whodb
WhoDB 是一款专为现代开发者打造的轻量级数据库管理工具,支持 Postgres、MySQL、SQLite、MongoDB、Redis 等多种主流数据库。它旨在解决传统数据库客户端启动慢、资源占用高以及操作界面复杂的问题,让数据探索和管理变得轻松高效。
无论是需要快速排查生产环境故障的后端工程师,还是希望直观理解数据架构的研究人员,WhoDB 都能提供流畅的体验。其核心优势在于极致的性能与智能化的交互:基于 Go 语言和 React 构建,安装包不足 50MB,启动时间少于 1 秒,且资源消耗仅为同类工具的十分之一。界面设计简洁直观,提供类似电子表格的数据网格和交互式架构可视化,无需专门学习即可上手。
此外,WhoDB 的一大亮点是内置了强大的 AI 对话功能。用户无需编写复杂的 SQL 语句,只需通过自然语言描述需求,即可借助 Ollama、OpenAI 等模型自动生成查询代码或直接与数据“对话”。这种将高性能引擎与人工智能相结合的设计,使得 WhoDB 成为日常开发、数据调试及架构探索的理想助手。
使用场景
某电商后端工程师在深夜紧急排查生产环境订单数据异常,需要快速定位特定用户的历史交易记录并分析关联的库存变动。
没有 whodb 时
- 启动缓慢且资源占用高:传统重型数据库客户端启动耗时久,在低配运维机上卡顿明显,严重影响排查效率。
- 复杂查询编写耗时:为了关联订单表与库存日志表,需手动编写冗长的 SQL JOIN 语句,极易因拼写错误导致二次报错。
- 数据浏览体验割裂:返回的海量结果集无法流畅滚动,缺乏类似电子表格的直观视图,难以快速筛选关键异常行。
- 多库切换繁琐:需要在 MySQL(订单)、Redis(缓存)和 MongoDB(日志)之间反复切换不同工具,上下文频繁中断。
使用 whodb 后
- 秒级启动轻盈运行:whodb 凭借小于 50MB 的体积瞬间启动,即使在资源受限的服务器上也能保持丝滑流畅,零等待进入工作状态。
- 自然语言直达数据:直接在聊天框输入“查找用户 ID 为 1024 的最近十笔订单及其库存扣减记录”,whodb 自动将其转化为精准 SQL 并执行,无需手写代码。
- 表格化交互高效直观:查询结果以现代化的数据网格呈现,支持像 Excel 一样自由排序、过滤和编辑,异常数据一眼可见。
- 全栈数据库统一入口:在一个界面内同时连接 MySQL、Redis 和 MongoDB,通过统一聊天接口跨库检索,彻底消除工具切换带来的心流打断。
whodb 通过 AI 对话式交互与极致轻量化的设计,将原本繁琐的数据库排查工作转变为直观、高效的自然语言探索过程。
运行环境要求
- Linux
- macOS
- Windows
- 非必需
- 若使用本地 AI 模型(如 Ollama),需依赖本地硬件支持,README 未指定具体 GPU 型号或显存要求
未说明(描述为轻量级 <50MB,资源占用比传统工具少 90%)
快速开始













🎯 What is WhoDB?
WhoDB 是开发者真正想要使用的现代化数据库管理工具。
基于 GoLang 和 React 构建,WhoDB 是一款轻量级(小于 50MB)但功能强大的数据库客户端,兼具极速性能与直观美观的界面。无论您是在调试生产环境中的问题、探索新的数据库模式,还是为下一个功能管理数据,WhoDB 都能让数据库管理工作变得轻松自如。
为什么选择 WhoDB?
|
🚀 极速响应
🎨 美观且直观
|
🤖 AI 驱动
🔧 开发者友好
|
✨ 核心功能
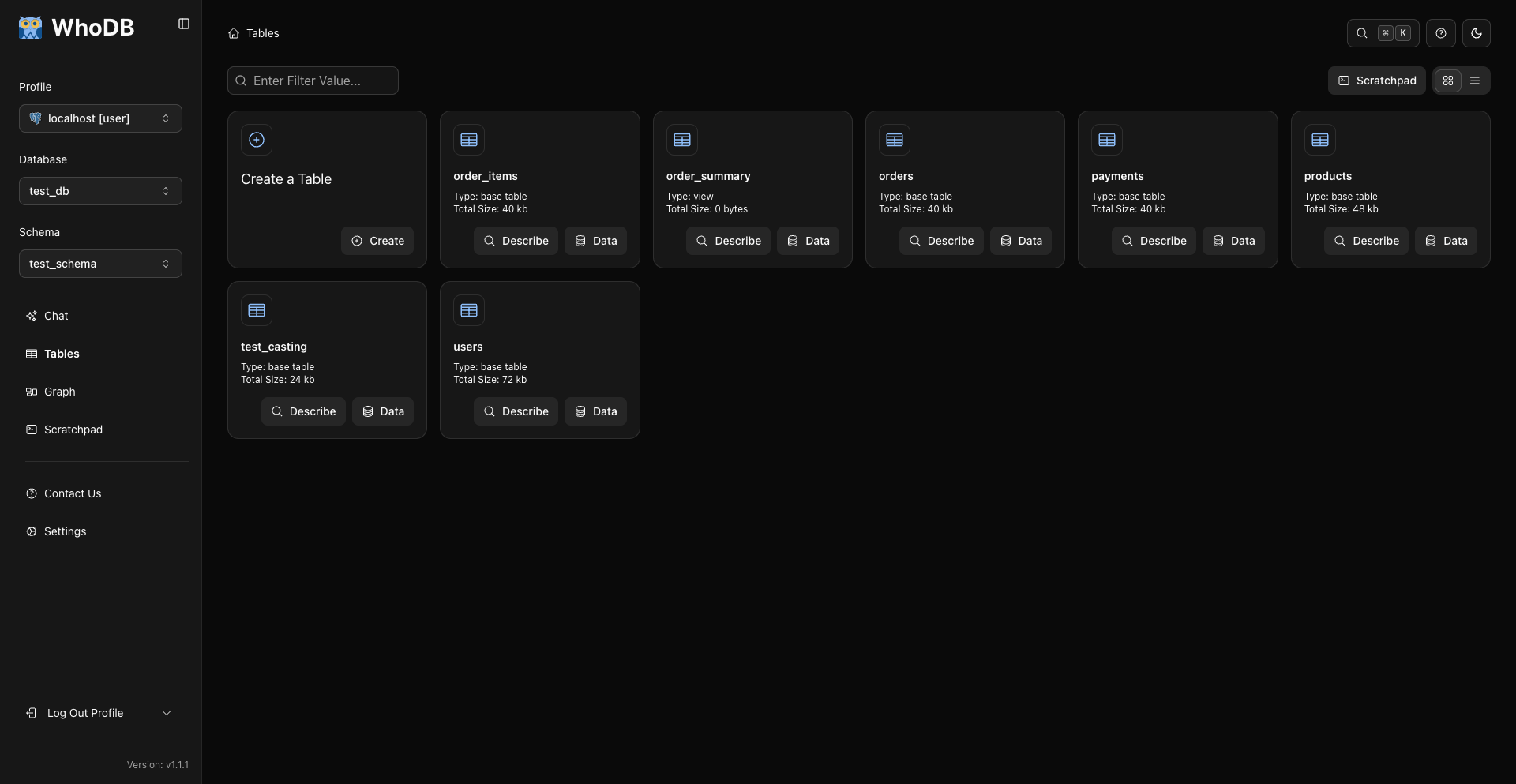
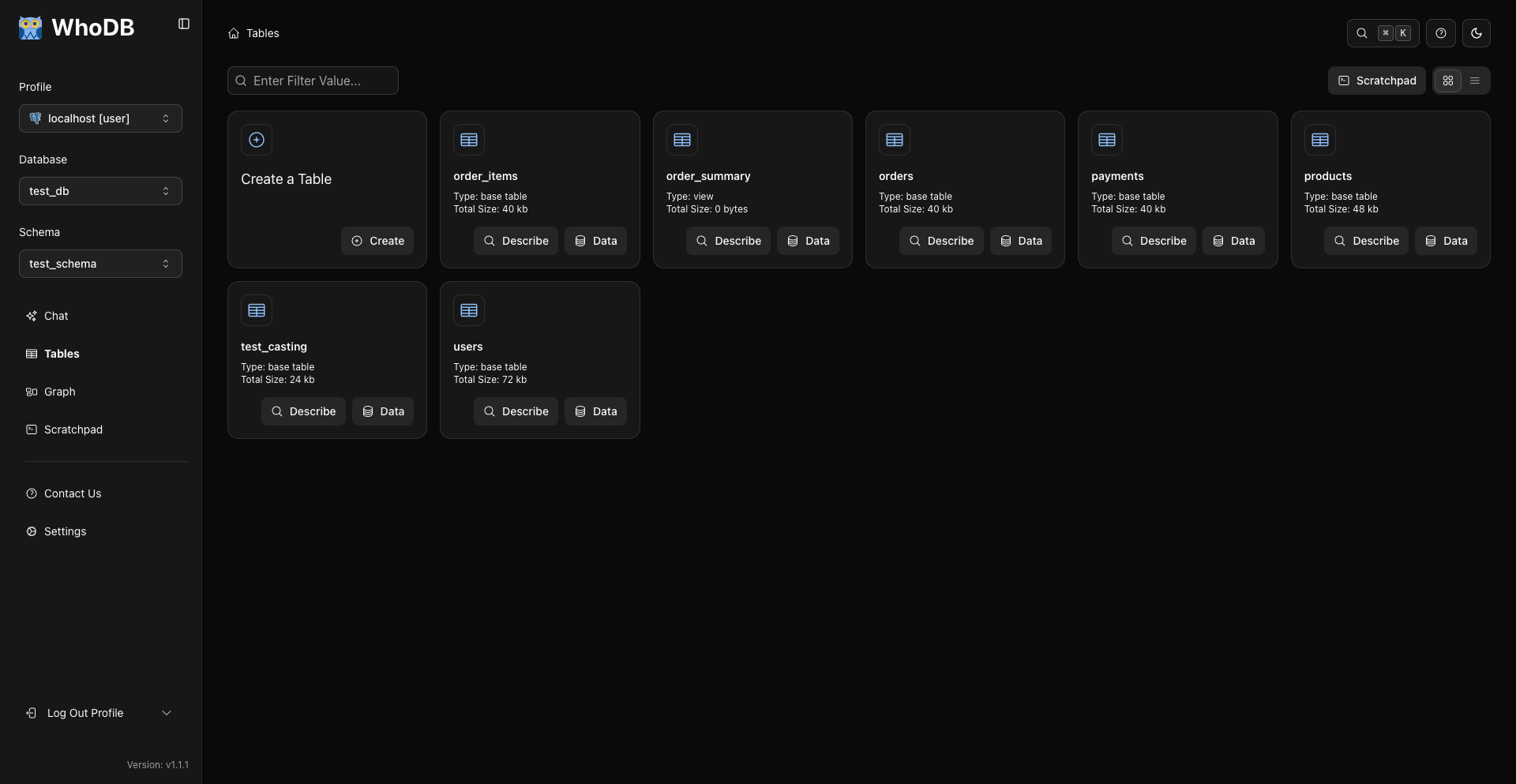
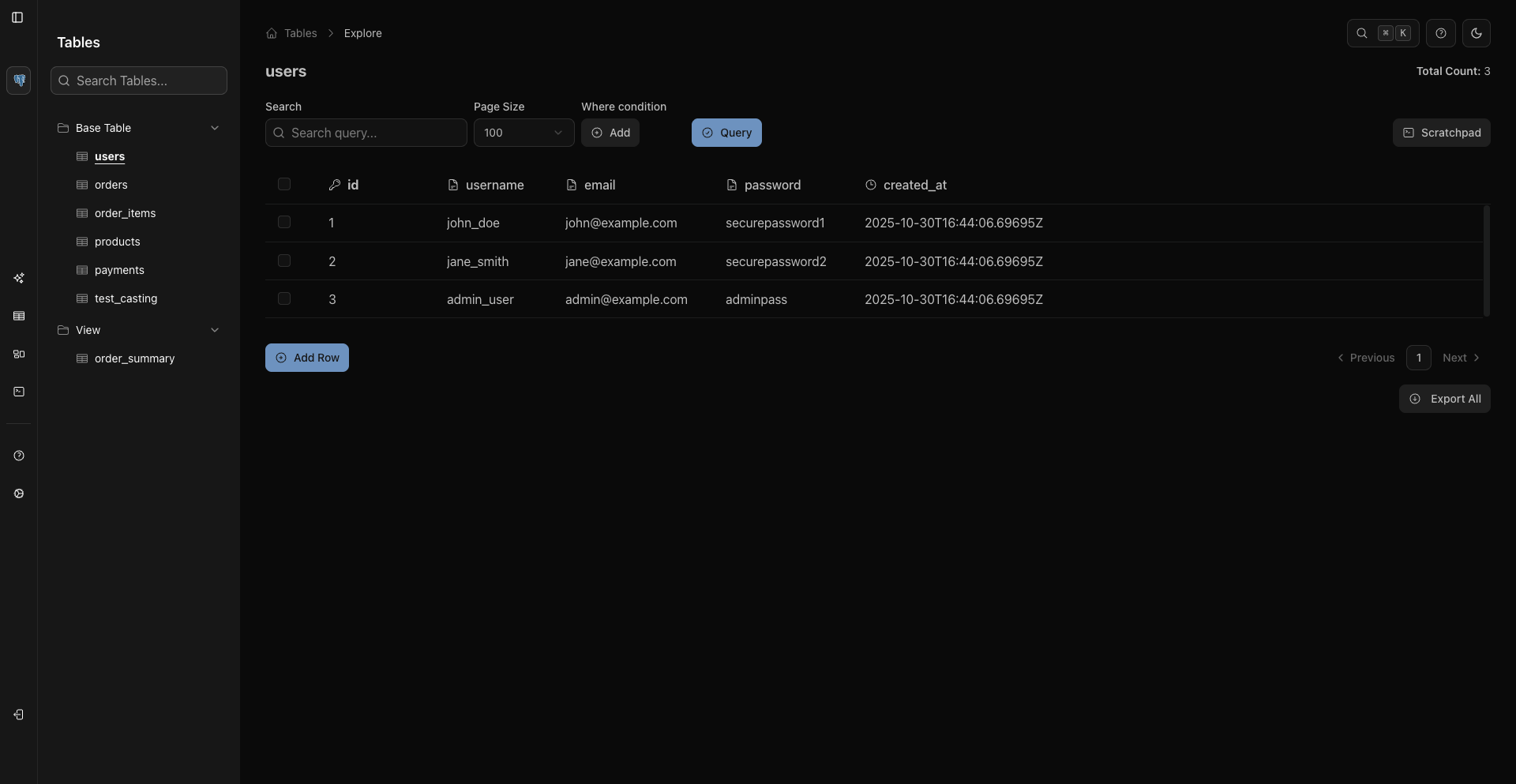
📊 可视化数据管理
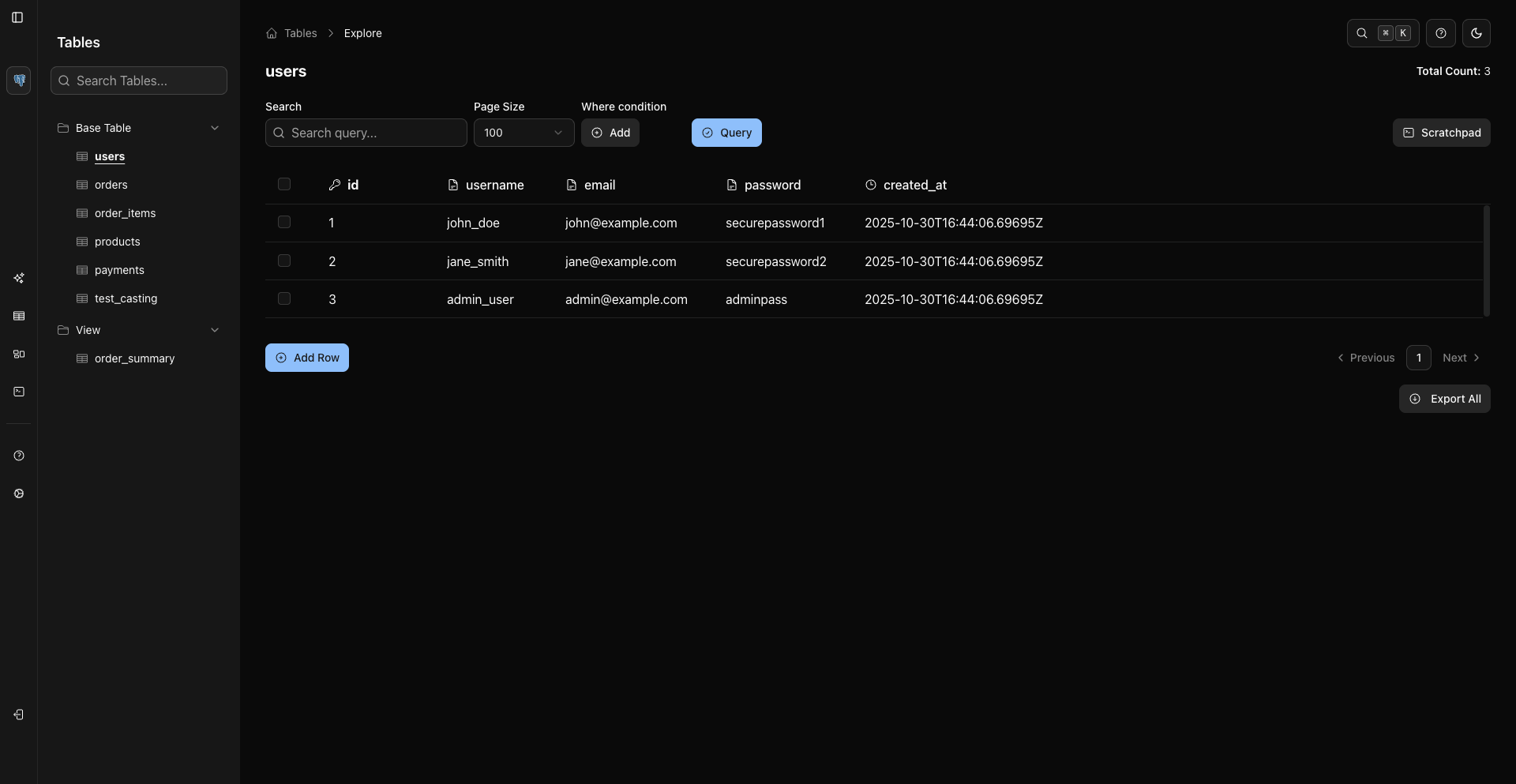
|
类似电子表格的数据网格
|
🔍 交互式模式浏览器
|
可视化模式拓扑
|

|
💻 强大的查询界面

|
草稿板查询编辑器
|
🗄️ 多数据库支持
社区版 (CE): PostgreSQL、MySQL、SQLite3、MongoDB、Redis、MariaDB、ElasticSearch
企业版 (EE): 包含 CE 版所有数据库,并额外支持 Oracle、SQL Server、DynamoDB、Athena、Snowflake、Cassandra 等更多数据库
🎯 高级功能
- 模拟数据生成 - 为开发生成逼真的测试数据
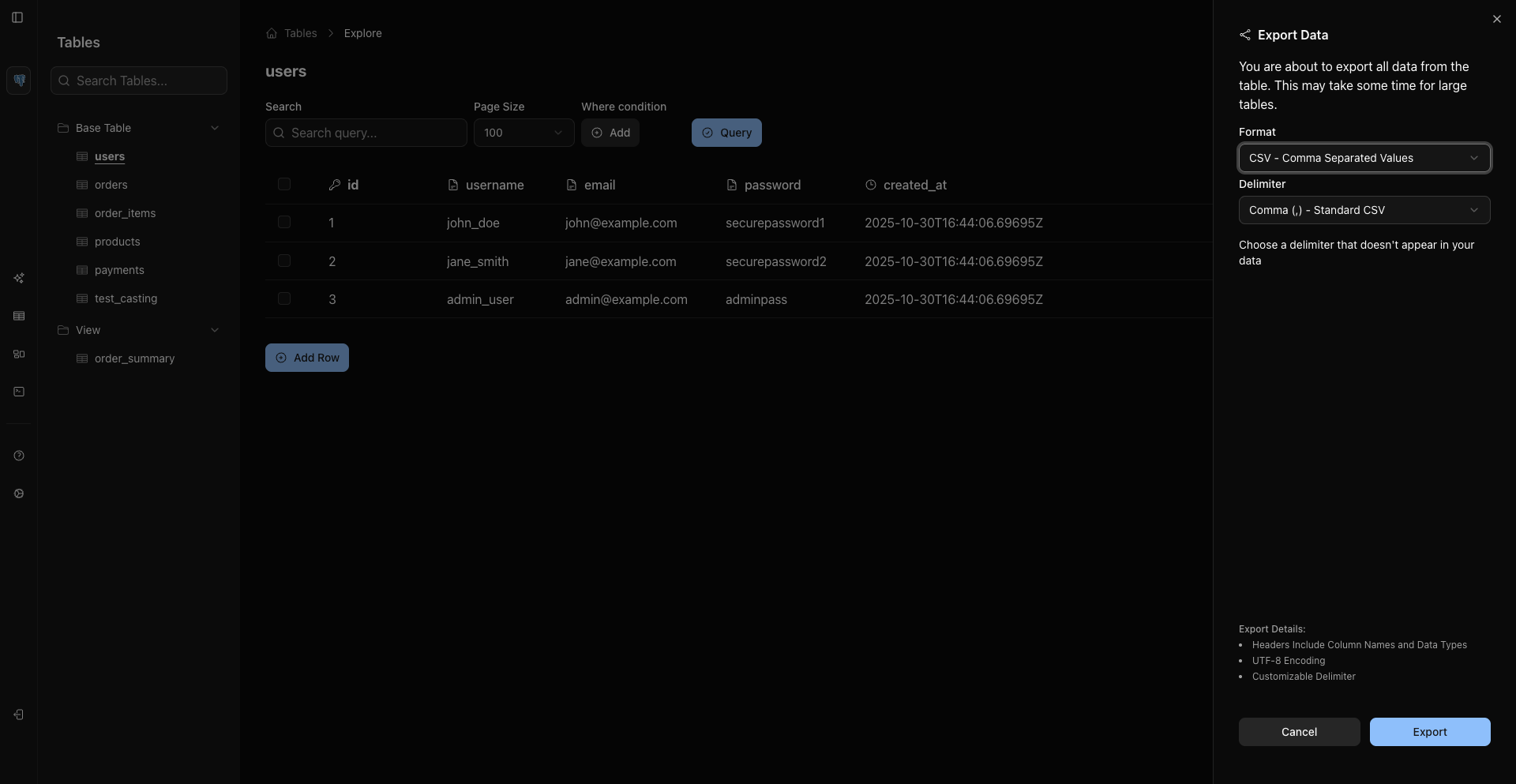
- 灵活的导出选项 - 支持导出为 CSV、Excel、JSON 或 SQL
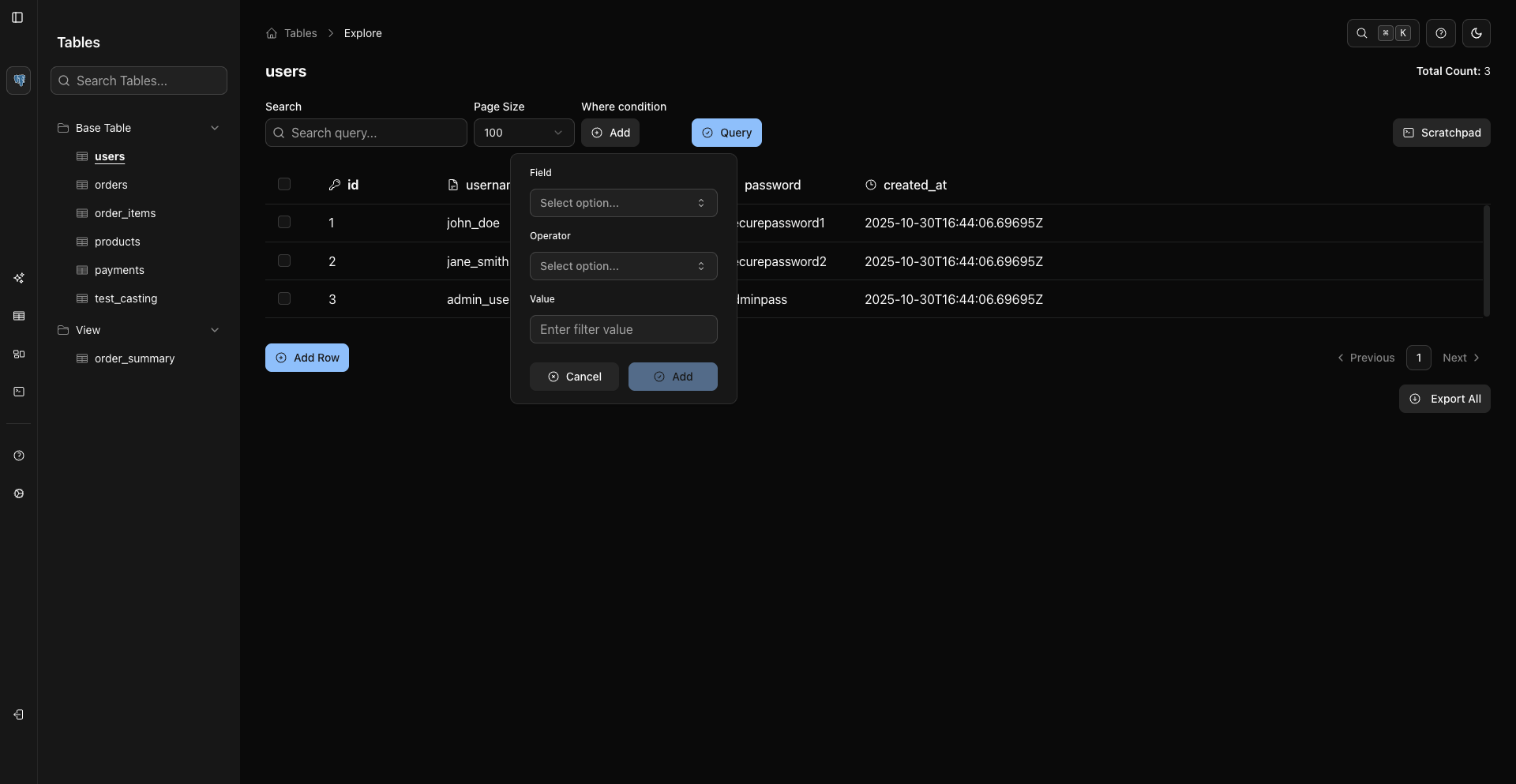
- 高级过滤 - 可视化构建复杂的 WHERE 条件
- AI 驱动的查询 - 使用 Ollama、OpenAI、Anthropic 或其他兼容 OpenAI 的服务将自然语言转换为 SQL
🎮 立即试用 WhoDB
无需任何设置,即可体验 WhoDB 的实际效果
🌐 在线演示使用我们的示例数据库,立即试用 WhoDB 
预先填充了示例 PostgreSQL 数据库 |
🎥 视频演示观看 WhoDB 的实际操作 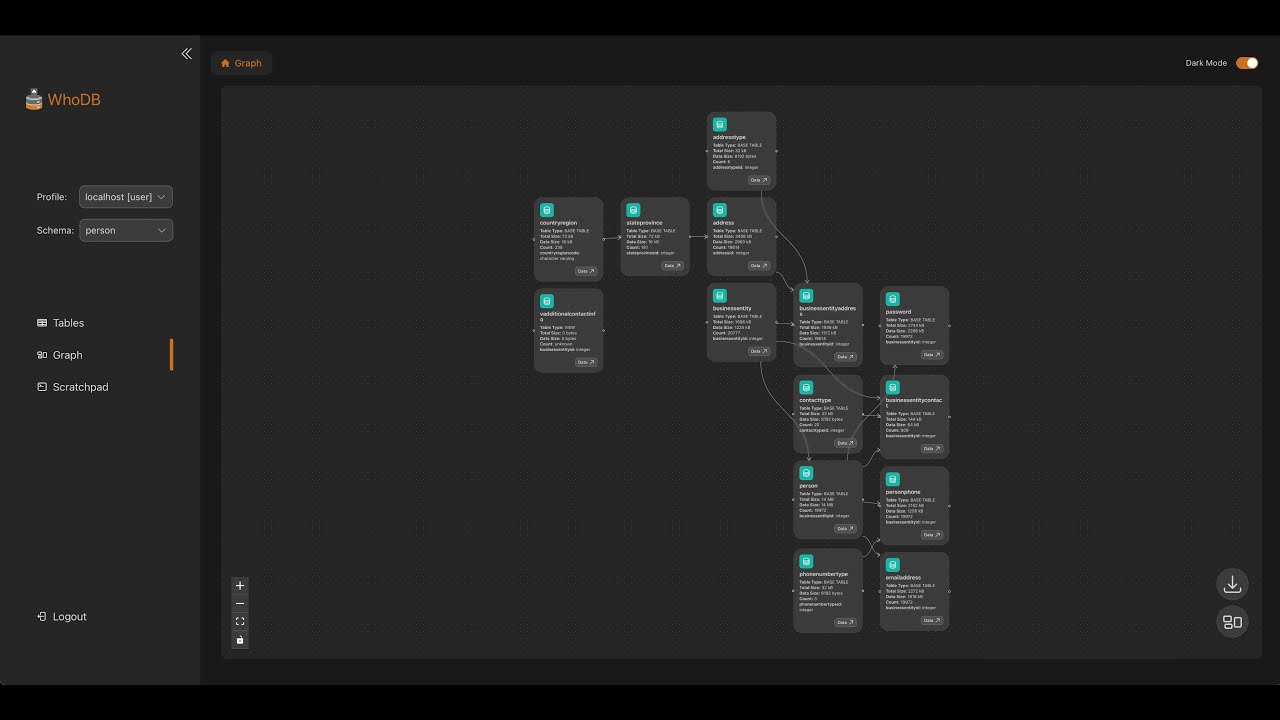
完整功能演示 |
🚀 快速入门
选项 1:Docker(推荐)
开始使用 WhoDB 的最快方式:
docker run -it -p 8080:8080 clidey/whodb
然后在浏览器中打开 http://localhost:8080。
选项 2:Docker Compose
如果您需要更多控制和配置:
version: "3.8"
services:
whodb:
image: clidey/whodb
ports:
- "8080:8080"
environment:
# AI 集成(可选)
# Ollama 配置
- WHODB_OLLAMA_HOST=localhost
- WHODB_OLLAMA_PORT=11434
# Anthropic 配置
- WHODB_ANTHROPIC_API_KEY=your_key_here
# - WHODB_ANTHROPIC_ENDPOINT=https://api.anthropic.com/v1
# OpenAI 配置
- WHODB_OPENAI_API_KEY=your_key_here
# - WHODB_OPENAI_ENDPOINT=https://api.openai.com/v1
# 通用 AI 提供商(兼容 OpenAI 的接口)
# 使用 WHODB_AI_GENERIC_<ID>_* 可以添加任何兼容 OpenAI 的提供商。
# <ID> 可以是任意唯一标识符(如 LMSTUDIO、OPENROUTER)。
#
# LM Studio 示例:
# - WHODB_AI_GENERIC_LMSTUDIO_NAME=LM Studio
# - WHODB_AI_GENERIC_LMSTUDIO_BASE_URL=http://host.docker.internal:1234/v1
# - WHODB_AI_GENERIC_LMSTUDIO_MODELS=mistral-7b,llama-3-8b
#
# OpenRouter 示例:
# - WHODB_AI_GENERIC_OPENROUTER_NAME=OpenRouter
# - WHODB_AI_GENERIC_OPENROUTER_BASE_URL=https://openrouter.ai/api/v1
# - WHODB_AI_GENERIC_OPENROUTER_API_KEY=your_key_here
# - WHODB_AI_GENERIC_OPENROUTER_MODELS=google/gemini-2.0-flash-001,anthropic/claude-3.5-sonnet
# volumes: # (SQLite 可选)
# - ./sample.db:/db/sample.db
接下来?
- 连接到您的数据库 - 在登录页面输入您的数据库凭据
- 探索您的模式 - 浏览表并可视化关系
- 运行查询 - 使用草稿板执行 SQL 查询
- 管理数据 - 轻松编辑、添加和删除记录
📖 有关详细的安装选项和配置,请参阅我们的文档
💻 WhoDB CLI
WhoDB 还提供了一个功能强大的命令行界面,带有交互式 TUI(终端用户界面)以及支持 AI 助手的 MCP 服务器。
特性
- 交互式 TUI - 全功能终端界面,用于数据库管理
- MCP 服务器 - 支持 Claude、Cursor 等 AI 工具的模型上下文协议
- 跨平台 - 适用于 macOS、Linux 和 Windows
快速安装
# macOS/Linux
curl -fsSL https://raw.githubusercontent.com/clidey/whodb/main/cli/install/install.sh | bash
# Homebrew(即将推出)
brew install whodb-cli
# npm
npm install -g @clidey/whodb-cli
使用方法
# 启动交互式 TUI
whodb-cli
# 作为 MCP 服务器为 AI 助手服务
whodb-cli mcp serve
📖 有关完整的 CLI 文档,请参阅CLI README
🛠️ 开发环境搭建
前提条件
- GoLang - 建议使用最新版本
- PNPM - 用于前端包管理
- Node.js - 版本 16 或更高
版本
|
社区版(CE)
|
企业版(EE)
|
📚 请参阅 BUILD_AND_RUN.md 获取详细的构建说明,以及 ARCHITECTURE.md 查看架构细节。
前端开发
进入 frontend/ 目录并启动开发服务器:
cd frontend
pnpm i
pnpm start
后端开发
1. 构建前端(首次设置)
如果 core/build/ 目录不存在,请先构建前端:
cd frontend
pnpm install
pnpm run build
rm -rf ../core/build/
cp -r ./build ../core/
cd ..
注意: 这仅需执行一次,因为 Go 会在启动时嵌入
build/文件夹。
2. 设置 AI 集成(可选)
要启用自然语言查询:
Ollama - 从 ollama.com 下载
# 安装 Llama 3.1 8b 模型 ollama pull llama3.1WhoDB 将自动检测已安装的模型,并在侧边栏中显示一个 聊天 选项。
OpenAI/Anthropic - 设置环境变量(参见上面的 Docker Compose 示例)
任何兼容 OpenAI 的提供商 - 使用
WHODB_AI_GENERIC_<ID>_*环境变量连接到 LM Studio、OpenRouter 或任何具有 OpenAI 兼容 API 的提供商(参见上面的 Docker Compose 示例)
3. 启动后端服务
cd core
go run .
后端将在 http://localhost:8080 上启动
💼 使用场景
👨💻 对于开发者
|
本地开发
|
API 开发
|
📊 对于数据分析师
- 快速运行临时 SQL 查询
- 将数据导出到 Excel 进行分析
- 可视化构建复杂筛选器
- 可视化表之间的关系
🧪 对于 QA 工程师
- 生成逼真的测试数据
- 在测试过程中验证数据库状态
- 快速调试测试失败
- 验证数据迁移
🛠️ 对于数据库管理员
- 监控表结构和索引
- 高效管理用户数据
- 快速探索模式
- 紧急数据修复
❓ 常见问题
WhoDB 与其他数据库工具相比有何不同?
WhoDB 结合了 Adminer 等轻量级工具的特点,同时具备现代化的用户体验、强大的可视化功能以及 AI 能力。与 DBeaver 等资源占用较高的工具不同,WhoDB 的内存占用减少了 90%,却提供了更快、更直观的操作体验。
WhoDB 是否适合用于生产环境?
是的,WhoDB 已经准备好用于生产环境,并被数千名开发者使用。对于生产环境,我们建议:
- 尽可能使用只读数据库账号
- 启用 SSL/TLS 连接
- 考虑使用企业版以获得审计日志和高级安全功能
WhoDB 如何处理大型数据集?
WhoDB 实施了多项性能优化措施:
- 表虚拟化以实现高效渲染
- 大型结果集的懒加载
- 分页控件
- 查询结果流式传输
支持哪些数据库?
社区版: PostgreSQL、MySQL、MariaDB、SQLite3、MongoDB、Redis、ElasticSearch
企业版: 包括所有社区版支持的数据库,以及 Oracle、SQL Server、DynamoDB、Athena、Snowflake、Cassandra 等更多数据库
如何部署 WhoDB?
WhoDB 可以通过多种方式部署:
- Docker - 单命令部署
- Docker Compose - 适用于生产环境
- Kubernetes - 适用于企业级环境
- 二进制文件 - 直接安装在服务器上
详情请参阅我们的 快速入门 部分。
WhoDB 会存储我的凭据吗?
不会。默认情况下,WhoDB 不会存储数据库凭据。连接是临时的,关闭浏览器后凭据将被清除。您也可以选择配置本地存储在浏览器中的连接配置文件。
我可以使用 WhoDB 的 AI 功能吗?
可以!WhoDB 集成了以下服务:
- Ollama - 用于本地私有 AI 模型
- OpenAI - GPT-4 及其他 OpenAI 模型
- Anthropic - Claude 模型
- 任何兼容 OpenAI 的提供商 - LM Studio、OpenRouter、vLLM 等,可通过
WHODB_AI_GENERIC_<ID>_*环境变量进行配置
这些集成使您可以使用自然语言而非 SQL 来查询数据库。
🤝 贡献
我们欢迎社区的贡献!无论是 bug 报告、功能请求,还是代码贡献,我们都感谢您为改进 WhoDB 所做的努力。
如何贡献
开发资源
📸 截图
查看更多截图
数据管理
添加/编辑记录
高级筛选
导出选项
模式图可视化
草稿区查询编辑器
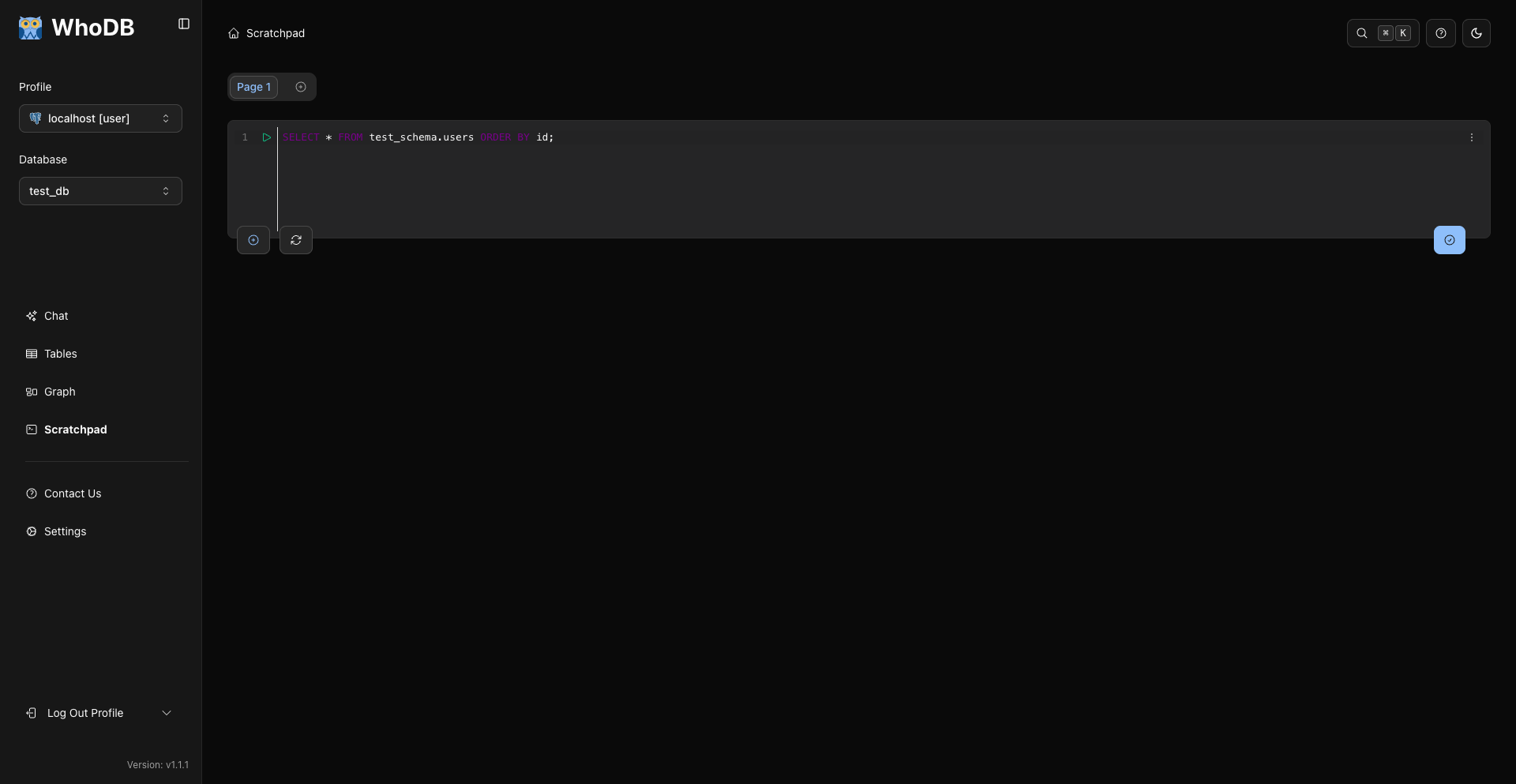
查询结果
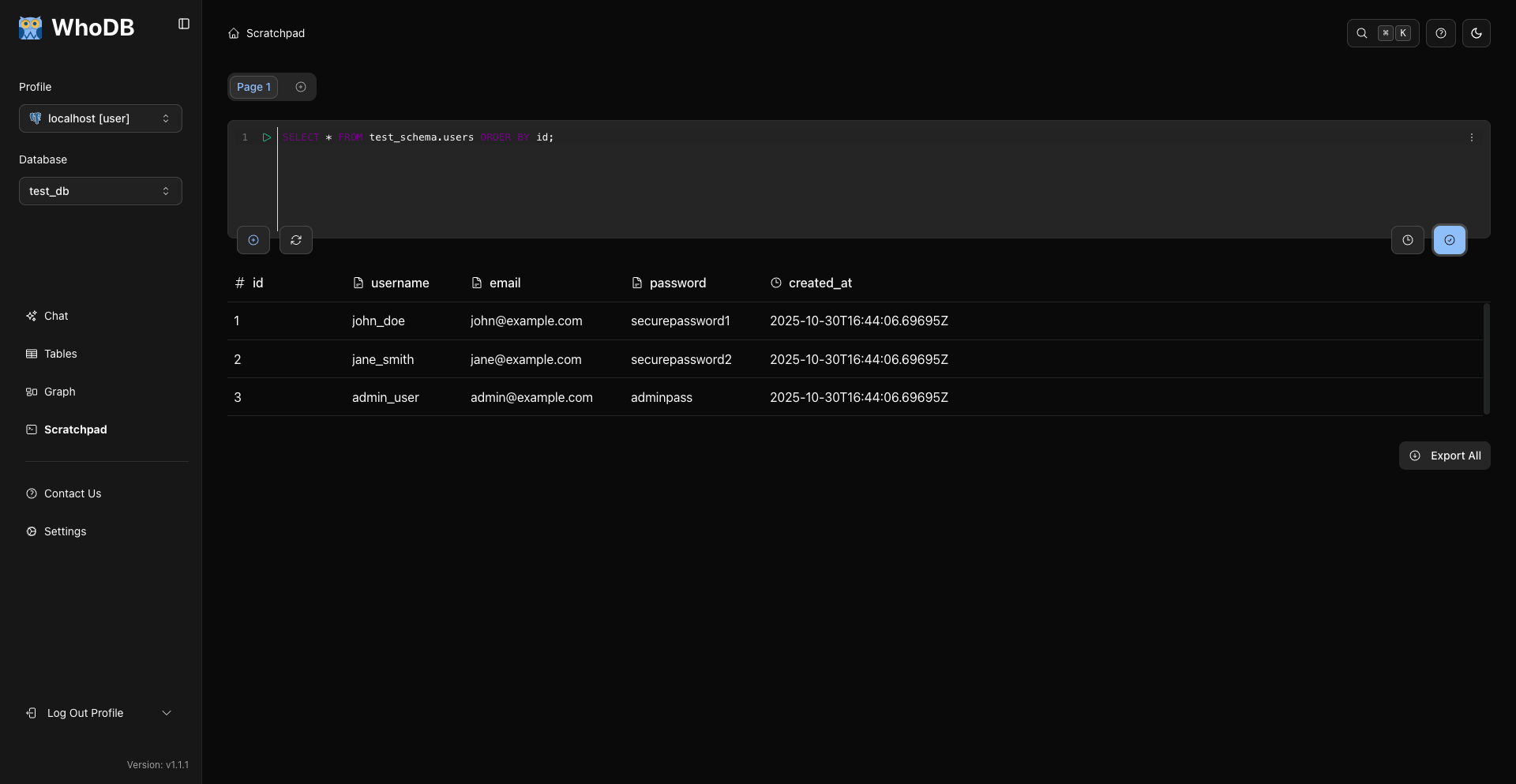
多数据库支持
🏢 基础设施与支持
WhoDB 的部署和 CI/CD 由 Clidey 提供支持,这是一个无代码的 DevOps 平台。
联系与支持
- 邮箱: support@clidey.com
- GitHub Issues: 报告 bug
- 讨论区: 加入讨论
- 文档: docs.whodb.com
⭐ 在 GitHub 上为我们点赞!
如果您觉得 WhoDB 很有用,请考虑在 GitHub 上给我们点个赞。这有助于我们扩大社区并持续改进 WhoDB。
由 Clidey 团队用心打造
"这是魔法吗?是巫术吗?不,这只是 WhoDB!"
版本历史
0.104.02026/04/020.103.02026/03/270.102.02026/03/270.101.02026/03/230.100.02026/03/190.99.02026/03/130.98.02026/03/090.97.02026/03/030.96.02026/03/030.95.02026/02/260.94.02026/02/190.93.02026/02/160.92.02026/02/110.91.02026/02/040.90.02026/01/270.89.02026/01/200.88.02026/01/150.87.02025/12/290.86.02025/12/190.85.02025/12/16相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。