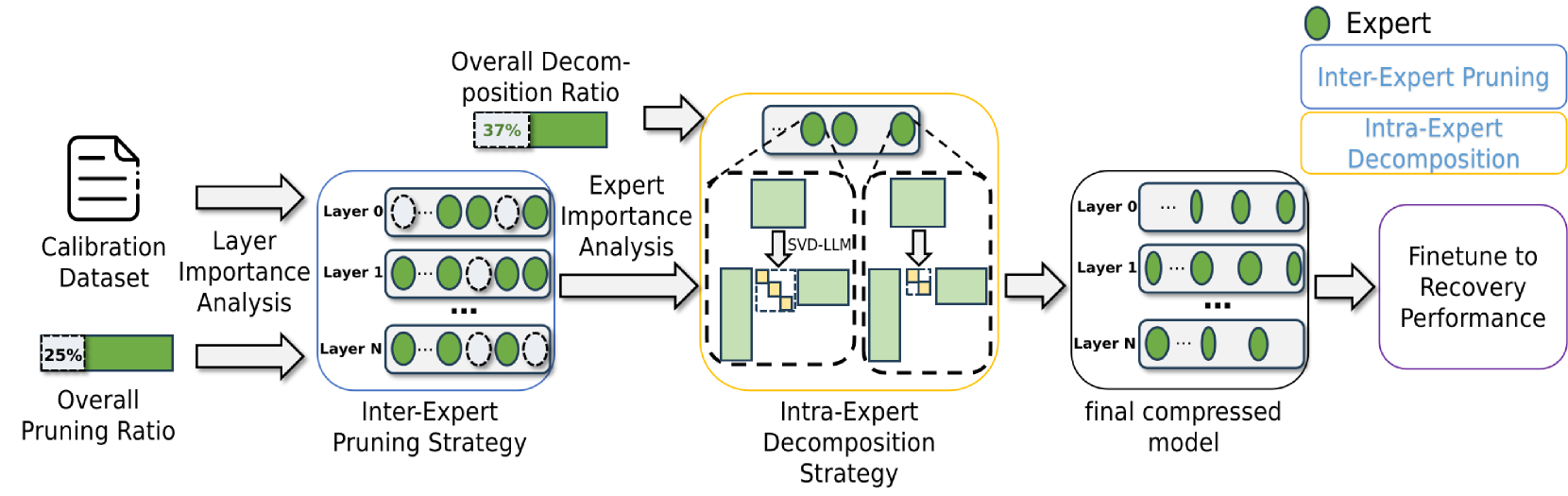 |
Github 论文 |
| HOBBIT:用于快速混合专家推理的混合精度专家卸载系统 唐鹏,刘嘉诚,侯晓峰,蒲一飞,王静,彭安妮·恒,李超,郭敏怡 |
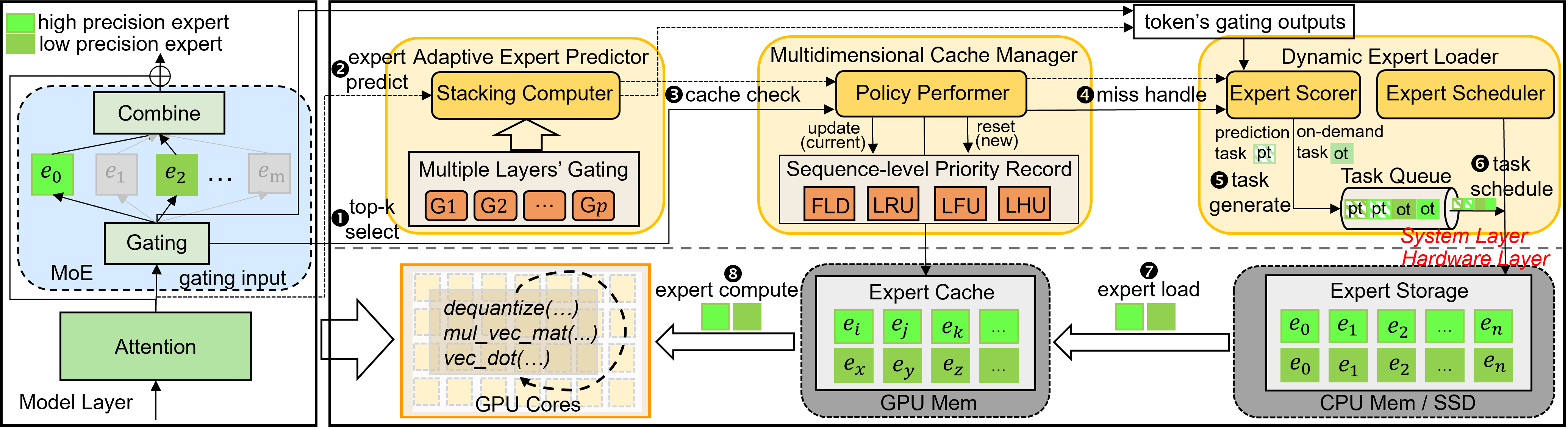 |
论文 |
| ProMoE:利用主动缓存实现基于混合专家的快速大模型服务 宋小牛,钟子航,陈荣 |
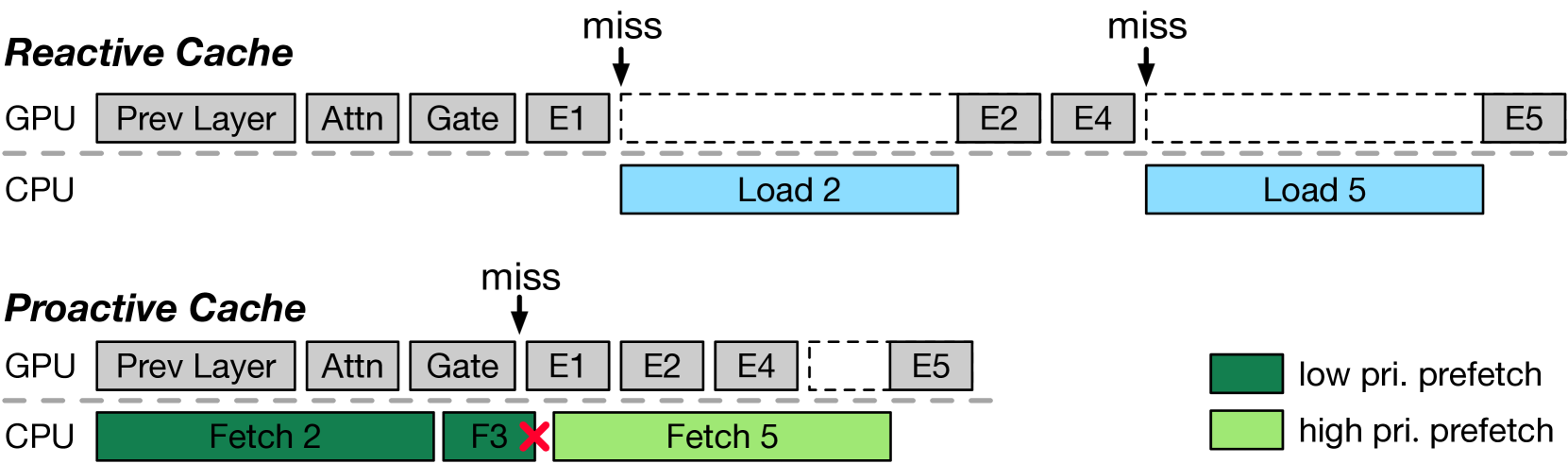 |
论文 |
| ExpertFlow:优化专家激活与标记分配以实现高效的混合专家推理 贺欣,张顺康,王宇鑫,殷海燕,曾子豪,史绍怀,唐振恒,楚晓雯,曾耀宗,翁友顺 |
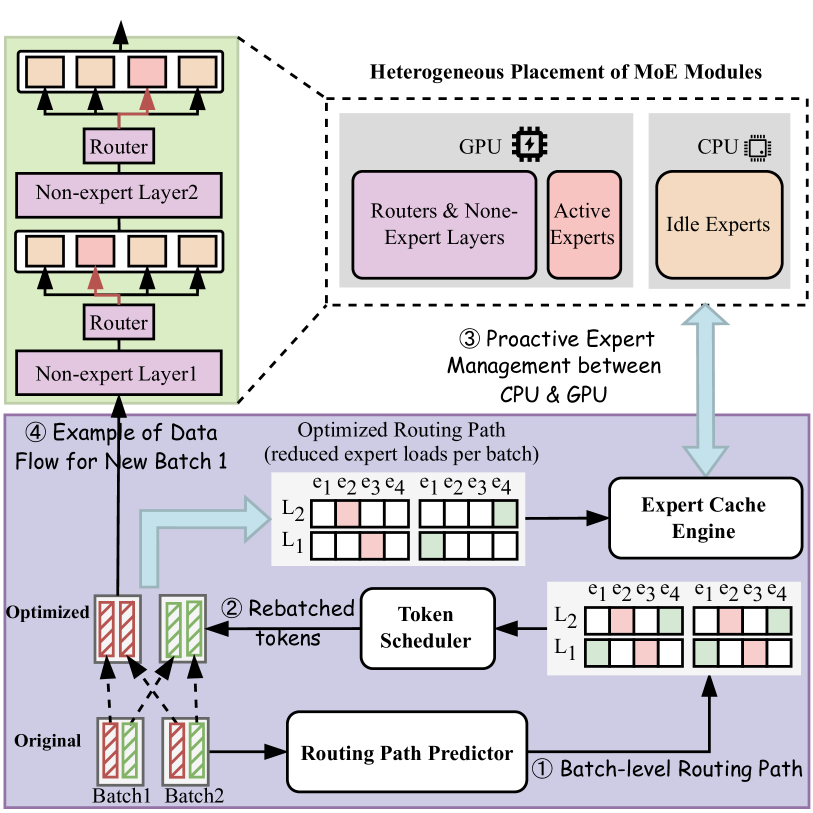 |
论文 |
| EPS-MoE:用于成本效益高的混合专家推理的专家流水线调度器 钱玉磊,李丰存,姬向阳,赵晓宇,谭建超,张克峰,蔡训良 |
论文 | |
 MC-MoE:混合压缩器为混合专家大模型带来更多收益 黄伟,廖悦,刘建辉,何瑞菲,谭浩儒,张世明,李洪生,刘思,齐小娟 |
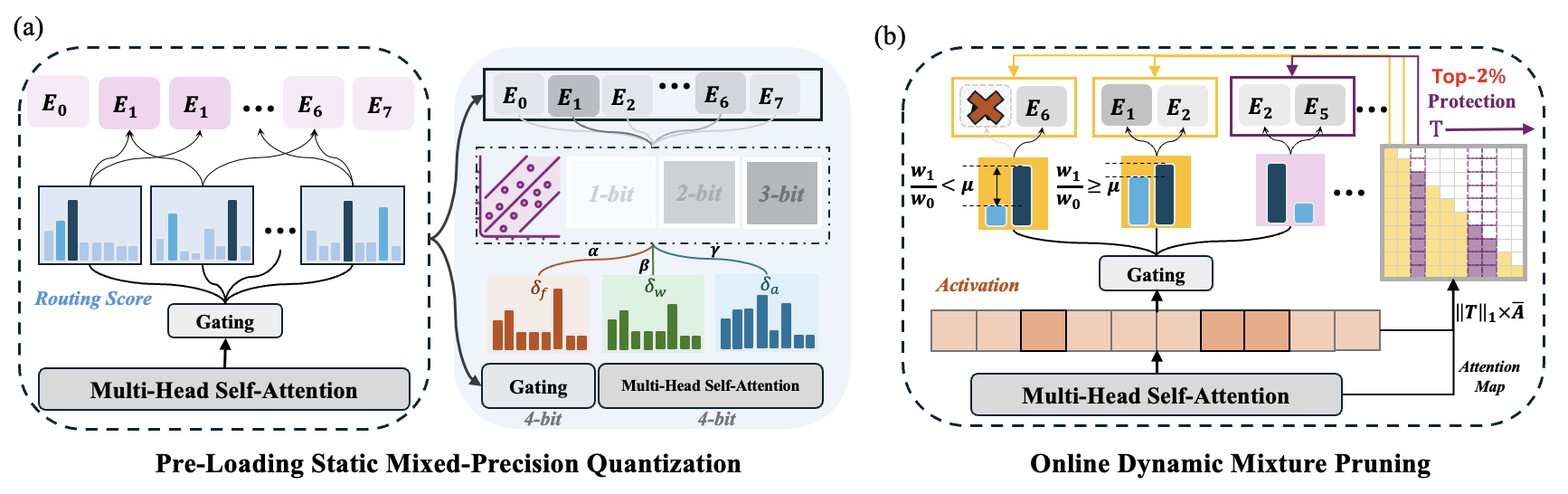 |
Github 论文 |
高效的大型语言模型架构
| 标题与作者 | 简介 | 链接 |
|---|---|---|
 Hymba:面向小型语言模型的混合头架构 Xin Dong, Yonggan Fu, Shizhe Diao, Wonmin Byeon, Zijia Chen, Ameya Sunil Mahabaleshwarkar, Shih-Yang Liu, Matthijs Van Keirsbilck, Min-Hung Chen, Yoshi Suhara, Yingyan Lin, Jan Kautz, Pavlo Molchanov |
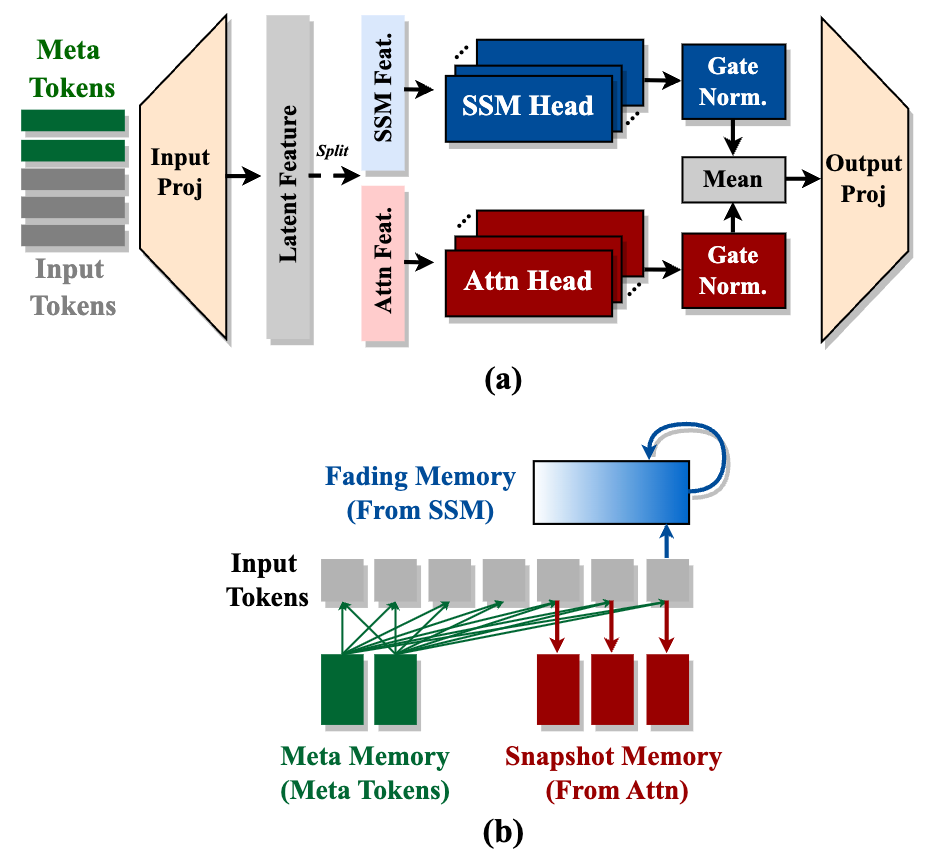 |
论文 |
 :star: MobiLlama:迈向准确且轻量级的完全透明GPT Omkar Thawakar, Ashmal Vayani, Salman Khan, Hisham Cholakal, Rao M. Anwer, Michael Felsberg, Tim Baldwin, Eric P. Xing, Fahad Shahbaz Khan |
 |
Github 论文 模型 |
 :star: Megalodon:具有无限上下文长度的高效LLM预训练与推理 Xuezhe Ma, Xiaomeng Yang, Wenhan Xiong, Beidi Chen, Lili Yu, Hao Zhang, Jonathan May, Luke Zettlemoyer, Omer Levy, Chunting Zhou |
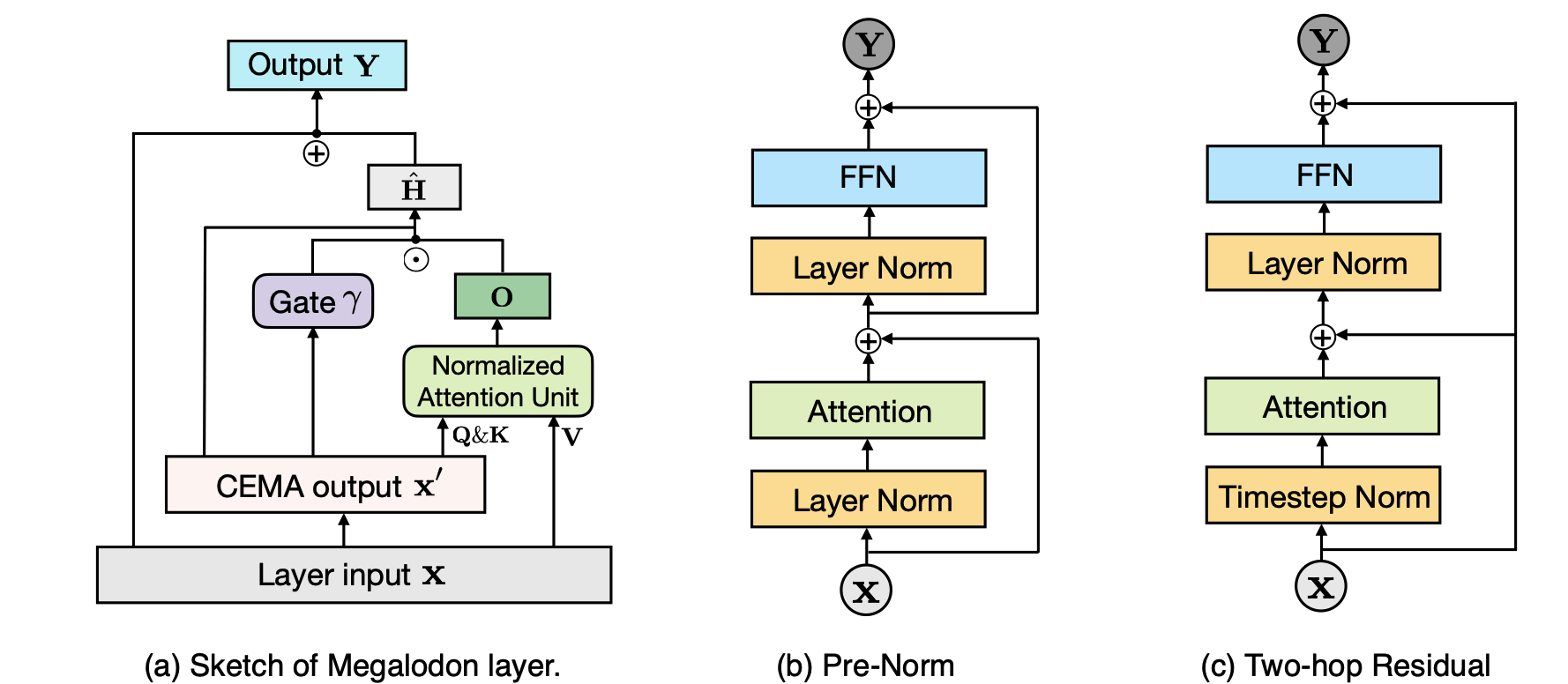 |
Github 论文 |
| Taipan:具有选择性注意力的高效且富有表现力的状态空间语言模型 Chien Van Nguyen, Huy Huu Nguyen, Thang M. Pham, Ruiyi Zhang, Hanieh Deilamsalehy, Puneet Mathur, Ryan A. Rossi, Trung Bui, Viet Dac Lai, Franck Dernoncourt, Thien Huu Nguyen |
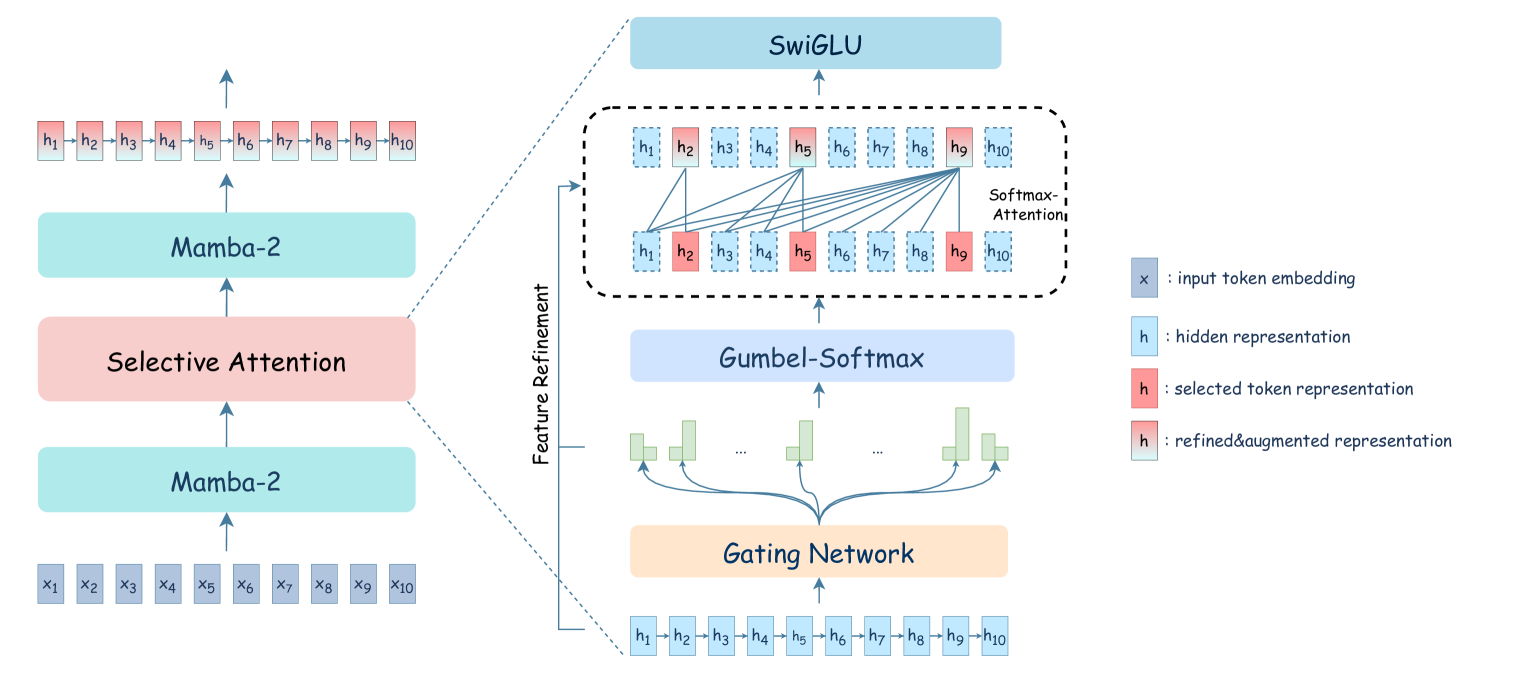 |
论文 |
 SeerAttention:在您的LLM中学习内在稀疏注意力 Yizhao Gao, Zhichen Zeng, Dayou Du, Shijie Cao, Hayden Kwok-Hay So, Ting Cao, Fan Yang, Mao Yang |
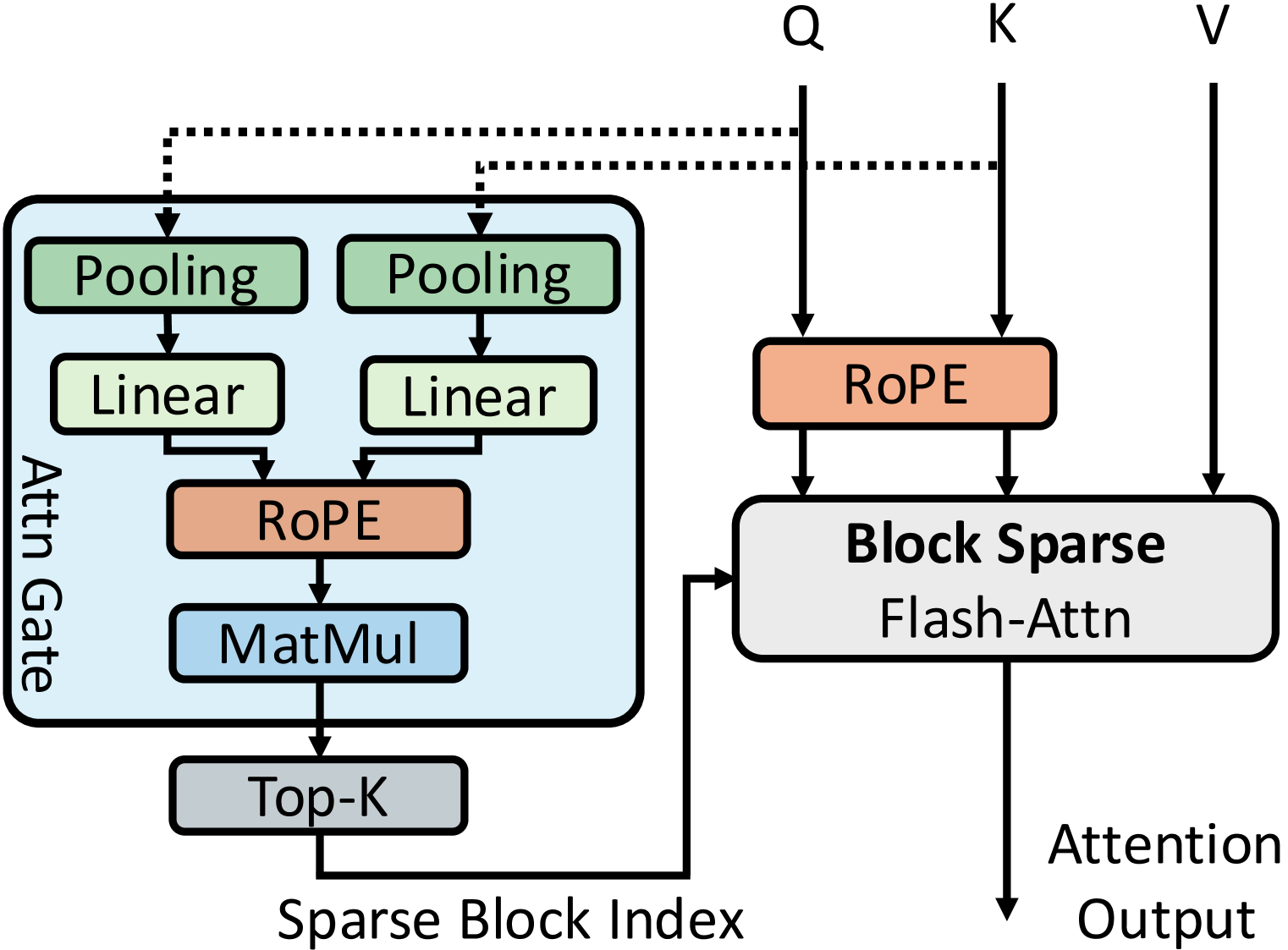 |
Github 论文 |
 Basis Sharing:用于大型语言模型压缩的跨层参数共享 Jingcun Wang, Yu-Guang Chen, Ing-Chao Lin, Bing Li, Grace Li Zhang |
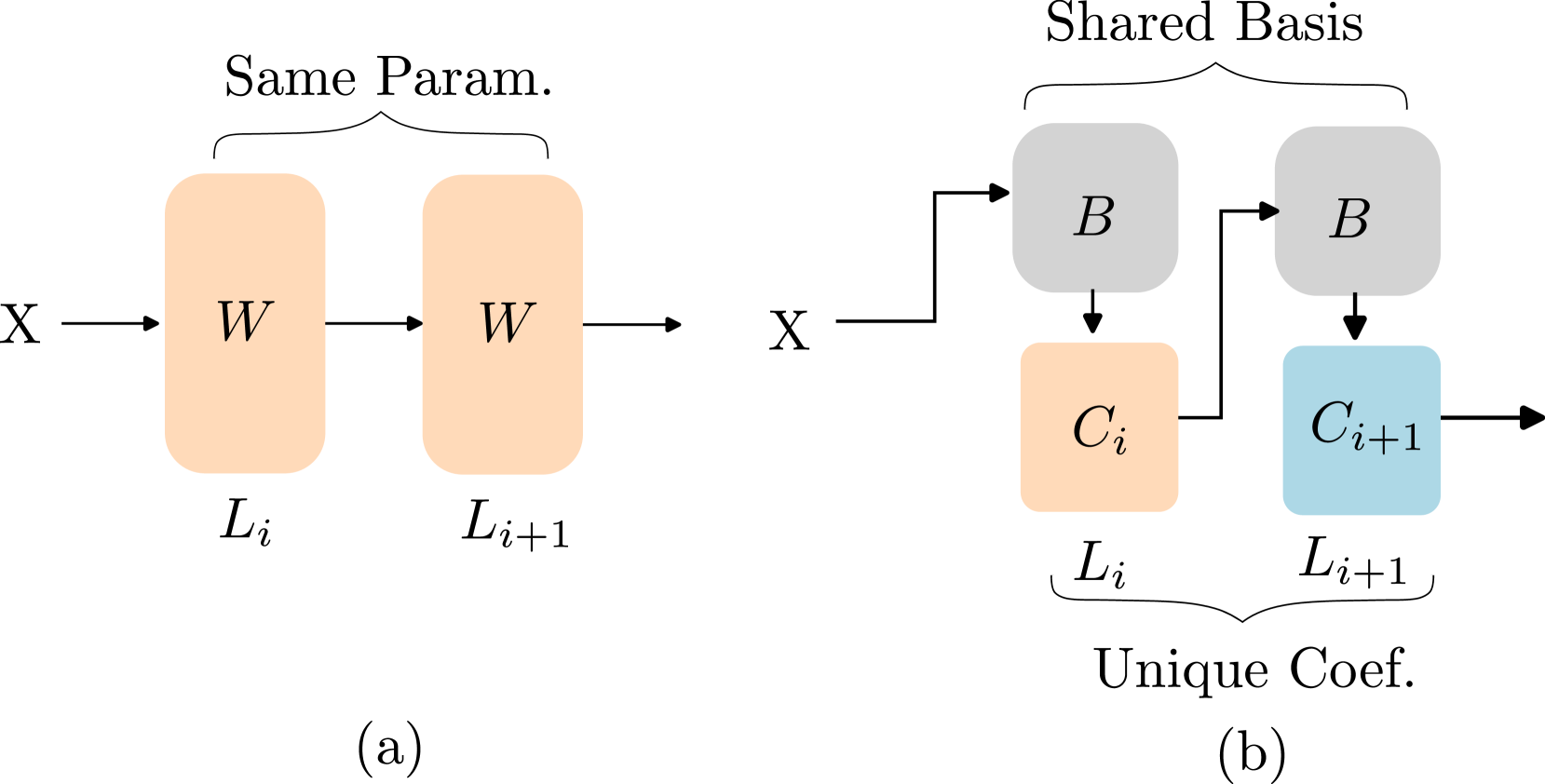 |
Github 论文 |
| Rodimus*:通过高效注意力打破准确率与效率的权衡 Zhihao He, Hang Yu, Zi Gong, Shizhan Liu, Jianguo Li, Weiyao Lin |
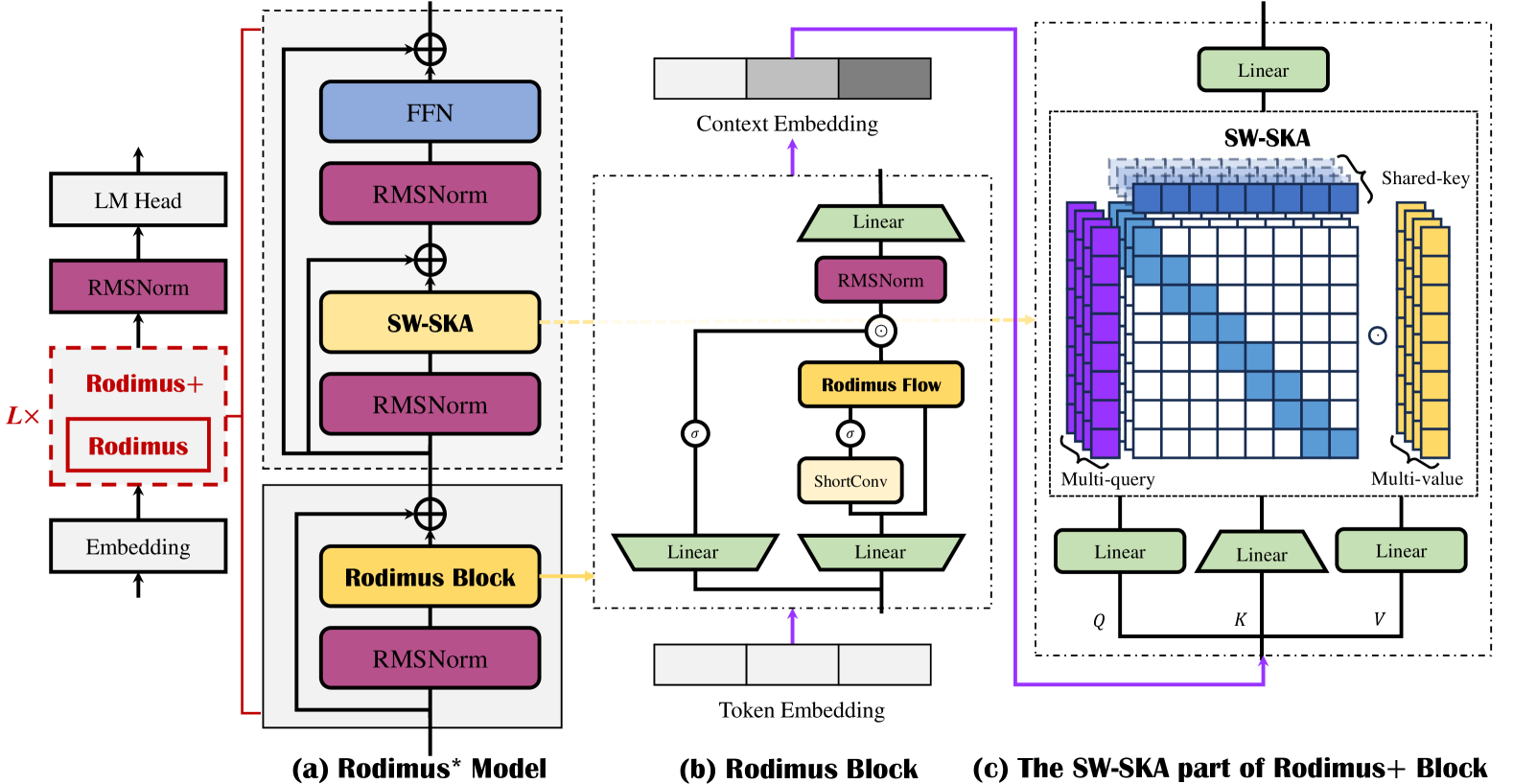 |
论文 |
| 压缩、聚合与重新计算:改革Transformer中的长上下文处理 Woomin Song, Sai Muralidhar Jayanthi, Srikanth Ronanki, Kanthashree Mysore Sathyendra, Jinwoo Shin, Aram Galstyan, Shubham Katiyar, Sravan Babu Bodapati |
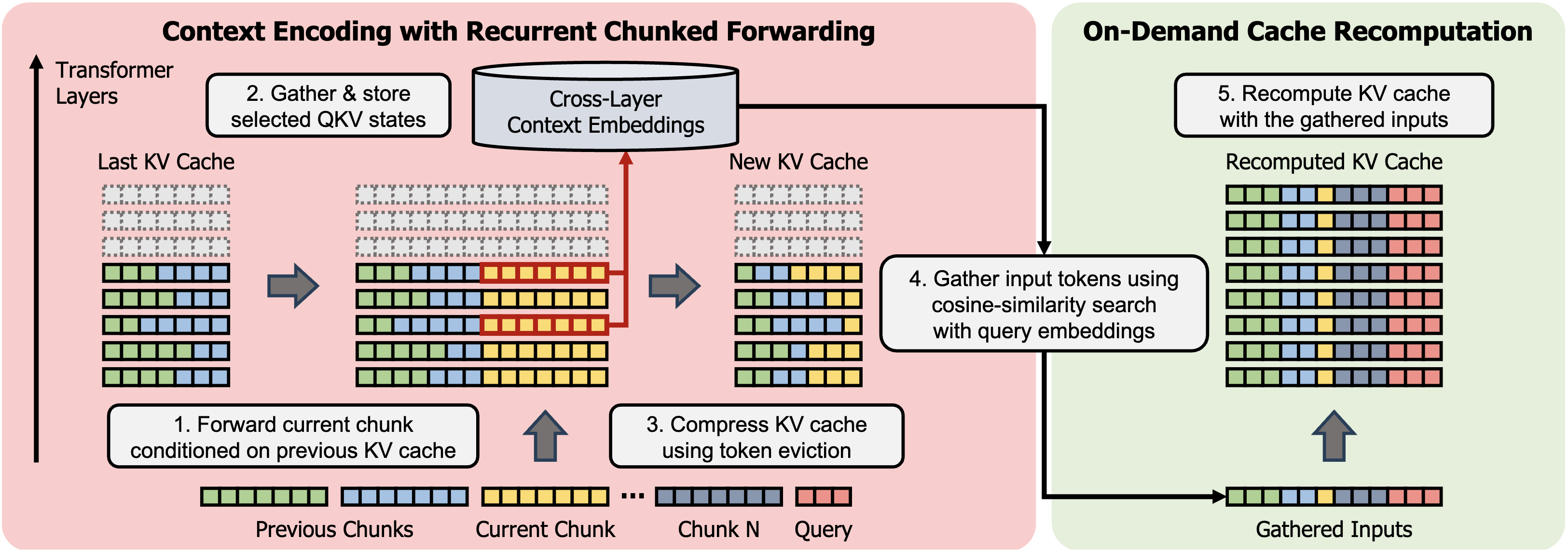 |
论文 |
KV 缓存压缩
| 标题与作者 | 简介 | 链接 |
|---|---|---|
| :star: 模型告诉你该丢弃什么:面向大语言模型的自适应 KV 缓存压缩 Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, Jianfeng Gao |
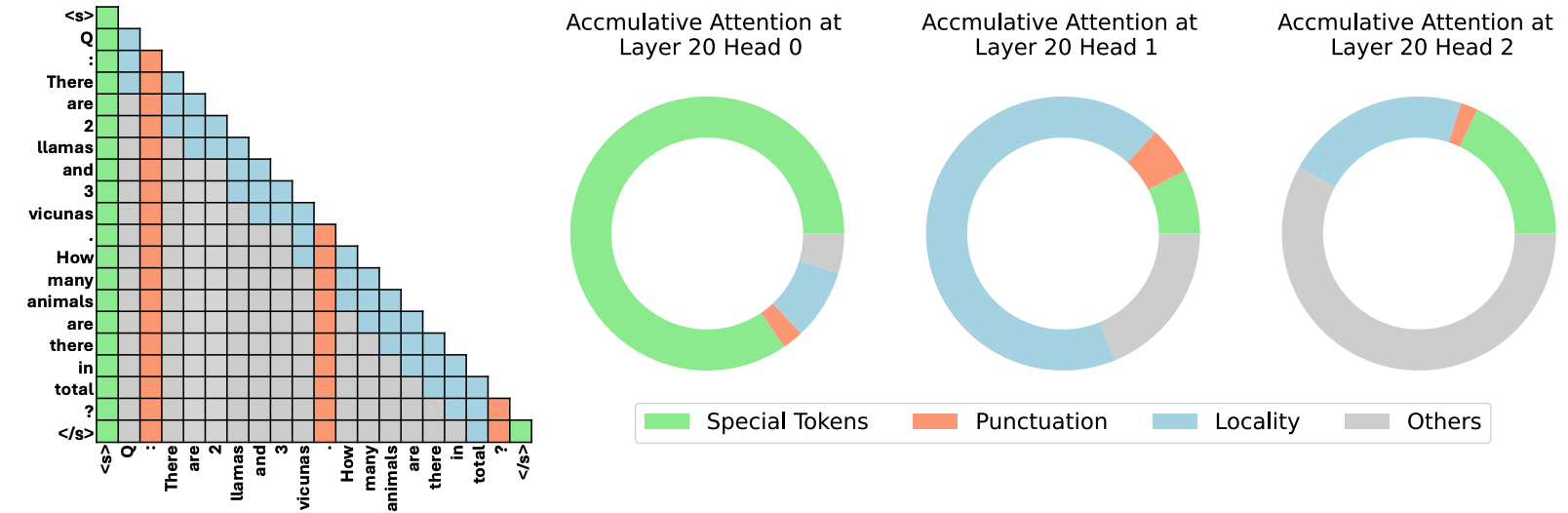 |
论文 |
| ClusterKV:在语义空间中操作 LLM 的 KV 缓存以实现可检索压缩 Guangda Liu, Chengwei Li, Jieru Zhao, Chenqi Zhang, Minyi Guo |
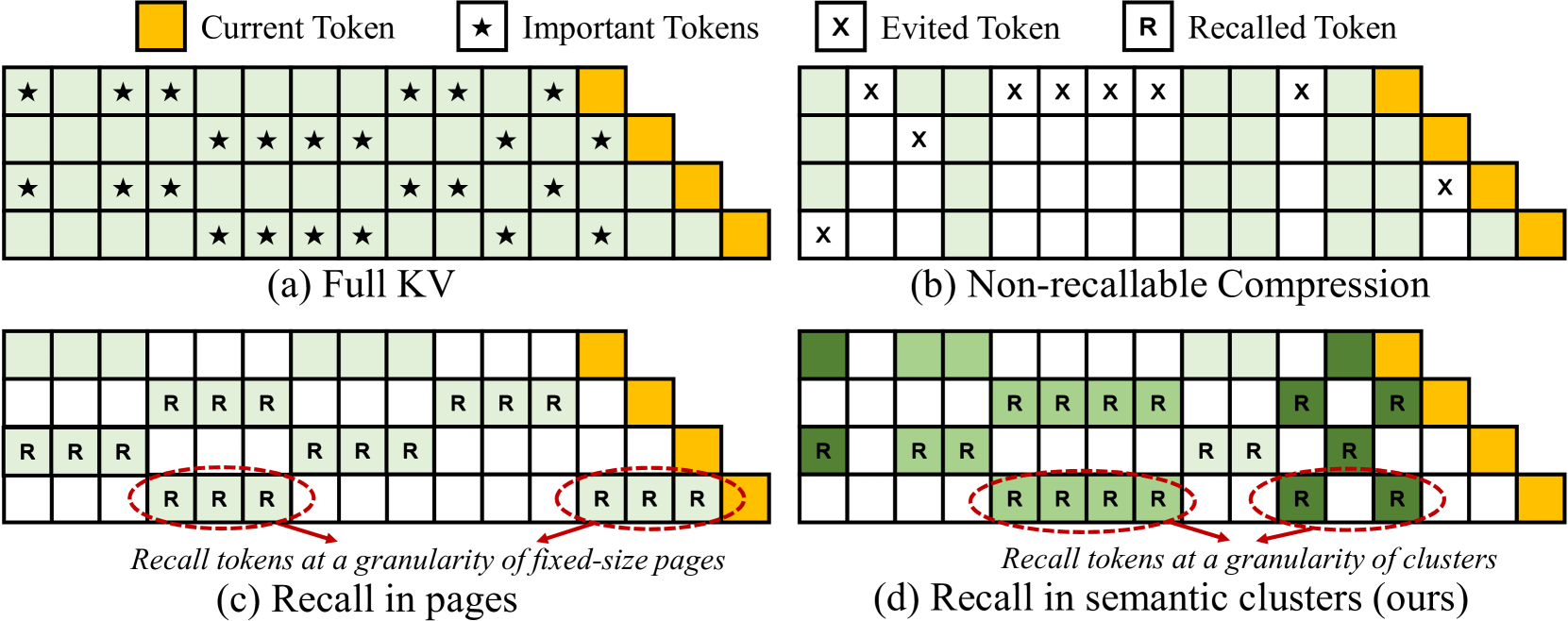 |
论文 |
| 使用 LeanKV 统一大语言模型的 KV 缓存压缩 Yanqi Zhang, Yuwei Hu, Runyuan Zhao, John C.S. Lui, Haibo Chen |
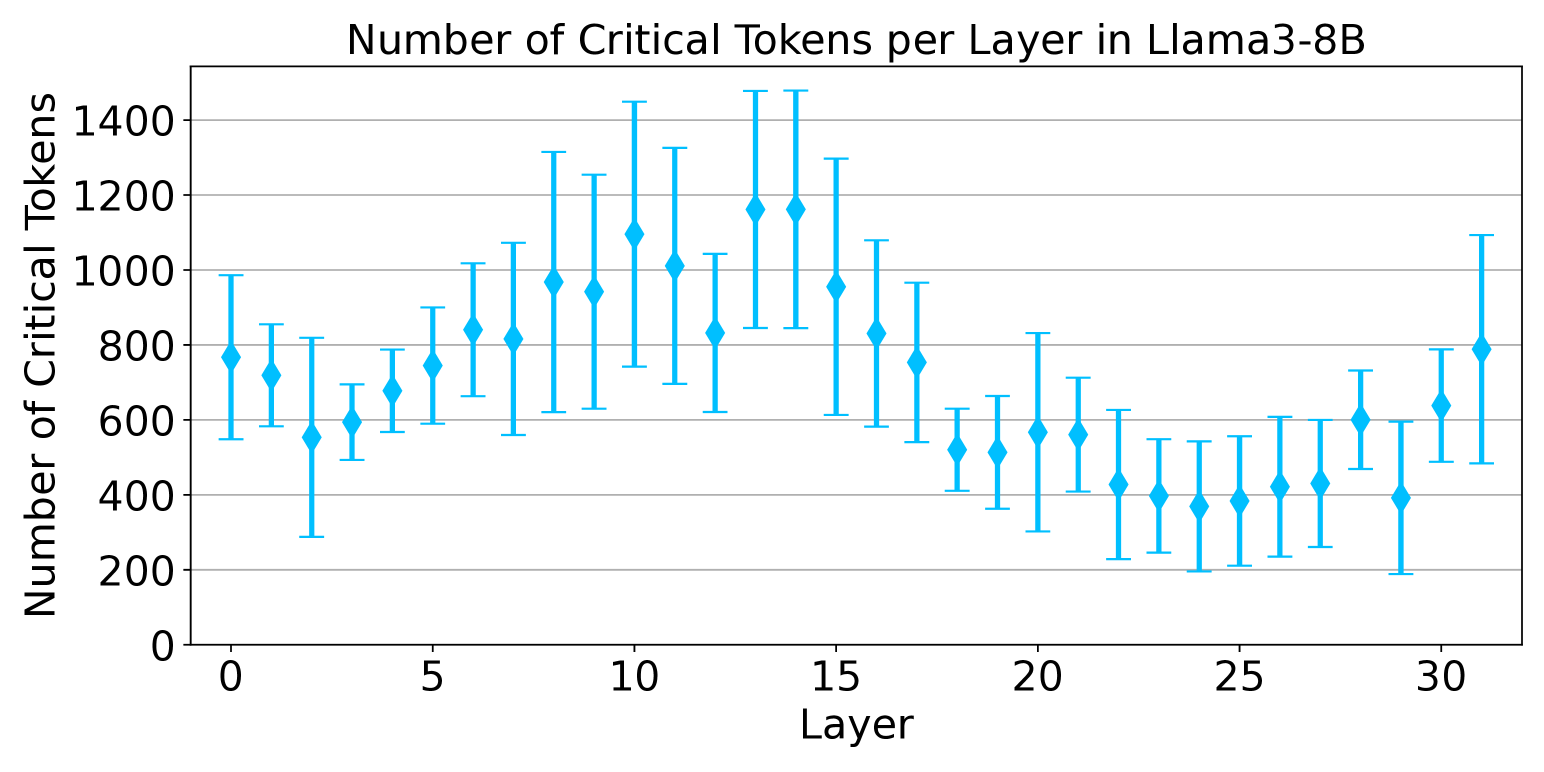 |
论文 |
| 利用层间注意力相似性压缩长上下文 LLM 推理中的 KV 缓存 Da Ma, Lu Chen, Situo Zhang, Yuxun Miao, Su Zhu, Zhi Chen, Hongshen Xu, Hanqi Li, Shuai Fan, Lei Pan, Kai Yu |
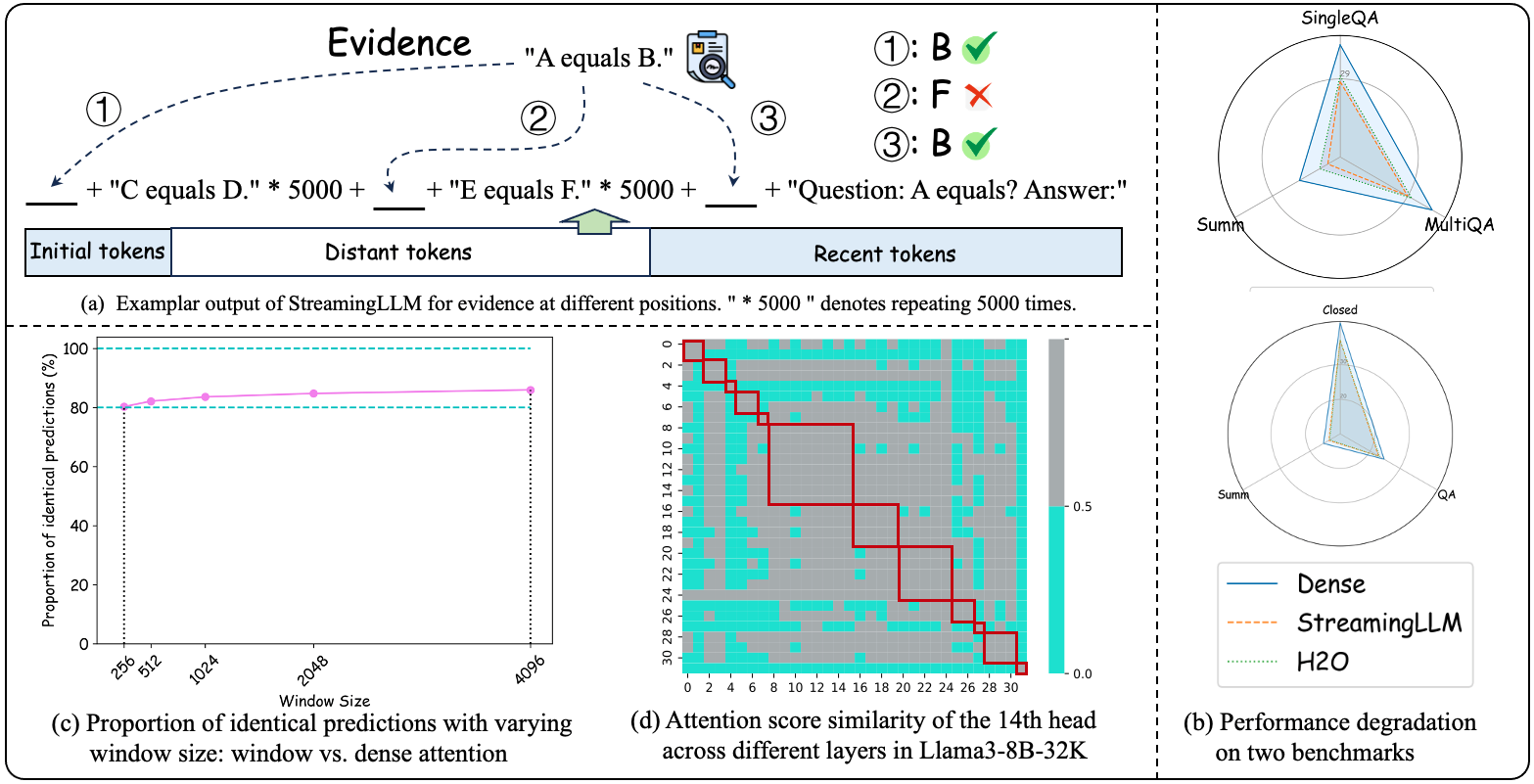 |
论文 |
| MiniKV:通过 2 比特的层区分性 KV 缓存突破 LLM 推理极限 Akshat Sharma, Hangliang Ding, Jianping Li, Neel Dani, Minjia Zhang |
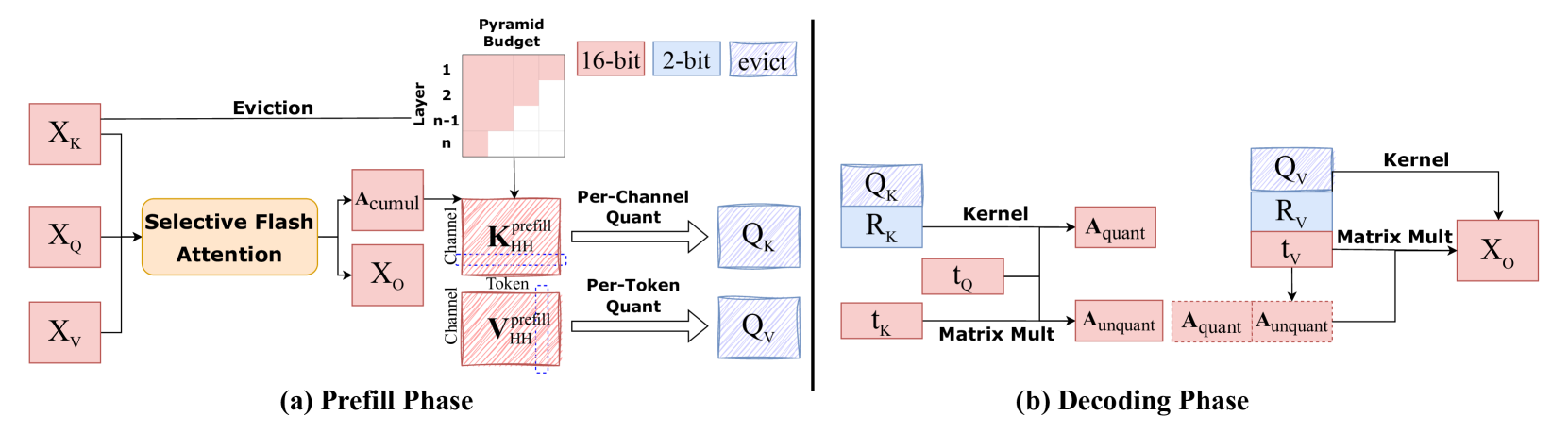 |
论文 |
| TokenSelect:通过动态令牌级 KV 缓存选择实现 LLM 的高效长上下文推理和长度外推 Wei Wu, Zhuoshi Pan, Chao Wang, Liyi Chen, Yunchu Bai, Kun Fu, Zheng Wang, Hui Xiong |
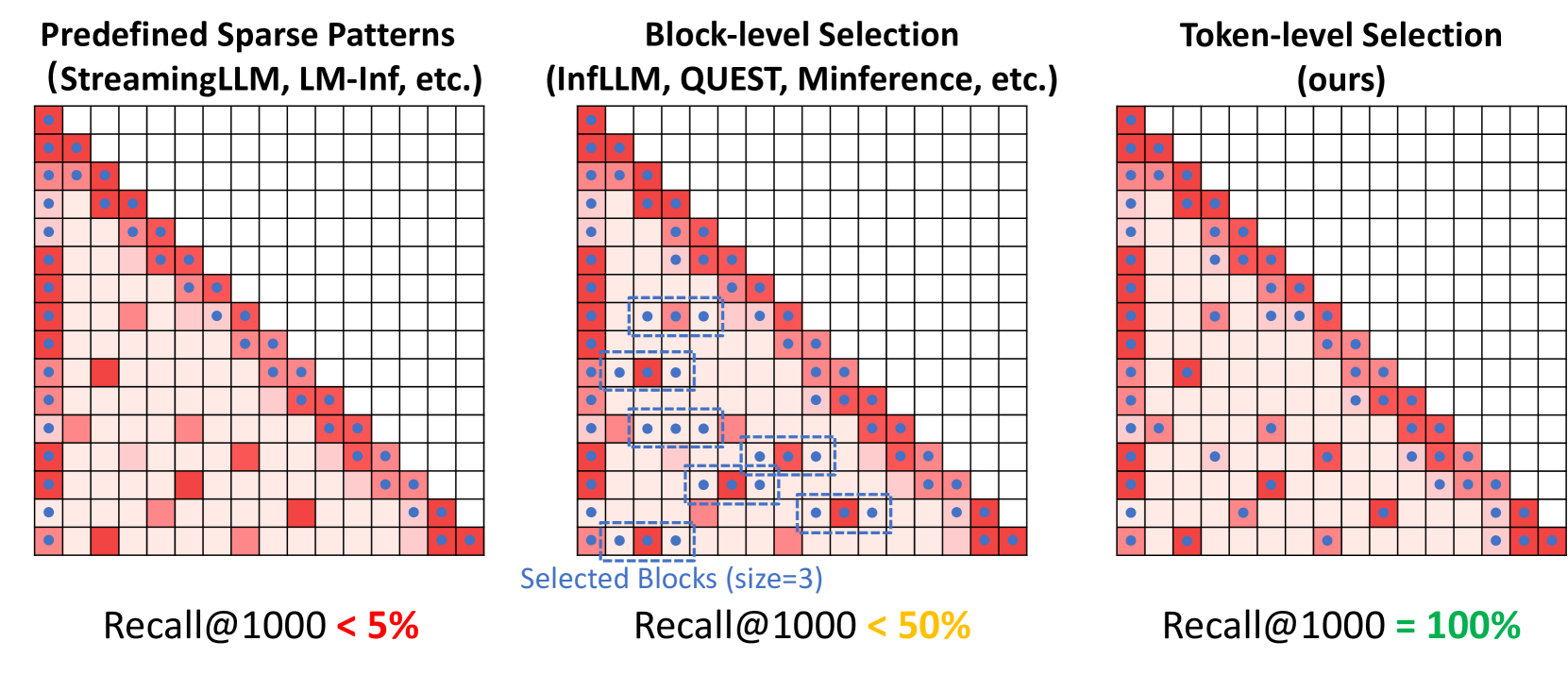 |
论文 |
 并非所有头都重要:一种集成检索与推理的头级别 KV 缓存压缩方法 Yu Fu, Zefan Cai, Abedelkadir Asi, Wayne Xiong, Yue Dong, Wen Xiao |
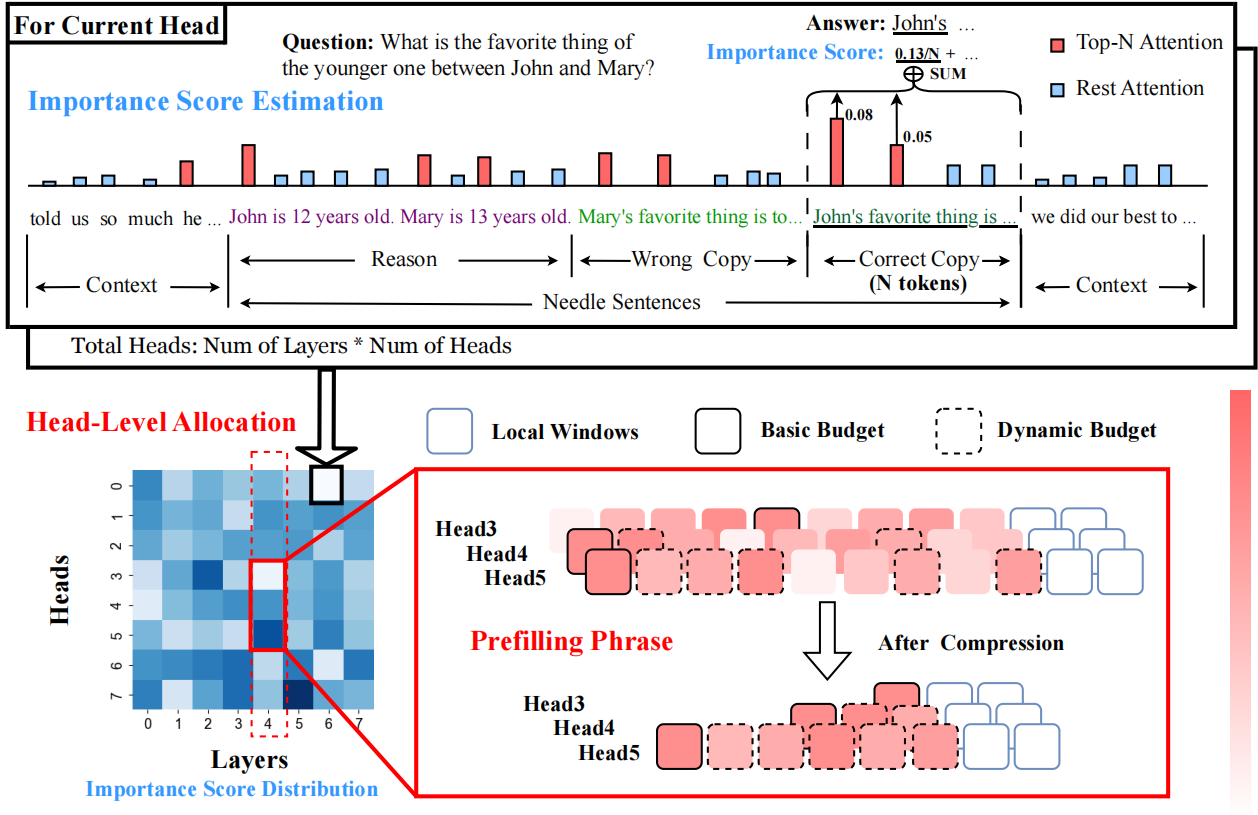 |
Github 论文 |
 BUZZ:基于蜂巢结构的稀疏 KV 缓存,结合分段热门项以实现高效的 LLM 推理 Junqi Zhao, Zhijin Fang, Shu Li, Shaohui Yang, Shichao He |
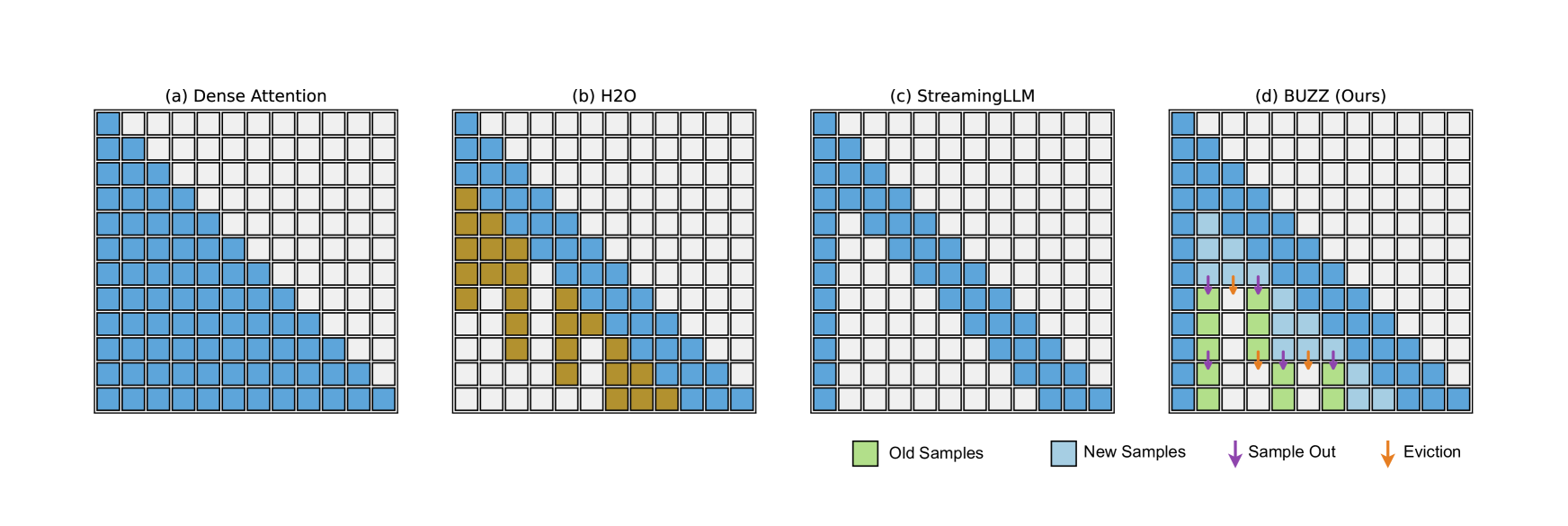 |
Github 论文 |
 跨层 KV 共享用于高效 LLM 推理的系统性研究 You Wu, Haoyi Wu, Kewei Tu |
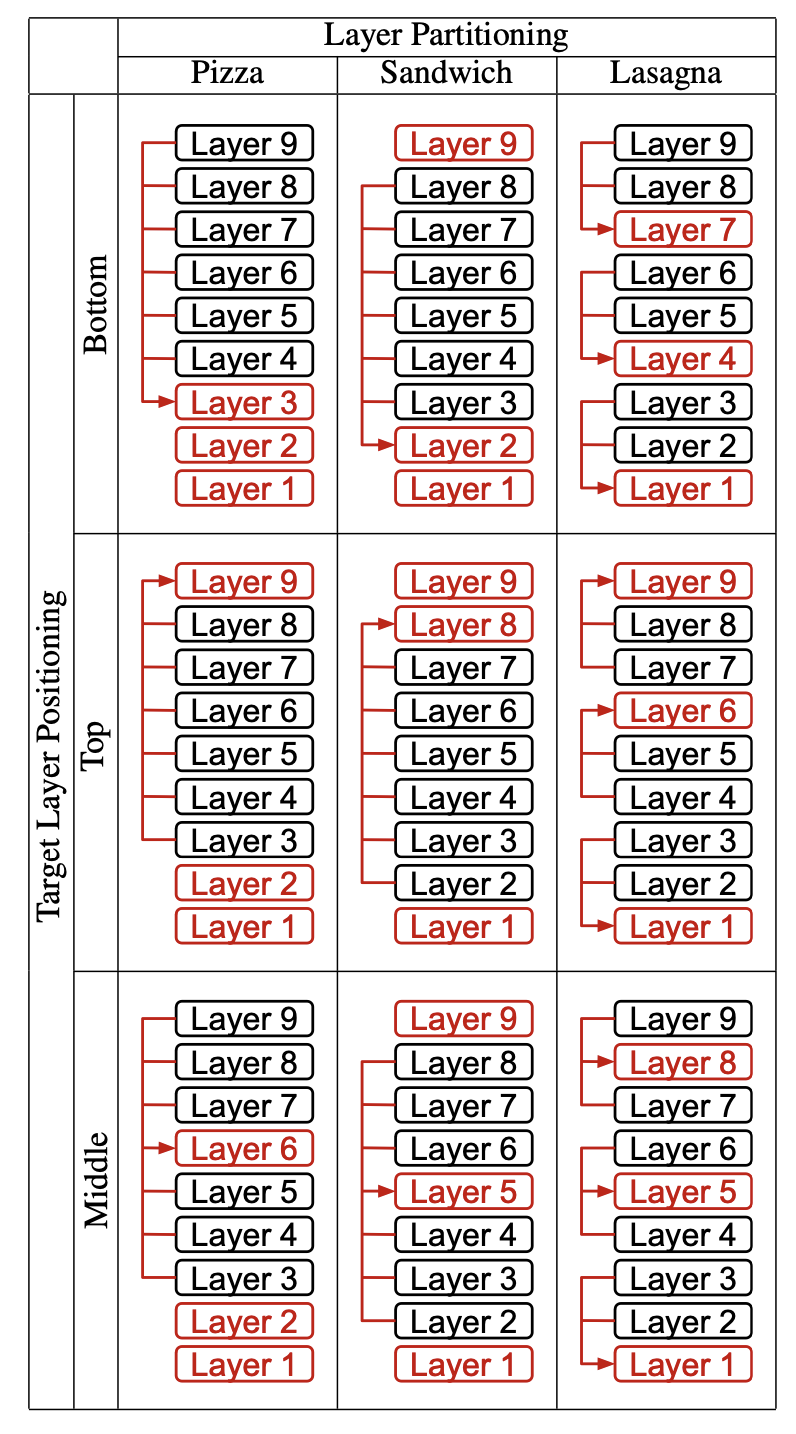 |
Github 论文 |
| 无损 KV 缓存压缩至 2% Zhen Yang, J.N.Han, Kan Wu, Ruobing Xie, An Wang, Xingwu Sun, Zhanhui Kang |
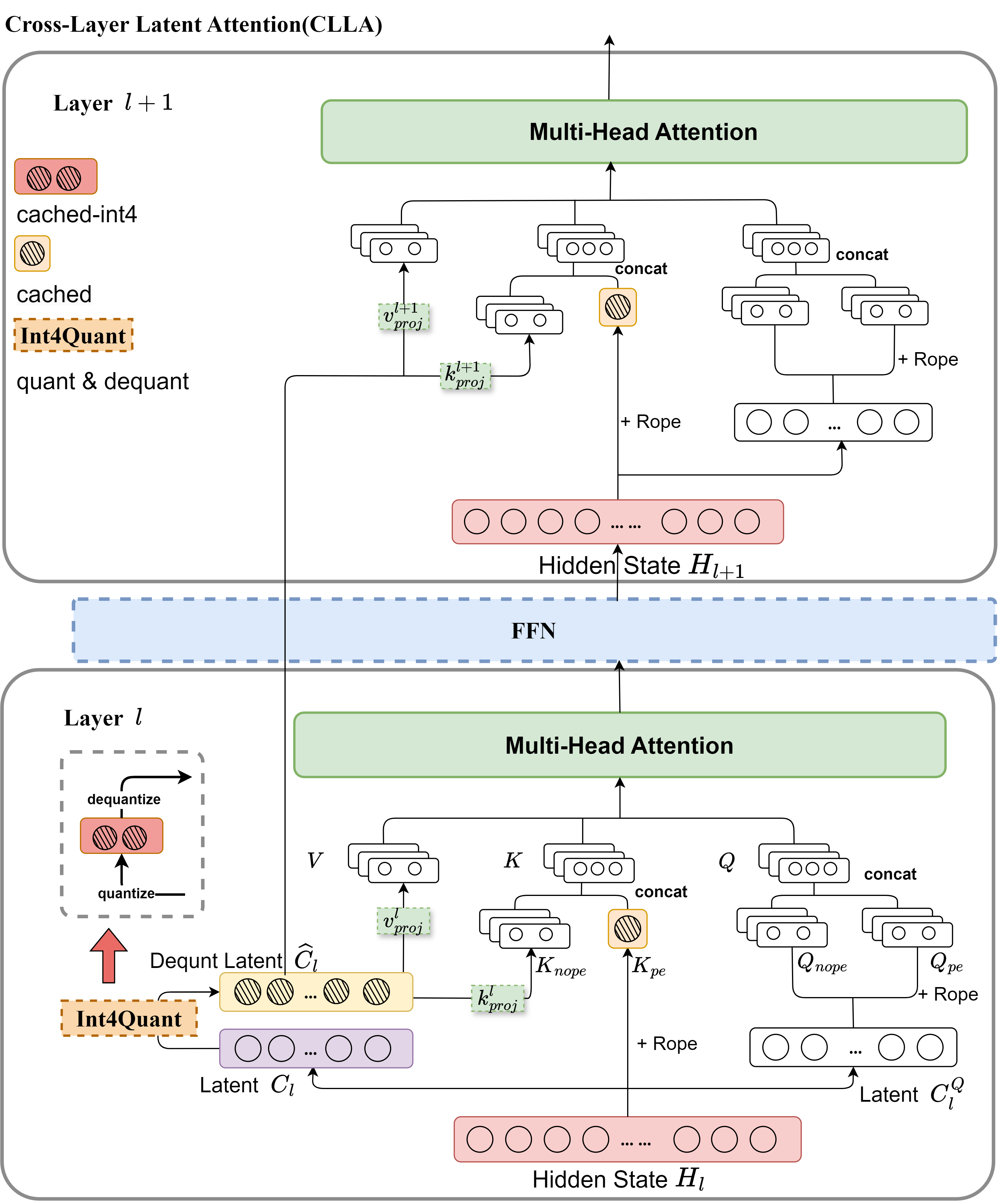 |
论文 |
| MatryoshkaKV:通过可训练正交投影实现自适应 KV 压缩 Bokai Lin, Zihao Zeng, Zipeng Xiao, Siqi Kou, Tianqi Hou, Xiaofeng Gao, Hao Zhang, Zhijie Deng |
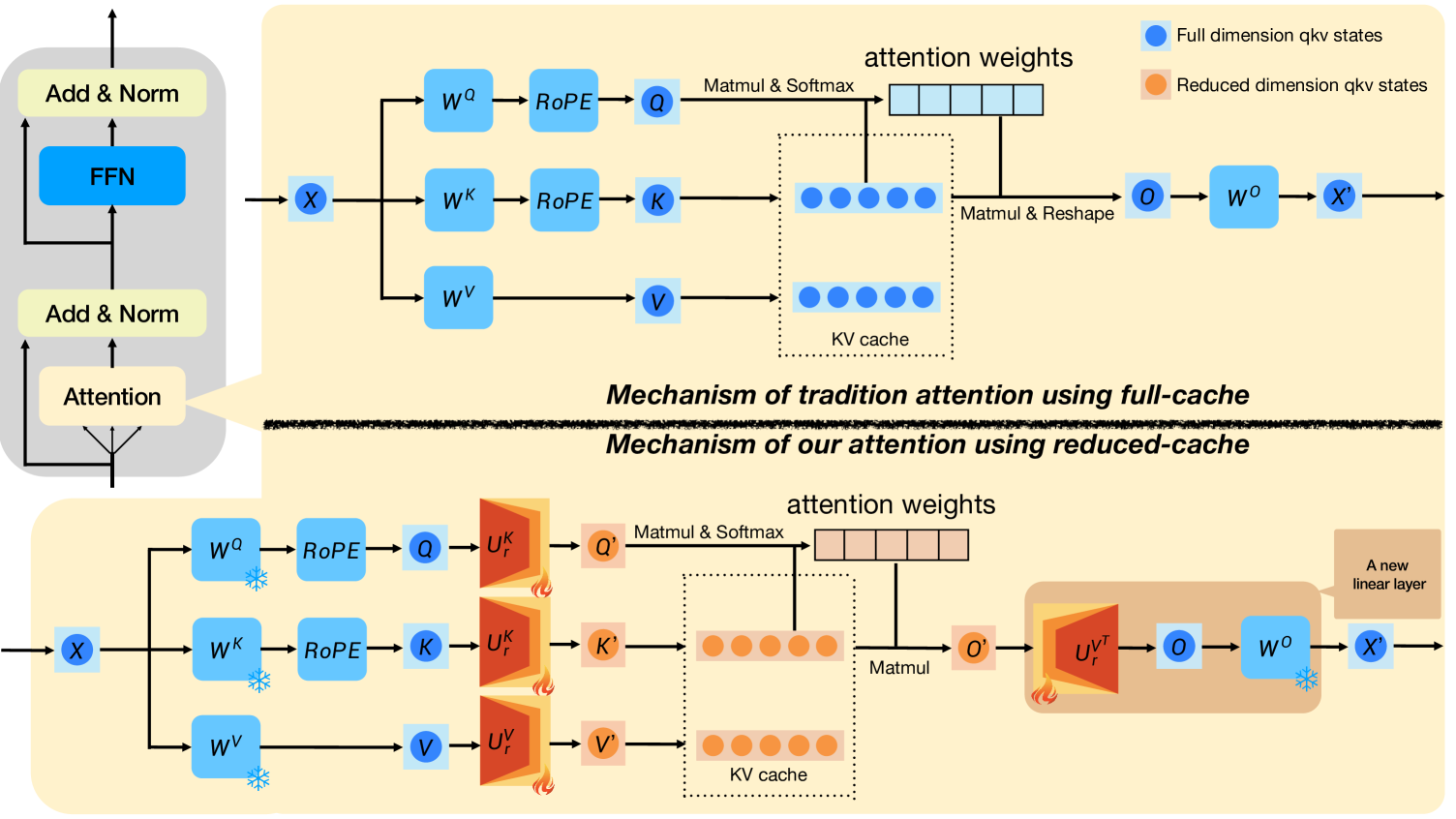 |
论文 |
 大型语言模型中 KV 缓存压缩的残差向量量化 Ankur Kumar |
Github 论文 |
|
 KVSharer:通过逐层不相似的 KV 缓存共享实现高效推理 Yifei Yang, Zouying Cao, Qiguang Chen, Libo Qin, Dongjie Yang, Hai Zhao, Zhi Chen |
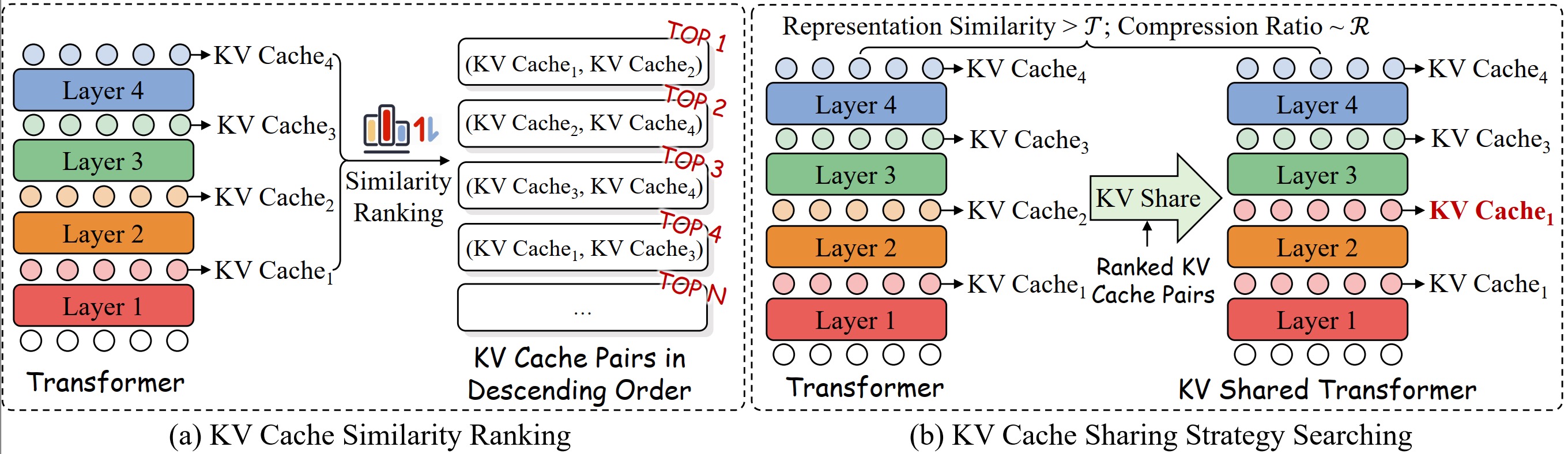 |
Github 论文 |
| LoRC:具有渐进式压缩策略的大语言模型 KV 缓存低秩压缩 Rongzhi Zhang, Kuang Wang, Liyuan Liu, Shuohang Wang, Hao Cheng, Chao Zhang, Yelong Shen |
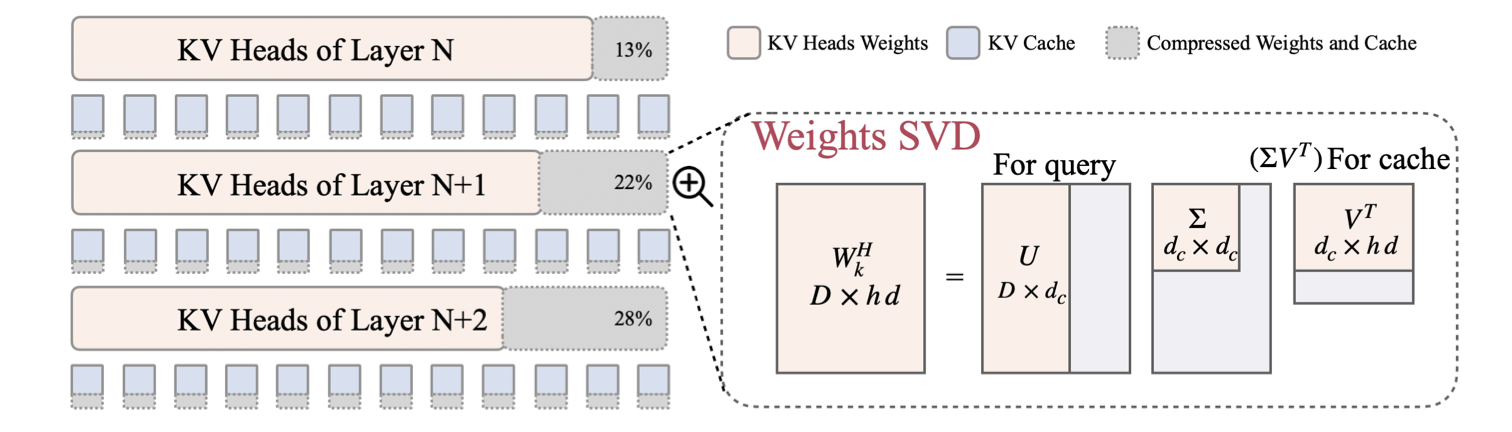 |
论文 |
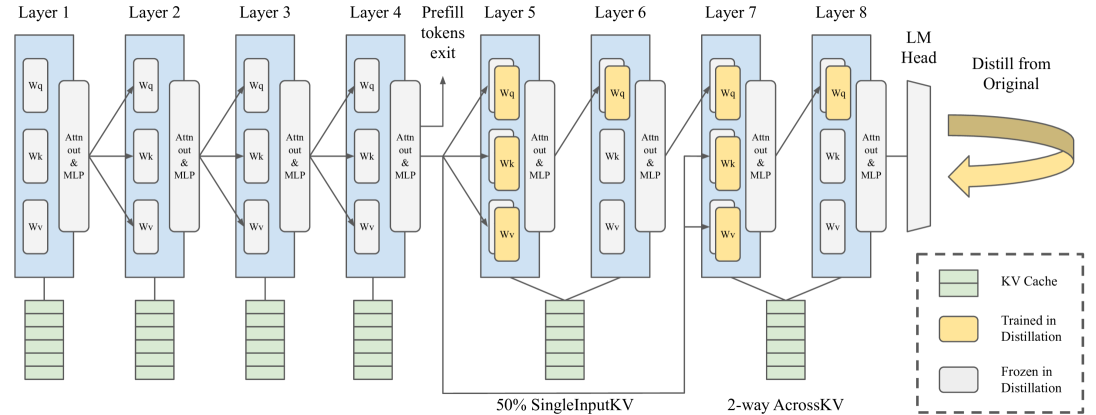
| SwiftKV:具有知识保留型模型转换的快速预填充优化推理 Aurick Qiao, Zhewei Yao, Samyam Rajbhandari, Yuxiong He |
 |
论文 |
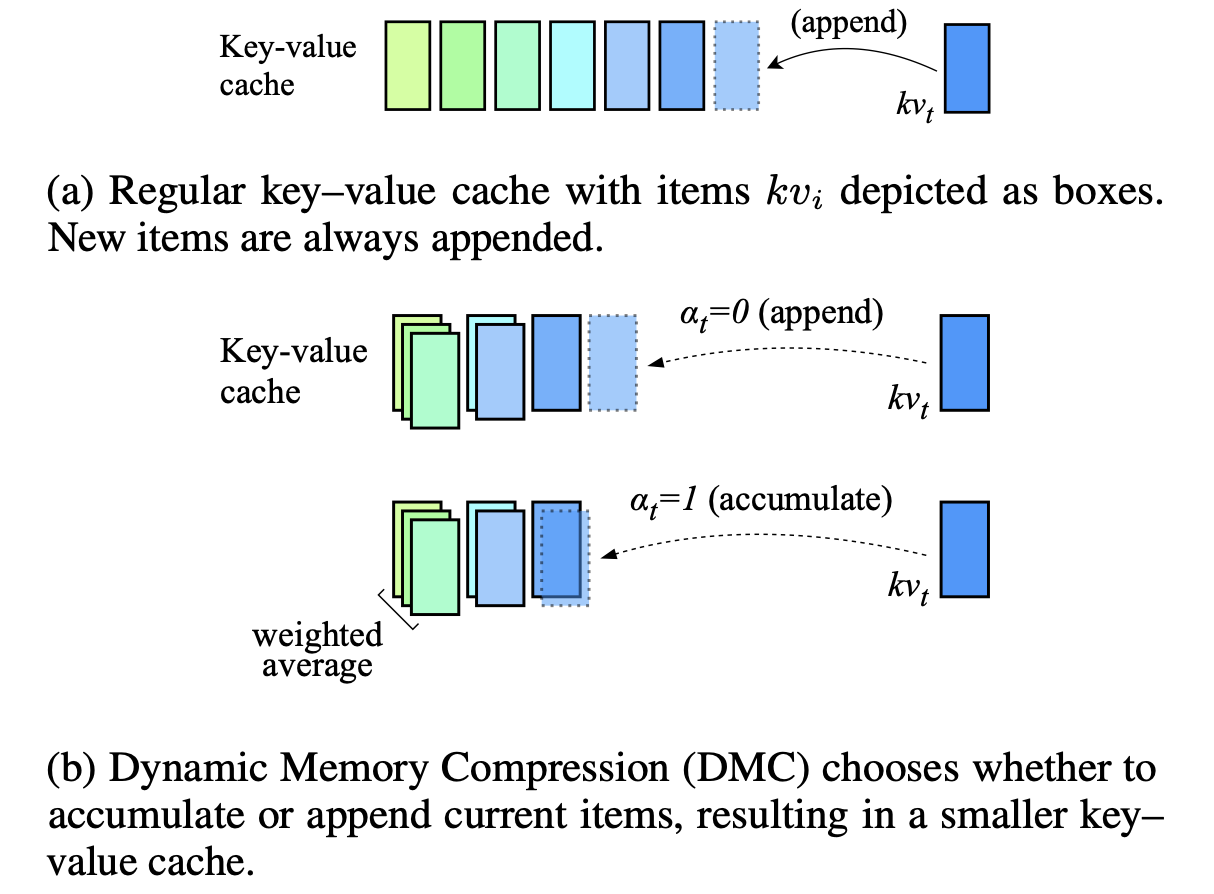
动态内存压缩:为加速推理而改造 LLM Piotr Nawrot, Adrian Łańcucki, Marcin Chochowski, David Tarjan, Edoardo M. Ponti |
 |
论文 |
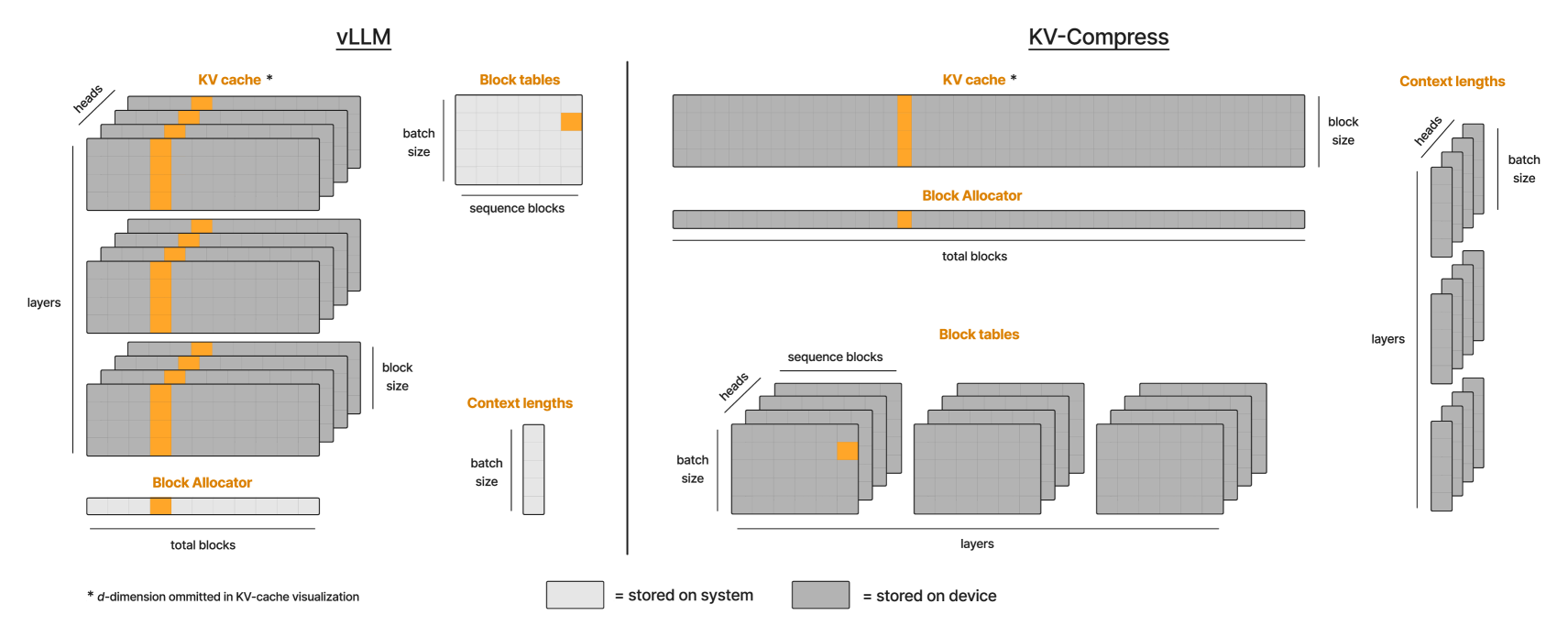
| KV-Compress:按注意力头设置可变压缩率的分页 KV 缓存压缩 Isaac Rehg |
 |
论文 |
 Ada-KV:通过自适应预算分配优化 KV 缓存淘汰以实现高效 LLM 推理 Yuan Feng, Junlin Lv, Yukun Cao, Xike Xie, S. Kevin Zhou |
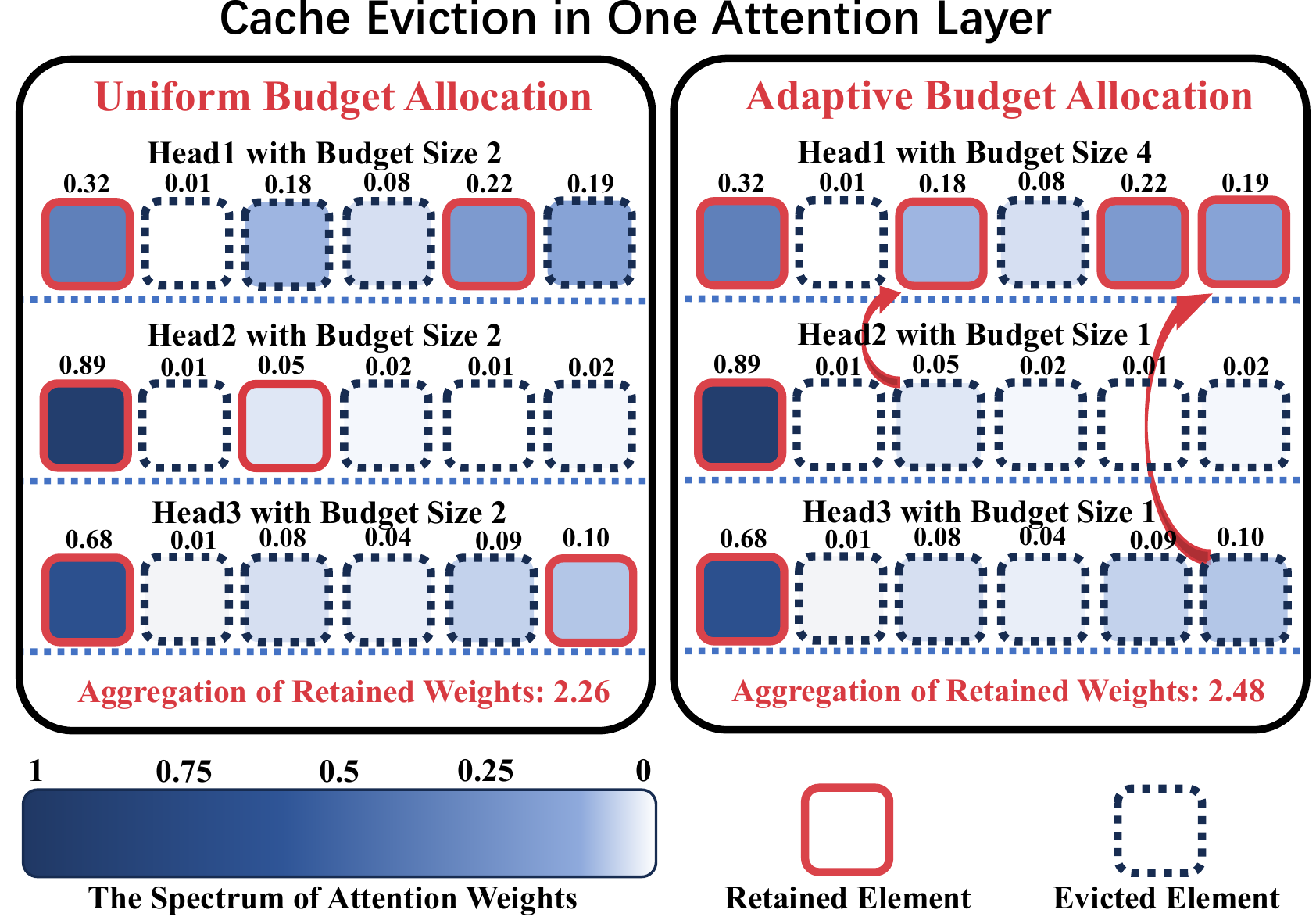 |
Github 论文 |
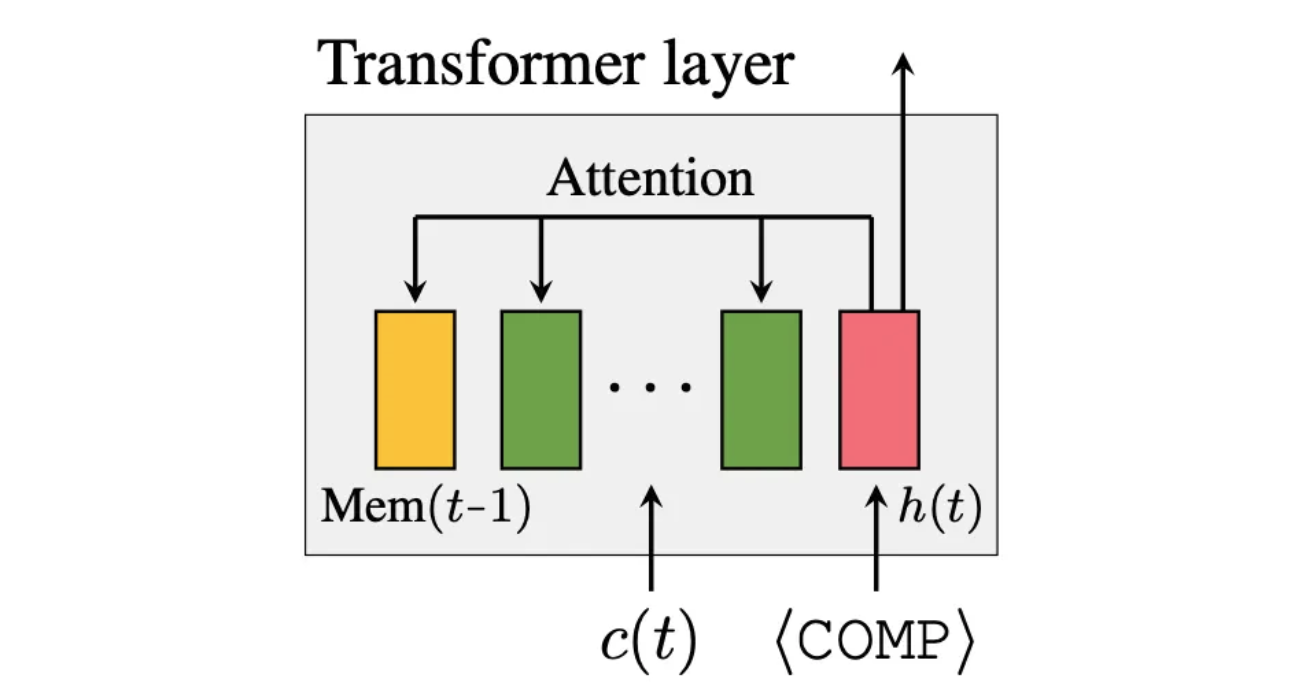
 用于在线语言模型交互的压缩上下文记忆 Jang-Hyun Kim, Junyoung Yeom, Sangdoo Yun, Hyun Oh Song |
 |
Github 论文 |
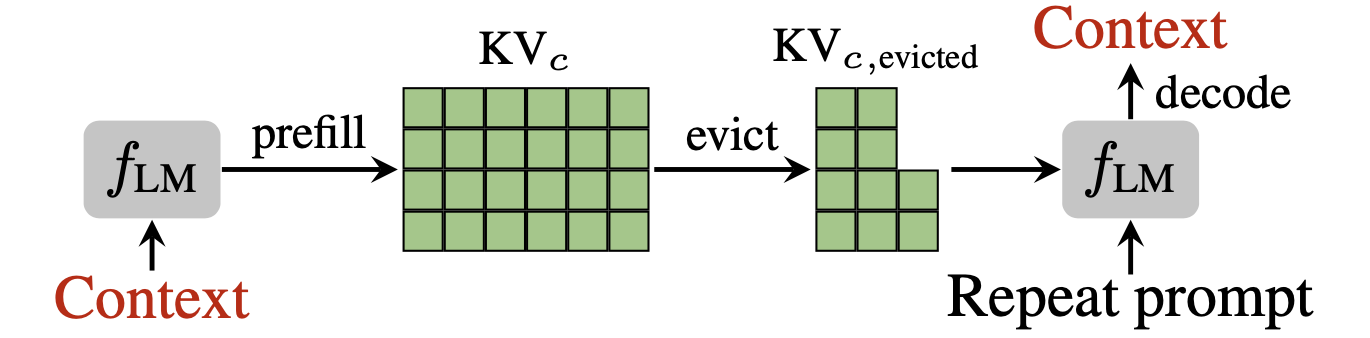
 KVzip:具有上下文重建功能的查询无关 KV 缓存压缩 Jang-Hyun Kim, Jinuk Kim, Sangwoo Kwon, Jae W. Lee, Sangdoo Yun, Hyun Oh Song |
 |
Github 论文 |
文本压缩
| 标题与作者 | 简介 | 链接 |
|---|---|---|
 :star: LLMLingua:用于加速大型语言模型推理的提示压缩 江辉强、吴千慧、林振宇、杨宇青、邱丽丽 |
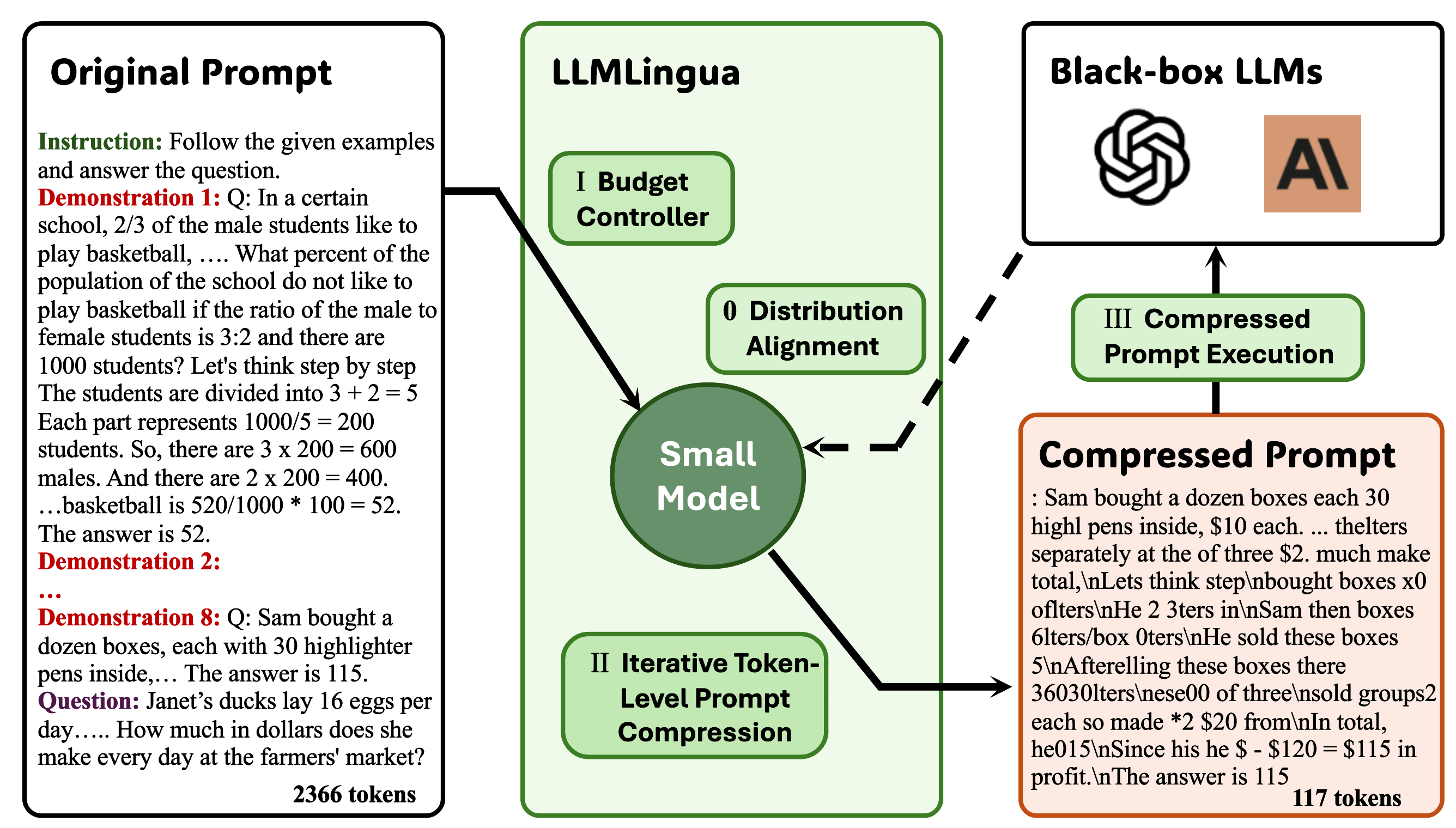 |
Github Paper |
 L3TC:利用RWKV实现学习型无损低复杂度文本压缩 张俊轩、程正雪、赵岩、王世豪、周大江、陆国、宋力 |
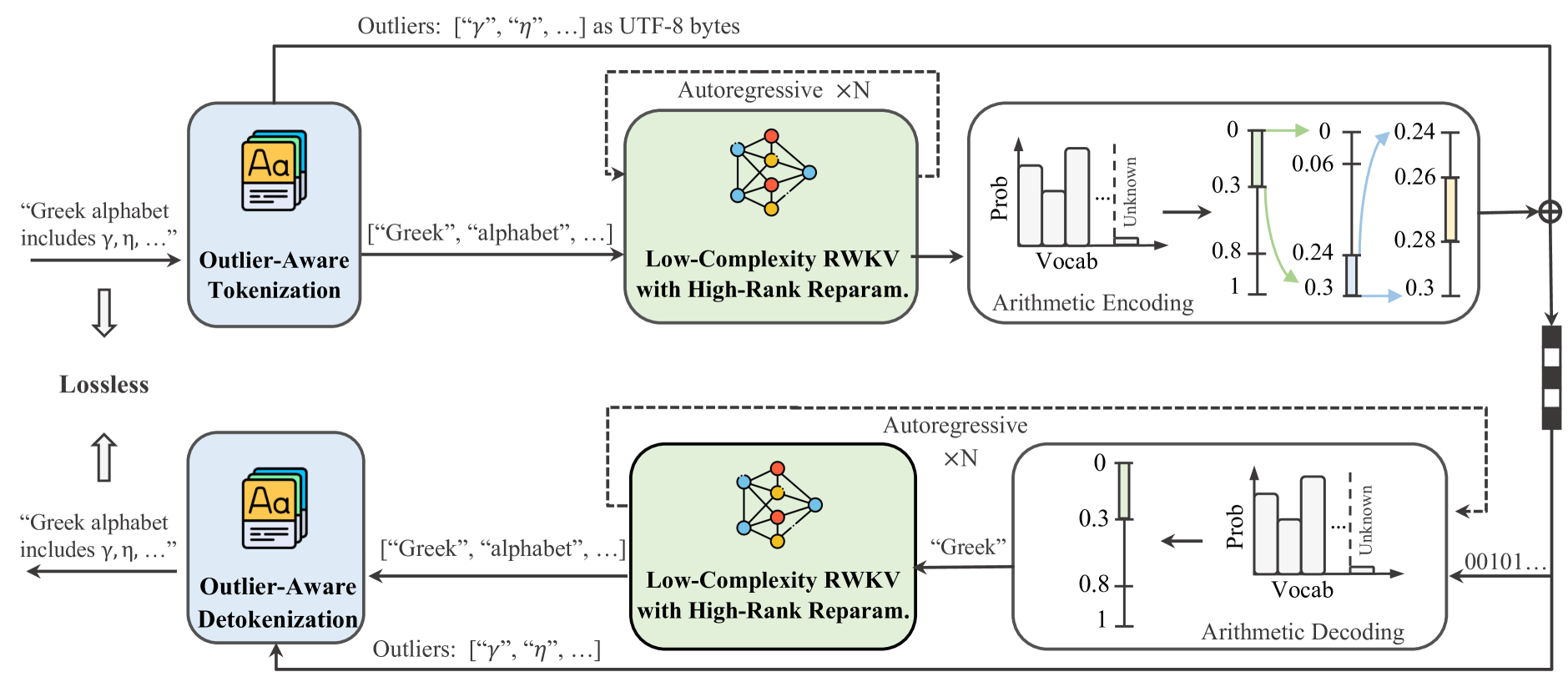 |
Github Paper |
 PromptOptMe:基于LLM的MT评估指标中的误差感知提示压缩 丹尼尔·拉里奥诺夫、施特芬·埃格尔 |
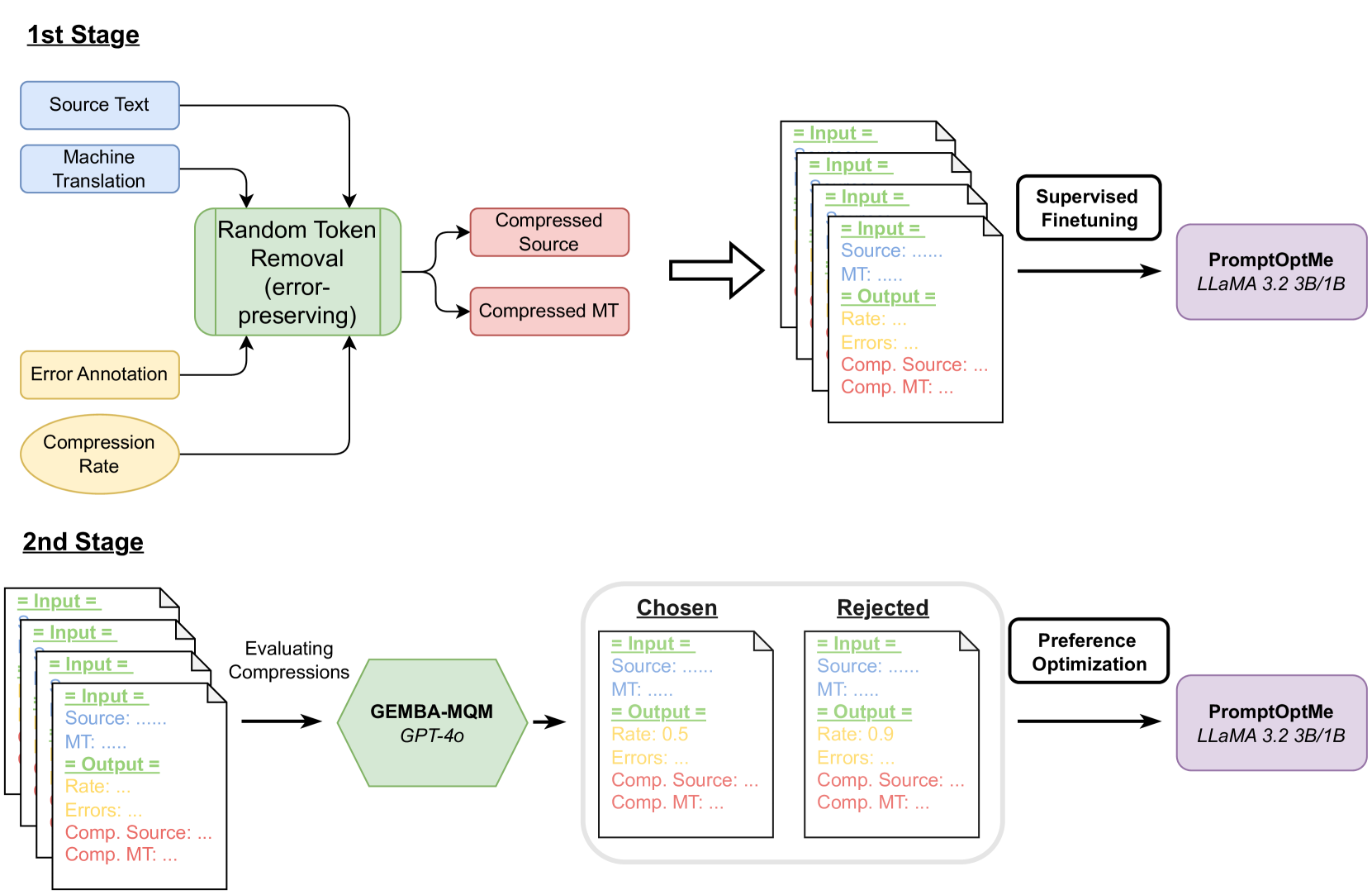 |
Github Paper |
:star: LongLLMLingua:通过提示压缩加速并增强长上下文场景下的LLM 江辉强、吴千慧、罗旭芳、李东升、林振宇、杨宇青、邱丽丽 |
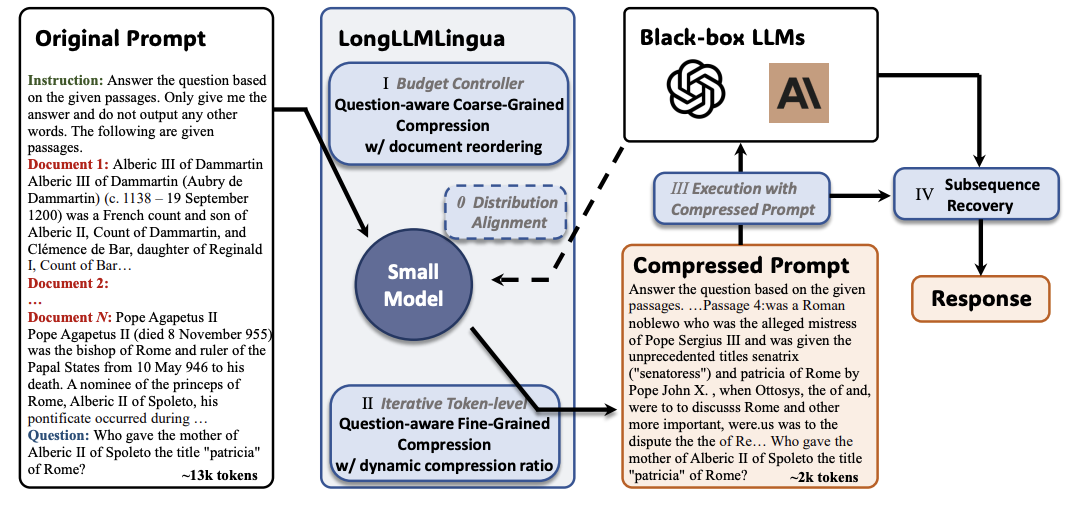 |
Github Paper |
| 关于全注意力机制的银弹还是折衷方案?基于摘要标记的上下文压缩综合研究 邓晨龙、张志松、毛克隆、李帅毅、黄欣婷、于东、窦志成 |
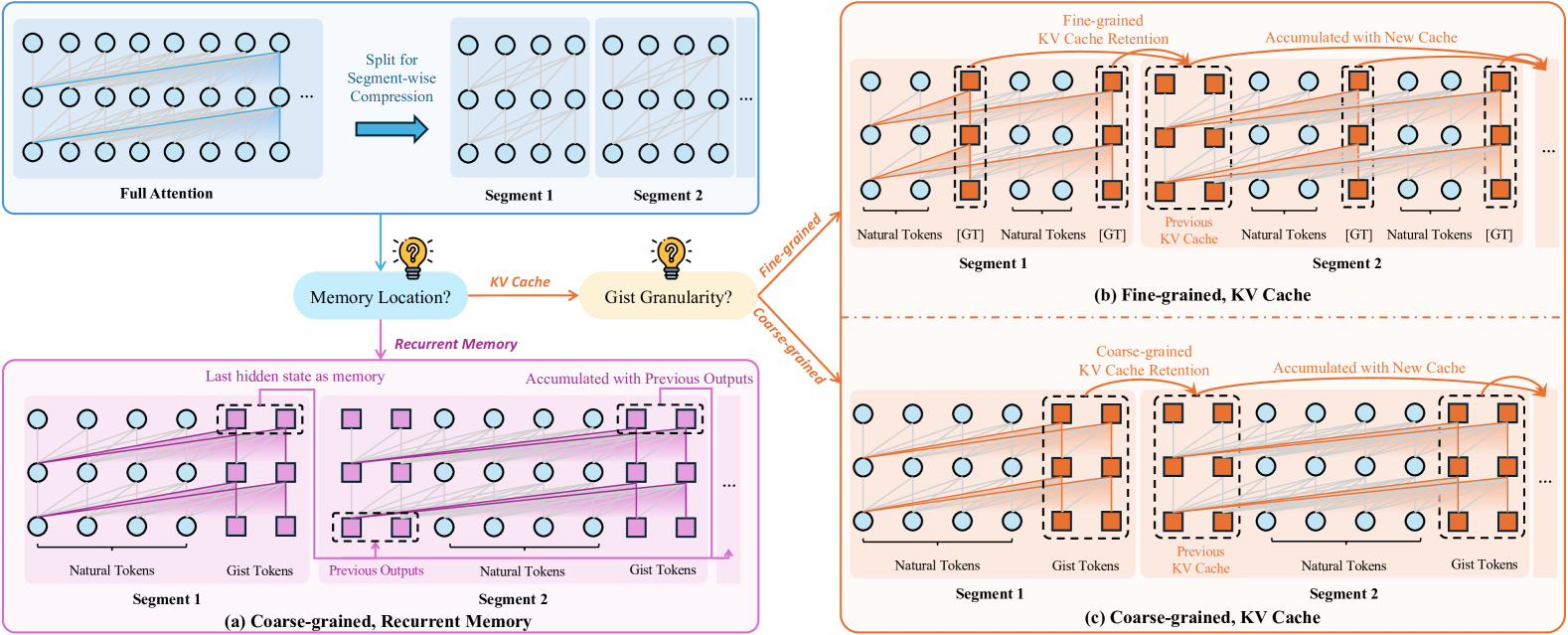 |
Paper |
| JPPO:联合功率与提示优化以加速大型语言模型服务 游飞然、杜洪洋、黄凯斌、阿巴斯·贾马利普尔 |
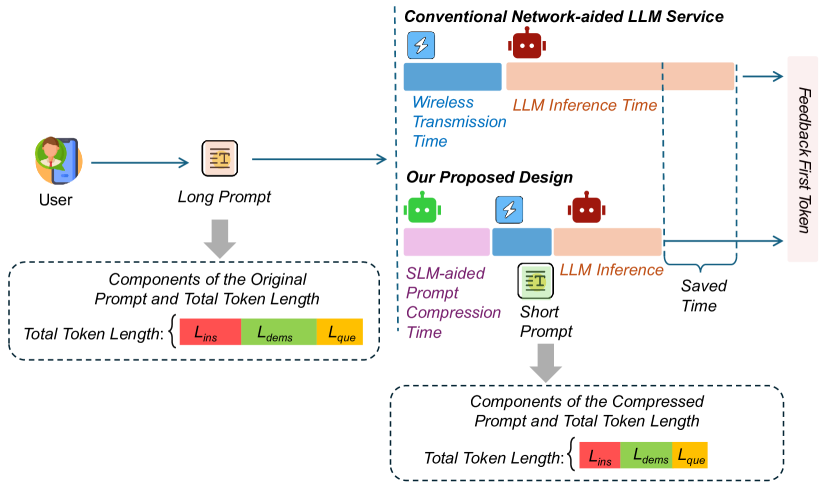 |
Paper |
生成式提示内化 申河彬、季磊、龚叶云、金成东、崔恩菲、徐敏俊 |
|
Github Paper |
 MultiTok:基于LZW压缩改进的高效LLM可变长度分词 诺埃尔·埃利亚斯、霍玛·埃斯法哈尼扎德、卡安·卡莱、斯里拉姆·维什瓦纳特、穆里埃尔·梅达尔 |
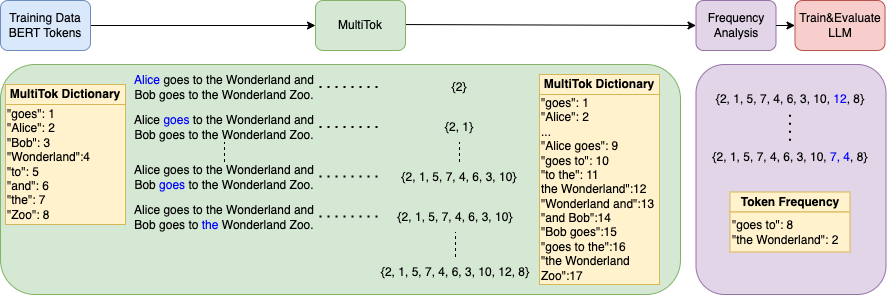 |
Github Paper |
Selection-p:自监督的任务无关提示压缩,兼顾忠实性和可迁移性 钟子婷、崔乐阳、刘乐茂、黄欣婷、史书铭、杨迪彦 |
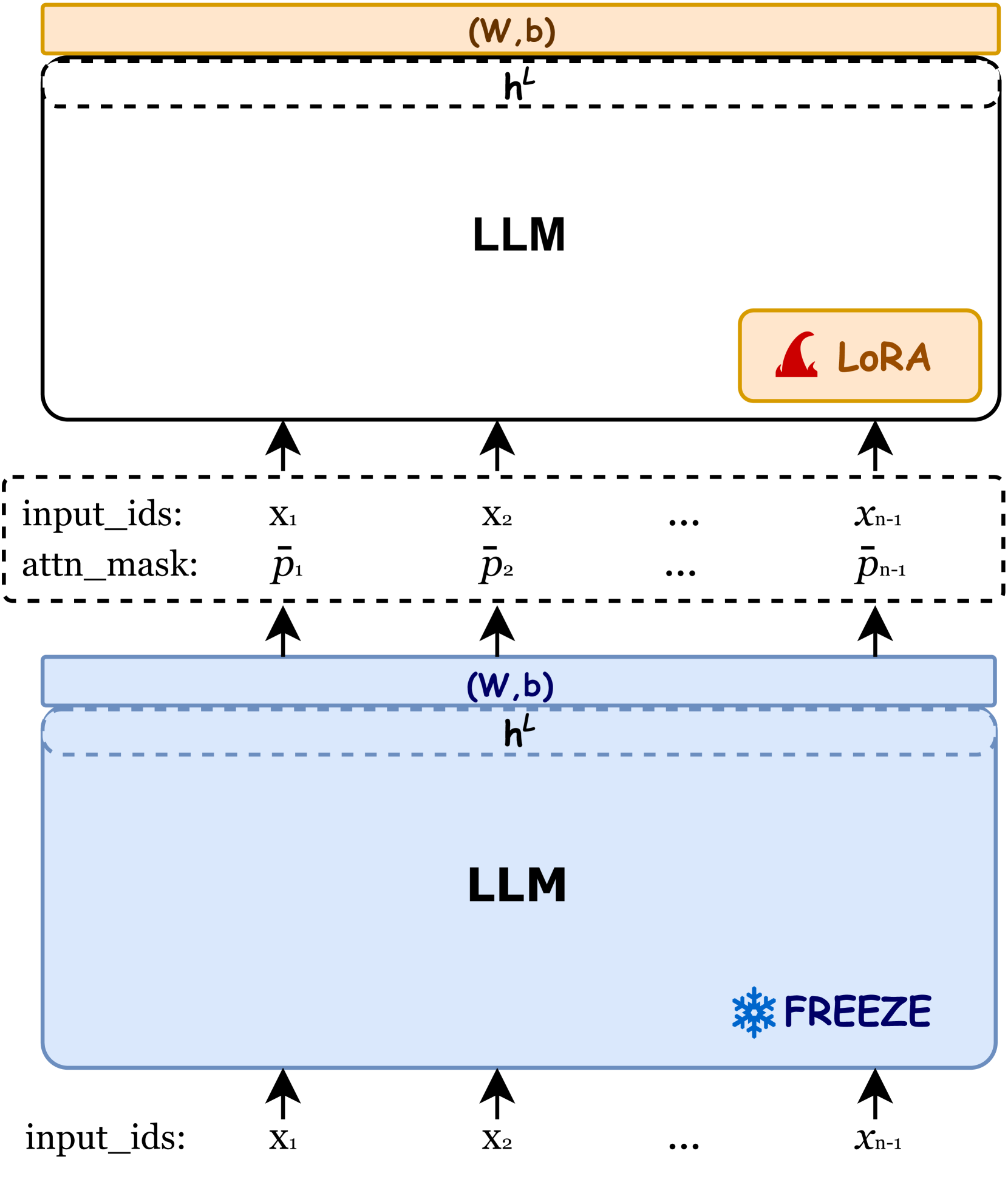 |
Paper |
从阅读到压缩:探索多文档阅读器在提示压缩中的应用 崔恩成、李善京、崔珉珍、朴俊、李钟郁 |
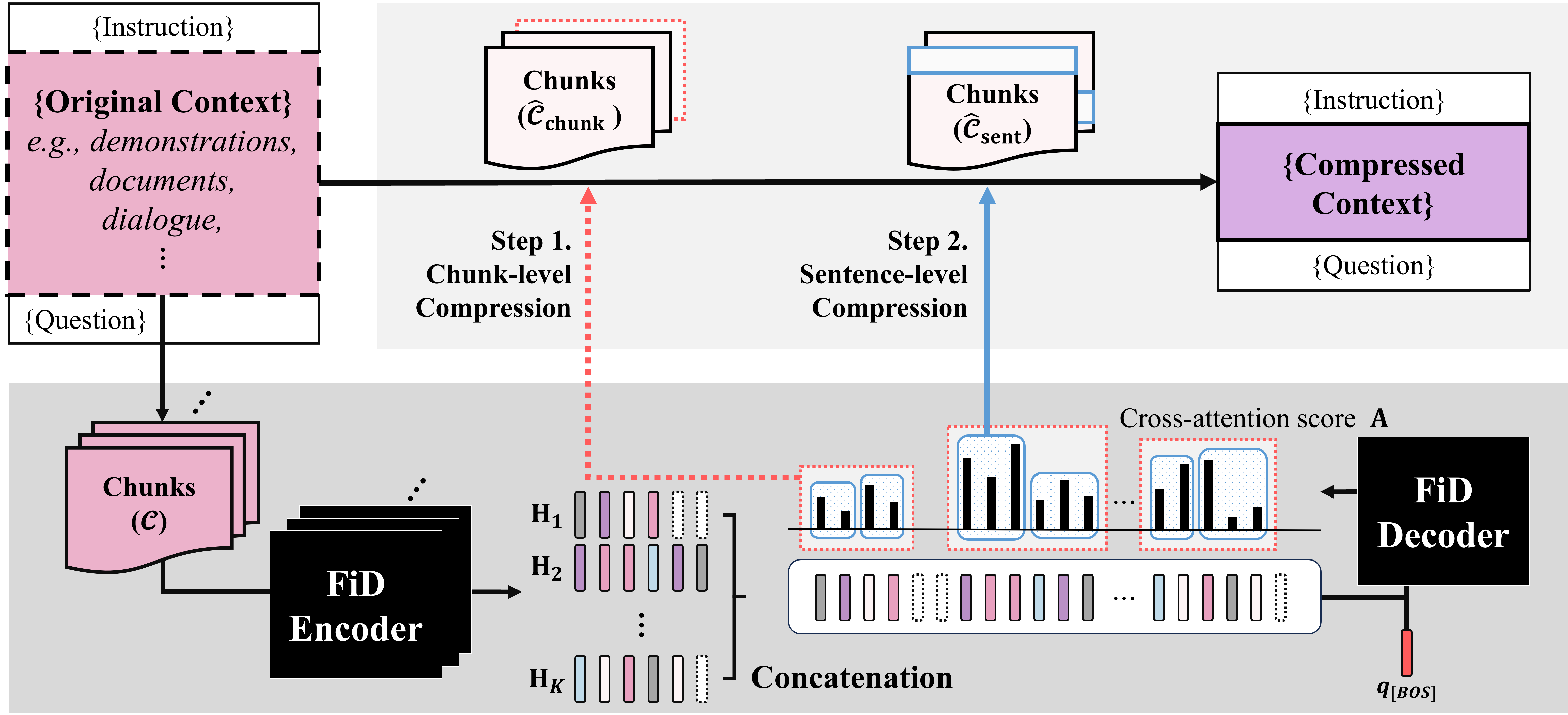 |
Paper |
| 感知压缩器:一种无需训练的长上下文场景下提示压缩方法 唐继伟、许进、卢廷伟、林海、赵一鸣、郑海涛 |
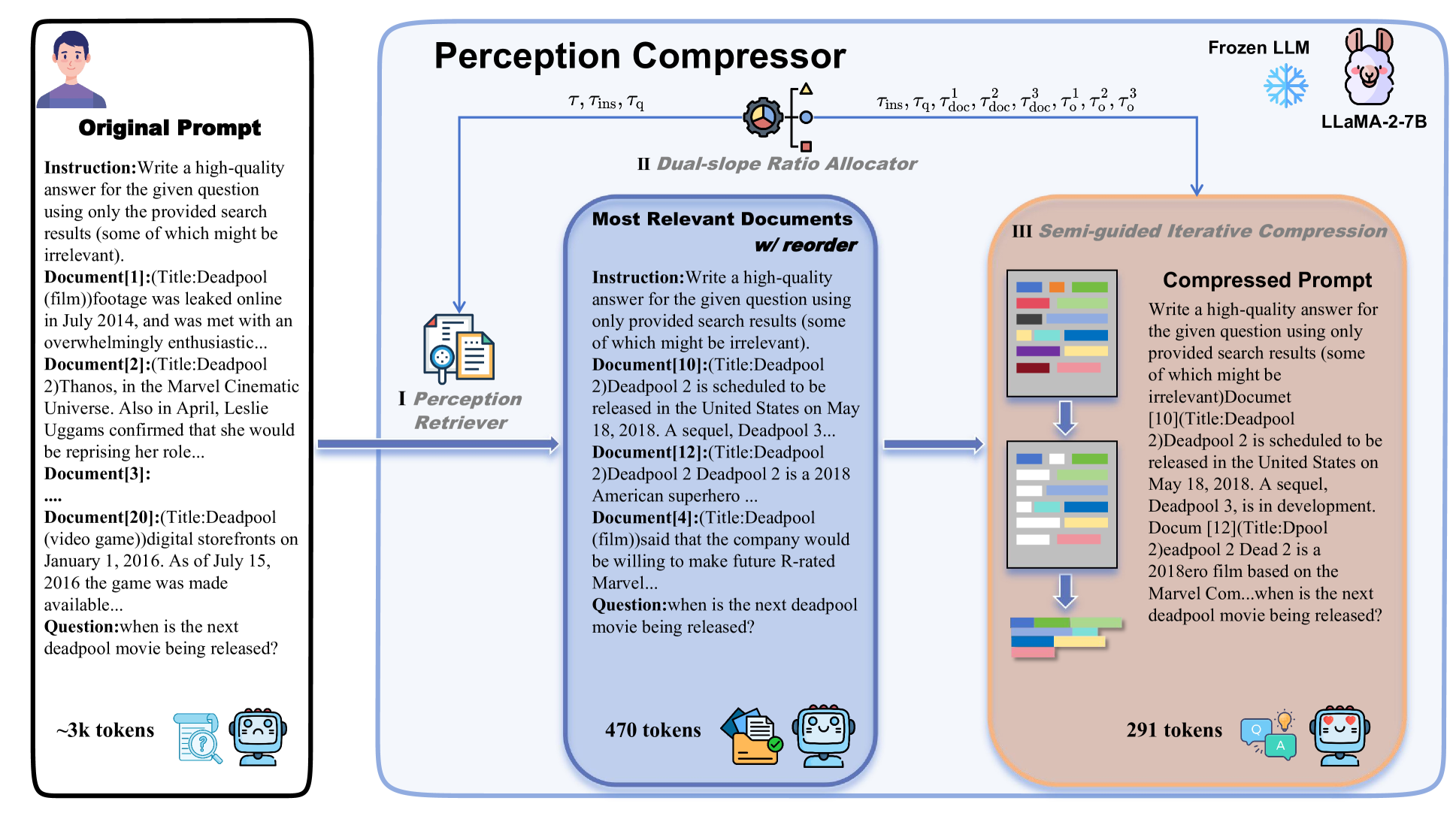 |
Paper |
 具有上下文感知句子编码的提示压缩,用于快速且改进的LLM推理 巴里斯·利斯卡韦茨、马克西姆·乌沙科夫、舒文杜·罗伊、马克·克利巴诺夫、阿里·埃特马德、谢恩·卢克 |
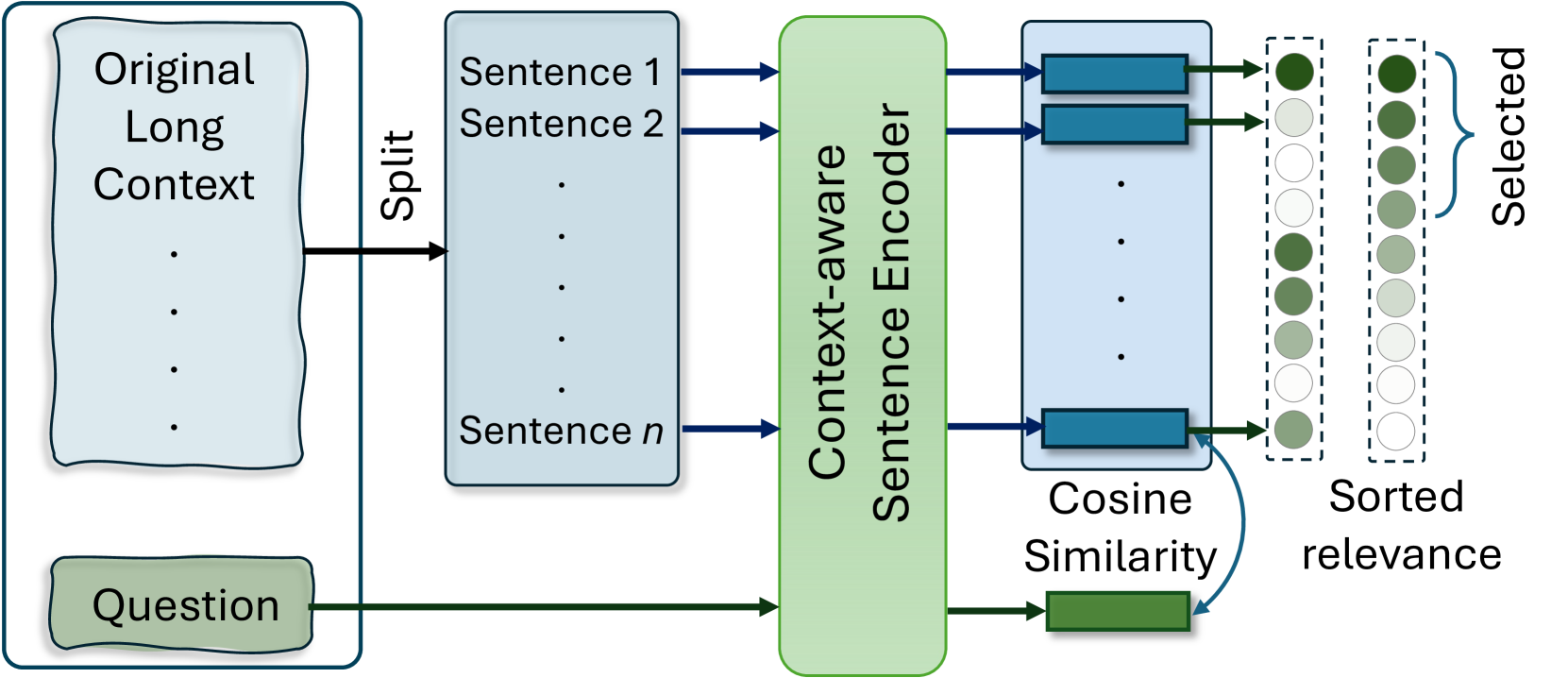 |
Github Paper |
| 任务无关的提示压缩:结合上下文感知句子嵌入与奖励引导的任务描述符 巴里斯·利斯卡韦茨、舒文杜·罗伊、马克西姆·乌沙科夫、马克·克利巴诺夫、阿里·埃特马德、谢恩·卢克 |
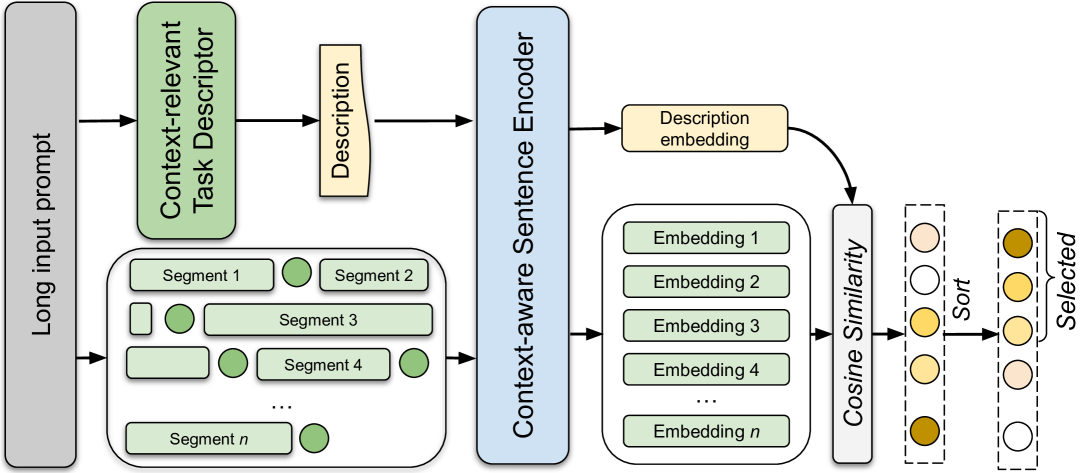 |
Paper |
低秩分解
| 标题及作者 | 简介 | 链接 |
|---|---|---|
ESPACE:用于模型压缩的激活维度约简 Charbel Sakr, Brucek Khailany |
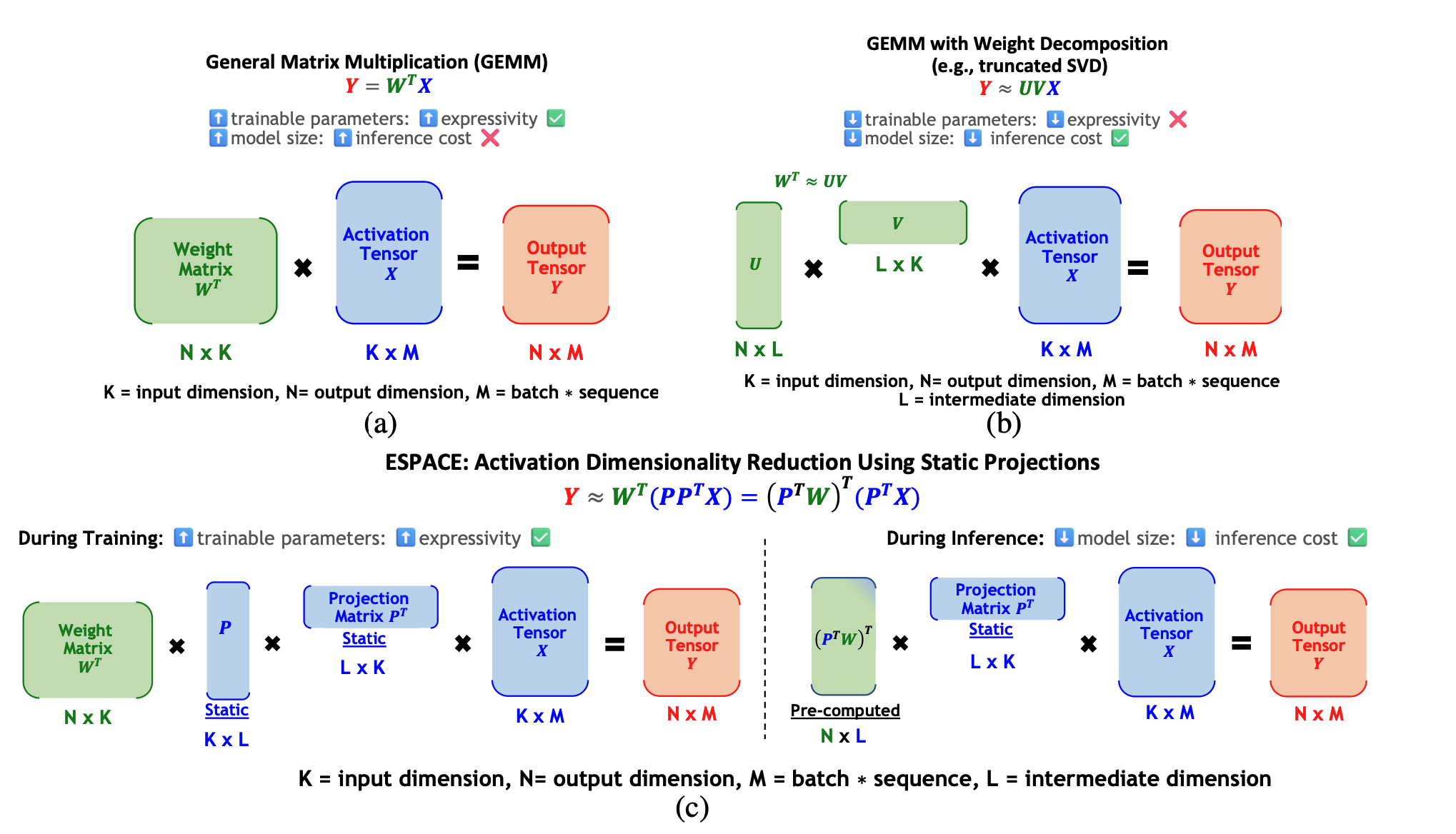 |
论文 |
 Natural GaLore:加速GaLore以实现内存高效的LLM训练和微调 Arijit Das |
Github 论文 |
|
| CompAct:用于内存高效LLM训练的压缩激活 Yara Shamshoum, Nitzan Hodos, Yuval Sieradzki, Assaf Schuster |
 |
论文 |
硬件/系统/推理服务
| 标题及作者 | 简介 | 链接 |
|---|---|---|
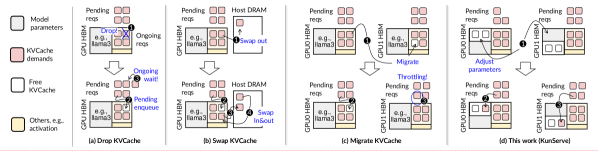
| KunServe:基于参数中心内存管理的弹性高效大语言模型推理服务 Rongxin Cheng, Yifan Peng, Yuxin Lai, Xingda Wei, Rong Chen, Haibo Chen |
 |
论文 |
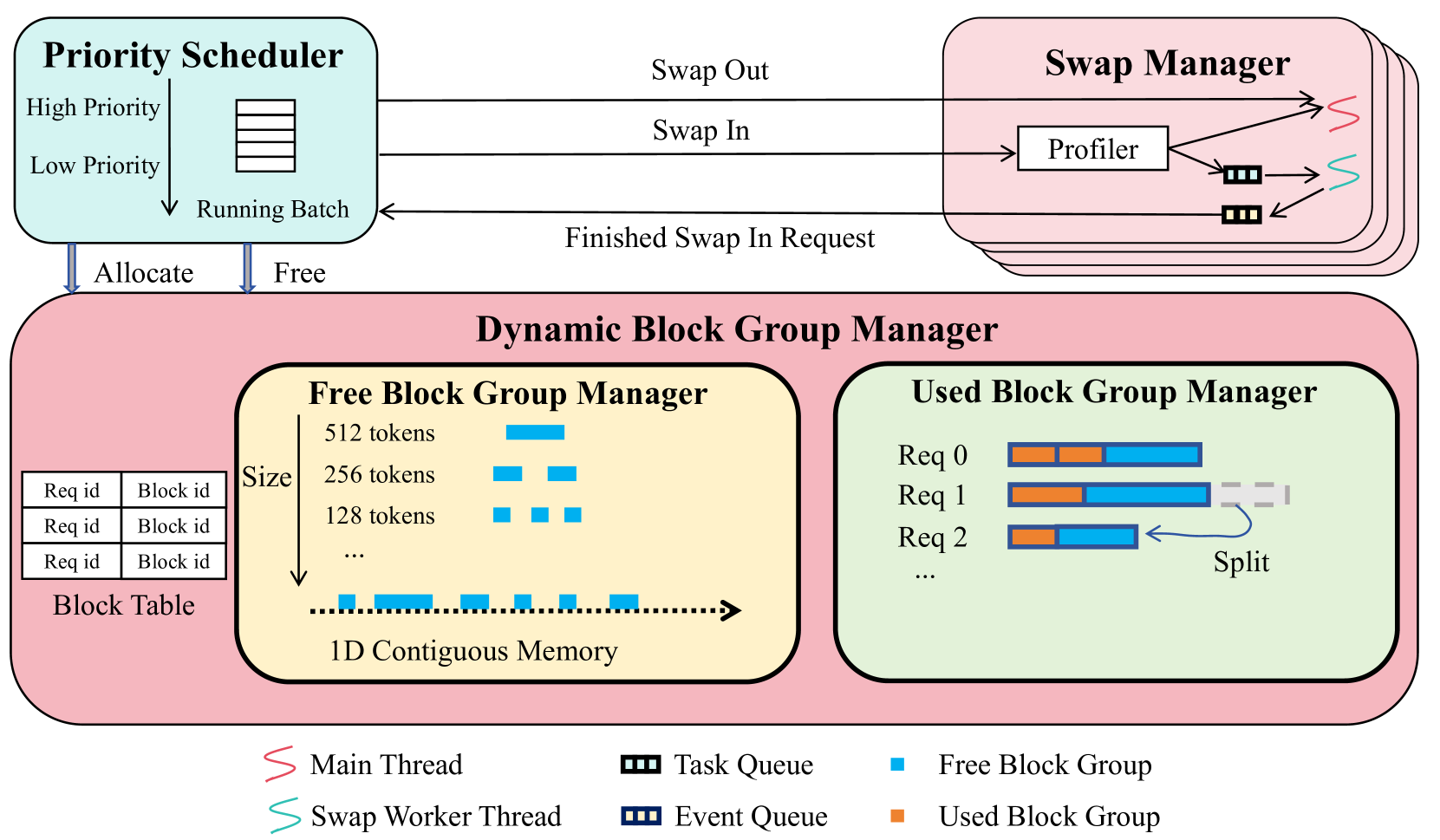
| FastSwitch:在公平性驱动的大语言模型推理服务中优化上下文切换效率 Ao Shen, Zhiyao Li, Mingyu Gao |
 |
论文 |
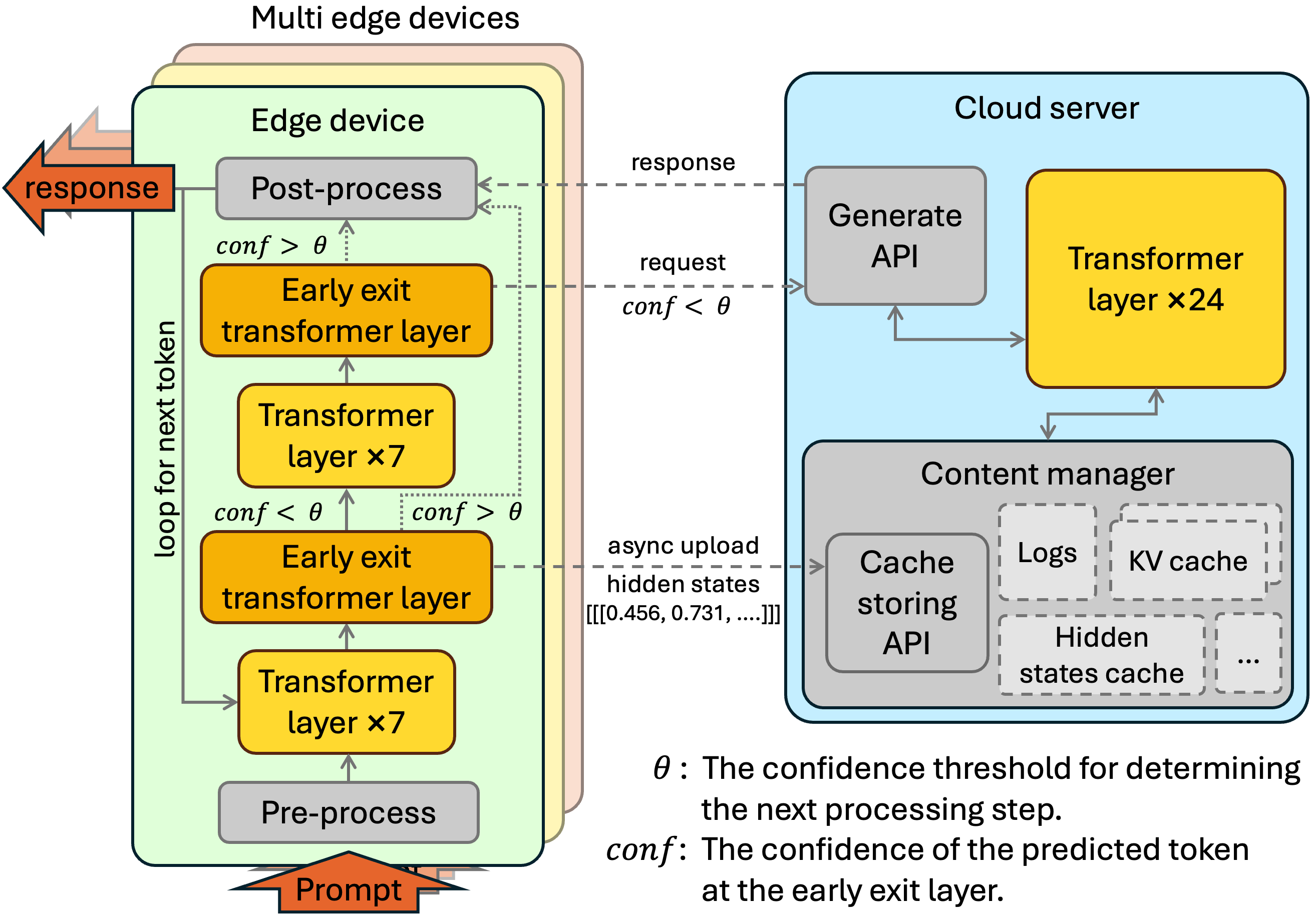
| CE-CoLLM:通过云边协同实现高效自适应大语言模型 Hongpeng Jin, Yanzhao Wu |
 |
论文 |
| Ripple:通过相关性感知的神经元管理加速智能手机上的LLM推理 Tuowei Wang, Ruwen Fan, Minxing Huang, Zixu Hao, Kun Li, Ting Cao, Youyou Lu, Yaoxue Zhang, Ju Ren |
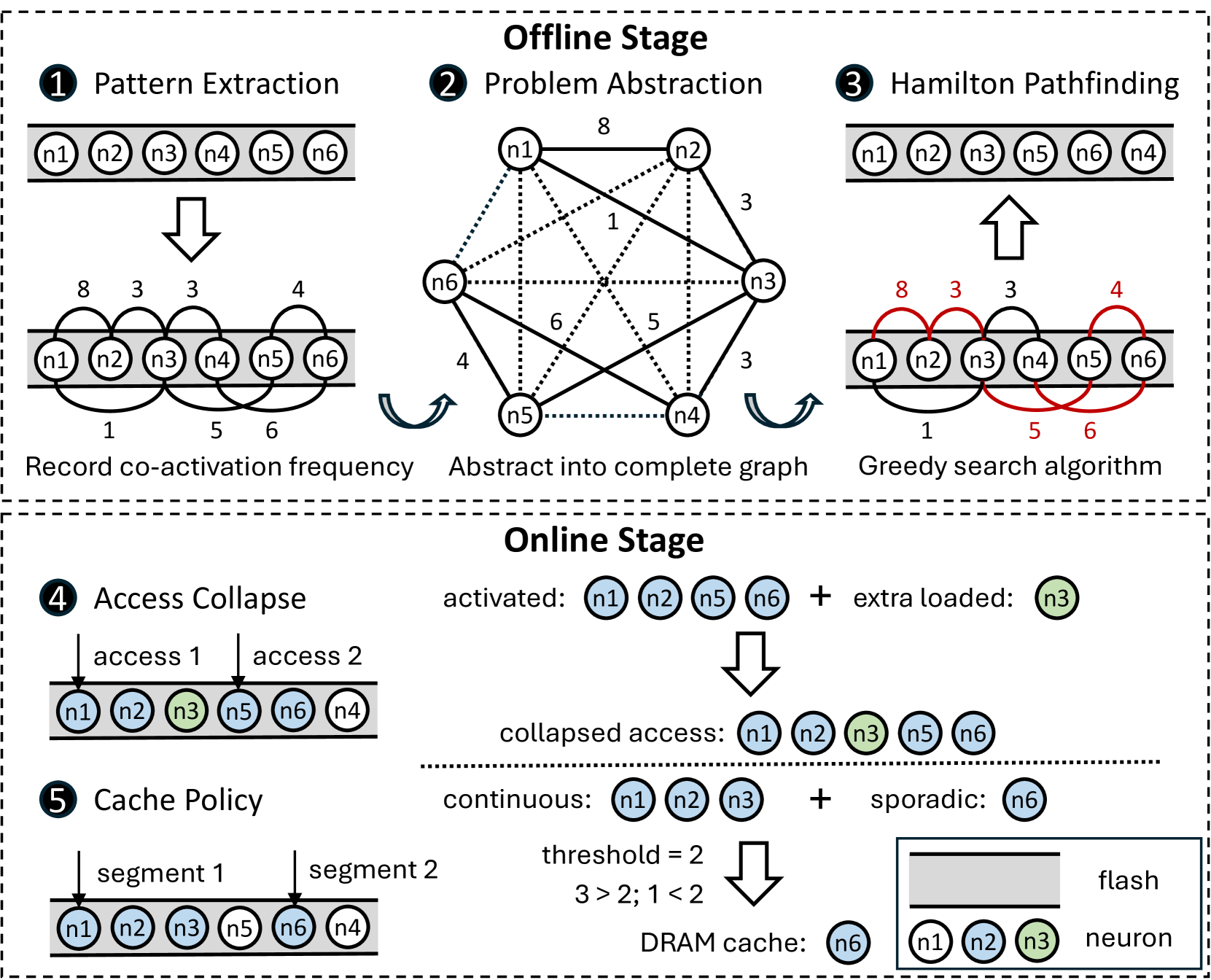 |
论文 |
ALISE:通过推测调度加速大语言模型推理服务 Youpeng Zhao, Jun Wang |
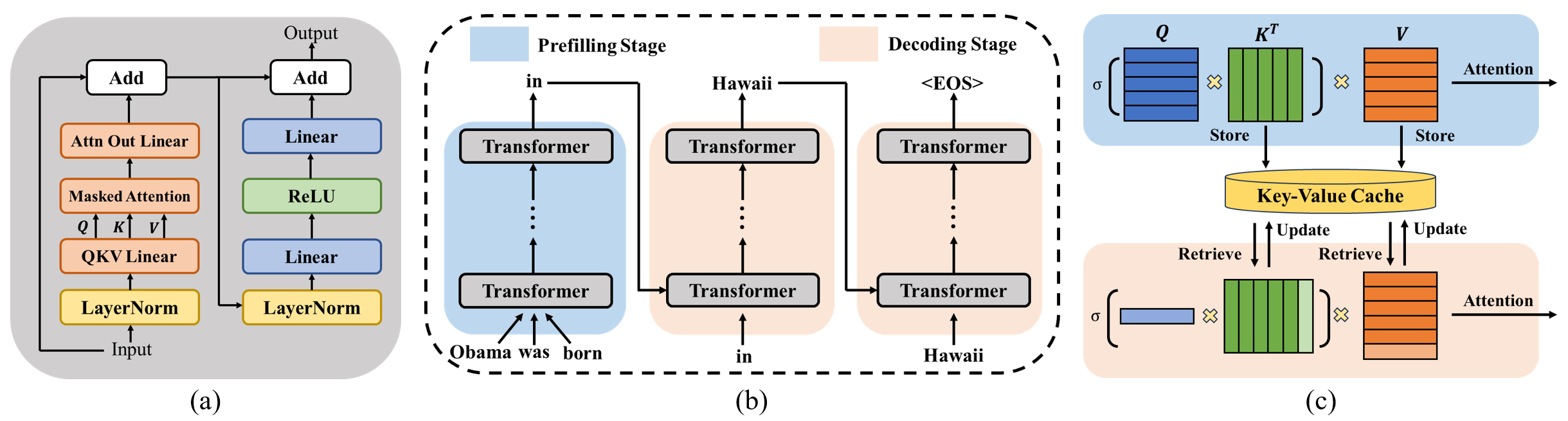 |
论文 |
| EPIC:用于大语言模型推理服务的高效位置无关上下文缓存 Junhao Hu, Wenrui Huang, Haoyi Wang, Weidong Wang, Tiancheng Hu, Qin Zhang, Hao Feng, Xusheng Chen, Yizhou Shan, Tao Xie |
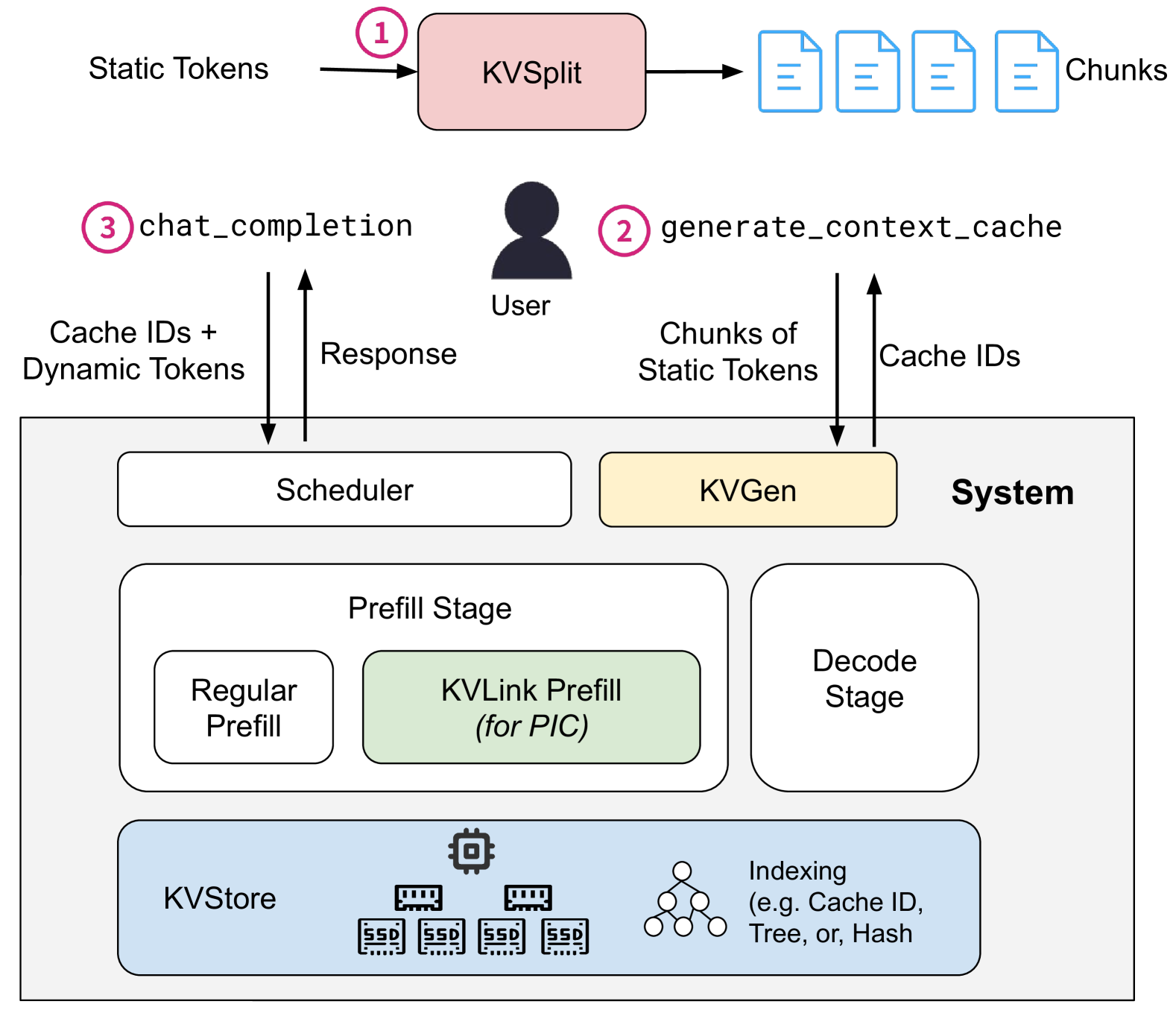 |
论文 |
SDP4Bit:迈向LLM训练中分片数据并行的4位通信量化 Jinda Jia, Cong Xie, Hanlin Lu, Daoce Wang, Hao Feng, Chengming Zhang, Baixi Sun, Haibin Lin, Zhi Zhang, Xin Liu, Dingwen Tao |
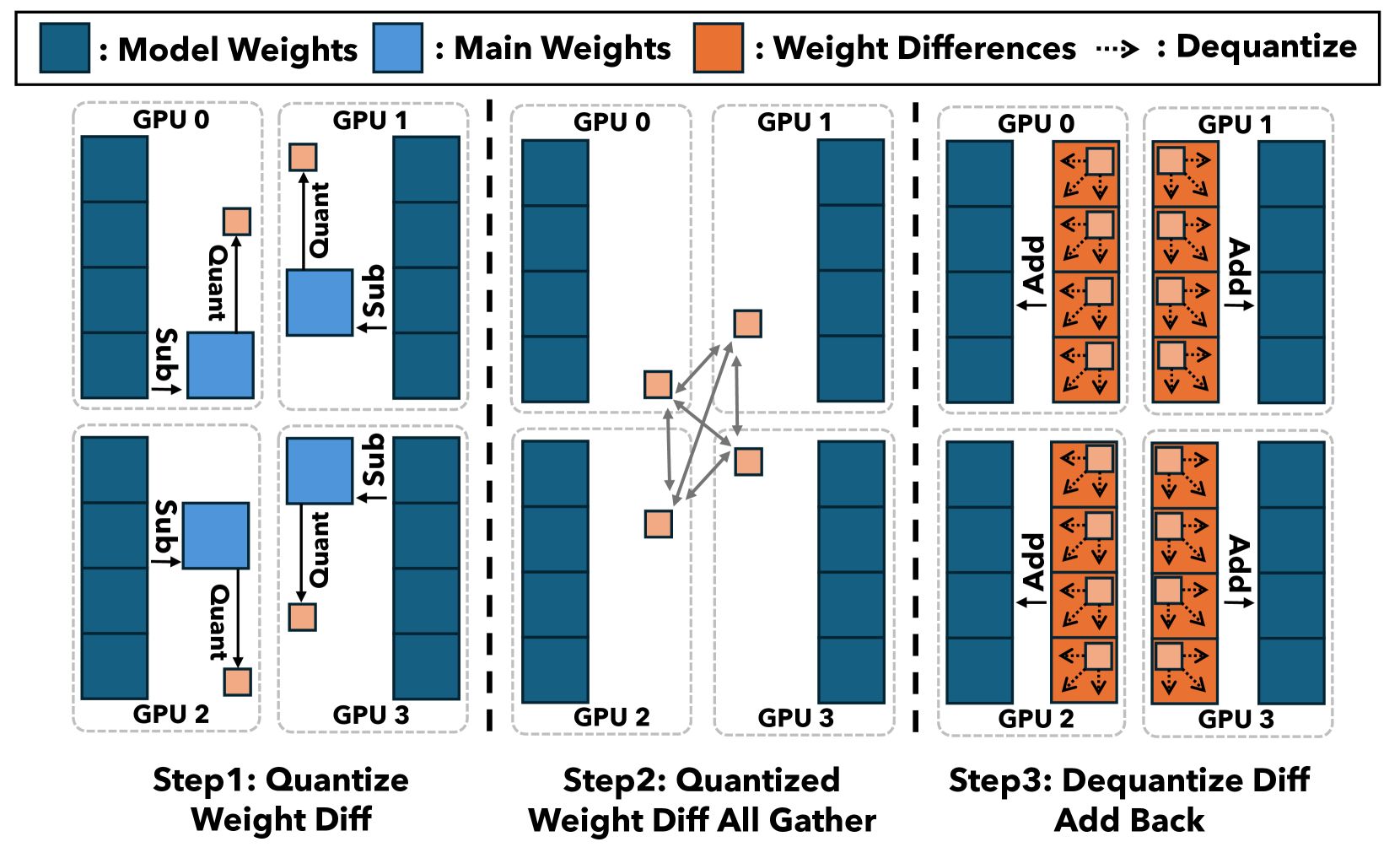 |
论文 |
| FastAttention:将FlashAttention2扩展到NPU和低资源GPU Haoran Lin, Xianzhi Yu, Kang Zhao, Lu Hou, Zongyuan Zhan等 |
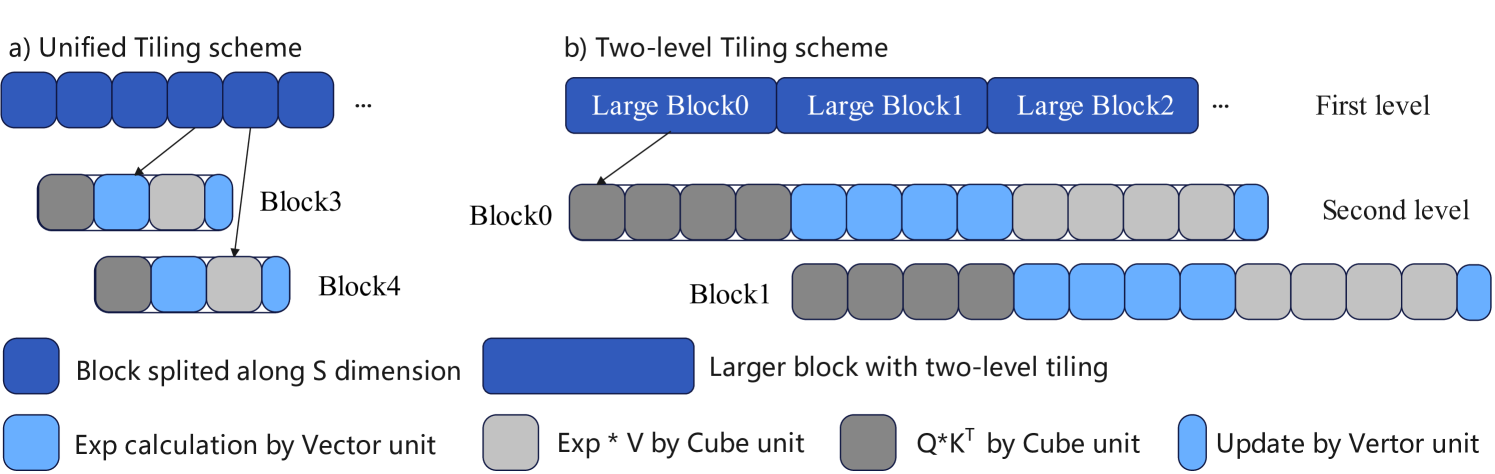 |
论文 |
| POD-Attention:解锁完整的预填充-解码重叠以加速LLM推理 Aditya K Kamath, Ramya Prabhu, Jayashree Mohan, Simon Peter, Ramachandran Ramjee, Ashish Panwar |
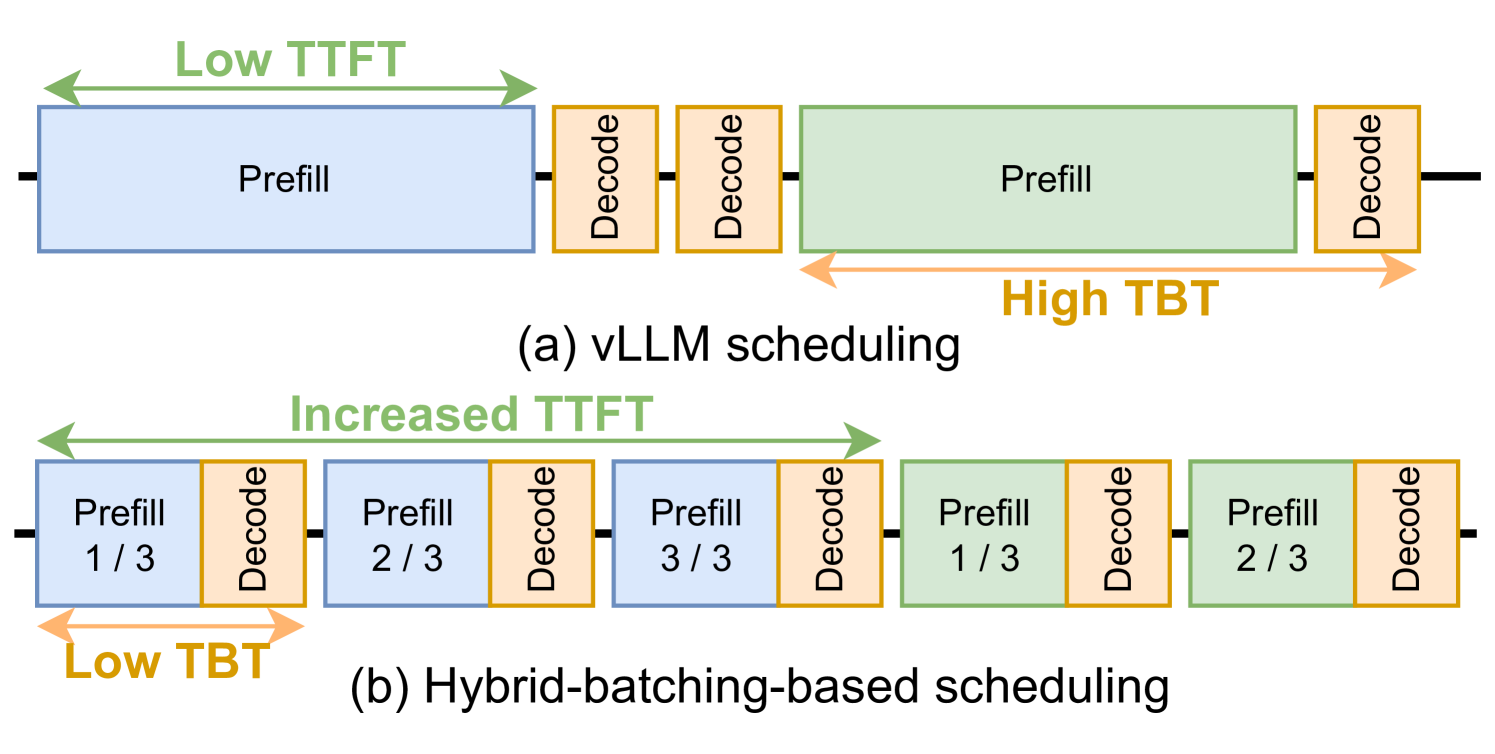 |
论文 |
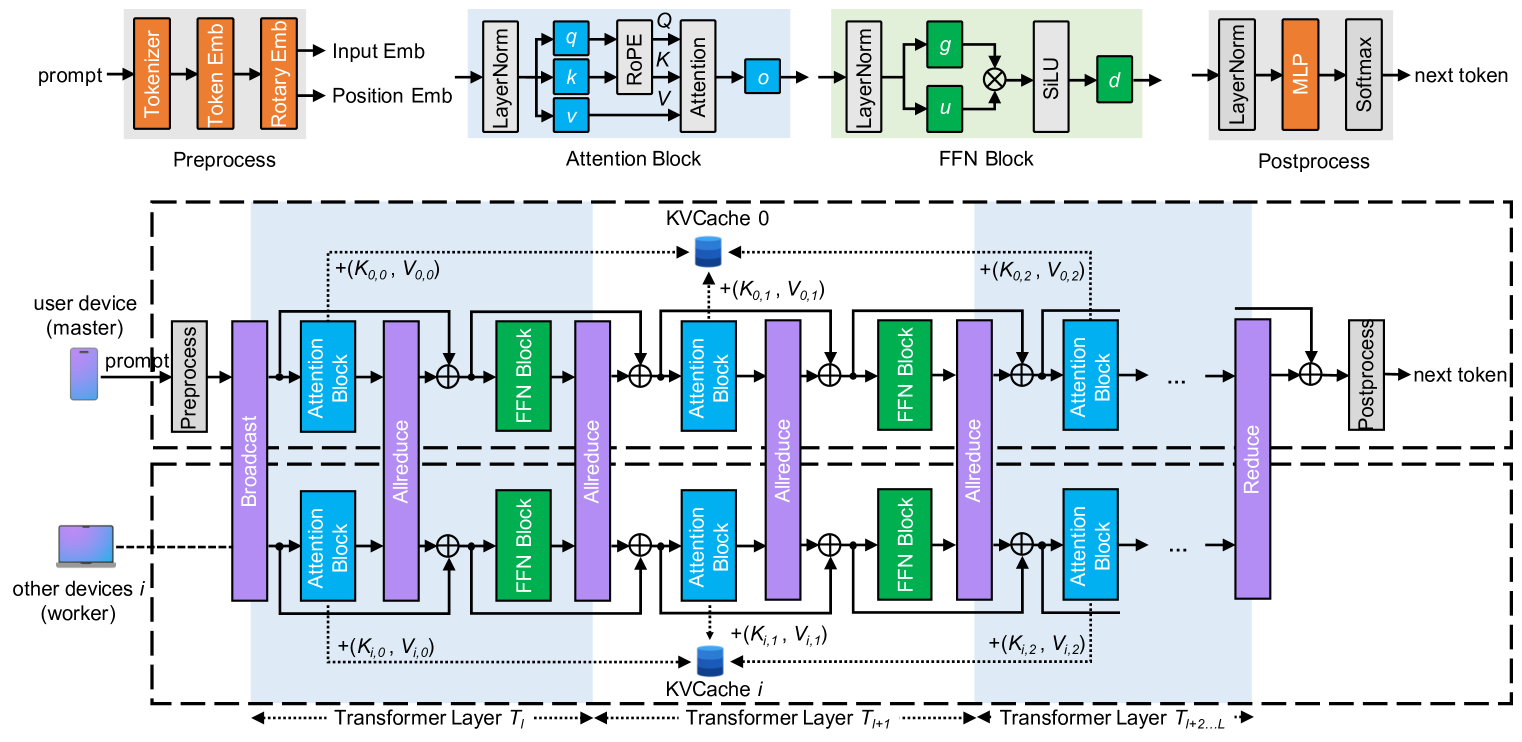
 TPI-LLM:在低资源边缘设备上高效服务70B规模的LLM Zonghang Li, Wenjiao Feng, Mohsen Guizani, Hongfang Yu |
 |
Github 论文 |
高效微调
| 标题与作者 | 简介 | 链接 |
|---|---|---|
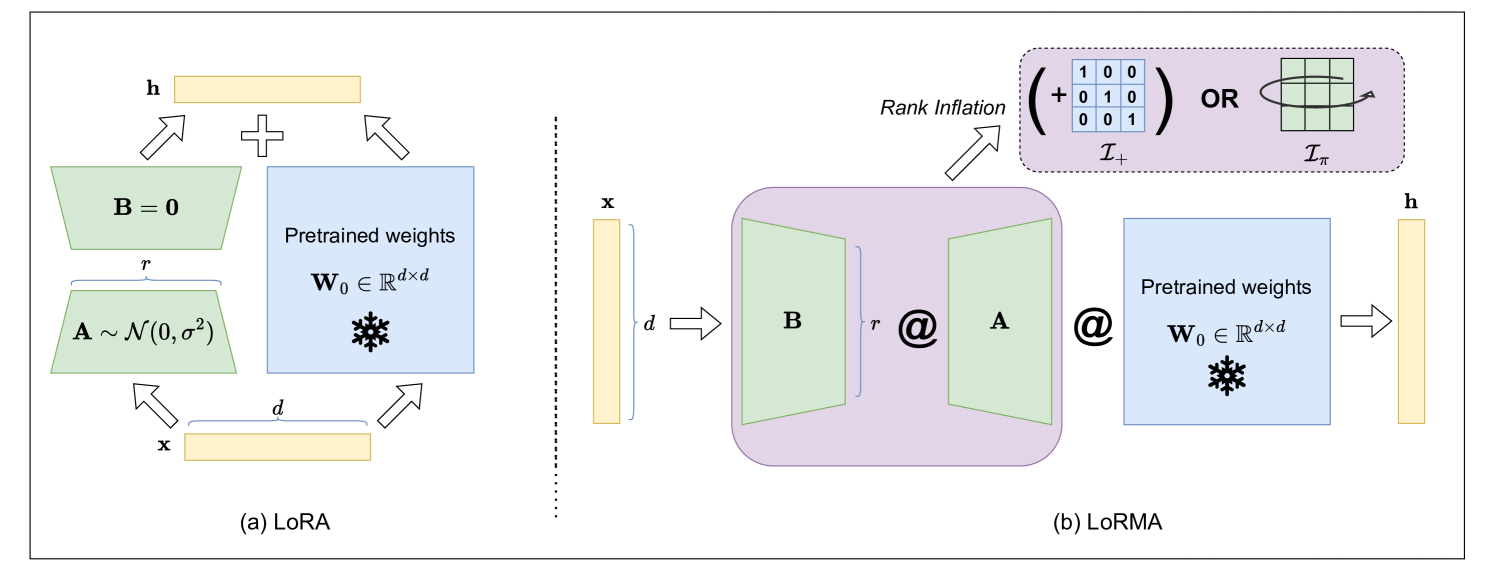
LoRMA:用于大语言模型的低秩乘法适配 Harsh Bihany, Shubham Patel, Ashutosh Modi |
 |
论文 |
| HELENE:利用二阶优化加速大语言模型微调的海森矩阵分层裁剪与梯度退火 Huaqin Zhao, Jiaxi Li, Yi Pan, Shizhe Liang, Xiaofeng Yang, Wei Liu, Xiang Li, Fei Dou, Tianming Liu, Jin Lu |
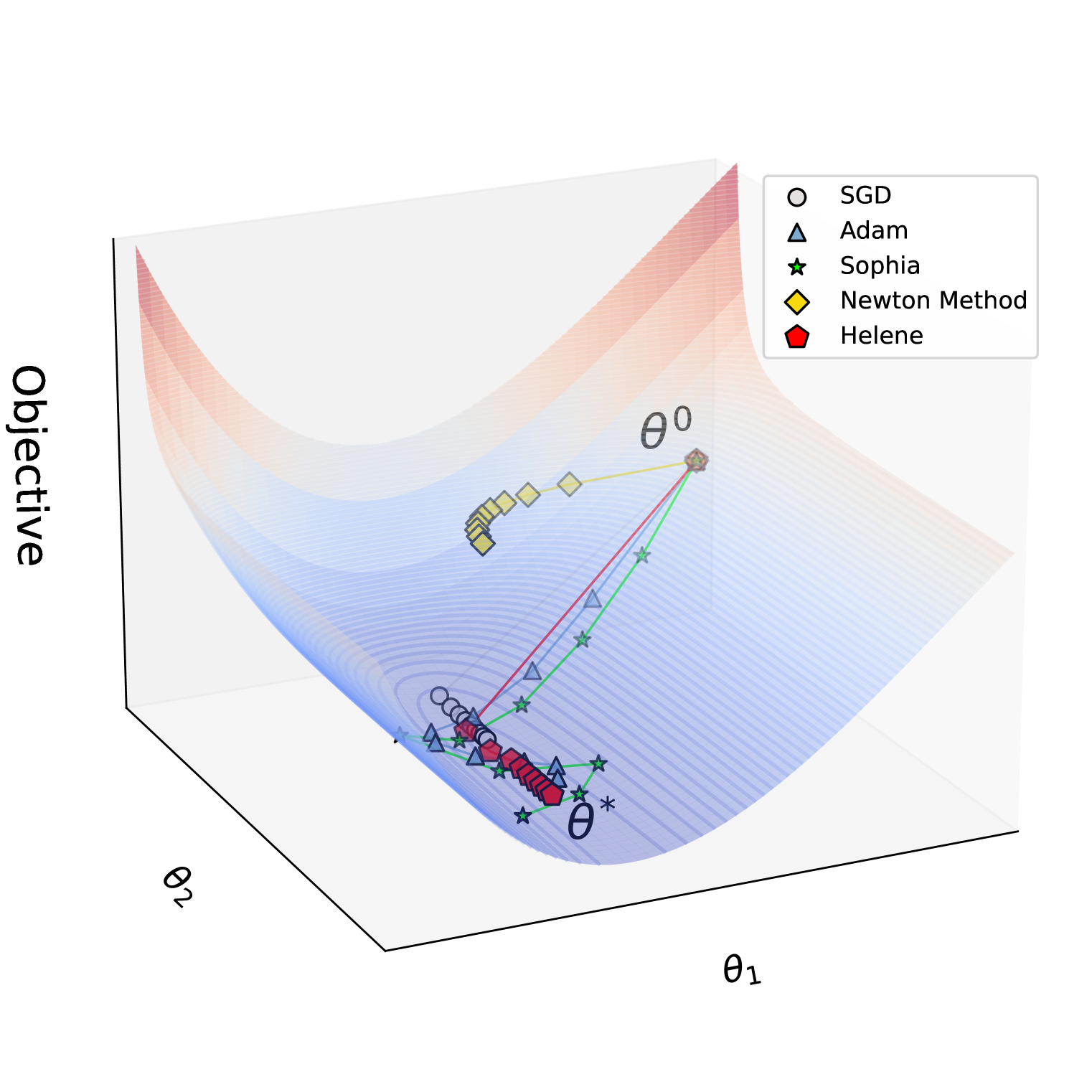 |
论文 |
 基于贝叶斯重参数化的低秩适配实现鲁棒高效的大语言模型微调 Ayan Sengupta, Vaibhav Seth, Arinjay Pathak, Natraj Raman, Sriram Gopalakrishnan, Tanmoy Chakraborty |
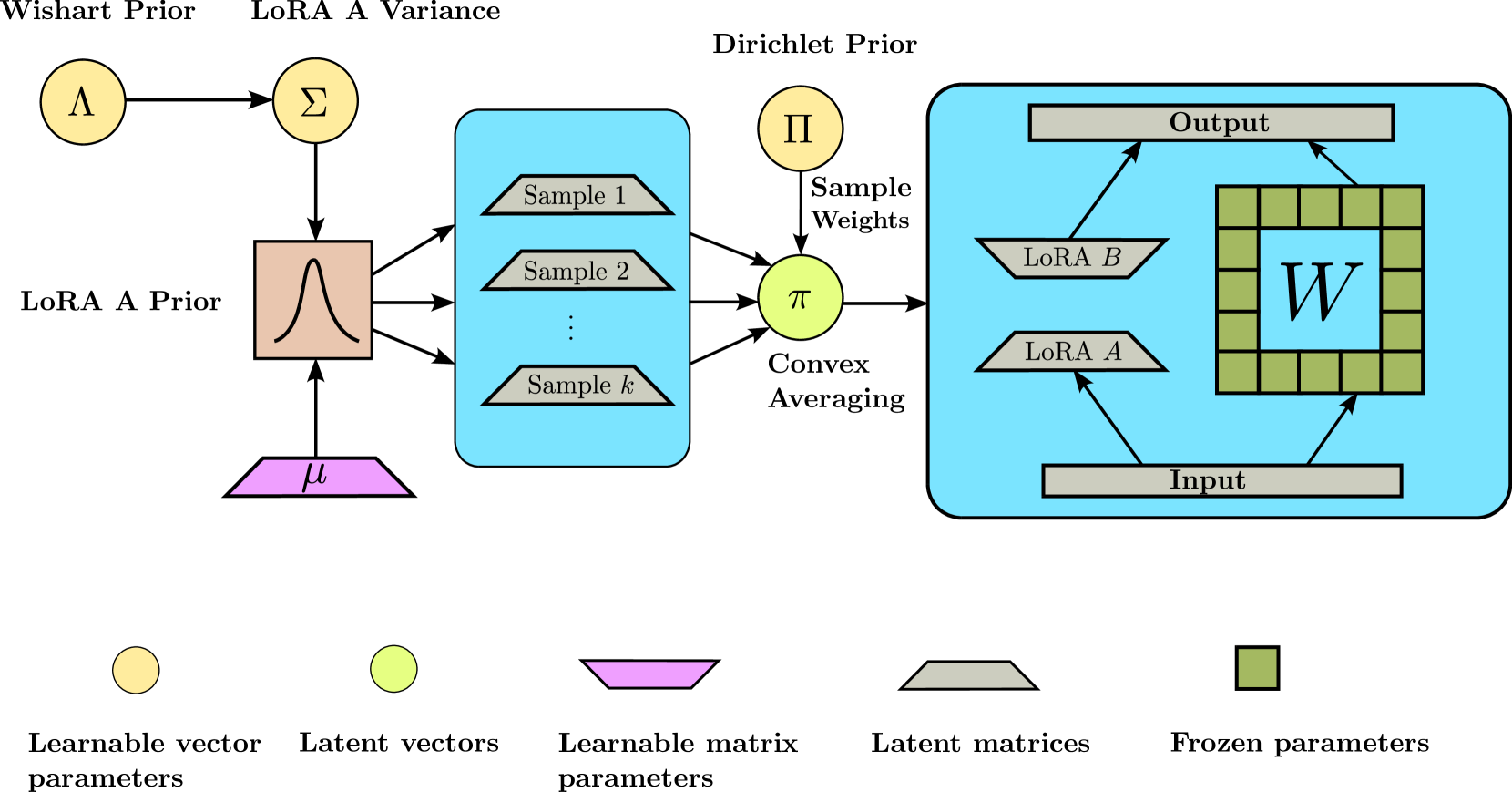 |
Github 论文 |
Natural GaLore:加速GaLore以实现内存高效的大语言模型训练和微调 Arijit Das |
Github 论文 |
|
| 少即是多:用于高效微调大语言模型的极端梯度提升秩1适配 Yifei Zhang, Hao Zhu, Aiwei Liu, Han Yu, Piotr Koniusz, Irwin King |
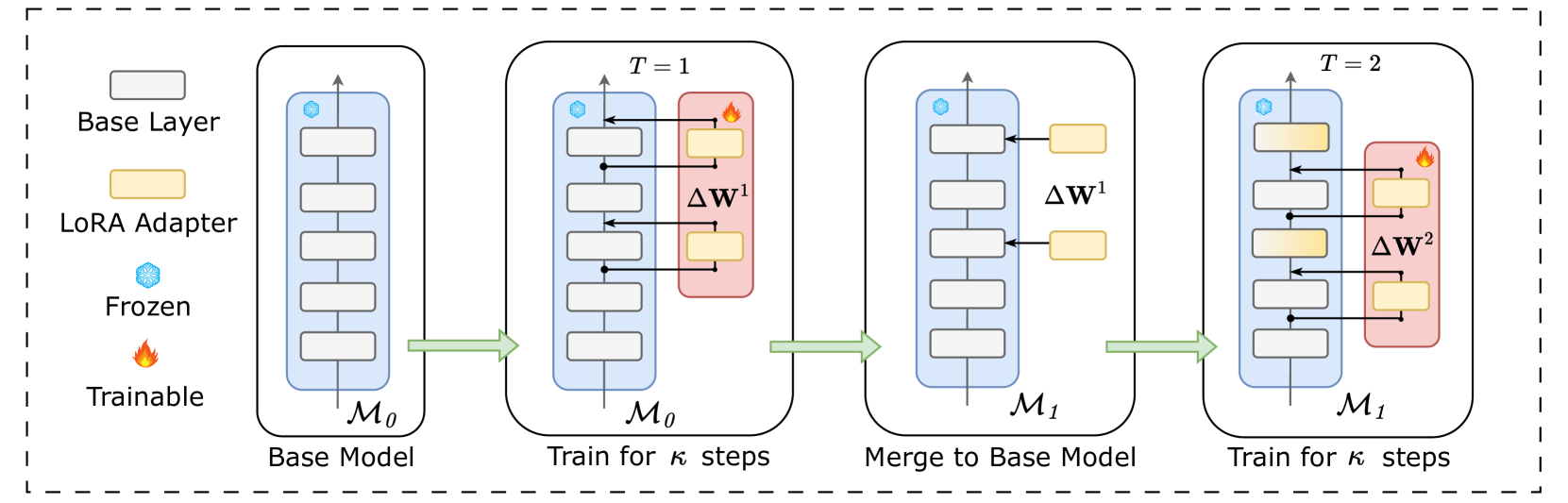 |
论文 |
MiLoRA:用于大语言模型微调的高效低秩适配混合方法 Jingfan Zhang, Yi Zhao, Dan Chen, Xing Tian, Huanran Zheng, Wei Zhu |
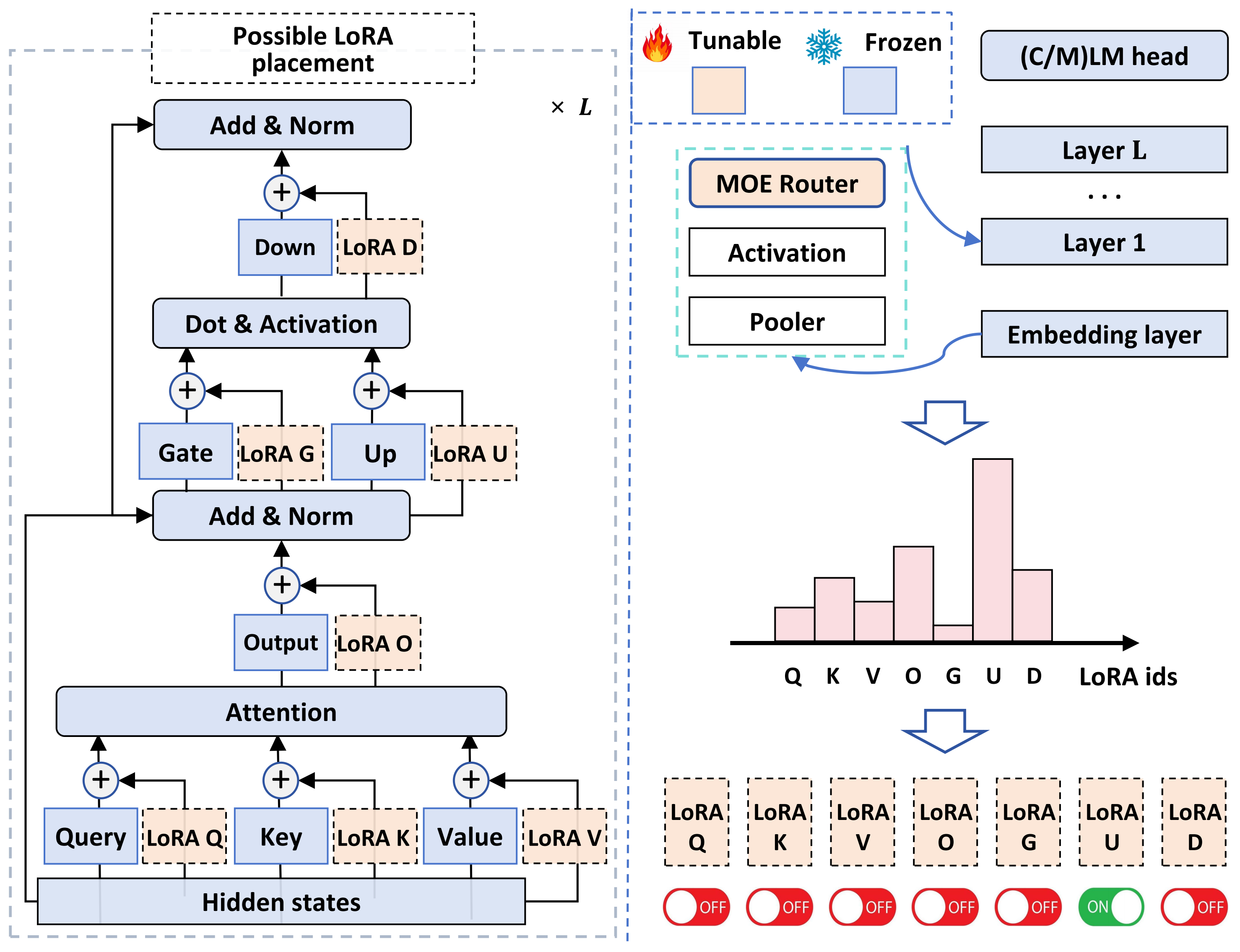 |
论文 |
 RoCoFT:通过行-列更新实现大语言模型的高效微调 Md Kowsher, Tara Esmaeilbeig, Chun-Nam Yu, Mojtaba Soltanalian, Niloofar Yousefi |
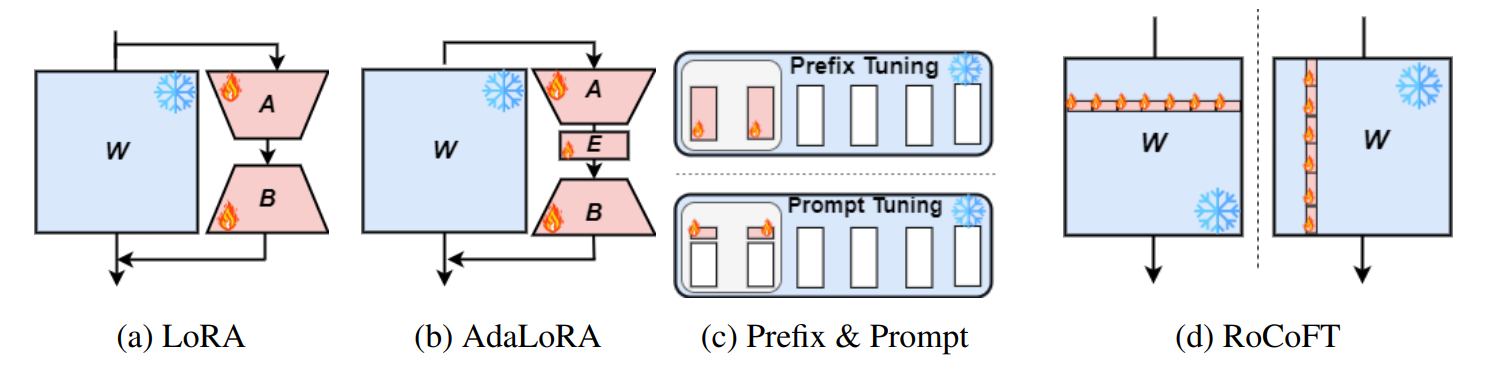 |
Github 论文 |
 层间重要性至关重要:在大语言模型的参数高效微调中用更少的内存获得更好的性能 Kai Yao, Penlei Gao, Lichun Li, Yuan Zhao, Xiaofeng Wang, Wei Wang, Jianke Zhu |
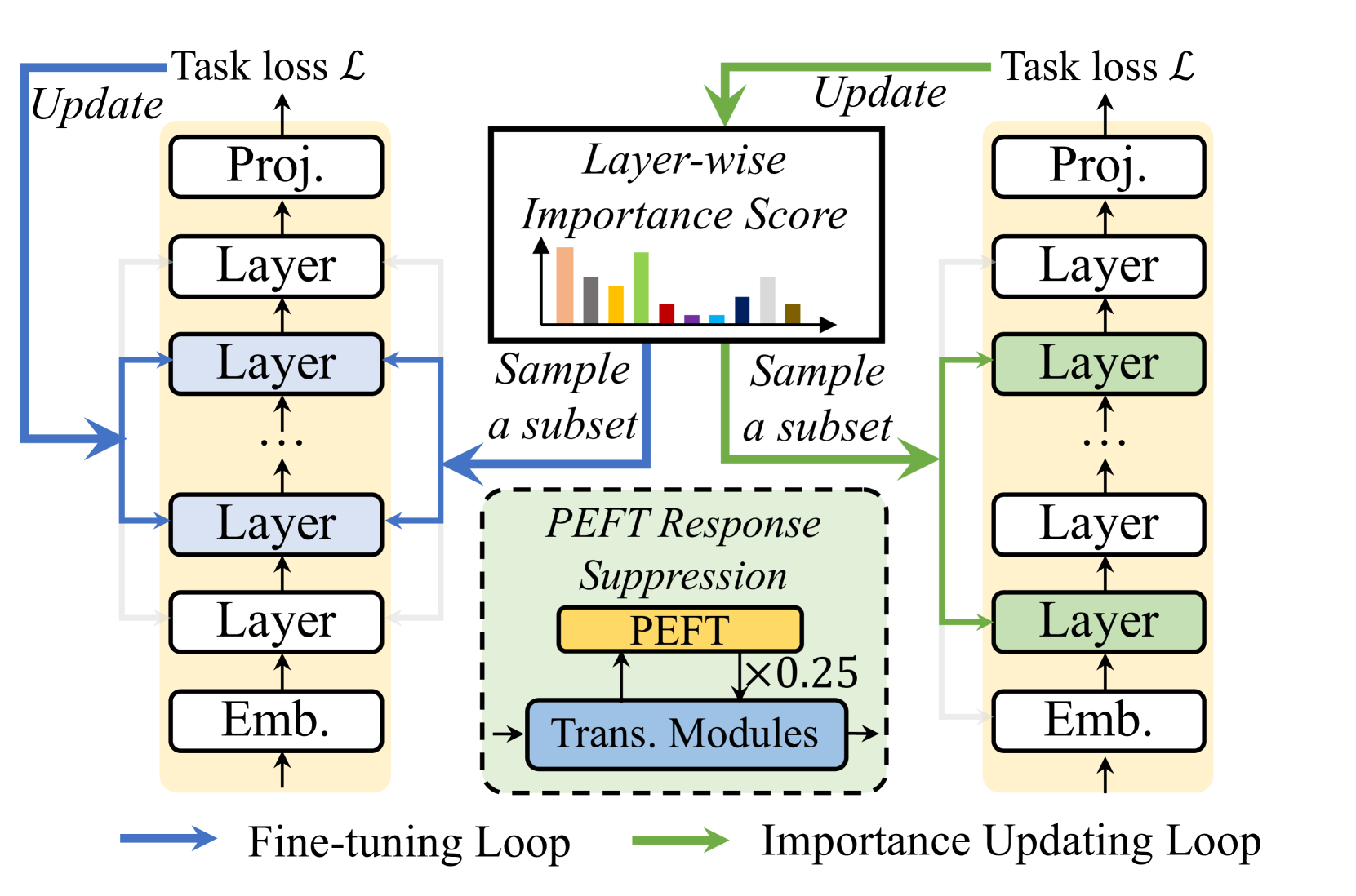 |
Github 论文 |
利用语义知识调优进行大语言模型的参数高效微调 Nusrat Jahan Prottasha, Asif Mahmud, Md. Shohanur Islam Sobuj, Prakash Bhat, Md Kowsher, Niloofar Yousefi, Ozlem Ozmen Garibay |
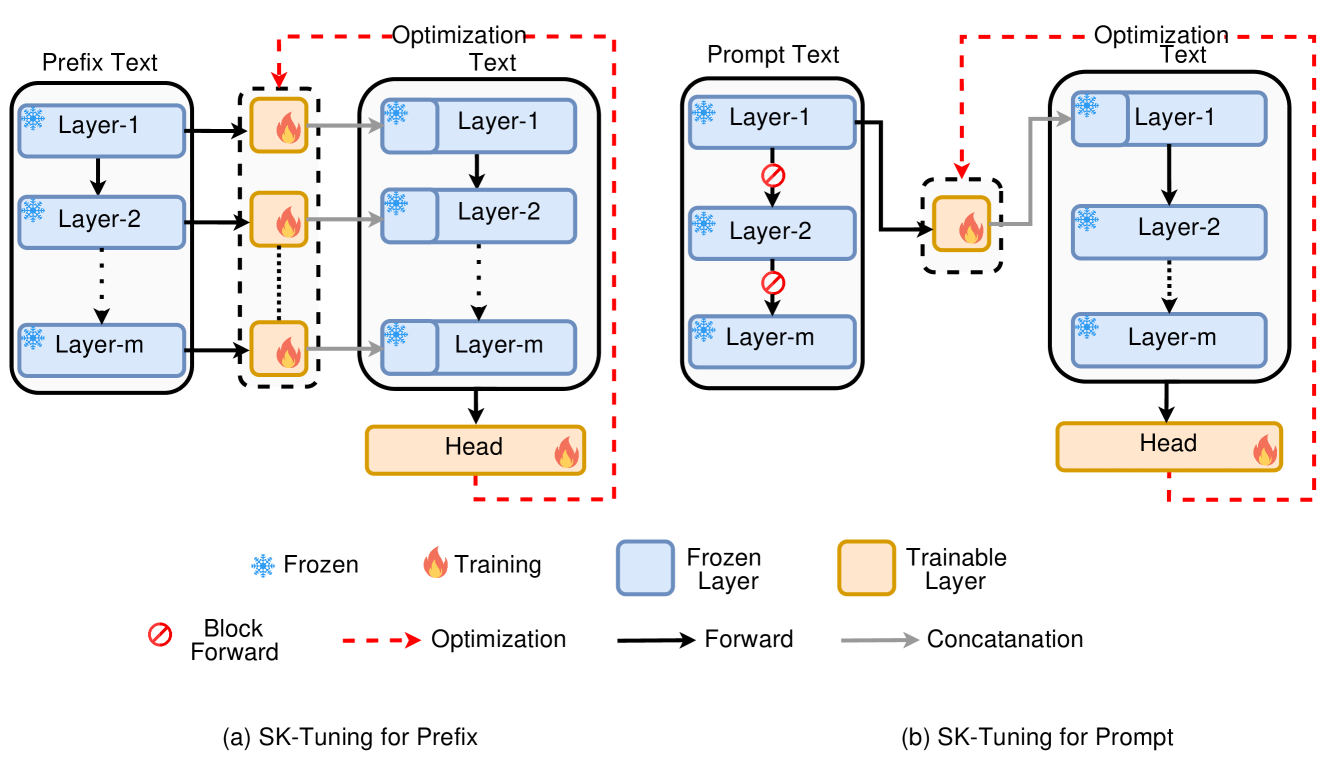 |
论文 |
 QEFT:用于高效微调大语言模型的量化方法 Changhun Lee, Jun-gyu Jin, Younghyun Cho, Eunhyeok Park |
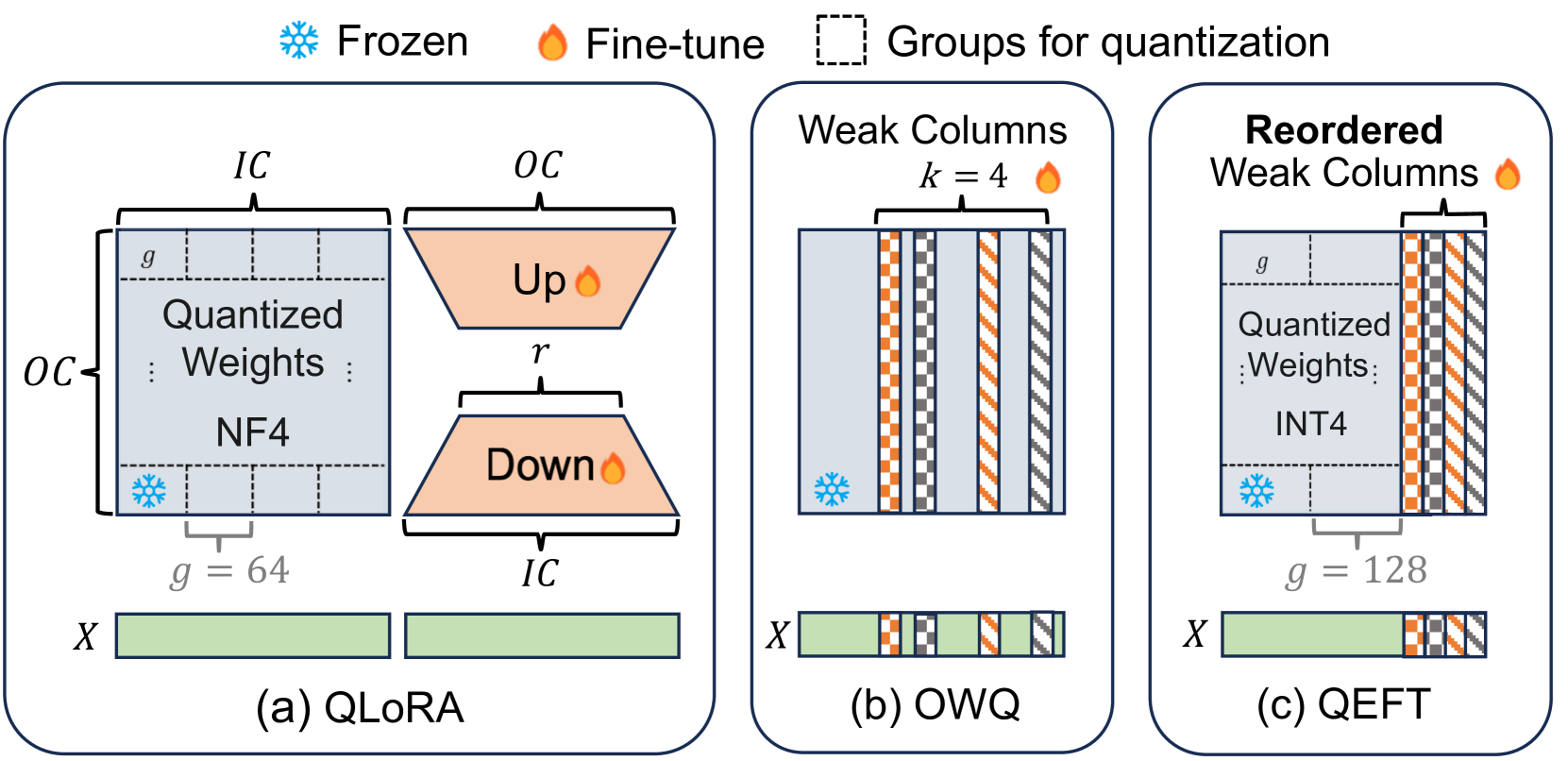 |
Github 论文 |
 BIPEFT:基于预算指导的迭代搜索,用于大型预训练语言模型的参数高效微调 Aofei Chang, Jiaqi Wang, Han Liu, Parminder Bhatia, Cao Xiao, Ting Wang, Fenglong Ma |
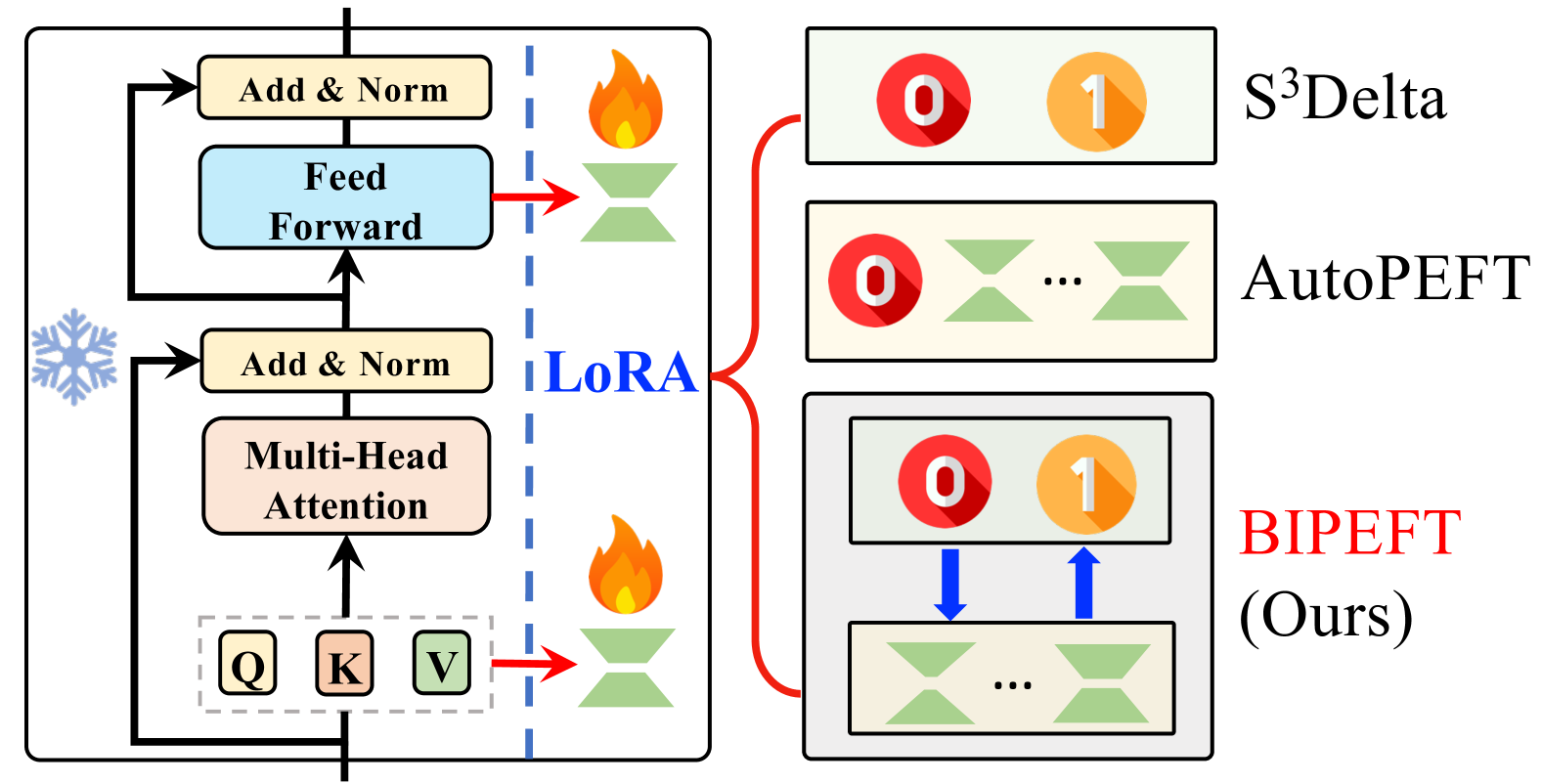 |
Github 论文 |
 SparseGrad:一种选择性方法,用于高效微调MLP层 Viktoriia Chekalina, Anna Rudenko, Gleb Mezentsev, Alexander Mikhalev, Alexander Panchenko, Ivan Oseledets |
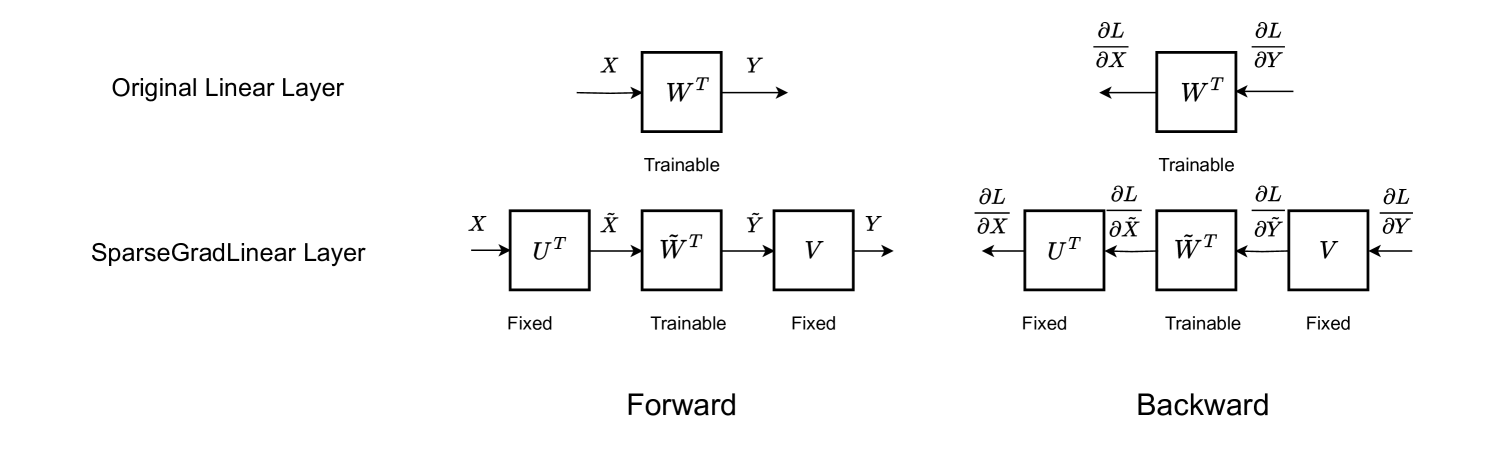 |
Github 论文 |
| SpaLLM:利用草图技术实现大语言模型的统一压缩适配 Tianyi Zhang, Junda Su, Oscar Wu, Zhaozhuo Xu, Anshumali Shrivastava |
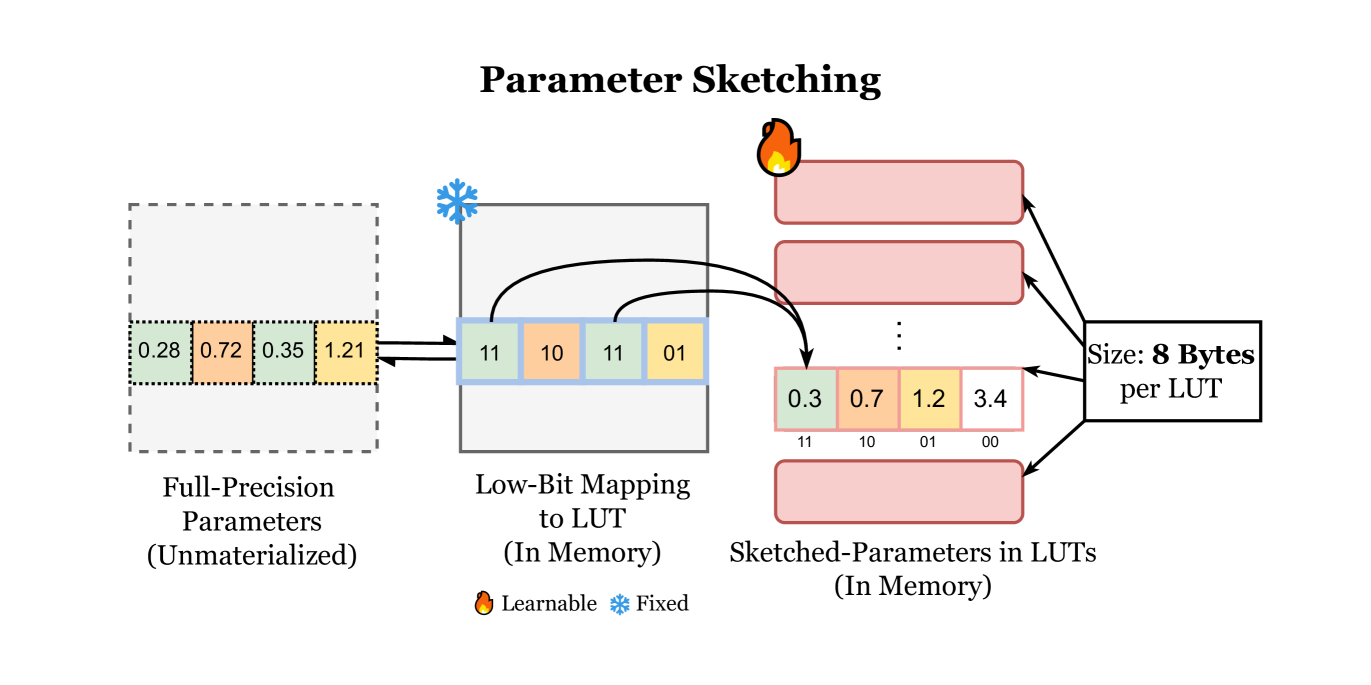 |
论文 |
高效训练
| 标题与作者 | 简介 | 链接 |
|---|---|---|
 LayerDropBack:一种通用的加速深度网络训练方法 Evgeny Hershkovitch Neiterman, Gil Ben-Artzi |
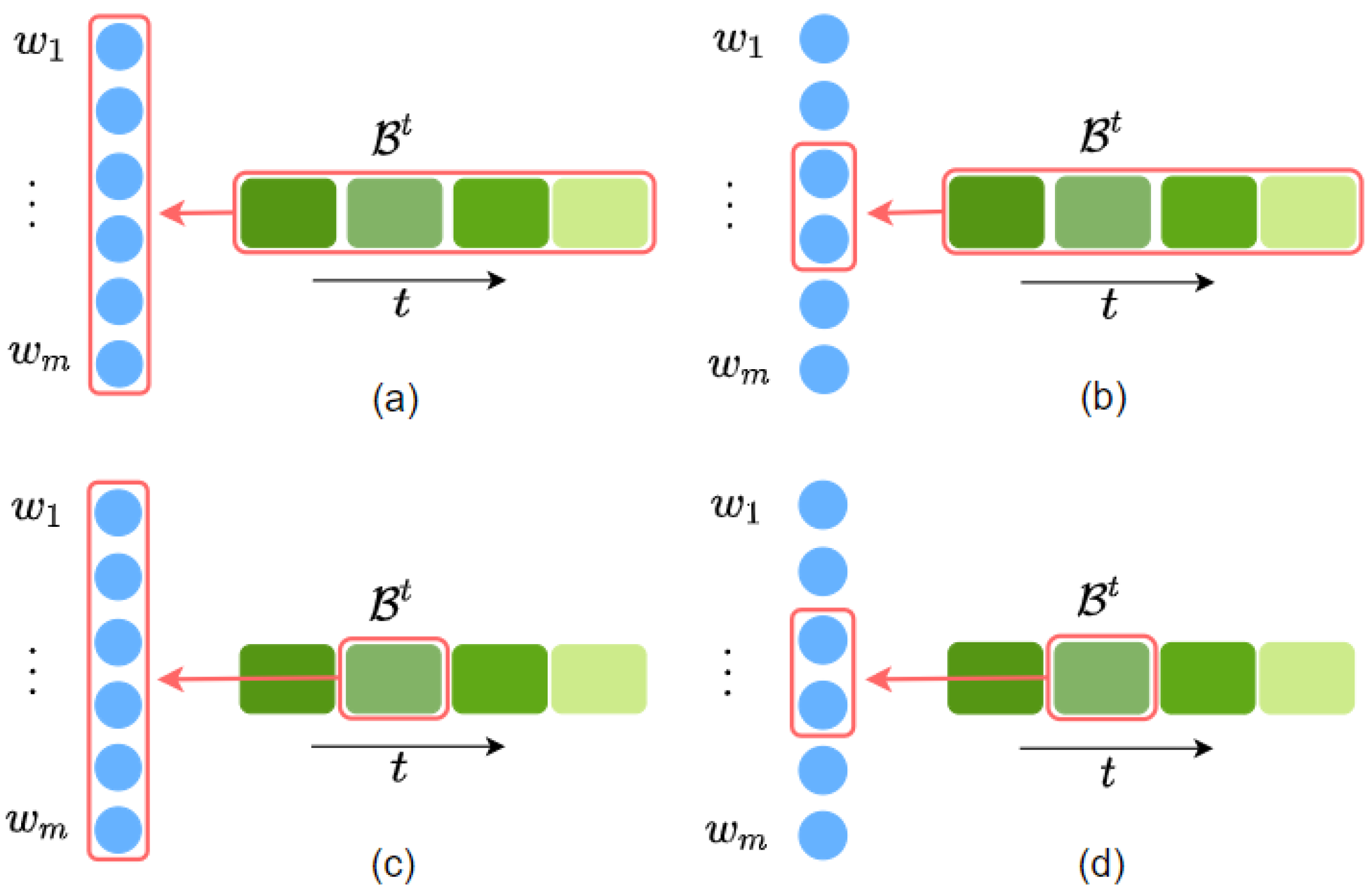 |
Github 论文 |
| AutoMixQ:用于高性能、内存高效的微调的自适应量化 Changhai Zhou, Shiyang Zhang, Yuhua Zhou, Zekai Liu, Shichao Weng |
 |
论文 |
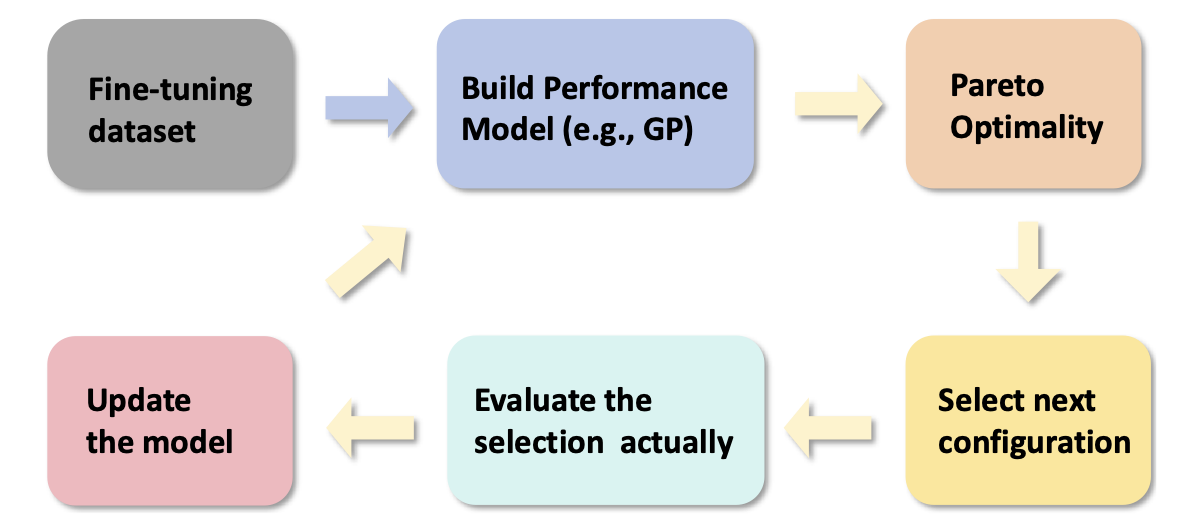
 基于低维投影注意力的大规模语言模型可扩展高效训练 Xingtai Lv, Ning Ding, Kaiyan Zhang, Ermo Hua, Ganqu Cui, Bowen Zhou |
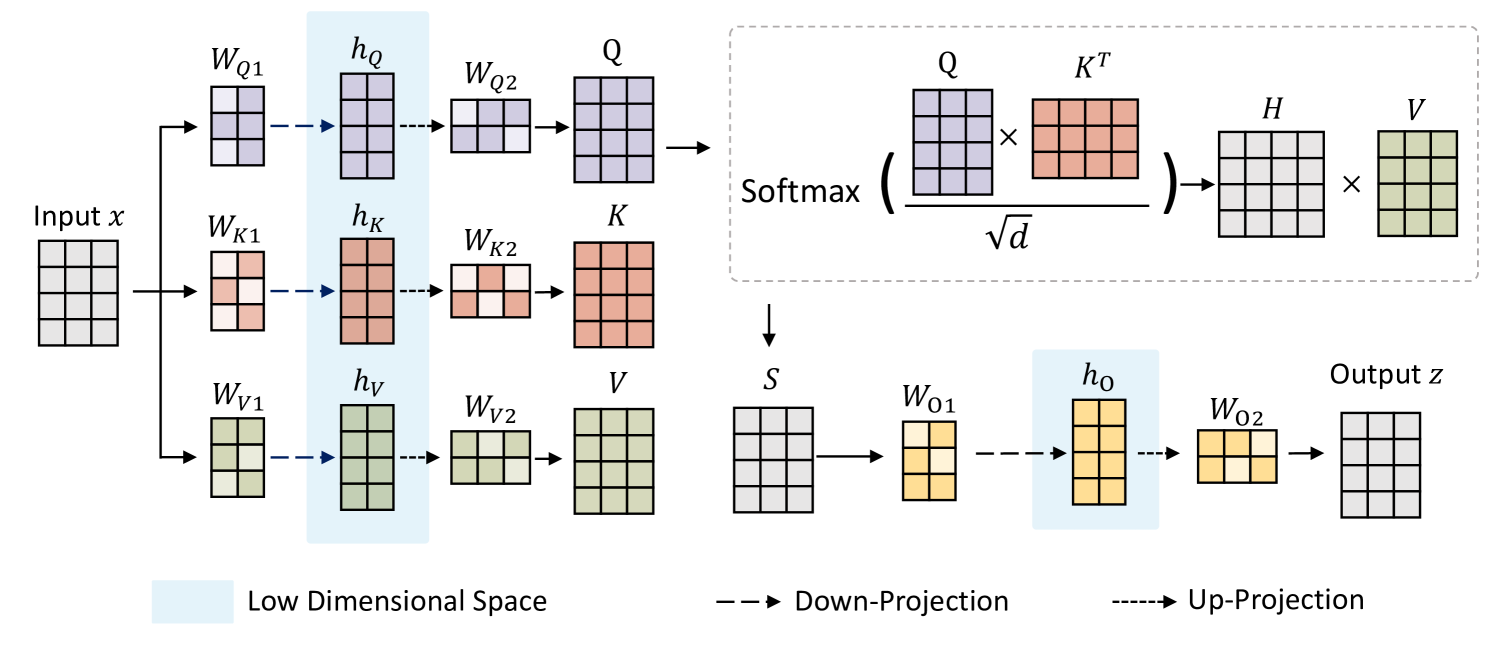 |
Github 论文 |
 COAT:用于内存高效FP8训练的优化器状态与激活压缩 Haocheng Xi, Han Cai, Ligeng Zhu, Yao Lu, Kurt Keutzer, Jianfei Chen, Song Han |
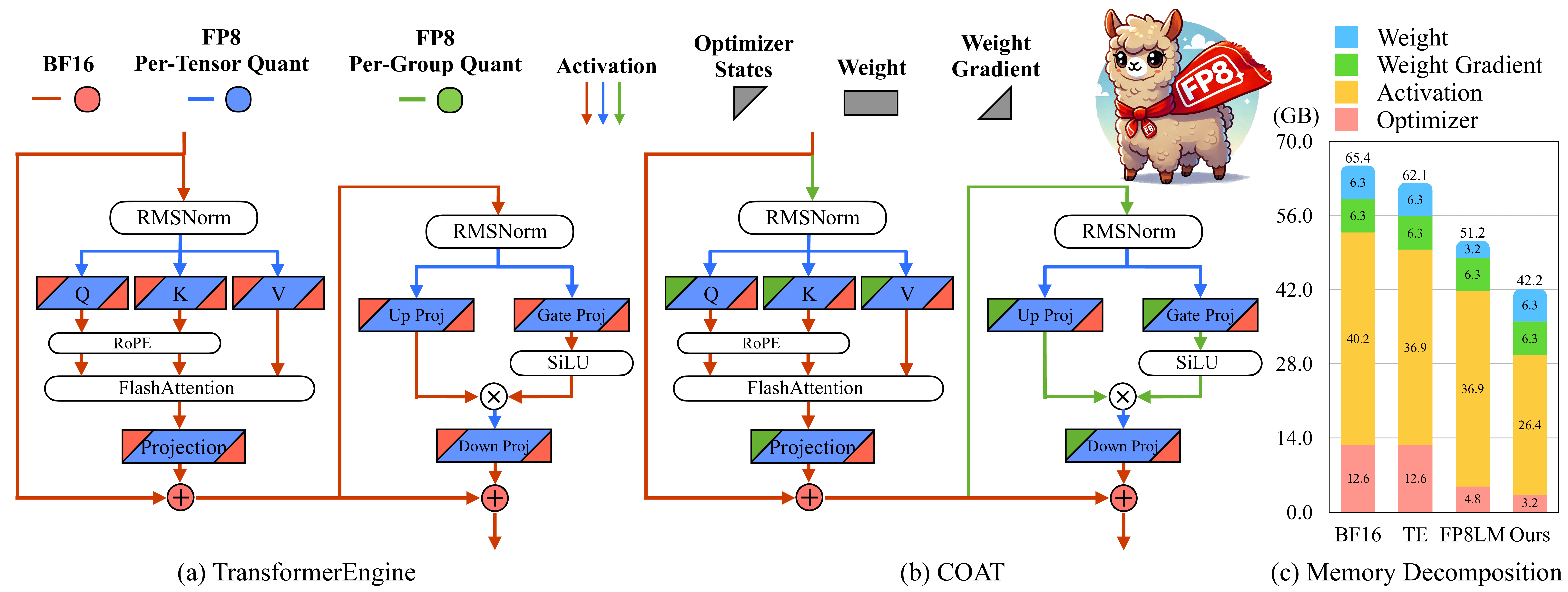 |
Github 论文 |
 BitPipe:用于加速大模型训练的双向交错流水线并行 Houming Wu, Ling Chen, Wenjie Yu |
 |
Github 论文 |
Natural GaLore:加速GaLore以实现内存高效的LLM训练和微调 Arijit Das |
Github 论文 |
|
| CompAct:用于内存高效LLM训练的压缩激活 Yara Shamshoum, Nitzan Hodos, Yuval Sieradzki, Assaf Schuster |
|
论文 |
综述(或基准测试)
| 标题与作者 | 简介 | 链接 |
|---|---|---|
| 深入探讨高效推理方法:推测解码综述 Hyun Ryu, Eric Kim |
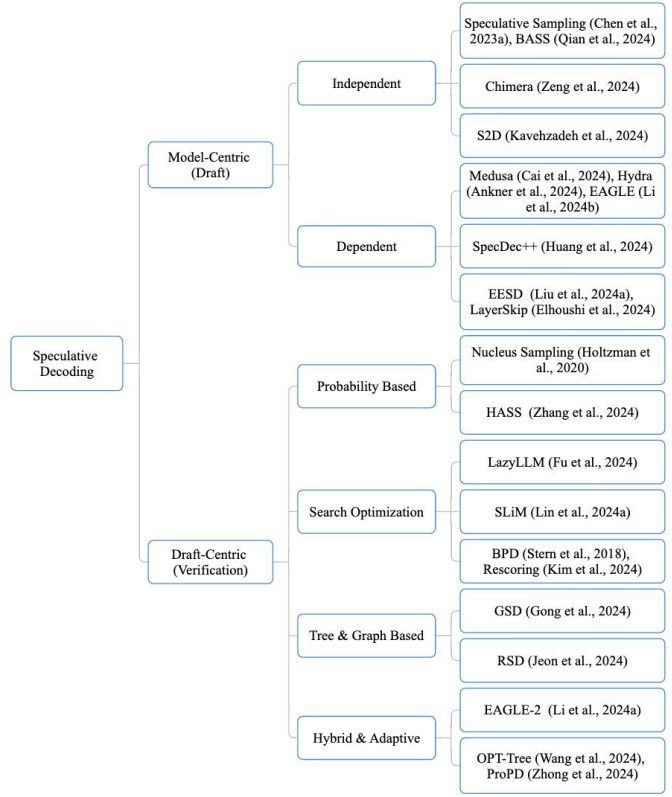 |
论文 |
 LLM-Inference-Bench:AI加速器上大型语言模型的推理基准测试 Krishna Teja Chitty-Venkata, Siddhisanket Raskar, Bharat Kale, Farah Ferdaus等 |
Github 论文 |
|
 大型语言模型中的提示压缩:综述 Zongqian Li, Yinhong Liu, Yixuan Su, Nigel Collier |
 |
Github 论文 |
| 大型语言模型推理加速:全面的硬件视角 Jinhao Li, Jiaming Xu, Shan Huang, Yonghua Chen, Wen Li, Jun Liu, Yaoxiu Lian, Jiayi Pan, Li Ding, Hao Zhou, Guohao Dai |
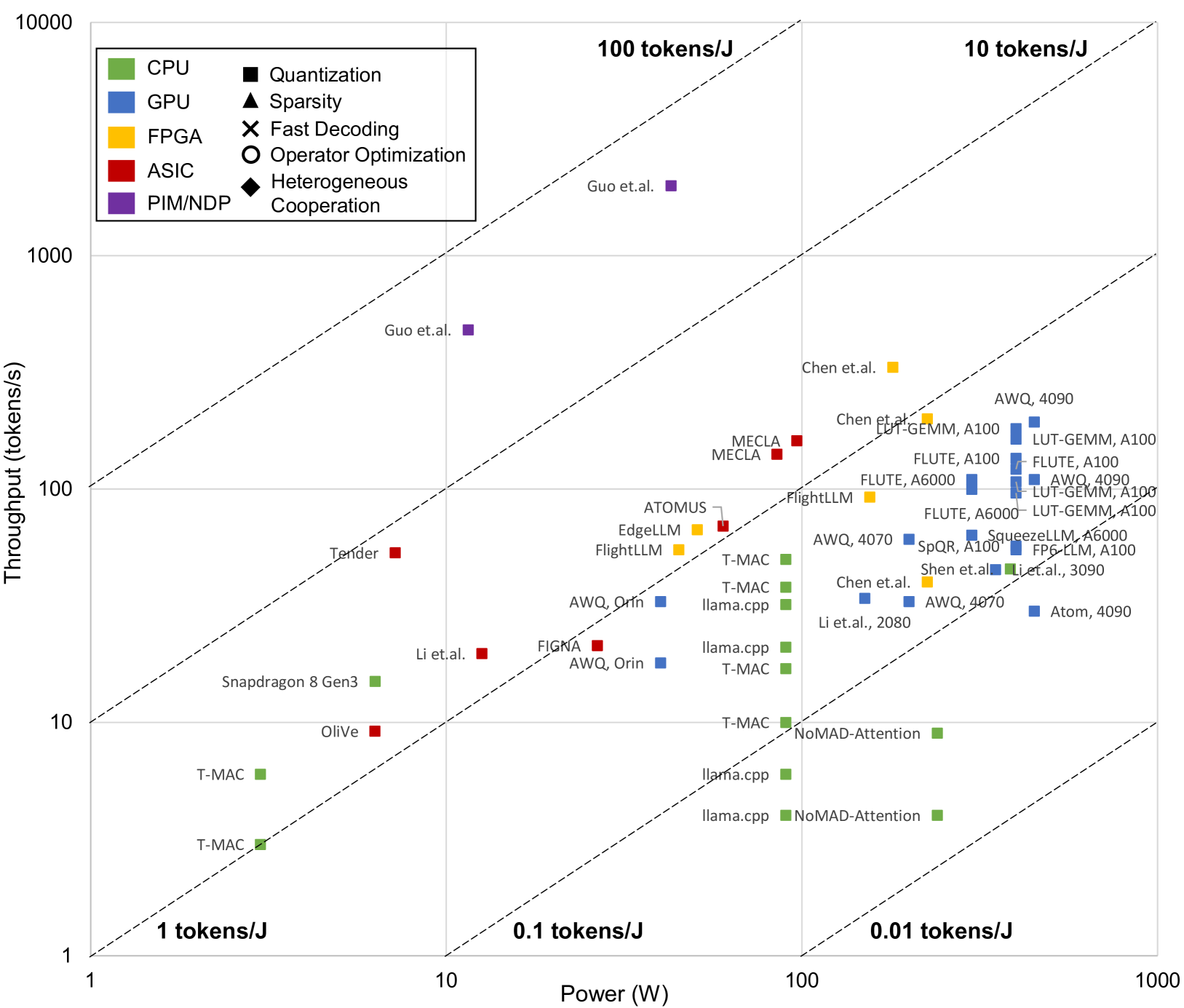 |
论文 |
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。