data-science-ipython-notebooks
data-science-ipython-notebooks 是一个专为数据科学爱好者打造的开源学习资源库,汇集了丰富的 Python Jupyter Notebook 实战教程。它旨在解决初学者和从业者在掌握复杂数据技术时面临的“理论脱离实践”痛点,通过提供可运行、可修改的代码示例,帮助用户快速上手从基础数据处理到前沿深度学习的全流程技能。
这套教程非常适合数据科学家、机器学习工程师、研究人员以及希望转行进入数据领域的开发者使用。无论是需要复习 Python 基础、精通 pandas 与 NumPy 进行数据分析,还是渴望深入探索 TensorFlow、Keras、Theano 等框架下的深度学习模型(如卷积神经网络、循环神经网络),都能在这里找到对应的实操指南。此外,它还涵盖了 Scikit-learn 机器学习、Spark 大数据处理以及 AWS 云服务应用等关键主题。
其独特的技术亮点在于内容覆盖面极广且结构清晰,不仅包含了经典的统计推断与可视化(matplotlib)教学,还整合了 Kaggle 竞赛案例与商业分析实战,甚至提供了 Hadoop MapReduce 等传统大数据技术的 Python 实现方案。所有笔记均以交互式形式呈现,让用户能在阅读代码的同时立即验证结果,极大地降低了学习门槛,是构建系统化数据科学知识体系的理想伴侣。
使用场景
某电商公司的数据科学团队正急需构建一个商品图像分类模型,以自动识别用户上传的服装风格,但团队中部分成员对深度学习框架的底层实现尚不熟悉。
没有 data-science-ipython-notebooks 时
- 环境配置耗时:工程师需花费数天时间独自摸索 TensorFlow 或 Keras 的环境搭建,常因版本依赖冲突导致项目启动受阻。
- 代码从零手写:缺乏标准参考,团队成员需重复编写基础的网络结构(如 CNN、RNN),不仅效率低下且容易引入难以排查的 Bug。
- 学习曲线陡峭:新手在面对复杂的矩阵运算和梯度下降逻辑时无从下手,缺乏可视化的中间步骤演示,理解成本极高。
- 最佳实践缺失:由于缺少经过验证的代码模板,模型训练过程中的超参数调整和数据处理流程往往不够规范,影响最终准确率。
使用 data-science-ipython-notebooks 后
- 即开即用:直接调用仓库中预置的 TensorFlow 和 Keras 教程笔记,几分钟内即可在本地复现从基础运算到 AlexNet 的完整环境。
- 站在巨人肩膀上:利用现成的卷积神经网络(CNN)和多層感知机(MLP)代码模板,将模型原型开发时间从数天缩短至几小时。
- 可视化教学:通过运行包含详细注释和中间结果展示的 Notebook,团队成员能直观理解反向传播等抽象概念,快速上手核心算法。
- 标准化流程:借鉴仓库中关于 Pandas 数据清洗和 Scikit-learn 评估的成熟案例,统一了团队的数据处理规范,显著提升了模型稳定性。
data-science-ipython-notebooks 通过将零散的知识点转化为可执行、可交互的标准代码库,极大地降低了深度学习项目的试错成本与入门门槛。
运行环境要求
- 未说明
未说明 (部分深度学习示例如 TensorFlow 多 GPU 计算可能需要 GPU,但无具体型号或版本要求)
未说明
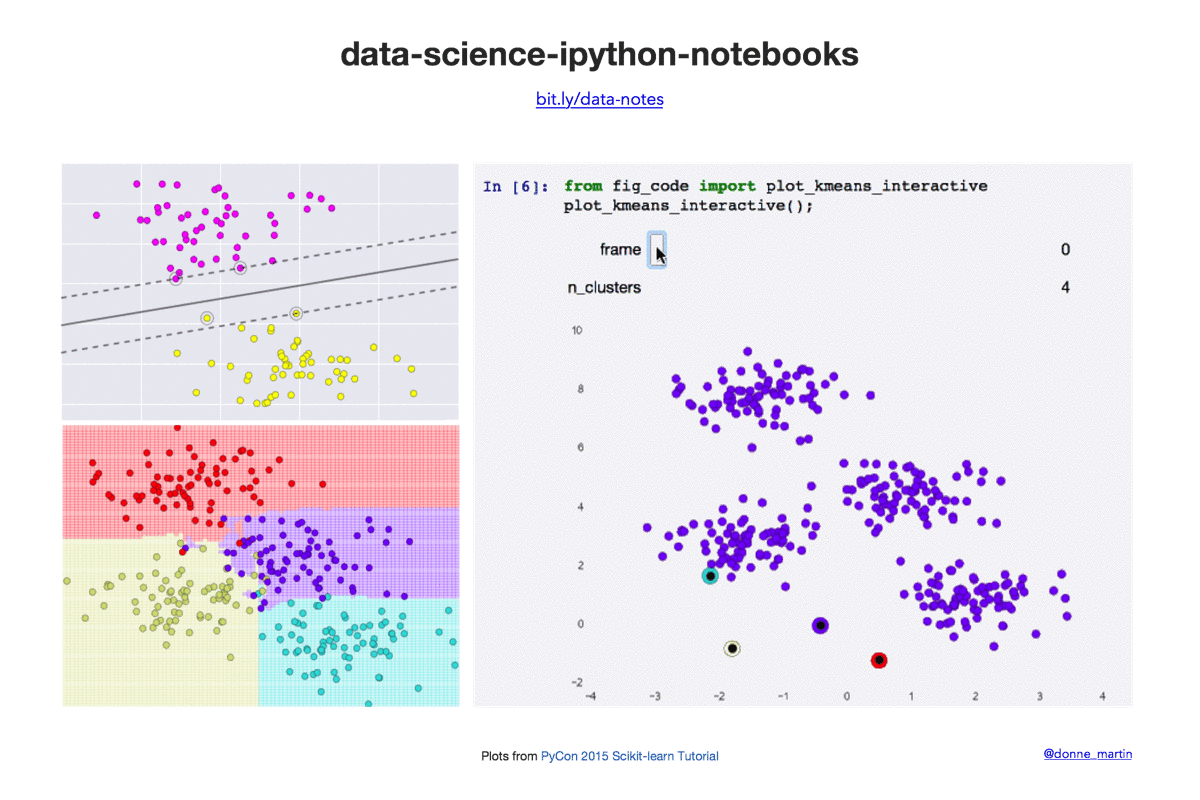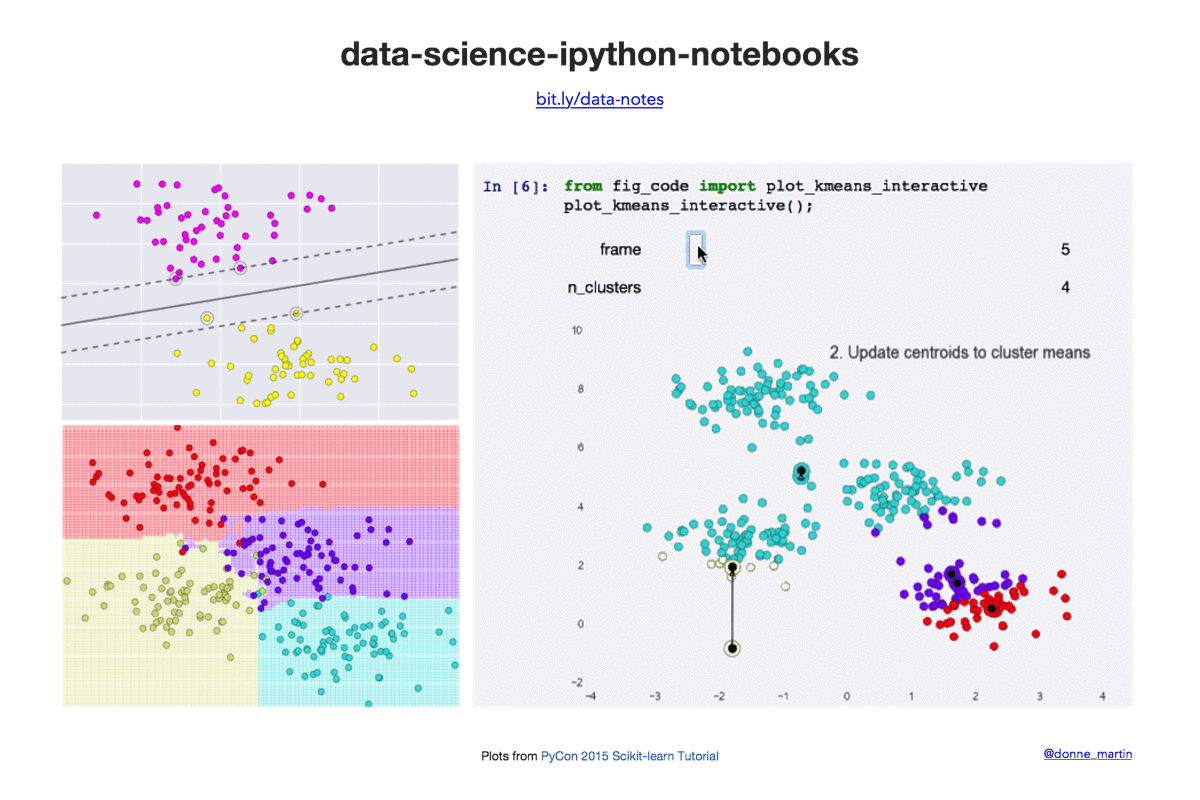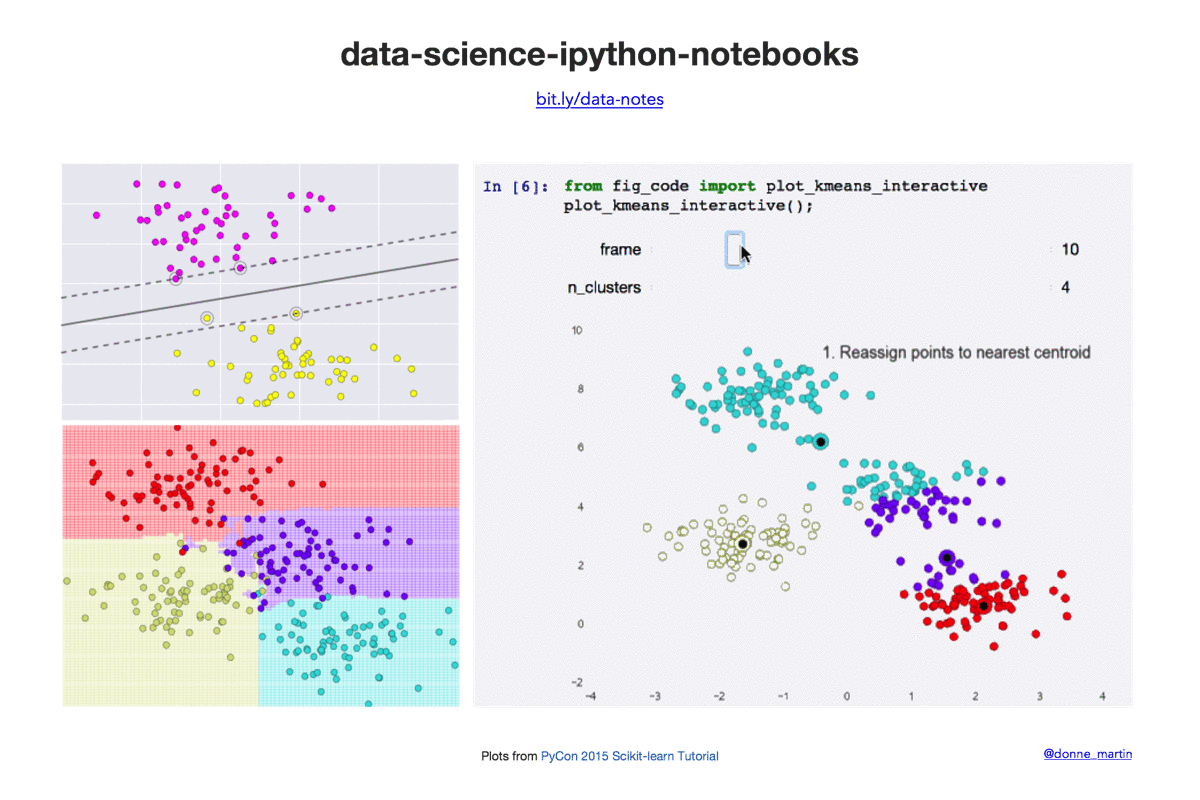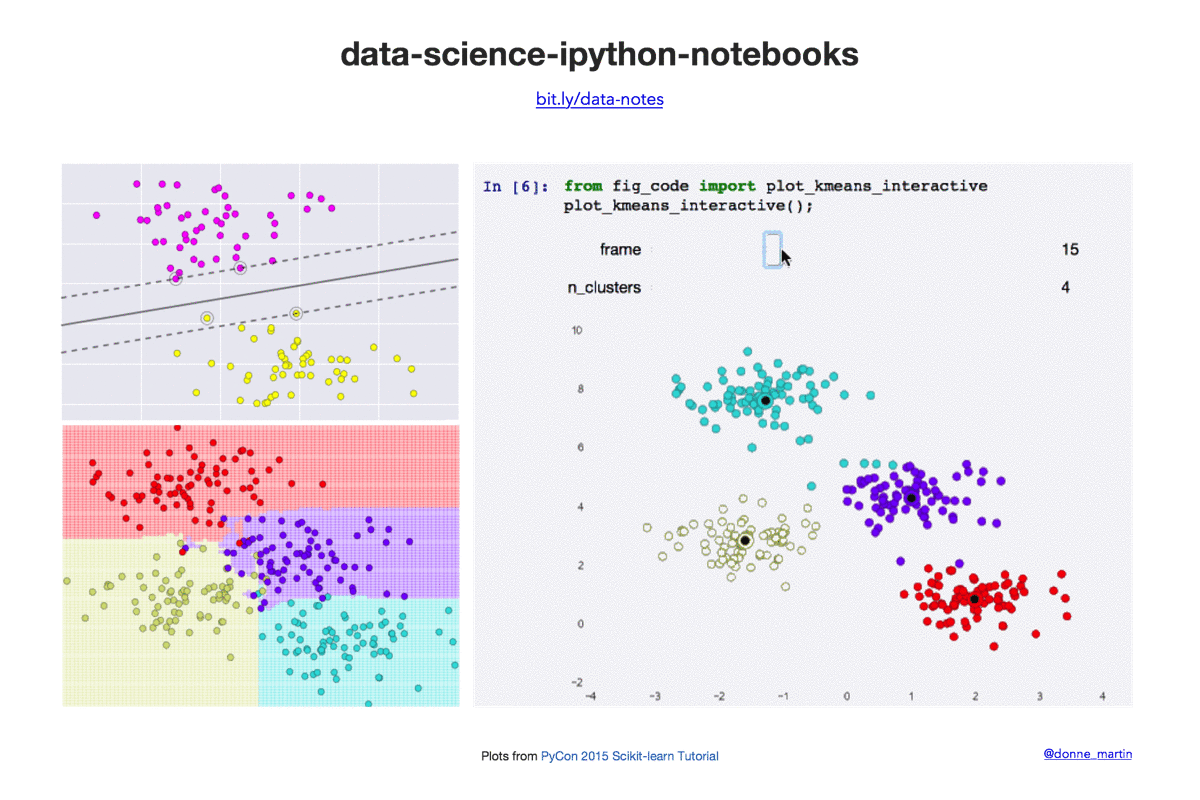
快速开始
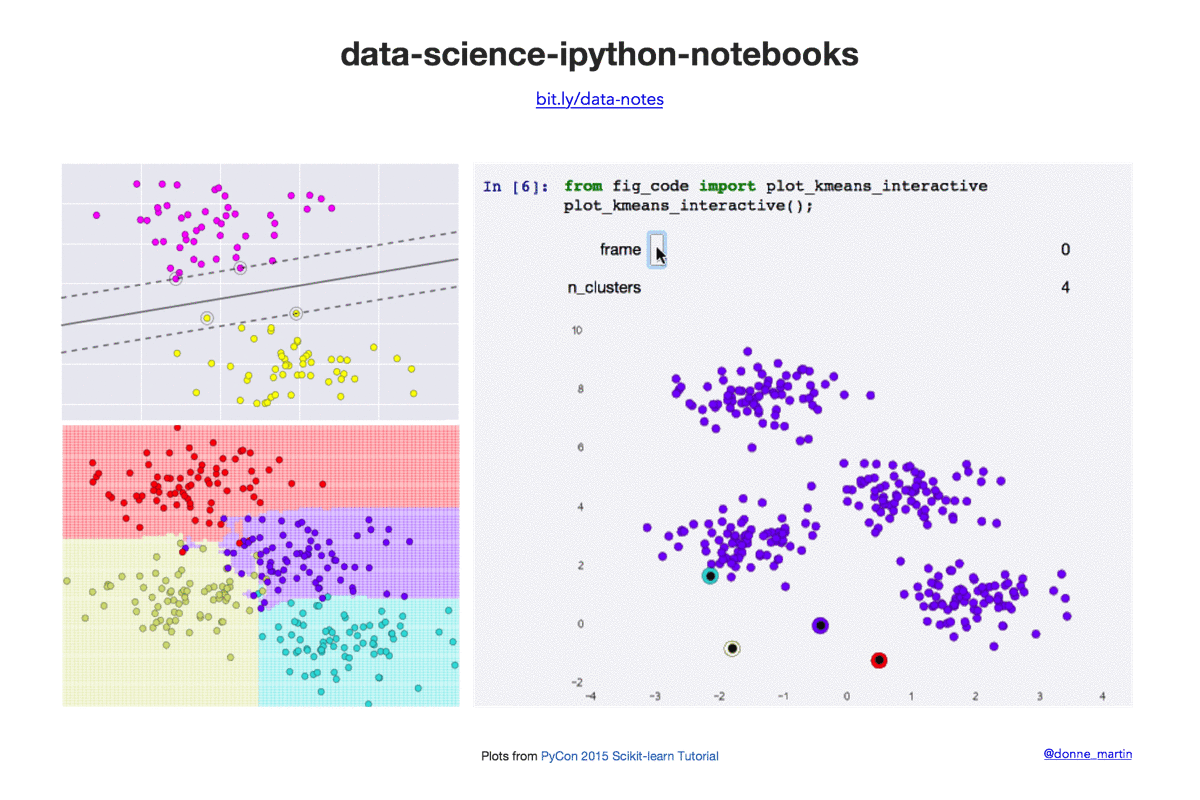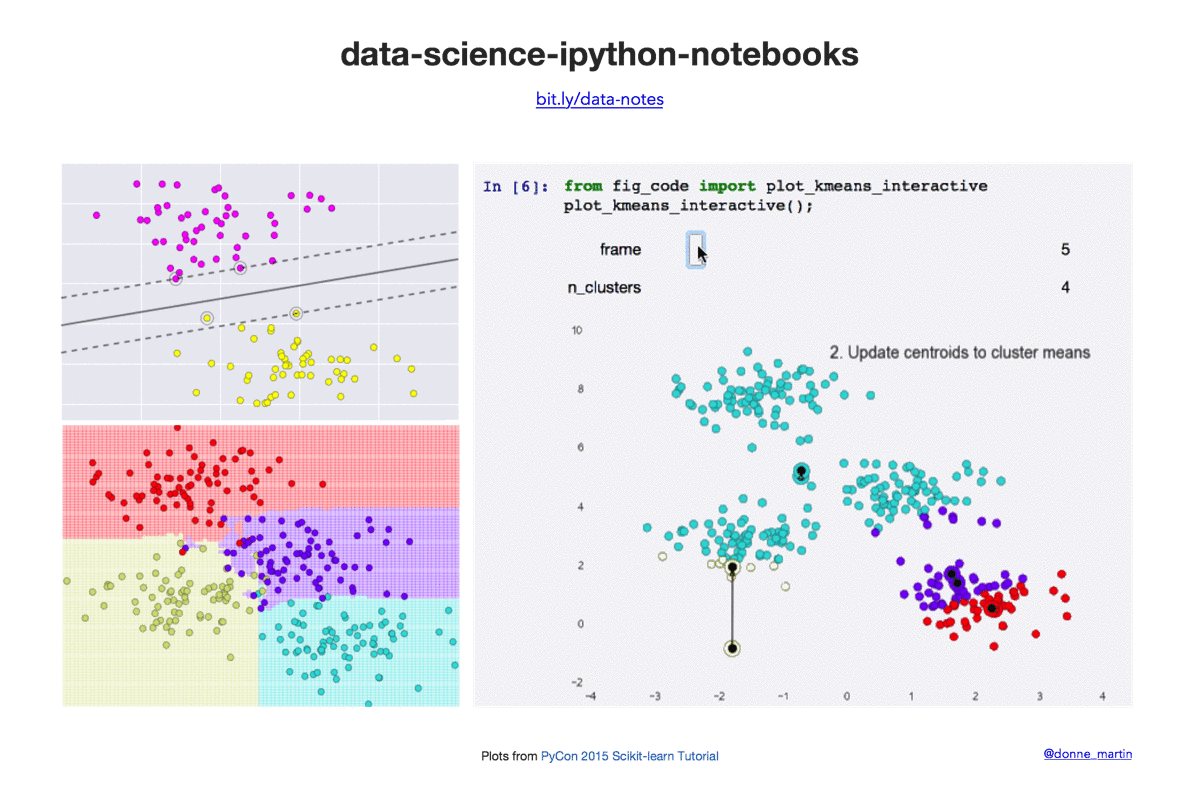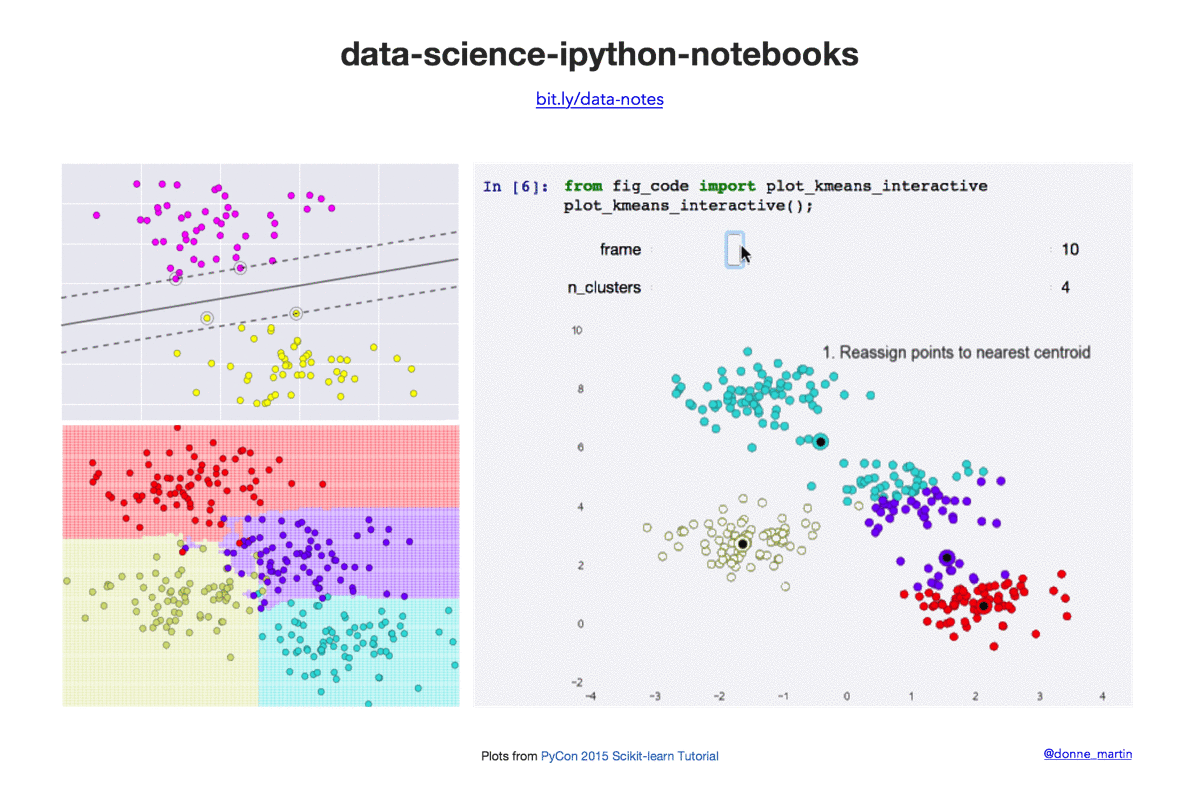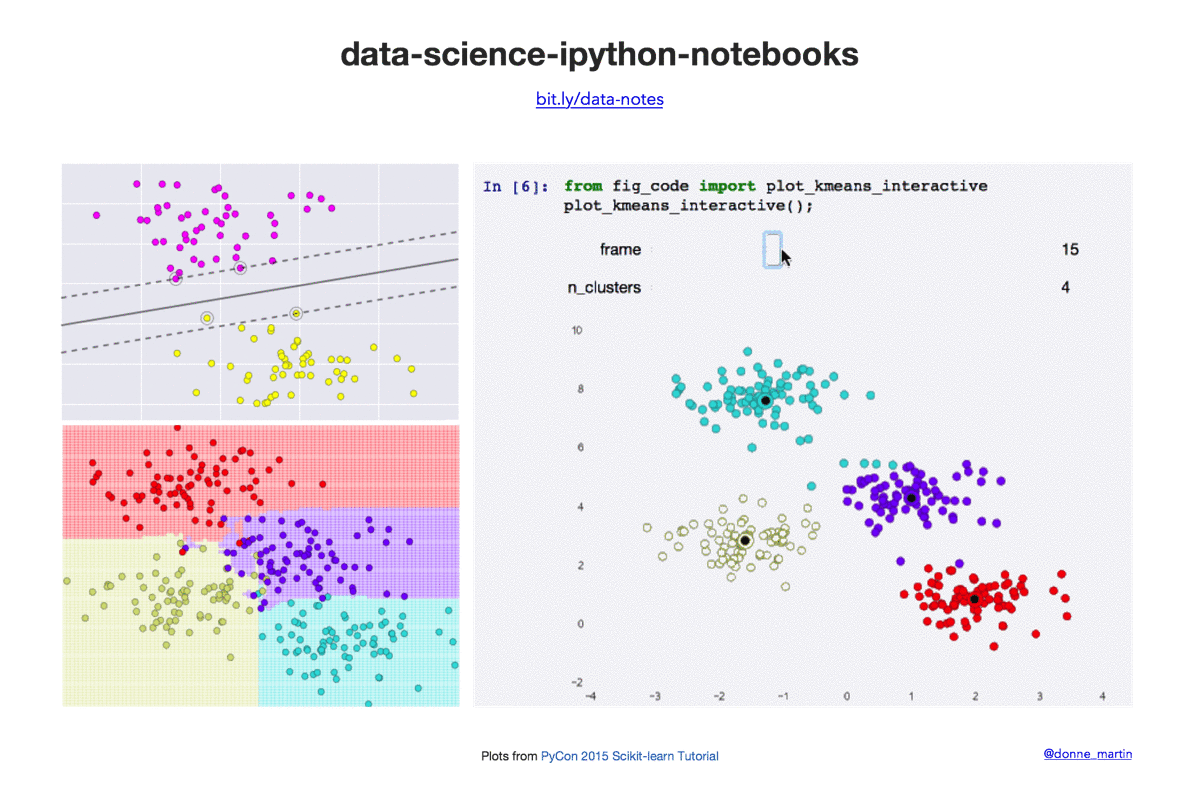
数据科学 IPython 笔记本
索引
- 深度学习
- scikit-learn
- 统计推断 - SciPy
- Pandas
- Matplotlib
- NumPy
- Python 数据处理
- Kaggle 与商业分析
- Spark
- MapReduce - Python
- 亚马逊云服务
- 命令行
- 杂项
- 笔记本安装
- 致谢
- 贡献
- 联系方式
- 许可证

深度学习
演示深度学习功能的 IPython 笔记本。

TensorFlow 教程
额外的 TensorFlow 教程:
- pkmital/tensorflow_tutorials
- nlintz/TensorFlow-Tutorials
- alrojo/tensorflow-tutorial
- BinRoot/TensorFlow-Book
- tuanavu/tensorflow-basic-tutorials
| 笔记本 | 描述 |
|---|---|
| tsf-basics | 学习 TensorFlow 中的基本操作,TensorFlow 是 Google 开发的一个用于各种感知和语言理解任务的库。 |
| tsf-linear | 在 TensorFlow 中实现线性回归。 |
| tsf-logistic | 在 TensorFlow 中实现逻辑回归。 |
| tsf-nn | 在 TensorFlow 中实现最近邻算法。 |
| tsf-alex | 在 TensorFlow 中实现 AlexNet。 |
| tsf-cnn | 在 TensorFlow 中实现卷积神经网络。 |
| tsf-mlp | 在 TensorFlow 中实现多层感知器。 |
| tsf-rnn | 在 TensorFlow 中实现循环神经网络。 |
| tsf-gpu | 学习 TensorFlow 中的基本多 GPU 计算。 |
| tsf-gviz | 学习 TensorFlow 中的图可视化。 |
| tsf-lviz | 学习 TensorFlow 中的损失可视化。 |
TensorFlow 练习
| 笔记本 | 描述 |
|---|---|
| tsf-not-mnist | 学习简单的数据整理,通过创建包含训练、开发和测试数据集的 pickle 文件来为 TensorFlow 准备数据。 |
| tsf-fully-connected | 使用逻辑回归和神经网络逐步训练更深层、更精确的模型。 |
| tsf-regularization | 通过训练全连接网络对 notMNIST 字符进行分类,探索正则化技术。 |
| tsf-convolutions | 在 TensorFlow 中创建卷积神经网络。 |
| tsf-word2vec | 在 TensorFlow 中基于 Text8 数据训练 skip-gram 模型。 |
| tsf-lstm | 在 TensorFlow 中基于 Text8 数据训练 LSTM 字符模型。 |
![]()
theano教程
| 笔记本 | 描述 |
|---|---|
| theano-intro | Theano简介,它允许你高效地定义、优化和评估涉及多维数组的数学表达式。它可以利用GPU,并进行高效的符号微分。 |
| theano-scan | 学习扫描操作,这是在Theano图中执行循环的一种机制。 |
| theano-logistic | 在Theano中实现逻辑回归。 |
| theano-rnn | 在Theano中实现循环神经网络。 |
| theano-mlp | 在Theano中实现多层感知机。 |

keras教程
| 笔记本 | 描述 |
|---|---|
| keras | Keras是一个用Python编写的开源神经网络库。它可以运行在TensorFlow或Theano之上。 |
| setup | 了解本教程的目标以及如何设置你的Keras环境。 |
| intro-deep-learning-ann | 通过Keras和人工神经网络(ANN)入门深度学习。 |
| theano | 通过处理权重矩阵和梯度来学习Theano。 |
| keras-otto | 通过Kaggle Otto挑战来学习Keras。 |
| ann-mnist | 回顾使用Keras对MNIST数据集的简单ANN实现。 |
| conv-nets | 使用Keras学习卷积神经网络(CNNs)。 |
| conv-net-1 | 使用Keras识别MNIST中的手写数字——第一部分。 |
| conv-net-2 | 使用Keras识别MNIST中的手写数字——第二部分。 |
| keras-models | 使用Keras调用预训练模型,如VGG16、VGG19、ResNet50和Inception v3。 |
| auto-encoders | 使用Keras学习自动编码器。 |
| rnn-lstm | 使用Keras学习循环神经网络(RNNs)。 |
| lstm-sentence-gen | 使用Keras的长短期记忆(LSTM)网络学习RNNs。 |
深度学习杂项
| 笔记本 | 描述 |
|---|---|
| deep-dream | 基于Caffe的计算机视觉程序,利用卷积神经网络在图像中寻找并增强模式。 |

scikit-learn
演示 scikit-learn 功能的 IPython 笔记本。
| 笔记本 | 描述 |
|---|---|
| intro | scikit-learn 入门笔记本。scikit-learn 为 Python 增加了对大型多维数组和矩阵的支持,并提供了一个庞大的高级数学函数库,用于对这些数组进行操作。 |
| knn | 在 scikit-learn 中实现 k 近邻分类器。 |
| linear-reg | 在 scikit-learn 中实现线性回归。 |
| svm | 在 scikit-learn 中实现带核与不带核的支持向量机分类器。 |
| random-forest | 在 scikit-learn 中实现随机森林分类器和回归器。 |
| k-means | 在 scikit-learn 中实现 k 均值聚类。 |
| pca | 在 scikit-learn 中实现主成分分析。 |
| gmm | 在 scikit-learn 中实现高斯混合模型。 |
| validation | 在 scikit-learn 中实现验证和模型选择。 |

statistical-inference-scipy
演示使用 SciPy 功能进行统计推断的 IPython 笔记本。
| 笔记本 | 描述 |
|---|---|
| scipy | SciPy 是基于 Python 的 NumPy 扩展构建的一组数学算法和便捷函数集合。它通过为用户提供用于数据操作和可视化的高级命令和类,显著增强了交互式 Python 会话的功能。 |
| effect-size | 通过分析男性和女性身高的差异,探讨量化效应大小的统计指标。利用行为风险因素监测系统 (BRFSS) 的数据,估算美国成年女性和男性的平均身高及标准差。 |
| sampling | 通过使用 BRFSS 数据分析美国男性和女性的平均体重,探索随机抽样方法。 |
| hypothesis | 通过比较第一胎婴儿与其他婴儿的差异,探讨假设检验的方法。 |

pandas
演示 pandas 功能的 IPython Notebook。
| Notebook | 描述 |
|---|---|
| pandas | 一个用 Python 编写的用于数据处理和分析的软件库。提供用于操作数值表格和时间序列的数据结构及操作。 |
| github-data-wrangling | 通过分析 Viz 仓库中的 GitHub 数据,学习如何加载、清洗、合并以及进行特征工程。 |
| Introduction-to-Pandas | Pandas 入门。 |
| Introducing-Pandas-Objects | 学习 Pandas 的对象。 |
| Data Indexing and Selection | 学习 Pandas 中的数据索引与选择。 |
| Operations-in-Pandas | 学习在 Pandas 中对数据进行操作。 |
| Missing-Values | 学习如何处理 Pandas 中的缺失数据。 |
| Hierarchical-Indexing | 学习 Pandas 中的层次化索引。 |
| Concat-And-Append | 学习如何在 Pandas 中组合数据集:使用 concat 和 append。 |
| Merge-and-Join | 学习如何在 Pandas 中组合数据集:使用 merge 和 join。 |
| Aggregation-and-Grouping | 学习 Pandas 中的聚合与分组操作。 |
| Pivot-Tables | 学习 Pandas 中的透视表。 |
| Working-With-Strings | 学习 Pandas 中的向量化字符串操作。 |
| Working-with-Time-Series | 学习如何在 Pandas 中处理时间序列数据。 |
| Performance-Eval-and-Query | 学习高性能 Pandas:eval() 和 query() 方法。 |
matplotlib
展示 matplotlib 功能的 IPython 笔记本。
| 笔记本 | 描述 |
|---|---|
| matplotlib | Python 2D 绘图库,可在多种打印格式和跨平台的交互式环境中生成出版质量的图表。 |
| matplotlib-applied | 将 matplotlib 可视化应用于 Kaggle 竞赛中的探索性数据分析。学习如何创建条形图、直方图、subplot2grid 布局、归一化图表、散点图、子图以及核密度估计图。 |
| Introduction-To-Matplotlib | matplotlib 入门。 |
| Simple-Line-Plots | 学习 matplotlib 中的简单折线图。 |
| Simple-Scatter-Plots | 学习 matplotlib 中的简单散点图。 |
| Errorbars.ipynb | 学习在 matplotlib 中可视化误差。 |
| Density-and-Contour-Plots | 学习 matplotlib 中的密度图和等高线图。 |
| Histograms-and-Binnings | 学习 matplotlib 中的直方图、分箱和密度估计。 |
| Customizing-Legends | 学习在 matplotlib 中自定义图例。 |
| Customizing-Colorbars | 学习在 matplotlib 中自定义颜色条。 |
| Multiple-Subplots | 学习 matplotlib 中的多个子图。 |
| Text-and-Annotation | 学习 matplotlib 中的文本和注释。 |
| Customizing-Ticks | 学习在 matplotlib 中自定义刻度。 |
| Settings-and-Stylesheets | 学习自定义 matplotlib:配置和样式表。 |
| Three-Dimensional-Plotting | 学习 matplotlib 中的三维绘图。 |
| Geographic-Data-With-Basemap | 学习在 matplotlib 中使用 basemap 处理地理数据。 |
| Visualization-With-Seaborn | 学习使用 Seaborn 进行可视化。 |

numpy
演示 NumPy 功能的 IPython 笔记本。
| 笔记本 | 描述 |
|---|---|
| numpy | 为 Python 添加对大型多维数组和矩阵的支持,并提供大量用于操作这些数组的高级数学函数库。 |
| Introduction-to-NumPy | NumPy 简介。 |
| Understanding-Data-Types | 学习 Python 中的数据类型。 |
| The-Basics-Of-NumPy-Arrays | 学习 NumPy 数组的基础知识。 |
| Computation-on-arrays-ufuncs | 学习 NumPy 数组上的计算:通用函数。 |
| Computation-on-arrays-aggregates | 学习聚合操作:NumPy 中的最小值、最大值以及介于两者之间的所有内容。 |
| Computation-on-arrays-broadcasting | 学习数组上的计算:NumPy 中的广播机制。 |
| Boolean-Arrays-and-Masks | 学习 NumPy 中的比较、掩码和布尔逻辑。 |
| Fancy-Indexing | 学习 NumPy 中的高级索引技术。 |
| Sorting | 学习 NumPy 中的数组排序。 |
| Structured-Data-NumPy | 学习结构化数据:NumPy 的结构化数组。 |

python-data
面向数据分析的 Python 功能演示 IPython 笔记本。
| 笔记本 | 描述 |
|---|---|
| data structures | 使用元组、列表、字典、集合学习 Python 基础知识。 |
| data structure utilities | 学习 Python 操作,如切片、range、xrange、bisect、sort、sorted、reversed、enumerate、zip 以及列表推导式。 |
| functions | 学习更高级的 Python 特性:函数作为对象、lambda 函数、闭包、*args、**kwargs currying、生成器、生成器表达式、itertools。 |
| datetime | 学习如何使用 Python 处理日期和时间:datetime、strftime、strptime、timedelta。 |
| logging | 学习使用 RotatingFileHandler 和 TimedRotatingFileHandler 进行 Python 日志记录。 |
| pdb | 学习使用交互式源代码调试器在 Python 中进行调试。 |
| unit tests | 学习使用 Nose 单元测试框架进行 Python 测试。 |

kaggle-and-business-analyses
用于 kaggle 竞赛和商业分析的 IPython 笔记本。
| 笔记本 | 描述 |
|---|---|
| titanic | 预测泰坦尼克号乘客的生存情况。学习数据清洗、探索性数据分析和机器学习。 |
| churn-analysis | 预测客户流失。实践逻辑回归、梯度提升分类器、支持向量机、随机森林和 k 最近邻算法。包含混淆矩阵、ROC 曲线、特征重要性、预测概率以及校准/区分度的讨论。 |

spark
展示 Spark 和 HDFS 功能的 IPython Notebook。
| Notebook | 描述 |
|---|---|
| spark | 基于内存的集群计算框架,在某些应用场景下速度可提升至 100 倍,非常适合机器学习算法。 |
| hdfs | 可靠地将超大文件跨多台机器存储在一个大型集群中。 |

mapreduce-python
展示使用 mrjob 实现 Hadoop MapReduce 功能的 IPython Notebook。
| Notebook | 描述 |
|---|---|
| mapreduce-python | 以 Python 运行 MapReduce 作业,可在本地或 Hadoop 集群上执行。演示了如何在 Python 代码中使用 Hadoop Streaming,并结合单元测试及 mrjob 配置文件来分析 Elastic MapReduce 上的 Amazon S3 存储桶日志。Disco 是另一个基于 Python 的替代方案。 |

aws
展示亚马逊云服务(AWS)及其工具功能的 IPython Notebook。
还可查看:
- SAWS:一款功能强大的 AWS 命令行界面(CLI)。
- Awesome AWS:精选的库、开源项目、指南、博客及其他资源列表。
| Notebook | 描述 |
|---|---|
| boto | 官方的 AWS Python SDK。 |
| s3cmd | 通过命令行与 S3 进行交互。 |
| s3distcp | 根据指定模式和目标文件,将较小的文件合并并聚合在一起。S3DistCp 还可用于将大量数据从 S3 传输到您的 Hadoop 集群。 |
| s3-parallel-put | 并行上传多个文件至 S3。 |
| redshift | 作为基于大规模并行处理(MPP)技术构建的快速数据仓库。 |
| kinesis | 实时流式传输数据,每秒可处理数千个数据流。 |
| lambda | 根据事件触发运行代码,并自动管理计算资源。 |

命令
展示 Linux、Git 等各种命令行的 IPython 笔记本。
| 笔记本 | 描述 |
|---|---|
| linux | 类 Unix 且大多符合 POSIX 标准的计算机操作系统。包括磁盘使用情况、文件分割、grep、sed、curl、查看运行中的进程、终端语法高亮以及 Vim。 |
| anaconda | 面向大规模数据处理、预测分析和科学计算的 Python 编程语言发行版,旨在简化包管理和部署。 |
| ipython notebook | 基于 Web 的交互式计算环境,可将代码执行、文本、数学公式、图表和富媒体整合到一个文档中。 |
| git | 分布式版本控制系统,强调速度、数据完整性以及对分布式、非线性工作流的支持。 |
| ruby | 用于与 AWS 命令行交互,以及 Jekyll——一个可在 GitHub Pages 上托管的博客框架。 |
| jekyll | 简单、具备博客功能的静态网站生成器,适用于个人、项目或组织的网站。它会渲染 Markdown 或 Textile 和 Liquid 模板,并生成一个完整的静态网站,可由 Apache HTTP Server、Nginx 或其他 Web 服务器提供服务。 |
| pelican | 基于 Python 的 Jekyll 替代方案。 |
| django | 高级 Python Web 框架,鼓励快速开发及简洁、实用的设计。可用于分享报告/分析内容,也可用于博客。更轻量级的替代方案包括 Pyramid、Flask、Tornado 和 Bottle。 |
杂项
展示各种功能的 IPython 笔记本。
| 笔记本 | 描述 |
|---|---|
| regex | 正则表达式速查表,适用于数据清洗。 |
| algorithmia | Algorithmia 是一个算法市场。该笔记本展示了四种不同的算法:人脸检测、内容摘要、潜在狄利克雷分配和光学字符识别。 |
笔记本安装
anaconda
Anaconda 是面向大规模数据处理、预测分析和科学计算的免费 Python 发行版,旨在简化包管理和部署。
请按照说明安装 Anaconda 或更轻量级的 miniconda。
开发环境搭建
如需详细说明、脚本和工具来设置您的数据分析开发环境,请查看 dev-setup 仓库。
运行笔记本
要查看交互式内容或修改 IPython 笔记本中的元素,您需要先克隆或下载仓库,然后运行笔记本。有关 IPython 笔记本的更多信息,请参阅 此处。
$ git clone https://github.com/donnemartin/data-science-ipython-notebooks.git
$ cd data-science-ipython-notebooks
$ jupyter notebook
笔记本已在 Python 2.7.x 上测试通过。
致谢
- 《Python 数据分析:使用 Pandas、NumPy 和 IPython 进行数据清洗》(作者:Wes McKinney)链接
- 2015 年 PyCon scikit-learn 教程(作者:Jake VanderPlas)链接
- 《Python 数据科学手册》(作者:Jake VanderPlas)链接
- 使用 scikit-learn 和 IPython 进行并行机器学习教程(作者:Olivier Grisel)链接
- 使用 Python 计算方法进行统计推断(作者:Allen Downey)链接
- TensorFlow 示例(作者:Aymeric Damien)链接
- TensorFlow 教程(作者:Parag K Mital)链接
- TensorFlow 教程(作者:Nathan Lintz)链接
- TensorFlow 教程(作者:Alexander R Johansen)链接
- TensorFlow 书籍(作者:Nishant Shukla)链接
- 2015 年夏季学校(由 mila-udem 组织)链接
- Keras 教程(作者:Valerio Maggio)链接
- Kaggle 网站
- Yhat 博客 网站
贡献
欢迎贡献!如发现 bug 或有需求,请 提交 issue。
联系方式
如有任何问题、疑问或意见,欢迎随时联系我。
- 邮箱:donne.martin@gmail.com
- Twitter:@donne_martin
- GitHub:donnemartin
- LinkedIn:donnemartin
- 网站:donnemartin.com
许可证
本仓库包含多种内容,其中一部分由Donne Martin开发,另一部分来自第三方。第三方内容根据其各自提供的许可证进行分发。
由Donne Martin开发的内容依据以下许可证进行分发:
我在此仓库中提供的代码和资源均采用开源许可证授权给您。由于这是我的个人仓库,您所获得的对我代码和资源的使用许可来自我本人,而非我的雇主(Facebook)。
版权所有 © 2015 Donne Martin
根据Apache许可证第2.0版(“许可证”)授权;
除非遵守该许可证的规定,否则不得使用本文件。
您可以在以下网址获取许可证的副本:
http://www.apache.org/licenses/LICENSE-2.0
除非适用法律要求或双方书面同意,否则软件按“原样”提供,不提供任何形式的担保或条件。有关具体语言的权限及限制,请参阅该许可证。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器