llama.vim
llama.vim 是一款专为 Vim 编辑器设计的本地大语言模型(LLM)辅助插件,旨在为开发者提供实时的代码与文本补全服务。它主要解决了传统自动补全功能上下文理解能力弱、依赖云端服务导致隐私泄露或网络延迟等痛点,让用户能在完全离线的本地环境中享受智能编程体验。
该工具非常适合习惯使用 Vim 或 Neovim 的软件开发人员,尤其是那些对代码隐私敏感、希望在低配置硬件上也能运行大模型的用户。llama.vim 的核心亮点在于支持“中间填充”(Fill-in-Middle)技术,不仅能根据光标前的内容预测后续代码,还能结合光标后的上下文进行精准补全。此外,它还具备基于指令的代码编辑功能,用户可通过快捷键输入自然语言指令来重构或生成代码片段。
技术上,llama.vim 深度集成了 llama.cpp 后端,通过智能上下文复用机制,即使在显存有限的设备上也能高效处理超长上下文窗口。插件配置灵活,支持自定义触发键、接受方式及生成时长限制,并实时显示性能统计信息。只需在本地启动 llama.cpp 服务并加载兼容的 FIM 模型,即可将 Vim 升级为具备强大 AI 辅助能力的现代化开发环境。
使用场景
资深后端工程师正在本地离线环境下重构一个遗留的 Python 数据处理模块,需要在不联网的前提下快速补全复杂的中间逻辑并优化现有代码。
没有 llama.vim 时
- 上下文断裂:编写“填空式”代码(Fill-in-Middle)时,必须手动切换窗口查阅上下文件定义,打断心流,极易出错。
- 重复劳动繁重:修改旧函数逻辑需逐行删除重写,无法通过自然语言指令让 AI 直接理解意图并重写代码块。
- 隐私与延迟顾虑:依赖云端 Copilot 存在代码泄露风险,且网络波动导致建议延迟高,低配机器无法运行大型模型。
- 配置繁琐:传统本地 AI 插件难以智能复用上下文,导致显存占用高,生成速度慢甚至无法启动。
使用 llama.vim 后
- 无缝中间补全:光标在代码中间停留时,llama.vim 自动基于前后文预测缺失逻辑,按
Tab即可一键接纳整段建议。 - 指令化编辑:选中代码后按下
<leader>lli输入“改为异步处理”,工具即刻原地重构代码,无需手动删改。 - 本地高效运行:结合 llama.cpp 服务端,即使在 8GB 显存笔记本上也能流畅运行量化模型,数据完全保留在本地。
- 智能上下文管理:自动缓存已打开文件和剪贴板内容作为背景知识,在低硬件成本下实现大上下文精准理解。
llama.vim 将本地大模型深度融入 Vim 工作流,让开发者在离线环境中也能享受智能、私密且高效的编码体验。
运行环境要求
- macOS
- Windows
- Linux
非必需(依赖 CPU 或 GPU 运行 llama.cpp),显存需求取决于模型大小:推荐 8GB+ (运行 1.5B 模型), 16GB+ (运行 7B 模型), 64GB+ (运行 30B 模型)
未说明(取决于加载的模型大小,建议与显存需求相匹配的系统内存)
快速开始
llama.vim
本地 LLM 辅助文本补全。
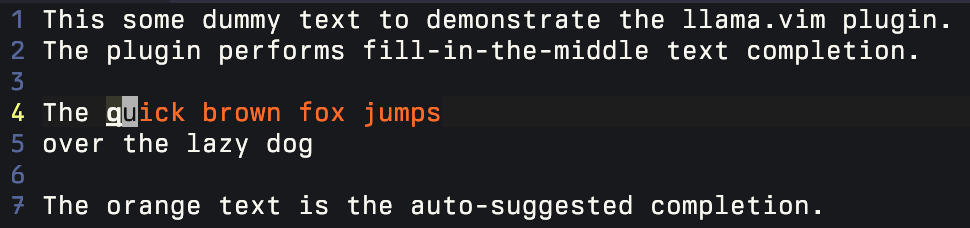
填空式(FIM)补全
基于指令的编辑
https://github.com/user-attachments/assets/641a6e72-f1a2-4fe5-b0fd-c2597c6f4cdc
https://github.com/user-attachments/assets/68bff15b-2d91-4800-985d-b7f110a0ccb7
特性
- 在
Insert模式下光标移动时自动提示 - 使用
Tab接受建议 - 使用
Shift+Tab接受建议的第一行 - 使用
<leader>lli进行基于指令的编辑 - 控制最大文本生成时间
- 配置光标周围上下文的范围
- 使用打开和已编辑文件以及粘贴板中的内容构建环形上下文缓冲区
- 通过智能上下文复用,即使在低端硬件上也能支持超大上下文
- 显示性能统计信息
安装
插件设置
vim-plug
Plug 'ggml-org/llama.vim'Vundle
cd ~/.vim/bundle git clone https://github.com/ggml-org/llama.vim然后在你的 .vimrc 文件中,在
vundle#begin()部分添加Plugin 'llama.vim'。lazy.nvim
{ 'ggml-org/llama.vim', }
插件配置
你可以通过设置 g:llama_config 变量来自定义 llama.vim。
示例:
禁用内联信息:
" 放在 llama.vim 加载之前 let g:llama_config = { 'show_info': 0 }同样的操作,直接设置:
let g:llama_config.show_info = v:false使用 lazy.nvim 禁用自动 FIM(填空式)补全:
{ 'ggml-org/llama.vim', init = function() vim.g.llama_config = { auto_fim = false, } end, }配置 FIM 的快捷键:
let g:llama_config.keymap_fim_trigger = "<leader>llf" let g:llama_config.keymap_fim_accept_full = "<Tab>" let g:llama_config.keymap_fim_accept_line = "<S-Tab>" let g:llama_config.keymap_fim_accept_word = "<leader>ll]"配置基于指令的编辑快捷键:
let g:llama_config.keymap_inst_trigger = "<leader>lli" let g:llama_config.keymap_inst_retry = "<leader>llr" let g:llama_config.keymap_inst_continue = "<leader>llc" let g:llama_config.keymap_inst_accept = "<Tab>" let g:llama_config.keymap_inst_cancel = "<Esc>"
请参考 :help llama_config 或 源代码 以获取完整的选项列表。
llama.cpp 设置
该插件需要一个运行中的 llama.cpp 服务器实例,监听地址为 g:llama_config.endpoint_fim 和/或 g:llama_config.endpoint_inst。
Mac OS
brew install llama.cpp
Windows
winget install llama.cpp
其他操作系统
你可以从源码编译,或者使用最新的二进制文件:https://github.com/ggml-org/llama.cpp/releases
llama.cpp 配置
以下是根据显存大小推荐的配置:
显存大于 64GB:
llama-server --fim-qwen-30b-default显存大于 16GB:
llama-server --fim-qwen-7b-default显存小于 16GB:
llama-server --fim-qwen-3b-default显存小于 8GB:
llama-server --fim-qwen-1.5b-default
使用 :help llama 获取更多详细信息。
推荐的 LLM 模型
该插件需要支持 FIM 的模型:HF 集合
示例
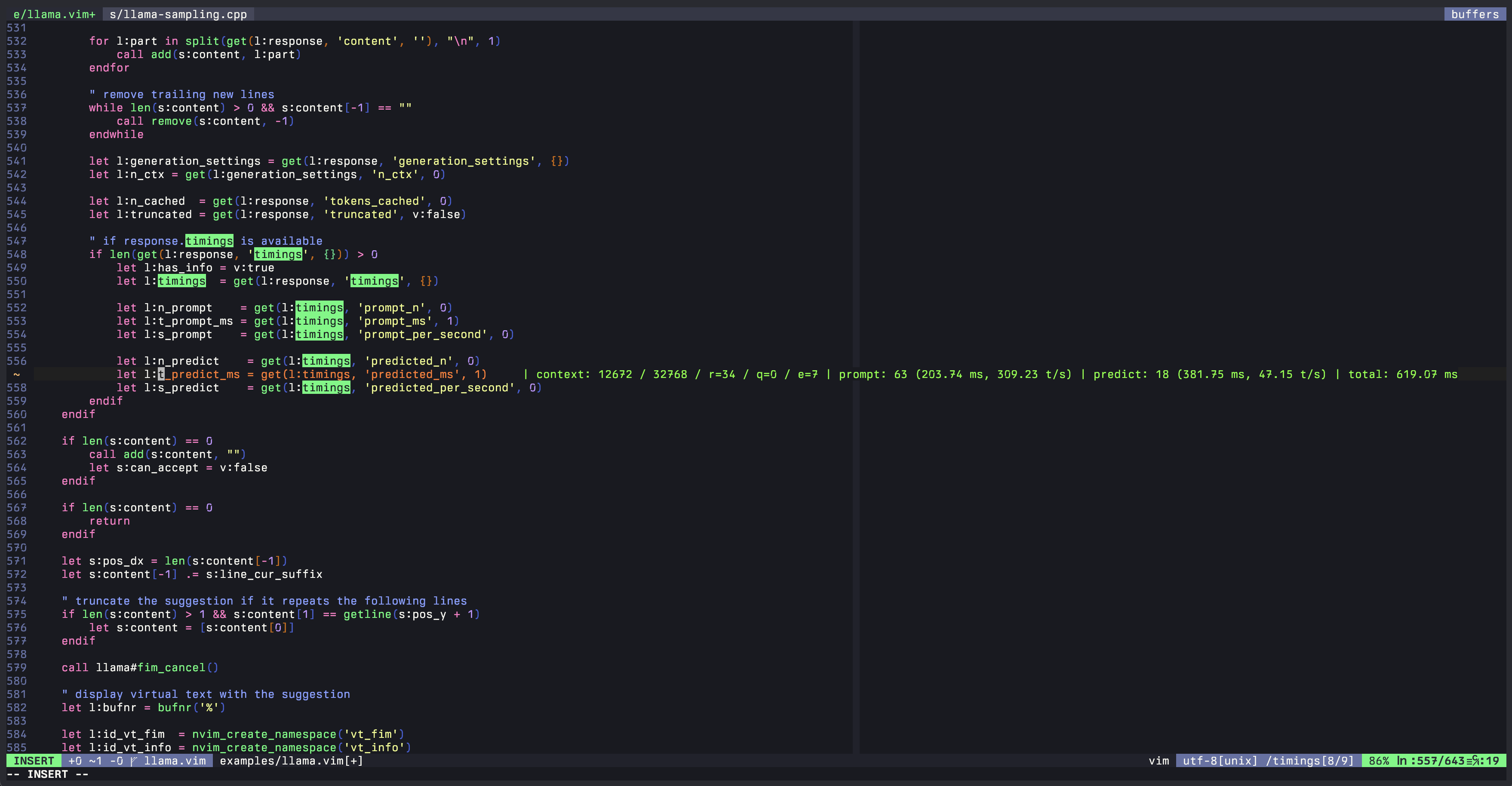
在 M1 Pro (2021) 上使用 Qwen2.5-Coder 1.5B Q8_0 运行 llama.vim:

橙色文字是生成的建议。绿色文字显示了 FIM 请求的性能统计信息:当前使用的上下文为 15186 个 token,最大值为 32768。环形缓冲区中有 30 个包含额外上下文的块(总共 64 个)。到目前为止,当前会话中已经驱逐了 1 个块,队列中没有等待处理的块。本次请求新计算的 prompt token 数为 260,生成的 token 数为 24。在当前行输入字母 c 后,生成此建议耗时 1245 ms。
在 M2 Ultra 上使用 Qwen2.5-Coder 7B Q8_0 运行 llama.vim:
https://github.com/user-attachments/assets/1f1eb408-8ac2-4bd2-b2cf-6ab7d6816754
展示了全局上下文如何跨不同文件累积和维护,并演示了在大型代码库中工作的整体延迟。
另一个 Swift 代码的小例子:
实现细节
该插件旨在保持极简和轻量级,同时提供高质量且高效的本地 FIM 补全功能,即使在消费级硬件上也能实现。有关其实现方式的更多信息,请参阅以下链接:
- 初始实现和技术说明:https://github.com/ggml-org/llama.cpp/pull/9787
- 经典 Vim 支持:https://github.com/ggml-org/llama.cpp/pull/9995
其他 IDE
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。