DeepEP
DeepEP 是一款专为混合专家模型(MoE)设计的高效通信库,旨在解决大规模分布式训练中专家并行(EP)带来的通信瓶颈问题。它通过提供高吞吐、低延迟的 GPU 内核,优化了数据在专家节点间的“分发”与“合并”过程,显著提升了训练和推理效率。
该工具特别适合从事大模型研发的工程师与研究人员,尤其是需要部署或优化 DeepSeek-V3 等采用群限制门控算法模型的团队。DeepEP 的核心亮点在于其针对不同场景的精细化优化:在训练及推理预填充阶段,它支持跨 NVLink 和 RDMA 域的非对称带宽转发,最大化利用硬件资源;而在对延迟敏感的推理解码阶段,则提供纯 RDMA 低延迟内核,并独创了基于钩子(hook)的通算重叠技术,在不占用计算核心的前提下隐藏通信开销。此外,DeepEP 原生支持 FP8 等低精度运算,并在最新更新中进一步融合了腾讯网络平台部的优化成果,大幅提升了性能表现。无论是单机多卡还是跨节点集群,DeepEP 都能为高性能 MoE 模型提供坚实的底层通信支撑。
使用场景
某大型 AI 实验室正在基于 DeepSeek-V3 架构训练千亿参数混合专家(MoE)大模型,面临多节点集群下专家并行通信效率低下的挑战。
没有 DeepEP 时
- 跨节点带宽瓶颈严重:在将数据从 NVLink 域转发至 RDMA 域时,缺乏针对非对称带宽的优化,导致 internode 通信吞吐量远低于硬件理论极限,拖慢整体训练进度。
- 推理延迟难以达标:在进行低延迟解码推理时,传统通信内核无法充分利用纯 RDMA 通道,单次 All-to-All 通信耗时过高,无法满足实时交互需求。
- 计算资源被通信占用:通信过程占用了宝贵的 SM(流多处理器)算力,导致计算与通信无法有效重叠,GPU 利用率在等待数据时出现明显空洞。
- 精度支持受限:缺乏对 FP8 等低精度原语的高效原生支持,强行适配不仅代码复杂,还难以发挥新一代硬件的算力优势。
使用 DeepEP 后
- 跨节点吞吐大幅提升:利用专为 DeepSeek-V3 优化的非对称域转发内核,在 64 路专家并行下,RDMA 瓶颈带宽稳定在 50 GB/s 以上,充分榨干 InfiniBand 网络性能。
- 微秒级低延迟推理:启用纯 RDMA 低延迟内核后,即使在 128 路专家并行的高复杂度场景下,通信延迟仍控制在 200 微秒以内,显著加速首字生成速度。
- 零 SM 占用的重叠执行:通过基于 Hook 的通信 - 计算重叠技术,在不占用任何 SM 资源的前提下实现数据预取,让 GPU 算力全程满负荷运转。
- 原生高效支持 FP8:直接提供针对 FP8 分发和 BF16 合并的高性能算子,无缝对接现代训练流程,既节省显存又提升了数据搬运效率。
DeepEP 通过极致的通信内核优化,彻底打破了大规模 MoE 模型在多节点训练与实时推理中的通信墙,让集群算力真正转化为模型智能。
运行环境要求
- Linux
- 必需 NVIDIA GPU (Ampere SM80 或 Hopper SM90 架构,如 H800)
- 显存大小未说明
- CUDA 11.0+ (SM80) 或 CUDA 12.3+ (SM90)
未说明

快速开始
DeepEP
DeepEP 是一款专为混合专家模型(MoE)和专家并行(EP)设计的通信库。它提供了高吞吐量、低延迟的全对全 GPU 内核,也称为 MoE 调度与组合。该库还支持低精度运算,包括 FP8。
为了配合 DeepSeek-V3 论文中提出的分组受限门控算法,DeepEP 提供了一组针对非对称域带宽转发优化的内核,例如从 NVLink 域向 RDMA 域的数据转发。这些内核具有高吞吐量,适用于训练和推理预填充任务。此外,它们还支持流式多处理器(SM)数量控制。
对于对延迟敏感的推理解码,DeepEP 包含一组纯 RDMA 的低延迟内核,以最大限度地减少延迟。该库还引入了一种基于钩子的通信-计算重叠方法,不会占用任何 SM 资源。
注意:本库中的实现可能与 DeepSeek-V3 论文中的描述存在一些细微差异。
性能
普通内核与 NVLink 和 RDMA 转发
我们在 H800 上测试了普通内核(NVLink 最大带宽约 160 GB/s),每台机器都连接到 CX7 InfiniBand 400 Gb/s RDMA 网卡(最大带宽约 50 GB/s)。我们遵循 DeepSeek-V3/R1 预训练设置(每批 4096 个 token,隐藏层大小 7168,top-4 分组,top-8 专家,FP8 调度和 BF16 组合)。
| 类型 | 调度 #EP | 瓶颈带宽 | 组合 #EP | 瓶颈带宽 |
|---|---|---|---|---|
| 节点内 | 8 | 153 GB/s (NVLink) | 8 | 158 GB/s (NVLink) |
| 节点间 | 16 | 43 GB/s (RDMA) | 16 | 43 GB/s (RDMA) |
| 节点间 | 32 | 58 GB/s (RDMA) | 32 | 57 GB/s (RDMA) |
| 节点间 | 64 | 51 GB/s (RDMA) | 64 | 50 GB/s (RDMA) |
新闻(2025.04.22):在腾讯网络平台部门的优化下,性能提升了高达 30%,详情请参阅 #130。感谢他们的贡献!
低延迟内核与纯 RDMA
我们使用 H800 测试了低延迟内核,每台机器都连接到 CX7 InfiniBand 400 Gb/s RDMA 网卡(最大带宽约 50 GB/s)。我们遵循典型的 DeepSeek-V3/R1 生产环境设置(每批 128 个 token,隐藏层大小 7168,top-8 专家,FP8 调度和 BF16 组合)。
| 调度 #EP | 延迟 | RDMA 带宽 | 组合 #EP | 延迟 | RDMA 带宽 |
|---|---|---|---|---|---|
| 8 | 77 us | 98 GB/s | 8 | 114 us | 127 GB/s |
| 16 | 118 us | 63 GB/s | 16 | 195 us | 74 GB/s |
| 32 | 155 us | 48 GB/s | 32 | 273 us | 53 GB/s |
| 64 | 173 us | 43 GB/s | 64 | 314 us | 46 GB/s |
| 128 | 192 us | 39 GB/s | 128 | 369 us | 39 GB/s |
| 256 | 194 us | 39 GB/s | 256 | 360 us | 40 GB/s |
新闻(2025.06.05):低延迟内核现在尽可能利用 NVLink,详情请参阅 #173。感谢他们的贡献!
快速入门
要求
- Ampere(SM80)、Hopper(SM90)GPU,或支持 SM90 PTX ISA 的其他架构
- Python 3.8 及以上版本
- CUDA 版本:
- SM80 GPU 需要 CUDA 11.0 及以上版本
- SM90 GPU 需要 CUDA 12.3 及以上版本
- PyTorch 2.1 及以上版本
- 节点内通信需使用 NVLink
- 节点间通信需使用 RDMA 网络
下载并安装 NVSHMEM 依赖
DeepEP 还依赖于 NVSHMEM。请参考我们的 NVSHMEM 安装指南 获取说明。
开发
# 构建并创建 SO 文件的符号链接
NVSHMEM_DIR=/path/to/installed/nvshmem python setup.py build
# 您可以根据自己的平台修改具体的 SO 文件名
ln -s build/lib.linux-x86_64-cpython-38/deep_ep_cpp.cpython-38-x86_64-linux-gnu.so
# 运行测试用例
# 注意:您可以根据自己的集群设置修改 `tests/utils.py` 中的 `init_dist` 函数,并在多个节点上启动
python tests/test_intranode.py
python tests/test_internode.py
python tests/test_low_latency.py
安装
NVSHMEM_DIR=/path/to/installed/nvshmem python setup.py install
安装环境变量
NVSHMEM_DIR:NVSHMEM 目录的路径,若未指定则禁用所有节点间和低延迟功能DISABLE_SM90_FEATURES:0 或 1,是否禁用 SM90 功能,对于 SM90 设备或 CUDA 11 需要设置此变量TORCH_CUDA_ARCH_LIST:目标架构列表,例如TORCH_CUDA_ARCH_LIST="9.0"DISABLE_AGGRESSIVE_PTX_INSTRS:0 或 1,是否禁用激进的加载/存储指令,详情请参阅 未定义行为 PTX 使用
然后,在您的 Python 项目中导入 deep_ep,即可开始使用!
网络配置
DeepEP 已在 InfiniBand 网络上进行了全面测试。然而,理论上它也兼容融合以太网上的 RDMA(RoCE)。
流量隔离
InfiniBand 通过虚拟通道(VL)支持流量隔离。
为防止不同类型流量之间的干扰,我们建议将工作负载划分到不同的虚拟通道中,如下所示:
- 使用普通内核的工作负载
- 使用低延迟内核的工作负载
- 其他工作负载
对于 DeepEP,您可以通过设置 NVSHMEM_IB_SL 环境变量来控制虚拟通道的分配。
自适应路由
自适应路由是 InfiniBand 交换机提供的一项高级路由功能,可以将流量均匀地分配到多条路径上。启用自适应路由可以完全消除由路由冲突引起的网络拥塞,但也会引入额外的延迟。我们建议采用以下配置以获得最佳性能:
- 在网络负载较重的环境中启用自适应路由
- 在网络负载较轻的环境中使用静态路由
拥塞控制
由于我们在生产环境中未观察到显著的拥塞现象,因此拥塞控制功能已被禁用。
接口与示例
模型训练或推理预填充中的使用示例
普通内核可用于模型训练或推理预填充阶段(不包含反向传播部分),如下示例代码所示。
import torch
import torch.distributed as dist
from typing import List, Tuple, Optional, Union
from deep_ep import Buffer, EventOverlap
# 通信缓冲区(将在运行时分配)
_buffer: Optional[Buffer] = None
# 设置使用的 SM 数量
# 注释:这是一个静态变量
Buffer.set_num_sms(24)
# 您可以在框架初始化时调用此函数
def get_buffer(group: dist.ProcessGroup, hidden_bytes: int) -> Buffer:
global _buffer
# 注释:您也可以用所有测试得到的自动调优结果替换 `get_*_config`
num_nvl_bytes, num_rdma_bytes = 0, 0
for config in (Buffer.get_dispatch_config(group.size()), Buffer.get_combine_config(group.size())):
num_nvl_bytes = max(config.get_nvl_buffer_size_hint(hidden_bytes, group.size()), num_nvl_bytes)
num_rdma_bytes = max(config.get_rdma_buffer_size_hint(hidden_bytes, group.size()), num_rdma_bytes)
# 如果缓冲区不存在或大小不足,则分配一个新的缓冲区
if _buffer is None or _buffer.group != group or _buffer.num_nvl_bytes < num_nvl_bytes or _buffer.num_rdma_bytes < num_rdma_bytes:
_buffer = Buffer(group, num_nvl_bytes, num_rdma_bytes)
return _buffer
def get_hidden_bytes(x: torch.Tensor) -> int:
t = x[0] if isinstance(x, tuple) else x
return t.size(1) * max(t.element_size(), 2)
def dispatch_forward(x: Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]],
topk_idx: torch.Tensor, topk_weights: torch.Tensor,
num_experts: int, previous_event: Optional[EventOverlap] = None) -> \
Tuple[Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]], torch.Tensor, torch.Tensor, List, Tuple, EventOverlap]:
# 注释:可选的 `previous_event` 表示您希望将其作为调度内核依赖项的 CUDA 事件,
# 这在通信与计算重叠时可能很有用。更多信息请参阅 `Buffer.dispatch` 的文档。
global _buffer
# 在实际调度之前计算布局
num_tokens_per_rank, num_tokens_per_rdma_rank, num_tokens_per_expert, is_token_in_rank, previous_event = \
_buffer.get_dispatch_layout(topk_idx, num_experts,
previous_event=previous_event, async_finish=True,
allocate_on_comm_stream=previous_event is not None)
# 执行 MoE 调度
# 注释:CPU 将等待 GPU 的信号到达,因此这与 CUDA 图不兼容。
# 除非您指定 `num_worst_tokens`,但该标志仅适用于节点内部。
# 更高级的用法请参阅 `dispatch` 函数的文档。
recv_x, recv_topk_idx, recv_topk_weights, num_recv_tokens_per_expert_list, handle, event = \
_buffer.dispatch(x, topk_idx=topk_idx, topk_weights=topk_weights,
num_tokens_per_rank=num_tokens_per_rank, num_tokens_per_rdma_rank=num_tokens_per_rdma_rank,
is_token_in_rank=is_token_in_rank, num_tokens_per_expert=num_tokens_per_expert,
previous_event=previous_event, async_finish=True,
allocate_on_comm_stream=True)
# 关于事件管理,请参阅 `EventOverlap` 类的文档。
return recv_x, recv_topk_idx, recv_topk_weights, num_recv_tokens_per_expert_list, handle, event
def dispatch_backward(grad_recv_x: torch.Tensor, grad_recv_topk_weights: torch.Tensor, handle: Tuple) -> \
Tuple[torch.Tensor, torch.Tensor, EventOverlap]:
global _buffer
# MoE 调度的反向过程实际上是组合操作。
# 更高级的用法请参阅 `combine` 函数的文档。
combined_grad_x, combined_grad_recv_topk_weights, event = \
_buffer.combine(grad_recv_x, handle, topk_weights=grad_recv_topk_weights, async_finish=True)
# 关于事件管理,请参阅 `EventOverlap` 类的文档。
return combined_grad_x, combined_grad_recv_topk_weights, event
def combine_forward(x: torch.Tensor, handle: Tuple, previous_event: Optional[EventOverlap] = None) -> \
Tuple[torch.Tensor, EventOverlap]:
global _buffer
# 执行 MoE 组合操作
# 更高级的用法请参阅 `combine` 函数的文档。
combined_x, _, event = _buffer.combine(x, handle, async_finish=True, previous_event=previous_event,
allocate_on_comm_stream=previous_event is not None)
# 关于事件管理,请参阅 `EventOverlap` 类的文档。
return combined_x, event
def combine_backward(grad_combined_x: Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]],
handle: Tuple, previous_event: Optional[EventOverlap] = None) -> \
Tuple[Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]], EventOverlap]:
global _buffer
# MoE 组合的反向过程实际上是调度操作。
# 更高级的用法请参阅 `dispatch` 函数的文档。
grad_x, _, _, _, _, event = _buffer.dispatch(grad_combined_x, handle=handle, async_finish=True,
previous_event=previous_event,
allocate_on_comm_stream=previous_event is not None)
# 关于事件管理,请参阅 `EventOverlap` 类的文档。
return grad_x, event
此外,在调度函数中,我们可能不知道当前进程需要接收多少个令牌。因此,会涉及 CPU 对 GPU 接收数量信号的隐式等待,如下图所示。
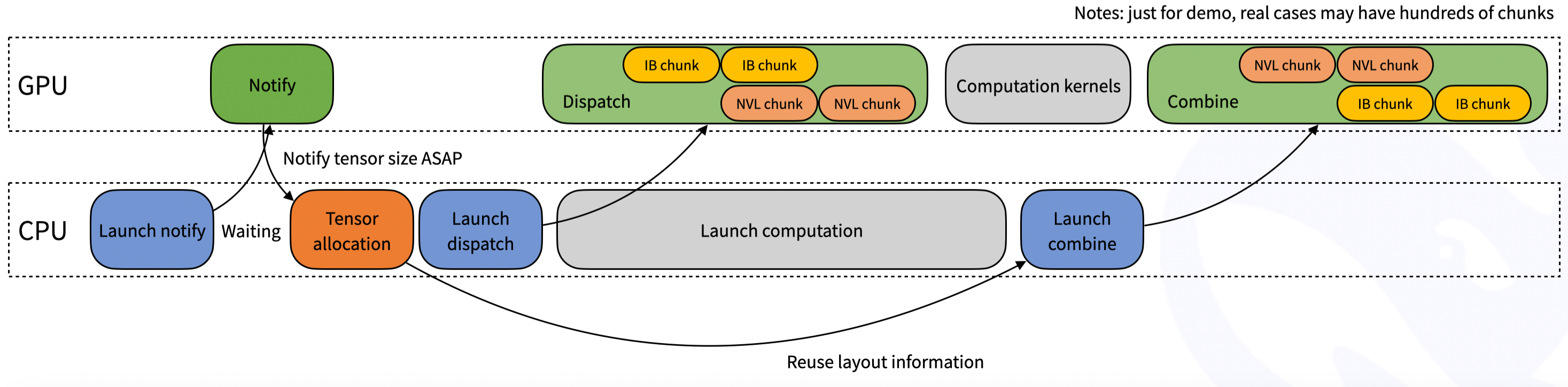
推理解码中的使用示例
低延迟内核可以用于推理解码阶段,如下方示例代码所示。
import torch
import torch.distributed as dist
from typing import Tuple, Optional
from deep_ep import Buffer
# 通信缓冲区(将在运行时分配)
# 注释:低延迟内核没有 SM 控制 API
_buffer: Optional[Buffer] = None
# 您可以在框架初始化时调用此函数
def get_buffer(group: dist.ProcessGroup, num_max_dispatch_tokens_per_rank: int, hidden: int, num_experts: int) -> Buffer:
# 注意:低延迟模式会比普通模式占用更多空间
# 因此我们建议 `num_max_dispatch_tokens_per_rank`(解码引擎中的实际批大小)应小于 256
global _buffer
num_rdma_bytes = Buffer.get_low_latency_rdma_size_hint(num_max_dispatch_tokens_per_rank, hidden, group.size(), num_experts)
# 如果缓冲区不存在或大小不足,则分配一个新的缓冲区
if _buffer is None or _buffer.group != group or not _buffer.low_latency_mode or _buffer.num_rdma_bytes < num_rdma_bytes:
# 注意:为了获得最佳性能,QP 数量**必须**等于本地专家的数量
assert num_experts % group.size() == 0
_buffer = Buffer(group, 0, num_rdma_bytes, low_latency_mode=True, num_qps_per_rank=num_experts // group.size())
return _buffer
def low_latency_dispatch(hidden_states: torch.Tensor, topk_idx: torch.Tensor, num_max_dispatch_tokens_per_rank: int, num_experts: int):
global _buffer
# 执行 MoE 调度,兼容 CUDA 图(但您在重放时可能需要恢复部分缓冲区状态)
recv_hidden_states, recv_expert_count, handle, event, hook = \
_buffer.low_latency_dispatch(hidden_states, topk_idx, num_max_dispatch_tokens_per_rank, num_experts,
async_finish=False, return_recv_hook=True)
# 注意:只有调用 `hook()` 时,实际张量才会被接收,
# 这对于双批次重叠很有用,而且**不会占用任何 SM**。
# 如果您不想进行重叠,请将 `return_recv_hook` 设置为 False。
# 稍后,您可以使用我们的 GEMM 库以这种特定格式进行计算。
return recv_hidden_states, recv_expert_count, handle, event, hook
def low_latency_combine(hidden_states: torch.Tensor,
topk_idx: torch.Tensor, topk_weights: torch.Tensor, handle: Tuple):
global _buffer
# 执行 MoE 组合,兼容 CUDA 图(但您在重放时可能需要恢复部分缓冲区状态)
combined_hidden_states, event_overlap, hook = \
_buffer.low_latency_combine(hidden_states, topk_idx, topk_weights, handle,
async_finish=False, return_recv_hook=True)
# 注意:行为与调度内核中描述的一致
return combined_hidden_states, event_overlap, hook
对于两个微批次的重叠,可以参考下图。借助我们的接收钩子接口,RDMA 网络流量会在后台进行,而不会占用计算部分的任何 GPU SM。不过请注意,重叠的部分是可以调整的,即注意力/调度/MoE/组合这四个部分的执行时间不一定完全相同。您可以根据自己的工作负载调整各个阶段的设置。
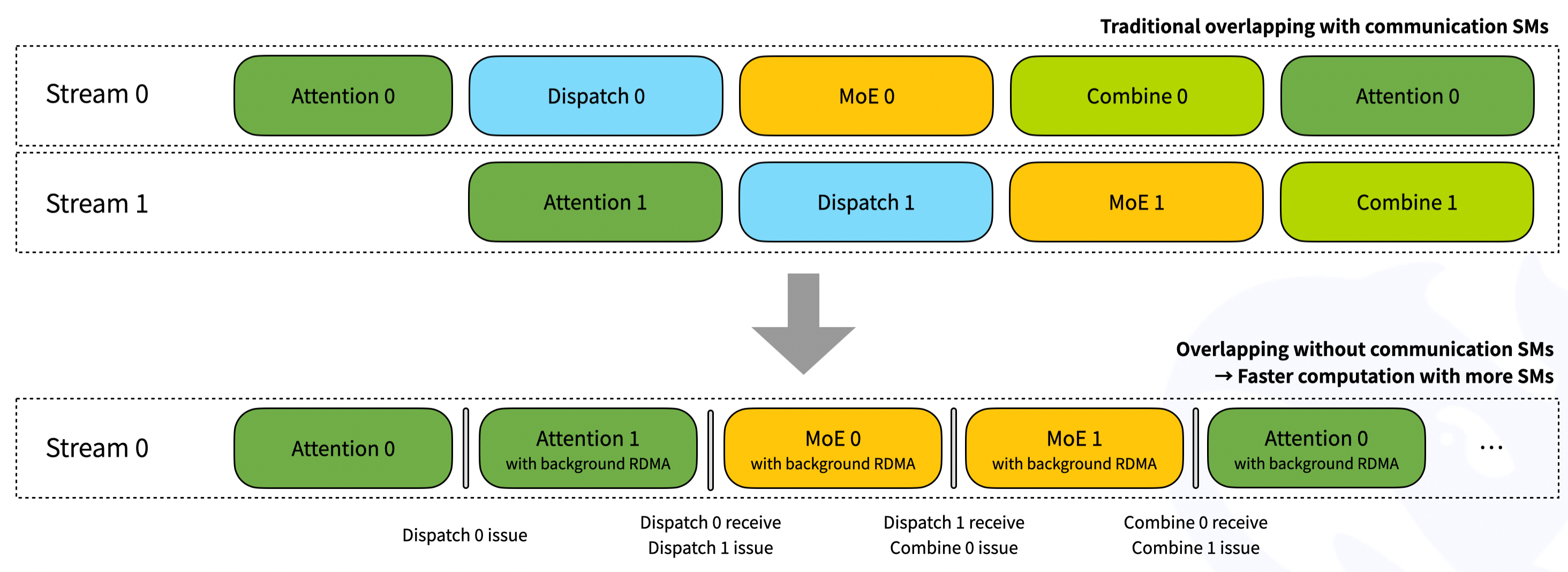
路线图
- 支持 AR
- 重构低延迟模式下的 AR 代码
- 支持 A100(仅节点内)
- 为低延迟调度内核支持 BF16
- 支持 NVLink 协议用于节点内低延迟内核
- 使用 TMA 复制代替 LD/ST
- 节点内内核
- 节点间内核
- 低延迟内核
- 实现无 SM 内核及相应重构
- 完全移除未定义行为的 PTX 指令
注意事项
更简单的潜在整体设计
当前的 DeepEP 实现使用队列作为通信缓冲区,虽然节省了内存,但也引入了复杂性和潜在的死锁问题。如果您基于 DeepEP 实现自己的版本,建议使用固定大小、按最大容量分配的缓冲区,以简化设计并提升性能。有关这一替代方案的详细讨论,请参阅:https://github.com/deepseek-ai/DeepEP/issues/39。
未定义行为的 PTX 使用
- 为了追求极致性能,我们发现并使用了一种未定义行为的 PTX 用法:利用只读 PTX
ld.global.nc.L1::no_allocate.L2::256B来读取易失性数据。PTX 修饰符.nc表示使用非相干缓存。但在 Hopper 架构上,通过结合.L1::no_allocate,我们测试确认其正确性有保障,并且性能显著提升。我们推测原因可能是:非相干缓存与 L1 缓存统一,而 L1 修饰符不仅仅是一个提示,更是一种强约束,因此只要 L1 中没有脏数据,就能保证正确性。 - 最初,由于 NVCC 无法自动展开易失性读取的 PTX 指令,我们尝试使用
__ldg(即ld.nc)。即使与手动展开的易失性读取相比,它的速度也快得多(很可能得益于编译器的额外优化)。然而,结果可能会不正确或包含脏数据。在查阅 PTX 文档后,我们发现 Hopper 架构上的 L1 和非相干缓存是统一的。我们推测,.L1::no_allocate可能会解决这个问题,从而促成了这一发现。 - 如果您发现内核在某些其他平台上无法正常工作,可以在
setup.py中添加DISABLE_AGGRESSIVE_PTX_INSTRS=1来禁用该功能,或者提交一个问题。
在您的集群上进行自动调优
为了在您的集群上获得更好的性能,我们建议运行所有测试,并采用最佳的自动调优配置。默认配置是在 DeepSeek 的内部集群上优化得到的。
许可证
本代码库采用 MIT 许可证 发布,但引用 NVSHMEM 的代码(包括 csrc/kernels/ibgda_device.cuh 和 third-party/nvshmem.patch)则适用 NVSHMEM SLA。
实验性分支
- 零拷贝
- 移除了 PyTorch 张量与通信缓冲区之间的拷贝,从而显著减少了常规内核对 SM 的占用。
- 该 PR 由 腾讯网络平台部 贡献。
- Eager
- 通过使用低延迟协议,消除了 RDMA 原子操作引入的额外 RTT 延迟。
- Hybrid-EP
- 一种新的后端实现,利用 TMA 指令以最小化 SM 使用并支持更大的 NVLink 域。
- 针对单批次场景实现了细粒度的通信-计算重叠。
- 支持非 NVLink 环境下的 PCIe 内核。
- 支持 NVFP4 数据类型。
- AntGroup-Opt
- 该优化系列由 蚂蚁集团网络平台部 贡献。
- Normal-SMFree 通过解耦通信内核执行与 NIC 令牌传输,将 SM 从 RDMA 路径中解放出来,从而释放 SM 用于计算。
- LL-SBO 利用信号机制将 Down GEMM 计算与 Combine Send 通信重叠,以降低端到端延迟。
- LL-Layered 采用轨道优化的转发和数据合并策略,优化跨节点 LL 算子的通信,进一步降低延迟。
- Mori-EP
- 基于 MORI 后端(低延迟模式)提供的 ROCm/AMD GPU 支持。
社区分叉
- uccl/uccl-ep - 允许在异构 GPU(如 Nvidia、AMD)和 NIC(如 EFA、Broadcom、CX7)上运行 DeepEP。
- Infrawaves/DeepEP_ibrc_dual-ports_multiQP - 在 IBRC 传输中增加了多 QP 解决方案和双端口 NIC 支持。
- antgroup/DeepXTrace - 一款诊断分析工具,用于高效、精准地定位运行缓慢的节点。
- ROCm/mori - AMD 面向高性能 AI 工作负载的新一代通信库(如 Wide EP、KVCache 传输、集体通信)。
引用
如果您使用本代码库或认为我们的工作具有价值,请引用以下内容:
@misc{deepep2025,
title={DeepEP:高效的专家并行通信库},
author={Chenggang Zhao 和 Shangyan Zhou 和 Liyue Zhang 和 Chengqi Deng 和 Zhean Xu 和 Yuxuan Liu 和 Kuai Yu 和 Jiashi Li 和 Liang Zhao},
year={2025},
publisher = {GitHub},
howpublished = {\url{https://github.com/deepseek-ai/DeepEP}},
}
版本历史
v1.2.12025/09/16常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器