BIRD-CRITIC-1
BIRD-CRITIC-1 是一个专为评估和提升大语言模型(LLM)在真实数据库环境中解决用户 SQL 问题能力而设计的开源基准测试工具。它直面当前 AI 在处理复杂、模糊的真实世界数据库故障时表现不足的痛点,不再局限于简单的文本转 SQL 任务,而是聚焦于诊断错误、调试查询以及优化现有代码全流程。
该工具构建了包含 600 个开发任务和 200 个隐藏测试题的高质量数据集,覆盖 MySQL、PostgreSQL、SQL Server 和 Oracle 四大主流数据库方言。其独特亮点在于引入了“人类专家协作”视角的评估标准,不仅提供标准的测试用例,还发布了自动回复系统以支持完整数据集的获取,并记录了人类专家在使用与不使用 AI 辅助下的性能对比数据,为研究人机协作模式提供了宝贵参考。此外,项目还衍生出了针对 SQLite 的专项数据集及支持多轮对话的交互版本。
BIRD-CRITIC-1 非常适合数据库研究人员、AI 算法工程师以及致力于提升代码智能体能力的开发者使用。通过这一基准,研究人员可以量化模型在真实场景下的鲁棒性,开发者则能利用其丰富的测试案例来训练和验证更强大的 SQL 辅助工具,共同推动人工智能在数据工程领域的落地应用。
使用场景
某电商公司的数据分析师正急需修复一个在 PostgreSQL 生产环境中运行缓慢且结果错误的复杂库存查询脚本,该脚本涉及多表连接和动态聚合逻辑。
没有 BIRD-CRITIC-1 时
- 面对模糊的报错信息,分析师需花费数小时手动翻阅官方文档和教科书,逐一排查是语法错误还是逻辑漏洞。
- 通用大模型生成的 SQL 代码往往忽略真实数据库的架构约束,导致“看似正确”但执行失败的幻觉代码。
- 缺乏针对特定方言(如 PostgreSQL)的深度调试能力,难以定位因版本差异导致的函数兼容性问题。
- 验证修复结果依赖人工构造测试数据,效率低下且容易遗漏边缘情况,无法确保修复后的绝对准确性。
使用 BIRD-CRITIC-1 后
- BIRD-CRITIC-1 直接基于真实用户问题数据集,快速诊断出脚本中特定的连接逻辑错误并提供可执行的修正方案。
- 依托其专为 PostgreSQL 等四大主流方言训练的调试能力,生成的代码完美适配当前数据库版本,消除兼容性幻觉。
- 内置的自动化测试用例系统立即验证修复效果,确保查询结果与预期完全一致,无需人工反复试错。
- 将原本需要数小时的排查过程压缩至分钟级,让分析师能专注于业务逻辑优化而非底层语法纠错。
BIRD-CRITIC-1 通过模拟专家级的人机协作模式,将现实世界中复杂的 SQL 故障排查从“盲目试错”转变为“精准治愈”。
运行环境要求
- Linux
- macOS
- Windows
未说明 (主要依赖 API 调用或本地数据库执行,无明确 GPU 训练/推理需求)
未说明 (建议具备运行 Docker 容器及多数据库实例的内存)
快速开始
BIRD-CRITIC 1.0 (SQL) 


新闻
- 📢 [2026-03-24] 我们发布了BIRD-Critic GT & Test Cases Auto-Reply System,支持通过邮件请求自动发送完整数据集(包括sol_sql和test_cases),邮箱地址为📧 bird.bench25@gmail.com,主题标签为[bird-critic-1 GT&Test Cases]。
- 📢 [2026-03-23] 我们发布了BIRD-Critic-SQLite,该数据集包含500个高质量的用户问题,专注于真实的SQLite数据库应用。
- 📢 [2026-01-08] 我们最近更新了评估代码(特别是
remove_distinct函数)。请从我们的GitHub仓库拉取最新代码。 - 📢 [2025-07-09] 我们在网站上公布了人类表现分数!三个排行榜上显示的分数均来自数据库专家的人工评估,他们可以使用标准工具(如数据库教材、官方文档或IDE),但不能使用AI助手。当允许另一组具有相同专业知识的人员使用AI工具(ChatGPT、Claude或Gemini)时,性能提升至Open版的83.33、PG版的87.90以及Flash版的90.00,这表明人机协作在SQL问题解决中具有巨大潜力。
- 📢 [2025-06-28] 我们在arXiv上发布了论文SWE-SQL(又名BIRD-CRITIC)。
- 📢 [2025-06-09] 我们发布了bird-interact-lite,该版本具备多轮对话和代理式交互功能,适用于现实世界中模糊且具有挑战性的文本转SQL任务。
- 📢 [2025-06-08] 我们发布了bird-critic-1.0-postgresql,这是一个包含530个复杂任务的单一方言SQL问题调试数据集。
- 📢 [2025-05-30] 我们很高兴发布LiveSQLBench-Base-Lite,其中包含18个终端用户级别的数据库和270个任务(180个仅SELECT任务,90个管理任务)。每个任务都涉及基于外部知识的明确且简单的用户查询,SQL语句难度介于中等至困难之间。
🧸 概述
BIRD-Critic 1.0推出了一种全新的SQL基准测试,旨在评估一项关键能力:大型语言模型(LLMs)是否能够在真实世界的数据库环境中诊断并解决用户问题?
该基准测试包含600个开发用任务和200个保留的分布外(OOD)测试任务。BIRD-CRITIC 1.0基于四种主流开源SQL方言中的真实用户问题构建:MySQL、PostgreSQL、SQL Server和Oracle。它不仅限于简单的SELECT查询,还涵盖了更广泛的SQL操作,以反映实际的应用场景。此外,还配备了一个优化的基于执行的评估环境,用于进行严格而高效的验证。
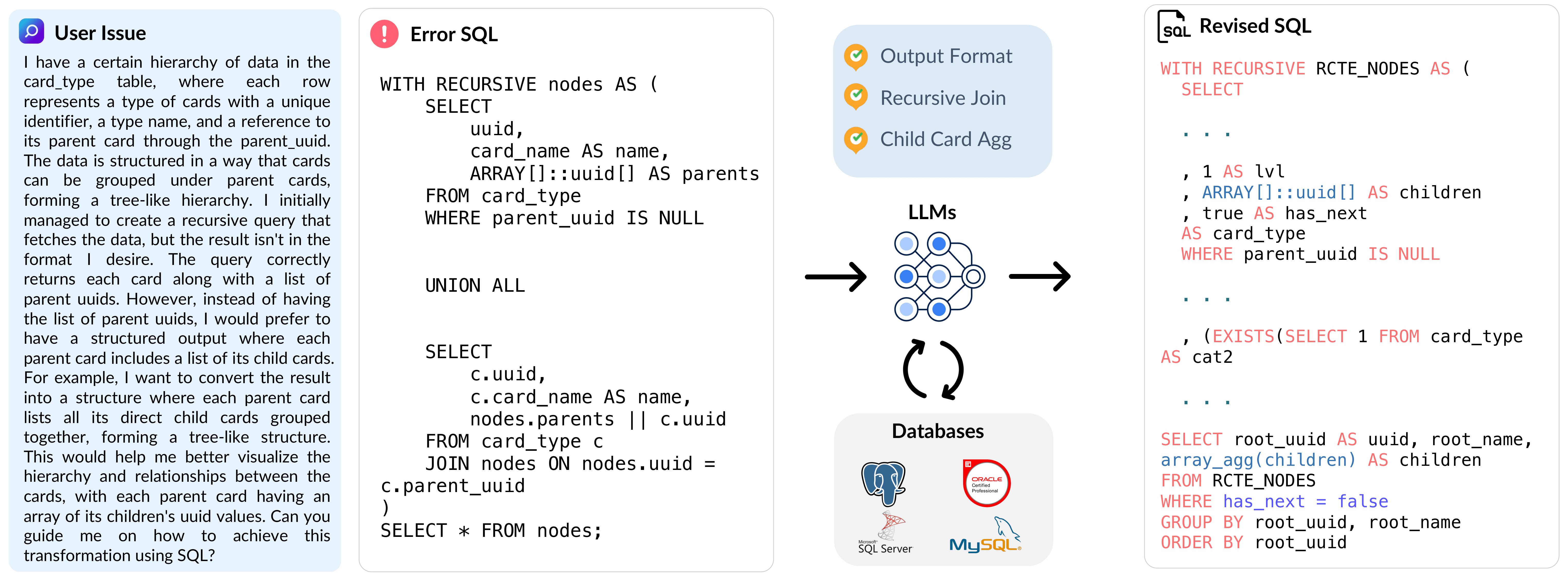
✅ 验证流程
BIRD-CRITIC中的每项任务都经过人工专家在以下几个方面的验证:
- 在BIRD环境中重现错误,以防止数据泄露。
- 为每项任务精心设计测试用例:
- Soft EX:此指标可用于评估仅包含SELECT语句的任务。
- Soft EX + 解析:此指标可用于评估具有特定用户需求或细化要求的任务。
- 测试用例:对于DBA任务,例如CRUD(创建、读取、更新、删除),测试用例旨在评估逻辑的正确性。这对于需要多个连续SQL查询才能解决的用户问题也非常有效。
- 查询执行计划:对于涉及效率提升或运行时错误的用户任务,可以通过QEP(查询执行计划)在算法层面评估解决方案SQL查询。
- 通过PostgreSQL模板和Docker快速搭建评估沙盒。
- 创建不同规模和专业领域的全新RDB。
🐣 精简版
我们发布了BIRD-Critic的精简版bird-critic-1.0-flash-exp,其中包括200个高质量的PostgreSQL用户问题,用于开发真实世界的应用程序。我们通过以下方式精选任务:
- 收集并理解真实的用户问题。
- 提炼问题定义和SQL知识。
- 在BIRD环境中重现错误和解决方案。
- 设计测试用例进行评估。
🦜 开放版
BIRD-CRITIC 1.0的开放版bird-critic-1.0-open是一个综合性的基准测试,包含570个任务,覆盖MySQL、PostgreSQL、SQL Server和Oracle四种SQL方言。它涵盖了广泛的SQL操作和用户问题。
BIRD-CRITIC 1.0 Open版模型性能结果
| 排名 | 模型名称 | 分数 | 等级 |
|---|---|---|---|
| 1 | o3-mini-2025-01-31 | 34.50 | 🏆 领先 |
| 2 | deepseek-reasoner (r1) | 33.67 | 🌟 精英 |
| 3 | o1-preview-2024-09-12 | 33.33 | 🌟 精英 |
| 4 | claude-3-7-sonnet-20250219(thinking) | 30.67 | 🌟 精英 |
| 5 | gemini-2.0-flash-thinking-exp-01-21 | 30.17 | 🌟 精英 |
| 6 | grok-3-beta | 29.83 | 💎 卓越 |
🕊️ PostgreSQL版
bird-critic-1.0-pg是一个包含530个高质量用户问题的数据集,专注于真实的PostgreSQL数据库应用。
代理在 BIRD-CRITIC 1.0 PG 上的性能结果
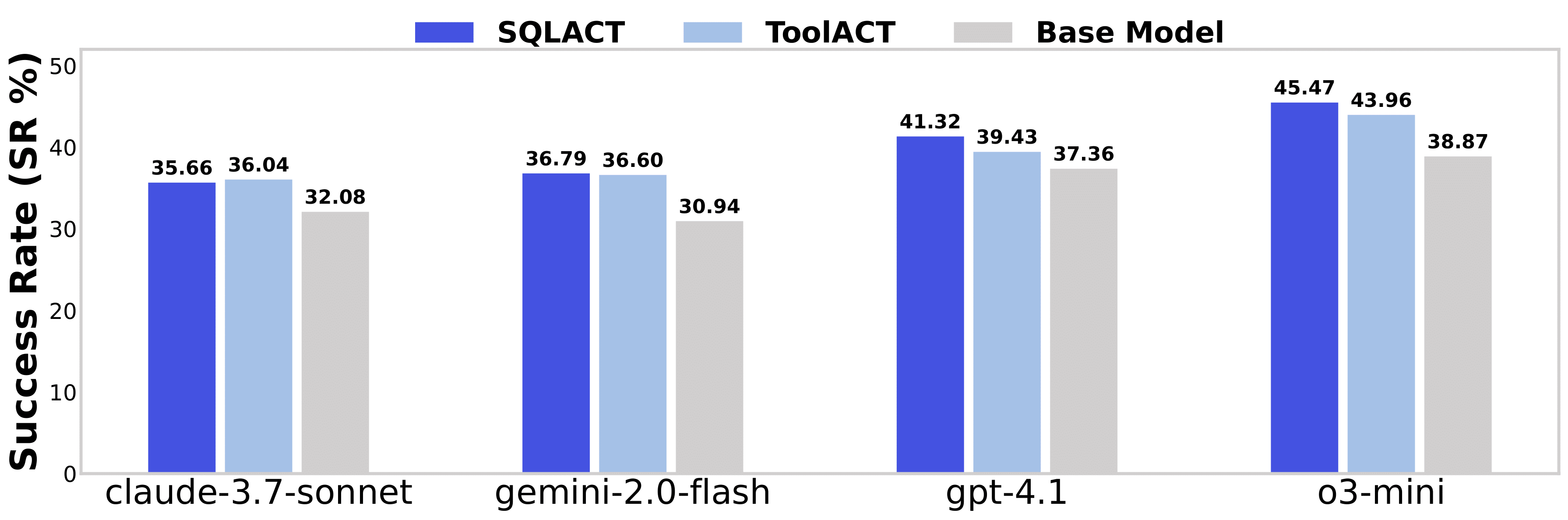
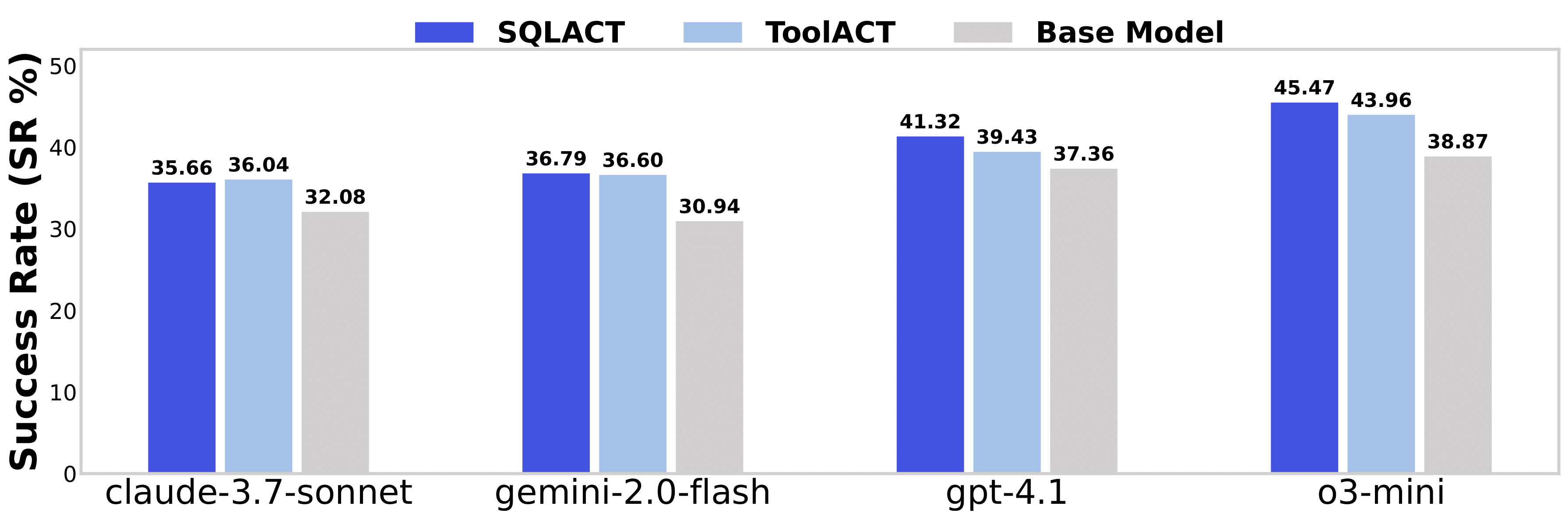
关键发现:
- 代理式工作流通过迭代的环境交互,显著提升了大语言模型在调试任务中的表现。
- SQLACT 在所有模型上均优于 ToolACT,这表明在处理复杂调试场景时,SQL 更丰富的动作空间具有明显优势。
🦅 BIRD-CRITIC 1.0 的完整数据集
BIRD-CRITIC 1.0 基准测试提供了以下几种配置:
bird-critic-1.0-flash-exp:精简版,包含 PostgreSQL 上的 200 个实例。bird-critic-1.0-open:完整版,涵盖 MySQL、PostgreSQL、SQL Server 和 Oracle,共 570 个实例。bird-critic-1.0-postgresql:专为 PostgreSQL 设计的版本,包含 530 个实例。bird-critic-1.0-bigquery:精简版,包含 BigQuery 上的 100 至 200 个实例。
📦 数据集详情
数据集描述
- 数据库: 完整数据库可从 Google Drive 下载。更多详情请参阅 快速评估 部分。
- 数据: 每个数据实例包含以下主要部分:
db_id:数据库名称。query:用户查询在 BIRD 环境中重写的版本。issue_sql:用户编写的有缺陷的 SQL 查询。sol_sql:正确答案的 SQL 解决方案。preprocess_sql:在执行解决方案或预测之前需要运行的 SQL 查询。clean_up_sql:在测试用例之后运行的 SQL 查询,用于撤销对数据库所做的任何更改。test_cases:一组用于验证预测修正后的 SQL 的测试用例。efficiency:如果该问题需要优化,则为真;通过查询执行计划 (QEP) 来衡量成本。external_data:如果有外部 JSON 数据,则包含在此字段中。
- 基线: 基线代码位于
./baseline目录中。 - 评估: 评估代码位于
./evaluation目录中。 - 策划者: BIRD 团队 & Google Cloud
- 许可证: cc-by-sa-4.0
- HuggingFace 数据集卡片: bird-critic-1.0-flash-exp
数据集用途
为避免因自动爬取导致的数据泄露,某些字段(如 sol_sql 和 test_cases)未包含在公开数据集中。如需完整数据集,请发送邮件至:📧 bird.bench25@gmail.com,主题标注为 [bird-critic-1 GT&Test Cases],我们将在 30 分钟内自动发送给您。
从 HuggingFace 使用数据集
您可以通过以下命令从 HuggingFace 下载数据集:
from datasets import load_dataset
# 加载闪存版数据集
dataset = load_dataset("birdsql/bird-critic-1.0-flash-exp")
print(dataset["flash"][0])
# 加载开放版数据集
dataset = load_dataset("birdsql/bird-critic-1.0-open")
print(dataset["open"][0])
或者您可以使用提供的脚本下载开放版数据集,并将其拆分为不同的方言版本。
cd baseline/data
python pull_data.py \
--schema_path path/to/open_schema.jsonl \
--input_path path/to/input.jsonl \ # 输入 JSONL 文件的路径(如果您想从 HuggingFace 下载数据集,此路径可以为空)
--output_folder path/to/output_dir # 拆分文件的输出文件夹
💨 快速评估
文件夹结构
.
├── LICENSE
├── README.md
├── baseline
│ ├── data
│ ├── outputs
│ ├── run
│ └── src
├── evaluation
│ ├── docker-compose.yml
│ ├── env
│ ├── mssql_table_dumps
│ ├── mysql_table_dumps
│ ├── oracle_table_dumps
│ ├── postgre_table_dumps
│ ├── run
│ └── src
├── materials
│ ├── ...
└── requirements.txt
环境设置
要运行基线代码,您需要安装以下依赖项:
conda create -n bird_critic python=3.10 -y
conda activate bird_critic
pip install -r requirements.txt
生成
您还需要在 config.py 文件中设置模型名称(例如 gpt-4o-2024-08-06)以及 API 密钥。然后您可以运行以下命令来生成输出:
# 生成提示
cd baseline/run
bash generate_prompt.sh
# LLM 推理,需在 config.py 中设置 API 密钥
bash run_baseline.sh
生成的输出将保存在 ./baseline/outputs/final_output/ 目录中。
评估
我们使用 Docker 提供一个一致的环境来运行基准测试。设置环境的步骤如下:
- 首先从 Google Drive 下载 PostgreSQL、MySQL、SQL Server 和 Oracle 数据库。
- 解压文件夹,并将其保存在
./evaluation目录下,分别命名为 postgre_table_dumps、mssql_table_dumps、mysql_table_dumps 和 oracle_table_dumps。 - 构建 Docker Compose:
cd evaluation
docker compose up --build
- 与数据库交互
您可以使用
evaluation/src/{dialect}_utils.py文件中的perform_query_on_{dialect}_databases()函数与各个数据库进行交互。该函数将返回查询结果。 - 在 so_eval_env 容器内运行评估脚本:
docker compose exec so_eval_env bash
cd run
bash run_eval.sh
您必须在 run_eval.sh 脚本中指定要评估的方言。选项包括:
postgresqlmysqlsqlserveroracle评估报告文件将保存在与输入文件相同的文件夹中。如果您希望为每个实例生成日志文件,可以在run_eval.sh脚本中将--logging设置为true。
📄 论文
如果您觉得我们的工作有所帮助,请引用如下:
@article{li2025swe,
title={SWE-SQL: Illuminating LLM Pathways to Solve User SQL Issues in Real-World Applications},
author={Li, Jinyang and Li, Xiaolong and Qu, Ge and Jacobsson, Per and Qin, Bowen and Hui, Binyuan and Si, Shuzheng and Huo, Nan and Xu, Xiaohan and Zhang, Yue and others},
journal={arXiv preprint arXiv:2506.18951},
year={2025}
}
📋 待办事项清单
- 发布精简版,bird-critic-1.0-flash (200)。
- 开源代码和排行榜页面。
- 发布完整版 bird-critic-1.0-open (570 个实例,涵盖 4 种方言)。
- 发布完整版 bird-critic-1.0-postgresql (530 个 PostgreSQL 任务)。
- 发布 SIX-GYM (Sql-fIX),包含 2000 多个类似健身房的训练环境。
- 发布经过训练的代理式基线 BIRD-Fixer。
- 更新代理式 (SQL-Act) 基线。
创作团队:
BIRD 团队 & Google Cloud
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。