vision_transformer
vision_transformer 是谷歌开源的一套基于 JAX/Flax 框架的视觉模型代码库,核心提供了 Vision Transformer (ViT) 和 MLP-Mixer 等前沿架构的实现。它主要解决了传统卷积神经网络在图像识别任务中的局限性,展示了 Transformer 架构如何在不依赖强数据增强或预训练的情况下,依然能超越 ResNet 等经典模型,实现高精度的图像分类与零样本迁移学习。
这套工具特别适合 AI 研究人员和深度学习开发者使用。如果你希望复现顶级论文成果、探索大规模视觉模型的训练技巧,或者需要在 ImageNet 等数据集上进行模型微调与推理,vision_transformer 提供了经过验证的预训练权重和完整的实验代码。其独特亮点在于不仅收录了多篇开创性论文的核心算法,还配套了详细的 Colab 交互式教程,支持直接在云端 GPU 或 TPU 上运行。此外,项目生成的数万个检查点甚至能被流行的 PyTorch 库直接加载,极大地降低了跨框架使用的门槛,是深入理解现代计算机视觉架构不可多得的实践资源。
使用场景
某医疗影像初创团队正致力于开发一套辅助诊断系统,需要从有限的肺部 CT 扫描数据中高精度识别早期结节病变。
没有 vision_transformer 时
- 传统卷积神经网络(CNN)在提取全局上下文信息时能力有限,容易漏诊位置隐蔽或形态微小的病灶。
- 由于缺乏大规模预训练模型支持,团队必须从头训练深度模型,导致在数据量不足时严重过拟合,泛化能力差。
- 调整网络结构以平衡精度与速度极为耗时,往往需要数周反复试验不同的 ResNet 变体才能勉强达标。
- 迁移学习过程复杂,难以直接利用业界最先进的 ImageNet-21k 预训练权重来加速特定医疗场景的收敛。
使用 vision_transformer 后
- 借助 ViT 的自注意力机制,模型能精准捕捉图像长距离依赖关系,显著提升了微小结节的检出率和分类准确度。
- 直接加载官方提供的 ImageNet-21k 预训练检查点进行微调,仅需少量标注数据即可快速收敛,有效解决了小样本难题。
- 通过 JAX/Flax 代码库灵活调用不同规模的 ViT 或 MLP-Mixer 架构,几天内即可完成从选型到部署的全流程验证。
- 利用 Colab 笔记本直接探索超过 5 万个预训练模型权重,快速锁定最适合当前医疗数据分布的最优解,大幅降低试错成本。
vision_transformer 通过将前沿的 Transformer 架构与高质量预训练权重相结合,让资源有限的团队也能轻松构建出超越传统 CNN 的高性能视觉诊断系统。
运行环境要求
- Linux
- 可选但推荐(支持 NVIDIA GPU 和 Google TPU)
- Colab 默认使用 Tesla T4
- 具体显存需求取决于模型大小和 batch size,若遇显存不足需调整 accum_steps 或 batch 大小
未说明(主机端需内存存储 shuffle buffer,默认 50000,若遇 OOM 需减小该值)

快速开始
视觉Transformer与MLP-Mixer架构
在本仓库中,我们发布了来自以下论文的模型:
- 《一张图像胜过16×16个词:大规模图像识别中的Transformer》(https://arxiv.org/abs/2010.11929)
- 《MLP-Mixer:一种全MLP的视觉架构》(https://arxiv.org/abs/2105.01601)
- 《如何训练你的ViT?视觉Transformer中的数据、增强与正则化》(https://arxiv.org/abs/2106.10270)
- 《当视觉Transformer无需预训练或强数据增强即可超越ResNet时》(https://arxiv.org/abs/2106.01548)
- 《LiT:基于锁定图像文本微调的零样本迁移》(https://arxiv.org/abs/2111.07991)
- 《代理差距最小化改进了尖锐度感知训练》(https://arxiv.org/abs/2203.08065)
这些模型已在ImageNet和ImageNet-21k数据集上进行了预训练。我们提供了使用JAX/Flax对已发布模型进行微调的代码。
目录:
Colab
以下Colab既可以使用GPU,也可以使用TPU(8核,数据并行)运行。
第一个Colab展示了视觉Transformer和MLP Mixer的JAX代码。该Colab允许您直接在Colab界面中编辑仓库中的文件,并配有注释过的单元格,逐步引导您理解代码,同时让您与数据进行交互。
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/vit_jax.ipynb
第二个Colab可以让您探索超过5万个用于生成第三篇论文“如何训练你的ViT?…”数据的视觉Transformer及混合模型检查点。该Colab包含用于探索和选择检查点的代码,以及使用本仓库的JAX代码和流行的timm PyTorch库进行推理的功能——后者可以直接加载这些检查点。需要注意的是,少数模型也可直接从TF-Hub获取:sayakpaul/collections/vision_transformer(由Sayak Paul贡献)。
第二个Colab还允许您在任何tfds数据集以及您自己的数据集上对检查点进行微调,这些数据集可以是单独的JPEG文件形式(可选地直接从Google Drive读取)。
注意:截至2021年6月20日,Google Colab仅支持单个GPU(Nvidia Tesla T4),而TPU(目前为TPUv2-8)则是间接连接到Colab虚拟机并通过较慢的网络通信,这导致训练速度非常慢。如果您有大量数据需要微调,通常建议搭建一台专用机器。有关详细信息,请参阅云端运行部分。
安装
请确保您的机器上已安装Python>=3.10。
通过运行以下命令安装JAX和Python依赖项:
# 如果使用GPU:
pip install -r vit_jax/requirements.txt
# 如果使用TPU:
pip install -r vit_jax/requirements-tpu.txt
对于较新版本的JAX,请遵循此处链接的相应仓库提供的说明。请注意,CPU、GPU和TPU的安装说明略有不同。
安装Flaxformer,并按照此处链接的相应仓库提供的说明进行操作。
更多详情请参阅下方的云端运行部分。
微调模型
您可以在感兴趣的自己的数据集上对下载的模型进行微调。所有模型都使用相同的命令行界面。
例如,要在 CIFAR10 数据集上微调一个在 ImageNet21k 上预训练的 ViT-B/16 模型(注意我们如何将 b16,cifar10 作为配置参数传入,以及如何指示代码直接从 GCS 存储桶中加载模型,而不是先将其下载到本地目录):
python -m vit_jax.main --workdir=/tmp/vit-$(date +%s) \
--config=$(pwd)/vit_jax/configs/vit.py:b16,cifar10 \
--config.pretrained_dir='gs://vit_models/imagenet21k'
如果要对在 ImageNet21k 上预训练的 Mixer-B/16 模型进行 CIFAR10 数据集上的微调:
python -m vit_jax.main --workdir=/tmp/vit-$(date +%s) \
--config=$(pwd)/vit_jax/configs/mixer_base16_cifar10.py \
--config.pretrained_dir='gs://mixer_models/imagenet21k'
论文《如何训练你的 ViT?》添加了超过 5 万个检查点,您可以使用 configs/augreg.py 配置对其进行微调。当您仅指定模型名称(即 configs/model.py 中的 config.name 值)时,系统会自动选择上游验证准确率最高的 i21k 检查点(“推荐”检查点,详见论文第 4.5 节)。要决定使用哪个模型,可以参考论文中的图 3。此外,您也可以选择其他检查点(参见 Colab 笔记本 vit_jax_augreg.ipynb),并指定来自 filename 或 adapt_filename 列的值,这些值对应于 gs://vit_models/augreg 目录中不带 .npz 后缀的文件名。
python -m vit_jax.main --workdir=/tmp/vit-$(date +%s) \
--config=$(pwd)/vit_jax/configs/augreg.py:R_Ti_16 \
--config.dataset=oxford_iiit_pet \
--config.base_lr=0.01
目前,代码会自动下载 CIFAR-10 和 CIFAR-100 数据集。其他公开或自定义数据集也可以通过 TensorFlow Datasets 库 轻松集成。请注意,您还需要更新 vit_jax/input_pipeline.py 文件,以指定新增数据集的相关参数。
需要注意的是,我们的代码会利用所有可用的 GPU/TPU 进行微调。
如需查看所有可用标志的详细列表,请运行 python3 -m vit_jax.train --help。
内存注意事项:
- 不同模型所需的内存不同。可用内存还取决于加速器的配置(类型和数量)。如果遇到内存不足错误,您可以将
--config.accum_steps=8的值调高;或者相应地降低--config.batch=512(并按比例调整--config.base_lr)。 - 主机端会在内存中维护一个打乱缓冲区。如果您遇到主机端 OOM 错误(而非加速器端 OOM),可以将默认的
--config.shuffle_buffer=50000值调低。
视觉 Transformer
作者:Alexey Dosovitskiy*†、Lucas Beyer*、Alexander Kolesnikov*、Dirk Weissenborn*、Xiaohua Zhai*、Thomas Unterthiner、Mostafa Dehghani、Matthias Minderer、Georg Heigold、Sylvain Gelly、Jakob Uszkoreit 和 Neil Houlsby*†。
(*) 共同技术贡献,(†) 共同指导。
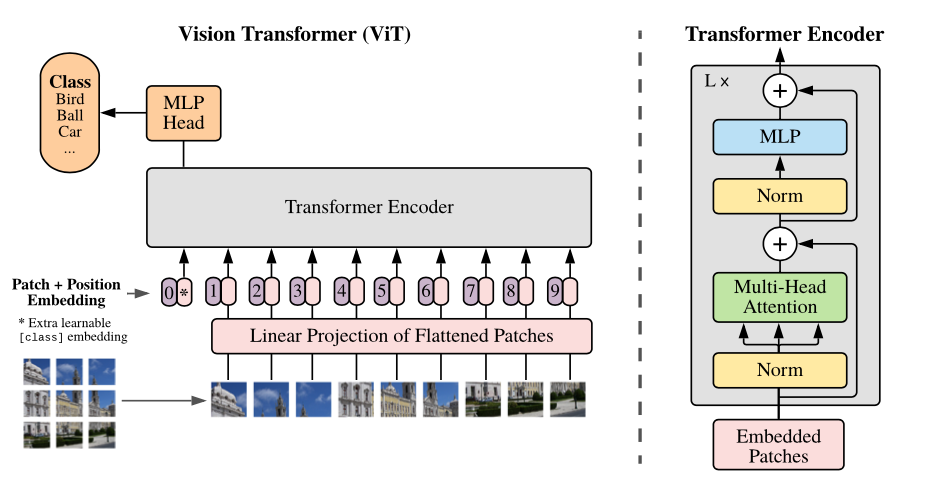
模型概述:我们将图像分割成固定大小的补丁,对每个补丁进行线性嵌入,加入位置嵌入,然后将得到的向量序列输入标准的 Transformer 编码器。为了进行分类,我们采用在序列中添加一个额外的可学习“分类标记”的标准方法。
可用的 ViT 模型
我们在不同的 GCS 存储桶中提供了多种 ViT 模型。例如,可以通过以下命令下载模型:
wget https://storage.googleapis.com/vit_models/imagenet21k/ViT-B_16.npz
模型文件名(不含 .npz 后缀)与 vit_jax/configs/models.py 中的 config.model_name 对应。
gs://vit_models/imagenet21k:在 ImageNet-21k 上预训练的模型。gs://vit_models/imagenet21k+imagenet2012:在 ImageNet-21k 上预训练并在 ImageNet 上微调的模型。gs://vit_models/augreg:在 ImageNet-21k 上预训练并应用不同程度 AugReg 技术的模型,性能有所提升。gs://vit_models/sam:使用 SAM 技术在 ImageNet 上预训练的模型。gs://vit_models/gsam:使用 GSAM 技术在 ImageNet 上预训练的模型。
我们推荐使用以下经过 AugReg 训练且预训练指标最优的检查点:
| 模型 | 预训练检查点 | 大小 | 微调后检查点 | 分辨率 | 图像/秒 | ImageNet 准确率 |
|---|---|---|---|---|---|---|
| L/16 | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0.npz |
1243 MiB | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz |
384 | 50 | 85.59% |
| B/16 | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0.npz |
391 MiB | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz |
384 | 138 | 85.49% |
| S/16 | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0.npz |
115 MiB | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz |
384 | 300 | 83.73% |
| R50+L/32 | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1.npz |
1337 MiB | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1--imagenet2012-steps_20k-lr_0.01-res_384.npz |
384 | 327 | 85.99% |
| R26+S/32 | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz |
170 MiB | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz |
384 | 560 | 83.85% |
| Ti/16 | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz |
37 MiB | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz |
384 | 610 | 78.22% |
| B/32 | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz |
398 MiB | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz |
384 | 955 | 83.59% |
| S/32 | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0.npz |
118 MiB | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz |
384 | 2154 | 79.58% |
| R+Ti/16 | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz |
40 MiB | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz |
384 | 2426 | 75.40% |
使用 gs://vit_models/imagenet21k 中的模型,已复现了原始 ViT 论文(https://arxiv.org/abs/2010.11929)中的结果:
| 模型 | 数据集 | dropout=0.0 | dropout=0.1 |
|---|---|---|---|
| R50+ViT-B_16 | cifar10 | 98.72%, 3.9小时 (A100), tb.dev | 98.94%, 10.1小时 (V100), tb.dev |
| R50+ViT-B_16 | cifar100 | 90.88%, 4.1小时 (A100), tb.dev | 92.30%, 10.1小时 (V100), tb.dev |
| R50+ViT-B_16 | imagenet2012 | 83.72%, 9.9小时 (A100), tb.dev | 85.08%, 24.2小时 (V100), tb.dev |
| ViT-B_16 | cifar10 | 99.02%, 2.2小时 (A100), tb.dev | 98.76%, 7.8小时 (V100), tb.dev |
| ViT-B_16 | cifar100 | 92.06%, 2.2小时 (A100), tb.dev | 91.92%, 7.8小时 (V100), tb.dev |
| ViT-B_16 | imagenet2012 | 84.53%, 6.5小时 (A100), tb.dev | 84.12%, 19.3小时 (V100), tb.dev |
| ViT-B_32 | cifar10 | 98.88%, 0.8小时 (A100), tb.dev | 98.75%, 1.8小时 (V100), tb.dev |
| ViT-B_32 | cifar100 | 92.31%, 0.8小时 (A100), tb.dev | 92.05%, 1.8小时 (V100), tb.dev |
| ViT-B_32 | imagenet2012 | 81.66%, 3.3小时 (A100), tb.dev | 81.31%, 4.9小时 (V100), tb.dev |
| ViT-L_16 | cifar10 | 99.13%, 6.9小时 (A100), tb.dev | 99.14%, 24.7小时 (V100), tb.dev |
| ViT-L_16 | cifar100 | 92.91%, 7.1小时 (A100), tb.dev | 93.22%, 24.4小时 (V100), tb.dev |
| ViT-L_16 | imagenet2012 | 84.47%, 16.8小时 (A100), tb.dev | 85.05%, 59.7小时 (V100), tb.dev |
| ViT-L_32 | cifar10 | 99.06%, 1.9小时 (A100), tb.dev | 99.09%, 6.1小时 (V100), tb.dev |
| ViT-L_32 | cifar100 | 93.29%, 1.9小时 (A100), tb.dev | 93.34%, 6.2小时 (V100), tb.dev |
| ViT-L_32 | imagenet2012 | 81.89%, 7.5小时 (A100), tb.dev | 81.13%, 15.0小时 (V100), tb.dev |
我们还想强调,通过较短的训练周期也能获得高质量的结果,并鼓励使用我们代码的用户尝试调整超参数,以在准确性和计算资源之间取得平衡。 下表展示了一些针对 CIFAR-10/100 数据集的例子。
| 上游 | 模型 | 数据集 | 总步数 / 预热步数 | 准确率 | 实际耗时 | 链接 |
|---|---|---|---|---|---|---|
| imagenet21k | ViT-B_16 | cifar10 | 500 / 50 | 98.59% | 17m | tensorboard.dev |
| imagenet21k | ViT-B_16 | cifar10 | 1000 / 100 | 98.86% | 39m | tensorboard.dev |
| imagenet21k | ViT-B_16 | cifar100 | 500 / 50 | 89.17% | 17m | tensorboard.dev |
| imagenet21k | ViT-B_16 | cifar100 | 1000 / 100 | 91.15% | 39m | tensorboard.dev |
MLP-Mixer
作者:Ilya Tolstikhin*、Neil Houlsby*、Alexander Kolesnikov*、Lucas Beyer*, Xiaohua Zhai、Thomas Unterthiner、Jessica Yung、Andreas Steiner、Daniel Keysers、 Jakob Uszkoreit、Mario Lucic、Alexey Dosovitskiy。
(*) 共同第一作者。
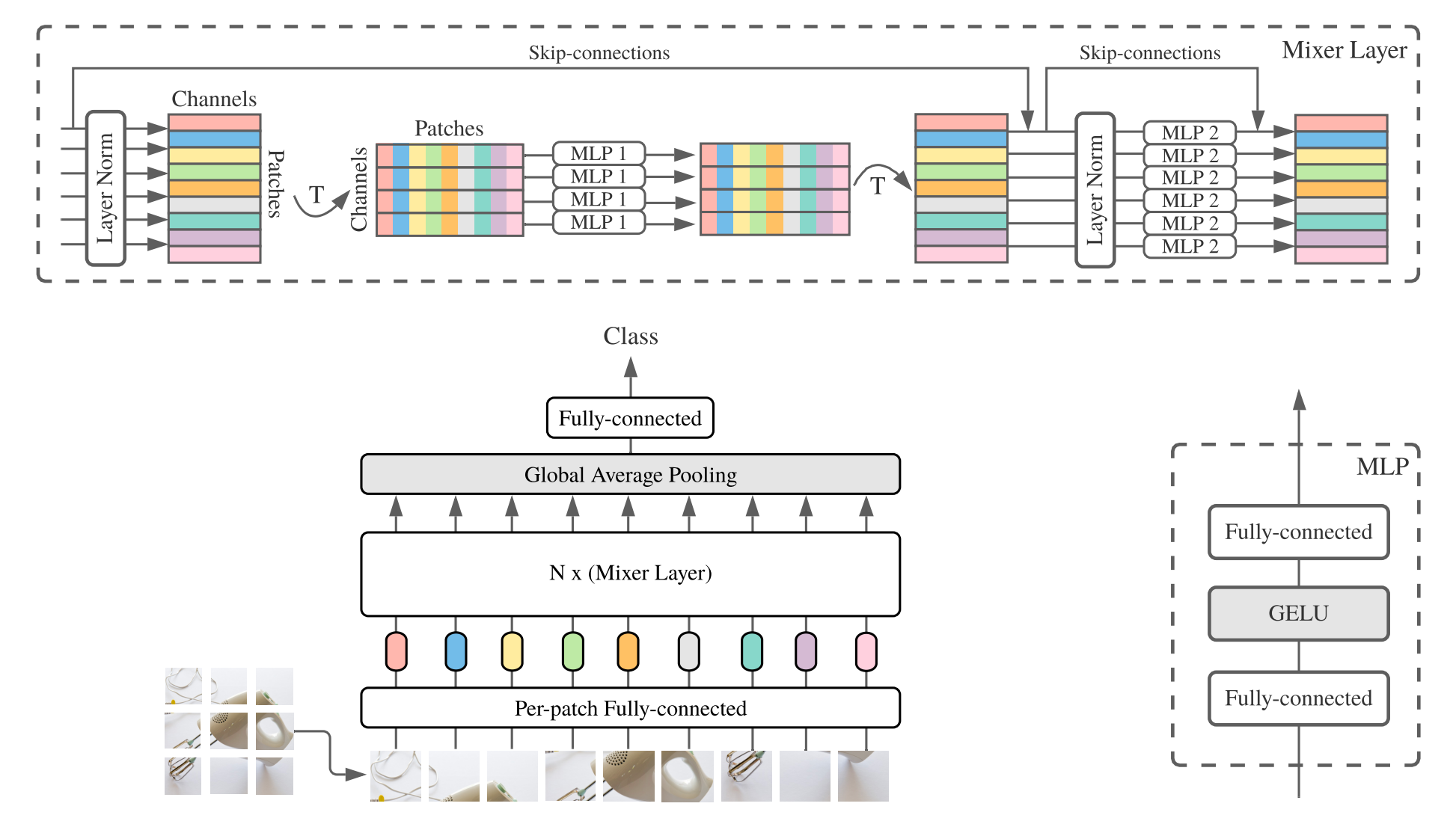
MLP-Mixer(简称Mixer)由逐块线性嵌入、Mixer层和分类头组成。Mixer层包含一个通道混合的MLP和一个特征混合的MLP,每个MLP由两个全连接层和一个GELU非线性激活函数构成。其他组件包括:残差连接、Dropout以及线性分类头。
安装步骤与上述相同,请参阅安装说明。
可用的Mixer模型
我们提供了在ImageNet和ImageNet-21k数据集上预训练的Mixer-B/16和Mixer-L/16模型。详细信息请参见Mixer论文中的表3。所有模型均可在以下地址找到:
https://console.cloud.google.com/storage/mixer_models/
请注意,这些模型也可直接从TF-Hub获取: sayakpaul/collections/mlp-mixer(由Sayak Paul贡献的外部资源)。
预期的Mixer结果
我们在Google Cloud的四张V100 GPU机器上运行了微调代码,并使用了本仓库中的默认适配参数。以下是结果:
| 上游 | 模型 | 数据集 | 准确率 | 实际耗时 | 链接 |
|---|---|---|---|---|---|
| ImageNet | Mixer-B/16 | cifar10 | 96.72% | 3.0小时 | tensorboard.dev |
| ImageNet | Mixer-L/16 | cifar10 | 96.59% | 3.0小时 | tensorboard.dev |
| ImageNet-21k | Mixer-B/16 | cifar10 | 96.82% | 9.6小时 | tensorboard.dev |
| ImageNet-21k | Mixer-L/16 | cifar10 | 98.34% | 10.0小时 | tensorboard.dev |
LiT模型
有关详情,请参阅Google AI博客文章 LiT:为图像模型添加语言理解能力, 或阅读CVPR论文“LiT:通过锁定图像文本微调实现零样本迁移” (https://arxiv.org/abs/2111.07991)。
我们发布了一个Transformer B/16-base模型,其在ImageNet上的零样本准确率为72.1%,以及一个L/16-large模型,其在ImageNet上的零样本准确率为75.7%。更多关于这些模型的详细信息,请参阅 LiT模型卡片。
我们提供了一个基于浏览器的演示,其中包含小型文本编码器,可供交互使用(最小的模型甚至可以在现代手机上运行):
https://google-research.github.io/vision_transformer/lit/
最后,还有一个Colab笔记本,用于使用带有图像和文本编码器的JAX模型:
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/lit.ipynb
需要注意的是,目前上述任何模型都不支持多语言输入,但我们正在开发此类模型,并将在它们可用时更新此仓库。
该仓库仅包含LiT模型的评估代码。训练代码可在big_vision仓库中找到:
https://github.com/google-research/big_vision/tree/main/big_vision/configs/proj/image_text
预期的零样本结果来自model_cards/lit.md(请注意,零样本评估与Colab中的简化评估略有不同):
| 模型 | B16B_2 | L16L |
|---|---|---|
| ImageNet 零样本 | 73.9% | 75.7% |
| ImageNet v2 零样本 | 65.1% | 66.6% |
| CIFAR100 零样本 | 79.0% | 80.5% |
| Pets37 零样本 | 83.3% | 83.3% |
| Resisc45 零样本 | 25.3% | 25.6% |
| MS-COCO 文字描述到图像检索 | 51.6% | 48.5% |
| MS-COCO 图像到文字描述检索 | 31.8% | 31.1% |
在云端运行
虽然上述Colab对于入门非常有用,但通常您会希望在配备更强大加速器的大型机器上进行训练。
创建虚拟机
您可以通过以下命令在Google Cloud上设置一台带有GPU的虚拟机:
# 设置以下所有命令中使用的变量。
# 注意,项目必须已设置账单。
# 关于拥有GPU的区域列表,请参考
# https://cloud.google.com/compute/docs/gpus/gpu-regions-zones
PROJECT=my-awesome-gcp-project # 项目必须启用计费。
VM_NAME=vit-jax-vm-gpu
ZONE=europe-west4-b
# 以下配置已在本仓库中测试过。您可以选择其他镜像和机器组合(例如),请参考相应的gcloud命令:
# gcloud compute images list --project ml-images
# gcloud compute machine-types list
# 等等。
gcloud compute instances create $VM_NAME \
--project=$PROJECT --zone=$ZONE \
--image=c1-deeplearning-tf-2-5-cu110-v20210527-debian-10 \
--image-project=ml-images --machine-type=n1-standard-96 \
--scopes=cloud-platform,storage-full --boot-disk-size=256GB \
--boot-disk-type=pd-ssd --metadata=install-nvidia-driver=True \
--maintenance-policy=TERMINATE \
--accelerator=type=nvidia-tesla-v100,count=8
# 连接到虚拟机(在机器设置并启动后的几分钟内)。
gcloud compute ssh --project $PROJECT --zone $ZONE $VM_NAME
# 使用完毕后停止虚拟机(停止后的虚拟机仅收取存储费用)。
gcloud compute instances stop --project $PROJECT --zone $ZONE $VM_NAME
# 使用完毕后删除虚拟机(这也将删除虚拟机上存储的所有数据)。
gcloud compute instances delete --project $PROJECT --zone $ZONE $VM_NAME
或者,您也可以使用以下类似的命令来设置带有 TPU 挂载的 Cloud 虚拟机(以下命令摘自 TPU 教程):
PROJECT=my-awesome-gcp-project # 项目必须启用结算功能。
VM_NAME=vit-jax-vm-tpu
ZONE=europe-west4-a
# 初始设置服务身份时需要执行此操作。
gcloud beta services identity create --service tpu.googleapis.com
# 创建直接挂载 TPU 的虚拟机。
gcloud alpha compute tpus tpu-vm create $VM_NAME \
--project=$PROJECT --zone=$ZONE \
--accelerator-type v3-8 \
--version tpu-vm-base
# 连接到虚拟机(在机器完成设置并启动后的几分钟内)。
gcloud alpha compute tpus tpu-vm ssh --project $PROJECT --zone $ZONE $VM_NAME
# 使用完毕后停止虚拟机(已停止的虚拟机仅按存储收费)。
gcloud alpha compute tpus tpu-vm stop --project $PROJECT --zone $ZONE $VM_NAME
# 使用完毕后删除虚拟机(这也将删除虚拟机上存储的所有数据)。
gcloud alpha compute tpus tpu-vm delete --project $PROJECT --zone $ZONE $VM_NAME
设置虚拟机
然后按照常规方式克隆仓库并安装依赖项(包括支持 TPU 的 jaxlib):
git clone --depth=1 --branch=master https://github.com/google-research/vision_transformer
cd vision_transformer
# 可选:安装 virtualenv
pip3 install virtualenv
python3 -m virtualenv env
. env/bin/activate
如果您连接的是带有 GPU 的虚拟机,请使用以下命令安装 JAX 和其他依赖项:
pip install -r vit_jax/requirements.txt
如果您连接的是带有 TPU 的虚拟机,请使用以下命令安装 JAX 和其他依赖项:
pip install -r vit_jax/requirements-tpu.txt
安装 Flaxformer,并按照此处链接的相应仓库中的说明进行操作。
无论是 GPU 还是 TPU,都请通过以下命令检查 JAX 是否能够连接到已挂载的加速器:
python -c 'import jax; print(jax.devices())'
最后,执行“微调模型”一节中提到的其中一个命令。
Bibtex
@article{dosovitskiy2020vit,
title={一张图胜过 16×16 个词:大规模图像识别中的 Transformer},
author={多索维茨基、卢卡斯·贝耶尔、亚历山大·科列斯尼科夫、迪尔克·魏森博恩、夏晓华·翟、托马斯·昂特尔蒂纳、莫斯塔法·德赫加尼、马蒂亚斯·明德勒、格奥尔格·海戈尔德、西尔万·盖利、雅各布·乌斯科雷特、尼尔·豪尔斯比},
journal={ICLR},
year={2021}
}
@article{tolstikhin2021mixer,
title={MLP-Mixer:一种用于视觉任务的全 MLP 架构},
author={伊利亚·托尔斯提欣、尼尔·豪尔斯比、亚历山大·科列斯尼科夫、卢卡斯·贝耶尔、夏晓华·翟、托马斯·昂特尔蒂纳、杰西卡·容、安德烈亚斯·施泰纳、丹尼尔·凯瑟斯、雅各布·乌斯科雷特、马里奥·卢奇奇、阿列克谢·多索维茨基},
journal={arXiv 预印本 arXiv:2105.01601},
year={2021}
}
@article{steiner2021augreg,
title={如何训练你的 ViT?视觉 Transformer 中的数据、增强与正则化},
author={安德烈亚斯·施泰纳、亚历山大·科列斯尼科夫、夏晓华·翟、罗斯·怀特曼、雅各布·乌斯科雷特、卢卡斯·贝耶尔},
journal={arXiv 预印本 arXiv:2106.10270},
year={2021}
}
@article{chen2021outperform,
title={当 Vision Transformer 在无需预训练或强大数据增强的情况下超越 ResNet 时},
author={陈翔宁、许祖辉、龚博清},
journal={arXiv 预印本 arXiv:2106.01548},
year={2021},
}
@article{zhuang2022gsam,
title={代理差距最小化改进了尖锐度感知训练},
author={庄俊堂、龚博清、袁良哲、崔寅、哈特维格·亚当、妮查·德沃内克、塞卡尔·塔蒂孔达、詹姆斯·邓肯、刘婷},
journal={ICLR},
year={2022},
}
@article{zhai2022lit,
title={LiT:基于锁定图像文本调优的零样本迁移学习},
author={夏晓华·翟、王肖、巴西尔·穆斯塔法、安德烈亚斯·施泰纳、丹尼尔·凯瑟斯、亚历山大·科列斯尼科夫、卢卡斯·贝耶尔},
journal={CVPR},
year={2022}
}
更改记录
按时间倒序排列:
2022-08-18:新增了在图像侧未使用线性头(LiT_B16B:768)且训练了6万步的LiT-B16B_2模型,其性能优于LiT_B16B。
2022-06-09:新增了在ImageNet数据集上使用GSAM从头开始训练的ViT和Mixer模型,未采用强数据增强。这些ViT模型的性能优于使用AdamW优化器、原始SAM算法或强数据增强训练的同规模模型。
2022-04-14:新增了LiT模型及其Colab笔记本。
2021-07-29:新增了ViT-B/8 AugReg模型(3个上游检查点及分辨率=224的适配版本)。
2021-07-02:新增了论文《当视觉Transformer超越ResNet时...》。
2021-07-02:新增了使用SAM(Sharpness-Aware Minimization,尖锐度感知最小化)优化的ViT和MLP-Mixer检查点。
2021-06-20:新增了论文《如何训练你的ViT?...》,并提供了一个新的Colab笔记本,用于探索论文中提到的5万多份预训练和微调检查点。
2021-06-18:本仓库已重写,采用Flax Linen API和
ml_collections.ConfigDict进行配置管理。2021-05-19:随着《如何训练你的ViT?...》论文的发表,我们新增了5万多份在ImageNet和ImageNet-21k数据集上预训练、并经过不同程度数据增强和模型正则化的ViT及混合模型,这些模型还在ImageNet、Pets37、Kitti-distance、CIFAR-100和Resisc45数据集上进行了微调。请查看
vit_jax_augreg.ipynb来浏览这一丰富的模型资源!例如,您可以通过该Colab获取论文中表3i21k_300列中推荐的预训练和微调检查点文件名。2020-12-01:新增了R50+ViT-B/16混合模型(在ResNet-50骨干网络之上叠加ViT-B/16)。当在imagenet21k数据集上预训练时,该模型仅需不到一半的计算资源即可达到与L/16模型相近的性能。需要注意的是,“R50”在B/16变体中有所调整:原始ResNet-50包含[3,4,6,3]层,每层都会使图像分辨率降低两倍。结合ResNet的stem部分,最终分辨率将被缩小32倍,即使使用(1,1)的patch size,也无法实现ViT-B/16变体。因此,我们在R50+B/16变体中采用了[3,4,9]层的配置。
2020-11-09:新增了ViT-L/16模型。
2020-10-29:新增了在ImageNet-21k数据集上预训练、随后在ImageNet数据集上以224x224分辨率(而非默认的384x384)微调的ViT-B/16和ViT-L/16模型。这些模型名称后均带有“-224”后缀。预计它们的top-1准确率分别为81.2%和82.7%。
免责声明
开源发布由Andreas Steiner整理。
注:本仓库基于google-research/big_transfer分叉并修改而来。
这并非谷歌官方产品。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器