OmniRoute
OmniRoute 是一款专为多模型大语言应用设计的智能 AI 网关。它提供了一个完全兼容 OpenAI 标准的统一接口,让开发者只需对接一个端点,即可灵活调用全球超过 100 家提供商的 AI 模型服务,涵盖文本对话、图像生成、音视频处理及网络搜索等多种能力。
在实际开发中,OmniRoute 有效解决了单一模型服务不稳定、成本高昂以及切换供应商复杂的痛点。通过内置的智能路由、负载均衡、自动重试和故障转移机制,它能确保服务持续在线,即使某个提供商出现故障,系统也会自动无缝切换至备用方案,实现真正的“零停机”。此外,它还支持策略配置、速率限制、响应缓存和全方位的可观测性监控,帮助团队在保障稳定性的同时优化推理成本。
这款工具特别适合后端开发者、AI 应用架构师以及需要构建高可用 AI 服务的研究团队。其独特的技术亮点包括原生支持 MCP 服务器(集成 25 种工具)、A2A 协议以及记忆与技能系统,且全栈采用 TypeScript 编写,提供 Docker、npm 包及 Electron 桌面应用等多种部署方式,极大地降低了集成与维护门槛,让构建可靠、低成本的 AI 应用变得更加简单高效。
使用场景
一家初创公司的后端团队正在开发一款面向全球用户的智能客服系统,需要同时调用多家大模型服务商以平衡成本与响应速度。
没有 OmniRoute 时
- 代码耦合严重:开发人员必须在业务代码中硬编码不同供应商(如 OpenAI、Anthropic、本地模型)的 API 地址和鉴权逻辑,导致切换模型时需大规模重构代码。
- 服务稳定性差:当某家免费或低成本模型提供商出现超时或宕机时,整个客服系统会直接报错中断,缺乏自动重试或故障转移机制。
- 成本不可控:无法统一设置速率限制或缓存策略,容易因突发流量导致高价模型调用激增,造成预算超支。
- 监控盲区:缺乏统一的观测面板,难以实时追踪各模型的延迟、成功率及具体消耗,排查问题如同“盲人摸象”。
使用 OmniRoute 后
- 架构解耦灵活:团队只需对接唯一的 OpenAI 兼容端点,通过配置文件即可动态调整路由策略,无缝切换至免费或低成本的备用模型,无需修改一行业务代码。
- 高可用保障:OmniRoute 内置的智能故障转移机制在主模型失败时自动降级到备用节点,并执行自动重试,确保客服对话 7x24 小时不中断。
- 精细化成本控制:利用内置的策略引擎设置全局速率限制和响应缓存,优先路由请求至低价模型,显著降低单次推理成本。
- 全链路可观测:通过统一的仪表盘实时监控所有供应商的性能指标与用量分布,快速定位瓶颈并优化资源分配。
OmniRoute 将复杂的多模型调度转化为简单的单一接口调用,让团队在大幅降低运营成本的同时,获得了企业级的系统稳定性。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明
快速开始
🚀 OmniRoute — 免费的 AI 网关
永不停歇地编码。智能路由至免费及低成本的 AI 模型,并具备自动回退机制。
您的通用 API 代理——一个端点,100 多家服务提供商,零 downtime。现已支持MCP 服务器(25 种工具)、A2A 协议、记忆/技能系统以及Electron 桌面应用。
聊天补全 • 嵌入 • 图像生成 • 视频 • 音乐 • 音频 • 重排序 • 网页搜索 • MCP 服务器 • A2A 协议 • 100% TypeScript




















🌐 支持语言: 🇺🇸 英语 | 🇧🇷 巴西葡萄牙语 | 🇪🇸 西班牙语 | 🇫🇷 法语 | 🇮🇹 意大利语 | 🇷🇺 俄语 | 🇨🇳 简体中文 | 🇩🇪 德语 | 🇮🇳 印地语 | 🇹🇭 泰语 | 🇺🇦 乌克兰语 | 🇸🇦 阿拉伯语 | 🇯🇵 日语 | 🇻🇳 越南语 | 🇧🇬 保加利亚语 | 🇩🇰 丹麦语 | 🇫🇮 芬兰语 | 🇮🇱 希伯来语 | 🇭🇺 匈牙利语 | 🇮🇩 印尼语 | 🇰🇷 韩语 | 🇲🇾 马来语 | 🇳🇱 荷兰语 | 🇳🇴 挪威语 | 🇵🇹 葡萄牙语 | 🇷🇴 罗马尼亚语 | 🇵🇱 波兰语 | 🇸🇰 斯洛伐克语 | 🇸🇪 瑞典语 | 🇵🇭 菲律宾语 | 🇨🇿 捷克语
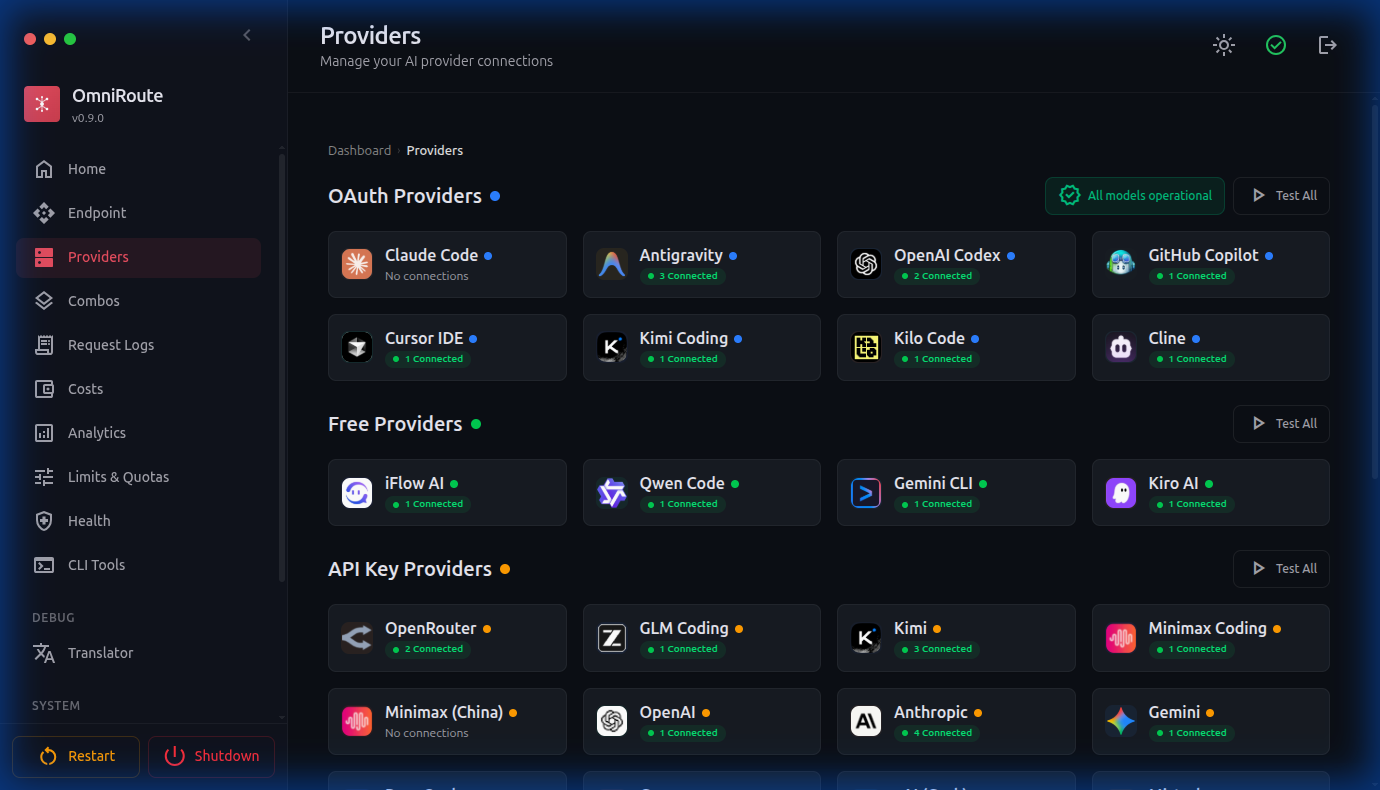
🖼️ 主仪表盘
📸 仪表盘预览
点击查看仪表盘截图
| 页面 | 截图 |
|---|---|
| 服务提供商 | 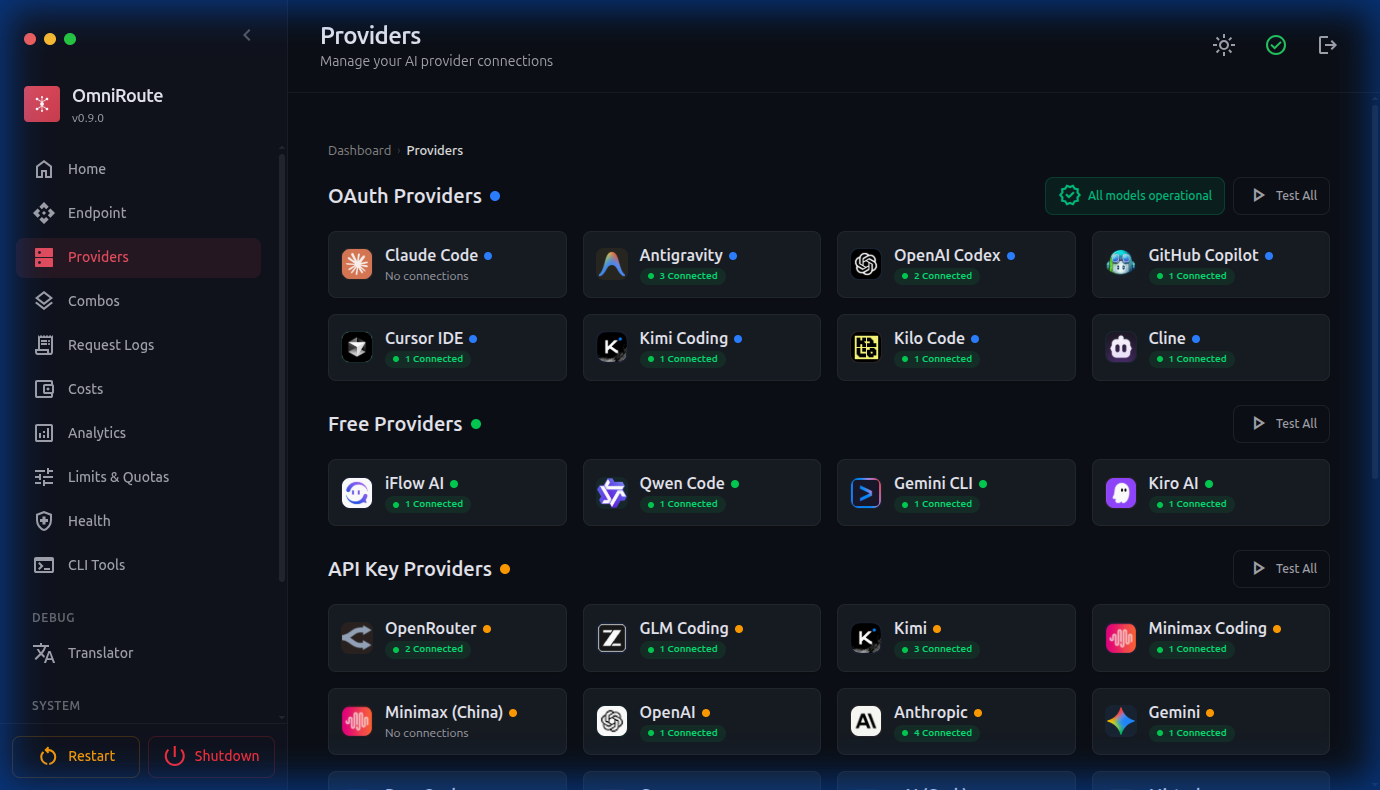 |
| 组合 | 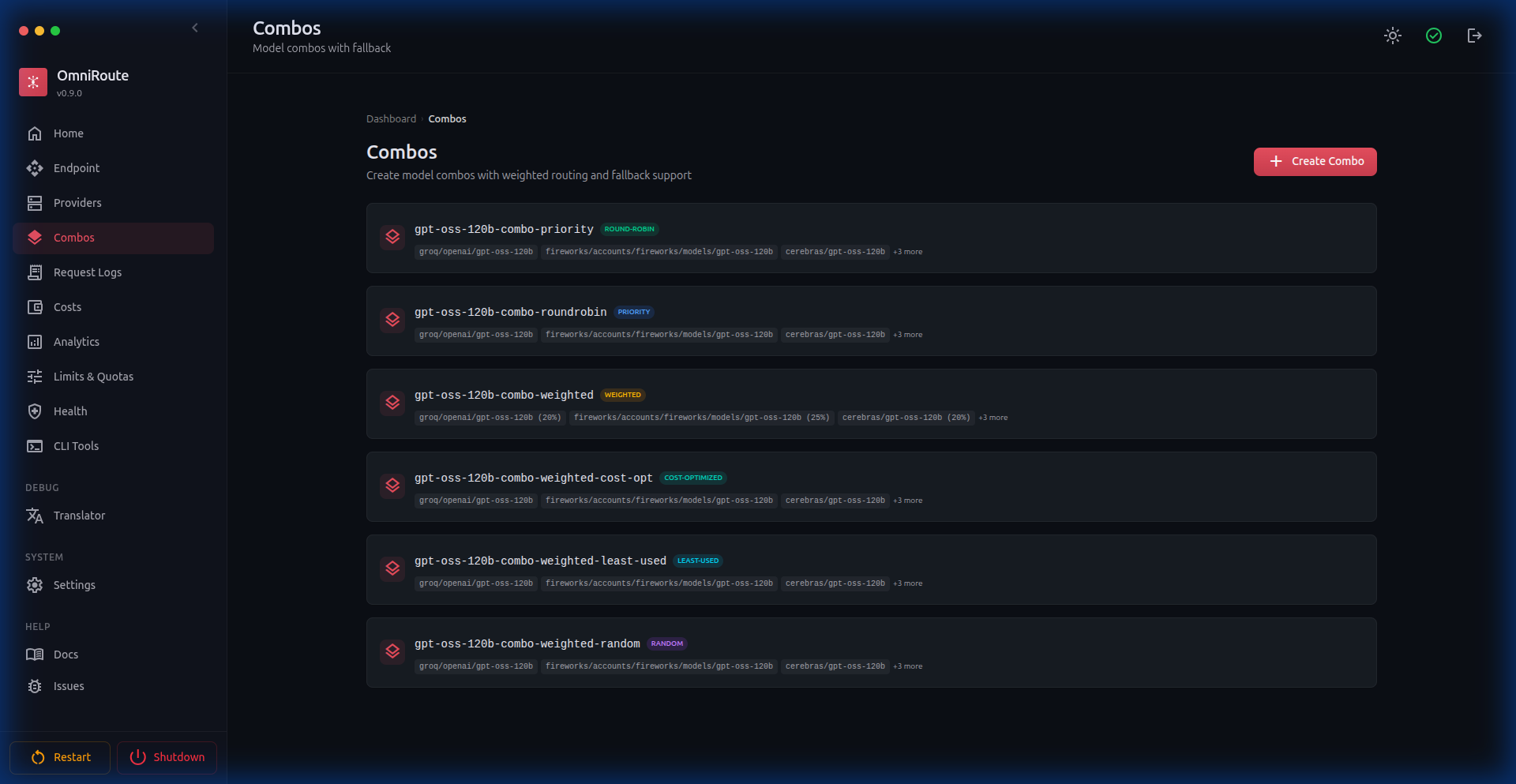 |
| 分析 |  |
| 健康状况 |  |
| 翻译器 |  |
| 设置 |  |
| CLI 工具 |  |
| 使用日志 |  |
| 端点 |  |
🤖 您喜爱的编码助手的免费 AI 提供商
通过 OmniRoute 连接任何 AI 驱动的 IDE 或 CLI 工具——一个用于无限编码的免费 API 网关。
|
OpenClaw ⭐ 205K |
NanoBot ⭐ 20.9K |
PicoClaw ⭐ 14.6K |
ZeroClaw ⭐ 9.9K |
IronClaw ⭐ 2.1K |
|
OpenCode ⭐ 106K |
Codex CLI ⭐ 60.8K |
Claude Code ⭐ 67.3K |
Gemini CLI ⭐ 94.7K |
Kilo Code ⭐ 15.5K |
📡 所有助手都通过 http://localhost:20128/v1 或 http://cloud.omniroute.online/v1 连接——只需一次配置,即可使用无限模型和配额。
🤔 为什么选择 OmniRoute?
停止浪费金钱和遭遇限制:
订阅配额每月未用完即失效
OmniRoute 解决了这些问题:
- ✅ 最大化订阅价值 - 跟踪配额,在重置前充分利用每一滴资源
- ✅ 自动回退 - 订阅 → API 密钥 → 廉价方案 → 免费方案,全程无停机
- ✅ 多账户支持 - 在同一提供商的不同账户间轮询使用
- ✅ 通用性 - 适用于 Claude Code、Codex、Gemini CLI、Cursor、Cline、OpenClaw 以及任何其他 CLI 工具
📧 支持
💬 加入我们的社区! WhatsApp 群组 — 获取帮助、分享技巧并随时了解最新动态。
- 官网: omniroute.online
- GitHub: github.com/diegosouzapw/OmniRoute
- 问题追踪: github.com/diegosouzapw/OmniRoute/issues
- WhatsApp: 社区群组
- 贡献: 参阅 CONTRIBUTING.md,提交拉取请求,或选择一个
good first issue - 原始项目: 9router by decolua
🐛 如何报告 bug?
在提交问题时,请运行 system-info 命令并附上生成的文件:
npm run system-info
该命令会生成一个 system-info.txt 文件,其中包含您的 Node.js 版本、OmniRoute 版本、操作系统详情、已安装的 CLI 工具(qoder、gemini、claude、codex、antigravity、droid 等)、Docker/PM2 的状态以及系统软件包信息——所有这些内容都能帮助我们快速复现您的问题。请将此文件直接附加到您的 GitHub 问题中。
🔄 工作原理
┌─────────────┐
│ 您的 CLI │ (Claude Code、Codex、Gemini CLI、OpenClaw、Cursor、Cline...)
│ 工具 │
└──────┬──────┘
│ http://localhost:20128/v1
↓
┌─────────────────────────────────────────┐
│ OmniRoute(智能路由) │
│ • 格式转换(OpenAI ↔ Claude) │
│ • 配额跟踪 + 嵌入向量 + 图像处理 │
│ • 自动刷新令牌 │
└──────┬──────────────────────────────────┘
│
├─→ [第一层:订阅] Claude Code、Codex、Gemini CLI
│ ↓ 配额用尽
├─→ [第二层:API 密钥] DeepSeek、Groq、xAI、Mistral、NVIDIA NIM 等
│ ↓ 预算限制
├─→ [第三层:廉价方案] GLM($0.6/100 万 token)、MiniMax($0.2/100 万 token)
│ ↓ 预算限制
└─→ [第四层:免费方案] Qoder、Qwen、Kiro(无限用量)
结果:持续编码,成本极低
🎯 OmniRoute 解决的问题——30 个真实痛点与用例
每位使用 AI 工具的开发者每天都会遇到这些问题。 OmniRoute 就是为解决这些问题而生——从成本超支到地区性封锁,从 OAuth 流程故障到协议操作及企业级可观ability。
💸 1. “我付了昂贵的订阅费,却仍会被限流打断”
开发者每月需支付 $20–200 不等,以使用 Claude Pro、Codex Pro 或 GitHub Copilot。即便付费,配额也有限制——每日使用时长上限、每周限制,或是每分钟的速率限制。在编码过程中,服务提供商突然停止响应,导致开发者思路中断,效率大打折扣。
OmniRoute 如何解决这个问题:
- 智能四层回退 — 如果订阅配额用尽,自动切换到 API Key → 低价 → 免费方案,全程无需人工干预
- 提供商限制跟踪 — 缓存的配额快照按服务器端计划刷新(默认
PROVIDER_LIMITS_SYNC_INTERVAL_MINUTES=70),同时支持在 UI 中手动刷新 - 多账户支持 — 每个提供商支持多个账户,自动轮询切换——当一个账户用尽时,无缝切换到下一个
- 自定义组合链 — 可自定义回退链,提供 13 种负载均衡策略(优先级、加权、先填满、轮询、P2C、随机、最少使用、成本优化、严格随机、自动、lkgp、上下文优化、上下文中继)
- 结构化组合构建器 — 分步骤构建组合,明确选择提供商、模型和账户,支持重复提供商及固定目标账户
- 配额感知的 P2C 策略 — 基于二的幂次账户选择现会考虑配额余量、退避机制、近期错误以及连续使用情况
- Codex 企业配额 — 直接在仪表板中监控企业/团队工作区的配额
🔌 2. “我需要使用多家提供商,但它们的 API 各不相同”
OpenAI 使用一种格式,Claude(Anthropic)使用另一种,Gemini 则是第三种。如果开发者想测试不同提供商的模型或在它们之间进行回退,就需要重新配置 SDK、更换端点,并处理不兼容的格式问题。而一些自定义提供商(如 FriendLI、NIM)还拥有非标准的模型端点。
OmniRoute 如何解决这个问题:
- 统一端点 — 单一的
http://localhost:20128/v1作为所有 100 多家提供商的代理 - 格式转换 — 自动且透明地实现 OpenAI ↔ Claude ↔ Gemini ↔ Responses API 的格式互转
- 响应净化 — 去除非标准字段(
x_groq、usage_breakdown、service_tier),避免这些字段导致 OpenAI SDK v1.83+ 出错 - 角色归一化 — 将非 OpenAI 提供商的
developer角色转换为system;将 GLM/ERNIE 的system角色转换为user - “思考”标签提取 — 从 DeepSeek R1 等模型中提取
<think>块,并将其标准化为reasoning_content - Gemini 的结构化输出 — 自动将
json_schema转换为responseMimeType/responseSchema stream默认为false— 符合 OpenAI 规范,避免在 Python/Rust/Go SDK 中出现意外的 SSE 流
🌐 3. “我的 AI 提供商屏蔽了我的地区/国家”
像 OpenAI 和 Codex 这样的提供商会屏蔽某些地理区域的访问。用户在进行 OAuth 授权或 API 调用时,经常会遇到 unsupported_country_region_territory 错误。这对来自发展中国家的开发者来说尤其令人沮丧。
OmniRoute 如何解决这个问题:
- 三层代理配置 — 支持全局(所有流量)、单提供商(仅针对某一家提供商)以及单连接/密钥级别的代理配置
- 彩色代理标识 — 可视化指示:🟢 全局代理,🟡 提供商代理,🔵 连接代理,始终显示当前 IP 地址
- 通过代理交换 OAuth Token — OAuth 流程也经过代理,从而解决
unsupported_country_region_territory问题 - 通过代理测试连接 — 连接测试均使用已配置的代理(不再直接绕过)
- SOCKS5 支持 — 完全支持 SOCKS5 代理用于出站路由
- TLS 指纹欺骗 — 通过
wreq-js模拟浏览器 TLS 指纹,以绕过机器人检测 - CLI 指纹匹配 — 重新排列请求头和请求体字段,使其与原生 CLI 二进制文件的签名一致,从而大幅降低账号被标记的风险。同时保留代理 IP——既能保持隐蔽性,又能实现 IP 匿名化
🆓 4. “我想用 AI 编程,但我没钱”
并非所有人都能负担每月 20 至 200 美元的 AI 订阅费用。学生、来自新兴国家的开发者、业余爱好者和自由职业者都需要以零成本获取高质量的模型。
OmniRoute 如何解决这个问题:
- 内置免费层级提供商 — 原生支持 100% 免费的提供商:Qoder(通过 OAuth 提供 5 款无限量模型:kimi-k2-thinking、qwen3-coder-plus、deepseek-r1、minimax-m2、kimi-k2);Qwen(4 款无限量模型:qwen3-coder-plus、qwen3-coder-flash、qwen3-coder-next、视觉模型);Kiro(Claude + AWS Builder ID 免费);Gemini CLI(每月 18 万 token 免费)
- Ollama Cloud — 在
api.ollama.com上托管的 Ollama 模型,提供免费的“轻量使用”层级;使用ollamacloud/<model>前缀 - 纯免费组合链 — 将
gc/gemini-3-flash → if/kimi-k2-thinking → qw/qwen3-coder-plus组合起来,即可实现每月零成本且无中断的服务 - NVIDIA NIM 免费访问 — 在 build.nvidia.com 上可获得约 40 RPM 的开发者永久免费访问权限,涵盖 70 多种模型(正从积分模式过渡到纯速率限制模式)
- 成本优化策略 — 自动选择最便宜可用提供商的路由策略
🔒 5. “我需要保护我的 AI 网关免受未经授权的访问”
当将 AI 网关暴露到网络(LAN、VPS、Docker)时,任何拥有该地址的人都可以消耗开发者的令牌或配额。如果没有保护措施,API 就容易遭到滥用、提示注入等攻击。
OmniRoute 如何解决这个问题:
- API 密钥管理 — 提供按提供商生成、轮换和范围限定密钥的功能,并设有专门的
/dashboard/api-manager页面 - 模型级权限控制 — 可将 API 密钥限制在特定模型上(如
openai/*或通配符模式),并提供“允许全部”或“限制”开关 - API 端点保护 — 要求访问
/v1/models必须使用密钥,并可阻止特定提供商出现在列表中 - 认证防护 + CSRF 保护 — 所有仪表板路由均受到
withAuth中间件和 CSRF 令牌的保护 - 速率限制器 — 基于 IP 的速率限制,窗口时间可配置
- IP 过滤 — 提供白名单和黑名单功能,用于访问控制
- 提示注入防护 — 对恶意提示模式进行净化处理
- AES-256-GCM 加密 — 静态存储中的凭据采用加密保护
🛑 6. “我的提供商宕机了,我的编程流程中断了”
AI 提供商可能会变得不稳定,返回 5xx 错误,或遭遇临时的速率限制。如果开发者只依赖一家提供商,就会被打断。如果没有熔断机制,反复重试可能导致应用程序崩溃。
OmniRoute 如何解决这个问题:
- 设置驱动的锁定层级 — 提供商配置文件可在同一界面控制默认账户/模型锁定、全局模型隔离以及提供商熔断机制,同时显式上游的
Retry-After窗口仍具有更高优先级 - 指数退避 — 针对账户/模型锁定以及更高级别的隔离,逐步延长重试间隔
- 防羊群效应 — 使用互斥锁和信号量保护,防止并发重试风暴
- 组合回退链 — 如果主提供商失败,系统会自动按链路顺序切换,无需人工干预
- 组合熔断器 — 自动禁用组合链中出现故障的提供商
- 健康仪表板 — 提供运行时间监控、熔断状态、锁定情况、缓存统计信息以及 p50/p95/p99 延迟数据
🔧 7. “配置每个 AI 工具既繁琐又重复”
开发者会使用 Cursor、Claude Code、Codex CLI、OpenClaw、Gemini CLI、Kilo Code 等工具。每款工具的配置都不一样(API 端点、密钥、模型)。当切换供应商或模型时,重新配置非常耗时。
OmniRoute 如何解决这个问题:
- CLI 工具仪表板 — 专用页面,支持 Claude Code、Codex CLI、OpenClaw、Kilo Code、Antigravity、Cline 的一键设置
- GitHub Copilot 配置生成器 — 可为 VS Code 生成
chatLanguageModels.json文件,并支持批量选择模型 - 入门向导 — 针对首次使用的用户,提供四步引导式设置流程
- 一个端点,支持所有模型 — 只需配置一次
http://localhost:20128/v1,即可访问 100 多家服务提供商
🔑 8. “管理多个供应商的 OAuth 令牌简直太麻烦了”
Claude Code、Codex、Gemini CLI、Copilot 等工具都使用 OAuth 2.0 协议,且令牌会过期。开发者需要不断重新认证,还会遇到 client_secret is missing、redirect_uri_mismatch 等问题,以及在远程服务器上出现的各种失败情况。尤其是在局域网或 VPS 上使用 OAuth 时,问题更加突出。
OmniRoute 如何解决这个问题:
- 自动刷新令牌 — OAuth 令牌会在过期前在后台自动刷新
- 内置 OAuth 2.0 (PKCE) — 自动化流程适用于 Claude Code、Codex、Gemini CLI、Copilot、Kiro、Qwen、Qoder 等工具
- 多账号 OAuth — 通过提取 JWT/ID 令牌,支持同一供应商下的多个账号
- 局域网/远程 OAuth 修复 — 自动检测私有 IP 以设置
redirect_uri,同时提供手动 URL 模式用于远程服务器 - Nginx 后端 OAuth 支持 — 使用
window.location.origin以兼容反向代理 - 远程 OAuth 指南 — 提供 Google Cloud 凭证在 VPS/Docker 环境中的详细步骤指南
📊 9. “我不知道自己花了多少钱,也不知道花在了哪里”
开发者会使用多家付费服务提供商,但却没有统一的费用视图。每个服务商都有自己的计费仪表板,但缺乏整合后的汇总信息。这可能导致意外的成本累积。
OmniRoute 如何解决这个问题:
- 成本分析仪表板 — 按照每个供应商跟踪每次调用的费用,并进行预算管理
- 分级预算限制 — 为每个级别设置支出上限,超出后会自动切换到备用方案
- 按模型定价配置 — 可针对不同模型自定义价格
- 按 API 密钥的使用统计 — 记录每个密钥的请求次数及最后使用时间
- 分析仪表板 — 包括统计卡片、模型使用图表、供应商表格等,显示成功率和延迟信息
🐛 10. “我无法诊断 AI 调用中的错误和问题”
当调用失败时,开发者往往不清楚是由于速率限制、令牌过期、格式错误,还是服务提供商自身的问题。日志分散在不同的终端中,缺乏可观ability,调试只能靠反复试错。
OmniRoute 如何解决这个问题:
- 统一日志仪表板 — 分为四个标签页:请求日志、代理日志、审计日志和控制台
- 控制台日志查看器 — 实时终端风格的查看器,带有颜色编码等级、自动滚动、搜索和筛选功能
- SQLite 摘要日志 — 请求和代理日志索引可在重启后继续查询,而无需将大型负载数据块加载到 SQLite 中
- 翻译 Playground — 提供四种调试模式:Playground(格式转换)、Chat Tester(往返测试)、Test Bench(批量测试)和 Live Monitor(实时监控)
- 请求遥测 — 提供 p50/p95/p99 延迟信息以及 X-Request-Id 追踪
- 基于文件的详细记录 — 应用日志会根据大小、保留天数和归档次数轮转;详细的请求/响应负载则保存在
DATA_DIR/call_logs/目录下,并独立于 SQLite 摘要日志进行轮转 - 系统信息报告 — 运行
npm run system-info可生成包含完整环境信息的system-info.txt文件(Node 版本、OmniRoute 版本、操作系统、CLI 工具、Docker/PM2 状态等)。提交问题时附上该文件,可帮助快速定位问题。
🏗️ 11. “部署和维护网关很复杂”
在不同环境中(本地、VPS、Docker、云)安装、配置和维护 AI 代理是一项繁重的工作。硬编码路径、目录权限错误(EACCES)、端口冲突以及跨平台构建等问题都会增加难度。
OmniRoute 如何解决这个问题:
- npm 全局安装 —
npm install -g omniroute && omniroute,简单完成 - Docker 多平台支持 — 原生支持 AMD64 和 ARM64 架构(Apple Silicon、AWS Graviton、Raspberry Pi)
- Docker Compose 配置文件 — 提供
base(不包含 CLI 工具)和cli(包含 Claude Code、Codex、OpenClaw)两种配置 - Electron 桌面应用 — 适用于 Windows/macOS/Linux 的原生应用,配备系统托盘、开机自启动和离线模式
- 分端口模式 — API 和仪表板分别运行在不同端口上,适用于高级场景(反向代理、容器网络)
- 云端同步 — 通过 Cloudflare Workers 在不同设备之间同步配置
- 数据库备份 — 自动备份、恢复、导出和导入所有设置,并提供
DISABLE_SQLITE_AUTO_BACKUP选项,方便外部管理备份
🌍 12. “界面只有英文,我的团队不会说英语”
非英语国家的团队,尤其是拉丁美洲、亚洲和欧洲的团队,常常因为界面仅支持英文而面临困难。语言障碍不仅降低了产品的采用率,还增加了配置错误的可能性。
OmniRoute 如何解决这个问题:
- 仪表板国际化 — 支持 30 种语言 — 所有 500 多个文本键均已翻译,包括阿拉伯语、保加利亚语、丹麦语、德语、西班牙语、芬兰语、法语、希伯来语、印地语、匈牙利语、印尼语、意大利语、日语、韩语、马来语、荷兰语、挪威语、波兰语、葡萄牙语(PT/BR)、罗马尼亚语、俄语、斯洛伐克语、瑞典语、泰语、乌克兰语、越南语、中文、菲律宾语以及英语
- RTL 支持 — 对阿拉伯语和希伯来语提供从右到左的支持
- 多语言 README 文档 — 提供 30 种语言的完整文档翻译
- 语言选择器 — 页眉处的地球图标,可实时切换语言
🔄 13. “我需要的不仅仅是聊天功能——我还想要嵌入向量、图片和音频”
AI 不仅仅局限于聊天补全。开发者还需要生成图片、转录音频、创建用于 RAG 的嵌入向量、对文档进行重新排序以及内容审核等功能。而每种功能对应的 API 端点和格式都不相同。
OmniRoute 如何解决这个问题:
- 嵌入 —
/v1/embeddings,支持 6 家供应商和 9 模型以上 - 图像生成 —
/v1/images/generations,支持 10 家供应商和 20 模型以上(OpenAI、xAI、Together、Fireworks、Nebius、Hyperbolic、NanoBanana、Antigravity、SD WebUI、ComfyUI) - 文本转视频 —
/v1/videos/generations— ComfyUI(AnimateDiff、SVD)和 SD WebUI - 文本转音乐 —
/v1/music/generations— ComfyUI(Stable Audio Open、MusicGen) - 音频转录 —
/v1/audio/transcriptions— Whisper + Nvidia NIM、HuggingFace、Qwen3 - 文本转语音 —
/v1/audio/speech— ElevenLabs、Nvidia NIM、HuggingFace、Coqui、Tortoise、Qwen3、Inworld、Cartesia、PlayHT,以及现有供应商 - 内容审核 —
/v1/moderations— 内容安全检查 - 重排序 —
/v1/rerank— 文档相关性重排序 - 响应 API — 对 Codex 的完整
/v1/responses支持
🧪 14. “我没有办法测试和比较不同模型的质量”
开发者希望知道哪种模型最适合自己的应用场景——代码生成、翻译、推理等——但手动比较效率太低。目前还没有集成的评估工具。
OmniRoute 如何解决:
- LLM 评估 — 使用预加载的 10 个案例进行黄金集测试,涵盖问候语、数学、地理、代码生成、JSON 格式合规性、翻译、Markdown 和安全性拒绝等内容
- 4 种匹配策略 —
exact、contains、regex和custom(JS 函数) - 翻译器 Playground 测试台 — 批量测试,支持多组输入和预期输出,并可跨供应商对比
- 聊天测试器 — 全流程交互,可视化响应结果
- 实时监控 — 实时展示所有通过代理的请求流
📈 15. “我需要在不降低性能的情况下扩展规模”
随着请求量的增长,如果没有缓存机制,相同的查询会导致重复计算,浪费成本。而缺乏幂等性则会使重复请求白白占用处理资源。此外,还需遵守各供应商的速率限制。
OmniRoute 如何解决:
- 语义缓存 — 两层缓存(签名 + 语义),有效降低成本并减少延迟
- 请求幂等性 — 为相同请求提供 5 秒去重窗口
- 速率限制检测 — 分别跟踪每个供应商的 RPM、最小间隔和最大并发数
- 可编辑的速率限制 — 在“设置 → 弹性”中配置默认值,并持久化保存
- API 密钥验证缓存 — 三层缓存,确保生产环境性能
- 健康仪表盘与遥测 — 提供 p50/p95/p99 延迟、缓存统计和运行时间等信息
🤖 16. “我想全局控制模型行为”
开发者希望所有响应都以特定语言呈现、采用特定语气,或者限制推理 token 数量。如果要在每个工具或每次请求中单独配置,显然不现实。
OmniRoute 如何解决:
- 系统提示注入 — 全局应用到所有请求的提示
- 思考预算验证 — 每个请求的推理 token 分配控制(透传、自动、自定义、适应性)
- 9 种路由策略 — 全局策略决定请求如何分发
- 通配符路由器 — 使用
provider/*模式动态路由到任意供应商 - 组合启用/禁用切换 — 可直接在仪表盘上切换组合
- 手动组合排序 — 拖动组合卡片调整顺序,并将排序结果持久化到 SQLite 中
- 供应商开关 — 一键启用或禁用某个供应商的所有连接
- 被屏蔽的供应商 — 将特定供应商从
/v1/models列表中排除
🧰 17. “我需要将 MCP 工具作为一级产品功能”
许多 AI 网关仅将 MCP 隐藏为实现细节,而团队需要一个可见且易于管理的操作层。
OmniRoute 如何解决:
- MCP 出现在仪表盘导航和端点协议选项卡中
- 专门的 MCP 管理页面,包含流程、工具、作用域和审计记录
- 内置快速入门指南,用于
omniroute --mcp和客户端接入
🧠 18. “我需要同步与流式任务路径的 A2A 协调”
智能体工作流既需要直接回复,也需要长时间的流式执行,并能够控制其生命周期。
OmniRoute 如何解决:
- A2A JSON-RPC 端点(
POST /a2a),支持message/send和message/stream - SSE 流式传输,可传递终端状态
- 任务生命周期 API,用于
tasks/get和tasks/cancel
🛰️ 19. “我需要真实的 MCP 进程健康状况,而不是猜测的状态”
运维团队需要了解 MCP 是否真正存活,而不仅仅是 API 是否可达。
OmniRoute 如何解决:
- 运行时心跳文件,包含 PID、时间戳、传输方式、工具数量和作用域模式
- MCP 状态 API 结合心跳和近期活动情况
- UI 状态卡片显示进程/运行时间/心跳新鲜度
📋 20. “我需要可审计的 MCP 工具执行记录”
当工具修改配置或触发运维操作时,团队需要具备法医级别的可追溯性。
OmniRoute 如何解决:
- 基于 SQLite 的审计日志记录 MCP 工具调用
- 支持按工具、成功/失败、API 密钥筛选,并提供分页功能
- 仪表盘审计表格及自动化统计端点
🔐 21. “我需要按集成划分的 MCP 权限”
不同的客户应仅拥有对工具类别的最小权限访问。
OmniRoute 如何解决:
- 10 种细粒度的 MCP 作用域,用于控制工具访问
- 在 MCP 管理界面中强制实施作用域并控制可见性
- 为运维工具设置安全的默认配置
⚙️ 22. “我需要无需重新部署即可进行的运维控制”
团队需要在突发事件或成本事件发生时,快速调整运行时配置。
OmniRoute 如何解决:
- 直接在 MCP 仪表盘上切换组合激活状态
- 从预定义的策略包中应用弹性配置
- 从同一运维面板重置熔断器状态
🔄 23. “我需要实时查看和取消 A2A 任务生命周期”
如果没有生命周期的可见性,任务故障将难以诊断。
OmniRoute 如何解决:
- 按状态和技能列出并筛选任务,支持分页
- 可深入查看任务元数据、事件和产物
- 提供任务取消端点和 UI 操作,并带有确认提示
🌊 24. “我需要 A2A 负载的实时流指标”
流式工作流需要对并发性和实时连接有清晰的运营洞察。
OmniRoute 如何解决:
- 将活跃流计数器集成到 A2A 状态中
- 显示最后任务的时间戳和各状态下的任务数量
- A2A 仪表盘卡片,用于实时监控运营状况
🪪 25. “我需要面向客户的标准化智能体发现”
外部客户和编排器需要机器可读的元数据来进行接入。
OmniRoute 如何解决:
- 代理卡片在
/.well-known/agent.json中公开 - 管理 UI 中展示了功能和技能
- A2A 状态 API 包含用于自动化的发现元数据
🧭 26. “我需要在产品用户体验中实现协议可发现性”
如果用户无法发现协议接口,采用率和支持质量就会下降。
OmniRoute 的解决方案:
- 整合的 端点 页面,设有代理、MCP、A2A 和 API 端点选项卡
- MCP 和 A2A 的内联服务状态切换(在线/离线)
- 从概览页面到专用管理选项卡的链接
🧪 27. “我需要使用真实客户端进行端到端协议验证”
仅靠模拟测试不足以在发布前验证协议兼容性。
OmniRoute 的解决方案:
- E2E 套件会启动应用,并使用真实的 MCP SDK 客户端传输层
- A2A 客户端测试涵盖发现、发送、流式传输、获取和取消流程
- 对 MCP 审计和 A2A 任务 API 进行交叉检查断言
📡 28. “我需要跨所有接口的统一可观测性”
按协议划分可观测性会导致盲区并延长 MTTR。
OmniRoute 的解决方案:
- 在一个产品中提供统一的仪表盘、日志和分析
- 覆盖 OpenAI、MCP 和 A2A 层的健康状况、审计和请求遥测
- 提供用于状态监控和自动化的运营 API
💼 29. “我需要一个运行时来同时处理代理、工具和代理编排”
运行多个独立的服务会增加运营成本并引入更多故障模式。
OmniRoute 的解决方案:
- 将兼容 OpenAI 的代理、MCP 服务器和 A2A 服务器集成在一个堆栈中
- 共享身份验证、弹性、数据存储和可观测性
- 在所有交互界面中保持一致的策略模型
🚀 30. “我需要在不产生大量胶水代码的情况下部署智能体工作流”
当团队拼接多个临时服务和脚本时,开发速度会显著下降。
OmniRoute 的解决方案:
- 面向客户端和智能体的统一端点策略
- 内置的协议管理 UI 和冒烟测试路径
- 生产就绪的基础架构(安全性、日志记录、弹性和备份)
📚 31. “我的长时间会话会因‘context_length_exceeded’限制而崩溃”
在深度调试过程中,包含工具结果的长对话历史会迅速超出提供商的令牌窗口,导致请求失败和孤立的上下文。
OmniRoute 的解决方案:
- 主动上下文压缩 — 在请求到达上游之前评估令牌预算,并通过智能二分查找机制主动修剪旧的对话历史。
- 结构完整性保护 — 自动跟踪显式的
tool_use定义,并确保如果工具输入被截断,其对应的tool_result也会被安全移除,从而防止 API 验证错误。 - 多层丢弃 — 逐步丢弃系统消息、常规消息,最终严格执行长度限制,同时不破坏对话逻辑。
示例剧本(集成用例)
剧本 A:最大化付费订阅 + 廉价备份
组合:“maximize-claude”
1. cc/claude-opus-4-6
2. glm/glm-4.7
3. if/kimi-k2-thinking
月度成本:$20 + 少量备份支出
结果:更高品质,几乎零中断
剧本 B:零成本编码栈
组合:“free-forever”
1. gc/gemini-3-flash
2. if/kimi-k2-thinking
3. qw/qwen3-coder-plus
月度成本:$0
结果:稳定的免费编码工作流
剧本 C:24/7 永久可用的后备链
组合:“always-on”
1. cc/claude-opus-4-6
2. cx/gpt-5.2-codex
3. glm/glm-4.7
4. minimax/MiniMax-M2.1
5. if/kimi-k2-thinking
结果:为关键任务负载提供深度后备能力
剧本 D:使用 MCP + A2A 进行智能体操作
1) 启动 MCP 传输(`omniroute --mcp`)以进行工具驱动的操作
2) 通过 `message/send` 和 `message/stream` 运行 A2A 任务
3) 通过 /dashboard/endpoint(MCP 和 A2A 选项卡)进行观察
4) 使用内联状态控件切换服务
🆓 免费开始 — 零配置成本
在几分钟内即可设置 AI 编码,每月费用为 $0。连接这些免费账户,并使用内置的 Free Stack 组合。
| 步骤 | 操作 | 解锁的提供商 |
|---|---|---|
| 1 | 连接 Kiro(AWS Builder ID OAuth) | Claude Sonnet 4.5、Haiku 4.5 — 无限量 |
| 2 | 连接 Qoder(Google OAuth) | kimi-k2-thinking、qwen3-coder-plus、deepseek-r1... — 无限量 |
| 3 | 连接 Qwen(设备码) | qwen3-coder-plus、qwen3-coder-flash... — 无限量 |
| 4 | 连接 Gemini CLI(Google OAuth) | gemini-3-flash、gemini-2.5-pro — 每月免费 18 万次调用 |
| 5 | /dashboard/combos → Free Stack ($0) 模板 |
自动轮换所有免费提供商 |
将任何 IDE/CLI 指向: http://localhost:20128/v1 · API 密钥:any-string · 完成。
可选额外覆盖(同样免费): Groq API 密钥(免费 30 RPM)、NVIDIA NIM(免费 40 RPM,70 多种模型)、Cerebras(每天 100 万个 token)、LongCat API 密钥(每天 5000 万个 token!)、Cloudflare Workers AI(每天 1 万个神经元,50 多种模型)。
⚡ 快速入门
1) 安装并运行
npm install -g omniroute
omniroute
pnpm 用户: 安装后运行
pnpm approve-builds -g以启用better-sqlite3和@swc/core所需的原生构建脚本:pnpm install -g omniroute pnpm approve-builds -g # 选择所有包 → 批准 omniroute
仪表盘将在 http://localhost:20128 打开,API 基础 URL 为 http://localhost:20128/v1。
| 命令 | 描述 |
|---|---|
omniroute |
启动服务器(PORT=20128,API 和仪表盘在同一端口) |
omniroute --port 3000 |
将标准/API 端口设置为 3000 |
omniroute --mcp |
启动 MCP 服务器(stdio 传输) |
omniroute --no-open |
不自动打开浏览器 |
omniroute --help |
显示帮助 |
可选的分端口模式:
PORT=20128 DASHBOARD_PORT=20129 omniroute
# API: http://localhost:20128/v1
# Dashboard: http://localhost:20129
2) 卸载
当您不再需要 OmniRoute 时,我们提供了两个快速脚本来进行干净卸载:
| 命令 | 操作 |
|---|---|
npm run uninstall |
移除系统应用,但会保留您的数据库和配置在 ~/.omniroute 中。 |
npm run uninstall:full |
移除应用并永久清除所有配置、密钥和数据库。 |
注意:要运行这些命令,请导航到 OmniRoute 项目文件夹(如果您克隆了它),然后执行。或者,如果已全局安装,您可以直接运行
npm uninstall -g omniroute。
长时间流式传输超时
对于大多数部署,您只需要:
| 变量 | 默认 | 用途 |
|---|---|---|
REQUEST_TIMEOUT_MS |
600000 |
上游响应开始超时的共享基线,隐藏的 Undici 超时、TLS 指纹请求以及 API 网关请求/代理超时 |
STREAM_IDLE_TIMEOUT_MS |
继承自 REQUEST_TIMEOUT_MS |
流式传输块之间的最大间隔,超过该时间 OmniRoute 将中止 SSE 流 |
向后兼容性得以保留:现有的 FETCH_TIMEOUT_MS、API_BRIDGE_PROXY_TIMEOUT_MS 等各层超时变量仍然有效,并会覆盖共享基线。
对于与 Claude Code 兼容的上游服务(anthropic-compatible-cc-*),OmniRoute 还会根据解析后的 fetch 超时值推导出 outbound 的 X-Stainless-Timeout 头,以确保提供商端的读取超时与您的环境配置保持一致。
对于第三方与 Claude Code 兼容的反向代理,OmniRoute 会将默认的 anthropic-beta 设置得较为保守,并且当 Client Cache Control 保持为 Auto 时,只会转发客户端提供的 cache_control 标记。如果请求中不包含 cache_control,OmniRoute 不会注入网关自身的标记。
如果您需要更精细的控制,还可以使用高级覆盖选项:
| 变量 | 默认 | 用途 |
|---|---|---|
FETCH_TIMEOUT_MS |
继承自 REQUEST_TIMEOUT_MS |
上游响应开始前的超时,直到收到响应头为止 |
FETCH_HEADERS_TIMEOUT_MS |
继承自 FETCH_TIMEOUT_MS |
Undici 接收上游响应头的时间限制 |
FETCH_BODY_TIMEOUT_MS |
继承自 FETCH_TIMEOUT_MS |
Undici 上游数据块之间的时间限制(设置为 0 则禁用) |
FETCH_CONNECT_TIMEOUT_MS |
30000 |
Undici TCP 连接超时 |
FETCH_KEEPALIVE_TIMEOUT_MS |
4000 |
Undici 空闲保持连接的套接字超时 |
TLS_CLIENT_TIMEOUT_MS |
继承自 FETCH_TIMEOUT_MS |
通过 wreq-js 发起的 TLS 指纹请求的超时 |
API_BRIDGE_PROXY_TIMEOUT_MS |
继承自 REQUEST_TIMEOUT_MS 或 30000 |
从 API 端口到仪表板端口的 /v1 代理转发超时 |
API_BRIDGE_SERVER_REQUEST_TIMEOUT_MS |
max(API_BRIDGE_PROXY_TIMEOUT_MS, 300000) |
API 网关服务器上的入站请求超时 |
API_BRIDGE_SERVER_HEADERS_TIMEOUT_MS |
60000 |
API 网关服务器上的入站头部超时 |
API_BRIDGE_SERVER_KEEPALIVE_TIMEOUT_MS |
5000 |
API 网关服务器上的保持连接超时 |
API_BRIDGE_SERVER_SOCKET_TIMEOUT_MS |
0 |
API 网关服务器上的套接字非活动超时(设置为 0 则禁用) |
对于流式请求,FETCH_TIMEOUT_MS 仅涵盖连接建立和等待第一个上游响应的过程。一旦流开始传输,OmniRoute 只会在实际停滞(STREAM_IDLE_TIMEOUT_MS)或 Undici 数据块长时间无活动(FETCH_BODY_TIMEOUT_MS)时才会中断流。
如果您在 Nginx、Caddy、Cloudflare 或其他反向代理之后运行 OmniRoute,请确保代理的超时设置也高于 OmniRoute 的流式传输或 fetch 超时。
2) 连接提供商并创建您的 API 密钥
- 打开仪表板 →
Providers,至少连接一个提供商(OAuth 或 API 密钥)。 - 打开仪表板 →
Endpoints,创建一个 API 密钥。 - (可选)打开仪表板 →
Combos,设置您的回退链。
3) 将您的编码工具指向 OmniRoute
基础 URL:http://localhost:20128/v1
API 密钥:[从 Endpoint 页面复制]
模型:if/kimi-k2-thinking(或任何提供商/模型前缀)
适用于 Claude Code、Codex CLI、Gemini CLI、Cursor、Cline、OpenClaw、OpenCode 以及与 OpenAI 兼容的 SDK。
4) 启用并验证协议(v2.0)
MCP(用于工具驱动的操作):
omniroute --mcp
然后通过 stdio 连接您的 MCP 客户端,并测试以下工具:
omniroute_get_healthomniroute_list_combos
A2A(用于代理间工作流):
curl http://localhost:20128/.well-known/agent.json
curl -X POST http://localhost:20128/a2a \
-H 'content-type: application/json' \
-d '{"jsonrpc":"2.0","id":"quickstart","method":"message/send","params":{"skill":"quota-management","messages":[{"role":"user","content":"给我一个简短的配额摘要。"}]}}'
5) 全流程端到端验证(推荐)
npm run test:protocols:e2e
此套件会针对正在运行的应用程序验证真实的 MCP 和 A2A 客户端流程。
替代方案:从源代码运行
cp .env.example .env
npm install
PORT=20128 DASHBOARD_PORT=20129 NEXT_PUBLIC_BASE_URL=http://localhost:20129 npm run dev
Void Linux (`xbps-src` 模板)
对于 Void Linux 用户,您可以使用 xbps-src 构建原生软件包。将以下内容保存为 srcpkgs/omniroute/template:
# ‘omniroute’ 的模板文件
pkgname=omniroute
version=3.4.1
revision=1
hostmakedepends="nodejs python3 make"
depends="openssl"
short_desc="支持多模型提供商的智能路由通用 AI 网关"
maintainer="zenobit <zenobit@disroot.org>"
license="MIT"
homepage="https://github.com/diegosouzapw/OmniRoute"
distfiles="https://github.com/diegosouzapw/OmniRoute/archive/refs/tags/v${version}.tar.gz"
checksum=009400afee90a9f32599d8fe734145cfd84098140b7287990183dde45ae2245b
system_accounts="_omniroute"
omniroute_homedir="/var/lib/omniroute"
export NODE_ENV=production
export npm_config_engine_strict=false
export npm_config_loglevel=error
export npm_config_fund=false
export npm_config_audit=false
do_build() {
# 根据目标 CPU 架构确定 node-gyp 使用的架构
local _gyp_arch
case "$XBPS_TARGET_MACHINE" in
aarch64*) _gyp_arch=arm64 ;;
armv7*|armv6*) _gyp_arch=arm ;;
i686*) _gyp_arch=ia32 ;;
*) _gyp_arch=x64 ;;
esac
# 1) 安装所有依赖 – 跳过脚本(do_build 中无网络,原生模块将在下面单独编译;better-sqlite3 是 serverExternalPackage,因此 Next.js 在 next build 期间不会执行它)
NODE_ENV=development npm ci --ignore-scripts
# 2) 构建 Next.js 单体包
npm run build
# 3) 将静态资源复制到单体包中
cp -r .next/static .next/standalone/.next/static
[ -d public ] && cp -r public .next/standalone/public || true
# 4) 为目标架构编译 better-sqlite3 的原生绑定。
# 直接使用 node-gyp,以便利用 xbps-src 交叉工具链中的 CC/CXX,而不会被 npm 修改。
local _node_gyp=/usr/lib/node_modules/npm/node_modules/node-gyp/bin/node-gyp.js
(cd node_modules/better-sqlite3 && node "$_node_gyp" rebuild --arch="$_gyp_arch")
# 5) 将编译好的绑定放入单体包中
local _bs3_release=.next/standalone/node_modules/better-sqlite3/build/Release
mkdir -p "$_bs3_release"
cp node_modules/better-sqlite3/build/Release/better_sqlite3.node "$_bs3_release/"
# 6) 移除特定于架构的 sharp 包 – 上游设置了 images.unoptimized=true,因此运行时不会使用 sharp;x64 的 .so 文件会破坏 aarch64 的剥离过程
rm -rf .next/standalone/node_modules/@img
# 7) 复制 Next.js 静态分析遗漏的 pino 运行时依赖:
# pino-abstract-transport – pino 工作线程所需
# split2 – pino-abstract-transport 的依赖
# process-warning – pino 自身的依赖
for _mod in pino-abstract-transport split2 process-warning; do
cp -r "node_modules/$_mod" .next/standalone/node_modules/
done
}
do_check() {
npm run test:unit
}
do_install() {
vmkdir usr/lib/omniroute/.next
vcopy .next/standalone/. usr/lib/omniroute/.next/standalone
# 防止安装后钩子删除空的 Next.js 应用路由器目录
for _d in \
.next/standalone/.next/server/app/dashboard \
.next/standalone/.next/server/app/dashboard/settings \
.next/standalone/.next/server/app/dashboard/providers; do
touch "${DESTDIR}/usr/lib/omniroute/${_d}/.keep"
done
cat > "${WRKDIR}/omniroute" <<'EOF'
#!/bin/sh
export PORT="${PORT:-20128}"
export DATA_DIR="${DATA_DIR:-${XDG_DATA_HOME:-${HOME}/.local/share}/omniroute}"
export APP_LOG_TO_FILE="${APP_LOG_TO_FILE:-false}"
mkdir -p "${DATA_DIR}"
exec node /usr/lib/omniroute/.next/standalone/server.js "$@"
EOF
vbin "${WRKDIR}/omniroute"
}
post_install() {
vlicense LICENSE
}
🐳 Docker
OmniRoute 已作为公共 Docker 镜像发布在 Docker Hub 上。
快速运行:
docker run -d \
--name omniroute \
--restart unless-stopped \
--stop-timeout 40 \
-p 20128:20128 \
-v omniroute-data:/app/data \
diegosouzapw/omniroute:latest
使用环境文件:
# 先复制并编辑 .env 文件
cp .env.example .env
docker run -d \
--name omniroute \
--restart unless-stopped \
--stop-timeout 40 \
--env-file .env \
-p 20128:20128 \
-v omniroute-data:/app/data \
diegosouzapw/omniroute:latest
使用 Docker Compose:
# 基础配置文件(不包含 CLI 工具)
docker compose --profile base up -d
# CLI 配置文件(内置 Claude Code、Codex、OpenClaw)
docker compose --profile cli up -d
Docker 部署的仪表板现在新增了一键式 Cloudflare Quick Tunnel 功能,位于“仪表板 → 终端节点”中。首次启用时,系统仅在需要时下载 cloudflared,启动一个临时隧道连接到当前的 /v1 端点,并将生成的 https://*.trycloudflare.com/v1 URL 直接显示在您正常的公开 URL 下方。
注意事项:
- Quick Tunnel URL 是临时的,每次重启后都会变化。
- Quick Tunnels 不会在 OmniRoute 或容器重启后自动恢复。如有需要,请从仪表板重新启用。
- 当前的托管安装支持 Linux、macOS 和 Windows 的
x64和arm64架构。 - 托管的 Quick Tunnels 默认使用 HTTP/2 传输协议,以避免在受限的容器环境中出现嘈杂的 QUIC UDP 缓冲警告。如果您希望使用其他传输方式,可以设置
CLOUDFLARED_PROTOCOL=quic或auto。 - Docker 镜像捆绑了系统 CA 根证书,并将其传递给托管的
cloudflared,从而避免在容器内部建立隧道时出现 TLS 信任失败。 - SQLite 以 WAL 模式运行。应允许
docker stop完成,以便 OmniRoute 可以将最新更改检查点写回storage.sqlite。 - 捆绑的 Compose 文件已设置 40 秒的停止宽限期。如果您直接运行镜像,请保持
--stop-timeout 40(或类似设置),以免手动停止中断关闭清理流程。 - 如果您希望 OmniRoute 使用现有的二进制文件而不是下载新版本,可以设置
CLOUDFLARED_BIN=/absolute/path/to/cloudflared。
使用 Docker Compose 结合 Caddy(HTTPS 自动 TLS):
OmniRoute 可以通过 Caddy 的自动 SSL 证书颁发功能安全地对外暴露。请确保您的域名 DNS A 记录指向服务器的 IP 地址。
services:
omniroute:
image: diegosouzapw/omniroute:latest
container_name: omniroute
restart: unless-stopped
volumes:
- omniroute-data:/app/data
environment:
- PORT=20128
- NEXT_PUBLIC_BASE_URL=https://your-domain.com
caddy:
image: caddy:latest
container_name: caddy
restart: unless-stopped
ports:
- "80:80"
- "443:443"
command: caddy reverse-proxy --from https://your-domain.com --to http://omniroute:20128
volumes:
omniroute-data:
| 镜像 | 标签 | 大小 | 描述 |
|---|---|---|---|
diegosouzapw/omniroute |
latest |
~250MB | 最新稳定版 |
diegosouzapw/omniroute |
3.6.2 |
~250MB | 当前版本 |
🖥️ 桌面应用 — 离线且常驻
🆕 全新! OmniRoute 现已推出适用于 Windows、macOS 和 Linux 的 原生桌面应用程序。
将 OmniRoute 作为独立的桌面应用运行——无需终端、无需浏览器,本地模型也不需要互联网连接。基于 Electron 的应用包含:
- 🖥️ 原生窗口 — 专用应用窗口,支持系统托盘集成
- 🔄 自动启动 — 在系统登录时自动启动 OmniRoute
- 🔔 原生通知 — 在配额用尽或服务提供商出现问题时接收提醒
- ⚡ 一键安装 — NSIS(Windows)、DMG(macOS)、AppImage(Linux)
- 🌐 离线模式 — 搭载内置服务器,完全离线工作
快速入门
# 开发模式
npm run electron:dev
# 构建适用于您平台的版本
npm run electron:build # 当前平台
npm run electron:build:win # Windows (.exe)
npm run electron:build:mac # macOS (.dmg) — x64 和 arm64
npm run electron:build:linux # Linux (.AppImage)
系统托盘
最小化后,OmniRoute 会驻留在系统托盘中,并提供快速操作:
- 打开仪表板
- 更改服务器端口
- 退出应用
📖 完整文档:electron/README.md
💰 价格一览
| 层级 | 提供商 | 费用 | 配额重置 | 适合人群 |
|---|---|---|---|---|
| 💳 订阅 | Claude Code (Pro) | $20/月 | 5小时 + 每周 | 已订阅用户 |
| Codex (Plus/Pro) | $20–200/月 | 5小时 + 每周 | OpenAI 用户 | |
| Gemini CLI | 免费 | 18万/月 + 1千/天 | 人人适用! | |
| GitHub Copilot | $10–19/月 | 每月 | GitHub 用户 | |
| 🔑 API 密钥 | NVIDIA NIM | 免费(开发环境永久免费) | ~40 RPM | 70+ 开源模型 |
| Cerebras | 免费(每天100万标记) | 6万 TPM / 30 RPM | 全球最快的 | |
| Groq | 免费(30 RPM) | 1.44万 RPD | 超高速 Llama/Gemma | |
| DeepSeek V3.2 | $0.27/$1.10 每100万标记 | 无 | 理论推理性价比最高 | |
| xAI Grok-4 Fast | $0.20/$0.50 每100万标记 🆕 | 无 | 最快且支持工具调用,超低成本 | |
| xAI Grok-4(标准版) | $0.20/$1.50 每100万标记 🆕 | 无 | xAI 的旗舰推理模型 | |
| Mistral | 免费试用 + 付费 | 速率限制 | 欧洲人工智能 | |
| OpenRouter | 按使用付费 | 无 | 超过100个模型聚合 | |
| 💰 廉价 | GLM-5(通过 Z.AI)🆕 | $0.5/100万标记 | 每日10点 | 输出高达12.8万标记,最新旗舰 |
| GLM-4.7 | $0.6/100万标记 | 每日10点 | 预算型备份 | |
| MiniMax M2.5 🆕 | $0.3/100万输入标记 | 5小时滚动 | 理论推理及智能任务 | |
| MiniMax M2.1 | $0.2/100万标记 | 5小时滚动 | 最经济实惠的选择 | |
| Kimi K2.5(Moonshot API)🆕 | 按使用付费 | 无 | 直接访问 Moonshot API | |
| Kimi K2 | $9/月固定费用 | 每月1000万标记 | 成本可预测 | |
| 🆓 免费 | Qoder | $0 | 无限量 | 5个模型无限量使用 |
| Qwen | $0 | 无限量 | 4个模型无限量使用 | |
| Kiro | $0 | 无限量 | Claude Sonnet/Haiku(AWS Builder) | |
| LongCat Flash-Lite 🆕 | $0(每日5000万标记🔥) | 1 RPS | 地球上最大的免费配额 | |
| Pollinations AI 🆕 | $0(无需密钥) | 每15秒1次请求 | GPT-5、Claude、DeepSeek、Llama 4 | |
| Cloudflare Workers AI 🆕 | $0(每天1万个神经元) | 每天约150次响应 | 超过50个模型,全球边缘计算节点 | |
| Scaleway AI 🆕 | $0(总共100万标记) | 速率限制 | 欧盟/GDPR,Qwen3 235B,Llama 70B |
🆕 2026年3月新增模型: Grok-4 Fast 系列,定价为每100万标记$0.20/$0.50(基准测试耗时1143毫秒,比 Gemini 2.5 Flash 快30%);GLM-5 通过 Z.AI 提供,输出高达12.8万标记;MiniMax M2.5 推理模型;DeepSeek V3.2 更新定价;Kimi K2.5 通过 Moonshot 直接 API 提供。
💡 $0 组合堆栈 — 完全免费配置:
# 🆒 2026年终极免费堆栈 — 11家服务商,永久$0
Kiro (kr/) → Claude Sonnet/Haiku 无限量
Qoder (if/) → kimi-k2-thinking、qwen3-coder-plus、deepseek-r1 无限量
LongCat Lite (lc/) → LongCat-Flash-Lite — 每日5000万标记🔥
Pollinations (pol/) → GPT-5、Claude、DeepSeek、Llama 4 — 不需密钥
Qwen (qw/) → qwen3-coder-plus、qwen3-coder-flash、qwen3-coder-next 无限量
Gemini (gemini/) → Gemini 2.5 Flash — 每天1500次请求免费API密钥
Cloudflare AI (cf/) → Llama 70B、Gemma 3、Mistral — 每天1万个神经元
Scaleway (scw/) → Qwen3 235B、Llama 70B — 100万免费标记(欧盟)
Groq (groq/) → Llama/Gemma 超高速 — 每天1.44万次请求
NVIDIA NIM (nvidia/) → 70+ 开源模型 — 永久40 RPM
Cerebras (cerebras/) → Llama/Qwen 全球最快 — 每天100万标记
零成本。永不停歇地编码。 将这些配置为一个 OmniRoute 组合,所有备用方案都会自动切换——无需手动操作。
🆒 免费模型 — 您真正能获得什么
以下所有模型均 100% 免费,无需任何信用卡信息。当某个模型的配额用尽时,OmniRoute 会自动在它们之间切换——将它们全部组合起来,即可获得牢不可破的 $0 组合。
🔵 CLAUDE 模型(通过 Kiro — AWS Builder ID)
| 模型 | 前缀 | 限制 | 速率限制 |
|---|---|---|---|
claude-sonnet-4.5 |
kr/ |
无限量 | 未报告每日上限 |
claude-haiku-4.5 |
kr/ |
无限量 | 未报告每日上限 |
claude-opus-4.6 |
kr/ |
无限量 | Kiro 提供的最新 Opus |
🟢 QODER 模型(通过 qodercli 免费 PAT)
| 模型 | 前缀 | 限制 | 速率限制 |
|---|---|---|---|
kimi-k2-thinking |
if/ |
无限 | 未报告上限 |
qwen3-coder-plus |
if/ |
无限 | 未报告上限 |
deepseek-r1 |
if/ |
无限 | 未报告上限 |
minimax-m2.1 |
if/ |
无限 | 未报告上限 |
kimi-k2 |
if/ |
无限 | 未报告上限 |
推荐连接方式:个人访问令牌 +
qodercli。浏览器 OAuth 处于实验阶段,默认已禁用,除非配置了QODER_OAUTH_*环境变量。
🟡 QWEN 模型(设备码认证)
| 模型 | 前缀 | 限制 | 速率限制 |
|---|---|---|---|
qwen3-coder-plus |
qw/ |
无限 | 未报告上限 |
qwen3-coder-flash |
qw/ |
无限 | 未报告上限 |
qwen3-coder-next |
qw/ |
无限 | 未报告上限 |
vision-model |
qw/ |
无限 | 多模态(图像) |
🟣 GEMINI CLI(Google OAuth)
| 模型 | 前缀 | 限制 | 速率限制 |
|---|---|---|---|
gemini-3-flash-preview |
gc/ |
18万 token/月 + 1千/day | 每月重置 |
gemini-2.5-pro |
gc/ |
18万/月(共享池) | 高质量 |
⚫ NVIDIA NIM(免费 API 密钥 — build.nvidia.com)
| 等级 | 日限额 | 速率限制 | 备注 |
|---|---|---|---|
| 免费(开发) | 无 token 上限 | ~40 RPM | 70+ 模型;将于 2025 年中过渡到纯速率限制 |
热门免费模型:moonshotai/kimi-k2.5(Kimi K2.5)、z-ai/glm4.7(GLM 4.7)、deepseek-ai/deepseek-v3.2(DeepSeek V3.2)、nvidia/llama-3.3-70b-instruct、deepseek/deepseek-r1
⚪ CEREBRAS(免费 API 密钥 — inference.cerebras.ai)
| 等级 | 日限额 | 速率限制 | 备注 |
|---|---|---|---|
| 免费 | 100万 tokens/天 | 6万 TPM / 30 RPM | 全球最快的 LLM 推理;每日重置 |
免费可用:llama-3.3-70b、llama-3.1-8b、deepseek-r1-distill-llama-70b
🔴 GROQ(免费 API 密钥 — console.groq.com)
| 等级 | 日限额 | 速率限制 | 备注 |
|---|---|---|---|
| 免费 | 1.44万 RPD | 每模型 30 RPM | 无需信用卡;超出限额返回 429 错误,不收费 |
免费可用:llama-3.3-70b-versatile、gemma2-9b-it、mixtral-8x7b、whisper-large-v3
🔴 LONGCAT AI(免费 API 密钥 — longcat.chat)🆕
| 模型 | 前缀 | 每日免费配额 | 备注 |
|---|---|---|---|
LongCat-Flash-Lite |
lc/ |
5000万 tokens 💥 | 史上最大免费配额 |
LongCat-Flash-Chat |
lc/ |
50万 tokens | 多轮对话 |
LongCat-Flash-Thinking |
lc/ |
50万 tokens | 推理 / CoT |
LongCat-Flash-Thinking-2601 |
lc/ |
50万 tokens | 2026年1月版本 |
LongCat-Flash-Omni-2603 |
lc/ |
50万 tokens | 多模态 |
在公开测试期间完全免费。请使用邮箱或电话在 longcat.chat 注册。每日 UTC 时间 00:00 重置。
🟢 POLLINATIONS AI(无需 API 密钥)🆕
| 模型 | 前缀 | 速率限制 | 背后提供者 |
|---|---|---|---|
openai |
pol/ |
1 请求/15秒 | GPT-5 |
claude |
pol/ |
1 请求/15秒 | Anthropic Claude |
gemini |
pol/ |
1 请求/15秒 | Google Gemini |
deepseek |
pol/ |
1 请求/15秒 | DeepSeek V3 |
llama |
pol/ |
1 请求/15秒 | Meta Llama 4 Scout |
mistral |
pol/ |
1 请求/15秒 | Mistral AI |
✨ 零摩擦: 无需注册,无需 API 密钥。将 Pollinations 提供者添加到设置中,API 密钥字段留空即可立即使用。
🟠 CLOUDFLARE WORKERS AI(免费 API 密钥 — cloudflare.com)🆕
| 等级 | 每日神经元 | 等效用量 | 备注 |
|---|---|---|---|
| 免费 | 1万个 | ~150 次 LLM 回答 / 500 秒音频 / 1.5万 次嵌入 | 全球边缘节点,50+ 模型 |
热门免费模型:@cf/meta/llama-3.3-70b-instruct、@cf/google/gemma-3-12b-it、@cf/openai/whisper-large-v3-turbo(免费音频!)、@cf/qwen/qwen2.5-coder-15b-instruct
需要从 dash.cloudflare.com 获取 API Token 和 Account ID。将 Account ID 存储在提供商设置中。
🟣 SCALEWAY AI(100万免费 tokens — scaleway.com)🆕
| 等级 | 免费配额 | 地点 | 备注 |
|---|---|---|---|
| 免费 | 100万 tokens | 🇫🇷 巴黎,欧盟 | 在限额内无需信用卡 |
免费可用:qwen3-235b-a22b-instruct-2507(Qwen3 235B!)、llama-3.1-70b-instruct、mistral-small-3.2-24b-instruct-2506、deepseek-v3-0324
符合欧盟/GDPR 标准。在 console.scaleway.com 获取 API 密钥。
💡 终极免费堆栈(11 家提供商,永久免费):
Kiro (kr/) → Claude Sonnet/Haiku 无限 Qoder (if/) → kimi-k2-thinking、qwen3-coder-plus、deepseek-r1 无限 LongCat Lite (lc/) → LongCat-Flash-Lite — 每日 5000万 tokens 🔥 Pollinations (pol/) → GPT-5、Claude、DeepSeek、Llama 4 — 无需密钥 Qwen (qw/) → qwen3-coder 模型 无限 Gemini (gemini/) → Gemini 2.5 Flash — 每日 1500 次请求免费 Cloudflare AI (cf/) → 50+ 模型 — 每日 1万 Neurons Scaleway (scw/) → Qwen3 235B、Llama 70B — 100万免费 tokens(欧盟) Groq (groq/) → Llama/Gemma — 每日 1.44万次请求超快速 NVIDIA NIM (nvidia/) → 70+ 开放模型 — 永久 40 RPM Cerebras (cerebras/) → Llama/Qwen 全球最快 — 每日 100万 tok
🎙️ 免费转录组合
以 $0 转录任何音频/视频 — Deepgram 提供 $200 免费额度,AssemblyAI 作为 $50 的备选方案,Groq Whisper 则是无限量的紧急备用。
| 提供商 | 免费额度 | 最佳模型 | 速率限制 |
|---|---|---|---|
| 🟢 Deepgram | $200 免费(注册即得) | nova-3 — 准确性最高,支持 30 多种语言 |
免费额度无 RPM 限制 |
| 🔵 AssemblyAI | $50 免费(注册即得) | universal-3-pro — 支持章节划分、情感分析及 PII 识别 |
免费额度无 RPM 限制 |
| 🔴 Groq | 永久免费 | whisper-large-v3 — OpenAI Whisper |
30 RPM(有限制) |
推荐组合,在 /dashboard/combos 中:
名称: free-transcription
策略: 优先级
节点:
[1] deepgram/nova-3 → 首先使用 $200 免费额度
[2] assemblyai/universal-3-pro → 当 Deepgram 额度用完时切换至该模型
[3] groq/whisper-large-v3 → 永久免费,作为紧急备用
然后在 /dashboard/media → 转录 选项卡:上传任意音频或视频文件 → 选择你的组合端点 → 即可获得支持格式的转录结果。
💡 核心功能
OmniRoute v3.6 不仅仅是一个中继代理,更是一个运营平台。
🆕 新功能 — v3.6.x 亮点(2026 年 4 月)
| 功能 | 描述 |
|---|---|
| 🌐 V1 WebSocket 桥接 | OpenAI 兼容的 WebSocket 流量已升级并通过 /v1/ws 进行代理转发 — 支持完整的流式传输,并带有会话认证(API 密钥或会话 Cookie) |
| 🔑 同步令牌与配置包 | 为配置同步端点颁发/撤销同步令牌。配置包采用 ETag 版本控制,实现高效带宽的轮询 |
| 🧠 GLM Thinking (glmt) 预设 | GLM Thinking 已注册为一等公民:最大 65,536 个 token,思考预算 24,576 个,超时 900 秒,使用情况同步及定价 — 与 Claude 兼容的 API |
| 🔢 混合 token 计数 | 在可用时使用提供商端的 /messages/count_tokens;若不可用则回退到估算 — 精确跟踪用量,无需猜测 |
| 🌱 模型别名自动初始化 | 启动时规范化 30 多种跨代理方言别名 — 再也不会出现路由不匹配 |
| 🛡️ 安全的出站请求 | 所有提供商验证和模型发现都通过受保护的请求层进行,阻止私有/本地 URL,同时具备重试、超时和 SSRF 防护功能 |
| 🔄 冷却时间感知的重试 | 聊天请求在遇到模型范围内的冷却时间时会自动重试,可配置 requestRetry 和 maxRetryIntervalSec |
| 🔍 运行时环境验证 | 启动时使用 Zod 模式验证所有环境变量 — 清晰地提示缺失的密钥、无效的 URL 或错误的类型 |
| 📋 合规审计扩展 | 结构化审计日志,支持分页、请求上下文、认证事件、提供商 CRUD 事件以及 SSRF 阻止的验证日志 |
| 🔐 TPS 日志指标 | 日志详情模态显示每秒 token 数(TPS)— 快速查看每次请求的性能 |
| 🗑️ 卸载 / 完全卸载 | npm run uninstall 保留数据,npm run uninstall:full 删除所有内容 — 适用于所有安装方式的干净卸载 |
| 🔧 OAuth 环境修复 | OAuth 提供商的一键“修复环境”操作可恢复缺失的环境变量,并修复损坏的认证状态 |
| 🔒 优雅的 Electron 关闭 | Electron 的 before-quit 会优雅地关闭 Next.js,防止桌面关闭时 SQLite WAL 数据库锁 |
| 👁️ 模型可见性切换 | 提供商页面上提供按模型切换可见性的按钮(👁 图标),并配有搜索过滤器和活跃计数徽章(N/M active) |
| 📧 电子邮件隐私遮蔽 | OAuth 账户邮箱被遮蔽(di*****@g****.com),鼠标悬停时显示完整地址 |
| 🔗 上下文接力策略 | 组合策略可在会话持续期间通过结构化的交接摘要来保持会话连续性,即使账户在对话中途切换 |
| 🛡️ 代理加固 | 令牌健康检查、API 密钥验证以及 undici 分发器均遵循代理配置 |
| ⚠️ Node.js 24 登录警告 | 登录页面主动检测不兼容的 Node.js 版本,并显示明确的警告横幅 |
| 📎 Gemini PDF 附件 | PDF 附件通过 inline_data 和通用 base64 检测正确路由至 Gemini |
| 🔒 CodeQL 安全加固 | 解决了 SSRF、不安全随机性、多项式 ReDoS 以及不完全的 URL 净化告警 |
🆕 新功能 — 受 ClawRouter 启发的改进(2026 年 3 月)
| 功能 | 描述 |
|---|---|
| ⚡ Grok-4 快速家族 | xAI 模型价格为 $0.20/$0.50/M — 基准测试耗时 1143ms(比 Gemini 2.5 Flash 快 30%) |
| 🧠 GLM-5 通过 Z.AI | 输出上下文 128K,$0.5/1M — GLM 家族最新旗舰 |
| 🔮 MiniMax M2.5 | 推理 + 代理任务价格为 $0.30/1M — 相较于 M2.1 有显著提升 |
| 🎯 每模型的 toolCalling 标志 | 注册表中每个模型都有 toolCalling: true/false 标志 — AutoCombo 会跳过不具备工具调用能力的模型 |
| 🌍 多语言意图检测 | AutoCombo 评分中加入 PT/ZH/ES/AR 关键词 — 更好地为非英语内容选择模型 |
| 📊 基于基准测试的回退机制 | 实时请求中的 p95 延迟数据会反馈到组合评分中 — AutoCombo 从实际数据中学习 |
| 🔁 请求去重 | 基于内容哈希的去重窗口 — 多智能体场景下安全,避免重复计费 |
| 🔌 可插拔的 RouterStrategy | 可扩展的 RouterStrategy 接口 — 可以添加自定义路由逻辑作为插件 |
🚀 之前的 v2.0.9+ — Playground、CLI 指纹匹配与 ACP
| 功能 | 作用 |
|---|---|
| 🎮 模型 Playground | 仪表板页面,可直接测试任意模型——提供提供商/模型/端点选择器、Monaco 编辑器、流式传输、取消请求、计时功能 |
| 🔏 CLI 指纹匹配 | 针对不同提供商的请求头/请求体顺序进行匹配,以适配原生 CLI 签名——可在设置 > 安全中为每个提供商单独开启或关闭。您的代理 IP 将被保留 |
| 🤝 ACP 支持(Agent Client Protocol) | CLI 代理发现(Codex、Claude、Goose、Gemini CLI、OpenClaw 等 9 种),进程启动器,以及 /api/acp/agents 端点 |
| 🤖 ACP 代理仪表板 | 调试 › 代理页面——以网格形式展示 14 个代理,显示其安装状态、版本,并提供用于任何 CLI 工具的自定义代理表单。OpenCode 用户会看到一个“下载 opencode.json”按钮,可自动生成包含所有可用模型的即用配置文件。 |
🔧 自定义模型 apiFormat 路由 |
具有 apiFormat: "responses" 的自定义模型现在能够正确路由到 Responses API 转换器 |
| 🏢 Codex 工作空间隔离 | 每个邮箱可拥有多个 Codex 工作空间——OAuth 会根据工作空间 ID 正确分离连接 |
| 🔄 Electron 自动更新 | 桌面应用会检查更新,并在重启时自动安装 |
🤖 代理与协议操作(v2.0)
| 功能 | 作用 |
|---|---|
| 🔧 MCP 服务器(25 种工具) | 通过三种传输方式提供 IDE/代理工具:stdio、SSE (/api/mcp/sse)、可流式 HTTP (/api/mcp/stream)。包括 18 种核心工具、3 种内存工具和 4 种技能工具 |
| 🤝 A2A 服务器(JSON-RPC + SSE) | 代理间任务执行,支持同步与流式流程 |
| 🧭 整合端点页面 | 带有端点代理、MCP、A2A 和 API 端点选项卡的管理页面 |
| 🎚️ 服务启用/禁用切换 | MCP 和 A2A 的开关,具有设置持久化功能(默认为关闭) |
| 🛰️ MCP 运行时心跳 | 实时进程状态(PID、运行时间、心跳年龄、传输方式、作用域模式) |
| 📋 MCP 审计日志 | 可筛选的成功/失败审计日志,并标注关键责任人 |
| 🔐 MCP 作用域强制 | 10 种细粒度的作用域权限,用于控制工具访问 |
| 📡 A2A 任务生命周期管理 | 列出/筛选任务、查看事件/成果、取消正在运行的任务 |
| 📋 代理卡片发现 | 通过 /.well-known/agent.json 实现客户端自动发现 |
| 🧪 协议端到端测试框架 | 在 test:protocols:e2e 中运行真实的 MCP SDK 和 A2A 客户端流程 |
| ⚙️ 运维控制 | 通过组合开关应用韧性配置文件,并从统一控制界面重置断路器 |
🧠 路由与智能
| 功能 | 作用 |
|---|---|
| 🎯 智能四层回退 | 自动路由:订阅 → API 密钥 → 低价 → 免费 |
| 📊 实时配额跟踪 | 实时显示各提供商的令牌数量及重置倒计时 |
| 🔄 格式转换 | OpenAI ↔ Claude ↔ Gemini ↔ 支持符合 Schema 的响应转换 |
| 👥 多账号支持 | 每个提供商支持多个账号,并进行智能选择 |
| 🔄 自动刷新令牌 | OAuth 令牌自动刷新,并具备重试机制 |
| 🎨 自定义组合 | 13 种负载均衡策略 + 回退链控制 |
| 🔗 上下文传递 | 会话轮换账号时,保持会话连续性 |
| 🌐 通配符路由器 | provider/* 动态路由 |
| 🧠 思维预算控制 | 直通、自动、自定义及自适应推理限制 |
| 🔀 模型别名 | 内置 + 自定义模型别名及迁移移安全 |
| ⚡ 后台降级 | 将低优先级的后台任务路由至更便宜的模型 |
| 🧪 任务感知智能路由 | 根据内容类型(编码/视觉/分析/摘要)自动选择模型 |
| 🔄 A2A 代理工作流 | 用于有状态多步代理执行的确定性有限状态机编排器 |
| 🔀 ** adaptive 路由** | 基于令牌用量和提示复杂度动态调整路由策略 |
| 🎲 提供商多样性 | 基于香农熵评分平衡自动组合的流量分配 |
| 💬 系统提示注入 | 全局行为控制一致应用 |
| 📄 Responses API 兼容性 | 完全支持 /v1/responses,适用于 Codex 和高级代理工作流 |
🎵 多模态 API
| 功能 | 作用 |
|---|---|
| 🖼️ 图像生成 | /v1/images/generations 支持云端和本地后端 |
| 📐 嵌入 | /v1/embeddings 用于搜索和 RAG 流程 |
| 🎤 音频转录 | /v1/audio/transcriptions — 7 家提供商(Deepgram Nova 3、AssemblyAI、Groq Whisper、HuggingFace、ElevenLabs、OpenAI、Azure),自动语言检测,支持 MP4/MP3/WAV 格式 |
| 🔊 文本转语音 | /v1/audio/speech — 10 家提供商(ElevenLabs、OpenAI、Deepgram、Cartesia、PlayHT、HuggingFace、Nvidia NIM、Inworld、Coqui、Tortoise),并提供准确的错误信息 |
| 🎬 视频生成 | /v1/videos/generations(ComfyUI + SD WebUI 工作流) |
| 🎵 音乐生成 | /v1/music/generations(ComfyUI 工作流) |
| 🛡️ 内容审核 | /v1/moderations 安全检查 |
| 🔀 重排序 | /v1/rerank 用于相关性评分 |
| 🔍 网页搜索 🆕 | /v1/search — 5 家提供商(Serper、Brave、Perplexity、Exa、Tavily),每月免费额度超过 6,500 次,自动故障转移,带缓存 |
🛡️ 弹性、安全与治理
| 功能 | 作用 |
|---|---|
| 🔌 熔断器 | 每个模型独立触发与恢复,支持阈值控制 |
| 🎯 端点感知模型 | 自定义模型声明支持的端点及 API 格式 |
| 🛡️ 防击垮保护 | 在重试/速率限制场景中使用互斥锁和信号量保护 |
| 🧠 语义+签名缓存 | 通过两层缓存降低开销与延迟 |
| ⚡ 请求幂等性 | 重复请求防护窗口 |
| 🔒 TLS 指纹欺骗 | 类似浏览器的 TLS 指纹 — 降低机器人检测与账号标记风险 |
| 🔏 CLI 指纹匹配 | 匹配原生 CLI 请求签名 — 在保留代理 IP 的同时降低封禁风险 |
| 🌐 IP 过滤 | 对公开部署进行白名单/黑名单控制 |
| 📊 可编辑的速率限制 | 可配置的全局/提供商级别限流,并支持持久化 |
| 📉 优雅降级 | 多层能力回退机制,保护核心网关操作 |
| 📜 配置审计追踪 | 基于差异的变更跟踪,防止运营漂移,并支持简单回滚 |
| ⏳ 提供商健康同步 | 主动监控 Token 过期,在授权失败前触发告警 |
| 🚪 自动禁用被封账号 | 运营熔断机制,自动永久封禁被阻止的 Token 账号 |
| 🔑 API 密钥管理 + 范围控制 | 安全的密钥发放/轮换,以及模型和提供商权限控制 |
| 👁️ 范围受限的 API 密钥显示 🆕 | 通过 ALLOW_API_KEY_REVEAL 选项选择性恢复 API 密钥 |
🛡️ 受保护的 /models |
模型目录可选认证与提供商隐藏功能 |
| 🛡️ 安全的出站请求 🆕 | 为提供商调用提供防护 — 阻止私有/本地 URL、实现重试机制,并防范 SSRF |
| 🔄 冷却时间感知的重试 🆕 | 在模型冷却时自动重试聊天;可配置 requestRetry 和 maxRetryIntervalSec |
| 🔍 运行时环境验证 🆕 | 启动时基于 Zod 的环境 Schema 验证,提供可操作的错误信息 |
| 📋 合规审计 v2 🆕 | 分页、请求上下文、认证事件、提供商 CRUD 操作,以及对 SSRF 的日志记录 |
📊 可观测性与分析
| 功能 | 作用 |
|---|---|
| 📝 请求 + 代理日志记录 | 记录完整的请求/响应及代理日志 |
| 📉 流式详细日志 🆕 | 将 SSE 数据流干净地重构到 UI 中 |
| 📋 统一日志仪表盘 | 在一个页面中查看请求、代理、审计和控制台视图 |
| 🔍 请求遥测 | 提供 p50/p95/p99 延迟及请求追踪 |
| 🏥 健康仪表盘 | 显示 uptime、熔断状态、锁定情况及缓存统计 |
| 💰 成本跟踪 | 预算控制及按模型定价的可见性 |
| 📈 分析可视化 | 提供模型/提供商使用洞察及趋势视图 |
| 🧪 评估框架 | 使用可配置的匹配策略进行黄金集测试 |
| 📡 实时诊断 🆕 | 绕过语义缓存,实现准确的组合式实时测试 |
| 🔐 TPS 日志指标 🆕 | 在日志详情模态框中显示每秒令牌数 |
☁️ 部署与平台
| 功能 | 作用 |
|---|---|
| 🌐 随处部署 | 支持 localhost、VPS、Docker 及云环境 |
| 🚇 Cloudflare Tunnel 🆕 | 从仪表盘一键集成 Quick Tunnel |
| 🔑 API 密钥模型过滤 | 原生 /v1/models 响应可根据分配的 Bearer 上下文角色进行过滤 |
| ⚡ 智能缓存绕过 | 可配置的 TTL 策略及强制重新获取数据的控制 |
| 🔄 备份/恢复 | 支持导出/导入及灾难恢复流程 |
| 🧙 引导向导 | 首次运行时的引导式设置 |
| 🔧 CLI 工具仪表盘 | 为常用编程工具提供一键式设置 |
| 🎮 模型 Playground | 可从仪表盘测试任意提供商/模型/端点 |
| 🔏 CLI 指纹切换 | 在设置 > 安全中按提供商启用指纹匹配 |
| 🌐 i18n(30 种语言) | 全面支持仪表盘与文档的语言,并覆盖 RTL 排版 |
| 🧹 清除所有模型 | 在提供商详情中一键清空模型列表 |
| 👁️ 侧边栏控件 🆕 | 可在外观设置中隐藏组件与集成 |
| 📋 问题模板 | 提供标准化的 GitHub 模板,用于报告 Bug 和功能需求 |
| 📂 自定义数据目录 | 支持通过 DATA_DIR 覆盖存储位置 |
| 🌐 V1 WebSocket 桥接 🆕 | 通过 /v1/ws 代理兼容 OpenAI 的 WebSocket 流量 |
| 🔑 同步 Token 与 Bundle 🆕 | 支持 ETag 的配置同步 Token 及版本化的 Bundle 端点 |
功能深度解析
智能回退与实用的成本控制
组合: "my-coding-stack"
1. cc/claude-opus-4-6
2. nvidia/llama-3.3-70b
3. glm/glm-4.7
4. if/kimi-k2-thinking
当配额、速率或健康状态出现问题时,OmniRoute 会自动切换到下一个候选模型,无需手动干预。
可视化且可操作的协议管理
- MCP 和 A2A 在 UI 和文档中均可发现(不隐藏)
- 协议状态 API 提供实时运行数据(
/api/mcp/*,/api/a2a/*) - 仪表板包含日常运维操作(组合切换、熔断器重置、任务取消)
转换器 + 验证工作流
转换器区域包括:
- 游乐场:请求转换检查
- 聊天测试器:完整的请求/响应往返
- 测试台:一次运行多个用例
- 实时监控:实时流量视图
此外,还可以通过 npm run test:protocols:e2e 使用真实客户端进行协议验证。
📖 MCP 服务器 README — 工具参考、IDE 配置和客户端示例
📖 A2A 服务器 README — 技能、JSON-RPC 方法、流式传输和任务生命周期
🧪 评估 (Evals)
OmniRoute 内置了一个评估框架,用于根据黄金数据集测试 LLM 的响应质量。可通过仪表板中的 Analytics → Evals 访问。
内置黄金数据集
预加载的“OmniRoute 黄金数据集”包含以下测试用例:
- 问候语、数学、地理、代码生成
- JSON 格式合规性、翻译、Markdown 生成
- 安全拒绝(有害内容)、计数、布尔逻辑
评估策略
| 策略 | 描述 | 示例 |
|---|---|---|
exact |
输出必须完全匹配 | "4" |
contains |
输出必须包含子字符串(不区分大小写) | "Paris" |
regex |
输出必须匹配正则表达式 | "1.*2.*3" |
custom |
自定义 JS 函数返回 true/false | (output) => output.length > 10 |
📖 设置指南
协议设置(MCP + A2A)
🧩 MCP 设置(模型上下文协议)
以 stdio 模式启动 MCP 传输:
omniroute --mcp
推荐的验证流程如下:
- 通过 stdio 连接你的 MCP 客户端。
- 运行
omniroute_get_health。 - 运行
omniroute_list_combos。 - 打开
/dashboard/mcp确认心跳、活动和审计记录。
用于自动化的有用 API:
GET /api/mcp/statusGET /api/mcp/toolsGET /api/mcp/auditGET /api/mcp/audit/stats
🤝 A2A 设置(Agent2Agent)
发现代理:
curl http://localhost:20128/.well-known/agent.json
发送任务:
curl -X POST http://localhost:20128/a2a \
-H 'content-type: application/json' \
-d '{"jsonrpc":"2.0","id":"setup-a2a","method":"message/send","params":{"skill":"quota-management","messages":[{"role":"user","content":"总结配额状态。"}]}}'
管理生命周期:
GET /api/a2a/statusGET /api/a2a/tasksGET /api/a2a/tasks/:idPOST /api/a2a/tasks/:id/cancel
运维 UI:
/dashboard/a2a用于任务/状态/流的可观ability 和快速操作
🧪 端到端协议验证
使用真实客户端验证两个协议:
npm run test:protocols:e2e
这将验证:
- MCP SDK 客户端连接/列表/调用
- A2A 发现/发送/流式传输/获取/取消
- 在 MCP 审计和 A2A 任务管理 API 中交叉核对数据
💳 订阅提供商
Claude Code (Pro/Max)
仪表板 → 供应商 → 连接 Claude Code
→ OAuth 登录 → 自动刷新令牌
→ 5 小时 + 每周配额跟踪
模型:
cc/claude-opus-4-6
cc/claude-sonnet-4-5-20250929
cc/claude-haiku-4-5-20251001
专业提示: 复杂任务使用 Opus,追求速度则用 Sonnet。OmniRoute 会按模型分别跟踪配额!
OpenAI Codex (Plus/Pro)
仪表板 → 供应商 → 连接 Codex
→ OAuth 登录(端口 1455)
→ 5 小时 + 每周重置
模型:
cx/gpt-5.2-codex
cx/gpt-5.1-codex-max
Codex 账户限额管理(5h + 每周)
每个 Codex 账户现在在 仪表板 -> 供应商 中都有策略开关:
5h(开启/关闭):强制执行 5 小时窗口阈值政策。Weekly(开启/关闭):强制执行每周窗口阈值政策。- 阈值行为:当启用的窗口使用率达到或超过 90% 时,该账户会被跳过。
- 轮转行为:OmniRoute 会自动路由到下一个符合条件的 Codex 账户。
-重置行为:当提供商的
resetAt时间过去后,该账户会自动重新进入轮转(无需手动重新启用)。
场景:
5h ON+Weekly ON:任一窗口达到阈值时,账户会被跳过。5h OFF+Weekly ON:只有每周用量会阻止该账户。5h ON+Weekly OFF:只有 5 小时用量会阻止该账户。- 当
resetAt过去后,账户会自动重新进入轮转(无需手动重新启用)。
Gemini CLI (免费 18 万/月!)
仪表板 → 供应商 → 连接 Gemini CLI
→ Google OAuth
→ 每月 18 万次补全 + 每日 1 千次
模型:
gc/gemini-3-flash-preview
gc/gemini-2.5-pro
超值选择: 巨大的免费层级!请在付费层级之前优先使用。
GitHub Copilot
仪表板 → 供应商 → 连接 GitHub
→ 通过 GitHub 进行 OAuth
→ 每月重置(每月 1 日)
模型:
gh/gpt-5
gh/claude-4.5-sonnet
gh/gemini-3.1-pro-preview
🔑 API 密钥提供商
NVIDIA NIM (免费开发者访问 — 70+ 模型)
- 注册:build.nvidia.com
- 获取免费 API 密钥(包含 1000 次推理积分)
- 仪表板 → 添加供应商 → NVIDIA NIM:
- API 密钥:
nvapi-your-key
- API 密钥:
模型: nvidia/llama-3.3-70b-instruct、nvidia/mistral-7b-instruct 以及 50 多种其他模型
专业提示: 兼容 OpenAI 的 API — 可无缝对接 OmniRoute 的格式转换!
DeepSeek
- 注册:platform.deepseek.com
- 获取 API 密钥
- 仪表板 → 添加供应商 → DeepSeek
模型: deepseek/deepseek-chat、deepseek/deepseek-coder
Groq(提供免费层级!)
- 注册:console.groq.com
- 获取 API 密钥(包含免费层级)
- 仪表板 → 添加供应商 → Groq
模型: groq/llama-3.3-70b、groq/mixtral-8x7b
专业提示: 超高速推理 — 非常适合实时编码!
OpenRouter(100+ 模型)
- 注册:openrouter.ai
- 获取 API 密钥
- 仪表板 → 添加提供商 → OpenRouter
模型: 通过一个 API 密钥即可访问来自所有主要提供商的 100 多种模型。
仪表板行为: OpenRouter 模型从“可用模型”中管理。手动添加、导入和自动同步都会更新同一列表。
💰 廉价提供商(备用)
GLM-4.7(每日重置,$0.6/1M)
- 注册:Zhipu AI
- 从 Coding Plan 获取 API 密钥
- 仪表板 → 添加 API 密钥:
- 提供商:
glm - API 密钥:
your-key
- 提供商:
使用: glm/glm-4.7
实用技巧: Coding Plan 以七分之一的价格提供三倍配额!每日上午 10:00 重置。
MiniMax M2.1(5 小时重置,$0.20/1M)
- 注册:MiniMax
- 获取 API 密钥
- 仪表板 → 添加 API 密钥
使用: minimax/MiniMax-M2.1
实用技巧: 长上下文(1M tokens)中最便宜的选择!
Kimi K2($9/月固定)
- 订阅:Moonshot AI
- 获取 API 密钥
- 仪表板 → 添加 API 密钥
使用: kimi/kimi-latest
实用技巧: 固定 $9/月可使用 10M tokens,相当于 $0.90/1M 的有效成本!
🆓 免费提供商(应急备用)
Qoder(通过 OAuth 提供 5 种免费模型)
仪表板 → 连接 Qoder
→ Qoder OAuth 登录
→ 无限使用
模型:
if/kimi-k2-thinking
if/qwen3-coder-plus
if/glm-4.7
if/minimax-m2
if/deepseek-r1
Qwen(通过设备码提供 4 种免费模型)
仪表板 → 连接 Qwen
→ 设备码授权
→ 无限使用
模型:
qw/qwen3-coder-plus
qw/qwen3-coder-flash
Kiro(Claude 免费版)
仪表板 → 连接 Kiro
→ AWS Builder ID 或 Google/GitHub
→ 无限使用
模型:
kr/claude-sonnet-4.5
kr/claude-haiku-4.5
🎨 创建组合
示例 1:最大化订阅 → 廉价备份
仪表板 → 组合 → 新建
名称:premium-coding
模型:
1. cc/claude-opus-4-6(订阅主模型)
2. glm/glm-4.7(廉价备份,$0.6/1M)
3. minimax/MiniMax-M2.1(最便宜的后备,$0.20/1M)
在 CLI 中使用:premium-coding
示例 2:纯免费(零成本)
名称:free-combo
模型:
1. gc/gemini-3-flash-preview(每月 18 万次免费调用)
2. if/kimi-k2-thinking(无限使用)
3. qw/qwen3-coder-plus(无限使用)
成本:永远 $0!
🔧 CLI 集成
Cursor IDE
设置 → 模型 → 高级:
OpenAI API 基础 URL:http://localhost:20128/v1
OpenAI API 密钥:[来自 OmniRoute 仪表板]
模型:cc/claude-opus-4-6
Claude Code
使用仪表板中的“CLI 工具”页面进行一键配置,或手动编辑 ~/.claude/settings.json。
Codex CLI
export OPENAI_BASE_URL="http://localhost:20128"
export OPENAI_API_KEY="your-omniroute-api-key"
codex "your prompt"
OpenClaw
选项 1 — 仪表板(推荐):
仪表板 → CLI 工具 → OpenClaw → 选择模型 → 应用
选项 2 — 手动: 编辑 ~/.openclaw/openclaw.json:
{
"models": {
"providers": {
"omniroute": {
"baseUrl": "http://127.0.0.1:20128/v1",
"apiKey": "sk_omniroute",
"api": "openai-completions"
}
}
}
}
注意: OpenClaw 只能在本地 OmniRoute 上运行。为避免 IPv6 解析问题,请使用
127.0.0.1而不是localhost。
Cline / Continue / RooCode
设置 → API 配置:
提供商:OpenAI 兼容
基础 URL:http://localhost:20128/v1
API 密钥:[来自 OmniRoute 仪表板]
模型:if/kimi-k2-thinking
OpenCode
步骤 1: 将 OmniRoute 添加为自定义提供商:
opencode
/connect
# 选择“其他”→ 输入 ID:“omniroute”→ 输入你的 OmniRoute API 密钥
步骤 2: 在项目根目录创建或编辑 opencode.json:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"omniroute": {
"npm": "@ai-sdk/openai-compatible",
"name": "OmniRoute",
"options": {
"baseURL": "http://localhost:20128/v1"
},
"models": {
"cc/claude-sonnet-4-20250514": { "name": "Claude Sonnet 4" },
"gg/gemini-2.5-pro": { "name": "Gemini 2.5 Pro" },
"if/kimi-k2-thinking": { "name": "Kimi K2(免费)" }
}
}
}
}
步骤 3: 在 OpenCode 中选择模型:
/models
# 从列表中选择任意 OmniRoute 模型
提示: 将你 OmniRoute
/v1/models端点中提供的任何模型添加到“models”部分。使用来自 OmniRoute 仪表板的格式“provider/model-id”。
🐛 故障排除
点击展开故障排除指南
“语言模型未提供消息”
- 提供商配额已耗尽 → 检查仪表板上的配额跟踪器
- 解决方案:使用组合后备或切换到更便宜的层级
速率限制
- 订阅配额用尽 → 切换到 GLM/MiniMax
- 添加组合:
cc/claude-opus-4-6 → glm/glm-4.7 → if/kimi-k2-thinking
OAuth 令牌过期
- OmniRoute 会自动刷新
- 如果问题仍然存在:仪表板 → 提供商 → 重新连接
费用过高
- 检查仪表板 → 成本中的使用统计
- 将主模型切换到 GLM/MiniMax
- 对于非关键任务,使用免费层级(Gemini CLI、Qoder)
仪表板/API 端口错误
PORT是标准基础端口(默认也是 API 端口)API_PORT仅覆盖 OpenAI 兼容 API 监听器DASHBOARD_PORT仅覆盖仪表板/Next.js 监听器- 将
NEXT_PUBLIC_BASE_URL设置为你的仪表板/公共 URL(用于 OAuth 回调)
云同步错误
- 确认
BASE_URL指向你正在运行的实例 - 确认
CLOUD_URL指向你期望的云端点 - 保持
NEXT_PUBLIC_*值与服务器端值一致
首次登录不成功
- 检查
.env中的INITIAL_PASSWORD - 如果未设置,回退密码为
123456
没有请求日志
- SQLite 中的
call_logs存储了请求日志表和分析视图的摘要元数据 - 详细的请求/响应负载会以每个请求一个 JSON 文件的形式写入
DATA_DIR/call_logs/ - 如果需要详细的各阶段负载,可在仪表板 → 日志 → 请求日志 中启用管道捕获
导出日志会按需读取这些文件,而导出全部会将call_logs/目录与storage.sqlite一起导出- 如果还希望将应用控制台日志记录到
logs/application/app.log,请设置APP_LOG_TO_FILE=true - 根据需要调整
APP_LOG_MAX_FILE_SIZE、APP_LOG_RETENTION_DAYS、APP_LOG_MAX_FILES和CALL_LOG_MAX_ENTRIES
连接测试显示 OpenAI 兼容提供商为“无效”
- 许多提供商并未公开
/models端点 - OmniRoute v1.0.6+ 包含通过聊天完成的回退验证
- 确保基础 URL 包含
/v1后缀
🔐 远程服务器上的 OAuth
⚠️ 对在 VPS、Docker 或任何远程服务器上运行 OmniRoute 的用户非常重要
为什么 Antigravity / Gemini CLI 的 OAuth 在远程服务器上会失败?
Antigravity 和 Gemini CLI 提供商使用 Google OAuth 2.0。Google 要求 OAuth 流程中的 redirect_uri 必须与应用在 Google Cloud 控制台中预先注册的 URI 完全匹配。
OmniRoute 中捆绑的 OAuth 凭证仅针对 localhost 注册。当您在远程服务器上访问 OmniRoute 时(例如 https://omniroute.myserver.com),Google 会以以下错误拒绝认证:
Error 400: redirect_uri_mismatch
解决方案:配置您自己的 OAuth 凭证
您需要在 Google Cloud 控制台中创建一个适用于您服务器 URI 的 OAuth 2.0 客户端 ID。
操作步骤
1. 打开 Google Cloud 控制台
访问:https://console.cloud.google.com/apis/credentials
2. 创建新的 OAuth 2.0 客户端 ID
- 点击 "+ Create Credentials" → "OAuth client ID"
- 应用程序类型:"Web application"
- 名称:任意名称(例如
OmniRoute Remote)
3. 添加已授权的重定向 URI
在 "Authorized redirect URIs" 字段中,添加:
https://your-server.com/callback
将
your-server.com替换为您的服务器域名或 IP 地址(如有必要,请包含端口,例如http://45.33.32.156:20128/callback)。
4. 保存并复制凭证
创建完成后,Google 会显示 客户端 ID 和 客户端密钥。
5. 设置环境变量
在您的 .env 文件(或 Docker 环境变量)中:
# 对于 Antigravity:
ANTIGRAVITY_OAUTH_CLIENT_ID=your-client-id.apps.googleusercontent.com
ANTIGRAVITY_OAUTH_CLIENT_SECRET=GOCSPX-your-secret
# 对于 Gemini CLI:
GEMINI_OAUTH_CLIENT_ID=your-client-id.apps.googleusercontent.com
GEMINI_OAUTH_CLIENT_SECRET=GOCSPX-your-secret
GEMINI_CLI_OAUTH_CLIENT_SECRET=GOCSPX-your-secret
6. 重启 OmniRoute
# 使用 npm:
npm run dev
# 使用 Docker:
docker restart omniroute
7. 再次尝试连接
仪表盘 → 提供商 → Antigravity(或 Gemini CLI)→ OAuth
现在 Google 将正确重定向到 https://your-server.com/callback。
临时解决方案(无需自定义凭证)
如果您目前不想设置自己的凭证,仍然可以使用 手动 URL 流程:
- OmniRoute 会打开 Google 授权 URL。
- 授权完成后,Google 会尝试重定向到
localhost(这在远程服务器上会失败)。 - 从浏览器地址栏复制完整 URL(即使页面未加载)。
- 将该 URL 粘贴到 OmniRoute 连接模态框中显示的字段。
- 点击 "Connect"。
这种方法可行,因为 URL 中的授权码是有效的,无论重定向页面是否成功加载。
🇧🇷 葡萄牙语版本
为什么 Antigravity / Gemini CLI 的 OAuth 在远程服务器上会失败?
提供商 Antigravity 和 Gemini CLI 使用 Google OAuth 2.0 进行身份验证。Google 要求 OAuth 流程中使用的 redirect_uri 必须 完全匹配 应用程序在 Google Cloud 控制台中预先注册的 URI 之一。
OmniRoute 中内置的 OAuth 凭证仅针对 localhost 注册。当您在远程服务器上访问 OmniRoute 时(例如 https://omniroute.meuservidor.com),Google 会以以下错误拒绝身份验证:
Error 400: redirect_uri_mismatch
解决方案:配置您自己的 OAuth 凭证
您需要在 Google Cloud 控制台中创建一个适用于您服务器 URI 的 OAuth 2.0 客户端 ID。
操作步骤
1. 访问 Google Cloud 控制台
打开:https://console.cloud.google.com/apis/credentials
2. 创建新的 OAuth 2.0 客户端 ID
- 点击 "+ Create Credentials" → "OAuth client ID"
- 应用程序类型:"Web application"
- 名称:您可以选择任意名称(例如
OmniRoute Remote)
3. 添加已授权的重定向 URI
在 "Authorized redirect URIs" 字段中,添加:
https://seu-servidor.com/callback
将
seu-servidor.com替换为您服务器的域名或 IP 地址(如有必要,请包含端口,例如http://45.33.32.156:20128/callback)。
4. 保存并复制凭证
创建完成后,Google 会显示 客户端 ID 和 客户端密钥。
5. 配置环境变量
在您的 .env 文件(或 Docker 环境变量)中:
# 对于 Antigravity:
ANTIGRAVITY_OAUTH_CLIENT_ID=seu-client-id.apps.googleusercontent.com
ANTIGRAVITY_OAUTH_CLIENT_SECRET=GOCSPX-seu-secret
# 对于 Gemini CLI:
GEMINI_OAUTH_CLIENT_ID=seu-client-id.apps.googleusercontent.com
GEMINI_OAUTH_CLIENT_SECRET=GOCSPX-seu-secret
GEMINI_CLI_OAUTH_CLIENT_SECRET=GOCSPX-seu-secret
6. 重启 OmniRoute
# 如果使用 npm:
npm run dev
# 如果使用 Docker:
docker restart omniroute
7. 再次尝试连接
仪表盘 → 提供商 → Antigravity(或 Gemini CLI)→ OAuth
现在 Google 将正确重定向到 https://seu-servidor.com/callback,身份验证将成功。
临时解决方法(无需配置自定义凭证)
如果您暂时不想创建自己的凭证,仍然可以使用 手动 URL 流程:
- OmniRoute 会打开 Google 的授权 URL。
- 授权完成后,Google 会尝试重定向到
localhost(这在远程服务器上会失败)。 - 从浏览器地址栏复制完整的 URL(即使页面没有加载)。
- 将该 URL 粘贴到 OmniRoute 连接模态框中显示的字段。
- 点击 "Connect"。
此方法之所以有效,是因为 URL 中的授权码是有效的,无论重定向页面是否成功加载。
🛠️ 技术栈
点击展开技术栈详情
- 运行时: Node.js 18–22 LTS (⚠️ Node.js 24+ 不支持 —
better-sqlite3的原生二进制文件不兼容) - 语言: TypeScript 5.9 —
src/和open-sse/全部采用 100% TypeScript(自 v2.0 起,核心模块中无any类型) - 框架: Next.js 16 + React 19 + Tailwind CSS 4
- 数据库: better-sqlite3 (SQLite) + LowDB (JSON 旧版) — 用于存储领域状态、代理日志、MCP 审计记录、路由决策、内存及技能数据
- Schema 验证: Zod(用于 MCP 工具的输入输出验证及 API 协议定义)
- 协议: MCP(通过标准输入输出/HTTP)+ A2A v0.3(基于 JSON-RPC 2.0 和 SSE)
- 流式传输: 服务器发送事件 (SSE)
- 认证: OAuth 2.0 (PKCE) + JWT + API 密钥 + MCP 作用域授权
- 测试: Node.js 测试运行器 + Vitest(包含单元测试、集成测试和端到端测试在内的 900 多个测试用例)
- CI/CD: GitHub Actions(发布时自动进行 npm 发布及 Docker Hub 更新)
- 网站: omniroute.online
- NPM 包: npmjs.com/package/omniroute
- Docker 镜像: hub.docker.com/r/diegosouzapw/omniroute
- 系统韧性: 熔断器、指数退避、防雪崩机制、TLS 欺骗防护、自动组合自我修复功能
📖 文档
| 文档 | 描述 |
|---|---|
| 用户指南 | 提供者、组合、CLI 集成、部署 |
| API 参考文档 | 所有接口及其示例 |
| MCP 服务器 | 25 个 MCP 工具、IDE 配置、Python/TS/Go 客户端 |
| A2A 服务器 | JSON-RPC 2.0 协议、技能、流式传输、任务管理 |
| 自动组合引擎 | 6 因素评分、模式包、自我修复 |
| 上下文传递 | 会话交接策略,用于账号轮换 |
| 故障排除 | 常见问题及解决方案 |
| 架构设计 | 系统架构及内部实现 |
| 代码库文档 | 针对初学者的代码库导览 |
| 卸载指南 | 适用于所有安装方式的干净卸载方法 |
| 环境配置 | 完整的 .env 变量说明及参考 |
| 贡献指南 | 开发环境搭建及贡献规范 |
| OpenAPI 规范 | OpenAPI 3.0 规范 |
| 安全策略 | 漏洞报告与安全实践 |
| 虚拟机部署 | 完整指南:虚拟机 + nginx + Cloudflare 设置 |
| 功能展示 | 带截图的可视化仪表盘导览 |
| 发布检查清单 | 发布前验证步骤 |
🗺️ 路线图
OmniRoute 在多个开发阶段中共规划了 218+ 项功能。以下是主要方向:
| 类别 | 计划功能 | 亮点 |
|---|---|---|
| 🧠 路由与智能 | 25+ | 最低延迟路由、基于标签的路由、配额预检、感知配额的 P2C、基于步骤的组合路由 |
| 🔒 安全与合规 | 20+ | SSRF 加固、凭据隐藏、按接口限流、管理密钥作用域划分 |
| 📊 可观测性 | 15+ | OpenTelemetry 集成、实时配额监控、组合目标健康状况、按模型成本跟踪 |
| 🔄 提供商集成 | 20+ | 动态模型注册中心、提供商冷却机制、多账号 Codex、Copilot 配额解析 |
| ⚡ 性能 | 15+ | 双层缓存、提示词缓存、响应缓存、流式连接保持、批量 API |
| 🌐 生态体系 | 10+ | WebSocket API、配置热加载、分布式配置存储、商业模式 |
🔜 即将推出
- 🔗 OpenCode 集成 — 原生支持 OpenCode AI 编程 IDE 的提供商
- 🔗 TRAE 集成 — 完全支持 TRAE AI 开发框架
- 📦 批量 API — 异步批量处理请求
- 🎯 基于标签的路由 — 根据自定义标签和元数据路由请求
- 💰 最低成本策略 — 自动选择最便宜的可用提供商
📝 完整的功能规格可在
docs/new-features/中找到(共 217 条详细规格)
👥 贡献者

如何贡献
- 分支仓库
- 创建功能分支 (
git checkout -b feature/amazing-feature) - 提交更改 (
git commit -m '添加超赞功能') - 推送到分支 (
git push origin feature/amazing-feature) - 打开拉取请求
详细指南请参阅 CONTRIBUTING.md。
发布新版本
# 创建发布 — npm 发布会自动完成
gh release create v2.0.0 --title "v2.0.0" --generate-notes
📊 星标历史
不同时期的星标数量

🙏 致谢
特别感谢 9router,由 decolua 开发——这是启发本项目分叉的原始项目。OmniRoute 在这一卓越基础上进一步扩展了功能,增加了多模态 API,并完全使用 TypeScript 重写。
同时,也特别感谢 CLIProxyAPI——最初的 Go 实现,为本次 JavaScript 移植提供了灵感。
📄 许可证
MIT 许可证 - 详情请参阅 LICENSE。
omniroute.online
版本历史
v3.6.62026/04/16v3.6.52026/04/14v3.6.42026/04/12v3.6.32026/04/11v3.6.22026/04/11v3.6.12026/04/10v3.6.02026/04/10v3.5.92026/04/10v3.5.82026/04/09v3.5.72026/04/09v3.5.62026/04/09v3.5.52026/04/08v3.5.42026/04/07v3.5.32026/04/07v3.5.22026/04/05v3.5.12026/04/04v3.5.02026/04/03v3.4.92026/04/03v3.4.82026/04/03v3.4.72026/04/03常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。