smartcat
smartcat 是一款专为终端高手打造的命令行工具,旨在将大语言模型(LLM)无缝融入传统的 Unix 命令生态中。它的核心理念是为经典的 cat 命令装上“大脑”,让用户能够通过标准的文本流管道,在终端内直接调用 AI 能力处理数据、代码或文档,而无需离开熟悉的命令行环境。
该工具主要解决了传统 CLI 工作流与现代化 AI 服务之间的割裂问题。以往用户需要在终端和网页聊天界面之间频繁切换,而 smartcat 允许通过管道直接将命令输出作为提示词发送给模型,并将结果返回到后续命令中,实现了真正的自动化与流程整合。它特别适合开发者、运维工程师及重度依赖终端的技术人员使用。
smartcat 的独特亮点在于其极简主义设计与高度的可配置性。它遵循 Unix 哲学,支持自定义提示词模板、多轮对话上下文以及通配符文件引用,能显著减少重复操作的开销。同时,它兼容多种主流 API(如 OpenAI、Anthropic、Mistral)及本地部署方案(如 Ollama),让用户在享受云端模型强大能力的同时,也能选择免费且隐私安全的本地运行模式,真正实现对工作流的全面掌控。
使用场景
一位后端工程师在清理遗留代码库时,需要快速理解并重构数百个分散的旧式 Shell 脚本和配置片段。
没有 smartcat 时
- 上下文割裂:必须手动打开多个文件复制内容到网页版 AI 对话框,无法直接利用 Unix 管道流式处理数据。
- 操作繁琐低效:每次询问不同问题(如“解释逻辑”、“生成单元测试”、“优化性能”)都要重复粘贴代码和重写提示词。
- 工作流中断:在终端、浏览器和编辑器之间频繁切换,打断了原本流畅的命令行操作节奏。
- 难以批量处理:面对通配符匹配的一批文件(如
*.sh),无法一次性让 AI 分析所有相关文件的上下文关联。
使用 smartcat 后
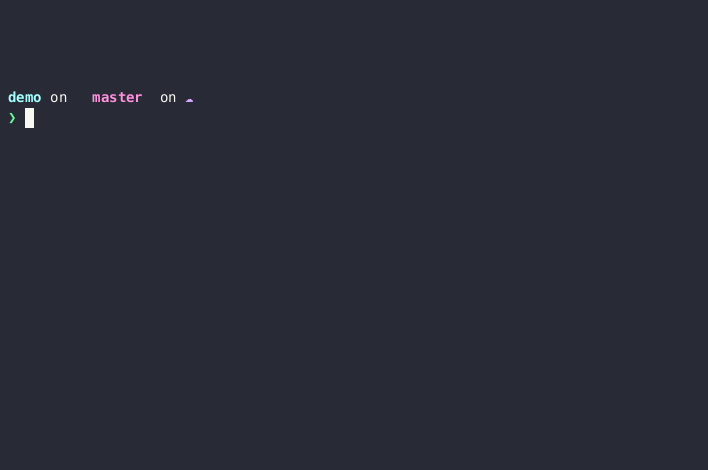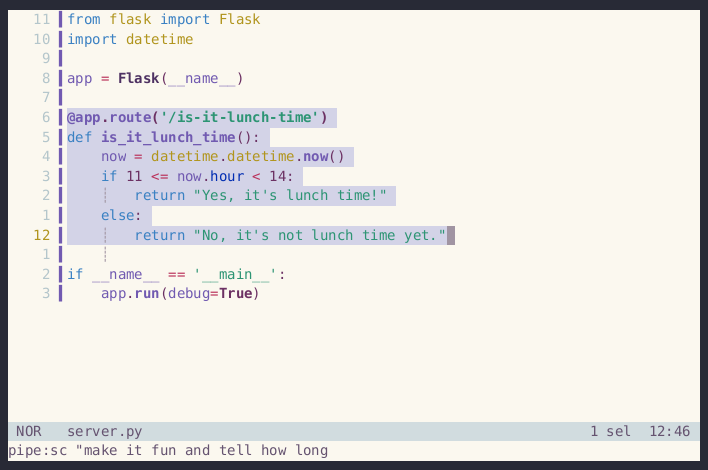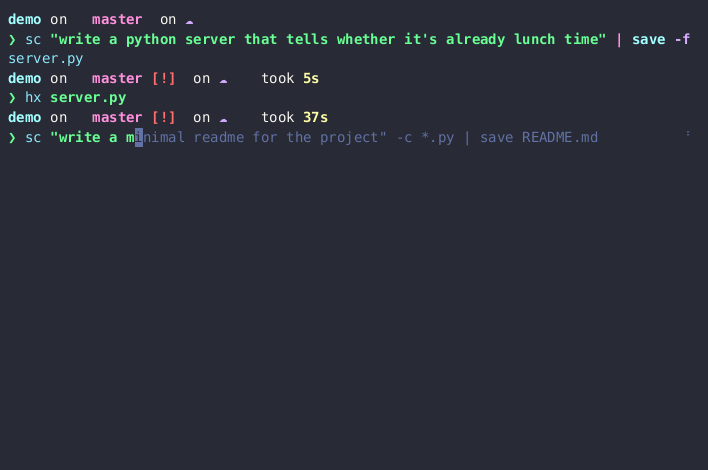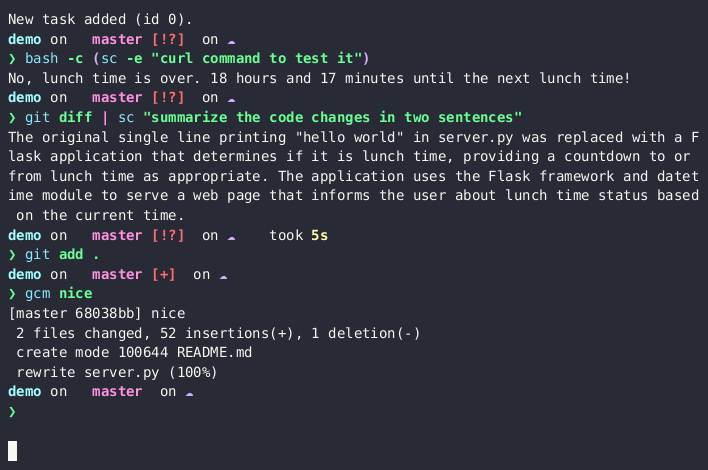
- 原生管道集成:直接使用
cat legacy.sh | sc "解释这段逻辑并重写为函数",像使用普通cat一样自然地将代码流传给大模型。 - 模板化高效复用:预设
refactor或test提示词模板,通过sc refactor *.sh即可对批量文件执行标准化的重构建议,无需重复输入指令。 - 终端内闭环操作:全程无需离开终端,结合编辑器插件可直接将
smartcat的输出结果插入当前文件,保持心流状态不中断。 - 智能上下文感知:利用 Glob 表达式自动包含依赖文件作为上下文,让 AI 基于完整的项目结构提供精准的修改方案,而非孤立的代码片段。
smartcat 真正将大模型的智力无缝嵌入了 Unix 哲学体系,让开发者能用最熟悉的管道命令驾驭 AI,实现从“复制粘贴”到“流式思维”的效率跃迁。
运行环境要求
- Linux
- macOS
- Windows
- 非必需
- 若使用本地 Ollama 运行模型,需根据所选模型配置相应 GPU(未指定具体型号或显存要求)
- 若使用远程 API 则无需本地 GPU
未说明

快速开始
![]()


smartcat (sc)
为 cat 赋予智慧!一个 CLI 界面,将语言模型引入 Unix 生态系统,让终端高手在完全掌控的同时,最大化利用大语言模型的能力。
它的独特之处在于:
- 专为高级用户设计;自定义配置以减少高频任务的开销
- 极简主义风格,遵循 Unix 哲学构建,注重与终端和编辑器的集成
- 优秀的输入输出处理能力,可将用户输入插入提示中,并将结果用于基于 CLI 的工作流
- 内置部分提示功能,使模型更适合作为 CLI 工具使用
- 完全可配置使用的 API、LLM 版本和温度参数
- 可编写并保存自己的提示模板,以加快重复性任务(简化、优化、测试等)
- 支持对话模式
- 使用 glob 表达式引入上下文文件
目前支持以下 API:
- 本地运行:通过 Ollama 或任何兼容其格式的服务器;请参阅 Ollama 设置 部分,了解免费且最简单的入门方式!
(根据您的配置,回答可能会较慢;您可能希望尝试第三方 API 以获得最佳工作流程。) - Anthropic、Azure OpenAI、Groq、Mistral AI、OpenAI
目录
安装
首次运行 (sc) 时,它会提示您生成默认配置文件,并指导您完成安装(请参阅 配置 部分)。
最低配置要求是设置一个调用已配置 API 的 default 提示模板(可以是带有 API 密钥的远程 API,也可以是使用 Ollama 的本地运行)。
接下来介绍如何获取它。
使用 Cargo
确保您已安装最新版本的 Rust 和 Cargo(您可以运行 rustup update):
cargo install smartcat
再次运行此命令即可更新 smartcat。
Arch Linux
如果您使用的是 Arch Linux,可以从 extra 仓库 安装该软件包:
pacman -S smartcat
下载二进制文件
请从 发布页面 选择适合您平台的编译版本。
推荐模型
目前,Anthropic、Mistral 或 OpenAI 的 API 效果最佳。使用这些顶级模型进行常规操作,每月费用约为 2–3 美元。
使用方法
用法:sc [选项] [输入或模板引用] [模板引用时的输入]
参数:
[输入或模板引用] 指向配置中的提示模板或直接输入(若未指定,则使用 `default` 提示模板)
[模板引用时的输入] 如果第一个参数匹配配置中的模板,则第二个参数将作为输入
选项:
-e, --extend-conversation 是否延续之前的对话或开始新对话
-r, --repeat-input 是否在输出前重复输入,适用于扩展而非替换场景
--api <API> 覆盖要调用的 API [可选值:ollama、anthropic、groq、mistral、openai]
-m, --model <MODEL> 覆盖要使用的模型(针对所选 API)
-t, --temperature <TEMPERATURE> 温度越高,回答越偏离平均值
-l, --char-limit <CHAR_LIMIT> 最多包含的字符数;超过时需用户确认,0 表示无限制
-c, --context <CONTEXT>... 用于提供上下文的 glob 模式或文件列表
必须放在最后。
-h, --help 显示帮助信息
-V, --version 显示版本号
您可以将其用于 CLI 中的任务,也可以在编辑器中使用(前提是编辑器能够良好地与 Shell 命令和文本流交互),以完成代码补全、重构、编写测试等任何操作!
要让其无缝运行的关键,在于设置一个良好的默认提示模板,告诉模型应像 CLI 工具一样工作,而不是输出不必要的内容,如 Markdown 格式或解释说明。
几个入门示例 🐈⬛
sc "say hi" # 直接提问(使用默认提示模板)
sc test # 使用模板化提示
sc test "and parametrize them" # 动态扩展模板
sc "explain how to use this program" -c **/*.md main.py # 使用文件作为上下文
git diff | sc "summarize the changes" # 通过管道传递数据
cat en.md | sc "translate in french" >> fr.md # 将数据写入文件
sc -e "use a more informal tone" -t 2 >> fr.md # 延续对话并提高温度
与编辑器集成
在编辑器中实现良好集成的关键在于设置一个合适的默认提示(或一组提示),并结合 -p 标志来指定当前任务。此外,可以使用 -r 标志来决定是替换还是扩展选中的内容。
Vim
首先选择一些文本,然后按下 : 键。接着可以将选中文本通过管道传递给 smartcat。
:'<,'>!sc "用通配符替换版本号"
:'<,'>!sc "修复这个函数"
这会覆盖当前选中的内容,用语言模型转换后的相同文本替换它。
:'<,'>!sc -r test
则会重复输入内容,相当于在当前选中文本的末尾追加语言模型的输出结果。
为了方便使用,可以在你的 vimrc 文件中添加以下映射:
nnoremap <leader>sc :'<,'>!sc
Helix 和 Kakoune
概念相同,但快捷键不同。只需按下管道键即可将选中文本重定向到 smartcat。
pipe:sc test -r
通过一些自定义映射,你可以将最常用的命令绑定到几个按键上,例如 <leader>wt!
示例工作流
用于快速提问:
sc "我的快速问题"
这很可能是你最快得到答案的方式:只需打开终端(如果你还没有在终端中),运行 sc 即可。无需寻找标签页、登录或跳转等操作。
帮助编写代码:
选择一个结构体:
:'<,'>!sc "为这个结构体实现 FromStr 和 ToString 特性"
选择生成的实现块:
:'<,'>!sc -e "能否让它更简洁一些?"
将光标放在文件底部,并提供示例用法作为输入:
:'<,'>!sc -e "现在根据它的使用方式为其编写测试" -c src/main.rs
……
从 Markdown 文件中与 LLM 进行完整对话:
vim problem_solving.md
> 在 Markdown 文件中以注释形式写下你的问题,然后选中该问题,
> 使用上述技巧将其发送到 smartcat,使用 `-r` 选项重复输入。
>
> 如果你想继续对话,可以再写一条新问题作为注释,然后重复之前的步骤,使用 `-e -r`。
>
> 这样可以记录下所有问题,形成一份便于复用的文档。

配置
- 默认情况下,配置文件位于
$HOME/.config/smartcat或 Windows 上的%USERPROFILE%\.config\smartcat。 - 可以通过
SMARTCAT_CONFIG_PATH环境变量来设置配置目录。 - 编写提示时,请使用
#[<input>]作为输入占位符;如果没有提供输入,系统会自动将其添加到用户最后一条消息的末尾。 - 默认模型是使用 Ollama 运行的本地
phi3模型,但建议尝试最新的模型,找到最适合你的那一款。 - 默认会使用名为
default的提示。 - 你可以根据每个提示的具体用途调整温度参数,并为每个提示设置默认值。
配置文件包含三个文件:
.api_configs.toml存储你的 API 凭证;至少需要一个支持 API 密钥的服务提供商,或者本地的 Ollama 部署。prompts.toml存储你的提示模板;至少需要一个名为default的提示。conversation.toml用于存储最近的对话记录,以便后续继续;该文件会自动管理,但你也可以根据需要进行备份。
.api_configs.toml
[ollama] # 本地 API,无需密钥
url = "http://localhost:11434/api/chat"
default_model = "phi3"
timeout_seconds = 180 # 如果未指定,默认超时时间为 180 秒
[openai] # 每个支持的 API 都有独立的配置部分,包含 API 密钥和 URL
api_key = "<your_api_key>"
default_model = "gpt-4-turbo-preview"
url = "https://api.openai.com/v1/chat/completions"
[mistral]
# 可以使用命令获取密钥,需要可用的 `sh` 命令
api_key_command = "pass mistral/api_key"
default_model = "mistral-medium"
url = "https://api.mistral.ai/v1/chat/completions"
[groq]
api_key_command = "echo $MY_GROQ_API_KEY"
default_model = "llama3-70b-8192"
url = "https://api.groq.com/openai/v1/chat/completions"
[anthropic]
api_key = "<yet_another_api_key>"
url = "https://api.anthropic.com/v1/messages"
default_model = "claude-3-opus-20240229"
version = "2023-06-01" # anthropic API 版本,详见 https://docs.anthropic.com/en/api/versioning
[cerebras]
api_key = "<your_api_key>"
default_model = "llama3.1-70b"
url = "https://api.cerebras.ai/v1/chat/completions"
prompts.toml
[default] # 每个提示是一个独立的部分
api = "ollama" # 必须引用 `.api_configs.toml` 中的条目
model = "phi3" # 每个提示可以单独定义使用的模型
[[default.messages]] # 接下来可以列出多条消息
role = "system"
content = """\
你是一位精通编程和 Shell 的专家。你始终将代码的效率和清晰度放在首位。 \
你编写的代码会被管道传递到 CLI 程序中,因此除非被明确要求,否则不会做任何解释。 \
请不要在回答中使用 ``` 包围代码,只需直接给出任务的结果。保持输入格式不变。\
"""
[empty] # 总是有一个空提示可用
api = "openai"
# 如果不指定模型,则使用 API 配置中的默认模型
messages = []
[test]
api = "anthropic"
temperature = 0.0
[[test.messages]]
role = "system"
content = """\
你是一位精通编程和 Shell 的专家。你始终将代码的效率和清晰度放在首位。 \
你编写的代码会被管道传递到 CLI 程序中,因此除非被明确要求,否则不会做任何解释。 \
请不要在回答中使用 ``` 包围代码,只需直接给出任务的结果。保持输入格式不变。\
"""
[[test.messages]]
role = "user"
# 下面的占位符字符串 #[<input>] 将被实际输入替换
# 每条消息都会查找并替换它
content ='''使用 pytest 为以下代码编写测试。如果合适,可以进行参数化。
#[<input>]
'''
更多详细信息请参阅 配置设置文件。
Ollama 设置
- 安装 Ollama
- 拉取你计划使用的模型:
ollama pull phi3 - 测试模型:
ollama run phi3 "say hi" - 确保服务已启动:
curl http://localhost:11434,应显示“Ollama is running”,否则可能需要运行ollama serve。 - 现在
smartcat就可以访问你的本地 Ollama 了,尽情使用吧!
⚠️ 根据你的配置,回答可能会比较慢,建议尝试第三方 API 以获得更流畅的工作流程。超时时间可配置,默认为 30 秒。
如何贡献?
请参阅 CONTRIBUTING.md。
版本历史
2.2.02024/11/062.1.02024/11/042.0.02024/10/301.7.22024/10/211.7.12024/10/211.7.02024/10/211.6.02024/10/211.5.02024/10/211.4.12024/07/291.4.02024/07/191.3.02024/05/161.3.0-rc.02024/05/161.2.22024/05/061.2.12024/04/251.2.02024/04/241.1.02024/04/221.0.02024/04/190.7.42024/04/180.7.32024/04/170.7.22024/04/04常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。