sphereface_pytorch
sphereface_pytorch 是经典人脸识别算法 SphereFace 的 PyTorch 版本实现,旨在通过深度学习提升人脸验证的准确率。它主要解决了传统方法在处理大角度姿态变化、光照差异及复杂背景时特征区分度不足的问题,利用“深度超球面嵌入”技术,将人脸特征映射到更具判别力的超球面空间,从而显著拉近同类人脸距离并推远不同类人脸距离。在 CASIA-WebFace 数据集上训练后,该模型在权威的 LFW 测试集上取得了 99.22% 的高准确率,证明了其卓越的性能。
这款工具特别适合人工智能研究人员、计算机视觉开发者以及需要构建高精度人脸识别系统的工程师使用。对于希望复现前沿论文成果或进行算法对比研究的学者,sphereface_pytorch 提供了清晰的训练与评估脚本,支持快速上手实验。其核心亮点在于独特的角度间隔损失函数(Angular Margin Loss),通过数学公式精确控制特征分布的几何结构,相比普通软最大值损失函数能学习到更鲁棒的人脸特征表示。无论是作为学术研究的基准代码,还是作为实际项目的算法基石,sphereface_pytorch 都是一个高效且可靠的选择。
使用场景
某安防科技公司的算法团队正在为新一代智能门禁系统研发高精度人脸识别模块,需解决复杂光照下身份误判的难题。
没有 sphereface_pytorch 时
- 团队需从零复现论文中复杂的超球面嵌入(Hypersphere Embedding)数学公式,极易在角度边界条件处理上出现代码逻辑错误。
- 缺乏成熟的训练策略参考,模型在 CASIA-WebFace 数据集上收敛缓慢,难以突破传统 Softmax 损失函数的性能瓶颈。
- 在 LFW 基准测试中准确率长期停滞在 98% 左右,无法满足金融级门禁对“万分之一误识率”的严苛要求。
- 缺少经过验证的预训练权重,导致新场景下的迁移学习成本高企,调试周期被大幅拉长。
使用 sphereface_pytorch 后
- 直接调用已封装好的 PyTorch 版本,完美还原了原文核心的角度间隔损失函数,避免了手动推导公式带来的潜在 Bug。
- 复用官方提供的训练脚本与超参数配置,模型在 CASIA-WebFace 上快速收敛,显著提升了特征区分度。
- 加载预训练的
sphere20a模型后,LFW 测试准确率直接提升至 99.22%,成功达到项目交付标准。 - 依托成熟的评估代码(
lfw_eval.py),团队能迅速完成数据格式转换与性能验证,将研发周期从数周缩短至几天。
sphereface_pytorch 通过提供工业级可用的实现细节与高精度预训练模型,让团队得以跳过繁琐的算法复现陷阱,直接聚焦于业务场景的落地优化。
运行环境要求
- 未说明
未说明(基于 PyTorch 实现,通常训练阶段需要 NVIDIA GPU,具体型号和显存取决于批次大小)
未说明

快速开始
SphereFace
SphereFace 的 PyTorch 实现。 该代码可以在 CASIA-Webface 数据集上进行训练,在 LFW 数据集上的最佳准确率为 99.22%。
训练
python train.py
测试
# 将 lfw.tgz 解压为 lfw.zip
tar zxf lfw.tgz; cd lfw; zip -r ../lfw.zip *; cd ..
# LFW 评估
python lfw_eval.py --model model/sphere20a_20171020.pth
预训练模型
| 模型名称 | LFW 准确率 | 训练数据集 |
|---|---|---|
| 20171020 | 0.9922 | CASIA-WebFace |
φ
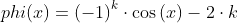
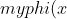 =1-\frac{x^2}{2!}+\frac{x^4}{4!}-\frac{x^6}{6!}+\frac{x^8}{8!}-\frac{x^9}{9!})
=1-\frac{x^2}{2!}+\frac{x^4}{4!}-\frac{x^6}{6!}+\frac{x^8}{8!}-\frac{x^9}{9!})
参考文献
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
opencv
OpenCV 是一个功能强大的开源计算机视觉库,被誉为机器视觉领域的“瑞士军刀”。它主要解决让计算机“看懂”图像和视频的核心难题,提供了从基础的图像读取、色彩转换、边缘检测,到复杂的人脸识别、物体追踪、3D 重建及深度学习模型部署等全方位算法支持。无论是处理静态图片还是分析实时视频流,OpenCV 都能高效完成特征提取与模式识别任务。 这款工具特别适合计算机视觉开发者、人工智能研究人员以及机器人工程师使用。对于希望将视觉感知能力集成到应用中的软件工程师,或是需要快速验证算法原型的学术研究者,OpenCV 都是不可或缺的基础设施。虽然普通用户通常不会直接操作代码,但日常生活中使用的扫码支付、美颜相机和自动驾驶系统,背后往往都有它的身影。 OpenCV 的独特亮点在于其卓越的性能与广泛的兼容性。它采用 C++ 编写以确保高速运算,同时提供 Python、Java 等多种语言接口,极大降低了开发门槛。库中内置了数千种优化算法,并支持跨平台运行,能够无缝对接各类硬件加速器。作为社区驱动的项目,OpenCV 拥有活跃的生态系统和丰富的学习资源,持续推动着视觉技术的前沿发展。