docling
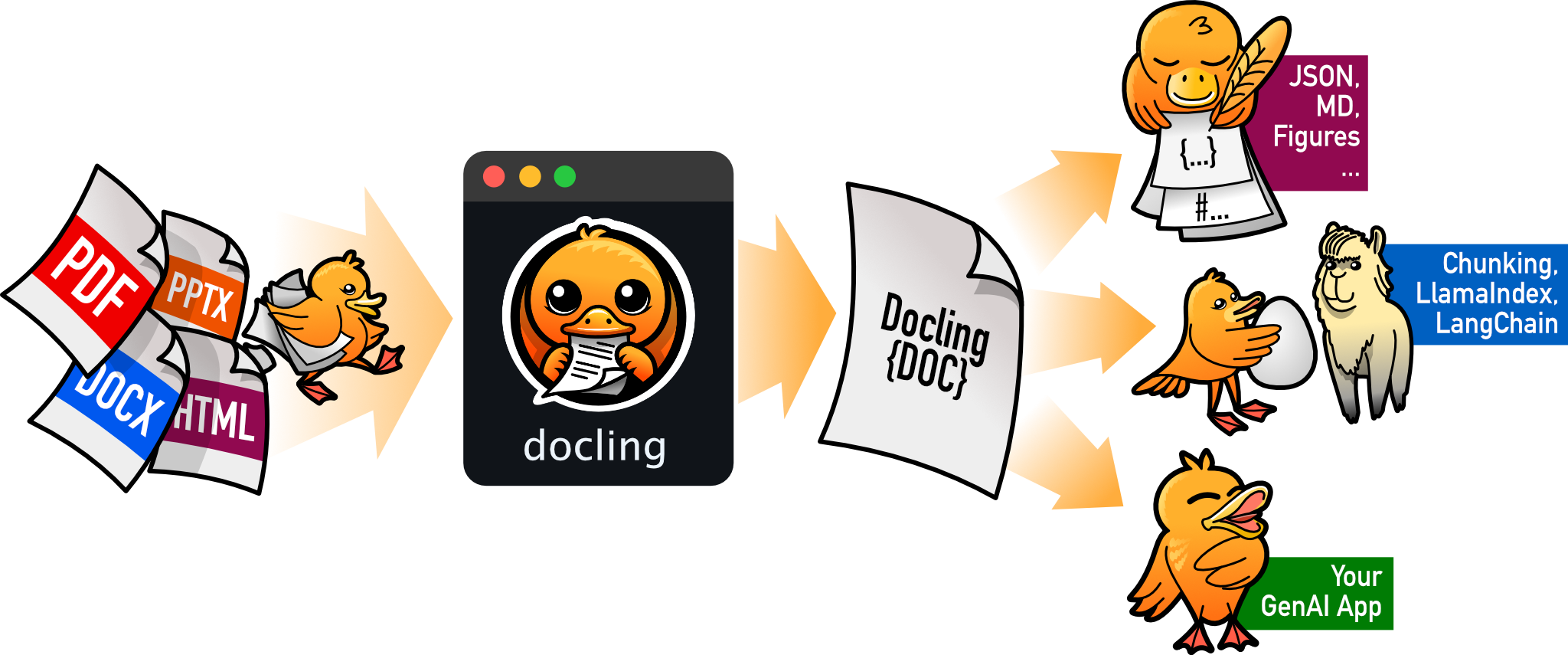
Docling 是一款专为生成式 AI 打造的文档处理工具,旨在将各种复杂格式的文档转化为机器易于理解的结构化数据。它有效解决了传统方法难以精准解析 PDF 布局、表格结构、数学公式及扫描图片等痛点,让非结构化文档能无缝接入大模型应用。
无论是开发者、数据科学家还是研究人员,都能利用 Docling 轻松构建高质量的 RAG(检索增强生成)系统或智能代理。其核心亮点在于强大的多格式支持,不仅涵盖 PDF、Office 文档、图片,甚至能处理音频和专利/财务等专业 XML 标准。Docling 具备先进的版面分析能力,能准确识别阅读顺序与表格逻辑,并提供统一的文档表示格式。此外,它支持本地离线运行以保障数据安全,内置 OCR 功能处理扫描件,并能通过 Visual Language Models 深度理解视觉内容。配合 LangChain、LlamaIndex 等主流框架的即插即用集成,以及便捷的命令行工具,Docling 让文档预处理变得简单高效,是连接真实世界文档与生成式 AI 的理想桥梁。
使用场景
某金融风控团队需要每天从数百份扫描版财报(PDF)和会议纪要(音频)中提取关键数据,以训练内部的风险预测大模型。
没有 docling 时
- 扫描版 PDF 中的表格被识别为乱码或纯文本,行列结构完全丢失,导致财务数据无法对齐。
- 处理音频会议纪要需单独搭建语音识别流程,再人工将文字与文档内容拼接,耗时且易出错。
- 复杂的页面布局(如双栏排版、页眉页脚)干扰阅读顺序,大模型常因上下文错乱而产生幻觉。
- 不同格式(DOCX, PPTX, 图片)需要编写多套解析脚本,维护成本极高且难以统一输出标准。
- 敏感财务数据必须上传至第三方云 API 处理,存在严重的数据合规与泄露风险。
使用 docling 后
- 利用高级 OCR 与布局分析能力,精准还原财报中的复杂表格结构,确保数值与表头准确对应。
- 内置 ASR 模型直接处理音频文件,自动将会议语音转为文本并与相关文档内容统一整合。
- 智能识别页面阅读顺序并过滤噪声,为大模型提供逻辑连贯的上下文,显著降低幻觉率。
- 通过统一的 DoclingDocument 格式一站式解析多种文件类型,直接输出高质量的 Markdown 或 JSON。
- 支持本地化部署,所有敏感数据均在内部服务器处理,完美满足金融行业的隐私合规要求。
docling 将杂乱无章的多模态文档转化为大模型可直接理解的结构化知识,让金融数据分析从“人工清洗”迈向“自动化智能”。
运行环境要求
- Linux
- macOS
- Windows
- 非必需
- 支持 Apple Silicon (M1/M2/M3) 通过 MLX 加速
- 若使用 NVIDIA GPU,具体型号和 CUDA 版本未在 README 中明确说明,但需支持 PyTorch 后端
未说明

快速开始
Docling

![]()




![]()


Docling 简化了文档处理流程,能够解析多种格式的文件——包括高级 PDF 解析——并提供与生成式 AI 生态系统的无缝集成。
功能特性
- 🗂️ 支持多种文档格式的解析 supported_formats,包括 PDF、DOCX、PPTX、XLSX、HTML、WAV、MP3、WebVTT、图像(PNG、TIFF、JPEG 等)、LaTeX、纯文本等
- 📑 高级 PDF 解析能力,涵盖页面布局、阅读顺序、表格结构、代码、公式、图像分类等
- 🧬 统一且表达力强的 DoclingDocument 表示格式
- ↪️ 多种导出格式及选项,包括 Markdown、HTML、WebVTT、DocTags 和无损 JSON
- 📜 支持多种特定于应用的 XML 模式,包括 USPTO 专利、JATS 文章以及 XBRL 财务报告。
- 🔒 支持本地执行,适用于敏感数据和气隙环境
- 🤖 即插即用的 integrations 集成,包括 LangChain、LlamaIndex、Crew AI 和 Haystack,用于代理型 AI 应用
- 🔍 对扫描 PDF 和图像的广泛 OCR 支持
- 👓 支持多种视觉语言模型(GraniteDocling)
- 🎙️ 支持音频处理,配备自动语音识别(ASR)模型
- 🔌 可通过 MCP 服务器 连接到任何代理
- 💻 简单便捷的命令行界面
最新功能
- 📤 结构化 信息提取 [🧪 测试版]
- 📑 默认采用新的布局模型(Heron),以提升 PDF 解析速度
- 🔌 MCP 服务器,专为代理型应用设计
- 💼 支持解析 XBRL(可扩展商业报告语言)文档,用于财务报告
- 💬 支持解析 WebVTT(Web 视频文本轨道)文件,并导出为 WebVTT 格式
- 💬 支持解析 LaTeX 文件
- 📝 支持解析纯文本文件(
.txt、.text)以及 Markdown 的扩展格式(.qmd、.Rmd) - 📝 图表理解(柱状图、饼图、折线图):可将其转换为表格、代码,或添加详细描述
即将推出
- 📝 元数据提取,包括标题、作者、参考文献及语言
- 📝 复杂化学结构解析(分子结构)
安装
要使用 Docling,只需从你的包管理器中安装 docling,例如 pip:
pip install docling
注意: Docling 2.70.0 版本已不再支持 Python 3.9。请使用 Python 3.10 或更高版本。
支持 macOS、Linux 和 Windows 环境,兼容 x86_64 和 arm64 架构。
更多详细的安装说明,请参阅文档:安装指南。
快速入门
要使用 Python 转换单个文档,可以使用 convert() 方法,例如:
from docling.document_converter import DocumentConverter
source = "https://arxiv.org/pdf/2408.09869" # 文档路径或 URL
converter = DocumentConverter()
result = converter.convert(source)
print(result.document.export_to_markdown()) # 输出: "## Docling Technical Report[...]"
更多高级用法,请参阅文档:高级用法。
命令行界面
Docling 内置了命令行工具,可用于执行转换操作。
docling https://arxiv.org/pdf/2206.01062
你还可以通过 Docling 命令行界面使用 🥚GraniteDocling 和其他 VLM 模型:
docling --pipeline vlm --vlm-model granite_docling https://arxiv.org/pdf/2206.01062
此命令将在支持 MLX 加速的 Apple Silicon 硬件上运行。
更多信息请参阅:命令行使用指南。
文档
请查阅 Docling 的文档,了解安装、使用、概念、配方、扩展等内容的详细信息。
示例
通过我们的示例动手实践,了解如何使用 Docling 解决不同的应用场景。
集成
为进一步加速你的 AI 应用开发,请查看 Docling 与流行框架和工具的原生集成。
获取帮助和支持
欢迎随时通过 讨论区 与我们联系。
技术报告
如需了解更多关于 Docling 内部工作机制的详细信息,请参阅 Docling 技术报告。
贡献
有关详细信息,请阅读 贡献指南。
参考文献
如果您在项目中使用了 Docling,请考虑引用以下内容:
@techreport{Docling,
author = {Deep Search Team},
month = {8},
title = {Docling Technical Report},
url = {https://arxiv.org/abs/2408.09869},
eprint = {2408.09869},
doi = {10.48550/arXiv.2408.09869},
version = {1.0.0},
year = {2024}
}
许可证
Docling 代码库采用 MIT 许可证。对于各个模型的使用,请参阅原始软件包中提供的模型许可证。
LF AI & Data
Docling 是 LF AI & Data 基金会 的一个托管项目。
IBM ❤️ 开源人工智能
该项目由 IBM 苏黎世研究院的知识型人工智能团队发起。
版本历史
v2.89.02026/04/16v2.88.02026/04/13v2.87.02026/04/13v2.86.02026/04/10v2.85.02026/04/07v2.84.02026/04/01v2.83.02026/03/31v2.82.02026/03/25v2.81.02026/03/20v2.80.02026/03/14v2.79.02026/03/12v2.78.02026/03/10v2.77.02026/03/06v2.76.02026/03/02v2.75.02026/02/24v2.74.02026/02/17v2.73.12026/02/13v2.73.02026/02/11v2.72.02026/02/03v2.71.02026/01/30常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。