limit
LIMIT 是一个专为评估嵌入模型(Embedding Models)理论极限而设计的开源数据集与测试框架。当前主流的基于单向量嵌入的检索技术虽然广泛应用,但其能力边界尚不清晰。LIMIT 基于严格的数学理论构建,证明了对于任意给定的嵌入维度,总存在某些文档组合无法被任何查询正确检索到。该项目通过实例化这一理论,创建了包含特定查询、文档及相关性标注的数据集,旨在对现有模型进行“压力测试”。
实验结果表明,即使是当前最先进的嵌入模型,在 LIMIT 数据集上也表现挣扎,这揭示了单向量嵌入范式存在的根本性局限。对于从事信息检索、自然语言处理的研究人员和开发者而言,LIMIT 提供了宝贵的基准工具,帮助大家客观认识模型能力的短板,从而推动更鲁棒的检索算法研发。其独特亮点在于将抽象的理论证明转化为可执行的评测数据,并兼容主流的 MTEB 评估框架与 Huggingface 数据集库,便于快速复现与集成。无论是希望深入理解嵌入机制的学者,还是致力于优化检索系统的工程师,都能从中获得关键洞察。
使用场景
某大型法律科技公司的算法团队正在优化其案例检索系统,试图通过向量嵌入技术提升律师查找相似判例的准确率。
没有 limit 时
- 团队盲目信任主流嵌入模型,误以为增加向量维度就能无限提升检索效果,导致在硬件扩容上浪费大量预算。
- 在常规测试集上表现优异的模型,上线后却频繁出现“明明有相关文档却完全搜不到”的诡异失效现象,且无法从理论上解释原因。
- 缺乏针对性的压力测试数据,难以发现单向量嵌入范式在处理特定逻辑组合文档时的根本性缺陷,系统存在隐蔽的召回盲区。
- 研发方向陷入瓶颈,只能在现有架构上反复微调参数,却无法意识到这是当前技术路线的理论天花板而非工程问题。
使用 limit 后
- 利用 limit 数据集提供的理论构造样本,团队迅速复现了检索失效场景,证实了特定文档组合在任何查询下都不可被召回的数学必然性。
- 清晰量化了当前模型的理論局限,帮助团队及时止损,停止了对单一向量维度扩充的无效投入,转而探索多向量或混合检索架构。
- 通过 limit 生成的对抗性数据作为新的基准测试,精准定位了模型在复杂逻辑关系下的弱点,为后续架构升级提供了明确的改进靶点。
- 将学术理论转化为工程实践依据,让团队在与管理层沟通技术债时拥有了无可辩驳的数据支撑,推动了技术栈的果断重构。
limit 不仅是一个数据集,更是一把揭示当前嵌入检索技术理论天花板的标尺,帮助开发者从盲目优化转向架构革新。
运行环境要求
- 未说明
未说明
未说明

快速开始
关于基于嵌入的检索的理论局限性
本仓库包含论文《关于基于嵌入的检索的理论局限性》(arXiv:2508.21038)的官方资源。
这项工作引入了 LIMIT 数据集,
旨在基于理论原理对嵌入模型进行压力测试。
我们证明,对于任意给定的嵌入维度 d,
都存在一组文档,无法被任何查询检索到。
我们利用这一理论构建了 LIMIT 数据集,
发现即使是当前最先进的模型也难以应对,从而凸显了当前单向量嵌入范式的根本性局限。
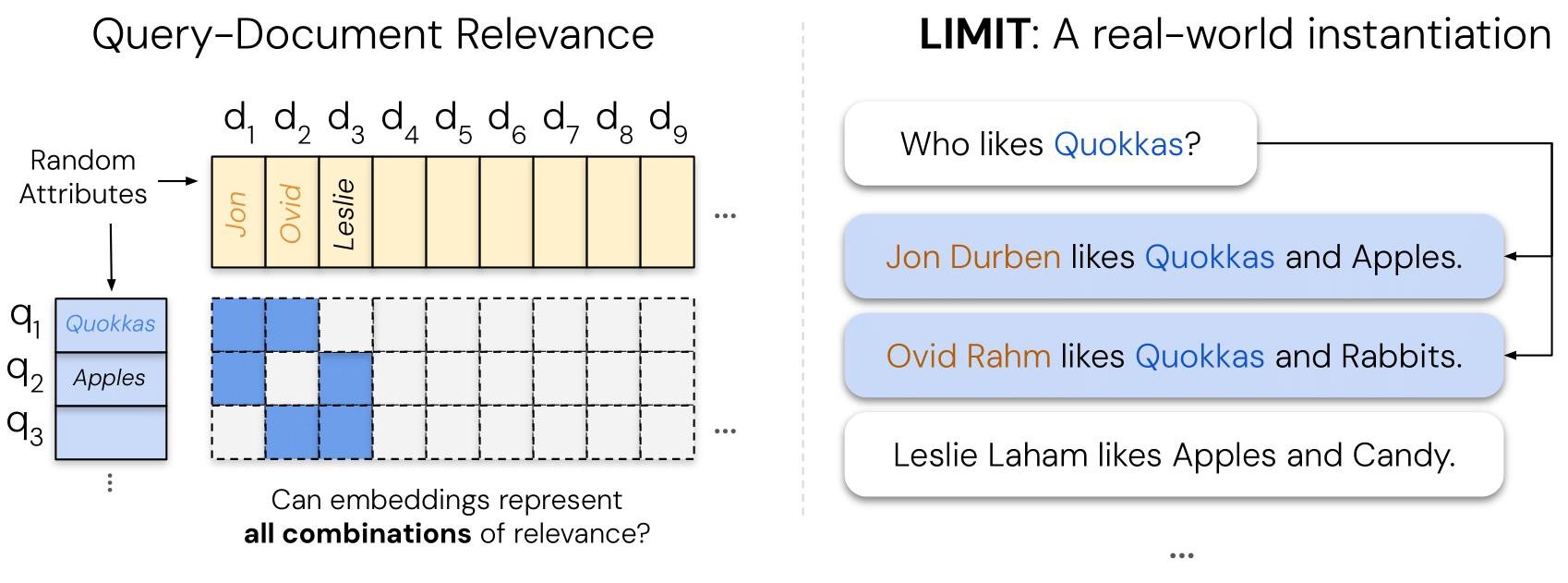
概览
数据
我们在实验中使用的数据集位于本仓库的 data/ 目录下,格式符合 MTEB 标准(即 JSON Lines 格式)。
每个数据集包含:
- 一个
queries.json文件,每行对应一个查询,共 1000 条,每条包含_id和text字段。 - 一个
corpus.json文件,每行对应一篇文档,共 50,000 篇(或使用small版本时为 46 篇),每篇包含_id、text和空的title字段。 - 一个
qrels.json文件,每行对应一个相关查询-文档映射,共 2000 条,将查询的query-id映射到文档的corpus-id,其中score表示相关性。
完整数据集 (
limit): 包含 50,000 篇文档的完整数据集。小样本 (
limit-small): 只包含与查询相关的 46 篇文档的小版本。
代码
我们在 code/ 文件夹中提供了生成 LIMIT 风格数据集以及运行免费嵌入实验的代码。
数据集生成: 若要从头开始生成数据集,可以使用位于
code/generate_limit_dataset.ipynb的 Jupyter 笔记本。该笔记本包含了所有必要的步骤和依赖项。免费嵌入实验: 运行免费嵌入实验的脚本位于
code/free_embedding_experiment.py。
如果您使用免费嵌入代码,需要安装以下依赖项。
安装
我们推荐使用 uv 包管理器。
# 创建虚拟环境
uv venv
source .venv/bin/activate
# 安装依赖
uv pip install -r https://raw.githubusercontent.com/google-deepmind/limit/refs/heads/main/code/requirements.txt
使用 Hugging Face Datasets 加载
您也可以使用 Hugging Face 的 datasets 库加载数据(LIMIT,LIMIT-small):
from datasets import load_dataset
ds = load_dataset("orionweller/LIMIT-small", "corpus") # 还有 queries 和 test(包含 qrels)可选。
评估
评估使用了 MTEB 框架。您只能在 v2.0.0 分支(即将成为 main 分支)上复现此评估。请注意,v2.0.0 分支正在快速更新,因此请在它成为主分支之前,安装需求文件中锁定的版本。示例如下:
import mteb
from sentence_transformers import SentenceTransformer
# 使用 MTEB 加载模型
model_name = "sentence-transformers/all-MiniLM-L6-v2"
model = mteb.get_model(model_name) # 如果 MTEB 中未实现,则默认使用 SentenceTransformers(model_name)
# 或直接使用 SentenceTransformers
model = SentenceTransformer(model_name)
# 选择所需任务并进行评估
tasks = mteb.get_tasks(tasks=["LIMITSmallRetrieval"]) # 对于完整数据集,可使用 LIMITRetrieval
results = mteb.evaluate(model, tasks=tasks)
更多详情请参阅他们的 GitHub 页面。
引用
如果您使用了本工作,请按以下方式引用论文:
@article{weller2025theoretical,
title={On the Theoretical Limitations of Embedding-Based Retrieval},
author={Weller, Orion and Boratko, Michael and Naim, Iftekhar and Lee, Jinhyuk},
journal={arXiv preprint arXiv:2508.21038},
year={2025}
}
许可与免责声明
版权所有 © 2025 Google LLC
所有软件均采用 Apache License, Version 2.0(Apache 2.0)许可;除非符合 Apache 2.0 许可条款,否则不得使用本文件。您可以在以下网址获取 Apache 2.0 许可协议: https://www.apache.org/licenses/LICENSE-2.0
其他所有材料均采用 Creative Commons Attribution 4.0 国际许可(CC-BY)。您可以在以下网址获取 CC-BY 许可协议: https://creativecommons.org/licenses/by/4.0/legalcode
除非适用法律另有规定或以书面形式达成一致,否则在此处根据 Apache 2.0 或 CC-BY 许可分发的所有软件和材料均“按原样”提供,不附带任何形式的明示或默示保证或条件。具体权限和限制请参阅相应许可协议中的语言表述。
本项目并非 Google 官方产品。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
cs-video-courses
cs-video-courses 是一个精心整理的计算机科学视频课程清单,旨在为自学者提供系统化的学习路径。它汇集了全球知名高校(如加州大学伯克利分校、新南威尔士大学等)的完整课程录像,涵盖从编程基础、数据结构与算法,到操作系统、分布式系统、数据库等核心领域,并深入延伸至人工智能、机器学习、量子计算及区块链等前沿方向。 面对网络上零散且质量参差不齐的教学资源,cs-video-courses 解决了学习者难以找到成体系、高难度大学级别课程的痛点。该项目严格筛选内容,仅收录真正的大学层级课程,排除了碎片化的简短教程或商业广告,确保用户能接触到严谨的学术内容。 这份清单特别适合希望夯实计算机基础的开发者、需要补充特定领域知识的研究人员,以及渴望像在校生一样系统学习计算机科学的自学者。其独特的技术亮点在于分类极其详尽,不仅包含传统的软件工程与网络安全,还细分了生成式 AI、大语言模型、计算生物学等新兴学科,并直接链接至官方视频播放列表,让用户能一站式获取高质量的教育资源,免费享受世界顶尖大学的课堂体验。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。