SocratiCode
SocratiCode 是一款专为 AI 编程助手打造的开源代码库智能引擎,旨在让 AI 真正“理解”而不仅仅是读取你的代码。它解决了大型项目中 AI 因缺乏全局上下文而导致回答不准、需要反复调用或消耗大量 Token 的痛点。通过零配置、本地化且完全隐私保护的部署方式,SocratiCode 能自动构建包含混合语义搜索、多语言依赖图谱以及数据库、API 和基础设施知识的深度索引。
这款工具特别适合需要在大规模代码库(支持超 4000 万行代码)中工作的开发者、技术团队及企业用户。无论是使用 Claude Code、Cursor、VS Code 还是其他兼容 MCP 协议的 AI 编辑器,都能无缝集成。其独特亮点在于极高的效率与稳定性:相比传统搜索方式,它能减少 61% 的 Token 消耗和 84% 的调用次数,速度提升高达 37 倍。此外,SocratiCode 具备断点续传索引、文件实时监听更新以及多智能体协同工作能力,确保在复杂开发环境中始终提供准确、即时且安全的代码上下文支持,是提升 AI 编程效能的理想搭档。
使用场景
某大型金融科技团队需要在数千万行代码的遗留系统中,快速定位一个涉及多语言微服务、数据库变更及基础设施配置的复杂支付漏洞。
没有 SocratiCode 时
- 搜索效率极低:开发者依赖传统的
grep或基础语义搜索,面对海量代码库时响应缓慢,且无法跨项目或跨分支关联查找,往往需要数小时才能拼凑出线索。 - 上下文理解割裂:AI 助手因缺乏全局索引,无法理解多语言(Polyglot)间的依赖关系,经常遗漏关键的数据库 Schema 变更或基础设施配置细节,导致排查方向错误。
- 资源消耗巨大:为了让 AI 理解代码,开发者不得不手动粘贴大量文件片段,导致 Token 消耗量激增,API 调用次数频繁,不仅成本高昂且容易触发速率限制。
- 协作与中断风险:多人同时分析时缺乏统一的索引机制,且一旦索引构建过程中断(如崩溃或网络波动),进度全部丢失,需重新开始。
使用 SocratiCode 后
- 秒级精准定位:SocratiCode 通过混合语义搜索和跨项目感知能力,瞬间锁定分散在不同仓库和分支中的相关代码段,将数小时的排查工作缩短至几分钟。
- 全栈深度洞察:工具自动构建包含数据库、API 规范及基础设施配置的全局依赖图谱,让 AI 能够“理解”而非仅仅“读取”代码,准确识别出底层配置引发的连锁反应。
- 极致降本增效:得益于智能索引管理,SocratiCode 使 Token 使用量减少 61%,API 调用降低 84%,搜索速度比传统 AI grep 快 37 倍,大幅节省计算资源。
- 稳健的自动化体验:零配置部署后,文件监听器自动实时更新索引,支持断点续传和多代理协同,确保团队在任意中断后都能无缝继续工作,无需重复劳动。
SocratiCode 将原本碎片化、高成本的代码排查过程,转变为私有、即时且具备企业级深度的智能决策流。
运行环境要求
- Linux
- macOS
- Windows
- 非必需
- 本地部署时,macOS/Windows 的 Docker 容器无法使用 GPU
- 建议安装原生 Ollama 以利用 Metal (Mac) 或 CUDA (Windows) 加速
- 未指定具体显卡型号、显存大小或 CUDA 版本要求
未说明

快速开始

SocratiCode
![]()
![]()

![]()

"唯一的好就是知识,唯一的恶就是无知。" — 苏格拉底
你的 AI 可以读代码。而 SocratiCode 能够理解它。
开源的代码库上下文引擎:为任何 AI 提供对你整个代码库(以及基础设施)的即时自动化知识——大规模、零配置、完全私密、彻底免费。
感谢 Altaire Limited 的赞助
如果 SocratiCode 对你有所帮助,请 ⭐ 给这个仓库加星 —— 这有助于其他人发现它——并将其分享给你的开发团队和其他开发者!
💬 有问题或只是想聊聊?欢迎加入我们的 Discord。
一件事,做到极致:深度代码库智能——无需设置,没有冗余,完全自动。 SocratiCode 为 AI 助手提供对代码库的深度语义理解——混合搜索、跨项目搜索、多语言代码依赖图,以及可搜索的上下文工件(数据库模式、API 规范、基础设施配置、架构文档)。零配置——只需将其添加到 任何 MCP 主机,或者为 Claude Code、Cursor、VS Code Copilot、Codex 或 Gemini CLI 安装原生 插件。一切均由其自动管理。
生产就绪,经过企业级大型代码库的实战考验(高达 ~4000 万行代码)。采用 批处理方式,自动且可恢复的索引检查点会持续推进——暂停、崩溃、重启和中断都不会丢失进度。文件监视器会在每次文件更改时以及跨会话期间保持 索引自动更新。支持多代理——多个 AI 代理可以同时在同一代码库上工作,共享单个索引,并实现自动协调,且无需任何配置。
默认私密且本地运行——Docker 处理一切,无需 API 密钥,数据不会离开你的机器。云端就绪,可用于嵌入(OpenAI、Google Gemini)和 Qdrant,并且在你需要时,还提供 全套配置选项。
☁️ SocratiCode Cloud(私密测试版)——基于与开源版本相同引擎的托管式共享团队索引,额外提供 SSO、审计日志、分支感知索引,以及 VPC / 空气隔离部署选项。开源核心部分将永远免费。申请提前访问 →
首个基于 Qdrant 的 MCP/Claude 插件/技能,将自动管理、零配置的本地 Docker 部署与 AST 感知的代码分块、混合语义 + BM25(RRF 融合)代码搜索、多语言依赖 图谱及循环依赖可视化,以及可搜索的 基础设施/API/数据库工件相结合,形成一个专注、零配置且易于使用的代码智能引擎。
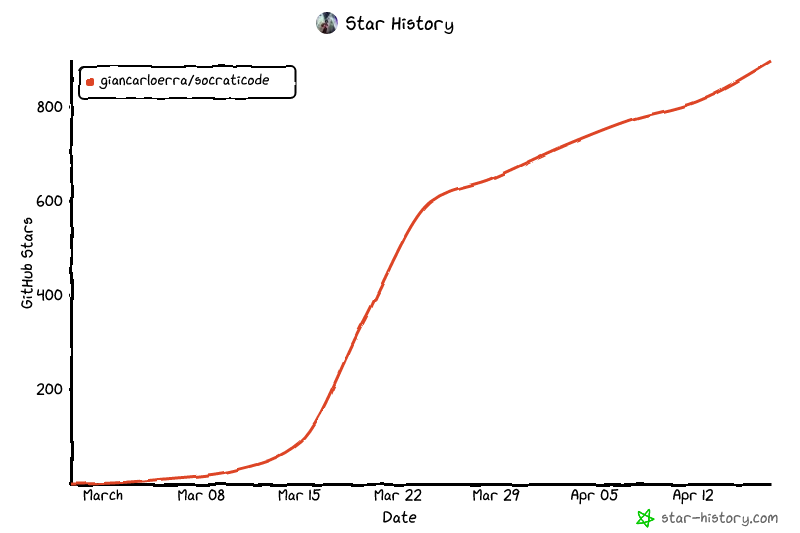
在 VS Code 上的基准测试(245 万行): SocratiCode 使用的 上下文减少了 61%,工具调用减少了 84%,并且比基于 grep 的探索快了 37 倍——使用 Claude Opus 4.6 实时测试。查看完整基准测试 →
目录
- 快速入门
- 插件
- 为什么选择 SocratiCode
- 功能
- 先决条件
- 示例工作流程
- 代理指令
- 配置
- 语言支持
- 忽略规则
- 上下文工件
- 环境变量
- Docker 资源
- 测试
- 为何不直接使用 grep?
- 常见问题解答
- 社区
- SocratiCode Cloud
- 许可证
快速入门
仅需运行 Docker。
一键安装 — Claude Code、VS Code 和 Cursor:
所有 MCP 主机 — 将以下内容添加到你的 mcpServers(Claude Desktop、Windsurf、Cline、Roo Code)或 servers(VS Code 项目本地的 .vscode/mcp.json)配置中:
"socraticode": {
"command": "npx",
"args": ["-y", "socraticode"]
}
Claude Code — 安装插件(推荐,包含工作流技能以获得最佳效果):
从你的终端:
claude plugin marketplace add giancarloerra/socraticode
claude plugin install socraticode@socraticode
或者在 Claude Code 内部:
/plugin marketplace add giancarloerra/socraticode
/plugin install socraticode@socraticode
自动更新: 安装后,打开
/plugin→ 市场 → 选择socraticode→ 启用自动更新。
或者仅作为 MCP 使用(不带技能):
claude mcp add socraticode -- npx -y socraticode
更新:
npx在首次运行后会缓存包。要获取最新版本,请清除缓存并重启你的 MCP 主机:rm -rf ~/.npm/_npx && claude mcp restart socraticode。或者,在你的配置中使用npx -y socraticode@latest,以便每次启动时都检查更新(速度稍慢)。
OpenCode — 添加到你的 opencode.json(或 opencode.jsonc):
{
"mcp": {
"socraticode": {
"type": "local",
"command": ["npx", "-y", "socraticode"],
"enabled": true
}
}
}
OpenAI Codex CLI — 添加到 ~/.codex/config.toml:
[mcp_servers.socraticode]
command = "npx"
args = ["-y", "socraticode"]
重启你的主机。首次使用时,SocratiCode 会自动拉取 Docker 镜像,启动自己的 Qdrant 和 Ollama 容器,并下载嵌入模型——这是一次性设置,根据你的网络情况大约需要 5 分钟。之后,它会在几秒钟内启动。
首次在项目上使用 — 询问你的 AI:“索引这个代码库”。索引会在后台运行;你可以询问“代码库索引状态如何?”来监控进度。根据代码库大小以及你是否使用 GPU 加速的 Ollama 或云端嵌入,首次索引可能需要几秒到几分钟不等(在 Macbook Pro M4 上首次索引超过 300 万行代码通常不到 10 分钟)。一旦完成,无需再次运行,你可以进行搜索、探索依赖图并查询上下文工件。
此后每次使用 — 直接使用工具(搜索、图表等)。在服务器启动时,SocratiCode 会自动检测之前已索引的项目,重启文件监视器,并执行增量更新以捕获服务器关闭期间发生的任何更改。如果索引被中断,它会从最后一个检查点自动恢复。你也可以通过 codebase_watch { action: "start" } 显式启动或重启监视器。
macOS / Windows 上的大规模代码库:Docker 容器无法使用 GPU。对于中大型仓库,建议安装原生 Ollama(自动检测,无需更改配置)以获得 Metal/CUDA 加速,或使用 OpenAI 嵌入以提升速度而无需本地安装。详细信息。
推荐: 为了获得最佳效果,将 代理指令 添加到你的 AI 助手的系统提示或项目说明文件(
CLAUDE.md、AGENTS.md等)中。关键原则——先搜索再阅读——有助于你的 AI 有效利用 SocratiCode 的工具,避免不必要的文件读取。
Claude Code 用户: 如果你安装了 SocratiCode 插件,代理指令会自动作为技能包含在内——无需将其添加到你的
CLAUDE.md中。该插件还捆绑了 MCP 服务器,因此你不需要单独执行claude mcp add。
高级选项: 云端嵌入(OpenAI / Google)、外部 Qdrant、远程 Ollama、原生 Ollama 以及数十种调优选项均可使用。请参阅下方的 配置。
插件
SocratiCode 可在多个 AI 编码平台上作为原生插件使用。这些插件将 MCP 服务器与工作流技能和代理指令打包在一起——只需一次安装即可获得所有功能。
| 平台 | 安装方法 |
|---|---|
| Claude Code | claude plugin marketplace add giancarloerra/socraticode — 完整说明 |
| Cursor | /add-plugin https://github.com/giancarloerra/socraticode |
| VS Code Copilot | 命令面板 → Chat: 从源安装插件 → https://github.com/giancarloerra/socraticode |
| Zed | 在 Zed 设置中添加为自定义 MCP 服务器 — 配置示例 |
| Gemini CLI | gemini extensions install https://github.com/giancarloerra/socraticode |
| OpenAI Codex | 尚未有公开的插件目录——使用 MCP 配置 或参阅下方的 Codex 本地安装 |
VS Code Copilot: 聊天插件功能目前处于预览阶段。请在 VS Code 设置中启用
chat.plugins.enabled: true。
Codex 本地插件安装: 克隆仓库并在你的个人插件市场中注册:
git clone https://github.com/giancarloerra/socraticode.git ~/.agents/plugins/socraticode然后将其添加到
~/.agents/plugins/marketplace.json中:{ "plugins": [ { "name": "socraticode", "path": "~/.agents/plugins/socraticode" } ] }下次启动时,Codex 将从
.codex-plugin/plugin.json中发现该插件。
所有其他 MCP 主机(Claude Desktop、Windsurf、Cline、Roo Code、OpenCode):使用 MCP 配置——适用于任何支持 MCP 协议的主机。
为什么选择 SocratiCode
我创建 SocratiCode 的原因在于,我经常需要处理跨多种语言的大型复杂代码库,并且需要快速理解这些代码并采取行动。然而,现有的解决方案要么功能过于有限,要么未经过充分的生产环境测试,要么充斥着不必要的复杂性。我希望有一个专注、单一的工具,能够出色地提供深度的代码库智能分析——无需任何设置、没有冗余功能、完全自动化——并且不会干扰我的工作流程。
内置代码搜索与 SocratiCode 对比
| 功能 | Claude Code | Cursor | VS Code Copilot | + SocratiCode |
|---|---|---|---|---|
| 文本 / grep 搜索 | ✅ | ✅ | ✅ | ✅ |
| 语义搜索 | — | ✅ | ✅¹ | ✅ |
| 混合搜索(融合) | — | — | — | ✅ |
| 代码依赖图 | — | — | ✅² | ✅ |
| 循环依赖检测 | — | — | — | ✅ |
| 非代码知识(模式、API 规范) | — | — | — | ✅ |
| 跨项目搜索 | — | — | — | ✅ |
| 分支感知索引 | — | — | — | ✅ |
| 多代理共享索引 | — | — | — | ✅ |
| 工具无关(切换 AI 时仍可用) | — | — | — | ✅ |
| 完全本地化 / 私有 | ✅ | —³ | —⁴ | ✅ |
| 可恢复索引 | — | — | — | ✅ |
| 实时文件监控 | — | ✅ | — | ✅ |
¹ VS Code Copilot:通过 GitHub / Azure DevOps 进行远程索引;本地“外部数据导入”功能正在逐步推出。 ² 基于 LSP 的“查找引用”/“转到定义”(用法工具),并非完整的依赖图。 ³ Cursor:嵌入向量在 Cursor 服务器上处理(传输和存储过程中均加密)。 ⁴ VS Code Copilot:远程索引托管在 GitHub / Azure DevOps 上。 来源:Cursor 文档、Claude Code 文档、VS Code Copilot 文档。
🔌 上下文与你的代码库绑定,而非与某个助手绑定。 内置索引(Cursor 和 Copilot 的)仅与特定工具相关联——一旦更换助手,就需要从头开始。而 SocratiCode 是独立的:只需索引一次,即可将其接入 Claude Code、Cursor、Copilot、Windsurf,或你自己的私有模型,甚至同时接入所有工具。它们将共享对你的代码的统一理解。
在 VS Code 的 245 万行代码库中,SocratiCode 在回答架构相关问题时,所需的数据量减少了 61%,步骤减少了 84%,响应速度更是快了 37 倍,相比基于 grep 的 AI 助手而言。完整基准测试 →
功能
混合代码搜索 — 基于 Qdrant 构建,Qdrant 是一款专为向量检索设计的数据库,支持 HNSW 索引、并发读写以及负载过滤。每个代码块同时存储稠密向量和 BM25 稀疏向量;Query API 会在一次请求中并行执行这两个子查询,并使用倒排秩融合(RRF)对结果进行融合。语义搜索能够处理“认证中间件”这类概念性查询,即使代码中并未出现这些确切词汇。而 BM25 则负责精确的标识符和关键词查找。在每次查询中,您都能同时获得两者的最佳效果,无需任何调优。
可配置的 Qdrant — 您可以使用内置的 Docker 版 Qdrant(默认设置,无需配置),也可以连接到您自己的实例(自托管、远程服务器或 Qdrant Cloud)。通过
QDRANT_MODE、QDRANT_URL和QDRANT_API_KEY环境变量进行配置。可配置的 Ollama — 您可以使用内置的 Docker 版 Ollama(默认设置,无需配置),也可以指向您自己的 Ollama 实例(原生安装且支持 GPU、远程服务器等)。通过
OLLAMA_MODE、OLLAMA_URL、EMBEDDING_MODEL和EMBEDDING_DIMENSIONS环境变量进行配置。多提供商嵌入模型 — 仅需一个环境变量即可在本地 Ollama(私有,支持 GPU)、Docker 版 Ollama(零配置)、OpenAI (
text-embedding-3-small, 最快) 或 Google Gemini (gemini-embedding-001, 免费层级) 之间切换。无需针对特定提供商的配置文件。私密且安全 — 所有操作均在您的机器上运行——您的代码永远不会离开您的网络。默认的 Docker 部署包含 Ollama(嵌入生成)和 Qdrant(向量存储),不涉及任何外部 API 调用。无 API 费用,无令牌限制。适用于气隙环境和本地部署场景。虽然可以选择 OpenAI、Google Gemini 或 Qdrant Cloud 等云服务提供商,但并非必需。
AST 感知的分块 — 文件通过 AST 解析(ast-grep)在函数或类的边界处进行分割,而非按任意行数切分。这样可以生成更高质量的搜索结果。对于不支持的语言,则回退到基于行数的分块方式。
多语言代码依赖图 — 使用 ast-grep 对 18 种以上语言的 import/require/use/include 语句进行静态分析。无需依赖 dependency-cruiser 等外部工具。能够检测循环依赖,并生成可视化的 Mermaid 图表。
语言无关性 — 开箱即用,支持所有编程语言、框架和文件类型。无需安装特定语言的解析器,无需维护语法文件,也不存在“不支持的语言”的限制。只要您的 AI 能够读取,SocratiCode 就能对其进行索引。
增量索引 — 在完成首次全量索引后,仅重新处理发生变更的文件。内容哈希值会持久化存储在 Qdrant 中,因此即使服务器重启,索引状态也能保持不变。
批处理与可恢复索引 — 文件以每批 50 个为单位进行处理,每处理完一批后都会将进度检查点记录到 Qdrant 中。如果进程崩溃或中断,下次运行时会自动从上次停止的地方继续,已索引的文件则通过哈希比对跳过。这种方式能够有效降低峰值内存占用,使索引过程即便面对超大规模代码库也十分可靠。
实时文件监控 — 可选择监控文件变化,并实时更新索引(防抖延迟 2 秒)。文件监控器还会失效代码图缓存。
并行处理 — 文件以并行批次(每次 50 个)扫描和分块,以实现快速 I/O;而嵌入向量的生成和插入操作则单独分批进行,以优化吞吐量。
多项目支持 — 可同时索引多个项目。每个项目拥有独立的集合,并完整记录项目路径。
跨项目搜索 — 可在一次查询中跨多个相关项目进行搜索。通过
.socraticode.json文件或SOCRATICODE_LINKED_PROJECTS环境变量链接项目,然后在codebase_search中设置includeLinked: true。结果会打上项目标签,并通过客户端 RRF 融合去重。分支感知索引 — 通过设置
SOCRATICODE_BRANCH_AWARE=true,可为每个 Git 分支维护独立的索引。每个分支都有自己的 Qdrant 集合,切换分支时会立即切换到正确的索引。非常适合 CI/CD 流水线和 PR 审查工作流。尊重忽略规则 — 会遵守所有
.gitignore文件(根目录及嵌套目录),并额外支持一个可选的.socraticodeignore文件用于进一步排除。内置合理的默认规则。可通过RESPECT_GITIGNORE=false禁用.gitignore处理。如需包含点目录(例如.agent),可设置INCLUDE_DOT_FILES=true。自定义文件扩展名 — 对于使用非标准扩展名的项目(如
.tpl、.blade),可通过EXTRA_EXTENSIONS环境变量或extraExtensions工具参数将其纳入索引。该功能同时适用于索引构建和代码依赖图生成。可配置的基础设施 — 所有端口、主机和 API 密钥均可通过环境变量进行配置。Qdrant API 密钥支持企业级部署。
企业级的简易性 — 无需调整代理协调参数,无需设置内存限制的环境变量,无需调节协调器或指挥官的容量旋钮,也不需要配置背压机制。SocratiCode 依靠生产级基础设施(Qdrant、成熟的嵌入式 API)来实现扩展,而非复杂的进程内编排。
自动安装与零配置 — 您只需安装 Claude 插件/技能,或将 MCP 服务器添加到您的 AI 主机配置中。首次使用时,服务器会自动检查 Docker 环境,拉取镜像,启动 Qdrant 和 Ollama 容器,并下载嵌入模型。无需配置文件、YAML 或环境变量调优,也不需要编译原生依赖项。只要 Docker 能运行,即可使用。
会话恢复 — 当重新打开一个已索引的项目时,首次使用任何工具(搜索、状态查询、更新或代码图查询)时,文件监控器会自动启动。它会捕获自上次会话以来的所有更改,并保持索引的实时更新——无需手动操作。
自动启动监控器 — 当您在已索引的项目上使用任何 SocratiCode 工具时,文件监控器会自动激活。它会在
codebase_index完成后、codebase_update完成后,以及首次进行codebase_search、codebase_status或代码图查询时启动。如有需要,您也可以通过codebase_watch { action: "start" }手动启动。自动构建代码图 — 代码依赖图会在索引完成后自动构建,并在受监控的文件发生变化时重新构建。除非您想强制重建,否则无需手动调用
codebase_graph_build。多智能体协作 — 多个 AI 代理(各自运行独立的 MCP 实例)可以同时在同一代码库上工作,并共享同一索引。由一个代理触发索引构建,所有代理都基于相同的数据进行搜索。每个项目仅运行一个文件监控器——所有代理都能受益于实时更新。跨进程文件锁机制会自动协调索引和监控操作。非常适合以下场景:一个代理编写测试用例,另一个代理修复代码;或者规划代理与实施代理并行工作。
跨进程安全性 — 基于文件的锁机制(
proper-lockfile)可防止多个 MCP 实例同时对同一个项目进行索引或监控。来自崩溃进程的过期锁会自动回收。当已有其他 MCP 进程正在监控某个项目时,codebase_status会报告“正在监控(由其他进程)”,而不是错误地显示“未监控”。并发保护 — 可防止重复的索引和图构建操作。如果您在索引正在进行时再次调用
codebase_index,系统会返回当前进度,而不是启动第二次操作。优雅停止 — 长时间运行的索引操作可以通过
codebase_stop安全终止。当前批次会完成并保存检查点,从而保留所有进度。重新运行codebase_index即可从中断处继续。优雅关机 — 服务器关闭时,正在运行的索引操作会被给予最多 60 秒完成剩余工作,所有文件监控器会干净地停止,整个系统也会平稳关闭。
结构化日志记录 — 所有操作都会附带结构化的上下文信息,便于可观ability 监控。日志级别可通过
SOCRATICODE_LOG_LEVEL进行配置。优雅降级 — 如果监控过程中基础设施出现故障,监控器会退避并重试,而不是直接崩溃。
前置条件
| 依赖项 | 用途 | 安装 |
|---|---|---|
| Docker | 运行 Qdrant(向量数据库)以及默认的 Ollama(嵌入模型) | docker.com |
| Node.js 18+ | 运行 MCP 服务器 | nodejs.org |
在使用默认的 managed 模式时,Docker 必须处于运行状态。
Qdrant 容器会自动管理。如果你将 QDRANT_MODE=external 设置,并将 QDRANT_URL 指向远程或云端的 Qdrant 实例,则此时 Docker 仅用于 Ollama(嵌入模型)。
Ollama 容器(嵌入模型)在默认的 auto 模式下也会自动管理。SocratiCode 首先会检查本地是否已运行 Ollama——如果已运行则直接使用;否则会为你管理一个 Docker 容器。首次下载 Docker 镜像或嵌入模型可能需要几分钟时间,具体取决于你的网络速度,且仅在首次启动时需要。
在 macOS / Windows 上的嵌入性能
macOS 和 Windows 上的 Docker 容器无法访问 GPU(没有 Metal 或 CUDA 直通)。对于小型项目这并无大碍,但对于中大型代码库而言,仅使用 CPU 的容器会明显更慢。
为获得最佳性能,请安装原生 Ollama:从 ollama.com/download 下载并运行安装程序。一旦 Ollama 运行起来,SocratiCode 将自动检测并使用它——无需额外配置(如果嵌入模型尚未下载,首次下载可能需要几分钟)。这样在 macOS 上可以获得 Metal GPU 加速,在 Windows/Linux 上则可利用 CUDA。
如果你希望在不进行本地安装的情况下追求速度,可参阅下方的 OpenAI Embeddings 和 Google Generative AI Embeddings,它们提供了基于云的服务选项。OpenAI 速度极快,且无需任何本地设置。而 Google 的免费层级虽然可用,但存在速率限制。有关配置详情,请参阅 环境变量。
示例工作流程
所有工具的默认 projectPath 都是当前工作目录,因此你无需为当前项目指定路径。
用户: “索引这个项目”
→ codebase_index {}
⚡ 索引已在后台开始——调用 codebase_status 查看进度
→ codebase_status {}
⚠ 全量索引正在进行中——阶段:生成嵌入(批次 1/1)
进度:已嵌入 247/1847 个块(13%)——耗时:12 秒
→ codebase_status {}
✓ 索引已完成:共 342 个文件,1,847 个块(耗时 115.2 秒)
文件监听器:已启用(更改时自动更新)
用户: “搜索身份验证是如何处理的”
→ codebase_search { query: "authentication handling" }
并行执行密集语义搜索和 BM25 关键字搜索,并通过 RRF 融合结果
返回按综合相关性排序的前 10 条结果
用户: “哪些文件依赖于认证中间件?”
→ codebase_graph_query { filePath: "src/middleware/auth.ts" }
返回导入与被依赖文件
(图谱在索引完成后自动构建——无需手动构建)
用户: “展示依赖关系图”
→ codebase_graph_visualize {}
返回按语言着色的 Mermaid 图表
用户: “是否存在循环依赖?”
→ codebase_graph_circular {}
发现 2 个循环:src/a.ts → src/b.ts → src/a.ts
助手指令
Claude Code 插件用户:这些指令已作为技能自动包含在 SocratiCode 插件中,你无需将其复制到
CLAUDE.md中。以下部分适用于非 Claude Code 用户(如 VS Code、Cursor、Claude Desktop 等)。
为获得最佳效果,建议将如下指令添加到你的 AI 助手的项目级指令文件中。核心原则是:先搜索再阅读。索引可在毫秒级内为你提供代码库的地图;而直接读取文件则既昂贵又会消耗大量上下文。
这些指令应放置的位置(按 IDE 分类):
| IDE / 工具 | 指令文件 |
|---|---|
| Claude Code | 项目根目录下的 CLAUDE.md(自动加载)。插件用户可通过技能自动获取此文件。 |
| Cursor | 项目根目录下的 AGENTS.md,或创建专用规则文件 .cursor/rules/socraticode.mdc |
| VS Code Copilot | .github/copilot-instructions.md,或在 VS Code 用户提示文件夹中创建自定义指令文件 |
| Zed | 项目根目录下的 AGENTS.md(Zed 会自动读取),或使用规则库创建默认规则 |
| Windsurf | 项目根目录下的 .windsurfrules |
| Claude Desktop / Cline / Roo Code | 直接添加到系统提示配置中 |
为何如此重要:仅安装 MCP 服务器即可使你的助手获得 SocratiCode 工具的访问权限,但助手仍会自行决定何时使用这些工具。将这些指令添加到项目中,可确保助手始终优先使用 SocratiCode 搜索而非直接读取文件,利用图谱完成依赖感知任务,并遵循“先搜索再读取”的工作流程。
## 代码库搜索(SocratiCode)
该项目已使用 SocratiCode 进行索引。在直接读取任何文件之前,请务必先使用其 MCP 工具探索代码库。
### 工作流程
1. **大多数探索都应从 `codebase_search` 开始。**
混合语义 + 关键词搜索(向量 + BM25,RRF 融合)可在一次调用中完成。
- 使用宽泛、概念性的查询来定位方向:例如“如何处理身份验证”、“数据库连接的设置”、“错误处理模式”。
- 使用精确的查询来进行符号查找:如确切的函数名、常量名或类型名。
- 优先根据搜索结果推断需要阅读哪些文件——不要盲目打开文件。
- **何时使用 grep**:如果你已经知道确切的标识符、错误字符串或正则表达式模式,grep/ripgrep 会更快且更精确——无需跨越语义鸿沟。而当你在探索、提出概念性问题,或者不确定该查看哪些文件时,则应使用 `codebase_search`。
2. **先查看依赖图,再逐级导入。**
在深入研究某个文件的内容之前,先使用 `codebase_graph_query` 查看该文件导入了哪些内容,以及哪些部分依赖于它。这样可以避免不必要地阅读传递性依赖项。
- **在修改或删除文件之前**,请通过 `codebase_graph_query` 检查其依赖关系,以了解可能的影响范围。
- **在计划重构时**,利用依赖图识别所有受影响的文件,然后再进行更改。
3. **仅在通过搜索缩小范围后才阅读文件。**
当搜索结果明确指向 1–3 个文件时,只需阅读相关部分即可。切勿仅仅为了判断文件是否相关就直接阅读——务必先进行搜索。
4. **调试意外行为时使用 `codebase_graph_circular`。**
循环依赖会导致微妙的运行时问题;应主动检查是否存在此类问题。此外,当遇到与导入相关的错误或初始化顺序不符合预期时,也应运行 `codebase_graph_circular`。
5. **如果搜索未返回任何结果,请检查 `codebase_status`。**
项目可能尚未被索引。如有需要,可运行 `codebase_index`,然后等待 `codebase_status` 确认索引已完成后再进行搜索。
6. **利用上下文工件获取非代码知识。**
项目可以定义一个 `.socraticodecontextartifacts.json` 配置文件,用于暴露数据库模式、API 规范、基础设施配置、架构文档等位于源代码之外的项目知识。这些工件会在 `codebase_index` 和 `codebase_update` 过程中与代码一同自动索引。
- 提前运行 `codebase_context` 以查看有哪些可用的工件。
- 使用 `codebase_context_search` 来查找特定的模式、端点或配置,而不是先询问数据库结构或 API 协议。
- 如果 `codebase_status` 显示工件已过时,请运行 `codebase_context_index` 来刷新它们。
### 各工具的适用场景
| 目标 | 工具 |
|------|------|
| 了解代码库的功能或某个功能的位置 | `codebase_search`(宽泛查询) |
| 查找特定的函数、常量或类型 | `codebase_search`(精确名称)或若已知确切字符串则使用 grep |
| 查找确切的错误信息、日志字符串或正则表达式模式 | grep / ripgrep |
| 查看文件导入了什么或哪些内容依赖于它 | `codebase_graph_query` |
| 在修改或删除文件前检查影响范围 | `codebase_graph_query`(查看依赖关系) |
| 发现架构问题 | `codebase_graph_circular`、`codebase_graph_stats` |
| 可视化模块结构 | `codebase_graph_visualize` |
| 验证索引是否最新 | `codebase_status` |
| 发现可用的项目知识(模式、规范、配置) | `codebase_context` |
| 查找数据库表、API 端点或基础设施配置 | `codebase_context_search` |
为何优先使用语义搜索? 一次
codebase_search调用可在毫秒级时间内返回来自整个代码库的排序且去重后的代码片段。这种方式以极低的 token 成本为你提供全局概览——远比盲目打开文件要经济得多。一旦确定了相关文件,有针对性地阅读不仅更快,而且更准确。当然,如果你已经有了确切的字符串或模式,grep 仍然是更合适的选择——应根据具体查询选择合适的工具。
索引过程中保持连接畅通。 索引是在后台运行的——MCP 服务器即使在未主动响应工具调用时也会继续工作。然而,某些 MCP 主机可能会在一段时间无活动后断开空闲连接,从而中断后台进程。建议你的 AI 在启动
codebase_index后,每隔约 60 秒调用一次codebase_status,直到索引完成。这样既能保持主机连接活跃,又能实时掌握进度。
配置
安装
Claude Code 插件(推荐给 Claude Code 用户)
SocratiCode 插件集成了 MCP 服务器和工作流技能,可指导 Claude 如何高效使用工具。只需一次安装,即可获得所有功能:
在终端中执行以下命令:
claude plugin marketplace add giancarloerra/socraticode
claude plugin install socraticode@socraticode
或在 Claude Code 内部执行:
/plugin marketplace add giancarloerra/socraticode
/plugin install socraticode@socraticode
该插件包含:
- MCP 服务器 — 包含全部 21 种 SocratiCode 工具(搜索、图表、上下文工件等)
- 探索技能 — 教导 Claude “先搜索再阅读”的工作流程
- 管理技能 — 指导设置、索引构建、监控及故障排除
- Explorer 代理 — 可委派的子代理,用于深度代码库分析
如果您之前已将 SocratiCode 作为独立的 MCP 安装(
claude mcp add socraticode),请在安装插件后将其移除,以避免重复:claude mcp remove socraticode
自动更新: 第三方插件默认不会自动更新。如需启用自动更新,请进入 /plugin → 市场 → 选择 socraticode → 启用自动更新。若需手动更新:
在终端中执行以下命令:
claude plugin marketplace update socraticode
claude plugin update socraticode@socraticode
或在 Claude Code 内部执行:
/plugin marketplace update socraticode
/plugin update socraticode@socraticode
配置环境变量: 对于大多数用户而言,SocratiCode 无需任何配置即可正常工作(本地 Ollama + 托管 Qdrant)。如果您需要云端嵌入、远程 Qdrant 或其他自定义配置:
Claude Code 设置(推荐)— 将以下内容添加到
~/.claude/settings.json文件中:{ "env": { "EMBEDDING_PROVIDER": "openai", "OPENAI_API_KEY": "sk-..." } }此方法适用于所有环境——CLI、VS Code 和 JetBrains。
Shell 配置文件 — 在
~/.zshrc或~/.bashrc中设置变量:export EMBEDDING_PROVIDER=openai export OPENAI_API_KEY=sk-...当 Claude Code 从终端启动时有效。请注意:通过 IDE 启动的会话(例如从 Finder/Dock 打开 VS Code)可能无法继承 Shell 配置文件中的变量——建议使用方法 1。
更改变量后,请重启 Claude Code。有关所有选项,请参阅环境变量部分。
npx(推荐给所有其他 MCP 主机——无需安装)
需要 Node.js 18+ 和正在运行的 Docker。已在上方的快速入门中介绍过,只需将以下内容添加到您的 mcpServers(Claude Desktop、Windsurf、Cline、Roo Code)或 servers(VS Code 项目本地 .vscode/mcp.json)配置中:
"socraticode": {
"command": "npx",
"args": ["-y", "socraticode"]
}
Zed
在 Zed 的设置中(Zed > Settings > Settings 或 cmd+,),将 SocratiCode 添加为自定义 MCP 服务器。在 context_servers 下添加:
{
"context_servers": {
"socraticode": {
"command": "npx",
"args": ["-y", "socraticode"],
"env": {}
}
}
}
如需传递环境变量(例如用于云端嵌入或分支感知索引),请将其添加到 env 对象中:
{
"context_servers": {
"socraticode": {
"command": "npx",
"args": ["-y", "socraticode"],
"env": {
"EMBEDDING_PROVIDER": "openai",
"OPENAI_API_KEY": "sk-..."
}
}
}
}
Zed 会自动读取项目根目录下的 AGENTS.md 文件以获取代理指令。请将代理指令部分复制到您项目的 AGENTS.md 文件中,以确保代理能够有效使用 SocratiCode 工具。您还可以将其作为默认规则添加到 Zed 的规则库中(agent: open rules library)。
从源码安装(面向贡献者)
git clone https://github.com/giancarloerra/socraticode.git
cd socraticode
npm install
npm run build
然后在下方的配置示例中,使用 node /absolute/path/to/socraticode/dist/index.js 替代 npx -y socraticode。
MCP 主机配置变体
以下所有
env选项同样适用于npx安装。只需将上述env块添加到 npx 配置中即可。
请将以下内容添加到您的 MCP 设置中——mcpServers(Claude Desktop、Windsurf、Cline、Roo Code)或 servers(VS Code 项目本地 .vscode/mcp.json):
默认配置(零配置,从源码安装)
使用
npx?您的配置已在快速入门中说明。如有需要,可按需添加下方示例中的任何env块。
{
"mcpServers": {
"socraticode": {
"command": "node",
"args": ["/absolute/path/to/socraticode/dist/index.js"]
}
}
}
提示:默认的
OLLAMA_MODE=auto会在启动时检测本地 Ollama(端口 11434),如果可用则优先使用;否则回退到托管的 Docker 容器。为使您的配置更具可读性,可添加带有明确值的env块。有关所有选项,请参阅环境变量部分。
外部 Ollama(本地安装)
如果您已本地安装了 Ollama,请将 OLLAMA_MODE 设置为 external,并指向您的实例:
{
"mcpServers": {
"socraticode": {
"command": "node",
"args": ["/absolute/path/to/socraticode/dist/index.js"],
"env": {
"OLLAMA_MODE": "external",
"OLLAMA_URL": "http://localhost:11434"
}
}
}
}
嵌入模型将在首次使用时自动拉取。如需提前下载:ollama pull nomic-embed-text
远程 Ollama 服务器
{
"mcpServers": {
"socraticode": {
"command": "node",
"args": ["/absolute/path/to/socraticode/dist/index.js"],
"env": {
"OLLAMA_MODE": "external",
"OLLAMA_URL": "http://gpu-server.local:11434"
}
}
}
}
OpenAI 嵌入
使用 OpenAI 的云端嵌入 API,而非本地 Ollama。需要一个 API 密钥。
{
"mcpServers": {
"socraticode": {
"command": "node",
"args": ["/absolute/path/to/socraticode/dist/index.js"],
"env": {
"EMBEDDING_PROVIDER": "openai",
"OPENAI_API_KEY": "sk-..."
}
}
}
}
默认设置:
EMBEDDING_MODEL=text-embedding-3-small,EMBEDDING_DIMENSIONS=1536。如需更高品质,可使用text-embedding-3-large,并设置EMBEDDING_DIMENSIONS=3072。
Google Generative AI 嵌入
使用 Google 的 Gemini 嵌入 API。需要一个 API 密钥。
{
"mcpServers": {
"socraticode": {
"command": "node",
"args": ["/absolute/path/to/socraticode/dist/index.js"],
"env": {
"EMBEDDING_PROVIDER": "google",
"GOOGLE_API_KEY": "AIza..."
}
}
}
}
默认设置:
EMBEDDING_MODEL=gemini-embedding-001,EMBEDDING_DIMENSIONS=3072。
Git 工作树(跨目录共享索引)
如果你使用 git worktrees,或者在多个目录中共享同一个仓库的工作流,通常每个路径都会拥有自己的 Qdrant 索引。这意味着对于本质上相同的代码库,会存在冗余的嵌入和存储。
通过设置 SOCRATICODE_PROJECT_ID,可以在同一项目的所有目录之间共享单个索引。
支持 git worktree 检测的 MCP 主机(如 Claude Code)
一些 MCP 主机(例如 Claude Code)会通过解析 git worktree 链接来确定项目根目录。由于 worktree 会指向主仓库的 .git 目录,主机可以自动将所有 worktree 映射到相同的项目配置。因此,你只需为主检出配置一次 MCP 服务器——所有 worktree 都会自动继承该配置。
以 Claude Code 为例,在主检出目录下以本地作用域添加服务器:
cd /path/to/main-checkout
claude mcp add -e SOCRATICODE_PROJECT_ID=my-project --scope local socraticode -- npx -y socraticode
从此仓库创建的所有 worktree 都会自动连接到 socraticode,并使用共享的项目 ID。无需为每个 worktree 单独进行设置。
注意: 这仅适用于 git worktree。对同一仓库执行的独立
git clone操作会有各自的.git目录,不会共享配置。
其他 MCP 主机(基于每个项目 .mcp.json)
对于无法解析 git worktree 路径的 MCP 主机,需要在每个 worktree 的根目录以及主检出目录下添加 .mcp.json 文件:
{
"mcpServers": {
"socraticode": {
"command": "npx",
"args": ["-y", "socraticode"],
"env": {
"SOCRATICODE_PROJECT_ID": "my-project"
}
}
}
}
如果你不希望跟踪 .mcp.json 文件,可以将其加入 .gitignore 中。
工作原理
通过此配置,在 /repo/main、/repo/worktree-feat-a 和 /repo/worktree-fix-b 中运行的代理都将共享相同的 codebase_my-project、codegraph_my-project 和 context_my-project Qdrant 集合。
实际工作方式:
- 语义索引会反映最近触发文件变更的 worktree;但由于分支之间通常只相差少量文件,因此该索引对于所有 worktree 的准确性可达 99% 以上。
- 你的 AI 代理会从其所在 worktree 中读取实际的文件内容;共享索引仅用于发现和导航。
- 当更改合并回主分支时,文件监视器会重新索引这些文件,从而使索引保持一致。
跨项目搜索(关联项目)
如果你同时处理多个相关仓库或包,可以通过一次查询同时搜索它们。
配置
在项目根目录下创建一个 .socraticode.json 文件:
{
"linkedProjects": [
"../shared-lib",
"/absolute/path/to/other-project"
]
}
或者设置 SOCRATICODE_LINKED_PROJECTS 环境变量(用逗号分隔的路径):
SOCRATICODE_LINKED_PROJECTS="../shared-lib,/absolute/path/to/other-project"
两种方式都会将源合并并去重。相对路径会从项目根目录解析,而不存在的路径则会被静默跳过。
使用方法
在调用 codebase_search 时传递 includeLinked: true 参数:
搜索“authentication middleware”,并启用 includeLinked: true
结果会带有 [project-name] 标签,标明每条结果来自哪个项目。当前项目始终具有最高的去重优先级——如果多个关联项目中存在相同的文件,则当前项目的版本将被优先选择。
注意: 每个关联项目必须先独立完成索引构建(
codebase_index),才能进行搜索。
分支感知索引
默认情况下,项目的各个分支共享同一个索引。当你切换分支时,文件监视器会重新索引已更改的文件,索引便会反映当前分支的状态。
对于需要 为每个分支维护独立且持久的索引 的工作流——例如 CI/CD 流水线或跨分支比较代码——可以启用分支感知模式:
SOCRATICODE_BRANCH_AWARE=true
启用后,集合名称会包含分支名称(例如 codebase_abc123__main、codebase_abc123__feat_my-feature)。每个分支将维护自己独立的索引、代码图和上下文数据。
适用场景:
- CI/CD 流水线中为每个分支/PR 单独索引
- 比较不同分支之间的搜索结果
- 保持
main分支的原始索引不受特性分支更改的影响
不适用场景:
- 经常切换分支的本地开发(默认共享索引更为高效)
- 使用
SOCRATICODE_PROJECT_ID追踪的项目(显式 ID 会绕过分支检测)
工作原理:
projectIdFromPath()会通过git rev-parse --abbrev-ref HEAD检测当前的 Git 分支,并将规范化后的分支后缀(例如feat/my-feature→feat_my-feature)附加到基于哈希的项目 ID 上。对于分离的 HEAD 状态,则会回退到无分支的 ID。
可用工具
连接后,您的 AI 助手将可以使用 21 种工具:
索引
| 工具 | 描述 |
|---|---|
codebase_index |
在后台开始索引代码库(可通过 codebase_status 轮询进度) |
codebase_stop |
优雅地停止正在进行的索引操作(当前批次会完成并生成检查点;可使用 codebase_index 恢复) |
codebase_update |
增量更新——仅重新索引已更改的文件 |
codebase_remove |
删除项目的索引(安全停止文件监视器,取消正在进行的索引/更新,并等待图构建完成) |
codebase_watch |
开始/停止文件监视——启动时会补全遗漏的更改,然后继续监视未来的更改 |
搜索
| 工具 | 描述 |
|---|---|
codebase_search |
混合语义 + 关键词搜索(稠密向量 + BM25,RRF 融合),支持可选的文件路径、语言过滤以及跨项目搜索 (includeLinked) |
codebase_status |
检查索引状态和分块数量 |
代码图
| 工具 | 描述 |
|---|---|
codebase_graph_build |
构建多语言依赖图(在后台运行——可通过 codebase_graph_status 轮询) |
codebase_graph_query |
查询特定文件的导入和依赖项 |
codebase_graph_stats |
获取图统计信息(最连接的文件、孤立文件、语言分布等) |
codebase_graph_circular |
检测循环依赖 |
codebase_graph_visualize |
生成依赖图的 Mermaid 图表 |
codebase_graph_status |
检查图构建进度或持久化图元数据 |
codebase_graph_remove |
删除项目的持久化代码图(会先等待正在进行的图构建完成) |
管理
| 工具 | 描述 |
|---|---|
codebase_health |
检查 Docker、Qdrant 和嵌入服务提供商的状态 |
codebase_list_projects |
列出所有已索引的项目及其路径和元数据 |
codebase_about |
显示 SocratiCode 的相关信息 |
上下文工件
| 工具 | 描述 |
|---|---|
codebase_context |
列出 .socraticodecontextartifacts.json 中定义的所有上下文工件,包括名称、描述和索引状态 |
codebase_context_search |
在上下文工件中进行语义搜索(首次使用时自动索引,自动检测过时情况) |
codebase_context_index |
对 .socraticodecontextartifacts.json 中的所有工件进行索引或重新索引 |
codebase_context_remove |
删除项目的所有已索引的上下文工件(索引进行中时无法执行) |
语言支持
SocratiCode 在三个层次上支持多种语言:
volle Unterstützung (Indexierung + Codegraph + AST-Chunking)
JavaScript, TypeScript, TSX, Python, Java, Kotlin, Scala, C, C++, C#, Go, Rust, Ruby, PHP, Swift, Bash/Shell, HTML, CSS/SCSS, Svelte, Vue
Svelte und Vue: Importe werden aus <script>-Blöcken extrahiert (wieder als TypeScript analysiert) und CSS @import/@require aus <style>-Blöcken (jede Kombination von lang, scoped, module, global Attributen). Pfalalias aus tsconfig.json/jsconfig.json compilerOptions.paths werden aufgelöst (einschließlich extends-Ketten). SCSS-Teillösung (_-Präfixkonvention) wird unterstützt.
Codegraph via Regex + Indexierung
Dart (Import/Export/Part), Lua (Require/Dofile/Loadfile), SASS, LESS (CSS @import Extraktion)
Nur Indexierung (Hybridsuche, zeilenbasiertes Chunking)
JSON, YAML, TOML, XML, INI/CFG, Markdown/MDX, RST, SQL, R, Dockerfile, TXT, sowie jede Datei, die einer unterstützten Erweiterung oder einem speziellen Dateinamen entspricht (Dockerfile, Makefile, Gemfile, Rakefile usw.).
54 Dateierweiterungen + 8 Sonderdateinamen sind sofort verfügbar.
Ignorierungsregeln
Der Indexer kombiniert drei Ebenen von Ignorierungsregeln:
- Integrierte Standardregeln —
node_modules,.git,dist,build, Lock-Dateien, IDE-Ordner usw. .gitignore— Alle.gitignore-Dateien im Projekt (Stammverzeichnis und verschachtelte Unterordner). Setzen SieRESPECT_GITIGNORE=false, um die Verarbeitung von.gitignorevollständig zu überspringen..socraticodeignore— Optionale Datei für indexer-spezifische Ausschlüsse. Gleiche Syntax wie.gitignore.
Kontext-Artefakte
Geben Sie der KI Einblick in Projektkenntnisse jenseits des Quellcodes — Datenbankschemata, API-Spezifikationen, Infrastrukturkonfigurationen, Architektur-Dokumentationen und mehr.
Einrichtung
Erstellen Sie eine .socraticodecontextartifacts.json-Datei im Stammverzeichnis Ihres Projekts (siehe .socraticodecontextartifacts.json.example für eine Startervorlage):
{
"artifacts": [
{
"name": "database-schema",
"path": "./docs/schema.sql",
"description": "Komplettes PostgreSQL-Schema — alle Tabellen, Indizes, Einschränkungen, Fremdschlüssel. Dient dazu, zu verstehen, welche Daten die Anwendung speichert und wie die Tabellen miteinander verbunden sind."
},
{
"name": "api-spec",
"path": "./docs/openapi.yaml",
"description": "OpenAPI 3.0 Spezifikation für die REST-API. Alle Endpunkte, Anforderungs-/Antwortschemas, Authentifizierungsanforderungen."
},
{
"name": "k8s-manifests",
"path": "./deploy/k8s/",
"description": "Kubernetes-Bereitstellungsmanifeste. Zeigt, wie Dienste bereitgestellt, skaliert und vernetzt werden."
}
]
}
Jedes Artefakt hat:
name— Eindeutiger Bezeichner (wird zum Filtern von Suchanfragen verwendet)path— Pfad zu einer Datei oder einem Verzeichnis (relativ zum Projektstamm oder absolut). Verzeichnisse werden rekursiv gelesen.description— Erklärt der KI, was dieses Artefakt ist und wie es verwendet werden kann
Funktionsweise
Artefakte werden in Qdrant mit demselben hybriden Ansatz aus dichter und BM25-Suche wie Code indexiert. Bei der ersten Suche werden Artefakte automatisch indiziert. Bei nachfolgenden Suchen wird durch Inhalts-Hashing automatisch erkannt, ob sie veraltet sind — geänderte Dateien werden transparent neu indiziert.
Nutzung
- Entdecken:
codebase_context— listet alle definierten Artefakte und deren Indexstatus auf - Suchen:
codebase_context_search— semantische Suche über alle Artefakte hinweg (oder nach Name filtern) - Neuindizieren:
codebase_context_index— erzwingt eine Neuindizierung (normalerweise nicht nötig, da die automatische Indizierung dies übernimmt) - Aufräumen:
codebase_context_remove— entfernt alle indizierten Artefakte
为什么这很重要:实际工作流示例
如果没有工件,代理只能看到源代码。而有了工件,它就能掌握全局信息,从一开始就编写符合项目需求的代码。
数据库模式 — 您提出:“在用户表中添加 last_login 时间戳。” 代理会运行 codebase_context_search 查询“用户表”,发现该模式使用 snake_case 命名的列,并且每张表都有一个带有触发器的 updated_at 字段。因此,生成的迁移脚本会遵循现有规范,而不是随意猜测。
{
"name": "database-schema",
"path": "./docs/schema.sql",
"description": "完整的 PostgreSQL 数据库模式——包括所有表、列、数据类型、约束、索引和触发器。在编写迁移脚本之前,请先查看此文件,以确保命名规范和现有模式一致。"
}
API 规范 — 您要求:“添加一个用于获取用户偏好设置的 GET 端点。” 代理会搜索 OpenAPI 规范,发现所有端点都使用 Bearer 认证,返回 { data, meta } 包装结构,并通过 cursor/limit 进行分页。新端点会自动遵循相同的模式。
{
"name": "api-spec",
"path": "./docs/openapi.yaml",
"description": "REST API 的 OpenAPI 3.0 规范——包含所有端点、请求/响应模式、认证方式和分页机制。在添加或修改端点之前,请先查阅此文档,以确保符合现有规范。"
}
领域术语表(DDD) — 您提出:“添加一种取消订单的方式。” 代理会搜索您的领域术语表,发现取消操作被建模为 OrderVoided 事件(而非“已取消”),只有处于 Confirmed 状态的订单才能被取消,并且需要通知 Fulfillment 限界上下文。最终实现会使用正确的领域术语,并与相应的限界上下文无缝集成。
{
"artifacts": [
{
"name": "ubiquitous-language",
"path": "./docs/ubiquitous-language.md",
"description": "领域术语表——限界上下文中的术语、定义及其关系。在命名实体、事件或命令之前,请务必查阅此文档,以确保使用正确的领域语言。"
},
{
"name": "context-map",
"path": "./docs/context-mapping.md",
"description": "限界上下文地图——上下文边界、相互关系(共享内核、客户-供应商等)以及集成模式。在实现跨上下文通信之前,请先检查此文档。"
},
{
"name": "event-storming",
"path": "./docs/event-storming/",
"description": "事件风暴输出——领域事件、命令、聚合、策略和读模型。在添加新的领域行为之前,请先查看此文档,以了解其如何融入现有的事件流。"
}
]
}
“description” 字段是关键杠杆。 它不仅告诉 AI 工件是什么,还说明了“何时应该查阅它”。请撰写类似“在执行 X 之前请先查阅此文档”的描述,以便代理能够在恰当的时候调用相应工件。
示例工件
| 类别 | 示例 |
|---|---|
| 数据库 | SQL 模式转储(pg_dump --schema-only)、Prisma 模式、Rails schema.rb、Django 模型转储、迁移文件 |
| API 合同 | OpenAPI/Swagger 规范、GraphQL 模式、Protobuf 定义、AsyncAPI 规范(Kafka、RabbitMQ) |
| 基础设施 | Terraform/Pulumi 配置、Kubernetes 清单、Docker Compose 文件、CI/CD 流水线配置 |
| 架构 | 架构决策记录 (ADR)、服务拓扑文档、数据流图、领域术语表 |
| 运维 | 监控/告警规则、RBAC/权限矩阵、认证流程文档、功能标记配置 |
| 外部 | 第三方 API 文档、合规性要求(SOC2、HIPAA、GDPR)、SLA 定义 |
提示:对于数据库模式,各大主流数据库都可以将其整个模式导出到一个文件中:
pg_dump --schema-only(PostgreSQL)、mysqldump --no-data(MySQL)、sqlite3 db.sqlite .schema(SQLite)。ORM 模式的文件(Prisma、Rails、Django)通常已经存在于您的代码库中。
环境变量
嵌入提供者
| 变量 | 默认值 | 描述 |
|---|---|---|
EMBEDDING_PROVIDER |
ollama |
嵌入后端:ollama(本地,默认)、openai 或 google |
EMBEDDING_MODEL |
(依提供商而定) | 模型名称。默认值:nomic-embed-text(ollama)、text-embedding-3-small(openai)、gemini-embedding-001(google) |
EMBEDDING_DIMENSIONS |
(依提供商而定) | 向量维度。默认值:768(ollama)、1536(openai)、3072(google) |
EMBEDDING_CONTEXT_LENGTH |
(自动检测) | 模型上下文窗口的令牌数。已知模型会自动检测,自定义模型则需手动设置。 |
Ollama 配置(当 EMBEDDING_PROVIDER=ollama 时)
| 变量 | 默认值 | 描述 |
|---|---|---|
OLLAMA_MODE |
auto |
auto = 如果本地 11434 端口可用,则使用原生 Ollama;否则管理一个 Docker 容器(推荐)。docker = 始终使用托管的 Docker 容器,运行在 11435 端口上。external = 用户自行管理的 Ollama 实例(本地、远程等)。 |
OLLAMA_URL |
http://localhost:11434(auto/external) / http://localhost:11435(docker) |
完整的 Ollama API 端点 |
OLLAMA_PORT |
11435 |
Ollama 容器端口(Docker 模式)。如果已明确设置了 OLLAMA_URL,则忽略此设置。 |
OLLAMA_HOST |
http://localhost:{OLLAMA_PORT} |
Ollama 基础 URL(替代 OLLAMA_URL) |
OLLAMA_API_KEY |
无 | 用于经过身份验证的 Ollama 代理的可选 API 密钥 |
云提供商 API 密钥
| 变量 | 默认值 | 描述 |
|---|---|---|
OPENAI_API_KEY |
无 | 当 EMBEDDING_PROVIDER=openai 时必需。可在 platform.openai.com 获取。 |
GOOGLE_API_KEY |
无 | 当 EMBEDDING_PROVIDER=google 时必需。可在 aistudio.google.com 获取。 |
Qdrant 配置
| 变量 | 默认值 | 描述 |
|---|---|---|
QDRANT_MODE |
managed |
managed = 使用 Docker 托管的本地 Qdrant(默认)。external = 用户提供的远程或云端 Qdrant(不使用 Docker 管理)。 |
QDRANT_URL |
无 | 远程/云上 Qdrant 实例的完整 URL(如 https://xyz.aws.cloud.qdrant.io:6333)。一旦设置,将优先于 QDRANT_HOST + QDRANT_PORT。端口会根据 URL 自动推断:若 URL 中明确指定了端口(如 :8443),则使用该端口;否则,https:// 使用 443 端口,http:// 使用 6333 端口。当 QDRANT_MODE=external 时,必须设置此字段或至少指定 QDRANT_HOST。 |
QDRANT_PORT |
16333 |
Qdrant REST API 端口(托管模式,或未使用 QDRANT_URL 的外部实例) |
QDRANT_GRPC_PORT |
16334 |
Qdrant gRPC 端口(仅托管模式) |
QDRANT_HOST |
localhost |
Qdrant 主机名(适用于非 HTTPS 的外部实例,作为 QDRANT_URL 的替代方案) |
QDRANT_API_KEY |
无 | Qdrant API 密钥(适用于 Qdrant Cloud 及其他需要身份验证的部署) |
索引行为
| 变量 | 默认值 | 描述 |
|---|---|---|
RESPECT_GITIGNORE |
true |
设置为 false 以跳过 .gitignore 处理。内置默认规则和 .socraticodeignore 仍会生效。 |
INCLUDE_DOT_FILES |
false |
设置为 true 以在索引中包含点目录(例如 .agent、.config)。默认情况下,以 . 开头的目录和文件会被排除。对于重要代码位于点目录中的项目非常有用。 |
EXTRA_EXTENSIONS |
(无) | 需要扫描的额外文件扩展名列表,用逗号分隔(例如 .tpl,.blade,.hbs)。适用于索引和代码图。带有额外扩展名的文件会被当作纯文本进行索引,并在代码图中显示为叶节点。也可以通过 extraExtensions 工具参数在每次操作时单独指定。 |
MAX_FILE_SIZE_MB |
5 |
最大文件大小,单位为 MB。超过此大小的文件在索引过程中会被跳过。对于包含大型生成文件或数据文件且希望被索引的仓库,可以适当提高该值。 |
SEARCH_DEFAULT_LIMIT |
10 |
codebase_search 返回的结果数量默认值(1-50)。每个结果都是一个按相关性排序的代码片段,包含文件路径、行范围和内容。数值越高,覆盖范围越广,但输出结果也会越多。仍可通过 limit 工具参数在每次查询时覆盖该设置。 |
SEARCH_MIN_SCORE |
0.10 |
最低 RRF(倒数排名融合)得分阈值(0-1)。低于此分数的结果将被过滤掉。有助于去除搜索结果中的低相关性噪声。设置为 0 可禁用过滤(返回所有不超过 limit 的结果)。也可通过 minScore 工具参数在每次查询时覆盖该设置。与 limit 配合使用:先按分数过滤结果,再限制到 limit 数量。 |
SOCRATICODE_PROJECT_ID |
(无) | 覆盖自动生成的项目 ID。设置后,所有路径都会解析到相同的 Qdrant 集合,允许多个目录(例如同一仓库的不同 Git 工作树)共享同一个索引。必须符合 [a-zA-Z0-9_-]+ 格式。 |
SOCRATICODE_BRANCH_AWARE |
false |
当设置为 true 时,会在项目 ID 后附加当前 Git 分支名称,从而为每个分支创建独立的 Qdrant 集合。如果已设置 SOCRATICODE_PROJECT_ID,则此选项将被忽略。 |
SOCRATICODE_LINKED_PROJECTS |
(无) | 需要纳入跨项目搜索的其他项目路径列表,用逗号分隔。与 .socraticode.json 中的路径合并。不存在的路径将被静默跳过。 |
SOCRATICODE_LOG_LEVEL |
info |
日志详细程度:debug、info、warn、error |
SOCRATICODE_LOG_FILE |
(无) | 日志文件的绝对路径。设置后,所有日志条目都会追加到该文件中(每次服务器启动时会写入会话分隔符)。当 MCP 主机无法显示日志通知时,此功能对调试非常有用。 |
重要提示:如果您在索引完成后更改了
EMBEDDING_PROVIDER、EMBEDDING_MODEL或EMBEDDING_DIMENSIONS,则必须重新索引您的项目(先执行codebase_remove,再执行codebase_index),因为现有向量的维度会发生变化。
Docker 资源
SocratiCode 管理 Docker 容器和持久化卷:
| 资源 | 名称 | 用途 | 使用场景 |
|---|---|---|---|
| 容器 | socraticode-qdrant |
Qdrant 向量数据库(固定版本 v1.17.0) |
仅限 managed 模式 |
| 容器 | socraticode-ollama |
Ollama 嵌入服务端 | 仅限 docker 模式 |
| 卷 | socraticode_qdrant_data |
持久化向量存储 | 仅限 managed 模式 |
| 卷 | socraticode_ollama_data |
持久化模型存储 | 仅限 docker 模式 |
在 QDRANT_MODE=external 模式下,不会创建或启动 Qdrant 容器和卷——SocratiCode 将直接连接到配置的远程端点。服务器端 BM25 推理(用于混合搜索)需要 Qdrant v1.15.2 或更高版本。托管容器运行的是 v1.17.0。如果您使用自己的 Qdrant 实例,请确保其满足此最低要求。
所有容器均使用 --restart unless-stopped 选项,以实现自动恢复。
为什么使用非标准端口? SocratiCode 故意为其托管容器使用非默认端口——
16333/16334替代 Qdrant 的默认端口(6333/6334),以及11435替代 Ollama 的默认端口(11434)。这样做是为了避免与您可能已经在本地运行的任何 Qdrant 或 Ollama 实例发生冲突。如有需要,所有端口均可通过环境变量进行覆盖。
测试
SocratiCode 拥有一套全面的测试套件,涵盖单元测试、集成测试和端到端测试,共计 634 个测试用例。
前置条件
- 单元测试:无需外部依赖。
- 集成测试和端到端测试:需要运行包含 Qdrant 和 Ollama 容器的 Docker。这些容器由测试基础设施自动管理。
运行测试
# 运行所有测试
npm test
# 仅运行单元测试(无需 Docker)
npm run test:unit
# 运行集成测试(需要 Docker)
npm run test:integration
# 运行端到端测试(需要 Docker)
npm run test:e2e
# 监视模式(文件更改时自动重跑)
npm run test:watch
# 生成覆盖率报告
npm run test:coverage
测试架构
| 层级 | 测试数量 | 是否需要 Docker | 描述 |
|---|---|---|---|
单元测试 (tests/unit/) |
477 | 否 | 配置、常量、忽略规则、进程间锁、日志记录、图分析、导入提取、路径解析、嵌入配置、索引器工具、嵌入计算、启动生命周期、监视器的进程间感知 |
集成测试 (tests/integration/) |
137 | 是 | Docker/Ollama 环境搭建、Qdrant 的 CRUD 操作、实际嵌入计算、索引器、监视器、代码图、所有 MCP 工具 |
端到端测试 (tests/e2e/) |
20 | 是 | 完整生命周期:健康检查 → 索引 → 搜索 → 图分析 → 监视 → 删除 |
当 Docker 不可用时,需要 Docker 的集成测试和端到端测试将自动跳过。
为什么不用单纯的 Grep?
针对真实仓库的现代评估表明,一旦涉及自然语言查询、大型代码库或编码代理,混合的词法+语义代码搜索始终优于单纯的 Grep:报告显示,在大规模场景下,BM25F 排序可提升约 20% 的搜索质量;AST 感知检索在 RepoEval 和 SWE-bench 上能提高召回率并改善 bug 修复表现;而采用 Grep 作为默认方式的混合方法(如 SocratiCode 所采用)在 70% 的代理式代码搜索任务中表现优于纯 Grep,同时将搜索操作次数减少了一半以上。
现实场景基准测试:VS Code(245万行代码)与 Claude Opus 4.6
我们以 VS Code 代码库(包含 5,300 多个文件,总计约 245 万行 TypeScript/JavaScript 代码,共 55,437 个索引片段)为基准,进行了一次直接对比,旨在衡量 Claude Opus 4.6 AI 代理在回答架构相关问题时的实际资源消耗。
方法论: 对于每个问题,grep 方法 模拟当前 AI 代理所采用的多步骤工作流程:使用 grep -rl 查找匹配文件,确定核心文件后按每批 200 行的方式逐段读取,并重复此过程直至获取足够的上下文。而 SocratiCode 方法 则只需一次语义搜索调用,即可从整个代码库中返回最相关的 10 个代码片段。
| 问题 | Grep(字节) | SocratiCode(字节) | 减少比例 | 加速倍数 |
|---|---|---|---|---|
| VS Code 如何实现工作区信任限制? | 56,383 | 21,149 | 62.5% | 49.7x |
| 差异编辑器如何计算并显示文本差异? | 37,650 | 15,961 | 57.6% | 40.2x |
| VS Code 如何处理扩展激活与生命周期? | 36,231 | 16,181 | 55.3% | 34.4x |
| 集成终端如何启动和管理 Shell? | 50,159 | 22,518 | 55.1% | 31.1x |
| VS Code 如何实现命令面板与快速选择功能的? | 70,087 | 20,676 | 70.5% | 31.7x |
| 总计 | 250,510 | 96,485 | 61.5% | 37.2x |
关键发现:
- 工具调用次数减少 84% — Grep 在 5 个问题中总共需要 31 步操作(平均每个问题 6–7 步)。而 SocratiCode 仅需 5 步(每个问题 1 步)。
- 数据消耗减少 61.5% — AI 代理处理的上下文减少了约 150KB,这将直接降低任何 LLM 的 token 成本。
- 速度提升 37 倍 — Grep 需要扫描 245 万行代码,每次查询可能耗时 2–3.5 秒;而语义搜索则可在 60–90 毫秒内完成。
注: 该基准测试对 grep 方法而言是“保守”的。它假设代理已经知道要读取哪些文件。实际上,真正的 AI 代理还需要进行额外的探索性 grep 调用,可能会遇到无效路径、读取无关文件,并且往往需要多次迭代才能缩小范围。因此,实际节省的数据量可能会更大。
混合搜索的优势所在
自然语言与概念性查询 — 诸如“我们在哪里处理数据库连接池?”或“这个库是如何实现指数退避算法的?”之类的查询,描述的是行为而非函数名称。基于仓库级别的基准测试(RepoEval、SWE-bench)表明,与基于固定行数的代码块相比,支持 AST 的语义检索可将召回率提高多达 4.3 个百分点,下游代码生成的准确率也提升约 2.7 个百分点。而在真实开源项目的代理评估中,混合搜索在解决复杂、概念性强的问题时,胜率比纯 grep 高出 70%,同时搜索操作次数减少 56%,每次复杂查询所需的 token 数量也减少了约 6 万个。
大型代码库与 monorepo — 当代码规模达到数百万 LOC 时,全文扫描的成本会显著上升。生产级搜索引擎报告称,使用 BM25F 排序相比以往方法,相关性提升了约 20%,并且将其作为语义重排序的第一阶段检索器。而基于倒排索引和向量索引的混合搜索则完全避免了全量扫描,从而在大规模场景下既更快又更精准。行业从业者明确指出,grep 和 find “难以扩展到数百万文件”,而经过优化的嵌入式索引在该规模下反而更为高效。
跨文件与跨语言推理 — 要找到所有最终会调用某个内部辅助函数的代码路径,或者将自然语言规范映射到 Go 和 SQL 中的实现,都需要超越字符串匹配的理解能力。评估结果表明,在命名不直观且需要语义理解的情况下,结合 tree-sitter 解析与依赖关系上下文的混合管道表现优于 grep。基于 AST 的分块技术配合学习型检索器,能够提升跨语言基准测试中的检索效果;而多向量语义模型则在各种复杂的代码搜索任务中(AppsRetrieval、CodeSearchNet、CosQA),当查询以自然语言提出且目标跨越多种语言时,相较于单独使用 BM25 显著提升了性能。
代码与上下文文档混合 — 例如“速率限制是在哪里配置的?”这样的问题,可能匹配 Nginx 配置、Terraform 文件或 YAML,而不仅仅是应用代码。在针对混合技术语料库(结构化字段 + 自由文本)的公开评估中,混合搜索始终优于纯词法或纯向量方法。
grep 仍然占优的情况
同一研究也明确了何时 grep(或 ripgrep)完全合理,甚至可能是最优选择:
- 你清楚确切的标识符、错误信息或正则表达式模式。 无需填补语义鸿沟。
- 代码库规模较小 — 全文扫描既便宜又快速。
- 内容有限且为结构化的代码,具有鲜明的命名风格,而非散文或文档。
对于简单或直接命名的查询,grep 完全可以媲美甚至超越语义方法。这就是为什么最佳架构并不是用其他方法取代 grep,而是对其进行扩展。SocratiCode 的混合方案会在每次查询时同时运行 BM25 关键字搜索和密集型语义搜索,并通过 RRF 融合结果,从而在一次调用中兼顾精确匹配的精度与语义理解的召回率。
常见问题解答
索引过程中出现错误并失败——能否从中断处继续,而无需重新开始?
可以。索引会自动从上次中断的地方恢复。索引器会在每批文件处理完成后记录文件哈希值。当你再次让 AI 开始索引(例如:“索引该项目”)时,它会检测到已有的数据,跳过所有已成功嵌入的文件,只重新处理那些在故障发生前尚未完成检查点的文件。已经索引过的代码片段绝不会被删除或重新嵌入。只需再次请求 AI 索引,它就会从中断处继续。
我的 MCP 主机在索引大型代码库时断开了连接,该怎么办?
索引过程会在 MCP 服务器后台运行。然而,某些 MCP 主机(如 VS Code、Claude Desktop 等)会在一段时间无活动后断开空闲连接,从而终止后台进程。为了保持连接畅通,建议在开始索引后每隔约 60 秒询问 AI 索引状态(例如:“检查索引状态”),直到索引完成。如果连接确实中断且索引被迫停止,只需再次请求 AI 索引——它会自动从中断处恢复(参见上文)。
索引总是失败或无法正确恢复,我应该怎么办?
如果索引反复失败、恢复时抛出错误,或陷入循环,最简单的解决办法就是从头开始:让 AI 执行“移除该项目的索引”命令,然后重新发起索引请求。这样会清除该项目的所有存储代码片段和元数据,并从头开始重新索引。这不会影响其他已索引的项目。
我的代码库非常大——我可以暂停索引并在稍后恢复吗?
可以。您可以在任何时候停止索引,并在之后恢复,而不会丢失进度:
- 让您的 AI 助手停止索引——只需说类似“停止索引”的话,它就会在下一个批次边界处取消当前操作。到目前为止已完成的所有批次都会被保存为检查点并保留。
- 或者直接关闭项目/编辑器——SocratiCode 会检测到断开连接并优雅地关闭,同时保留所有已保存的检查点进度。
- 随时回来继续——在编辑器中重新打开同一项目,然后让 AI 恢复索引(例如:“恢复索引”)。SocratiCode 会自动检测到未完成的索引,跳过所有已经嵌入的文件,并从上次中断的地方继续。
这使得即使在较慢的硬件上,对大型代码库进行索引也成为可能——您可以分多次、跨越数小时或数天来完成索引工作,而且不会重复任何工作或丢失任何内容。
我重新打开了项目,但新文件或更改后的文件没有出现在搜索结果中。
对于之前已经索引过的项目,文件监视器会在首次使用工具时自动启动。启动后,它会先同步所有在 SocratiCode 停止运行期间修改过的文件,然后再开始监控未来的更改。
如果您希望在搜索之前立即同步这些更改,可以让 AI 执行“开始监视该项目”或“更新索引”命令——这两个命令都会同步执行增量更新,然后开始监视。
如果当前正在进行完整索引或增量更新、项目尚未被索引,或者已经有其他 MCP 进程正在监视同一项目,则文件监视器不会自动启动。
多个 AI 代理能否同时处理同一个代码库?
可以——这是系统原生支持的工作流。当多个代理(各自运行自己的 MCP 服务器实例)指向同一个项目目录时,它们会自动共享同一个 Qdrant 索引。第一个触发索引的代理会获取跨进程锁并构建索引;任何试图同时进行索引的其他代理都会接收到当前的进度信息,而不是启动重复的操作。所有代理都可以并发搜索,无需任何协调——Qdrant 原生支持并行读取。
文件监视器也会自动协调:每个项目只有一个进程负责监视。其他实例会检测到这一点并跳过监视器的启动。当监视进程检测到文件变更时,它会更新共享索引——这样,所有代理的下一次搜索都会看到最新的结果。
如果拥有监视器或索引锁的代理崩溃了,其锁将在 2 分钟后失效,下一个与之交互的代理会自动重新获取该锁。整个过程无需人工干预。
这使得 SocratiCode 非常适合多代理工作流:一个代理编写测试,另一个代理修复代码;规划代理和实现代理并行工作;或者任何需要共享深度代码库知识而不重复工作的 AI 助手组合。
我可以同时索引多个项目吗?
可以。SocratiCode 会为每个项目路径维护一个独立的隔离集合。您可以询问 AI“列出所有已索引的项目”,以查看当前已索引的所有项目。
如果我更换嵌入提供者或模型,会发生什么?
每个集合都是在索引时使用特定模型创建的,向量维度是固定的。如果您在 MCP 配置中更改 EMBEDDING_PROVIDER、EMBEDDING_MODEL 或 EMBEDDING_DIMENSIONS,那么使用旧模型索引的项目将会返回维度不匹配的错误。此时,您可以请 AI 删除该项目的索引,然后使用新模型重新索引。而您尚未触碰的项目则不受影响。
如何删除某个项目的索引(例如为了切换嵌入模型或从头开始重新索引)?
- 先停止——如果索引正在进行中,请说“停止索引该项目”。在索引进行中删除索引会导致数据损坏,因此系统会拒绝删除请求,直到当前批次完成。
- 删除索引——请说“删除该项目的索引”。此操作将仅删除该项目的向量集合、所有存储的块元数据、代码图以及上下文工件元数据。其他项目不受影响。
- 重新索引——如有必要,更新您的 MCP 配置以使用新的参数,然后让 AI 执行“索引该项目”以重新开始。
SocratiCode 标志中苏格拉底脸背后的代码是什么?
您在苏格拉底背后看到的代码来自阿波罗 11 号指令舱(Comanche055)原始制导计算机(AGC)的源代码!
社区
- 💬 Discord——与用户和维护者交流,提问“我该怎么做……”,分享您的项目成果
- 🐛 GitHub Issues——用于报告 bug 和确认功能请求(请使用模板)
- 📣 发布通知——订阅仓库(GitHub 页面右上角 → Custom → Releases),以便及时获取新版本信息
如果您觉得 SocratiCode 对您有帮助,最能帮上忙的一件事就是给这个仓库点个赞——这能让更多人发现这个项目。
SocratiCode Cloud
完整的 SocratiCode 引擎目前及未来都将以 AGPL-3.0 许可证开源。SocratiCode Cloud 是基于相同引擎的可选托管版本,目前处于私密测试阶段,专为希望使用共享、受管且合规基础设施的团队设计。
Cloud 在开源引擎的基础上增加了以下功能:
- 共享团队索引——每位开发者都能搜索相同的数据,每次推送和每个分支都会自动索引。
- 跨仓库搜索——只需一次查询即可搜索贵组织拥有的所有仓库。
- SSO / SAML、审计日志、IP 允许列表——这些功能内置其中,而非后期附加功能。
- 部署模式——托管云(欧盟/美国)、您自己的 VPC(AWS/GCP/Azure),或完全气隙的本地部署。
- Web 控制面板——用于搜索、依赖关系图、工件管理、团队和仓库管理。
- 零本地基础设施——团队无需管理 Docker、Qdrant 或 Ollama。
目前正接入少量工程团队。申请早期访问→
此仓库中的开源引擎始终是驱动 Cloud 的同一引擎。绝无欺骗行为,也不会对开源核心进行功能限制。Cloud 只是在其基础上增加了团队、部署和合规层。
许可证
SocratiCode 采用双重许可证:
开源许可证——AGPL-3.0。您可以自由使用、修改和分发。如果您修改了 SocratiCode 并将其作为网络服务提供,必须根据 AGPL-3.0 许可证公开您的修改内容。
商业许可证——适用于需要在专有产品或服务中使用 SocratiCode 而无需遵守 AGPL 条款的组织。详情请参阅 LICENSE-COMMERCIAL,或联系 giancarlo@altaire.com。
版权所有 © 2026 Giancarlo Erra - Altaire Limited。
第三方许可证
SocratiCode 包含遵循各自许可证的开源依赖项(MIT、Apache 2.0、ISC)。详情请参阅 THIRD-PARTY-LICENSES。
贡献
我们欢迎贡献。通过提交拉取请求,即表示您同意 贡献者许可协议。
版本历史
v1.6.12026/04/17v1.6.02026/04/16v1.5.02026/04/13v1.4.12026/04/12v1.4.02026/04/12v1.3.22026/03/26v1.3.12026/03/24v1.3.02026/03/19v1.2.02026/03/18v1.1.32026/03/16v1.1.22026/03/16v1.1.12026/03/16v1.1.02026/03/16v1.0.12026/03/04v1.0.02026/02/28常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。