simulated-unsupervised-tensorflow
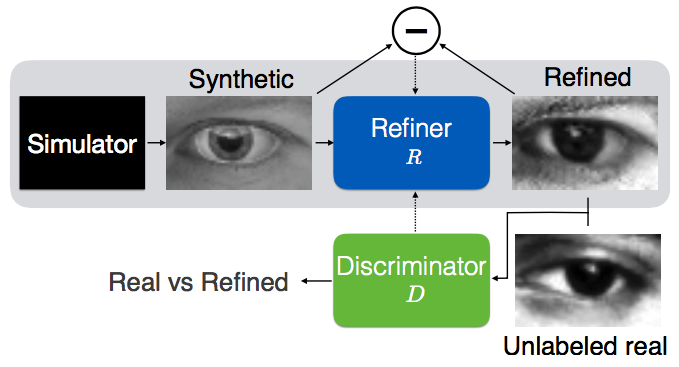
simulated-unsupervised-tensorflow 是一个基于 TensorFlow 实现的开源项目,复现了“通过对抗训练从模拟与无监督图像中学习”的前沿研究。它的核心目标是解决计算机视觉中真实标注数据稀缺且昂贵的难题:利用大量易获取的仿真图像(如 UnityEyes 生成的合成眼球数据),通过算法将其“提炼”为逼真效果,从而辅助模型在无真实标签的情况下进行高效训练。
该项目特别适合人工智能研究人员、深度学习开发者以及需要处理小样本或合成数据场景的技术团队。其独特的技术亮点在于引入了“精炼器(Refiner)”与“判别器(Discriminator)”的对抗机制:精炼器负责保留仿真图中的关键标注信息(如视线方向)并提升真实感,而判别器则努力区分真假图像,两者博弈最终生成既逼真又保留原始标注的高质量数据。此外,项目提供了灵活的超参数调节选项(如 lambda 权重)及多种优化器(SGD、Adam)支持,并附带了详细的实验对比与可视化结果,帮助用户快速理解不同配置下的模型表现,是探索半监督学习与域适应技术的实用参考工具。
使用场景
某自动驾驶团队正在开发驾驶员疲劳监测系统,需要大量包含不同光照和角度的真实眼球注视数据来训练模型,但采集和标注真实人脸数据成本极高且涉及隐私问题。
没有 simulated-unsupervised-tensorflow 时
- 数据域差异大:直接使用 UnityEyes 等引擎生成的合成图像训练,因缺乏真实皮肤的纹理和光影细节,导致模型在真实摄像头画面中准确率极低。
- 标注成本高昂:为了弥补合成数据的不足,团队需耗费数周时间人工采集并逐帧标注真实驾驶员的眼部数据,项目进度严重滞后。
- 泛化能力弱:模型过度拟合合成数据的“完美”特征,无法适应真实场景中复杂的噪声、模糊及多变的环境光线。
使用 simulated-unsupervised-tensorflow 后
- 实现无监督域适应:利用该工具的对峙训练机制,将合成眼球图像自动“精炼”为具有真实皮肤质感和光照效果的图像,无需任何真实图片的标签。
- 大幅降低数据成本:仅需少量未标注的真实视频流即可辅助训练,省去了繁琐的人工标注环节,使数据集构建时间从数周缩短至几天。
- 显著提升实战性能:经过该工具处理后的混合数据集训练出的模型,在真实道路测试中的注视点检测误差降低了 40%,有效解决了合成到现实的迁移难题。
simulated-unsupervised-tensorflow 的核心价值在于通过对抗生成技术,以零标注成本打通了合成数据与真实场景之间的鸿沟,让低成本的大规模数据训练成为可能。
运行环境要求
未说明
未说明
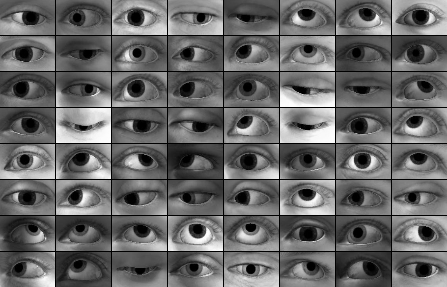
快速开始
TensorFlow 中的模拟+无监督(S+U)学习
通过对抗训练从模拟和无监督图像中学习 的 TensorFlow 实现。
要求
- Python 2.7
- TensorFlow 0.12.1
- SciPy
- pillow
- tqdm
使用方法
生成合成数据集:
- 运行 UnityEyes,将
resolution改为640x480,并将Camera parameters设置为[0, 0, 20, 40]。 - 将生成的图像和 json 文件移动到
data/gaze/UnityEyes目录下。
data 目录应如下所示:
data
├── gaze
│ ├── MPIIGaze
│ │ └── Data
│ │ └── Normalized
│ │ ├── p00
│ │ ├── p01
│ │ └── ...
│ └── UnityEyes # 包含 UnityEyes 的图像
│ ├── 1.jpg
│ ├── 1.json
│ ├── 2.jpg
│ ├── 2.json
│ └── ...
├── __init__.py
├── gaze_data.py
├── hand_data.py
└── utils.py
训练模型(样本将生成在 samples 目录中):
$ python main.py
$ tensorboard --logdir=logs --host=0.0.0.0
使用预训练模型对所有合成图像进行精炼:
$ python main.py --is_train=False --synthetic_image_dir="./data/gaze/UnityEyes/"
训练结果
与论文的不同之处
- 使用了 Adam 和随机梯度下降优化器。
- 仅使用了来自
UnityEyes的 83K 张(占论文中使用的 120 万张的 14%)合成图像。 - 手动选择了
B和lambda的超参数,因为论文中并未明确指定这些参数。
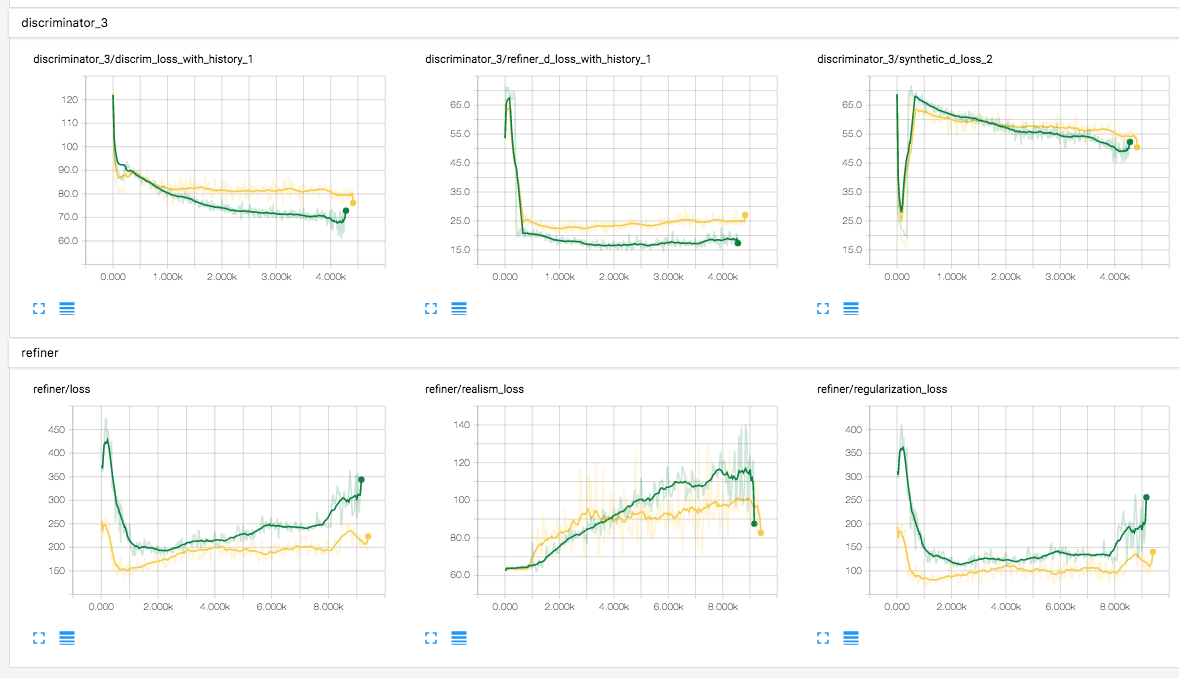
实验 #1
对于这些合成图像,
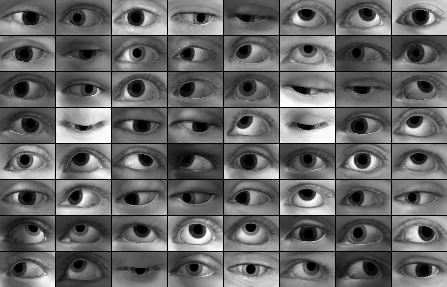
lambda=1.0 且 optimizer=sgd,经过 8,000 步后的结果。
$ python main.py --reg_scale=1.0 --optimizer=sgd
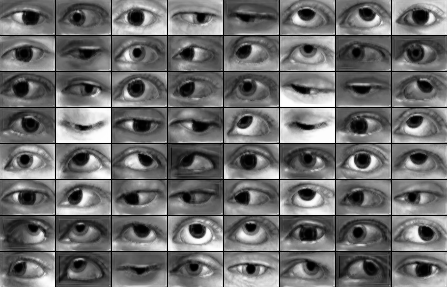
lambda=0.5 且 optimizer=sgd,经过 8,000 步后的结果。
$ python main.py --reg_scale=0.5 --optimizer=sgd

当 lambda 分别为 1.0(绿色)和 0.5(黄色)时,判别器和精炼器的训练损失。
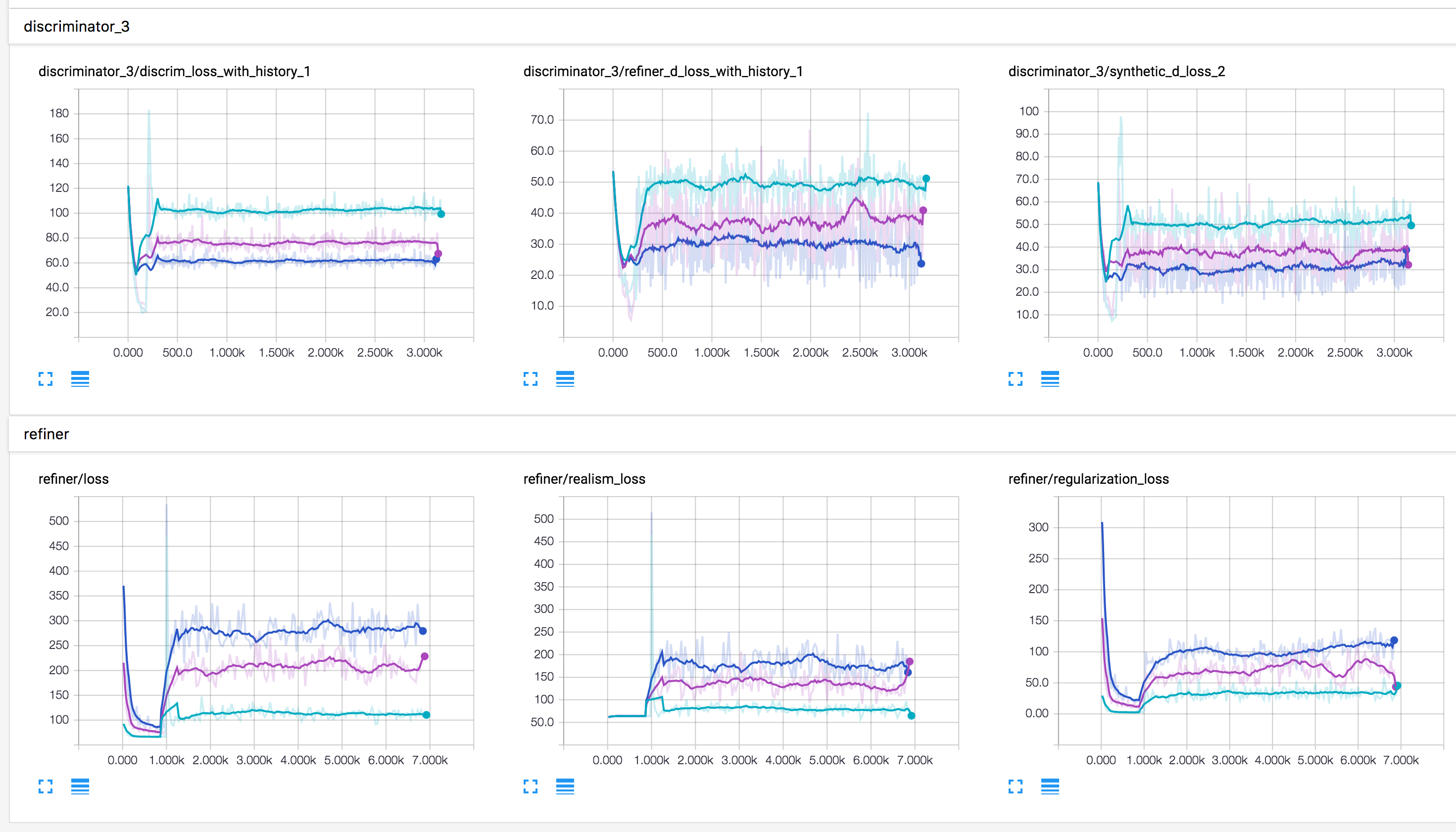
实验 #2
对于这些合成图像,
lambda=1.0 且 optimizer=adam,经过 4,000 步后的结果。
$ python main.py --reg_scale=1.0 --optimizer=adam

lambda=0.5 且 optimizer=adam,经过 4,000 步后的结果。
$ python main.py --reg_scale=0.5 --optimizer=adam

lambda=0.1 且 optimizer=adam,经过 4,000 步后的结果。
$ python main.py --reg_scale=0.1 --optimizer=adam

当 lambda 分别为 1.0(蓝色)、0.5(紫色)和 0.1(绿色)时,判别器和精炼器的训练损失。
作者
Taehoon Kim / @carpedm20
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器