Machine-Learning-for-Asset-Managers
Machine-Learning-for-Asset-Managers 是马科斯·洛佩斯·德·普拉多(Marcos López de Prado)教授著作《机器学习在资产管理中的应用》的开源代码实现库。它专注于将书中复杂的量化金融理论转化为可执行的 Python 代码,涵盖去噪、去调协方差矩阵计算、最优带宽估计及聚类分析等核心算法。
该工具主要解决了金融数据中常见的“噪声”干扰问题。通过应用 Marchenko-Pastur 分布理论和特征值修正方法,它能有效清洗随机矩阵,提取真实的市场信号,从而构建更稳定的最小方差投资组合。此外,项目还针对书中部分算法(如最优聚类数算法 ONC)存在的潜在缺陷进行了探讨与修正,为用户提供了更严谨的实践参考。
这款软件非常适合量化研究员、金融数据科学家以及希望深入理解机器学习在资管领域应用的开发者使用。其独特的技术亮点在于不仅复现了经典理论,还通过交叉验证等方法优化了核密度估计(KDE)中的带宽选择,并直观展示了去噪前后特征值分布的对比。对于想要从理论走向实战,或利用 Hudson & Thames 的 mlfinlab 库进行更深层次开发的从业者来说,这是一个极佳的学习起点和实验沙箱。
使用场景
某量化对冲基金的分析师正在构建多资产最小方差组合,试图从充满噪声的历史收益率数据中提取稳定的协方差矩阵以优化配置。
没有 Machine-Learning-for-Asset-Managers 时
- 噪声干扰严重:直接使用原始样本协方差矩阵,导致随机噪声被误判为有效信号,使得投资组合对历史数据过度拟合。
- 参数选择盲目:在使用核密度估计(KDE)去噪时,缺乏科学的交叉验证机制来确定最佳带宽(bandwidth),只能凭经验猜测,导致概率密度函数拟合不准。
- 组合表现不稳定:由于输入矩阵包含大量虚假相关性,计算出的最优权重在实盘中频繁剧烈调仓,交易成本高昂且夏普比率低下。
- 理论复现困难:团队需手动复现 Marcos López de Prado 教授书中复杂的 Marchenko-Pastur 分布推导和特征值清洗算法,开发周期长且易出错。
使用 Machine-Learning-for-Asset-Managers 后
- 精准信号提取:利用工具内置的固定残差特征值方法,自动识别并剔除随机噪声特征值,保留真实的市场信号结构。
- 自动化参数寻优:调用
ch2_fitKDE_find_best_bandwidth模块,通过交叉验证自动计算出如 0.0351 这样的最优带宽,确保密度估计平滑且准确。 - 稳健资产配置:基于去噪后的协方差矩阵构建最小方差组合,有效前沿更加稳定,显著降低了实盘中的无效调仓频率。
- 快速落地前沿理论:直接复用书中第 2 章经过验证的代码片段,将原本数周的算法研发时间缩短至几小时,让团队能专注于策略逻辑而非底层数学实现。
Machine-Learning-for-Asset-Managers 通过将顶尖量化理论转化为可执行的代码工具,帮助机构在嘈杂的市场数据中构建出真正稳健的投资组合。
运行环境要求
未说明
未说明
快速开始
安装库
使用 pip install -U git+https://github.com/emoen/Machine-Learning-for-Asset-Managers 命令进行安装。
>>> from Machine_Learning_for_Asset_Managers import ch2_fitKDE_find_best_bandwidth as c
>>> import numpy as np
>>> c.findOptimalBWidth(np.asarray([21,3]))
{'bandwidth': 10.0}
资产管理者的机器学习
本项目实现了由Marcos López de Prado教授所著的《资产管理者的机器学习(量化金融要素)》一书中代码片段及习题的实现。该书链接为:https://www.amazon.com/Machine-Learning-Managers-Elements-Quantitative/dp/1108792898。
此项目主要用于个人学习。若希望直接应用书中的概念,建议前往Hudson & Thames公司,他们已在mlfinlab中实现了这些概念及其他更多内容。
如需实际应用,请参考以下仓库:Machine-Learning-for-Asset-Managers-Oslo-Bors。
注意:在第4章中,书中“最优聚类数”算法(ONC)的实现存在一个错误。(论文《利用无监督学习方法检测虚假投资策略》,de Prado和Lewis,2018年中的代码与此不同,但同样不正确)。相关讨论请见:https://quant.stackexchange.com/questions/60486/bug-found-in-optimal-number-of-clusters-algorithm-from-de-prado-and-lewis-201。
ONC采用的子空间分治法可能存在潜在问题:当将某个子空间嵌入到具有较大特征值的空间中时,较大的空间可能会扭曲子空间中发现的聚类结构。ONC正是将子空间嵌入到由相关性矩阵中最大特征值构成的空间中,从而导致这一问题。更严谨的问题描述可参见:https://math.stackexchange.com/questions/4013808/metric-on-clustering-of-correlation-matrix-using-silhouette-score/4050616#4050616。
因此,应进一步研究其他聚类算法,例如层次聚类。
第2章 去噪与去偏
马尔琴科-帕斯图尔理论概率密度函数与经验密度函数:
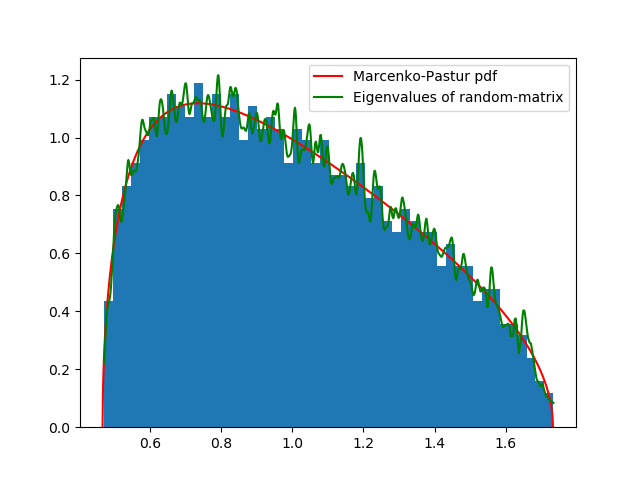 |
|---|
| 图2.1:马尔琴科-帕斯图尔理论概率密度函数与经验密度函数: |
使用恒定残差特征值法对含信号的随机矩阵进行去噪。该方法通过固定随机特征值来实现。具体参见代码片段2.5。
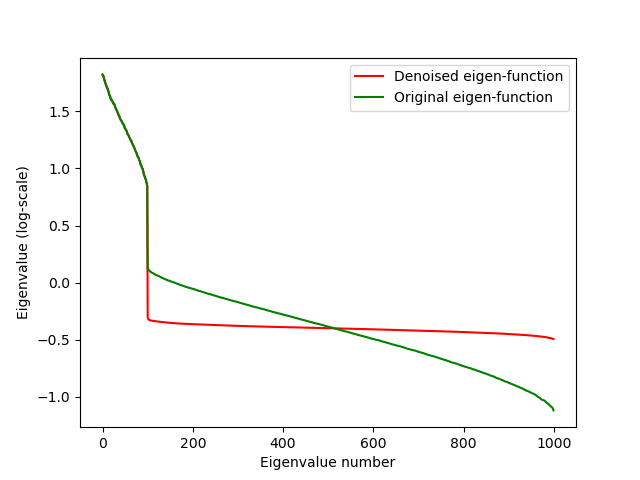 |
|---|
| 图2.2:应用残差特征值法前后特征值的对比: |
经过去偏后的协方差矩阵可用于计算最小方差组合。有效前沿是自最小方差组合开始的最小方差前沿的上半部分。而经去噪处理后的协方差矩阵则更为稳定,不易受变化影响。
注:练习2.7:“扩展代码片段2.2中的fitKDE函数,使其能够通过交叉验证估计最佳带宽(bWidth)”。
脚本ch2_fitKDE_find_bandwidth.py实现了上述过程,并生成了图2.3中的绿色核密度估计曲线:
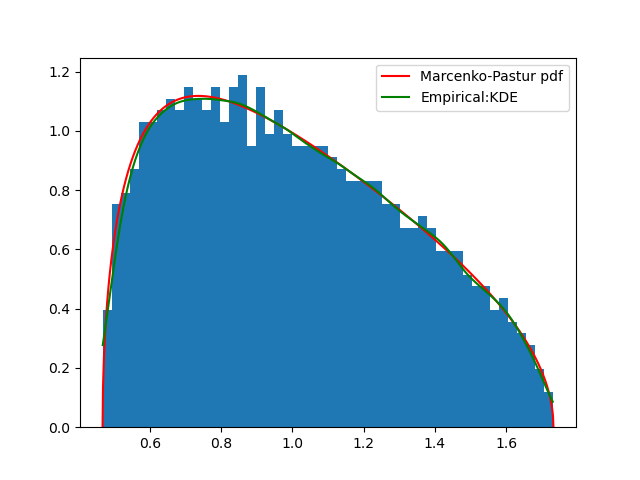 |
|---|
| 图2.3:计算得到的带宽(绿线)与直方图、PDF曲线。绿线更加平滑。找到的带宽为:0.03511191734215131 |
来自代码片段2.3——含信号的随机矩阵:直方图展示了含信号的随机矩阵特征值的分布情况。随后,以fitKDE作为经验密度函数,计算理论概率密度函数的方差。因此,找到fitKDE中合适的带宽值,对于确定理论MP-PDF最可能的方差至关重要。
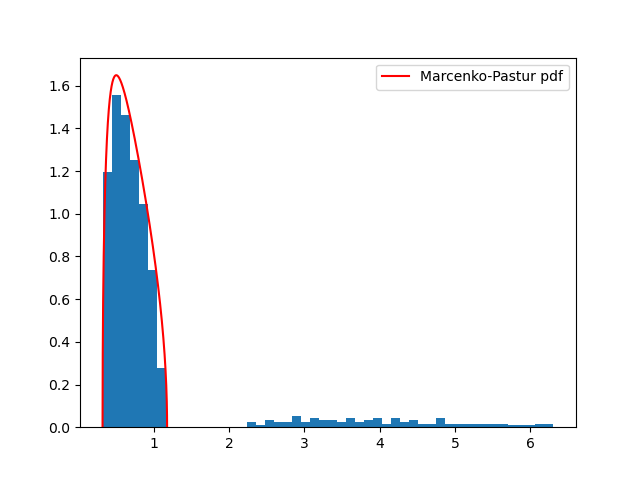 |
|---|
| 图2.4:含信号特征值的直方图与PDF曲线 |
第3章 距离度量
- 距离度量的定义:
- 不可区分元素同一性:d(x,y) = 0 => x=y
- 对称性:d(x,y) = d(y,x)
- 三角不等式。
- 1、2、3共同保证非负性:d(x,y) >= 0
- 皮尔逊相关系数
- 距离相关系数
- 角距离
- 信息论中的共依存/熵依赖
- 交叉熵:H[X] = - Σs ∈ SX p[x] log (p[x])
- 基拉巴-莱布勒散度:DKL[p||q] = - Σs ∈ SX p[x] log (q[x]/p[x]) = p[x] Σs ∈ S log (p[x]/q[x])
- 交叉熵:Hc[p||q] = H[x] = DKL[p||q]
- 互信息:已知Y后X的不确定性降低:I[X,Y] = H[X] - H[X|Y] = H[X] + H[Y] - H[X,Y] = EX[DKL[p[y|x]||p[y]]]
- 信息差异:VI[X,Y] = H[X|Y] + H[Y|X] = H[X,Y] - I[X,Y]。它是给定一个变量时另一个变量的预期不确定性:VI[X,Y] = 0 <=> X=Y
- 基拉巴-莱布勒散度并非距离度量,而信息差异则是。
>>> ss.entropy([1./2,1./2], base=2)
1.0
>>> ss.entropy([1,0], base=2)
0.0
>>> ss.entropy([1./3,2./3], base=2)
0.9182958340544894
- 抛硬币时的信息量为1比特
- 确定性结果的信息量为0比特
- 不公平抛硬币时的信息量小于1比特
- 角距离:p_d = sqrt(1/2 - (1-rho(X, Y)))
- 绝对角距离:p_d = sqrt(1/2 - (1-|rho|(X, Y)))
- 平方角距离:p_d = sqrt(1/2 - (1-rho^2(X, Y)))
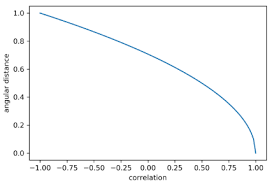
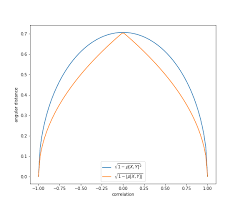 标准角距离更适合用于多头投资组合的应用场景。而平方角距离和绝对角距离则更适合多空投资组合。
标准角距离更适合用于多头投资组合的应用场景。而平方角距离和绝对角距离则更适合多空投资组合。
第4章 最优聚类
使用无监督学习方法,最大化组内相似性并最小化组间相似性。考虑形状为N×F的矩阵X,其中N表示对象数量,F表示特征数量。利用这些特征计算N个对象之间的邻近度(相关性、互信息),形成一个N×N的邻近度矩阵。
聚类算法主要分为两类:划分式和层次式:
- 连通性:层次聚类
- 质心:如K均值聚类
- 分布:高斯混合模型
- 密度:寻找连通的密集区域,如DBSCAN、OPTICS
- 子空间:基于特征和观测两个维度建模。示例
生成随机块状相关性矩阵用于模拟具有相关性的金融工具。代码片段4.3展示了这一用途,并结合了片段4.1和4.2中定义的“最优聚类数”(ONC)算法。该算法无需预先设定聚类数量(与K均值不同),而是采用“肘部法”来确定停止增加聚类的时机。当组内相关性较高而组间相关性较低时,即可得到最优聚类数。轮廓系数被用来最小化组内距离并最大化组间距离。
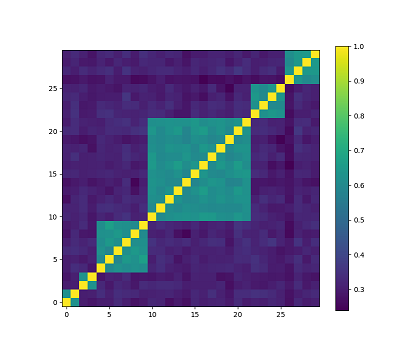 |
|---|
| 随机块状相关性矩阵。浅色表示高相关性,深色表示低相关性。在本例中,块数K=6,最小块大小minBlockSize=2,金融工具数量N=30 |
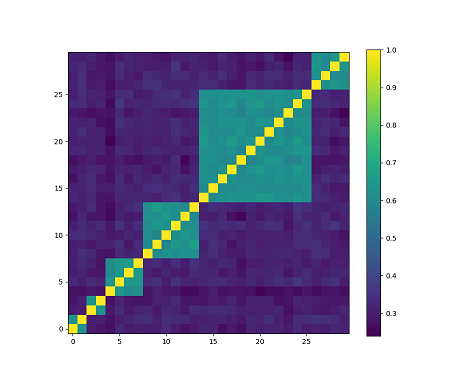 |
| 将ONC算法应用于随机块状相关性矩阵。ONC能够找到所有聚类。 |
第5章 金融标签
- 固定时间窗口法
- 时间柱法
- 成交量柱法
三重屏障法是指持仓直到:
- 未实现盈利目标达成
- 未实现亏损达到上限
- 持仓超过最大柱数限制
趋势扫描法的核心思想是识别趋势,并让其持续运行,直至趋势不再有效,而不设置任何障碍。
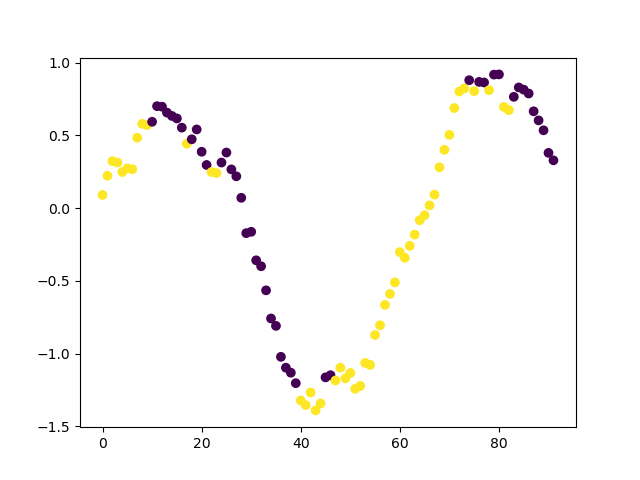 |
|---|
| 带有高斯噪声的正弦波上的趋势扫描标签示例: |
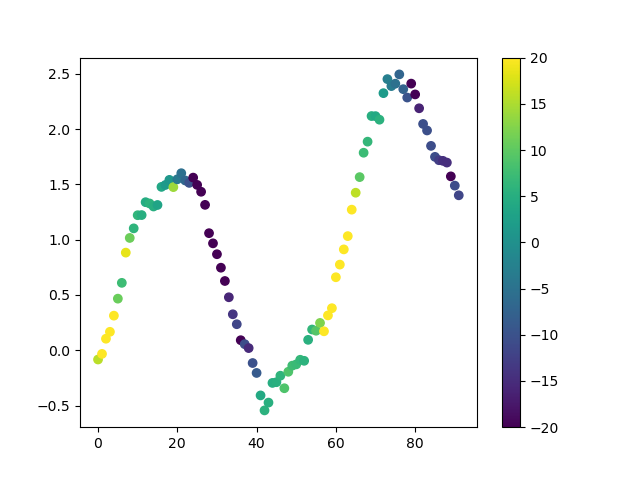 |
|---|
| 使用t值进行趋势扫描,t值反映了对趋势的信心。1表示高度看涨,-1表示高度看跌。 |
书中介绍的向前看算法之外,另一种方法是从最新数据点开始,向后回溯至指定窗口大小的数据范围。例如,若最新数据点位于索引20处,窗口大小为3到10天,则向后算法会从索引17至20逐次回溯至索引11至20,从而仅考虑最近期的信息。
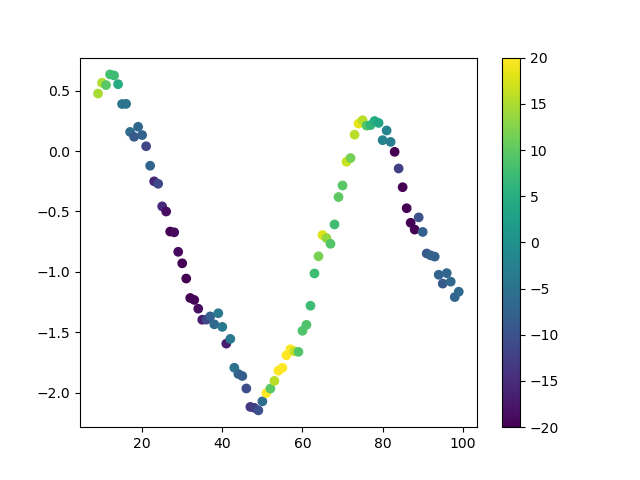 |
|---|
| 使用向后回溯方式的趋势扫描及t值 |
第6章 特征重要性分析
“p值并不衡量原假设或备择假设不成立的概率,也不代表结果的重要性。”
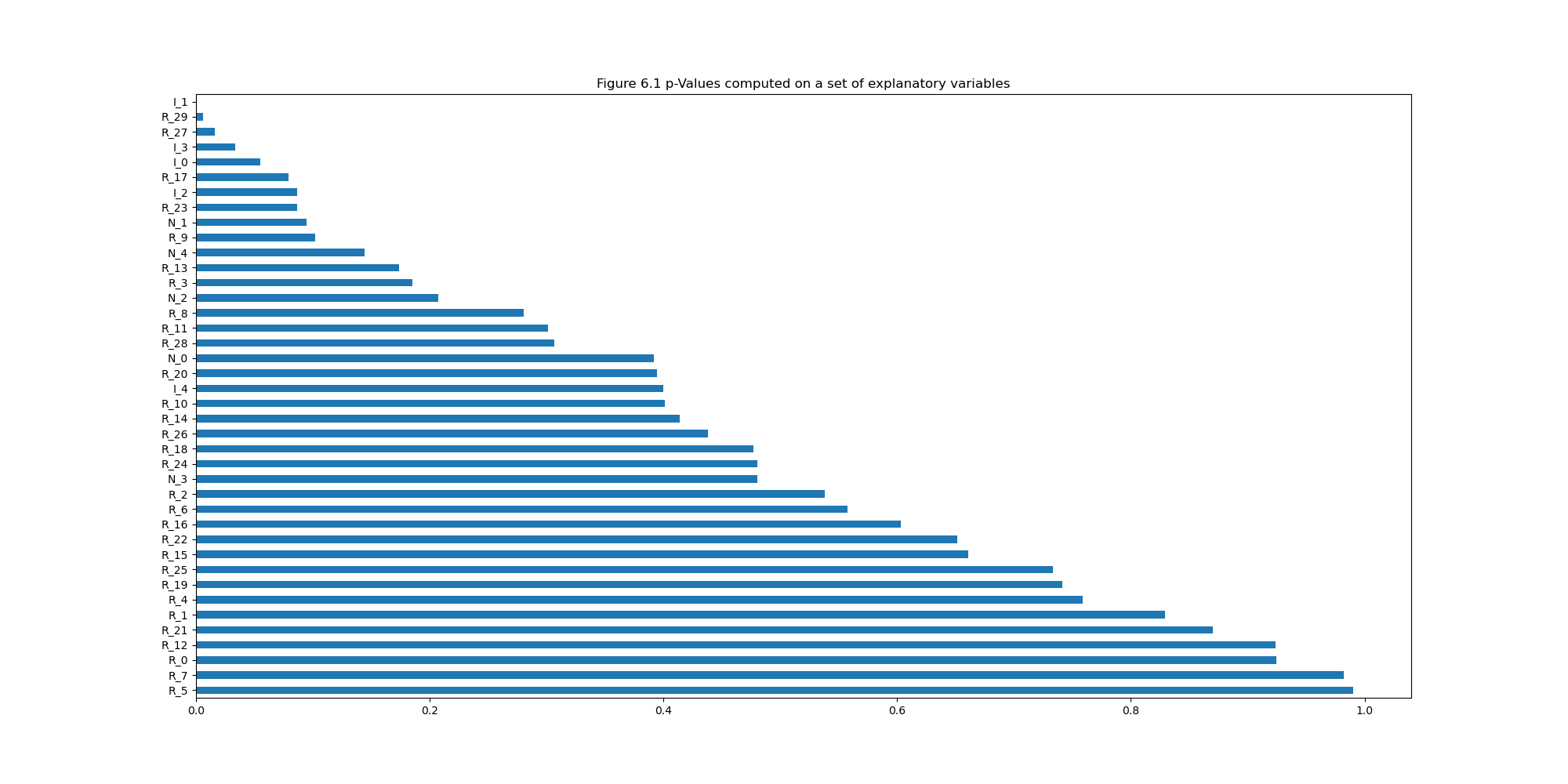 |
|---|
| 在一组包含信息性、冗余性和噪声性解释变量上计算的p值。解释变量并未呈现最高的p值。 |
“回测并非研究工具,特征重要性才是。”(洛佩兹·德·普拉多)平均不纯度减少(MDI)算法解决了p值存在的四个问题中的三个:
- MDI不依赖于树结构、代数表达式,也不依赖于残差的随机性或分布特性(如y=b0+b1*xi+ε)。
- 通常单一样本估计出的贝塔系数方差较大,而MDI通过随机森林集成中的多棵树进行自助采样,从而降低方差。
- 在MDI中,目标不是估计描述原假设概率的代数方程系数(b_hat_0、b_hat_1)。
- MDI不进行交叉验证,因此无法纠正样本内计算偏差。
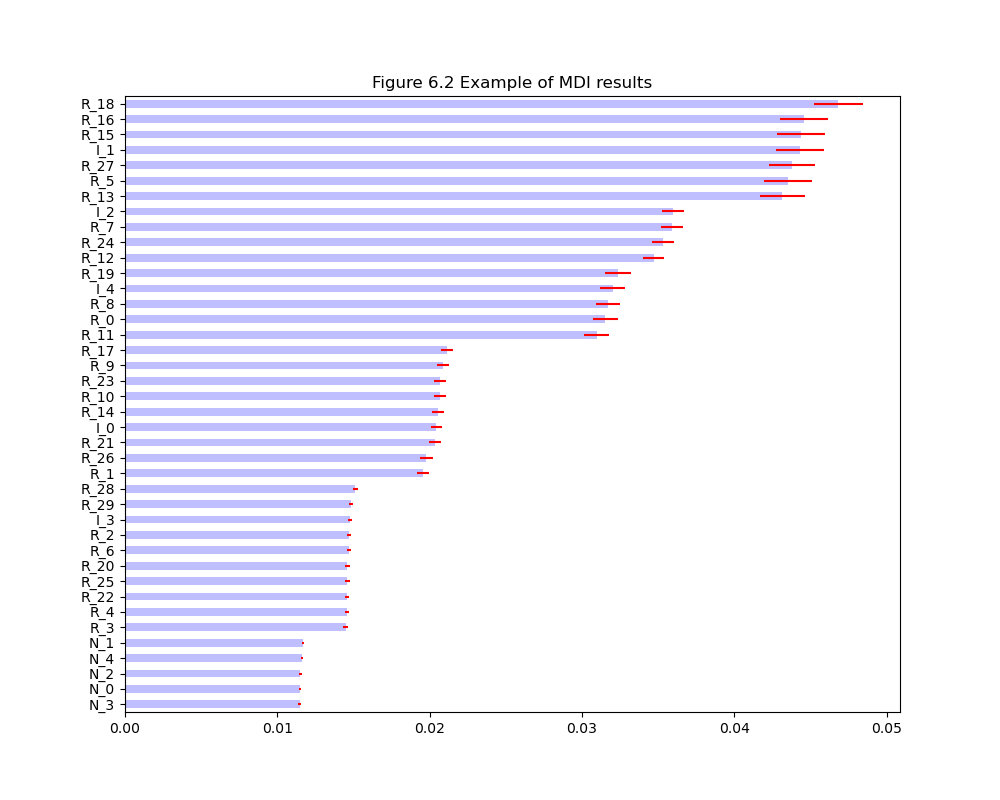 |
|---|
| MDI算法示例 |
图6.4显示,ONC正确识别出六个相关聚类(每个信息性特征对应一个聚类,再加上一个噪声特征聚类),并将冗余特征归入其源自的信息性特征所在的聚类。由于各聚类间的相关性较低,无需用残差替换原有特征。
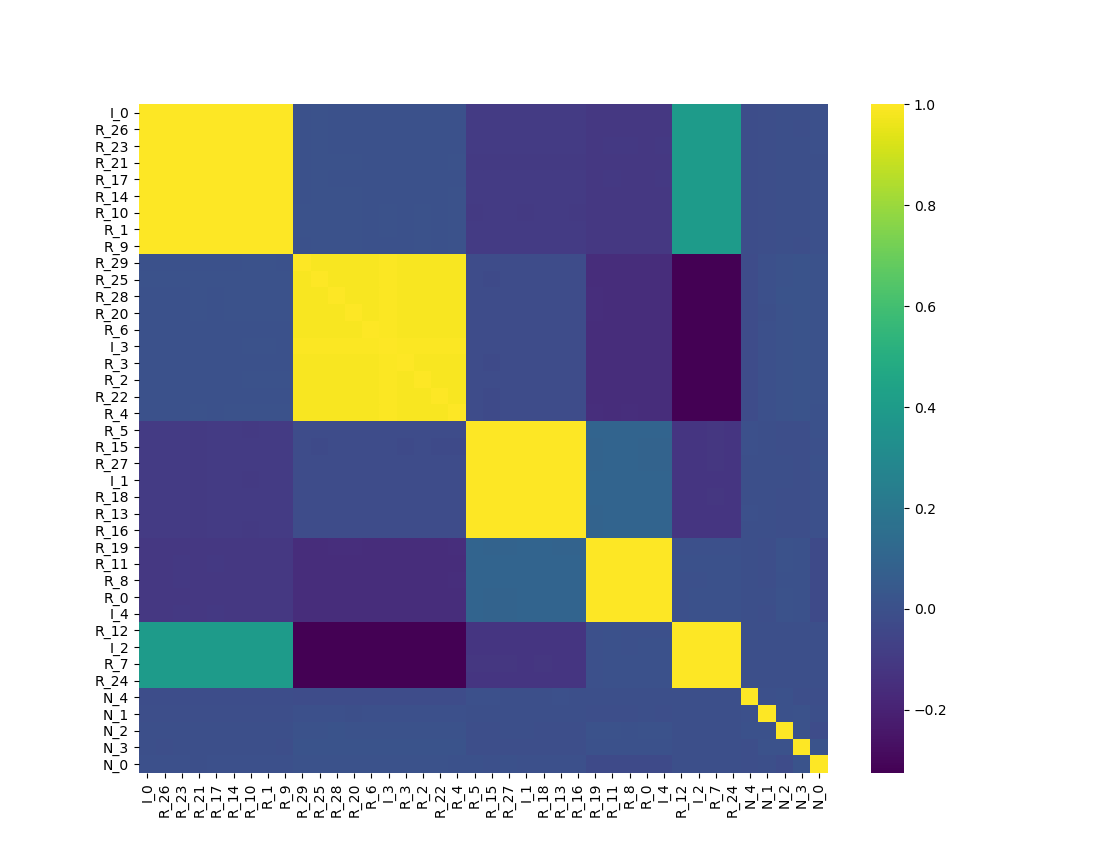 |
|---|
接下来,将聚类后的MDI方法应用于聚类后的数据:
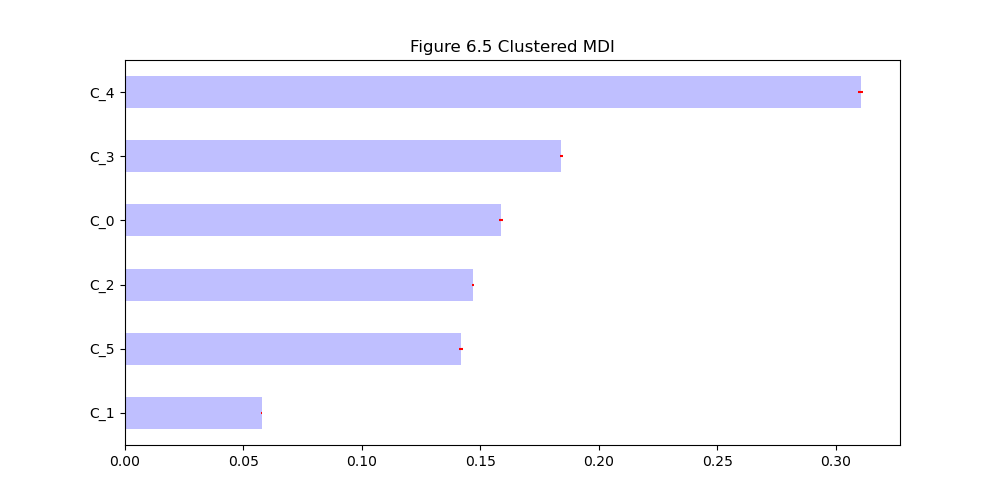 |
|---|
| 图6.5 聚类后的MDI |
相比非聚类的MDI,聚类后的MDI效果更好。最后,将聚类后的MDA方法应用于同一数据:
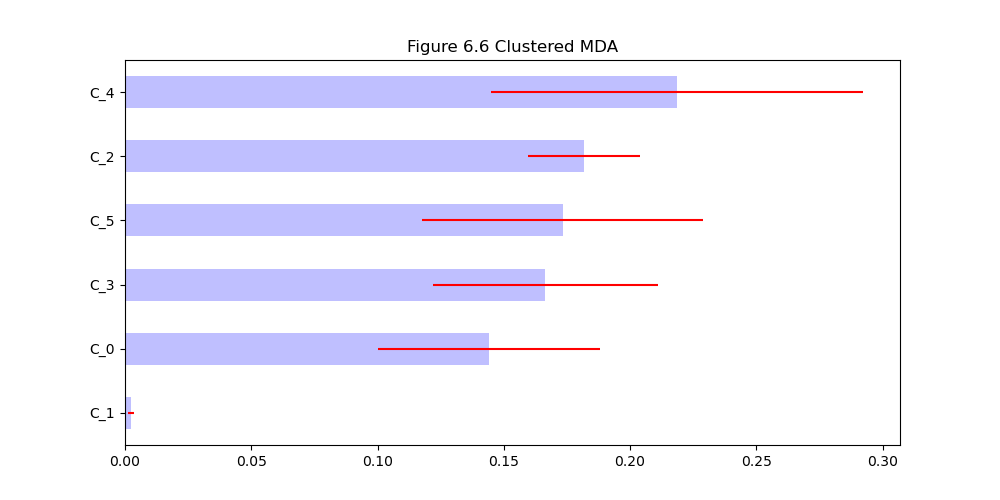 |
|---|
| 图6.6 聚类后的MDA |
结论:与噪声特征相关的C_5聚类并不重要,其余各聚类的重要性相近。
第7章 投资组合构建
凸优化方法可用于计算最小方差投资组合和最大夏普比率投资组合。
条件数的定义:最大特征值与最小特征值之比的绝对值,即A_n_n / A_m_m。条件数反映了由协方差结构引起的不稳定程度。
迹的定义:矩阵对角线元素之和,即trace = sum(diag(A))。
高度相关的时序数据会导致相关性矩阵的条件数较高。
马科维茨的诅咒
相关性矩阵C只有在相关系数$\ro = 0$——即完全不相关时——才是稳定的。
分层风险平价(HRP)在样本外蒙特卡洛实验中表现优于马科维茨模型,但在样本内却并非最优。
代码片段7.1展示了由信号引起的相关性矩阵不稳定现象。
>>> corr0 = mc.formBlockMatrix(2, 2, .5)
>>> corr0
array([[1. , 0.5, 0. , 0. ],
[0.5, 1. , 0. , 0. ],
[0. , 0. , 1. , 0.5],
[0. , 0. , 0.5, 1. ]])
>>> eVal, eVec = np.linalg.eigh(corr0)
>>> print(max(eVal)/min(eVal))
3.0
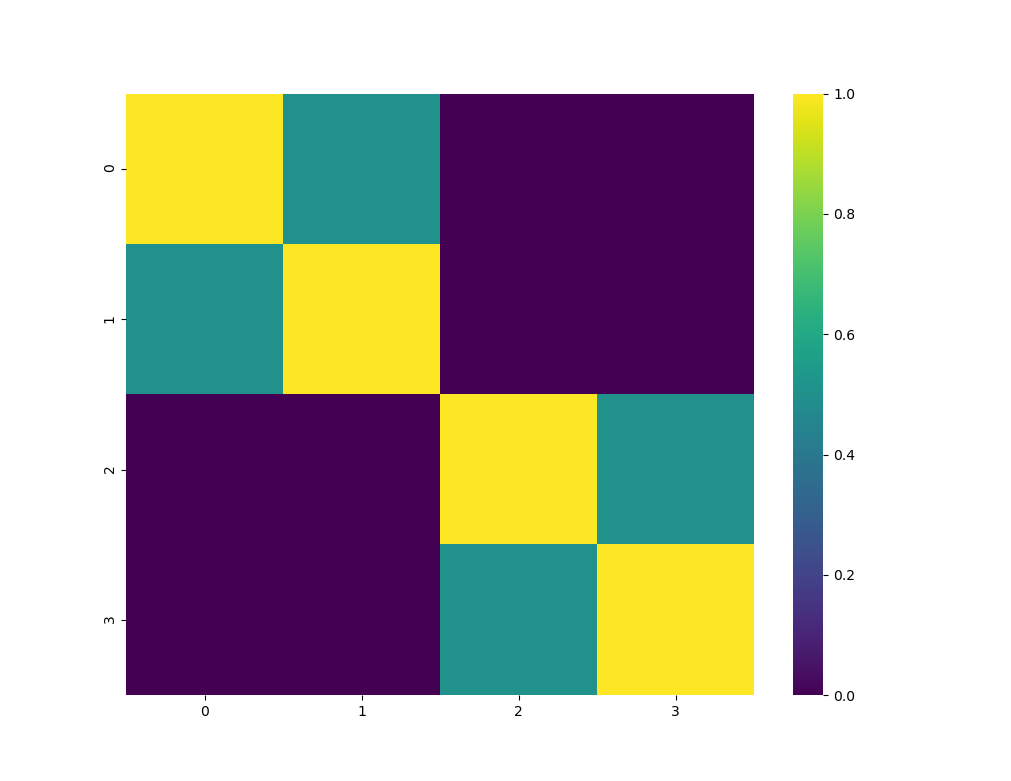 |
|---|
| 图7.1 块对角相关性矩阵热图 |
代码片段7.2创建了相同的块对角矩阵,但其中一个区块占主导地位。然而,条件数仍然相同。
>>> corr0 = block_diag(mc.formBlockMatrix(1,2, .5))
>>> corr1 = mc.formBlockMatrix(1,2, .0)
>>> corr0 = block_diag(corr0, corr1)
>>> corr0
array([[1. , 0.5, 0. , 0. ],
[0.5, 1. , 0. , 0. ],
[0. , 0. , 1. , 0. ],
[0. , 0. , 0. , 1. ]])
>>> eVal, eVec = np.linalg.eigh(corr0)
>>> matrix_condition_number = max(eVal)/min(eVal)
>>> print(matrix_condition_number)
3.0
这表明,仅降低两个区块中的一个区块内部的相关性,并不能降低矩阵的条件数。这也说明,马科维茨解中的不稳定性可以追溯到那些占主导地位的区块。
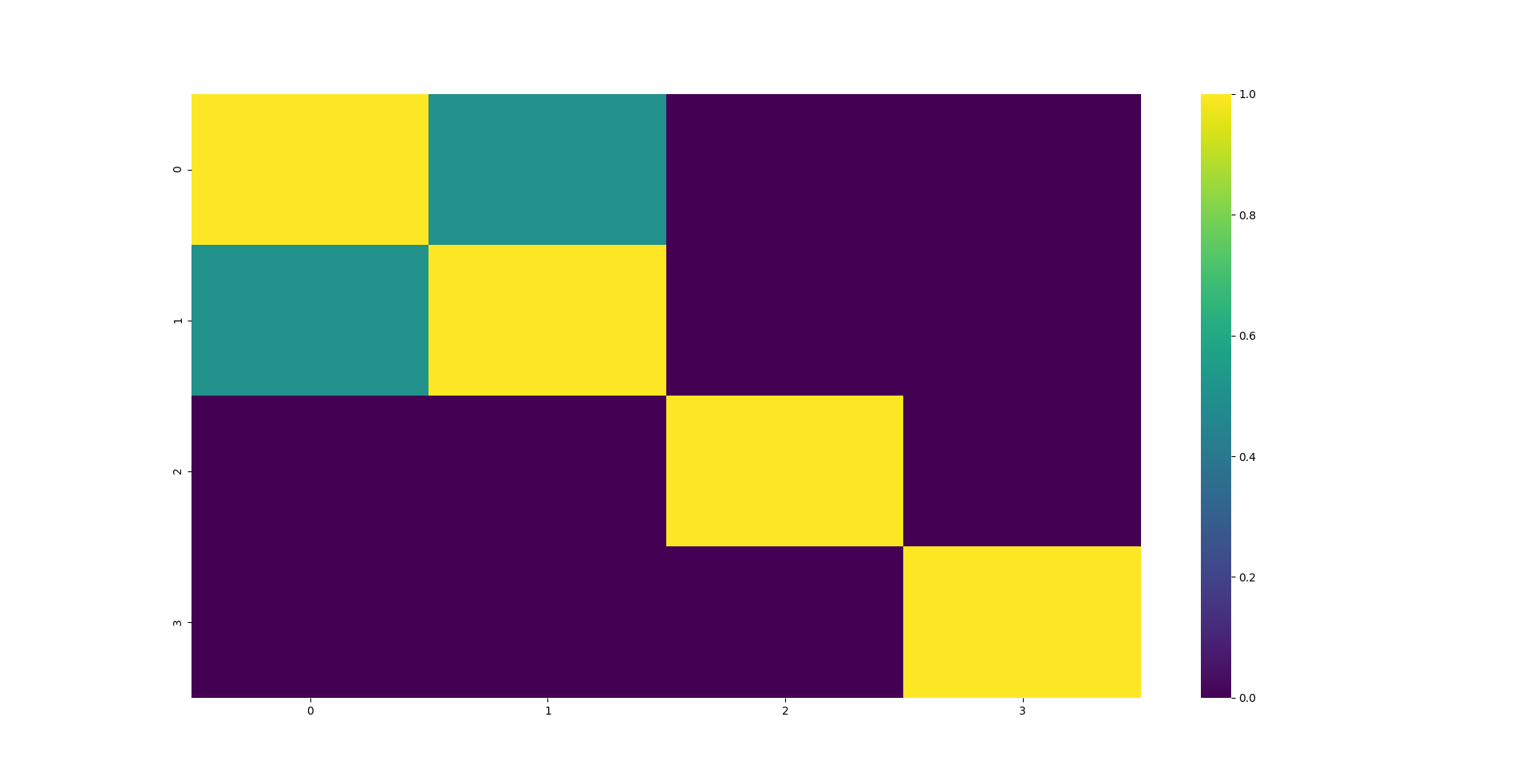 |
|---|
| 图7.2 占主导地位的块对角相关性矩阵热图 |
嵌套聚类优化算法(NCO)
NCO提供了一种策略,用于解决马科维茨诅咒对现有均值方差配置方法的影响。
- 步骤:对相关性矩阵进行聚类
- 步骤:使用去噪后的协方差矩阵计算簇内最优配置
- 步骤:使用接近对角矩阵的简化协方差矩阵计算簇间最优配置,此时优化问题接近于理想化的马科维茨情形,即当$\ro$ = 0时
第8章 测试集过拟合
回测是对投资策略在过去表现的一种历史模拟。在多重测试的情况下,回测会受到选择偏差的影响:研究人员会在历史数据上运行数百万次测试,并报告其中表现最好的结果(即过拟合的结果)。本章研究如何衡量选择偏差的影响。
精确率与召回率
多重测试下的精确率与召回率
夏普比率
夏普比率 = μ/σ
“虚假策略”定理
研究人员可能会运行大量历史模拟,并只报告表现最佳的一次(最大夏普比率)。然而,最大夏普比率的分布并不等于预期的夏普比率。因此,存在多重重复测试下的选择偏差(SBuMT)。
实验结果
一项蒙特卡洛实验表明,即使预期夏普比率是0(E[sharp_ratio]),最大夏普比率的期望值也会增加(E[max(sharp_ratio)] = 3.26)。这意味着,即便实际上并不存在有效的投资策略,某些策略仍可能显得颇具前景。
当进行多次试验时,最大夏普比率的期望值将高于随机试验中夏普比率的期望值(当真实夏普比率=0且方差>0时)。
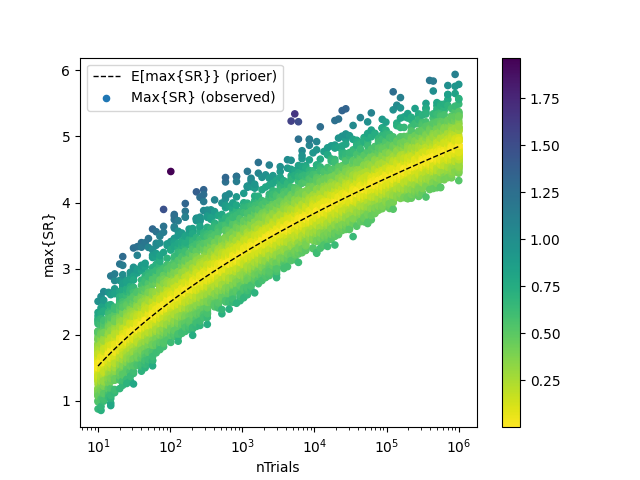 |
|---|
| 图8.1 虚假策略定理的实验结果与理论结果对比 |
通胀夏普比率
“虚假策略”定理的主要结论是:除非$maxk{SR^k}>>E[maxk{SR^k}]$,否则所发现的策略很可能是假阳性。
多重测试下的第二类错误
第一类错误与第二类错误之间的相互作用
附录A:基于合成数据的测试
无论是通过重采样还是蒙特卡洛方法
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。