hamilton
Apache Hamilton 是一款轻量级的 Python 库,旨在帮助开发者构建可测试、模块化且自带文档的数据转换流程。它通过有向无环图(DAG)来组织数据逻辑,让复杂的数据流向清晰可见。
在传统数据工程中,管道代码往往耦合严重、难以追踪数据来源且缺乏自文档化能力。Hamilton 巧妙地解决了这些痛点:用户只需编写普通的 Python 函数,并通过函数参数自然声明依赖关系,Hamilton 即可自动解析并构建出完整的数据流程图。这种方式不仅让代码像脚本一样易读,还天然记录了数据血缘和元数据,极大提升了调试与维护效率。
这款工具特别适合数据科学家、数据工程师以及需要处理 ETL 流水线、机器学习工作流、大语言模型(LLM)应用或生物信息学分析的开发者。无论是本地脚本、Jupyter 笔记本,还是 Airflow、FastAPI 等生产环境,只要支持 Python,Hamilton 就能无缝运行。
其独特的技术亮点在于“代码即定义”的理念——无需学习复杂的配置语法,利用标准的 Python 函数签名即可实现强大的流程编排、数据验证及实验追踪功能。同时,它还提供了可视化界面,让抽象的数据流转过程一目了然,是提升数据项目结构化水平的得力助手。
使用场景
某电商数据团队正在构建一个每日用户行为分析管道,需要从原始日志中清洗数据、计算转化漏斗并生成 BI 报表。
没有 hamilton 时
- 依赖管理混乱:工程师需手动维护复杂的函数调用顺序,一旦修改中间逻辑,极易引发“牵一发而动全身”的隐性报错。
- 血缘追踪缺失:当最终报表数据异常时,难以快速定位是上游哪个清洗步骤或特征计算出了问题,排查耗时极长。
- 文档与代码脱节:数据转换逻辑散落在巨大的脚本文件中,缺乏自动生成的文档,新成员接手需要花费数周理解业务逻辑。
- 测试困难:由于函数间耦合紧密且状态共享,无法针对单个指标逻辑编写独立的单元测试,导致回归测试成本高昂。
使用 hamilton 后
- 声明式依赖自动解析:只需定义普通 Python 函数并通过参数名声明依赖,hamilton 自动构建有向无环图(DAG),彻底消除手动排序的执行风险。
- 全链路血缘可视化:系统自动记录每个数据列的来源与去向,出现数据异常时可秒级定位到具体的故障节点和输入源。
- 代码即文档:函数名和参数直接构成自解释的数据流图,hamilton 能自动生成实时更新的逻辑文档,大幅降低沟通与上手门槛。
- 模块化轻松测试:每个数据转换步骤被解耦为独立函数,数据科学家可直接对特定指标逻辑进行单元测试,确保迭代安全。
hamilton 将原本脆弱黑盒的数据脚本,转变为可测试、自文档化且具备清晰血缘的模块化资产,显著提升了数据管道的开发效率与维护信心。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明
快速开始
 Apache Hamilton — 可移植且表达力强的
Apache Hamilton — 可移植且表达力强的
数据转换有向无环图



免责声明
Apache Hamilton 是 Apache 软件基金会(ASF)孵化中的一个项目,由 Apache 孵化器 PMC 赞助。
所有新接受的项目都必须经过孵化期,直到进一步评估表明其基础设施、沟通机制和决策流程已稳定下来,达到与其他成功 ASF 项目一致的标准。
虽然孵化状态并不一定反映代码的完整性和稳定性,但它确实意味着该项目尚未得到 ASF 的完全认可。
Apache Hamilton(孵化中)是一个轻量级的 Python 库,用于构建数据转换的有向无环图(DAG)。您的 DAG 具有可移植性,无论是在脚本、笔记本、Airflow 流水线、FastAPI 服务器等任何可以运行 Python 的环境中,它都能正常运行。同时,Apache Hamilton 的 DAG 具有表达力,提供了丰富的功能来定义和修改 DAG 的执行过程(例如,数据验证、实验跟踪、远程执行等)。
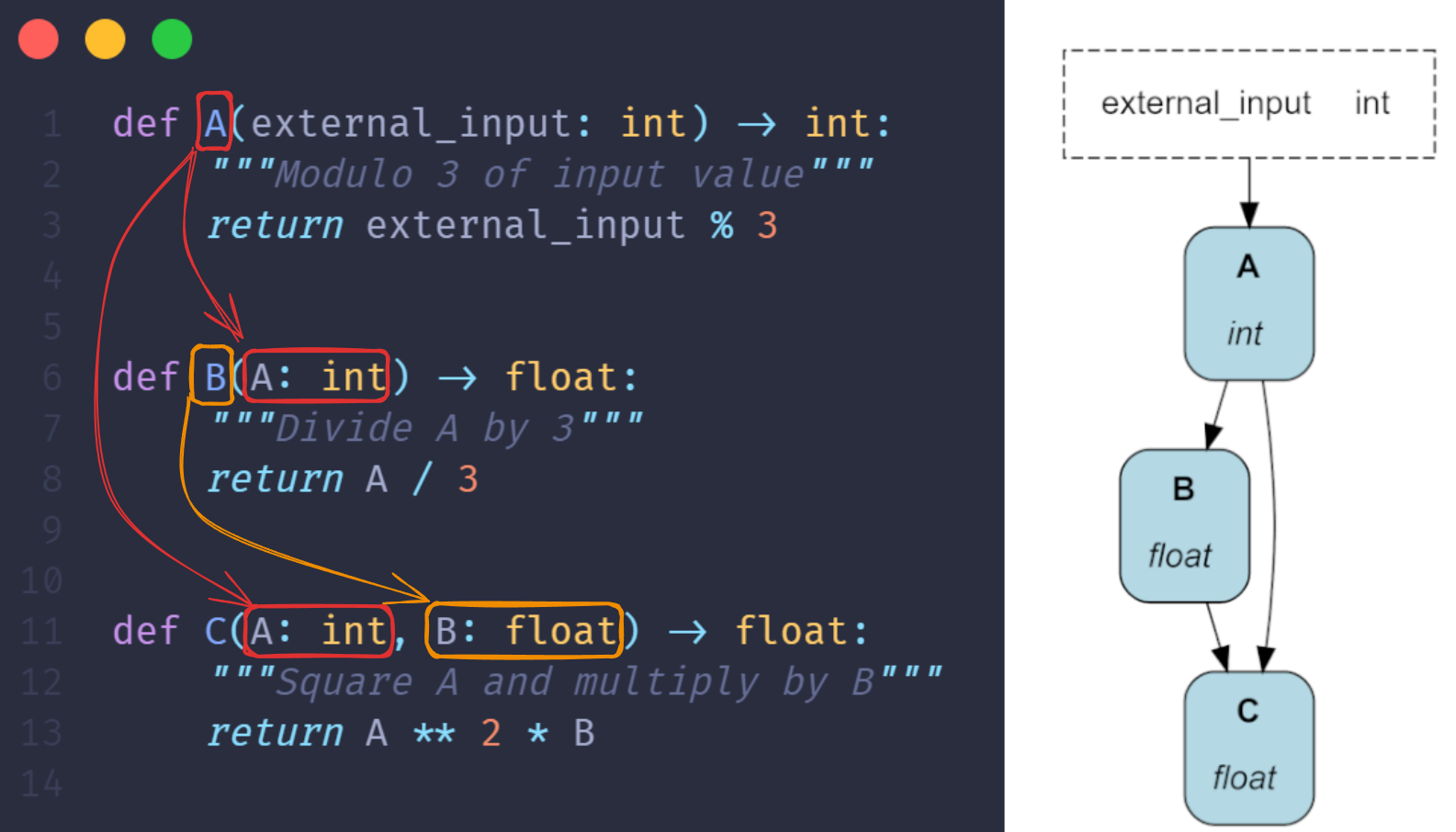
要创建一个 DAG,只需编写普通的 Python 函数,并通过函数参数指定它们之间的依赖关系。如下所示,这样生成的代码既易于阅读,又始终可以可视化。Apache Hamilton 会加载这些定义并自动为您构建 DAG!
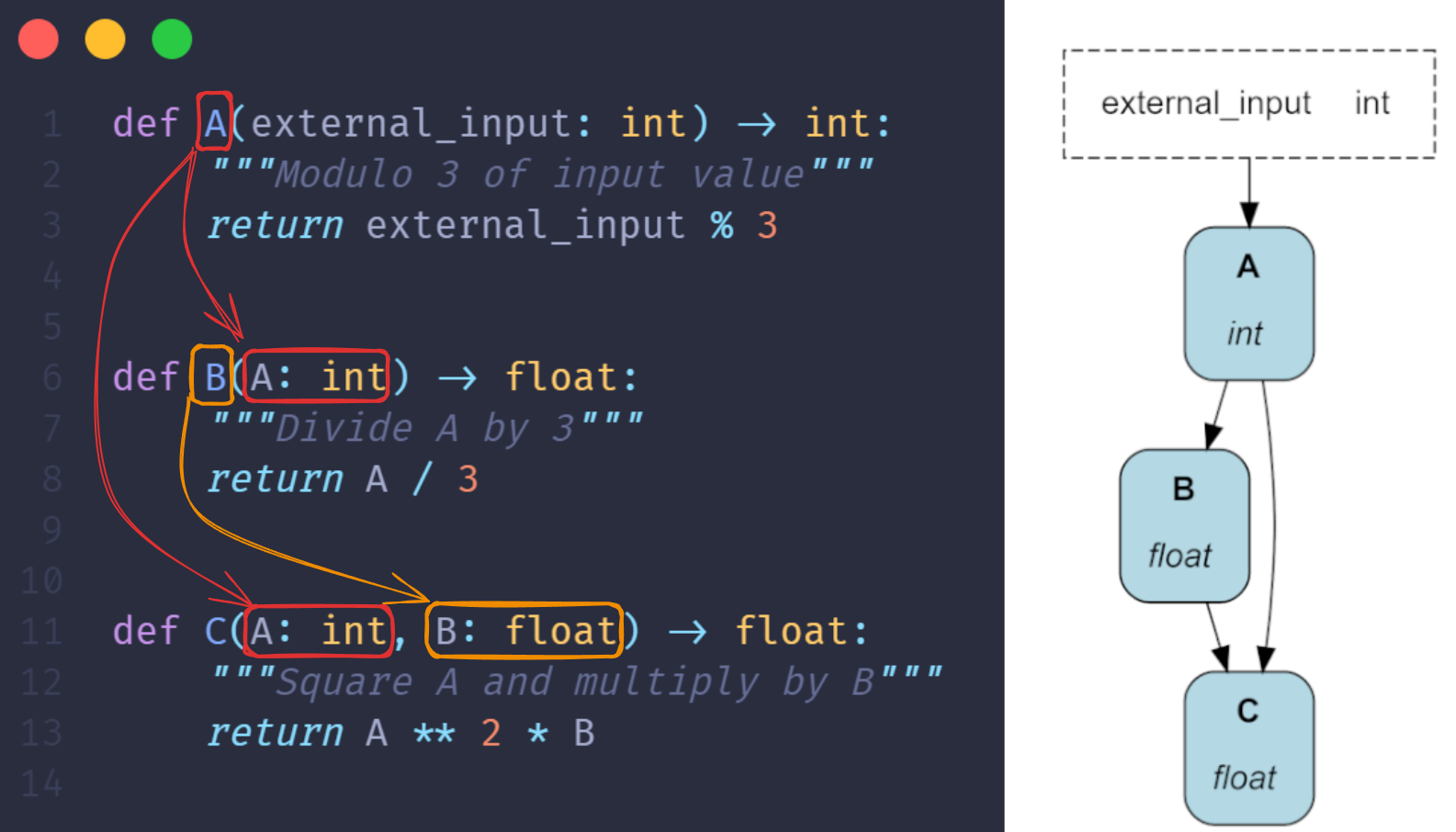
B() 和 C() 通过其参数引用函数 A
Apache Hamilton 为任何涉及数据流动的 Python 应用程序带来了模块化和结构化:ETL 流水线、机器学习工作流、大型语言模型应用、RAG 系统、BI 仪表盘等。而 Apache Hamilton UI 则允许您自动可视化、编目并监控 DAG 的执行情况。
Apache Hamilton 非常适合处理 DAG,但如果您需要循环或条件逻辑来构建大型语言模型代理或进行模拟,不妨看看我们的姊妹库 Burr 🤖 .
安装
Apache Hamilton 支持 Python 3.8 及以上版本。我们包含了可选的 visualization 依赖项,用于显示 Apache Hamilton DAG。对于可视化功能,您需要在系统上单独安装 Graphviz。
pip install "sf-hamilton[visualization]"
若要使用 Apache Hamilton UI,还需安装 ui 和 sdk 依赖项。
pip install "sf-hamilton[ui,sdk]"
如需在浏览器中试用 Apache Hamilton,请访问 www.tryhamilton.dev
为什么使用 Apache Hamilton?
数据团队编写代码以实现业务价值,但很少有资源来标准化实践并提供质量保证。无论团队规模大小,从概念验证过渡到生产环境以及跨职能协作(例如数据科学、工程和运维)仍然是挑战。Apache Hamilton 旨在在整个项目生命周期中提供帮助:
关注点分离。Apache Hamilton 将 DAG 的“定义”与“执行”分离,使数据科学家能够专注于解决问题,而工程师则负责管理生产管道。
高效协作。Apache Hamilton UI 提供一个共享界面,供团队在整个开发周期内检查结果并调试故障。
低摩擦的开发到生产。使用
@config.when()在不同执行环境中修改 DAG,而不是依赖容易出错的if/else功能标志。Notebook 扩展可以避免将代码从 Notebook 迁移到 Python 模块时的麻烦。可移植的转换。您的 DAG 独立于基础设施或编排系统,这意味着您可以在本地开发和调试,并在不同上下文中重用代码(本地、Airflow、FastAPI 等)。
可维护的 DAG 定义。Apache Hamilton 可以从一行代码自动构建 DAG,无论其包含 10 个节点还是 1000 个节点。它还可以将多个 Python 模块组装成一个管道,从而鼓励模块化设计。
表达性强的 DAG。函数修饰器是一项独特功能,可帮助您保持代码的 DRY 原则,并降低维护大型 DAG 的复杂性。其他框架往往会导致代码冗余或函数臃肿。
内置编码风格。Apache Hamilton DAG 是通过 Python 函数定义的,这有助于编写模块化、易读、自文档化且易于单元测试的代码。
数据和模式验证。使用
@check_output装饰函数以验证输出属性,并触发警告或异常。添加SchemaValidator()适配器,即可自动检查类似 DataFrame 的对象(pandas、polars、Ibis 等),从而跟踪和验证其模式。为插件而生。Apache Hamilton 专为与各种工具良好兼容而设计,并提供了适当的抽象层,以便您根据自身技术栈创建自定义集成。我们活跃的社区将帮助您构建所需的功能!
Apache Hamilton UI
您可以在 Apache Hamilton UI 中跟踪 Apache Hamilton DAG 的执行情况。它会自动填充包含血缘关系和追踪信息的数据目录,并提供执行可观测性,以便检查结果和调试错误。您可以将其作为 本地服务器 或使用 Docker 部署的 自托管应用 来运行。
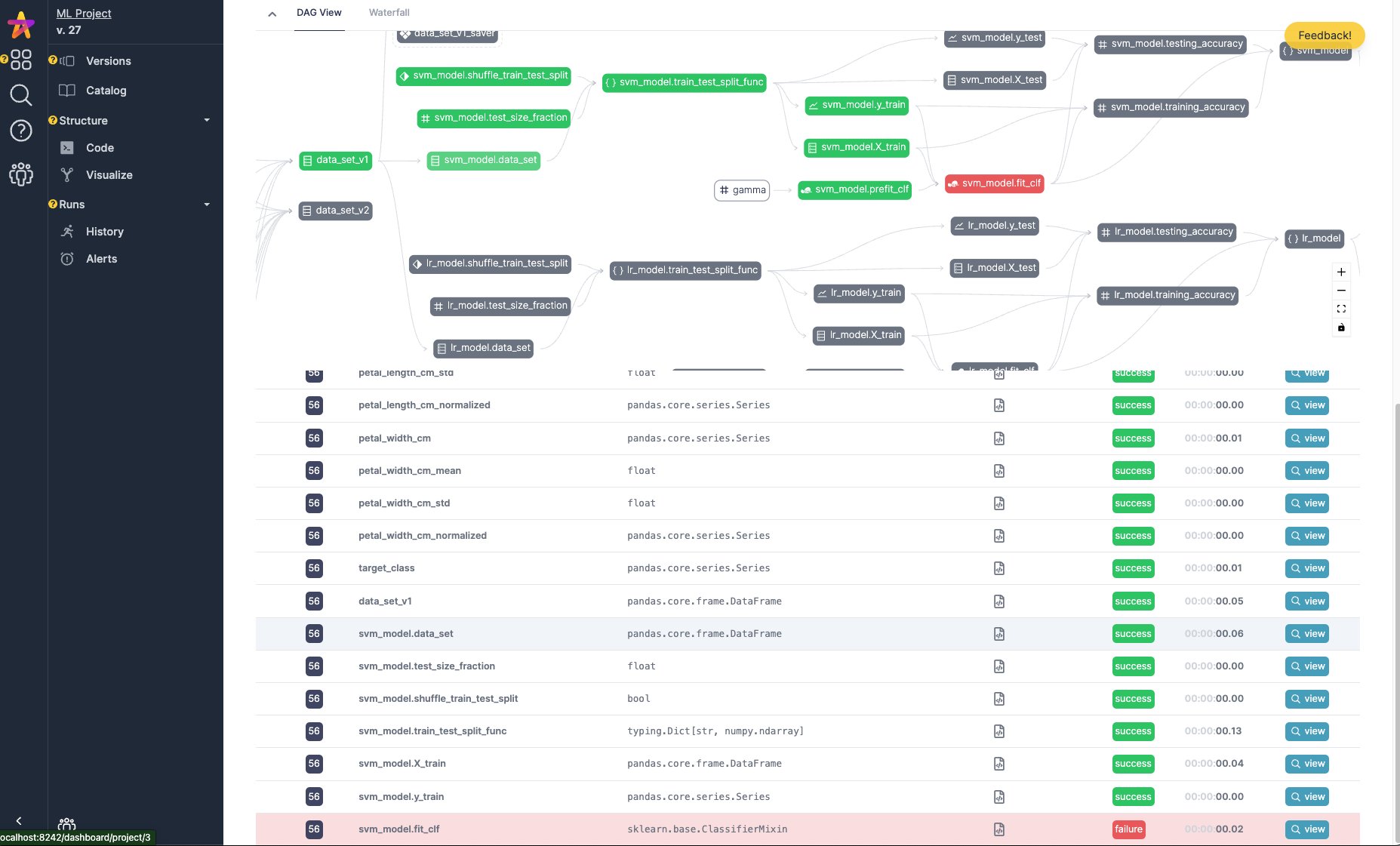
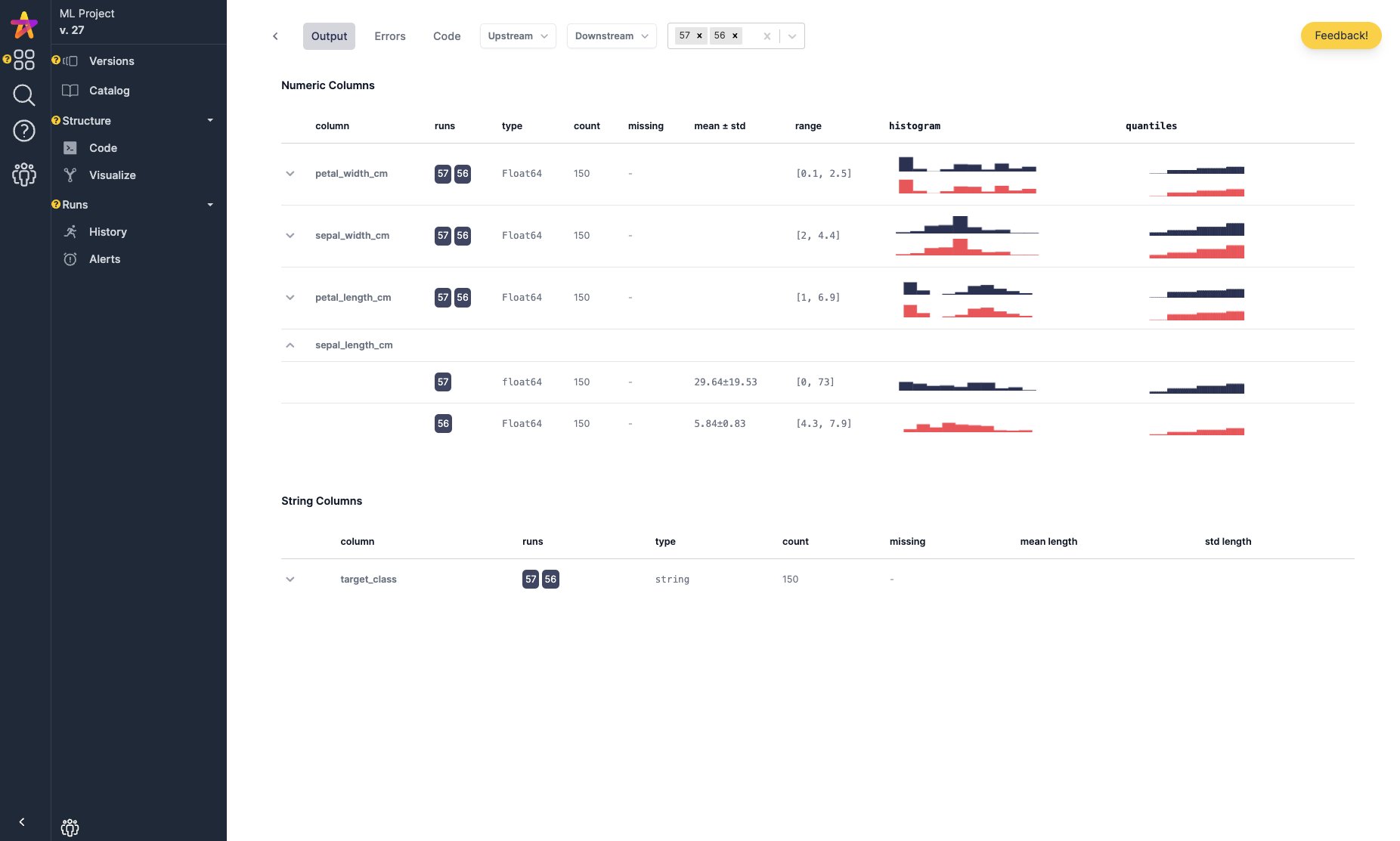
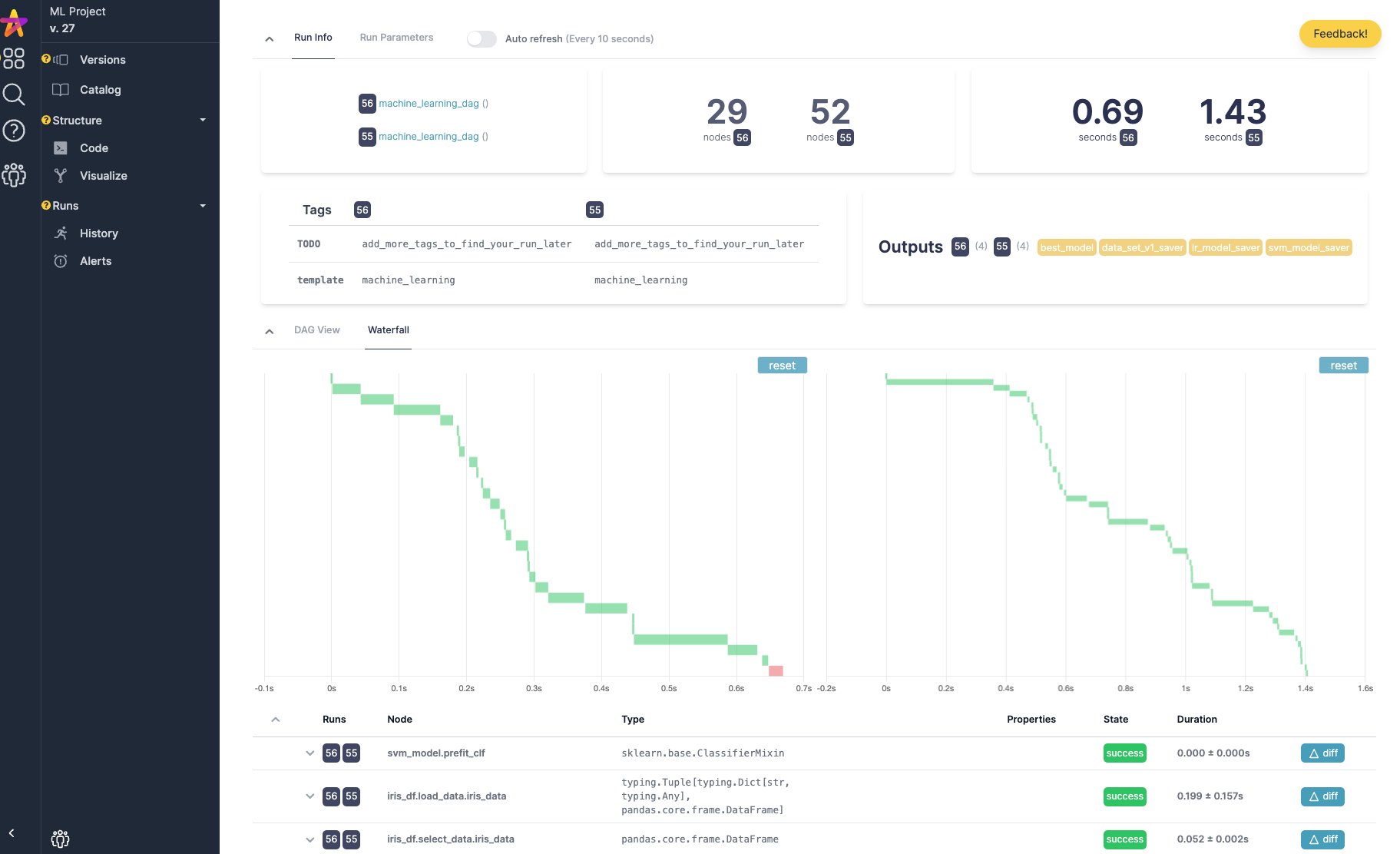
DAG 目录、自动数据集分析和执行追踪
开始使用 Apache Hamilton UI
要使用 Apache Hamilton UI,您需要安装依赖项(参见“安装”部分),然后通过以下命令启动服务器:
hamilton ui首次连接时,请创建一个用户名并新建一个项目(
project_id应设置为 1)。
通过使用您的用户名和项目 ID 创建一个
HamiltonTracker对象,并将其添加到Builder中,即可跟踪您的 Apache Hamilton DAG。现在,您的 DAG 将显示在 UI 的目录中,所有执行操作都会被记录下来!from hamilton import driver from hamilton_sdk.adapters import HamiltonTracker import my_dag # 使用您的用户名和项目 ID tracker = HamiltonTracker( username="my_username", project_id=1, dag_name="hello_world", ) # 将跟踪器添加到 Builder 中,DAG 就会被加入目录 dr = ( driver.Builder() .with_modules(my_dag) .with_adapters(tracker) # 在此处添加您的跟踪器 .build() ) # 执行 Driver 将会记录结果 dr.execute(["C"])
文档与学习资源
📚 请参阅 官方文档,了解 Apache Hamilton 的核心概念。
👨🏫 可以查阅 GitHub 上的示例,学习特定功能或与其他框架的集成方法。
📰 DAGWorks 博客 包含有关如何构建数据平台的指南和叙事式教程。
📺 您可以在 DAGWorks YouTube 频道 上找到视频教程。
📣 如需帮助或故障排除,请通过 Apache Hamilton Slack 社区 联系我们。
Apache Hamilton 与 X 相比如何?
Apache Hamilton 既不是编排工具(你可能并不需要一个),也不是特征存储库(不过你可以用它来构建一个!)。它的主要用途是帮助你组织和管理数据转换逻辑。如果你熟悉 dbt,那么 Apache Hamilton 对 Python 的作用就类似于 dbt 对 SQL 的作用。
另一种理解方式是从数据栈的不同层次来考虑。Apache Hamilton 处于资产层。它可以帮助你将数据转换代码(即表达式层)组织起来,管理变更,并对数据进行验证和测试。
| 层 | 目的 | 示例工具 |
|---|---|---|
| 编排 | 用于创建资产的运行时系统 | Airflow、Metaflow、Prefect、Dagster |
| 资产 | 将表达式组织成有意义的单元 (例如:数据集、机器学习模型、表) |
Apache Hamilton、dbt、dlt、SQLMesh、Burr |
| 表达式 | 用于编写数据转换的语言 | pandas、SQL、polars、Ibis、LangChain |
| 执行 | 实际执行数据转换 | Spark、Snowflake、DuckDB、RAPIDS |
| 数据 | 数据的物理表示形式,包括输入和输出 | S3、Postgres、文件系统、Snowflake |
更多信息请参阅我们的页面 为什么使用 Apache Hamilton? 以及框架间的代码比较。
📑 许可证
Apache Hamilton 根据 Apache 2.0 许可证发布。详细信息请参阅 LICENSE。
🌎 社区
👨💻 贡献
我们非常欢迎新贡献者提出的各种大小改动!在提交拉取请求之前,请务必通过创建议题或在现有议题上留言来讨论潜在的更改。不错的首次贡献包括创建示例或与你喜欢的 Python 库集成!
如需贡献,请查看我们的贡献指南、开发者设置指南,以及我们的行为准则。
😎 使用情况
Apache Hamilton 最初是在 Stitch Fix 开发的,后来由其原作者创立了 DAGWorks Inc!该库经过实战检验,自 2019 年以来一直支持生产环境中的各类用例。
更多关于起源故事的信息。
- Stitch Fix — 时间序列预测
- 英国政府数字服务 — 全国反馈流水线(处理与分析)
- IBM — 内部搜索与机器学习流水线
- Opendoor — 管理 PySpark 流水线
- Lexis Nexis — 特征处理与血缘关系追踪
- Adobe — 提示工程研究
- WrenAI — 异步文本转 SQL 工作流
- British Cycling — 遥测数据分析
- Oak Ridge 和 PNNL — Naturf 项目
- ORNL
- 联邦储备委员会
- Joby Aviation — 飞行数据处理
- Two
- Transfix — 在线特征提取与预测
- Railofy — 编排 pandas 代码
- Habitat Energy — 时间序列特征工程
- KI-Insurance — 特征工程
- Ascena Retail — 特征工程
- NaroHQ
- EquipmentShare
- Everstream.ai
- Flectere
- F33.ai
- Kora Money
- Capitec Bank
- Best Egg
- RTV Euro AGD
- Wealth.com
- wren.ai
🤝 代码贡献者

🙌 特别感谢 & 🦟 漏洞猎人
感谢我们出色的社区及其对 Apache Hamilton 库的积极参与。
Nils Olsson、Michał Siedlaczek、Alaa Abedrabbo、Shreya Datar、Baldo Faieta、Anwar Brini、Gourav Kumar、Amos Aikman、Ankush Kundaliya、David Weselowski、Peter Robinson、Seth Stokes、Louis Maddox、Stephen Bias、Anup Joseph、Jan Hurst、Flavia Santos、Nicolas Huray、Manabu Niseki、Kyle Pounder、Alex Bustos、Andy Day、Alexander Cai、Nils Müller-Wendt、Paul Larsen、 Kemal Eren、Jernej Frank、Noah Ridge
🎓 引用
如果您使用了 Apache Hamilton,请通过以下任一方式引用我们:
@inproceedings{DBLP:conf/vldb/KrawczykI22,
title = {Hamilton: 一种模块化的开源声明式范式,用于数据流的高层次建模},
author = {Stefan Krawczyk 和 Elijah ben Izzy},
editor = {Satyanarayana R. Valluri 和 Mohamed Za{\"{\i}}t},
booktitle = {第一届可组合数据管理系统国际研讨会,CDMS@VLDB 2022,澳大利亚悉尼,2022年9月9日},
year = {2022},
url = {https://cdmsworkshop.github.io/2022/Proceedings/ShortPapers/Paper6\_StefanKrawczyk.pdf},
timestamp = {Wed, 19 Oct 2022 16:20:48 +0200},
biburl = {https://dblp.org/rec/conf/vldb/KrawczykI22.bib},
bibsource = {dblp 计算机科学文献数据库,https://dblp.org}
}
@inproceedings{CEURWS:conf/vldb/KrawczykIQ22,
title = {Hamilton:通过广义数据流图实现数据转换中的软件工程最佳实践},
author = {Stefan Krawczyk、Elijah ben Izzy 和 Danielle Quinn},
editor = {Cinzia Cappiello、Sandra Geisler 和 Maria-Esther Vidal},
booktitle = {与第48届非常大规模数据库国际会议(VLDB 2022)同期举办的首届数据生态系统国际研讨会},
pages = {41--50},
url = {https://ceur-ws.org/Vol-3306/paper5.pdf},
year = {2022}
}
📚 基于或为 Apache Hamilton 构建的库
- Hypster - 超参数管理
- DSP Decision Engine - 决策树
- NaturF - 用于天气预报的数据转换库
- WrenAI - RAG
- FlowerPower - Apache Hamilton 的调度器
版本历史
v1.89.0-incubating2025/10/11v1.89.0-incubating-RC12025/10/04sf-hamilton-1.88.02025/03/29sf-hamilton-1.87.02025/02/12sf-hamilton-1.86.12025/01/06sf-hamilton-1.85.12024/12/17sf-hamilton-1.85.02024/12/12sf-hamilton-1.84.02024/12/04sf-hamilton-1.83.32024/11/26sf-hamilton-1.83.22024/11/22sf-hamilton-1.83.12024/11/14sf-hamilton-1.83.02024/11/06sf-hamilton-1.82.02024/10/30sf-hamilton-1.81.22024/10/24sf-hamilton-1.81.12024/10/24sf-hamilton-1.81.02024/10/16sf-hamilton-1.80.02024/10/10sf-hamilton-1.79.02024/10/03sf-hamilton-1.78.02024/09/26sf-hamilton-1.77.12024/09/23常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备