WordLlama
WordLlama 是一款轻量级、高性能的自然语言处理工具包,专为快速执行文本去重、相似度计算、文档排序、聚类分析及语义分割等任务而设计。它巧妙地复用了大型语言模型(LLM)中的词元嵌入(token embeddings),通过简单的查找与平均池化机制生成文本向量,从而在无需复杂推理依赖的情况下实现高效的语义理解。
针对传统嵌入模型部署成本高、推理速度慢的痛点,WordLlama 进行了极致的 CPU 优化,显著降低了资源消耗,使其能在配置受限的环境中流畅运行。无论是需要清洗海量数据的工程师,还是追求快速原型的算法研究人员,都能利用它轻松解决文本匹配与组织难题。
其技术亮点包括支持二值化嵌入以进一步加速计算、具备“套娃”式维度截断灵活性,以及原生兼容 Model2Vec 静态嵌入。此外,WordLlama 还能直接作为 Python 标准库函数(如 sorted、max)的键值参数使用,让开发者仅需几行代码即可实现智能排序与检索。如果你正在寻找一个无需显卡、即插即用的 NLP 解决方案,WordLlama 将是理想之选。
使用场景
某初创公司的数据工程师需要在资源有限的 CPU 服务器上,对每日抓取的数万条新闻标题进行实时去重和语义分类,以构建高质量的训练数据集。
没有 WordLlama 时
- 硬件成本高昂:传统嵌入模型依赖 GPU 推理,导致服务器采购和维护成本居高不下,难以在边缘设备或低成本云实例上部署。
- 处理延迟严重:面对海量文本流,复杂的模型推理速度慢,无法在数据入库前完成实时的模糊去重,导致数据库充斥着大量重复内容。
- 集成复杂度高:引入重型 NLP 库需要管理繁琐的依赖环境和庞大的模型文件,增加了运维负担和系统不稳定性。
- 语义切分困难:缺乏轻量级的语义分割工具,只能按固定字符数粗暴截断长文本,破坏了内容的逻辑连贯性,影响下游任务效果。
使用 WordLlama 后
- 极致轻量化部署:WordLlama 专为 CPU 优化且依赖极少,直接利用现有低配服务器即可流畅运行,大幅降低了基础设施开支。
- 毫秒级实时处理:凭借简单的 Token 查找和平均池化机制,WordLlama 能快速计算相似度并执行模糊去重,确保数据流的清洁与实时性。
- 开箱即用的便捷性:通过简单的 pip 安装即可加载默认模型,无需配置复杂环境,轻松实现文档排序、聚类和 Top-K 检索等功能。
- 智能语义分割:利用内置的语义分割算法,WordLlama 能根据内容逻辑自动将长文章切分为连贯片段,显著提升了数据质量。
WordLlama 通过将大模型的 Token 嵌入转化为轻量级工具,让资源受限环境也能拥有高效、精准的语义处理能力。
运行环境要求
- 未说明 (基于 Python/NumPy,通常支持 Linux
- macOS
- Windows)
- 不需要 GPU
- 专为 CPU 推理优化,无需 CUDA
未说明 (模型极小,默认模型仅 16MB,适合资源受限环境)

快速开始
WordLlama 📝🦙
WordLlama 是一个快速、轻量级的自然语言处理工具包,专为模糊去重、相似度计算、排序、聚类以及语义文本分割等任务而设计。它在推理时依赖极少,并针对 CPU 硬件进行了优化,因此非常适合部署在资源受限的环境中。

新闻与更新 🔥
- 2025-02-01 支持标准库函数(sorted/min/max)的可调用接口
- 2025-01-04 我们很高兴地宣布支持 model2vec 静态嵌入。更多信息请参阅:Model2Vec
- 2024-10-04 添加了语义分割推理算法。请查看我们的技术概述。
目录
快速入门
通过 pip 安装 WordLlama:
pip install wordllama
加载默认的 256 维模型:
from wordllama import WordLlama
# 加载默认的 WordLlama 模型
wl = WordLlama.load()
query = "机器学习方法"
candidates = [
"神经科学基础",
"神经网络导论",
"在家烹饪美味意大利面",
"哲学导论:逻辑学",
]
# 返回一个 Callable[[str], float] 函数
sim_key = wl.key(query)
# 对候选列表按相似度从高到低排序
sorted_candidates = sorted(candidates, key=sim_key, reverse=True)
# 最相似的候选
best_candidate = max(candidates, key=sim_key)
# 打印结果
print("排序后的候选列表:")
for i, candidate in enumerate(sorted_candidates, 1):
print(f"{i}. {candidate} (得分: {sim_key(candidate):.4f})")
print(f"\n最佳匹配:{best_candidate} (得分: {sim_key(best_candidate):.4f})")
# 排序后的候选列表:
# 1. 神经网络导论 (得分: 0.3414)
# 2. 神经科学基础 (得分: 0.2115)
# 3. 哲学导论:逻辑学 (得分: 0.1067)
# 4. 在家烹饪美味意大利面 (得分: 0.0045)
#
# 最佳匹配:神经网络导论 (得分: 0.3414)
功能特性
- 快速嵌入:通过简单的词元查找和平均池化,高效生成文本嵌入。
- 相似度计算:计算文本之间的余弦相似度。
- 排序:根据文档与查询的相似度对文档进行排序。
- 模糊去重:基于相似度阈值去除重复文本。
- 聚类:使用 KMeans 聚类算法将文档分组。
- 过滤:根据文档与查询的相似度筛选文档。
- Top-K 检索:检索与查询最相似的前 K 个文档。
- 语义文本分割:将文本分割成语义连贯的块。
- 二进制嵌入:支持二进制嵌入和汉明相似度,以实现更快的计算。
- 套娃式表示:可根据需要截断嵌入维度,提供更大的灵活性。
- 低资源需求:针对 CPU 推理进行了优化,依赖项极少。
什么是 WordLlama?
WordLlama 是一种自然语言处理工具,它复用了大型语言模型(LLMs)中的组件,以创建高效且紧凑的词表示,类似于 GloVe、Word2Vec 或 FastText。
WordLlama 首先从最先进的 LLMs(例如 LLaMA 2、LLaMA 3 70B)中提取词元嵌入码本,然后在一个通用的嵌入框架内训练一个小规模的无上下文模型。这种方法生成了一个轻量级模型,在所有 MTEB 基准测试上都优于传统的词模型(如 GloVe 300d),同时体积也小得多(例如,256 维的默认模型仅 16MB)。
WordLlama 的主要特点包括:
- 套娃式表示:允许根据需要截断嵌入维度,从而在模型大小和性能之间取得灵活平衡。
- 低资源需求:采用简单的词元查找结合平均池化,可在 CPU 上快速运行,无需 GPU。
- 二进制嵌入:使用直通估计器训练的模型可以打包成小型整数数组,以实现更快的汉明距离计算。
- 纯 NumPy 推理:轻量级的推理流程完全依赖 NumPy,便于部署和集成。
由于其速度快、体积小且便携,WordLlama 可作为探索性分析和实用应用程序的多功能工具,例如用于评估 LLM 输出或在多跳式、代理式工作流中执行预处理任务。
MTEB 评测结果
下表展示了 WordLlama 模型与其他类似模型的性能对比。
| 指标 | WL64 | WL128 | WL256 (X) | WL512 | WL1024 | GloVe 300d | Komninos | all-MiniLM-L6-v2 |
|---|---|---|---|---|---|---|---|---|
| 聚类 | 30.27 | 32.20 | 33.25 | 33.40 | 33.62 | 27.73 | 26.57 | 42.35 |
| 重排序 | 50.38 | 51.52 | 52.03 | 52.32 | 52.39 | 43.29 | 44.75 | 58.04 |
| 分类 | 53.14 | 56.25 | 58.21 | 59.13 | 59.50 | 57.29 | 57.65 | 63.05 |
| 对分类 | 75.80 | 77.59 | 78.22 | 78.50 | 78.60 | 70.92 | 72.94 | 82.37 |
| STS | 66.24 | 67.53 | 67.91 | 68.22 | 68.27 | 61.85 | 62.46 | 78.90 |
| CQA DupStack | 18.76 | 22.54 | 24.12 | 24.59 | 24.83 | 15.47 | 16.79 | 41.32 |
| SummEval | 30.79 | 29.99 | 30.99 | 29.56 | 29.39 | 28.87 | 30.49 | 30.81 |
WL64 至 WL1024:WordLlama 模型,嵌入维度从 64 到 1024 不等。
注:l2_supercat 是一个 LLaMA 2 词汇表模型。为了训练该模型,我们在移除额外的特殊标记后,将来自多个模型(包括 LLaMA 2 70B 和 phi 3 medium)的代码本拼接在一起。由于多个模型使用了 LLaMA 2 的分词器,它们的代码本可以拼接并一起训练。最终得到的模型性能与训练 LLaMA 3 70B 代码本相当,但规模仅为前者的四分之一(32k 词汇量 vs. 128k 词汇量)。
其他模型
- 基于 LLaMA 3 的:l3_supercat
- 结果
运行速度如何? :zap:
ag_news 数据集中的 8,000 条文档
- 单核性能(CPU),i9 第 12 代,DDR4 3200
- NVIDIA A4500(GPU)
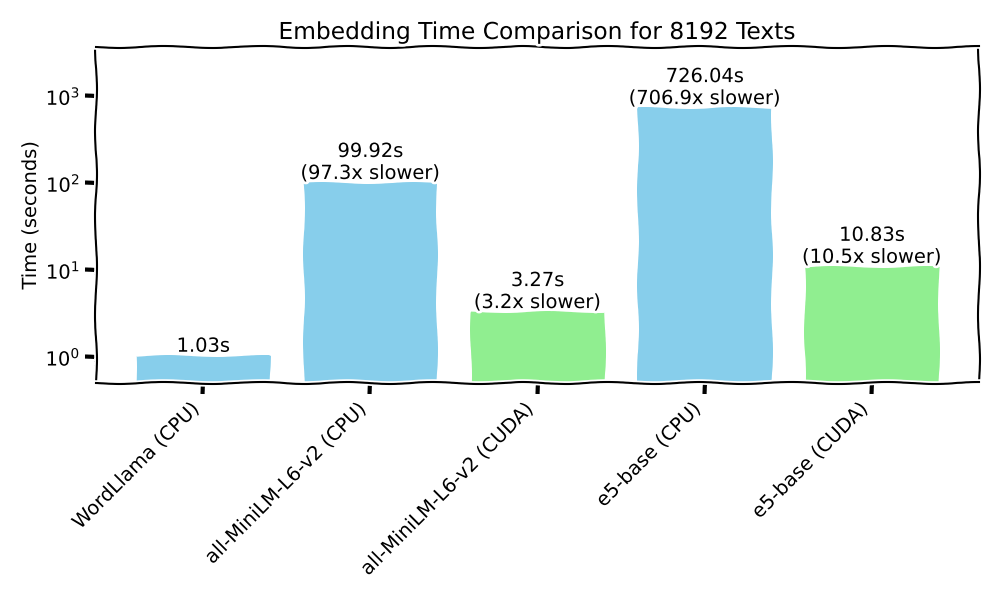
使用方法
文本嵌入
加载预训练的嵌入并向文本进行嵌入:
from wordllama import WordLlama
# 加载预训练的嵌入(截断维度至 64)
wl = WordLlama.load(trunc_dim=64)
# 向文本进行嵌入
embeddings = wl.embed(["The quick brown fox jumps over the lazy dog", "And all that jazz"])
print(embeddings.shape) # 输出:(2, 64)
标准库示例
通过 .key(query) 返回一个可调用函数。
query = "Machine learning methods"
candidates = [
"Foundations of neural science",
"Introduction to neural networks",
"Cooking delicious pasta at home",
"Introduction to philosophy: logic",
]
# 返回一个 Callable[[str], float] 函数
sim_key = wl.key(query)
# 对候选者按相似度排序,最相似的排在前面
sorted_candidates = sorted(candidates, key=sim_key, reverse=True)
# 最相似的候选者
best_candidate = max(candidates, key=sim_key)
# 打印结果
print("Ranked Candidates:")
for i, candidate in enumerate(sorted_candidates, 1):
print(f"{i}. {candidate} (Score: {sim_key(candidate):.4f})")
print(f"\nBest Match: {best_candidate} (Score: {sim_key(best_candidate):.4f})")
# Ranked Candidates:
# 1. Introduction to neural networks (Score: 0.3414)
# 2. Foundations of neural science (Score: 0.2115)
# 3. Introduction to philosophy: logic (Score: 0.1067)
# 4. Cooking delicious pasta at home (Score: 0.0045)
#
# Best Match: Introduction to neural networks (Score: 0.3414)
计算相似度
计算两段文本之间的相似度:
similarity_score = wl.similarity("I went to the car", "I went to the pawn shop")
print(similarity_score) # 输出:例如 0.0664
文档排名
根据文档与查询的相似度对文档进行排名:
query = "I went to the car"
candidates = ["I went to the park", "I went to the shop", "I went to the truck", "I went to the vehicle"]
ranked_docs = wl.rank(query, candidates, sort=True, batch_size=64)
print(ranked_docs)
# 输出:
# [
# ('I went to the vehicle', 0.7441),
# ('I went to the truck', 0.2832),
# ('I went to the shop', 0.1973),
# ('I went to the park', 0.1510)
# ]
模糊去重
根据相似度阈值去除重复文本:
deduplicated_docs = wl.deduplicate(candidates, return_indices=False, threshold=0.5)
print(deduplicated_docs)
# 输出:
# ['I went to the park',
# 'I went to the shop',
# 'I went to the truck']
聚类
使用 KMeans 聚类算法将文档聚为若干组:
labels, inertia = wl.cluster(candidates, k=3, max_iterations=100, tolerance=1e-4, n_init=3)
print(labels, inertia)
# 输出:
# [2, 0, 1, 1], 0.4150
过滤
根据文档与查询的相似度进行过滤:
filtered_docs = wl.filter(query, candidates, threshold=0.3)
print(filtered_docs)
# 输出:
# ['I went to the vehicle']
Top-K 检索
检索与查询最相似的前 K 个文档:
top_docs = wl.topk(query, candidates, k=2)
print(top_docs)
# 输出:
# ['I went to the vehicle', 'I went to the truck']
语义文本分割
将文本分割成语义块:
long_text = "Your very long text goes here... " * 100
chunks = wl.split(long_text, target_size=1536)
print(list(map(len, chunks)))
# 输出:[1055, 1055, 1187]
请注意,目标大小也是最大大小。.split() 功能会尝试聚合不超过 target_size 的部分,同时保留文本的顺序以及句子和尽可能多的段落结构。它使用 wordllama 嵌入来找到更自然的分割点。因此,输出中会出现一系列大小不一的块,但都不会超过目标大小。
推荐的目标大小范围是 512 到 2048 个字符,默认大小为 1536。如果需要更大的块,可能需要在分割后进行批量处理,并且通常会由多个语义块组合而成。
更多信息请参阅:技术概述
加载 Model2Vec
wl = WordLlama.list_configs()
# 配置名称字典
wl = WordLlama.load_m2v("potion_base_8m") # 256 维模型
wl = WordLlama.load_m2v("m2v_multilingual") # 多语言模型
Model2Vec 是一种使用 PCA 创建静态嵌入的不同方法。 值得注意的是,他们已经开发出多语言模型和基于 GloVe 的模型,在词语相似度任务中表现优异。
欢迎前往 Hugging Face 查看!minishlab
推理类
from wordllama import WordLlamaInference
from tokenizers import Tokenizer
tokenizer = Tokenizer.from_pretrained(...)
wl = WordLlamaInference(np_embeddings_ar, tokenizer)
推理类可以直接与用户自定义的静态嵌入数组(n_vocab, dim)一起使用,而无需使用加载器。
训练注意事项
二值化嵌入模型在较高维度下表现出了更为显著的提升,因此建议为二值化嵌入选择512或1024维。
L2 Supercat 模型是在单张 A100 GPU 上以 512 的批量大小训练了 12 小时。
路线图
- 更多示例笔记本:
- DSPy 评估器
- 检索增强生成(RAG)流水线
开发
本地开发步骤如下:
git clone https://github.com/dleemiller/WordLlama.git
cd WordLlama
pip install uv
uv sync --all-extras
uv run python setup.py build_ext --inplace
uv run pytest
更多常用开发命令请参阅 Makefile。
提取 Token 嵌入
要从模型中提取 Token 嵌入,请确保已同意用户协议并使用 Hugging Face CLI 登录(适用于 LLaMA 模型)。然后可以使用以下代码片段:
from wordllama.extract.extract_safetensors import extract_safetensors
# 提取指定配置的嵌入
extract_safetensors("llama3_70B", "path/to/saved/model-0001-of-00XX.safetensors")
提示:嵌入通常位于第一个 safetensors 文件中,但并不总是如此。有时会有清单文件,有时则需要手动检查并确定。
训练时,请使用 GitHub 仓库中的脚本。您需要添加一个配置文件(复制或修改现有配置文件并放入相应文件夹)。
pip install wordllama[train]
python train.py train --config your_new_config
# (开始训练过程)
python train.py save --config your_new_config --checkpoint ... --outdir /path/to/weights/
# (按每个 Matryoshka 维度保存一个模型)
社区项目
引用
如果您在研究或项目中使用 WordLlama,请考虑按照以下方式引用:
@software{miller2024wordllama,
author = {Miller, D. Lee},
title = {WordLlama: 从大型语言模型中回收的 Token 嵌入},
year = {2024},
url = {https://github.com/dleemiller/wordllama},
version = {0.3.9}
}
许可证
本项目采用 MIT 许可证授权。
版本历史
v0.4.02025/12/01v0.3.92025/02/02v0.3.82025/01/05常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。