deepfabric
DeepFabric 是一款专为大语言模型和智能体系统打造的数据生成与评估工具。它能在一个统一的流程中,自动生成高质量的合成训练数据,并支持后续的模型训练、度量与效果评估。
在开发智能体时,获取既多样化又紧扣特定领域的高质量训练数据往往是一大难题,传统方法容易导致数据冗余或模型过拟合。DeepFabric 通过独特的“主题图”生成算法,系统地覆盖所有必要子话题,确保数据丰富且不重复。它能教会模型如何进行逻辑推理、规划步骤、正确调用工具以及遵循严格的结构化格式。此外,该工具利用隔离的 WebAssembly 环境执行真实工具调用,并结合约束解码技术,保证生成的每一条数据在语法和执行逻辑上都准确无误。
生成后的数据集可直接上传至 Hugging Face,并无缝对接 TRL、Unsloth 等主流训练框架。训练完成后,DeepFabric 内置的评估引擎还能基于未见过的任务对模型表现进行验证。
这款工具非常适合 AI 开发者、研究人员以及需要构建定制化智能体的团队使用。无论是希望提升模型的工具调用能力,还是需要构建符合特定 Schema 的专业数据集,DeepFabric 都能提供从数据生产到效果验证的一站式解决方案,让模型训练更加高效可靠。
使用场景
某金融科技公司正在开发一个能自动执行复杂数据分析的智能体,需要模型精准掌握 Python 代码生成、文件操作及外部 API 调用的组合技能。
没有 deepfabric 时
- 数据质量参差不齐:人工编写或简单生成的训练数据缺乏真实的推理链条(Reasoning Traces),导致模型只会“猜”代码而不会“规划”步骤。
- 工具调用频繁出错:难以构造严格符合 Schema 结构的工具调用样本,模型在真实环境中常因参数格式错误导致执行失败。
- 场景覆盖存在盲区:手动构建数据集容易陷入重复模式,遗漏边缘业务场景,造成模型在遇到未见过的任务时表现糟糕。
- 验证成本高昂:缺乏自动化的执行环境,无法在训练前确认生成的代码和工具调用是否真正可运行,调试周期漫长。
使用 deepfabric 后
- 推理与行动深度融合:deepfabric 自动生成包含完整思考过程和工具调用序列的高质量合成数据,教会模型像专家一样先规划后行动。
- 严格的格式约束保障:利用受限解码和 WebAssembly 隔离环境实时执行验证,确保每一条训练数据的语法、参数结构绝对正确且可运行。
- 话题图谱避免过拟合:通过独特的话题图算法生成多样化样本,自动覆盖所有子领域并消除冗余,显著提升模型对未知任务的泛化能力。
- 端到端流水线提效:从数据生成、自动上传至 Hugging Face 到直接接入 TRL/Unsloth 训练框架,再到训后自动化评估,全流程无缝衔接。
deepfabric 将原本需要数周的数据工程与验证工作压缩为单一管道,让团队能快速迭代出既懂思考又能精准操作工具的高可靠智能体。
运行环境要求
- Linux
- macOS
- Windows
未说明 (工具主要调用外部 LLM API,本地仅运行评估和轻量级逻辑)
未说明
快速开始

在代理系统中训练模型行为
![]()
![]()



DeepFabric 为语言模型和智能体评估生成合成训练数据。通过将推理轨迹与工具调用模式相结合,它能够创建高质量的领域特定数据集,教导模型如何有效思考、规划和行动,正确调用工具,并符合严格的模式结构。
DeepFabric 与其他数据集生成工具的不同之处在于,它利用独特的主题图生成算法,确保高多样性的同时保持领域相关的准确性。这种方法引导样本生成覆盖所有必要的子主题,同时避免冗余,而其他工具往往在这方面做得不够,导致模型过拟合。
受限解码和响应验证,以及在隔离的 WebAssembly 环境中执行真实工具,确保生成的样本严格遵守结构化模式、变量约束和执行正确性,从而保证数据集具有精确的语法和结构,可用于模型训练流程。工具定义可以直接从 MCP(模型上下文协议)服务器模式导入并自动模拟,也可以使用现实生活中的接口及一组常用工具(list_files()、'read_file() 等)。
一旦您的数据集生成完毕,可以自动上传到 Hugging Face,并直接导入到 TRL、Unsloth 和 Axolotl 等流行的训练框架中。
训练完成后,DeepFabric 内置的评估引擎会评估模型性能,使模型能够在来自训练分割的未见任务上证明其能力——涵盖仅用于评估的问题、答案和工具调用轨迹。
快速入门
DeepFabric 可以作为库、CLI 工具或通过 YAML 配置文件使用。以下是使用 CLI 的快速示例:
pip install deepfabric
export OPENAI_API_KEY="your-api-key"
deepfabric generate \
--topic-prompt "Python编程基础" \
--generation-system-prompt "你是一位Python专家" \
--mode graph \
--depth 3 \
--degree 3 \
--num-samples 9 \
--batch-size 3 \
--provider openai \
--model gpt-4o \
--output-save-as dataset.jsonl
此命令会生成一个主题图,并创建 27 个唯一节点,然后生成 27 个训练样本保存到 dataset.jsonl 文件中,从而实现 100% 的主题覆盖。
配置
DeepFabric 还使用 YAML 配置文件,包含三个主要部分以及可选的共享 LLM 默认设置。
[!NOTE]
下面的内容使用了模拟的工具执行,因此需要运行 Spin 服务,我们提供了一个 Docker 镜像:
docker run -d -p 3000:3000 ghcr.io/always-further/deepfabric/tools-sdk:latest`
将以下内容保存为 config.yaml:
# 可选:共享 LLM 默认设置(由主题和生成过程继承)
llm:
provider: "openai"
model: "gpt-4o"
temperature: 0.7
# 主题:生成主题树/图
topics:
prompt: "使用Python构建生产就绪的REST API"
mode: tree # tree | graph
depth: 3
degree: 3
save_as: "topics.jsonl"
# 可选:覆盖共享 LLM 设置
llm:
model: "gpt-4o-mini" # 在生成主题时使用更便宜的模型
# 生成:从主题中创建训练样本
generation:
system_prompt: |
您是一位精通 REST API 设计的 Python 后端开发专家。
请创建实用且可直接投入生产的代码示例,并附上清晰的解释。
示例应包含错误处理、类型提示,并遵循 PEP 8 编码规范。
请使用以下工具在虚拟文件系统中读取、写入和列出文件:
- read_file
- write_file
- list_files
# 生成样本的附加说明
instructions: |
重点关注开发者在使用 Python 构建 REST API 时日常遇到的真实场景。
包含正常流程和边界情况的处理。
提供关于何时以及为何使用特定模式或库的背景信息。
确保代码模块化、可测试且易于维护。
# 配置工具时,代理模式会自动启用
conversation:
type: cot # basic | cot
reasoning_style: agent # freetext | agent (for cot)
# 工具配置(自动启用代理模式)
tools:
spin_endpoint: "http://localhost:3000" # 用于执行工具的 Spin 服务
components: # 将组件名称映射到工具名称
builtin: # 路由至 /vfs/execute
- read_file
- write_file
- list_files
max_per_query: 3 # 每次查询允许使用的最大工具数量
max_agent_steps: 5 # 最大 ReAct 推理迭代次数
# 可选:在生成前将初始文件注入 Spin,用于工具调用
scenario_seed:
files:
"Dockerfile": |
FROM python:3.13
WORKDIR /usr/local/app
# 安装应用程序依赖项
COPY requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txt
# 复制源代码
COPY src ./src
EXPOSE 8080
# 创建应用用户,避免容器以 root 用户运行
RUN useradd app
USER app
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080"]
"main.py": |
def greet(name):
return f"Hello, {name}!"
if __name__ == "__main__":
print(greet("World"))
"config.json": |
{
"version": "1.0.0",
"debug": true,
"max_retries": 3
}
# 生成控制与重试设置
max_retries: 3 # 生成失败时的重试次数
sample_retries: 2 # 样本验证失败时的重试次数
max_tokens: 2000 # 每次生成的最大 token 数量
# 可选:覆盖共享的 LLM 设置
llm:
temperature: 0.3 # 较低的温度以确保代码的一致性
# 输出:最终数据集配置
output:
# 将纳入训练数据的系统提示
# 这是训练后的模型将看到的系统消息
system_prompt: |
您是一位专注于 REST API 开发的 Python 编程助手。您提供清晰、可直接投入生产的代码及相应解释。
始终考虑安全性、错误处理和最佳实践。
include_system_message: true # 是否在输出中包含系统消息
num_samples: 4 # 总共要生成的训练样本数
batch_size: 3 # 并行生成批次大小
save_as: "api-dataset.jsonl"
可选:上传至 Hugging Face
huggingface:
repository: "your-username/api-dataset-training-name"
tags: ["python", "programming"]
通过加载 config.yaml 文件来运行生成:
deepfabric generate config.yaml
生成、训练、评估
DeepFabric 返回标准的 Hugging Face 数据集,便于与任何训练框架集成。
Colab 笔记本:
快速了解 DeepFabric 的实际操作方法,可通过 notebooks/ 文件夹中的笔记本或 Google Colab 来实现:
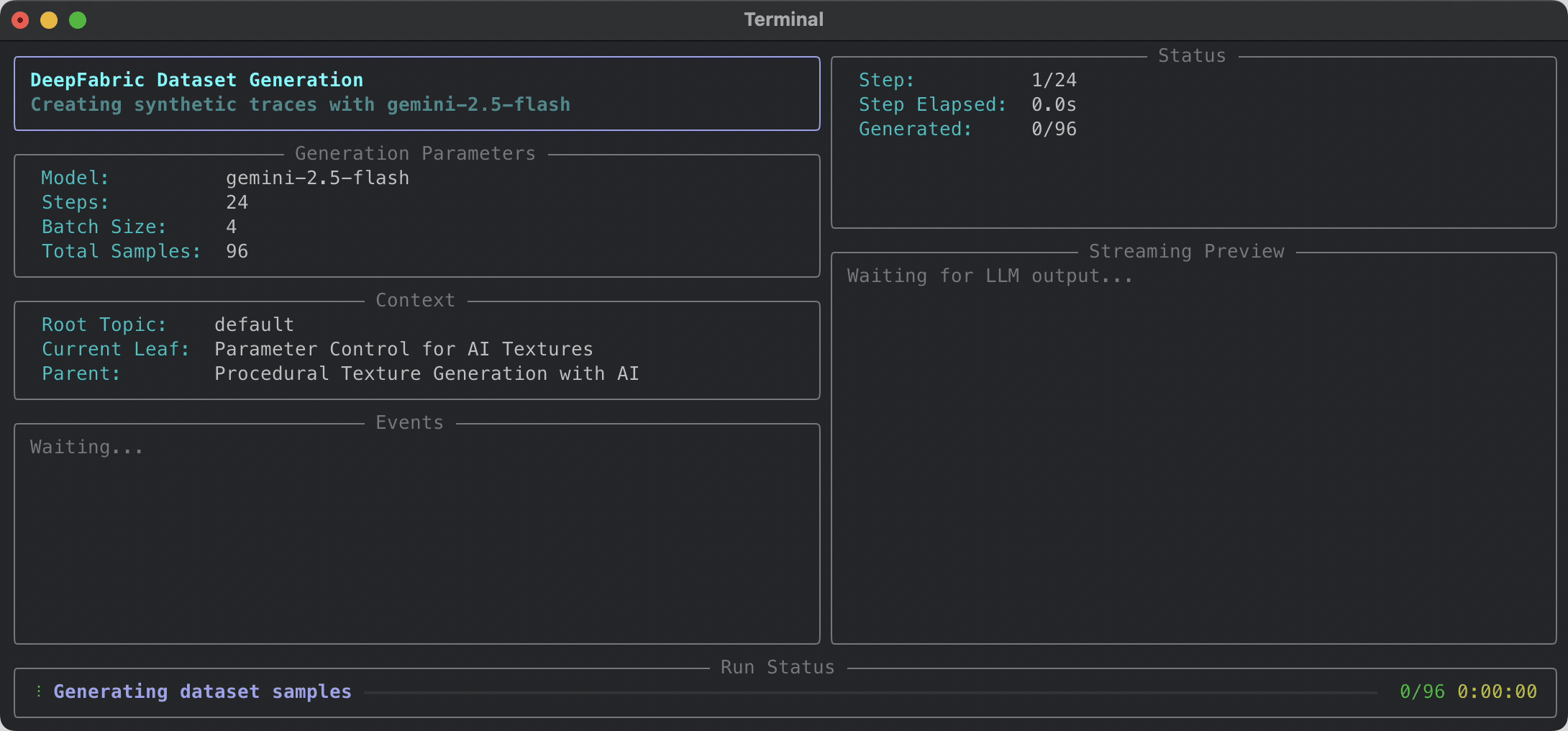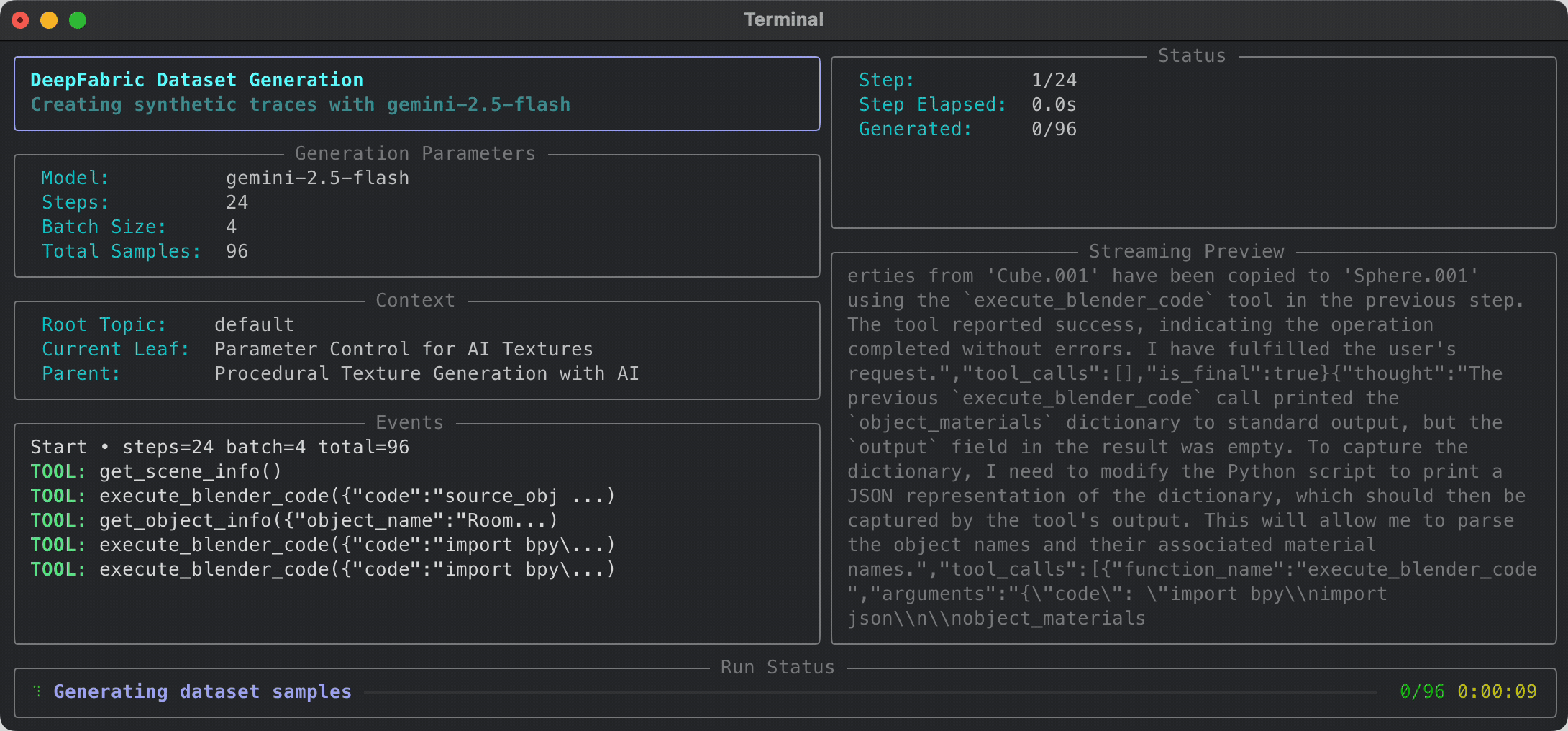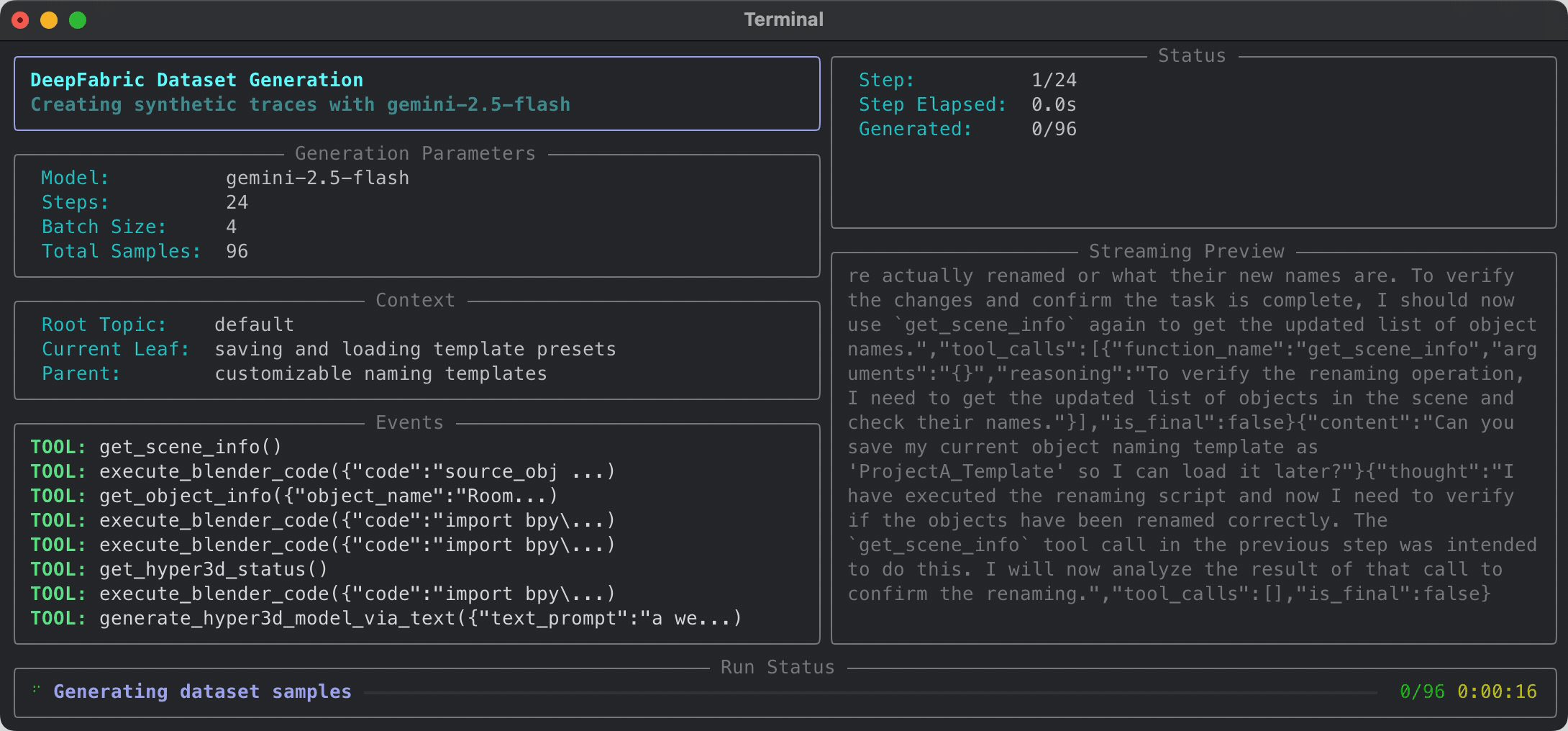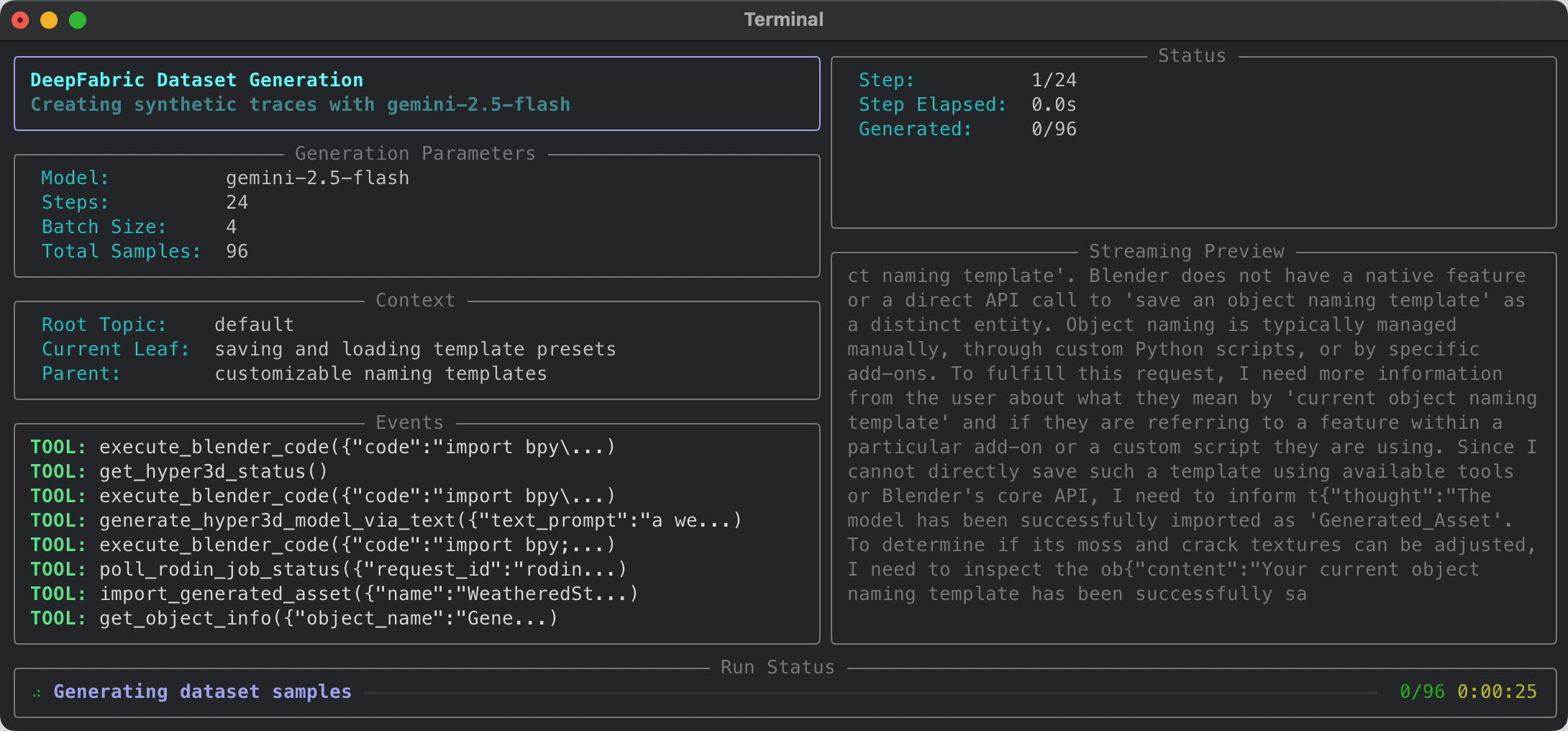
Qwen4b Blender MCP:
![]()
1. 生成数据集
deepfabric generate config.yaml --output-save-as dataset.jsonl
或者上传至 Hugging Face Hub:
deepfabric upload-hf dataset.jsonl --repo your-username/my-dataset
2. 加载并拆分用于训练
from datasets import load_dataset
from transformers import AutoTokenizer
# 从 Hub 加载数据集
dataset = load_dataset("alwaysfurther/deepfabric-generic-tools", split="train")
# 拆分为训练集和验证集
splits = dataset.train_test_split(test_size=0.1, seed=42)
train_ds = splits["train"]
eval_ds = splits["test"]
# 使用您的分词器进行格式化
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
def format_example(example):
messages = [{k: v for k, v in msg.items() if v is not None}
for msg in example["messages"]]
return {"text": tokenizer.apply_chat_template(messages, tokenize=False)}
formatted_train = train_ds.map(format_example)
3. 使用 TRL 或 Unsloth 进行训练
from trl import SFTTrainer, SFTConfig
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=formatted_train,
args=SFTConfig(output_dir="./output", num_train_epochs=3),
)
trainer.train()
4. 评估您的模型
from deepfabric.evaluation import Evaluator, EvaluatorConfig, InferenceConfig
config = EvaluatorConfig(
inference_config=InferenceConfig(
model_path="./output/checkpoint-final", # 本地路径或 HF Hub ID
backend="transformers",
),
)
evaluator = Evaluator(config)
results = evaluator.evaluate(dataset=eval_ds) # 直接传入 HF 数据集
print(f"工具选择准确率: {results.metrics.tool_selection_accuracy:.2%}")
print(f"参数准确率: {results.metrics.parameter_accuracy:.2%}")
print(f"综合得分: {results.metrics.overall_score:.2%}")
评估
DeepFabric 提供了一套全面的评估体系,用于衡量您微调后的模型在工具调用任务上的表现。
基本评估
from datasets import load_dataset
from deepfabric.evaluation import Evaluator, EvaluatorConfig, InferenceConfig
# 加载您的评估数据集
dataset = load_dataset("your-username/your-dataset", split="test")
# 配置评估者
config = EvaluatorConfig(
inference_config=InferenceConfig(
model_path="./output/checkpoint-final", # 本地路径或 HF Hub ID
backend="transformers", // "transformers" 或 "ollama"
temperature=0.1, // 低温以获得确定性输出
max_tokens=2048,
),
max_samples=100, // 限制样本数量以便快速测试(None 表示全部)
save_predictions=True, // 保存单个预测结果
output_path="eval_results.json",
)
// 运行评估
evaluator = Evaluator(config)
results = evaluator.evaluate(dataset=dataset)
// 打印总结
evaluator.print_summary(results.metrics)
# 清理 GPU 内存
evaluator.cleanup()
使用 LoRA 适配器进行评估
from deepfabric.evaluation import Evaluator, EvaluatorConfig, InferenceConfig
config = EvaluatorConfig(
inference_config=InferenceConfig(
model_path="Qwen/Qwen2.5-7B-Instruct", # 基础模型
adapter_path="./output/lora-adapter", # LoRA 适配器路径
backend="transformers",
load_in_4bit=True, # 4位量化
max_seq_length=2048,
),
)
evaluator = Evaluator(config)
results = evaluator.evaluate(dataset=eval_dataset)
理解评估指标
评估器会为工具调用任务计算多个指标:
results = evaluator.evaluate(dataset=eval_dataset)
metrics = results.metrics
# 核心指标
print(f"已评估样本数: {metrics.samples_evaluated}")
print(f"已处理样本数: {metrics.samples_processed}")
print(f"处理错误数: {metrics.processing_errors}")
# 工具调用指标
print(f"工具选择准确率: {metrics.tool_selection_accuracy:.2%}")
print(f"参数准确率: {metrics.parameter_accuracy:.2%}")
print(f"执行成功率: {metrics.execution_success_rate:.2%}")
print(f"响应质量: {metrics.response_quality:.2%}")
print(f"综合得分: {metrics.overall_score:.2%}")
| 指标 | 描述 |
|---|---|
tool_selection_accuracy |
模型正确选择工具的频率 |
parameter_accuracy |
工具参数与预期值匹配的频率 |
execution_success_rate |
有效且可执行的工具调用比例 |
response_quality |
非工具相关响应的质量评分 |
overall_score |
所有指标的加权组合 |
访问单个预测结果
results = evaluator.evaluate(dataset=eval_dataset)
# 遍历每个样本的评估结果
for pred in results.predictions:
print(f"样本 {pred.sample_id}:")
print(f" 查询: {pred.query}")
print(f" 预期工具: {pred.expected_tool}")
print(f" 预测工具: {pred.predicted_tool}")
print(f" 工具选择是否正确: {pred.tool_selection_correct}")
print(f" 参数是否正确: {pred.parameters_correct}")
if pred.error:
print(f" 错误: {pred.error}")
从 JSONL 文件进行评估
from deepfabric.evaluation import Evaluator, EvaluatorConfig, InferenceConfig
config = EvaluatorConfig(
dataset_path="eval_dataset.jsonl", # 直接从文件加载数据集
inference_config=InferenceConfig(
model_path="./my-model",
backend="transformers",
),
output_path="results.json",
)
evaluator = Evaluator(config)
results = evaluator.evaluate() # 无需传入数据集参数
使用 Ollama 后端
from deepfabric.evaluation import Evaluator, EvaluatorConfig, InferenceConfig
config = EvaluatorConfig(
inference_config=InferenceConfig(
model_path="llama3.2:latest", # Ollama 模型名称
backend="ollama",
temperature=0.1,
),
)
evaluator = Evaluator(config)
results = evaluator.evaluate(dataset=eval_dataset)
服务提供商
| 服务提供商 | 本地/云端 | 最适合场景 |
|---|---|---|
| OpenAI | 云端 | 高质量、复杂任务 |
| Anthropic | 云端 | 细致的推理能力 |
| Google Gemini | 云端 | 大规模应用时成本效益高 |
| Ollama | 本地 | 注重隐私、无限生成能力 |
| OpenRouter | 云端 | 灵活的模型选择 |
使用 Spin 进行工具追踪
DeepFabric 支持在数据集生成过程中真实执行工具,借助 Spin 框架实现。不同于模拟工具输出,工具会在隔离的 WebAssembly 沙盒中真正执行,从而生成真实的训练数据。
为什么真实执行很重要?
传统的合成数据生成器会模拟工具输出,这会导致生成不真实的训练数据:
# 模拟(存在问题)
代理:read_file("config.json")
结果:{"setting": "value"} # LLM 幻觉出的内容
而通过集成 Spin,工具会基于真实状态执行:
# 真实执行(准确)
代理:read_file("config.json")
结果:FileNotFound # 实际文件系统状态
代理:write_file("config.json", "{...}")
结果:成功写入 42 字节 # 真实操作
ReAct 式执行流程
DeepFabric 使用 ReAct(思考-行动-观察)循环来调用工具。代理会根据实际观察到的结果再决定下一步行动:
步骤 1:代理认为“应该检查配置文件是否存在”
-> 调用 read_file("config.json")
-> 观察到:FileNotFound
步骤 2:代理认为“配置文件不存在,需要创建它”
-> 调用 write_file("config.json", 内容)
-> 观察到:成功
这种方式生成的训练数据是基于真实观察做出决策,而非基于幻觉假设。
配置
在 YAML 配置中启用工具追踪:
generation:
conversation:
type: cot
reasoning_style: agent
tools:
spin_endpoint: "http://localhost:3000" # Spin 服务地址
available: # 仅允许使用指定工具
- read_file
- write_file
- list_files
max_agent_steps: 5 # 最大 ReAct 迭代次数
# 可选:为场景设置初始状态
scenario_seed:
files:
"config.json": '{"debug": true}'
内置 VFS 工具
DeepFabric 包含一个虚拟文件系统(VFS)组件,提供以下工具:
| 工具 | 描述 |
|---|---|
read_file |
读取文件内容 |
write_file |
写入文件内容 |
list_files |
列出当前会话中的所有文件 |
delete_file |
删除文件 |
每个会话都拥有独立的文件系统——更改不会在不同样本之间保留。
在本地运行 Spin
cd tools-sdk
spin build
spin up
Spin 服务默认运行在 http://localhost:3000。
添加自定义工具
你可以使用 Python、JavaScript、Go 或 Rust 编写自定义工具并扩展 DeepFabric。详细文档请参阅 tool-traces.md,内容包括:
- 创建自定义 Spin 组件
- 工具定义模式
- 多语言示例
- 容器化与部署
资源
开发
git clone https://github.com/always-further/deepfabric
cd deepfabric
uv sync --all-extras
make test
数据分析
我们收集匿名使用数据以改进 DeepFabric。不会收集任何个人数据、提示或 API 密钥。
# 禁用数据分析
export ANONYMIZED_TELEMETRY=False
版本历史
v4.12.02026/02/03v4.11.02026/02/02v4.10.12026/01/29v4.4.02025/12/20v4.3.12025/12/11v4.3.02025/12/11v4.2.12025/12/08v4.2.02025/12/07v4.10.02026/01/26v4.9.02026/01/14v4.8.32026/01/12v4.8.22026/01/06v4.8.12026/01/05v4.8.02026/01/05v4.7.12026/01/04v4.7.02026/01/04v4.6.02026/01/03v4.5.12025/12/26v4.5.02025/12/25v4.4.12025/12/21常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。