seq2seq-signal-prediction
seq2seq-signal-prediction 是一个基于 TensorFlow 构建的开源教学项目,旨在帮助开发者掌握如何使用序列到序列(seq2seq)循环神经网络(RNN)进行时间序列信号预测。该项目通过四个难度递增的实战练习,引导用户从基础的多维信号预测入手,逐步挑战更复杂的波形叠加预测任务,最终理解编码器 - 解码器架构的核心原理。
它主要解决了初学者在学习深度学习时序预测时缺乏系统性代码实践的问题。不同于仅提供理论讲解的资料,seq2seq-signal-prediction 提供了完整的 Jupyter Notebook 环境和 Google Colab 支持,让用户能够直接运行、修改并观察模型超参数及架构变化对预测结果的影响。其独特的技术亮点在于将抽象的 seq2seq 模型具象化为可视化的信号预测任务,并涵盖了多维数据联合预测(如同时预测多种股票或货币走势)的实际应用场景。
这款工具非常适合具有一定 RNN 基础知识、希望深入理解 seq2seq 架构内部机制的 AI 开发者、数据科学家及高校研究人员。对于想要从理论迈向实战,特别是关注自然语言处理(NLP)之外时序预测应用的工程师来说,这是一个极佳的入门与进阶资源。
使用场景
某量化交易团队正在开发一套加密货币多币种联动预测系统,需要基于历史数据同时预判比特币(BTC)对美元和欧元的未来汇率走势。
没有 seq2seq-signal-prediction 时
- 多变量关联建模困难:传统单输出模型难以捕捉 USD/BTC 与 EUR/BTC 两条时间序列之间复杂的动态耦合关系,往往只能单独预测,忽略了币种间的联动效应。
- 长序列依赖丢失:使用简单的回归方法无法有效记忆长期的历史波动模式,导致在面对具有周期性或长滞后特征的市场信号时,预测结果严重失真。
- 架构调整成本高昂:每当需要处理不同长度或复杂度的信号组合时,开发人员必须从头重写大量底层 TensorFlow 代码来调整网络结构,试错周期极长。
- 缺乏确定性基准验证:在没有类似 Exercise 1 这样的确定性信号练习作为基准的情况下,团队难以判断模型是未收敛还是架构本身存在缺陷,调试方向模糊。
使用 seq2seq-signal-prediction 后
- 原生支持多维序列输出:利用其 Encoder-Decoder 架构,轻松实现输入过去多币种数据、同时输出未来多条关联曲线的功能,精准捕捉汇率间的协同变化。
- 强大的时序特征提取:基于 RNN 的序列到序列机制有效保留了长短期记忆,即使面对叠加了不同波长和偏移量的复杂正弦波信号(如 Exercise 2),也能还原出平滑准确的趋势。
- 模块化实验流程:直接复用项目中预设的四个渐进式练习框架,只需修改超参数或少量架构代码即可适配新场景,将模型迭代时间从数天缩短至数小时。
- 可视化调试直观:借助项目自带的图表生成逻辑,清晰对比“已知历史”与“黄色预测区”,快速定位模型在特定波形下的表现瓶颈,大幅降低调优门槛。
seq2seq-signal-prediction 通过成熟的编码器 - 解码器范式,将复杂的多变量时间序列预测转化为可快速迭代的标准工程任务,显著提升了量化策略的研发效率。
运行环境要求
- 未说明
可选(推荐用于加速),需安装 tensorflow-gpu==2.1,具体显卡型号和显存大小未说明
未说明
快速开始
用于时间序列预测的序列到序列(seq2seq)循环神经网络(RNN)
注:您可以在此处找到配套的seq2seq RNN 预测演示文稿幻灯片,以及用于运行本笔记本的 Google Colab 文件(如果您尚未在 Colab 中)。
这是一系列练习,您可以尝试解决这些练习来学习如何编写编码器-解码器结构的序列到序列循环神经网络(seq2seq RNN)。您可以通过解决不同的简单玩具信号预测问题来实践。Seq2seq 架构也可用于其他更复杂的应用场景,例如自然语言处理(NLP)。
本项目提供了 4 个难度逐步递增的练习。我假定您至少对 RNN 的工作原理及其如何构建为最简单的编码器-解码器 seq2seq 模型(不带注意力机制)有一定的了解。如需深入了解 TensorFlow 中的 RNN,您可以访问我为此专门构建的另一个 RNN 项目。
当前项目最初是用法语编写的示例系列,但由于时间有限,我没有重新生成所有带有正确英文文本的图表。该项目最初是我为在魁北克 Web 大会(WAQ)上主讲的一场大师班第三小时的实践部分而设计的,该课程于 2017 年 3 月首次举办。
如何使用此“.ipynb”Python 笔记本?
我在仓库中提供了本教程的“.py”Python 版本,但直接在笔记本或 Google Colab 中运行代码更为方便。
要运行笔记本,您可以在命令行中输入 jupyter-notebook 启动 Web 笔记本 IDE,并选择 .ipynb 文件。对于 Google Colab,如果您希望使用 GPU 运行代码,请确保依次点击“Runtime > Change Runtime Type”,并将“Python 3”的运行时类型设置为“GPU”。
练习
请注意,数据集会根据不同的练习而变化。大多数情况下,您需要调整神经网络的训练参数才能完成练习,但在某些阶段,则需要修改网络架构本身。本练习所使用的数据集位于 datasets.py 文件中。
练习 1
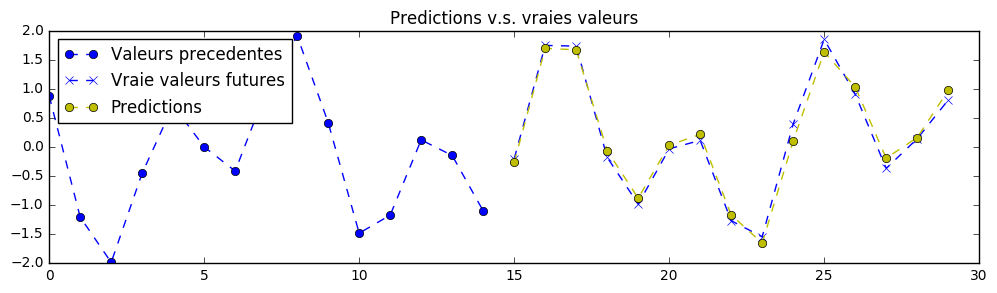
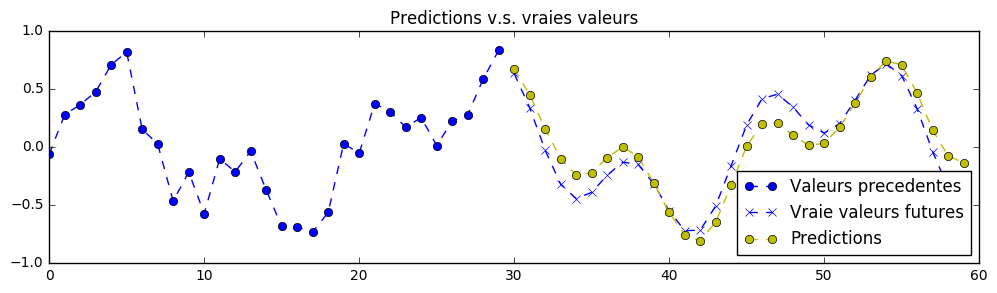
理论上,由于该练习中的信号是确定性的,因此可以实现完美的预测。神经网络的参数已设置为第一次训练时“勉强”可接受的值。您需要不断调整超参数,直到获得类似以下的预测结果:
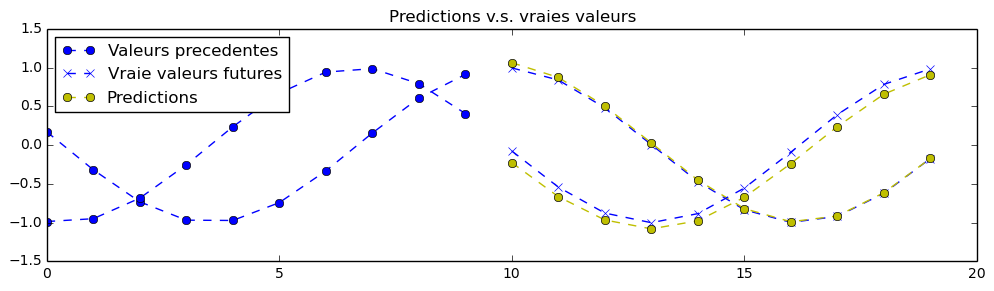
注意:神经网络仅能看到图表左侧的数据,并被训练用来预测右侧的内容(黄色部分为预测结果)。
我们同时需要预测两条相互关联的时间序列。这意味着我们的神经网络处理的是多维数据。一个简单的例子就是,将多个股票代码的历史价格作为输入,然后利用神经网络预测这些股票未来的同步走势。这正是我们在练习 4 中将要做的——同时预测比特币兑美元和欧元的价格。
练习 2
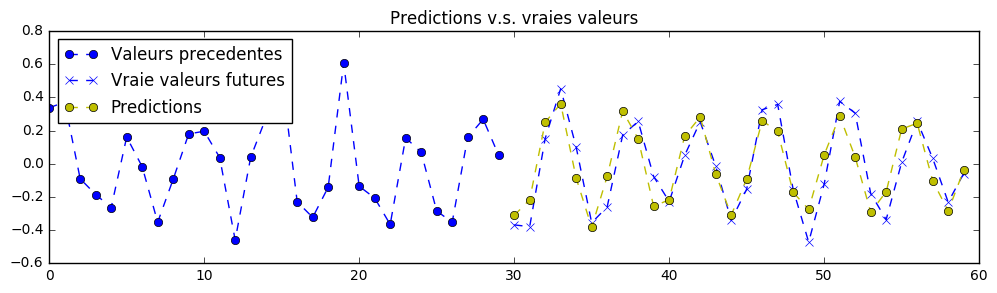
与前一个练习不同,这里为了简化起见,我们只需预测一条信号。然而,这条信号是由两个波长和偏移量不断变化的正弦波叠加而成的,并且其波长被限制在特定的最小值和最大值范围内。
要顺利完成此练习,您需要调整神经网络的超参数。我们建议先尝试以下超参数组合:
n_samples = 125000epochs = 1batch_size = 50hidden_dim = 35
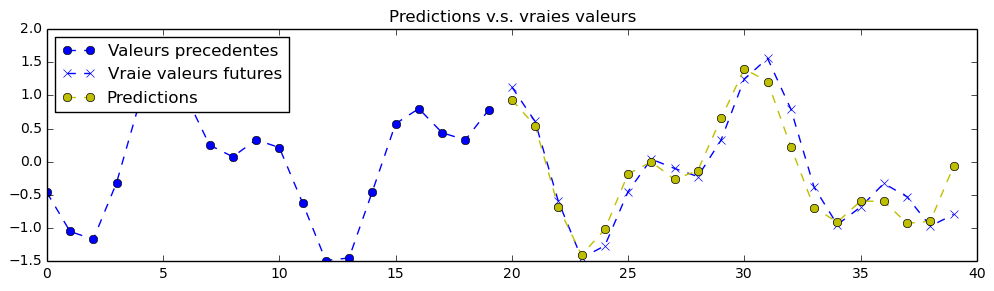
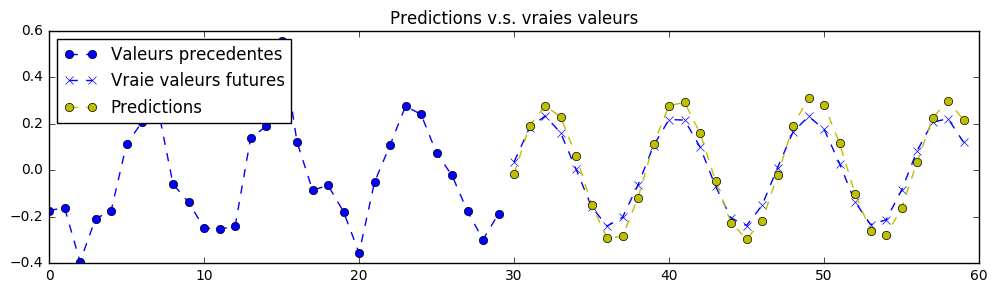
以下是使用更大型神经网络(包含 3 个堆叠的循环单元,每个单元有 500 个隐藏单元)得到的预测结果:
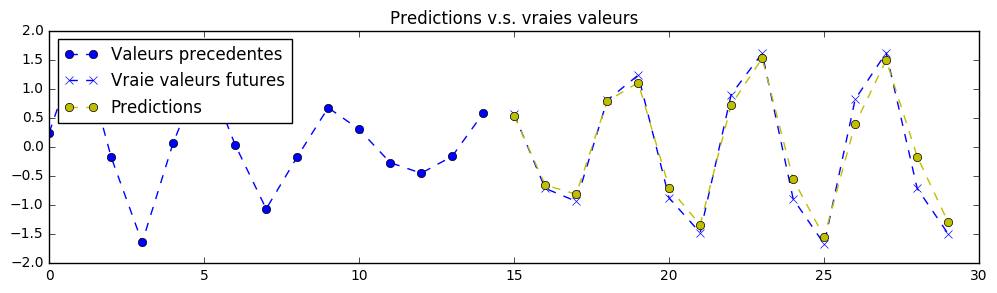
需要注意的是,如果采用更小规模的神经网络,配合更好的训练超参数、更长时间的训练、添加 Dropout 等技术手段,同样可以获得更优的结果。
练习 3
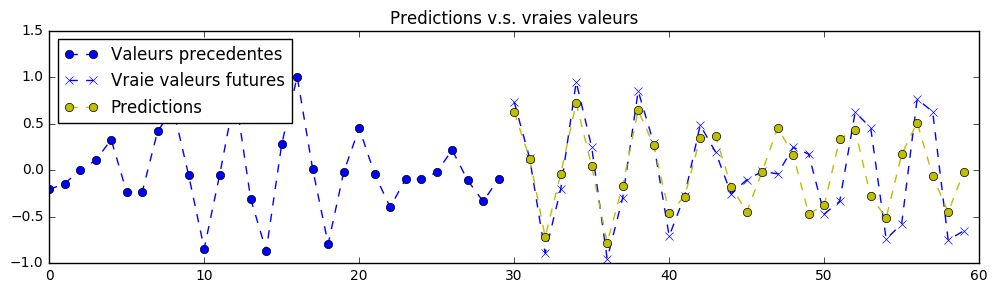
本练习与前一个类似,唯一的区别在于输入编码器的数据是带有噪声的。而期望的输出则没有噪声,这使得任务难度有所增加。在这种特定的数据背景下,我们可以将我们的神经网络称为去噪自回归自动编码器。以下是一个训练样本(以及预测结果)的示例:
因此,神经网络的任务是去除信号中的噪声,从而准确地预测其未来的平滑值。以下是针对该数据集版本的一些更优预测示例:
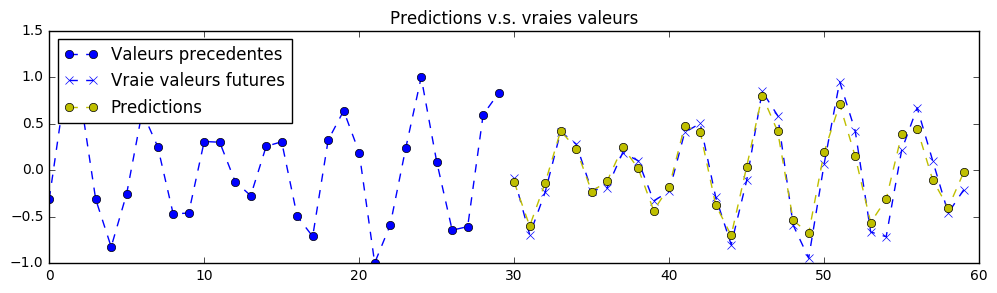
正如我在练习 2 中提到的那样,此处同样有可能获得更好的结果。此外,我们也可以要求您从噪声输入中重建去噪后的信号(而不是预测其未来值),即将其作为去噪自动编码器来使用。这种架构还适用于数据压缩,例如图像处理等场景。
练习 4
本练习比之前的要困难得多,更像是一个开放性的建议。任务是预测比特币价格的未来值。我们这里有一些比特币每日市场数据,即 BTC/USD 和 BTC/EUR 的汇率。仅凭这些数据还不足以构建一个优秀的预测模型——至少需要分钟级甚至秒级的精确数据,这样才会更有意义。以下是一个基于实际未来值的预测结果:该神经网络并未在这些未来值上进行训练,因此在拥有足够好的、针对该任务训练过的模型的情况下,这仍是一个合法的预测:
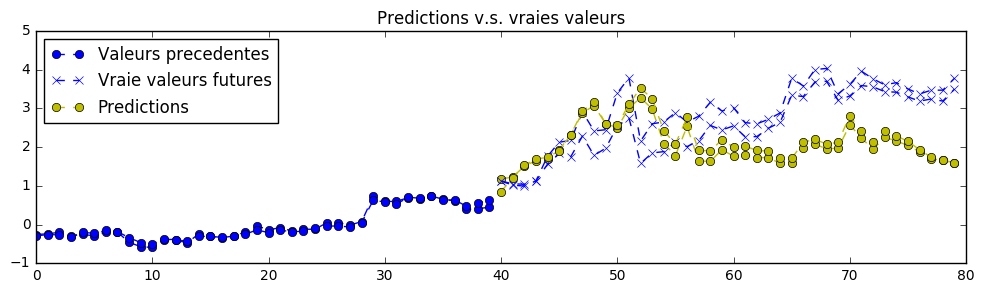
免责声明:这个对未来值的预测确实非常出色,但请不要期望使用如此少量的数据时,预测效果总是这么好(顺便提一句:本项目中的其他预测图表大多属于“一般”水平,唯有这一张例外)。我并没有花太多时间将该模型与其他金融模型进行比较。对于本练习,你可以尝试向模型中引入更多有价值的金融数据,以提高预测的准确性。提醒一下,我在 datasets.py 中提供了数据集的代码,但你可以用更全面的数据来替换,从而更准确地预测比特币价格。
该模型的输入和输出维度均为二维,分别对应 BTC/USD 和 BTC/EUR。例如,你还可以创建额外的输入维度或数据流,比如天气数据以及更多的金融指标,如标普 500 指数、道琼斯工业平均指数等。更具创意的输入数据还可以是正弦波(或其他形状的波形,如锯齿波、三角波,或者同时使用 cos 和 sin 信号),用来表示分钟、小时、天、周、月、年、月相等不同时间尺度上的波动变化(正如我们在 Neuraxio 时间序列解决方案 中所做的那样)。此外,还可以结合社交媒体上关于“比特币”一词的情感分析流,作为另一路更加以人为本且抽象的输入信号。另外,了解“比特币在全球哪些地区使用最为广泛”也很有意思,相关信息可以参考:bitcoin heatmap world。
综合以上提到的各种示例,我们可以将所有这些内容作为每一步的时间序列输入特征:(BTC/USD, BTC/EUR, 道琼斯指数, 标普 500 指数, 当前小时数, 星期几, 本月第几天, 一年中的第几周, 年份, 月相, 美国天气数据, 欧洲天气数据, 社交媒体情感分析)。最终,输出可以是两维或多维:(BTC/USD, BTC/EUR)。
这种预测概念以及类似的时间序列预测算法,可以应用于许多领域,例如工业 4.0 中的自动纠错设备、生产链中的质量保证、交通流量预测、天气预报、运动与行为预测,以及其他各种短期和中期的统计预测或预报任务。
安装依赖
!pip install tensorflow-gpu==2.1 neuraxle==0.3.1 neuraxle_tensorflow==0.1.0
需求已满足:tensorflow-gpu==2.1,位于 /usr/local/lib/python3.6/dist-packages (2.1.0) 需求已满足:neuraxle==0.3.1,位于 /usr/local/lib/python3.6/dist-packages (0.3.1) 需求已满足:neuraxle_tensorflow==0.1.0,位于 /usr/local/lib/python3.6/dist-packages (0.1.0) 需求已满足:google-pasta>=0.1.6,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorflow-gpu==2.1)(0.1.8) 需求已满足:opt-einsum>=2.3.2,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorflow-gpu==2.1)(3.1.0) 需求已满足:tensorboard<2.2.0,>=2.1.0,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorflow-gpu==2.1)(2.1.0) 需求已满足:gast==0.2.2,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorflow-gpu==2.1)(0.2.2) 需求已满足:protobuf>=3.8.0,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorflow-gpu==2.1)(3.10.0) 需求已满足:termcolor>=1.1.0,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorflow-gpu==2.1)(1.1.0) 需求已满足:wrapt>=1.11.1,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorflow-gpu==2.1)(1.11.2) 需求已满足:absl-py>=0.7.0,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorflow-gpu==2.1)(0.9.0) 需求已满足:six>=1.12.0,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorflow-gpu==2.1)(1.12.0) 需求已满足:keras-applications>=1.0.8,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorflow-gpu==2.1)(1.0.8) 需求已满足:tensorflow-estimator<2.2.0,>=2.1.0rc0,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorflow-gpu==2.1)(2.1.0) 需求已满足:astor>=0.6.0,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorflow-gpu==2.1)(0.8.1) 需求已满足:keras-preprocessing>=1.1.0,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorflow-gpu==2.1)(1.1.0) 需求已满足:numpy<2.0,>=1.16.0,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorflow-gpu==2.1)(1.17.5) 需求已满足:wheel>=0.26;python_version >= "3",位于 /usr/local/lib/python3.6/dist-packages(源自 tensorflow-gpu==2.1)(0.33.6) 需求已满足:grpcio>=1.8.6,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorflow-gpu==2.1)(1.15.0) 需求已满足:scipy==1.4.1;python_version >= "3",位于 /usr/local/lib/python3.6/dist-packages(源自 tensorflow-gpu==2.1)(1.4.1) 需求已满足:matplotlib,位于 /usr/local/lib/python3.6/dist-packages(源自 neuraxle==0.3.1)(3.1.2) 需求已满足:Flask-RESTful>=0.3.7,位于 /usr/local/lib/python3.6/dist-packages(源自 neuraxle==0.3.1)(0.3.7) 需求已满足:conv==0.2,位于 /usr/local/lib/python3.6/dist-packages(源自 neuraxle==0.3.1)(0.2) 需求已满足:Flask>=1.1.1,位于 /usr/local/lib/python3.6/dist-packages(源自 neuraxle==0.3.1)(1.1.1) 需求已满足:joblib>=0.13.2,位于 /usr/local/lib/python3.6/dist-packages(源自 neuraxle==0.3.1)(0.14.1) 需求已满足:scikit-learn>=0.20.3,位于 /usr/local/lib/python3.6/dist-packages(源自 neuraxle==0.3.1)(0.22.1) 需求已满足:werkzeug>=0.11.15,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorboard<2.2.0,>=2.1.0->tensorflow-gpu==2.1)(0.16.0) 需求已满足:google-auth<2,>=1.6.3,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorboard<2.2.0,>=2.1.0->tensorflow-gpu==2.1)(1.10.1) 需求已满足:google-auth-oauthlib<0.5,>=0.4.1,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorboard<2.2.0,>=2.1.0->tensorflow-gpu==2.1)(0.4.1) 需求已满足:markdown>=2.6.8,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorboard<2.2.0,>=2.1.0->tensorflow-gpu==2.1)(3.1.1) 需求已满足:setuptools>=41.0.0,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorboard<2.2.0,>=2.1.0->tensorflow-gpu==2.1)(42.0.2) 需求已满足:requests<3,>=2.21.0,位于 /usr/local/lib/python3.6/dist-packages(源自 tensorboard<2.2.0,>=2.1.0->tensorflow-gpu==2.1)(2.21.0) 需求已满足:h5py,位于 /usr/local/lib/python3.6/dist-packages(源自 keras-applications>=1.0.8->tensorflow-gpu==2.1)(2.8.0) 需求已满足:kiwisolver>=1.0.1,位于 /usr/local/lib/python3.6/dist-packages(源自 matplotlib->neuraxle==0.3.1)(1.1.0) 需求已满足:pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1,位于 /usr/local/lib/python3.6/dist-packages(源自 matplotlib->neuraxle==0.3.1)(2.4.6) 需求已满足:python-dateutil>=2.1,位于 /usr/local/lib/python3.6/dist-packages(源自 matplotlib->neuraxle==0.3.1)(2.6.1) 需求已满足:cycler>=0.10,位于 /usr/local/lib/python3.6/dist-packages(源自 matplotlib->neuraxle==0.3.1)(0.10.0) 需求已满足:aniso8601>=0.82,位于 /usr/local/lib/python3.6/dist-packages(源自 Flask-RESTful>=0.3.7->neuraxle==0.3.1)(8.0.0) 需求已满足:pytz,位于 /usr/local/lib/python3.6/dist-packages(源自 Flask-RESTful>=0.3.7->neuraxle==0.3.1)(2018.9) 需求已满足:click>=5.1,位于 /usr/local/lib/python3.6/dist-packages(源自 Flask>=1.1.1->neuraxle==0.3.1)(7.0) 需求已满足:Jinja2>=2.10.1,位于 /usr/local/lib/python3.6/dist-packages(源自 Flask>=1.1.1->neuraxle==0.3.1)(2.10.3) 需求已满足:itsdangerous>=0.24,位于 /usr/local/lib/python3.6/dist-packages(源自 Flask>=1.1.1->neuraxle==0.3.1)(1.1.0) 需求已满足:rsa<4.1,>=3.1.4,位于 /usr/local/lib/python3.6/dist-packages(源自 google-auth<2,>=1.6.3->tensorboard<2.2.0,>=2.1.0->tensorflow-gpu==2.1)(4.0) 需求已满足:pyasn1-modules>=0.2.1,位于 /usr/local/lib/python3.6/dist-packages(源自 google-auth<2,>=1.6.3->tensorboard<2.2.0,>=2.1.0->tensorflow-gpu==2.1)(0.2.7) 需求已满足:cachetools<5.0,>=2.0.0,位于 /usr/local/lib/python3.6/dist-packages(源自 google-auth<2,>=1.6.3->tensorboard<2.2.0,>=2.1.0->tensorflow-gpu==2.1)(4.0.0) 需求已满足:requests-oauthlib>=0.7.0,位于 /usr/local/lib/python3.6/dist-packages(源自 google-auth-oauthlib<0.5,>=0.4.1->tensorboard<2.2.0,>=2.1.0->tensorflow-gpu==2.1)(1.3.0) 需求已满足:chardet<3.1.0,>=3.0.2,位于 /usr/local/lib/python3.6/dist-packages(源自 requests<3,>=2.21.0->tensorboard<2.2.0,>=2.1.0->tensorflow-gpu==2.1)(3.0.4) 需求已满足:urllib3<1.25,>=1.21.1,位于 /usr/local/lib/python3.6/dist-packages(源自 requests<3,>=2.21.0->tensorboard<2.2.0,>=2.1.0->tensorflow-gpu==2.1)(1.24.3) 需求已满足:certifi>=2017.4.17,位于 /usr/local/lib/python3.6/dist-packages(源自 requests<3,>=2.21.0->tensorboard<2.2.0,>=2.1.0->tensorflow-gpu==2.1)(2019.11.28) 需求已满足:idna<2.9,>=2.5,位于 /usr/local/lib/python3.6/dist-packages(源自 requests<3,>=2.21.0->tensorboard<2.2.0,>=2.1.0->tensorflow-gpu==2.1)(2.8) 需求已满足:MarkupSafe>=0.23,位于 /usr/local/lib/python3.6/dist-packages(源自 Jinja2>=2.10.1->Flask>=1.1.1->neuraxle==0.3.1)(1.1.1) 需求已满足:pyasn1>=0.1.3,位于 /usr/local/lib/python3.6/dist-packages(源自 rsa<4.1,>=3.1.4->google-auth<2,>=1.6.3->tensorboard<2.2.0,>=2.1.0->tensorflow-gpu==2.1)(0.4.8) 需求已满足:oauthlib>=3.0.0,位于 /usr/local/lib/python3.6/dist-packages(源自 requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard<2.2.0,>=2.1.0->tensorflow-gpu==2.1)(3.1.0)
import urllib
def download_import(filename):
with open(filename, "wb") as f:
# 之所以需要以这种方式下载,是因为 Colab 是从一个仅“与您共享”的 Google Drive 文件夹中运行的。
# https://drive.google.com/drive/folders/1U0xQMxVespjQilMhYW4mDxN02IwEW67I
url = 'https://raw.githubusercontent.com/guillaume-chevalier/seq2seq-signal-prediction/master/{}'.format(filename)
f.write(urllib.request.urlopen(url).read())
download_import("datasets.py")
download_import("plotting.py")
download_import("steps.py")
from typing import List
from logging import warning
import tensorflow as tf
from neuraxle.data_container import DataContainer
from neuraxle.hyperparams.space import HyperparameterSamples
from neuraxle.metaopt.random import ValidationSplitWrapper
from neuraxle.metrics import MetricsWrapper
from neuraxle.pipeline import Pipeline, MiniBatchSequentialPipeline
from neuraxle.steps.data import EpochRepeater, DataShuffler
from neuraxle.steps.flow import TrainOnlyWrapper
from neuraxle.steps.loop import ForEachDataInput
from sklearn.metrics import mean_squared_error
from tensorflow_core.python.client import device_lib
from tensorflow_core.python.keras import Input, Model
from tensorflow_core.python.keras.layers import GRUCell, RNN, Dense
from tensorflow_core.python.training.adam import AdamOptimizer
from datasets import generate_data
from datasets import metric_3d_to_2d_wrapper
from neuraxle_tensorflow.tensorflow_v1 import TensorflowV1ModelStep
from neuraxle_tensorflow.tensorflow_v2 import Tensorflow2ModelStep
from plotting import plot_metrics
from steps import MeanStdNormalizer, ToNumpy, PlotPredictionsWrapper
%matplotlib inline
def choose_tf_device():
"""
选择 TensorFlow 设备(例如:如果有 GPU 则使用 GPU)进行计算。
"""
tf.debugging.set_log_device_placement(True)
devices = [x.name for x in device_lib.list_local_devices()]
print('您可以使用的 TensorFlow 设备有:{}'.format(devices))
try:
chosen_device = [d for d in devices if 'gpu' in d.lower()][0]
except:
warning(
"未找到 GPU 设备。请确保在 `Runtime > Change Runtime Type` 中选择 Python 3 的 GPU 配置。")
chosen_device = devices[0]
print('选定设备:{}'.format(chosen_device))
return chosen_device
chosen_device = choose_tf_device()
您可以使用的 TensorFlow 设备有: ['/device:CPU:0', '/device:XLA_CPU:0', '/device:XLA_GPU:0', '/device:GPU:0']
选定设备: /device:XLA_GPU:0
神经网络架构定义
基本的序列到序列(seq2seq)RNN
以下是一个基本的序列到序列神经网络架构。“ABC”是过去的输入,“WXYZ”既是未来的输出,也是作为反馈回路的未来输入。这种反馈回路在某些情况下已被证明可以提升 RNN 的性能(了解更多)。

但在我们的案例中,我们不会采用这样的反馈回路,因为这需要在训练和测试过程中进行更复杂的采样,对于今天的实践示例来说会过于复杂。
我们的堆叠 GRU 序列到序列 RNN
我们采用的是如下方法:“H”是编码器 RNN 最后一个时间步的隐藏状态输出。我们将这个值在未来的各个时间步上复制,作为 RNN 的未来输入,从而使它在预测未来时始终能够记住当前的上下文信息。
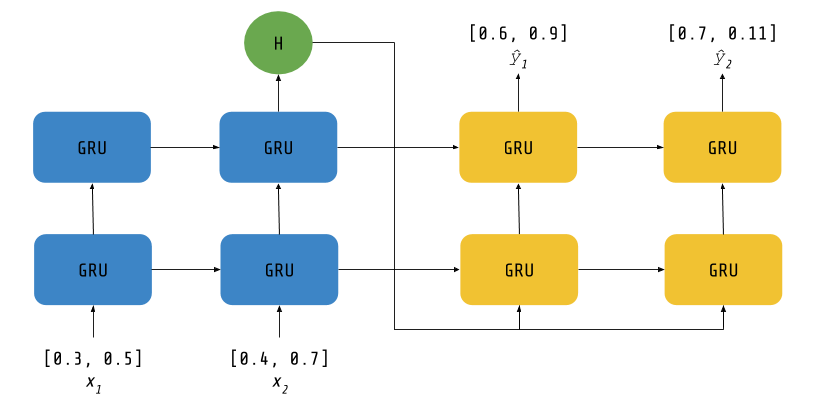
需要注意的是,我们也可以在此处引入注意力机制。这样做的好处是,神经网络可以在未来的每一个时间步重新分析过去的信息,如果需要的话。注意力机制在机器翻译(MT)等场景中更为有用,因为在这些场景中,有时需要逐字逐句地回顾之前的内容,而不是仅仅依赖于一次性读取所有内容后形成的短期记忆。近年来,像 BERT 这样的机器翻译方法(关于 BERT 的更多信息 / BERT 使用示例)已经完全基于注意力机制,而不再使用 RNN,尽管这样做也存在一些权衡。
创建 TensorFlow 2 模型
让我们继续编写上方图片中所示的内容。
def create_model(step: Tensorflow2ModelStep) -> tf.keras.Model:
"""
创建一个 TensorFlow v2 序列到序列(seq2seq)编码器-解码器模型。
:param step: TensorFlow v2 的 Neuraxle 基础步骤(Tensorflow2ModelStep)
:return: TensorFlow v2 Keras 模型
"""
# 形状:(batch_size, seq_length, input_dim)
encoder_inputs = Input(
shape=(None, step.hyperparams['input_dim']),
batch_size=None,
dtype=tf.dtypes.float32,
name='encoder_inputs'
)
last_encoder_outputs, last_encoders_states = _create_encoder(step, encoder_inputs)
decoder_outputs = _create_decoder(step, last_encoder_outputs, last_encoders_states)
return Model(encoder_inputs, decoder_outputs)
def _create_encoder(step: Tensorflow2ModelStep, encoder_inputs: Input) -> (tf.Tensor, List[tf.Tensor]):
"""
使用 GRU 单元创建编码器 RNN。GRU 单元与 LSTM 单元类似。
:param step: TensorFlow v2 的 Neuraxle 基础步骤(类 Tensorflow2ModelStep)
:param encoder_inputs: 编码器输入层,形状为 (batch_size, seq_length, input_dim)
:return: (最后的编码器输出, 最后堆叠的编码器状态)
last_encoder_outputs 形状:(batch_size, hidden_dim)
last_encoder_states 形状:(layers_stacked_count, batch_size, hidden_dim)
"""
encoder = RNN(cell=_create_stacked_rnn_cells(step), return_sequences=False, return_state=True)
last_encoder_outputs_and_states = encoder(encoder_inputs)
# last_encoder_outputs 形状:(batch_size, hidden_dim)
# last_encoder_states 形状:(layers_stacked_count, batch_size, hidden_dim)
# 参考:https://www.tensorflow.org/api_docs/python/tf/keras/layers/RNN?version=stable#output_shape_2
last_encoder_outputs, *last_encoders_states = last_encoder_outputs_and_states
return last_encoder_outputs, last_encoders_states
def _create_decoder(step: Tensorflow2ModelStep, last_encoder_outputs: tf.Tensor, last_encoders_states: List[tf.Tensor]) -> tf.Tensor:
"""
使用 GRU 单元创建解码器 RNN。
:param step: TensorFlow v2 的 Neuraxle 基础步骤(Tensorflow2ModelStep)
:param last_encoders_states: 最后的编码器状态张量
:param last_encoder_outputs: 最后的编码器输出张量
:return: 解码器输出
"""
decoder_lstm = RNN(cell=_create_stacked_rnn_cells(step), return_sequences=True, return_state=False)
last_encoder_output = tf.expand_dims(last_encoder_outputs, axis=1)
# 最后的编码器输出形状:(batch_size, 1, hidden_dim)
replicated_last_encoder_output = tf.repeat(
input=last_encoder_output,
repeats=step.hyperparams['window_size_future'],
axis=1
)
# 复制后的最后编码器输出形状:(batch_size, window_size_future, hidden_dim)
decoder_outputs = decoder_lstm(replicated_last_encoder_output, initial_state=last_encoders_states)
# 解码器输出形状:(batch_size, window_size_future, hidden_dim)
decoder_dense = Dense(step.hyperparams['output_dim'])
# 解码器输出形状:(batch_size, window_size_future, output_dim)
return decoder_dense(decoder_outputs)
def _create_stacked_rnn_cells(step: Tensorflow2ModelStep) -> List[GRUCell]:
"""
创建 `layers_stacked_count` 个 GRU 单元,并将它们堆叠在一起。
它们的神经元层数为 `hidden_dim`。
:param step: TensorFlow v2 的 Neuraxle 基础步骤(Tensorflow2ModelStep)
:return: GRU 单元列表
"""
cells = []
for _ in range(step.hyperparams['layers_stacked_count']):
cells.append(GRUCell(step.hyperparams['hidden_dim']))
return cells
创建损失函数
使用均方误差(MSE)和权重衰减(L2 正则化)。
def create_loss(step: Tensorflow2ModelStep, expected_outputs: tf.Tensor, predicted_outputs: tf.Tensor) -> tf.Tensor:
"""
创建模型损失。
:param step: TensorFlow v2 的 Neuraxle 基础步骤(Tensorflow2ModelStep)
:param expected_outputs: 预期输出,形状为 (batch_size, window_size_future, output_dim)
:param predicted_outputs: 预测输出,形状为 (batch_size, window_size_future, output_dim)
:return: 损失(一个浮点类型的 tf 张量)
"""
l2 = step.hyperparams['lambda_loss_amount'] * sum(
tf.reduce_mean(tf.nn.l2_loss(tf_var))
for tf_var in step.model.trainable_variables
)
output_loss = sum(
tf.reduce_mean(tf.nn.l2_loss(pred - expected))
for pred, expected in zip(predicted_outputs, expected_outputs)
) / float(len(predicted_outputs))
return output_loss + l2
创建优化器
Adam 通常表现优异。
def create_optimizer(step: TensorflowV1ModelStep) -> AdamOptimizer:
"""
创建 TensorFlow 2 的优化器:这里是 AdamOptimizer。
:param step: TensorFlow v2 的 Neuraxle 基础步骤(Tensorflow2ModelStep)
:return: 优化器
"""
return AdamOptimizer(learning_rate=step.hyperparams['learning_rate'])
生成或加载数据
要更改您正在进行的练习,请更改 exercise_number 变量的值(即下方代码单元的第一行):
exercice_number = 1
print('exercice {}\n=================='.format(exercice_number))
data_inputs, expected_outputs = generate_data(
# 参见:https://github.com/guillaume-chevalier/seq2seq-signal-prediction/blob/master/datasets.py
exercice_number=exercice_number,
n_samples=None,
window_size_past=None,
window_size_future=None
)
print('data_inputs shape: {} => (n_samples, window_size_past, input_dim)'.format(data_inputs.shape))
print('expected_outputs shape: {} => (n_samples, window_size_future, output_dim)'.format(expected_outputs.shape))
sequence_length = data_inputs.shape[1]
input_dim = data_inputs.shape[2]
output_dim = expected_outputs.shape[2]
batch_size = 100
epochs = 15
validation_size = 0.15
max_plotted_validation_predictions = 10
练习 1
==================
data_inputs 形状:(1000, 10, 2) => (n_samples, window_size_past, input_dim)
expected_outputs 形状:(1000, 10, 2) => (n_samples, window_size_future, output_dim)
神经网络的超参数
seq2seq_pipeline_hyperparams = HyperparameterSamples({
'hidden_dim': 12,
'layers_stacked_count': 2,
'lambda_loss_amount': 0.0003,
'learning_rate': 0.001,
'window_size_future': sequence_length,
'output_dim': output_dim,
'input_dim': input_dim
})
print('hyperparams: {}'.format(seq2seq_pipeline_hyperparams))
超参数:HyperparameterSamples([('hidden_dim', 12), ('layers_stacked_count', 2), ('lambda_loss_amount', 0.0003), ('learning_rate', 0.001), ('window_size_future', 10), ('output_dim', 2), ('input_dim', 2)])
管道
看到脏乱的机器学习代码几乎已经成为行业常态。而这无疑也是导致87%的数据科学项目从未投入生产的原因之一。
在这里,我们使用先进的设计模式(管道与过滤器)来实现所谓的整洁机器学习。这些设计模式的灵感来源于scikit-learn的Pipeline类。
定义深度学习管道
首先,我们使用TF2ModelStep来定义管道。MeanStdNormalizer可以帮助我们对数据进行归一化,因为神经网络需要处理归一化的输入数据。
feature_0_metric = metric_3d_to_2d_wrapper(mean_squared_error)
metrics = {'mse': feature_0_metric}
signal_prediction_pipeline = Pipeline([
ForEachDataInput(MeanStdNormalizer()),
ToNumpy(),
PlotPredictionsWrapper(Tensorflow2ModelStep(
# 参见:https://github.com/Neuraxio/Neuraxle-TensorFlow
create_model=create_model,
create_loss=create_loss,
create_optimizer=create_optimizer,
expected_outputs_dtype=tf.dtypes.float32,
data_inputs_dtype=tf.dtypes.float32,
print_loss=False,
device_name=chosen_device
).set_hyperparams(seq2seq_pipeline_hyperparams))]).set_name('SignalPrediction')
定义如何训练我们的深度学习管道
最后,我们将管道包裹在EpochRepeater、ValidationSplitWrapper、DataShuffler、MiniBatchSequentialPipeline和MetricsWrapper中,以处理训练所需的所有步骤。有关这些组件的更多信息,请参阅Neuraxle的文档。
pipeline = Pipeline([EpochRepeater(
ValidationSplitWrapper(
MetricsWrapper(Pipeline([
TrainOnlyWrapper(DataShuffler()),
MiniBatchSequentialPipeline([
MetricsWrapper(
signal_prediction_pipeline,
metrics=metrics,
name='batch_metrics'
)], batch_size=batch_size)
]),
metrics=metrics,
name='epoch_metrics',
print_metrics=True
),
test_size=validation_size,
scoring_function=feature_0_metric),
epochs=epochs)
])
/usr/local/lib/python3.6/dist-packages/neuraxle/pipeline.py:353: UserWarning: 正在用MiniBatchSequentialPipeline.batch_size替换MiniBatchSequentialPipeline[Joiner].batch_size。
'Replacing {}[{}].batch_size by {}.batch_size.'.format(self.name, step.name, self.name))
训练神经网络
现在是时候将模型拟合到数据上了。
pipeline, outputs = pipeline.fit_transform(data_inputs, expected_outputs)
在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 RandomUniform 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Sub 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Mul 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Add 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 VarHandleOp 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 VarIsInitializedOp 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 LogicalNot 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Assert 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 AssignVariableOp 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 RandomStandardNormal 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Qr 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 DiagPart 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Sign 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Transpose 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Reshape 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 VarHandleOp 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Fill 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Cast 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference_keras_scratch_graph_365 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference_keras_scratch_graph_370 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference_keras_scratch_graph_375 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference_keras_scratch_graph_380 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference_keras_scratch_graph_385 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference_keras_scratch_graph_390 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference_keras_scratch_graph_395 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference_keras_scratch_graph_400 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference_keras_scratch_graph_405 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference_keras_scratch_graph_410 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference_keras_scratch_graph_415 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 VarHandleOp 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 VarHandleOp 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 VarHandleOp 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 AssignVariableOp 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Shape 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 StridedSlice 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Unpack 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 StridedSlice 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 ReadVariableOp 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Unpack 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 MatMul 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 BiasAdd 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Split 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 SplitV 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 AddV2 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Sigmoid 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Tanh 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Less 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 AddV2 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Pack 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __forward__defun_call_1537 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __forward__defun_call_1547 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference__defun_call_1557 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference__defun_call_1566 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __forward__defun_call_1580 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __forward__defun_call_1606 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference__defun_call_1617 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __forward__defun_call_1631 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 L2Loss 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Mean 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 RealDiv 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 BroadcastGradientArgs 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Sum 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Neg 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Tile 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 StridedSliceGrad 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 AddN 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 BiasAddGrad 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 MatMul 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 MatMul 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 InvertPermutation 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 TanhGrad 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 AddN 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 SigmoidGrad 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 ConcatV2 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 Pack 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 AddN 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference___backward__defun_call_1625_1632 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference___backward__defun_call_1589_1607 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference___backward__defun_call_1574_1581 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference___backward__defun_call_1531_1538 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 AddN 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 VarHandleOp 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 ResourceApplyAdam 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference__defun_call_1530 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference__defun_call_1544 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference__defun_call_1573 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference__defun_call_1588 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference__defun_call_1624 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __forward__defun_call_65540 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __forward__defun_call_65550 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __forward__defun_call_65567 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __forward__defun_call_65593 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __forward__defun_call_65610 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 AddN 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference___backward__defun_call_65604_65611 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference___backward__defun_call_65576_65594 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference___backward__defun_call_65561_65568 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference___backward__defun_call_65534_65541 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference__defun_call_65533 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference__defun_call_65547 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference__defun_call_65560 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference__defun_call_65575 操作 在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 __inference__defun_call_65603 操作 {'mse': 0.18414642847122925} {'mse': 0.1778781379709343} {'mse': 0.1723181842129053} {'mse': 0.1658200688421554} {'mse': 0.1591329577983185} {'mse': 0.15131258011101834} {'mse': 0.1436201535512516} {'mse': 0.1343595503512161} {'mse': 0.12474072112690562} {'mse': 0.11462532630747631} {'mse': 0.10271182130173581} {'mse': 0.0906442166022616} {'mse': 0.07585859336447773} {'mse': 0.06317439259405164} {'mse': 0.04988300184267241} {'mse': 0.041345448752856694} {'mse': 0.034553488508200454} {'mse': 0.03218617403485365} {'mse': 0.02922688138678744} {'mse': 0.02631547230588055} {'mse': 0.022075968214915552} {'mse': 0.018800000904722468} {'mse': 0.01640079469351695} {'mse': 0.014737265865397323} {'mse': 0.013079363146911618} {'mse': 0.01166897820815228} {'mse': 0.010537850442431971} {'mse': 0.00938083864872879} {'mse': 0.008495135058422493} {'mse': 0.007566329717239811}
可视化测试预测
查看您的训练效果。
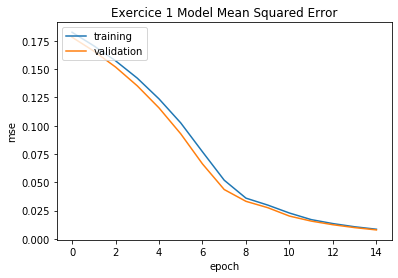
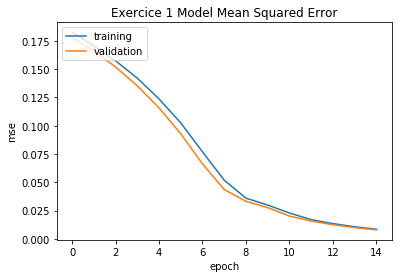
plot_metrics(pipeline=pipeline, exercice_number=exercice_number)
最后一次训练集 MSE:0.008495135058422493
最佳训练集 MSE:0.008495135058422493
最后一次验证集 MSE:0.007566329717239811
最佳验证集 MSE:0.007566329717239811
def plot_predictions(data_inputs, expected_outputs, pipeline, max_plotted_predictions):
_, _, data_inputs_validation, expected_outputs_validation = \
pipeline.get_step_by_name('ValidationSplitWrapper').split(data_inputs, expected_outputs)
pipeline.apply('toggle_plotting')
pipeline.apply('set_max_plotted_predictions', max_plotted_predictions)
signal_prediction_pipeline = pipeline.get_step_by_name('SignalPrediction')
signal_prediction_pipeline.transform_data_container(DataContainer(
data_inputs=data_inputs_validation,
expected_outputs=expected_outputs_validation
))
plot_predictions(data_inputs, expected_outputs, pipeline, max_plotted_validation_predictions)
在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 op __inference__defun_call_1562783
在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 op __inference__defun_call_1562789
在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 op __inference__defun_call_1562798
在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 op __inference__defun_call_1562805
在设备 /job:localhost/replica:0/task:0/device:XLA_GPU:0 上执行 op __inference__defun_call_1562813
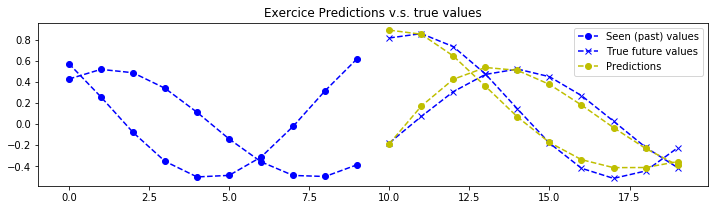
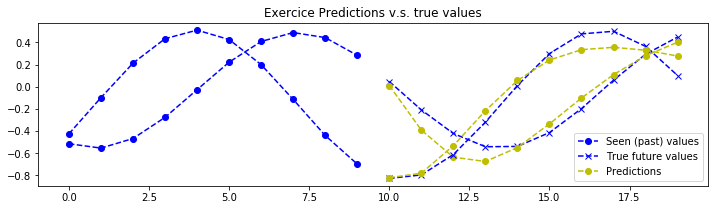
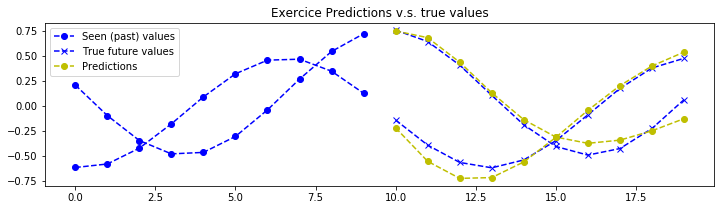
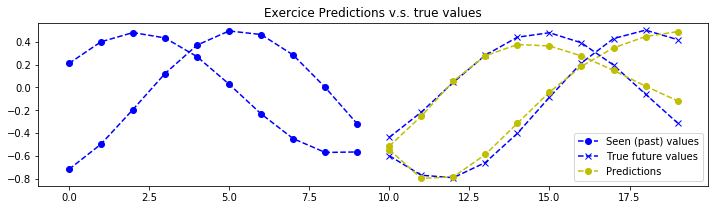
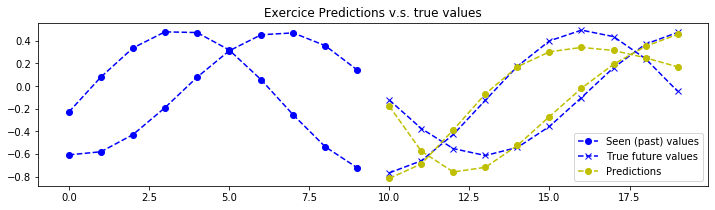
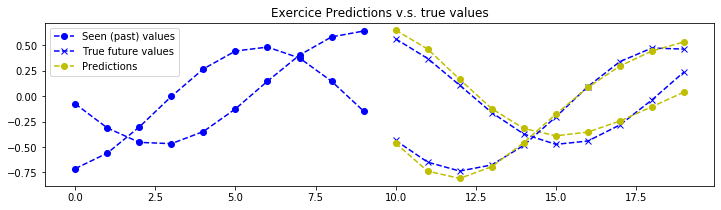
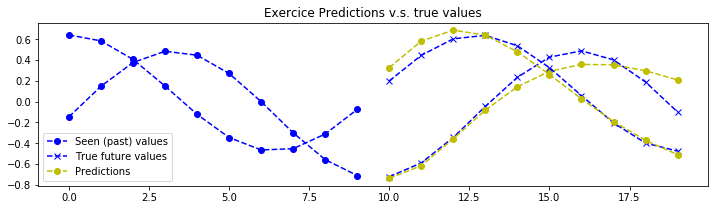
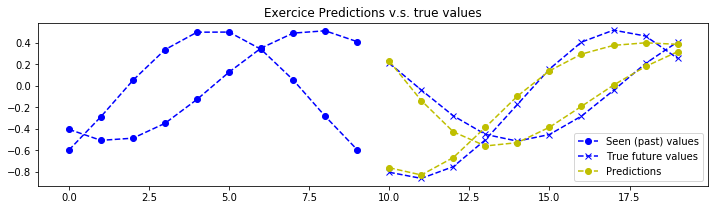
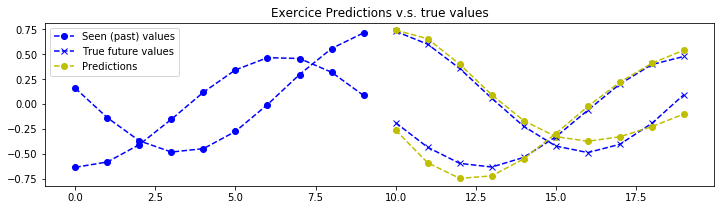
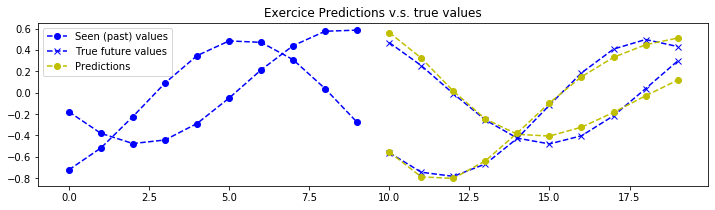
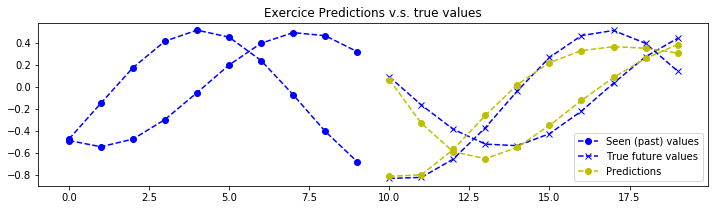
结论
循环神经网络非常出色。它们能够学习预测复杂的数据模式。它们可以从序列数据中读取多个特征,并输出长度可变的序列,这些序列可以是相同特征的,也可以是完全不同特征的。有些人甚至将 RNN 与其他神经网络架构(如 CNN)结合使用,用于自动图像描述生成任务(用 CNN 对图像进行编码,再用 RNN 对描述进行解码)。
您在本项目中学到了:
- 如何构建时间序列机器学习流水线
- 如何构建 TensorFlow v2 的编码器-解码器序列到序列模型
- 如何使用 Neuraxle 构建整洁的机器学习流水线
- 如何正确地将数据划分为训练集和验证集
- 在训练过程中对数据进行打乱
- 使用小批量数据处理技术,通过 MiniBatchSequentialPipeline 处理数据
关于
与我联系:
- https://github.com/guillaume-chevalier/
- https://ca.linkedin.com/in/chevalierg
- https://twitter.com/guillaume_che
许可与引用
本项目可根据 Apache 2.0 许可协议 自由使用,但前提是您需要链接到该项目(即引用),并且遵守该许可协议(详情请参阅许可协议)。您可以引用以下链接:
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。