ComfyUI_LayerStyle_Advance
ComfyUI_LayerStyle_Advance 是 ComfyUI Layer Style 插件的进阶扩展包,专门剥离并独立发布了那些对依赖环境要求较为复杂的节点。它主要解决了用户在尝试使用高级图层样式功能时,常因缺少特定第三方库(如 psd_tools、hydra_core 等)或模型文件而导致安装失败、节点无法加载的痛点。
通过提供一键式的依赖安装脚本和清晰的模型下载指引,该工具大幅降低了复杂节点的部署门槛,让用户能更专注于创意工作流本身。其技术亮点在于支持专业的 PSD 文件解析与处理,并集成了如 Ultra 系列节点所需的高精度 vitmatte 抠图模型,实现了更精细的图像合成与控制。
这款工具非常适合已经熟悉 ComfyUI 基础操作,希望在工作流中引入专业级图层混合、蒙版处理及 PSD 交互功能的设计师、数字艺术家及 AI 绘画爱好者。对于需要稳定运行复杂自定义节点的研究人员而言,它也是一个可靠的模块化解决方案。只需按照指引配置好环境与模型,即可轻松解锁更强大的图像编辑能力。
使用场景
一位电商设计师正在为促销海报批量生成带有复杂光影和纹理合成的商品展示图,需要精确控制图层混合模式与蒙版细节。
没有 ComfyUI_LayerStyle_Advance 时
- 设计师必须在 Photoshop 中手动处理每张图的图层样式(如投影、内发光),无法融入 ComfyUI 的自动化工作流,导致 AI 生成与后期修图割裂。
- 遇到需要复杂依赖包(如 psd_tools)的高级节点时,手动配置环境极易报错,非技术背景的设计师往往卡在安装步骤,无法运行工作流。
- 调整图层混合效果需反复导出图片到外部软件修改再重新导入,单次迭代耗时超过 10 分钟,严重拖慢创意验证速度。
- 缺乏原生的超精细抠图(Ultra Matte)支持,处理毛发或透明物体边缘时效果生硬,必须额外寻找插件或手动修补。
使用 ComfyUI_LayerStyle_Advance 后
- 设计师直接在 ComfyUI 中调用分离出的高级节点,将投影、颜色叠加等图层样式纳入自动化流程,实现从生成到精修的一站式完成。
- 通过一键脚本自动解决 docopt、hydra_core 等复杂依赖问题,无需深究代码即可稳定运行包含高级功能的复杂工作流。
- 利用节点实时预览调整混合参数,修改即见成效,将单张图的风格迭代时间从 10 分钟压缩至 30 秒以内。
- 内置集成的 vitmatte 模型提供了电影级的超精细抠图能力,轻松处理商品边缘的半透明阴影与细节,无需切换工具。
ComfyUI_LayerStyle_Advance 通过补齐高级图层处理与依赖管理短板,让专业级平面设计工作流在 ComfyUI 中真正实现了全链路自动化。
运行环境要求
- Windows
- 可选(支持 CUDA),若使用 ONNX Runtime GPU 加速需安装对应版本的 CUDA 和 cuDNN
- 具体显存需求未说明,取决于加载的模型(如 SAM2, Florence2, VitMatte 等)
未说明
快速开始
ComfyUI 层样式增强版
从 ComfyUI Layer Style 中分离出来的节点,主要是那些对依赖包有复杂要求的节点。
示例工作流
在 workflow 目录中有一些 JSON 工作流文件,这些是展示如何在 ComfyUI 中使用这些节点的示例。
安装方法
(以 ComfyUI 官方便携版和 Aki ComfyUI 包为例,其他 ComfyUI 环境请相应修改依赖环境目录)
安装插件
推荐使用 ComfyUI Manager 进行安装。
或者在 ComfyUI 的插件目录下打开命令提示符窗口,例如
ComfyUI\custom_nodes,输入:git clone https://github.com/chflame163/ComfyUI_LayerStyle_Advance.git或者下载压缩包并解压后,将解压得到的文件夹复制到
ComfyUI\custom_nodes目录下。
安装依赖包
对于 ComfyUI 官方便携版,在插件目录下双击
install_requirements.bat;对于 Aki ComfyUI 包,则双击插件目录下的install_requirements_aki.bat,等待安装完成。或者手动安装依赖包:在 ComfyUI_LayerStyle 插件目录下打开命令提示符窗口,例如
ComfyUI\custom_nodes\ComfyUI_LayerStyle_Advance,输入以下命令:
对于 ComfyUI 官方便携版,输入:
..\..\..\python_embeded\python.exe -s -m pip install .\whl\docopt-0.6.2-py2.py3-none-any.whl
..\..\..\python_embeded\python.exe -s -m pip install .\whl\hydra_core-1.3.2-py3-none-any.whl
..\..\..\python_embeded\python.exe -s -m pip install -r requirements.txt
.\repair_dependency.bat
对于 Aki ComfyUI 包,输入:
..\..\python\python.exe -s -m pip install .\whl\docopt-0.6.2-py2.py3-none-any.whl
..\..\python\python.exe -s -m pip install .\whl\hydra_core-1.3.2-py3-none-any.whl
..\..\python\python.exe -s -m pip install -r requirements.txt
.\repair_dependency.bat
- 重启 ComfyUI。
下载模型文件
中国国内用户可以从 百度网盘 或 夸克网盘 下载;其他用户则可以从 huggingface.co/chflame163/ComfyUI_LayerStyle 下载所有文件,并将其复制到 ComfyUI\models 文件夹中。该链接提供了本插件所需的所有模型文件。
或者根据各个节点的说明单独下载模型文件。
一些名为“Ultra”的节点会使用 vitmatte 模型,请下载 vitmatte 模型 并复制到 ComfyUI/models/vitmatte 文件夹中,上述下载链接中也包含了该模型。
常见问题
如果节点无法正常加载或使用过程中出现错误,请检查 ComfyUI 终端窗口中的错误信息。以下是常见错误及其解决方法。
警告:xxxx.ini 未找到,使用默认 xxxx..
此警告表示找不到 ini 文件,但不影响正常使用。若不想看到这些警告,请将插件目录中的所有 *.ini.example 文件重命名为 *.ini。
ModuleNotFoundError: 没有名为 'psd_tools' 的模块
此错误表明 psd_tools 没有正确安装。
解决方案:
- 关闭 ComfyUI,在插件目录下打开终端窗口,执行以下命令:
../../../python_embeded/python.exe -s -m pip install psd_tools如果在安装 psd_tool 时出现类似ModuleNotFoundError: 没有名为 'docopt' 的模块的错误,请下载 docopt 的 whl 文件 并手动安装。 在终端窗口中执行以下命令:../../../python_embeded/python.exe -s -m pip install 路径/docopt-0.6.2-py2.py3-none-any.whl,其中路径是 whl 文件的存放路径。
无法从 'cv2.ximgproc' 导入名称 'guidedFilter'
此错误是由 opencv-contrib-python 包版本不正确,或被其他 OpenCV 包覆盖导致的。
NameError: 名称 'guidedFilter' 未定义
问题原因与上一条相同。
无法从 'transformers' 导入名称 'VitMatteImageProcessor'
此错误是由 transformers 包版本过低引起的。
insightface 加载非常慢
此错误是由 protobuf 包版本过低造成的。
对于以上三个依赖包的问题,请在插件文件夹中双击 repair_dependency.bat(适用于官方 ComfyUI 便携版)或 repair_dependency_aki.bat(适用于 ComfyUI-aki-v1.x),即可自动修复。
onnxruntime::python::CreateExecutionProviderInstance CUDA_PATH 已设置,但无法加载 CUDA。请按照 GPU 要求页面上的说明安装正确版本的 CUDA 和 cuDNN。
解决方案:
重新安装 onnxruntime 依赖包。
加载模型 xxx 时出错:我们无法连接到 huggingface.co ...
请检查网络环境。如果在中国无法正常访问 huggingface.co,请尝试修改 huggingface_hub 包,强制使用镜像源。
找到
huggingface_hub包目录下的constants.py文件(通常位于虚拟环境路径下的Lib/site packages/huggingface_hub), 在import os后添加一行:os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
ValueError: 三元图中没有前景像素值 (xxxx...)
此错误是在使用 PyMatting 方法处理遮罩边缘时,遮罩区域过大或过小导致的。
解决方案:
- 请调整参数以改变遮罩的有效区域。或者改用其他方法处理边缘。
Requests.exceptions.ProxyError: HTTPSConnectionPool(xxxx...)
当出现此错误时,请检查网络环境。
UnboundLocalError: 在赋值前引用了局部变量 'clip_processor'
UnboundLocalError: 在赋值之前引用了局部变量 'text_model'
如果在执行 JoyCaption2 节点时出现此错误,并且已确认模型文件放置在正确目录中,请检查 transformers 依赖包的版本是否至少为 4.43.2 或更高。
如果 transformers 版本高于或等于 4.45.0,同时出现以下错误信息:
加载模型时出错:无法直接创建 De️️scriptors。
如果此调用来自 _pb2.py 文件,则您的生成代码已过时,必须使用 protoc >= 3.19.0 重新生成。
......
请尝试将 protobuf 依赖包降级到 3.20.3,或者设置环境变量:PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python。
更新
**如果更新后仍然存在依赖包错误,请双击插件文件夹中的 repair_dependency.bat(适用于官方 ComfyUI 便携版)或 repair_dependency_aki.bat(适用于 ComfyUI-aki-v1.x),以重新安装依赖包。
- 修复了 Florence2 在较高版本的 Transformers 中运行时的问题,该解决方案来自 kijai,感谢 @flybirdxx 的反馈。
插件更新后,请从florence2_models文件夹中找到modeling_florence2.py和configuration_florence2.py,将其复制并覆盖到ComfyUI/models/florence2目录下的模型文件夹中。 - 提交了 JimengImageToImageAPI 节点,使用 Instant Dreaming Image 3.0 API 编辑图像。在 Volcano Engine 上注册账号,并申请 API AccessKeyID 和 SecretAccessKey。将这些密钥填写到插件目录下的
api_key.ini文件中。 - 提交了 SAM2UltraV2 和 LoadSAM2Model 节点,将 SAM 模型改为外部输入,以便在使用多个节点时节省资源。
- 提交了 JoyCaptionBetaOne、LoadJoyCaptionBeta1Model 和 JoyCaptionBeta1ExtraOptions 节点,使用 JoyCaption Beta One 模型生成提示词。
- 提交了 SaveImagePLusV2 节点,增加了自定义文件名功能,并可设置图像的 DPI。
- 提交了 GeminiImageEdit 节点,支持使用 gemini-2.0-flash-exp-image-generation API 进行图像编辑。
- 提交了 GeminiV2 和 ObjectDetectorGeminiV2 节点,使用 google-genai 依赖包,支持 gemini-2.0-flash-exp 和 gemini-2.5-pro-exp-03-25 模型。
- 添加了 QuarkNetdisk 模型下载链接。
- 支持 numpy 2.x 依赖包。
- 提交了 DeepseekAPI_V2 节点,支持阿里云和 VolcEngine 的 API。
- 提交了 Collage 节点,用于将多张图片拼接成一张大图。
- 提交了 DeepSeekAPI 节点,使用 DeepSeek API 进行文本推理。
- 提交了 SegmentAnythingUltraV3 和 LoadSegmentAnythingModels 节点,避免在使用多个 SAM 节点时重复加载模型。
- 提交了 ZhipuGLM4 和 ZhipuGLM4V 节点,使用智谱 API 进行文本和视觉推理。目前智谱的 GLM-4-Flash 和 glm-4v-flash 模型是免费的。
请在 https://bigmodel.cn/usercenter/proj-mgmt/apikeys 免费申请 API 密钥,并将密钥填写到
zhipu_api_key=中。 - 提交了 Gemini 节点,使用 Gemini API 进行文本或视觉推理。
- 提交了 ObjectDetectorGemini 节点,使用 Gemini API 进行目标检测。
- 提交了 DrawBBOXMaskV2 节点,可以绘制圆角矩形掩码。
- 提交了 SmolLM2、SmolVLM、LoadSmolLM2Model 和 LoadSmolVLMModel 节点,使用 SMOL 模型进行文本推理和图像识别。
请从 百度网盘 或 huggingface 下载模型文件,并将其复制到
ComfyUI/models/smol文件夹。 - Florence2 增加了对 gokaygokay/Florence-2-Flux-Large 和 gokaygokay/Florence-2-Flux 模型的支持,
请从 百度网盘 或 huggingface 下载 Florence-2-Flux-Large 和 Florence-2-Flux 文件夹,并将其复制到
ComfyUI/models/florence2文件夹。 - 从 requirements.txt 文件中移除了 ObjectDetector YOLOWorld 节点所需的依赖项。若要使用该节点,请手动安装相关依赖包。
- 将 ComfyUI Layer Style 中的部分节点剥离至本仓库。
说明
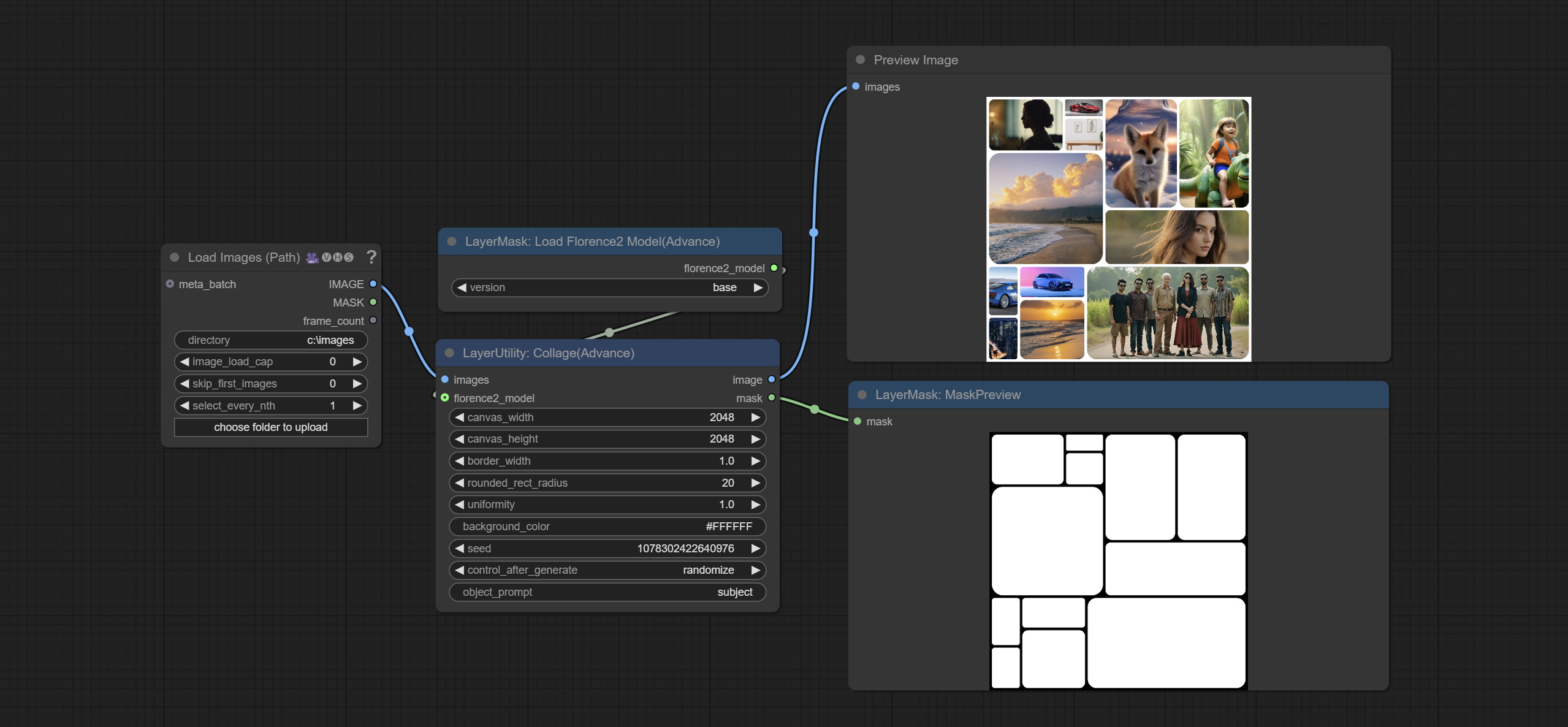
Collage
随机将输入的多张图片拼接成一张大图。
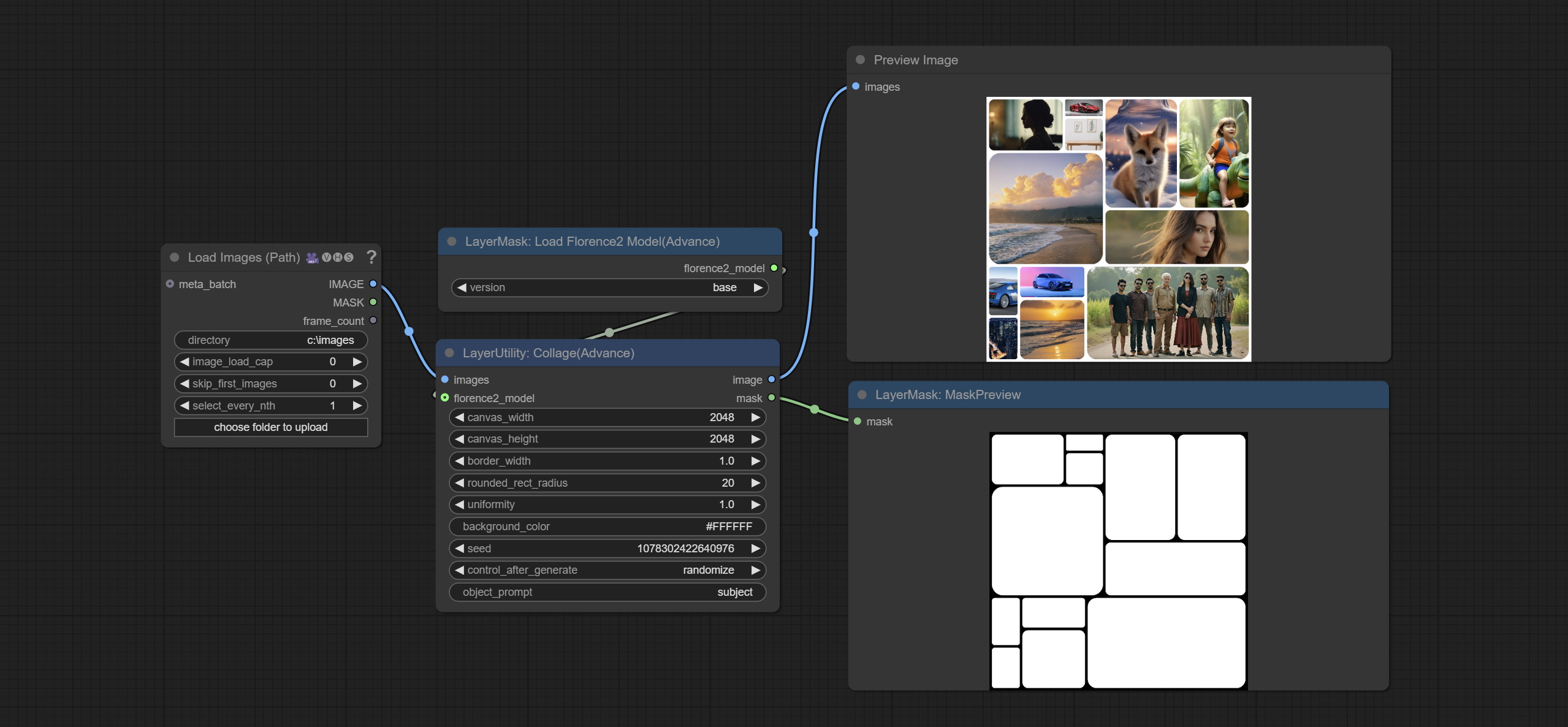
节点选项: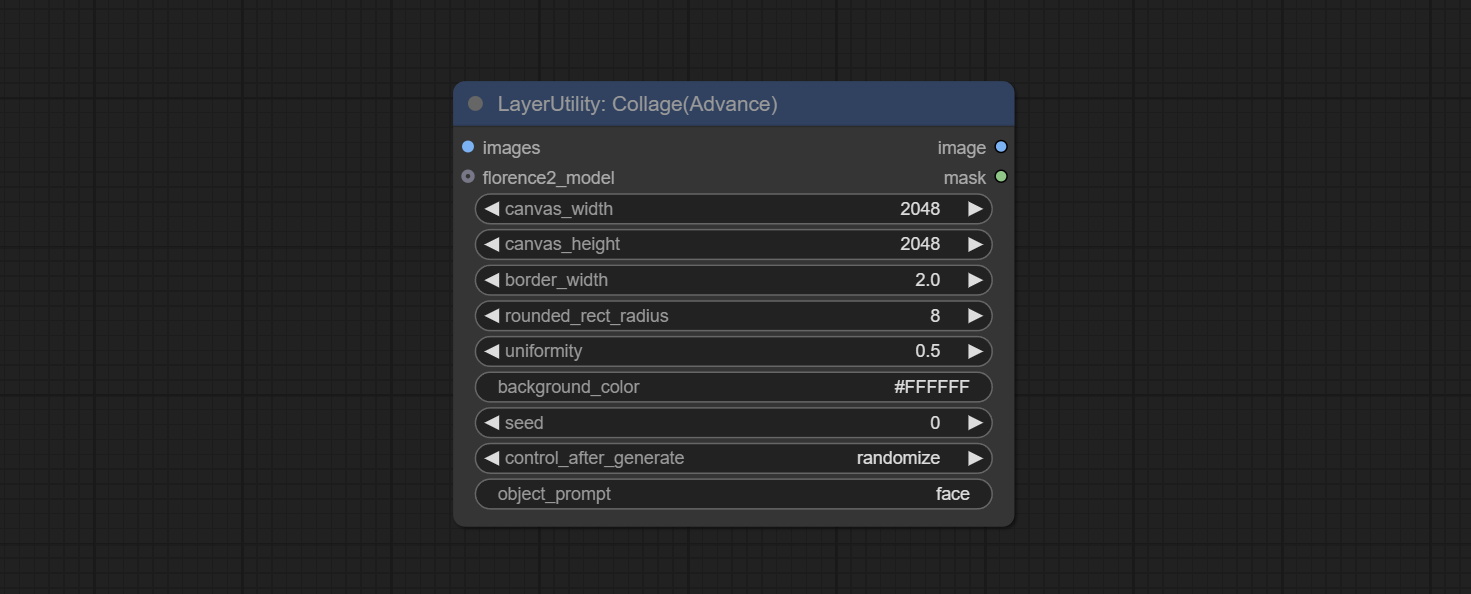
- 增加了多语言支持,现支持中文、法语、日语、韩语和俄语。此功能由 ComfyUI-Globalization-Node-Translation 开发,感谢原作者。
- images:输入的图片。
- florence2_model:可选输入,用于目标识别和裁剪。
- canvas_width:输出图像的宽度。
- canvas_height:输出图像的高度。
- border_width:边框宽度。
- rounded_rect_radius:边框圆角半径。
- uniformity:图片拼接大小的随机性。取值范围为 0–1,数值越大,拼接大小的随机性越高。
- background_color:背景颜色。
- seed:随机数种子。
- control_after_generate:种子变化选项。若固定此选项,则每次生成的随机数将始终相同。
- object_prompt:当连接 florence2_model 时,此处填写用于目标识别的提示词。
QWenImage2Prompt
根据图片推断提示词。该节点是对 ComfyUI_VLM_nodes 中的 UForm-Gen2 Qwen Node 的重新封装,感谢原作者。
请从 huggingface 或 百度网盘 下载模型文件,存入 ComfyUI/models/LLavacheckpoints/files_for_uform_gen2_qwen 文件夹。
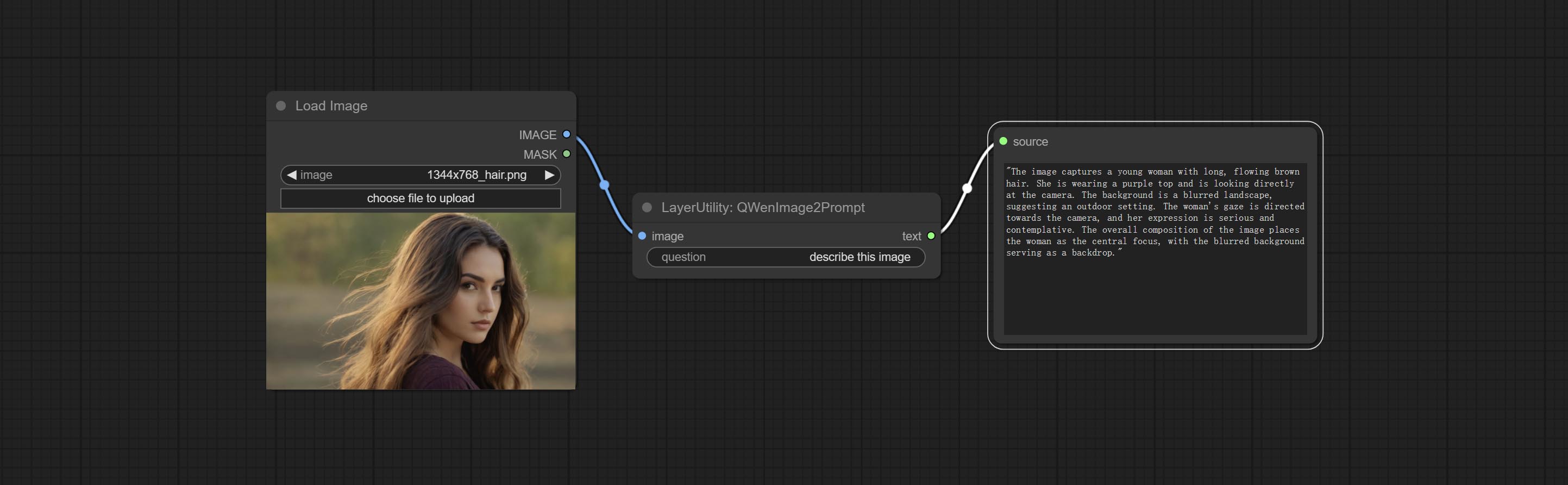
节点选项:
- question:UForm-Gen-QWen 模型的提示语。
LlamaVision
使用 Llama 3.2 视觉模型进行本地推理。可用于生成提示词。该节点的部分代码来自 ComfyUI-PixtralLlamaMolmoVision,感谢原作者。
要使用此节点,需将 transformers 升级至 4.45.0 或更高版本。
从 百度网盘 或 huggingface/SeanScripts 下载模型,并将其复制到 ComfyUI/models/LLM 目录下。
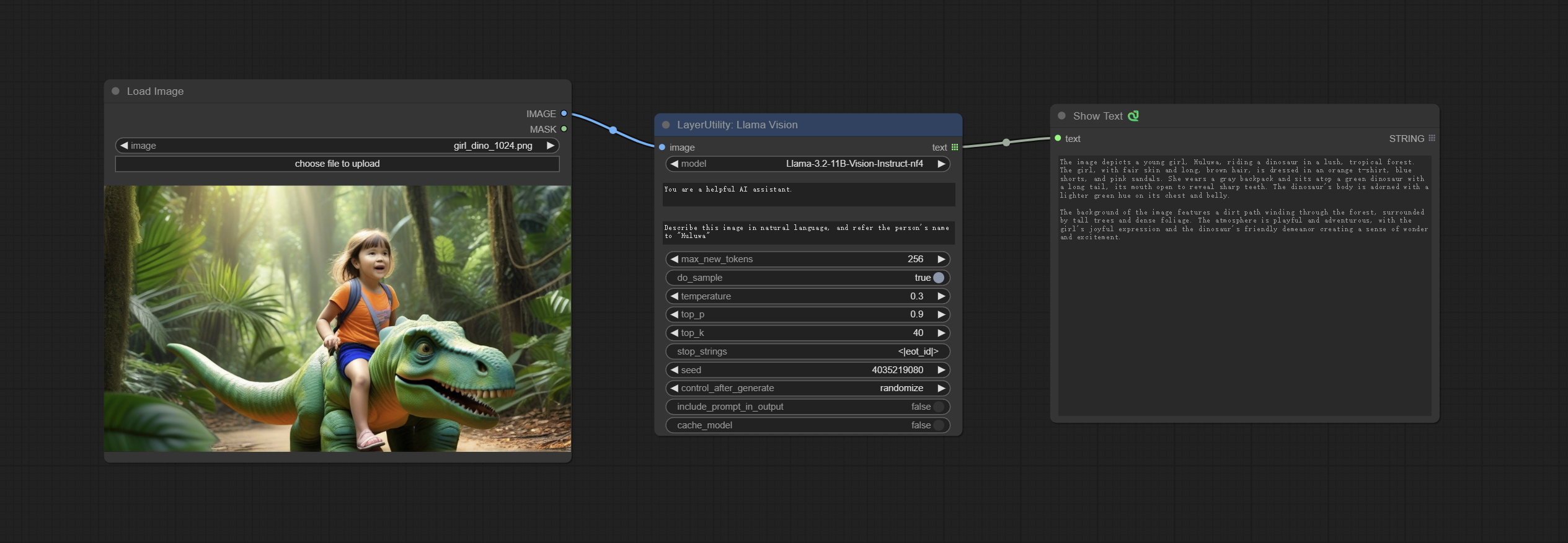
节点选项: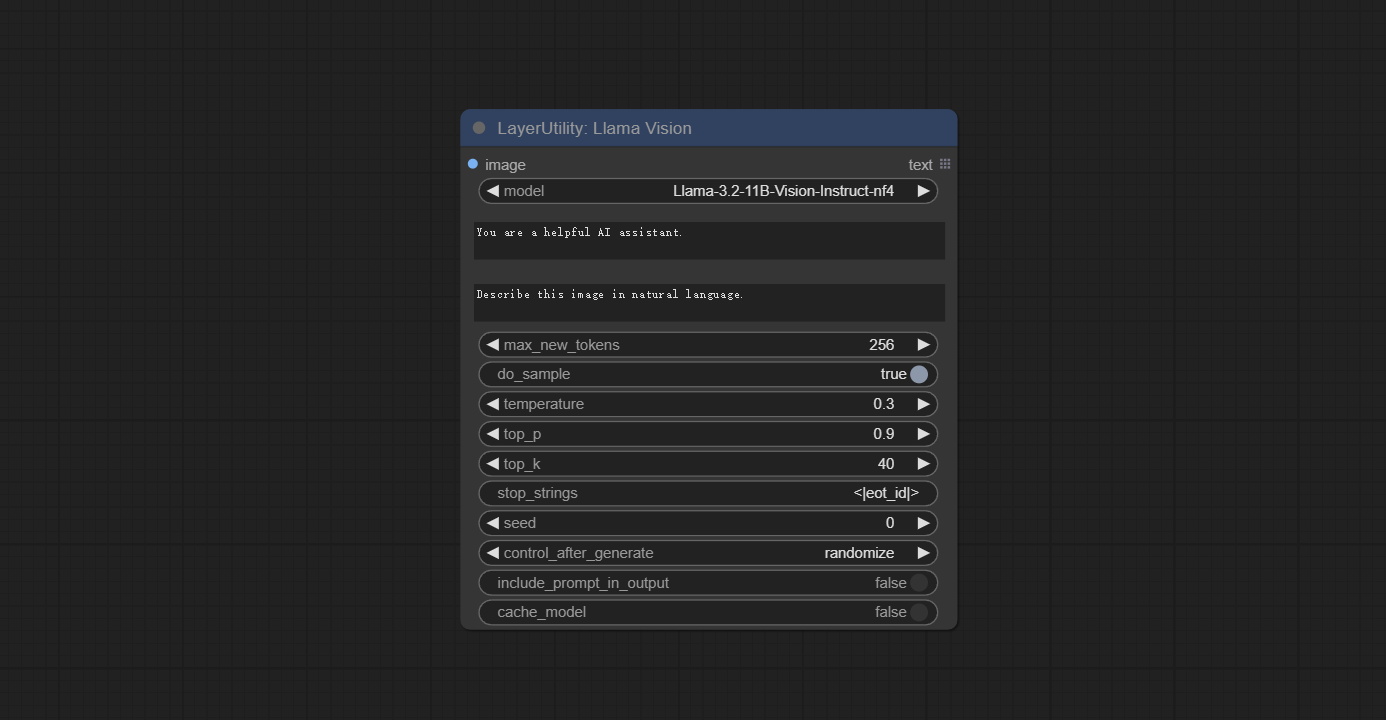
- image: 图像输入。
- model: 目前仅支持 “Llama-3.2-11B-Vision-Instruct-nf4” 模型。
- system_prompt: LLM 模型的系统提示词。
- user_prompt: LLM 模型的用户提示词。
- max_new_tokens: LLM 模型的最大生成 token 数。
- do_sample: LLM 模型的采样开关。
- top-p: LLM 模型的 top-p 参数。
- top_k: LLM 模型的 top-k 参数。
- stop_strings: 停止字符串。
- seed: 随机数种子。
- control_after_generate: 种子变化选项。若固定此选项,则每次生成的随机数将始终相同。
- include_prompt_in_output: 输出是否包含提示词。
- cache_model: 是否缓存模型。
JoyCaption2
使用 JoyCaption-alpha-two 模型进行本地推理。可用于生成提示词。该节点是 https://huggingface.co/John6666/joy-caption-alpha-two-cli-mod 在 ComfyUI 中的实现,感谢原作者。
从 百度网盘 和 百度网盘,
或 huggingface/Orenguteng 和 huggingface/unsloth 下载模型,然后将其复制到 ComfyUI/models/LLM 目录下。
从 百度网盘 或 huggingface/google 下载模型,并将其复制到 ComfyUI/models/clip 目录下。
从 百度网盘 或 huggingface/John6666 下载 cgrkzexw-599808 文件夹,并将其复制到 ComfyUI/models/Joy_caption 目录下。
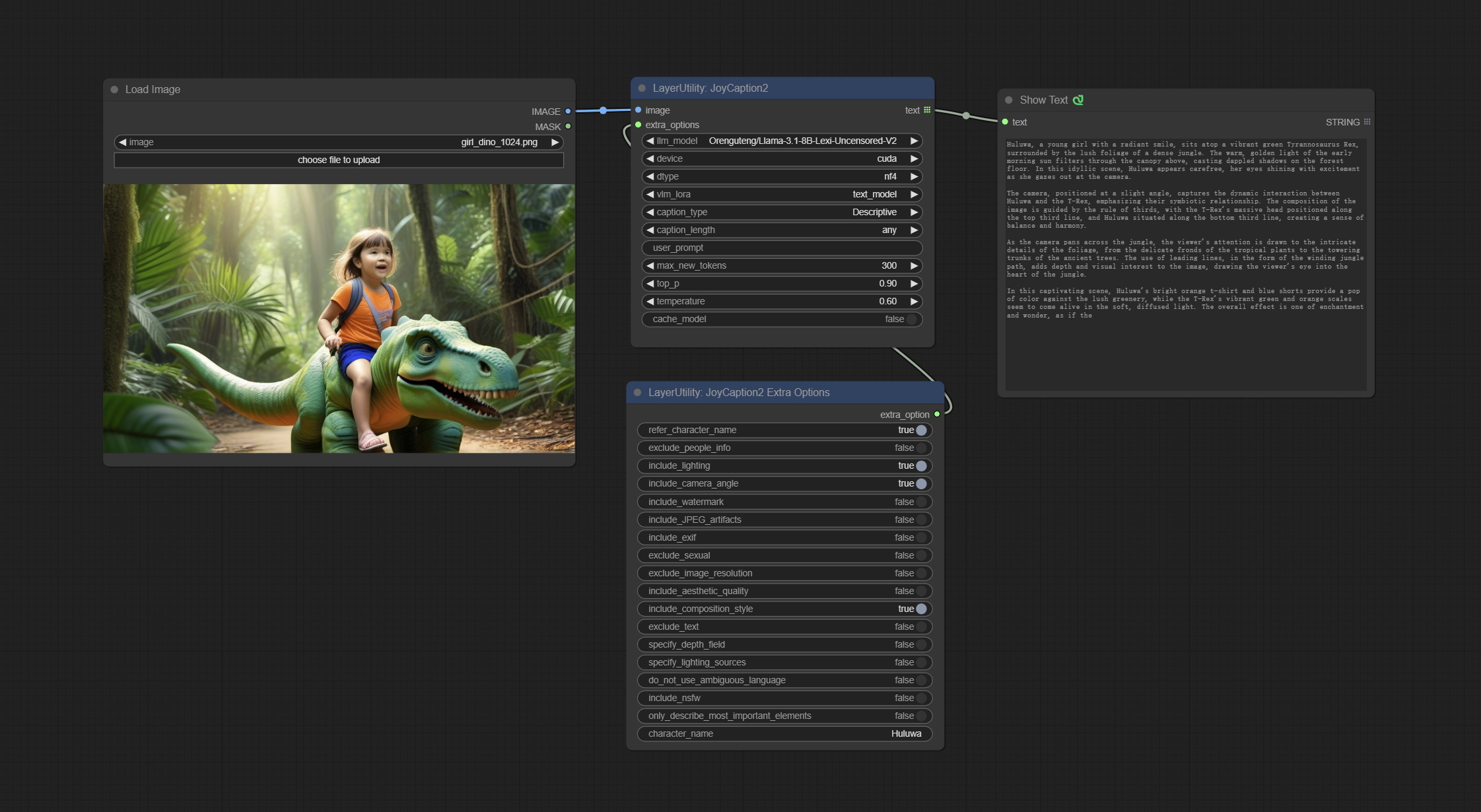
节点选项: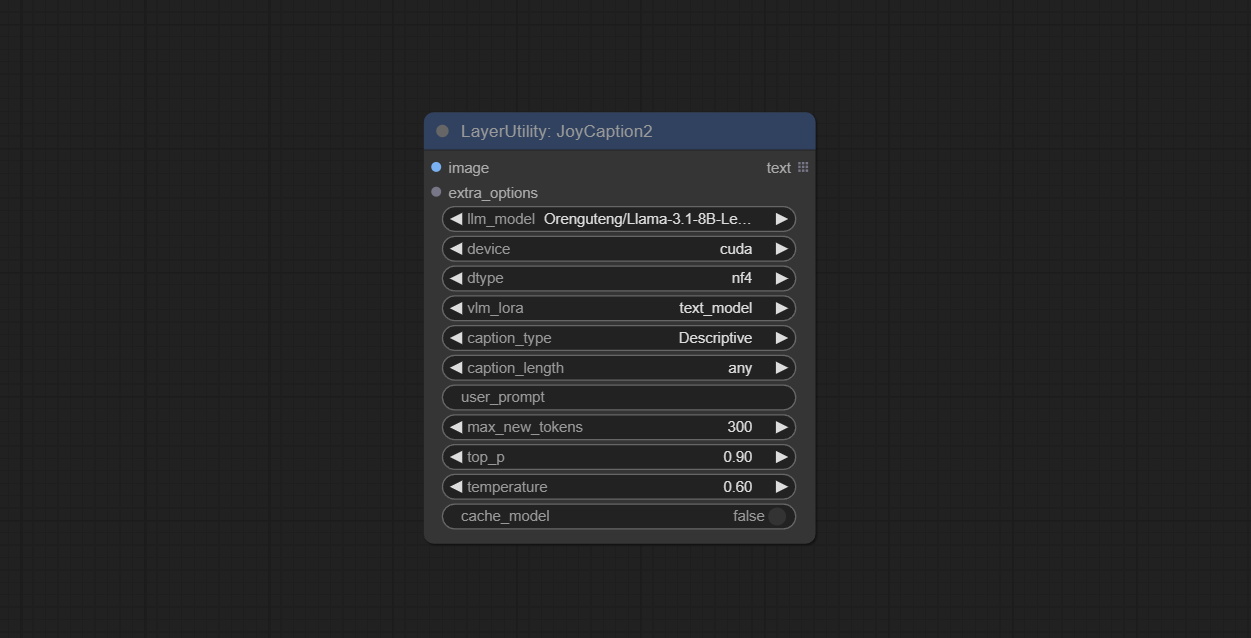
- image: 图像输入。
- extra_options: 输入额外选项。
- llm_model: 可选择两种 LLM 模型,分别为 Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 和 unsloth/Meta-Llama-3.1-8B-Instruct。
- device: 模型加载设备。目前仅支持 CUDA。
- dtype: 模型精度,包括 nf4 和 bf16。
- vlm_lora: 是否加载文本适配器。
- caption_type: 标题类型选项,包括:“描述性”、“非正式描述性”、“训练提示”、“MidJourney”、“Booru 标签列表”、“类似 Booru 的标签列表”、“艺术评论家”、“商品列表”、“社交媒体帖子”。
- caption_length: 标题长度。
- user_prompt: LLM 模型的用户提示词。若此处有内容,则会覆盖所有 caption_type 和 extra_options 的设置。
- max_new_tokens: LLM 模型的最大生成 token 数。
- do_sample: LLM 模型的采样开关。
- top-p: LLM 模型的 top-p 参数。
- temperature: LLM 模型的温度参数。
- cache_model: 是否缓存模型。
JoyCaption2Split
该节点将 JoyCaption2 的模型加载与推理分离,当使用多个 JoyCaption2 节点时,可共享模型以提高效率。
节点选项: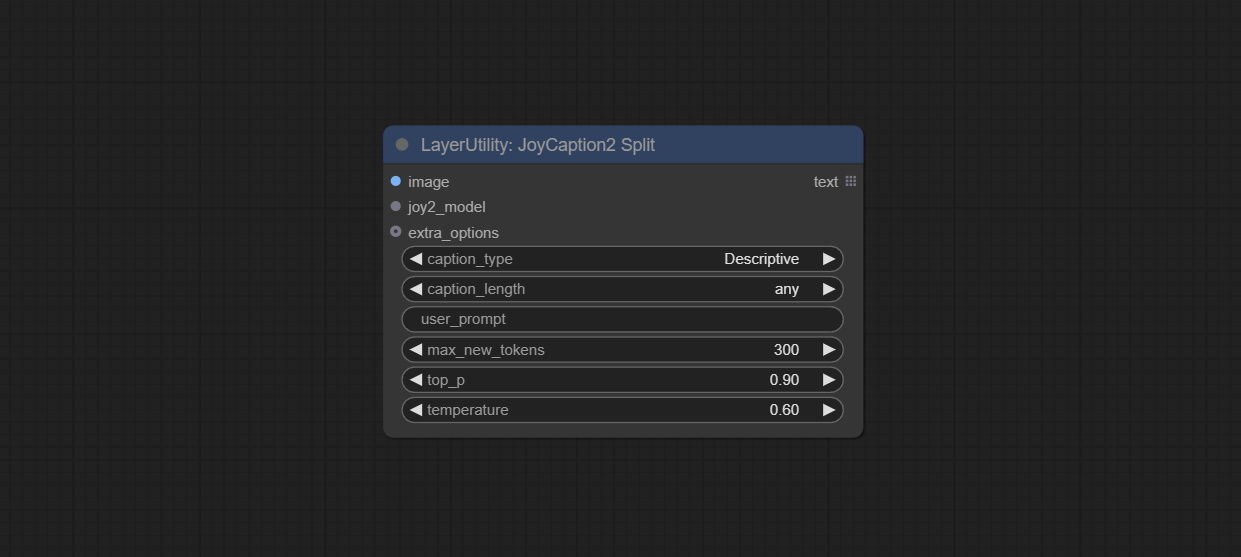
- image: 图像输入。
- joy2_model: JoyCaption 模型输入。
- extra_options: 输入额外选项。
- caption_type: 标题类型选项,包括:“描述性”、“非正式描述性”、“训练提示”、“MidJourney”、“Booru 标签列表”、“类似 Booru 的标签列表”、“艺术评论家”、“商品列表”、“社交媒体帖子”。
- caption_length: 标题长度。
- user_prompt: 模型的用户提示词。若此处有内容,则会覆盖所有 caption_type 和 extra_options 的设置。
- max_new_tokens: 模型的最大生成 token 数。
- do_sample: 模型的采样开关。
- top-p: 模型的 top-p 参数。
- temperature: 模型的温度参数。
LoadJoyCaption2Model
JoyCaption2 的模型加载节点,与 JoyCaption2Split 配合使用。
节点选项: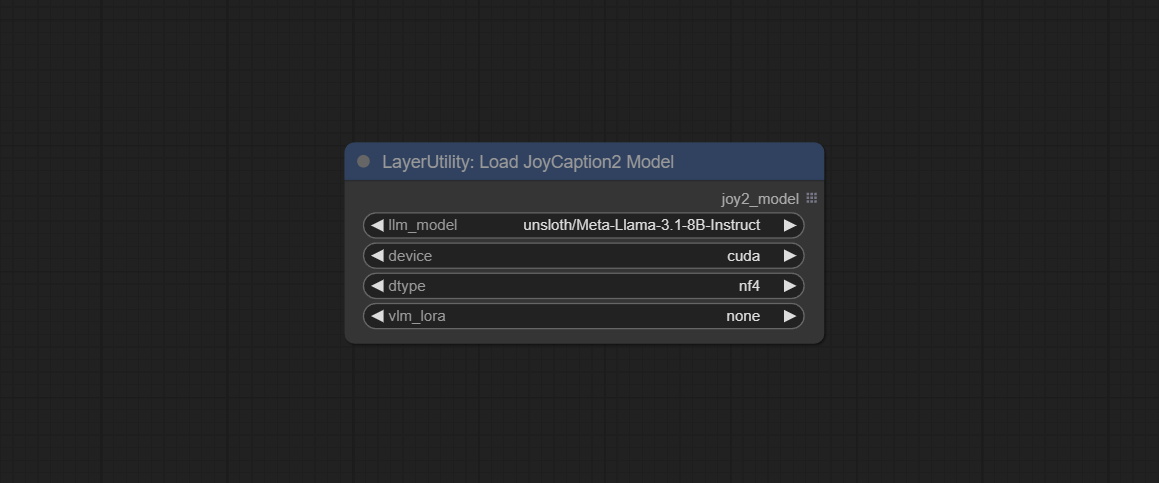
- llm_model: 可选择两种 LLM 模型,分别为 Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 和 unsloth/Meta-Llama-3.1-8B-Instruct。
- device: 模型加载设备。目前仅支持 CUDA。
- dtype: 模型精度,包括 nf4 和 bf16。
- vlm_lora: 是否加载文本适配器。
JoyCaption2ExtraOptions
JoyCaption2 的额外选项参数节点。
节点选项: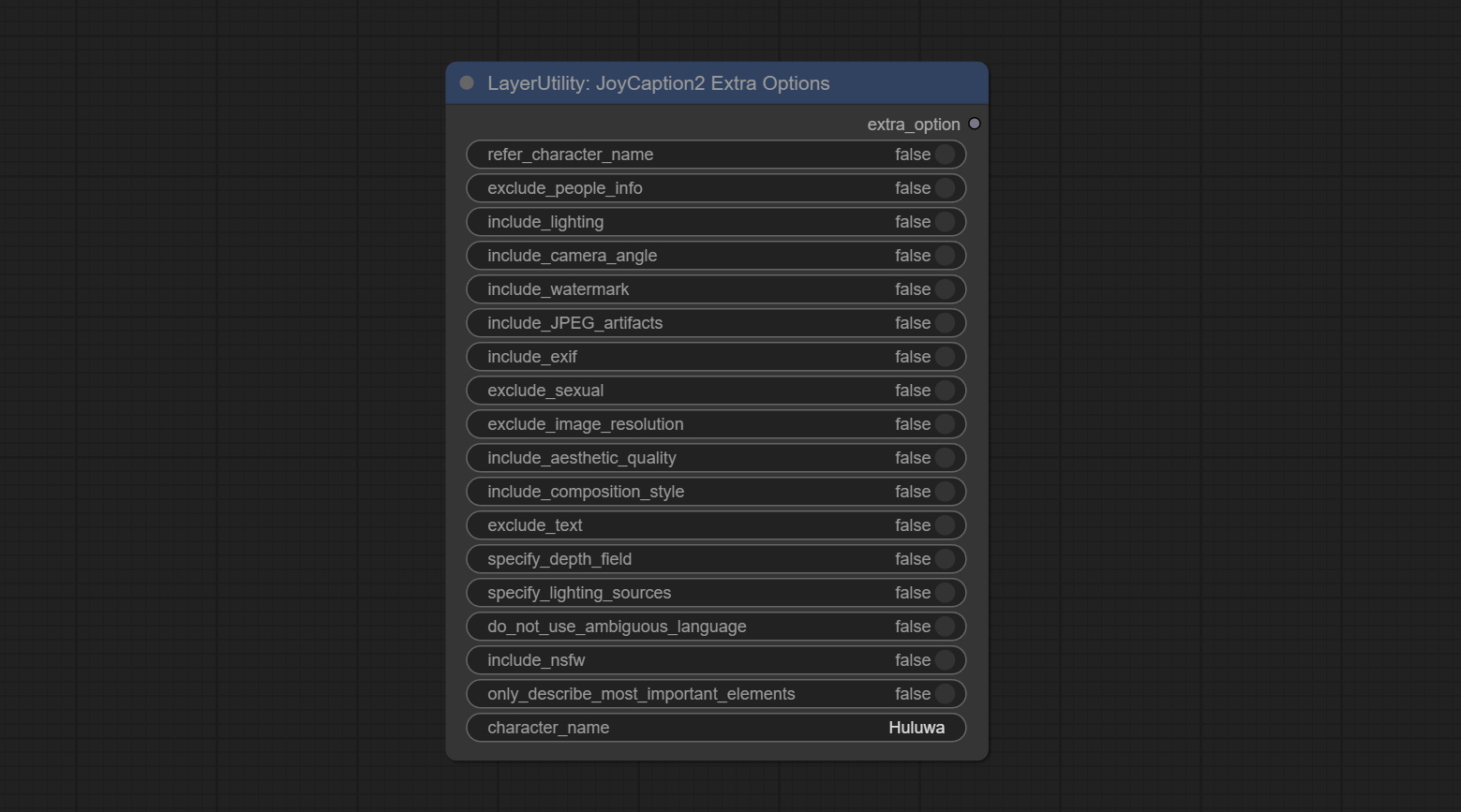
- refer_character_name: 若图像中存在人物/角色,必须以 {name} 的形式提及。
- exclude_people_info: 不包含无法改变的人体特征信息(如种族、性别等),但应保留可变属性(如发型)。
- include_lighting: 包含光照信息。
- include_camera_angle: 包含相机角度信息。
- include_watermark: 包含是否存在水印的信息。
- include_JPEG_artifacts: 包含是否存在 JPEG 码块效应的信息。
- include_exif: 若为照片,必须包含可能使用的相机型号及光圈、快门速度、ISO 等详细信息。
- exclude_sexual: 不得包含任何色情内容;保持 PG 分级。
- exclude_image_resolution: 不得提及图像分辨率。
- include_aesthetic_quality: 必须包含关于图像主观美学质量的描述,从低到极高。
- include_composition_style: 包含图像构图风格信息,例如引导线、三分法或对称性。
- exclude_text: 不得提及图像中的任何文字。
- specify_depth_field: 明确景深范围,以及背景是清晰还是模糊。
- specify_lighting_sources: 如适用,说明可能使用了人工或自然光源。
- do_not_use_ambiguous_language: 不得使用模棱两可的语言。
- include_nsfw: 包含图像属于 SFW、暗示性还是 NSFW 的信息。
- only_describe_most_important_elements: 仅描述图像中最重要元素。
- character_name: 人物/角色名称,若选择了
refer_character_name。
JoyCaptionBetaOne
使用 JoyCaption Beta One 模型生成提示词。该节点是 https://huggingface.co/fancyfeast/llama-joycaption-beta-one-hf-llava 在 ComfyUI 中的实现。
首次使用该节点时,模型将自动下载到 ComfyUI/models/LLavacheckpoints/llama-joycaption-beta-one-hf-llava 文件夹中。
您也可以从 百度网盘 或 夸克网盘 或 Hugging Face/fancyfeast/llama-joycaption-beta-one-hf-llava 下载 llama-joycaption-beta-one-hf-llava 文件夹,并将其复制到 ComfyUI/models/LLavacheckpoints 目录下。
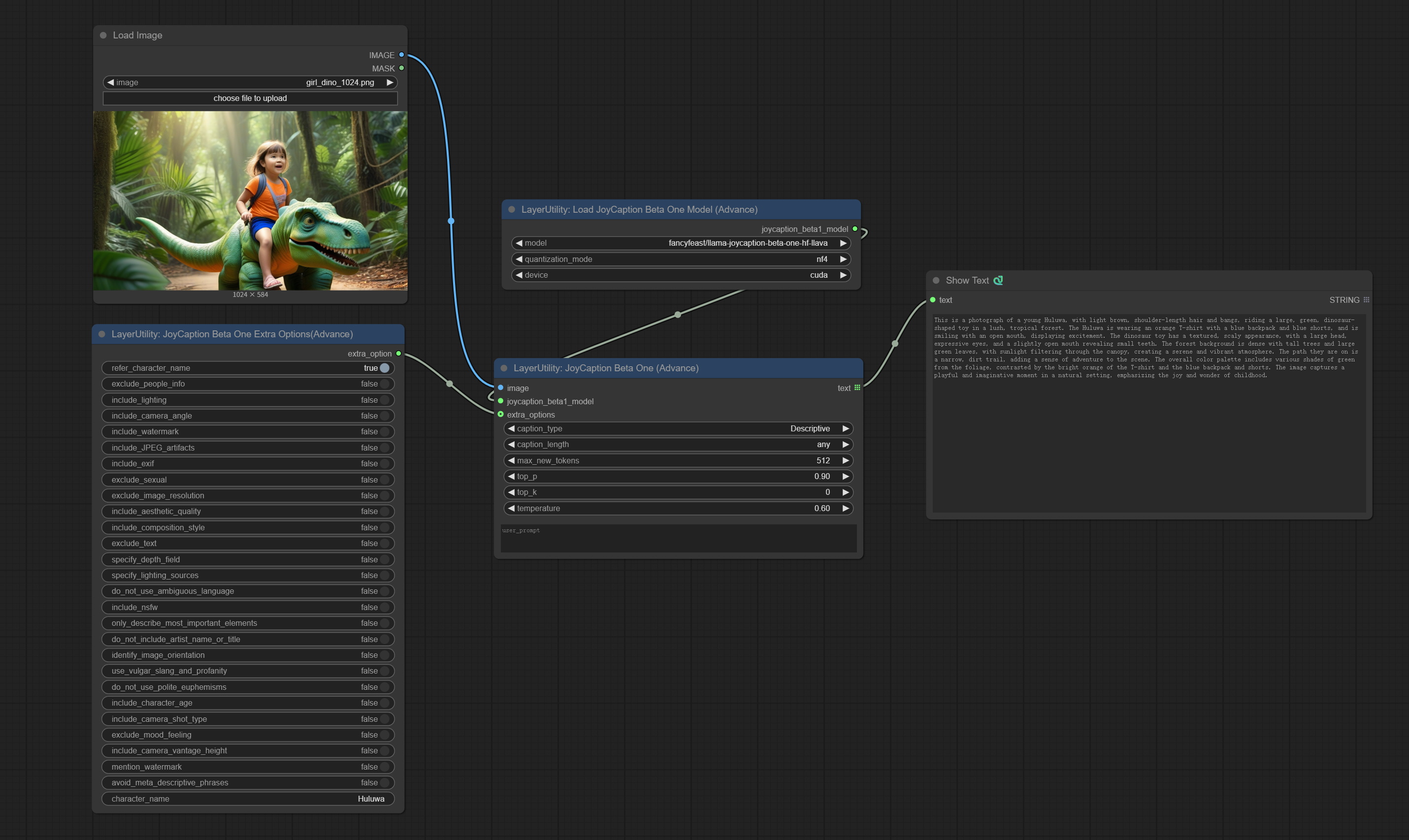
节点选项: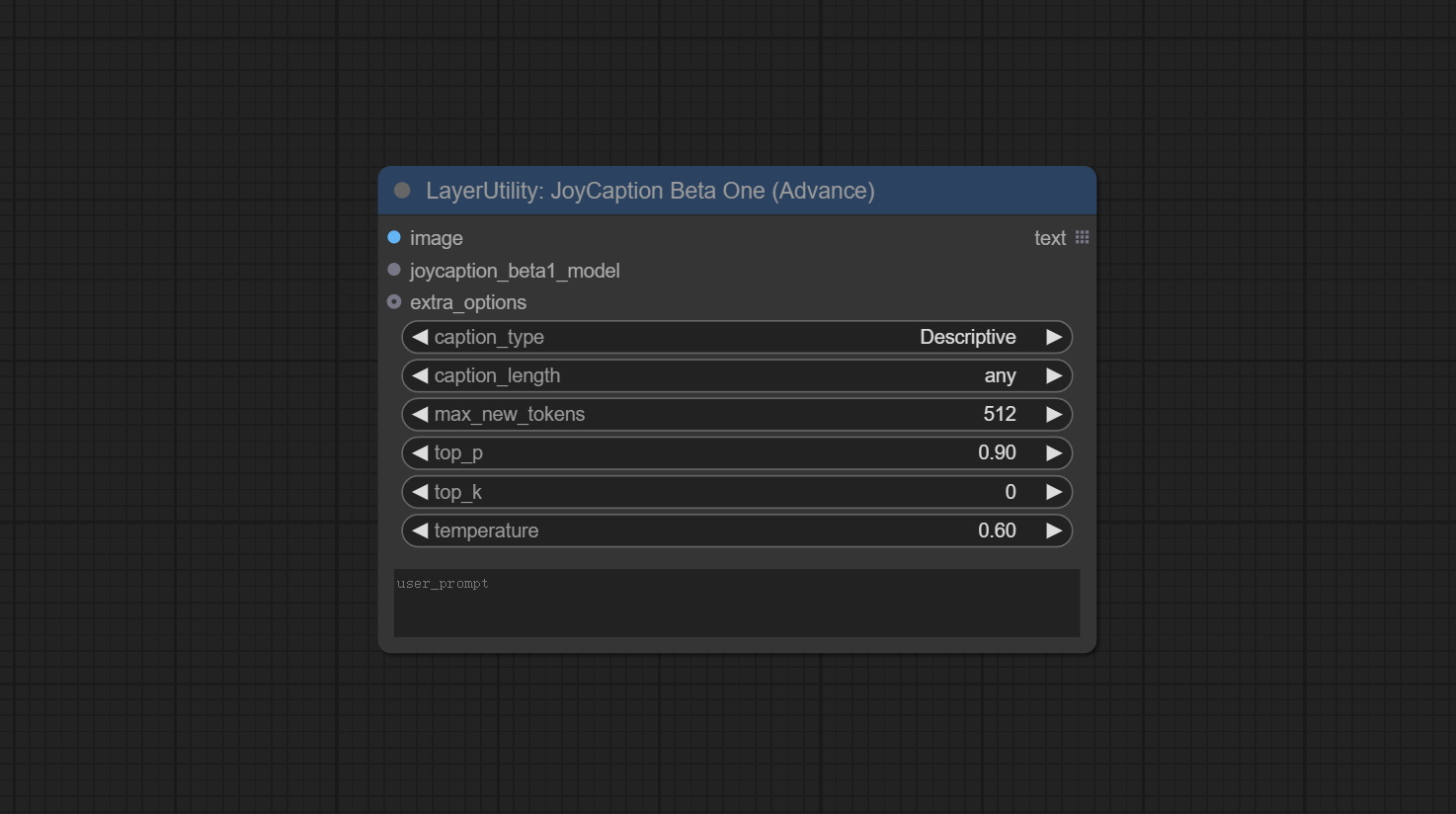
- image:图像输入。
- joycaption_beta1_model:JoyCaption Beta One 模型输入。该模型从
Load JoyCaption Beta One Model节点加载。 - extra_options:输入额外选项。
- caption_type:字幕类型选项,包括:“描述性”、“描述性(休闲)”、“直白”、“Stable Diffusion 提示词”、“MidJourney”、“Danbooru 标签列表”、“e621 标签列表”、“Rule34 标签列表”、“类似 Booru 的标签列表”、“艺术评论家”、“商品列表”和“社交媒体帖子”。
- caption_length:字幕长度。
- max_new_tokens:模型的 max_new_token 参数。
- top-p:模型的 top-p 参数。
- top-k:模型的 top-k 参数。
- temperature:模型的温度参数。
- user_prompt:模型的用户提示词。如果此处有内容,则会覆盖所有 caption_type 和 extra_options 的设置。
LoadJoyCaptionBeta1Model
JoyCaption Beta One 的模型加载节点,与 JoyCaption Beta One 配合使用。
节点选项: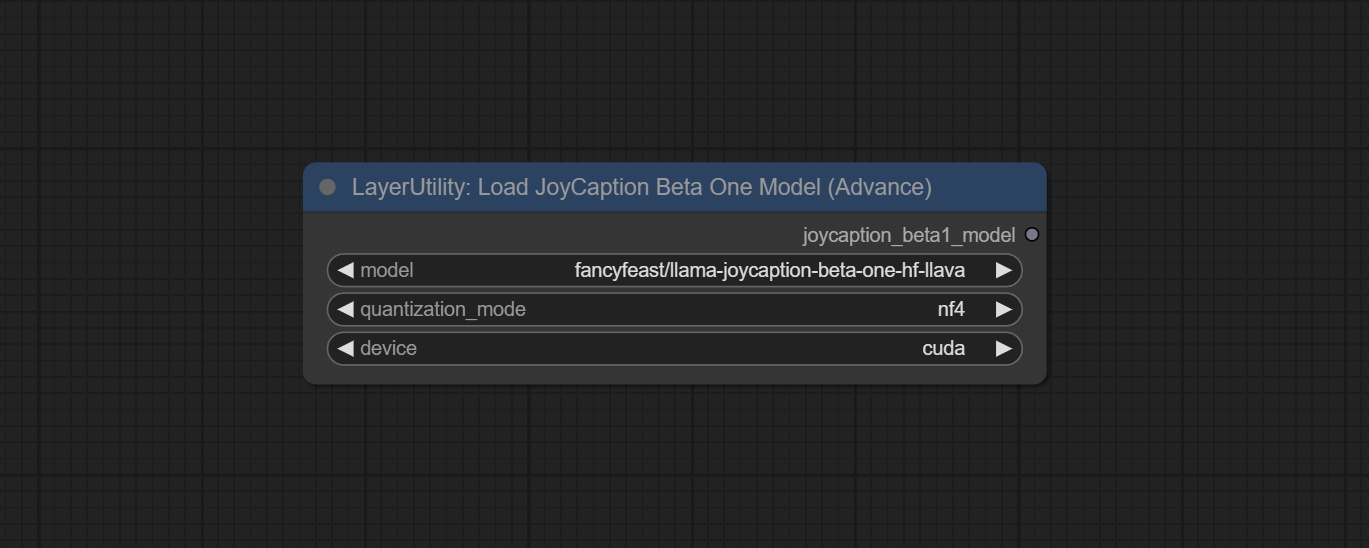
- model:目前仅可选择
fancyfeast/llama-joycaption-beta-one-hf-llava模型。 - quantization_mode:模型量化模式有三种选项:nf4、int8 和 bf16。
- device:模型加载设备。
JoyCaptionBeta1ExtraOptions
JoyCaption Beta One 的 extra_options 参数节点。
节点选项: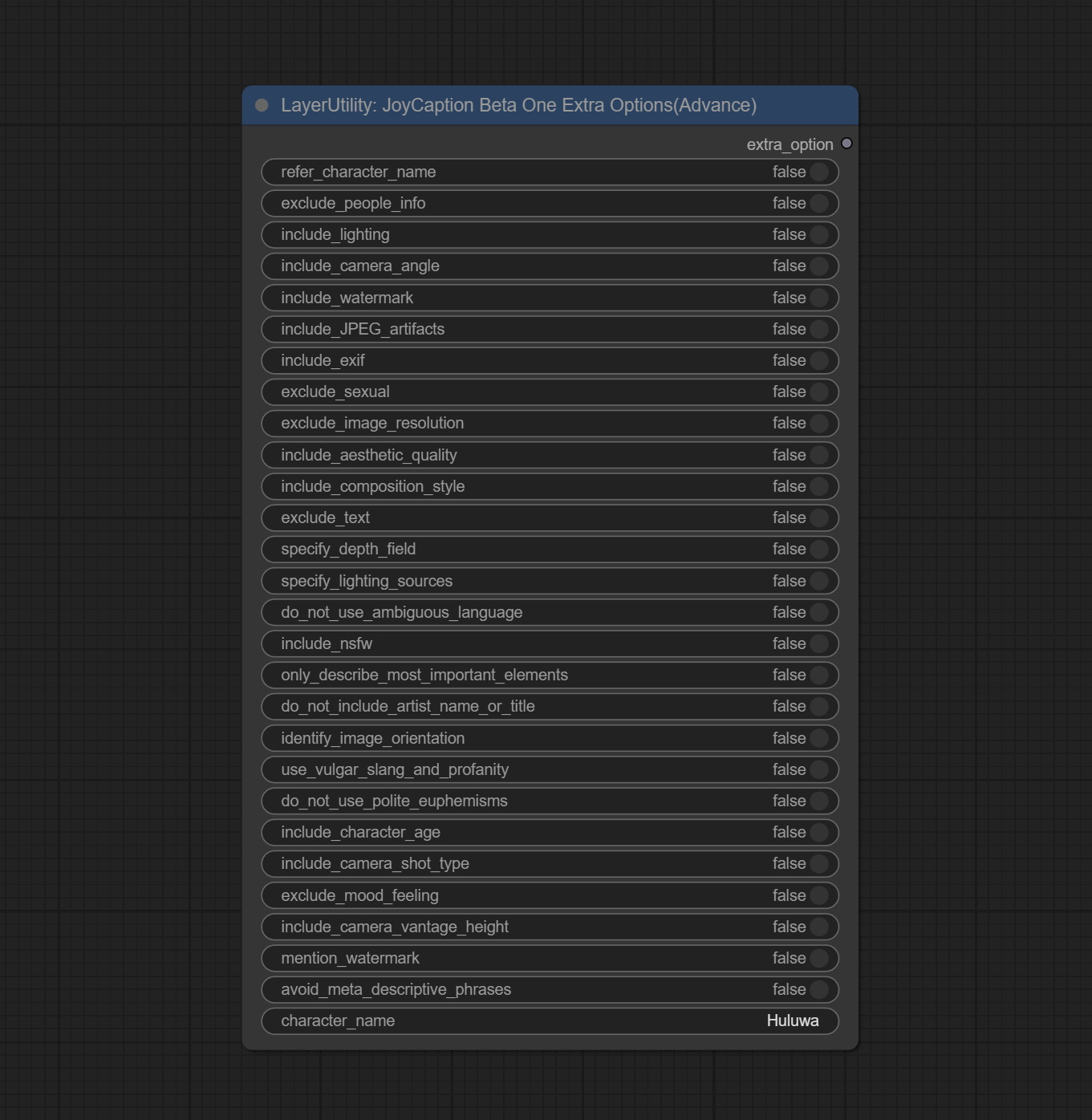
- refer_character_name:如果图像中有人物/角色,必须以 {name} 来指代他们。
- exclude_people_info:不要包含无法改变的人或角色信息(如种族、性别等),但仍需包含可变属性(如发型)。
- include_lighting:包含光照信息。
- include_camera_angle:包含相机角度信息。
- include_watermark:包含是否有水印的信息。
- include_JPEG_artifacts:包含是否存在 JPEG 艺术伪影的信息。
- include_exif:如果是照片,必须包含可能使用的相机信息以及光圈、快门速度、ISO 等细节。
- exclude_sexual:不要包含任何性相关的内容;保持 PG 级别。
- exclude_image_resolution:不要提及图像的分辨率。
- include_aesthetic_quality:必须包含关于图像主观美学质量的信息,从低到非常高。
- include_composition_style:包含图像构图风格的信息,例如引导线、三分法或对称性。
- exclude_text:不要提及图像中的任何文字。
- specify_depth_field:指定景深范围,以及背景是清晰还是模糊。
- specify_lighting_sources:如果适用,说明可能使用了人工或自然光源。
- do_not_use_ambiguous_language:不要使用任何模棱两可的语言。
- include_nsfw:包含图像是否属于 SFW、暗示性或 NSFW。
- only_describe_most_important_elements:仅描述图像中最重要元素。
- do_not_include_artist_name_or_title:如果是艺术作品,不要包含艺术家姓名或作品标题。
- identify_image_orientation:识别图像方向(竖版、横版或正方形)及明显的长宽比。
- use_vulgar_slang_and_profanity:使用粗俗俚语和脏话。
- do_not_use_polite_euphemisms:不要使用委婉语——直接采用直白、随意的表达方式。
- include_character_age:在适用情况下,包含人物/角色的年龄信息。
- include_camera_shot_type:说明图像拍摄的是特写、近景、中近景、中景、牛仔镜头、中远景、远景还是超远景。
- exclude_mood_feeling:不要提及图像的情绪/感觉等。
- include_camera_vantage_height:明确说明拍摄视角高度(平视、低角度虫瞰、鸟瞰、无人机、屋顶等)。
- mention_watermark:如果有水印,必须提及。
- avoid_meta_descriptive_phrases:您的回复将被文本转图像模型使用,因此请避免使用无用的元描述短语,如“这张图像显示……”、“您正在观看……”等。
- character_name:人物/角色名称,若选择
refer_character_name。
PhiPrompt
使用 Microsoft Phi 3.5 文本和视觉模型进行本地推理。可用于生成提示词、处理提示词或从图像中推断提示词。运行此模型至少需要 16GB 显存。
从 百度网盘 或 Hugging Face/microsoft/Phi-3.5-vision-instruct 以及 Hugging Face/microsoft/Phi-3.5-mini-instruct 下载模型文件,并将其复制到 ComfyUI\models\LLM 文件夹中。
节点选项: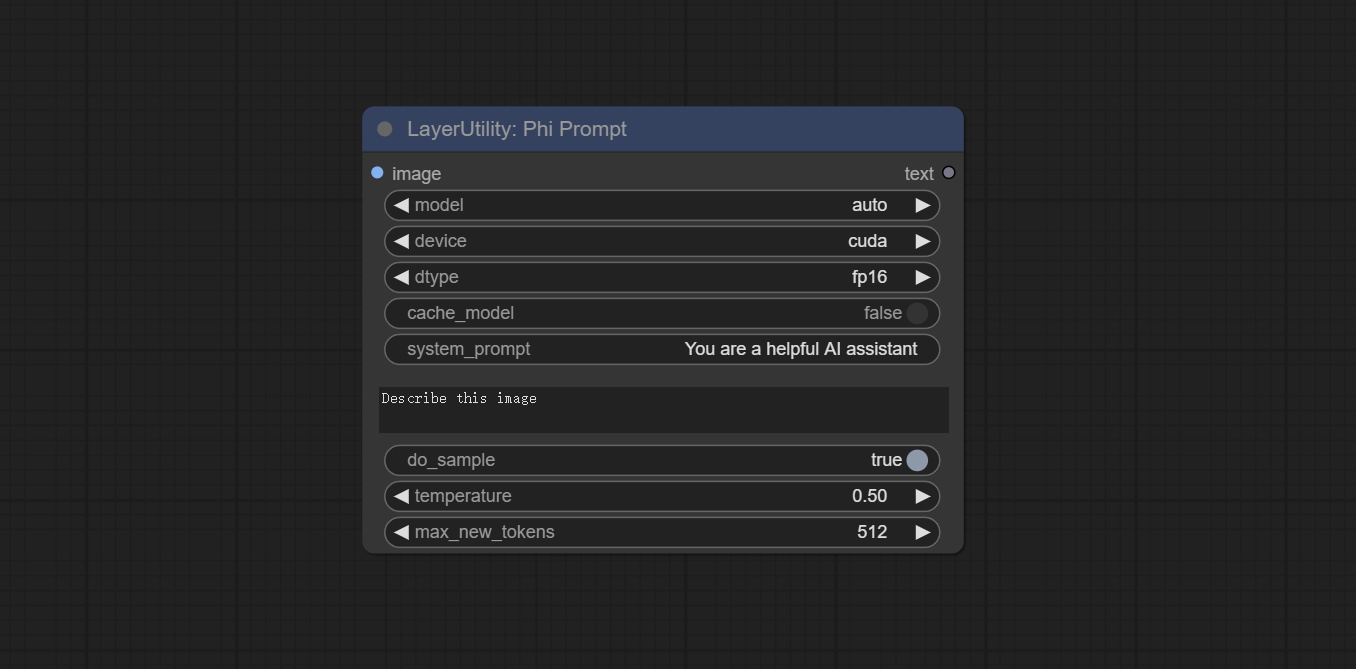
- image:可选输入。输入图像将作为 Phi-3.5-vision-instruct 的输入。
- model:可选择加载 Phi-3.5-vision-instruct 或 Phi-3.5-mini-instruct 模型。默认值 auto 会根据是否有图像输入自动加载相应模型。
- device:模型加载设备。支持 CPU 和 CUDA。
- dtype:模型加载精度有三种选项:fp16、bf16 和 fp32。
- cache_model:是否缓存模型。
- system_prompt:Phi-3.5-mini-instruct 的系统提示词。
- user_prompt:LLM 模型的用户提示词。
- do_sample:LLM 的 do_Sample 参数默认为 True。
- temperature:LLM 的温度参数默认为 0.5。
- max_new_tokens:LLM 的 max_new_token 参数默认为 512。
Gemini
使用 Google Gemini API 的文本和视觉模型进行本地推理。可用于生成提示词、处理提示词,或从图像中推断提示词。
请在 Google AI Studio 上申请您的 API 密钥,并将其填写到插件根目录下的 api_key.ini 文件中。该文件默认名为 api_key.ini.example。首次使用时,需将文件后缀改为 .ini。用文本编辑软件打开文件,在 google_api_key= 后填入您的 API 密钥并保存。
节点选项:
- image_1:可选输入。如果此处有图像输入,请在 user_dempt 中说明 'image_1' 的用途。
- image_2:可选输入。如果此处有图像输入,请在 user_dempt 中说明 'image_2' 的用途。
- model:选择 Gemini 模型。
- max_output_tokens:Gemini 的 max_output_token 参数默认为 4096。
- temperature:Gemini 的 temperature 参数默认为 0.5。
- words_limit:回复的默认字数限制为 200。
- response_language:回复的语言。
- system_prompt:系统提示。
- user_prompt:用户提示。
GeminiV2
在 Gemini 节点的基础上,切换至使用新的 google-genai 依赖包,该包支持最新的 gemini-2.0-flash、gemini-2.0-flash-lite 和 gemini-2.5-pro-exp-03-25 模型。
在原有节点基础上新增: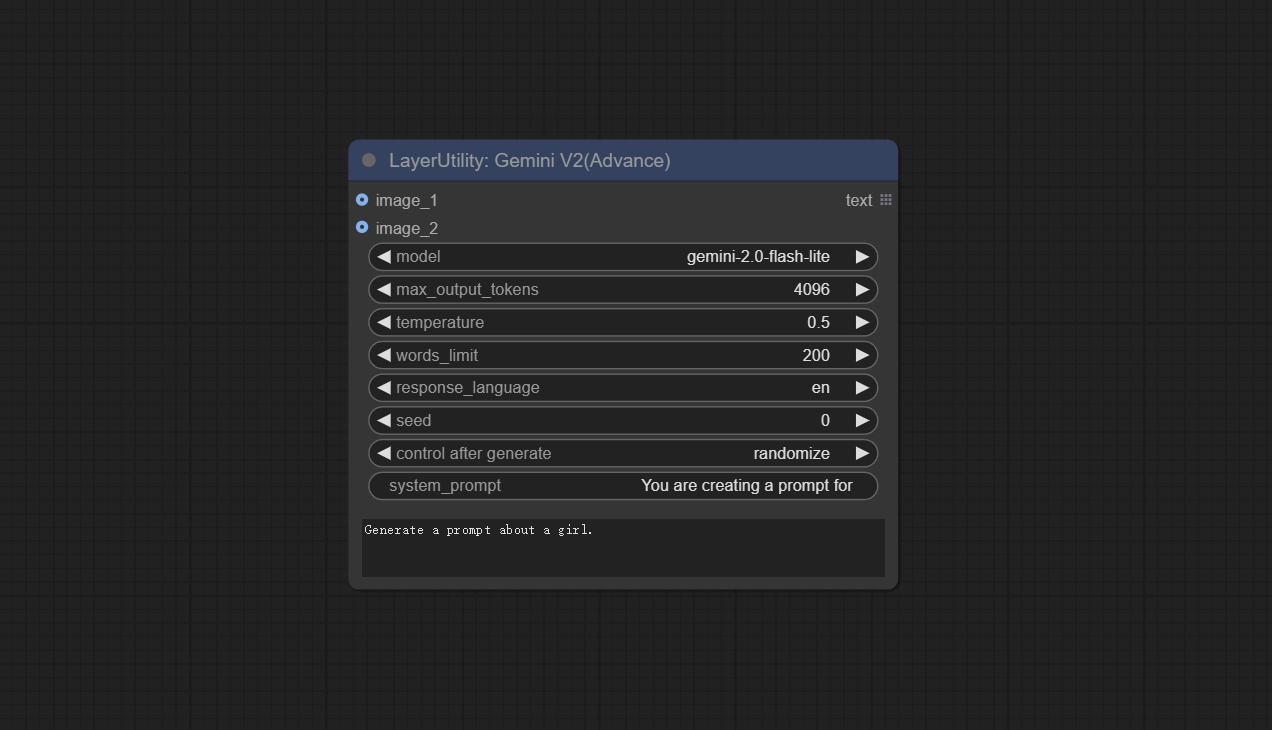
- seed:请求 Google API 时使用的随机种子值。
GeminiImageEdit
使用 gemini-2.0-flash-exp-image-generation 模型实现多模态图像编辑。
请在 Google AI Studio 上申请您的 API 密钥,并将其填写到插件根目录下的 api_key.ini 文件中。该文件默认名为 api_key.ini.example。首次使用时,需将文件后缀改为 .ini。用文本编辑软件打开文件,在 google_api_key= 后填入您的 API 密钥并保存。
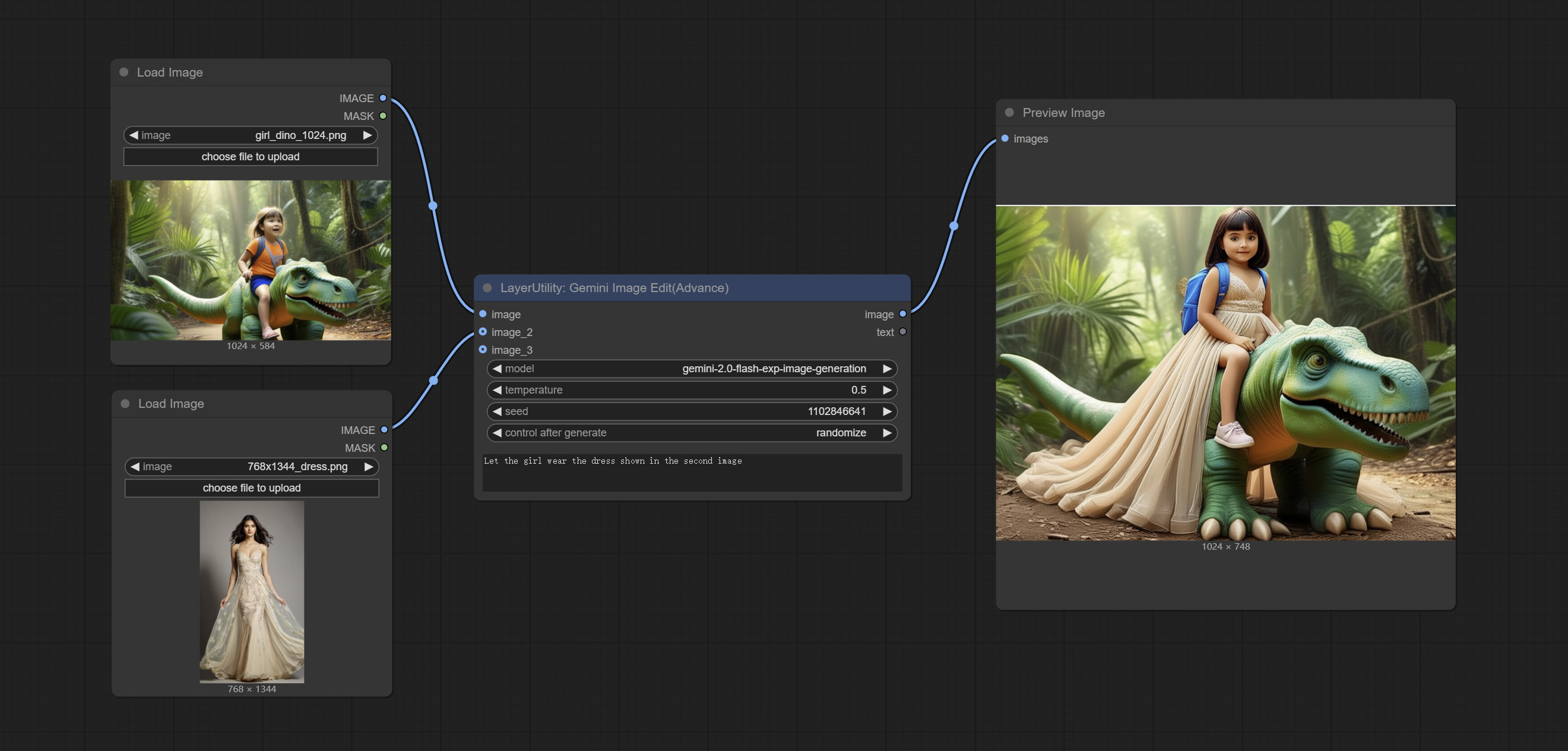
节点选项: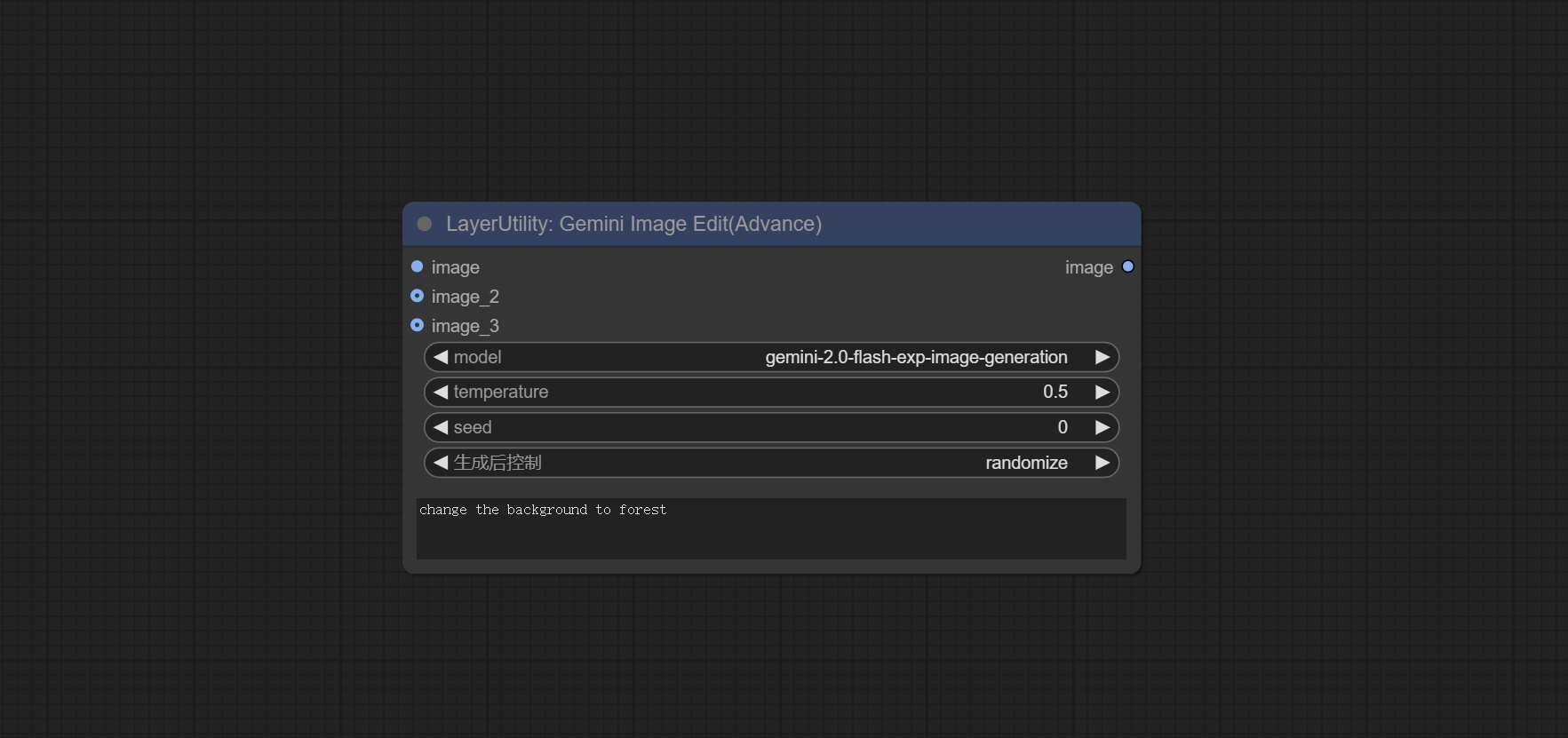
- image:输入图像。
- image_2:可选的第二张输入图像。
- image_3:可选的第三张输入图像。
- model:选择 Gemini 模型。目前仅支持 gemini-2.0-flash-exp-image-generation 模型。
- temperature:Gemini 的 temperature 参数默认为 0.5。
- seed:请求 Google API 时使用的随机种子值。
- control_after_generate:设置是否每次生成后都更换种子。
- user_prompt:用户提示。
DeepSeekAPI
使用 DeepSeek API 进行文本推理,支持多节点上下文拼接。
请在 https://platform.deepseek.com/api_keys 免费申请 API 密钥,并将其填写到插件根目录下的 api_key.ini 文件中。该文件默认名为 api_key.ini.example。首次使用时,需将文件后缀改为 .ini。用文本编辑软件打开文件,在 deepseek_api_key= 后填入您的 API 密钥并保存。
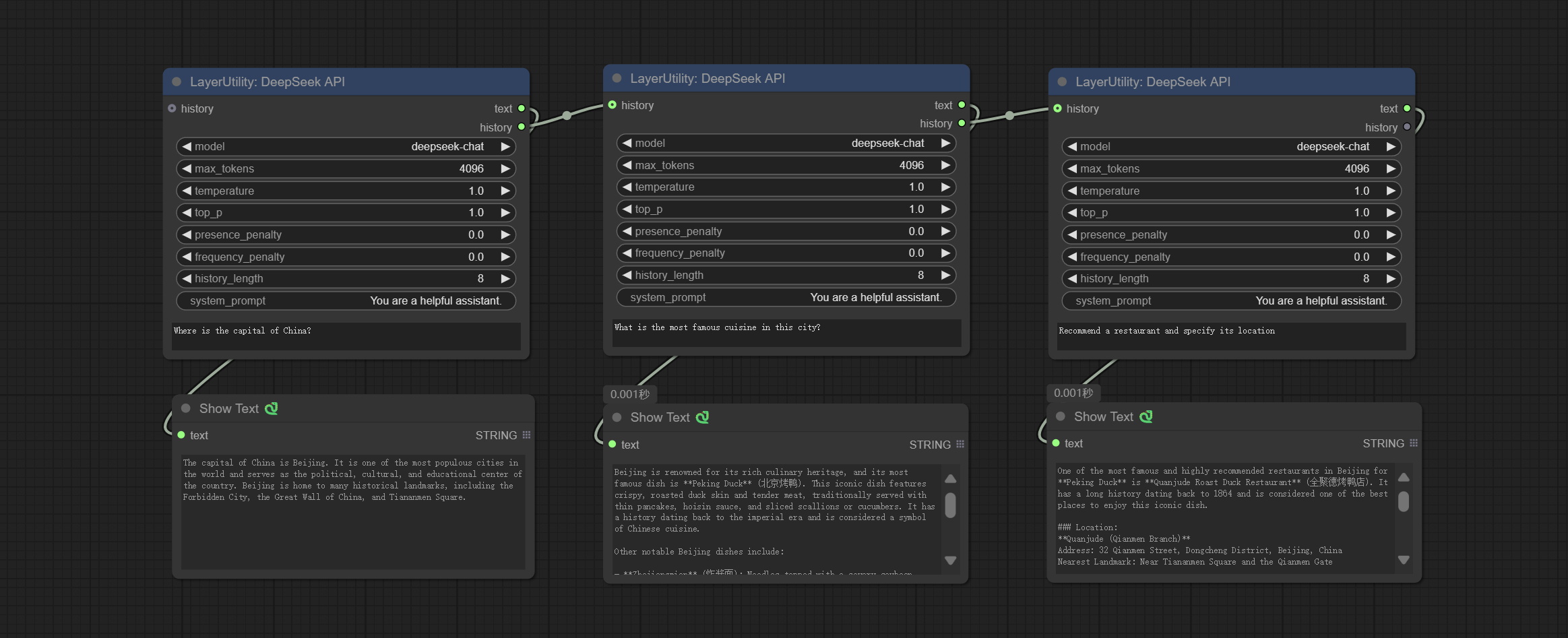
节点选项: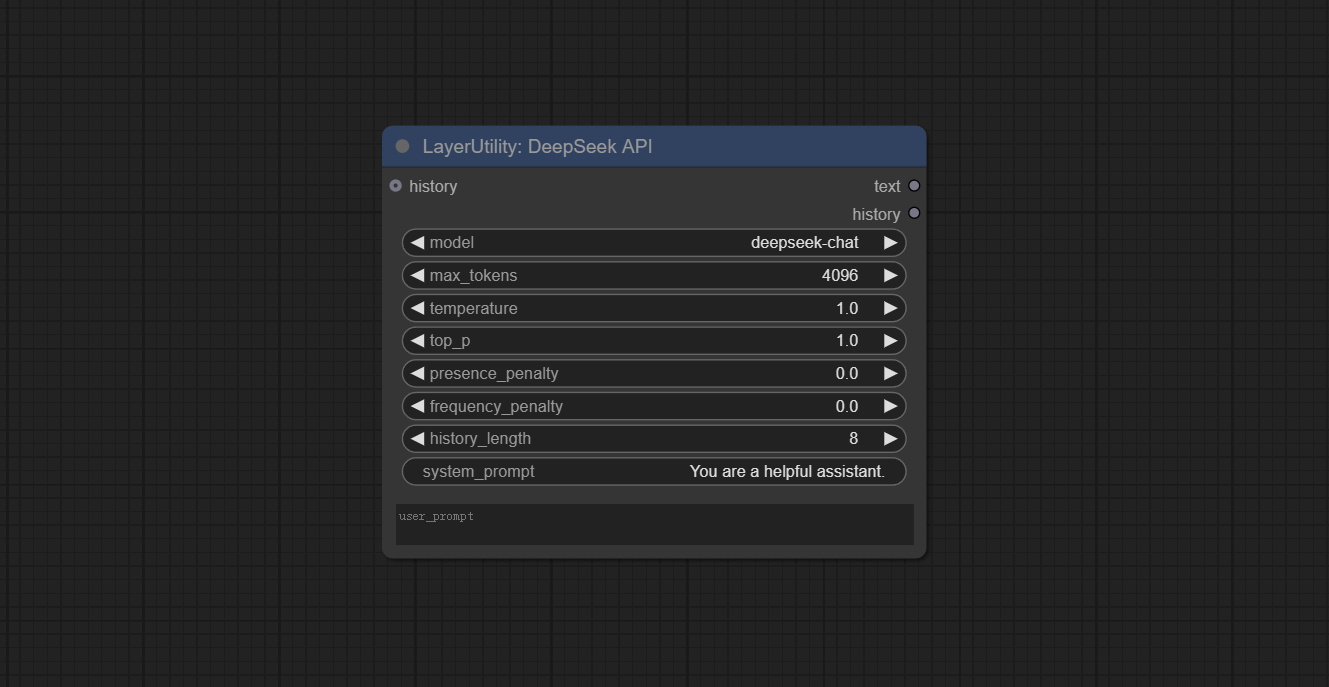
- history:DeepSeekAPI 节点的历史记录,可选输入。如果有输入,历史记录将被用作上下文。
- model:选择 DeepSeek 模型,目前只有一个选项:“deepseek-chat”,即 DeepSeek-V3 模型。
- max_tokens:DeepSeek 的 max_token 参数默认为 4096。
- temperature:DeepSeek 的 temperature 参数默认为 1。
- top_p:DeepSeek 的 top_p 参数默认为 1。
- presence_penalty:DeepSeek 的 presence_penalty 参数默认为 0。
- frequency_penalty:DeepSeek 的 frequency_penalty 参数默认为 0。
- history_length:历史记录长度。超过此长度的记录将被丢弃。
- system_prompt:系统提示。
- user_prompt:用户提示。
输出:
- text:DeepSeek 的输出文本。
- history:DeepSeek 对话的历史记录。
DeepSeekAPI_V2
在 DeepSeekAPI 节点的基础上,新增支持阿里云和火山引擎的 DeepSeek API,这两家中国云服务提供商将提供更稳定的 API 服务。
在 火山引擎 申请火山引擎 API 密钥时,可获得 50 万 token 的免费额度。如果您在申请时填写我的邀请码
27RVS1QN,还将额外获得 375 万个 R1 模型的免费 token。在 阿里云 申请阿里云 API 密钥。
将获取到的 API 密钥分别填写到
api_key.ini文件中的volcengine_api_key和aliyun_api_key字段中。该文件位于插件根目录,默认名为api_key.ini.example。编辑后将文件扩展名改为.ini。
新增选项: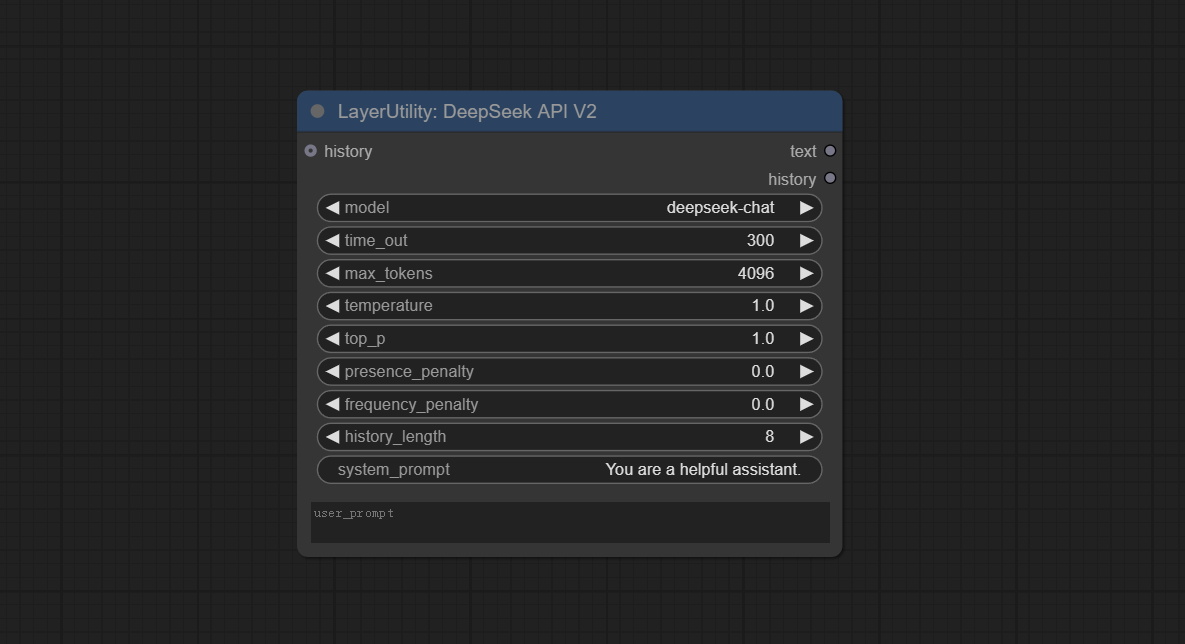
- time_out:超时时间默认设置为 300 秒。
ZhipuGLM4
使用智谱 API 进行文本推理,支持多节点上下文拼接。
请在 https://bigmodel.cn/usercenter/proj-mgmt/apikeys 免费申请 API 密钥,并将其填写到插件根目录下的 api_key.ini 文件中。该文件默认名为 api_key.ini.example。首次使用时,需将文件后缀改为 .ini。用文本编辑软件打开文件,在 zhipu_api_key= 后填入您的 API 密钥并保存。
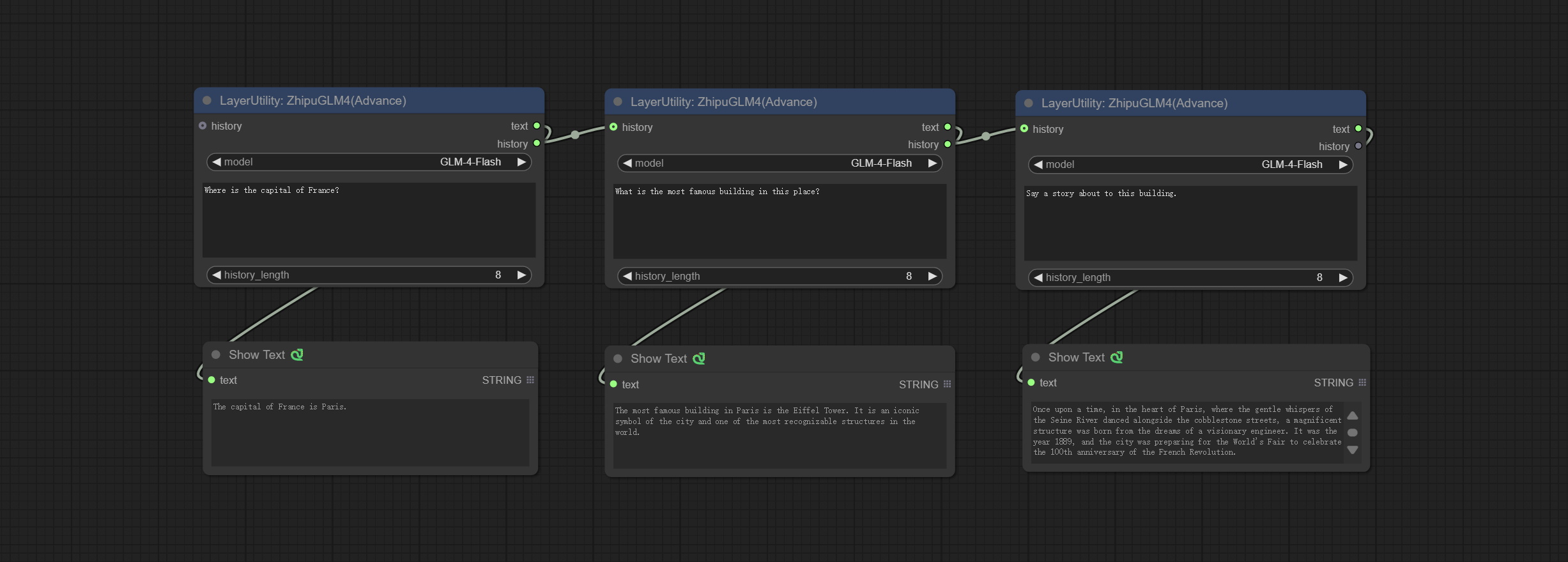
节点选项: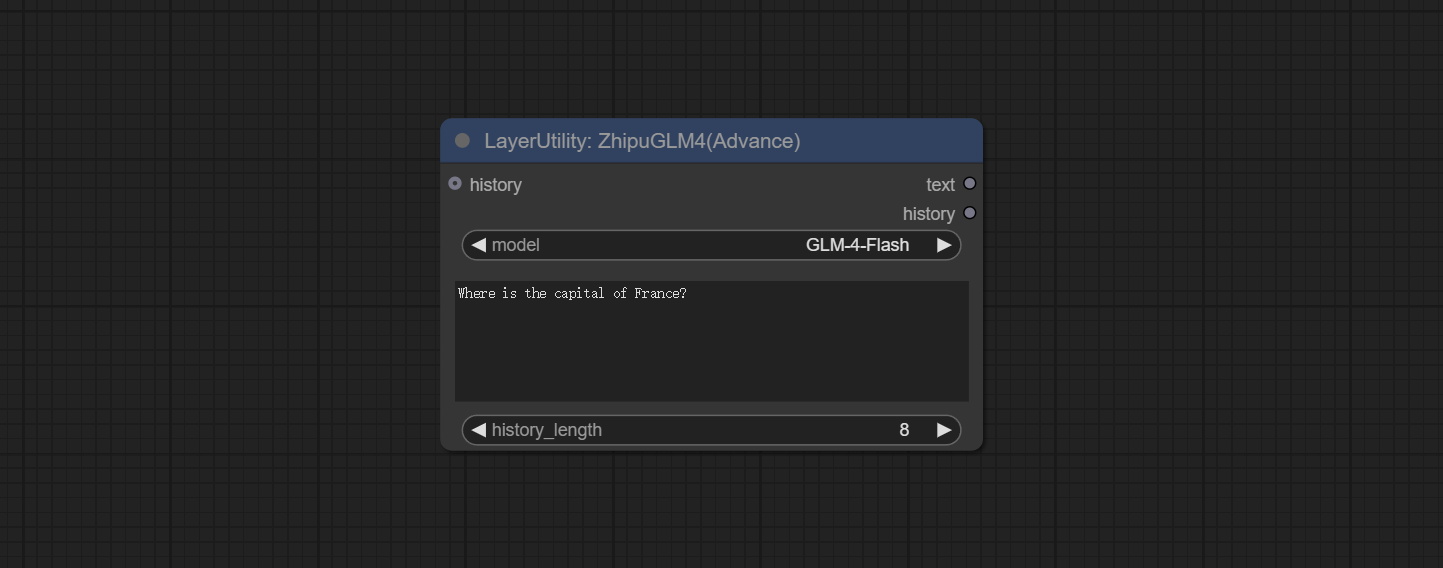
- history:GLM4 节点的历史记录,可选输入。如果有输入,历史记录将被用作上下文。
- model:选择 GLM4 模型。GLM-4-Flash 是一款免费模型。
- user_prompt:用户提示。
- history_length:历史记录长度。超过此长度的记录将被丢弃。
输出:
- text:GLM4 的输出文本。
- history:GLM4 对话的历史记录。
智普GLM4V
使用智普API进行视觉推理。
请在https://bigmodel.cn/usercenter/proj-mgmt/apikeys免费申请API密钥,并将其填写到api_key.ini文件中。该文件位于插件的根目录下,默认名称为api_key.ini.example。首次使用时,需将文件后缀改为.ini。用文本编辑软件打开文件,在zhipu_api_key=后填入您的API密钥并保存。
节点选项:
- image:输入图像。
- model:选择GLM4V模型。glm-4v-flash是免费模型。
- user_prompt:用户提示词。
输出:
- text:GLM4V的输出文本。
SmolLM2
使用SmolLM2模型进行本地推理。
从百度网盘或Hugging Face下载模型文件,找到SmolLM2-135M-Instruct、SmolLM2-360M-Instruct、SmolLM2-1.7B-Instruct文件夹,至少下载其中一个,然后复制到ComfyUI/models/smol文件夹。
节点选项:
- smolLM2_model:SmolLM2模型的输入由LoadSmolLM2Model节点加载。
- max_new_tokens:最大token数默认为512。
- do_sample:do_Sample参数默认为True。
- temperature:temperature参数默认为0.5。
- top-p:top_p参数默认为0.9。
- system_prompt:系统提示词。
- user_prompt:用户提示词。
LoadSmolLM2Model
加载SmolLM2模型。
节点选项:
- model:SmolLM2模型有三个选项:SmolLM2-135M-Instruct、SmolLM2-360M-Instruct和SmolLM2-1.7B-Instruct。
- dtype:模型精度有两个选项:bf16和fp32。
- device:模型加载设备有两个选项:cuda或cpu。
SmolVLM
使用Hugging Face上的轻量级视觉模型进行本地推理。
从百度网盘或Hugging Face下载SmolVLM-Instruct文件夹,并复制到ComfyUI/models/smol文件夹。
节点选项: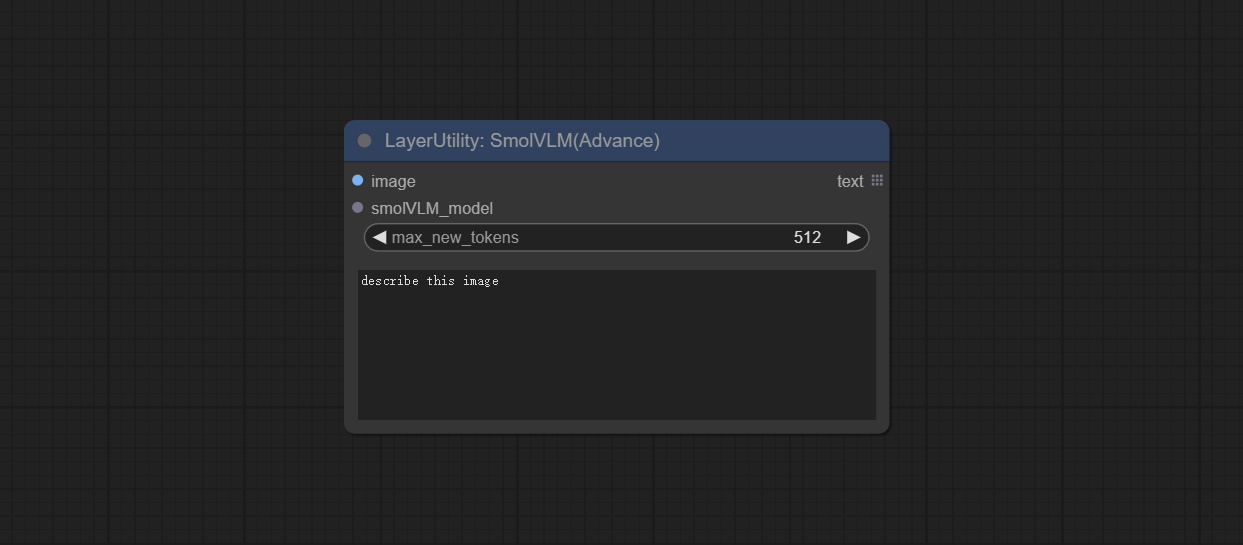
- image:图像输入,支持批量图像。
- smolVLM_model:SmolVLM模型的输入由LoadSmolVLMModel节点加载。
- max_new_tokens:最大token数默认为512。
- user_prompt:用户提示词。
LoadSmolVLMModel
加载SmolVLM模型。
节点选项: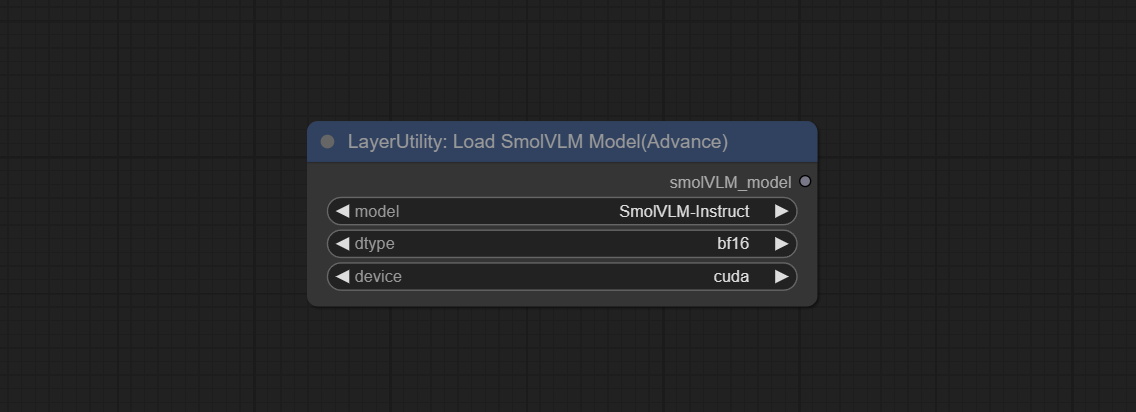
- model:目前SmolVLM模型仅有一个选项:SmolVLM-Instruct。
- dtype:模型精度有两个选项:bf16和fp32。
- device:模型加载设备有两个选项:cuda或cpu。
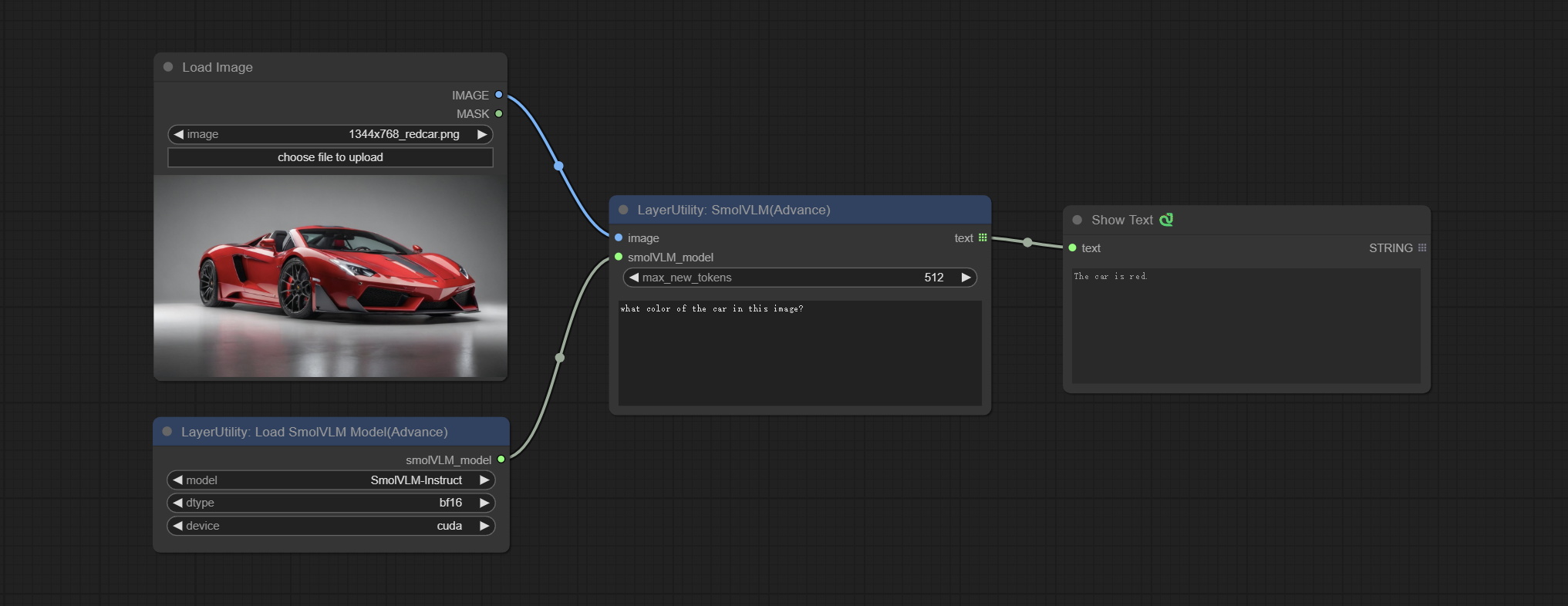
JimengImageToImageAPI
使用Jimeng API编辑图片。
请在火山引擎注册账号,申请API AccessKeyID和SecretAccessKey,并将其填写到api_key.ini文件中。该文件位于插件的根目录下,默认名称为api_key.ini.example。首次使用时,需将文件后缀改为'.ini'。用文本编辑软件打开文件,在volcengine_SecretAccessKey=和volcengine_AccessKeyID=后填入相应值。
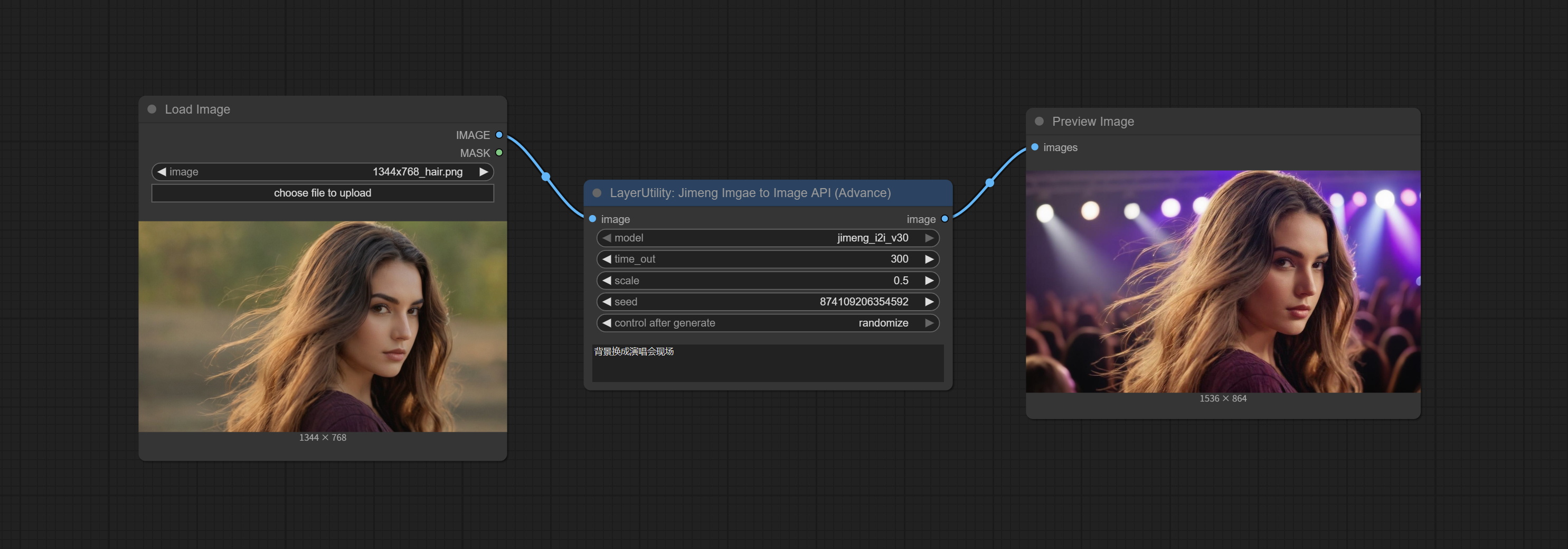
节点选项: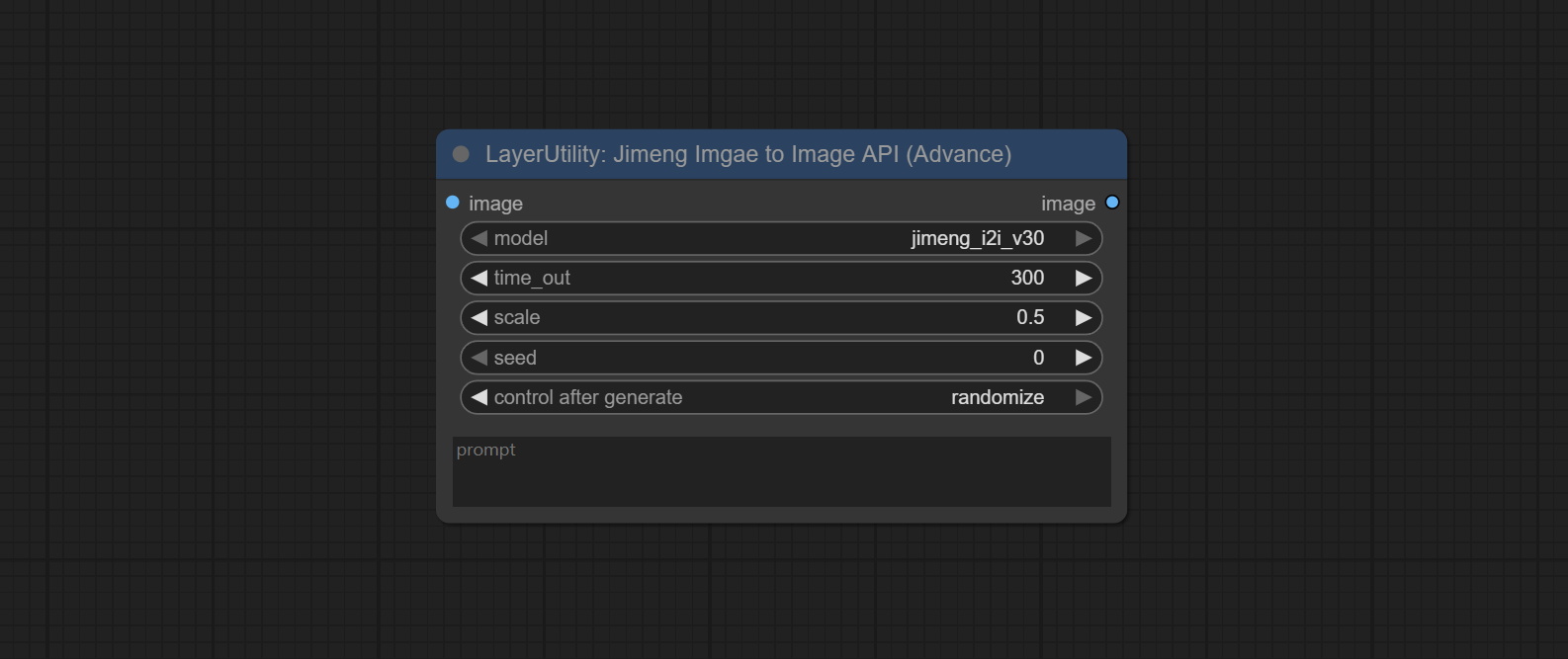
- image:输入图像。
- model:选择DreamMap和Life Map模型。目前仅支持Jimeng_i2i-v30模型。
- time_out:等待API返回的最大时间限制,单位为秒。超过此时间,节点将停止运行。
- scale:Jimeng_i2iuv30的scale参数默认为0.5。
- seed:种子值。
- prompt:提示词。
UserPromptGeneratorTxtImg
用于生成SD文本转图像提示词的预设用户提示。
节点选项: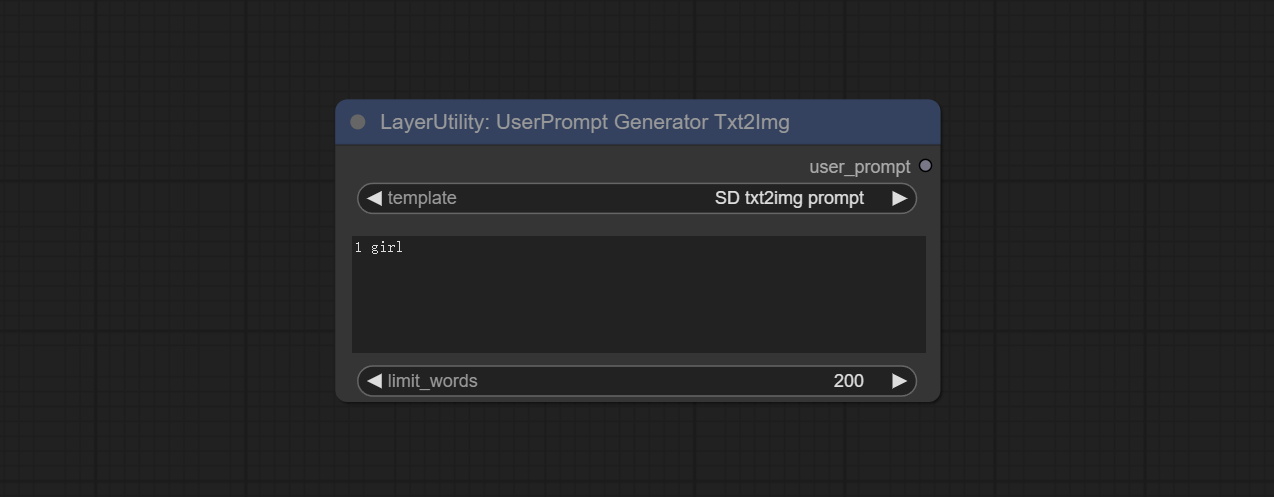
- template:提示词模板。目前仅提供'SD txt2img提示'。
- describe:提示词描述。在此输入简单的描述。
- limit_word:输出提示词的最大长度限制。例如,200表示输出文本将被限制在200个单词以内。
UserPromptGeneratorTxtImgWithReference
基于输入内容生成SD文本转图像提示词的预设用户提示。
节点选项: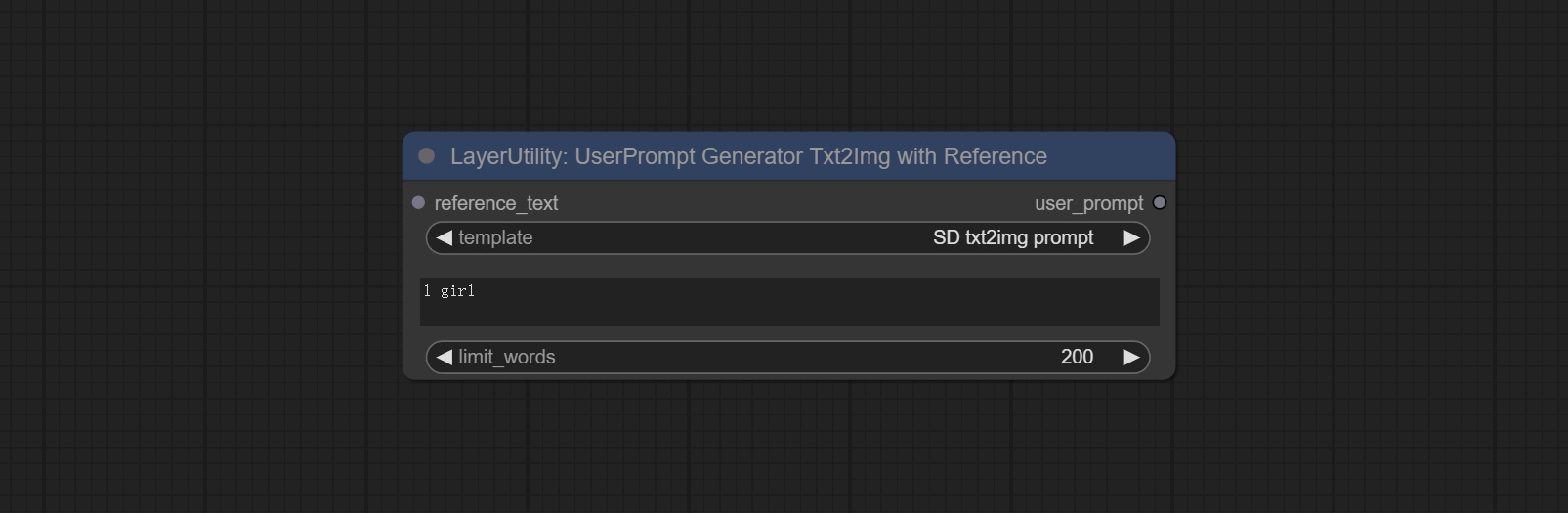
- reference_text:参考文本输入。通常为图像的风格描述。
- template:提示词模板。目前仅提供'SD txt2img提示'。
- describe:提示词描述。在此输入简单的描述。
- limit_word:输出提示词的最大长度限制。例如,200表示输出文本将被限制在200个单词以内。
UserPromptGeneratorReplaceWord
用于将文本中的关键词替换为不同内容的预设用户提示。这不仅是简单的替换,还会根据提示词的上下文对文本进行逻辑排序,以确保输出内容的合理性。
节点选项: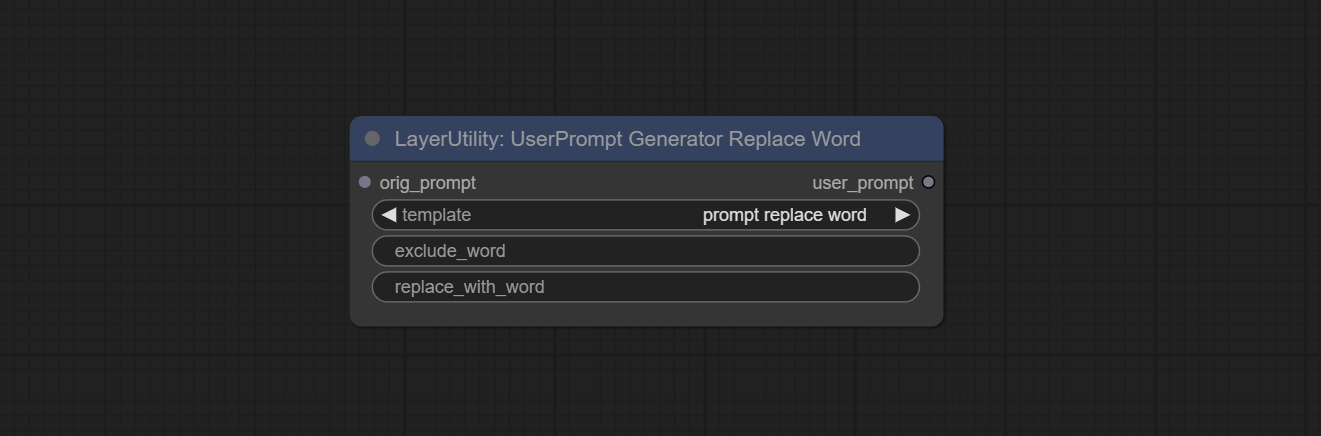
- orig_prompt:原始提示词输入。
- template:提示词模板。目前仅提供'提示词替换'。
- exclude_word:需要排除的关键词。
- replace_with_word:将替换exclude_word的词语。
PromptTagger
根据图像推理生成提示词,可以替换提示词中的关键词。该节点目前使用 Google Gemini API 作为后端服务,请确保网络环境能够正常访问 Gemini。
请在 Google AI Studio 上申请您的 API 密钥,并将其填写到插件根目录下的 api_key.ini 文件中。该文件默认名为 api_key.ini.example,首次使用时需将文件后缀改为 .ini。用文本编辑软件打开文件,在 google_api_key= 后填入您的 API 密钥并保存。
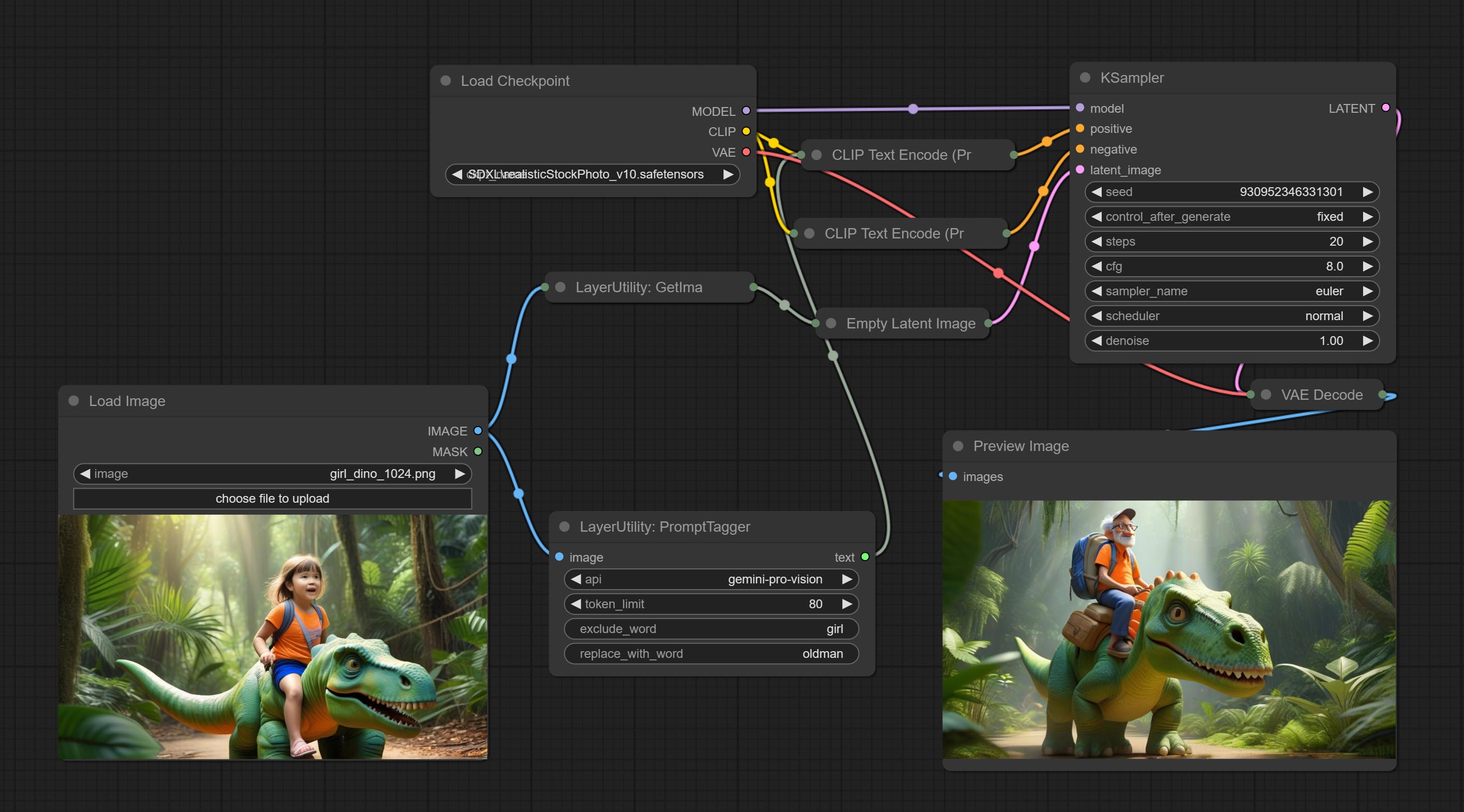
节点选项: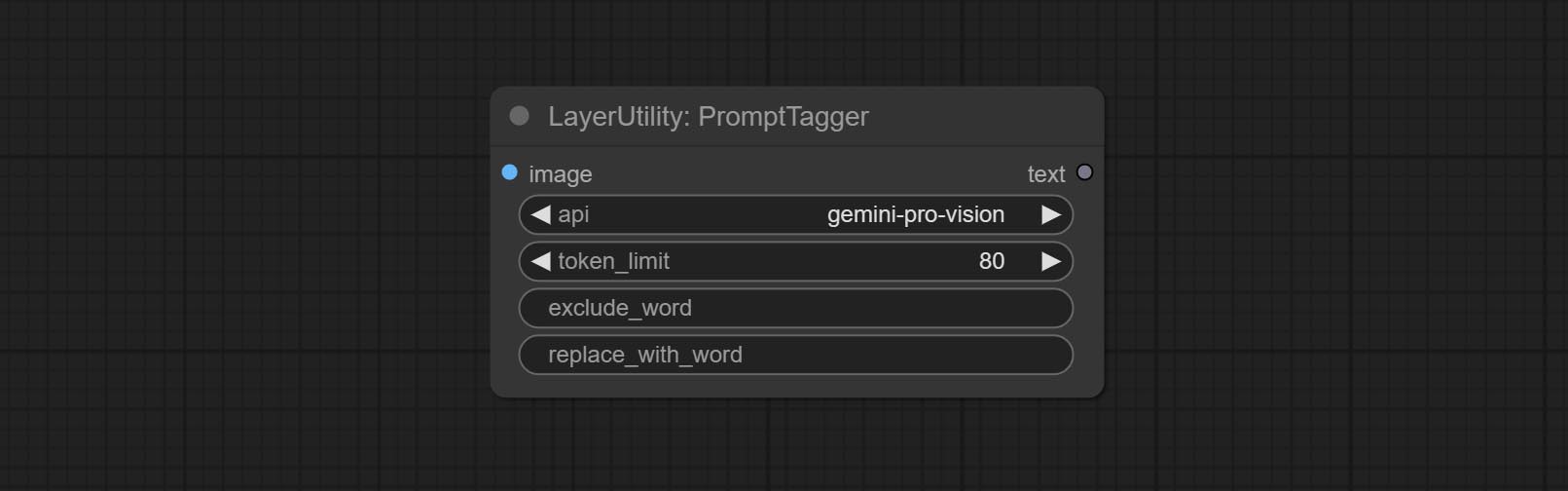
- api: 使用的 API。目前有两个选项:“gemini-1.5-flash” 和 “google-gemini”。
- token_limit: 生成提示词的最大令牌限制。
- exclude_word: 需要排除的关键词。
- replace_with_word: 将用于替换
exclude_word的词语。
PromptEmbellish
输入简单的提示词,输出经过润色的提示词;支持输入图片作为参考,并且支持中文输入。该节点目前使用 Google Gemini API 作为后端服务,请确保网络环境能够正常访问 Gemini。
请在 Google AI Studio 上申请您的 API 密钥,并将其填写到插件根目录下的 api_key.ini 文件中。该文件默认名为 api_key.ini.example,首次使用时需将文件后缀改为 .ini。用文本编辑软件打开文件,在 google_api_key= 后填入您的 API 密钥并保存。
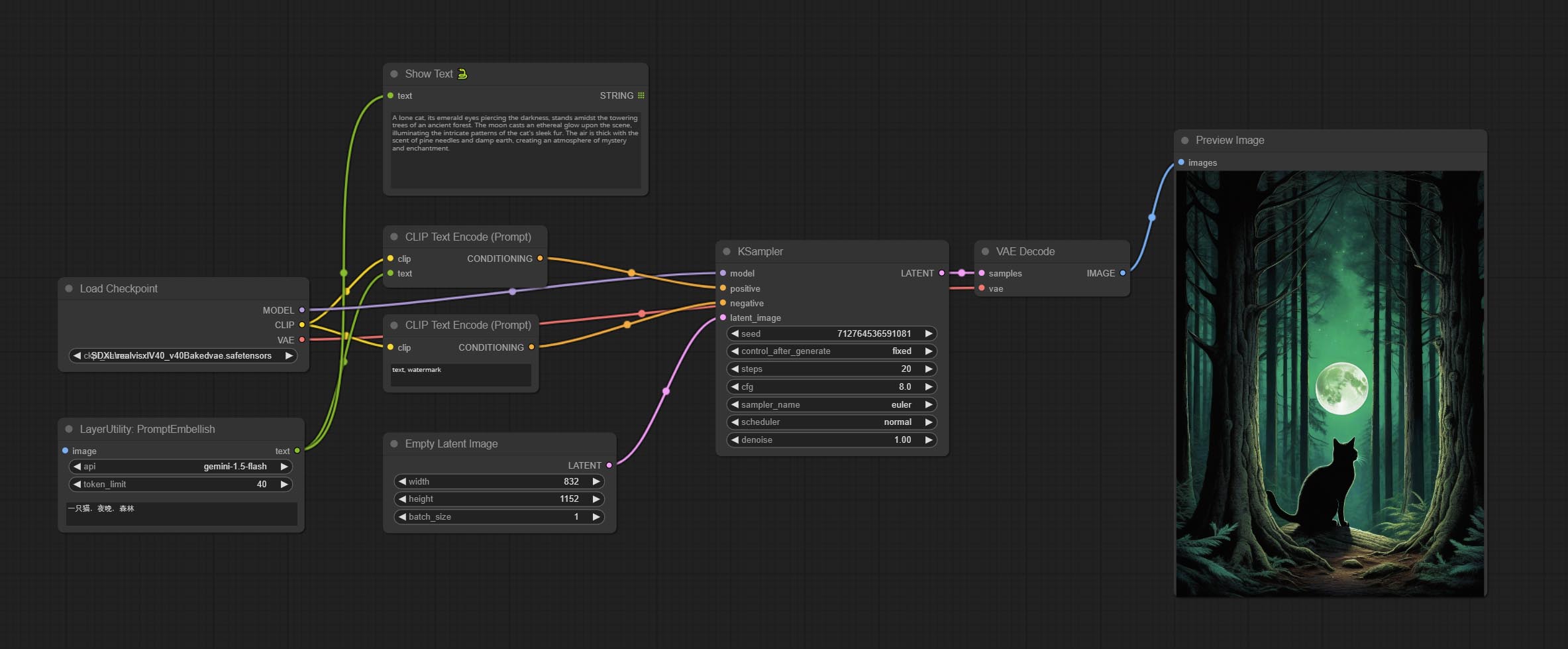
节点选项: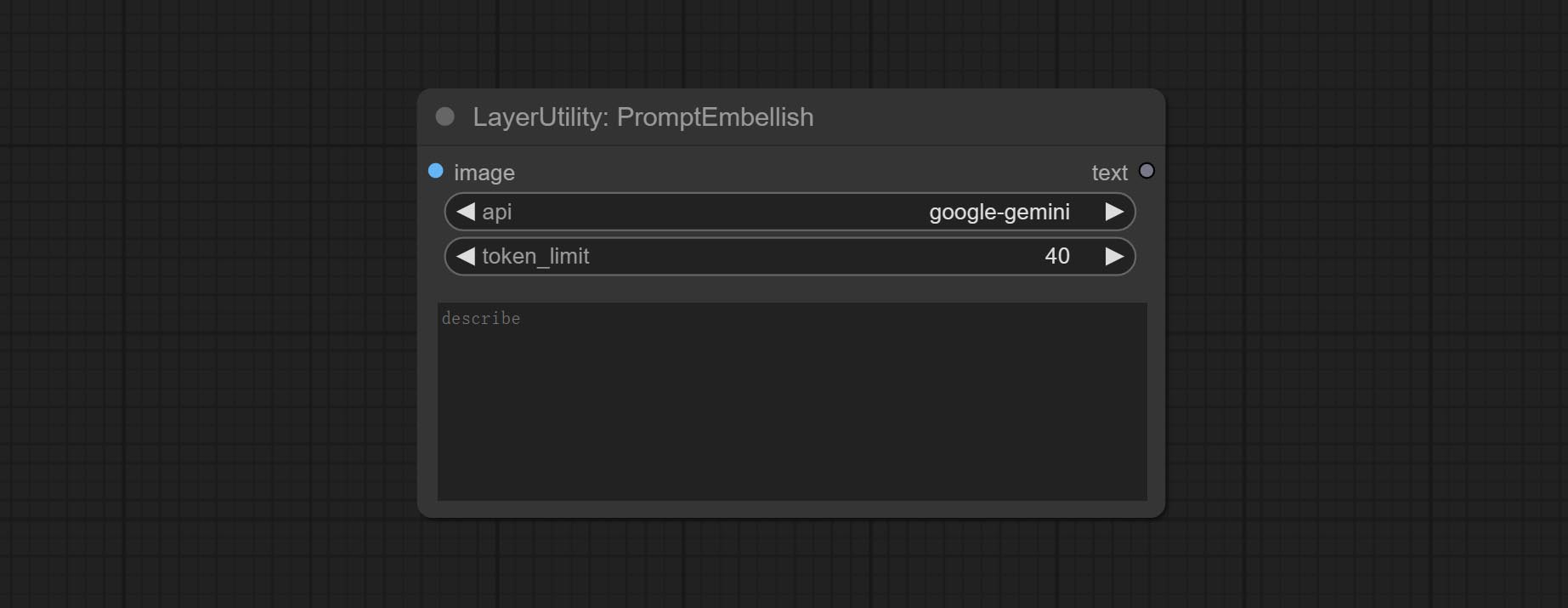
- image: 可选,输入图片作为提示词的参考。
- api: 使用的 API。目前有两个选项:“gemini-1.5-flash” 和 “google-gemini”。
- token_limit: 生成提示词的最大令牌限制。
- discribe: 在此处输入简单的描述,支持中文文本输入。
Florence2Image2Prompt
使用 Florence 2 模型推理生成提示词。该节点部分代码来自 yiwangsimple/florence_dw,感谢原作者。
*首次使用时,模型会自动下载。您也可以从 百度网盘 下载模型文件至 ComfyUI/models/florence2 文件夹。
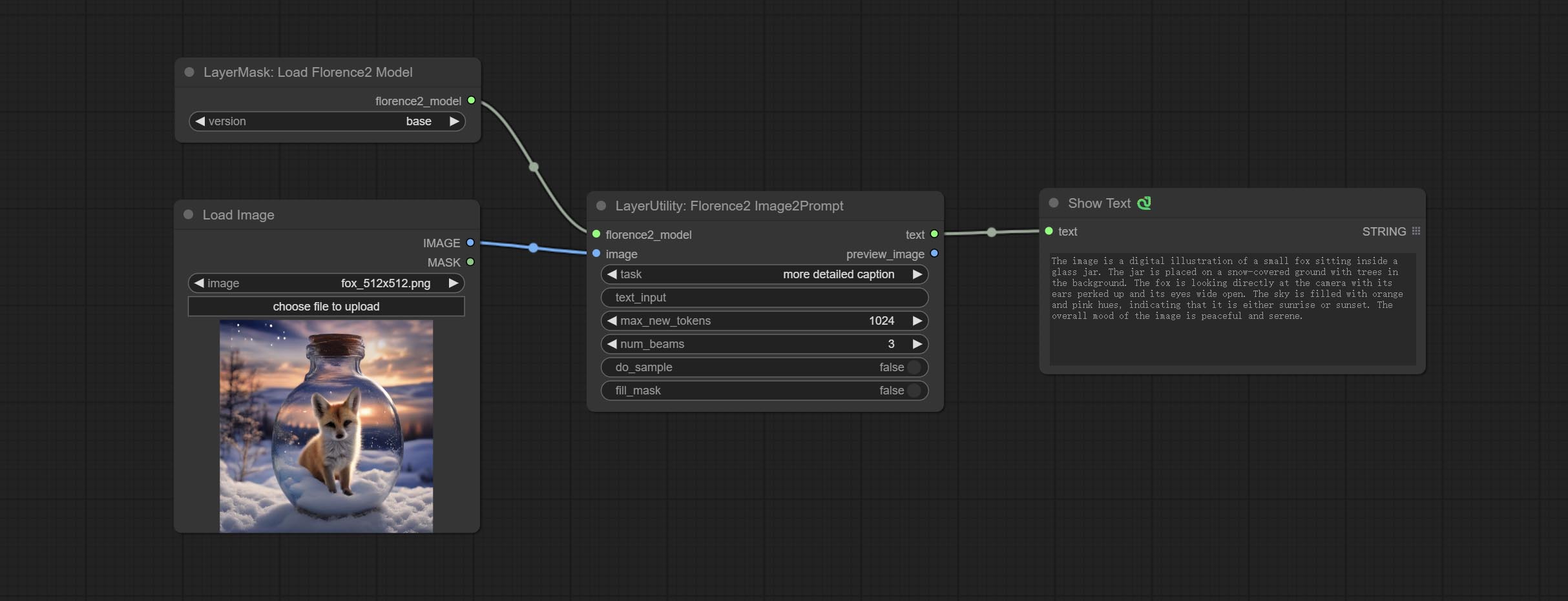
节点选项:
- florence2_model: Florence2 模型输入。
- image: 图像输入。
- task: 选择 Florence2 的任务。
- text_input: Florence2 的文本输入。
- max_new_tokens: 生成文本的最大令牌数。
- num_beams: 生成文本的束搜索数量。
- do_sample: 是否使用文本生成采样。
- fill_mask: 是否使用文本标记掩码填充。
GetColorTone
从图像中获取主色调或平均颜色,并输出 RGB 值。
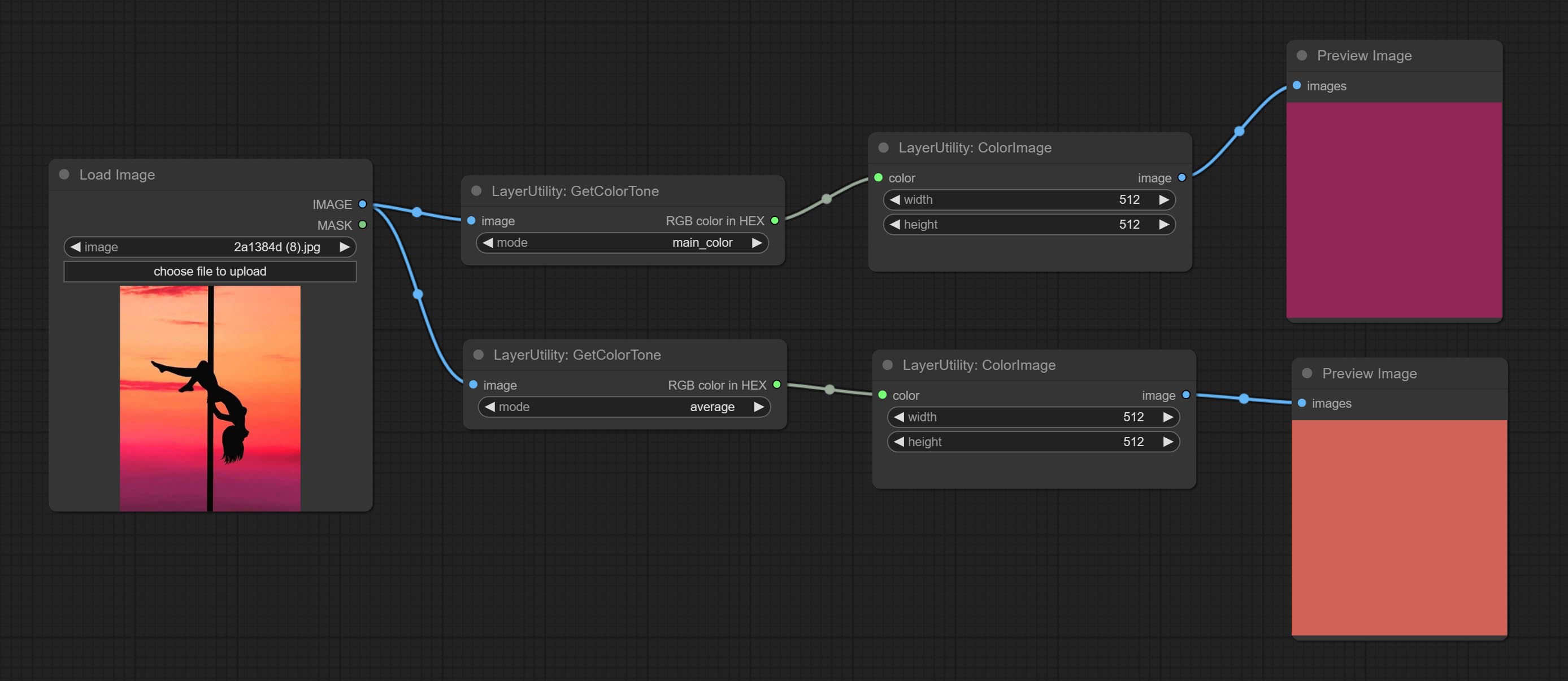
节点选项:
- mode:有两种模式可选,分别为主色调和平均颜色。
输出类型:
- HEX 格式的 RGB 颜色:以十六进制 RGB 格式表示的 RGB 颜色,例如 '#FA3D86'。
- 列表格式的 HSV 颜色:以 Python 列表数据格式表示的 HSV 颜色。
GetColorToneV2
GetColorTone 的 V2 版本升级。您可以指定获取主体或背景的主导色或平均色。
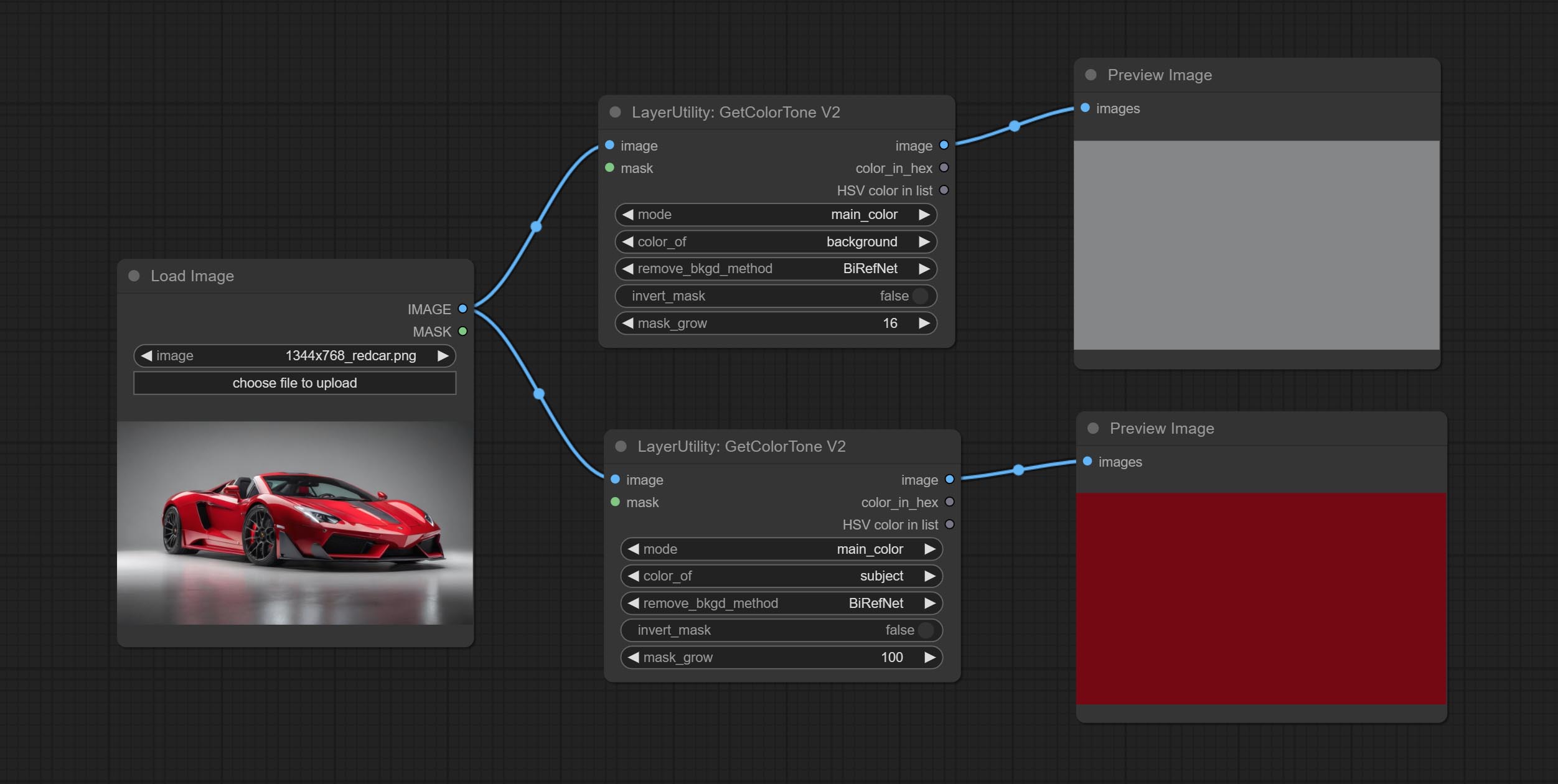
在 GetColorTong 的基础上进行了以下改进:
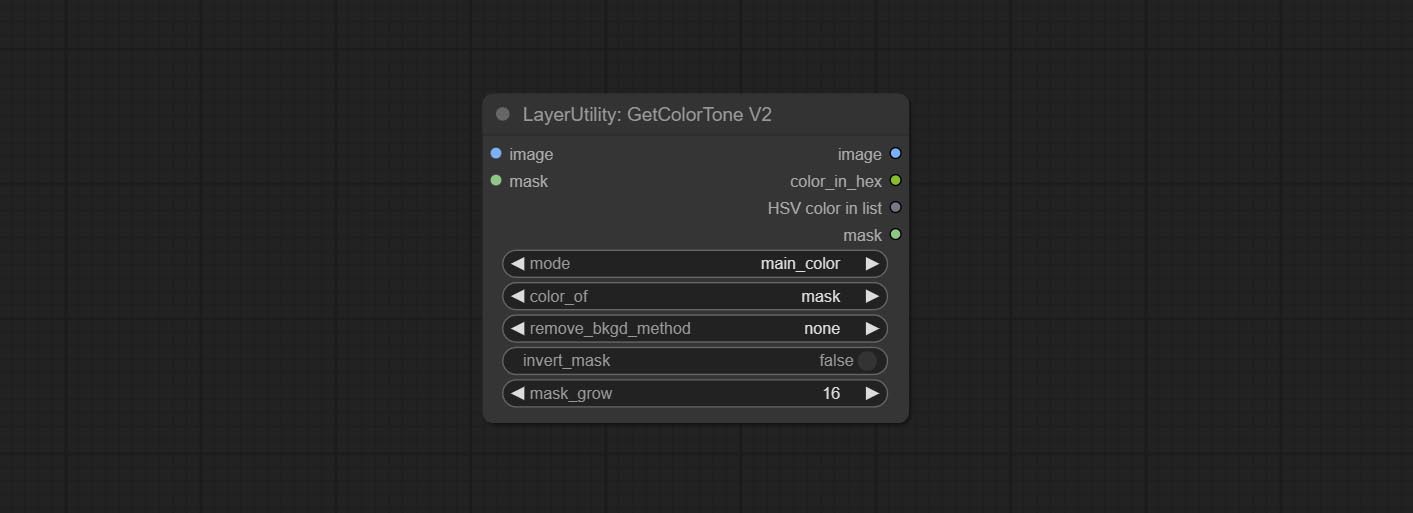
- color_of: 提供 4 种选项,分别是遮罩区域、整幅图像、背景和主体,分别用于选择相应区域的颜色。
- remove_background_method: 背景识别有两种方法:BiRefNet 和 RMBG V1.4。
- invert_mask: 是否反转遮罩。
- mask_grow: 遮罩扩展。对于主体而言,数值越大,获得的颜色越接近身体中心的颜色。
输出:
- image: 单色图片输出,尺寸与输入图片相同。
- mask: 遮罩输出。
ImageRewardFilter
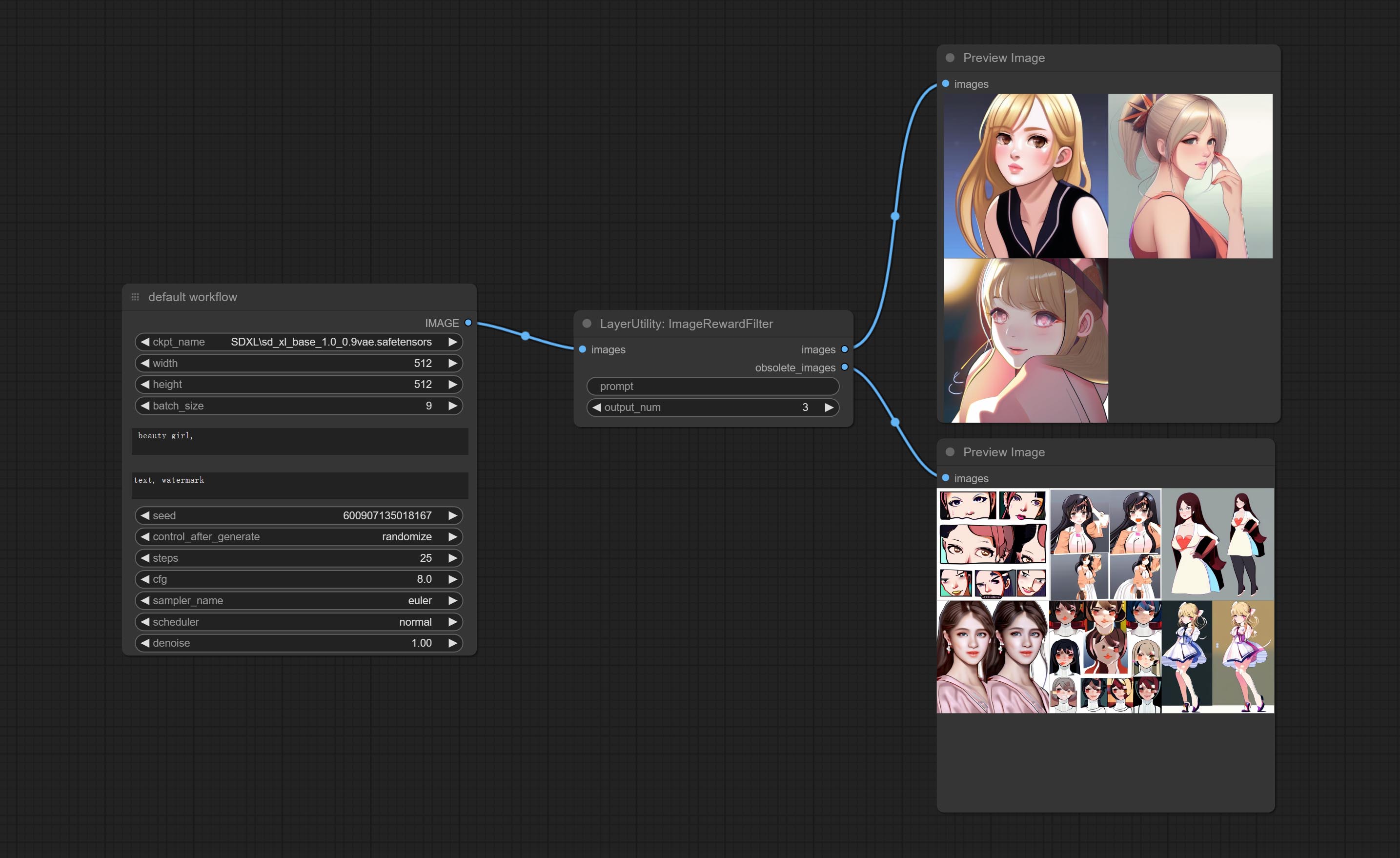
对批量图片进行评分,并输出排名靠前的图片。它使用了 [ImageReward] (https://github.com/THUDM/ImageReward) 进行图像评分,感谢原作者。
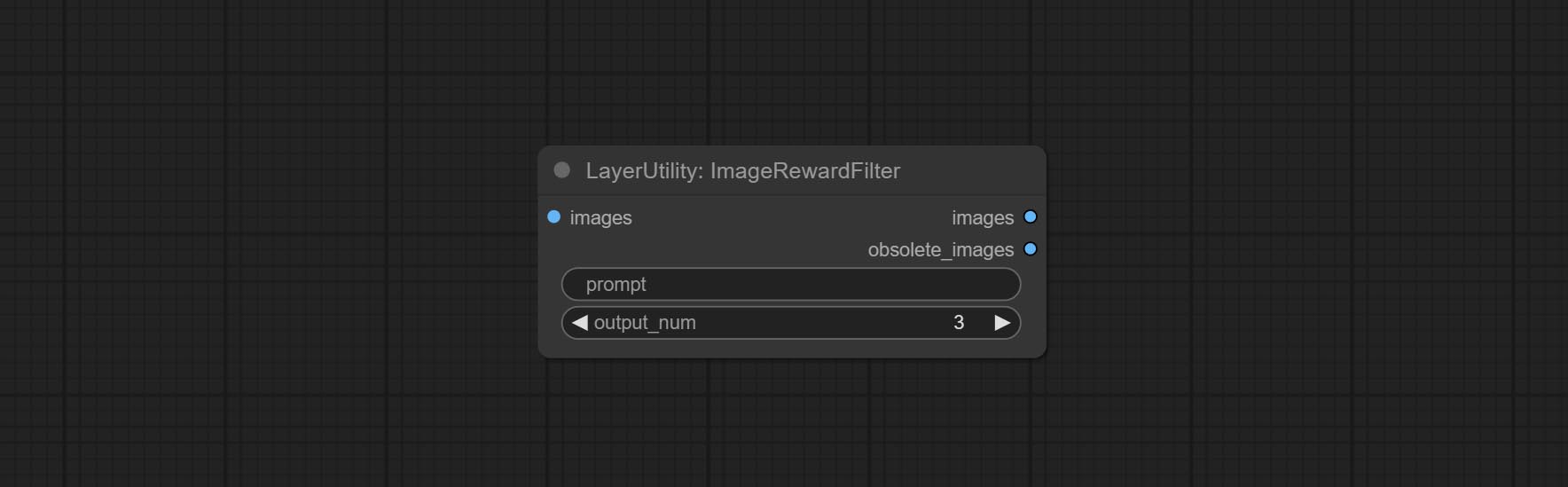
节点选项:
- prompt: 可选输入。在此处输入提示词将作为判断图片与提示词匹配程度的依据。
- output_nun: 输出图片的数量。此值应小于输入的图片批次数量。
输出:
- images: 按评分从高到低排序的批量图片。
- obsolete_images: 被淘汰的图片。同样按评分从高到低排序输出。
LaMa
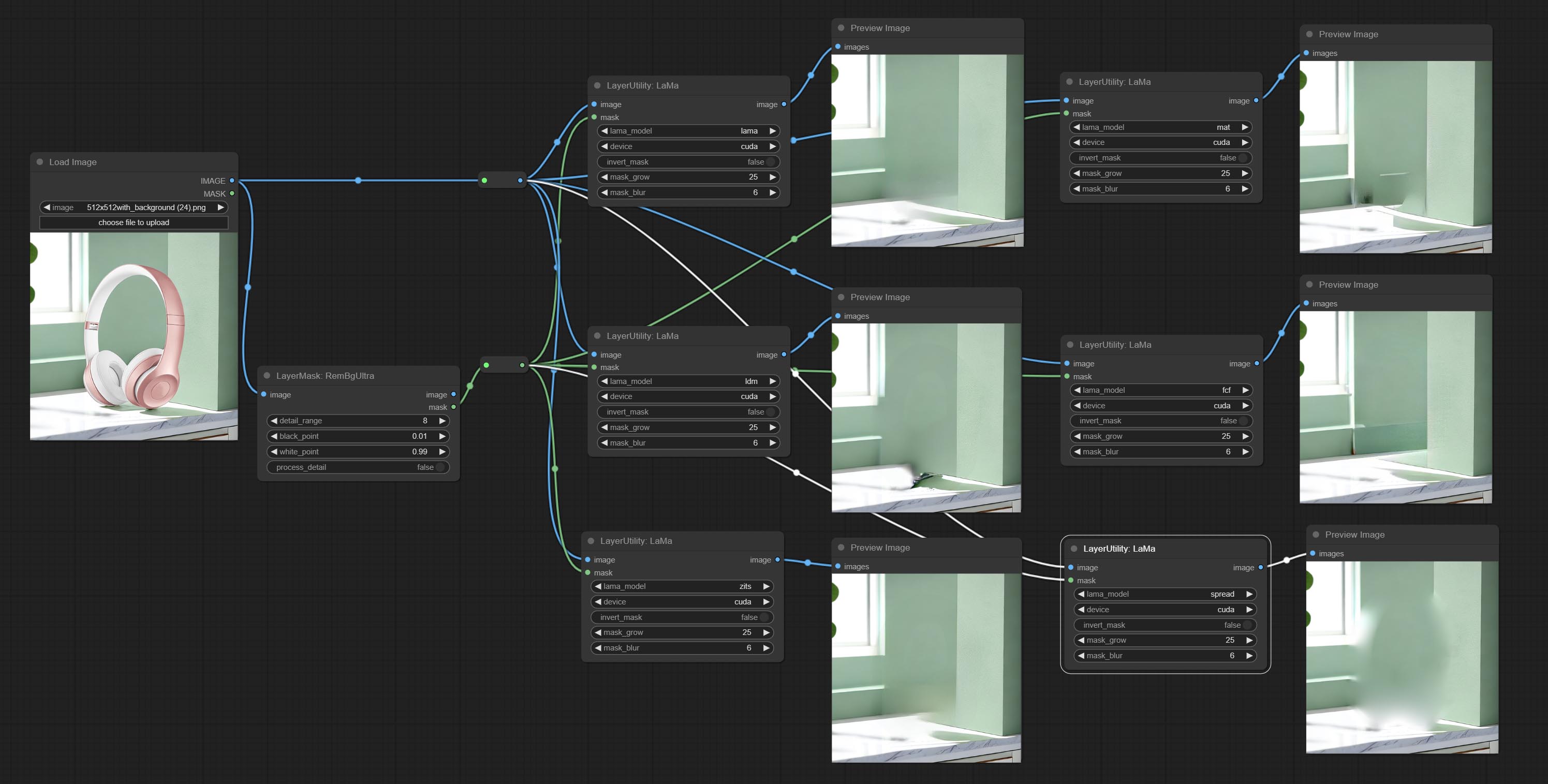
根据遮罩从图像中擦除物体。该节点是对 IOPaint 的重新封装,由最先进的 AI 模型驱动,感谢原作者。
它使用了 LaMa、LDM、ZITS、MAT、FcF、Manga 等模型以及 SPREAD 方法来进行擦除。各模型的介绍请参阅原始链接。
请从 lama 模型(百度网盘) 或 lama 模型(Google Drive) 下载模型文件至 ComfyUI/models/lama 文件夹。
节点选项:
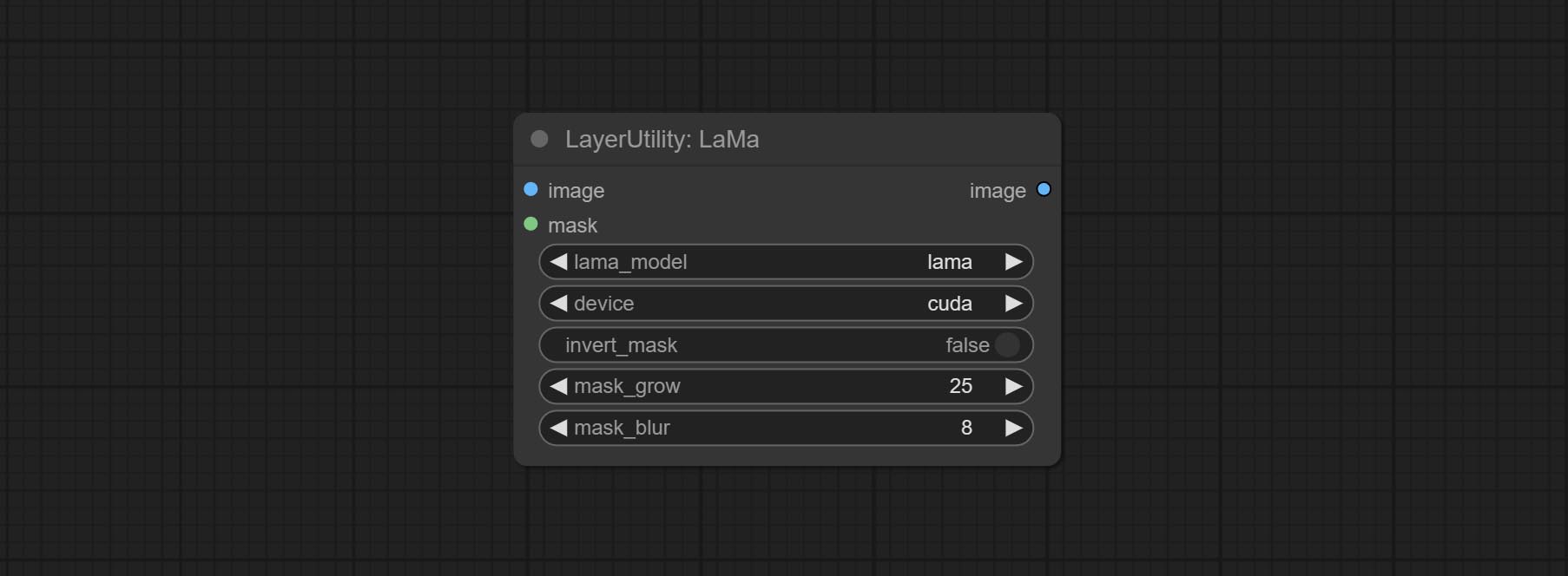
- lama_model: 选择模型或方法。
- device: 正确安装 Torch 和 Nvidia CUDA 驱动程序后,使用 CUDA 可显著提升运行速度。
- invert_mask: 是否反转遮罩。
- grow: 正值向外扩展,负值向内收缩。
- blur: 对边缘进行模糊处理。
ImageAutoCrop
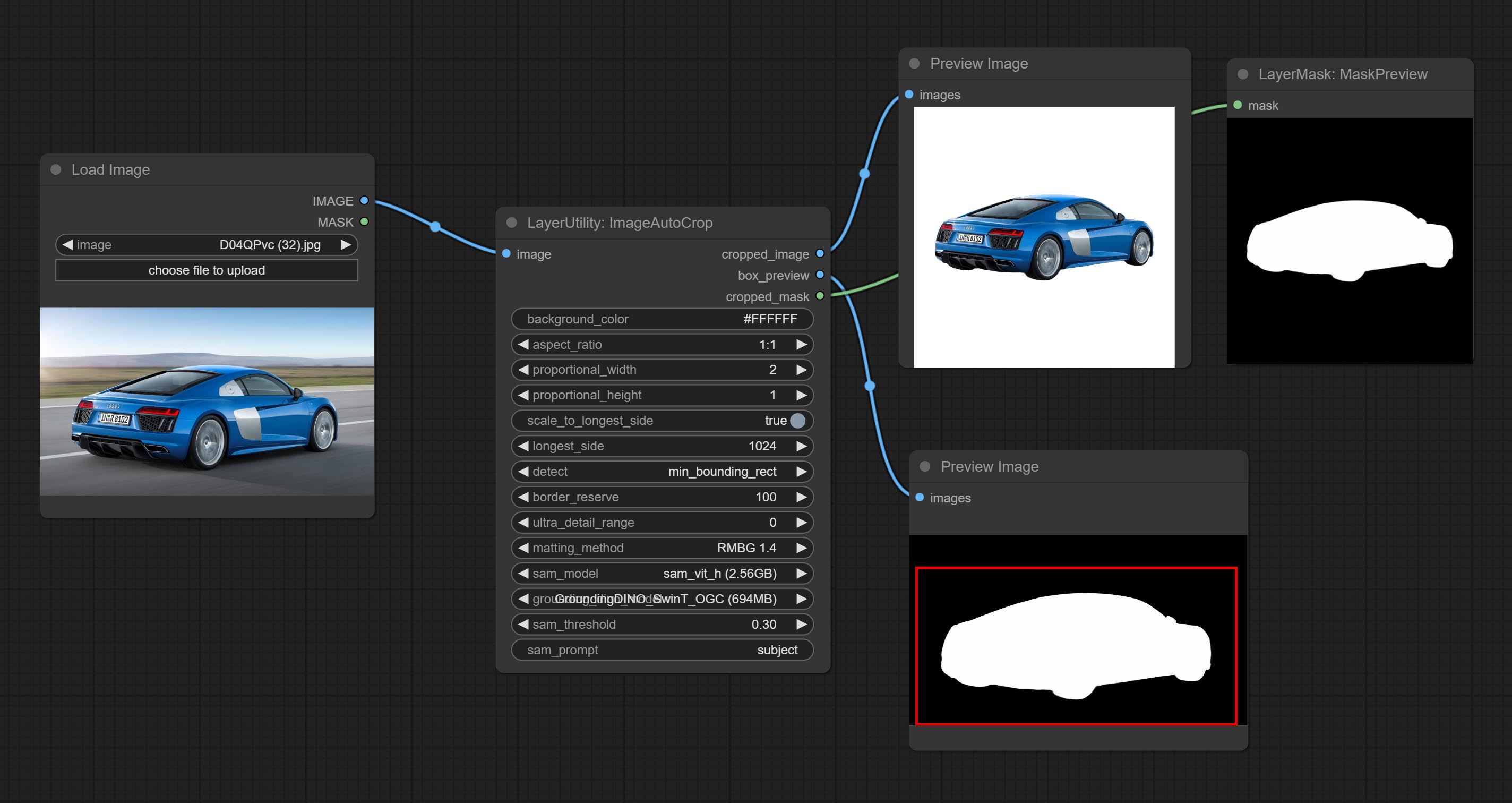
根据掩码自动抠图并裁剪图像。可以指定背景颜色、宽高比和输出图像的尺寸。该节点旨在为模型训练生成图像素材。
*请参考SegmentAnythingUltra和RemBgUltra的模型安装方法。
节点选项:
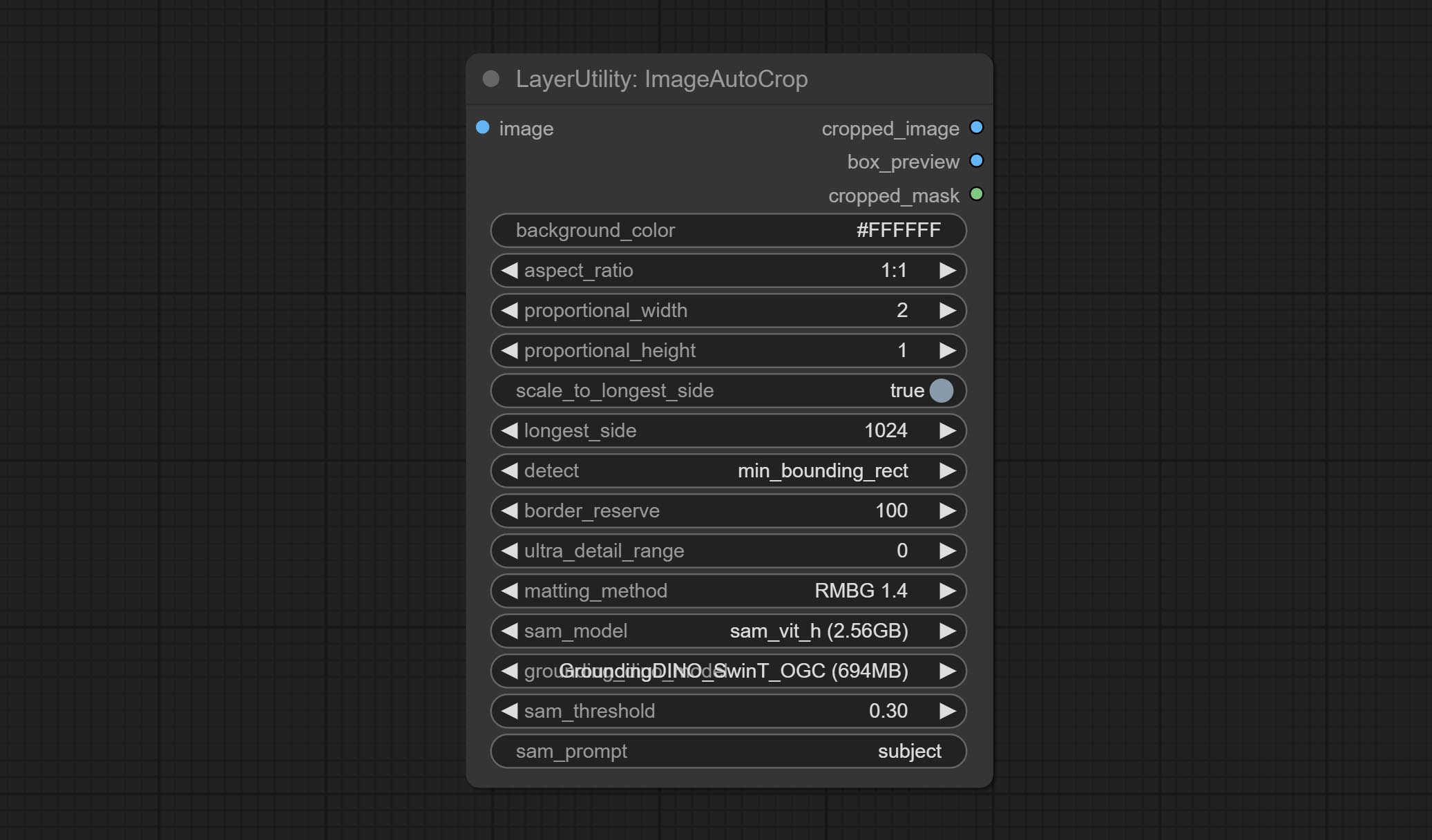
- background_color4: 背景颜色。
- aspect_ratio: 提供了几种常见的画面比例。此外,您也可以选择“original”以保持原始比例,或使用“custom”来自定义比例。
- proportional_width: 按比例设置的宽度。如果宽高比选项不是“custom”,则此设置将被忽略。
- proportional_height: 按比例设置的高度。如果宽高比选项不是“custom”,则此设置将被忽略。
- scale_by_longest_side: 允许按最长边的尺寸进行缩放。
- longest_side: 当scale_by_longest_side设置为True时,此值将用于图像的长边。当输入了original_size时,此设置将被忽略。
- detect: 检测方法,min_bounding_rect是最小外接矩形,max_inscribed_rect是最大内切矩形。
- border_reserve: 保留边框。将裁剪范围扩展到检测到的掩码主体区域之外。
- ultra_detail_range: 掩码边缘超精细处理范围,0表示不处理,这样可以节省生成时间。
- matting_method: 生成掩码的方法。有两种方法可供选择:Segment Anything和RMBG 1.4。RMBG 1.4运行速度更快。
- sam_model: 在此处选择Segment Anything使用的SAM模型。
- grounding_dino_model: 在此处选择Segment Anything使用的Grounding_Dino模型。
- sam_threshold: Segment Anything的阈值。
- sam_prompt: Segment Anything的提示词。
输出: cropped_image: 裁剪并替换背景后的图像。 box_preview: 裁剪位置预览。 cropped_mask: 裁剪后的掩码。
ImageAutoCropV2
ImageAutoCrop的升级版本V2,在原有基础上做了以下改动:
- 增加了掩码的可选输入。当有掩码输入时,直接使用该输入,跳过内置的掩码生成过程。
- 增加了
fill_background选项。当设置为False时,背景将不会被处理,超出框架的部分也不会包含在输出范围内。 aspect_ratio增加了original选项。- scale_by: 允许按指定的最长边、最短边、宽度或高度进行缩放。
- scale_by_length: 此处的值用作
scale_by,用于指定边的长度。
ImageAutoCropV3
自动将图像裁剪为指定尺寸。您可以输入掩码来保留掩码的指定区域。该节点旨在为模型训练生成图像素材。
节点选项:
- image: 输入图像。
- mask: 可选的输入掩码。遮罩部分将在裁剪宽高比的范围内保留。
- aspect_ratio: 输出的宽高比。提供了常见的画面比例,其中“custom”为自定义比例,“original”为原始画面比例。
- proportional_width: 按比例设置的宽度。如果aspect_ratio选项不是‘custom’,则此设置将被忽略。
- proportional_height: 按比例设置的高度。如果aspect_ratio选项不是‘custom’,则此设置将被忽略。
- method: 缩放采样方法包括Lanczos、Bicubic、Hamming、Bilinear、Box和Nearest。
- scale_to_side: 允许按长边、短边、宽度、高度或总像素数指定缩放。
- scale_to_length: 此处的值用作scale_to-side,用于指定边的长度或总像素数(千像素)。
- round_to_multiple: 四舍五入到最接近的整数倍。例如,若设置为8,则宽度和高度将强制设定为8的倍数。
输出: cropped_image: 裁剪后的图像。 box_preview: 裁剪位置预览。
SaveImagePlus
增强型保存图像节点。您可以自定义图片保存的目录,为文件名添加时间戳,选择保存格式,设置图像压缩率,决定是否保存工作流,并可选地为图片添加不可见水印。(以肉眼不可见的方式添加信息,并使用ShowBlindWaterMark节点解码水印)。还可以选择性输出工作流的json文件。
节点选项:
- image: 输入图像。
- custom_path*: 用户自定义目录,请以正确格式输入目录名称。若为空,则保存至ComfyUI的默认输出目录。
- filename_prefix*: 文件名前缀。
- timestamp: 为文件名添加时间戳,可选择日期、精确到秒的时间以及精确到毫秒的时间。
- format: 图片保存格式。目前支持
png和jpg。请注意,RGBA模式的图片仅支持png格式。 - quality: 图像质量,取值范围为10-100,数值越高,画质越好,但文件体积也会相应增大。
- meta_data: 是否将元数据保存到png文件中,即工作流信息。如果您不希望工作流信息泄露,请将其设置为false。
- blind_watermark: 此处输入的文字(不支持多语言)将被转换为二维码,并以不可见水印的形式保存。使用
ShowBlindWaterMark节点可以解码水印。请注意,带有水印的图片建议保存为png格式,而较低质量的jpg格式可能会导致水印信息丢失。 - save_workflow_as_json: 是否同时输出工作流的json文件(输出的json文件与图片位于同一目录)。
- preview: 预览开关。
* 输入%date表示当前日期(YY-mm-dd),输入%time表示当前时间(HH-MM-SS)。您可以在路径中使用/来创建子目录。例如,%date/name_%tiem会将图片输出到YY-mm-dd文件夹,文件名前缀为name_HH-MM-SS。
SaveImagePlusV2
在SaveImagePlus节点中新增了自定义文件名和DPI选项。
节点选项:
- custom_filename*: 用户自定义文件名,若在此处输入,则将使用该文件名。请注意,重复的文件将会被覆盖。若此项为空,则会使用文件名前缀和时间戳作为文件名。
- dpi: 设置图像文件的DPI值。
* 输入%date表示当前日期(YY-mm-dd),输入%time表示当前时间(HH-MM-SS)。可以使用/来创建子目录。例如,%date/name_%tiem会将图片输出到YY-mm-dd文件夹下,并以name_HH-MM-SS作为文件名前缀。
AddBlindWaterMark

为图片添加不可见水印。以肉眼无法察觉的方式嵌入水印图像,并使用ShowBlindWaterMark节点解码水印。
节点选项:
- image: 输入图像。
- watermark_image: 水印图像。此处输入的图像将自动转换为方形黑白图像作为水印。建议使用二维码作为水印。
ShowBlindWaterMark
解码由AddBlindWaterMark和SaveImagePlus节点添加的不可见水印。
CreateQRCode
生成方形二维码图片。
节点选项:
- size: 图片的边长。
- border: 二维码周围的边框大小,数值越大,边框越宽。
- text: 在此处输入二维码的内容,不支持多语言。
DecodeQRCode
解码二维码。
节点选项: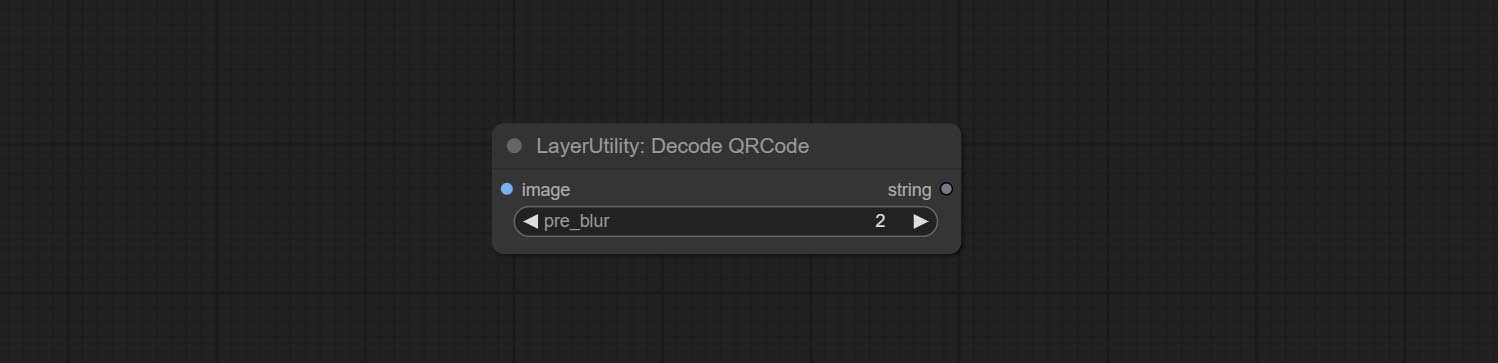
- image: 输入的二维码图像。
- pre_blur: 预处理模糊,对于难以识别的二维码,可以尝试调整此参数。
LoadPSD

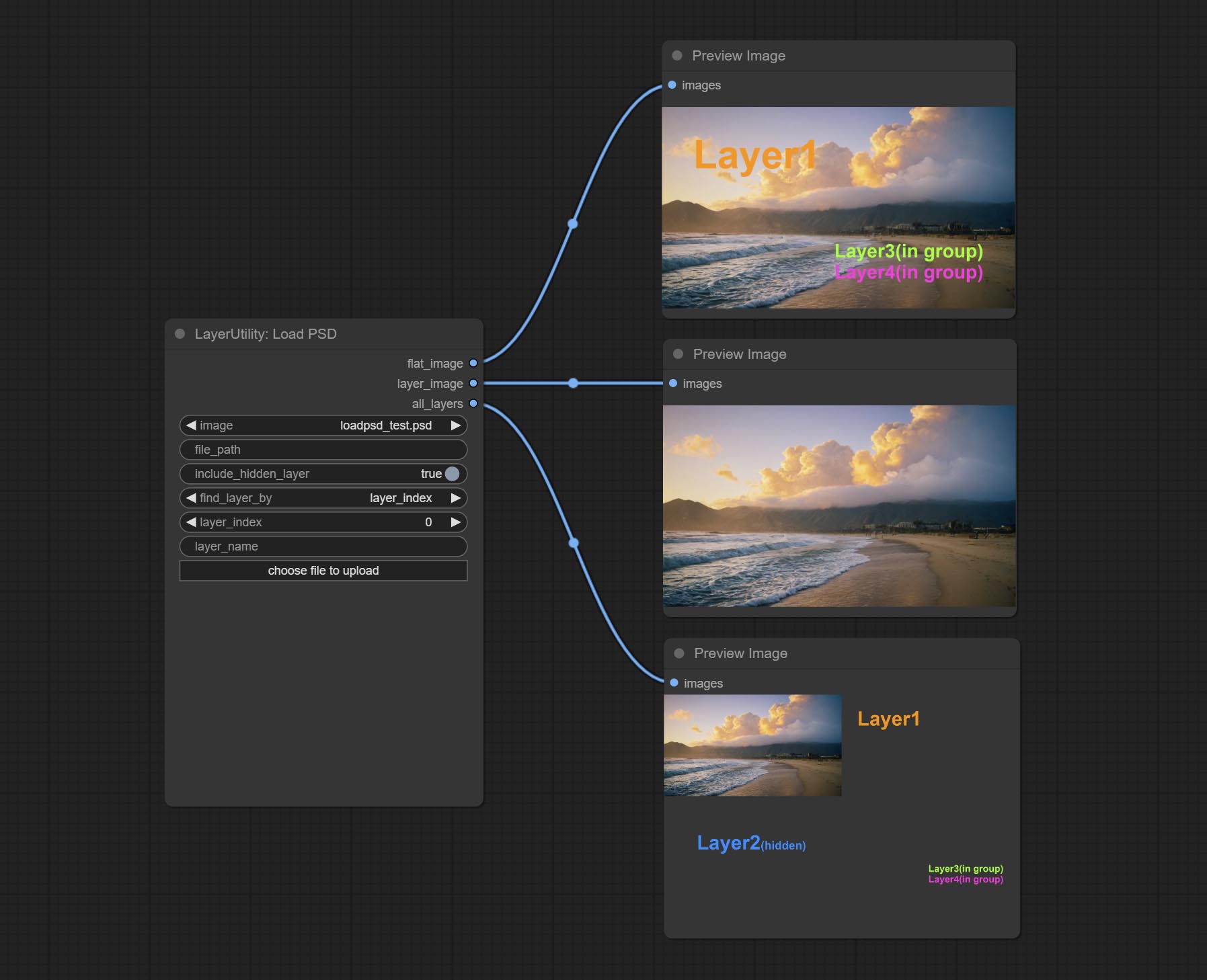
加载PSD格式文件并导出图层。
请注意,此节点需要安装psd_tools依赖包。如果在安装psd_tool时出现错误,例如ModuleNotFoundError: No module named 'docopt',请下载docopt的whl文件并手动安装。
节点选项: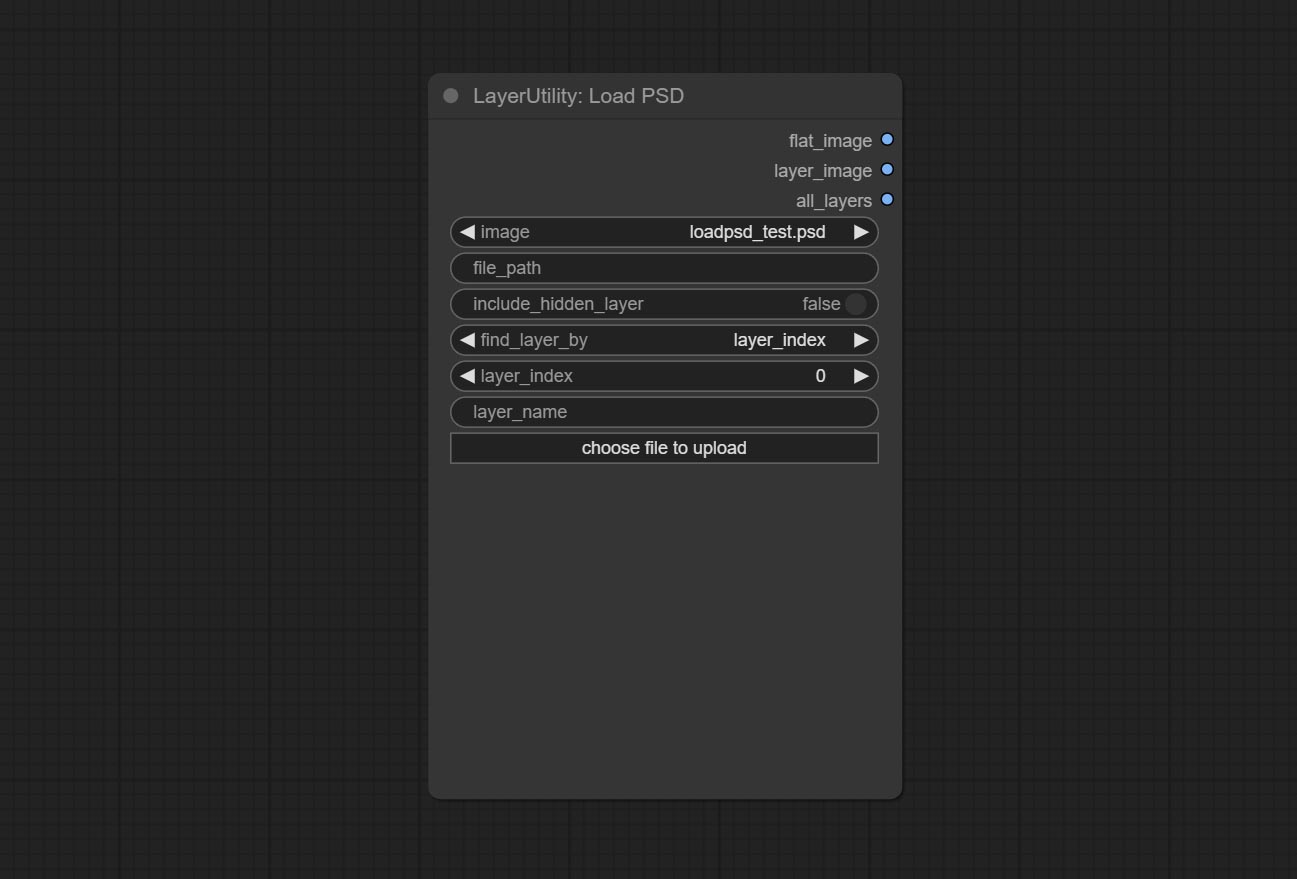
- image: 这里列出了
ComfyUI/input下的*.psd文件,可以选择之前已加载的PSD图像。 - file_path: PSD文件的完整路径和文件名。
- include_hidden_layer: 是否包含隐藏层。
- find_layer_by: 可以通过图层编号或图层名称来查找图层。图层组被视为一个图层。
- layer_index: 图层编号,0为最底层,依次递增。若设置为false,则不计算隐藏层。设置为-1则输出最顶层。
- layer_name: 图层名称。请注意,大小写和标点符号必须完全匹配。
输出: flat_image: PSD预览图像。 layer_iamge: 查找并输出指定图层。 all_layers: 包含所有图层的批量图像。
SD3NegativeConditioning
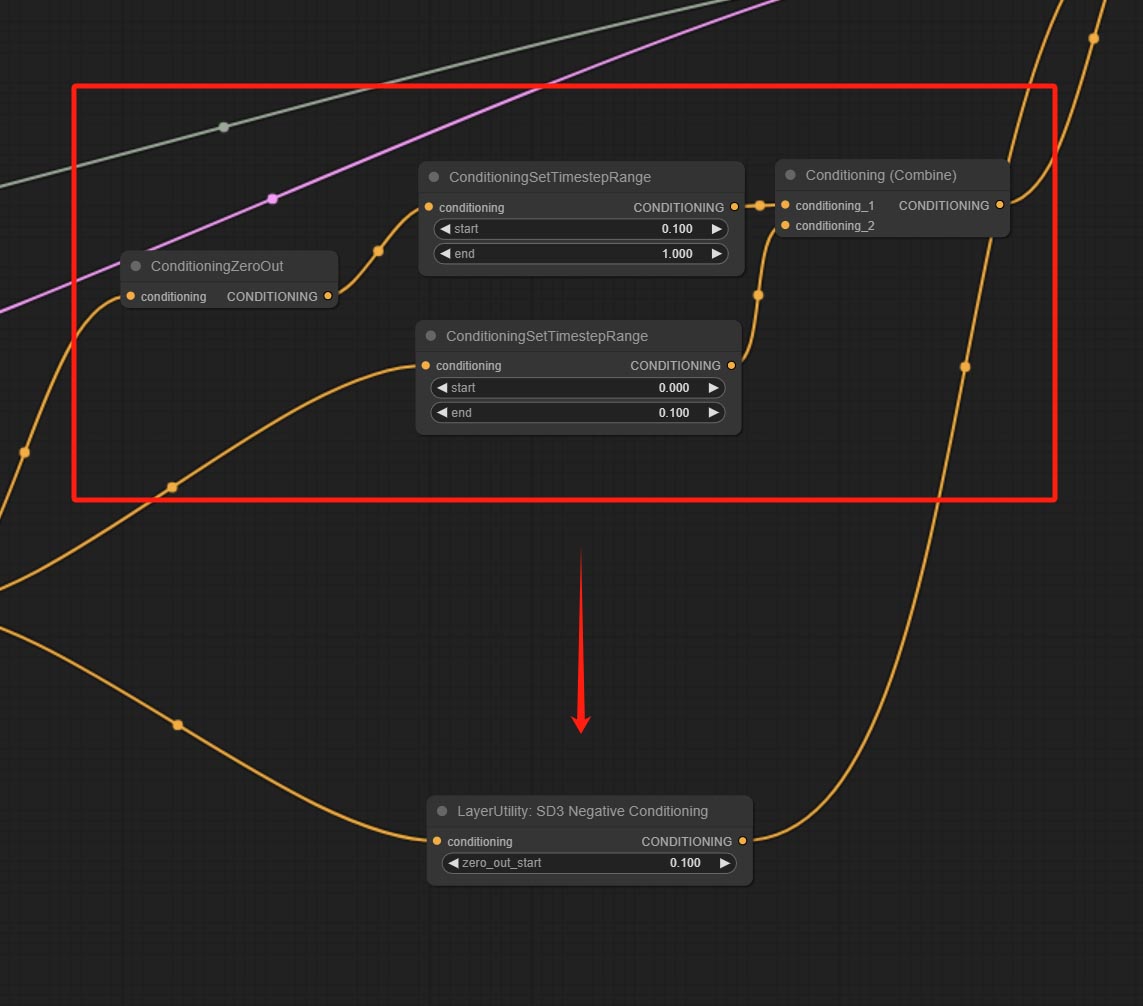
将SD3中的四个负面条件节点封装成一个单独的节点。
节点选项:
- zero_out_start: 设置负面条件ZeroOut的ConditioningSetTimestepRange起始值,该值与负面条件的ConditioningSetTimestepRange结束值相同。
BenUltra
这是PramaLLC/BEN项目在ComfyUI中的实现。感谢原作者。请从huggingface或BaiduNetdisk下载所有文件,并复制到ComfyUI/models/BEN文件夹。

节点选项:

- ben_model: BEN模型输入。有两个模型可供选择:BEN_Base和BEN2_base。
- image: 图像输入。
- detail_method: 边缘处理方法。提供VITMatte、VITMatte(local)、PyMatting、GuidedFilter。如果首次使用VITMatte后已下载模型,则后续可使用VITMatte (local)。
- detail_erode: 从边缘向内侵蚀遮罩范围。数值越大,向内修复的范围越大。
- detail_dilate: 遮罩边缘向外扩展。数值越大,向外修复的范围越大。
- black_point: 边缘黑色采样阈值。
- white_point: 边缘白色采样阈值。
- process_detail: 若设置为false,则跳过边缘处理以节省运行时间。
- max_megapixels: 设置VitMate操作的最大尺寸。
LoadBenModel
加载BEN模型。
节点选项:
- model: 选择模型。目前仅可选择Ben_Sase模型。
SegmentAnythingUltra
对ComfyUI Segment Anything的改进,感谢原作者。
*请参考ComfyUI Segment Anything的安装说明来安装模型。如果ComfyUI Segment Anything已正确安装,则可跳过此步骤。
- 从这里下载config.json、model.safetensors、tokenizer_config.json、tokenizer.json和vocab.txt这5个文件,并将其放入
ComfyUI/models/bert-base-uncased文件夹中。 - 下载GroundingDINO_SwinT_OGC配置文件、GroundingDINO_SwinT_OGC模型、
GroundingDINO_SwinB配置文件、GroundingDINO_SwinB模型,并将它们放入
ComfyUI/models/grounding-dino文件夹中。 - 下载sam_vit_h、sam_vit_l、
sam_vit_b、sam_hq_vit_h、
sam_hq_vit_l、sam_hq_vit_b、
mobile_sam,并将它们放入
ComfyUI/models/sams文件夹中。 *或者从百度网盘上的GroundingDino模型和百度网盘上的SAM模型下载。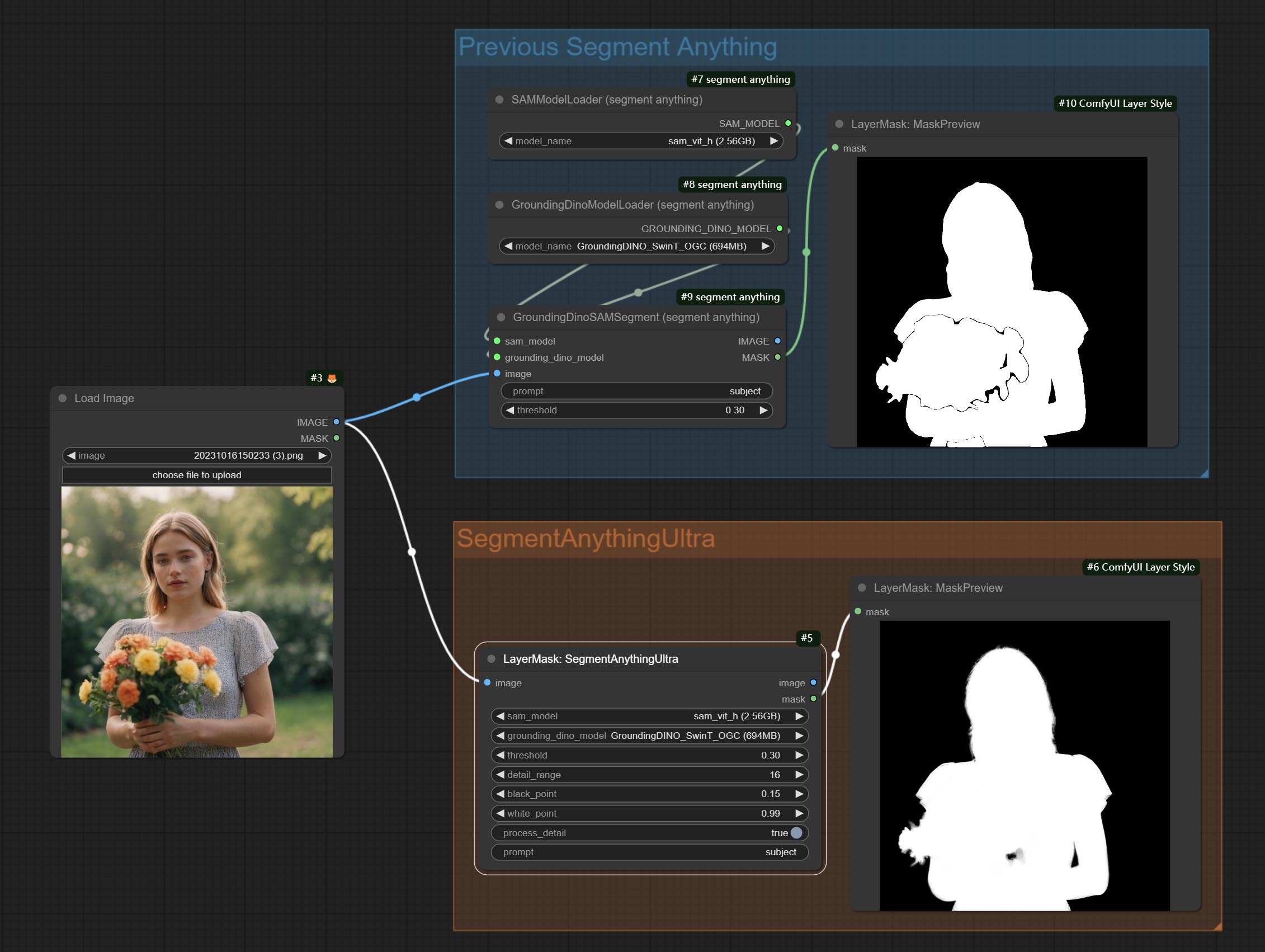
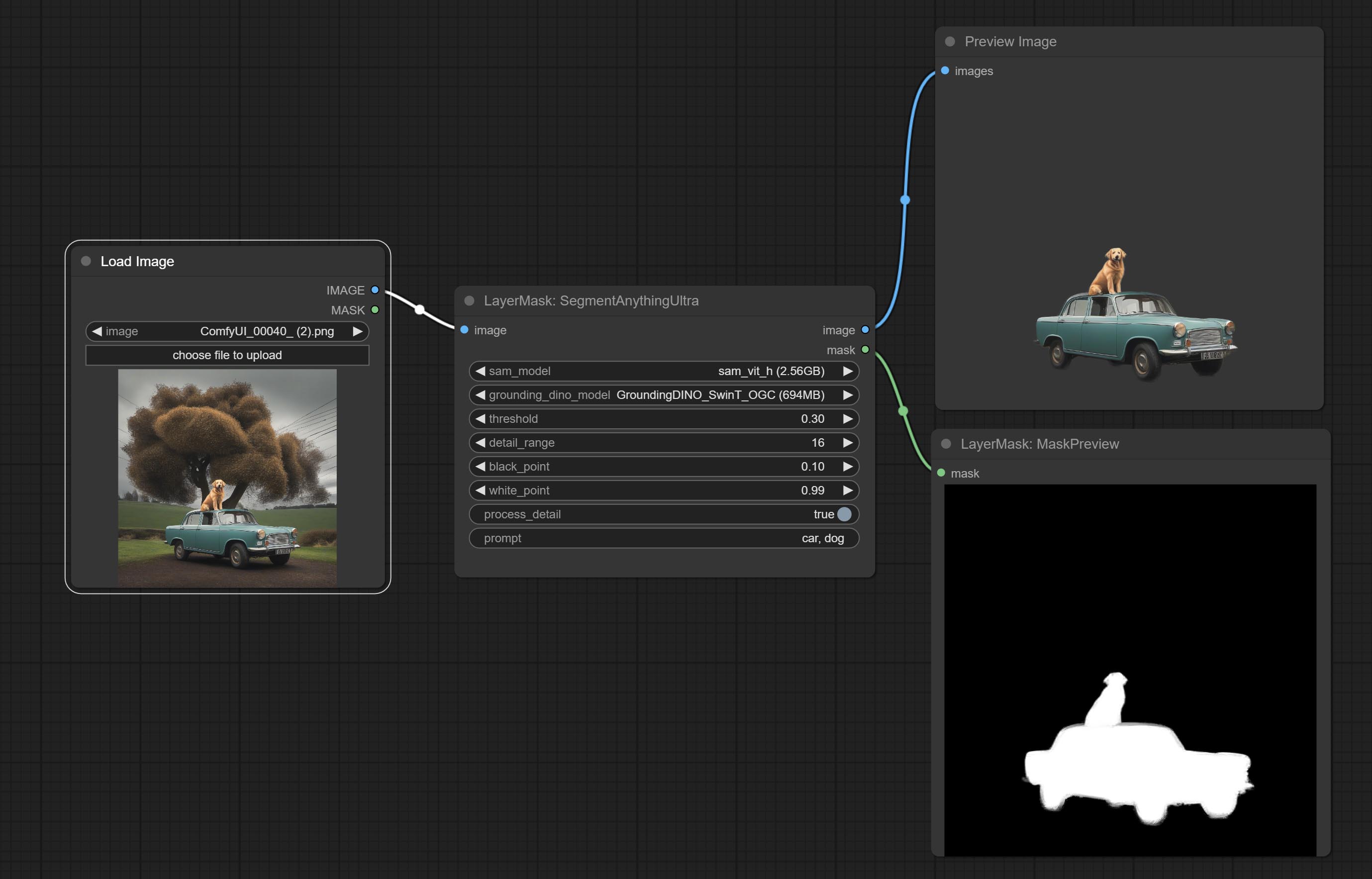
节点选项:
- sam_model:选择SAM模型。
- ground_dino_model:选择Grounding DINO模型。
- threshold:SAM的阈值。
- detail_range:边缘细节范围。
- black_point:边缘黑色采样阈值。
- white_point:边缘白色采样阈值。
- process_detail:此处设置为false将跳过边缘处理以节省运行时间。
- prompt:SAM的提示输入。
- cache_model:设置是否缓存模型。
SegmentAnythingUltraV2
SegmentAnythingUltra的V2升级版本增加了VITMatte边缘处理方法。(注:使用此方法处理超过2K尺寸的图像会消耗大量内存)
在SegmentAnythingUltra的基础上,进行了以下更改:
- detail_method:边缘处理方法。提供VITMatte、VITMatte(本地)、PyMatting、GuidedFilter。如果首次使用VITMatte后已下载模型,则后续可使用VITMatte(本地)。
- detail_erode:从边缘向内侵蚀掩膜范围。数值越大,向内修复的范围越大。
- detail_dilate:掩膜边缘向外扩张。数值越大,向外修复的范围越大。
- device:设置VitMatte是否使用CUDA。
- max_megapixels:设置VitMate操作的最大尺寸。
SegmentAnythingUltraV3
将模型加载与推理节点分离,以避免在使用多个SAM节点时重复加载模型。
节点选项:
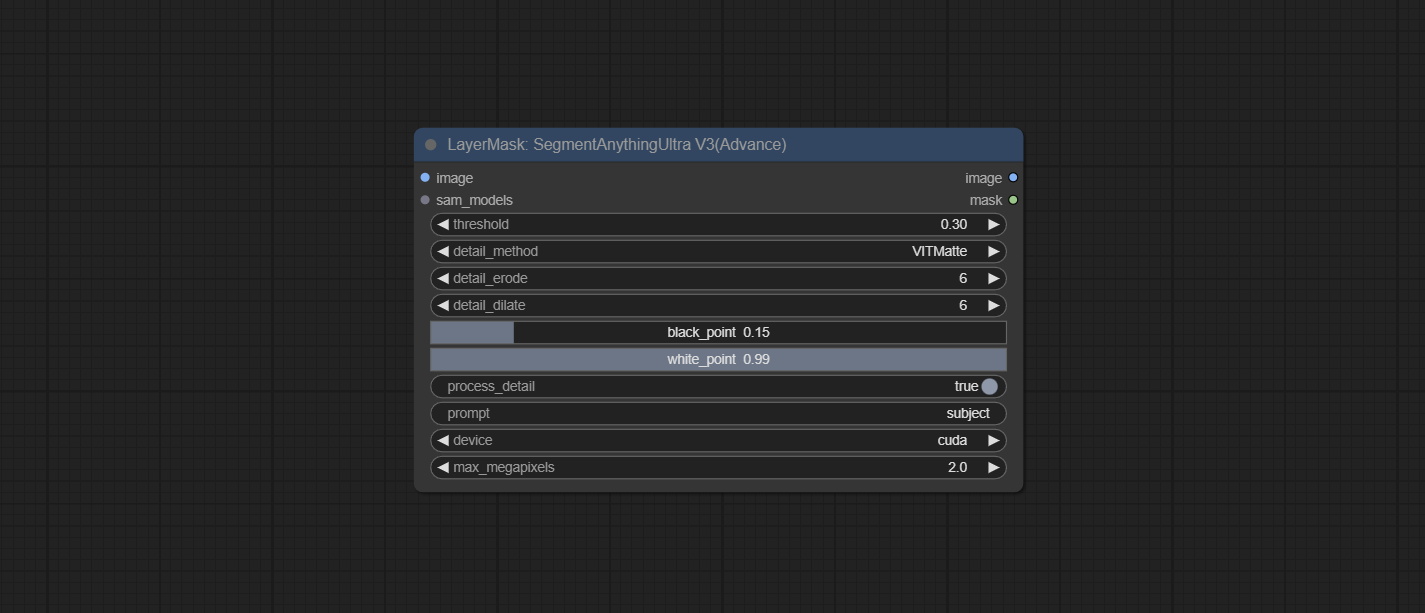 与SegmentAnythingUltra相同,移除了
与SegmentAnythingUltra相同,移除了sam_comodel和ground-dino_comodel,改为从节点输入获取。
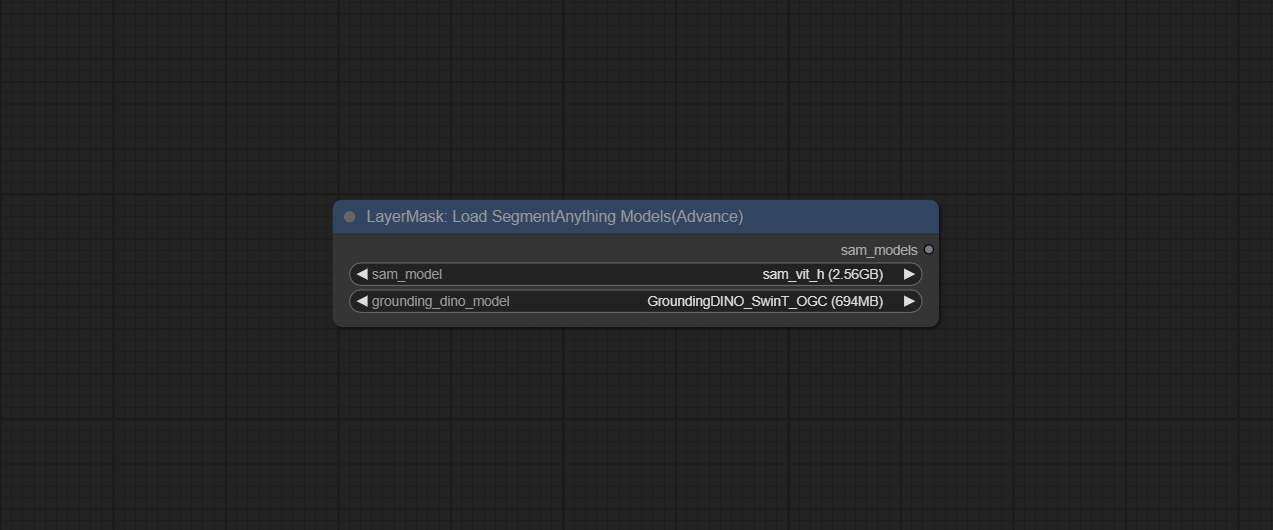
LoadSegmentAnythingModels
加载SegmentAnything模型。
SAM2Ultra
该节点由kijai/ComfyUI-segment-anything-2修改而来。感谢kijai为Comfyui社区做出的重大贡献。
SAM2 Ultra节点仅支持单张图像。如需处理多张图像,请先将图像批次转换为图像列表。
*从百度网盘或huggingface.co/Kijai/sam2-safetensors下载模型,并复制到ComfyUI/models/sam2文件夹中。
节点选项: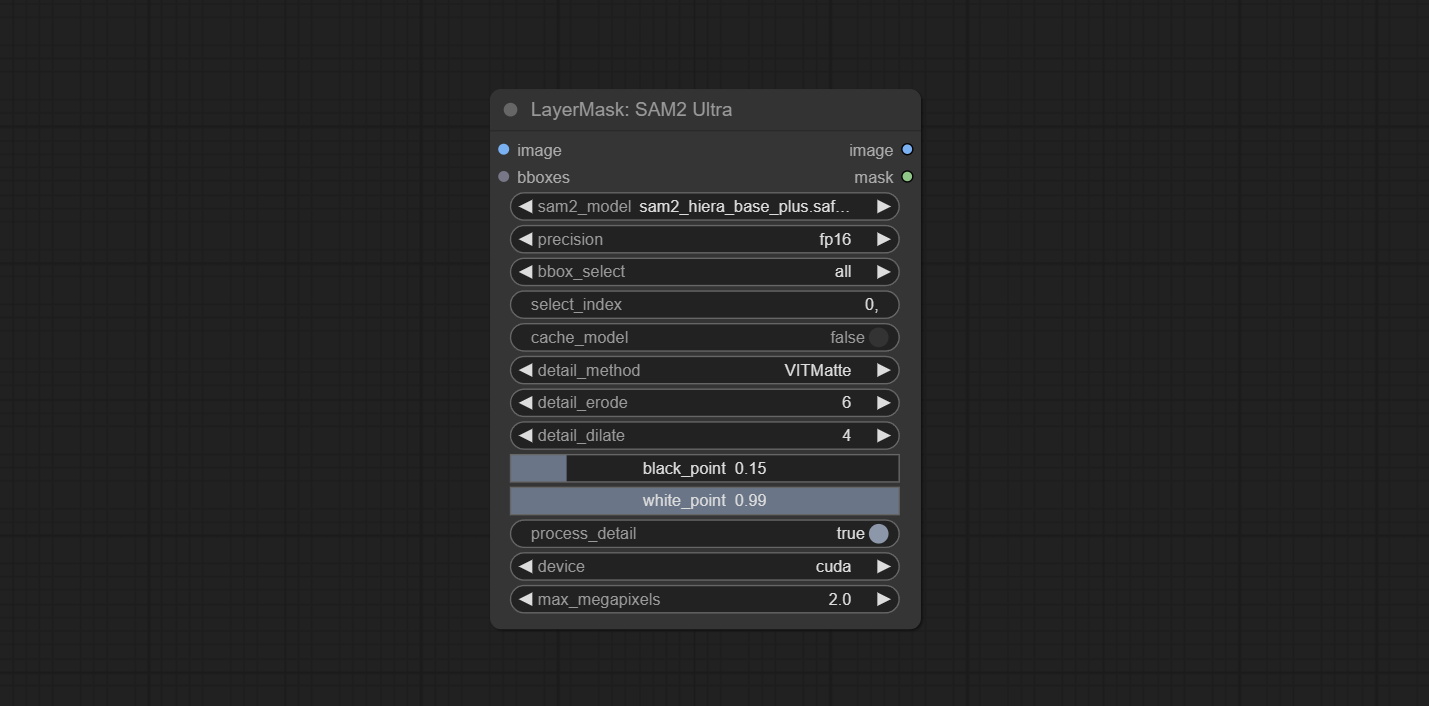
- image:待分割的图像。
- bboxes:输入识别框数据。
- sam2_model:选择SAM2模型。
- presicion:模型精度。可选择fp16、bf16和fp32。
- bbox_select:选择输入框数据。有三种选项:“all”选择所有框,“first”选择置信度最高的框,“by_index”指定框的索引。
- select_index:当bbox_delect为“by_index”时有效。0表示第一个。可输入多个值,用任何非数字字符分隔,包括但不限于逗号、句号、分号、空格或字母,甚至中文。
- cache_model:是否缓存模型。缓存模型后,可节省模型加载时间。
- detail_method:边缘处理方法。提供VITMatte、VITMatte(本地)、PyMatting、GuidedFilter。如果首次使用VITMatte后已下载模型,则后续可使用VITMatte(本地)。
- detail_erode:从边缘向内侵蚀掩膜范围。数值越大,向内修复的范围越大。
- detail_dilate:掩膜边缘向外扩张。数值越大,向外修复的范围越大。
- black_point:边缘黑色采样阈值。
- white_point:边缘白色采样阈值。
- process_detail:此处设置为false将跳过边缘处理以节省运行时间。
- device:设置VitMatte是否使用CUDA。
- max_megapixels:设置VitMate操作的最大尺寸。
SAM2UltraV2
在SAM2 Ultra节点的基础上,将SAM2模型改为外部输入,这样在使用多个节点时可以节省资源。
修改后的节点选项:
- sam2_model:SAM2模型输入,该模型由
Load SAM2 Model节点加载。
LoadSAM2Model
加载SAM2模型。
节点选项:
- sam2_model:选择SAM2模型。
- presicion:模型精度。可选择fp16、bf16和fp32。
- device:设置是否使用CUDA。
SAM2VideoUltra
SAM2 Video Ultra 节点支持处理多帧图像或视频序列。请在序列的第一帧中定义识别框数据,以确保正确识别。
https://github.com/user-attachments/assets/4726b8bf-9b98-4630-8f54-cb7ed7a3d2c5
https://github.com/user-attachments/assets/b2a45c96-4be1-4470-8ceb-addaf301b0cb
节点选项:
- image: 需要分割的图像。
- bboxes: 可选的识别框输入数据。
bboxes和first_frame_mask至少需要一个输入。如果输入了first_frame_mask,则会忽略bboxes。 - first_frame_mask: 可选的第一帧掩码输入。该掩码将被用作第一帧的识别对象。
bboxes和first_frame_mask至少需要一个输入。如果输入了first_frame_mask,则会忽略bboxes。 - pre_mask: 可选的输入掩码,用作传播焦点范围的限制,有助于提高识别精度。
- sam2_model: 选择 SAM2 模型。
- presicion: 模型的精度。可选择 fp16 和 bf16。
- cache_model: 是否缓存模型。缓存模型后,可以节省模型加载时间。
- individual_object: 当设置为 True 时,将专注于识别单个对象。当设置为 False 时,则会尝试为多个对象生成识别框。
- mask_preview_color: 在预览输出中显示未遮罩区域的颜色。
- detail_method: 边缘处理方法。目前仅支持 VITMatte 方法。
- detail_erode: 从边缘向内侵蚀掩码范围。数值越大,向内修复的范围越大。
- detail_dilate: 掩码边缘向外扩展。数值越大,向外修复的范围越大。
- black_point: 边缘黑色采样阈值。
- white_point: 边缘白色采样阈值。
- process_detail: 如果设置为 false,则会跳过边缘处理以节省运行时间。
- device: 仅支持 cuda。
- max_megapixels: 设置 VitMate 操作的最大尺寸。尺寸越大,掩码边缘越精细,但计算速度会显著下降。
ObjectDetectorGemini
使用 Gemini API 进行目标检测。
请在 Google AI Studio 上申请您的 API 密钥,并将其填写到插件根目录下的 api_key.ini 文件中。该文件默认名为 api_key.ini.example。首次使用时,需将文件后缀改为 .ini。使用文本编辑软件打开文件,在 google_api_key= 后填入您的 API 密钥并保存。
节点选项:
- image: 输入图像。
- model: 选择 Gemini 模型。
- prompt: 描述需要识别的目标。
ObjectDetectorGeminiV2
在 ObjectDetectorGemini 节点的基础上,改用新的 google-genai 依赖包,支持最新的 gemini-2.5-pro-exp-03-25 模型。
节点选项:
与 ObjectDetectorGemini 相同。
ObjectDetectorFL2
使用 Florence2 模型识别图像中的目标,并输出识别框数据。
*请从 BaiduNetdisk 下载模型,并复制到 ComfyUI/models/florence2 文件夹中。
节点选项:
- image: 需要分割的图像。
- florence2_model: Florence2 模型,来自 LoadFlorence2Model 节点。
- prompt: 描述需要识别的目标。
- sort_method: 选择框排序方式有四种选项:“left_to_right”、“top_to_bottom”、“big_to_small”和“confidence”。
- bbox_select: 选择输入框数据。有三种选项:“all”选择所有框,“first”选择置信度最高的框,“by_index”指定框的索引。
- select_index: 此选项在 bbox_delect 为 ‘by_index’ 时有效。0 表示第一个框。可以输入多个值,用任何非数字字符分隔,包括但不限于逗号、句号、分号、空格或字母,甚至中文。
ObjectDetectorYOLOWorld
(已弃用。若仍需使用,需手动安装依赖包)
由于依赖包可能存在安装问题,该节点已被弃用。如需使用,请手动安装以下依赖包:
pip install inference-cli>=0.13.0
pip install inference-gpu[yolo-world]>=0.13.0
使用 YOLO-World 模型识别图像中的目标,并输出识别框数据。
*请从 BaiduNetdisk 或 GoogleDrive 下载模型,并复制到 ComfyUI/models/yolo-world 文件夹中。
节点选项:
- image: 需要分割的图像。
- confidence_threshold: 置信度阈值。
- nms_iou_threshold: 非极大值抑制阈值。
- prompt: 描述需要识别的目标。
- sort_method: 选择框排序方式有四种选项:“left_to_right”、“top_to_bottom”、“big_to_small”和“confidence”。
- bbox_select: 选择输入框数据。有三种选项:“all”选择所有框,“first”选择置信度最高的框,“by_index”指定框的索引。
- select_index: 此选项在 bbox_delect 为 ‘by_index’ 时有效。0 表示第一个框。可以输入多个值,用任何非数字字符分隔,包括但不限于逗号、句号、分号、空格或字母,甚至中文。
ObjectDetectorYOLO8
使用 YOLO-8 模型识别图像中的物体,并输出检测框数据。
*请从 GoogleDrive 或 BaiduNetdisk 下载模型,并将其复制到 ComfyUI/models/yolo 文件夹中。
节点选项:
- image: 需要进行分割的图像。
- yolo_model: 选择 YOLO 模型。
- sort_method: 检测框排序方法有四种选项:“left_to_right”(从左到右)、“top_to_bottom”(从上到下)、“big_to_small”(从大到小)和“confidence”(按置信度排序)。
- bbox_select: 选择输入的检测框数据。共有三种选项:“all”选择所有检测框,“first”选择置信度最高的检测框,“by_index”指定检测框的索引。
- select_index: 当 bbox_delect 设置为 ‘by_index’ 时,此选项有效。0 表示第一个检测框。可以输入多个值,用任何非数字字符分隔,包括但不限于逗号、句号、分号、空格或字母,甚至中文。
ObjectDetectorMask
使用掩码作为检测框数据。掩码上白色区域所包围的所有区域都将被识别为一个物体。多个封闭区域将分别被识别。
节点选项:
- object_mask: 掩码输入。
- sort_method: 检测框排序方法有四种选项:“left_to_right”(从左到右)、“top_to_bottom”(从上到下)、“big_to_small”(从大到小)和“confidence”(按置信度排序)。
- bbox_select: 选择输入的检测框数据。共有三种选项:“all”选择所有检测框,“first”选择置信度最高的检测框,“by_index”指定检测框的索引。
- select_index: 当 bbox_delect 设置为 ‘by_index’ 时,此选项有效。0 表示第一个检测框。可以输入多个值,用任何非数字字符分隔,包括但不限于逗号、句号、分号、空格或字母,甚至中文。
BBoxJoin
合并检测框数据。
节点选项:
- bboxes_1: 必填项。第一组检测框。
- bboxes_2: 可选输入。第二组检测框。
- bboxes_3: 可选输入。第三组检测框。
- bboxes_4: 可选输入。第四组检测框。
DrawBBoxMask
将 Object Detector 节点输出的检测框数据绘制为掩码。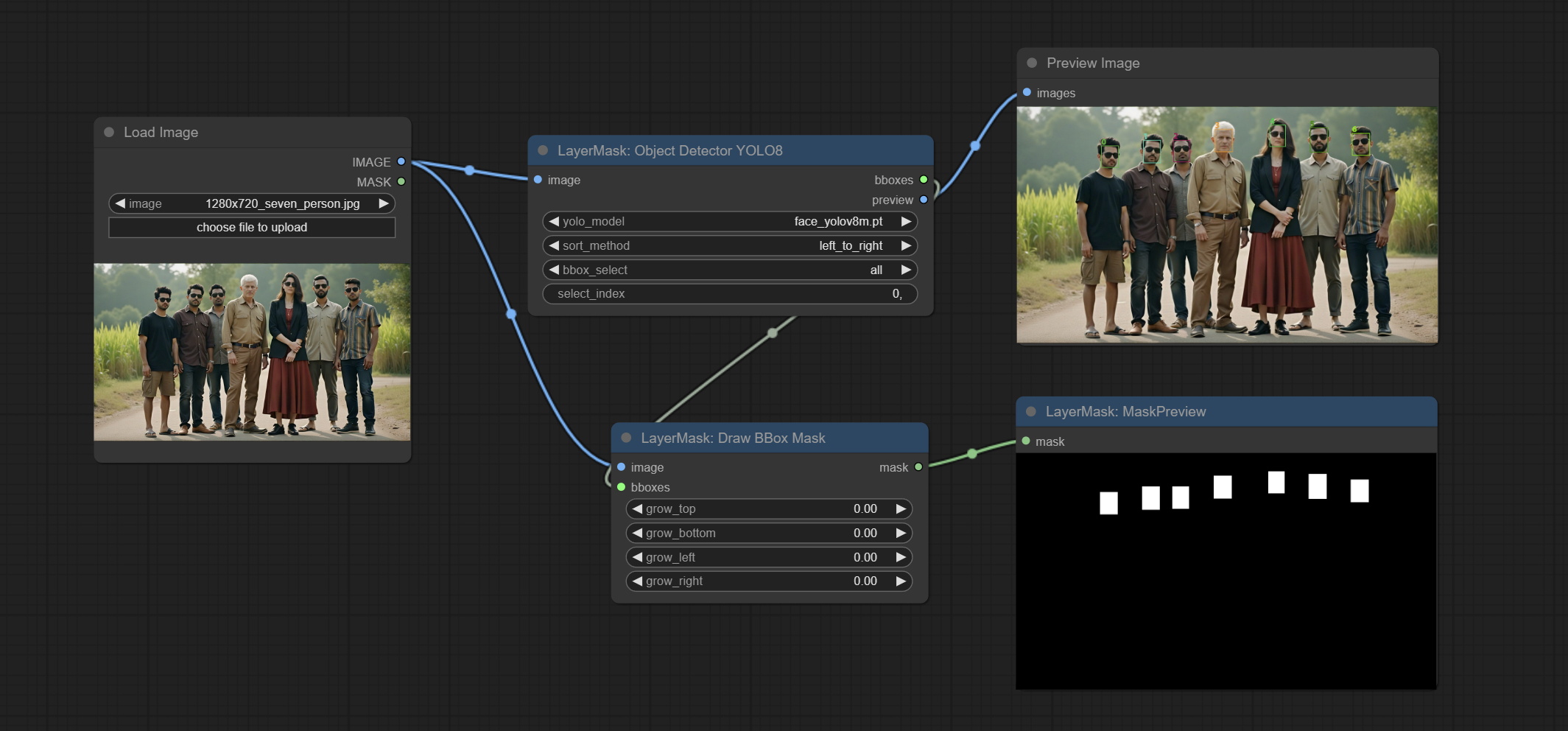
节点选项: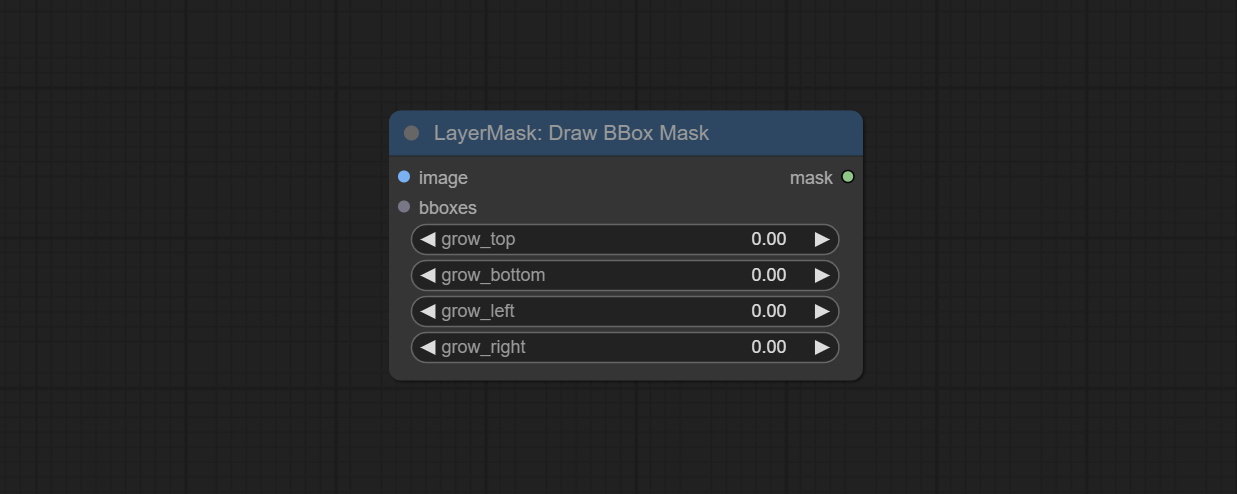
- image: 图像输入。必须与 Object Detector 节点识别的图像一致。
- bboxes: 输入的检测框数据。
- grow_top: 每个检测框会按照其高度的百分比向上扩展,正值表示向上扩展,负值表示向下扩展。
- grow_bottom: 每个检测框会按照其高度的百分比向下扩展,正值表示向下扩展,负值表示向上扩展。
- grow_left: 每个检测框会按照其宽度的百分比向左扩展,正值表示向左扩展,负值表示向右扩展。
- grow_right: 每个检测框会按照其宽度的百分比向右扩展,正值表示向右扩展,负值表示向左扩展。
DrawBBoxMaskV2
在 DrawBBoxMask 节点的基础上增加了圆角矩形绘制功能。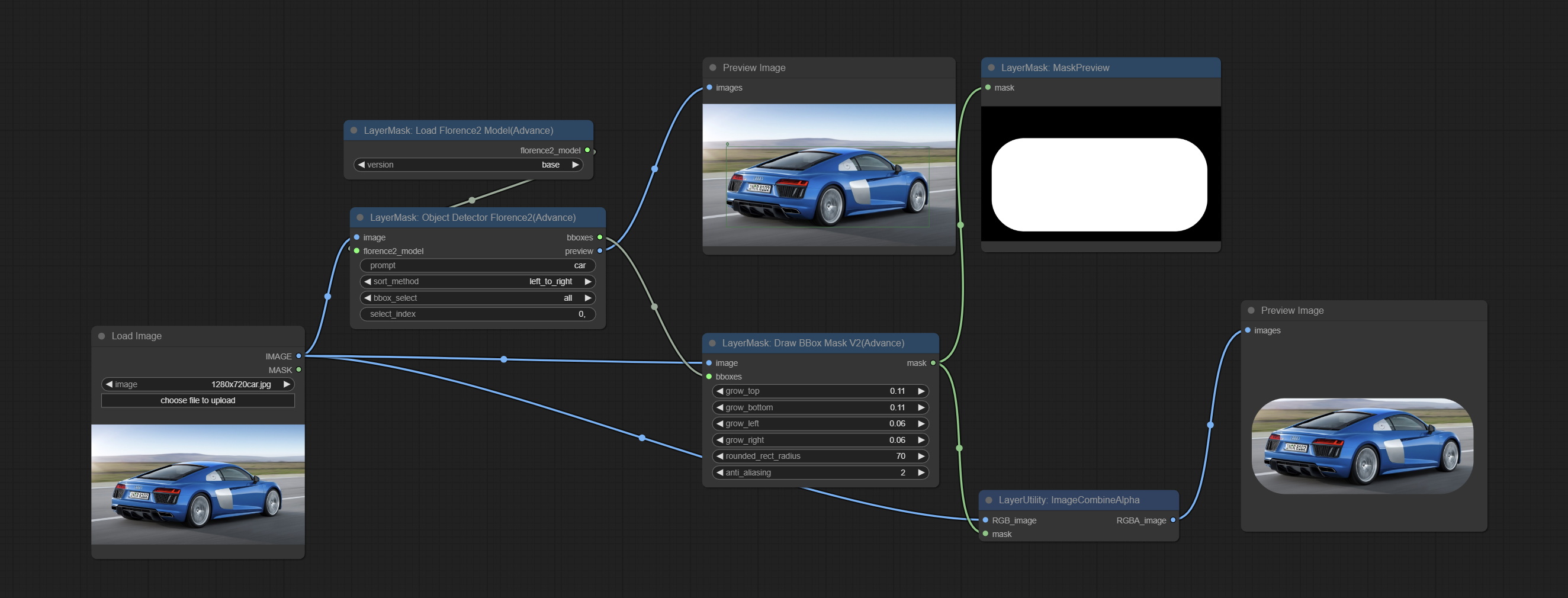
新增选项: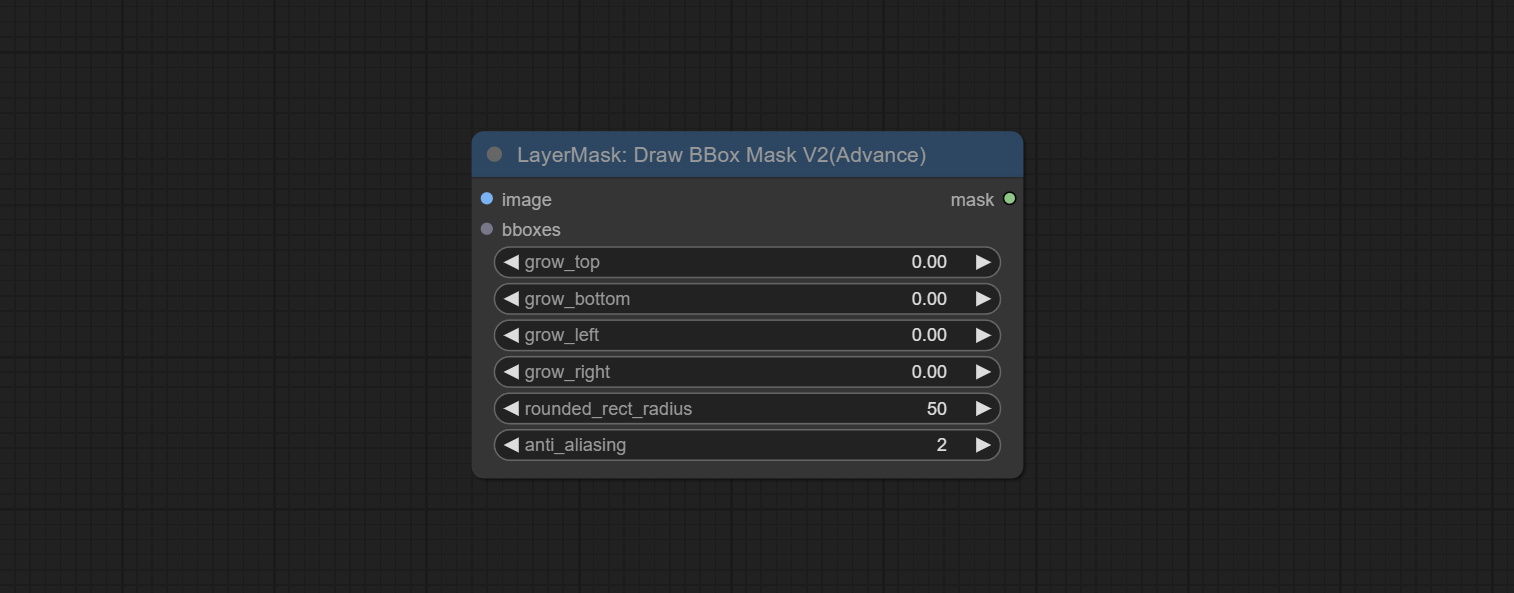
- rounded_rect_radius: 圆角半径。范围为 0-100,数值越大,圆角越明显。
- anti_aliasing: 抗锯齿效果,范围为 0-16,数值越大,锯齿现象越不明显。过高的数值会显著降低节点的处理速度。
EVF-SAMUltra
该节点是 EVF-SAM 在 ComfyUI 中的实现。
*请从 BaiduNetdisk 或 huggingface/EVF-SAM2、huggingface/EVF-SAM 下载模型文件,并将其保存到 ComfyUI/models/EVF-SAM 文件夹中(将模型分别存放在各自的子目录中)。
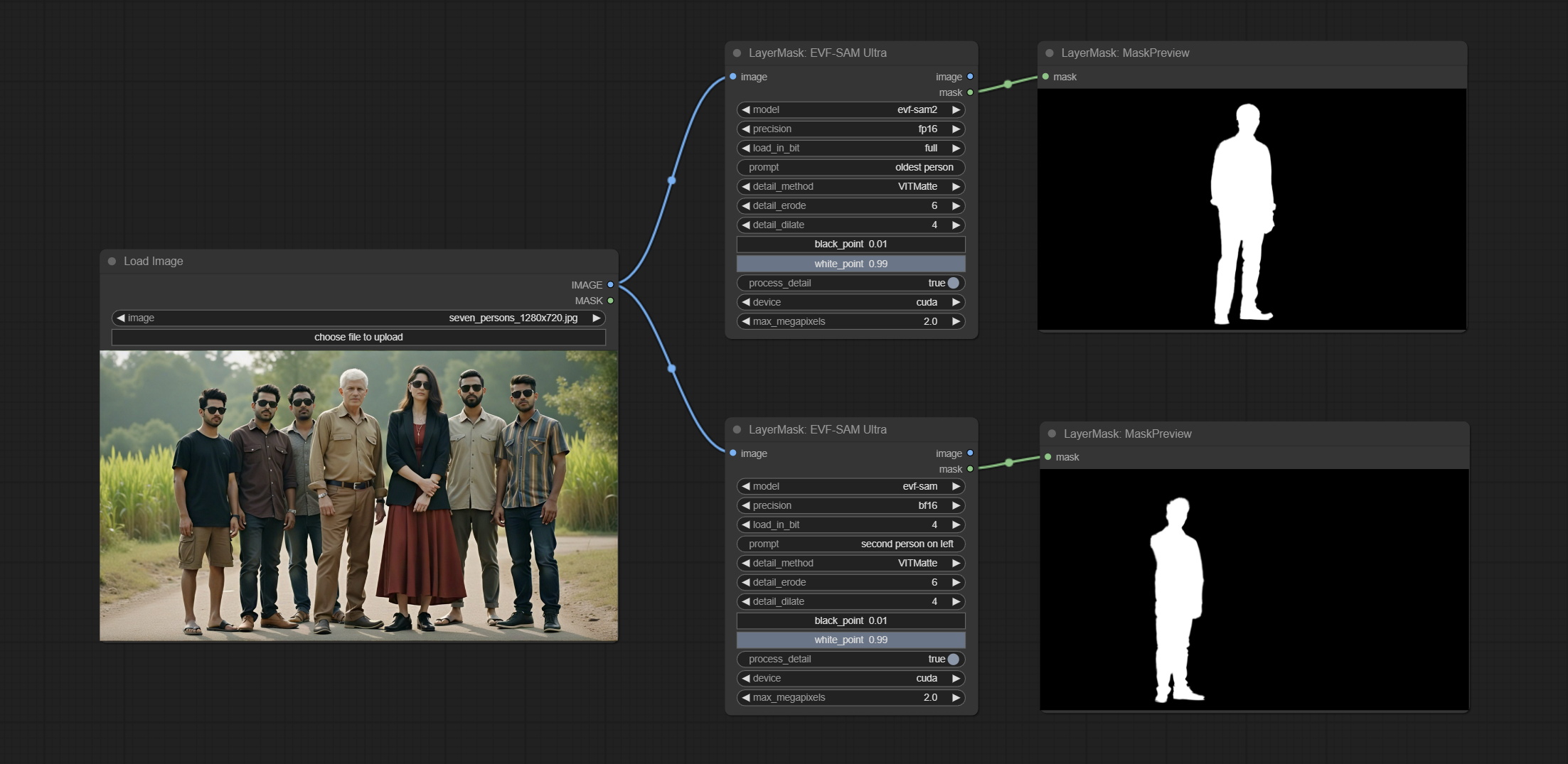
节点选项:
- image: 输入图像。
- model: 选择模型。目前有 evf-sam2 和 evf sam 两种选项。
- presicion: 模型精度可选择 fp16、bf16 和 fp32。
- load_in_bit: 按位精度加载模型。可以选择 full、8 和 4。
- pormpt: 用于分割的提示词。
- detail_method: 边缘处理方法。提供 VITMatte、VITMatte(local)、PyMatting、GuidedFilter。如果首次使用 VITMatte 后下载了模型,则后续可使用 VITMatte (local)。
- detail_erode: 从边缘向内侵蚀掩码范围。数值越大,向内修复的范围越大。
- detail_dilate: 掩码边缘向外扩张。数值越大,向外修复的范围越大。
- black_point: 边缘黑色采样阈值。
- white_point: 边缘白色采样阈值。
- process_detail: 如果设置为 false,则跳过边缘处理以节省运行时间。
- device: 设置是否使用 cuda 的 VitMatte。
- max_megapixels: 设置 VitMate 操作的最大尺寸。
Florence2Ultra
利用 Florence2 模型的分割功能,同时具备超高的边缘细节。
该节点部分代码来自 spacepxl/ComfyUI-Florence-2,感谢原作者。
*请从 BaiduNetdisk 下载模型文件,并将其复制到 ComfyUI/models/florence2 文件夹中。
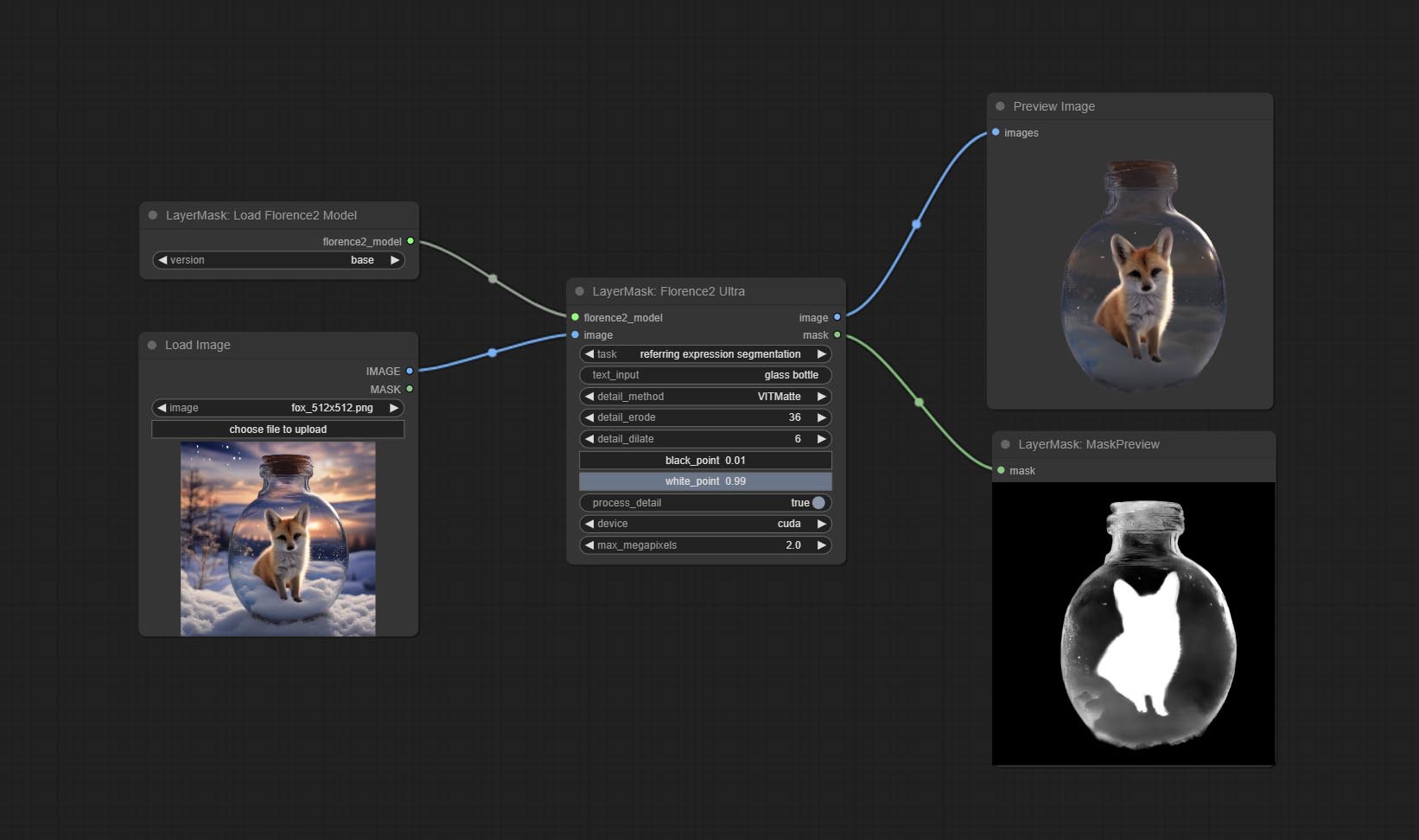
节点选项:
- florence2_model: Florence2 模型输入。
- image: 图像输入。
- task: 选择 Florence2 的任务。
- text_input: Florence2 的文本输入。
- detail_method: 边缘处理方法。提供 VITMatte、VITMatte(local)、PyMatting、GuidedFilter。如果首次使用 VITMatte 后下载了模型,则后续可使用 VITMatte (local)。
- detail_erode: 从边缘向内侵蚀掩码范围。数值越大,向内修复的范围越大。
- detail_dilate: 掩码边缘向外扩张。数值越大,向外修复的范围越大。
- black_point: 边缘黑色采样阈值。
- white_point: 边缘白色采样阈值。
- process_detail: 如果设置为 false,则跳过边缘处理以节省运行时间。
- device: 设置是否使用 cuda 的 VitMatte。
- max_megapixels: 设置 VitMate 操作的最大尺寸。
LoadFlorence2Model
Florence2 模型加载器。 *首次使用时,模型将自动下载。
目前可供选择的模型包括 base、base-ft、large、large-ft、DocVQA、SD3-Captioner 和 base-PromptGen。
BiRefNetUltra
使用 BiRefNet 模型进行背景去除,具有更好的识别能力和超高的边缘细节。 该节点的模型部分代码来自 Viper 的 ComfyUI-BiRefNet,感谢原作者。
*从 https://huggingface.co/ViperYX/BiRefNet 或 百度网盘 下载 BiRefNet-ep480.pth,pvt_v2_b2.pth,pvt_v2_b5.pth,swin_base_patch4_window12_384_22kto1k.pth, swin_large_patch4_window12_384_22kto1k.pth 5 个文件,放入 ComfyUI/models/BiRefNet 文件夹中。
节点选项: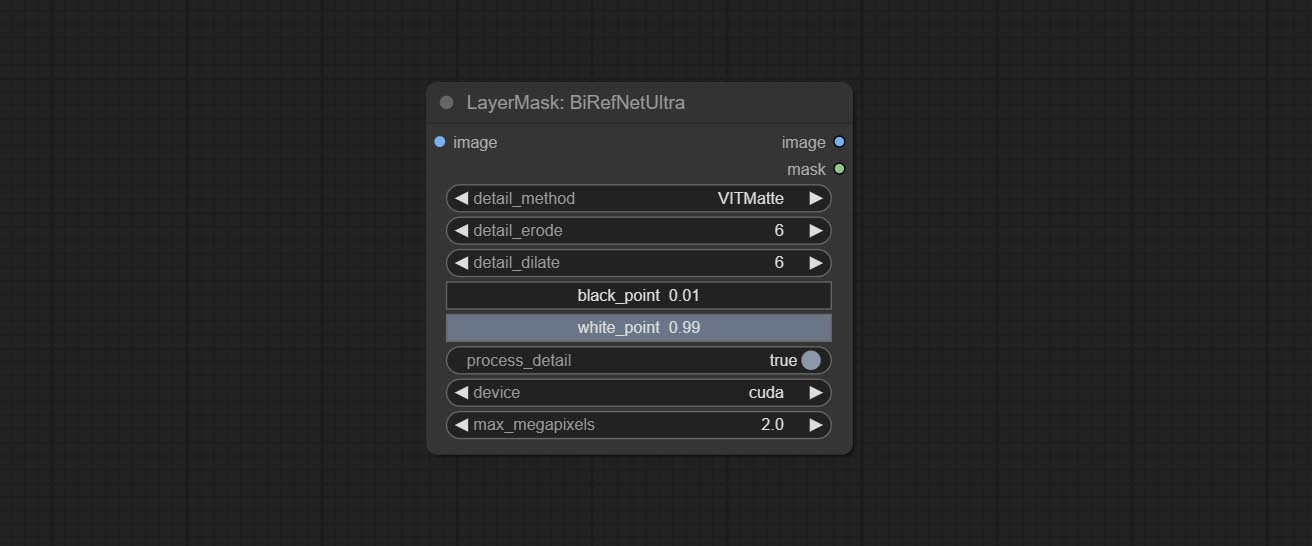
- detail_method:边缘处理方法。提供 VITMatte、VITMatte(local)、PyMatting、GuidedFilter。如果在首次使用 VITMatte 后已下载模型,则后续可使用 VITMatte (local)。
- detail_erode:从边缘向内侵蚀掩膜范围。数值越大,向内修复的范围越大。
- detail_dilate:掩膜边缘向外扩张。数值越大,向外修复的范围越宽。
- black_point:边缘黑色采样阈值。
- white_point:边缘白色采样阈值。
- process_detail:此处设置为 false 将跳过边缘处理以节省运行时间。
- device:设置是否使用 CUDA 进行 VitMate 处理。
- max_megapixels:设置 VitMate 操作的最大尺寸。
BiRefNetUltraV2
该节点支持使用最新的 BiRefNet 模型。
*从 百度网盘 或 GoogleDrive 下载名为 BiRefNet-general-epoch_244.pth 的模型文件,放入 ComfyUI/Models/BiRefNet/pth 文件夹中。您也可以下载更多 BiRefNet 模型并放置于此处。
节点选项: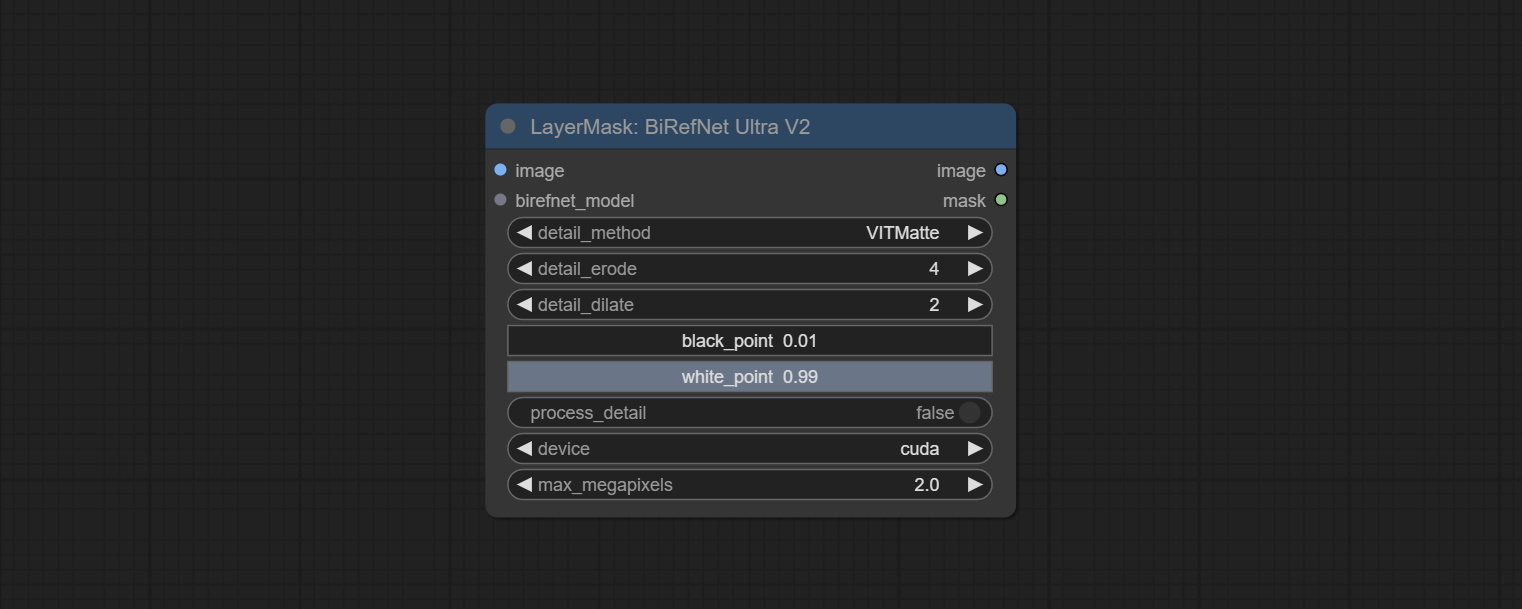
- image:输入图像。
- birefnet_model:BiRefNet 模型作为输入,由 LoadBiRefNetModel 节点输出。
- detail_method:边缘处理方法。提供 VITMatte、VITMatte(local)、PyMatting、GuidedFilter。如果在首次使用 VITMatte 后已下载模型,则后续可使用 VITMatte (local)。
- detail_erode:从边缘向内侵蚀掩膜范围。数值越大,向内修复的范围越大。
- detail_dilate:掩膜边缘向外扩张。数值越大,向外修复的范围越宽。
- black_point:边缘黑色采样阈值。
- white_point:边缘白色采样阈值。
- process_detail:由于 BiRefNet 具有出色的边缘处理能力,此处默认设置为 False。
- device:设置是否使用 CUDA 进行 VitMate 处理。
- max_megapixels:设置 VitMate 操作的最大尺寸。
LoadBiRefNetModel
加载 BiRefNet 模型。
节点选项: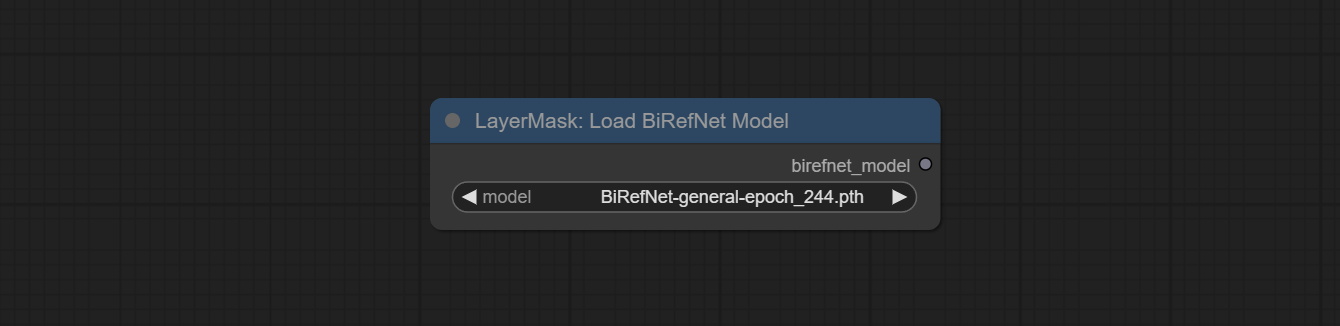
- model:选择模型。列出
CoomfyUI/models/BiRefNet/pth文件夹中的文件供选择。
LoadBiRefNetModelV2
该节点是由 jimlee2048 提交的 PR,支持加载 RMBG-2.0 模型。
从 huggingface 或 百度网盘 下载模型文件,并复制到 ComfyUI/models/BiRefNet/RMBG-2.0 文件夹中。
节点选项: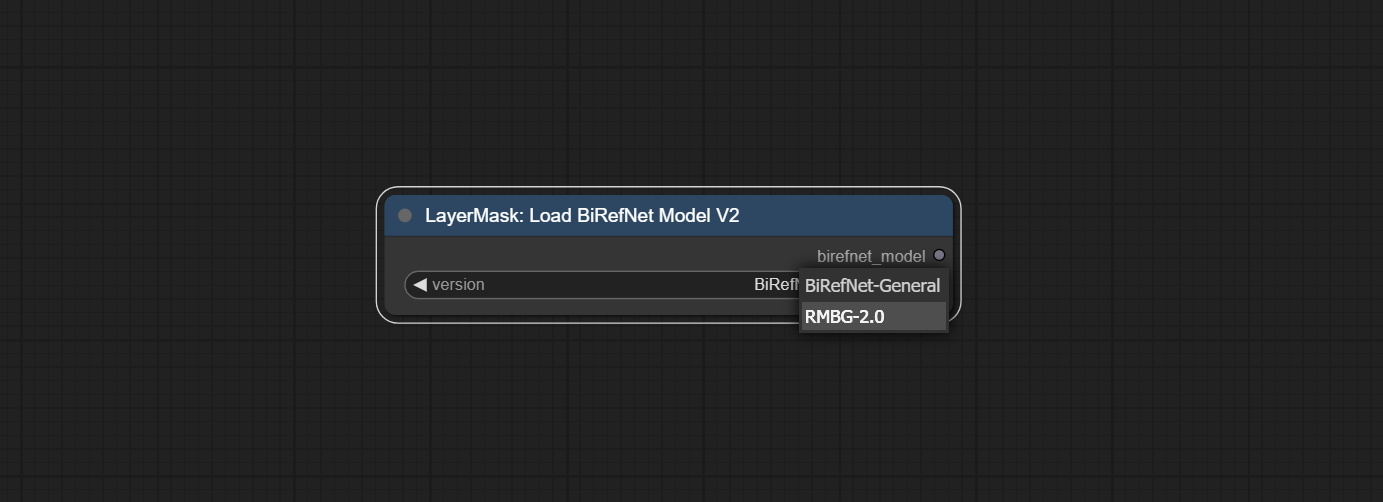
- model:选择模型。有两个选项,分别是
BiRefNet-General和RMBG-2.0。
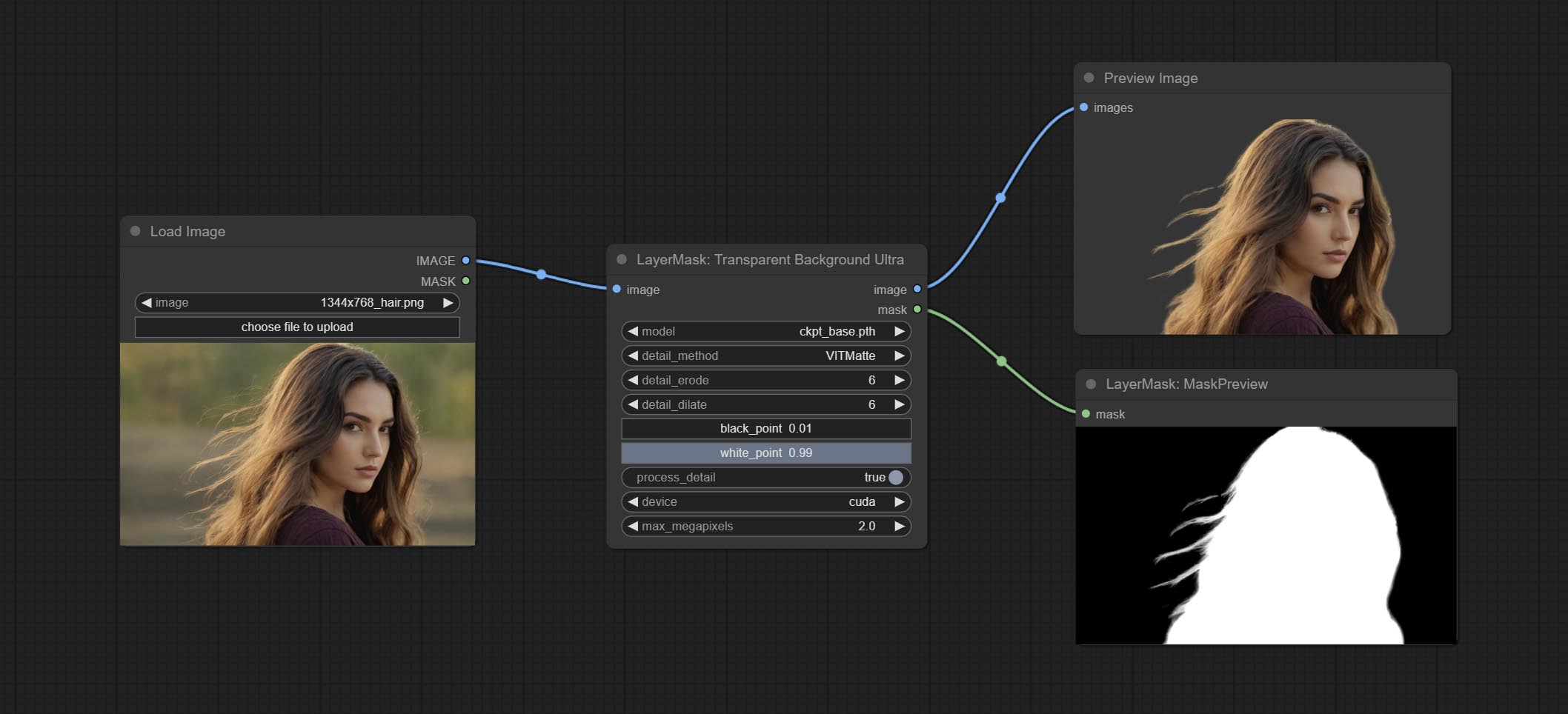
TransparentBackgroundUltra
使用透明背景模型进行背景去除,具有更好的识别能力和速度,同时拥有超高的边缘细节。
*从 googledrive 或 百度网盘 下载所有文件,放入 ComfyUI/models/transparent-background 文件夹中。
节点选项: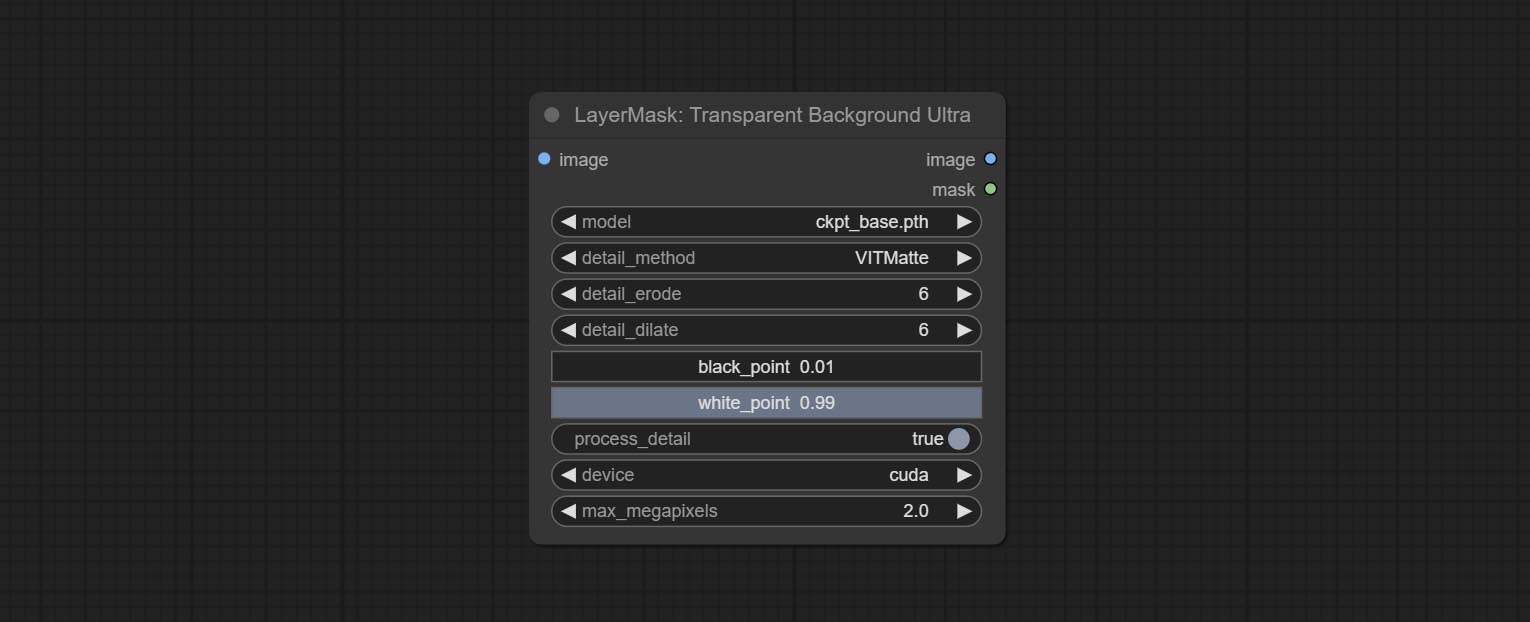
- model:选择模型。
- detail_method:边缘处理方法。提供 VITMatte、VITMatte(local)、PyMatting、GuidedFilter。如果在首次使用 VITMatte 后已下载模型,则后续可使用 VITMatte (local)。
- detail_erode:从边缘向内侵蚀掩膜范围。数值越大,向内修复的范围越大。
- detail_dilate:掩膜边缘向外扩张。数值越大,向外修复的范围越宽。
- black_point:边缘黑色采样阈值。
- white_point:边缘白色采样阈值。
- process_detail:此处设置为 false 将跳过边缘处理以节省运行时间。
- device:设置是否使用 CUDA 进行 VitMate 处理。
- max_megapixels:设置 VitMate 操作的最大尺寸。
PersonMaskUltra
为人物的面部、头发、身体皮肤、衣物或配饰生成掩膜。与之前的 A Person Mask Generator 节点相比,该节点具有超高的边缘细节。
该节点的模型代码来自 a-person-mask-generator,边缘处理代码来自 ComfyUI-Image-Filters,感谢原作者。
*从 百度网盘 下载模型文件,放入 ComfyUI/models/mediapipe 文件夹中。
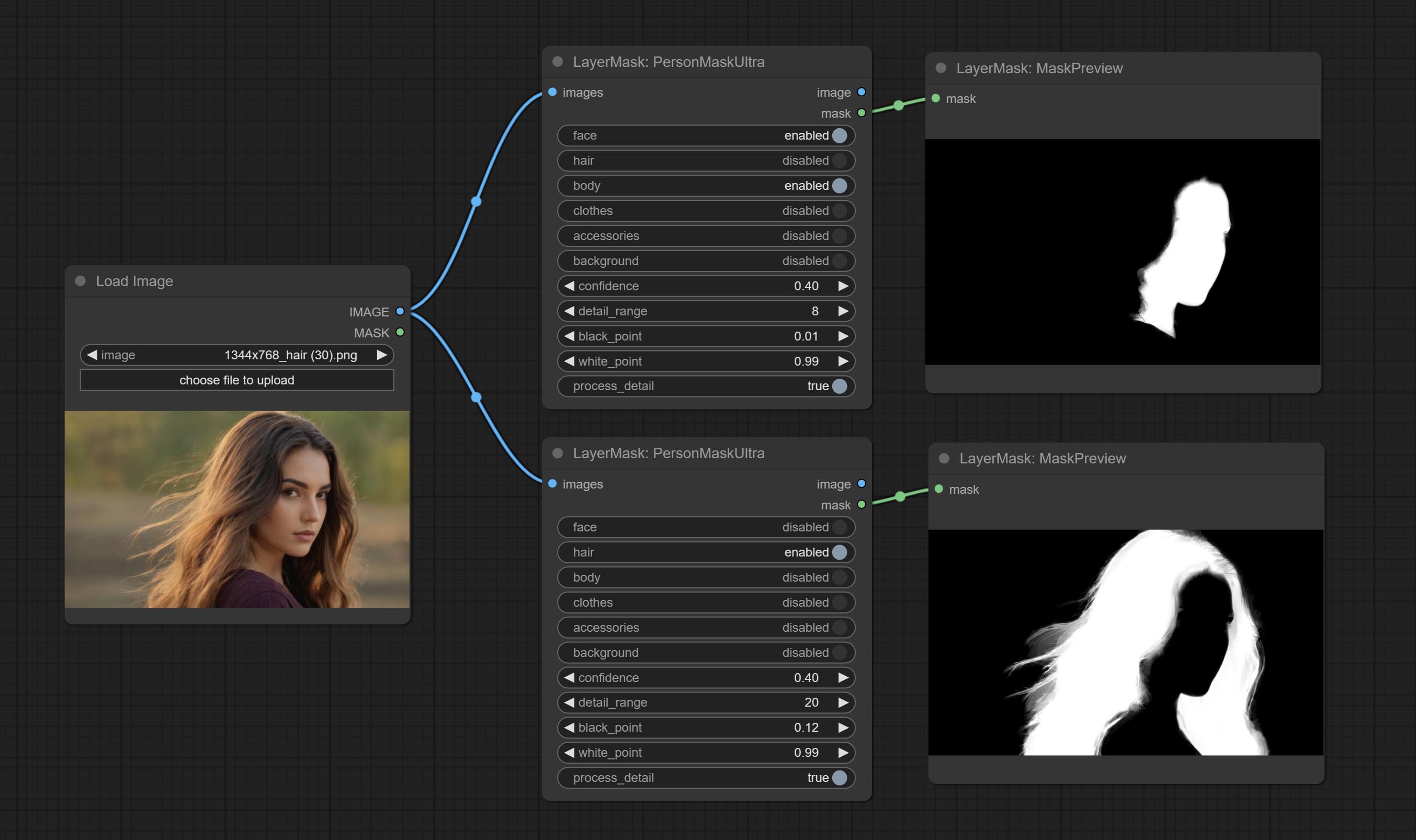
节点选项: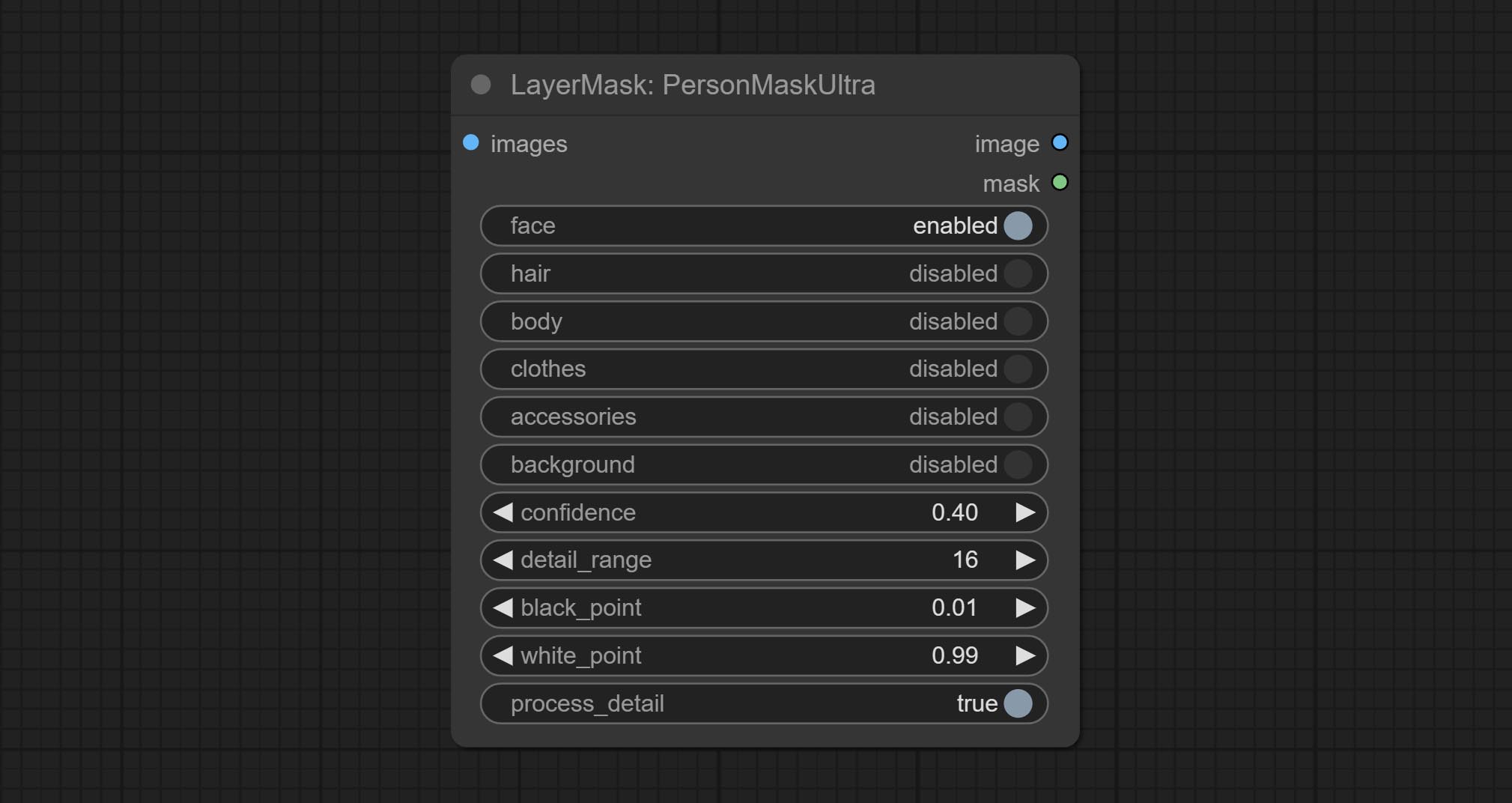
- face:面部识别。
- hair:头发识别。
- body:身体皮肤识别。
- clothes:衣物识别。
- accessories:配饰识别(如背包)。
- background:背景识别。
- confidence:识别阈值,数值越低,输出的掩膜范围越大。
- detail_range:边缘细节范围。
- black_point:边缘黑色采样阈值。
- white_point:边缘白色采样阈值。
- process_detail:此处设置为 false 将跳过边缘处理以节省运行时间。
PersonMaskUltraV2
PersonMaskUltra 的 V2 升级版本新增了 VITMatte 边缘处理方法。(注意:使用此方法处理超过 2K 分辨率的图像会消耗大量内存)
在 PersonMaskUltra 的基础上,进行了以下更改: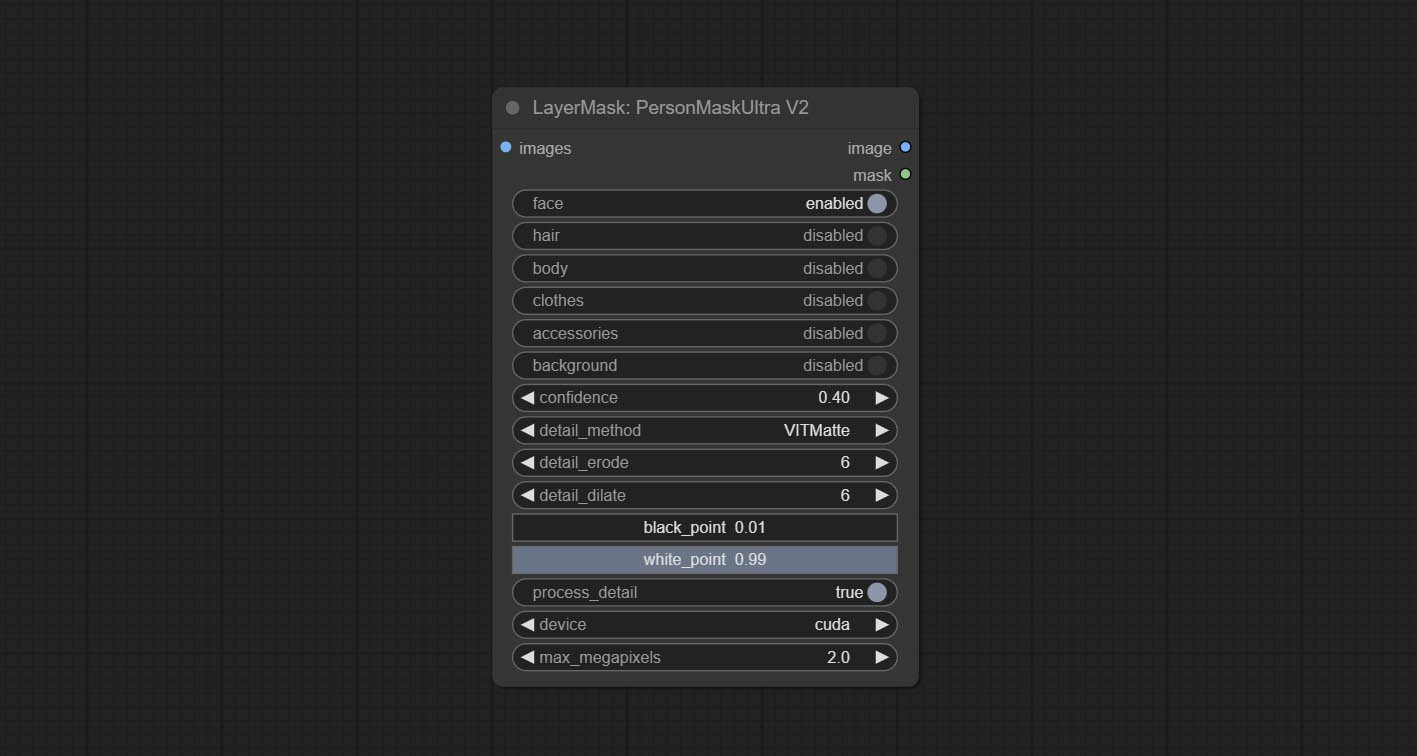
- detail_method:边缘处理方法。提供 VITMatte、VITMatte(本地)、PyMatting 和 GuidedFilter。如果首次使用 VITMatte 后已下载模型,则后续可使用 VITMatte(本地)。
- detail_erode:从边缘向内侵蚀遮罩范围。值越大,向内修复的范围越大。
- detail_dilate:遮罩边缘向外扩展。值越大,向外修复的范围越大。
- device:设置是否使用 CUDA 加速的 VitMatte。
- max_megapixels:设置 VitMate 操作的最大尺寸。
HumanPartsUltra
用于生成人体各部位的掩码,基于 metal3d/ComfyUI_Human_Parts 的封装,感谢原作者。
该节点在原有基础上增加了超精细的边缘处理功能。请从 百度网盘 或 Hugging Face 下载模型文件,并将其复制到 ComfyUI\models\onnx\human-parts 文件夹中。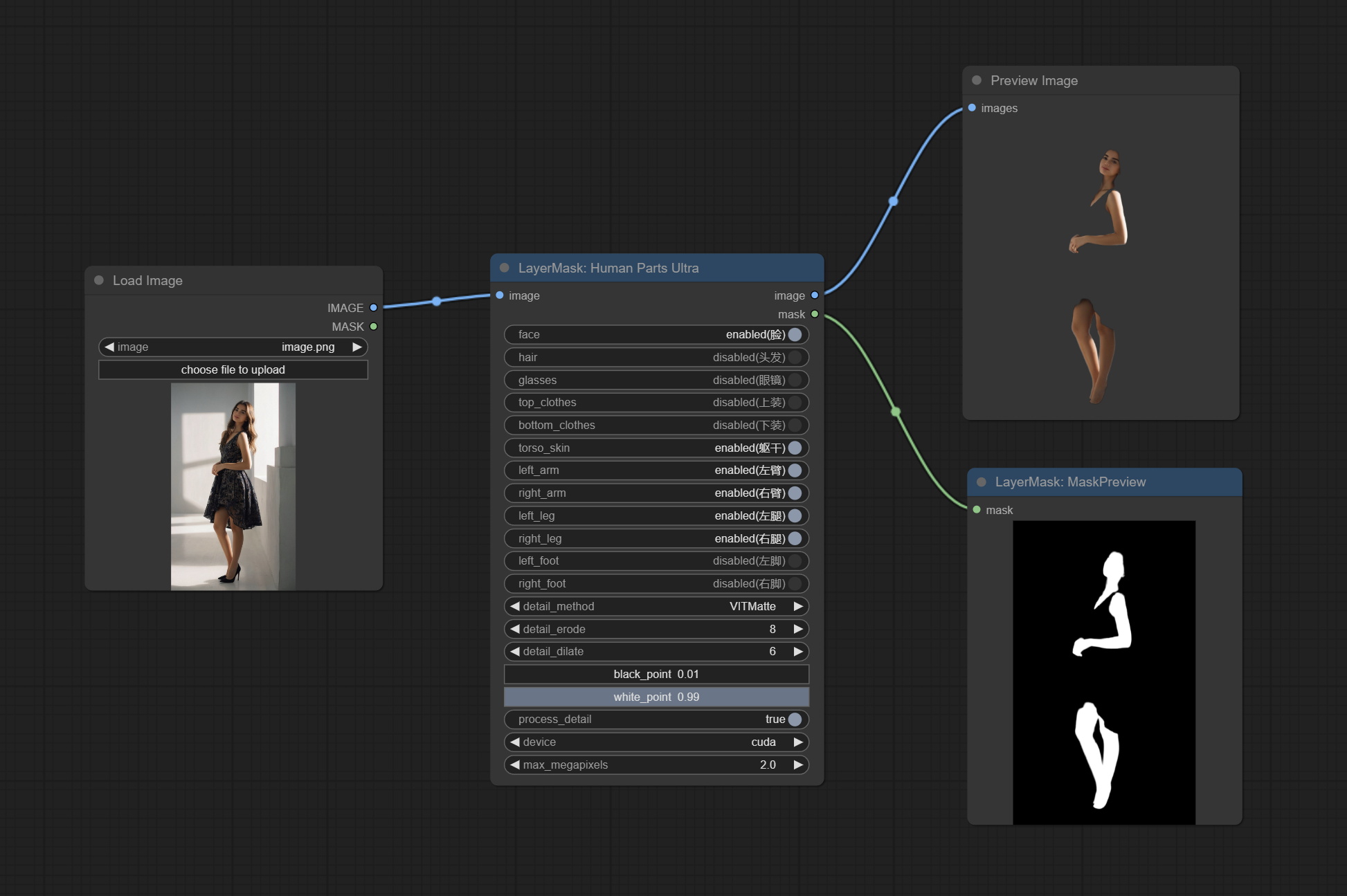
节点选项: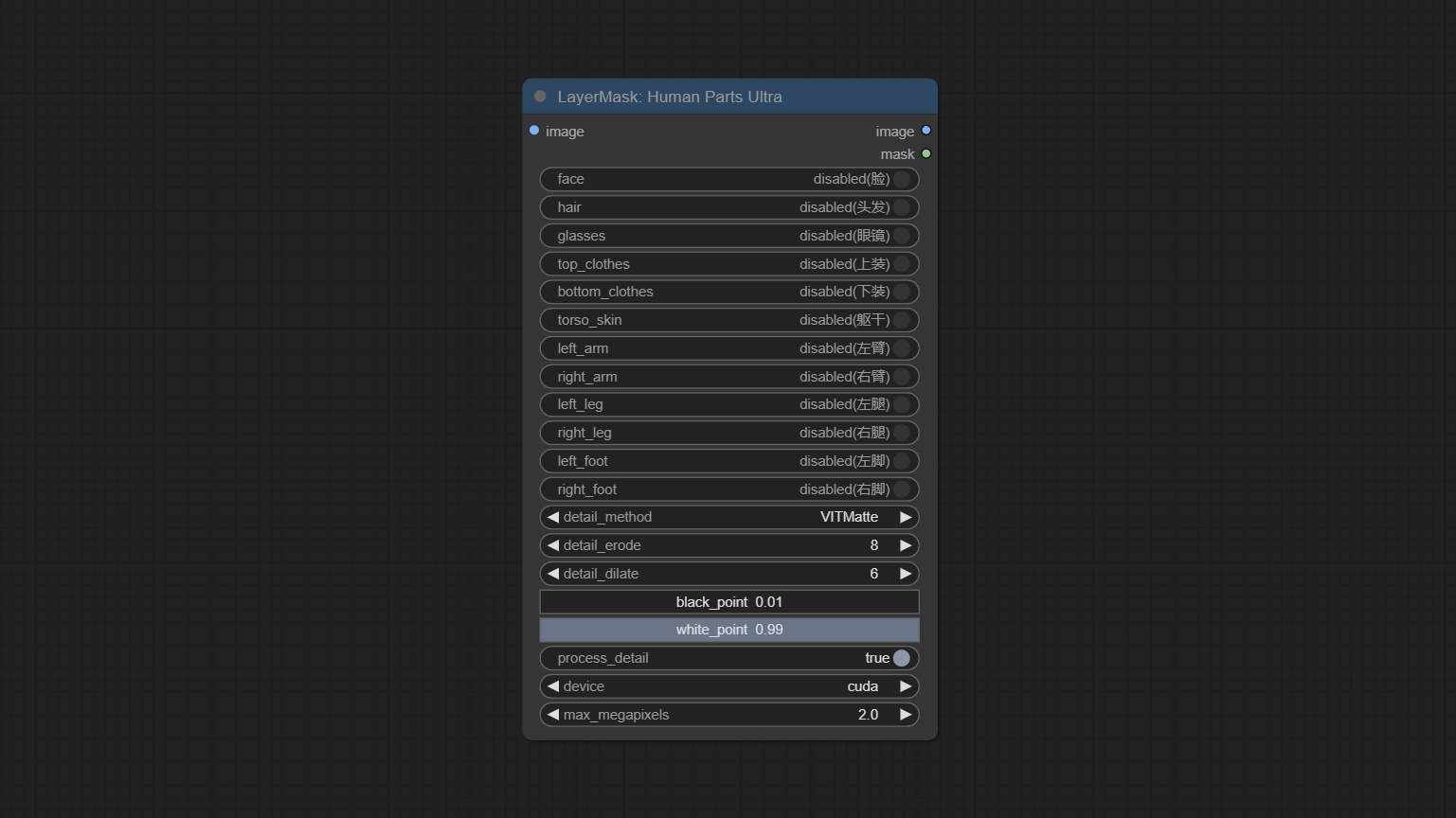
- image:输入图像。
- face:人脸识别开关。
- hair:头发识别开关。
- glasses:眼镜识别开关。
- top_clothes:上衣识别开关。
- bottom_clothes:下装识别开关。
- torso_skin:躯干皮肤识别开关。
- left_arm:左臂识别开关。
- right_arm:右臂识别开关。
- left_leg:左腿识别开关。
- right_leg:右腿识别开关。
- left_foot:左脚识别开关。
- right_foot:右脚识别开关。
- detail_method:边缘处理方法。提供 VITMatte、VITMatte(本地)、PyMatting 和 GuidedFilter。如果首次使用 VITMatte 后已下载模型,则后续可使用 VITMatte(本地)。
- detail_erode:从边缘向内侵蚀遮罩范围。值越大,向内修复的范围越大。
- detail_dilate:遮罩边缘向外扩展。值越大,向外修复的范围越大。
- black_point:边缘黑色采样阈值。
- white_point:边缘白色采样阈值。
- process_detail:此处设为 false 将跳过边缘处理以节省运行时间。
- device:设置是否使用 CUDA 加速的 VitMatte。
- max_megapixels:设置 VitMate 操作的最大尺寸。
YoloV8Detect
使用 YoloV8 模型检测人脸、手部框区域或字符分割。支持输出选定数量的通道。
请从 Google Drive 或 百度网盘 下载模型文件,并将其放置到 ComfyUI\models/yolo 文件夹中。
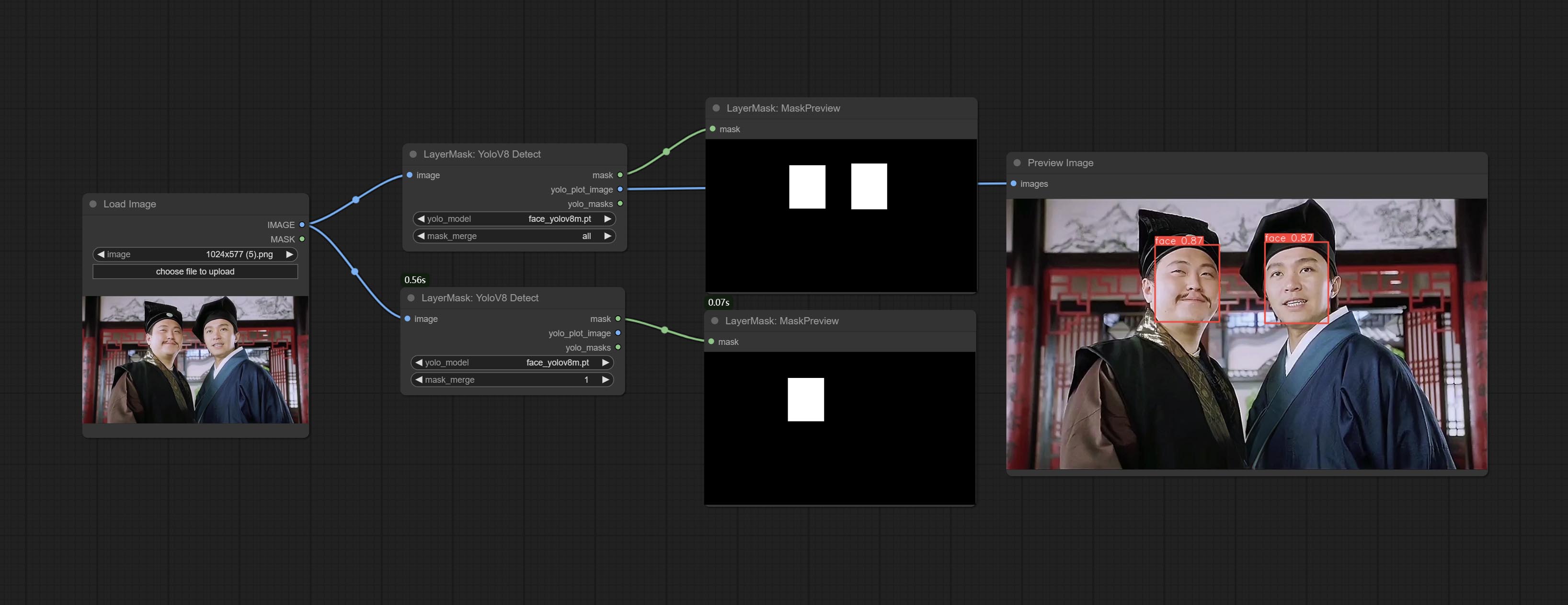
节点选项: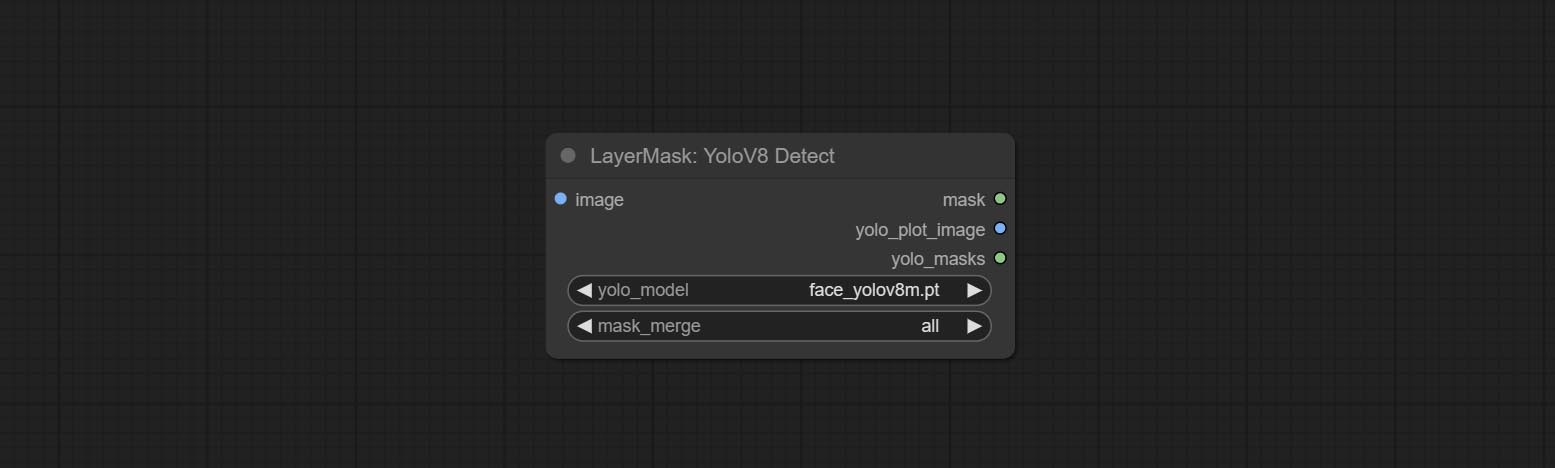
- yolo_model:Yolo 模型选择。名称中带有
seg的模型可以输出分割掩码,否则仅能输出框形掩码。 - mask_merge:选择合并后的掩码。
all表示合并所有掩码输出;若选择具体数字,则按识别置信度排序后合并相应数量的掩码并输出。
输出:
- mask:输出的掩码。
- yolo_plot_image:Yolo 识别结果预览。
- yolo_masks:对于 Yolo 识别出的所有掩码,每个单独的掩码都会作为独立输出。
MediapipeFacialSegment
使用 Mediapipe 模型检测面部特征,分割左右眉毛、眼睛、嘴唇和牙齿。
请从 百度网盘 下载模型文件,并将其复制到 ComfyUI\models/mediapipe 文件夹中。
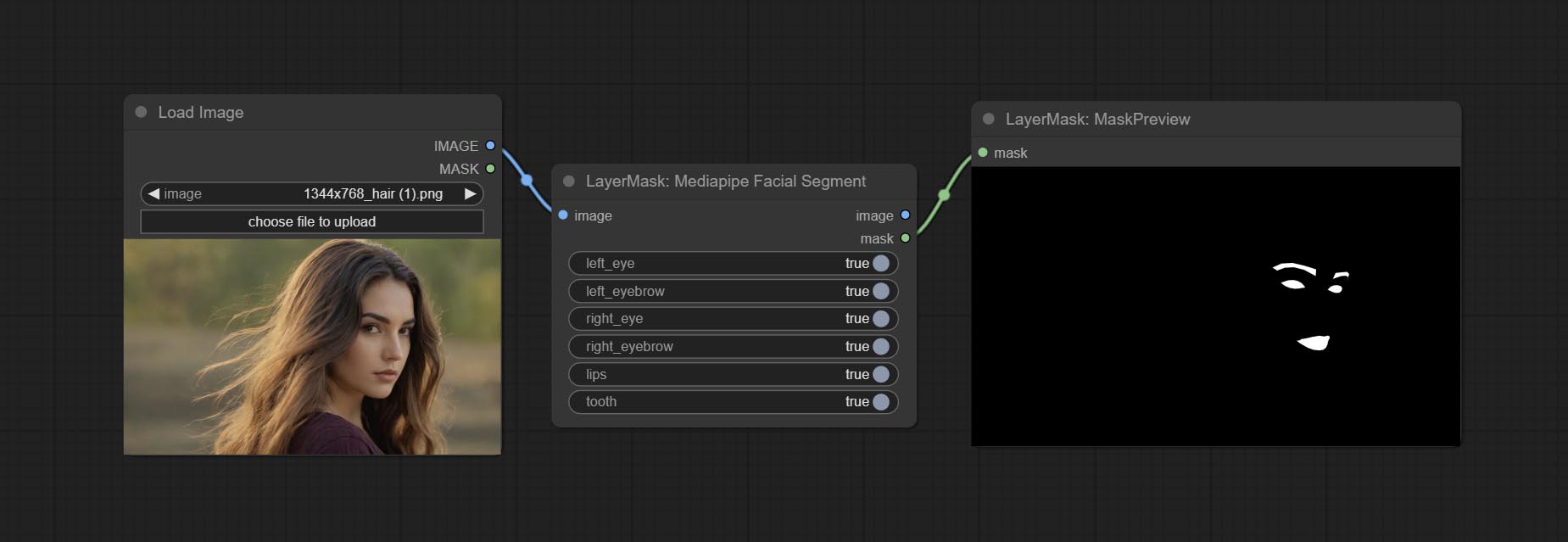
节点选项: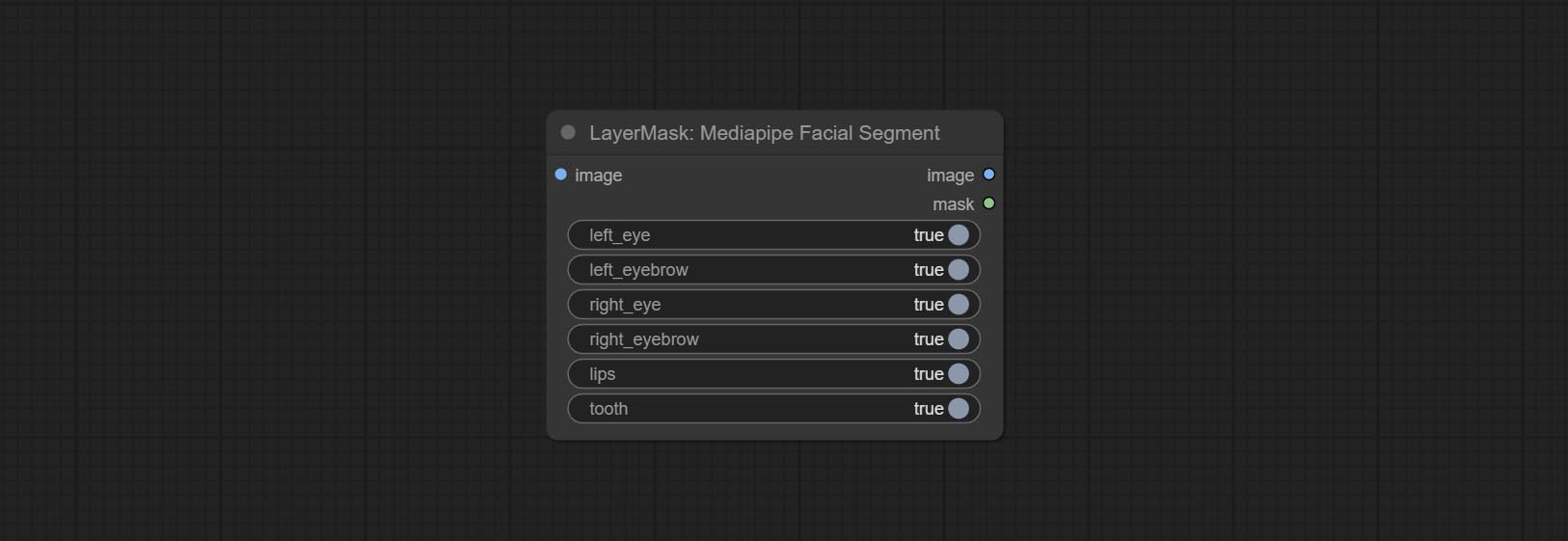
- left_eye:左眼识别开关。
- left_eyebrow:左眉识别开关。
- right_eye:右眼识别开关。
- right_eyebrow:右眉识别开关。
- lips:嘴唇识别开关。
- tooth:牙齿识别开关。
MaskByDifferent
计算两张图像之间的差异,并将其输出为掩码。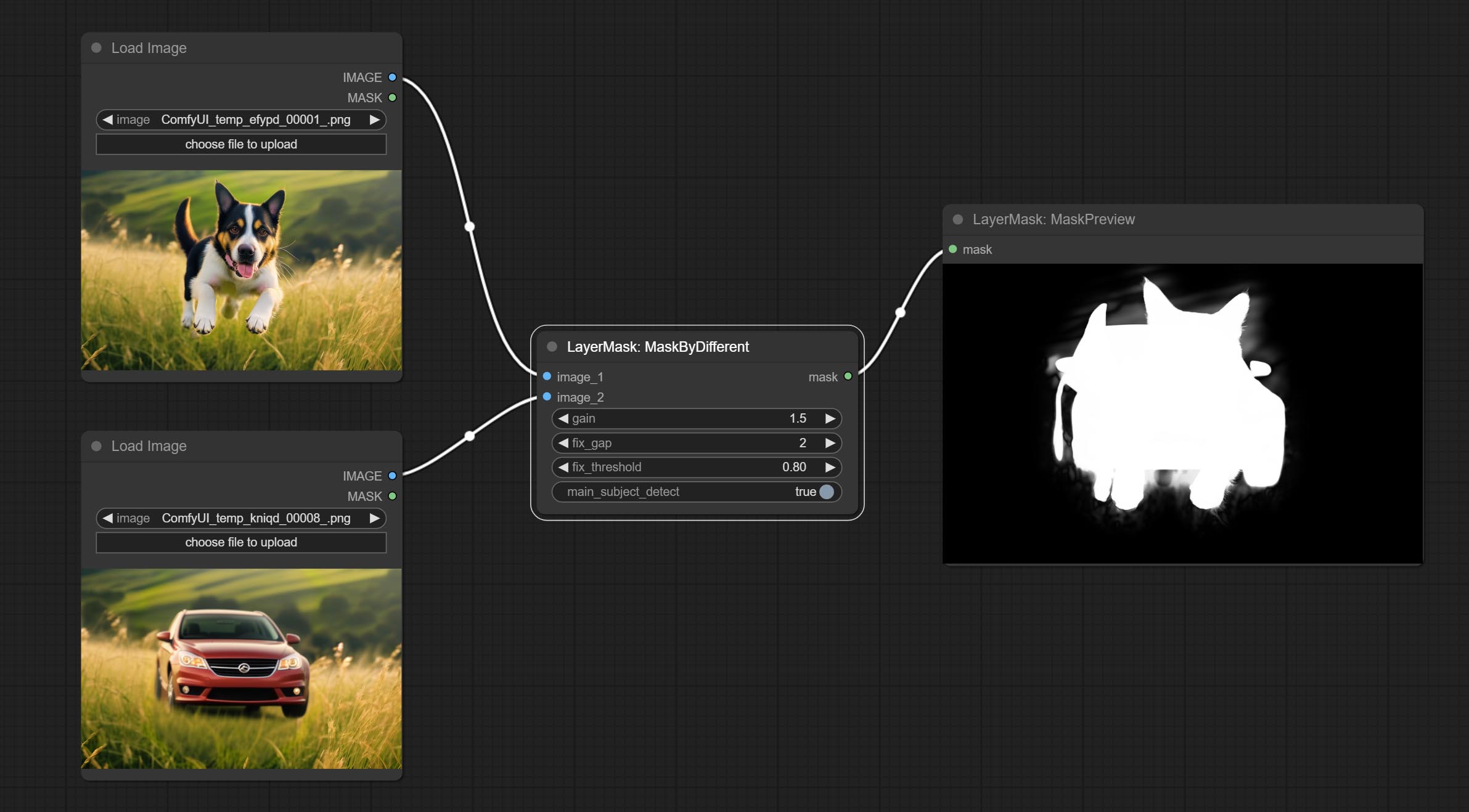
节点选项: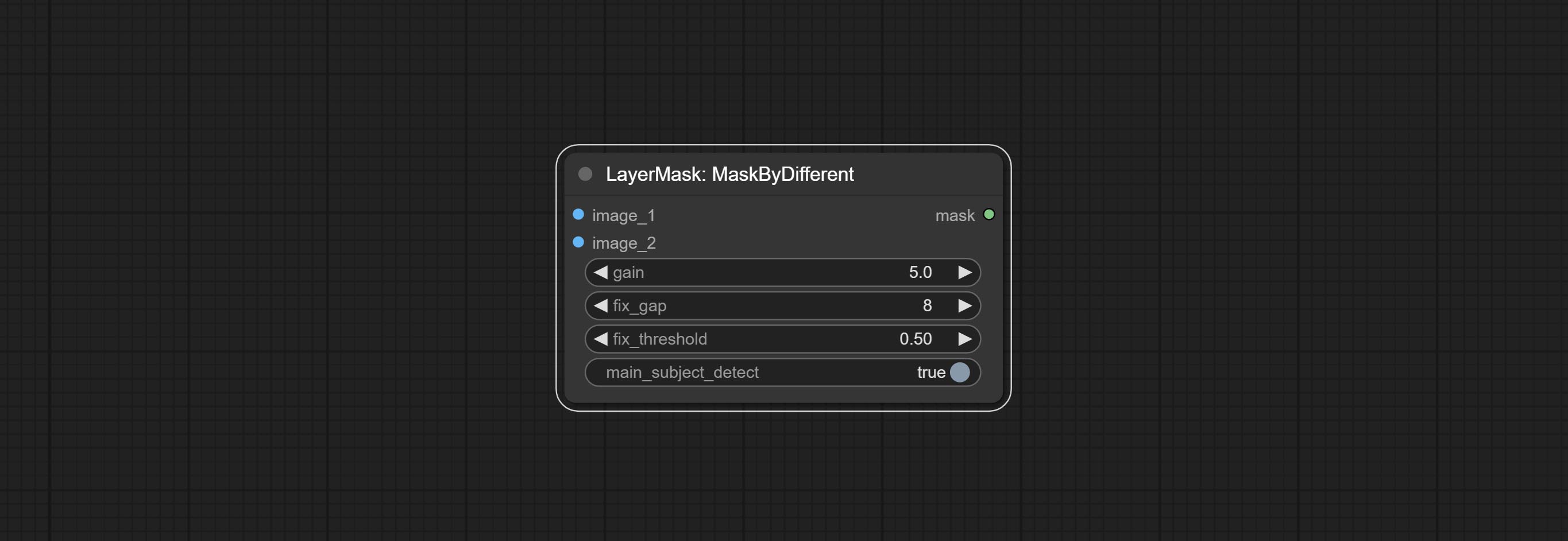
- gain:差异计算的增益。值越高,细微差异越明显。
- fix_gap:修复掩码内部的空隙。值越高,修复的空隙越大。
- fix_threshold:fix_gap 的阈值。
- main_subject_detect:设置为 True 时启用主体检测,忽略主体以外的差异。
注释说明 notes
1 layer_image、layer_mask 以及 background_image(如有输入),这三者必须具有相同的尺寸。
2 掩码并非必填项。默认情况下会使用图像的 Alpha 通道。如果输入图像不包含 Alpha 通道,则会自动创建整个图像的 Alpha 通道。若同时输入掩码,Alpha 通道将被掩码覆盖。
3 Blend 模式包括 正常、正片叠底、滤色、添加、减去、差值、变暗、颜色加深、颜色减淡、线性加深、线性减淡、叠加、柔光、强光、亮光、点光、线性光和硬混,共计 19 种混合模式。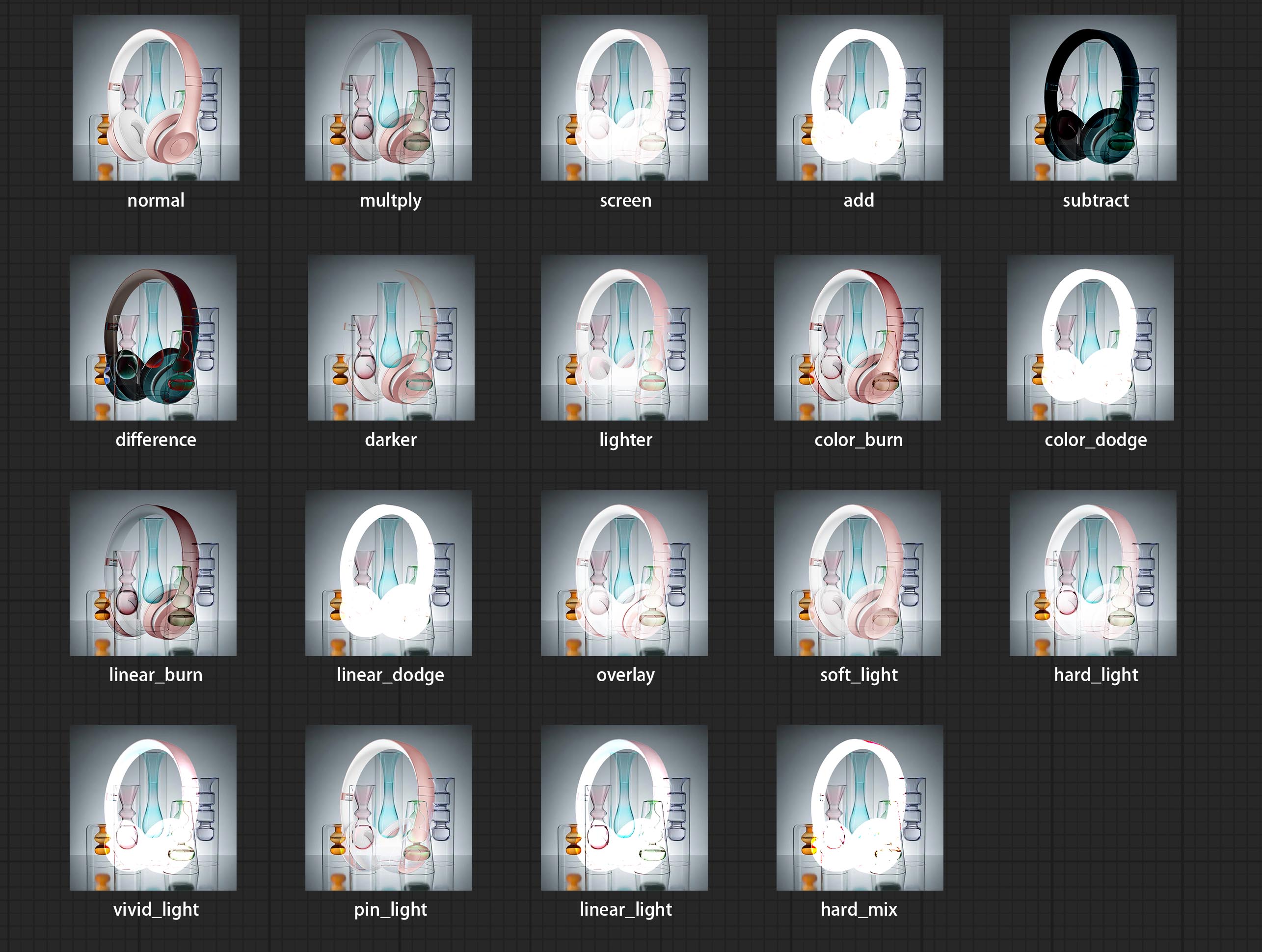
混合模式预览
3 BlendModeV2 包括 正常、溶解、变暗、正片叠底、颜色加深、线性加深、深色、变亮、滤色、颜色减淡、线性减淡(加法)、浅色、排除、叠加、柔光、强光、亮光、线性光、点光、硬混、差值、排除、减去、除法、色调、饱和度、颜色、明度、颗粒提取、颗粒合并,共计 30 种混合模式。
BlendMode V2 的部分代码来自 Virtuoso Nodes for ComfyUI,感谢原作者。
Blend Mode V2 预览
4 RGB 颜色采用十六进制 RGB 格式描述,例如 '#FA3D86'。
5 layer_image 和 layer_mask 必须具有相同的尺寸。
星标

声明
LayerStyle Advance 节点遵循 MIT 许可证,其中部分功能代码来源于其他开源项目。感谢原作者。如用于商业用途,请参考原项目许可证以达成授权协议。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。