multimodal-deep-learning
multimodal-deep-learning 是一个专注于多模态深度学习的开源代码库,旨在帮助开发者和研究人员解决文本、音频与视觉等多源数据的融合与分析难题。它核心解决了如何让机器同时理解多种感官信息的问题,特别适用于多模态情感分析、讽刺检测及对话中的情绪识别等复杂任务。
该工具非常适合人工智能领域的研究人员、算法工程师及高校学生使用,为他们提供了从经典到前沿的多种模型实现,包括基于 PyTorch、TensorFlow 和 Keras 框架的完整代码。其独特的技术亮点在于集成了如 Multimodal-Infomax(MMIM)和 MISA 等先进算法:MMIM 通过层级互信息最大化技术显著提升了特征融合效果,而 MISA 则巧妙地将模态不变性与特异性表示分离,增强了模型的鲁棒性。此外,库中还整理了 MELD、MUStARD 等多个高质量多模态数据集,方便用户直接开展实验。无论是希望复现顶级会议论文成果,还是想要构建自己的多模态应用原型,multimodal-deep-learning 都能提供坚实的技术支撑和丰富的参考范例。
使用场景
某电商团队正致力于升级其视频评论分析系统,旨在从用户上传的评测视频中精准识别对产品的真实情感倾向。
没有 multimodal-deep-learning 时
- 模态割裂导致误判:团队只能单独分析字幕文本或音频语调,无法捕捉用户“嘴上说喜欢但表情嫌弃”的反讽场景,导致情感打分严重失真。
- 特征融合粗糙:自行编写的简单拼接代码无法处理视觉、听觉和文本间的复杂非线性关系,模型在噪声较大的真实视频数据上泛化能力极差。
- 研发周期漫长:复现论文中的多模态注意力机制或互信息最大化算法需要从零搭建底层架构,耗费数周时间调试且难以保证效果对齐。
- 缺乏专用数据集支持:找不到针对多模态幽默或讽刺检测的标准数据集(如 MUStARD),导致模型训练缺乏高质量的标注数据支撑。
使用 multimodal-deep-learning 后
- 精准捕捉细微情感:直接调用 MISA 或 BBFN 等预置模型,成功分离并融合了模态不变性与特异性特征,准确识别出用户视频中的反讽与隐含情绪。
- 高级融合策略落地:利用内置的 Multimodal-Infomax 算法,通过层级互信息最大化自动优化多源数据融合,显著提升了在嘈杂环境下的分析准确率。
- 快速验证与部署:基于提供的 PyTorch/TensorFlow 实现代码和详细环境配置,团队在两天内即可完成从数据加载到模型训练的全流程,大幅缩短上线时间。
- 丰富数据资源集成:直接接入仓库集成的 MELD 和 MUStARD 等多模态数据集,快速构建了针对特定场景(如多人对话、幽默检测)的鲁棒模型。
multimodal-deep-learning 将复杂的多模态算法研发转化为高效的模块化调用,让团队能专注于业务逻辑而非底层数学实现的重复造轮子。
运行环境要求
- 未说明
未说明 (项目涉及深度学习模型训练,通常建议配备 NVIDIA GPU,但 README 中未明确具体型号或显存要求)
未说明

快速开始
多模态深度学习
🎆 🎆 🎆 宣布推出多模态深度学习仓库,其中包含多种基于深度学习的模型实现,用于解决不同的多模态问题,例如多模态表示学习、面向下游任务的多模态融合(如多模态情感分析)。
对于那些询问如何提取视觉和音频特征的人,请查看这里:https://github.com/soujanyaporia/MUStARD
模型
通过层次化互信息最大化改进多模态融合以进行多模态情感分析
本仓库包含论文《通过层次化互信息最大化改进多模态融合以进行多模态情感分析》的官方实现代码,该论文已被EMNLP 2021接收。
:fire: 如果您对我们DeCLaRe实验室的其他多模态研究感兴趣,欢迎访问聚类仓库。
简介
多模态信息最大化(MMIM)通过两级互信息(MI)最大化来综合多模态输入的融合结果。我们使用Barber-Agakov下界和对比预测编码作为需要最大化的目标函数。为了便于计算,我们设计了一个带有历史数据存储的熵估计模块,以帮助计算BA下界并加速训练过程。

使用方法
- 从Google Drive或百度网盘下载CMU-MOSI和CMU-MOSEI数据集,并将其放置在
Multimodal-Infomax/datasets文件夹下。 - 设置环境(需先安装conda)
conda env create -f environment.yml
conda activate MMIM
- 开始训练
python main.py --dataset mosi --contrast
引用
如果您认为我们的工作对您的研究有帮助,请引用我们的论文:
@article{han2021improving,
title={Improving Multimodal Fusion with Hierarchical Mutual Information Maximization for Multimodal Sentiment Analysis},
author={Han, Wei and Chen, Hui and Poria, Soujanya},
journal={Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)},
year={2021}
}
联系方式
如有任何问题,请随时通过henryhan88888@gmail.com与我联系。
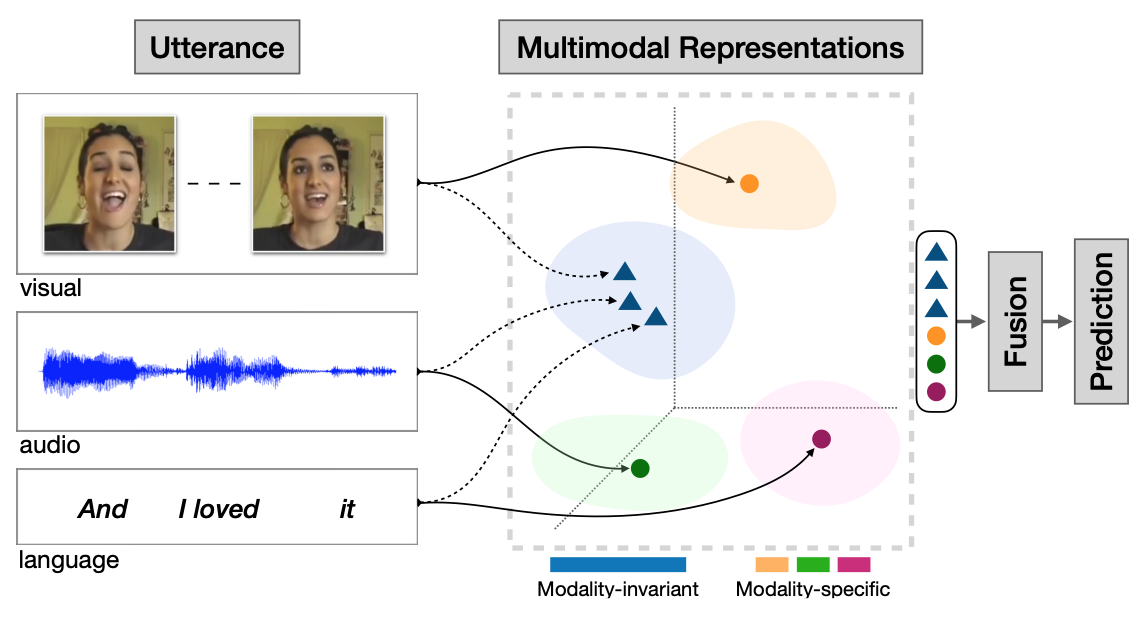
MISA:面向多模态情感分析的模态不变与特定表示
这是ACM MM 2020会议论文《MISA:面向多模态情感分析的模态不变与特定表示》的代码实现(论文链接:https://arxiv.org/pdf/2005.03545.pdf)
环境设置
我们使用conda环境。
conda env create -f environment.yml
conda activate misa-code
数据下载
- 安装CMU多模态SDK。确保可以执行
from mmsdk import mmdatasdk。 - 方案一:下载预计算好的划分,并将内容放入
datasets文件夹中。 - 方案二:从MMSDK下载数据并重新创建划分。为此,只需按照以下说明运行代码。
运行代码
cd src- 将
config.py中的word_emb_path设置为glove词向量文件。 - 将
sdk_dir设置为CMU-MultimodalSDK的路径。 python train.py --data mosi。对于其他数据集,将mosi替换为mosei或ur_funny。
引用
如果本文对您的研究有所帮助,请引用我们:
@article{hazarika2020misa,
title={MISA: Modality-Invariant and-Specific Representations for Multimodal Sentiment Analysis},
author={Hazarika, Devamanyu and Zimmermann, Roger and Poria, Soujanya},
journal={arXiv preprint arXiv:2005.03545},
year={2020}
}
联系方式
如有任何问题,请发送邮件至hazarika@comp.nus.edu.sg。
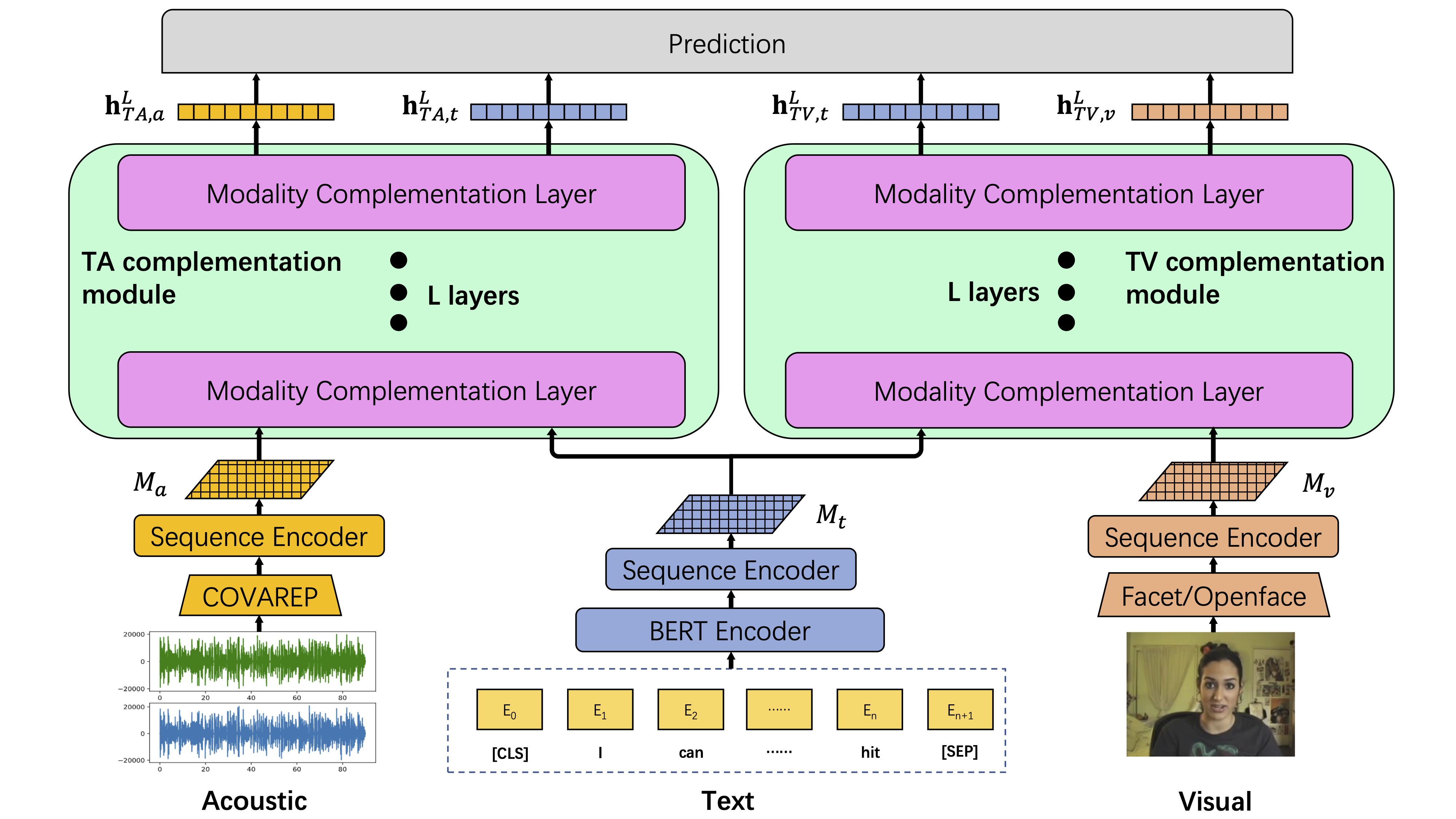
双双模态融合用于相关性控制的多模态情感分析
本仓库包含论文《双双模态融合用于相关性控制的多模态情感分析(ICMI 2021)》的官方实现。
模型架构
我们的双双模态融合网络(BBFN)概述。它通过强制每对模态相互补充,学习两组与文本相关的表示:文本-声学和文本-视觉。最后,将这四组(两对)主要表示拼接在一起,生成最终的预测。
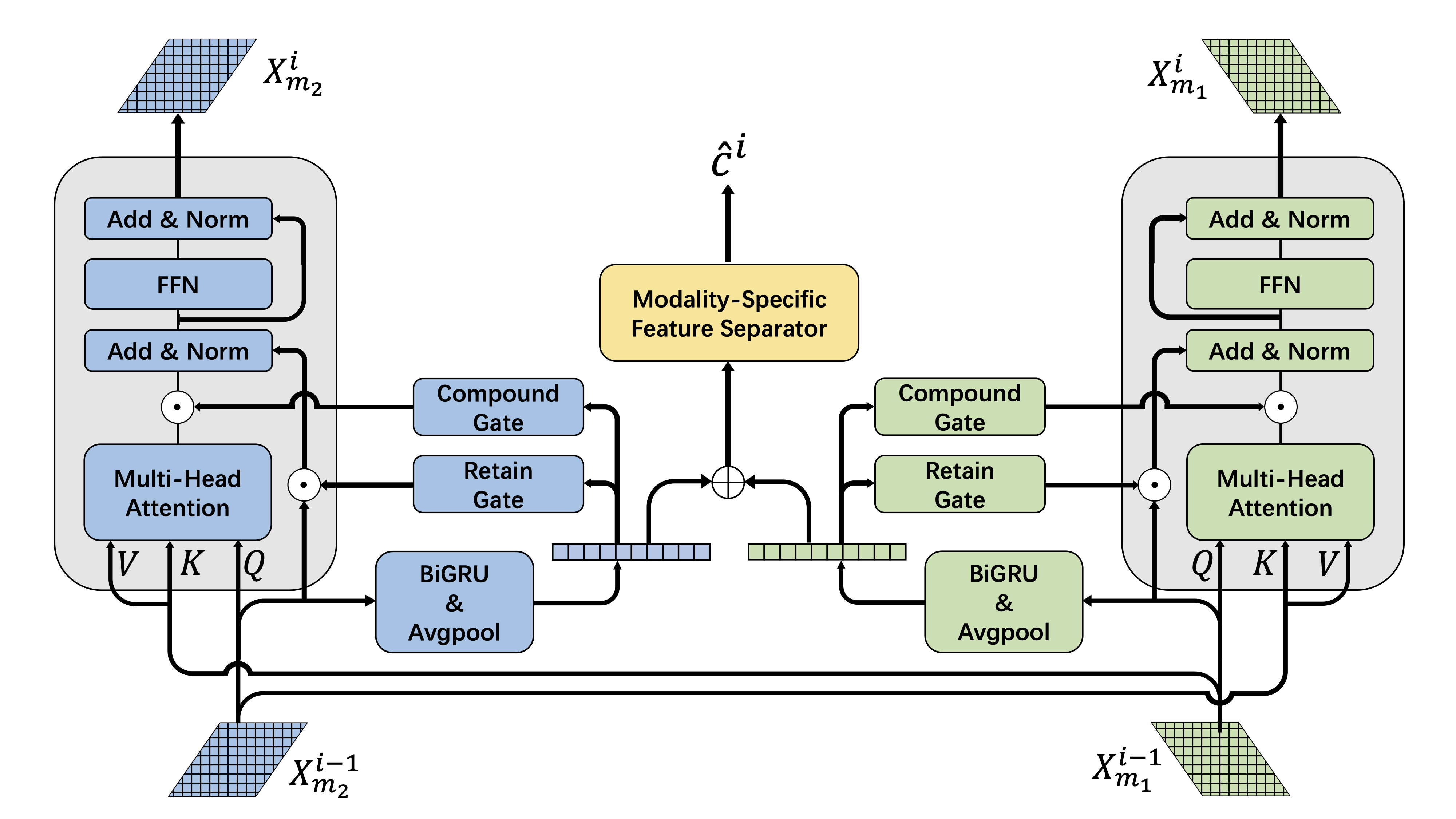
单个互补层:左右两条相同的管道分别传播主模态,并在正则化和门控控制下将其与互补模态融合。
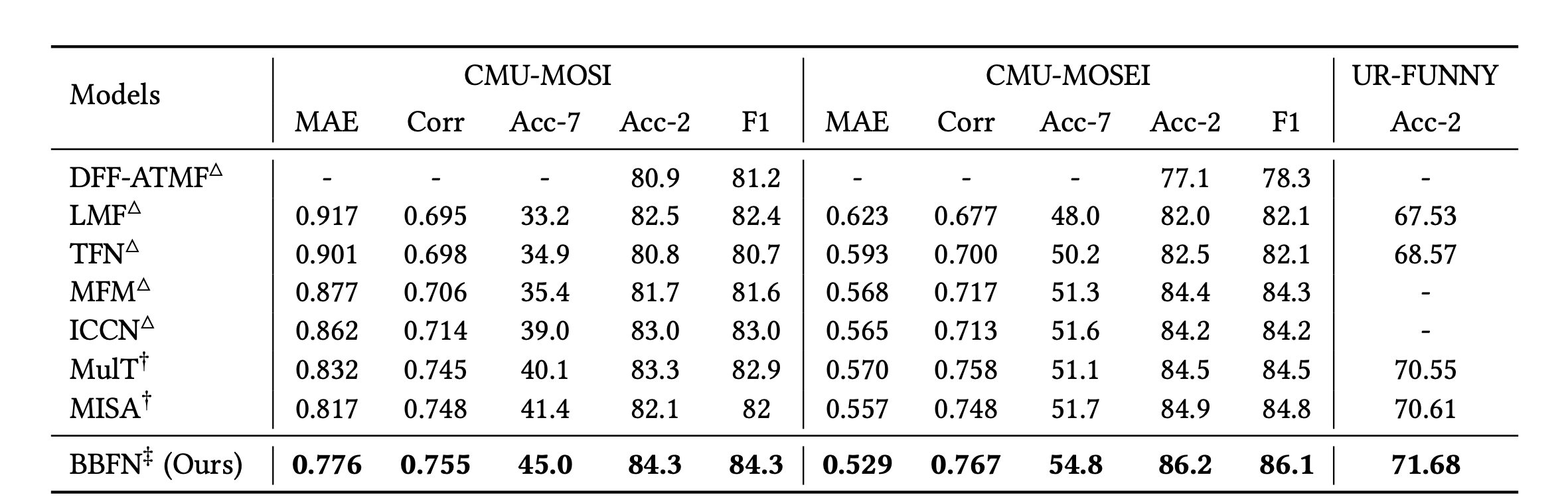
结果
CMU-MOSI和CMU-MOSEI数据集测试集上的结果。符号说明:△表示相应行的结果摘自先前的论文;†表示结果是根据公开的源代码和适用的超参数设置复现的;‡表示结果经过配对t检验,p值小于0.05,表明相比当前最先进的模型MISA有显著提升。
使用方法
- 设置 conda 环境
conda env create -f environment.yml
conda activate BBFN
安装 CMU 多模态 SDK
将
src/config.py中的sdk_dir设置为 CMU-MultimodalSDK 的路径训练模型
cd src
python main.py --dataset <数据集名称> --data_path <数据集路径>
我们提供了一个脚本 scripts/run.sh 供您参考。
引用
如果您认为我们的工作对您的研究有帮助,请引用我们的论文:
@article{han2021bi,
title={Bi-Bimodal Modality Fusion for Correlation-Controlled Multimodal Sentiment Analysis},
author={Han, Wei and Chen, Hui and Gelbukh, Alexander and Zadeh, Amir and Morency, Louis-philippe and Poria, Soujanya},
journal={ICMI 2021},
year={2021}
}
联系方式
如有任何问题,欢迎通过 henryhan88888@gmail.com 与我联系。
Hfusion
用于论文《使用上下文建模的层次融合进行多模态情感分析》的代码
运行方法
python3 hfusion.py
需求
Keras >= 2.0, Tensorflow >= 1.7, Numpy, Scikit-learn
引用
Majumder, N., Hazarika, D., Gelbukh, A., Cambria, E. and Poria, S., 2018. Multimodal sentiment analysis using hierarchical fusion with context modeling. Knowledge-Based Systems, 161, pp.124-133.
基于注意力的多模态情感分析融合
基于注意力的多模态情感分析融合
论文代码
用户生成视频中的上下文依赖情感分析(ACL 2017)。
用于上下文多模态情感分析的多级多注意力机制(ICDM 2017)。
")
预处理
编辑: create_data.py 已经过时。预处理后的数据集已经放在仓库的 dataset/ 文件夹中,请直接使用。
由于数据通常以话语形式存在,我们使用以下代码将属于同一视频的所有话语合并在一起:
python create_data.py
注意:这将创建与说话者无关的训练和测试划分。
在 dataset/mosei 中,将压缩包解压到名为 'raw' 的文件夹中。同时解压 'unimodal_mosei_3way.pickle.zip'。
运行模型
示例命令:
使用基于注意力的融合:
python run.py --unimodal True --fusion True
python run.py --unimodal False --fusion True
不使用基于注意力、采用拼接融合的方式:
python run.py --unimodal True --fusion False
python run.py --unimodal False --fusion False
话语级别的注意力:
python run.py --unimodal False --fusion True --attention_2 True
python run.py --unimodal False --fusion True --attention_2 True
注意:
- 将 unimodal 标志保持为 True(默认为 False)会先训练所有单模态 LSTM(论文中提到的网络第一层)。
- 设置 --fusion True 仅适用于多模态网络。
数据集:
我们提供了在 MOSI、MOSEI 和 IEMOCAP 数据集上的结果。
请引用数据集的创建者。
我们正在添加更多数据集,敬请期待。
在上述命令中使用 --data [mosi|mosei|iemocap] 和 --classes [2|3|6] 来测试不同配置在不同数据集上的表现。
mosi:2 类
mosei:3 类
iemocap:6 类
示例:
python run.py --unimodal False --fusion True --attention_2 True --data mosei --classes 3
数据集详情
MOSI:
2 类:正面/负面
原始特征:(Pickle 文件)
音频:dataset/mosi/raw/audio_2way.pickle
文本:dataset/mosi/raw/text_2way.pickle
视频:dataset/mosi/raw/video_2way.pickle
每个文件包含:
train_data、train_label、test_data、test_label、maxlen、train_length、test_length
train_data - 维度为 (62, 63, 特征维度) 的 np.array
train_label - 维度为 (62, 63, 2) 的 np.array
test_data - 维度为 (31, 63, 特征维度) 的 np.array
test_label - 维度为 (31, 63, 2) 的 np.array
maxlen - 最大话语长度,值为 63
train_length - 训练数据中每段视频的话语长度。
test_length - 测试数据中每段视频的话语长度。
训练/测试划分:62/31 段视频。每段视频都有话语。视频被填充至 63 个话语。
IEMOCAP:
6 类:高兴/悲伤/ neutral/愤怒/兴奋/沮丧
原始特征:dataset/iemocap/raw/IEMOCAP_features_raw.pkl(Pickle 文件)
该文件包含:
videoIDs[vid] = 该视频中话语 ID 列表,按出现顺序排列
videoSpeakers[vid] = 说话人轮次列表。例如 [M, M, F, M, F]。其中 M = 男性,F = 女性
videoText[vid] = 该视频中每段话语的文本特征列表。
videoAudio[vid] = 该视频中每段话语的音频特征列表。
videoVisual[vid] = 该视频中每段话语的视觉特征列表。
videoLabels[vid] = 该视频中每段话语的标签索引列表。
videoSentence[vid] = 该视频中每段话语的句子列表。
trainVid = 训练集中视频(视频 ID)列表。
testVid = 测试集中视频(视频 ID)列表。
更多信息请参阅文件 dataset/iemocap/raw/loadIEMOCAP.py。 我们使用这些数据创建了格式化的、与说话者无关的训练和测试划分。(视频 x 话语 x 特征)
训练/测试划分:120/31 段视频。每段视频都有话语。视频被填充至 110 个话语。
MOSEI:
3 类:正面/负面/neutral
原始特征:(Pickle 文件)
音频:dataset/mosei/raw/audio_3way.pickle
文本:dataset/mosei/raw/text_3way.pickle
视频:dataset/mosei/raw/video_3way.pickle
该文件包含: train_data、train_label、test_data、test_label、maxlen、train_length、test_length
train_data - 维度为 (2250, 98, 特征维度) 的 np.array
train_label - 维度为 (62, 63, 2) 的 np.array
test_data - 维度为 (31, 63, 特征维度) 的 np.array
test_label - 维度为 (31, 63, 2) 的 np.array
maxlen - 最大话语长度,值为 98
train_length - 训练数据中每段视频的话语长度。
test_length - 测试数据中每段视频的话语长度。
训练/测试划分:2250/678 段视频。每段视频都有话语。视频被填充至 98 个话语。
引用
如果您使用此代码,请使用以下方式引用我们的工作:
@inproceedings{soujanyaacl17,
title={上下文相关的用户生成视频情感分析},
author={Poria, Soujanya and Cambria, Erik and Hazarika, Devamanyu and Mazumder, Navonil and Zadeh, Amir and Morency, Louis-Philippe},
booktitle={计算语言学协会},
year={2017}
}
@inproceedings{poriaicdm17,
author={S. Poria and E. Cambria and D. Hazarika and N. Mazumder and A. Zadeh and L. P. Morency},
booktitle={2017 IEEE数据挖掘国际会议(ICDM)},
title={用于情境多模态情感分析的多级多注意力机制},
year={2017},
pages={1033-1038},
keywords={数据挖掘;特征提取;图像分类;图像融合;机器学习(人工智能);情感分析;基于注意力的网络;情境学习;情境信息;情境多模态情感;动态特征融合;多级多注意力机制;多模态情感分析;循环模型;话语;视频;情境建模;特征提取;熔接器;情感分析;社交网络服务;视频;可视化},
doi={10.1109/ICDM.2017.134},
month={11月},}
致谢
Gangeshwar Krishnamurthy (gangeshwark@gmail.com; Github: @gangeshwark)
用户生成视频中的上下文相关情感分析
用于论文《用户生成视频中的上下文相关情感分析》(ACL 2017)的代码。
要求
代码使用 Python 2.7 编写,需要 Keras 2.0.6 和 Theano 后端。
描述
在本文中,我们提出了一种基于 LSTM 的模型,该模型使话语能够从同一视频中的周围环境中捕获上下文信息,从而帮助进行多模态情感分析的分类过程。

此仓库包含上述论文的代码。每个上下文 LSTM(论文中的图 2)都如上图所示实现。更多细节请参阅论文。
注意:与论文不同的是,我们在倒数第二层未使用 SVM。这是为了保持整个网络的可微性,尽管可能会牺牲一些性能。
数据集
我们在 MOSI 数据集 上提供了结果。
请引用数据集的创建者。
预处理
由于数据通常以话语形式存在,我们使用以下代码将属于同一视频的所有话语合并在一起:
python create_data.py
注意:这将创建与说话人无关的训练和测试分割。
运行 sc-lstm
示例命令:
python lstm.py --unimodal True
python lstm.py --unimodal False
注意:将 unimodal 标志保持为 True(默认为 False)将首先训练所有单模态 LSTM(论文中提到的网络第 1 层)。
引用
如果您使用此代码,请使用以下方式引用我们的工作:
@inproceedings{soujanyaacl17,
title={上下文相关的用户生成视频情感分析},
author={Poria, Soujanya and Cambria, Erik and Hazarika, Devamanyu and Mazumder, Navonil and Zadeh, Amir and Morency, Louis-Philippe},
booktitle={计算语言学协会},
year={2017}
}
致谢
Devamanyu Hazarika、Soujanya Poria
多模态情感分析中的情境跨模态注意力
用于论文《多模态情感分析中的情境跨模态注意力》(EMNLP 2018)的代码。
数据集
我们在 MOSI 数据集 上提供了结果。
请引用数据集的创建者。
需求:
Python 3.5
Keras(TensorFlow 后端)2.2.4
Scikit-learn 0.20.0
实验
python create_data.py
python trimodal_attention_models.py
引用
如果您在研究中使用此代码,请使用以下方式引用我们的工作:
@inproceedings{ghosal2018contextual,
title={多模态情感分析中的情境跨模态注意力},
author={Ghosal, Deepanway and Akhtar, Md Shad and Chauhan, Dushyant and Poria, Soujanya and Ekbal, Asif and Bhattacharyya, Pushpak},
booktitle={2018年自然语言处理经验方法会议论文集},
pages={3454--3466},
year={2018}
}
致谢
此仓库中的部分功能借鉴自 https://github.com/soujanyaporia/contextual-utterance-level-multimodal-sentiment-analysis。
作者
Deepanway Ghosal、Soujanya Poria
张量融合网络(TFN)
重要通知
此仓库所依赖的 CMU 多模态 SDK 自编写此代码以来,其 API 已发生重大变化。因此,此仓库中的代码已无法直接运行。然而,模型本身的代码仍可供参考。
张量融合网络
这是对以下内容的 PyTorch 实现:
Zadeh, Amir, 等人。“用于多模态情感分析的张量融合网络。” EMNLP 2017 口头报告。
它需要 PyTorch 和 CMU 多模态数据 SDK(https://github.com/A2Zadeh/CMU-MultimodalDataSDK)才能正常运行。如果您首次运行脚本,训练数据(CMU-MOSI 数据集)将自动下载。
模型定义在 model.py 中,训练脚本是 train.py。以下是 train.py 的命令行参数列表:
--dataset:默认为 'MOSI',目前不支持其他数据集。请忽略此选项。
--epochs:最大训练轮数,默认为 50。
--batch_size:批量大小,默认为 32。
--patience:指定早停条件,类似于 Keras 中的设置,默认为 20。
--cuda:是否使用 GPU,默认为 False。
--model_path:指定保存训练模型的位置的字符串,默认为 'models'。
--max_len:预处理数据时的最大序列长度,默认为 20。
简而言之,您可以使用以下命令训练模型:
python train.py --epochs 100 --patience 10
该脚本最初会随机选择一组超参数。如果您想调整它们,可以自行在脚本中修改。
引用
如果您在研究中使用此代码,请使用以下方式引用我们的工作:
@inproceedings{tensoremnlp17,
title={用于多模态情感分析的张量融合网络},
author={Zadeh, Amir and Chen, Minghai and Poria, Soujanya and Cambria, Erik and Morency, Louis-Philippe},
booktitle={自然语言处理经验方法会议,EMNLP},
year={2017}
}
低秩多模态融合
这是 Liu 和 Shen 等人 ACL 2018 论文“具有模态特异性因子的有效低秩多模态融合”的代码库。
依赖项
Python 2.7(现已实验性地支持 Python 3.6+)
torch=0.3.1
sklearn
numpy
您可以通过 python -m pip install -r requirements.txt 安装这些库。
实验数据
用于实验的处理后数据(CMU-MOSI、IEMOCAP、POM)可在此下载:
https://drive.google.com/open?id=1CixSaw3dpHESNG0CaCJV6KutdlANP_cr
要运行代码,您需要下载这些序列化数据集,并将其放置在 data 目录中。
请注意,声学特征中可能存在 NaN 值,您可以将其替换为 0。
训练您的模型
要运行实验代码(网格搜索),请使用脚本 train_xxx.py。这些脚本包含以下命令行参数:
`--run_id`: 用户指定的唯一 ID,以确保保存的结果/模型不会相互覆盖。
`--epochs`: 训练的最大轮数。由于使用了早停机制来防止过拟合,实际训练的轮数可能少于此处指定的值。
`--patience`: 如果模型性能在连续 `--patience` 次验证评估中没有提升,则训练将提前停止。
`output_dim`: 模型的输出维度。每个脚本中的默认值通常适用。
`signiture`: 可选字符串,会添加到输出文件名中,用作某种注释。
`cuda`: 是否在训练中使用 GPU。如果未指定,则使用 CPU。
`data_path`: 数据目录的路径。默认为 './data',但如果您希望将数据存储在其他位置,可以更改此设置。
`model_path`: 用于保存模型的目录路径。
`output_path`: 用于保存网格搜索结果的目录路径。
`max_len`: 训练数据序列的最大长度。超过此长度的序列会被截断或填充。
`emotion`: (仅适用于 IEMOCAP)指定您希望模型预测的情绪类别。可以是 'happy'、'sad'、'angry' 或 'neutral'。
示例命令如下:
python train_mosi.py --run_id 19260817 --epochs 50 --patience 20 --output_dim 1 --signiture test_run_big_model
超参数
用于复现论文中结果的一些超参数位于 hyperparams.txt 文件中。
引用
@misc{liu2018efficient,
title={Efficient Low-rank Multimodal Fusion with Modality-Specific Factors},
author={Zhun Liu and Ying Shen and Varun Bharadhwaj Lakshminarasimhan and Paul Pu Liang and Amir Zadeh and Louis-Philippe Morency},
year={2018},
eprint={1806.00064},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
数据集
MELD:多模态多人对话情感识别数据集
注意
:fire: :fire: :fire: 如需更新的基线,请访问此链接:conv-emotion
排行榜
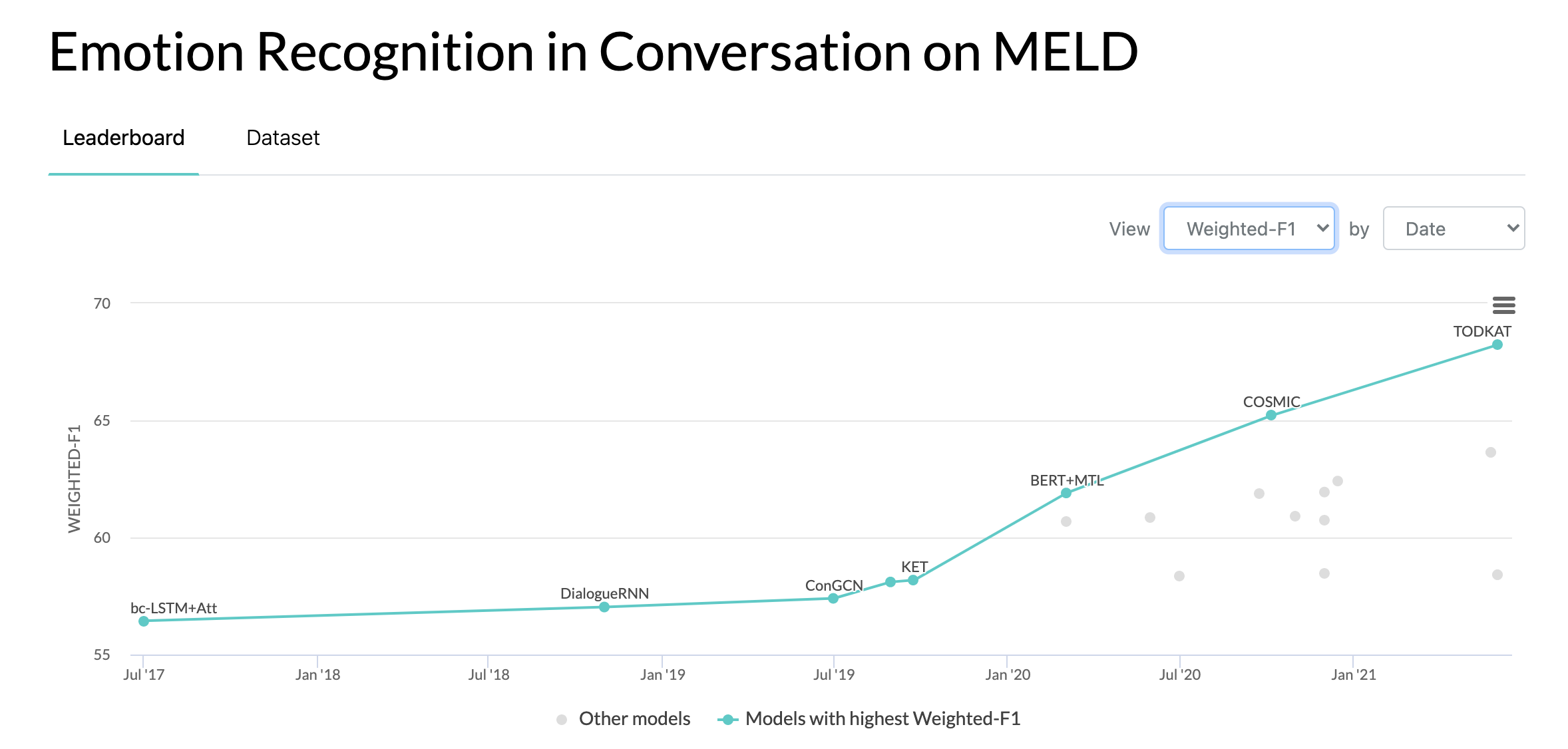
更新
2020年10月10日:关于 MELD 数据集上对话情感识别的新论文及 SOTA 结果。相关代码请参阅 COSMIC 目录。论文标题为——COSMIC: COmmonSense knowledge for eMotion Identification in Conversations。
2019年5月22日:MELD:多模态多人对话情感识别数据集已被 ACL 2019 全文接收。更新后的论文可在 https://arxiv.org/pdf/1810.02508.pdf 查看。
2019年5月22日:双人版 MELD 已发布,可用于测试双人对话模型。
2018年11月15日:修复了 train.tar.gz 中的问题。
使用 MELD 的研究工作
Zhang, Yazhou, Qiuchi Li, Dawei Song, Peng Zhang, and Panpan Wang. “受量子启发的交互网络用于对话情感分析。” IJCAI 2019。
Zhang, Dong, Liangqing Wu, Changlong Sun, Shoushan Li, Qiaoming Zhu, and Guodong Zhou. “建模上下文与说话者敏感依赖性以进行多说话者对话中的情感检测。” IJCAI 2019。
Ghosal, Deepanway, Navonil Majumder, Soujanya Poria, Niyati Chhaya, and Alexander Gelbukh. “DialogueGCN:用于对话情感识别的图卷积神经网络。” EMNLP 2019。
简介
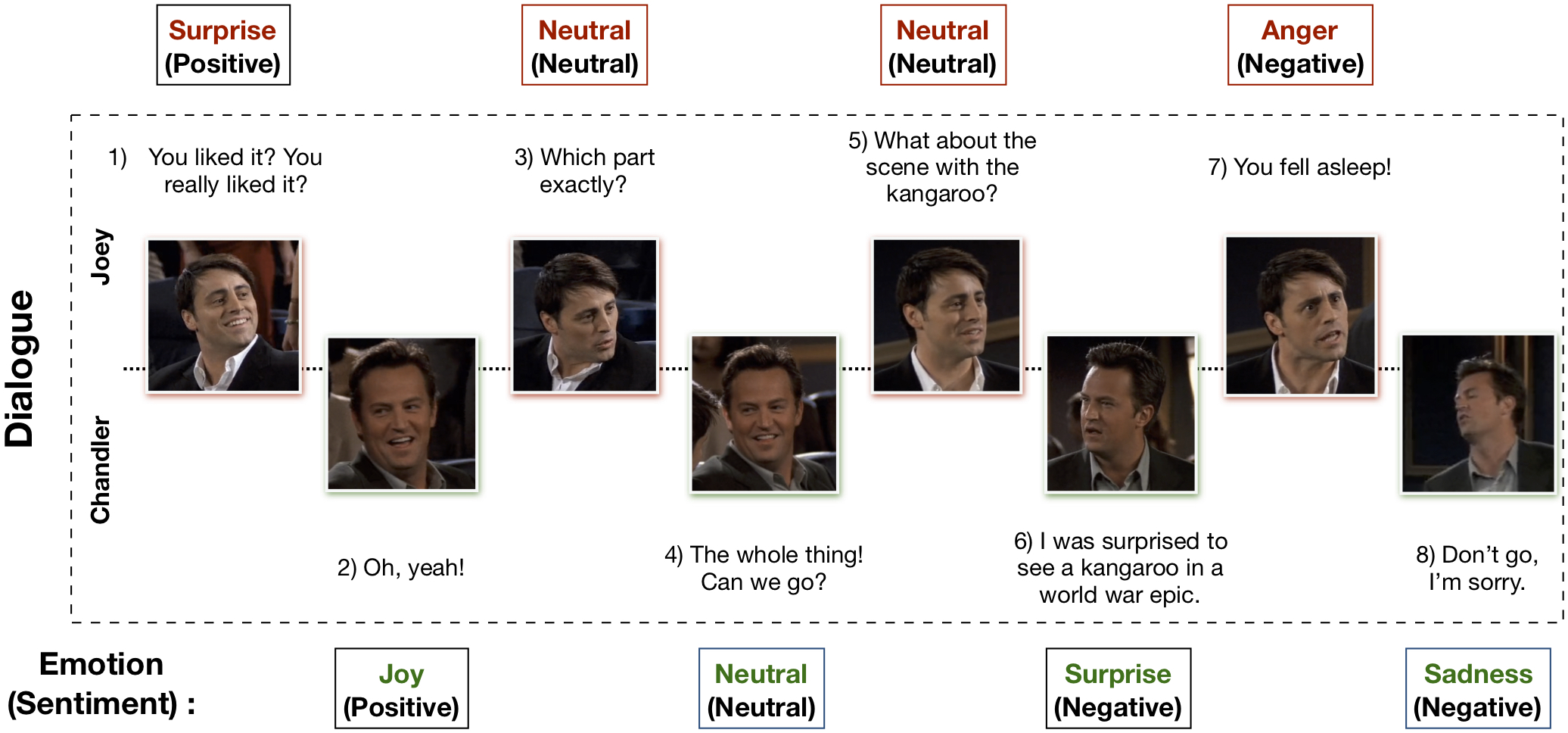
多模态 EmotionLines 数据集(MELD)是在 EmotionLines 数据集的基础上扩展和增强而创建的。MELD 包含 EmotionLines 中的所有对话实例,同时还增加了音频和视觉模态信息。MELD 包含来自电视剧《老友记》的 1400 多段对话和 13000 条话语。对话中有多个说话者参与。每条话语都被标注为七种情绪之一——愤怒、厌恶、悲伤、喜悦、 neutral、惊讶和恐惧。此外,MELD 还为每条话语提供了情感标注(正面、负面和 neutral)。
示例对话
数据集统计
| 统计指标 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|
| 模态数量 | {a,v,t} | {a,v,t} | {a,v,t} |
| 唯一词数 | 10,643 | 2,384 | 4,361 |
| 平均话语长度 | 8.03 | 7.99 | 8.28 |
| 最大话语长度 | 69 | 37 | 45 |
| 每段对话平均情绪数 | 3.30 | 3.35 | 3.24 |
| 对话数量 | 1039 | 114 | 280 |
| 话语数量 | 9989 | 1109 | 2610 |
| 说话者数量 | 260 | 47 | 100 |
| 情绪转换次数 | 4003 | 427 | 1003 |
| 平均话语时长 | 3.59s | 3.59s | 3.58s |
更多详情请访问 https://affective-meld.github.io。
数据分布
| 训练集 | 验证集 | 测试集 | |
|---|---|---|---|
| 愤怒 | 1109 | 153 | 345 |
| 厌恶 | 271 | 22 | 68 |
| 恐惧 | 268 | 40 | 50 |
| 喜悦 | 1743 | 163 | 402 |
| Neutral | 4710 | 470 | 1256 |
| 悲伤 | 683 | 111 | 208 |
| 惊讶 | 1205 | 150 | 281 |
目的
多模态数据分析利用多个并行数据通道中的信息来进行决策。随着人工智能的快速发展,多模态情感识别已成为研究热点,这主要得益于其在对话生成、多模态交互等众多挑战性任务中的潜在应用。对话式情感识别系统可以通过分析用户的情感来生成适当的回应。尽管已有大量关于多模态情感识别的研究工作,但真正专注于理解对话中情感的研究却寥寥无几。然而,这些研究仅限于两人之间的对话理解,因此无法扩展到包含两个以上参与者的多方对话情感识别。EmotionLines 可以作为纯文本情感识别的资源,因为它不包含视觉和音频等其他模态的数据。同时需要注意的是,目前尚不存在用于情感识别研究的多模态多方对话数据集。在本工作中,我们对 EmotionLines 数据集进行了扩展、改进,并进一步开发以适应多模态场景。在连续轮次中进行情感识别存在诸多挑战,其中上下文理解便是其中之一。对话中轮次序列的情感变化与情感流动使得准确建模上下文成为一项艰巨的任务。在本数据集中,由于我们能够获取每个对话的多模态数据源,我们假设这将有助于改善上下文建模,从而提升整体的情感识别性能。该数据集还可用于开发多模态情感对话系统。IEMOCAP 和 SEMAINE 是包含每句话情感标签的多模态对话数据集。然而,这些数据集本质上是两人对话,这也凸显了我们提出的 Multimodal-EmotionLines 数据集的重要性。其他公开可用的多模态情感与情绪识别数据集包括 MOSEI、MOSI 和 MOUD,但这些数据集均非对话形式。
数据集创建
第一步是为 EmotionLines 数据集中每个对话中的每一句台词找到时间戳。为此,我们遍历了所有剧集的字幕文件,从中提取了每句台词的开始和结束时间戳。通过这一过程,我们获得了每集的季号、集号以及每句台词的时间戳。在获取时间戳时,我们设定了两个约束条件:(a) 对话中各句台词的时间戳必须按顺序递增;(b) 对话中的所有台词必须属于同一集和同一场景。基于这两个条件的限制,我们发现 EmotionLines 中有少数对话由多个自然对话组成。我们将这些情况从数据集中剔除。由于这一纠错步骤,我们的数据集所包含的对话数量与原始 EmotionLines 数据集有所不同。在获取每句台词的时间戳后,我们从原始剧集中提取了相应的视听片段,并单独截取出这些视频片段中的音频内容。最终,本数据集为每个对话提供了视觉、音频和文本三种模态的数据。
论文
有关该数据集的论文可参见:https://arxiv.org/pdf/1810.02508.pdf
下载数据
请访问 http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz 下载原始数据。数据以 .mp4 格式存储,压缩包为 XXX.tar.gz 文件。标注信息可在 https://github.com/declare-lab/MELD/tree/master/data/MELD 找到。
.csv 文件说明
列说明
| 列名 | 说明 |
|---|---|
| 序号 | 发言的序号,主要用于在不同版本或包含不同子集的多个副本中引用具体的发言。 |
| 发言内容 | EmotionLines 数据集中以字符串形式表示的单个发言。 |
| 发言者 | 与该发言相关的发言者姓名。 |
| 情感 | 发言者在该发言中表达的情感(中性、喜悦、悲伤、愤怒、惊讶、恐惧、厌恶)。 |
| 情感倾向 | 发言者在该发言中表达的情感倾向(正面、中性、负面)。 |
| 对话语篇ID | 对话语篇的索引,从0开始。 |
| 发言ID | 该发言在对话语篇中的索引,从0开始。 |
| 季节数 | 该发言所属的《老友记》电视剧的季节数。 |
| 集数 | 该发言所属的某一季中具体剧集的集数。 |
| 开始时间 | 该发言在给定剧集中开始的时间,格式为“时:分:秒,毫秒”。 |
| 结束时间 | 该发言在给定剧集中结束的时间,格式为“时:分:秒,毫秒”。 |
文件说明
- /data/MELD/train_sent_emo.csv - 包含训练集中的话语及其情感和情绪标签。
- /data/MELD/dev_sent_emo.csv - 包含验证集中的话语及其情感和情绪标签。
- /data/MELD/test_sent_emo.csv - 包含测试集中的话语及其情感和情绪标签。
- /data/MELD_Dyadic/train_sent_emo_dya.csv - 包含MELD双人对话变体训练集中的话语及其情感和情绪标签。要获取与特定话语对应的视频片段,请参考“Old_Dialogue_ID”和“Old_Utterance_ID”两列。
- /data/MELD_Dyadic/dev_sent_emo_dya.csv - 包含双人对话变体验证集中的话语及其情感和情绪标签。要获取与特定话语对应的视频片段,请参考“Old_Dialogue_ID”和“Old_Utterance_ID”两列。
- /data/MELD_Dyadic/test_sent_emo_dya.csv - 包含双人对话变体测试集中的话语及其情感和情绪标签。要获取与特定话语对应的视频片段,请参考“Old_Dialogue_ID”和“Old_Utterance_ID”两列。
Pickle 文件说明
共有13个Pickle文件,包含了用于训练基线模型的数据和特征。以下是每个Pickle文件的简要说明。
数据Pickle文件:
- data_emotion.p、data_sentiment.p - 这是主要的数据文件,包含以列表形式存储的5个不同元素。
- data: 一个字典,包含以下键值对:
- text: 原始句子。
- split: train/val/test - 表示该元组所属的划分(训练集、验证集或测试集)。
- y: 句子的标签。
- dialog: 该话语所属对话的ID。
- utterance: 对话ID中的话语编号。
- num_words: 话语中的单词数。
- W: Glove嵌入矩阵。
- vocab: 数据集的词汇表。
- word_idx_map: 词汇表中每个词到其在W中索引的映射。
- max_sentence_length: 数据集中话语的最大标记数。
- label_index: 每个标签(情绪或情感)与其分配索引的映射,例如label_index['neutral']=0。
- data: 一个字典,包含以下键值对:
import pickle
data, W, vocab, word_idx_map, max_sentence_length, label_index = pickle.load(open(filepath, 'rb'))
- text_glove_average_emotion.pkl、text_glove_average_sentiment.pkl - 包含每个话语的300维文本特征向量,这些特征向量由该话语中所有标记的Glove嵌入取平均得到。它是一个列表,包含针对训练集、验证集和测试集的3个字典,每个字典以dia_utt格式索引,其中dia为对话ID,utt为话语ID。例如,train_text_avg_emb['0_0'].shape = (300, )。
import pickle
train_text_avg_emb、val_text_avg_emb、test_text_avg_emb = pickle.load(open(filepath, 'rb'))
- audio_embeddings_feature_selection_emotion.pkl、audio_embeddings_feature_selection_sentiment.pkl - 包含每个话语的1611/1422维音频特征向量,这些特征是为情绪/情感分类训练得到的。这些特征最初是从openSMILE提取的,随后使用基于L2范数的特征选择方法,并通过SVM进行筛选。它是一个列表,包含针对训练集、验证集和测试集的3个字典,每个字典以dia_utt格式索引,其中dia为对话ID,utt为话语ID。例如,train_audio_emb['0_0'].shape = (1611, )或(1422, )。
import pickle
train_audio_emb、val_audio_emb、test_audio_emb = pickle.load(open(filepath, 'rb'))
模型输出Pickle文件:
- text_glove_CNN_emotion.pkl、text_glove_CNN_sentiment.pkl - 包含在基于CNN的网络上训练后得到的100维文本特征,用于情绪/情感分类。它是一个列表,包含针对训练集、验证集和测试集的3个字典,每个字典以dia_utt格式索引,其中dia为对话ID,utt为话语ID。例如,train_text_CNN_emb['0_0'].shape = (100, )。
import pickle
train_text_CNN_emb、val_text_CNN_emb、test_text_CNN_emb = pickle.load(open(filepath, 'rb'))
- text_emotion.pkl、text_sentiment.pkl - 这些文件包含由单模态bcLSTM模型生成的上下文特征表示。它们为每个话语存储600维文本特征向量,用于情绪/情感分类,以对话ID为索引的字典形式呈现。它是一个列表,包含针对训练集、验证集和测试集的3个字典。例如,train_text_emb['0'].shape = (33, 600),其中33是对话中最多的话语数量。话语较少的对话会用零向量填充。
import pickle
train_text_emb、val_text_emb、test_text_emb = pickle.load(open(filepath, 'rb'))
- audio_emotion.pkl、audio_sentiment.pkl - 这些文件包含由单模态bcLSTM模型生成的上下文特征表示。它们为每个话语存储300/600维音频特征向量,用于情绪/情感分类,以对话ID为索引的字典形式呈现。它是一个列表,包含针对训练集、验证集和测试集的3个字典。例如,train_audio_emb['0'].shape = (33, 300)或(33, 600),其中33是对话中最多的话语数量。话语较少的对话会用零向量填充。
import pickle
train_audio_emb、val_audio_emb、test_audio_emb = pickle.load(open(filepath, 'rb'))
- bimodal_sentiment.pkl - 该文件包含由双模态bcLSTM模型生成的上下文特征表示。它为每个话语存储600维双模态(文本、音频)特征向量,用于情感分类,以对话ID为索引的字典形式呈现。它是一个列表,包含针对训练集、验证集和测试集的3个字典。例如,train_bimodal_emb['0'].shape = (33, 600),其中33是对话中最多的话语数量。话语较少的对话会用零向量填充。
import pickle
train_bimodal_emb、val_bimodal_emb、test_bimodal_emb = pickle.load(open(filepath, 'rb'))
原始数据描述
- 数据集包含3个文件夹(.tar.gz文件):train、dev和test;每个文件夹分别对应3个.csv文件中的语音片段。
- 在任何一个文件夹中,原始数据中的每个视频片段都对应于相应.csv文件中的一个语句。视频片段的命名格式为:diaX1_uttX2.mp4,其中X1是对话ID,X2是语句ID,与相应.csv文件中的信息一致,用于标识特定的语句。
- 例如,考虑train.tar.gz中的视频片段dia6_utt1.mp4。该视频片段对应的语句将在train_sent_emp.csv文件中,其Dialogue_ID=6且Utterance_ID=1,即*'You liked it? You really liked it?'*。
数据读取
在’./utils/’目录下提供了2个Python脚本:
- read_meld.py - 显示MELD数据集中.csv文件中某一语句对应的视频文件路径。
- read_emorynlp - 显示多模态EmoryNLP情感识别数据集中.csv文件中某一语句对应的视频文件路径。
标签定义
在实验中,所有标签均以独热编码表示,其索引如下:
- 情感 - {'neutral': 0, 'surprise': 1, 'fear': 2, 'sadness': 3, 'joy': 4, 'disgust': 5, 'anger': 6}。因此,情感为*'joy'*的标签为[0., 0., 0., 0., 1., 0., 0.]
- 情绪 - {'neutral': 0, 'positive': 1, 'negative': 2}。因此,情绪为*'positive'*的标签为[0., 1., 0.]
类别权重
在情感分类的基线模型中,使用了以下类别权重。索引方式与上述相同。 类别权重:[4.0, 15.0, 15.0, 3.0, 1.0, 6.0, 3.0]。
运行基线模型
请按照以下步骤运行基线模型:
- 从这里下载特征文件。
- 将这些特征文件复制到
./data/pickles/目录下。 - 要训练或测试基线模型,请运行文件:
baseline/baseline.py,命令如下:python baseline.py -classify [Sentiment|Emotion] -modality [text|audio|bimodal] [-train|-test]- 示例命令:训练文本单模态的情感分类模型:
python baseline.py -classify Sentiment -modality text -train - 使用
python baseline.py -h可获取参数帮助信息。
- 对于预训练模型,从这里下载模型权重,并将pickle文件放入
./data/models/目录中。
引用
如果您在研究中使用了本数据集,请引用以下论文:
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, R. Mihalcea. MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversation. ACL 2019.
Chen, S.Y., Hsu, C.C., Kuo, C.C. and Ku, L.W. EmotionLines: An Emotion Corpus of Multi-Party Conversations. arXiv preprint arXiv:1802.08379 (2018).
多模态EmoryNLP情感识别数据集
描述
多模态EmoryNLP情感检测数据集是在EmoryNLP情感检测数据集的基础上扩展和增强而创建的。它包含了EmoryNLP情感检测数据集中相同的对话实例,同时还增加了音频和视觉模态,与文本模态一起构成了多模态数据。多模态EmoryNLP数据集中包含来自电视剧《老友记》的800多个对话和9000多个语句。对话中有多个说话者参与。每个语句都被标注为以下七种情感之一——中性、喜悦、平静、强大、恐惧、愤怒和悲伤。这些标注直接来源于原始数据集。
数据集统计信息
| 统计指标 | Train | Dev | Test |
|---|---|---|---|
| 模态数量 | {a,v,t} | {a,v,t} | {a,v,t} |
| 独特词汇数 | 9,744 | 2,123 | 2,345 |
| 平均语句长度 | 7.86 | 6.97 | 7.79 |
| 最大语句长度 | 78 | 60 | 61 |
| 每个场景平均情感数量 | 4.10 | 4.00 | 4.40 |
| 对话数量 | 659 | 89 | 79 |
| 语句数量 | 7551 | 954 | 984 |
| 说话者数量 | 250 | 46 | 48 |
| 情感转换次数 | 4596 | 575 | 653 |
| 平均语句时长 | 5.55s | 5.46s | 5.27s |
数据分布
| Train | Dev | Test | |
|---|---|---|---|
| 喜悦 | 1677 | 205 | 217 |
| 愤怒 | 785 | 97 | 86 |
| 中性 | 2485 | 322 | 288 |
| 平静 | 638 | 82 | 111 |
| 强大 | 551 | 70 | 96 |
| 悲伤 | 474 | 51 | 70 |
| 恐惧 | 941 | 127 | 116 |
数据
本数据集的视频片段可以从此链接下载。 标注文件可在https://github.com/SenticNet/MELD/tree/master/data/emorynlp找到。共有3个.csv文件。这些csv文件的第一列每条记录都包含一个语句,其对应的视频片段可以在[此处](https://drive.google.com/file/d/1UQduKw8QTqGf3RafxrTDfI1NyInYK3fr/view?usp=sharing)找到。每个语句及其视频片段都按季号、集号、场景编号和语句编号进行索引。例如,**sea1\_ep2\_sc6\_utt3.mp4**表示该片段对应于第1季第2集第6场景第3语句。一个场景即为一段对话。这种索引方式与原始数据集保持一致。csv文件和视频文件均按照原始数据集的划分方式分为训练集、验证集和测试集。标注直接沿用了原始的EmoryNLP数据集(Zahiri等,2018)。
.csv 文件说明
列规范
| 列名 | 说明 |
|---|---|
| Utterance | 来自 EmoryNLP 的单个话语,以字符串形式表示。 |
| Speaker | 与该话语相关联的说话者姓名。 |
| Emotion | 说话者在该话语中表达的情绪(中性、喜悦、平静、强大、害怕、愤怒和悲伤)。 |
| Scene_ID | 对话的索引,从 0 开始。 |
| Utterance_ID | 对话中特定话语的索引,从 0 开始。 |
| Season | 该话语所属的《老友记》电视剧的季数。 |
| Episode | 该话语所属的某一季中的集数。 |
| StartTime | 该话语在相应集中的开始时间,格式为“hh:mm:ss,ms”。 |
| EndTime | 该话语在相应集中的结束时间,格式为“hh:mm:ss,ms”。 |
注:由于字幕存在一些不一致之处,我们未能找到少数话语的开始和结束时间。这些话语已被从数据集中剔除。不过,我们鼓励用户从原始数据集中找到相应的话语,并为其生成视频片段。
引用
如果您在研究中使用了本数据集,请引用以下论文:
S. Zahiri 和 J. D. Choi. 基于序列卷积神经网络的电视剧剧本情感检测。载于 AAAI 情感内容分析研讨会,AFFCON'18,2018 年。
S. Poria、D. Hazarika、N. Majumder、G. Naik、E. Cambria、R. Mihalcea. MELD:用于对话中情感识别的多模态多人数据集。ACL 2019。
MUStARD:多模态讽刺检测数据集
本仓库包含我们2019年ACL论文的数据集和代码:
我们发布了MUStARD数据集,这是一个用于自动化讽刺识别研究的多模态视频语料库。该数据集来源于热门电视剧,包括《老友记》、《黄金女郎》、《生活大爆炸》和《讽刺狂人匿名会》。MUStARD由带有讽刺标签的视听话语组成。每个话语都附有其上下文,提供了话语发生场景的额外信息。
示例实例

数据集中的一段讽刺性话语及其上下文和文字稿。
原始视频
我们提供了一个包含原始视频片段的Google Drive文件夹,其中包括话语及其各自的上下文。
数据格式
视听片段的标注和文字稿可在data/sarcasm_data.json中找到。JSON文件中的每个实例都被分配了一个标识符(例如“1_60”),它是一个包含以下项的字典:
| 键 | 值 |
|---|---|
utterance |
待分类目标话语的文本。 |
speaker |
目标话语的说话者。 |
context |
在目标话语之前按时间顺序排列的话语列表。 |
context_speakers |
上下文话语各自的说话者。 |
sarcasm |
讽刺标签的二值标记。 |
JSON中的示例格式:
{
"1_60": {
"utterance": "能亲眼见证你的思维运作,真是莫大的荣幸。",
"speaker": "谢尔顿",
"context": [
"我从未想到能在宇宙大爆炸的余波中发现弦理论的指纹。",
"抱歉,请问你的计划是什么?"
],
"context_speakers": [
"莱纳德",
"谢尔顿"
],
"sarcasm": true
}
}
引用
如果您在研究中使用了此数据集,请引用以下论文:
@inproceedings{mustard,
title = "迈向多模态讽刺检测(一篇\_显然\_完美的论文)",
author = "Castro, Santiago and
Hazarika, Devamanyu and
P{\'e}rez-Rosas, Ver{\'o}nica and
Zimmermann, Roger and
Mihalcea, Rada and
Poria, Soujanya",
booktitle = "第57届计算语言学协会年会论文集(第一卷:长篇论文)",
month = "7",
year = "2019",
address = "意大利佛罗伦萨",
publisher = "计算语言学协会",
}
运行代码
使用Conda设置环境:
conda env create -f environment.yml conda activate mustard python -c "import nltk; nltk.download('punkt')"将Common Crawl预训练的300维、8400亿词的GloVe词向量下载到某个位置。
下载预提取的视觉特征到
data/文件夹中(使data/features/包含context_final/和utterances_final/两个文件夹,内含特征),或者自行提取视觉特征。下载预提取的BERT特征,并将两个文件直接放置在
data/文件夹下(即data/bert-output.jsonl和data/bert-output-context.jsonl),或在另一个配备Python 2和TensorFlow 1.11.0的环境中,按照BERT仓库中的“使用BERT提取固定特征向量(如ELMo)”方法提取BERT特征,并运行:# 在某个目录下载BERT-base uncased模型: wget https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip # 然后将路径赋给这个变量: BERT_BASE_DIR=... python extract_features.py \ --input_file=data/bert-input.txt \ --output_file=data/bert-output.jsonl \ --vocab_file=${BERT_BASE_DIR}/vocab.txt \ --bert_config_file=${BERT_BASE_DIR}/bert_config.json \ --init_checkpoint=${BERT_BASE_DIR}/bert_model.ckpt \ --layers=-1,-2,-3,-4 \ --max_seq_length=128 \ --batch_size=8检查
python train_svm.py -h中的选项以选择运行配置(或修改config.py),然后运行:python train_svm.py # 添加您需要的标志评估:我们使用加权F分数指标,在5折交叉验证方案中进行评估。折索引可在
data/split_incides.p中找到。更多细节请参考我们的基线脚本。
M2H2:多模态多人印地语对话幽默识别数据集
:zap: :zap: :zap: 基线代码即将发布!
:fire::fire::fire: 阅读论文
M2H2数据集来源于著名电视剧《Shrimaan Shrimati Phir Se》(总时长4.46小时),并进行了人工标注。我们根据上下文将这些样本(话语)分组为场景。每个场景中的每条话语都带有标签,指示该话语是否具有幽默性,即幽默或非幽默。此外,每条话语还标注了说话者和听者的信息。在多人对话中,识别听者是一项重大挑战。在我们的数据集中,我们将听者定义为对话中说话者正在回应的那一方。每个场景中的每条话语都与其上下文话语相关联,这些上下文话语是由参与对话的各方轮流说出的。该数据集还包括多人对话,其分类难度比两人对话更高。
数据格式

文本数据
:fire::fire::fire: Raw-Text/Ep-NUMBER.tsv 文件充当主标注文件,不仅包含文本数据,还包含如下所述的其他元数据。它同样包含了对话语句的手动标注标签。通过使用剧集 ID 和场景 ID,可以将 Raw-Text 文件夹中的话语句映射到 Raw-Audio 和 Raw-Visual 中对应的音频和视觉片段,从而形成多模态数据。TSV 文件中的 Label 列,例如 Raw-Text/Ep-NUMBER.tsv,包含了每条话语句所需的手动标注标签。
文本数据以 TSV 格式存储。每个文件的命名格式为 Raw-Text/Ep-NUMBER.tsv。其中的 NUMBER 表示剧集编号,可用于与相应的音频和视觉片段进行匹配。文本数据包含以下字段:
Scenes:场景 ID,用于与对应的音频和视觉片段相匹配。
SI. No.:话语句编号。
Start_time:话语句在视频中的开始时间。
End_time:话语句在视频中的结束时间。
Utterance:口头话语句。
Label:话语句的标注标签,可为幽默或非幽默。
Speaker:格式为“说话者,听者”,形式为“说话者姓名,话语句编号”,例如“Dilruba,u3”,表示说话者是 Dilruba,且其回应的是第 3 号话语句。这一信息对于解析多方对话中的指代关系尤为有用。
音频数据
每个剧集都有一个专用文件夹,例如 Raw-Audio/22/ 包含第 22 集的所有已标注音频样本。
对于每集而言,每个场景也有一个专用文件夹,例如 Raw-Audio/22/Scene_1 包含第 22 集第 1 场的所有已标注音频样本。
视觉数据
每个剧集都有一个专用文件夹,例如 Raw-Visual/22/ 包含第 22 集的所有已标注视觉样本。
对于每集而言,每个场景也有一个专用文件夹,例如 Raw-Visual/22/Scene_1 包含第 22 集第 1 场的所有已标注视觉样本。
基线模型
:zap: :zap: :zap: 基线代码即将发布!
引用
Dushyant Singh Chauhan, Gopendra Vikram Singh, Navonil Majumder, Amir Zadeh, Asif Ekbal, Pushpak Bhattacharyya, Louis-philippe Morency, and Soujanya Poria. 2021. M2H2:用于对话中幽默识别的多模态多方印地语数据集。收录于 ICMI ’21:第 23 届 ACM 国际多模态交互会议,加拿大蒙特利尔。ACM,美国纽约州纽约市,5 页。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器